AIスーパーチップ市場規模とシェア
市場概要
| 調査期間 | 2020 - 2031 |
|---|---|
| 市場規模 (2026) | 84.97 十億米ドル |
| 市場規模 (2031) | 195.22 十億米ドル |
| 成長率 (2026 - 2031) | 18.10% CAGR |
| 最も急速に成長している市場 | アジア太平洋地域 |
| 最大市場 | 北米 |
| 市場集中度 | 高 |
主要プレーヤー *免責事項:主要選手の並び順不同 画像 © Mordor Intelligence。再利用にはCC BY 4.0の表示が必要です。 | |
Mordor IntelligenceによるAIスーパーチップ市場分析
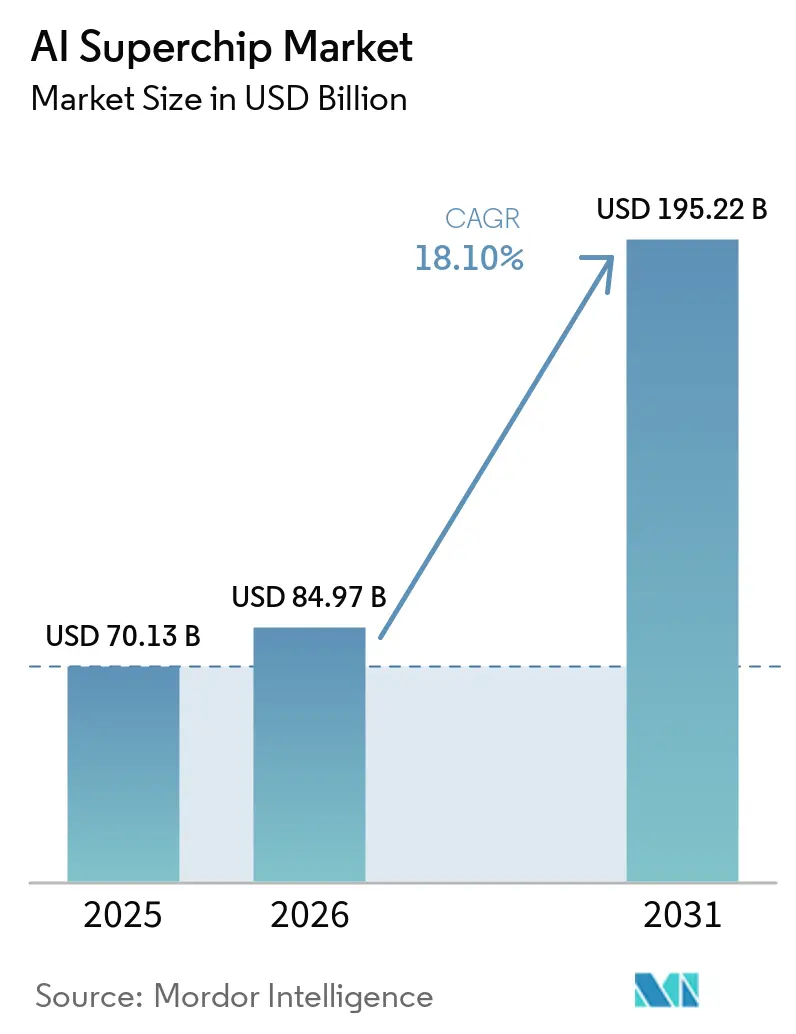
AIスーパーチップ市場規模は、2025年の700.13億米ドルから2026年には849.7億米ドルに成長し、2026年から2031年にかけて18.10%のCAGRで2031年までに1,952.2億米ドルに達すると予測されています。市場は、AIアクセラレーター、カスタムシリコン、次世代データセンター構築へのハイパースケール支出の急増によって押し上げられています。また、コンピュートが単一の大規模トレーニングサイクルではなく、事前トレーニング、事後トレーニング、テスト時スケーリング、エージェント型ワークロードにわたって消費されるようになったため、需要も拡大しています。メモリ、先進パッケージング、ラックレベルの冷却が納期スケジュールと製品戦略に影響を与えるため、供給状況は純粋なチップ性能と同様に強く結果を左右しています。競争上のポジションは、ソフトウェアエコシステム、インターコネクト標準、サプライチェーンアクセスを中心に深化しており、スケールベンダーに明確な優位性をもたらしています。ソブリンコンピュートプログラムとレイテンシに敏感なエッジデプロイメントも、AIスーパーチップのアドレス可能市場を拡大しており、モデル効率の向上がトレーニングスループットと推論効率のバランスを取るようベンダーに圧力をかけている中でも、その傾向は続いています。
主要レポートのポイント
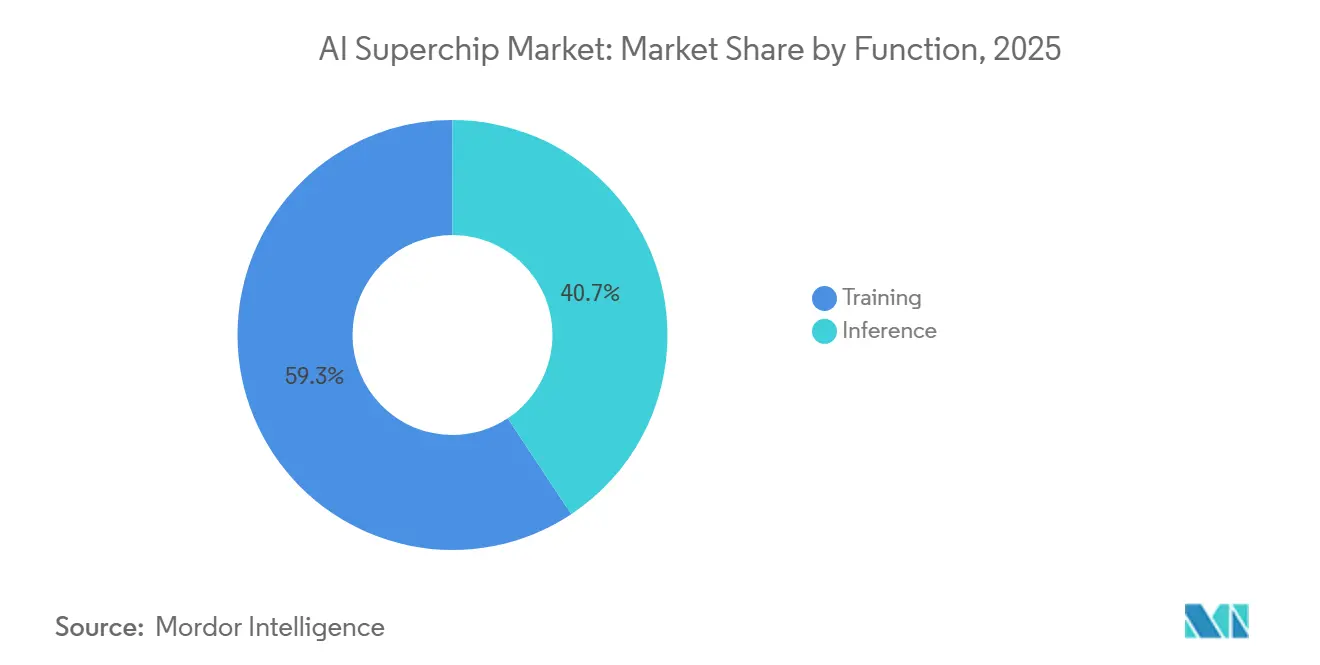
- 機能別では、トレーニングが2025年のAIスーパーチップ市場の59.32%を占め、推論は2031年にかけて18.49%のCAGRで拡大すると予測されています。
- アーキテクチャタイプ別では、CPU-GPU統合型スーパーチップが2025年の市場の43.76%を占め、AIアプリケーション特化型集積回路(ASIC)ベースのスーパーチップが2031年にかけて18.81%という最高のCAGRを記録すると予測されています。
- パッケージング技術別では、マルチチップモジュールパッケージングが2025年に48.14%のシェアを獲得し、チップレットベースのSoCは2031年にかけて18.89%のCAGRで成長すると予測されています。
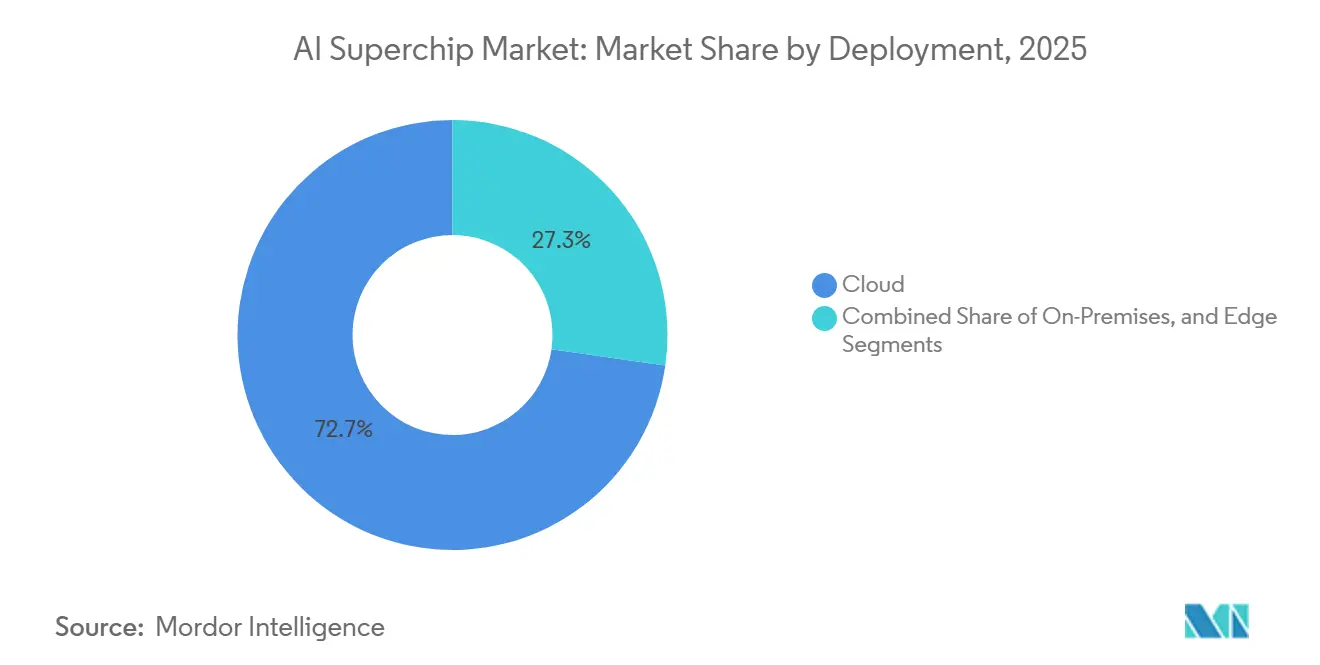
- デプロイメント別では、クラウドが2025年の人工知能(AI)スーパーチップ市場で72.73%のシェアを保持し、エッジは2031年にかけて18.68%という最速のCAGRで成長すると予測されています。
- エンドユーザー産業別では、ハイパースケールクラウドプロバイダーが2025年の支出の62.12%を占め、政府・防衛は2031年にかけて19.94%のCAGRで拡大すると予測されています。
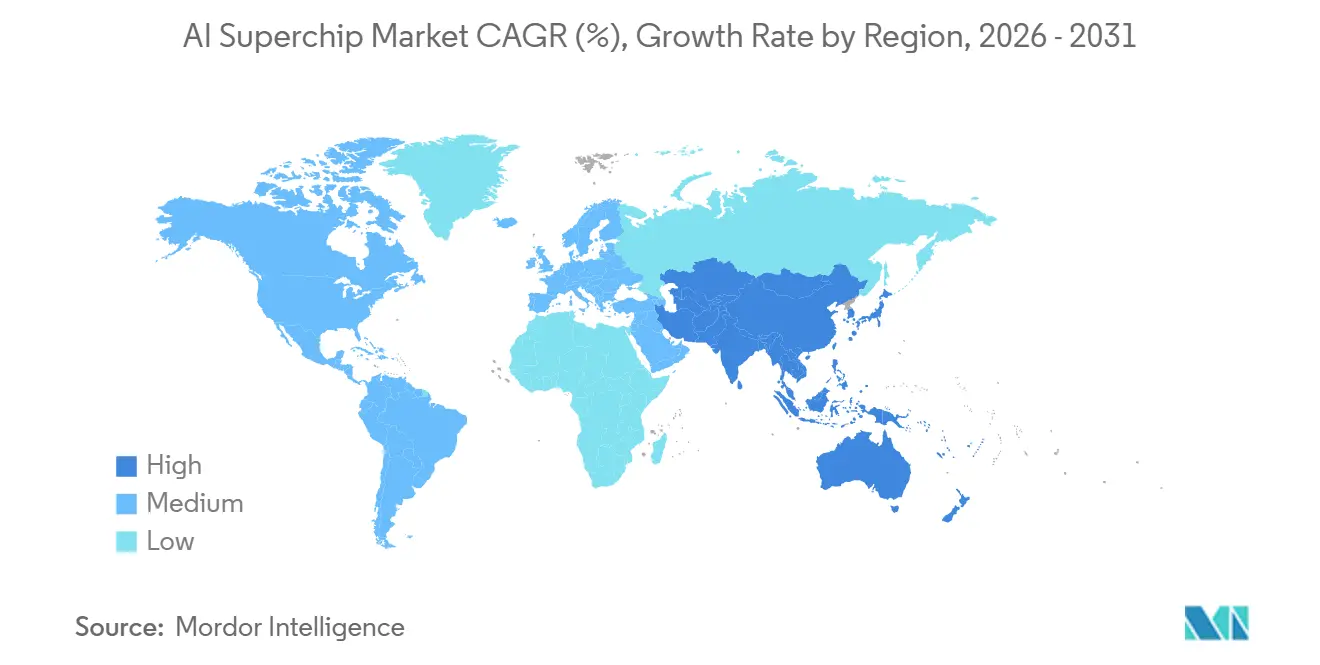
- 地域別では、北米が2025年の収益の55.69%を占め、アジア太平洋地域は2031年にかけて19.09%という最速のCAGRを記録すると予測されています。
注:本レポートの市場規模および予測数値は、Mordor Intelligence 独自の推定フレームワークを使用して作成されており、2026年1月時点の最新の利用可能なデータとインサイトで更新されています。
グローバルAIスーパーチップ市場のトレンドとインサイト
ドライバーインパクト分析*
| ドライバー | (~)CAGR予測への影響(%) | 地理的関連性 | 影響タイムライン |
|---|---|---|---|
| フロンティアモデルトレーニングコンピュートの拡大 | +3.2% | グローバル、北米とアジア太平洋地域に集中 | 短期(2年以内) |
| HBMコロケーションとメモリ帯域幅スケーリング | +2.8% | グローバル、サプライチェーンは韓国と台湾に集中 | 短期(2年以内) |
| チップレットベースの異種統合 | +2.5% | グローバル、パッケージングは台湾主導、設計活動は北米と欧州 | 中期(2〜4年) |
| ソブリンAIインフラ構築 | +2.0% | GCC、欧州、南アジア、東南アジア | 中期(2〜4年) |
| 産業システムにおける大規模エッジ推論 | +1.6% | アジア太平洋製造ベルト、北米、ドイツ | 中期(2〜4年) |
| マルチダイシステム向け先進インターコネクト需要 | +1.2% | 北米、台湾、韓国 | 長期(4年以上) |
| 情報源: Mordor Intelligence | |||
フロンティアモデルトレーニングコンピュートの拡大が持続的なシリコン需要を牽引
フロンティアモデルのトレーニングは、新しい言語、ビジョン、マルチモーダルシステムが以前の世代よりも実質的に多くの並列コンピュートを必要とするため、AIスーパーチップ市場を急峻な支出軌道に乗せ続けています。混合エキスパート設計と多段階事後トレーニングへの移行は、ハードウェア需要を単一の事前トレーニングウィンドウを超えて、チューニング、アライメント、評価サイクルにまで拡大しました。NVIDIAは2026年1月5日にRubinプラットフォームを発表し、GPU当たり50ペタフロップスのNVFP4推論コンピュートを提供し、同プラットフォームは以前のBlackwellジェネレーションと比較して4倍少ないGPUで混合エキスパートモデルをトレーニングできると述べました。[1]NVIDIA、「NVIDIAがRubinで次世代AIを開始 - 6つの新チップ、1台の驚異的なAIスーパーコンピューター」、NVIDIA Newsroom、nvidia.com モデル当たりのコンピュートコストの低下は、研究機関が通常より大規模なシステムを目標とし、より多くの実験を実施することで対応するため、全体的なチップ需要を緩和しません。この同じパターンはデプロイメントにも引き継がれており、推論ワークロードは固定された推論予算ではなく、クエリごとに可変のコンピュートを消費します。その結果、AIスーパーチップ市場ではモデルライフサイクル全体にわたって需要が蓄積されており、トレーニングクラスターと大量推論フリートの両方を支えています。
HBMコロケーションとメモリ帯域幅スケーリングがチップアーキテクチャを再形成
高帯域幅メモリは、現代のアクセラレーターがコンピュートに近いメモリなしにスループットを維持できないため、AIスーパーチップ市場においてパフォーマンス差別化要因から基本的な設計要件へと移行しました。JEDECは2024年12月にHBM4標準を発表し、2,048ビットインターフェースとスタック当たり1.5〜2TB/sの帯域幅目標を設定し、将来のアクセラレーター設計の上限を引き上げました。シーメンスは、HBM4がスタック容量を64GBに増加させ、設計者が同一パッケージ内で帯域幅、容量、電力のバランスを取る余地を広げると指摘しました。このメモリシフトは、コンピュートブロック、インターポーザー、熱経路が最初からメモリ制約を中心に設計されるようになったため、アーキテクチャの選択を変えています。また、メモリの可用性がロジック設計と同様に強く発売タイミングを左右するため、韓国と台湾のサプライヤーの準備状況の重要性も強調しています。その結果、製品の成功はプロセッサのスループットだけでなく、ベンダーがメモリ、パッケージング、システム統合をいかにうまく調整するかにますます依存するようになっています。
チップレットベースの異種統合がレチクル限界を突破
チップレット統合は、モノリシックダイがリソグラフィ限界内で自由にスケールできなくなったため、AIスーパーチップ市場の中心となりつつあります。シーメンスは、TSMCのCoWoS-Lロードマップが2027年から2029年にかけてレチクルサイズを9〜14倍に拡大することを目標としており、将来のパッケージにおけるコンピュートタイルとHBMスタックのためのより多くのスペースの必要性を反映していると報告しました。シノプシスは2026年に64GbpsのUCIe IPテープアウトを完了し、ダイ間リンクが非常に短い距離でマルチテラビット帯域幅に向かって進んでいることを実証しました。CEA-Letiも2026年5月に1µmピッチでのダイ対ウェーハハイブリッドボンディングを実証し、チップレット間のインターコネクト密度の向上を示しました。これらの進歩により、単一パッケージ内の異なるプロセスノードにわたってコンピュート、メモリ、I/Oを組み合わせることが容易になります。この移行により、競争優位性はパッケージアーキテクチャ、コデザイン、組み立てノウハウへと移行しており、半導体スタック全体にわたる深い統合を持つプレイヤーが有利になっています。
ソブリンAIインフラ構築が需要基盤を多様化
ソブリンコンピュートプログラムは、政府が国内管理のAIインフラをますます求めるようになっていため、ハイパースケーラーを超えてAIスーパーチップ市場の需要を拡大しています。英国政府は2026年6月8日に11億ポンド(14.1億米ドル)のAIハードウェアプランを発表し、国家AIスーパーコンピューターに7億5,000万ポンド(9.6億米ドル)、チップ調達に4億ポンド(5.12億米ドル)を含みます。同プランには、英国およびスタートアップサプライヤーからの新型推論チップへの1億5,000万ポンド(1.92億米ドル)の事前コミットメントも含まれており、公共バイヤーがベンダーミックスと需要量を形成していることを示しています。これらのプログラムは、機密ワークロードが商業クラウド環境を経由することがほとんどないため、オンプレミスおよびエッジ構成をサポートする傾向があります。また、アクセラレーターベンダーだけでなく、パッケージング、ストレージ、ネットワーキング、セキュアシステム設計のサプライヤーにも機会を創出します。ソブリン構築がより多くの国に広がるにつれて、需要基盤は少数のグローバルクラウドバイヤーへの依存度が低下し、公共部門プログラム全体に分散されます。
抑制要因インパクト分析*
| 抑制要因 | (~)CAGR予測への影響(%) | 地理的関連性 | 影響タイムライン |
|---|---|---|---|
| 先進パッケージング能力の制約 | -2.0% | グローバル、台湾に集中 | 短期(2年以内) |
| 最先端アクセラレーターへの輸出規制 | -1.8% | 北米(供給)、中国・中東・アフリカ(需要)、グローバル貿易ルート | 中期(2〜4年) |
| 高密度ラックにおける電力密度と冷却の限界 | -1.0% | グローバル、欧州と北米の既存データセンターで深刻 | 中期(2〜4年) |
| インクリメンタルなシリコン需要を削減するモデル効率の向上 | -0.8% | グローバル | 長期( |
| 情報源: Mordor Intelligence | |||
先進パッケージング能力の制約が近期の供給スループットを制限
先進パッケージングは、アクセラレーターがコンピュートダイとHBMを同一パッケージ内に配置する複雑な組み立てなしには出荷できないため、AIスーパーチップ市場における最も明確な近期の制動要因であり続けています。ウェーハ供給が改善しても、パッケージングラインには設置と認定に時間を要する専用ボンダー、配置ツール、検査システムが依然として必要です。これにより、多くのベンダーが割り当て制約を受け、パッケージの可用性がチップ設計やウェーハ投入と同様に重要な商業的レバーとなっています。この不足は、大規模企業が小規模な競合他社よりも基板、メモリ、ファウンドリへのアクセスを確保しやすいため、集中化を強化しています。冷却とインターコネクト設計標準が高密度デプロイメントの技術的ハードルを引き上げており、パッケージング制約がラック設計とシステム認定にも波及しています。能力がより完全に拡大するまで、納期スケジュールはプロセッサ需要と同様にパッケージングの準備況に依存し続けるでしょう。
最先端アクセラレーターへの輸出規制がグローバル市場アクセスを分断
輸出規制は市場アクセスを分断し、最先端AIスーパーチップの地域間の自由な移動を制限しています。米国商務省産業安全保障局は2026年5月31日に、先進コンピューティング品目のライセンス要件が中国国外の中国企業の子会社にも適用されることを明確にし、以前は間接的なアクセスを提供していたチャネルを締め付けました。[2]米国商務省産業安全保障局 / Mondaq、「執行停止には限界がある:産業安全保障局が中国関連事業体への先進コンピューティング品に対する継続的なライセンス要件を明確化」、Mondaq、mondaq.com これにより需要が別々の地政学的プールに分割され、一部の西側サプライヤーのアドレス可能な基盤が縮小しています。また、制限された市場での国内チッププログラムを加速させており、これが時間の経過とともに代替サプライチェーンを生み出す可能性があります。調達決定は、価格とパフォーマンスに加えて、コンプライアンス、地理、政治的整合性によって形成されています。その結果、グローバル市場の統合度が低下し、主要ベンダーは製品ロードマップと変化する規制境界の両方を管理しなければなりません。
*当社の予測では、推進要因および抑制要因の影響を加算的ではなく方向性のあるものとして扱います。影響予測は、ベースライン成長、構成効果、および変数間の相互作用を反映しています。
セグメント分析
機能別:トレーニングが市場規模を支え、推論がギャップを縮める
トレーニングは2025年のAIスーパーチップ市場の59.32%を占め、フロンティアモデル開発が依然として最も多くのコンピュートを消費するため、市場の最大セグメントを占めました。このリードは、最先端モデルが長期的な開発サイクルにわたって数万台のGPUを使用できる大規模クラスタートレーニングの強度を反映していました。トレーニングは、主要な研究機関がモデルサイズをスケールアップするだけでなく、チューニングと評価のためにより多くの段階を追加しているため、依然として中心的な役割を果たしています。これらの追加ステップにより、初期の事前トレーニングフェーズが完了した後もクラスターの使用率が高く保たれます。NVIDIAは、Rubinプラットフォームが以前のBlackwellジェネレーションと比較して4倍少ないGPUで混合エキスパートモデルをトレーニングできると述べ、効率性のベースラインがいかに急速に進歩しているかを示しました。
この効率性の変化は時間の経過とともにトレーニングシェアを圧縮する可能性がありますが、絶対的な支出面でのトレーニングの重要性を低下させるわけではありません。推論は、企業ソフトウェア、消費者サービス、自律システム全体でデプロイされたモデル数が増加するにつれて、2031年にかけて18.49%のCAGRで拡大すると予測されています。したがって、AIスーパーチップ産業はトレーニングから離れているのではなく、リアルタイム推論を通じて第二の大きな需要プールを追加しています。推論ワークロードは、固定された応答パスに従うのではなく、各プロンプトに可変のGPU時間を割り当てることができるため、デプロイメント中のコンピュート使用量も増加します。これは、推論の成長がトレーニング需要に取って代わるのではなく、既存のトレーニング需要に加わることを意味します。AIスーパーチップ市場は、大規模なトレーニングクラスターを必要とする研究機関と、高速で効率的な推論フリートを必要とするオペレーターの間でバランスを保ち続ける可能性が高いです。


アーキテクチャタイプ別:CPU-GPU統合がリードし、カスタムASICが加速
CPU-GPU統合型スーパーチップは2025年に43.76%のシェアを保持し、大規模トレーニングと混合コンピュート環境のニーズを満たすため、AIスーパーチップ市場の最大シェアを占めました。そのリードは、Armベースの CPUとGPUを非常に高いインターコネクト帯域幅で結びつけるGrace BlackwellやVera Rubinなどのプラットフォームに基づいて構築されてきました。CPUとGPUのより緊密な連携により、データ移動が改善され、別々のメモリドメインを横断することによるパフォーマンスの損失が軽減されます。この組み合わせは、オーケストレーション、メモリアクセス、アクセラレーター実行が単一のシステムとして機能する必要がある場合に有用です。また、統合プラットフォームが大規模AIクラスターの優先基盤であり続ける理由も説明しています。
AIアプリケーション特化型集積路(ASIC)ベースのスーパーチップは、ハイパースケーラーが特定のワークロード経済性にシリコンをますます合わせるにつれて、2031年にかけて18.81%という最速のCAGRを記録すると予測されています。AIスーパーチップ産業は、予測可能で反復的なワークロードがカスタムチップ設計に有利な推論において、これを最も明確に見ています。Googleは2026年4月にトレーニング用TPU 8tと推論用TPU 8iを発表し、ワークロード固有のアクセラレーターパスの間のより明確な分割を示しました。これは、バイヤーがソフトウェアスタックとデプロイメントモデルを制御する場合に、コスト、電力、スループットをより厳密に調整できるため重要です。GPU-GPUカップル型および異種マルチアクセラレーター設定は特殊な環境で引き続き重要ですが、最も強い成長シグナルはハイパースケールでのカスタムASICデプロイメントから来ています。そのミックスが拡大するにつれて、マーチャントGPUベンダーは、所有コストがより強い購買要因となる推論重視のユースケースでより大きな圧力に直面するでしょう。
パッケージング技術別:MCMがシェアを支配し、チップレットアーキテクチャが成長曲線を定義
マルチチップモジュールパッケージングは2025年に48.14%のシェアを獲得し、熱制御、製造スケーラビリティ、帯域幅効率にわたって実用的なバランスを提供するため、パッケージングミックスをリードしました。MCMフォーマットは確立されたファウンドリおよびOSATエコシステムによってもサポートされており、ベンダーが成熟度の低いアプローチよりも速く生産をスケールするのに役立ちます。これは、パッケージの選択が技術的パフォーマンスと同様に納期速度に影響を与える現在のサイクルで重要です。したがって、MCMは大型コンピュートダイとHBMスタックを組み合わせる多くのハイエンドAIアクセラレーターのデフォルト構造であり続けています。サプライチェーンが実績のある組み立てパスを優先し続ける限り、そのリードは近期に維持される可能性が高いです。
チップレットベースのSoCは、レチクル限界が設計者にコンピュートを複数のダイに分割させるにつれて、2031年にかけて18.89%のCAGRで成長すると予測されています。これは、AIスーパーチップ市場が単純なパフォーマンス目標ではなく、物理的な設計限界によって形成されている最も明確な例の一つです。シノプシスは2026年に64GbpsのUCIe IPテープアウトを完了し、CEA-Letiは2026年5月に1µmのダイ対ウェーハハイブリッドボンディングを実証し、どちらもより高密度なダイ間統合をサポートしています。これらの進歩により、パッケージを単一の大型チップとしてではなく、モジュラーシステムとして扱うことが容易になります。モノリシックSoCとシステムインパッケージ設計は、より小型のエッジおよびラグタイズド設定では依然として重要ですが、ハイエンドでの将来のスケーリングはチップレット重視の組み立てに向かっています。このシフトが深まるにつれて、パッケージアーキテクチャは単一ダイモデルよりも強力な製品差別化の源泉となります。
デプロイメント別:クラウドが70%超のシェアを支配し、エッジが戦略的戦場に
クラウドデプロイメントは2025年に72.73%のシェアを保持し、ハイパースケールデータセンターが依然として最も重いトレーニングと大規模推論負荷をホストしているため、人工知能(AI)スーパーチップ市場の最大シェアを占めました。ハイパースケーラーは、他のほとんどのバイヤーが匹敵できない専用インフラ、先進冷却、ソフトウェア環境に資金を提供できます。このスケール優位性により、クラウドはモデル開発と広範なサービスデプロイメントの両方の中心に位置し続けています。また、高密度なラックレベル統合を必要とする新しいアーキテクチャの主要な参入点となっています。最先端システムが依然として電力、冷却、ネットワーク密度に最適化された環境を必要とするため、AIスーパーチップ市場はハイパースケール能力に依存し続けています。
NVIDIAはRubinベースのシステムを大規模AIインフラ構築を中心に位置づけ、フラッグシッププラットフォームが依然としてクラウドスケールデプロイメントを最初に念頭に置いて設計されているという考えを強化しました。エッジデプロイメントは、より多くの産業および防衛ワークロードがクラウドのラウンドトリップレイテンシを許容できないため、2031年にかけて18.68%のCAGRで拡大すると予測されています。その成長は消費者デバイスよりも、ローカル推論を必要とするフィールドオペレーション、工場、リモートシステムによって牽引されています。エマーソンとSiMa Technologiesは2026年5月に製造業とリモートフィールドサイト向けのAI対応産業用PCを発表し、フィジカルAIが制御された産業環境にどのように移行しているかを示しました。オンプレミスシステムは、医療、金融、政府などの規制された分野で引き続き重要です。しかし、より鮮明な成長シグナルはエッジにあり、電力制限、ラグタイズドデプロイメント、ローカル制御がハイパースケールクラウドとは異なる独自のハードウェアパスを生み出しています。
注記: 個別セグメントのシェアはレポート購入時に入手可能
エンドユーザー産業別:ハイパースケールプロバイダーが支出速度を設定し、防衛が最速で拡大
ハイパースケールクラウドプロバイダーは2025年のエンドユーザー支出の62.12%を占め、最大の調達予算が少数のクラウドプラットフォームに集中しているため、人工知能(AI)スーパーチップ市場の支出リズムを設定しました。彼らの購買決定は、より広いバリューチェーン全体のアクセラレーターロードマップ、パッケージング割り当て、ソフトウェアサポートに影響を与えます。このバイヤー集中により、主要なクラウド企業は何が最初に構築され、どのベンダーが最速でスケールするかについて異常な影響力を持っています。また、多くのサプライヤー関係が少数の非常に大規模な顧客を中心に形成されていることも意味します。したがって、現在の需要環境は、エンドユーザー需要と市場上位のバイヤー集中の両方を反映しています。
政府・防衛組織は、より多くの国がAIコンピュートを戦略的インフラとして扱うようになるにつれて、2031年にかけて19.94%という最速のCAGRを記録すると予測されています。AIスーパーチップ産業は、ソブリンコンピュート、セキュアデプロイメント、管理された調達チャネルへの需要を通じてこのシフトから恩恵を受けています。2026年6月に発表された英国のAIハードウェアプランは、コンピュート能力、チップ調達、国内ハードウェア開発への直接的な公共部門の支援を示しました。研究・学術機関は絶対的な支出では依然として小規模ですが、科学指向のインフラ展開を通じて先進システムへのより良いアクセスを得ています。NVIDIAは、科学コンピューティング向けのVera Rubin NVL4ベースのシステムが2026年第4四半期にDell Technologies、HPE、GIGABYTE、Supermicroから入手可能になると述べました。このアクセスの拡大は支出の階層を変えませんが、ハイパースケーラーと防衛環境を超えてハイエンドコンピュートを拡大します。
地域分析
北米は2025年のAIスーパーチップ市場の55.69%を占め、フロンティアAI研究機関、ハイパースケーラー本社、最大の発表済みインフラ予算がそこに集中しているため、最大のシェアを保持しました。米国はマーチャントアクセラレーター設計とカスタムシリコン戦略の中心であり続けており、業界の知的財産の多くがそこに固定されています。この地域はまた、クラウドバイヤー、チップ設計者、システムビルダー、ソフトウェアエコシステム間の緊密な連携からも恩恵を受けています。カナダはソブリンコンピュートの取り組みの支援ノードとして台頭しており、メキシコは主要な需要源というよりも近岸生産拠点としてより関連性が高いです。これらの要因により、製造が他の場所にある場合でも、北米は構造的に強い状態を維持しています。
アジア太平洋地域は2031年にかけて19.09%のCAGRで拡大すると予測されており、人工知能(AI)スーパーチップ市場で最も成長の速い地域となっています。この地域は最先端ファウンドリ作業、高帯域幅メモリ生産、先進パッケージングの中心に位置しており、グローバルな供給タイミングに直接的な影響を与えています。製造の深さとメモリ制御が先進アクセラレーターの展開ペースを形成するため、台湾と韓国は依然として重要です。インドのIndiaAIミッションは2026年初頭に38,000台のGPUを持つコンピュート施設を運営し、年末までに100,000台を目標としており、急速に上昇するローカル需要基盤を示しています。[3]カーネギー国際平和財団、「ソブリンAI追求における初期の教訓」、カーネギー財団、carnegieendowment.org
欧州は2025年に中規模の収益シェアを保持し、ドイツ、英国、フランスが主導しました。英国政府は2026年6月に11億ポンド(14.1億米ドル)のAIハードウェアランを発表し、国家AIスーパーコンピューターとチップ調達への資金を含みます。この政策の方向性は、より多くのローカルコンピュート能力をサポートし、規制された環境でのオンプレミス需要を強化します。南米、中東、アフリカは収益面では依然として小規模ですが、ソブリンインフラプログラムが新たな機会を開いており、特に国家支援のデジタル投資が増加している湾岸市場でその傾向が顕著です。

競争環境
AIスーパーチップ市場は、その大きな収益基盤と拡大するアプリケーション範囲にもかかわらず、依然として高度に集中しています。NVIDIAは2026年にAIアクセラレーター収益の推定80〜85%を保持し、マーチャント競合他社をはるかに小さな規模に留めています。そのリードは、CUDAソフトウェアのロックイン、強力なパッケージアクセス、個々のチップではなく完全なプラットフォームを販売する能力に基づいています。AMDは最も近いマーチャントチャレンジャーであり続けており、Instinctラインが特定のワークロードにおける技術的なギャップを縮めています。それでも、この市場での競争力は、純粋なシリコン性能と同様に、ソフトウェア採用、供給アクセス、エコシステムリーチに依存しています。
ハイパースケーラーのカスタムシリコンは、最大のバイヤーがコストとワークロード設計のより厳密な制御をますます求めるため、マーチャントGPUベンダーにとって最も重要な構造的課題です。Googleは2026年4月にトレーニング用TPU 8tと推論用TPU 8iを発表し、ハイパースケーラーが特定のデプロイメント経済性に合わせてアクセラレーターパスを分離している様子を示しました。NVIDIAはNVLink Fusionを拡張することで対応し、サードパーティのASICとXPUがそのスケールアップファブリックに接続できるようにしました。Lightmatterは2026年6月にNVLink Fusionに参加し、NVIDIAが完全にクローズドなハードウェアスタックを守るのではなく、インターコネクトと光学分野でのポジションを拡大していることを示しました。[4]Lightmatter、「LightmatterがNVIDIA NVLink Fusionに参加し、フォトニックインターコネクトで次世代AIインフラを強化」、Lightmatter、lightmatter.co
スタートアップは、明確なアーキテクチャまたはデプロイメントの角度を提供する場合、依然として余地を見けていますが、トップラインの収益は依然として集中しています。Groqは2026年6月に6億5,000万米ドルの資金調達ラウンドを確認した後、ネオクラウド推論フットプリントを拡大し、推論に特化したプラットフォームモデルへの投資家の支持を示しました。MicronとAnthropicも2026年6月に、メモリとストレージの供給、技術協力、MicronのAnthropicシリーズH資金調達ラウンドへの戦略的投資を含む複数年の戦略的合意を発表しました。BroadcomやMarvellなどの設計サービス企業も、フルハイパースケーラー規模なしにセミカスタムシリコンを求める企業および政府バイヤーに対して有利な位置にあります。したがって、競争優位性は、収益プールが少数の支配的プレイヤーを中心に集中したままであっても、チップ設計、メモリ、パッケージング、光学、ソフトウェアにわたって広がっています。
AIスーパーチップ産業リーダー
NVIDIA Corporation
Advanced Micro Devices, Inc.
Intel Corporation
Google LLC
Amazon.com, Inc.
- *免責事項:主要選手の並び順不同

最近の産業動向
- 2026年6月:NVIDIAがGroqの言語処理ユニット技術に関する非独占的ライセンス契約を締結してから6ヶ月後、Groqは6億5,000万米ドルの資金調達ラウンドを確認しました。Groqはこの資本を活用してネオクラウド推論ビジネスをグローバルで13のデータセンターに拡大し、2027年までに200MWの能力を目標としています。この取引は、NVIDIAが推論の知的財産を統合しながら、立された推論スタートアップがハードウェアで正面から競争するのではなくプラットフォームビジネスへとピボットしている様子を浮き彫りにしています。
- 2026年6月:MicronとAnthropicは、メモリとストレージの供給、技術協力、MicronのAnthropicシリーズH資金調達ラウンドへの戦略的投資を含む複数年の戦略的合意を発表しました。この合意は、次世代HBM供給コミットメントをフロンティアAIモデルインフラに、標準的なベンダー関係をはるかに超えるタイムスケールで直接結びつけています。
- 2026年6月:NVIDIAはハンブルクで開催されたISC High Performance 2026において、科学コンピューティング向けのVera Rubin NVL4ベースのシステムが2026年第4四半期にDell Technologies、HPE、GIGABYTE、Supermicroから入手可能になると発表しました。この動きにより、Vera Rubinプラットフォームはハイパースケールデプロイメントを超えて国立研究所や研究機関にまで拡大されます。
- 2026年6月:LightmatterがNVIDIA NVLink Fusionに参加し、コパッケージド光学製品とニアパッケージド光学製品をNVIDIAのスケールアップインターコネクトエコシステムに統合しました。このパートナーシップにより、NVLink Fusionベースのデプロイメントにおけるファイバーとコネクタの要件が50%削減され、NVIDIAのコアファブリックアーキテクチャ内での最初の光接続レイヤーとなります。


グローバルAIスーパーチップ市場レポートの範囲
AIスーパーチップ市場は、人工知能(AI)ワークロードに最適化された統一アーキテクチャに、複数の処理要素、アクセラレーター、メモリサブシステム、高速インターコネクト技術を組み合わせた高度に統合されたコンピューティングプラットフォームで構成されています。AIスーパーチップは、大規模言語モデル(LLM)、生成AI、マルチモーダルAI、レコメンデーションシステム、科学シミュレーション、高度な分析を含む、ますます複雑化するAIモデルを処理できるよう、トレーニングおよび推論アプリケーション向けに卓越した計算性能、メモリ帯域幅、電力効率、スケーラビリティを提供するよう設計されています。
AIスーパーチップ市場は、機能別(トレーニング、推論)、アーキテクチャタイプ別(CPU-GPU統合型スーパーチップ、GPU-GPUカップル型スーパーチップ、AIアプリケーション特化型集積回路(ASIC)ベースのスーパーチップ、異種マルチアクセラレータースーパーチップ)、パッケージング技術別(モノリシックシステムオンチップ(SoC)、チップレットベースのSoC、システムインパッケージ(SiP)、マルチチップモジュール(MCM))、デプロイメント別(クラウド、オンプレミス、エッジ)、エンドユーザー別(ハイパースケールクラウドプロバイダー、データセンター、企業、政府・防衛組織、研究・学術機関)、地域別(北米、欧州、アジア太平洋、南米、中東・アフリカ)に区分されています。市場予測は金額ベース(米ドル)で提供されています。
| トレーニング |
| 推論 |
| CPU-GPU統合型スーパーチップ |
| GPU-GPUカップル型スーパーチップ |
| AIアプリケーション特化型集積回路(ASIC)ベースのスーパーチップ |
| 異種マルチアクセラレータースーパーチップ |
| モノリシックシステムオンチップ(SoC) |
| チップレットベースのSoC |
| システムインパッケージ(SiP) |
| マルチチップモジュール(MCM) |
| クラウド |
| オンプレミス |
| エッジ |
| ハイパースケールクラウドプロバイダー |
| ータセンター |
| 企業 |
| 政府・防衛組織 |
| 研究・学術機関 |
| 北米 | 米国 |
| カナダ | |
| メキシコ | |
| 欧州 | ドイツ |
| 英国 | |
| フランス | |
| イタリア | |
| その他の欧州 | |
| アジア太平洋 | 中国 |
| 日本 | |
| 韓国 | |
| インド | |
| 東南アジア | |
| その他のアジア太平洋 | |
| 南米 | |
| 中東・アフリカ |
| 機能別 | トレーニング | |
| 推論 | ||
| アーキテクチャタイプ別 | CPU-GPU統合型スーパーチップ | |
| GPU-GPUカップル型スーパーチップ | ||
| AIアプリケーション特化型集積回路(ASIC)ベースのスーパーチップ | ||
| 異種マルチアクセラレータースーパーチップ | ||
| パッケージング技術別 | モノリシックシステムオンチップ(SoC) | |
| チップレットベースのSoC | ||
| システムインパッケージ(SiP) | ||
| マルチチップモジュール(MCM) | ||
| デプロイメント別 | クラウド | |
| オンプレミス | ||
| エッジ | ||
| エンドユーザー別 | ハイパースケールクラウドプロバイダー | |
| ータセンター | ||
| 企業 | ||
| 政府・防衛組織 | ||
| 研究・学術機関 | ||
| 地域別 | 北米 | 米国 |
| カナダ | ||
| メキシコ | ||
| 欧州 | ドイツ | |
| 英国 | ||
| フランス | ||
| イタリア | ||
| その他の欧州 | ||
| アジア太平洋 | 中国 | |
| 日本 | ||
| 韓国 | ||
| インド | ||
| 東南アジア | ||
| その他のアジア太平洋 | ||
| 南米 | ||
| 中東・アフリカ | ||


レポートで回答される主要な質問
AIスーパーチップ市場の規模と成長見通しは?
AIスーパーチップ市場は2025年に700.13億米ドルに達し、2026年には849.7億米ドルとなり、18.10%のCAGRで2031年までに1,952.2億米ドルに達すると予測されています。
AIスーパーチップの需要をリードする機能は何ですか?
トレーニングは、フロンティアモデル開発が依然として大規模なGPUクラスター全体で最高のコンピュート強度を吸収するため、2025年に59.32%のシェアでリードしました。
AIスーパーチップの最速成長を牽引しているものは何ですか?
推論は18.49%のCAGRで最も成長の速い機能であり、企業ソフトウェア、消費者サービス、自律システム全体でのより広いAIデプロイメントによって支えられています。
現在の支出を支配しているデプロイメントモデルはどれですか?
クラウドは2025年に72.73%のシェアでリードしました。ハイパースケールデータセンターがフロンティアトレーニングと大規模推論の中核的な場であり続けているためです。
最も速く拡大しているエンドユーザーグループはどれですか?
政府・防衛は、ソブリンコンピュートとセキュアAIインフラプログラムが拡大するにつれて、2031年にかけて19.94%のCAGRで成長すると予測されています。
最も強い成長機会を提供している地域はどこですか?
アジア太平洋地域は、ファウンドリ、メモリ、先進パッケージングサプライチェーンの中心に位置しているため、2031年にかけて19.09%という最速のCAGRを記録すると予測されています。
最終更新日:




