Tamanho e Participação do Mercado de AI Superchip
Visão Geral do Mercado
| Período de Estudo | 2020 - 2031 |
|---|---|
| Tamanho do Mercado (2026) | 84.97 Bilhões de dólares |
| Tamanho do Mercado (2031) | 195.22 Bilhões de dólares |
| Taxa de crescimento (2026 - 2031) | 18.10% CAGR |
| Mercado de Crescimento Mais Rápido | Ásia-Pacífico |
| Maior Mercado | América do Norte |
| Concentração do Mercado | Alto |
Principais jogadores
*Isenção de responsabilidade: Principais participantes classificados em nenhuma ordem específica Imagem © Mordor Intelligence. O reuso requer atribuição conforme CC BY 4.0. |
|
Análise do Mercado de AI Superchip por Mordor Intelligence
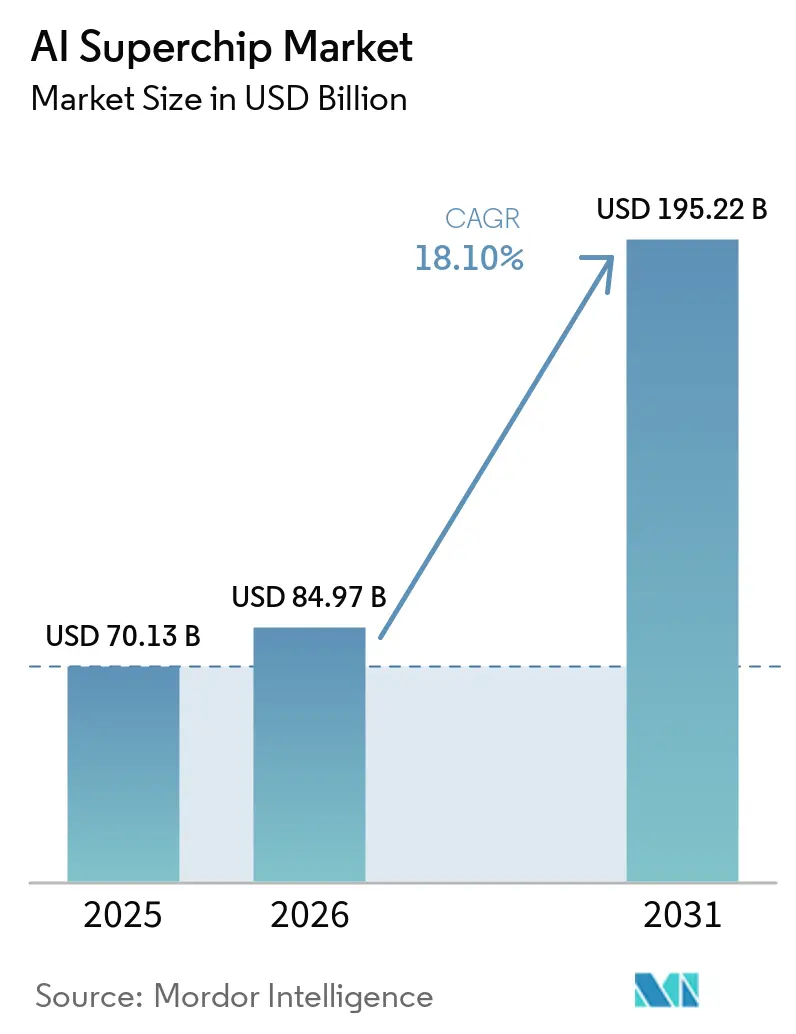
O tamanho do mercado de AI Superchip deve crescer de 70,13 bilhões USD em 2025 para 84,97 bilhões USD em 2026 e está previsto para atingir 195,22 bilhões USD até 2031 a um CAGR de 18,10% no período 2026-2031. O mercado está sendo impulsionado por um aumento acentuado nos gastos de hiperescala em aceleradores de IA, silício personalizado e construções de centros de dados de próxima geração. A demanda também está se ampliando porque o processamento agora é consumido em pré-treinamento, pós-treinamento, escalonamento em tempo de teste e cargas de trabalho agênticas, em vez de se concentrar em um único grande ciclo de treinamento. As condições de fornecimento estão moldando os resultados com a mesma força que o desempenho bruto do chip, porque memória, empacotamento avançado e resfriamento em nível de rack agora influenciam os cronogramas de entrega e a estratégia de produto. As posições competitivas estão se aprofundando em torno de ecossistemas de software, padrões de interconexão e acesso à cadeia de suprimentos, o que confere uma vantagem clara aos fornecedores de escala. Programas de computação soberana e implantações de borda sensíveis à latência também estão expandindo o mercado endereçável para o AI Superchip, mesmo que os ganhos de eficiência dos modelos pressionem os fornecedores a equilibrar o rendimento de treinamento com a eficiência de inferência.
Principais Conclusões do Relatório
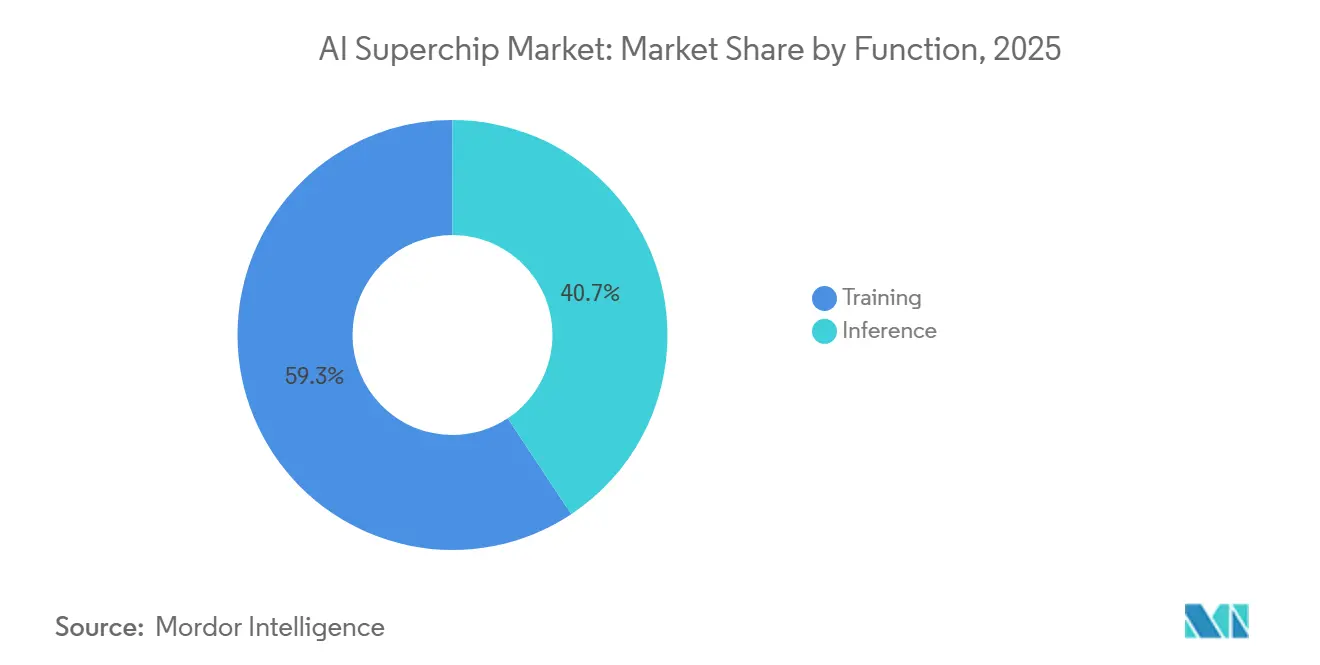
- Por função, o treinamento representou 59,32% do mercado de AI Superchip em 2025, enquanto a inferência está projetada para se expandir a um CAGR de 18,49% até 2031.
- Por tipo de arquitetura, os superchips integrados CPU-GPU representaram 43,76% do mercado em 2025, enquanto os superchips baseados em ASIC de IA devem registrar o maior CAGR de 18,81% até 2031.
- Por tecnologia de empacotamento, o empacotamento em módulo multichip capturou 48,14% de participação em 2025, enquanto o SoC baseado em chiplet está projetado para avançar a um CAGR de 18,89% até 2031.
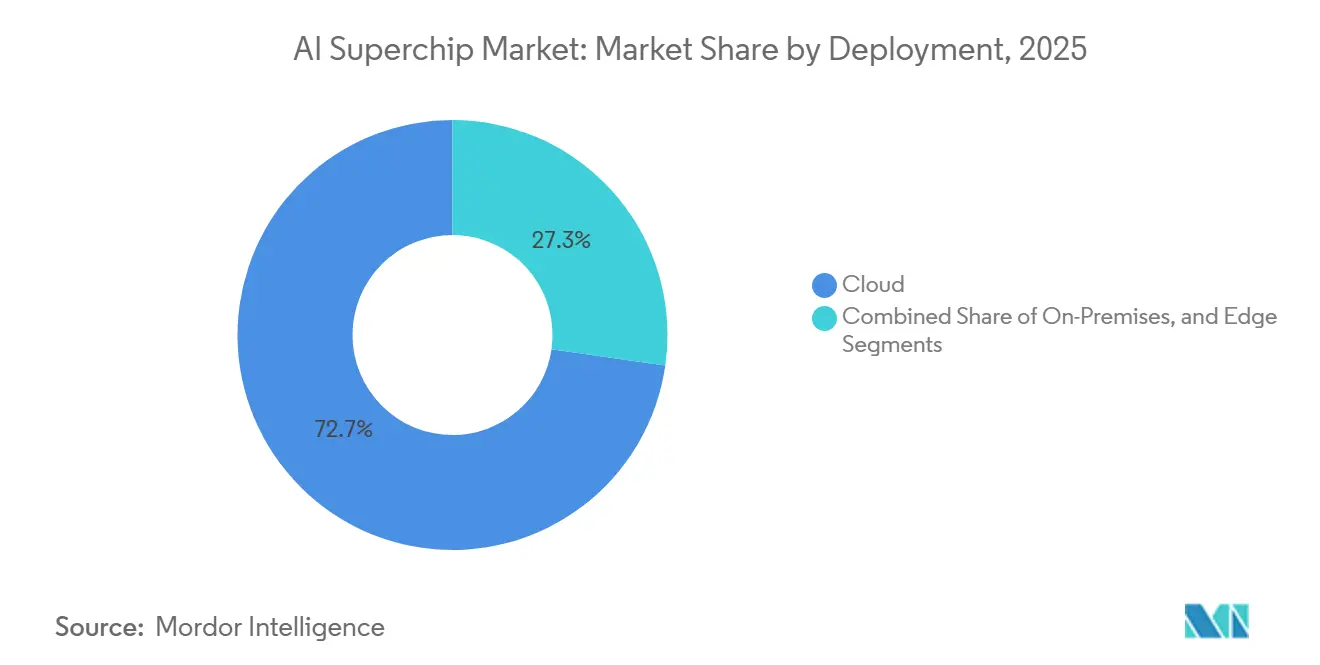
- Por implantação, a nuvem deteve 72,73% de participação no mercado de AI Superchip de inteligência artificial (IA) em 2025, enquanto a borda deve crescer ao CAGR mais rápido de 18,68% até 2031.
- Por setor de usuário final, os provedores de nuvem em hiperescala representaram 62,12% dos gastos em 2025, enquanto governo e defesa estão projetados para se expandir a um CAGR de 19,94% até 2031.
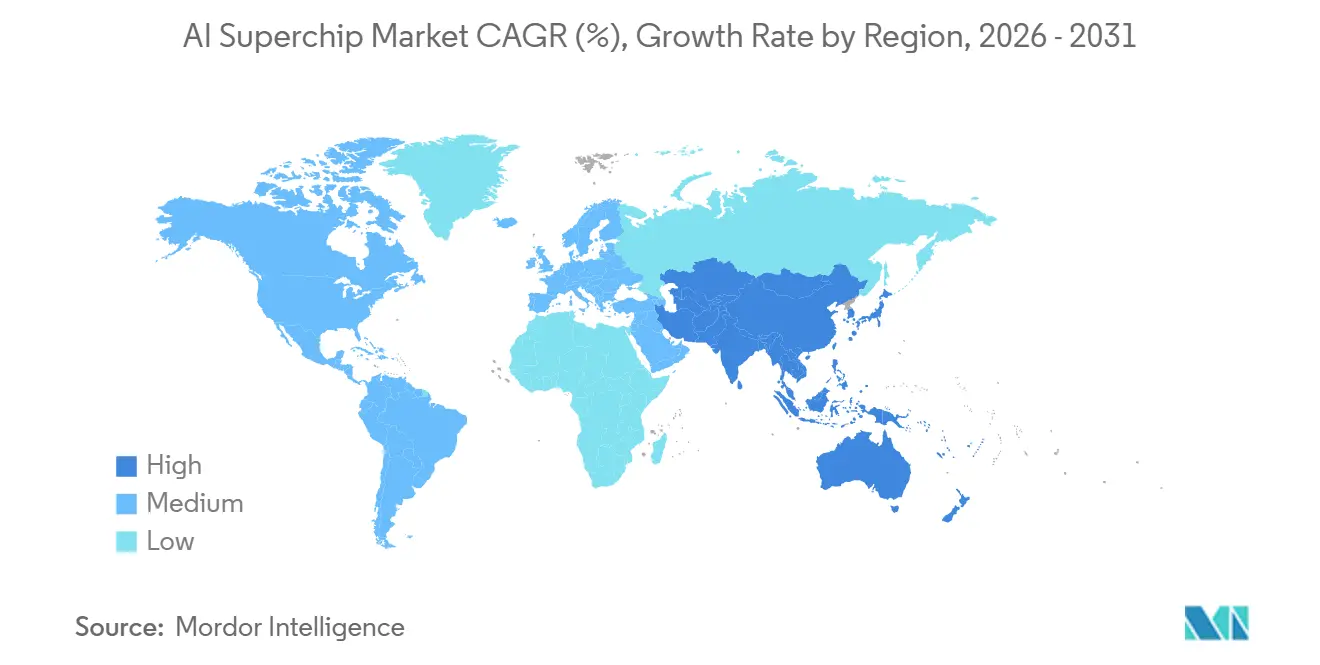
- Por geografia, a América do Norte representou 55,69% da receita em 2025, enquanto a Ásia-Pacífico deve registrar o CAGR mais rápido de 19,09% até 2031.
Nota: O tamanho do mercado e os números de previsão neste relatório são gerados usando a estrutura de estimativa proprietária da Mordor Intelligence, atualizada com os dados e percepções mais recentes disponíveis em janeiro de 2026.
Tendências e Perspectivas do Mercado Global de AI Superchip
Análise de Impacto dos Impulsionadores*
| Impulsionador | (~) % de Impacto na Previsão de CAGR | Relevância Geográfica | Prazo de Impacto |
|---|---|---|---|
| Expansão do Processamento para Treinamento de Modelos de Fronteira | +3.2% | Global, concentrado na América do Norte e Ásia-Pacífico | Curto prazo (≤ 2 anos) |
| Co-localização de HBM e Escalonamento de Largura de Banda de Memória | +2.8% | Global, com cadeia de suprimentos concentrada na Coreia do Sul e em Taiwan | Curto prazo (≤ 2 anos) |
| Integração Heterogênea Baseada em Chiplet | +2.5% | Global, empacotamento liderado por Taiwan, atividade de design na América do Norte e Europa | Médio prazo (2-4 anos) |
| Construção de Infraestrutura de IA Soberana | +2.0% | GCC, Europa, Sul da Ásia, Sudeste Asiático | Médio prazo (2-4 anos) |
| Inferência de Borda em Escala em Sistemas Industriais | +1.6% | Cinturões de manufatura da Ásia-Pacífico, América do Norte, Alemanha | Médio prazo (2-4 anos) |
| Demanda por Interconexão Avançada para Sistemas Multi-Die | +1.2% | América do Norte, Taiwan, Coreia do Sul | Longo prazo (≥ 4 anos) |
| Fonte: Mordor Intelligence | |||
A Expansão do Processamento para Treinamento de Modelos de Fronteira Impulsiona o Apetite Sustentado por Silício
O treinamento de modelos de fronteira continua a manter o mercado de AI Superchip em uma trajetória acentuada de gastos, porque os sistemas de linguagem, visão e multimodais mais recentes exigem materialmente mais processamento paralelo do que as gerações anteriores. A transição para designs de mistura de especialistas e pós-treinamento em múltiplos estágios estendeu a demanda por hardware além de uma única janela de pré-treinamento e para ciclos de ajuste fino, alinhamento e avaliação. A NVIDIA lançou a plataforma Rubin em 5 de janeiro de 2026, com 50 petaflops de processamento de inferência NVFP4 por GPU, e a empresa afirmou que a plataforma pode treinar modelos de mistura de especialistas com 4 vezes menos GPUs do que a geração Blackwell anterior.[1]NVIDIA, "NVIDIA Kicks Off the Next Generation of AI with Rubin - Six New Chips, One Incredible AI Supercomputer," NVIDIA Newsroom, nvidia.com O menor custo de processamento por modelo não reduz a demanda geral por chips, porque os laboratórios geralmente respondem visando sistemas maiores e executando mais experimentos. Esse mesmo padrão se estende à implantação, onde as cargas de trabalho de raciocínio consomem processamento variável por consulta, em vez de um orçamento de inferência fixo. O resultado é que o mercado de AI Superchip está vendo a demanda se acumular ao longo de todo o ciclo de vida do modelo, o que sustenta tanto os clusters de treinamento quanto as frotas de inferência de alto volume.
A Co-localização de HBM e o Escalonamento de Largura de Banda de Memória Reformulam a Arquitetura dos Chips
A memória de alta largura de banda passou de um diferencial de desempenho para um requisito básico de design para o mercado de AI Superchip, pois os aceleradores modernos não conseguem sustentar o rendimento sem memória próxima ao processamento. A JEDEC publicou o padrão HBM4 em dezembro de 2024 com uma interface de 2.048 bits e uma meta de 1,5-2 TB/s de largura de banda por pilha, o que elevou o teto para futuros designs de aceleradores. A Siemens observou que o HBM4 também aumenta a capacidade da pilha para 64 GB, dando aos designers mais espaço para equilibrar largura de banda, capacidade e energia dentro do mesmo pacote. Essa mudança de memória está alterando as escolhas de arquitetura porque blocos de processamento, interposers e caminhos térmicos agora estão sendo projetados em torno das restrições de memória desde o início. Isso também ressalta a importância da prontidão dos fornecedores na Coreia do Sul e em Taiwan, pois a disponibilidade de memória pode moldar o cronograma de lançamento com a mesma força que o design lógico. Como resultado, o sucesso do produto depende cada vez mais de quão bem os fornecedores coordenam memória, empacotamento e integração de sistemas, em vez de depender apenas do rendimento do processador.
A Integração Heterogênea Baseada em Chiplet Rompe o Limite do Retículo
A integração de chiplets está se tornando central para o mercado de AI Superchip porque os dies monolíticos não podem mais escalar livremente dentro dos limites de litografia. A Siemens relatou que o roteiro CoWoS-L da TSMC visa um aumento de 9 a 14 vezes no tamanho do retículo de 2027 a 2029, refletindo a necessidade de muito mais espaço para tiles de processamento e pilhas de HBM em pacotes futuros. A Synopsys concluiu uma gravação de IP UCIe de 64 Gbps em 2026, demonstrando que os links die-a-die estão avançando para largura de banda de múltiplos terabits em alcances muito curtos. O CEA-Leti também demonstrou a ligação híbrida die-a-wafer com passo de 1 µm em maio de 2026, indicando maior densidade de interconexão entre chiplets. Esses avanços facilitam a combinação de processamento, memória e E/S em diferentes nós de processo dentro de um único pacote. A mudança está deslocando a vantagem competitiva para a arquitetura de pacotes, co-design e conhecimento de montagem, favorecendo os players com profunda integração em toda a pilha de semicondutores.
A Construção de Infraestrutura de IA Soberana Diversifica a Base de Demanda
Os programas de computação soberana estão ampliando a demanda pelo mercado de AI Superchip além dos hiperescaladores, à medida que os governos buscam cada vez mais infraestrutura de IA controlada domesticamente. O governo do Reino Unido anunciou um Plano de Hardware de IA de 1,1 bilhão GBP (1,41 bilhão USD) em 8 de junho de 2026, incluindo 750 milhões GBP (960 milhões USD) para um supercomputador nacional de IA e 400 milhões GBP (512 milhões USD) para aquisição de chips. O mesmo plano incluiu um compromisso antecipado de 150 milhões GBP (192 milhões USD) para chips de inferência inovadores de fornecedores britânicos e startups, o que mostra que os compradores públicos estão moldando o mix de fornecedores e o volume de demanda. Esses programas tendem a apoiar configurações locais e de borda porque cargas de trabalho sensíveis raramente são roteadas por ambientes de nuvem comercial. Eles também criam oportunidades para fornecedores de empacotamento, armazenamento, redes e design de sistemas seguros, não apenas para fornecedores de aceleradores. À medida que as construções soberanas se espalham por mais países, a base de demanda torna-se menos dependente de alguns compradores globais de nuvem e mais distribuída entre programas do setor público.
Análise de Impacto das Restrições*
| Restrição | (~) % de Impacto na Previsão de CAGR | Relevância Geográfica | Prazo de Impacto |
|---|---|---|---|
| Restrições de Capacidade de Empacotamento Avançado | -2.0% | Global, concentrado em Taiwan | Curto prazo (≤ 2 anos) |
| Controles de Exportação sobre Aceleradores de Ponta | -1.8% | América do Norte (oferta), China e Oriente Médio e África (demanda), rotas comerciais globais | Médio prazo (2-4 anos) |
| Limites de Densidade de Energia e Resfriamento em Racks Densos | -1.0% | Global, agudo em centros de dados brownfield na Europa e América do Norte | Médio prazo (2-4 anos) |
| Ganhos de Eficiência de Modelos que Reduzem a Demanda Incremental por Silício | -0.8% | Global | Longo prazo ( |
| Fonte: Mordor Intelligence | |||
As Restrições de Capacidade de Empacotamento Avançado Limitam o Rendimento de Fornecimento no Curto Prazo
O empacotamento avançado continua sendo o freio de curto prazo mais claro no mercado de AI Superchip, porque os aceleradores não podem ser enviados sem uma montagem complexa que coloca dies de processamento e HBM dentro do mesmo pacote. Mesmo quando o fornecimento de wafers melhora, as linhas de empacotamento ainda precisam de equipamentos de ligação especializados, ferramentas de posicionamento e sistemas de inspeção que levam tempo para instalar e qualificar. Isso mantém muitos fornecedores com restrições de alocação e torna a disponibilidade de pacotes um alavancador comercial tão importante quanto o design do chip ou os inícios de wafer. A escassez também reforça a concentração porque empresas maiores podem garantir acesso a substrato, memória e fundição com mais facilidade do que rivais menores. Os padrões de design de resfriamento e interconexão estão elevando o nível técnico para implantações densas, o que significa que as restrições de empacotamento agora se estendem ao design de rack e à qualificação de sistemas também. Até que a capacidade se expanda mais plenamente, os cronogramas de entrega continuarão dependendo da prontidão do empacotamento tanto quanto da demanda por processadores.
Os Controles de Exportação sobre Aceleradores de Ponta Fragmentam o Acesso ao Mercado Global
Os controles de exportação estão fragmentando o acesso ao mercado e limitando a livre circulação de AI Superchips de ponta entre regiões. O Departamento de Indústria e Segurança dos EUA esclareceu em 31 de maio de 2026 que os requisitos de licença para itens de computação avançada também se aplicam a subsidiárias de empresas chinesas fora da China, o que restringiu um canal que anteriormente oferecia acesso indireto.[2]Departamento de Comércio dos EUA BIS / Mondaq, "Enforcement Pause Has Limits: BIS Clarifies Ongoing License Requirement for Advanced Computing Items to China-Linked Entities," Mondaq, mondaq.com Isso está dividindo a demanda em pools geopolíticos separados e reduzindo a base endereçável para alguns fornecedores ocidentais. Também está acelerando programas domésticos de chips em mercados restritos, o que pode, ao longo do tempo, criar cadeias de suprimentos alternativas. As decisões de aquisição estão, portanto, sendo moldadas por conformidade, geografia e alinhamento político, além de preço e desempenho. O resultado é um mercado global menos integrado, onde os principais fornecedores devem gerenciar tanto os roteiros de produtos quanto as fronteiras regulatórias em constante mudança.
*Nossas previsões tratam os impactos dos impulsionadores e restrições como direcionais, e não aditivos. As previsões de impacto refletem o crescimento de base, os efeitos de composição e as interações entre variáveis.
Análise de Segmentos
Por Função: O Treinamento Ancora a Escala do Mercado Enquanto a Inferência Fecha a Lacuna
O treinamento deteve 59,32% do mercado de AI Superchip em 2025 e representou a maior fatia do mercado porque o desenvolvimento de modelos de fronteira ainda consome o maior processamento. Essa liderança refletiu a intensidade do treinamento em grandes clusters, onde modelos de última geração podem usar dezenas de milhares de GPUs ao longo de ciclos de desenvolvimento prolongados. O treinamento também permanece central porque os laboratórios líderes não estão apenas escalando o tamanho dos modelos, mas também adicionando mais estágios para ajuste fino e avaliação. Essas etapas adicionais mantêm o uso do cluster elevado mesmo após a conclusão da fase inicial de pré-treinamento. A NVIDIA afirmou que a plataforma Rubin pode treinar modelos de mistura de especialistas com 4 vezes menos GPUs do que a geração Blackwell anterior, demonstrando com que rapidez a linha de base de eficiência está avançando.
Essa mudança de eficiência pode comprimir a participação do treinamento ao longo do tempo, mas não reduz a importância do treinamento em termos absolutos de gastos. A inferência está prevista para se expandir a um CAGR de 18,49% até 2031, à medida que o número de modelos implantados aumenta em software empresarial, serviços ao consumidor e sistemas autônomos. O setor de AI Superchip, portanto, não está se afastando do treinamento; está adicionando um segundo grande pool de demanda por meio de inferência em tempo real. As cargas de trabalho de raciocínio também aumentam o uso de processamento durante a implantação porque podem alocar tempo variável de GPU para cada prompt, em vez de seguir um caminho de resposta fixo. Isso significa que o crescimento da inferência se soma à demanda de treinamento existente, em vez de substituí-la. O mercado de AI Superchip provavelmente permanecerá equilibrado entre laboratórios que precisam de grandes clusters de treinamento e operadores que precisam de frotas de inferência rápidas e eficientes.


Por Tipo de Arquitetura: A Integração CPU-GPU Lidera enquanto os ASICs Personalizados Aceleram
Os superchips integrados CPU-GPU detiveram uma participação de 43,76% em 2025 e representaram a maior participação do mercado de AI Superchip porque atendem às necessidades de treinamento em larga escala e ambientes de processamento misto. Sua liderança foi construída em plataformas como Grace Blackwell e Vera Rubin, que unem CPUs baseadas em Arm e GPUs com largura de banda de interconexão muito alta. A coordenação mais estreita entre CPU e GPU melhora o movimento de dados e reduz a perda de desempenho causada pelo cruzamento de domínios de memória separados. Essa combinação é útil quando orquestração, acesso à memória e execução do acelerador devem funcionar como um único sistema. Isso também ajuda a explicar por que as plataformas integradas permanecem a base preferida para grandes clusters de IA.
Os superchips baseados em ASIC de IA estão projetados para registrar o CAGR mais rápido de 18,81% até 2031, à medida que os hiperescaladores combinam cada vez mais o silício com a economia de cargas de trabalho específicas. O setor de AI Superchip está vendo isso mais claramente na inferência, onde cargas de trabalho previsíveis e repetitivas favorecem o design de chips personalizados. O Google introduziu o TPU 8t para treinamento e o TPU 8i para inferência em abril de 2026, o que mostrou uma divisão mais clara entre caminhos de acelerador específicos para cada carga de trabalho. Isso importa porque custo, energia e rendimento podem ser ajustados com mais precisão quando o comprador controla a pilha de software e o modelo de implantação. As configurações acopladas GPU-GPU e de múltiplos aceleradores heterogêneos permanecerão importantes em ambientes especializados, mas o sinal de crescimento mais forte está vindo da implantação de ASIC personalizado em hiperescala. À medida que esse mix se expande, os fornecedores de GPU de mercado enfrentarão maior pressão em casos de uso com uso intensivo de inferência, onde os custos de propriedade se tornam um fator de compra mais forte.
Por Tecnologia de Empacotamento: O MCM Comanda a Participação enquanto as Arquiteturas de Chiplet Definem a Curva de Crescimento
O empacotamento em módulo multichip capturou 48,14% de participação em 2025 e liderou o mix de empacotamento porque oferece um equilíbrio viável entre controle térmico, escalabilidade de fabricação e eficiência de largura de banda. Os formatos MCM também são suportados por um ecossistema estabelecido de fundição e OSAT, o que ajuda os fornecedores a escalar a produção mais rapidamente do que com abordagens menos maduras. Isso importa no ciclo atual porque a escolha do pacote influencia a velocidade de entrega tanto quanto o desempenho técnico. O MCM, portanto, permanece a estrutura padrão para muitos aceleradores de IA de alto desempenho que combinam grandes dies de processamento e pilhas de HBM. Sua liderança provavelmente se manterá no curto prazo, enquanto as cadeias de suprimentos continuarem a favorecer caminhos de montagem comprovados.
Os SoCs baseados em chiplet estão previstos para crescer a um CAGR de 18,89% até 2031, à medida que os limites do retículo levam os designers a dividir o processamento em múltiplos dies. Este é um dos exemplos mais claros em que o mercado de AI Superchip está sendo moldado por limites de design físico, em vez de simples metas de desempenho. A Synopsys concluiu uma gravação de IP UCIe de 64 Gbps em 2026, e o CEA-Leti demonstrou ligação híbrida die-a-wafer de 1 µm em maio de 2026, ambos os quais suportam integração die-a-die mais densa. Esses avanços facilitam o tratamento de um pacote como um sistema modular, em vez de um único chip grande. Os designs de SoC monolítico e de sistema em pacote ainda serão importantes em configurações menores de borda e robustecidas, mas o escalonamento futuro no topo está se movendo em direção a montagens com uso intensivo de chiplets. À medida que essa mudança se aprofunda, a arquitetura de pacotes torna-se uma fonte mais forte de diferenciação de produtos do que o modelo de die único.
Por Implantação: A Nuvem Domina com Mais de 70% de Participação enquanto a Borda se Torna o Campo de Batalha Estratégico
A implantação em nuvem deteve uma participação de 72,73% em 2025 e representou a maior participação do mercado de AI Superchip de inteligência artificial (IA), pois os centros de dados em hiperescala ainda hospedam as cargas de treinamento mais pesadas e de inferência em larga escala. Os hiperescaladores podem financiar infraestrutura especializada, resfriamento avançado e ambientes de software que poucos outros compradores conseguem igualar. Essa vantagem de escala mantém a nuvem no centro tanto do desenvolvimento de modelos quanto da implantação ampla de serviços. Também torna a nuvem o principal ponto de entrada para novas arquiteturas que exigem integração densa em nível de rack. O mercado de AI Superchip continua a depender da capacidade de hiperescala porque os sistemas mais avançados ainda exigem ambientes otimizados para energia, resfriamento e densidade de rede.
A NVIDIA posicionou os sistemas baseados em Rubin em torno de grandes construções de infraestrutura de IA, reforçando a ideia de que as plataformas principais ainda estão sendo projetadas primeiro para implantação em escala de nuvem. A implantação de borda está projetada para se expandir a um CAGR de 18,68% até 2031 porque mais cargas de trabalho industriais e de defesa não podem tolerar a latência de ida e volta da nuvem. Esse crescimento está sendo impulsionado menos por dispositivos de consumo e mais por operações de campo, fábricas e sistemas remotos que precisam de inferência local. A Emerson e a SiMa Technologies anunciaram PCs industriais habilitados para IA para manufatura e locais de campo remotos em maio de 2026, o que mostrou como a IA física está se movendo para ambientes industriais controlados. Os sistemas locais permanecerão importantes em setores regulamentados, como saúde, finanças e governo. O sinal de crescimento mais acentuado, no entanto, está na borda, onde limites de energia, implantação robustecida e controle local estão criando um caminho de hardware distinto da nuvem em hiperescala.

Por Setor de Usuário Final: Os Provedores de Hiperescala Definem a Velocidade dos Gastos enquanto a Defesa Cresce Mais Rapidamente
Os provedores de nuvem em hiperescala representaram 62,12% dos gastos do usuário final em 2025 e definiram o ritmo de gastos para o mercado de AI Superchip de inteligência artificial (IA), pois os maiores orçamentos de aquisição permanecem concentrados em algumas plataformas de nuvem. Suas decisões de compra afetam os roteiros de aceleradores, a alocação de empacotamento e o suporte de software em toda a cadeia de valor mais ampla. Essa concentração de compradores confere às principais empresas de nuvem uma influência incomum sobre o que é construído primeiro e quais fornecedores escalam mais rapidamente. Isso também significa que muitos relacionamentos com fornecedores estão sendo formados em torno de um pequeno grupo de clientes muito grandes. O ambiente de demanda atual, portanto, reflete tanto a demanda do usuário final quanto a concentração de compradores no topo do mercado.
As organizações governamentais e de defesa estão projetadas para registrar o CAGR mais rápido de 19,94% até 2031, à medida que mais países tratam o processamento de IA como infraestrutura estratégica. O setor de AI Superchip está se beneficiando dessa mudança por meio da demanda por computação soberana, implantação segura e canais de aquisição controlados. O Plano de Hardware de IA do Reino Unido, anunciado em junho de 2026, mostrou apoio direto do setor público para capacidade de processamento, aquisição de chips e desenvolvimento de hardware doméstico. As instituições de pesquisa e acadêmicas permanecem menores em gastos absolutos, mas estão obtendo melhor acesso a sistemas avançados por meio de implementações de infraestrutura orientadas à ciência. A NVIDIA afirmou que os sistemas baseados em Vera Rubin NVL4 para computação científica estarão disponíveis pela Dell Technologies, HPE, GIGABYTE e Supermicro no quarto trimestre de 2026. Esse acesso mais amplo não muda a hierarquia de gastos, mas estende o processamento de alto desempenho além dos ambientes de hiperescaladores e de defesa.
Análise Geográfica
A América do Norte deteve 55,69% do mercado de AI Superchip em 2025, a maior participação, porque os laboratórios de IA de fronteira, as sedes dos hiperescaladores e os maiores orçamentos de infraestrutura anunciados estão concentrados lá. Os Estados Unidos permanecem o centro do design de aceleradores de mercado e da estratégia de silício personalizado, o que mantém grande parte da propriedade intelectual do setor ancorada lá. A região também se beneficia do estreito alinhamento entre compradores de nuvem, designers de chips, construtores de sistemas e ecossistemas de software. O Canadá está emergindo como um nó de suporte para esforços de computação soberana, enquanto o México permanece mais relevante como local de produção próximo do que como uma grande fonte de demanda. Esses fatores mantêm a América do Norte estruturalmente forte, mesmo quando a fabricação está em outro lugar.
A Ásia-Pacífico está projetada para se expandir a um CAGR de 19,09% até 2031, tornando-a a geografia de crescimento mais rápido no mercado de AI Superchip de inteligência artificial (IA). A região está no centro do trabalho de fundição de ponta, produção de memória de alta largura de banda e empacotamento avançado, o que lhe confere influência direta sobre o cronograma de fornecimento global. Taiwan e Coreia do Sul permanecem críticos porque a profundidade de fabricação e o controle de memória moldam o ritmo de lançamento de aceleradores avançados. A Missão IndiaAI da Índia operou uma instalação de processamento com 38.000 GPUs no início de 2026 e tinha como meta 100.000 até o final do ano, indicando uma base de demanda local em rápido crescimento.[3]Carnegie Endowment for International Peace, "Early Lessons in the Pursuit of Sovereign AI," Carnegie Endowment, carnegieendowment.org
A Europa deteve uma participação de receita de médio porte em 2025, liderada pela Alemanha, Reino Unido e França. O governo do Reino Unido anunciou um Plano de Hardware de IA de 1,1 bilhão GBP (1,41 bilhão USD) em junho de 2026, incluindo financiamento para um supercomputador nacional de IA e aquisição de chips. Essa direção política apoia mais capacidade de processamento local e reforça a demanda local em ambientes regulamentados. A América do Sul, o Oriente Médio e a África permanecem menores em termos de receita, mas os programas de infraestrutura soberana estão abrindo novas oportunidades, especialmente nos mercados do Golfo, onde o investimento digital apoiado pelo Estado está crescendo.

Cenário Competitivo
O mercado de AI Superchip permanece altamente concentrado, apesar de sua grande base de receita e escopo de aplicação em expansão. A NVIDIA detinha uma estimativa de 80%-85% da receita de aceleradores de IA em 2026, deixando os rivais de mercado em uma escala muito menor. Sua liderança tem se baseado no bloqueio de software CUDA, forte acesso a pacotes e na capacidade de vender plataformas completas em vez de chips individuais. A AMD permanece o desafiante de mercado mais próximo, com a linha Instinct reduzindo a lacuna técnica em cargas de trabalho direcionadas. Mesmo assim, o poder competitivo neste mercado ainda depende da adoção de software, acesso ao fornecimento e alcance do ecossistema tanto quanto depende do desempenho bruto do silício.
O silício personalizado dos hiperescaladores é o desafio estrutural mais significativo para os fornecedores de GPU de mercado, pois os maiores compradores buscam cada vez mais um controle mais rígido sobre custos e design de cargas de trabalho. O Google introduziu o TPU 8t para treinamento e o TPU 8i para inferência em abril de 2026, o que mostrou como os hiperescaladores estão separando os caminhos dos aceleradores para corresponder à economia de implantação específica. A NVIDIA respondeu expandindo o NVLink Fusion, para que ASICs de terceiros e XPUs possam se conectar ao seu fabric de escalonamento. A Lightmatter aderiu ao NVLink Fusion em junho de 2026, mostrando que a NVIDIA está ampliando sua posição em interconexões e óptica, em vez de defender uma pilha de hardware totalmente fechada.[4]Lightmatter, "Lightmatter Joins NVIDIA NVLink Fusion and Powers Next-Generation AI Infrastructure with Photonic Interconnects," Lightmatter, lightmatter.co
As startups ainda estão encontrando espaço onde oferecem uma arquitetura clara ou ângulo de implantação, mesmo que a receita principal permaneça concentrada. A Groq expandiu seu footprint de inferência em nuvem especializada após confirmar uma rodada de financiamento de 650 milhões USD em junho de 2026, o que mostrou o apoio dos investidores para modelos de plataforma focados em inferência. A Micron e a Anthropic também anunciaram um acordo estratégico plurianual em junho de 2026 que vinculou mais estreitamente o fornecimento de memória e armazenamento às necessidades da infraestrutura de IA de fronteira. Empresas de serviços de design como Broadcom e Marvell também estão bem posicionadas para compradores empresariais e governamentais que desejam silício semicustomizado sem a escala total de hiperescaladores. A vantagem competitiva está, portanto, se espalhando pelo design de chips, memória, empacotamento, óptica e software, mesmo enquanto o pool de receita permanece concentrado em torno de um pequeno número de players dominantes.
Líderes do Setor de AI Superchip
-
NVIDIA Corporation
-
Advanced Micro Devices, Inc.
-
Intel Corporation
-
Google LLC
-
Amazon.com, Inc.
- *Isenção de responsabilidade: Principais participantes classificados em nenhuma ordem específica

Desenvolvimentos Recentes do Setor
- Junho de 2026: A Groq confirmou uma rodada de financiamento de 650 milhões USD, seis meses após a NVIDIA assinar um acordo de licenciamento não exclusivo para a tecnologia de unidade de processamento de linguagem da Groq. A Groq usou o capital para expandir seu negócio de inferência em nuvem especializada para 13 centros de dados globalmente, com meta de 200 MW de capacidade até 2027. O acordo ressalta como a NVIDIA está consolidando a propriedade intelectual de inferência enquanto as startups de inferência estabelecidas se voltam para negócios de plataforma em vez de competir diretamente em hardware.
- Junho de 2026: A Micron e a Anthropic anunciaram um acordo estratégico plurianual abrangendo fornecimento de memória e armazenamento, colaboração tecnológica e o investimento estratégico da Micron na rodada de financiamento Série H da Anthropic. O acordo vincula diretamente os compromissos de fornecimento de HBM de próxima geração às necessidades de infraestrutura de modelos de IA de fronteira em um prazo que se estende muito além dos relacionamentos padrão com fornecedores.
- Junho de 2026: A NVIDIA anunciou no ISC High Performance 2026 em Hamburgo que os sistemas baseados em Vera Rubin NVL4 para computação científica estarão disponíveis pela Dell Technologies, HPE, GIGABYTE e Supermicro no quarto trimestre de 2026. Esse movimento estende a plataforma Vera Rubin além das implantações em hiperescala e para laboratórios nacionais e instituições de pesquisa.
- Junho de 2026: A Lightmatter aderiu ao NVIDIA NVLink Fusion, integrando seus produtos de óptica co-empacotada e óptica quase empacotada ao ecossistema de interconexão de escalonamento da NVIDIA. Essa parceria reduz os requisitos de fibra e conector em 50% nas implantações baseadas em NVLink Fusion e marca a primeira camada de conectividade óptica dentro da arquitetura de fabric central da NVIDIA.


Escopo do Relatório do Mercado Global de AI Superchip
O Mercado de AI Superchip compreende plataformas de computação altamente integradas que combinam múltiplos elementos de processamento, aceleradores, subsistemas de memória e tecnologias de interconexão de alta velocidade em uma arquitetura unificada otimizada para cargas de trabalho de inteligência artificial (IA). Os AI Superchips são projetados para oferecer desempenho computacional excepcional, largura de banda de memória, eficiência energética e escalabilidade para aplicações de treinamento e inferência, permitindo que as organizações processem modelos de IA cada vez mais complexos, incluindo grandes modelos de linguagem (LLMs), IA generativa, IA multimodal, sistemas de recomendação, simulações científicas e análises avançadas.
O Mercado de AI Superchip é Segmentado por Função (Treinamento e Inferência), Tipo de Arquitetura (Superchips Integrados CPU-GPU, Superchips Acoplados GPU-GPU, Superchips Baseados em ASIC de IA e Superchips de Múltiplos Aceleradores Heterogêneos), Tecnologia de Empacotamento (Sistema Monolítico em Chip (SoC), SoC Baseado em Chiplet, Sistema em Pacote (SiP) e Módulo Multichip (MCM)), Implantação (Nuvem, Local e Borda), Usuário Final (Provedores de Nuvem em Hiperescala, Centros de Dados, Empresas, Organizações Governamentais e de Defesa e Instituições de Pesquisa e Acadêmicas) e Geografia (América do Norte, Europa, Ásia-Pacífico, América do Sul e Oriente Médio e África). As Previsões de Mercado são Fornecidas em Termos de Valor (USD).
| Treinamento |
| Inferência |
| Superchips Integrados CPU-GPU |
| Superchips Acoplados GPU-GPU |
| Superchips Baseados em ASIC de IA |
| Superchips de Múltiplos Aceleradores Heterogêneos |
| Sistema Monolítico em Chip (SoC) |
| SoC Baseado em Chiplet |
| Sistema em Pacote (SiP) |
| Módulo Multichip (MCM) |
| Nuvem |
| Local |
| Borda |
| Provedores de Nuvem em Hiperescala |
| Centros de Dados |
| Empresas |
| Organizações Governamentais e de Defesa |
| Instituições de Pesquisa e Acadêmicas |
| América do Norte | Estados Unidos |
| Canadá | |
| México | |
| Europa | Alemanha |
| Reino Unido | |
| França | |
| Itália | |
| Restante da Europa | |
| Ásia-Pacífico | China |
| Japão | |
| Coreia do Sul | |
| Índia | |
| Sudeste Asiático | |
| Restante da Ásia-Pacífico | |
| América do Sul | |
| Oriente Médio e África |
| Por Função | Treinamento | |
| Inferência | ||
| Por Tipo de Arquitetura | Superchips Integrados CPU-GPU | |
| Superchips Acoplados GPU-GPU | ||
| Superchips Baseados em ASIC de IA | ||
| Superchips de Múltiplos Aceleradores Heterogêneos | ||
| Por Tecnologia de Empacotamento | Sistema Monolítico em Chip (SoC) | |
| SoC Baseado em Chiplet | ||
| Sistema em Pacote (SiP) | ||
| Módulo Multichip (MCM) | ||
| Por Implantação | Nuvem | |
| Local | ||
| Borda | ||
| Por Usuário Final | Provedores de Nuvem em Hiperescala | |
| Centros de Dados | ||
| Empresas | ||
| Organizações Governamentais e de Defesa | ||
| Instituições de Pesquisa e Acadêmicas | ||
| Por Geografia | América do Norte | Estados Unidos |
| Canadá | ||
| México | ||
| Europa | Alemanha | |
| Reino Unido | ||
| França | ||
| Itália | ||
| Restante da Europa | ||
| Ásia-Pacífico | China | |
| Japão | ||
| Coreia do Sul | ||
| Índia | ||
| Sudeste Asiático | ||
| Restante da Ásia-Pacífico | ||
| América do Sul | ||
| Oriente Médio e África | ||


Principais Perguntas Respondidas no Relatório
Qual é o tamanho do mercado de AI Superchip e qual é sua perspectiva de crescimento?
O mercado de AI Superchip atingiu 70,13 bilhões USD em 2025, está em 84,97 bilhões USD em 2026 e está previsto para atingir 195,22 bilhões USD até 2031 a um CAGR de 18,10%.
Qual função lidera a demanda por AI Superchips?
O treinamento liderou em 2025 com 59,32% de participação porque o desenvolvimento de modelos de fronteira ainda absorve a maior intensidade de processamento em grandes clusters de GPU.
O que está impulsionando o crescimento mais rápido em AI Superchips?
A inferência é a função de crescimento mais rápido a um CAGR de 18,49%, apoiada pela implantação mais ampla de IA em software empresarial, serviços ao consumidor e sistemas autônomos.
Qual modelo de implantação domina os gastos atuais?
A nuvem liderou com 72,73% de participação em 2025 porque os centros de dados em hiperescala permanecem o principal local para treinamento de fronteira e inferência em larga escala.
Qual grupo de usuários finais está se expandindo mais rapidamente?
Governo e defesa está projetado para crescer a um CAGR de 19,94% até 2031 à medida que os programas de computação soberana e infraestrutura de IA segura se expandem.
Qual região oferece a maior oportunidade de crescimento?
A Ásia-Pacífico deve registrar o CAGR mais rápido de 19,09% até 2031 porque está no centro das cadeias de suprimentos de fundição, memória e empacotamento avançado.
Página atualizada pela última vez em:




