Taille et parts du marché des services de bioinformatique
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2020 - 2031 |
|---|---|
| Taille du Marché (2026) | 4.32 Milliards de dollars |
| Taille du Marché (2031) | 7.75 Milliards de dollars |
| Taux de croissance (2026 - 2031) | 12.44% CAGR |
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Amérique du Nord |
| Concentration du Marché | Moyen |
Acteurs majeurs *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. | |
Analyse du marché des services de bioinformatique par Mordor Intelligence
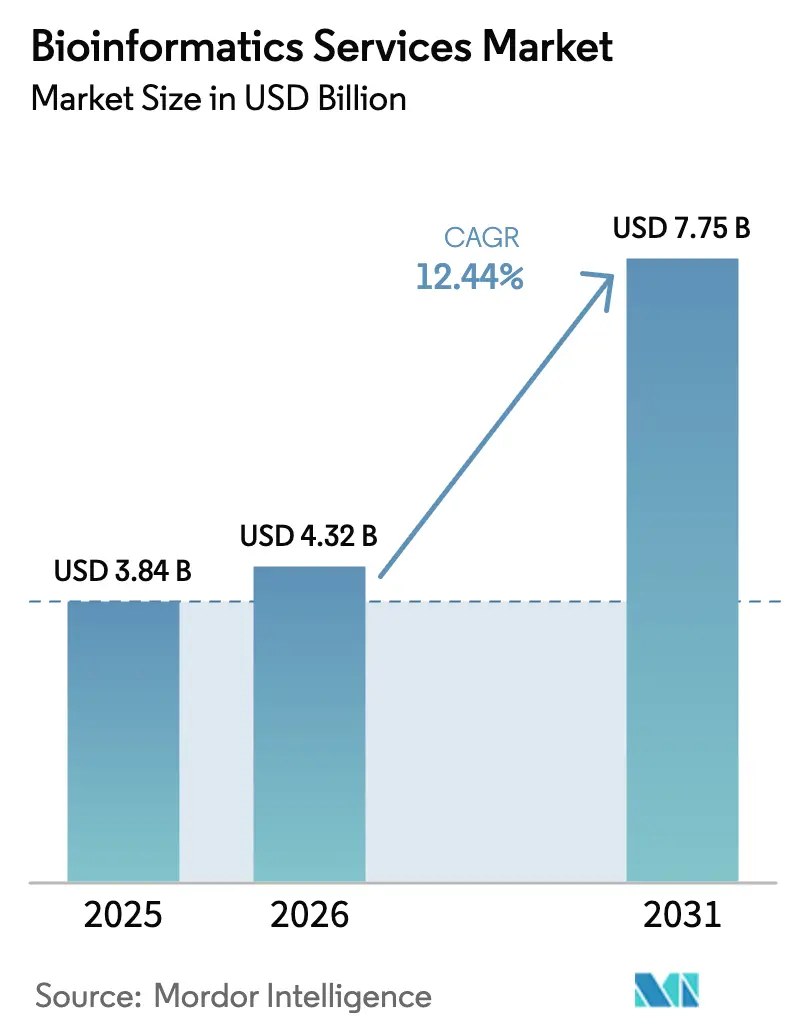
La taille du marché des services de bioinformatique en 2026 est estimée à 4,32 milliards USD, en croissance par rapport à la valeur de 2025 de 3,84 milliards USD, avec des projections pour 2031 montrant 7,75 milliards USD, croissant à un CAGR de 12,44 % sur la période 2026-2031.
Cette expansion reflète un passage du traitement conventionnel des données vers des plateformes natives en cloud dotées d'intelligence artificielle, qui fournissent une interprétation génomique en temps réel pour la découverte de médicaments et la prise de décision clinique.[1]Teng Zhou, « Les grands modèles de langage en génomique — Une perspective sur la médecine personnalisée », MDPI, mdpi.com Les pipelines pharmaceutiques, les publications de biobanques nationales et l'intégration multi-omique maintiennent collectivement les charges de travail analytiques sur une courbe de croissance soutenue. Les gouvernements investissent massivement dans le séquençage à l'échelle de la population, ce qui augmente les volumes de données tout en démocratisant l'accès aux données pour les petites entreprises. Dans le même temps, la hausse des frais de sortie cloud et une pénurie aiguë de talents en bioinformatique font augmenter les coûts opérationnels et ralentissent les délais des projets. Les prestataires capables d'intégrer des flux de travail automatisés par intelligence artificielle, de réduire le coût analytique par échantillon et de naviguer dans les règles émergentes de souveraineté des données captent une demande disproportionnée. Les pionniers lancent également des plateformes par abonnement combinant analyse, stockage et gestion de la conformité, positionnant le marché des services de bioinformatique pour une croissance soutenue à deux chiffres.
Points clés du rapport
- Par type de service, l'analyse de données détenait 37,55 % des parts du marché des services de bioinformatique en 2025, tandis que les offres d'intégration et de plateforme en tant que service devraient croître à un CAGR de 18,08 % jusqu'en 2031.
- Par application, la génomique et la protéomique représentaient 41,90 % des parts de revenus en 2025 ; les diagnostics cliniques et la médecine de précision devraient se développer à un CAGR de 19,25 % jusqu'en 2031.
- Par utilisateur final, les entreprises pharmaceutiques et biotechnologiques représentaient 46,72 % de la taille du marché des services de bioinformatique en 2025, tandis que les hôpitaux et les laboratoires de diagnostic progressent à un CAGR de 17,12 % jusqu'en 2031.
- Par géographie, l'Amérique du Nord était en tête avec 46,10 % des parts de revenus en 2025 ; l'Asie-Pacifique enregistre la croissance la plus rapide avec un CAGR de 16,62 % jusqu'en 2031.
Remarque : Les chiffres de la taille du marché et des prévisions de ce rapport sont générés à l’aide du cadre d’estimation propriétaire de Mordor Intelligence, mis à jour avec les données et analyses les plus récentes disponibles en 2026.
Tendances et perspectives mondiales du marché des services de bioinformatique
Analyse de l'impact des moteurs*
| Moteur | (~) % d'impact sur les prévisions de CAGR | Pertinence géographique | Calendrier d'impact |
|---|---|---|---|
| Demande croissante de médecine personnalisée et de soins de santé de précision | +2.80% | Mondial, porté par l'Amérique du Nord et l'UE | Moyen terme (2-4 ans) |
| Avancées rapides dans les technologies de génomique et de protéomique | +2.10% | Pôles de recherche mondiaux | Long terme (≥ 4 ans) |
| Utilisation croissante de l'IA/ML pour l'analyse de données multi-omiques à grande échelle | +3.20% | Amérique du Nord, UE, Asie-Pacifique | Court terme (≤ 2 ans) |
| Expansion des biobanques nationales offrant un accès API ouvert aux prestataires de services | +1.90% | Europe, Amérique du Nord, certaines régions d'Asie-Pacifique | Moyen terme (2-4 ans) |
| Adoption croissante de plateformes de bioinformatique natives en cloud à paiement à l'utilisation | +1.70% | Marchés développés dans le monde entier | Court terme (≤ 2 ans) |
| Accélération des programmes de biologie synthétique et d'édition génique nécessitant un soutien informatique | +1.40% | Amérique du Nord, UE, Chine, Singapour | Long terme (≥ 4 ans) |
| Source: Mordor Intelligence | |||
Demande croissante de médecine personnalisée et de soins de santé de précision
Les systèmes de santé mondiaux passent de régimes basés sur la population à des thérapies spécifiques aux patients, élargissant les exigences en matière d'analyse multi-omique. Le Projet du protéome humain a atteint une couverture protéique de 93 % en 2024, offrant un complément protéomique à la stratification génomique. L'initiative PROMISE de la Suède mélange des données omiques avec des dossiers du monde réel, démontrant comment les prestataires de services doivent fournir une interprétation de qualité clinique ainsi que des pipelines computationnels.[2]Centre médical universitaire Vanderbilt, « Données génomiques dans le programme de recherche All of Us », nature.com Les commanditaires pharmaceutiques exigent de plus en plus des flux de travail clés en main reliant les résultats de séquençage aux recommandations de traitement, renforçant les modèles basés sur des plateformes au sein du marché des services de bioinformatique.
Avancées rapides dans les technologies de génomique et de protéomique
Les courbes de coût du séquençage continuent de baisser tandis que le débit augmente, générant des ensembles de données de l'ordre du pétaoctet. Le partenariat d'Illumina avec NVIDIA en 2025 place les algorithmes DRAGEN sur des GPU, réduisant les temps d'analyse du génome entier et élargissant l'adoption multi-omique. Des approbations réglementaires telles que la validation par la FDA en 2024 de la thérapie génique Kebilidi soulignent la complexité clinique en aval qui nécessite un soutien informatique continu.[3]Bureau du commissaire, « La FDA approuve la première thérapie génique pour le déficit en décarboxylase des acides aminés aromatiques L », fda.gov La cellule unique et l'omique spatiale amplifient encore la densité des données, augmentant la demande pour des prestataires capables de traiter des millions de profils cellulaires avec une latence minimale.
Utilisation croissante de l'IA/ML pour l'analyse de données multi-omiques à grande échelle
L'intelligence artificielle fait migrer la bioinformatique des statistiques descriptives vers la modélisation prédictive. Le modèle ESM3 d'EvolutionaryScale peut simuler 500 millions d'années d'évolution pour concevoir de nouvelles protéines, illustrant comment l'IA génère désormais des hypothèses biologiques plutôt que de simplement les tester. Des alliances pharmaceutiques, telles que la collaboration de NVIDIA avec Novo Nordisk en 2025, intègrent des agents d'IA sur mesure dans les pipelines de découverte de médicaments. Les prestataires de services capables d'affiner les grands modèles de langage pour des domaines thérapeutiques spécifiques acquièrent un avantage différenciateur sur le marché des services de bioinformatique.
Expansion des biobanques nationales offrant un accès API ouvert aux prestataires de services
Les programmes de biobanques convertissent des référentiels de données statiques en plateformes de recherche dynamiques. Le programme de recherche All of Us a publié 245 388 génomes de qualité clinique — environ 77 % provenant de cohortes minoritaires — via un espace de travail basé sur le cloud qui réduit les coûts d'analyse et encourage la collaboration mondiale. La biobanque du Royaume-Uni héberge désormais plus de 30 pétaoctets de données avec des environnements Jupyter et RStudio intégrés, démontrant un passage vers une distribution exclusivement par plateforme que les prestataires de services peuvent exploiter pour des analyses personnalisées.
Analyse de l'impact des contraintes*
| Contrainte | (~) % d'impact sur les prévisions de CAGR | Pertinence géographique | Calendrier d'impact |
|---|---|---|---|
| Défis d'intégration des données et d'interopérabilité entre des ensembles de données hétérogènes | -1.80% | Mondial, avec un impact plus élevé dans les régions aux normes de données diversifiées | Moyen terme (2-4 ans) |
| Pénurie de bioinformaticiens qualifiés et de scientifiques des données | -2.10% | Mondial, particulièrement aiguë dans les marchés émergents | Long terme (≥ 4 ans) |
| Incertitudes de conformité liées au transfert transfrontalier de données génomiques | -1.40% | Corridors UE-États-Unis, collaborations transfrontalières en Asie-Pacifique | Court terme (≤ 2 ans) |
| Hausse des frais de sortie cloud pour les ensembles de données omiques à l'échelle du pétaoctet | -1.20% | Mondial, avec un impact plus élevé sur les organisations dépendantes du cloud | Moyen terme (2-4 ans) |
| Source: Mordor Intelligence | |||
Défis d'intégration des données et d'interopérabilité entre des ensembles de données hétérogènes
Des formats de fichiers, des nomenclatures et des protocoles d'échantillonnage divergents obligent souvent les analystes à consacrer plus de temps à l'harmonisation qu'à l'interprétation biologique. Les études d'intégration multi-omique rapportent des résultats incohérents lorsque les données sources varient selon la plateforme ou le point temporel, compromettant la reproductibilité clinique. Les lacunes sémantiques dans les dossiers de santé électroniques entravent davantage la liaison entre les ensembles de données génomiques et phénotypiques. Le règlement sur l'Espace européen des données de santé introduit des normes communes, tout en imposant simultanément de nouveaux audits de conformité, retardant les projets transfrontaliers lors du déploiement initial.
Pénurie de bioinformaticiens qualifiés et de scientifiques des données
Les estimations du secteur indiquent un déficit de compétences de 35 % d'ici 2030, la demande d'expertise interdisciplinaire dépassant la production académique. Les marchés émergents souffrent d'une pénurie prononcée, faisant grimper les coûts salariaux et le taux de rotation. De plus, l'intégration de l'IA élève le niveau de compétence requis : les analystes doivent désormais maîtriser Python, le calcul sur GPU et l'informatique réglementaire, une combinaison rarement trouvée chez un seul professionnel. Les petits prestataires du marché des services de bioinformatique sont les plus touchés, car leurs réserves de trésorerie limitées entravent les programmes de recrutement agressif ou de montée en compétences.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des segments
Par type de service : les plateformes intégrées propulsent la croissance future
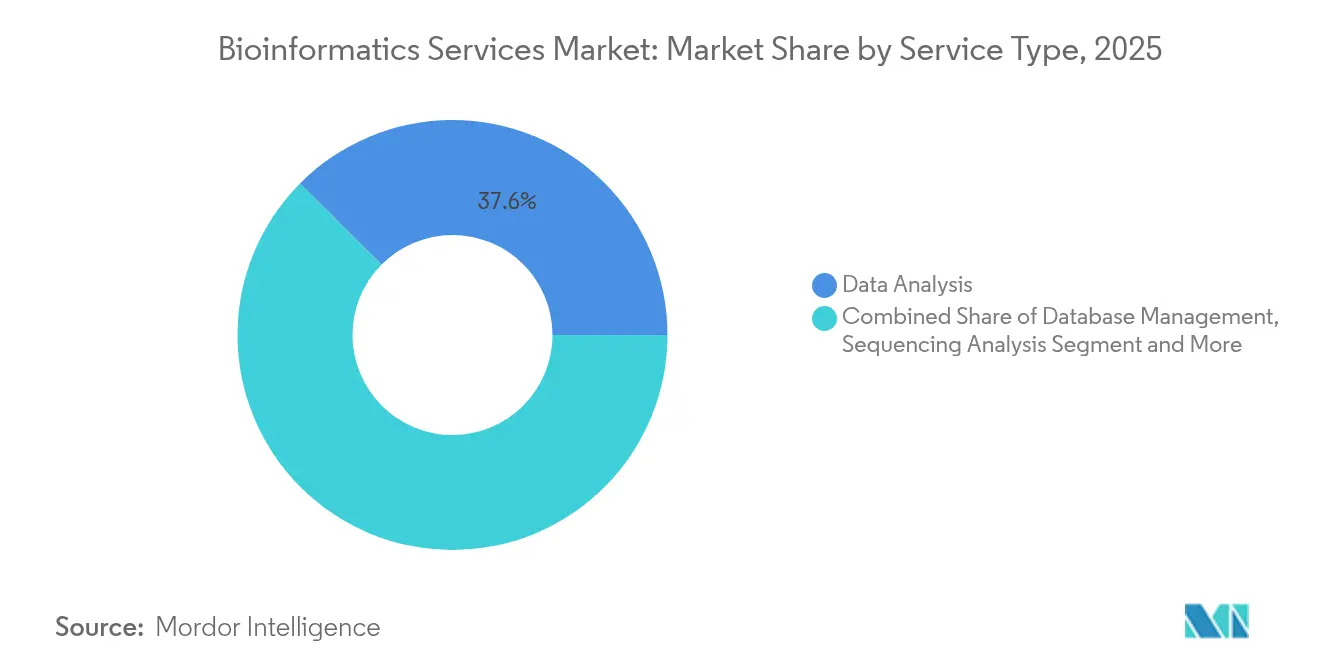
Les services d'analyse de données ont généré le plus grand pool de revenus en 2025, captant 37,55 % du marché des services de bioinformatique. La domination du segment découle de l'exigence fondamentale de convertir des fichiers FASTQ, mzML ou CEL bruts en signaux biologiques interprétables. Pourtant, les offres de plateforme en tant que service dépasseront toutes les autres catégories avec un CAGR de 18,08 %, reflétant la préférence des clients pour des flux de travail de bout en bout hébergés dans le cloud. Les prestataires combinant stockage, analyses pilotées par l'IA et tableaux de bord de conformité réduisent le coût total de possession et élargissent la demande adressable, augmentant ainsi la taille globale du marché des services de bioinformatique. Les services de gestion de bases de données et d'archivage maintiennent une adoption régulière car la conservation des données à long terme reste une nécessité réglementaire.
Le conseil et le développement de flux de travail personnalisés enregistrent une croissance à un chiffre moyen, les clients recherchant des correctifs d'interopérabilité spécialisés et une documentation de validation. L'essor des moteurs d'IA par abonnement pour la découverte de médicaments encourage les petites startups biotechnologiques à adopter des modèles à paiement à l'utilisation plutôt que d'embaucher des scientifiques des données en interne, élargissant la base d'utilisateurs. À mesure que l'élasticité des plateformes s'améliore, le coût de calcul marginal diminue, permettant aux prestataires de services de regrouper des pipelines d'apprentissage automatique qui recommandent automatiquement des paramètres d'alignement optimaux. Cette automatisation atténue les pénuries de talents et améliore le débit dans l'ensemble du secteur des services de bioinformatique.



Par application : la montée en puissance des diagnostics défie les segments axés sur la recherche
La génomique et la protéomique ont conservé 41,90 % des parts du marché des services de bioinformatique en 2025, grâce à un financement important pour la découverte de cibles. Cependant, le créneau des diagnostics cliniques et de la médecine de précision s'accélère à un CAGR de 19,25 %, porté par l'adoption hospitalière de panels de séquençage de nouvelle génération pour l'oncologie et le dépistage des maladies rares. Chaque nouvelle approbation diagnostique accroît la demande d'informatique conforme et à haute fiabilité. En conséquence, la taille du marché des services de bioinformatique liée aux applications cliniques devrait presque doubler d'ici 2030.
Parallèlement, les flux de travail de conception de médicaments assistés par l'IA gagnent du terrain, car l'apprentissage automatique peut prédire les effets hors cible avant une validation coûteuse en laboratoire humide. La métabolomique et la transcriptomique progressent également, les chercheurs examinant les lectures fonctionnelles pour compléter les données de séquence d'ADN. L'agrigénomique et l'analyse du microbiome offrent des opportunités de diversification, notamment dans les économies émergentes à la recherche de solutions pour la sécurité alimentaire. Les prestataires de services se taillant des niches dans l'informatique du microbiome bénéficient d'une intensité concurrentielle plus faible au sein du secteur plus large des services de bioinformatique.
Par utilisateur final : les laboratoires hospitaliers réduisent l'écart
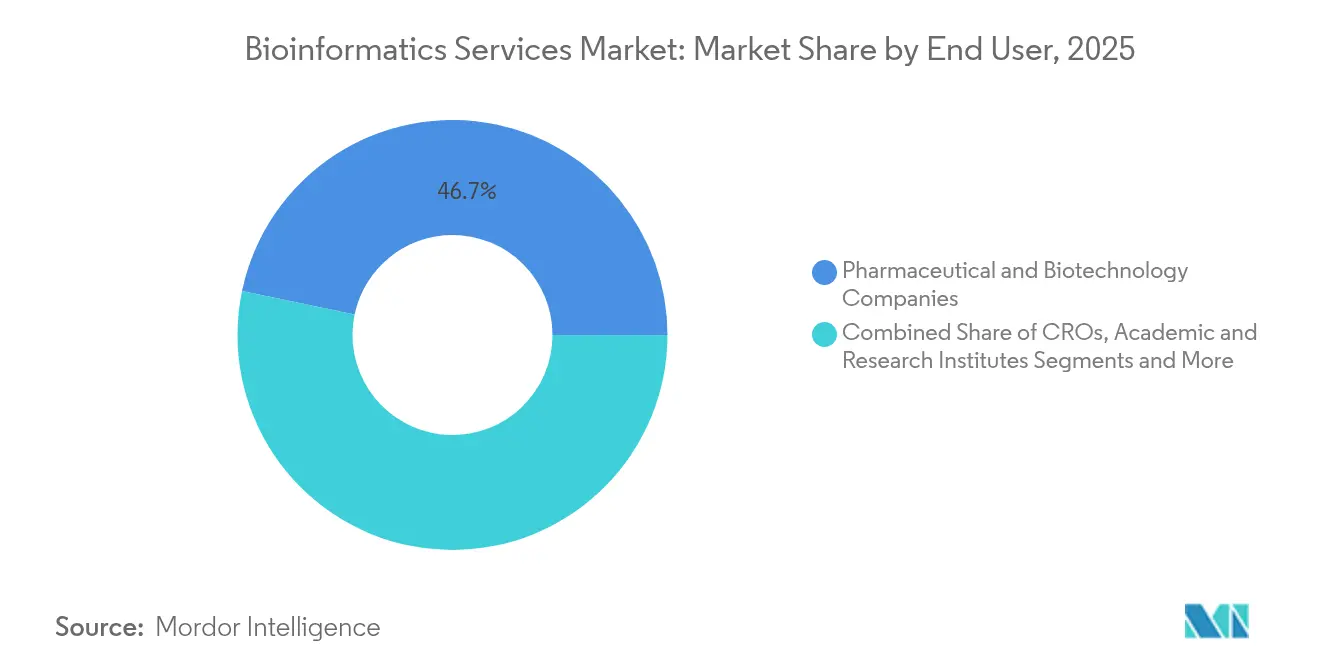
Les entreprises pharmaceutiques et biotechnologiques représentaient 46,72 % de la taille du marché des services de bioinformatique en 2025, reflétant l'externalisation continue de l'analyse de séquences lors du développement de médicaments. Pourtant, les hôpitaux et les laboratoires de diagnostic progressent rapidement, soutenus par la baisse des coûts de séquençage et les initiatives de soins basés sur la valeur. Les tests de cancer au point de soins sont désormais livrés avec des logiciels intégrés qui transmettent les lectures brutes aux pipelines cloud et renvoient les appels de variants en quelques heures, comprimant les cycles de décision clinique.
Les organisations de recherche sous contrat maintiennent une part stable en regroupant des offres de laboratoire humide, in vivo et informatiques. Les instituts académiques exploitent les crédits cloud financés par des subventions pour accéder à des flux de travail de niveau entreprise sans investissement en capital. Les agences agricoles adoptent des pipelines de données de sélection génomique visant des cultures résistantes au changement climatique, une contribution modeste mais croissante au marché des services de bioinformatique. Collectivement, ces évolutions réduisent la domination historique des clients pharmaceutiques et diversifient les revenus.
Par modèle de déploiement : le cloud occupe le devant de la scène malgré les coûts de sortie
Les configurations hébergées dans le cloud sous-tendent désormais la plupart des nouvelles installations, car les ressources de calcul élastiques correspondent à une demande irrégulière et axée sur les projets. L'écosystème de 30 pétaoctets exclusivement sur plateforme de la biobanque du Royaume-Uni prouve que les données sensibles peuvent être gérées de manière sécurisée à l'hyperéchelle tout en respectant le RGPD, encourageant des migrations similaires dans le monde entier. La croissance du cloud bénéficie également de coûts d'entrée plus faibles, amenant les startups sur le marché des services de bioinformatique plus rapidement que les cycles d'approvisionnement sur site ne le permettent.
Néanmoins, la flambée des frais de sortie pour le déplacement d'ensembles de données omiques à l'échelle du pétaoctet complique la planification budgétaire, notamment lorsque des analyses multi-régionales nécessitent des transferts répétitifs. Des architectures hybrides émergent comme un compromis pratique : les données brutes résident dans un stockage d'objets verrouillé par région tandis que les formats dérivés se déplacent vers des zones de calcul mondiales. Les règles de localisation de l'Espace européen des données de santé motivent davantage les prestataires à ajouter des zones de disponibilité régionales, garantissant que les acteurs du secteur des services de bioinformatique restent conformes sans sacrifier la vitesse analytique.
Analyse géographique
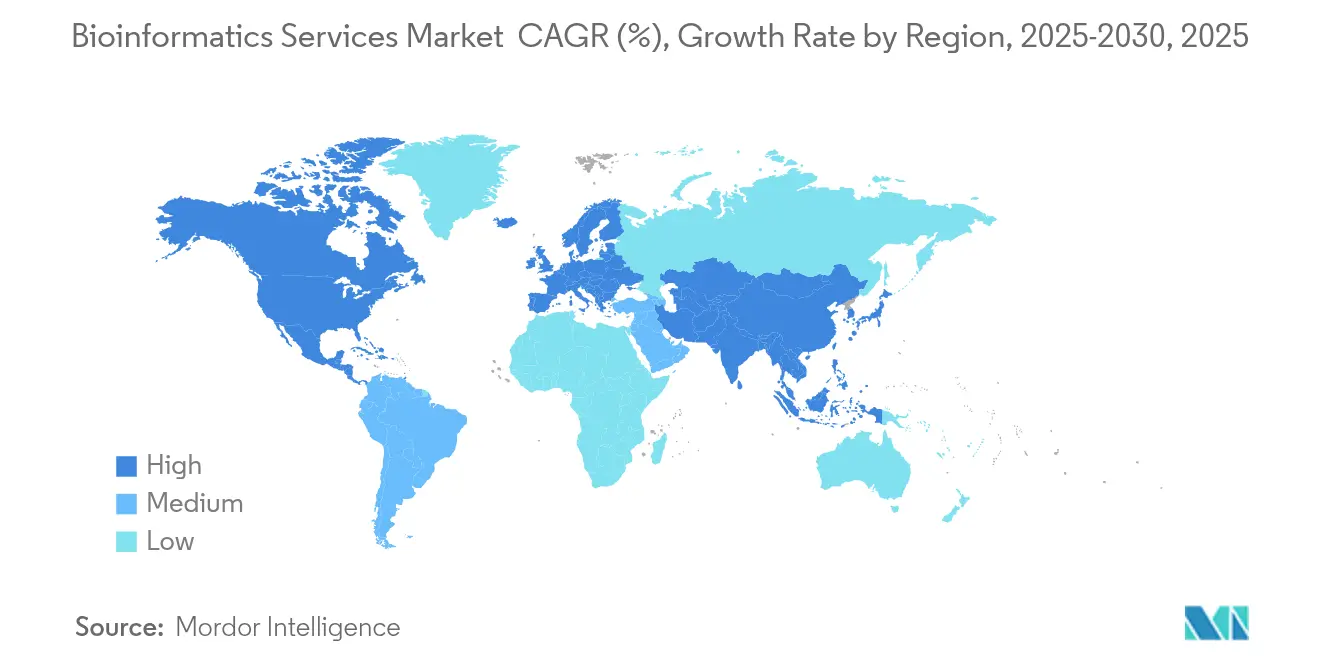
L'Amérique du Nord est restée le plus grand contributeur régional, détenant 46,10 % des revenus mondiaux en 2025. Des pipelines pharmaceutiques solides, un financement en capital-risque abondant et une adoption précoce de la bioinformatique dotée d'intelligence artificielle soutiennent ce leadership. Des projets fédéraux tels que le programme de recherche All of Us injectent des millions de génomes liés cliniquement dans des clouds publics, soutenant la demande de services. Pourtant, les débats sur le contrôle des exportations et les nouvelles règles relatives aux tests développés en laboratoire augmentent les charges de conformité pour les études transfrontalières.
L'Europe affiche une croissance solide à deux chiffres moyens, aidée par le programme de séquençage de référence Génome de l'Europe doté de 45 millions EUR (52 millions USD) et le cadre continental de l'Espace des données de santé. Bien que des lois strictes sur la confidentialité augmentent les coûts d'intégration initiaux, elles créent également une prime pour les prestataires capables de certifier leur conformité au RGPD. Des initiatives nationales comme PROMISE en Suède démontrent comment la bioinformatique intégrée accélère l'adoption clinique à grande échelle.
L'Asie-Pacifique est l'arène à la croissance la plus rapide, enregistrant un CAGR de 16,62 % alors que la Chine, le Japon et Singapour canalisent des fonds publics vers des programmes de médecine de précision, de biologie synthétique et de recherche sur le vieillissement. L'orientation stratégique de la Chine sur la rivalité biotechnologique avec les États-Unis maintient la demande intérieure à un niveau élevé, bien que les frictions géopolitiques compliquent les collaborations à l'étranger. La société super-vieillissante du Japon finance des études gériatriques multi-omiques, tandis que les incitations de Singapour attirent les multinationales vers des sièges régionaux. Cette diversité oblige les prestataires de services à adapter les modèles de déploiement et les postures de conformité à chaque juridiction, mais le potentiel en termes de couverture de population et de dépenses de santé place l'Asie-Pacifique comme principal moteur à long terme du marché des services de bioinformatique.

Paysage concurrentiel
L'écosystème de prestataires est modérément fragmenté, avec des conglomérats mondiaux des sciences de la vie en concurrence avec des spécialistes agiles. Les grands acteurs recherchent des économies d'échelle par le biais de fusions et d'intégration de plateformes ; la déclaration de Thermo Fisher Scientific selon laquelle il pourrait dépenser jusqu'à 50 milliards USD en acquisitions illustre une consolidation accélérée. Les accords stratégiques combinent le matériel de séquençage, les réactifs de laboratoire humide et l'informatique en offres unifiées qui ancrent les clients dans des écosystèmes à long terme.
Le leadership technologique repose désormais sur des pipelines d'IA propriétaires capables d'ingérer des données multi-omiques et de fournir rapidement des biomarqueurs prédictifs. QIAGEN a doublé son investissement dans sa suite Digital Insights, s'engageant à au moins cinq nouvelles versions améliorées par l'IA en 2025. Les nouveaux entrants exploitent des architectures natives en cloud, proposant des plans d'abonnement qui réduisent les frais initiaux et accélèrent l'intégration. Ces challengers s'associent souvent à des clouds hyperscale pour accéder à des clusters GPU et à des régions mondiales, leur permettant de fournir une sécurité de niveau entreprise sans capital important.
Des opportunités d'espaces blancs abondent dans des secteurs de niche tels que les outils de conception en biologie synthétique, la surveillance de la maladie résiduelle minimale et l'analyse du microbiome. Les entreprises qui associent une expertise spécifique au domaine à des API interopérables peuvent s'intégrer de manière transparente dans les pipelines de recherche pharmaceutique, créant des flux de revenus plus fidélisants au sein du marché des services de bioinformatique. À mesure que davantage d'ensembles de données à l'échelle du pétaoctet migrent vers des environnements SaaS, les prestataires d'intégration capables d'agréger et de dédupliquer des données entre clouds acquièrent une importance stratégique.
Leaders du secteur des services de bioinformatique
CD Genomics
Charles River Laboratories
Illumina, Inc.
PerkinElmer Inc.
QIAGEN
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Développements récents du secteur
- Juin 2025 : NVIDIA et Novo Nordisk se sont associés pour développer des agents d'IA pour la découverte de médicaments sur le supercalculateur Gefion.
- Mai 2025 : Charles River Laboratories a conclu un accord avec l'Hôpital général de Singapour pour fournir des services de banque de cellules maîtresses CGMP et des tests NGS pour les programmes CAR-T à partir de sang de cordon.
- Avril 2025 : GeneDx a acquis Fabric Genomics pour un montant pouvant atteindre 51 millions USD, ajoutant une interprétation alimentée par l'IA pour le séquençage néonatal.
- Janvier 2025 : Illumina et NVIDIA ont intégré les pipelines DRAGEN avec l'accélération GPU pour démocratiser l'analyse multi-omique.


Cadre de la méthodologie de recherche et portée du rapport
Définitions du marché et couverture principale
Notre étude traite le marché des services de bioinformatique comme l'ensemble des offres computationnelles tierces payantes, allant du nettoyage des lectures NGS brutes à l'interprétation complexe multi-omique, vendues aux utilisateurs finaux des sciences de la vie, de la santé et de l'agrigénomique dans le monde entier. Les solutions regroupées uniquement en tant que couches de services gérés sur du matériel propriétaire sont comptabilisées une fois que la composante service est facturée séparément.
Exclusion du périmètre : les licences de logiciels de bioinformatique développés en interne et les ventes d'instruments de séquençage autonomes sont exclues du dimensionnement.
Aperçu de la segmentation
- Par type de service
- Analyse de données
- Gestion de bases de données
- Analyse et assemblage de séquençage
- Conseil et développement de flux de travail personnalisés
- Intégration et plateforme en tant que service (iPaaS)
- Autres
- Par application
- Conception et découverte de médicaments
- Génomique et protéomique
- Métabolomique
- Transcriptomique
- Diagnostics cliniques et médecine de précision
- Agrigénomique et santé animale
- Microbiome et métagénomique
- Autres
- Par utilisateur final
- Entreprises pharmaceutiques et biotechnologiques
- Organisations de recherche sous contrat
- Instituts académiques et centres de recherche
- Hôpitaux et laboratoires de diagnostic
- Agences agricoles et environnementales
- Autres
- Par modèle de déploiement
- Sur site
- Basé sur le cloud
- Géographie
- Amérique du Nord
- États-Unis
- Canada
- Mexique
- Europe
- Allemagne
- Royaume-Uni
- France
- Italie
- Espagne
- Reste de l'Europe
- Asie-Pacifique
- Chine
- Japon
- Inde
- Corée du Sud
- Australie
- Reste de l'Asie-Pacifique
- Moyen-Orient et Afrique
- CCG
- Afrique du Sud
- Reste du Moyen-Orient et de l'Afrique
- Amérique du Sud
- Brésil
- Argentine
- Reste de l'Amérique du Sud
- CCG
- Amérique du Nord
Méthodologie de recherche détaillée et validation des données
Recherche primaire
Nous avons complété le travail documentaire par des discussions structurées et de courtes enquêtes couvrant des prestataires de services, des responsables de bioinformatique pharmaceutique, des directeurs de laboratoires cliniques et des gestionnaires de plateformes académiques en Amérique du Nord, en Europe et en Asie-Pacifique. Ces entretiens ont permis de clarifier les ratios de mix de services en vigueur, les répercussions des coûts de séquençage et l'intensité attendue de l'externalisation, nous aidant à réconcilier des indicateurs secondaires divergents.
Recherche documentaire
Nous avons commencé par des points d'ancrage accessibles au public, en tirant des volumes de base annuels et des indices de prix d'organismes tels que le Centre national d'information sur la biotechnologie, les Archives de lecture de séquences des NIH, les codes commerciaux d'Eurostat pour les réactifs de séquençage et les tableaux de dépenses en R&D de la Banque mondiale. L'analyse de brevets de Questel et les répartitions des revenus des entreprises accessibles via D&B Hoovers nous ont permis d'évaluer l'exposition des prestataires à l'externalisation. Des signaux de croissance comparables ont été recueillis dans des revues à comité de lecture et des portails d'associations tels que l'Alliance mondiale pour la génomique et la santé, tandis que les communiqués de presse et les dépôts 10-K ont fourni des valeurs de contrats à court terme et des prix de vente moyens. La liste des sources secondaires est illustrative ; de nombreuses références supplémentaires ont été examinées pour compléter et recouper l'ensemble de données.
Dimensionnement du marché et prévisions
Une construction descendante convertit la production mondiale de NGS (en térabases) en un pool de demande, en appliquant des taux d'externalisation spécifiques à chaque région et des prix de vente moyens de services mixtes. Les agrégations de fournisseurs et les valeurs de contrats échantillonnées servent de vérifications ascendantes pour affiner les totaux. Les principaux intrants comprennent : le coût moyen par séquençage du génome entier, la proportion des budgets de R&D pharmaceutique allouée à la bioinformatique externe, les tendances des prix du calcul cloud et les jalons réglementaires qui déclenchent des pics de demande d'analyse de données. Les prévisions reposent sur une régression multivariée, avec la trajectoire des coûts de séquençage et l'adoption de la médecine de précision indexées comme variables avancées ; l'analyse de scénarios capture les changements soudains dans le financement de la recherche publique. Lorsque des données granulaires sur les prestataires manquaient, les lacunes ont été comblées par des ratios de proxy conservateurs validés par des appels d'experts.
Validation des données et cycle de mise à jour
Les résultats modélisés font l'objet de contrôles d'anomalies et de variance avant la révision par un analyste senior. Nous les comparons ensuite à des indicateurs indépendants tels que les rapports de consommation de calcul cloud et les volumes de publications académiques. Le modèle est actualisé tous les douze mois, et des mises à jour intermédiaires sont publiées si des événements importants, comme un génome à moins de 400 USD, modifient notre scénario de base.
Pourquoi la base de référence des services de bioinformatique de Mordor mérite confiance
Les chiffres publiés divergent souvent parce que les entreprises choisissent des paniers de services inégaux, des bases de devises distinctes et des cadences d'actualisation incohérentes.
Les principaux facteurs d'écart ici comprennent des périmètres limités au seul séquençage, des courbes d'adoption agressives non ancrées dans les réalités de financement, et des instantanés de devises ponctuels qui obscurcissent la récente vigueur du dollar.
Comparaison de référence
| Taille du marché | Source anonymisée | Principal facteur d'écart |
|---|---|---|
| 3,84 milliards USD (2025) | ||
| 3,62 milliards USD (2025) | Consultance régionale A | ne comptabilise que l'analyse de séquençage, omet les revenus de conseil et de développement de flux de travail personnalisés |
| 6,51 milliards USD (2025) | Consultance mondiale B | regroupe les ventes de licences logicielles, applique une adoption optimiste sans recalibrage en milieu de cycle |
La comparaison montre que notre périmètre rigoureux, notre actualisation annuelle et notre validation à double piste offrent aux décideurs une base de référence équilibrée et reproductible sur laquelle ils peuvent s'appuyer pour les discussions budgétaires et stratégiques.


Questions clés auxquelles le rapport répond
Quelle est la taille projetée du marché des services de bioinformatique d'ici 2031 ?
Le marché devrait atteindre 7,75 milliards USD d'ici 2031, avec un CAGR de 12,44 %.
Quel type de service domine actuellement les dépenses ?
Les services d'analyse de données sont en tête avec 37,55 % des parts de revenus, bien que les services de plateformes intégrées connaissent la croissance la plus rapide.
Pourquoi l'Asie-Pacifique est-elle la région à la croissance la plus rapide ?
Les programmes de médecine de précision soutenus par les gouvernements, la hausse des investissements biotechnologiques et l'augmentation des dépenses de santé alimentent un CAGR de 16,62 % en Asie-Pacifique.
Quelle est la principale contrainte à la croissance du marché ?
Une pénurie mondiale de bioinformaticiens et de scientifiques des données formés freine les efforts de mise à l'échelle et entraîne des retards dans les projets.
Comment les technologies d'IA modifient-elles le paysage concurrentiel ?
Les prestataires intégrant des modèles d'IA propriétaires pour l'interprétation multi-omique offrent des informations plus rapides et prédictives, se différenciant ainsi et attirant des clients pharmaceutiques.
Quel segment d'utilisateurs finaux se développe le plus rapidement ?
Les hôpitaux et les laboratoires de diagnostic progressent à un CAGR de 17,12 % à mesure que les tests génomiques deviennent courants dans les soins cliniques.
Dernière mise à jour de la page le:




