Taille et part du marché des AI Superchips
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2020 - 2031 |
|---|---|
| Taille du Marché (2026) | 84.97 Milliards de dollars |
| Taille du Marché (2031) | 195.22 Milliards de dollars |
| Taux de croissance (2026 - 2031) | 18.10% CAGR |
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Amérique du Nord |
| Concentration du Marché | Élevé |
Acteurs majeurs *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. | |
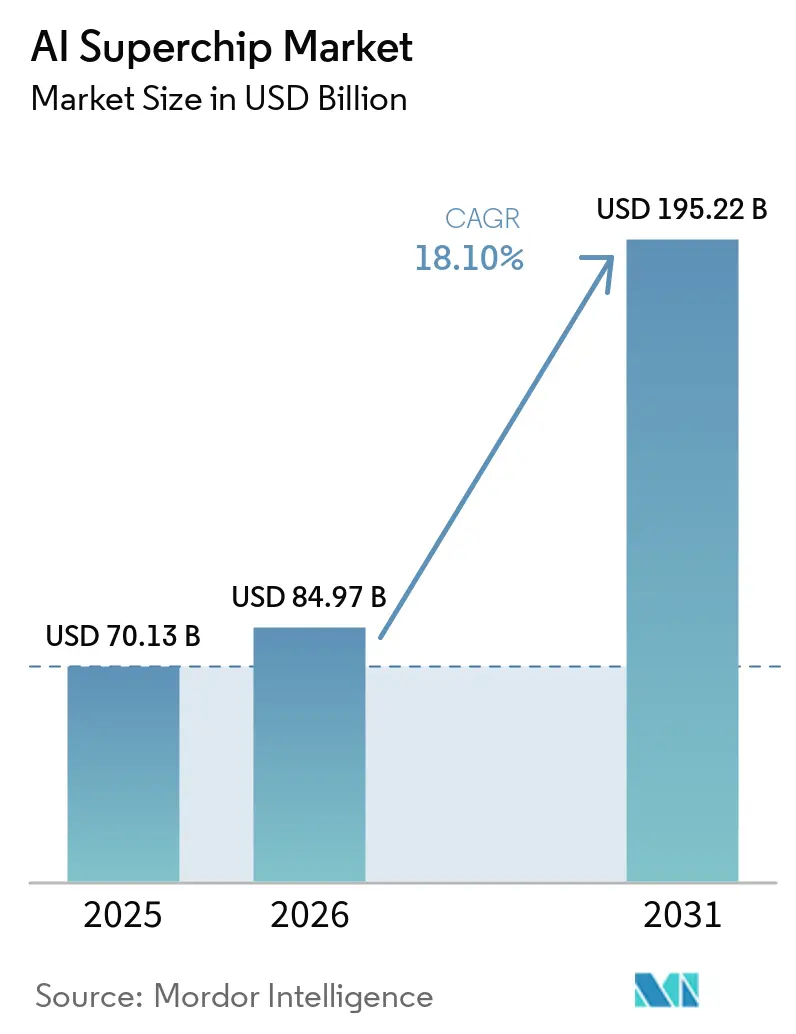
Analyse du marché des AI Superchips par Mordor Intelligence
La taille du marché des AI Superchips devrait passer de 70,13 milliards USD en 2025 à 84,97 milliards USD en 2026, et est prévue pour atteindre 195,22 milliards USD d'ici 2031, à un CAGR de 18,10 % sur la période 2026-2031. Le marché est porté par une forte hausse des dépenses hyperscale en accélérateurs d'IA, en silicium personnalisé et en constructions de centres de données de nouvelle génération. La demande s'élargit également parce que la puissance de calcul est désormais consommée à travers le pré-entraînement, le post-entraînement, la mise à l'échelle au moment du test et les charges de travail agentiques, plutôt qu'autour d'un seul grand cycle d'entraînement. Les conditions d'approvisionnement façonnent les résultats aussi fortement que les performances brutes des puces, car la mémoire, le packaging avancé et le refroidissement au niveau des racks influencent désormais les calendriers de livraison et la stratégie produit. Les positions concurrentielles se renforcent autour des écosystèmes logiciels, des normes d'interconnexion et de l'accès à la chaîne d'approvisionnement, ce qui confère un avantage clair aux fournisseurs à grande échelle. Les programmes de calcul souverain et les déploiements edge sensibles à la latence élargissent également le marché adressable des AI Superchips, même si les gains d'efficacité des modèles exercent une pression sur les fournisseurs pour qu'ils équilibrent le débit d'entraînement et l'efficacité de l'inférence.
Principaux enseignements du rapport
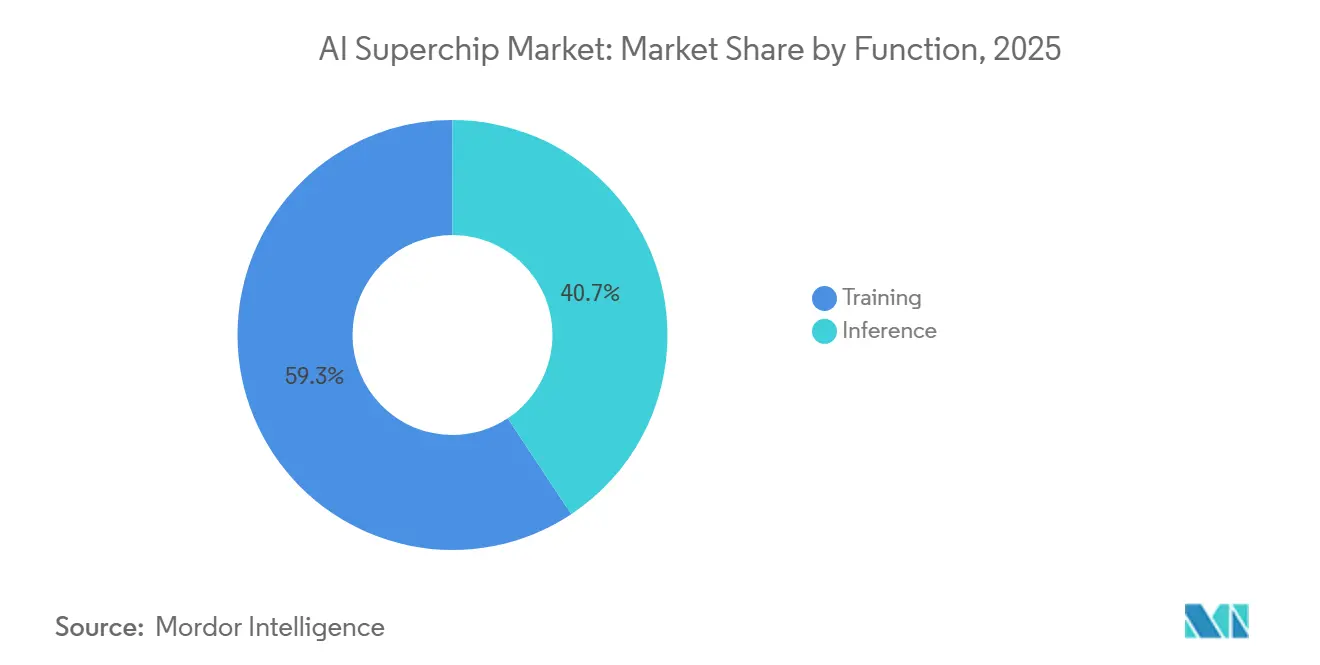
- Par fonction, l'entraînement représentait 59,32 % du marché des AI Superchips en 2025, tandis que l'inférence devrait progresser à un CAGR de 18,49 % jusqu'en 2031.
- Par type d'architecture, les superchips intégrés CPU-GPU représentaient 43,76 % du marché en 2025, tandis que les superchips à base d'ASIC pour l'IA devraient enregistrer le CAGR le plus élevé de 18,81 % jusqu'en 2031.
- Par technologie de packaging, le packaging en module multi-puces a capturé une part de 48,14 % en 2025, tandis que le SoC à base de chiplets devrait progresser à un CAGR de 18,89 % jusqu'en 2031.
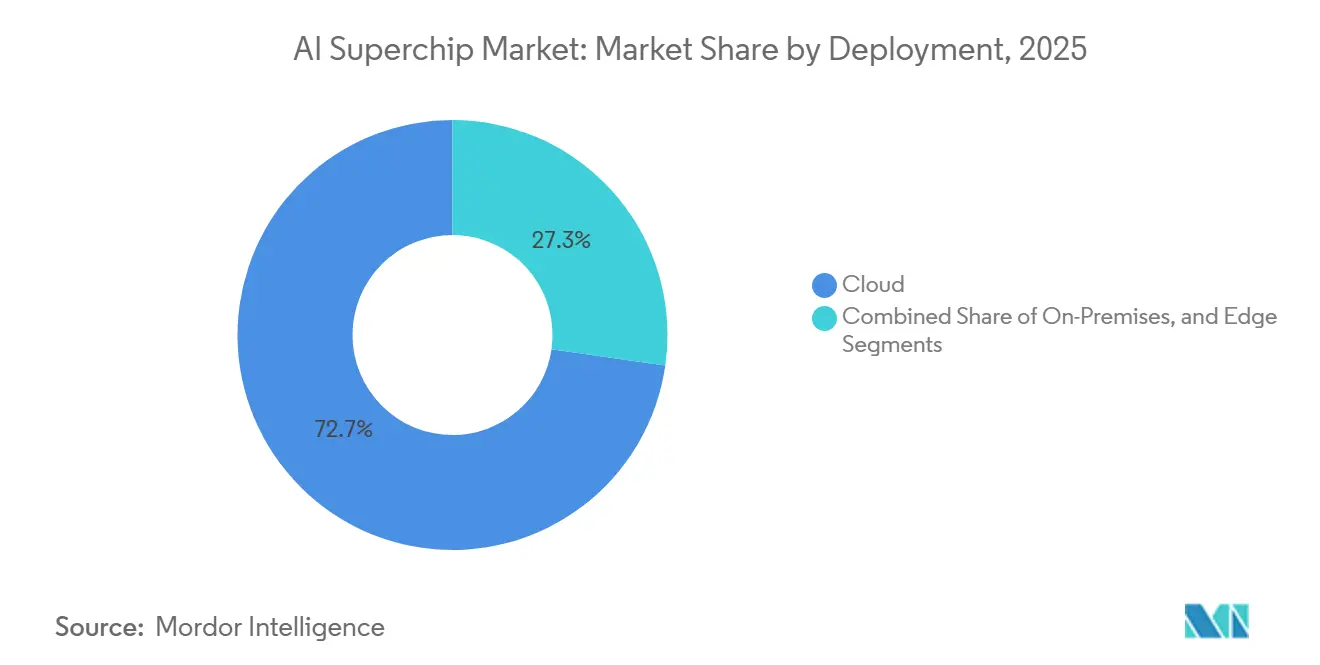
- Par déploiement, le cloud détenait une part de 72,73 % sur le marché des AI Superchips en 2025, tandis que l'edge devrait afficher le CAGR le plus rapide de 18,68 % jusqu'en 2031.
- Par secteur d'utilisation finale, les fournisseurs cloud hyperscale représentaient 62,12 % des dépenses en 2025, tandis que le gouvernement et la défense devraient progresser à un CAGR de 19,94 % jusqu'en 2031.
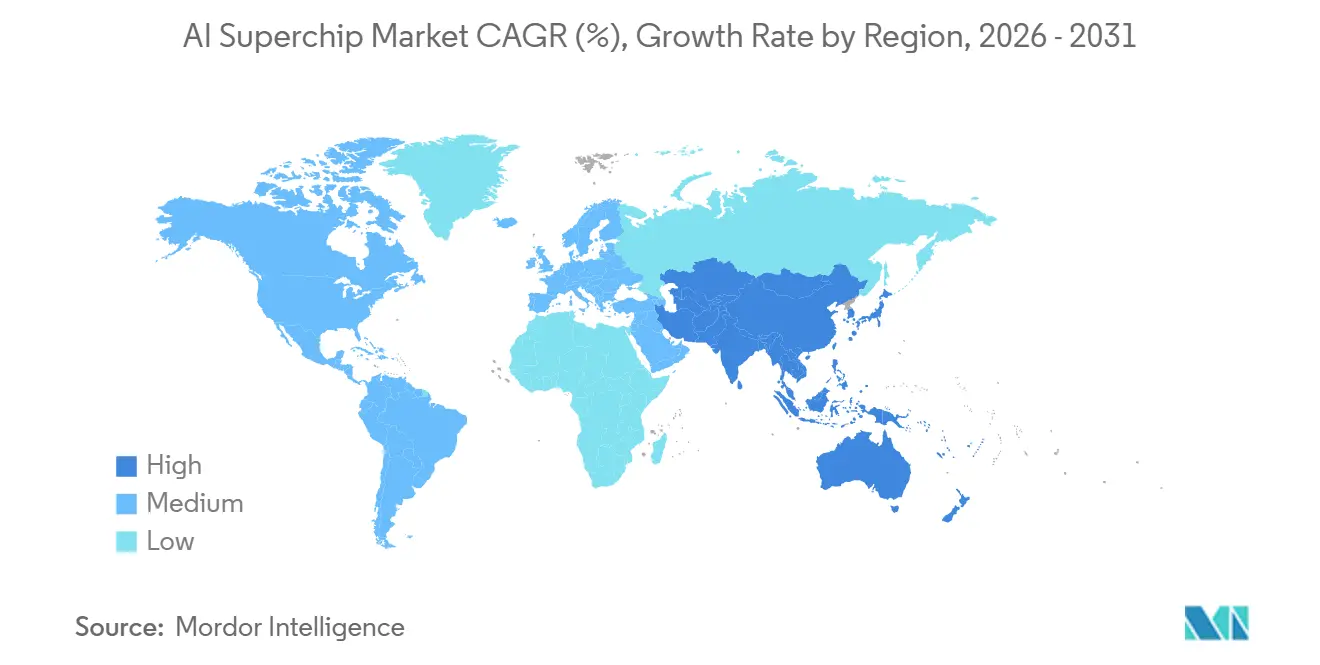
- Par géographie, l'Amérique du Nord représentait 55,69 % des revenus en 2025, tandis que l'Asie-Pacifique devrait afficher le CAGR le plus rapide de 19,09 % jusqu'en 2031.
Note : La taille du marché et les prévisions figurant dans ce rapport sont générées à l'aide du cadre d'estimation exclusif de Mordor Intelligence, mis à jour avec les dernières données et informations disponibles en janvier 2026.
Tendances et perspectives du marché mondial des AI Superchips
Analyse de l'impact des moteurs*
| Moteur | (~) % d'impact sur les prévisions de CAGR | Pertinence géographique | Horizon temporel |
|---|---|---|---|
| Expansion de la puissance de calcul pour l'entraînement des modèles frontières | +3.2% | Mondial, concentré en Amérique du Nord et en Asie-Pacifique | Court terme (≤ 2 ans) |
| Co-localisation HBM et mise à l'échelle de la bande passante mémoire | +2.8% | Mondial, avec une chaîne d'approvisionnement concentrée en Corée du Sud et à Taïwan | Court terme (≤ 2 ans) |
| Intégration hétérogène à base de chiplets | +2.5% | Mondial, packaging dirigé par Taïwan, activité de conception en Amérique du Nord et en Europe | Moyen terme (2-4 ans) |
| Construction d'infrastructures d'IA souveraines | +2.0% | GCC, Europe, Asie du Sud, Asie du Sud-Est | Moyen terme (2-4 ans) |
| Inférence edge à grande échelle dans les systèmes industriels | +1.6% | Zones manufacturières d'Asie-Pacifique, Amérique du Nord, Allemagne | Moyen terme (2-4 ans) |
| Demande d'interconnexions avancées pour les systèmes multi-puces | +1.2% | Amérique du Nord, Taïwan, Corée du Sud | Long terme (≥ 4 ans) |
| Source: Mordor Intelligence | |||
L'expansion de la puissance de calcul pour l'entraînement des modèles frontières stimule un appétit soutenu pour le silicium
L'entraînement des modèles frontières continue de maintenir le marché des AI Superchips sur une trajectoire de dépenses soutenue, car les nouveaux systèmes de langage, de vision et multimodaux nécessitent sensiblement plus de calcul parallèle que les générations précédentes. L'évolution vers des architectures de type mixture-of-experts et le post-entraînement en plusieurs étapes ont étendu la demande matérielle au-delà d'une seule fenêtre de pré-entraînement, vers des cycles d'ajustement, d'alignement et d'évaluation. NVIDIA a lancé la plateforme Rubin le 5 janvier 2026, avec 50 pétaflops de puissance de calcul d'inférence NVFP4 par GPU, et la société a indiqué que la plateforme peut entraîner des modèles mixture-of-experts avec 4 fois moins de GPU que la génération Blackwell précédente.[1]NVIDIA, "NVIDIA Kicks Off the Next Generation of AI with Rubin - Six New Chips, One Incredible AI Supercomputer," NVIDIA Newsroom, nvidia.com Un coût de calcul plus faible par modèle ne réduit pas la demande globale de puces, car les laboratoires répondent généralement en ciblant des systèmes plus grands et en menant davantage d'expériences. Ce même schéma se retrouve dans le déploiement, où les charges de travail de raisonnement consomment un calcul variable par requête plutôt qu'un budget d'inférence fixe. Il en résulte que le marché des AI Superchips voit la demande s'accumuler sur l'ensemble du cycle de vie du modèle, ce qui soutient à la fois les clusters d'entraînement et les flottes d'inférence à haut volume.
La co-localisation HBM et la mise à l'échelle de la bande passante mémoire reconfigurent l'architecture des puces
La mémoire à haute bande passante est passée d'un différenciateur de performance à une exigence de conception fondamentale pour le marché des AI Superchips, car les accélérateurs modernes ne peuvent pas maintenir leur débit sans mémoire proche du calcul. JEDEC a publié la norme HBM4 en décembre 2024 avec une interface de 2 048 bits et un objectif de 1,5 à 2 To/s de bande passante par pile, ce qui a relevé le plafond pour les futures conceptions d'accélérateurs. Siemens a noté que HBM4 augmente également la capacité de la pile à 64 Go, offrant aux concepteurs plus de marge pour équilibrer la bande passante, la capacité et la puissance au sein du même package. Cette évolution de la mémoire modifie les choix d'architecture, car les blocs de calcul, les interposeurs et les chemins thermiques sont désormais conçus dès le départ en tenant compte des contraintes mémoire. Elle souligne également l'importance de la disponibilité des fournisseurs en Corée du Sud et à Taïwan, car la disponibilité de la mémoire peut influencer le calendrier de lancement aussi fortement que la conception logique. En conséquence, le succès d'un produit dépend de plus en plus de la capacité des fournisseurs à coordonner la mémoire, le packaging et l'intégration système, plutôt que du seul débit du processeur.
L'intégration hétérogène à base de chiplets franchit le plafond du réticule
L'intégration de chiplets devient centrale pour le marché des AI Superchips, car les puces monolithiques ne peuvent plus évoluer librement dans les limites de la lithographie. Siemens a rapporté que la feuille de route CoWoS-L de TSMC vise une augmentation de 9 à 14 fois de la taille du réticule entre 2027 et 2029, reflétant le besoin de beaucoup plus d'espace pour les tuiles de calcul et les piles HBM dans les futurs packages. Synopsys a réalisé un tape-out d'IP UCIe à 64 Gbps en 2026, démontrant que les liaisons die-to-die évoluent vers une bande passante multi-térabits à très courte portée. CEA-Leti a également démontré un collage hybride die-to-wafer à un pas de 1 µm en mai 2026, indiquant une densité d'interconnexion plus élevée entre les chiplets. Ces avancées facilitent la combinaison de calcul, de mémoire et d'E/S sur différents nœuds de procédé au sein d'un même package. Cette évolution déplace l'avantage concurrentiel vers l'architecture de package, la co-conception et le savoir-faire d'assemblage, favorisant les acteurs disposant d'une intégration approfondie dans la chaîne des semi-conducteurs.
La construction d'infrastructures d'IA souveraines diversifie la base de demande
Les programmes de calcul souverain élargissent la demande pour le marché des AI Superchips au-delà des hyperscalers, car les gouvernements cherchent de plus en plus à disposer d'une infrastructure d'IA sous contrôle national. Le gouvernement britannique a annoncé un plan matériel pour l'IA de 1,1 milliard GBP (1,41 milliard USD) le 8 juin 2026, comprenant 750 millions GBP (960 millions USD) pour un supercalculateur national dédié à l'IA et 400 millions GBP (512 millions USD) pour l'acquisition de puces. Le même plan comprenait un engagement anticipé de 150 millions GBP (192 millions USD) pour des puces d'inférence innovantes provenant de fournisseurs britanniques et de startups, ce qui montre que les acheteurs publics façonnent le mix de fournisseurs et le volume de la demande. Ces programmes tendent à soutenir les configurations sur site et edge, car les charges de travail sensibles sont rarement acheminées via des environnements cloud commerciaux. Ils créent également des opportunités pour les fournisseurs de packaging, de stockage, de réseaux et de conception de systèmes sécurisés, et pas seulement pour les fournisseurs d'accélérateurs. À mesure que les constructions souveraines se répandent dans davantage de pays, la base de demande devient moins dépendante de quelques grands acheteurs cloud mondiaux et plus distribuée entre les programmes du secteur public.
Analyse de l'impact des freins*
| Frein | (~) % d'impact sur les prévisions de CAGR | Pertinence géographique | Horizon temporel |
|---|---|---|---|
| Contraintes de capacité de packaging avancé | -2.0% | Mondial, concentré à Taïwan | Court terme (≤ 2 ans) |
| Contrôles à l'exportation sur les accélérateurs de pointe | -1.8% | Amérique du Nord (offre), Chine et Moyen-Orient et Afrique (demande), routes commerciales mondiales | Moyen terme (2-4 ans) |
| Limites de densité de puissance et de refroidissement dans les racks denses | -1.0% | Mondial, aigu dans les centres de données existants en Europe et en Amérique du Nord | Moyen terme (2-4 ans) |
| Gains d'efficacité des modèles réduisant la demande incrémentale de silicium | -0.8% | Mondial | Long terme ( |
| Source: Mordor Intelligence | |||
Les contraintes de capacité de packaging avancé limitent le débit d'approvisionnement à court terme
Le packaging avancé reste le frein à court terme le plus évident sur le marché des AI Superchips, car les accélérateurs ne peuvent pas être expédiés sans un assemblage complexe qui place les puces de calcul et la HBM dans le même package. Même lorsque l'approvisionnement en tranches s'améliore, les lignes de packaging ont encore besoin de machines de collage spécialisées, d'outils de placement et de systèmes d'inspection qui prennent du temps à installer et à qualifier. Cela maintient de nombreux fournisseurs sous contrainte d'allocation et fait de la disponibilité du package un levier commercial aussi important que la conception de la puce ou les démarrages de tranches. La pénurie renforce également la concentration, car les grandes entreprises peuvent sécuriser l'accès aux substrats, à la mémoire et aux fonderies plus facilement que les concurrents plus petits. Les normes de conception du refroidissement et des interconnexions élèvent la barre technique pour les déploiements denses, ce qui signifie que les contraintes de packaging se répercutent désormais sur la conception des racks et la qualification des systèmes. Jusqu'à ce que la capacité se développe plus pleinement, les calendriers de livraison continueront de dépendre de la disponibilité du packaging autant que de la demande de processeurs.
Les contrôles à l'exportation sur les accélérateurs de pointe fragmentent l'accès au marché mondial
Les contrôles à l'exportation fragmentent l'accès au marché et limitent la libre circulation des AI Superchips de pointe entre les régions. Le Bureau de l'industrie et de la sécurité américain a précisé le 31 mai 2026 que les exigences de licence pour les articles informatiques avancés s'appliquent également aux filiales d'entreprises chinoises situées en dehors de la Chine, ce qui a resserré un canal qui offrait auparavant un accès indirect.[2]Département du Commerce américain BIS / Mondaq, "Enforcement Pause Has Limits: BIS Clarifies Ongoing License Requirement for Advanced Computing Items to China-Linked Entities," Mondaq, mondaq.com Cela divise la demande en bassins géopolitiques distincts et réduit la base adressable pour certains fournisseurs occidentaux. Cela accélère également les programmes nationaux de puces sur les marchés restreints, ce qui peut, à terme, créer des chaînes d'approvisionnement alternatives. Les décisions d'achat sont donc façonnées par la conformité, la géographie et l'alignement politique, en plus du prix et des performances. Il en résulte un marché mondial moins intégré, où les fournisseurs leaders doivent gérer à la fois les feuilles de route produits et les frontières réglementaires en évolution.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des segments
Par fonction : l'entraînement ancre l'échelle du marché tandis que l'inférence comble l'écart
L'entraînement détenait 59,32 % du marché des AI Superchips en 2025 et représentait la plus grande part du marché, car le développement des modèles frontières consomme encore le plus de puissance de calcul. Cette avance reflétait l'intensité de l'entraînement sur de grands clusters, où les modèles de pointe peuvent utiliser des dizaines de milliers de GPU sur des cycles de développement prolongés. L'entraînement reste également central car les laboratoires leaders ne font pas que mettre à l'échelle la taille des modèles, mais ajoutent également davantage d'étapes pour l'ajustement et l'évaluation. Ces étapes supplémentaires maintiennent l'utilisation des clusters à un niveau élevé même après la phase initiale de pré-entraînement. NVIDIA a indiqué que la plateforme Rubin peut entraîner des modèles mixture-of-experts avec 4 fois moins de GPU que la génération Blackwell précédente, démontrant à quelle vitesse la base d'efficacité progresse.
Cette évolution de l'efficacité pourrait comprimer la part de l'entraînement au fil du temps, mais elle ne réduit pas l'importance de l'entraînement en termes de dépenses absolues. L'inférence devrait progresser à un CAGR de 18,49 % jusqu'en 2031, à mesure que le nombre de modèles déployés augmente dans les logiciels d'entreprise, les services aux consommateurs et les systèmes autonomes. Le secteur des AI Superchips ne s'éloigne donc pas de l'entraînement ; il ajoute un second grand bassin de demande via l'inférence en temps réel. Les charges de travail de raisonnement augmentent également l'utilisation du calcul lors du déploiement, car elles peuvent allouer un temps GPU variable à chaque requête plutôt que de suivre un chemin de réponse fixe. Cela signifie que la croissance de l'inférence s'ajoute à la demande d'entraînement existante plutôt que de la remplacer. Le marché des AI Superchips devrait rester équilibré entre les laboratoires qui ont besoin de grands clusters d'entraînement et les opérateurs qui ont besoin de flottes d'inférence rapides et efficaces.


Par type d'architecture : l'intégration CPU-GPU domine tandis que les ASIC personnalisés accélèrent
Les superchips intégrés CPU-GPU détenaient une part de 43,76 % en 2025 et représentaient la plus grande part du marché des AI Superchips, car ils répondent aux besoins des environnements d'entraînement à grande échelle et de calcul mixte. Leur avance a été construite sur des plateformes telles que Grace Blackwell et Vera Rubin, qui associent des CPU basés sur Arm et des GPU avec une très haute bande passante d'interconnexion. Une coordination plus étroite CPU-GPU améliore le mouvement des données et réduit la perte de performance causée par le franchissement de domaines mémoire séparés. Cette combinaison est utile lorsque l'orchestration, l'accs à la mémoire et l'exécution de l'accélérateur doivent fonctionner comme un système unique. Cela explique également pourquoi les plateformes intégrées restent la base privilégiée pour les grands clusters d'IA.
Les superchips à base d'ASIC pour l'IA devraient afficher le CAGR le plus rapide de 18,81 % jusqu'en 2031, car les hyperscalers adaptent de plus en plus le silicium à l'économie de charges de travail spécifiques. Le secteur des AI Superchips observe cela le plus clairement dans l'inférence, où des charges de travail prévisibles et répétitives favorisent la conception de puces personnalisées. Google a introduit le TPU 8t pour l'entraînement et le TPU 8i pour l'inférence en avril 2026, ce qui a montré une séparation plus nette entre les voies d'accélérateurs spécifiques aux charges de travail. Cela est important car le coût, la puissance et le débit peuvent être ajustés plus précisément lorsque l'acheteur contrôle la pile logicielle et le modèle de déploiement. Les configurations couplées GPU-GPU et multi-accélérateurs hétérogènes resteront importantes dans des environnements spécialisés, mais le signal de croissance le plus fort provient du déploiement d'ASIC personnalisés à l'échelle hyperscale. À mesure que ce mix s'élargit, les fournisseurs de GPU marchands feront face à une pression accrue dans les cas d'utilisation à forte inférence, où les coûts de possession deviennent un facteur d'achat plus déterminant.
Par technologie de packaging : le MCM commande la part tandis que les architectures à chiplets définissent la courbe de croissance
Le packaging en module multi-puces a capturé une part de 48,14 % en 2025 et a dominé le mix de packaging car il offre un équilibre praticable entre contrôle thermique, évolutivité de la fabrication et efficacité de la bande passante. Les formats MCM sont également soutenus par un écosystème de fonderies et d'OSAT établi, ce qui aide les fournisseurs à augmenter la production plus rapidement qu'avec des approches moins matures. Cela est important dans le cycle actuel, car le choix du package influence la vitesse de livraison autant que les performances techniques. Le MCM reste donc la structure par défaut pour de nombreux accélérateurs d'IA haut de gamme qui combinent de grandes puces de calcul et des piles HBM. Son avance devrait se maintenir à court terme tant que les chaînes d'approvisionnement continueront de favoriser les voies d'assemblage éprouvées.
Les SoC à base de chiplets devraient croître à un CAGR de 18,89 % jusqu'en 2031, car les limites du réticule poussent les concepteurs à répartir le calcul sur plusieurs puces. C'est l'un des exemples les plus clairs où le marché des AI Superchips est façonné par les limites de conception physique plutôt que par de simples objectifs de performance. Synopsys a réalisé un tape-out d'IP UCIe à 64 Gbps en 2026, et CEA-Leti a démontré un collage hybride die-to-wafer à 1 µm en mai 2026, les deux soutenant une intégration die-to-die plus dense. Ces avancées facilitent le traitement d'un package comme un système modulaire plutôt que comme une seule grande puce. Les conceptions SoC monolithiques et system-in-package auront encore leur importance dans les environnements edge plus petits et robustifiés, mais la mise à l'échelle future au niveau supérieur évolue vers un assemblage à forte densité de chiplets. À mesure que cette évolution s'approfondit, l'architecture de package devient une source de différenciation produit plus forte que le modèle à puce unique.
Par déploiement : le cloud domine avec plus de 70 % de part tandis que l'edge devient le champ de bataille stratégique
Le déploiement cloud détenait une part de 72,73 % en 2025 et représentait la plus grande part du marché des AI Superchips, car les centres de données hyperscale hébergent encore les charges d'entraînement les plus lourdes et les inférences à grande échelle. Les hyperscalers peuvent financer des infrastructures spécialisées, un refroidissement avancé et des environnements logiciels que peu d'autres acheteurs peuvent égaler. Cet avantage d'échelle maintient le cloud au centre du développement des modèles et du déploiement de services à grande échelle. Il fait également du cloud le principal point d'entrée pour les nouvelles architectures nécessitant une intégration dense au niveau des racks. Le marché des AI Superchips continue de s'appuyer sur la capacité hyperscale, car les systèmes les plus avancés nécessitent encore des environnements optimisés pour la puissance, le refroidissement et la densité réseau.
NVIDIA a positionné les systèmes basés sur Rubin autour de grandes constructions d'infrastructure d'IA, renforçant l'idée que les plateformes phares sont encore conçues en premier pour le déploiement à l'échelle cloud. Le déploiement edge devrait progresser à un CAGR de 18,68 % jusqu'en 2031, car de plus en plus de charges de travail industrielles et de défense ne peuvent pas tolérer la latence des allers-retours cloud. Cette croissance est moins portée par les appareils grand public et davantage par les opérations de terrain, les usines et les systèmes distants qui ont besoin d'une inférence locale. Emerson et SiMa Technologies ont annoncé des PC industriels dotés d'IA pour les sites de fabrication et les sites de terrain distants en mai 2026, montrant comment l'IA physique s'intègre dans des environnements industriels contrôlés. Les systèmes sur site resteront importants dans les secteurs réglementés tels que la santé, la finance et le gouvernement. Le signal de croissance le plus fort, cependant, se situe à l'edge, où les limites de puissance, le déploiement robuste et le contrôle local créent une voie matérielle distincte du cloud hyperscale.
Note: Les parts de segments de tous les segments individuels sont disponibles à l'achat du rapport
Par secteur d'utilisation finale : les fournisseurs hyperscale fixent la vélocité des dépenses tandis que la défense croît le plus rapidement
Les fournisseurs cloud hyperscale représentaient 62,12 % des dépenses des utilisateurs finaux en 2025 et fixaient le rythme des dépenses sur le marché des AI Superchips, car les budgets d'achat les plus importants restent concentrés parmi quelques plateformes cloud. Leurs décisions d'achat affectent les feuilles de route des accélérateurs, l'allocation du packaging et le support logiciel dans l'ensemble de la chaîne de valeur. Cette concentration d'acheteurs confère aux grandes entreprises cloud une influence inhabituelle sur ce qui est construit en premier et quels fournisseurs évoluent le plus rapidement. Cela signifie également que de nombreuses relations fournisseurs se forment autour d'un petit groupe de très grands clients. L'environnement de demande actuel reflète donc à la fois la demande des utilisateurs finaux et la concentration des acheteurs au sommet du marché.
Les organisations gouvernementales et de défense devraient enregistrer le CAGR le plus rapide de 19,94 % jusqu'en 2031, car de plus en plus de pays considèrent le calcul d'IA comme une infrastructure stratégique. Le secteur des AI Superchips bénéficie de cette évolution à travers la demande de calcul souverain, de déploiement sécurisé et de canaux d'approvisionnement contrôlés. Le plan matériel pour l'IA du Royaume-Uni, annoncé en juin 2026, a montré un soutien direct du secteur public à la capacité de calcul, à l'acquisition de puces et au développement matériel national. Les institutions de recherche et académiques restent plus modestes en termes de dépenses absolues, mais elles bénéficient d'un meilleur accès aux systèmes avancés grâce aux déploiements d'infrastructures orientés vers la science. NVIDIA a indiqué que les systèmes basés sur Vera Rubin NVL4 pour le calcul scientifique seront disponibles auprès de Dell Technologies, HPE, GIGABYTE et Supermicro au quatrième trimestre 2026. Cet accès élargi ne modifie pas la hiérarchie des dépenses, mais il étend le calcul haut de gamme au-delà des environnements hyperscalers et de défense.
Analyse géographique
L'Amérique du Nord détenait 55,69 % du marché des AI Superchips en 2025, la plus grande part, car les laboratoires d'IA frontières, les sièges des hyperscalers et les budgets d'infrastructure annoncés les plus importants y sont concentrés. Les États-Unis restent le centre de la conception d'accélérateurs marchands et de la stratégie en matière de silicium personnalisé, ce qui maintient une grande partie de la propriété intellectuelle du secteur ancrée là-bas. La région bénéficie également d'une étroite convergence entre les acheteurs cloud, les concepteurs de puces, les constructeurs de systèmes et les écosystèmes logiciels. Le Canada émerge comme un nœud de soutien pour les efforts de calcul souverain, tandis que le Mexique reste plus pertinent en tant que site de production nearshore que comme source majeure de demande. Ces facteurs maintiennent l'Amérique du Nord structurellement forte même lorsque la fabrication se trouve ailleurs.
L'Asie-Pacifique devrait progresser à un CAGR de 19,09 % jusqu'en 2031, ce qui en fait la géographie à la croissance la plus rapide sur le marché des AI Superchips. La région se trouve au centre des travaux de fonderie de pointe, de la production de mémoire à haute bande passante et du packaging avancé, ce qui lui confère une influence directe sur le calendrier d'approvisionnement mondial. Taïwan et la Corée du Sud restent essentiels, car la profondeur de fabrication et le contrôle de la mémoire façonnent le rythme de déploiement des accélérateurs avancés. La mission IndiaAI de l'Inde exploitait une installation de calcul avec 38 000 GPU début 2026 et visait 100 000 d'ici la fin de l'année, indiquant une base de demande locale en forte croissance.[3]Carnegie Endowment for International Peace, "Early Lessons in the Pursuit of Sovereign AI," Carnegie Endowment, carnegieendowment.org
L'Europe détenait une part de revenus intermédiaire en 2025, portée par l'Allemagne, le Royaume-Uni et la France. Le gouvernement britannique a annoncé un plan matériel pour l'IA de 1,1 milliard GBP (1,41 milliard USD) en juin 2026, comprenant un financement pour un supercalculateur national dédié à l'IA et l'acquisition de puces. Cette orientation politique soutient une plus grande capacité de calcul locale et renforce la demande sur site dans les environnements réglementés. L'Amérique du Sud, le Moyen-Orient et l'Afrique restent plus modestes en termes de revenus, mais les programmes d'infrastructure souveraine ouvrent de nouvelles opportunités, notamment dans les marchés du Golfe, où l'investissement numérique soutenu par l'État est en hausse.

Paysage concurrentiel
Le marché des AI Superchips reste très concentré malgré sa large base de revenus et l'élargissement de son champ d'application. NVIDIA détenait environ 80 % à 85 % des revenus des accélérateurs d'IA en 2026, laissant les concurrents marchands à une échelle bien plus réduite. Son avance repose sur le verrouillage logiciel CUDA, un accès solide au packaging et la capacité à vendre des plateformes complètes plutôt que des puces individuelles. AMD reste le concurrent marchand le plus proche, avec la gamme Instinct réduisant l'écart technique sur des charges de travail ciblées. Néanmoins, le pouvoir concurrentiel sur ce marché dépend encore de l'adoption logicielle, de l'accès à l'approvisionnement et de la portée de l'écosystème autant que des performances brutes du silicium.
Le silicium personnalisé des hyperscalers représente le défi structurel le plus significatif pour les fournisseurs de GPU marchands, car les plus grands acheteurs cherchent de plus en plus à contrôler étroitement les coûts et la conception des charges de travail. Google a introduit le TPU 8t pour l'entraînement et le TPU 8i pour l'inférence en avril 2026, montrant comment les hyperscalers séparent les voies d'accélérateurs pour correspondre à l'économie de déploiement spécifique. NVIDIA a répondu en élargissant NVLink Fusion, afin que les ASIC tiers et les XPU puissent se connecter à son tissu de montée en charge. Lightmatter a rejoint NVLink Fusion en juin 2026, montrant que NVIDIA élargit sa position dans les interconnexions et l'optique plutôt que de défendre une pile matérielle entièrement fermée.[4]Lightmatter, "Lightmatter Joins NVIDIA NVLink Fusion and Powers Next-Generation AI Infrastructure with Photonic Interconnects," Lightmatter, lightmatter.co
Les startups trouvent encore de la place là où elles offrent une architecture ou un angle de déploiement clair, même si les revenus globaux restent concentrés. Groq a étendu son empreinte d'inférence neocloud après avoir confirmé une levée de fonds de 650 millions USD en juin 2026, ce qui a montré le soutien des investisseurs pour les modèles de plateformes axées sur l'inférence. Micron et Anthropic ont également annoncé un accord stratégique pluriannuel en juin 2026 liant plus étroitement les engagements d'approvisionnement en HBM et en stockage aux besoins de l'infrastructure d'IA frontière. Les sociétés de services de conception telles que Broadcom et Marvell sont également bien positionnées pour les acheteurs d'entreprises et de gouvernements qui souhaitent du silicium semi-personnalisé sans l'échelle complète des hyperscalers. L'avantage concurrentiel se répand donc dans la conception de puces, la mémoire, le packaging, l'optique et les logiciels, même si le bassin de revenus reste concentré autour d'un petit nombre d'acteurs dominants.
Leaders du secteur des AI Superchips
NVIDIA Corporation
Advanced Micro Devices, Inc.
Intel Corporation
Google LLC
Amazon.com, Inc.
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Développements récents du secteur
- Juin 2026 : Groq a confirmé une levée de fonds de 650 millions USD, six mois après que NVIDIA a signé un accord de licence non exclusif pour la technologie d'unité de traitement du langage de Groq. Groq a utilisé les capitaux pour étendre son activité d'inférence neocloud à 13 centres de données dans le monde, visant une capacité de 200 MW d'ici 2027. L'accord souligne comment NVIDIA consolide la propriété intellectuelle d'inférence tandis que les startups d'inférence établies pivotent vers des modèles de plateformes plutôt que de concurrencer directement dans le matériel.
- Juin 2026 : Micron et Anthropic ont annoncé un accord stratégique pluriannuel englobant l'approvisionnement en mémoire et en stockage, la collaboration technologique et l'investissement stratégique de Micron dans le tour de financement de série H d'Anthropic. L'accord lie directement les engagements d'approvisionnement en HBM de nouvelle génération aux besoins de l'infrastructure de modèles d'IA frontières sur un horizon temporel qui s'étend bien au-delà des relations fournisseurs standard.
- Juin 2026 : NVIDIA a annoncé lors de l'ISC High Performance 2026 à Hambourg que les systèmes basés sur Vera Rubin NVL4 pour le calcul scientifique seront disponibles auprès de Dell Technologies, HPE, GIGABYTE et Supermicro au quatrième trimestre 2026. Cette initiative étend la plateforme Vera Rubin au-delà des déploiements hyperscale vers les laboratoires nationaux et les institutions de recherche.
- Juin 2026 : Lightmatter a rejoint NVIDIA NVLink Fusion, intégrant ses produits d'optique co-packagée et d'optique near-packaged dans l'écosystème d'interconnexion de montée en charge de NVIDIA. Ce partenariat réduit les besoins en fibres et connecteurs de 50 % dans les déploiements basés sur NVLink Fusion et marque la première couche de connectivité optique au sein de l'architecture de tissu central de NVIDIA.


Périmètre du rapport sur le marché mondial des AI Superchips
Le marché des AI Superchips comprend des plateformes informatiques hautement intégrées qui combinent plusieurs éléments de traitement, des accélérateurs, des sous-systèmes mémoire et des technologies d'interconnexion à haute vitesse dans une architecture unifiée optimisée pour les charges de travail d'intelligence artificielle (IA). Les AI Superchips sont conçus pour offrir des performances de calcul exceptionnelles, une bande passante mémoire élevée, une efficacité énergétique et une évolutivité pour les applications d'entraînement et d'inférence, permettant aux organisations de traiter des modèles d'IA de plus en plus complexes, notamment les grands modèles de langage (LLM), l'IA générative, l'IA multimodale, les systèmes de recommandation, les simulations scientifiques et l'analytique avancée.
Le marché des AI Superchips est segmenté par fonction (entraînement et inférence), type d'architecture (superchips intégrés CPU-GPU, superchips couplés GPU-GPU, superchips à base d'ASIC pour l'IA et superchips multi-accélérateurs hétérogènes), technologie de packaging (système monolithique sur puce (SoC), SoC à base de chiplets, system-in-package (SiP) et module multi-puces (MCM)), déploiement (cloud, sur site et edge), utilisateur final (fournisseurs cloud hyperscale, centres de données, entreprises, organisations gouvernementales et de défense, et institutions de recherche et académiques), et géographie (Amérique du Nord, Europe, Asie-Pacifique, Amérique du Sud, et Moyen-Orient et Afrique). Les prévisions du marché sont fournies en termes de valeur (USD).
| Entraînement |
| Inférence |
| Superchips intégrés CPU-GPU |
| Superchips couplés GPU-GPU |
| Superchips à base d'ASIC pour l'IA |
| Superchips multi-accélérateurs hétérogènes |
| Système monolithique sur puce (SoC) |
| SoC à base de chiplets |
| System-in-Package (SiP) |
| Module multi-puces (MCM) |
| Cloud |
| Sur site |
| Edge |
| Fournisseurs cloud hyperscale |
| Centres de données |
| Entreprises |
| Organisations gouvernementales et de défense |
| Institutions de recherche et académiques |
| Amérique du Nord | États-Unis |
| Canada | |
| Mexique | |
| Europe | Allemagne |
| Royaume-Uni | |
| France | |
| Italie | |
| Reste de l'Europe | |
| Asie-Pacifique | Chine |
| Japon | |
| Corée du Sud | |
| Inde | |
| Asie du Sud-Est | |
| Reste de l'Asie-Pacifique | |
| Amérique du Sud | |
| Moyen-Orient et Afrique |
| Par fonction | Entraînement | |
| Inférence | ||
| Par type d'architecture | Superchips intégrés CPU-GPU | |
| Superchips couplés GPU-GPU | ||
| Superchips à base d'ASIC pour l'IA | ||
| Superchips multi-accélérateurs hétérogènes | ||
| Par technologie de packaging | Système monolithique sur puce (SoC) | |
| SoC à base de chiplets | ||
| System-in-Package (SiP) | ||
| Module multi-puces (MCM) | ||
| Par déploiement | Cloud | |
| Sur site | ||
| Edge | ||
| Par utilisateur final | Fournisseurs cloud hyperscale | |
| Centres de données | ||
| Entreprises | ||
| Organisations gouvernementales et de défense | ||
| Institutions de recherche et académiques | ||
| Par géographie | Amérique du Nord | États-Unis |
| Canada | ||
| Mexique | ||
| Europe | Allemagne | |
| Royaume-Uni | ||
| France | ||
| Italie | ||
| Reste de l'Europe | ||
| Asie-Pacifique | Chine | |
| Japon | ||
| Corée du Sud | ||
| Inde | ||
| Asie du Sud-Est | ||
| Reste de l'Asie-Pacifique | ||
| Amérique du Sud | ||
| Moyen-Orient et Afrique | ||


Questions clés auxquelles le rapport répond
Quelle est la taille du marché des AI Superchips et quelles sont ses perspectives de croissance ?
Le marché des AI Superchips a atteint 70,13 milliards USD en 2025, s'établit à 84,97 milliards USD en 2026, et devrait atteindre 195,22 milliards USD d'ici 2031 à un CAGR de 18,10 %.
Quelle fonction domine la demande d'AI Superchips ?
L'entraînement était en tête en 2025 avec une part de 59,32 %, car le développement des modèles frontières absorbe encore la plus haute intensité de calcul sur les grands clusters de GPU.
Qu'est-ce qui stimule la croissance la plus rapide dans les AI Superchips ?
L'inférence est la fonction à la croissance la plus rapide avec un CAGR de 18,49 %, soutenue par un déploiement plus large de l'IA dans les logiciels d'entreprise, les services aux consommateurs et les systèmes autonomes.
Quel modèle de déploiement domine les dépenses actuelles ?
Le cloud était en tête avec une part de 72,73 % en 2025, car les centres de données hyperscale restent le principal lieu d'entraînement frontière et d'inférence à grande échelle.
Quel groupe d'utilisateurs finaux se développe le plus rapidement ?
Le gouvernement et la défense devraient croître à un CAGR de 19,94 % jusqu'en 2031, à mesure que les programmes de calcul souverain et d'infrastructure d'IA sécurisée se développent.
Quelle région offre la plus forte opportunité de croissance ?
L'Asie-Pacifique devrait afficher le CAGR le plus rapide à 19,09 % jusqu'en 2031, car elle se trouve au centre des chaînes d'approvisionnement en fonderies, en mémoire et en packaging avancé.
Dernière mise à jour de la page le:




