GPU Interconnect Market Size and Share
Market Overview
| Study Period | 2020 - 2031 |
|---|---|
| Market Size (2026) | USD 89.43 Billion |
| Market Size (2031) | USD 184.80 Billion |
| Growth Rate (2026 - 2031) | 15.62% CAGR |
| Fastest Growing Market | Asia-Pacific |
| Largest Market | North America |
| Market Concentration | Medium |
Major Players *Disclaimer: Major Players sorted in no particular order Image © Mordor Intelligence. Reuse requires attribution under CC BY 4.0. | |
GPU Interconnect Market Analysis by Mordor Intelligence
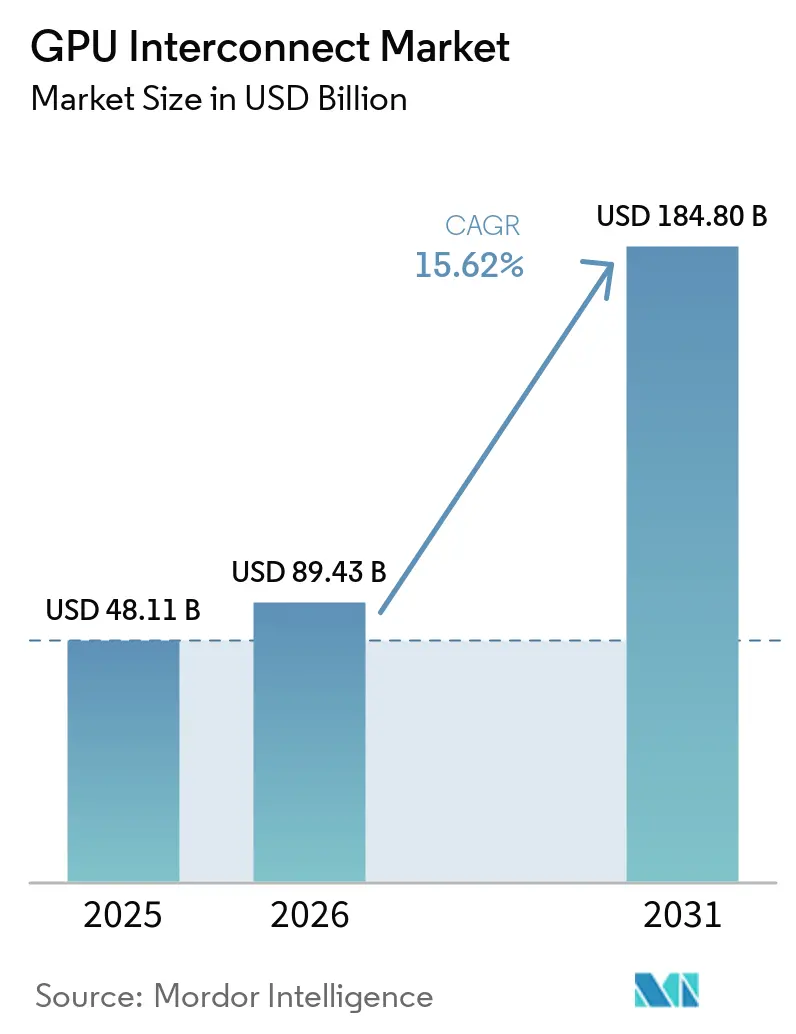
The GPU interconnect market size is expected to increase from USD 48.11 billion in 2025 to USD 89.43 Billion in 2026 and reach USD 184.80 billion by 2031, growing at a CAGR of 15.62% over 2026-2031. Hyperscaler spending and the move toward rack-scale AI systems have made interconnect design a core infrastructure decision instead of a secondary server component choice. Buyers are now treating bandwidth, latency, and fabric efficiency as direct drivers of usable GPU output, which is shortening refresh cycles in the GPU interconnect market. Optical networking, silicon photonics, and denser switch designs are also improving power efficiency and space efficiency, widening the commercial case for larger AI clusters. Competition remains concentrated in proprietary scale-up links, while open standards and Ethernet-based designs are giving customers more flexibility in scale-out deployments. The strongest opportunities in the GPU interconnect market are emerging, driven by cloud expansion, sovereign compute programs, and enterprise AI deployments, all of which require higher-performance fabrics with lower integration risk and better operating economics.
Key Report Takeaways
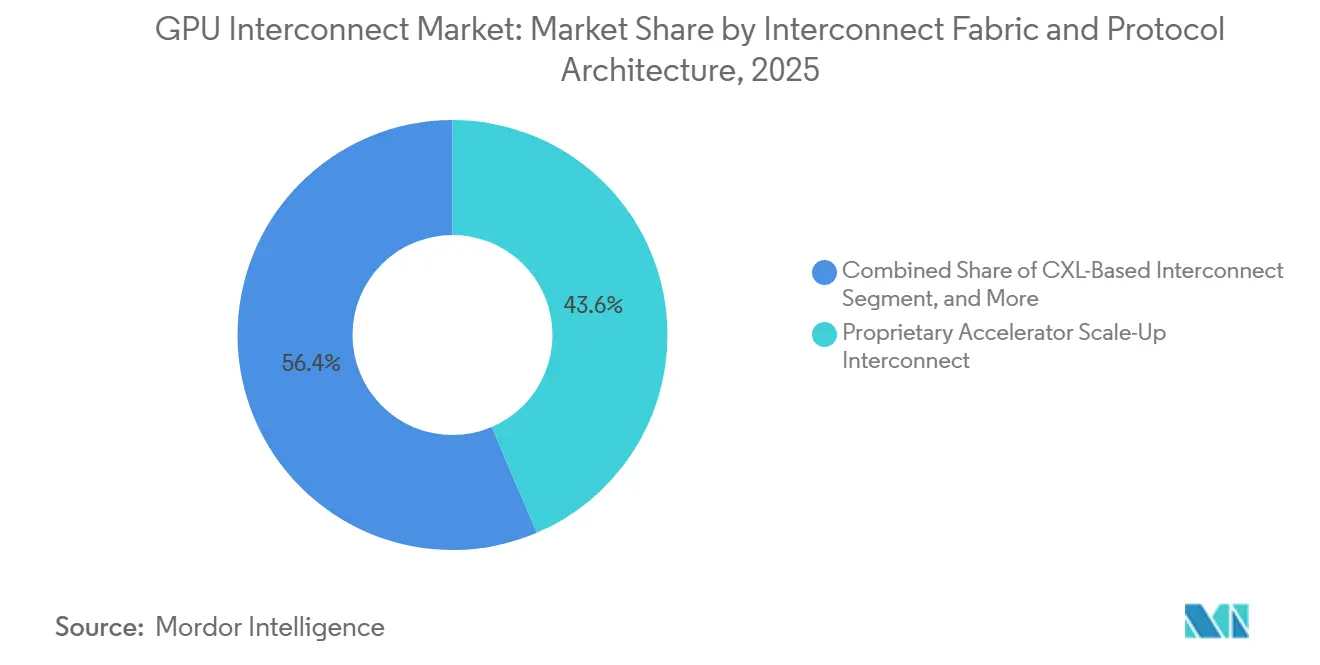
- By interconnect fabric, proprietary accelerator-scale-up interconnect held 43.59% of the GPU interconnect market share in 2025, while open accelerator-scale-up interconnect is expected to remain the fastest-growing fabric segment through 2031.
- By connectivity domain, scale-up connectivity accounted for 49.32% of the graphics processing unit (GPU) interconnect market size in 2025, while inter-pod and campus AI connectivity is projected to expand the fastest through 2031.
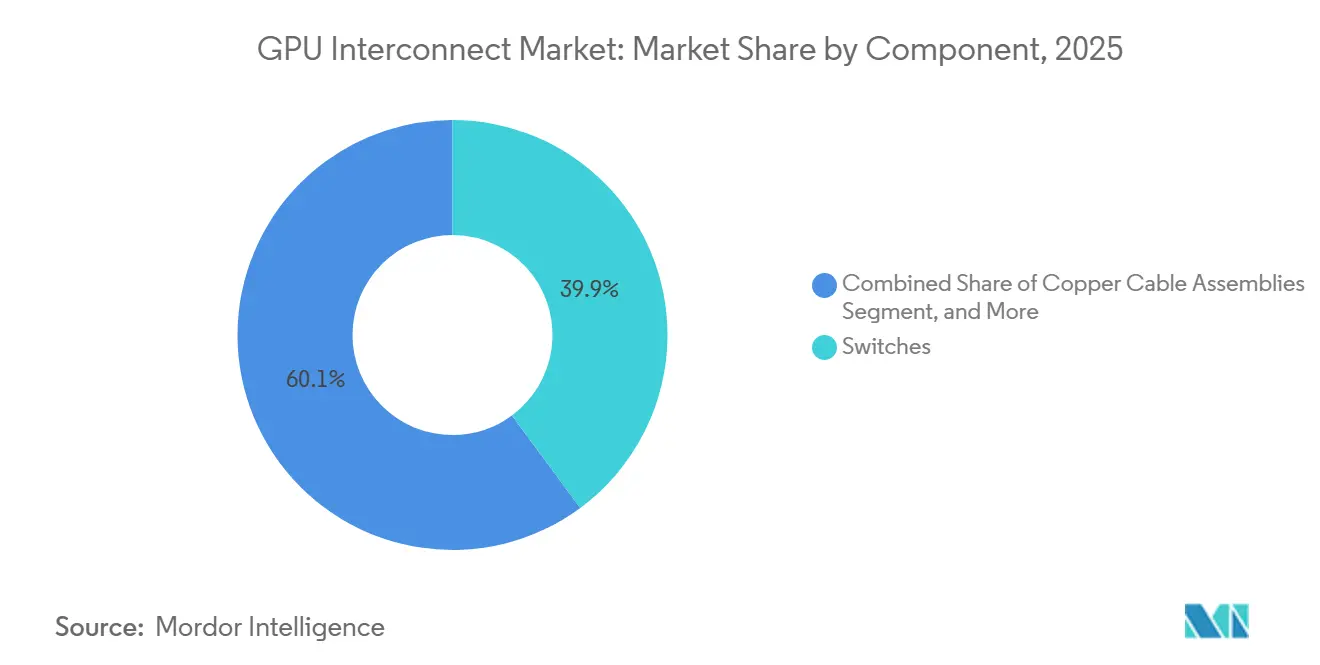
- By component, switches held 39.87% share of the GPU interconnect market in 2025, while optical interconnects are projected to grow at a 16.58% CAGR through 2031.
- By end user, hyperscalers and Tier-1 cloud service providers captured 68.84% share in 2025, while AI-native cloud providers and neoclouds are expected to record the fastest growth through 2031.
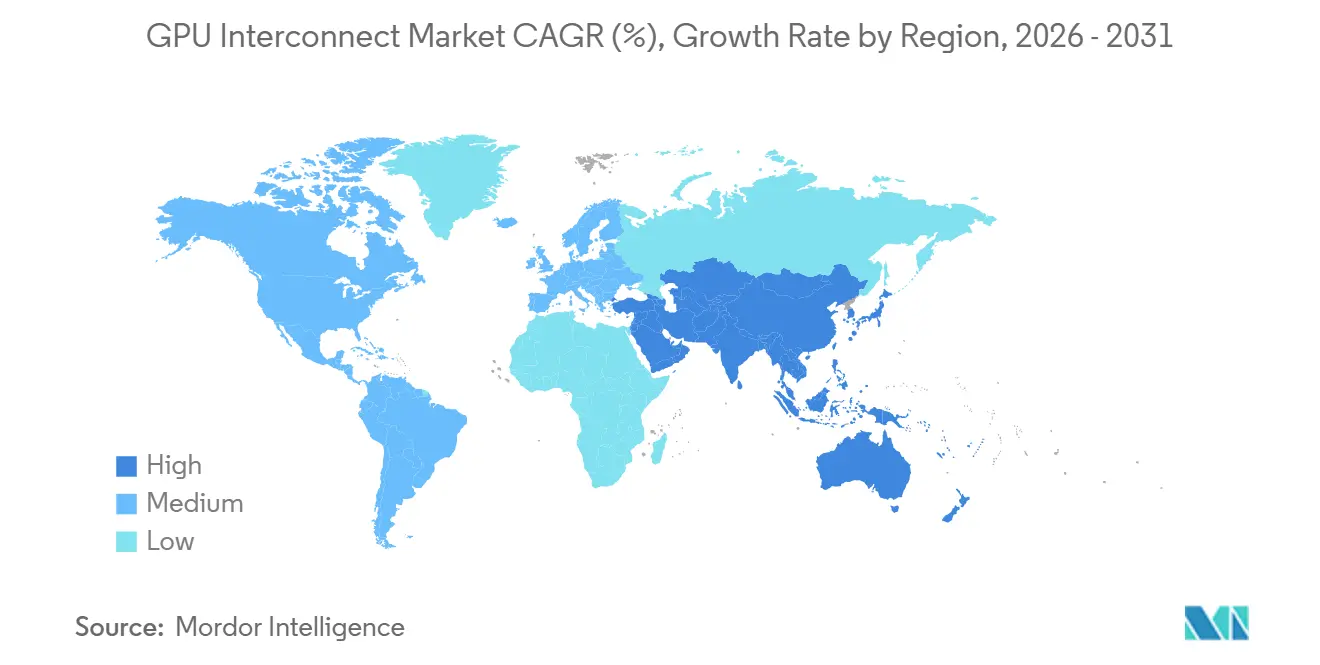
- By geography, North America held 56.62% share of the GPU interconnect market in 2025, while Asia-Pacific is projected to grow at a 16.44% CAGR through 2031.
Note: Market size and forecast figures in this report are generated using Mordor Intelligence’s proprietary estimation framework, updated with the latest available data and insights as of January 2026.
Global GPU Interconnect Market Trends and Insights
Driver Impact Analysis*
| Driver | (~) % Impact on CAGR Forecast | Geographic Relevance | Impact Timeline |
|---|---|---|---|
| Rising Generative AI Cluster Bandwidth Demand | +4.5% | Global, concentrated in North America and Asia-Pacific | Short term (≤ 2 years) |
| Shift From Compute Bottlenecks to Interconnect Bottlenecks | +3.2% | Global | Medium term (2-4 years) |
| Expansion of Rack-Scale GPU Systems in Hyperscale Data Centers | +2.8% | North America and Asia-Pacific core, with spillover to Europe | Medium term (2-4 years) |
| Growth of Open Interconnect Standards to Reduce Vendor Lock-In | +2.1% | Global, with early gains in North America and Europe | Medium term (2-4 years) |
| Transition to Co-Packaged Optics and Silicon Photonics | +1.6% | Global, with early adoption in North America and Taiwan | Long term (≥ 4 years) |
| Demand for CPU-GPU Co-Design in Enterprise AI Infrastructure | +0.8% | North America and Europe | Medium term (2-4 years) |
| Source: Mordor Intelligence | |||
Rising Generative AI Cluster Bandwidth Demand
Generative AI training keeps pushing the GPU interconnect market higher because collective communication tasks fill the network fabric much faster than raw compute can offset. NVIDIA said its GB300 NVL72 platform delivers 130 TB/s of aggregate intra-rack bandwidth across 72 Blackwell Ultra GPUs, and that NVLink 6 for Rubin will raise per-GPU bandwidth to 3.6 TB/s, underscoring how quickly bandwidth requirements are rising as cluster density increases.[1]NVIDIA Corporation, “NVIDIA GB300 NVL72 Designed for AI Reasoning Performance and Efficiency,” NVIDIA, nvidia.com As model sizes rise, east-west traffic within the cluster becomes too expensive to ignore, shifting spending from a server line item to a dedicated network fabric budget. This change shortens replacement cycles in the GPU interconnect market because many frontier operators now align fabric upgrades more closely with accelerator generations than with traditional network refresh habits. It also raises the commercial value of designs that can keep thousands of GPUs busy simultaneously, since any bandwidth shortfall can reduce effective utilization and weaken returns on large compute investments. The result is a market where demand growth is being driven not only by more GPUs, but also by the need to connect them with much more capable fabrics.
Shift from Compute Bottlenecks to Interconnect Bottlenecks
The GPU interconnect market is also benefiting from a shift in where performance problems now occur within large AI clusters. NVIDIA has positioned Spectrum-X around topology-aware scheduling, load balancing, and network tuning for large Ethernet-based AI clusters, which reflects how fabric behavior now shapes whether scaling remains efficient as deployment size grows. Buyers who secured strong GPU capacity without matching it with enough bandwidth are finding that distributed training does not deliver the throughput they expected from their capital spending. This has created a practical upgrade cycle within existing clusters, where operators add NICs, switches, and related connectivity hardware without waiting for a new accelerator purchase. That pattern supports the GPU interconnect market even when the compute purchasing cadence becomes uneven across customer groups. It also improves the position of switch, NIC, and DPU suppliers because interconnect demand is becoming less dependent on a one-time GPU shipment event and more tied to ongoing cluster tuning.
Expansion of Rack-Scale GPU Systems in Hyperscale Data Centers
Rack-scale system design has changed the revenue mix of the graphics processing unit (GPU) interconnect market by concentrating more fabric within each deployed AI system. NVIDIA built GB300 NVL72 around NVLink-native communication, and that architecture replaces a more conventional server-level arrangement with a tightly integrated rack approach that depends on dedicated fabric hardware across the full system. The four largest cloud operators confirmed a combined 2026 capital expenditure of USD 725 billion, with a large portion of that budget directed to AI compute and networking infrastructure, which supports continued demand for dense interconnect deployments. This favors vendors that provide switch silicon, optical links, fabric controllers, and other components that gain content as system integration moves up from the board level to the rack level. It also puts pressure on suppliers tied mainly to older PCIe signal conditioning categories, because some of that value shifts toward new switch and optical layers as rack-scale adoption expands. In practical terms, the GPU interconnect market is seeing higher revenue intensity per deployment as hyperscalers move from isolated accelerator servers toward integrated AI factory designs.
Growth of Open Interconnect Standards to Reduce Vendor Lock-In
Open standards are becoming increasingly important in the GPU interconnect market as large buyers seek greater supplier flexibility amid rising cluster budgets. The UALink Consortium published its 2.0 release in April 2026 with in-network compute, chiplet definition, and manageability features, and the group said 115 or more member companies are now involved in shaping the standard. The Ultra Ethernet Consortium also launched Specification 1.0 in June 2025, providing the scale-out side of the GPU interconnect market with an open framework built on Ethernet for AI and HPC traffic. Evaluation hardware for UALink 1.0 is expected in the second half of 2026, but commercial silicon is still expected later, which means adoption will depend on how quickly vendors can move from consortium work to deployable products. Even so, open frameworks are already shaping buying behavior by providing enterprises and cloud operators with a clearer path toward multi-vendor GPU fabrics. Over time, this should make the GPU interconnect market less dependent on a single architecture in the scale-up layer, even if proprietary systems maintain a strong near-term lead.
Restraint Impact Analysis*
| Restraint | (~) % Impact on CAGR Forecast | Geographic Relevance | Impact Timeline |
|---|---|---|---|
| Limited Availability of Advanced Packaging and High-Speed SerDes Capacity | -2.1% | Global, concentrated around advanced manufacturing hubs in Taiwan | Medium term (2-4 years) |
| High Total Cost of Ownership for Scale-Up GPU Fabrics | -1.4% | Global, acute in mid-market and sovereign AI deployments | Medium term (2-4 years) |
| Proprietary Ecosystem Lock-In Slowing Multi-Vendor Adoption | -0.9% | Global | Long term (≥ 4 years) |
| Persistent Thermal and Power-Delivery Constraints at Rack Scale | -0.7% | Global, acute in brownfield and colocation deployments | Medium term (2-4 years) |
| Source: Mordor Intelligence | |||
Limited Availability of Advanced Packaging and High-Speed SerDes Capacity
The GPU interconnect market still faces a supply-side limit because advanced packaging capacity remains tight across AI semiconductor programs. Epoch AI said NVIDIA, Google, AMD, and Amazon together accounted for more than 90% of global CoWoS packaging capacity by value in 2025, underscoring how much of the supply base is already being absorbed by a small group of very large buyers.[2]Epoch AI, “Advanced Packaging and HBM, Not Logic Dies, Were the Bottlenecks on AI Chip Production in 2025,” Epoch AI, epoch.ai This matters because interconnect ASICs, advanced optical components, and related high-speed silicon all compete for the same manufacturing ecosystem that supports next-generation AI hardware. Even when a vendor wins a design slot, deliveries can still lag customer schedules if packaging and SerDes supply do not scale at the same pace as demand. That creates uneven shipment timing across the GPU interconnect market and can delay full cluster deployment, especially when customers need synchronized delivery of accelerators, switches, optics, and supporting connectivity devices. The restraint is most severe for suppliers that need both advanced packaging and high-speed networking content at the same time, since any gap in one part of the chain can slow the whole program.
High Total Cost of Ownership for Scale-Up GPU Fabrics
Total cost of ownership is another clear restraint in the GPU interconnect market because high-performance scale-up fabrics require more than just the switch ASIC. Dense AI racks often require liquid cooling, specialized power delivery, and facility upgrades, which significantly increase the full operating cost beyond a simple compute purchase. That cost burden matters most for sovereign compute projects, enterprises, and mid-sized cloud operators that cannot spread infrastructure spending across the same deployment scale as the largest hyperscalers. UALink is trying to address part of this issue by promising rack-scale performance with a more open supply model, but commercial products are still moving through the evaluation stage in 2026. Until those products are widely available, many buyers in the GPU interconnect market will continue to weigh performance gains against higher cooling, integration, and site retrofit costs. This means some organizations will stick with smaller cluster sizes or favor Ethernet-based expansion paths rather than the most expensive proprietary scale-up systems.
*Our forecasts treat driver/restraint impacts as directional, not additive. The impact forecasts reflect baseline growth, mix effects, and variable interactions.
Segment Analysis
By Interconnect Fabric / Protocol Architecture: Proprietary Leadership Meets A Broader Standards Push
Proprietary accelerator-scale-up interconnect held 43.59% of the GPU interconnect market in 2025, while open accelerator-scale-up interconnect is expected to be the fastest-growing fabric category through 2031. That leading position came from the early and wide deployment of NVLink-based rack-scale systems across hyperscaler environments, where the interconnect is packaged as a core part of the full compute architecture rather than an optional add-on. NVIDIA reinforced this model by tying NVLink and NVSwitch closely to its rack-scale design approach, which kept proprietary scale-up links central to high-density AI infrastructure. At the same time, the UALink 2.0 release added in-network compute, chiplet, and manageability features, giving open-scale-up designs a more credible roadmap for multi-vendor clusters. This leaves the GPU interconnect market with a near-term structure where proprietary systems still dominate the top end, while open frameworks are building a stronger technical base for later adoption.
Native PCIe-based interconnect remains relevant in the GPU interconnect industry for heterogeneous inference servers, where cost control and broad compatibility often matter more than the highest possible bandwidth. CXL-based interconnect is also gaining attention in inference-oriented designs because shared memory and pooling features can help reduce memory bottlenecks across mixed CPU and GPU workloads. Astera Labs moved its Leo CXL memory controller into volume production for Microsoft Azure-related workloads in 2026, demonstrating that CXL is moving from concept to commercial deployment in cloud infrastructure. Ethernet-based scale-out fabrics are gaining ground because they align with large installed network ecosystems, while InfiniBand remains important where tightly coupled training performance and established operating behavior still carry weight. The GPU interconnect market is therefore moving toward a more mixed fabric environment, even though proprietary scale-up systems still command the strongest early position in the highest-density AI clusters.



By Connectivity Domain: Scale-Up Revenue Stays Largest While Campus Links Expand Faster
Scale-up connectivity accounted for 49.32% of the GPU interconnect market size in 2025, while inter-pod and campus AI connectivity is projected to expand faster than the other connectivity domains through 2031. Scale-up maintained the largest revenue position because dense rack-scale systems embed significant fabric content directly into each deployed unit, thereby increasing interconnect value per installation. NVIDIA centered this approach in the GB300 NVL72, where the rack itself is built around high-bandwidth internal communication rather than a more conventional loose-server arrangement. That structure supports a large bill of materials for switch trays, internal links, and related connectivity hardware, which keeps scale-up central to revenue in the GPU interconnect market. It also helps explain why buyers who choose tightly integrated AI systems often commit to an interconnect architecture at the same time they choose the accelerator platform.
Inter-pod and campus AI connectivity is growing faster because many AI deployments can no longer fit all required compute into one room or one building. As operators spread GPU capacity across larger campuses to address power, cooling, and space constraints, they need robust optical connectivity between pods, clusters, and facilities. Scale-out connectivity remains important inside each cluster because GPUs still need predictable low-latency communication across racks, while intra-node connectivity continues to matter in mixed CPU and GPU servers that rely on PCIe or CXL attachment. Operators that improve only the GPU-to-GPU path can still face bottlenecks if the CPU-to-GPU path remains constrained, which means performance tuning must cover multiple traffic layers simultaneously. This keeps the GPU interconnect market broad across connectivity types, with different domains gaining value depending on cluster size, workload design, and physical data center layout.
By Component: Switches Hold The Largest Revenue Pool While Optics Grow Fastest
Optical interconnects are projected to grow at a 16.58% CAGR from 2026 to 2031, while switches held 39.87% of the GPU interconnect market in 2025. Optical growth is being driven by the move toward co-packaged optics and silicon photonics, especially as cluster density pushes operators to lower power use and improve signal quality over more demanding links. NVIDIA said the Quantum-X800 InfiniBand CPO reached availability in early 2026, and Spectrum-X Ethernet Photonics entered production in May 2026, marking a meaningful commercial step for optical switching in AI infrastructure. That shift matters because optical scaling enables larger, more power-efficient fabrics, which is becoming increasingly important as the GPU interconnect market serves larger AI factories rather than isolated accelerator racks. Switches still held the largest revenue share because they remain central to both rack-level and cluster-level connectivity, and every dense AI deployment needs substantial switching capacity.
The supplier pipeline also shows how quickly component roadmaps are advancing around the GPU interconnect market. Arista introduced the 7060XE7 Series in June 2026 with 64 ports at 1.6T per port and up to 102.4 Tb/s of aggregate bandwidth, signaling a rapid move beyond 800G networking in AI data centers. Network interface cards and DPUs are also gaining importance because dense AI systems need stronger north-south traffic handling alongside internal fabric bandwidth, and NVIDIA positioned ConnectX-8 at 800 Gb/s per port for GB300-based platforms. Retimers and connectivity ICs remain important because higher lane speeds increase signal integrity challenges across boards, cables, and backplanes. Astera Labs reported USD 308.4 million in Q1 2026 revenue while expanding its presence across these categories. Copper cable assemblies still serve short-reach links where cost and operational familiarity matter, but the GPU interconnect market is steadily directing more growth toward optical systems and the switching platforms that support them.
By End User: Hyperscalers Lead Current Demand While Neoclouds Expand Quickly
Hyperscalers and Tier-1 cloud service providers accounted for 68.84% of the GPU interconnect market in 2025, while AI-native cloud providers and neoclouds are set to grow the fastest through 2031. This dominance reflects the scale at which Microsoft, Amazon, Google, and Meta deploy infrastructure for both AI training and inference. Their combined 2026 capital expenditure commitments reached USD 725 billion, with a large portion aimed at AI compute and networking, providing the GPU interconnect market with its deepest and most predictable spending base. These customers also adopt new architectures early, which is why they have been central to the roll-out of rack-scale systems, high-bandwidth fabrics, and advanced optical switching. Even when some hyperscalers design parts of their networking stack internally, their procurement scale still shapes product roadmaps across the supplier ecosystem.
AI-native cloud providers and neoclouds are expanding quickly because they use access to newer fabrics as a direct selling point for enterprise and research customers. NVIDIA said CoreWeave, Lambda, and Oracle Cloud Infrastructure were among the first adopters of Spectrum-X Ethernet Photonics, which shows how newer cloud platforms are using networking performance and power efficiency to differentiate their services. Government and sovereign compute programs are also widening the buyer base, and Canada launched its AI Sovereign Compute Infrastructure Program in April 2026 with CAD 2.4 billion (USD 1.76 billion) in federal support. Large enterprises, academic computing centers, and telecom-related deployments add further demand, though they often prefer cost-aware scale-out fabrics rather than the most expensive proprietary scale-up systems. This broadening customer mix gives the graphics processing unit (GPU) interconnect market a larger demand base than it had in earlier accelerator cycles, when hyperscaler purchases accounted for a much larger share of total activity.
Geography Analysis
North America held 56.62% of the GPU interconnect market share in 2025, leaving it well ahead of all other regional segments. The region benefits from concentrated hyperscaler investment in the United States and from the fact that many of the companies shaping the GPU interconnect market, including NVIDIA, Broadcom, Arista Networks, Astera Labs, Credo Technology, Coherent, and Lumentum, are headquartered or have significant commercial operations there. The region also remains the largest early adopter base for rack-scale AI infrastructure, which means product launches often translate into North American deployments before broader global rollouts. Large cloud capital spending is reinforcing this lead, with the biggest operators directing major 2026 budgets toward AI compute and networking infrastructure. Canada is also helping broaden regional demand through public compute investments, and its AI Sovereign Compute Infrastructure Program added CAD 2.4 billion (USD 1.76 billion) in federal support in April 2026.[3]Government of Canada, “Canada Launches National Initiative to Build Large-Scale AI Supercomputing Capacity,” Government of Canada, canada.ca
Asia-Pacific is projected to expand at a 16.44% CAGR through 2031, making it the fastest-growing geography in the GPU interconnect market. Growth in the region is being supported by sovereign AI ambitions, local cloud buildouts, and the need for domestic technology stacks in countries seeking greater control over compute infrastructure. The region also matters because several large technology groups from Asia-Pacific are part of the UALink Consortium, indicating that open scale-up standards are attracting real interest from major platform companies and hardware participants. This regional push is likely to support both local manufacturing ecosystems and demand for alternative interconnect approaches as customers weigh cost, supply access, and technology control. For the GPU interconnect market, Asia-Pacific is becoming important not only as a demand center but also as a region that can influence future standards adoption and component sourcing patterns.
Europe is smaller today, but it remains strategically important because data sovereignty rules and AI governance frameworks continue to support demand for regional compute infrastructure. The United Kingdom said in 2026 that it would allocate GBP 1.1 billion (USD 1.4 billion), under its AI hardware plan, including GBP 750 million (USD 1.02 billion) for a national AI supercomputer scheduled for deployment by 2030. South America remains earlier in adoption, with activity tied more closely to hyperscaler cloud expansion and research computing than to large domestic fabric programs. Middle East and Africa demand is still smaller in absolute terms, but sovereign compute interest is increasing, which gives the graphics processing unit (GPU) interconnect market another long-term regional growth path beyond the current hyperscaler core.

Competitive Landscape
The GPU interconnect market is moderately concentrated and has a split structure, with proprietary scale-up links among a small number of suppliers, while scale-out networking is contested across a broader vendor group. NVIDIA holds the strongest position in proprietary scale-up connectivity because NVLink and NVSwitch are embedded directly into its rack-scale system design, which gives it a powerful advantage in the highest-density AI deployments. In scale-out networking, the field is wider, with Broadcom, Marvell, Cisco, and Arista Networks competing across Ethernet switching, optical connectivity, and related AI networking layers.[4]Arista Networks, “Arista Introduces Next-Generation 1.6Terabit Portfolio for AI Fabrics,” Arista Networks, arista.com Open standards groups are also shaping future competition by providing customers with a path to multi-vendor fabrics in both scale-up and scale-out environments. This means the GPU interconnect market is concentrated at the top end, but more open and competitive in the broader networking layers that support cluster-to-cluster scaling.
Several company actions in 2026 show how the competitive landscape is evolving in the GPU interconnect market. NVIDIA announced strategic investments of USD 2 billion each in Lumentum and Coherent, along with large purchase commitments, which shows a direct move to secure upstream optical supply for its co-packaged optics roadmap. Arista then introduced the 7060XE7 Series for 1.6T AI fabrics, signaling that Ethernet-centric competitors are moving quickly into higher-speed AI switching rather than waiting for a slower migration cycle. Astera Labs expanded its Taiwan operations in June 2026 to deepen AI platform validation and local integration work, reflecting how suppliers are moving closer to the manufacturing and system-assembly base that supports the GPU interconnect market. Consortium participation has also become a strategic tool, as vendors seek to influence future socket decisions before open-scale-up silicon reaches broad production. Together, these moves show that competition is now centered on supply access, ecosystem position, and content expansion per accelerator rather than on isolated component launches alone.
There is still open space in the GPU interconnect market for software-defined fabric management, heterogeneous cluster control, and commercially proven UALink-compliant switch silicon. The Register reported that UALink evaluation hardware is expected in the second half of 2026, and that commercial silicon will follow later, indicating the market still lacks a fully established open-scale-up product set at volume. That gap gives incumbents more time to deepen customer relationships, but it also creates room for challengers that can ship credible open alternatives before buyer frustration with lock-in grows. Oracle, despite being active in GPU cloud deployments, remains primarily an end user in this context rather than a supply-side designer of interconnect hardware, so the competitive field is still defined mainly by networking, semiconductor, and optical vendors.
GPU Interconnect Industry Leaders
NVIDIA Corporation
Broadcom Inc.
Marvell Technology, Inc.
Advanced Micro Devices, Inc.
Astera Labs, Inc.
- *Disclaimer: Major Players sorted in no particular order

Recent Industry Developments
- June 2026: Arista Networks introduced the 7060XE7 Series, a next-generation 1.6T AI networking portfolio built on Broadcom Tomahawk 6 silicon, supporting 64 ports at 1.6T per port and aggregate switching capacity of 102.4 Tb/s, in both air-cooled and liquid-cooled configurations. Air-cooled variants are scheduled for Q4 2026 and liquid-cooled variants for Q1 2027, positioning the portfolio for both scale-up and scale-out AI fabric deployments.
- June 2026: Astera Labs expanded its Taiwan operations, establishing an enlarged Cloud-Scale Interoperability Lab and growing engineering presence to deepen integration with AI platform providers and Taiwan system manufacturers, targeting AI cluster validation for the GB300 generation.
- May 2026: NVIDIA announced that Spectrum-X Ethernet Photonics is now in production at Taiwan GTC, Computex 2026, marking it as the world's first CPO Ethernet switch built on 200G SerDes technology with up to 409.6 Tb/s aggregate bandwidth. CoreWeave, Lambda, and Oracle Cloud Infrastructure were among the first adopters, and broad availability is guided to the second half of 2026.
- April 2026: The UALink Consortium published four specifications in its 2.0 release, introducing in-network compute, chiplet definition, and manageability frameworks for multi-workload AI deployments, with 115 or more member companies now governing the standard.


Global GPU Interconnect Market Report Scope
The GPU Interconnect Market comprises hardware, software, protocols, and networking technologies that enable high-speed communication and data exchange between graphics processing units (GPUs), accelerators, CPUs, memory resources, and distributed computing infrastructure. GPU interconnect solutions are designed to address the bandwidth, latency, scalability, and efficiency requirements of modern artificial intelligence (AI), machine learning, high-performance computing (HPC), cloud computing, and data-intensive workloads by facilitating seamless communication across increasingly large and complex compute environments.
The GPU Interconnect Market Report is Segmented by Interconnect Architecture/Protocol Architecture (Native PCIe-Based Interconnect, CXL-Based Interconnect, Proprietary Accelerator Scale-Up Interconnect, Open Accelerator Scale-Up Interconnect, InfiniBand-Based Scale-Out Interconnect, and Ethernet-Based Scale-Out Interconnect), Connectivity Domain (Intra-Node/Intra-Server Connectivity, Scale-Up Connectivity, Scale-Out Connectivity, and Inter-Pod/Campus AI Connectivity), Component (Switches, Network Interface Cards and DPUs, Retimers, Redrivers, and Connectivity ICs, Copper Cable Assemblies, and Optical Interconnects), End-User (Hyperscalers and Tier-1 Cloud Service Providers, AI-Native Cloud Providers and Neoclouds, Large Enterprises and Private AI Infrastructure Operators, Government, Sovereign AI Programs, and National Research Laboratories, Academic and HPC Research Institutions, and Telecom, Edge Cloud, and Managed-Service Providers), and Geography (North America, Europe, Asia-Pacific, South America, and Middle East and Africa). The Market Forecasts are Provided in Terms of Value (USD).
| Native PCIe-Based Interconnect |
| CXL-Based Interconnect |
| Proprietary Accelerator Scale-Up Interconnect |
| Open Accelerator Scale-Up Interconnect |
| InfiniBand-Based Scale-Out Interconnect |
| Ethernet-Based Scale-Out Interconnect |
| Intra-Node/Intra-Server Connectivity |
| Scale-Up Connectivity |
| Scale-Out Connectivity |
| Inter-Pod/Campus AI Connectivity |
| Switches |
| Network Interface Cards and DPUs |
| Retimers, Redrivers, and Connectivity ICs |
| Copper Cable Assemblies |
| Optical Interconnects |
| Hyperscalers and Tier-1 Cloud Service Providers |
| AI-Native Cloud Providers and Neoclouds |
| Large Enterprises and Private AI Infrastructure Operators |
| Government, Sovereign AI Programs, and National Research Laboratories |
| Academic and HPC Research Institutions |
| Telecom, Edge Cloud, and Managed-Service Providers |
| North America | United States |
| Canada | |
| Mexico | |
| Europe | Germany |
| United Kingdom | |
| France | |
| Italy | |
| Rest of Europe | |
| Asia-Pacific | China |
| Japan | |
| South Korea | |
| India | |
| Southeast Asia | |
| Rest of Asia-Pacific | |
| South America | |
| Middle East And Africa |
| By Interconnect Fabric/Protocol Architecture | Native PCIe-Based Interconnect | |
| CXL-Based Interconnect | ||
| Proprietary Accelerator Scale-Up Interconnect | ||
| Open Accelerator Scale-Up Interconnect | ||
| InfiniBand-Based Scale-Out Interconnect | ||
| Ethernet-Based Scale-Out Interconnect | ||
| By Connectivity Domain | Intra-Node/Intra-Server Connectivity | |
| Scale-Up Connectivity | ||
| Scale-Out Connectivity | ||
| Inter-Pod/Campus AI Connectivity | ||
| By Component | Switches | |
| Network Interface Cards and DPUs | ||
| Retimers, Redrivers, and Connectivity ICs | ||
| Copper Cable Assemblies | ||
| Optical Interconnects | ||
| By End-User | Hyperscalers and Tier-1 Cloud Service Providers | |
| AI-Native Cloud Providers and Neoclouds | ||
| Large Enterprises and Private AI Infrastructure Operators | ||
| Government, Sovereign AI Programs, and National Research Laboratories | ||
| Academic and HPC Research Institutions | ||
| Telecom, Edge Cloud, and Managed-Service Providers | ||
| By Geography | North America | United States |
| Canada | ||
| Mexico | ||
| Europe | Germany | |
| United Kingdom | ||
| France | ||
| Italy | ||
| Rest of Europe | ||
| Asia-Pacific | China | |
| Japan | ||
| South Korea | ||
| India | ||
| Southeast Asia | ||
| Rest of Asia-Pacific | ||
| South America | ||
| Middle East And Africa | ||


Key Questions Answered in the Report
What is the current size of the GPU interconnect market?
The GPU interconnect market reached USD 89.43 Billion in 2026 and is forecast to reach USD 184.8 Billion by 2031 at a 15.62% CAGR.
Which interconnect fabric leads current revenue?
Proprietary accelerator scale-up interconnect led with 43.59% share in 2025, supported by early rack-scale deployment around NVLink-based architectures.
Which connectivity domain is expanding the fastest?
Scale-up connectivity held the largest share in 2025, but inter-pod and campus AI connectivity is expected to grow the fastest through 2031 as clusters spread across larger campuses.
Why are optical interconnects gaining traction in GPU clusters?
Optical interconnects are projected to grow at a 16.58% CAGR because denser AI systems need better power efficiency, signal integrity, and higher-bandwidth switching.
Who buys the most GPU interconnect hardware today?
Hyperscalers and Tier-1 cloud service providers led demand with 68.84% share in 2025, driven by very large AI training and inference infrastructure programs.
Which region shows the strongest growth outlook?
North America led with 56.62% share in 2025, while Asia-Pacific is projected to post the fastest growth at a 16.44% CAGR through 2031.
Page last updated on:






