Größe und Marktanteil des KI-Superchip-Markts
Marktübersicht
| Studienzeitraum | 2020 - 2031 |
|---|---|
| Marktgröße (2026) | 84.97 Milliarden US-Dollar |
| Marktgröße (2031) | 195.22 Milliarden US-Dollar |
| Wachstumsrate (2026 - 2031) | 18.10% CAGR |
| Schnellstwachsender Markt | Asien-Pazifik |
| Größter Markt | Nordamerika |
| Marktkonzentration | Hoch |
Hauptakteure *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. | |
KI-Superchip-Marktanalyse von Mordor Intelligence
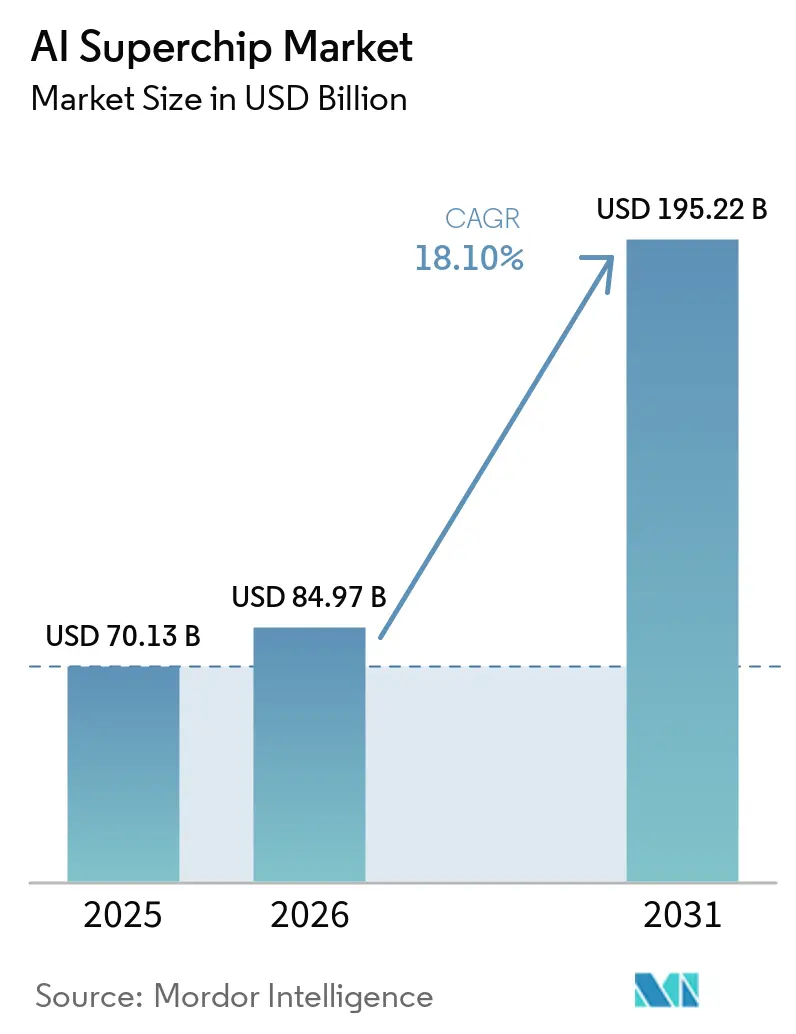
Die Größe des KI-Superchip-Markts wird voraussichtlich von 70,13 Milliarden USD im Jahr 2025 auf 84,97 Milliarden USD im Jahr 2026 wachsen und bis 2031 mit einer CAGR von 18,10 % über den Zeitraum 2026–2031 einen Wert von 195,22 Milliarden USD erreichen. Der Markt wird durch einen starken Anstieg der Hyperscale-Ausgaben für KI-Beschleuniger, kundenspezifische Siliziumlösungen und den Aufbau von Rechenzentren der nächsten Generation angetrieben. Die Nachfrage weitet sich auch aus, weil Rechenleistung nun über Vortraining, Nachtraining, Test-Time-Skalierung und agentische Workloads hinweg genutzt wird, anstatt sich auf einen einzigen großen Trainingszyklus zu konzentrieren. Die Versorgungsbedingungen prägen die Ergebnisse ebenso stark wie die reine Chip-Leistung, da Speicher, fortschrittliche Verpackung und Kühlung auf Rack-Ebene nun Lieferpläne und Produktstrategien beeinflussen. Wettbewerbspositionen werden zunehmend durch Software-Ökosysteme, Interconnect-Standards und den Zugang zur Lieferkette gefestigt, was großen Anbietern einen klaren Vorteil verschafft. Souveräne Computerprogramme und latenzempfindliche Edge-Deployments erweitern ebenfalls den adressierbaren Markt für den KI-Superchip, auch wenn Effizienzgewinne bei Modellen den Druck auf Anbieter erhöhen, den Trainingsdurchsatz mit der Inferenzeffizienz in Einklang zu bringen.
Wichtigste Erkenntnisse des Berichts
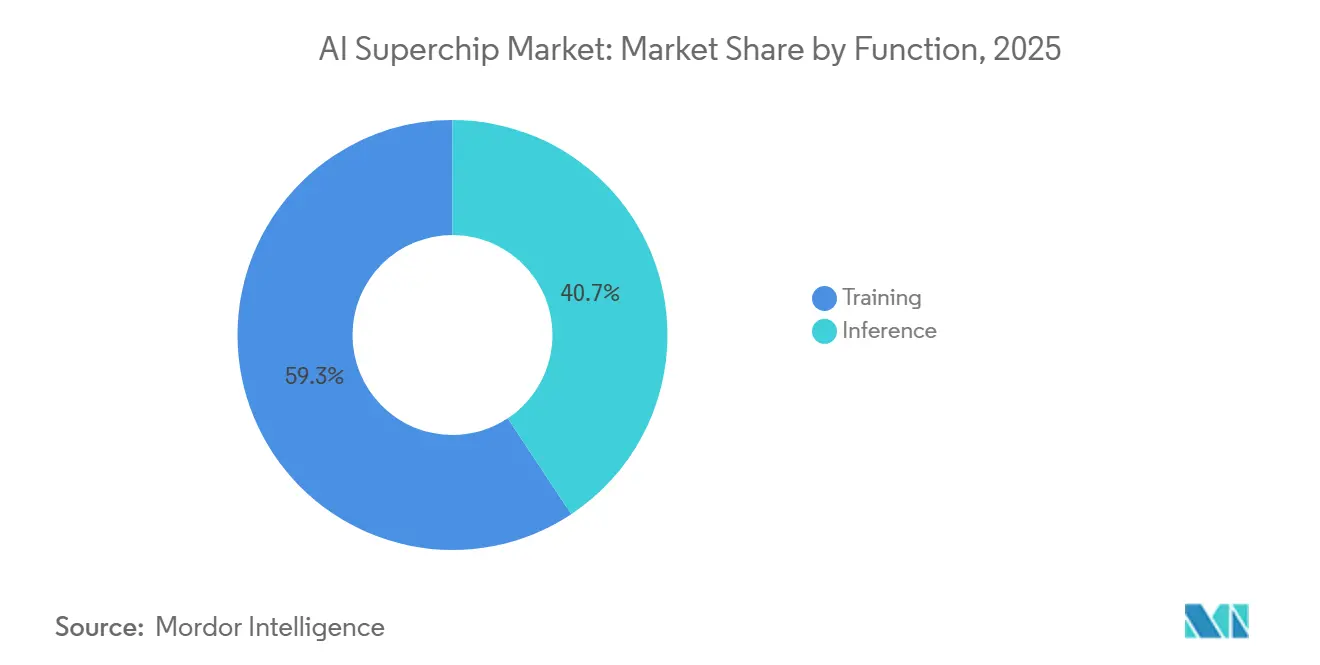
- Nach Funktion entfiel im Jahr 2025 ein Anteil von 59,32 % des KI-Superchip-Markts auf Training, während Inferenz bis 2031 voraussichtlich mit einer CAGR von 18,49 % wachsen wird.
- Nach Architekturtyp entfielen im Jahr 2025 43,76 % des Markts auf CPU-GPU-integrierte Superchips, während KI-ASIC-basierte Superchips bis 2031 voraussichtlich die höchste CAGR von 18,81 % verzeichnen werden.
- Nach Verpackungstechnologie entfiel im Jahr 2025 ein Anteil von 48,14 % auf Multi-Chip-Modul-Verpackung, während Chiplet-basierte SoCs bis 2031 voraussichtlich mit einer CAGR von 18,89 % wachsen werden.
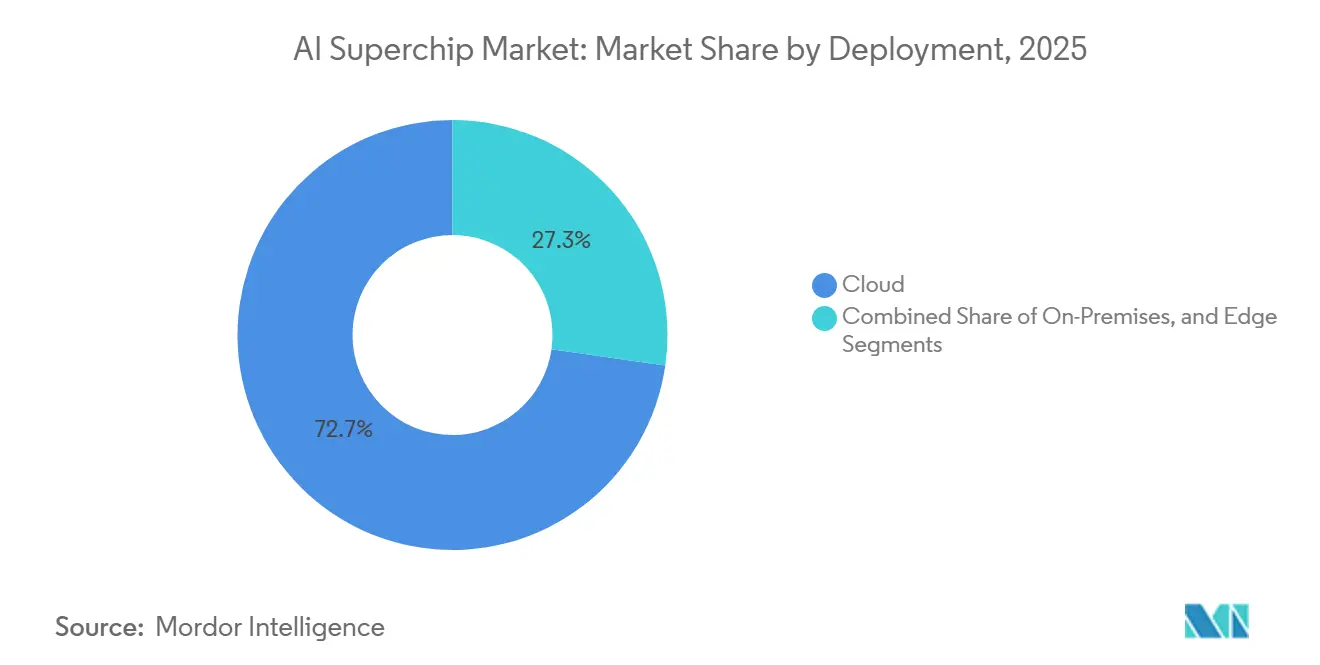
- Nach Bereitstellung hielt Cloud im Jahr 2025 einen Anteil von 72,73 % am Markt für künstliche Intelligenz (KI)-Superchips, während Edge bis 2031 voraussichtlich mit der schnellsten CAGR von 18,68 % wachsen wird.
- Nach Endnutzerbranche repräsentierten Hyperscale-Cloud-Anbieter im Jahr 2025 62,12 % der Ausgaben, während Regierung und Verteidigung bis 2031 voraussichtlich mit einer CAGR von 19,94 % wachsen werden.
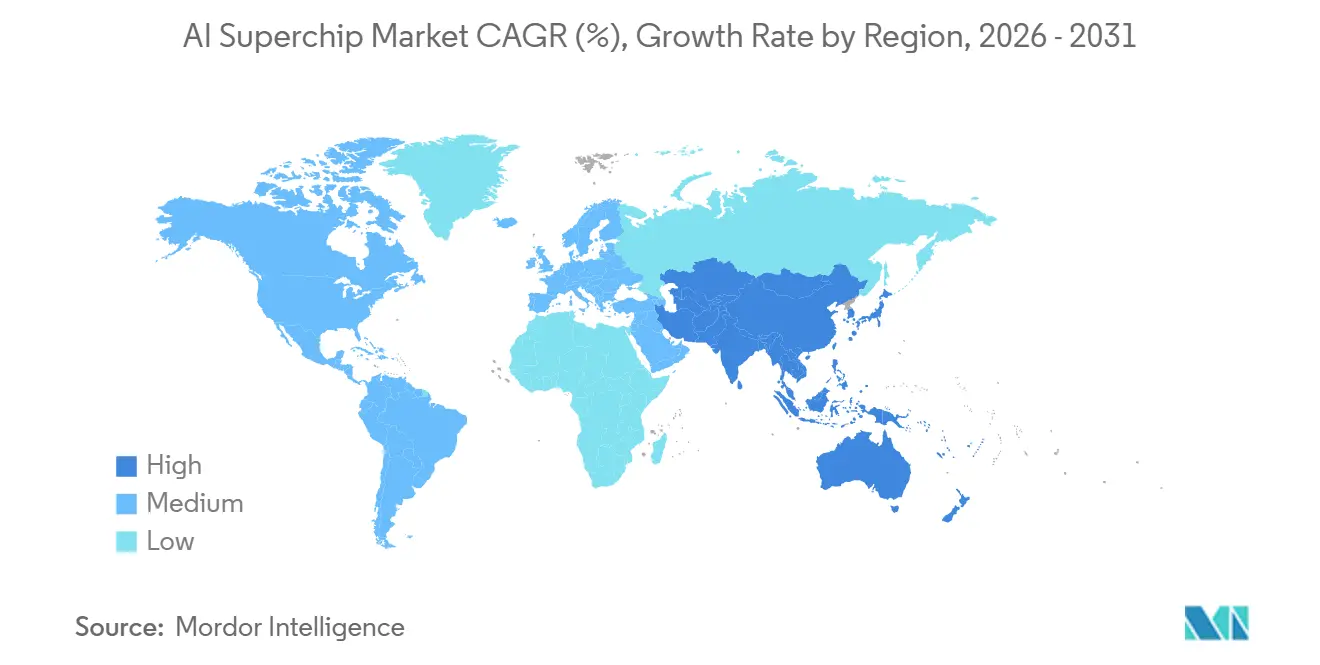
- Nach Geografie entfielen im Jahr 2025 55,69 % des Umsatzes auf Nordamerika, während Asien-Pazifik bis 2031 voraussichtlich die schnellste CAGR von 19,09 % verzeichnen wird.
Hinweis: Die Marktgröße und Prognosezahlen in diesem Bericht werden mithilfe des proprietären Schätzungsrahmens von Mordor Intelligence erstellt und mit den neuesten verfügbaren Daten und Erkenntnissen vom Januar 2026 aktualisiert.
Globale Trends und Erkenntnisse im KI-Superchip-Markt
Analyse der Treiberwirkung*
| Treiber | (~) % Einfluss auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Wirkung |
|---|---|---|---|
| Ausweitung der Rechenkapazität für das Training von Frontier-Modellen | +3.2% | Global, konzentriert in Nordamerika und Asien-Pazifik | Kurzfristig (≤ 2 Jahre) |
| HBM-Co-Location und Skalierung der Speicherbandbreite | +2.8% | Global, mit Lieferkette konzentriert in Südkorea und Taiwan | Kurzfristig (≤ 2 Jahre) |
| Chiplet-basierte heterogene Integration | +2.5% | Global, Verpackung geführt von Taiwan, Designaktivitäten in Nordamerika und Europa | Mittelfristig (2–4 Jahre) |
| Aufbau souveräner KI-Infrastruktur | +2.0% | GCC, Europa, Südasien, Südostasien | Mittelfristig (2–4 Jahre) |
| Edge-Inferenz im großen Maßstab in Industriesystemen | +1.6% | Fertigungsgürtel Asien-Pazifik, Nordamerika, Deutschland | Mittelfristig (2–4 Jahre) |
| Nachfrage nach fortschrittlichen Interconnects für Multi-Die-Systeme | +1.2% | Nordamerika, Taiwan, Südkorea | Langfristig (≥ 4 Jahre) |
| Quelle: Mordor Intelligence | |||
Ausweitung der Rechenkapazität für das Training von Frontier-Modellen treibt anhaltenden Siliziumhunger
Das Training von Frontier-Modellen hält den KI-Superchip-Markt weiterhin auf einem steilen Ausgabenpfad, da neuere Sprach-, Bild- und multimodale Systeme wesentlich mehr parallele Rechenleistung erfordern als frühere Generationen. Der Übergang zu Mixture-of-Experts-Designs und mehrstufigem Nachtraining hat die Hardware-Nachfrage über ein einzelnes Vortraining-Fenster hinaus auf Feinabstimmungs-, Ausrichtungs- und Evaluierungszyklen ausgedehnt. NVIDIA stellte am 5. Januar 2026 die Rubin-Plattform mit 50 Petaflops NVFP4-Inferenzrechenleistung pro GPU vor und erklärte, dass die Plattform Mixture-of-Experts-Modelle mit 4-mal weniger GPUs trainieren kann als die vorherige Blackwell-Generation.[1]NVIDIA, "NVIDIA Kicks Off the Next Generation of AI with Rubin - Six New Chips, One Incredible AI Supercomputer," NVIDIA Newsroom, nvidia.com Niedrigere Rechenkosten pro Modell verringern die Gesamtnachfrage nach Chips nicht, da Labore in der Regel mit größeren Systemen und mehr Experimenten reagieren. Dieses Muster setzt sich auch bei der Bereitstellung fort, wo Reasoning-Workloads variablen Rechenaufwand pro Anfrage verbrauchen, anstatt einem festen Inferenzbudget zu folgen. Das Ergebnis ist, dass der KI-Superchip-Markt eine Nachfrageakkumulation über den gesamten Modell-Lebenszyklus hinweg erlebt, was sowohl Trainingscluster als auch hochvolumige Inferenzflotten unterstützt.
HBM-Co-Location und Skalierung der Speicherbandbreite gestalten die Chip-Architektur neu
Hochbandbreitenspeicher hat sich im KI-Superchip-Markt von einem Leistungsdifferenziator zu einer grundlegenden Designanforderung entwickelt, da moderne Beschleuniger ohne speichernahe Rechenleistung keinen Durchsatz aufrechterhalten können. JEDEC veröffentlichte im Dezember 2024 den HBM4-Standard mit einer 2.048-Bit-Schnittstelle und einem Ziel von 1,5–2 TB/s Bandbreite pro Stack, was die Obergrenze für zukünftige Beschleunigerdesigns angehoben hat. Siemens stellte fest, dass HBM4 auch die Stack-Kapazität auf 64 GB erhöht, was Designern mehr Spielraum gibt, Bandbreite, Kapazität und Leistung innerhalb desselben Gehäuses auszubalancieren. Diese Speicherverschiebung verändert Architekturentscheidungen, da Rechenblöcke, Interposer und thermische Pfade nun von Anfang an um Speicherbeschränkungen herum konzipiert werden. Sie unterstreicht auch die Bedeutung der Lieferantenbereitschaft in Südkorea und Taiwan, da die Speicherverfügbarkeit den Einführungszeitplan ebenso stark beeinflussen kann wie das Logikdesign. Infolgedessen hängt der Produkterfolg zunehmend davon ab, wie gut Anbieter Speicher, Verpackung und Systemintegration koordinieren, und nicht allein vom Prozessordurchsatz.
Chiplet-basierte heterogene Integration durchbricht die Retikel-Grenze
Die Chiplet-Integration wird für den KI-Superchip-Markt immer zentraler, da monolithische Dies innerhalb der Lithografiegrenzen nicht mehr frei skaliert werden können. Siemens berichtete, dass TSMCs CoWoS-L-Roadmap von 2027 bis 2029 eine 9- bis 14-fache Vergrößerung der Retikelgröße anstrebt, was den Bedarf an wesentlich mehr Platz für Compute-Tiles und HBM-Stacks in zukünftigen Gehäusen widerspiegelt. Synopsys schloss 2026 einen 64-Gbps-UCIe-IP-Tape-out ab und demonstrierte damit, dass Die-zu-Die-Verbindungen sich auf Multi-Terabit-Bandbreite bei sehr kurzer Reichweite zubewegen. CEA-Leti demonstrierte im Mai 2026 auch Die-zu-Wafer-Hybridbonden bei einem 1-µm-Pitch, was auf eine dichtere Interconnect-Dichte zwischen Chiplets hindeutet. Diese Fortschritte erleichtern die Kombination von Rechenleistung, Speicher und I/O über verschiedene Prozessknoten hinweg innerhalb eines einzigen Gehäuses. Die Verschiebung verlagert den Wettbewerbsvorteil hin zu Gehäusearchitektur, Co-Design und Montagekompetenz und begünstigt Akteure mit tiefer Integration über den gesamten Halbleiter-Stack.
Aufbau souveräner KI-Infrastruktur diversifiziert die Nachfragebasis
Souveräne Computerprogramme weiten die Nachfrage nach dem KI-Superchip-Markt über Hyperscaler hinaus aus, da Regierungen zunehmend eine inländisch kontrollierte KI-Infrastruktur anstreben. Die britische Regierung kündigte am 8. Juni 2026 einen KI-Hardware-Plan im Wert von 1,1 Milliarden GBP (1,41 Milliarden USD) an, darunter 750 Millionen GBP (960 Millionen USD) für einen nationalen KI-Supercomputer und 400 Millionen GBP (512 Millionen USD) für die Chip-Beschaffung. Derselbe Plan umfasste eine Vorabverpflichtung von 150 Millionen GBP (192 Millionen USD) für neuartige Inferenzchips von britischen und Start-up-Lieferanten, was zeigt, dass öffentliche Käufer den Anbietermix und das Nachfragevolumen mitgestalten. Diese Programme tendieren dazu, On-Premises- und Edge-Konfigurationen zu unterstützen, da sensible Workloads selten über kommerzielle Cloud-Umgebungen geleitet werden. Sie schaffen auch Chancen für Anbieter von Verpackung, Speicher, Netzwerktechnik und sicherem Systemdesign, nicht nur für Beschleuniger-Anbieter. Da sich souveräne Ausbauprogramme auf mehr Länder ausweiten, wird die Nachfragebasis weniger abhängig von einigen wenigen globalen Cloud-Käufern und stärker auf öffentliche Sektorprogramme verteilt.
Analyse der Hemmnisse*
| Hemmnis | (~) % Einfluss auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Wirkung |
|---|---|---|---|
| Kapazitätsengpässe bei fortschrittlicher Verpackung | -2.0% | Global, konzentriert in Taiwan | Kurzfristig (≤ 2 Jahre) |
| Exportkontrollen für führende Beschleuniger | -1.8% | Nordamerika (Angebot), China und Naher Osten und Afrika (Nachfrage), globale Handelsrouten | Mittelfristig (2–4 Jahre) |
| Leistungsdichte und Kühlgrenzen in dichten Racks | -1.0% | Global, akut in Bestandsrechenzentren in Europa und Nordamerika | Mittelfristig (2–4 Jahre) |
| Effizienzgewinne bei Modellen, die die inkrementelle Silizium-Nachfrage reduzieren | -0.8% | Global | Langfristig ( |
| Quelle: Mordor Intelligence | |||
Kapazitätsengpässe bei fortschrittlicher Verpackung begrenzen den kurzfristigen Versorgungsdurchsatz
Fortschrittliche Verpackung bleibt die deutlichste kurzfristige Bremse für den KI-Superchip-Markt, da Beschleuniger ohne komplexe Montage, die Compute-Dies und HBM im selben Gehäuse platziert, nicht ausgeliefert werden können. Selbst wenn sich die Waferversorgung verbessert, benötigen Verpackungslinien noch spezialisierte Bonder, Platzierungswerkzeuge und Inspektionssysteme, deren Installation und Qualifizierung Zeit in Anspruch nimmt. Dies hält viele Anbieter in einer Zuteilungsbeschränkung und macht die Gehäuseverfügbarkeit zu einem kommerziellen Hebel, der ebenso wichtig ist wie Chip-Design oder Wafer-Starts. Der Engpass verstärkt auch die Konzentration, da größere Unternehmen leichter Zugang zu Substraten, Speicher und Foundry-Kapazitäten sichern können als kleinere Wettbewerber. Kühlungs- und Interconnect-Designstandards erhöhen die technische Hürde für dichte Deployments, was bedeutet, dass Verpackungsengpässe nun auch in das Rack-Design und die Systemqualifizierung übergehen. Bis die Kapazität vollständiger ausgebaut ist, werden Lieferpläne weiterhin ebenso stark von der Verpackungsbereitschaft wie von der Prozessornachfrage abhängen.
Exportkontrollen für führende Beschleuniger fragmentieren den globalen Marktzugang
Exportkontrollen fragmentieren den Marktzugang und schränken den freien Verkehr führender KI-Superchips zwischen Regionen ein. Das US Bureau of Industry and Security stellte am 31. Mai 2026 klar, dass Lizenzanforderungen für fortschrittliche Computergüter auch für Tochtergesellschaften chinesischer Unternehmen außerhalb Chinas gelten, was einen Kanal verschloss, der zuvor indirekten Zugang ermöglicht hatte.[2]US-Handelsministerium BIS / Mondaq, "Enforcement Pause Has Limits: BIS Clarifies Ongoing License Requirement for Advanced Computing Items to China-Linked Entities," Mondaq, mondaq.com Dies spaltet die Nachfrage in separate geopolitische Pools auf und reduziert die adressierbare Basis für einige westliche Anbieter. Es beschleunigt auch inländische Chip-Programme in eingeschränkten Märkten, die im Laufe der Zeit alternative Lieferketten schaffen können. Beschaffungsentscheidungen werden daher neben Preis und Leistung auch durch Compliance, Geografie und politische Ausrichtung geprägt. Das Ergebnis ist ein weniger integrierter globaler Markt, in dem führende Anbieter sowohl Produkt-Roadmaps als auch sich verschiebende regulatorische Grenzen managen müssen.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Funktion: Training verankert die Marktgröße, während Inferenz aufholt
Training hielt im Jahr 2025 einen Anteil von 59,32 % am KI-Superchip-Markt und repräsentierte den größten Anteil des Markts, da die Entwicklung von Frontier-Modellen nach wie vor den höchsten Rechenaufwand verursacht. Dieser Vorsprung spiegelte die Intensität des Trainings großer Cluster wider, bei dem modernste Modelle über ausgedehnte Entwicklungszyklen hinweg Zehntausende von GPUs nutzen können. Training bleibt auch deshalb zentral, weil führende Labore nicht nur die Modellgröße skalieren, sondern auch mehr Stufen für Feinabstimmung und Evaluierung hinzufügen. Diese zusätzlichen Schritte halten die Cluster-Auslastung auch nach Abschluss der anfänglichen Vortrainingsphase hoch. NVIDIA erklärte, dass die Rubin-Plattform Mixture-of-Experts-Modelle mit 4-mal weniger GPUs trainieren kann als die vorherige Blackwell-Generation, was zeigt, wie schnell die Effizienz-Baseline voranschreitet.
Diese Effizienzverschiebung könnte den Trainingsanteil im Laufe der Zeit komprimieren, reduziert jedoch nicht die Bedeutung des Trainings in absoluten Ausgaben. Inferenz wird bis 2031 voraussichtlich mit einer CAGR von 18,49 % wachsen, da die Anzahl der eingesetzten Modelle in Unternehmenssoftware, Verbraucherdiensten und autonomen Systemen steigt. Die KI-Superchip-Branche bewegt sich daher nicht vom Training weg, sondern fügt durch Echtzeit-Inferenz einen zweiten großen Nachfragepool hinzu. Reasoning-Workloads erhöhen auch den Rechenaufwand während der Bereitstellung, da sie jedem Prompt variablen GPU-Zeitaufwand zuweisen können, anstatt einem festen Antwortpfad zu folgen. Das bedeutet, dass das Inferenzwachstum zur bestehenden Trainingsnachfrage hinzukommt, anstatt sie zu ersetzen. Der KI-Superchip-Markt wird wahrscheinlich ausgewogen zwischen Laboren, die große Trainingscluster benötigen, und Betreibern, die schnelle, effiziente Inferenzflotten benötigen, bleiben.


Nach Architekturtyp: CPU-GPU-Integration führt, während kundenspezifische ASICs beschleunigen
CPU-GPU-integrierte Superchips hielten im Jahr 2025 einen Anteil von 43,76 % und machten den größten Anteil am KI-Superchip-Markt aus, da sie die Anforderungen von groß angelegtem Training und gemischten Rechenumgebungen erfüllen. Ihr Vorsprung wurde auf Plattformen wie Grace Blackwell und Vera Rubin aufgebaut, die Arm-basierte CPUs und GPUs mit sehr hoher Interconnect-Bandbreite verbinden. Eine engere CPU-GPU-Koordination verbessert die Datenbewegung und reduziert den Leistungsverlust durch das Überqueren separater Speicherdomänen. Diese Kombination ist nützlich, wenn Orchestrierung, Speicherzugriff und Beschleunigerausführung als ein einziges System funktionieren müssen. Es erklärt auch, warum integrierte Plattformen die bevorzugte Grundlage für große KI-Cluster bleiben.
KI-ASIC-basierte Superchips werden bis 2031 voraussichtlich die schnellste CAGR von 18,81 % verzeichnen, da Hyperscaler Silizium zunehmend auf spezifische Workload-Ökonomien abstimmen. Die KI-Superchip-Branche sieht dies am deutlichsten bei der Inferenz, wo vorhersehbare, repetitive Workloads kundenspezifisches Chip-Design begünstigen. Google stellte im April 2026 TPU 8t für Training und TPU 8i für Inferenz vor, was eine klarere Trennung zwischen workload-spezifischen Beschleunigerpfaden zeigte. Dies ist wichtig, weil Kosten, Leistung und Durchsatz enger abgestimmt werden können, wenn der Käufer den Software-Stack und das Bereitstellungsmodell kontrolliert. GPU-GPU-gekoppelte und heterogene Multi-Beschleuniger-Setups werden in spezialisierten Umgebungen wichtig bleiben, aber das stärkste Wachstumssignal kommt vom Einsatz kundenspezifischer ASICs im Hyperscale-Bereich. Da sich dieser Mix ausweitet, werden Merchant-GPU-Anbieter in inferenzintensiven Anwendungsfällen, wo Eigentumskosten zu einem stärkeren Kauffaktor werden, einem größeren Druck ausgesetzt sein.
Nach Verpackungstechnologie: MCM dominiert den Marktanteil, während Chiplet-Architekturen die Wachstumskurve definieren
Multi-Chip-Modul-Verpackung erfasste im Jahr 2025 einen Anteil von 48,14 % und führte den Verpackungsmix an, da sie eine praktikable Balance zwischen thermischer Kontrolle, Fertigungsskalierbarkeit und Bandbreiteneffizienz bietet. MCM-Formate werden auch von einem etablierten Foundry- und OSAT-Ökosystem unterstützt, das Anbietern hilft, die Produktion schneller zu skalieren als mit weniger ausgereiften Ansätzen. Dies ist im aktuellen Zyklus wichtig, da die Wahl der Verpackung die Liefergeschwindigkeit ebenso stark beeinflusst wie die technische Leistung. MCM bleibt daher die Standardstruktur für viele High-End-KI-Beschleuniger, die große Compute-Dies und HBM-Stacks kombinieren. Sein Vorsprung wird kurzfristig wahrscheinlich bestehen bleiben, solange Lieferketten weiterhin bewährte Montagepfade bevorzugen.
Chiplet-basierte SoCs werden bis 2031 voraussichtlich mit einer CAGR von 18,89 % wachsen, da Retikelgrenzen Designer dazu zwingen, Rechenleistung auf mehrere Dies aufzuteilen. Dies ist eines der deutlichsten Beispiele dafür, dass der KI-Superchip-Markt durch physische Designgrenzen und nicht durch einfache Leistungsziele geprägt wird. Synopsys schloss 2026 einen 64-Gbps-UCIe-IP-Tape-out ab, und CEA-Leti demonstrierte im Mai 2026 1-µm-Die-zu-Wafer-Hybridbonden, was beide eine dichtere Die-zu-Die-Integration unterstützt. Diese Fortschritte erleichtern es, ein Gehäuse als modulares System statt als einzelnen großen Chip zu behandeln. Monolithische SoC- und System-in-Package-Designs werden in kleineren Edge- und robusten Umgebungen weiterhin wichtig sein, aber die zukünftige Skalierung im High-End-Bereich bewegt sich in Richtung chiplet-intensiver Montage. Da sich diese Verschiebung vertieft, wird die Gehäusearchitektur zu einer stärkeren Quelle der Produktdifferenzierung als das Einzelchip-Modell.
Nach Bereitstellung: Cloud dominiert mit über 70 % Marktanteil, während Edge zum strategischen Schlachtfeld wird
Cloud-Bereitstellung hielt im Jahr 2025 einen Anteil von 72,73 % und machte den größten Anteil am Markt für künstliche Intelligenz (KI)-Superchips aus, da Hyperscale-Rechenzentren nach wie vor die schwersten Trainings- und groß angelegten Inferenzlasten beherbergen. Hyperscaler können spezialisierte Infrastruktur, fortschrittliche Kühlung und Software-Umgebungen finanzieren, die nur wenige andere Käufer erreichen können. Dieser Skalenvorteil hält die Cloud im Mittelpunkt sowohl der Modellentwicklung als auch der breiten Servicebereitstellung. Es macht die Cloud auch zum wichtigsten Einstiegspunkt für neue Architekturen, die eine dichte Integration auf Rack-Ebene erfordern. Der KI-Superchip-Markt verlässt sich weiterhin auf Hyperscale-Kapazität, da die fortschrittlichsten Systeme nach wie vor Umgebungen erfordern, die für Leistung, Kühlung und Netzwerkdichte optimiert sind.
NVIDIA positionierte Rubin-basierte Systeme rund um große KI-Infrastrukturaufbauten und bekräftigte damit die Idee, dass Flaggschiff-Plattformen immer noch zuerst für Cloud-Scale-Deployments konzipiert werden. Edge-Deployment wird bis 2031 voraussichtlich mit einer CAGR von 18,68 % wachsen, da mehr industrielle und Verteidigungs-Workloads keine Cloud-Roundtrip-Latenz tolerieren können. Dieses Wachstum wird weniger durch Verbrauchergeräte als vielmehr durch Feldeinsätze, Fabriken und Remote-Systeme angetrieben, die lokale Inferenz benötigen. Emerson und SiMa Technologies kündigten im Mai 2026 KI-fähige Industrie-PCs für Fertigungs- und Remote-Feldstandorte an, was zeigt, wie physische KI in kontrollierte industrielle Umgebungen vordringt. On-Premises-Systeme werden in regulierten Sektoren wie Gesundheitswesen, Finanzen und Regierung wichtig bleiben. Das schärfere Wachstumssignal liegt jedoch am Edge, wo Leistungsgrenzen, robuste Bereitstellung und lokale Kontrolle einen eigenständigen Hardware-Pfad vom Hyperscale-Cloud-Bereich schaffen.

Nach Endnutzerbranche: Hyperscale-Anbieter bestimmen das Ausgabentempo, während Verteidigung am schnellsten wächst
Hyperscale-Cloud-Anbieter machten im Jahr 2025 62,12 % der Endnutzerausgaben aus und bestimmten den Ausgabenrhythmus für den Markt für künstliche Intelligenz (KI)-Superchips, da die größten Beschaffungsbudgets weiterhin bei einigen wenigen Cloud-Plattformen konzentriert sind. Ihre Kaufentscheidungen beeinflussen Beschleuniger-Roadmaps, Verpackungszuteilung und Software-Support in der gesamten Wertschöpfungskette. Diese Käuferkonzentration gibt führenden Cloud-Unternehmen ungewöhnlichen Einfluss darauf, was zuerst gebaut wird und welche Anbieter am schnellsten skalieren. Es bedeutet auch, dass viele Lieferantenbeziehungen rund um eine kleine Gruppe sehr großer Kunden geknüpft werden. Das aktuelle Nachfrageumfeld spiegelt daher sowohl die Endnutzernachfrage als auch die Käuferkonzentration an der Spitze des Markts wider.
Regierungs- und Verteidigungsorganisationen werden bis 2031 voraussichtlich die schnellste CAGR von 19,94 % verzeichnen, da immer mehr Länder KI-Rechenleistung als strategische Infrastruktur betrachten. Die KI-Superchip-Branche profitiert von dieser Verschiebung durch die Nachfrage nach souveräner Rechenleistung, sicherer Bereitstellung und kontrollierten Beschaffungskanälen. Der KI-Hardware-Plan des Vereinigten Königreichs, der im Juni 2026 angekündigt wurde, zeigte direkte öffentliche Unterstützung für Rechenkapazität, Chip-Beschaffung und inländische Hardware-Entwicklung. Forschungs- und akademische Einrichtungen bleiben in absoluten Ausgaben kleiner, erhalten aber durch wissenschaftsorientierte Infrastrukturausbauten besseren Zugang zu fortschrittlichen Systemen. NVIDIA erklärte, dass Vera Rubin NVL4-basierte Systeme für wissenschaftliches Rechnen von Dell Technologies, HPE, GIGABYTE und Supermicro im vierten Quartal 2026 verfügbar sein werden. Dieser erweiterte Zugang verändert die Ausgabenhierarchie nicht, erweitert jedoch High-End-Rechenleistung über Hyperscaler- und Verteidigungsumgebungen hinaus.
Geografische Analyse
Nordamerika hielt im Jahr 2025 mit 55,69 % den größten Anteil am KI-Superchip-Markt, da Frontier-KI-Labore, Hyperscaler-Hauptsitze und die größten angekündigten Infrastrukturbudgets dort konzentriert sind. Die Vereinigten Staaten bleiben das Zentrum des Merchant-Beschleuniger-Designs und der kundenspezifischen Siliziumstrategie, was einen Großteil des geistigen Eigentums der Branche dort verankert. Die Region profitiert auch von einer engen Abstimmung zwischen Cloud-Käufern, Chip-Designern, Systemherstellern und Software-Ökosystemen. Kanada entwickelt sich zu einem unterstützenden Knotenpunkt für souveräne Computerbemühungen, während Mexiko eher als Nearshore-Produktionsstandort als als wichtige Nachfragequelle relevant bleibt. Diese Faktoren halten Nordamerika strukturell stark, auch wenn die Fertigung anderswo stattfindet.
Asien-Pazifik wird bis 2031 voraussichtlich mit einer CAGR von 19,09 % wachsen und damit die am schnellsten wachsende Geografie im Markt für künstliche Intelligenz (KI)-Superchips sein. Die Region steht im Mittelpunkt der führenden Foundry-Arbeit, der Hochbandbreitenspeicherproduktion und der fortschrittlichen Verpackung, was ihr direkten Einfluss auf den globalen Versorgungszeitplan gibt. Taiwan und Südkorea bleiben kritisch, da Fertigungstiefe und Speicherkontrolle das Einführungstempo fortschrittlicher Beschleuniger prägen. Indiens IndiaAI Mission betrieb Anfang 2026 eine Rechenanlage mit 38.000 GPUs und strebte bis Jahresende 100.000 an, was auf eine schnell wachsende lokale Nachfragebasis hindeutet.[3]Carnegie Endowment for International Peace, "Early Lessons in the Pursuit of Sovereign AI," Carnegie Endowment, carnegieendowment.org
Europa hielt im Jahr 2025 einen mittelgroßen Umsatzanteil, angeführt von Deutschland, dem Vereinigten Königreich und Frankreich. Die britische Regierung kündigte im Juni 2026 einen KI-Hardware-Plan im Wert von 1,1 Milliarden GBP (1,41 Milliarden USD) an, einschließlich Finanzierung für einen nationalen KI-Supercomputer und Chip-Beschaffung. Diese politische Ausrichtung unterstützt mehr lokale Rechenkapazität und stärkt die On-Premises-Nachfrage in regulierten Umgebungen. Südamerika, der Nahe Osten und Afrika bleiben umsatzmäßig kleiner, aber souveräne Infrastrukturprogramme eröffnen neue Chancen, insbesondere in Golfmärkten, wo staatlich unterstützte digitale Investitionen steigen.

Wettbewerbslandschaft
Der KI-Superchip-Markt bleibt trotz seiner großen Umsatzbasis und seines sich ausweitenden Anwendungsbereichs stark konzentriert. NVIDIA hielt im Jahr 2026 schätzungsweise 80–85 % des KI-Beschleuniger-Umsatzes, was Merchant-Wettbewerber auf einem wesentlich kleineren Maßstab zurücklässt. Sein Vorsprung beruht auf der CUDA-Software-Bindung, starkem Verpackungszugang und der Fähigkeit, vollständige Plattformen statt einzelner Chips zu verkaufen. AMD bleibt der nächste Merchant-Herausforderer, wobei die Instinct-Linie die technische Lücke bei gezielten Workloads verringert. Dennoch hängt die Wettbewerbsstärke in diesem Markt ebenso stark von der Software-Akzeptanz, dem Versorgungszugang und der Ökosystemreichweite ab wie von der reinen Siliziumleistung.
Kundenspezifisches Silizium von Hyperscalern ist die bedeutendste strukturelle Herausforderung für Merchant-GPU-Anbieter, da die größten Käufer zunehmend eine engere Kontrolle über Kosten und Workload-Design anstreben. Google stellte im April 2026 TPU 8t für Training und TPU 8i für Inferenz vor, was zeigt, wie Hyperscaler Beschleunigerpfade trennen, um spezifische Bereitstellungsökonomien zu erfüllen. NVIDIA reagierte mit der Erweiterung von NVLink Fusion, sodass ASICs und XPUs von Drittanbietern eine Verbindung zu seinem Scale-up-Fabric herstellen können. Lightmatter trat im Juni 2026 NVLink Fusion bei, was zeigt, dass NVIDIA seine Position bei Interconnects und Optik ausweitet, anstatt einen vollständig geschlossenen Hardware-Stack zu verteidigen.[4]Lightmatter, "Lightmatter Joins NVIDIA NVLink Fusion and Powers Next-Generation AI Infrastructure with Photonic Interconnects," Lightmatter, lightmatter.co
Start-ups finden weiterhin Raum, wo sie einen klaren Architektur- oder Bereitstellungsansatz bieten, auch wenn der Gesamtumsatz konzentriert bleibt. Groq erweiterte seinen Neocloud-Inferenz-Fußabdruck, nachdem im Juni 2026 eine Finanzierungsrunde von 650 Millionen USD bestätigt wurde, was die Unterstützung von Investoren für inferenzfokussierte Plattformmodelle zeigte. Micron und Anthropic kündigten im Juni 2026 auch eine mehrjährige strategische Vereinbarung an, die Speicher- und Speicherversorgung enger mit den Anforderungen der Frontier-KI-Infrastruktur verknüpft. Design-Service-Unternehmen wie Broadcom und Marvell sind auch gut positioniert für Unternehmens- und Regierungskäufer, die halbkundenspezifisches Silizium ohne den vollen Hyperscaler-Maßstab wünschen. Der Wettbewerbsvorteil verteilt sich daher auf Chip-Design, Speicher, Verpackung, Optik und Software, auch wenn der Umsatzpool weiterhin um eine kleine Anzahl dominanter Akteure konzentriert bleibt.
Marktführer im KI-Superchip-Bereich
NVIDIA Corporation
Advanced Micro Devices, Inc.
Intel Corporation
Google LLC
Amazon.com, Inc.
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Jüngste Branchenentwicklungen
- Juni 2026: Groq bestätigte eine Finanzierungsrunde von 650 Millionen USD, sechs Monate nachdem NVIDIA eine nicht-exklusive Lizenzvereinbarung für Groqs Language-Processing-Unit-Technologie unterzeichnet hatte. Groq nutzte das Kapital, um sein Neocloud-Inferenzgeschäft auf 13 Rechenzentren weltweit auszuweiten und bis 2027 eine Kapazität von 200 MW anzustreben. Der Deal unterstreicht, wie NVIDIA Inferenz-IP konsolidiert, während etablierte Inferenz-Start-ups sich zu Plattformunternehmen wandeln, anstatt direkt im Hardware-Bereich zu konkurrieren.
- Juni 2026: Micron und Anthropic kündigten eine mehrjährige strategische Vereinbarung an, die Speicher- und Speicherversorgung, technologische Zusammenarbeit und Microns strategische Investition in Anthropics Series-H-Finanzierungsrunde umfasst. Die Vereinbarung verknüpft Lieferverpflichtungen für HBM der nächsten Generation direkt mit der Frontier-KI-Modellinfrastruktur in einem Zeitrahmen, der weit über standardmäßige Lieferantenbeziehungen hinausgeht.
- Juni 2026: NVIDIA kündigte auf der ISC High Performance 2026 in Hamburg an, dass Vera Rubin NVL4-basierte Systeme für wissenschaftliches Rechnen von Dell Technologies, HPE, GIGABYTE und Supermicro im vierten Quartal 2026 verfügbar sein werden. Dieser Schritt erweitert die Vera Rubin-Plattform über Hyperscale-Deployments hinaus auf nationale Labore und Forschungseinrichtungen.
- Juni 2026: Lightmatter trat NVIDIA NVLink Fusion bei und integrierte seine Co-Packaged-Optics- und Near-Packaged-Optics-Produkte in NVIDIAs Scale-up-Interconnect-Ökosystem. Diese Partnerschaft reduziert den Faser- und Steckverbinderbedarf in NVLink-Fusion-basierten Deployments um 50 % und markiert die erste optische Konnektivitätsschicht innerhalb von NVIDIAs Kern-Fabric-Architektur.


Berichtsumfang des globalen KI-Superchip-Markts
Der KI-Superchip-Markt umfasst hochintegrierte Rechenplattformen, die mehrere Verarbeitungselemente, Beschleuniger, Speichersubsysteme und Hochgeschwindigkeits-Interconnect-Technologien in einer einheitlichen Architektur kombinieren, die für Workloads der künstlichen Intelligenz (KI) optimiert ist. KI-Superchips sind darauf ausgelegt, außergewöhnliche Rechenleistung, Speicherbandbreite, Energieeffizienz und Skalierbarkeit für Training- und Inferenzanwendungen zu liefern, sodass Organisationen zunehmend komplexe KI-Modelle verarbeiten können, einschließlich großer Sprachmodelle (LLMs), generativer KI, multimodaler KI, Empfehlungssysteme, wissenschaftlicher Simulationen und fortschrittlicher Analytik.
Der KI-Superchip-Markt ist segmentiert nach Funktion (Training und Inferenz), Architekturtyp (CPU-GPU-integrierte Superchips, GPU-GPU-gekoppelte Superchips, KI-ASIC-basierte Superchips und heterogene Multi-Beschleuniger-Superchips), Verpackungstechnologie (monolithisches System-on-Chip (SoC), Chiplet-basiertes SoC, System-in-Package (SiP) und Multi-Chip-Modul (MCM)), Bereitstellung (Cloud, On-Premises und Edge), Endnutzer (Hyperscale-Cloud-Anbieter, Rechenzentren, Unternehmen, Regierungs- und Verteidigungsorganisationen sowie Forschungs- und akademische Einrichtungen) und Geografie (Nordamerika, Europa, Asien-Pazifik, Südamerika sowie Naher Osten und Afrika). Die Marktprognosen werden in Wertangaben (USD) bereitgestellt.
| Training |
| Inferenz |
| CPU-GPU-integrierte Superchips |
| GPU-GPU-gekoppelte Superchips |
| KI-ASIC-basierte Superchips |
| Heterogene Multi-Beschleuniger-Superchips |
| Monolithisches System-on-Chip (SoC) |
| Chiplet-basiertes SoC |
| System-in-Package (SiP) |
| Multi-Chip-Modul (MCM) |
| Cloud |
| On-Premises |
| Edge |
| Hyperscale-Cloud-Anbieter |
| Rechenzentren |
| Unternehmen |
| Regierungs- und Verteidigungsorganisationen |
| Forschungs- und akademische Einrichtungen |
| Nordamerika | Vereinigte Staaten |
| Kanada | |
| Mexiko | |
| Europa | Deutschland |
| Vereinigtes Königreich | |
| Frankreich | |
| Italien | |
| Übriges Europa | |
| Asien-Pazifik | China |
| Japan | |
| Südkorea | |
| Indien | |
| Südostasien | |
| Übriges Asien-Pazifik | |
| Südamerika | |
| Naher Osten und Afrika |
| Nach Funktion | Training | |
| Inferenz | ||
| Nach Architekturtyp | CPU-GPU-integrierte Superchips | |
| GPU-GPU-gekoppelte Superchips | ||
| KI-ASIC-basierte Superchips | ||
| Heterogene Multi-Beschleuniger-Superchips | ||
| Nach Verpackungstechnologie | Monolithisches System-on-Chip (SoC) | |
| Chiplet-basiertes SoC | ||
| System-in-Package (SiP) | ||
| Multi-Chip-Modul (MCM) | ||
| Nach Bereitstellung | Cloud | |
| On-Premises | ||
| Edge | ||
| Nach Endnutzer | Hyperscale-Cloud-Anbieter | |
| Rechenzentren | ||
| Unternehmen | ||
| Regierungs- und Verteidigungsorganisationen | ||
| Forschungs- und akademische Einrichtungen | ||
| Nach Geografie | Nordamerika | Vereinigte Staaten |
| Kanada | ||
| Mexiko | ||
| Europa | Deutschland | |
| Vereinigtes Königreich | ||
| Frankreich | ||
| Italien | ||
| Übriges Europa | ||
| Asien-Pazifik | China | |
| Japan | ||
| Südkorea | ||
| Indien | ||
| Südostasien | ||
| Übriges Asien-Pazifik | ||
| Südamerika | ||
| Naher Osten und Afrika | ||


Im Bericht beantwortete Schlüsselfragen
Wie groß ist der KI-Superchip-Markt und wie ist sein Wachstumsausblick?
Der KI-Superchip-Markt erreichte im Jahr 2025 einen Wert von 70,13 Milliarden USD, steht im Jahr 2026 bei 84,97 Milliarden USD und wird bis 2031 mit einer CAGR von 18,10 % voraussichtlich einen Wert von 195,22 Milliarden USD erreichen.
Welche Funktion führt die Nachfrage nach KI-Superchips an?
Training führte im Jahr 2025 mit einem Anteil von 59,32 %, da die Entwicklung von Frontier-Modellen nach wie vor die höchste Rechenintensität über große GPU-Cluster hinweg absorbiert.
Was treibt das schnellste Wachstum bei KI-Superchips an?
Inferenz ist die am schnellsten wachsende Funktion mit einer CAGR von 18,49 %, unterstützt durch eine breitere KI-Bereitstellung in Unternehmenssoftware, Verbraucherdiensten und autonomen Systemen.
Welches Bereitstellungsmodell dominiert die aktuellen Ausgaben?
Cloud führte im Jahr 2025 mit einem Anteil von 72,73 %, da Hyperscale-Rechenzentren weiterhin der Kernschauplatz für Frontier-Training und groß angelegte Inferenz sind.
Welche Endnutzergruppe wächst am schnellsten?
Regierung und Verteidigung wird bis 2031 voraussichtlich mit einer CAGR von 19,94 % wachsen, da souveräne Computerprogramme und sichere KI-Infrastrukturprogramme expandieren.
Welche Region bietet die stärkste Wachstumschance?
Asien-Pazifik wird bis 2031 voraussichtlich die schnellste CAGR von 19,09 % verzeichnen, da es im Mittelpunkt der Lieferketten für Foundry, Speicher und fortschrittliche Verpackung steht.
Seite zuletzt aktualisiert am:




