AI Superchip Market Size and Share
Market Overview
| Study Period | 2020 - 2031 |
|---|---|
| Market Size (2026) | USD 84.97 Billion |
| Market Size (2031) | USD 195.22 Billion |
| Growth Rate (2026 - 2031) | 18.10% CAGR |
| Fastest Growing Market | Asia-Pacific |
| Largest Market | North America |
| Market Concentration | High |
Major Players *Disclaimer: Major Players sorted in no particular order Image © Mordor Intelligence. Reuse requires attribution under CC BY 4.0. | |
AI Superchip Market Analysis by Mordor Intelligence
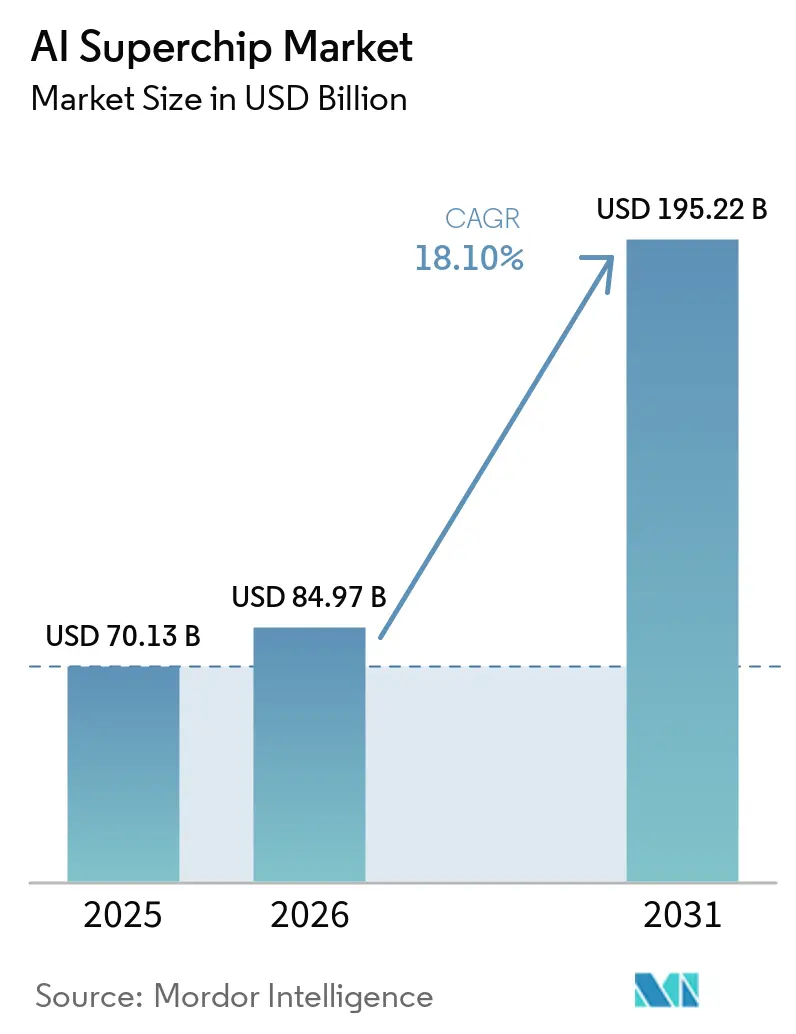
The AI superchip market size is expected to grow from USD 70.13 billion in 2025 to USD 84.97 billion in 2026 and is forecast to reach USD 195.22 billion by 2031 at 18.10% CAGR over 2026-2031. The market is being pushed by a sharp rise in hyperscale spending on AI accelerators, custom silicon, and next-generation data center buildouts. Demand is also broadening because compute is now consumed across pretraining, post-training, test-time scaling, and agentic workloads, rather than around one large training cycle. Supply conditions are shaping outcomes as strongly as raw chip performance, because memory, advanced packaging, and rack-level cooling now influence delivery schedules and product strategy. Competitive positions are deepening around software ecosystems, interconnect standards, and supply chain access, which gives scale vendors a clear advantage. Sovereign compute programs and latency-sensitive edge deployments are also expanding the addressable market for the AI superchip, even as model efficiency gains put pressure on vendors to balance training throughput with inference efficiency.
Key Report Takeaways
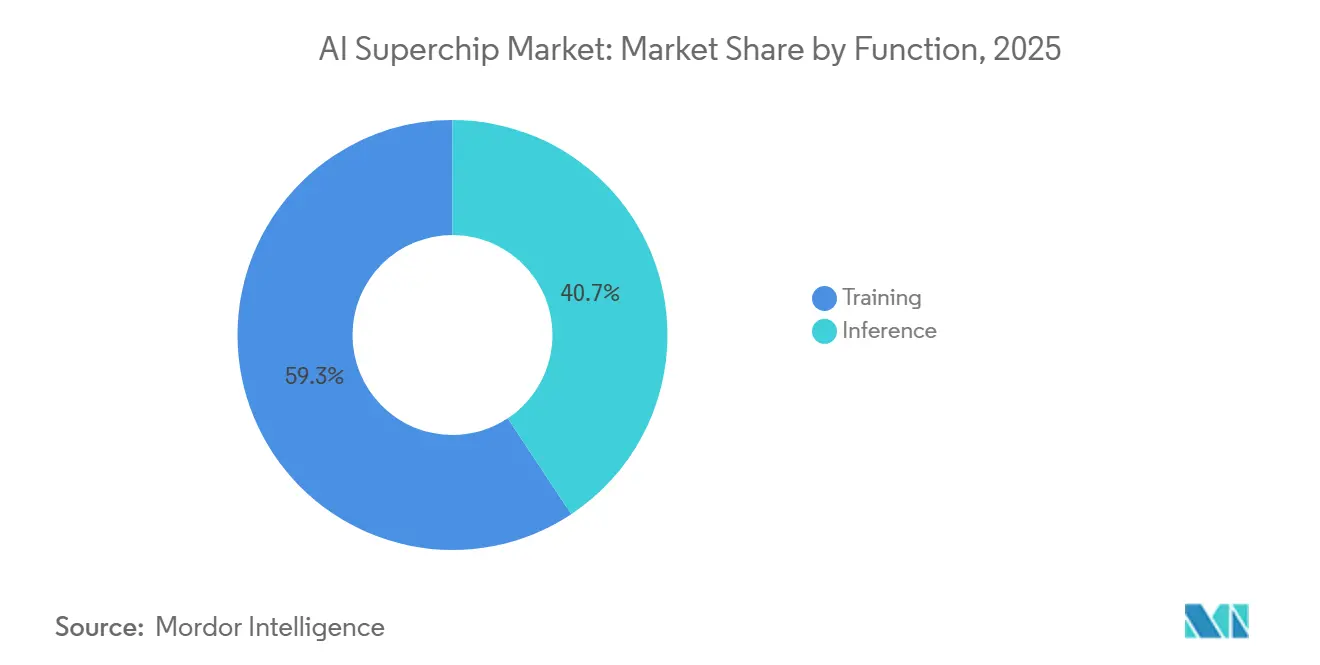
- By function, training accounted for 59.32% of the AI superchip market in 2025, while inference is projected to expand at a 18.49% CAGR through 2031.
- By architecture type, CPU-GPU integrated superchips accounted for 43.76% of the market in 2025, while AI ASIC-based superchips are expected to record the highest CAGR of 18.81% through 2031.
- By packaging technology, multi-chip module packaging captured 48.14% share in 2025, while chiplet-based SoC is projected to advance at an 18.89% CAGR through 2031.
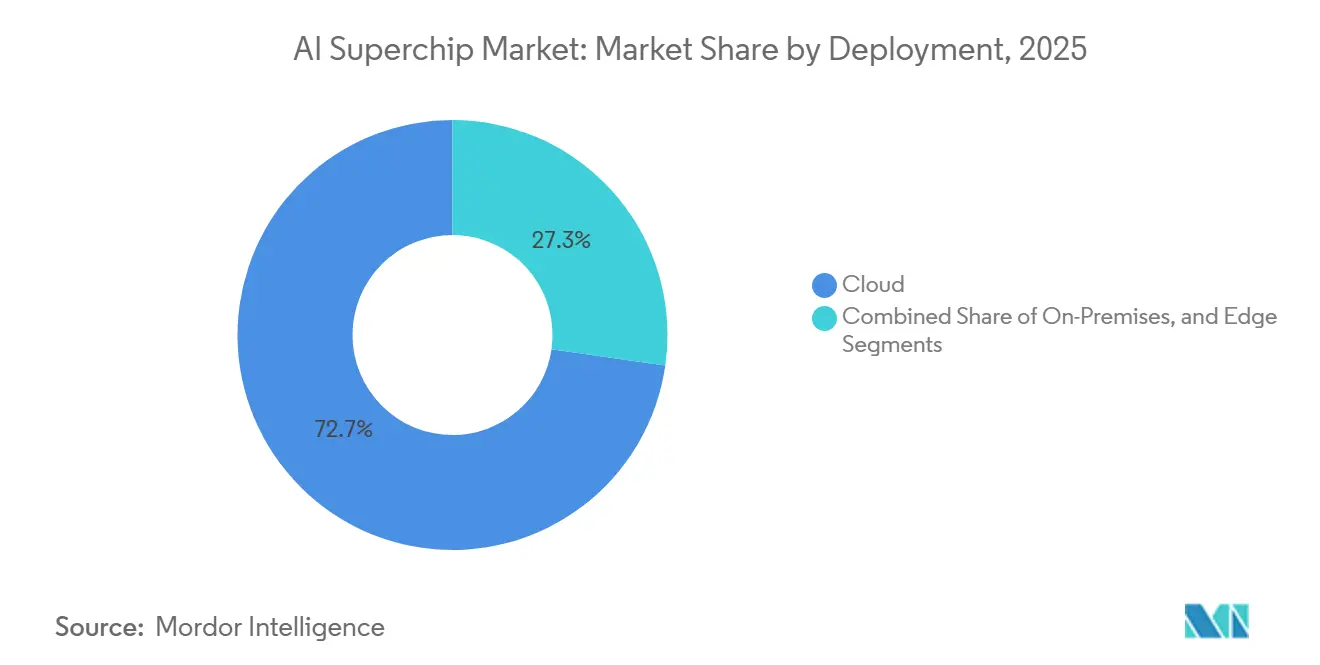
- By deployment, cloud held 72.73% share in the artificial intelligence (AI) superchip market in 2025, while edge is expected to grow at the fastest CAGR of 18.68% through 2031.
- By end-user industry, hyperscale cloud providers represented 62.12% of spending in 2025, while government and defense are projected to expand at a 19.94% CAGR through 2031.
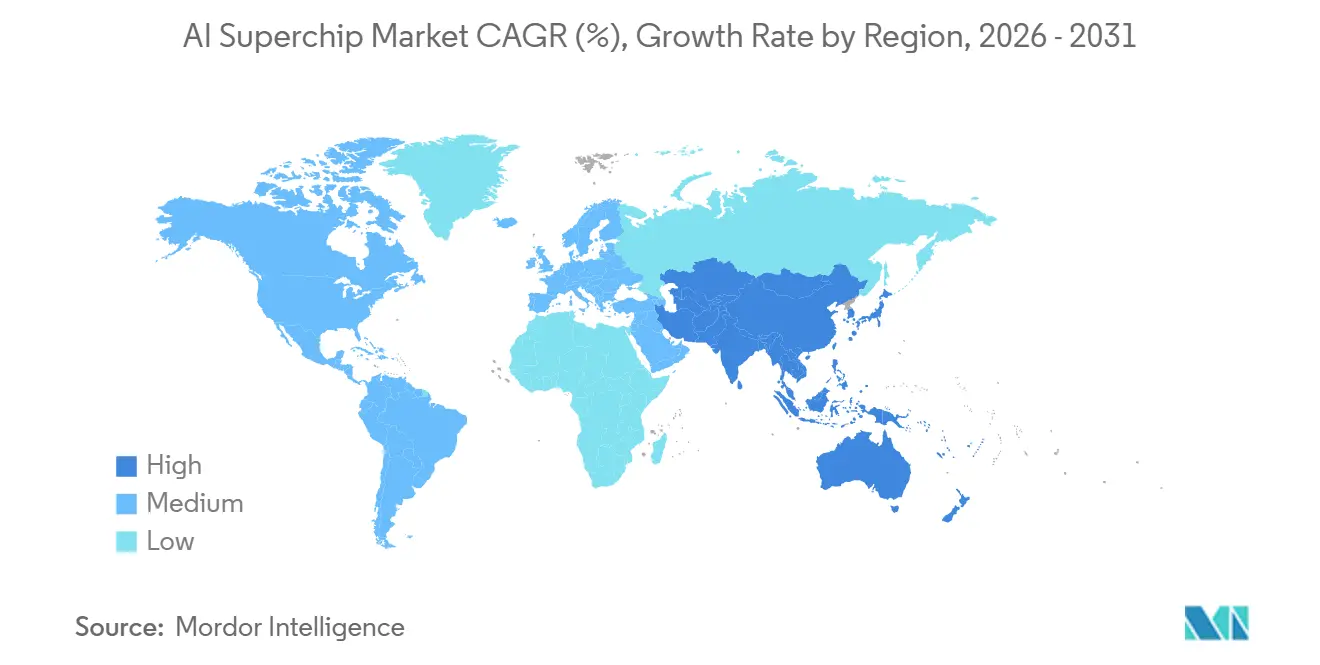
- By geography, North America accounted for 55.69% of revenue in 2025, while Asia-Pacific is expected to post the fastest CAGR of 19.09% through 2031.
Note: Market size and forecast figures in this report are generated using Mordor Intelligence’s proprietary estimation framework, updated with the latest available data and insights as of January 2026.
Global AI Superchip Market Trends and Insights
Driver Impact Analysis*
| Driver | (~) % Impact on CAGR Forecast | Geographic Relevance | Impact Timeline |
|---|---|---|---|
| Frontier Model Training Compute Expansion | +3.2% | Global, concentrated in North America and Asia-Pacific | Short term (≤ 2 years) |
| HBM Co-Location and Memory Bandwidth Scaling | +2.8% | Global, with supply chain concentrated in South Korea and Taiwan | Short term (≤ 2 years) |
| Chiplet-Based Heterogeneous Integration | +2.5% | Global, packaging led by Taiwan, design activity in North America and Europe | Medium term (2-4 years) |
| Sovereign AI Infrastructure Buildout | +2.0% | GCC, Europe, South Asia, Southeast Asia | Medium term (2-4 years) |
| Edge Inferencing at Scale in Industrial Systems | +1.6% | Asia-Pacific manufacturing belts, North America, Germany | Medium term (2-4 years) |
| Advanced Interconnect Demand for Multi-Die Systems | +1.2% | North America, Taiwan, South Korea | Long term (≥ 4 years) |
| Source: Mordor Intelligence | |||
Frontier Model Training Compute Expansion Drives Sustained Silicon Appetite
Frontier model training continues to keep the AI superchip market on a steep spending path because newer language, vision, and multimodal systems require materially more parallel compute than earlier generations. The move toward mixture-of-experts designs and multi-stage post-training has extended hardware demand beyond a single pre-training window and into tuning, alignment, and evaluation cycles. NVIDIA launched the Rubin platform on January 5, 2026, with 50 petaflops of NVFP4 inference compute per GPU, and the company said the platform can train mixture-of-experts models with 4x fewer GPUs than the prior Blackwell generation.[1]NVIDIA, “NVIDIA Kicks Off the Next Generation of AI with Rubin - Six New Chips, One Incredible AI Supercomputer,” NVIDIA Newsroom, nvidia.com Lower compute cost per model does not ease overall chip demand because labs usually respond by targeting larger systems and running more experiments. This same pattern is carried over into deployment, where reasoning workloads consume variable compute per query rather than a fixed inference budget. The result is that the AI superchip market is seeing demand accumulate across the full model lifecycle, which supports both training clusters and high-volume inference fleets.
HBM Co-Location and Memory Bandwidth Scaling Reshapes Chip Architecture
High-bandwidth memory has moved from a performance differentiator to a basic design requirement for the AI superchip market, as modern accelerators cannot sustain throughput without memory close to compute. JEDEC published the HBM4 standard in December 2024 with a 2,048-bit interface and a target of 1.5-2TB/s bandwidth per stack, which raised the ceiling for future accelerator designs. Siemens noted that HBM4 also increases stack capacity to 64GB, giving designers more room to balance bandwidth, capacity, and power within the same package. This memory shift is changing architecture choices because compute blocks, interposers, and thermal paths are now being designed around memory constraints from the start. It also underscores the importance of supplier readiness in South Korea and Taiwan, as memory availability can shape launch timing as strongly as logic design. As a result, product success increasingly depends on how well vendors coordinate memory, packaging, and system integration, rather than on processor throughput alone.
Chiplet-Based Heterogeneous Integration Breaks Through The Reticle Ceiling
Chiplet integration is becoming central to the AI superchip market because monolithic dies can no longer scale freely within lithography limits. Siemens reported that TSMC's CoWoS-L roadmap targets a 9-to-14x increase in reticle size from 2027 to 2029, reflecting the need for much more space for compute tiles and HBM stacks in future packages. Synopsys completed a 64 Gbps UCIe IP tape-out in 2026, demonstrating that die-to-die links are moving toward multi-terabit bandwidth at very short reach. CEA-Leti also demonstrated die-to-wafer hybrid bonding at a 1µm pitch in May 2026, indicating tighter interconnect density between chiplets. These advances make it easier to combine compute, memory, and I/O across different process nodes within a single package. The shift is moving competitive advantage toward package architecture, co-design, and assembly know-how, favoring players with deep integration across the semiconductor stack.
Sovereign AI Infrastructure Buildout Diversifies The Demand Base
Sovereign compute programs are broadening demand for the AI superchip market beyond hyperscalers, as governments increasingly seek domestically controlled AI infrastructure. The UK government announced a GBP 1.1 billion (USD 1.41 billion) AI Hardware Plan on June 8, 2026, including GBP 750 million (USD 960 million) for a national AI supercomputer and GBP 400 million (USD 512 million) for chip procurement. The same plan included a GBP 150 million (USD 192 million) advance commitment to novel inference chips from British and startup suppliers, which shows that public buyers are shaping the vendor mix and demand volume. These programs tend to support on-premises and edge configurations because sensitive workloads are rarely routed through commercial cloud environments. They also create opportunities for suppliers of packaging, storage, networking, and secure system design, not only for accelerator vendors. As sovereign buildouts spread across more countries, the demand base becomes less dependent on a few global cloud buyers and more distributed across public-sector programs.
Restraint Impact Analysis*
| Restraint | (~) % Impact on CAGR Forecast | Geographic Relevance | Impact Timeline |
|---|---|---|---|
| Advanced Packaging Capacity Constraints | -2.0% | Global, concentrated in Taiwan | Short term (≤ 2 years) |
| Export Controls on Leading-Edge Accelerators | -1.8% | North America (supply), China and Middle East and Africa (demand), global trade routes | Medium term (2-4 years) |
| Power Density and Cooling Limits in Dense Racks | -1.0% | Global, acute in brownfield data centers in Europe and North America | Medium term (2-4 years) |
| Model Efficiency Gains That Reduce Incremental Silicon Demand | -0.8% | Global | Long term ( |
| Source: Mordor Intelligence | |||
Advanced Packaging Capacity Constraints Cap Near-Term Supply Throughput
Advanced packaging remains the clearest near-term brake on the AI superchip market because accelerators cannot ship without complex assembly that places compute dies and HBM inside the same package. Even when wafer supply improves, packaging lines still need specialized bonders, placement tools, and inspection systems that take time to install and qualify. This keeps many vendors allocation-constrained and makes package availability a commercial lever as important as chip design or wafer starts. The shortage also reinforces concentration because larger firms can secure substrate, memory, and foundry access more easily than smaller rivals. Cooling and interconnect design standards are raising the technical bar for dense deployments, which means packaging constraints now spill into rack design and system qualification as well. Until capacity expands more fully, delivery schedules will continue to depend on packaging readiness as much as on processor demand.
Export Controls On Leading-Edge Accelerators Fragment Global Market Access
Export controls are fragmenting market access and limiting the free movement of leading-edge AI superchips across regions. The US Bureau of Industry and Security clarified on May 31, 2026, that license requirements for advanced computing items also apply to subsidiaries of Chinese companies outside China, which tightened a channel that had previously offered indirect access.[2]US Department of Commerce BIS / Mondaq, “Enforcement Pause Has Limits: BIS Clarifies Ongoing License Requirement for Advanced Computing Items to China-Linked Entities,” Mondaq, mondaq.com This is splitting demand into separate geopolitical pools and reducing the addressable base for some Western suppliers. It is also accelerating domestic chip programs in restricted markets, which can, over time, create alternative supply chains. Procurement decisions are therefore being shaped by compliance, geography, and political alignment alongside price and performance. The result is a less integrated global market, where leading vendors must manage both product road maps and shifting regulatory boundaries.
*Our forecasts treat driver/restraint impacts as directional, not additive. The impact forecasts reflect baseline growth, mix effects, and variable interactions.
Segment Analysis
By Function: Training Anchors Market Scale While Inference Closes The Gap
Training held 59.32% of the AI superchip market in 2025, and it represented the largest slice of the market because frontier model development still consumes the most compute. That lead reflected the intensity of large cluster training, where state-of-the-art models can use tens of thousands of GPUs over extended development cycles. Training also remains central because leading labs are not only scaling model size but also adding more stages for tuning and evaluation. These added steps keep cluster usage high even after the initial pretraining phase is complete. NVIDIA said the Rubin platform can train mixture-of-experts models with 4x fewer GPUs than the prior Blackwell generation, demonstrating how quickly the efficiency baseline is advancing.
That efficiency shift may compress training share over time, but it does not reduce the importance of training in absolute spending terms. Inference is forecast to expand at a 18.49% CAGR through 2031 as deployed model counts rise across enterprise software, consumer services, and autonomous systems. The AI superchip industry is therefore not moving away from training; it is adding a second large demand pool through real-time inference. Reasoning workloads also increase compute usage during deployment because they can allocate variable GPU time to each prompt rather than following a fixed response path. This means inference growth adds to existing training demand rather than replacing it. The AI superchip market is likely to remain balanced between labs that need large training clusters and operators that need fast, efficient inference fleets.


By Architecture Type: CPU-GPU Integration Leads as Custom ASICs Accelerate
CPU-GPU integrated superchips held a 43.76% share in 2025 and accounted for the largest share of the AI superchip market because they meet the needs of large-scale training and mixed-compute environments. Their lead has been built on platforms such as Grace Blackwell and Vera Rubin, which tie Arm-based CPUs and GPUs together with very high interconnect bandwidth. Tighter CPU-GPU coordination improves data movement and reduces the performance loss caused by crossing separate memory domains. That combination is useful when orchestration, memory access, and accelerator execution must work as a single system. It also helps explain why integrated platforms remain the preferred foundation for large AI clusters.
AI ASIC-based superchips are projected to post the fastest CAGR of 18.81% through 2031, as hyperscalers increasingly match silicon to specific workload economics. The AI superchip industry is seeing this most clearly in inference, where predictable, repetitive workloads favor custom chip design. Google introduced TPU 8t for training and TPU 8i for inference in April 2026, which showed a clearer split between workload-specific accelerator paths. This matters because cost, power, and throughput can be tuned more tightly when the buyer controls the software stack and deployment model. GPU-GPU coupled and heterogeneous multi-accelerator setups will remain important in specialized environments, but the strongest growth signal is coming from custom ASIC deployment at hyperscale. As that mix expands, merchant GPU vendors will face greater pressure in inference-heavy use cases, where ownership costs become a stronger buying factor.
By Packaging Technology: MCM Commands Share As Chiplet Architectures Define The Growth Curve
Multi-chip module packaging captured 48.14% share in 2025, and it led the packaging mix because it offers a workable balance across thermal control, manufacturing scalability, and bandwidth efficiency. MCM formats are also supported by an established foundry and OSAT ecosystem, which helps vendors scale production faster than with less mature approaches. This matters in the current cycle because package choice influences delivery speed as much as technical performance. MCM therefore remains the default structure for many high-end AI accelerators that combine large compute dies and HBM stacks. Its lead is likely to hold in the near term as long as supply chains continue to favor proven assembly paths.
Chiplet-based SoCs are forecast to grow at a 18.89% CAGR through 2031, as reticle limits push designers to split compute across multiple dies. This is one of the clearest examples where the AI superchip market is being shaped by physical design limits rather than by simple performance targets. Synopsys completed a 64Gbps UCIe IP tape-out in 2026, and CEA-Leti demonstrated 1µm die-to-wafer hybrid bonding in May 2026, both of which support denser die-to-die integration. These advances make it easier to treat a package as a modular system rather than as a single large chip. Monolithic SoC and system-in-package designs will still matter in smaller edge and ruggedized settings, but future scaling at the high end is moving toward chiplet-heavy assembly. As this shift deepens, packaging architecture becomes a stronger source of product differentiation than the single-die model.
By Deployment: Cloud Dominates With Over 70% Share While Edge Becomes The Strategic Battleground
Cloud deployment held a 72.73% share in 2025 and accounted for the largest share of the artificial intelligence (AI) superchip market, as hyperscale data centers still host the heaviest training and large-scale inference loads. Hyperscalers can fund specialized infrastructure, advanced cooling, and software environments that few other buyers can match. That scale advantage keeps the cloud at the center of both model development and broad service deployment. It also makes the cloud the main entry point for new architectures that require dense, rack-level integration. The AI superchip market continues to rely on hyperscale capacity because the most advanced systems still require environments optimized for power, cooling, and network density.
NVIDIA positioned Rubin-based systems around large AI infrastructure builds, reinforcing the idea that flagship platforms are still being designed first for cloud-scale deployment. Edge deployment is projected to expand at an 18.68% CAGR through 2031 because more industrial and defense workloads cannot tolerate cloud round-trip latency. That growth is being driven less by consumer devices and more by field operations, factories, and remote systems that need local inference. Emerson and SiMa Technologies announced AI-enabled industrial PCs for manufacturing and remote field sites in May 2026, which showed how physical AI is moving into controlled industrial settings. On-premises systems will remain important in regulated sectors such as healthcare, finance, and government. The sharper growth signal, however, is at the edge, where power limits, rugged deployment, and local control are creating a distinct hardware path from hyperscale cloud.

By End-User Industry: Hyperscale Providers Set Spending Velocity While Defense Scales Fastest
Hyperscale cloud providers accounted for 62.12% of end-user spending in 2025 and set the spending rhythm for the artificial intelligence (AI) superchip market, as the largest procurement budgets remain concentrated among a few cloud platforms. Their purchasing decisions affect accelerator road maps, packaging allocation, and software support across the wider value chain. This buyer concentration gives leading cloud firms unusual influence over what gets built first and which vendors scale fastest. It also means many supplier relationships are being formed around a small group of very large customers. The current demand environment, therefore, reflects both end-user demand and buyer concentration at the top of the market.
Government and defense organizations are projected to record the fastest CAGR of 19.94% through 2031, as more countries treat AI compute as strategic infrastructure. The AI superchip industry is benefiting from this shift through demand for sovereign compute, secure deployment, and controlled procurement channels. The UK's AI Hardware Plan, announced in June 2026, showed direct public-sector backing for compute capacity, chip procurement, and domestic hardware development. Research and academic institutions remain smaller in absolute spending, but they are gaining better access to advanced systems through science-oriented infrastructure rollouts. NVIDIA said Vera Rubin NVL4-based systems for scientific computing will be available from Dell Technologies, HPE, GIGABYTE, and Supermicro in Q4 2026. That widening access does not change the spending hierarchy, but it does extend high-end compute beyond hyperscaler and defense environments.
Geography Analysis
North America held 55.69% of the AI superchip market in 2025, the largest share, because frontier AI labs, hyperscaler headquarters, and the largest announced infrastructure budgets are concentrated there. The United States remains the center of merchant-accelerator design and custom silicon strategy, which keeps much of the industry's intellectual property anchored there. The region also benefits from close alignment between cloud buyers, chip designers, system builders, and software ecosystems. Canada is emerging as a supporting node for sovereign compute efforts, while Mexico remains more relevant as a nearshore production location than as a major source of demand. These factors keep North America structurally strong even when manufacturing is elsewhere.
Asia-Pacific is projected to expand at a 19.09% CAGR through 2031, making it the fastest-growing geography in the artificial intelligence (AI) superchip market. The region sits at the center of leading-edge foundry work, high-bandwidth memory production, and advanced packaging, which gives it direct influence over global supply timing. Taiwan and South Korea remain critical because manufacturing depth and memory control shape the rollout pace of advanced accelerators. India's IndiaAI Mission operated a compute facility with 38,000 GPUs in early 2026 and targeted 100,000 by year-end, indicating a rapidly rising local demand base.[3]Carnegie Endowment for International Peace, “Early Lessons in the Pursuit of Sovereign AI,” Carnegie Endowment, carnegieendowment.org
Europe held a mid-sized share of revenue in 2025, led by Germany, the United Kingdom, and France. The UK government announced a GBP 1.1 billion (USD 1.41 billion) AI Hardware Plan in June 2026, including funding for a national AI supercomputer and chip procurement. That policy direction supports more local compute capacity and reinforces on-premises demand in regulated environments. South America, the Middle East, and Africa remain smaller in terms of revenue, but sovereign infrastructure programs are opening new opportunities, especially in Gulf markets, where state-backed digital investment is rising.

Competitive Landscape
The AI superchip market remains highly concentrated despite its large revenue base and broadening application scope. NVIDIA held an estimated 80%-85% of AI accelerator revenue in 2026, leaving merchant rivals at a much smaller scale. Its lead has rested on CUDA software lock-in, strong package access, and the ability to sell full platforms rather than individual chips. AMD remains the closest merchant challenger, with the Instinct line narrowing the technical gap in targeted workloads. Even so, competitive power in this market still depends on software adoption, supply access, and ecosystem reach as much as it depends on raw silicon performance.
Hyperscaler custom silicon is the most significant structural challenge for merchant GPU vendors, as the largest buyers increasingly seek tighter control over costs and workload design. Google introduced TPU 8t for training and TPU 8i for inference in April 2026, which showed how hyperscalers are separating accelerator paths to match specific deployment economics. NVIDIA responded by expanding NVLink Fusion, so third-party ASICs and XPUs can connect to its scale-up fabric. Lightmatter joined NVLink Fusion in June 2026, showing that NVIDIA is widening its position in interconnects and optics rather than defending a fully closed hardware stack.[4]Lightmatter, “Lightmatter Joins NVIDIA NVLink Fusion and Powers Next-Generation AI Infrastructure with Photonic Interconnects,” Lightmatter, lightmatter.co
Startups are still finding room where they offer a clear architecture or deployment angle, even though top-line revenue remains concentrated. Groq expanded its neocloud inference footprint after confirming a USD 650 million funding round in June 2026, which showed investor support for inference-focused platform models. Micron and Anthropic also announced a multi-year strategic agreement in June 2026 that more closely linked memory and storage supply to the needs of frontier AI infrastructure. Design-service companies such as Broadcom and Marvell are also well-positioned for enterprise and government buyers who want semi-custom silicon without the full hyperscaler scale. Competitive advantage is therefore spreading across chip design, memory, packaging, optics, and software, even while the revenue pool remains concentrated around a small number of dominant players.
AI Superchip Industry Leaders
NVIDIA Corporation
Advanced Micro Devices, Inc.
Intel Corporation
Google LLC
Amazon.com, Inc.
- *Disclaimer: Major Players sorted in no particular order

Recent Industry Developments
- June 2026: Groq confirmed a USD 650 million funding round, six months after NVIDIA signed a non-exclusive licensing agreement for Groq's language processing unit technology. Groq used the capital to expand its neocloud inference business to 13 data centers globally, targeting 200 MW of capacity by 2027. The deal underscores how NVIDIA is consolidating inference IP while established inference startups pivot toward platform businesses rather than competing head-on in hardware.
- June 2026: Micron and Anthropic announced a multi-year strategic agreement encompassing memory and storage supply, technology collaboration, and Micron's strategic investment in Anthropic's Series H funding round. The agreement directly ties next-generation HBM supply commitments to frontier AI model infrastructure at a timescale that extends well beyond standard vendor relationships.
- June 2026: NVIDIA announced at ISC High Performance 2026 in Hamburg that Vera Rubin NVL4-based systems for scientific computing will be available from Dell Technologies, HPE, GIGABYTE, and Supermicro in Q4 2026. This move extends the Vera Rubin platform beyond hyperscale deployments and into national labs and research institutions.
- June 2026: Lightmatter joined NVIDIA NVLink Fusion, integrating its co-packaged optics and near-packaged optics products into NVIDIA's scale-up interconnect ecosystem. This partnership reduces fiber and connector requirements by 50% in NVLink Fusion-based deployments and marks the first optical connectivity layer inside NVIDIA's core fabric architecture.


Global AI Superchip Market Report Scope
The AI Superchip Market comprises highly integrated computing platforms that combine multiple processing elements, accelerators, memory subsystems, and high-speed interconnect technologies into a unified architecture optimized for artificial intelligence (AI) workloads. AI superchips are designed to deliver exceptional computational performance, memory bandwidth, power efficiency, and scalability for training and inference applications, enabling organizations to process increasingly complex AI models, including large language models (LLMs), generative AI, multimodal AI, recommendation systems, scientific simulations, and advanced analytics.
The AI Superchip Market is Segmented by Function (Training, and Inference), Architecture Type (CPU-GPU Integrated Superchips, GPU-GPU Coupled Superchips, AI ASIC-Based Superchips, and Heterogeneous Multi-Accelerator Superchips), Packaging Technology (Monolithic System-on-Chip (SoC), Chiplet-Based SoC, System-in-Package (SiP), and Multi-Chip Module (MCM), Deployment (Cloud, On-Premises, and Edge), End-User (Hyperscale Cloud Providers, Data Centers, Enterprises, Government and Defense Organizations, and Research and Academic Institutions), and Geography (North America, Europe, Asia-Pacific, South America, and Middle East and Africa). The Market Forecasts are Provided in Terms of Value (USD).
| Training |
| Inference |
| CPU-GPU Integrated Superchips |
| GPU-GPU Coupled Superchips |
| AI ASIC-Based Superchips |
| Heterogeneous Multi-Accelerator Superchips |
| Monolithic System-on-Chip (SoC) |
| Chiplet-Based SoC |
| System-in-Package (SiP) |
| Multi-Chip Module (MCM) |
| Cloud |
| On-Premises |
| Edge |
| Hyperscale Cloud Providers |
| Data Centers |
| Enterprises |
| Government and Defense Organizations |
| Research and Academic Institutions |
| North America | United States |
| Canada | |
| Mexico | |
| Europe | Germany |
| United Kingdom | |
| France | |
| Italy | |
| Rest of Europe | |
| Asia-Pacific | China |
| Japan | |
| South Korea | |
| India | |
| Southeast Asia | |
| Rest of Asia-Pacific | |
| South America | |
| Middle East and Africa |
| By Function | Training | |
| Inference | ||
| By Architecture Type | CPU-GPU Integrated Superchips | |
| GPU-GPU Coupled Superchips | ||
| AI ASIC-Based Superchips | ||
| Heterogeneous Multi-Accelerator Superchips | ||
| By Packaging Technology | Monolithic System-on-Chip (SoC) | |
| Chiplet-Based SoC | ||
| System-in-Package (SiP) | ||
| Multi-Chip Module (MCM) | ||
| By Deployment | Cloud | |
| On-Premises | ||
| Edge | ||
| By End-User | Hyperscale Cloud Providers | |
| Data Centers | ||
| Enterprises | ||
| Government and Defense Organizations | ||
| Research and Academic Institutions | ||
| By Geography | North America | United States |
| Canada | ||
| Mexico | ||
| Europe | Germany | |
| United Kingdom | ||
| France | ||
| Italy | ||
| Rest of Europe | ||
| Asia-Pacific | China | |
| Japan | ||
| South Korea | ||
| India | ||
| Southeast Asia | ||
| Rest of Asia-Pacific | ||
| South America | ||
| Middle East and Africa | ||


Key Questions Answered in the Report
How large is the AI superchip market and what is its growth outlook?
The AI superchip market reached USD 70.13 billion in 2025, stands at USD 84.97 billion in 2026, and is forecast to reach USD 195.22 billion by 2031 at an 18.10% CAGR.
Which function leads demand for AI superchips?
Training led in 2025 with 59.32% share because frontier model development still absorbs the highest compute intensity across large GPU clusters.
What is driving the fastest growth in AI superchips?
Inference is the fastest-growing function at an 18.49% CAGR, supported by wider AI deployment across enterprise software, consumer services, and autonomous systems.
Which deployment model dominates current spending?
Cloud led with 72.73% share in 2025 because hyperscale data centers remain the core venue for frontier training and large-scale inference.
Which end-user group is expanding the fastest?
Government and defense is projected to grow at a 19.94% CAGR through 2031 as sovereign compute and secure AI infrastructure programs expand.
Which region offers the strongest growth opportunity?
Asia-Pacific is expected to post the fastest CAGR at 19.09% through 2031 because it sits at the center of foundry, memory, and advanced packaging supply chains.
Page last updated on:






