Tamanho e Participação do Mercado de GPU Interconnect
Visão Geral do Mercado
| Período de Estudo | 2020 - 2031 |
|---|---|
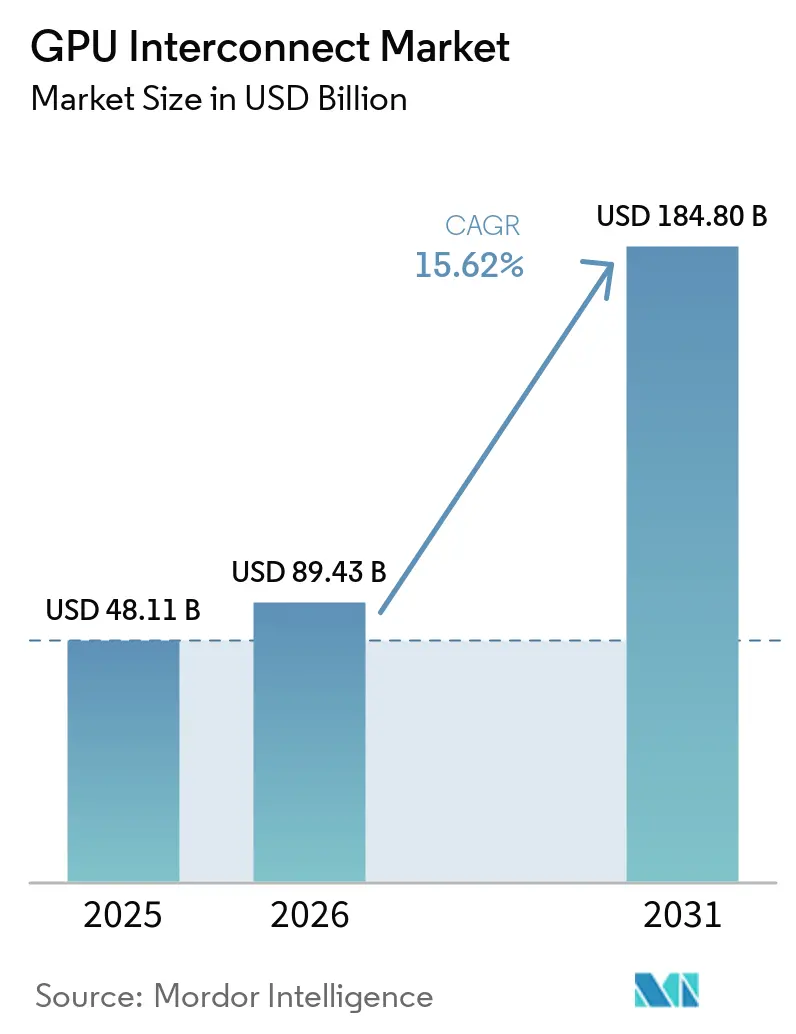
| Tamanho do Mercado (2026) | 89.43 Bilhões de dólares |
| Tamanho do Mercado (2031) | 184.80 Bilhões de dólares |
| Taxa de crescimento (2026 - 2031) | 15.62% CAGR |
| Mercado de Crescimento Mais Rápido | Ásia-Pacífico |
| Maior Mercado | América do Norte |
| Concentração do Mercado | Médio |
Principais jogadores
*Isenção de responsabilidade: Principais participantes classificados em nenhuma ordem específica Imagem © Mordor Intelligence. O reuso requer atribuição conforme CC BY 4.0. |
|
Análise do Mercado de GPU Interconnect por Mordor Intelligence
O tamanho do mercado de GPU interconnect deve aumentar de 48,11 bilhões de USD em 2025 para 89,43 bilhões de USD em 2026 e atingir 184,80 bilhões de USD até 2031, crescendo a um CAGR de 15,62% no período de 2026 a 2031. Os gastos dos hyperscalers e a transição para sistemas de IA em escala de rack tornaram o design de interconexão uma decisão central de infraestrutura, em vez de uma escolha secundária de componente de servidor. Os compradores estão tratando largura de banda, latência e eficiência de malha como impulsionadores diretos da produção utilizável de GPU, o que está encurtando os ciclos de atualização no mercado de GPU interconnect. Redes ópticas, fotônica de silício e designs de switches mais densos também estão melhorando a eficiência energética e espacial, ampliando o argumento comercial para clusters de IA maiores. A concorrência permanece concentrada em links proprietários de scale-up, enquanto padrões abertos e designs baseados em Ethernet estão oferecendo aos clientes maior flexibilidade em implantações de scale-out. As oportunidades mais fortes no mercado de GPU interconnect estão emergindo, impulsionadas pela expansão da nuvem, programas de computação soberana e implantações de IA empresarial, todos os quais exigem malhas de maior desempenho com menor risco de integração e melhores economias operacionais.
Principais Conclusões do Relatório
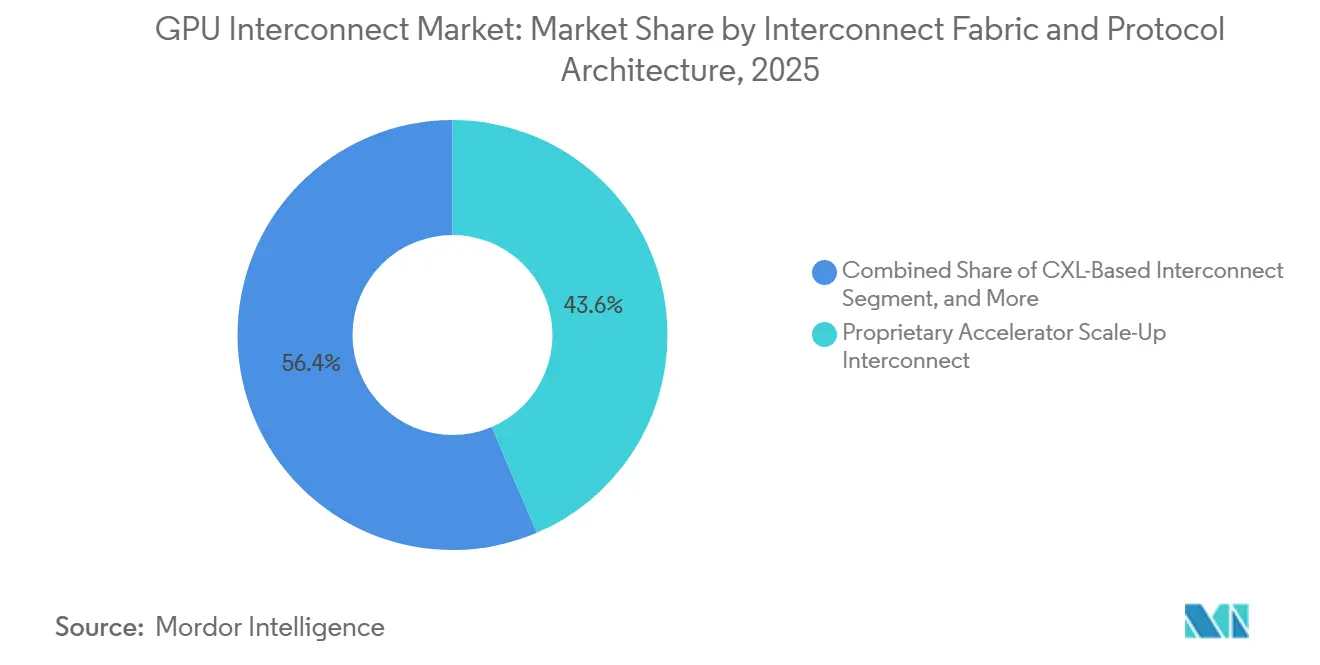
- Por malha de interconexão, a interconexão proprietária de scale-up de acelerador deteve 43,59% da participação do mercado de GPU interconnect em 2025, enquanto a interconexão aberta de scale-up de acelerador deve permanecer o segmento de malha de crescimento mais rápido até 2031.
- Por domínio de conectividade, a conectividade de scale-up representou 49,32% do tamanho do mercado de GPU interconnect (unidade de processamento gráfico) em 2025, enquanto a conectividade de IA entre pods e campus deve expandir-se mais rapidamente até 2031.
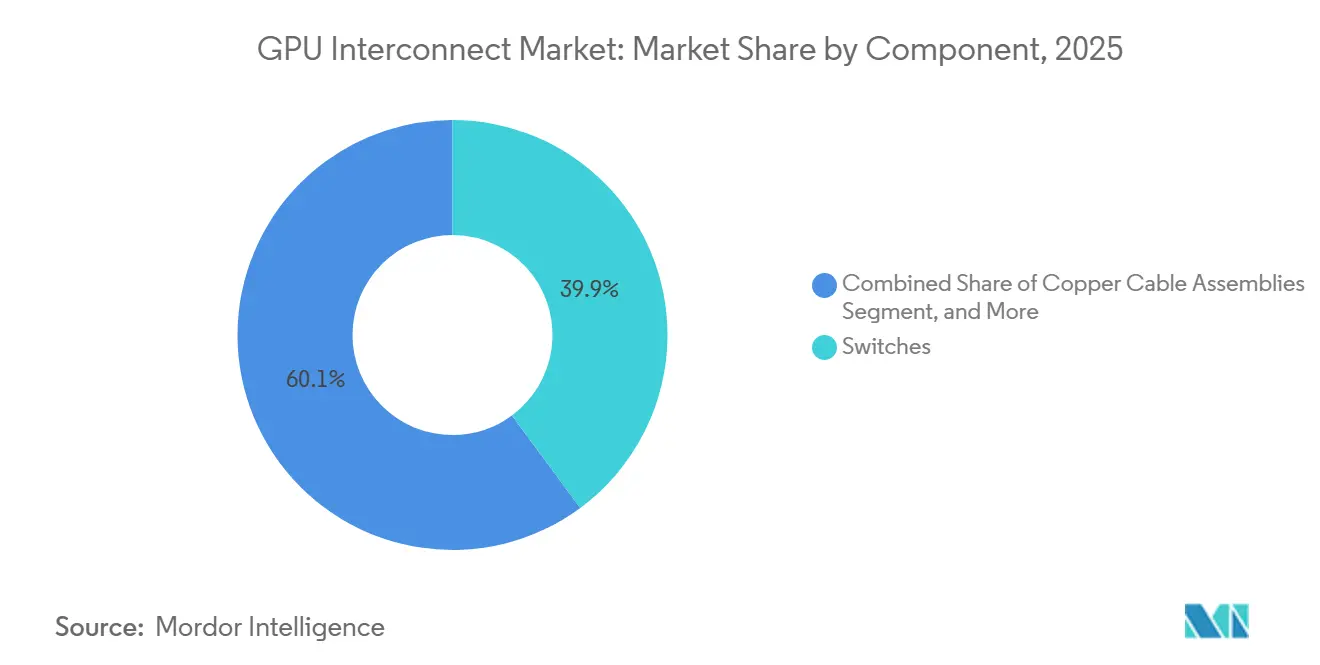
- Por componente, os switches detiveram 39,87% de participação no mercado de GPU interconnect em 2025, enquanto as interconexões ópticas devem crescer a um CAGR de 16,58% até 2031.
- Por usuário final, hyperscalers e provedores de serviços em nuvem de Nível 1 capturaram 68,84% de participação em 2025, enquanto provedores de nuvem nativos de IA e neoclouds devem registrar o crescimento mais rápido até 2031.
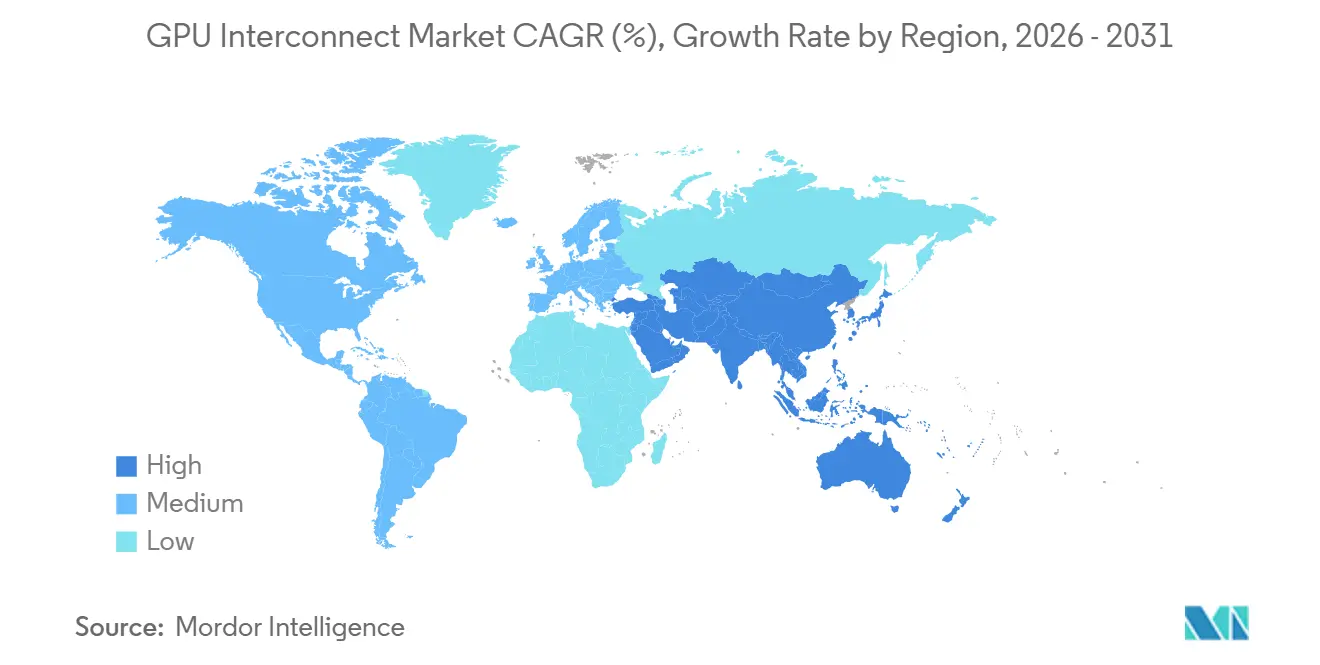
- Por geografia, a América do Norte deteve 56,62% de participação no mercado de GPU interconnect em 2025, enquanto a Ásia-Pacífico deve crescer a um CAGR de 16,44% até 2031.
Nota: O tamanho do mercado e os números de previsão neste relatório são gerados usando a estrutura de estimativa proprietária da Mordor Intelligence, atualizada com os dados e percepções mais recentes disponíveis em janeiro de 2026.
Tendências e Perspectivas do Mercado Global de GPU Interconnect
Análise de Impacto dos Impulsionadores*
| Impulsionador | (~) % de Impacto na Previsão de CAGR | Relevância Geográfica | Prazo de Impacto |
|---|---|---|---|
| Crescente Demanda por Largura de Banda em Clusters de IA Generativa | +4.5% | Global, concentrado na América do Norte e Ásia-Pacífico | Curto prazo (≤ 2 anos) |
| Mudança de Gargalos de Computação para Gargalos de Interconexão | +3.2% | Global | Médio prazo (2 a 4 anos) |
| Expansão de Sistemas de GPU em Escala de Rack em Data Centers de Hiperescala | +2.8% | América do Norte e Ásia-Pacífico como núcleo, com expansão para a Europa | Médio prazo (2 a 4 anos) |
| Crescimento de Padrões Abertos de Interconexão para Reduzir a Dependência de Fornecedor | +2.1% | Global, com ganhos iniciais na América do Norte e Europa | Médio prazo (2 a 4 anos) |
| Transição para Óptica Co-Empacotada e Fotônica de Silício | +1.6% | Global, com adoção inicial na América do Norte e em Taiwan | Longo prazo (≥ 4 anos) |
| Demanda por Co-Design de CPU-GPU em Infraestrutura de IA Empresarial | +0.8% | América do Norte e Europa | Médio prazo (2 a 4 anos) |
| Fonte: Mordor Intelligence | |||
Crescente Demanda por Largura de Banda em Clusters de IA Generativa
O treinamento de IA generativa continua impulsionando o mercado de GPU interconnect para cima, porque as tarefas de comunicação coletiva preenchem a malha de rede muito mais rapidamente do que a computação bruta pode compensar. A NVIDIA afirmou que sua plataforma GB300 NVL72 oferece 130 TB/s de largura de banda agregada intra-rack em 72 GPUs Blackwell Ultra, e que o NVLink 6 para Rubin elevará a largura de banda por GPU para 3,6 TB/s, ressaltando a rapidez com que os requisitos de largura de banda estão aumentando à medida que a densidade dos clusters cresce.[1]NVIDIA Corporation, "NVIDIA GB300 NVL72 Projetado para Desempenho e Eficiência em Raciocínio de IA," NVIDIA, nvidia.com À medida que os tamanhos dos modelos aumentam, o tráfego leste-oeste dentro do cluster torna-se caro demais para ser ignorado, deslocando os gastos de um item de linha de servidor para um orçamento dedicado de malha de rede. Essa mudança encurta os ciclos de substituição no mercado de GPU interconnect, porque muitos operadores de fronteira agora alinham as atualizações de malha mais estreitamente com as gerações de aceleradores do que com os hábitos tradicionais de atualização de rede. Também eleva o valor comercial de designs capazes de manter milhares de GPUs ocupadas simultaneamente, uma vez que qualquer deficiência de largura de banda pode reduzir a utilização efetiva e enfraquecer os retornos sobre grandes investimentos em computação. O resultado é um mercado onde o crescimento da demanda é impulsionado não apenas por mais GPUs, mas também pela necessidade de conectá-las com malhas muito mais capazes.
Mudança de Gargalos de Computação para Gargalos de Interconexão
O mercado de GPU interconnect também está se beneficiando de uma mudança no local onde os problemas de desempenho ocorrem dentro de grandes clusters de IA. A NVIDIA posicionou o Spectrum-X em torno de agendamento com reconhecimento de topologia, balanceamento de carga e ajuste de rede para grandes clusters de IA baseados em Ethernet, o que reflete como o comportamento da malha agora determina se o escalonamento permanece eficiente à medida que o tamanho da implantação cresce. Compradores que garantiram forte capacidade de GPU sem correspondê-la com largura de banda suficiente estão descobrindo que o treinamento distribuído não entrega o throughput esperado de seus gastos de capital. Isso criou um ciclo prático de atualização dentro dos clusters existentes, onde os operadores adicionam NICs, switches e hardware de conectividade relacionado sem esperar por uma nova compra de acelerador. Esse padrão sustenta o mercado de GPU interconnect mesmo quando o ritmo de compra de computação se torna irregular entre grupos de clientes. Também melhora a posição dos fornecedores de switches, NICs e DPUs, porque a demanda por interconexão está se tornando menos dependente de um evento único de envio de GPU e mais vinculada ao ajuste contínuo de clusters.
Expansão de Sistemas de GPU em Escala de Rack em Data Centers de Hiperescala
O design de sistemas em escala de rack mudou o mix de receita do mercado de GPU (unidade de processamento gráfico) interconnect ao concentrar mais malha em cada sistema de IA implantado. A NVIDIA construiu o GB300 NVL72 em torno da comunicação nativa via NVLink, e essa arquitetura substitui um arranjo mais convencional em nível de servidor por uma abordagem de rack altamente integrada que depende de hardware de malha dedicado em todo o sistema. Os quatro maiores operadores de nuvem confirmaram um gasto de capital combinado de 725 bilhões de USD para 2026, com grande parte desse orçamento direcionada à computação de IA e infraestrutura de rede, o que sustenta a demanda contínua por implantações densas de interconexão. Isso favorece fornecedores que oferecem silício de switch, links ópticos, controladores de malha e outros componentes que ganham conteúdo à medida que a integração de sistemas avança do nível de placa para o nível de rack. Também pressiona os fornecedores vinculados principalmente a categorias mais antigas de condicionamento de sinal PCIe, porque parte desse valor migra para novas camadas de switch e óptica à medida que a adoção em escala de rack se expande. Em termos práticos, o mercado de GPU interconnect está registrando maior intensidade de receita por implantação à medida que os hyperscalers migram de servidores de acelerador isolados para designs integrados de fábricas de IA.
Crescimento de Padrões Abertos de Interconexão para Reduzir a Dependência de Fornecedor
Os padrões abertos estão se tornando cada vez mais importantes no mercado de GPU interconnect à medida que grandes compradores buscam maior flexibilidade de fornecedores diante do aumento dos orçamentos de clusters. O Consórcio UALink publicou sua versão 2.0 em abril de 2026 com recursos de computação em rede, definição de chiplet e gerenciabilidade, e o grupo afirmou que 115 ou mais empresas membros estão agora envolvidas na definição do padrão. O Ultra Ethernet Consortium também lançou a Especificação 1.0 em junho de 2025, fornecendo ao lado de scale-out do mercado de GPU interconnect uma estrutura aberta construída sobre Ethernet para tráfego de IA e HPC. O hardware de avaliação para UALink 1.0 é esperado no segundo semestre de 2026, mas o silício comercial ainda é esperado para mais tarde, o que significa que a adoção dependerá da rapidez com que os fornecedores conseguem passar do trabalho no consórcio para produtos implantáveis. Mesmo assim, as estruturas abertas já estão moldando o comportamento de compra ao oferecer às empresas e operadores de nuvem um caminho mais claro em direção a malhas de GPU multi-fornecedor. Com o tempo, isso deve tornar o mercado de GPU interconnect menos dependente de uma única arquitetura na camada de scale-up, mesmo que os sistemas proprietários mantenham uma forte liderança no curto prazo.
Análise de Impacto das Restrições*
| Restrição | (~) % de Impacto na Previsão de CAGR | Relevância Geográfica | Prazo de Impacto |
|---|---|---|---|
| Disponibilidade Limitada de Empacotamento Avançado e Capacidade de SerDes de Alta Velocidade | -2.1% | Global, concentrado em torno dos centros de fabricação avançada em Taiwan | Médio prazo (2 a 4 anos) |
| Alto Custo Total de Propriedade para Malhas de GPU de Scale-Up | -1.4% | Global, agudo em implantações de IA de médio porte e soberanas | Médio prazo (2 a 4 anos) |
| Dependência de Ecossistema Proprietário Retardando a Adoção Multi-Fornecedor | -0.9% | Global | Longo prazo (≥ 4 anos) |
| Restrições Persistentes de Temperatura e Fornecimento de Energia em Escala de Rack | -0.7% | Global, agudo em implantações em instalações existentes e de colocalização | Médio prazo (2 a 4 anos) |
| Fonte: Mordor Intelligence | |||
Disponibilidade Limitada de Empacotamento Avançado e Capacidade de SerDes de Alta Velocidade
O mercado de GPU interconnect ainda enfrenta um limite do lado da oferta porque a capacidade de empacotamento avançado permanece restrita em todos os programas de semicondutores de IA. A Epoch AI afirmou que NVIDIA, Google, AMD e Amazon juntos responderam por mais de 90% da capacidade global de empacotamento CoWoS por valor em 2025, ressaltando o quanto da base de fornecimento já está sendo absorvida por um pequeno grupo de compradores muito grandes.[2]Epoch AI, "Empacotamento Avançado e HBM, Não os Dies Lógicos, Foram os Gargalos na Produção de Chips de IA em 2025," Epoch AI, epoch.ai Isso importa porque ASICs de interconexão, componentes ópticos avançados e silício de alta velocidade relacionado competem pelo mesmo ecossistema de fabricação que suporta o hardware de IA de próxima geração. Mesmo quando um fornecedor ganha um slot de design, as entregas ainda podem atrasar os cronogramas dos clientes se o fornecimento de empacotamento e SerDes não escalar no mesmo ritmo que a demanda. Isso cria um timing de envio irregular em todo o mercado de GPU interconnect e pode atrasar a implantação completa do cluster, especialmente quando os clientes precisam de entrega sincronizada de aceleradores, switches, óptica e dispositivos de conectividade de suporte. A restrição é mais severa para fornecedores que precisam de empacotamento avançado e conteúdo de rede de alta velocidade ao mesmo tempo, pois qualquer lacuna em uma parte da cadeia pode retardar todo o programa.
Alto Custo Total de Propriedade para Malhas de GPU de Scale-Up
O custo total de propriedade é outra restrição clara no mercado de GPU interconnect, porque as malhas de scale-up de alto desempenho exigem mais do que apenas o ASIC de switch. Racks de IA densos frequentemente requerem resfriamento líquido, fornecimento de energia especializado e atualizações de instalações, o que aumenta significativamente o custo operacional total além de uma simples compra de computação. Esse ônus de custo importa mais para projetos de computação soberana, empresas e operadores de nuvem de médio porte que não conseguem distribuir os gastos de infraestrutura na mesma escala de implantação que os maiores hyperscalers. O UALink está tentando resolver parte desse problema prometendo desempenho em escala de rack com um modelo de fornecimento mais aberto, mas os produtos comerciais ainda estão passando pela fase de avaliação em 2026. Até que esses produtos estejam amplamente disponíveis, muitos compradores no mercado de GPU interconnect continuarão a ponderar os ganhos de desempenho em relação aos custos mais elevados de resfriamento, integração e retrofit de instalações. Isso significa que algumas organizações optarão por tamanhos de cluster menores ou preferirão caminhos de expansão baseados em Ethernet em vez dos sistemas proprietários de scale-up mais caros.
*Nossas previsões tratam os impactos dos impulsionadores e restrições como direcionais, e não aditivos. As previsões de impacto refletem o crescimento de base, os efeitos de composição e as interações entre variáveis.
Análise de Segmentos
Por Malha de Interconexão / Arquitetura de Protocolo: Liderança Proprietária Encontra uma Pressão Mais Ampla por Padrões
A interconexão proprietária de scale-up de acelerador deteve 43,59% do mercado de GPU interconnect em 2025, enquanto a interconexão aberta de scale-up de acelerador deve ser a categoria de malha de crescimento mais rápido até 2031. Essa posição de liderança veio da implantação precoce e ampla de sistemas em escala de rack baseados em NVLink em ambientes de hyperscaler, onde a interconexão é empacotada como parte central da arquitetura de computação completa, em vez de um complemento opcional. A NVIDIA reforçou esse modelo ao vincular estreitamente o NVLink e o NVSwitch à sua abordagem de design em escala de rack, o que manteve os links proprietários de scale-up centrais na infraestrutura de IA de alta densidade. Ao mesmo tempo, a versão UALink 2.0 adicionou recursos de computação em rede, chiplet e gerenciabilidade, oferecendo aos designs de scale-up abertos um roteiro mais credível para clusters multi-fornecedor. Isso deixa o mercado de GPU interconnect com uma estrutura de curto prazo onde os sistemas proprietários ainda dominam o topo, enquanto as estruturas abertas estão construindo uma base técnica mais sólida para adoção posterior.
A interconexão nativa baseada em PCIe permanece relevante no setor de GPU interconnect para servidores de inferência heterogêneos, onde o controle de custos e a ampla compatibilidade frequentemente importam mais do que a maior largura de banda possível. A interconexão baseada em CXL também está ganhando atenção em designs orientados à inferência, porque os recursos de memória compartilhada e pooling podem ajudar a reduzir gargalos de memória em cargas de trabalho mistas de CPU e GPU. A Astera Labs colocou seu controlador de memória CXL Leo em produção em volume para cargas de trabalho relacionadas ao Microsoft Azure em 2026, demonstrando que o CXL está passando do conceito para a implantação comercial em infraestrutura de nuvem. As malhas de scale-out baseadas em Ethernet estão ganhando terreno porque se alinham com grandes ecossistemas de rede instalados, enquanto o InfiniBand permanece importante onde o desempenho de treinamento fortemente acoplado e o comportamento operacional estabelecido ainda têm peso. O mercado de GPU interconnect está, portanto, caminhando para um ambiente de malha mais misto, mesmo que os sistemas proprietários de scale-up ainda comandem a posição inicial mais forte nos clusters de IA de maior densidade.
Nota: Participações de segmentos de todos os segmentos individuais disponíveis mediante compra do relatório


Por Domínio de Conectividade: A Receita de Scale-Up Permanece a Maior Enquanto os Links de Campus Expandem Mais Rapidamente
A conectividade de scale-up representou 49,32% do tamanho do mercado de GPU interconnect em 2025, enquanto a conectividade de IA entre pods e campus deve expandir-se mais rapidamente do que os outros domínios de conectividade até 2031. O scale-up manteve a maior posição de receita porque os sistemas densos em escala de rack incorporam conteúdo significativo de malha diretamente em cada unidade implantada, aumentando assim o valor de interconexão por instalação. A NVIDIA centrou essa abordagem no GB300 NVL72, onde o próprio rack é construído em torno de comunicação interna de alta largura de banda, em vez de um arranjo mais convencional de servidores soltos. Essa estrutura suporta um grande custo de materiais para bandejas de switch, links internos e hardware de conectividade relacionado, o que mantém o scale-up central para a receita no mercado de GPU interconnect. Também ajuda a explicar por que os compradores que escolhem sistemas de IA altamente integrados frequentemente se comprometem com uma arquitetura de interconexão ao mesmo tempo em que escolhem a plataforma de acelerador.
A conectividade de IA entre pods e campus está crescendo mais rapidamente porque muitas implantações de IA não conseguem mais acomodar toda a computação necessária em uma sala ou um edifício. À medida que os operadores distribuem a capacidade de GPU por campi maiores para lidar com restrições de energia, resfriamento e espaço, eles precisam de conectividade óptica robusta entre pods, clusters e instalações. A conectividade de scale-out permanece importante dentro de cada cluster porque as GPUs ainda precisam de comunicação previsível de baixa latência entre racks, enquanto a conectividade intra-nó continua sendo importante em servidores mistos de CPU e GPU que dependem de conexão PCIe ou CXL. Operadores que melhoram apenas o caminho GPU a GPU ainda podem enfrentar gargalos se o caminho CPU a GPU permanecer restrito, o que significa que o ajuste de desempenho deve cobrir múltiplas camadas de tráfego simultaneamente. Isso mantém o mercado de GPU interconnect amplo em todos os tipos de conectividade, com diferentes domínios ganhando valor dependendo do tamanho do cluster, do design da carga de trabalho e do layout físico do data center.
Por Componente: Switches Detêm o Maior Pool de Receita Enquanto a Óptica Cresce Mais Rapidamente
As interconexões ópticas devem crescer a um CAGR de 16,58% de 2026 a 2031, enquanto os switches detiveram 39,87% do mercado de GPU interconnect em 2025. O crescimento óptico está sendo impulsionado pela transição para óptica co-empacotada e fotônica de silício, especialmente à medida que a densidade dos clusters leva os operadores a reduzir o consumo de energia e melhorar a qualidade do sinal em links mais exigentes. A NVIDIA afirmou que o Quantum-X800 InfiniBand CPO atingiu disponibilidade no início de 2026, e o Spectrum-X Ethernet Photonics entrou em produção em maio de 2026, marcando um passo comercial significativo para a comutação óptica em infraestrutura de IA. Essa mudança importa porque o escalonamento óptico permite malhas maiores e mais eficientes em termos de energia, o que está se tornando cada vez mais importante à medida que o mercado de GPU interconnect atende a fábricas de IA maiores em vez de racks de acelerador isolados. Os switches ainda detiveram a maior participação de receita porque permanecem centrais tanto para a conectividade em nível de rack quanto em nível de cluster, e toda implantação densa de IA precisa de capacidade substancial de comutação.
O pipeline de fornecedores também mostra a rapidez com que os roteiros de componentes estão avançando em torno do mercado de GPU interconnect. A Arista introduziu a Série 7060XE7 em junho de 2026 com 64 portas a 1,6T por porta e até 102,4 Tb/s de largura de banda agregada, sinalizando uma rápida transição além das redes de 800G em data centers de IA. As placas de interface de rede e DPUs também estão ganhando importância porque os sistemas de IA densos precisam de um tratamento mais robusto do tráfego norte-sul ao lado da largura de banda da malha interna, e a NVIDIA posicionou o ConnectX-8 a 800 Gb/s por porta para plataformas baseadas em GB300. Retimers e CIs de conectividade permanecem importantes porque velocidades de lane mais altas aumentam os desafios de integridade de sinal em placas, cabos e backplanes. A Astera Labs reportou 308,4 milhões de USD em receita no primeiro trimestre de 2026, enquanto expandia sua presença nessas categorias. Os conjuntos de cabos de cobre ainda atendem links de curto alcance onde o custo e a familiaridade operacional importam, mas o mercado de GPU interconnect está direcionando cada vez mais crescimento para sistemas ópticos e as plataformas de comutação que os suportam.
Nota: Participações de segmentos de todos os segmentos individuais disponíveis mediante compra do relatório
Por Usuário Final: Hyperscalers Lideram a Demanda Atual Enquanto Neoclouds Expandem Rapidamente
Hyperscalers e provedores de serviços em nuvem de Nível 1 representaram 68,84% do mercado de GPU interconnect em 2025, enquanto provedores de nuvem nativos de IA e neoclouds devem crescer mais rapidamente até 2031. Essa dominância reflete a escala em que Microsoft, Amazon, Google e Meta implantam infraestrutura tanto para treinamento quanto para inferência de IA. Seus compromissos combinados de gasto de capital para 2026 atingiram 725 bilhões de USD, com grande parte direcionada à computação de IA e redes, fornecendo ao mercado de GPU interconnect sua base de gastos mais profunda e previsível. Esses clientes também adotam novas arquiteturas cedo, razão pela qual foram centrais para o lançamento de sistemas em escala de rack, malhas de alta largura de banda e comutação óptica avançada. Mesmo quando alguns hyperscalers projetam partes de sua pilha de rede internamente, sua escala de aquisição ainda molda os roteiros de produtos em todo o ecossistema de fornecedores.
Os provedores de nuvem nativos de IA e neoclouds estão expandindo rapidamente porque usam o acesso a malhas mais novas como um argumento de venda direto para clientes empresariais e de pesquisa. A NVIDIA afirmou que CoreWeave, Lambda e Oracle Cloud Infrastructure estavam entre os primeiros adotantes do Spectrum-X Ethernet Photonics, o que mostra como as plataformas de nuvem mais novas estão usando desempenho de rede e eficiência energética para diferenciar seus serviços. Os programas governamentais e de computação soberana também estão ampliando a base de compradores, e o Canadá lançou seu Programa de Infraestrutura de Computação Soberana de IA em abril de 2026 com 2,4 bilhões de CAD (1,76 bilhão de USD) em apoio federal. Grandes empresas, centros de computação acadêmica e implantações relacionadas a telecomunicações acrescentam demanda adicional, embora frequentemente prefiram malhas de scale-out com consciência de custo em vez dos sistemas proprietários de scale-up mais caros. Esse mix de clientes em expansão oferece ao mercado de GPU (unidade de processamento gráfico) interconnect uma base de demanda maior do que tinha em ciclos anteriores de acelerador, quando as compras de hyperscalers representavam uma parcela muito maior da atividade total.
Análise Geográfica
A América do Norte deteve 56,62% da participação do mercado de GPU interconnect em 2025, ficando bem à frente de todos os outros segmentos regionais. A região se beneficia do investimento concentrado de hyperscalers nos Estados Unidos e do fato de que muitas das empresas que moldam o mercado de GPU interconnect, incluindo NVIDIA, Broadcom, Arista Networks, Astera Labs, Credo Technology, Coherent e Lumentum, têm sede ou operações comerciais significativas lá. A região também permanece a maior base de adoção inicial de infraestrutura de IA em escala de rack, o que significa que os lançamentos de produtos frequentemente se traduzem em implantações norte-americanas antes de lançamentos globais mais amplos. Os grandes gastos de capital em nuvem estão reforçando essa liderança, com os maiores operadores direcionando grandes orçamentos de 2026 para computação de IA e infraestrutura de rede. O Canadá também está ajudando a ampliar a demanda regional por meio de investimentos públicos em computação, e seu Programa de Infraestrutura de Computação Soberana de IA adicionou 2,4 bilhões de CAD (1,76 bilhão de USD) em apoio federal em abril de 2026.[3]Governo do Canadá, "O Canadá Lança Iniciativa Nacional para Construir Capacidade de Supercomputação de IA em Grande Escala," Governo do Canadá, canada.ca
A Ásia-Pacífico deve expandir-se a um CAGR de 16,44% até 2031, tornando-a a geografia de crescimento mais rápido no mercado de GPU interconnect. O crescimento na região está sendo sustentado por ambições de IA soberana, construções locais de nuvem e a necessidade de pilhas de tecnologia domésticas em países que buscam maior controle sobre a infraestrutura de computação. A região também importa porque vários grandes grupos de tecnologia da Ásia-Pacífico fazem parte do Consórcio UALink, indicando que os padrões abertos de scale-up estão atraindo interesse real de grandes empresas de plataforma e participantes de hardware. Esse impulso regional provavelmente apoiará tanto os ecossistemas de fabricação locais quanto a demanda por abordagens alternativas de interconexão, à medida que os clientes avaliam custo, acesso ao fornecimento e controle de tecnologia. Para o mercado de GPU interconnect, a Ásia-Pacífico está se tornando importante não apenas como um centro de demanda, mas também como uma região que pode influenciar a adoção futura de padrões e os padrões de fornecimento de componentes.
A Europa é menor hoje, mas permanece estrategicamente importante porque as regras de soberania de dados e as estruturas de governança de IA continuam a sustentar a demanda por infraestrutura de computação regional. O Reino Unido afirmou em 2026 que alocaria 1,1 bilhão de GBP (1,4 bilhão de USD), sob seu plano de hardware de IA, incluindo 750 milhões de GBP (1,02 bilhão de USD) para um supercomputador nacional de IA programado para implantação até 2030. A América do Sul permanece em estágio mais inicial de adoção, com atividade mais estreitamente ligada à expansão de nuvem de hyperscalers e computação de pesquisa do que a grandes programas domésticos de malha. A demanda no Oriente Médio e África ainda é menor em termos absolutos, mas o interesse em computação soberana está aumentando, o que oferece ao mercado de GPU (unidade de processamento gráfico) interconnect outro caminho de crescimento regional de longo prazo além do núcleo atual de hyperscalers.

Cenário Competitivo
O mercado de GPU interconnect é moderadamente concentrado e tem uma estrutura dividida, com links proprietários de scale-up entre um pequeno número de fornecedores, enquanto a rede de scale-out é disputada por um grupo mais amplo de fornecedores. A NVIDIA detém a posição mais forte em conectividade proprietária de scale-up porque o NVLink e o NVSwitch estão incorporados diretamente em seu design de sistema em escala de rack, o que lhe confere uma vantagem poderosa nas implantações de IA de maior densidade. Na rede de scale-out, o campo é mais amplo, com Broadcom, Marvell, Cisco e Arista Networks competindo em comutação Ethernet, conectividade óptica e camadas relacionadas de rede de IA.[4]Arista Networks, "Arista Apresenta Portfólio de Próxima Geração de 1,6 Terabit para Malhas de IA," Arista Networks, arista.com Os grupos de padrões abertos também estão moldando a concorrência futura ao oferecer aos clientes um caminho para malhas multi-fornecedor tanto em ambientes de scale-up quanto de scale-out. Isso significa que o mercado de GPU interconnect está concentrado no topo, mas mais aberto e competitivo nas camadas de rede mais amplas que suportam o escalonamento de cluster a cluster.
Várias ações de empresas em 2026 mostram como o cenário competitivo está evoluindo no mercado de GPU interconnect. A NVIDIA anunciou investimentos estratégicos de 2 bilhões de USD cada na Lumentum e na Coherent, juntamente com grandes compromissos de compra, o que demonstra um movimento direto para garantir o fornecimento óptico upstream para seu roteiro de óptica co-empacotada. A Arista então introduziu a Série 7060XE7 para malhas de IA de 1,6T, sinalizando que os concorrentes centrados em Ethernet estão avançando rapidamente para a comutação de IA de maior velocidade, em vez de aguardar um ciclo de migração mais lento. A Astera Labs expandiu suas operações em Taiwan em junho de 2026 para aprofundar a validação de plataformas de IA e o trabalho de integração local, refletindo como os fornecedores estão se aproximando da base de fabricação e montagem de sistemas que suporta o mercado de GPU interconnect. A participação em consórcios também se tornou uma ferramenta estratégica, à medida que os fornecedores buscam influenciar futuras decisões de soquete antes que o silício de scale-up aberto atinja produção ampla. Em conjunto, esses movimentos mostram que a concorrência agora está centrada no acesso ao fornecimento, posição no ecossistema e expansão de conteúdo por acelerador, em vez de apenas lançamentos isolados de componentes.
Ainda há espaço aberto no mercado de GPU interconnect para gerenciamento de malha definido por software, controle de cluster heterogêneo e silício de switch compatível com UALink comprovado comercialmente. O The Register relatou que o hardware de avaliação UALink é esperado no segundo semestre de 2026, e que o silício comercial seguirá mais tarde, indicando que o mercado ainda carece de um conjunto de produtos de scale-up aberto totalmente estabelecido em volume. Essa lacuna dá aos incumbentes mais tempo para aprofundar os relacionamentos com clientes, mas também cria espaço para desafiantes que consigam lançar alternativas abertas credíveis antes que a frustração dos compradores com a dependência de fornecedor cresça. A Oracle, apesar de ser ativa em implantações de nuvem de GPU, permanece principalmente um usuário final neste contexto, em vez de um designer do lado da oferta de hardware de interconexão, portanto o campo competitivo ainda é definido principalmente por fornecedores de rede, semicondutores e óptica.
Líderes do Setor de GPU Interconnect
-
NVIDIA Corporation
-
Broadcom Inc.
-
Marvell Technology, Inc.
-
Advanced Micro Devices, Inc.
-
Astera Labs, Inc.
- *Isenção de responsabilidade: Principais participantes classificados em nenhuma ordem específica

Desenvolvimentos Recentes do Setor
- Junho de 2026: A Arista Networks introduziu a Série 7060XE7, um portfólio de rede de IA de 1,6T de próxima geração construído sobre o silício Broadcom Tomahawk 6, suportando 64 portas a 1,6T por porta e capacidade de comutação agregada de 102,4 Tb/s, em configurações resfriadas a ar e resfriadas a líquido. As variantes resfriadas a ar estão programadas para o quarto trimestre de 2026 e as variantes resfriadas a líquido para o primeiro trimestre de 2027, posicionando o portfólio para implantações de malha de IA tanto de scale-up quanto de scale-out.
- Junho de 2026: A Astera Labs expandiu suas operações em Taiwan, estabelecendo um Laboratório de Interoperabilidade em Escala de Nuvem ampliado e aumentando a presença de engenharia para aprofundar a integração com provedores de plataformas de IA e fabricantes de sistemas em Taiwan, visando a validação de clusters de IA para a geração GB300.
- Maio de 2026: A NVIDIA anunciou que o Spectrum-X Ethernet Photonics está agora em produção no GTC de Taiwan, Computex 2026, marcando-o como o primeiro switch Ethernet CPO do mundo construído sobre tecnologia SerDes de 200G com até 409,6 Tb/s de largura de banda agregada. CoreWeave, Lambda e Oracle Cloud Infrastructure estavam entre os primeiros adotantes, e a disponibilidade ampla está prevista para o segundo semestre de 2026.
- Abril de 2026: O Consórcio UALink publicou quatro especificações em sua versão 2.0, introduzindo estruturas de computação em rede, definição de chiplet e gerenciabilidade para implantações de IA com múltiplas cargas de trabalho, com 115 ou mais empresas membros agora governando o padrão.


Escopo do Relatório Global do Mercado de GPU Interconnect
O Mercado de GPU Interconnect compreende hardware, software, protocolos e tecnologias de rede que permitem comunicação de alta velocidade e troca de dados entre unidades de processamento gráfico (GPUs), aceleradores, CPUs, recursos de memória e infraestrutura de computação distribuída. As soluções de GPU interconnect são projetadas para atender aos requisitos de largura de banda, latência, escalabilidade e eficiência de cargas de trabalho modernas de inteligência artificial (IA), aprendizado de máquina, computação de alto desempenho (HPC), computação em nuvem e intensivas em dados, facilitando a comunicação perfeita em ambientes de computação cada vez maiores e mais complexos.
O Relatório do Mercado de GPU Interconnect é Segmentado por Arquitetura de Interconexão/Arquitetura de Protocolo (Interconexão Nativa Baseada em PCIe, Interconexão Baseada em CXL, Interconexão Proprietária de Scale-Up de Acelerador, Interconexão Aberta de Scale-Up de Acelerador, Interconexão de Scale-Out Baseada em InfiniBand e Interconexão de Scale-Out Baseada em Ethernet), Domínio de Conectividade (Conectividade Intra-Nó/Intra-Servidor, Conectividade de Scale-Up, Conectividade de Scale-Out e Conectividade de IA entre Pods/Campus), Componente (Switches, Placas de Interface de Rede e DPUs, Retimers, Redrivers e CIs de Conectividade, Conjuntos de Cabos de Cobre e Interconexões Ópticas), Usuário Final (Hyperscalers e Provedores de Serviços em Nuvem de Nível 1, Provedores de Nuvem Nativos de IA e Neoclouds, Grandes Empresas e Operadores de Infraestrutura de IA Privada, Governo, Programas de IA Soberana e Laboratórios Nacionais de Pesquisa, Instituições Acadêmicas e de Pesquisa em HPC e Provedores de Telecomunicações, Nuvem de Borda e Serviços Gerenciados) e Geografia (América do Norte, Europa, Ásia-Pacífico, América do Sul e Oriente Médio e África). As Previsões de Mercado são Fornecidas em Termos de Valor (USD).
| Interconexão Nativa Baseada em PCIe |
| Interconexão Baseada em CXL |
| Interconexão Proprietária de Scale-Up de Acelerador |
| Interconexão Aberta de Scale-Up de Acelerador |
| Interconexão de Scale-Out Baseada em InfiniBand |
| Interconexão de Scale-Out Baseada em Ethernet |
| Conectividade Intra-Nó/Intra-Servidor |
| Conectividade de Scale-Up |
| Conectividade de Scale-Out |
| Conectividade de IA entre Pods/Campus |
| Switches |
| Placas de Interface de Rede e DPUs |
| Retimers, Redrivers e CIs de Conectividade |
| Conjuntos de Cabos de Cobre |
| Interconexões Ópticas |
| Hyperscalers e Provedores de Serviços em Nuvem de Nível 1 |
| Provedores de Nuvem Nativos de IA e Neoclouds |
| Grandes Empresas e Operadores de Infraestrutura de IA Privada |
| Governo, Programas de IA Soberana e Laboratórios Nacionais de Pesquisa |
| Instituições Acadêmicas e de Pesquisa em HPC |
| Provedores de Telecomunicações, Nuvem de Borda e Serviços Gerenciados |
| América do Norte | Estados Unidos |
| Canadá | |
| México | |
| Europa | Alemanha |
| Reino Unido | |
| França | |
| Itália | |
| Restante da Europa | |
| Ásia-Pacífico | China |
| Japão | |
| Coreia do Sul | |
| Índia | |
| Sudeste Asiático | |
| Restante da Ásia-Pacífico | |
| América do Sul | |
| Oriente Médio e África |
| Por Malha de Interconexão/Arquitetura de Protocolo | Interconexão Nativa Baseada em PCIe | |
| Interconexão Baseada em CXL | ||
| Interconexão Proprietária de Scale-Up de Acelerador | ||
| Interconexão Aberta de Scale-Up de Acelerador | ||
| Interconexão de Scale-Out Baseada em InfiniBand | ||
| Interconexão de Scale-Out Baseada em Ethernet | ||
| Por Domínio de Conectividade | Conectividade Intra-Nó/Intra-Servidor | |
| Conectividade de Scale-Up | ||
| Conectividade de Scale-Out | ||
| Conectividade de IA entre Pods/Campus | ||
| Por Componente | Switches | |
| Placas de Interface de Rede e DPUs | ||
| Retimers, Redrivers e CIs de Conectividade | ||
| Conjuntos de Cabos de Cobre | ||
| Interconexões Ópticas | ||
| Por Usuário Final | Hyperscalers e Provedores de Serviços em Nuvem de Nível 1 | |
| Provedores de Nuvem Nativos de IA e Neoclouds | ||
| Grandes Empresas e Operadores de Infraestrutura de IA Privada | ||
| Governo, Programas de IA Soberana e Laboratórios Nacionais de Pesquisa | ||
| Instituições Acadêmicas e de Pesquisa em HPC | ||
| Provedores de Telecomunicações, Nuvem de Borda e Serviços Gerenciados | ||
| Por Geografia | América do Norte | Estados Unidos |
| Canadá | ||
| México | ||
| Europa | Alemanha | |
| Reino Unido | ||
| França | ||
| Itália | ||
| Restante da Europa | ||
| Ásia-Pacífico | China | |
| Japão | ||
| Coreia do Sul | ||
| Índia | ||
| Sudeste Asiático | ||
| Restante da Ásia-Pacífico | ||
| América do Sul | ||
| Oriente Médio e África | ||


Principais Perguntas Respondidas no Relatório
Qual é o tamanho atual do mercado de GPU interconnect?
O mercado de GPU interconnect atingiu 89,43 bilhões de USD em 2026 e tem previsão de atingir 184,8 bilhões de USD até 2031 a um CAGR de 15,62%.
Qual malha de interconexão lidera a receita atual?
A interconexão proprietária de scale-up de acelerador liderou com 43,59% de participação em 2025, sustentada pela implantação precoce em escala de rack em torno de arquiteturas baseadas em NVLink.
Qual domínio de conectividade está expandindo mais rapidamente?
A conectividade de scale-up deteve a maior participação em 2025, mas a conectividade de IA entre pods e campus deve crescer mais rapidamente até 2031, à medida que os clusters se espalham por campi maiores.
Por que as interconexões ópticas estão ganhando tração em clusters de GPU?
As interconexões ópticas devem crescer a um CAGR de 16,58% porque os sistemas de IA mais densos precisam de melhor eficiência energética, integridade de sinal e comutação de maior largura de banda.
Quem compra mais hardware de GPU interconnect hoje?
Hyperscalers e provedores de serviços em nuvem de Nível 1 lideraram a demanda com 68,84% de participação em 2025, impulsionados por programas de infraestrutura de treinamento e inferência de IA de grande escala.
Qual região apresenta as perspectivas de crescimento mais fortes?
A América do Norte liderou com 56,62% de participação em 2025, enquanto a Ásia-Pacífico deve registrar o crescimento mais rápido a um CAGR de 16,44% até 2031.
Página atualizada pela última vez em:




