GPU Interconnect Marktgröße und Marktanteil
Marktübersicht
| Studienzeitraum | 2020 - 2031 |
|---|---|
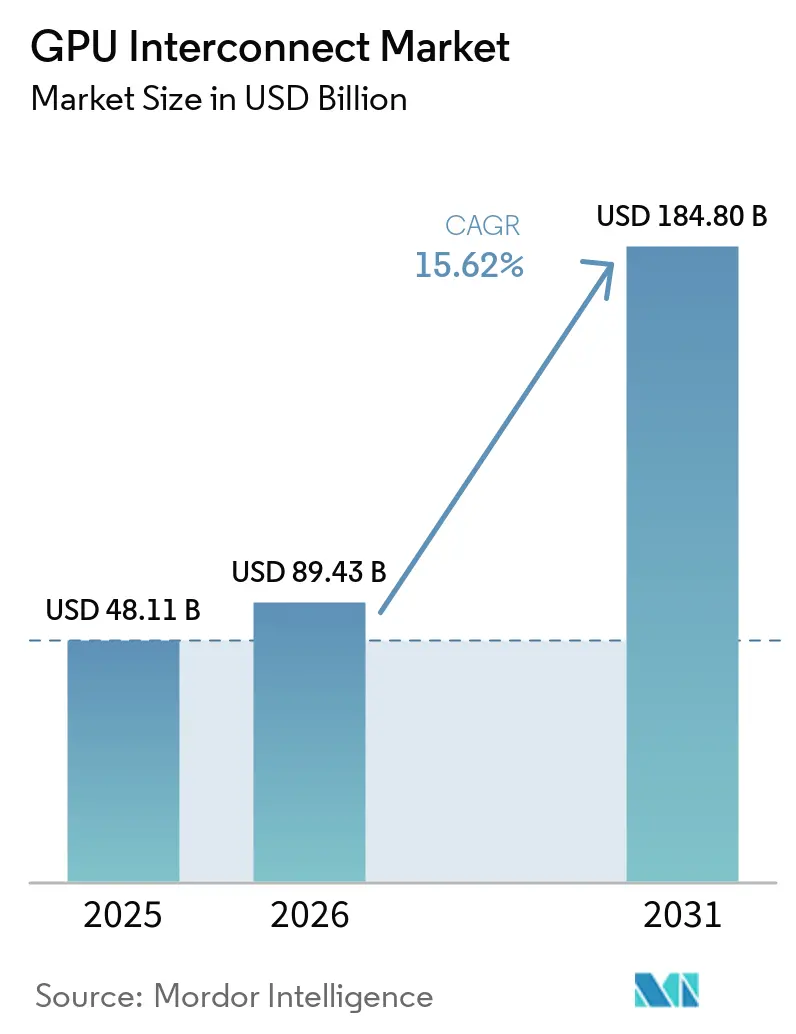
| Marktgröße (2026) | 89.43 Milliarden US-Dollar |
| Marktgröße (2031) | 184.80 Milliarden US-Dollar |
| Wachstumsrate (2026 - 2031) | 15.62% CAGR |
| Schnellstwachsender Markt | Asien-Pazifik |
| Größter Markt | Nordamerika |
| Marktkonzentration | Mittel |
Hauptakteure *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. | |
GPU Interconnect Marktanalyse von Mordor Intelligence
Die Größe des GPU Interconnect Marktes wird voraussichtlich von USD 48,11 Milliarden im Jahr 2025 auf USD 89,43 Milliarden im Jahr 2026 steigen und bis 2031 USD 184,80 Milliarden erreichen, mit einer CAGR von 15,62 % über den Zeitraum 2026–2031. Die Ausgaben von Hyperscalern und der Übergang zu KI-Systemen auf Rack-Ebene haben das Interconnect-Design zu einer zentralen Infrastrukturentscheidung gemacht, anstatt es als sekundäre Serverkomponentenwahl zu betrachten. Käufer behandeln Bandbreite, Latenz und Fabric-Effizienz nun als direkte Treiber der nutzbaren GPU-Leistung, was die Erneuerungszyklen im GPU Interconnect Markt verkürzt. Optische Vernetzung, Silizium-Photonik und dichtere Switch-Designs verbessern zudem die Energie- und Raumeffizienz und erweitern den kommerziellen Anwendungsfall für größere KI-Cluster. Der Wettbewerb bleibt auf proprietäre Scale-up-Links konzentriert, während offene Standards und Ethernet-basierte Designs den Kunden mehr Flexibilität bei Scale-out-Deployments bieten. Die stärksten Chancen im GPU Interconnect Markt entstehen, angetrieben durch Cloud-Expansion, souveräne Rechenprogramme und den Einsatz von KI in Unternehmen, die alle leistungsfähigere Fabrics mit geringerem Integrationsrisiko und besserer Betriebswirtschaftlichkeit erfordern.
Wichtigste Erkenntnisse des Berichts
- Nach Interconnect-Fabric hielt proprietäres Accelerator-Scale-up-Interconnect im Jahr 2025 einen Anteil von 43,59 % am GPU Interconnect Markt, während offenes Accelerator-Scale-up-Interconnect bis 2031 voraussichtlich das am schnellsten wachsende Fabric-Segment bleibt.
- Nach Konnektivitätsdomäne entfiel auf Scale-up-Konnektivität im Jahr 2025 ein Anteil von 49,32 % an der Marktgröße des Grafikprozessor (GPU) Interconnect Marktes, während Inter-Pod- und Campus-KI-Konnektivität bis 2031 voraussichtlich am schnellsten wächst.
- Nach Komponente hielten Switches im Jahr 2025 einen Anteil von 39,87 % am GPU Interconnect Markt, während optische Interconnects bis 2031 voraussichtlich mit einer CAGR von 16,58 % wachsen.
- Nach Endnutzer entfielen auf Hyperscaler und Tier-1-Cloud-Dienstleister im Jahr 2025 68,84 % des Marktanteils, während KI-native Cloud-Anbieter und Neoclouds bis 2031 voraussichtlich das stärkste Wachstum verzeichnen.
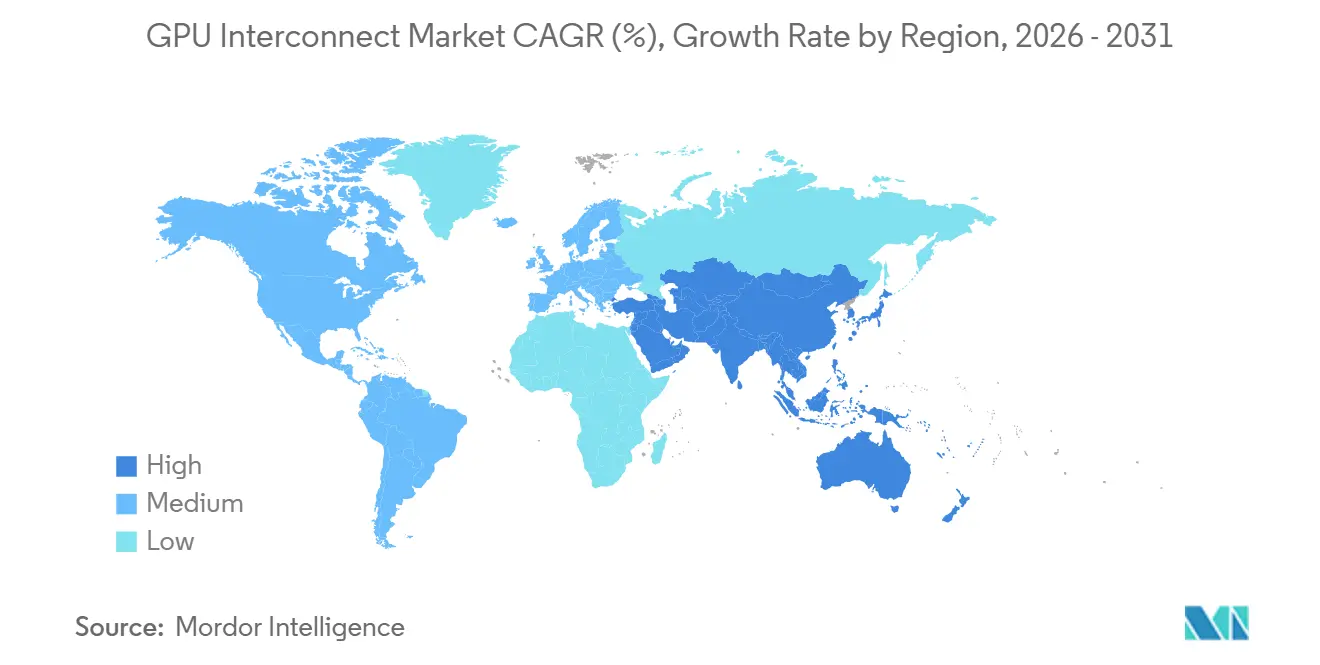
- Nach Geografie hielt Nordamerika im Jahr 2025 einen Anteil von 56,62 % am GPU Interconnect Markt, während Asien-Pazifik bis 2031 voraussichtlich mit einer CAGR von 16,44 % wächst.
Hinweis: Die Marktgröße und Prognosezahlen in diesem Bericht werden mithilfe des proprietären Schätzungsrahmens von Mordor Intelligence erstellt und mit den neuesten verfügbaren Daten und Erkenntnissen vom Januar 2026 aktualisiert.
Globale GPU Interconnect Markttrends und Einblicke
Analyse der Treiberwirkung*
| Treiber | (~) % Einfluss auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Wirkung |
|---|---|---|---|
| Steigende Bandbreitennachfrage für generative KI-Cluster | +4.5% | Global, konzentriert in Nordamerika und Asien-Pazifik | Kurzfristig (≤ 2 Jahre) |
| Verlagerung von Rechenengpässen zu Interconnect-Engpässen | +3.2% | Global | Mittelfristig (2–4 Jahre) |
| Expansion von GPU-Systemen auf Rack-Ebene in Hyperscale-Rechenzentren | +2.8% | Nordamerika und Asien-Pazifik als Kern, mit Ausstrahlungseffekten nach Europa | Mittelfristig (2–4 Jahre) |
| Wachstum offener Interconnect-Standards zur Reduzierung von Anbieterabhängigkeit | +2.1% | Global, mit frühen Gewinnen in Nordamerika und Europa | Mittelfristig (2–4 Jahre) |
| Übergang zu Co-Packaged Optics und Silizium-Photonik | +1.6% | Global, mit früher Einführung in Nordamerika und Taiwan | Langfristig (≥ 4 Jahre) |
| Nachfrage nach CPU-GPU-Co-Design in der KI-Infrastruktur von Unternehmen | +0.8% | Nordamerika und Europa | Mittelfristig (2–4 Jahre) |
| Quelle: Mordor Intelligence | |||
Steigende Bandbreitennachfrage für generative KI-Cluster
Das Training generativer KI treibt den GPU Interconnect Markt weiter nach oben, da kollektive Kommunikationsaufgaben das Netzwerk-Fabric viel schneller füllen, als rohe Rechenleistung ausgleichen kann. NVIDIA gab an, dass seine GB300 NVL72-Plattform 130 TB/s aggregierte Intra-Rack-Bandbreite über 72 Blackwell Ultra GPUs liefert und dass NVLink 6 für Rubin die GPU-Bandbreite auf 3,6 TB/s erhöhen wird, was unterstreicht, wie schnell die Bandbreitenanforderungen mit zunehmender Clusterdichte steigen.[1]NVIDIA Corporation, "NVIDIA GB300 NVL72 Designed for AI Reasoning Performance and Efficiency," NVIDIA, nvidia.com Mit zunehmender Modellgröße wird der Ost-West-Datenverkehr innerhalb des Clusters zu kostspielig, um ihn zu ignorieren, was die Ausgaben von einem Serverposten zu einem dedizierten Netzwerk-Fabric-Budget verlagert. Diese Veränderung verkürzt die Ersatzzyklen im GPU Interconnect Markt, da viele Frontier-Betreiber Fabric-Upgrades nun enger an Accelerator-Generationen ausrichten als an traditionellen Netzwerkerneuerungsgewohnheiten. Sie erhöht auch den kommerziellen Wert von Designs, die Tausende von GPUs gleichzeitig auslasten können, da jeder Bandbreitenengpass die effektive Auslastung verringern und die Rendite großer Recheninvestitionen schwächen kann. Das Ergebnis ist ein Markt, auf dem das Nachfragewachstum nicht nur durch mehr GPUs, sondern auch durch die Notwendigkeit angetrieben wird, diese mit wesentlich leistungsfähigeren Fabrics zu verbinden.
Verlagerung von Rechenengpässen zu Interconnect-Engpässen
Der GPU Interconnect Markt profitiert auch von einer Verlagerung dahin, wo Leistungsprobleme in großen KI-Clustern auftreten. NVIDIA hat Spectrum-X auf topologiebewusstes Scheduling, Lastausgleich und Netzwerkoptimierung für große Ethernet-basierte KI-Cluster ausgerichtet, was widerspiegelt, wie das Fabric-Verhalten nun bestimmt, ob die Skalierung mit wachsender Deployment-Größe effizient bleibt. Käufer, die starke GPU-Kapazität gesichert haben, ohne diese mit ausreichend Bandbreite abzugleichen, stellen fest, dass verteiltes Training nicht den erwarteten Durchsatz aus ihren Kapitalausgaben liefert. Dies hat einen praktischen Upgrade-Zyklus innerhalb bestehender Cluster geschaffen, bei dem Betreiber NICs, Switches und zugehörige Konnektivitätshardware hinzufügen, ohne auf einen neuen Accelerator-Kauf zu warten. Dieses Muster stützt den GPU Interconnect Markt auch dann, wenn der Beschaffungsrhythmus für Rechenleistung bei verschiedenen Kundengruppen ungleichmäßig wird. Es verbessert auch die Position von Switch-, NIC- und DPU-Anbietern, da die Interconnect-Nachfrage weniger von einem einmaligen GPU-Lieferereignis abhängig wird und stärker mit der laufenden Cluster-Optimierung verknüpft ist.
Expansion von GPU-Systemen auf Rack-Ebene in Hyperscale-Rechenzentren
Das Design von Systemen auf Rack-Ebene hat den Umsatzmix des Grafikprozessor (GPU) Interconnect Marktes verändert, indem mehr Fabric in jedes eingesetzte KI-System integriert wird. NVIDIA hat den GB300 NVL72 auf NVLink-native Kommunikation aufgebaut, und diese Architektur ersetzt eine konventionellere Anordnung auf Serverebene durch einen eng integrierten Rack-Ansatz, der auf dedizierter Fabric-Hardware im gesamten System basiert. Die vier größten Cloud-Betreiber bestätigten gemeinsame Investitionsausgaben für 2026 von USD 725 Milliarden, wobei ein großer Teil dieses Budgets auf KI-Rechenleistung und Netzwerkinfrastruktur ausgerichtet ist, was die anhaltende Nachfrage nach dichten Interconnect-Deployments stützt. Dies begünstigt Anbieter, die Switch-Silizium, optische Links, Fabric-Controller und andere Komponenten bereitstellen, die an Bedeutung gewinnen, wenn die Systemintegration von der Platinen- auf die Rack-Ebene übergeht. Es übt auch Druck auf Anbieter aus, die hauptsächlich an ältere PCIe-Signalkonditionierungskategorien gebunden sind, da ein Teil dieses Wertes zu neuen Switch- und optischen Schichten verlagert wird, wenn die Einführung auf Rack-Ebene zunimmt. In der Praxis verzeichnet der GPU Interconnect Markt eine höhere Umsatzintensität pro Deployment, da Hyperscaler von isolierten Accelerator-Servern zu integrierten KI-Factory-Designs übergehen.
Wachstum offener Interconnect-Standards zur Reduzierung von Anbieterabhängigkeit
Offene Standards gewinnen im GPU Interconnect Markt zunehmend an Bedeutung, da große Käufer angesichts steigender Cluster-Budgets mehr Anbieterflexibilität anstreben. Das UALink-Konsortium veröffentlichte im April 2026 seine Version 2.0 mit In-Network-Computing-, Chiplet-Definitions- und Verwaltbarkeitsfunktionen, und die Gruppe gab an, dass nun 115 oder mehr Mitgliedsunternehmen an der Gestaltung des Standards beteiligt sind. Das Ultra Ethernet Consortium startete im Juni 2025 ebenfalls Spezifikation 1.0 und stellte damit der Scale-out-Seite des GPU Interconnect Marktes ein offenes Framework auf Ethernet-Basis für KI- und HPC-Datenverkehr zur Verfügung. Evaluierungshardware für UALink 1.0 wird in der zweiten Hälfte des Jahres 2026 erwartet, kommerzielles Silizium wird jedoch noch später erwartet, was bedeutet, dass die Einführung davon abhängt, wie schnell Anbieter von der Konsortiumsarbeit zu einsetzbaren Produkten übergehen können. Dennoch prägen offene Frameworks bereits das Kaufverhalten, indem sie Unternehmen und Cloud-Betreibern einen klareren Weg zu Multi-Vendor-GPU-Fabrics bieten. Langfristig sollte dies den GPU Interconnect Markt weniger abhängig von einer einzigen Architektur in der Scale-up-Schicht machen, auch wenn proprietäre Systeme kurzfristig eine starke Führungsposition behalten.
Analyse der Hemmnisswirkung*
| Hemmnis | (~) % Einfluss auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Wirkung |
|---|---|---|---|
| Begrenzte Verfügbarkeit von Advanced Packaging und Hochgeschwindigkeits-SerDes-Kapazität | -2.1% | Global, konzentriert um fortgeschrittene Fertigungszentren in Taiwan | Mittelfristig (2–4 Jahre) |
| Hohe Gesamtbetriebskosten für Scale-up-GPU-Fabrics | -1.4% | Global, ausgeprägt bei mittelgroßen und souveränen KI-Deployments | Mittelfristig (2–4 Jahre) |
| Proprietäre Ökosystem-Abhängigkeit verlangsamt Multi-Vendor-Einführung | -0.9% | Global | Langfristig (≥ 4 Jahre) |
| Anhaltende thermische und Stromversorgungseinschränkungen auf Rack-Ebene | -0.7% | Global, ausgeprägt bei Brownfield- und Colocation-Deployments | Mittelfristig (2–4 Jahre) |
| Quelle: Mordor Intelligence | |||
Begrenzte Verfügbarkeit von Advanced Packaging und Hochgeschwindigkeits-SerDes-Kapazität
Der GPU Interconnect Markt steht weiterhin vor einer angebotsseitigen Einschränkung, da die Advanced-Packaging-Kapazität in KI-Halbleiterprogrammen knapp bleibt. Epoch AI gab an, dass NVIDIA, Google, AMD und Amazon zusammen im Jahr 2025 mehr als 90 % der globalen CoWoS-Packaging-Kapazität nach Wert ausmachten, was unterstreicht, wie viel der Versorgungsbasis bereits von einer kleinen Gruppe sehr großer Käufer absorbiert wird.[2]Epoch AI, "Advanced Packaging and HBM, Not Logic Dies, Were the Bottlenecks on AI Chip Production in 2025," Epoch AI, epoch.ai Dies ist von Bedeutung, da Interconnect-ASICs, fortschrittliche optische Komponenten und verwandtes Hochgeschwindigkeitssilizium alle um dasselbe Fertigungsökosystem konkurrieren, das die nächste Generation von KI-Hardware unterstützt. Selbst wenn ein Anbieter einen Design-Slot gewinnt, können Lieferungen immer noch hinter den Kundenplänen zurückbleiben, wenn Packaging- und SerDes-Angebot nicht im gleichen Tempo wie die Nachfrage skalieren. Dies führt zu ungleichmäßigem Liefertiming im GPU Interconnect Markt und kann die vollständige Cluster-Bereitstellung verzögern, insbesondere wenn Kunden eine synchronisierte Lieferung von Acceleratoren, Switches, Optiken und unterstützenden Konnektivitätsgeräten benötigen. Das Hemmnis ist am stärksten für Anbieter, die gleichzeitig Advanced Packaging und Hochgeschwindigkeits-Netzwerkinhalte benötigen, da jede Lücke in einem Teil der Kette das gesamte Programm verlangsamen kann.
Hohe Gesamtbetriebskosten für Scale-up-GPU-Fabrics
Die Gesamtbetriebskosten sind ein weiteres klares Hemmnis im GPU Interconnect Markt, da leistungsstarke Scale-up-Fabrics mehr als nur den Switch-ASIC erfordern. Dichte KI-Racks erfordern häufig Flüssigkühlung, spezialisierte Stromversorgung und Anlagenaufrüstungen, was die vollen Betriebskosten weit über einen einfachen Rechenkauf hinaus erhöht. Diese Kostenbelastung ist am bedeutendsten für souveräne Rechenprojekte, Unternehmen und mittelgroße Cloud-Betreiber, die Infrastrukturausgaben nicht über denselben Deployment-Maßstab wie die größten Hyperscaler verteilen können. UALink versucht, einen Teil dieses Problems zu lösen, indem es Leistung auf Rack-Ebene mit einem offeneren Versorgungsmodell verspricht, aber kommerzielle Produkte befinden sich 2026 noch in der Evaluierungsphase. Bis diese Produkte weit verbreitet verfügbar sind, werden viele Käufer im GPU Interconnect Markt weiterhin Leistungsgewinne gegen höhere Kühlungs-, Integrations- und Standortnachrüstungskosten abwägen. Das bedeutet, dass einige Organisationen bei kleineren Cluster-Größen bleiben oder Ethernet-basierte Erweiterungspfade gegenüber den teuersten proprietären Scale-up-Systemen bevorzugen werden.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Interconnect-Fabric / Protokollarchitektur: Proprietäre Führung trifft auf einen breiteren Standardisierungsschub
Proprietäres Accelerator-Scale-up-Interconnect hielt im Jahr 2025 43,59 % des GPU Interconnect Marktes, während offenes Accelerator-Scale-up-Interconnect bis 2031 voraussichtlich die am schnellsten wachsende Fabric-Kategorie sein wird. Diese führende Position resultierte aus der frühen und weitverbreiteten Einführung von NVLink-basierten Rack-Scale-Systemen in Hyperscaler-Umgebungen, wo das Interconnect als zentraler Bestandteil der vollständigen Rechenarchitektur und nicht als optionales Add-on verpackt ist. NVIDIA verstärkte dieses Modell, indem NVLink und NVSwitch eng mit seinem Rack-Scale-Designansatz verknüpft wurden, was proprietäre Scale-up-Links für hochdichte KI-Infrastruktur zentral hielt. Gleichzeitig fügte die UALink-2.0-Version In-Network-Computing-, Chiplet- und Verwaltbarkeitsfunktionen hinzu, was offenen Scale-up-Designs eine glaubwürdigere Roadmap für Multi-Vendor-Cluster gibt. Dies hinterlässt den GPU Interconnect Markt mit einer kurzfristigen Struktur, in der proprietäre Systeme das obere Ende noch dominieren, während offene Frameworks eine stärkere technische Basis für eine spätere Einführung aufbauen.
Natives PCIe-basiertes Interconnect bleibt in der GPU Interconnect Branche für heterogene Inferenz-Server relevant, wo Kostenkontrolle und breite Kompatibilität oft wichtiger sind als die höchstmögliche Bandbreite. CXL-basiertes Interconnect gewinnt auch bei inferenzorientierten Designs an Aufmerksamkeit, da gemeinsame Speicher- und Pooling-Funktionen dazu beitragen können, Speicherengpässe bei gemischten CPU- und GPU-Workloads zu reduzieren. Astera Labs brachte seinen Leo CXL-Speichercontroller 2026 für Microsoft Azure-bezogene Workloads in die Serienproduktion, was zeigt, dass CXL von der Konzept- zur kommerziellen Deployment-Phase in der Cloud-Infrastruktur übergeht. Ethernet-basierte Scale-out-Fabrics gewinnen an Boden, weil sie mit großen installierten Netzwerkökosystemen übereinstimmen, während InfiniBand dort wichtig bleibt, wo eng gekoppelte Trainingsleistung und etabliertes Betriebsverhalten noch Gewicht haben. Der GPU Interconnect Markt bewegt sich daher auf eine gemischtere Fabric-Umgebung zu, auch wenn proprietäre Scale-up-Systeme in den dichtesten KI-Clustern noch die stärkste frühe Position einnehmen.
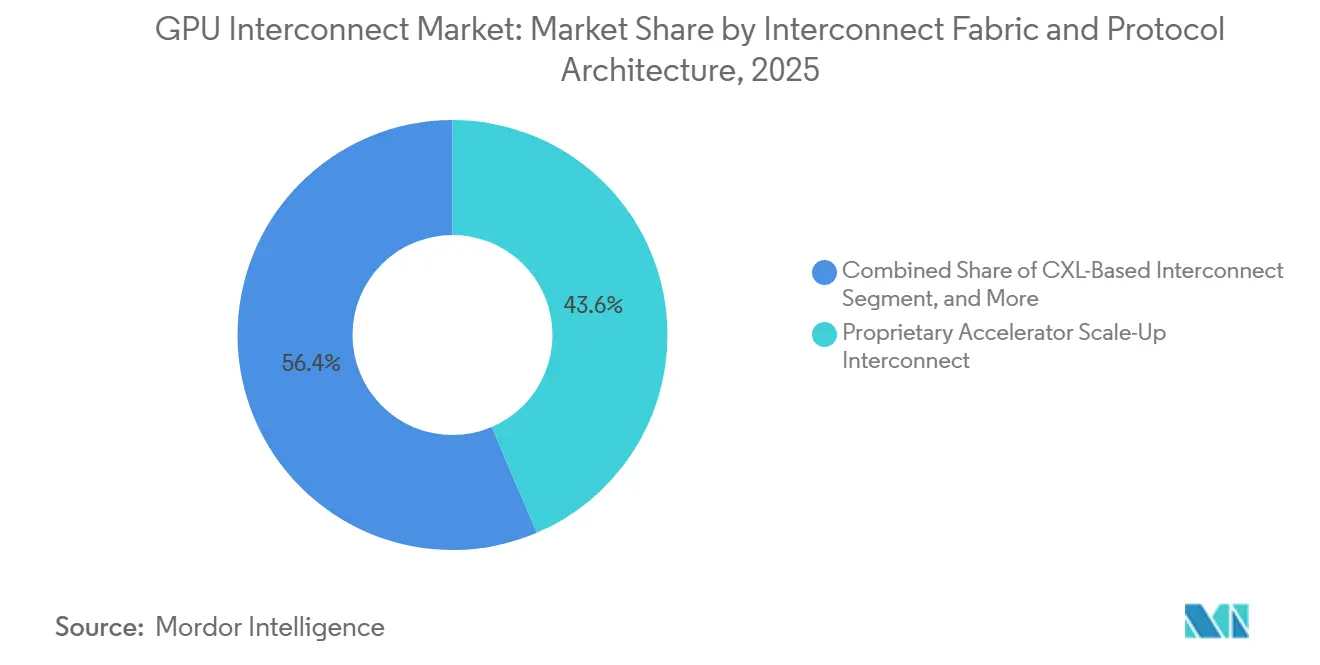
Notiz: Segmentanteile aller einzelnen Segmente sind nach dem Berichtskauf verfügbar


Nach Konnektivitätsdomäne: Scale-up-Umsatz bleibt am größten, während Campus-Links schneller wachsen
Scale-up-Konnektivität entfiel im Jahr 2025 auf 49,32 % der Marktgröße des GPU Interconnect Marktes, während Inter-Pod- und Campus-KI-Konnektivität bis 2031 voraussichtlich schneller wächst als die anderen Konnektivitätsdomänen. Scale-up behielt die größte Umsatzposition, da dichte Rack-Scale-Systeme erhebliche Fabric-Inhalte direkt in jede eingesetzte Einheit einbetten und dadurch den Interconnect-Wert pro Installation erhöhen. NVIDIA zentrierte diesen Ansatz im GB300 NVL72, wo das Rack selbst auf hochbandbreitiger interner Kommunikation aufgebaut ist und nicht auf einer konventionelleren losen Server-Anordnung. Diese Struktur unterstützt eine große Stückliste für Switch-Trays, interne Links und zugehörige Konnektivitätshardware, was Scale-up im GPU Interconnect Markt umsatzzentral hält. Es hilft auch zu erklären, warum Käufer, die sich für eng integrierte KI-Systeme entscheiden, oft gleichzeitig mit der Wahl der Accelerator-Plattform eine Interconnect-Architektur festlegen.
Inter-Pod- und Campus-KI-Konnektivität wächst schneller, weil viele KI-Deployments nicht mehr alle erforderlichen Rechenkapazitäten in einem Raum oder einem Gebäude unterbringen können. Da Betreiber GPU-Kapazitäten über größere Campusse verteilen, um Strom-, Kühlungs- und Platzeinschränkungen zu begegnen, benötigen sie robuste optische Konnektivität zwischen Pods, Clustern und Einrichtungen. Scale-out-Konnektivität bleibt innerhalb jedes Clusters wichtig, da GPUs weiterhin vorhersehbare Niedriglatenz-Kommunikation über Racks hinweg benötigen, während Intra-Node-Konnektivität in gemischten CPU- und GPU-Servern, die auf PCIe- oder CXL-Anbindung angewiesen sind, weiterhin von Bedeutung ist. Betreiber, die nur den GPU-zu-GPU-Pfad verbessern, können immer noch auf Engpässe stoßen, wenn der CPU-zu-GPU-Pfad eingeschränkt bleibt, was bedeutet, dass die Leistungsoptimierung mehrere Datenverkehrsschichten gleichzeitig abdecken muss. Dies hält den GPU Interconnect Markt über Konnektivitätstypen hinweg breit, wobei verschiedene Domänen je nach Clustergröße, Workload-Design und physischem Rechenzentrumlayout an Wert gewinnen.
Nach Komponente: Switches halten den größten Umsatzpool, während Optiken am schnellsten wachsen
Optische Interconnects werden voraussichtlich von 2026 bis 2031 mit einer CAGR von 16,58 % wachsen, während Switches im Jahr 2025 39,87 % des GPU Interconnect Marktes hielten. Das optische Wachstum wird durch den Übergang zu Co-Packaged Optics und Silizium-Photonik angetrieben, insbesondere da die Clusterdichte Betreiber dazu veranlasst, den Stromverbrauch zu senken und die Signalqualität über anspruchsvollere Links zu verbessern. NVIDIA gab an, dass das Quantum-X800 InfiniBand CPO Anfang 2026 verfügbar wurde und Spectrum-X Ethernet Photonics im Mai 2026 in Produktion ging, was einen bedeutenden kommerziellen Schritt für optisches Switching in der KI-Infrastruktur markiert. Diese Verlagerung ist wichtig, da optische Skalierung größere, energieeffizientere Fabrics ermöglicht, was zunehmend wichtiger wird, da der GPU Interconnect Markt größere KI-Fabriken statt isolierter Accelerator-Racks bedient. Switches hielten weiterhin den größten Umsatzanteil, da sie sowohl für die Konnektivität auf Rack- als auch auf Cluster-Ebene zentral bleiben und jedes dichte KI-Deployment erhebliche Switching-Kapazität benötigt.
Die Anbieter-Pipeline zeigt auch, wie schnell sich Komponenten-Roadmaps rund um den GPU Interconnect Markt weiterentwickeln. Arista stellte im Juni 2026 die 7060XE7-Serie mit 64 Ports bei 1,6T pro Port und bis zu 102,4 Tb/s aggregierter Bandbreite vor, was einen raschen Übergang über 800G-Vernetzung in KI-Rechenzentren hinaus signalisiert. Netzwerkschnittstellenkarten und DPUs gewinnen ebenfalls an Bedeutung, da dichte KI-Systeme eine stärkere Nord-Süd-Datenverkehrsabwicklung neben interner Fabric-Bandbreite benötigen, und NVIDIA positionierte ConnectX-8 bei 800 Gb/s pro Port für GB300-basierte Plattformen. Retimer und Konnektivitäts-ICs bleiben wichtig, da höhere Lane-Geschwindigkeiten die Signalintegritätsherausforderungen über Platinen, Kabel und Backplanes hinweg erhöhen. Astera Labs meldete USD 308,4 Millionen Umsatz im ersten Quartal 2026 und erweiterte seine Präsenz in diesen Kategorien. Kupferkabelbaugruppen bedienen weiterhin Kurzstreckenverbindungen, wo Kosten und betriebliche Vertrautheit wichtig sind, aber der GPU Interconnect Markt lenkt stetig mehr Wachstum auf optische Systeme und die Switch-Plattformen, die diese unterstützen.
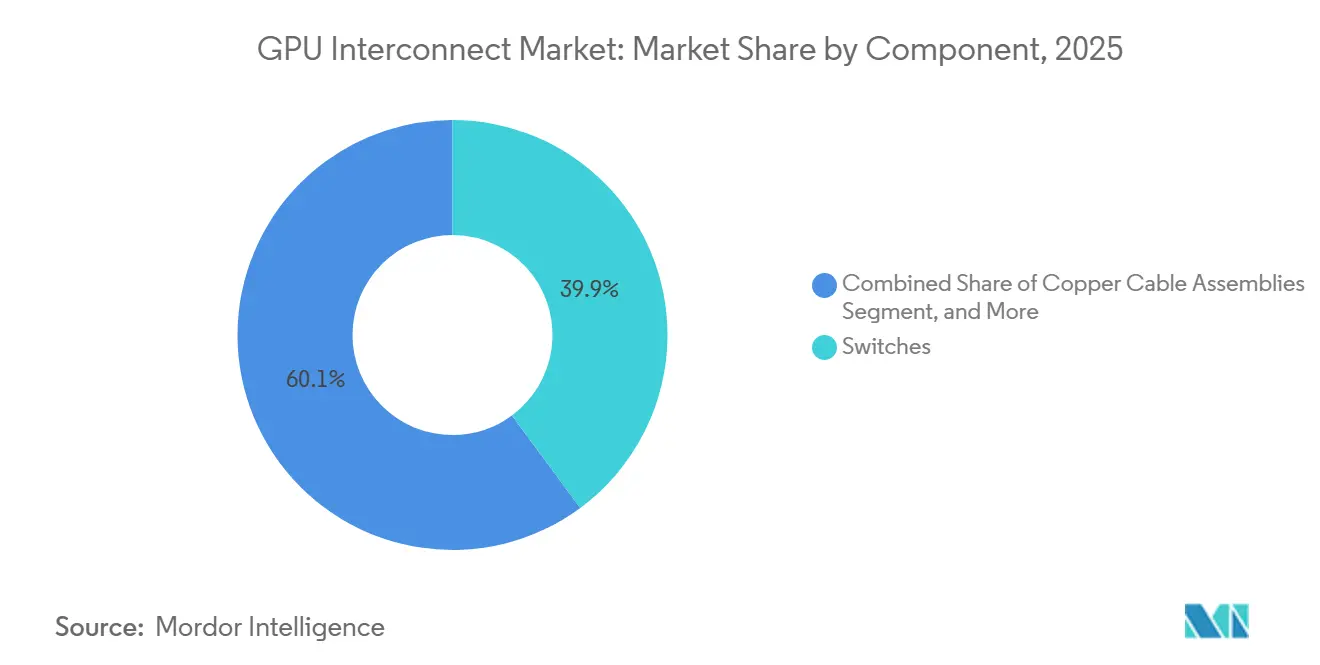
Notiz: Segmentanteile aller einzelnen Segmente sind nach dem Berichtskauf verfügbar
Nach Endnutzer: Hyperscaler führen die aktuelle Nachfrage an, während Neoclouds schnell expandieren
Hyperscaler und Tier-1-Cloud-Dienstleister entfielen im Jahr 2025 auf 68,84 % des GPU Interconnect Marktes, während KI-native Cloud-Anbieter und Neoclouds bis 2031 voraussichtlich am schnellsten wachsen. Diese Dominanz spiegelt das Ausmaß wider, in dem Microsoft, Amazon, Google und Meta Infrastruktur sowohl für KI-Training als auch für Inferenz einsetzen. Ihre kombinierten Investitionsausgabenverpflichtungen für 2026 erreichten USD 725 Milliarden, wobei ein großer Teil auf KI-Rechenleistung und Vernetzung ausgerichtet ist, was dem GPU Interconnect Markt seine tiefste und vorhersehbarste Ausgabenbasis bietet. Diese Kunden übernehmen auch früh neue Architekturen, weshalb sie bei der Einführung von Rack-Scale-Systemen, hochbandbreitigen Fabrics und fortschrittlichem optischen Switching zentral waren. Selbst wenn einige Hyperscaler Teile ihres Netzwerk-Stacks intern entwerfen, prägt ihr Beschaffungsmaßstab weiterhin Produkt-Roadmaps im gesamten Anbieterökosystem.
KI-native Cloud-Anbieter und Neoclouds expandieren schnell, weil sie den Zugang zu neueren Fabrics als direktes Verkaufsargument für Unternehmens- und Forschungskunden nutzen. NVIDIA gab an, dass CoreWeave, Lambda und Oracle Cloud Infrastructure zu den ersten Anwendern von Spectrum-X Ethernet Photonics gehörten, was zeigt, wie neuere Cloud-Plattformen Netzwerkleistung und Energieeffizienz nutzen, um ihre Dienste zu differenzieren. Staatliche und souveräne Rechenprogramme erweitern ebenfalls die Käuferbasis, und Kanada startete im April 2026 sein KI-Souveränes-Recheninfrastruktur-Programm mit CAD 2,4 Milliarden (USD 1,76 Milliarden) an Bundesunterstützung. Große Unternehmen, akademische Rechenzentren und telekommunikationsbezogene Deployments fügen weitere Nachfrage hinzu, obwohl sie oft kostenorientierte Scale-out-Fabrics gegenüber den teuersten proprietären Scale-up-Systemen bevorzugen. Diese sich verbreiternde Kundenmischung gibt dem Grafikprozessor (GPU) Interconnect Markt eine größere Nachfragebasis als in früheren Accelerator-Zyklen, als Hyperscaler-Käufe einen viel größeren Anteil der Gesamtaktivität ausmachten.
Geografische Analyse
Nordamerika hielt im Jahr 2025 56,62 % des GPU Interconnect Marktanteils und lag damit weit vor allen anderen regionalen Segmenten. Die Region profitiert von konzentrierten Hyperscaler-Investitionen in den Vereinigten Staaten und davon, dass viele der Unternehmen, die den GPU Interconnect Markt prägen, darunter NVIDIA, Broadcom, Arista Networks, Astera Labs, Credo Technology, Coherent und Lumentum, dort ihren Hauptsitz haben oder bedeutende kommerzielle Aktivitäten betreiben. Die Region bleibt auch die größte frühe Einführungsbasis für KI-Infrastruktur auf Rack-Ebene, was bedeutet, dass Produkteinführungen oft in nordamerikanische Deployments münden, bevor breitere globale Rollouts erfolgen. Große Cloud-Kapitalausgaben verstärken diesen Vorsprung, wobei die größten Betreiber wichtige 2026-Budgets auf KI-Rechenleistung und Netzwerkinfrastruktur ausrichten. Kanada trägt ebenfalls dazu bei, die regionale Nachfrage durch öffentliche Recheninvestitionen zu verbreitern, und sein KI-Souveränes-Recheninfrastruktur-Programm fügte im April 2026 CAD 2,4 Milliarden (USD 1,76 Milliarden) an Bundesunterstützung hinzu.[3]Regierung von Kanada, "Kanada startet nationale Initiative zum Aufbau großer KI-Supercomputing-Kapazitäten," Regierung von Kanada, canada.ca
Asien-Pazifik wird voraussichtlich bis 2031 mit einer CAGR von 16,44 % expandieren und ist damit die am schnellsten wachsende Geografie im GPU Interconnect Markt. Das Wachstum in der Region wird durch souveräne KI-Ambitionen, lokale Cloud-Ausbauten und den Bedarf an inländischen Technologie-Stacks in Ländern unterstützt, die eine größere Kontrolle über die Recheninfrastruktur anstreben. Die Region ist auch deshalb bedeutsam, weil mehrere große Technologiegruppen aus Asien-Pazifik Teil des UALink-Konsortiums sind, was darauf hindeutet, dass offene Scale-up-Standards echtes Interesse von großen Plattformunternehmen und Hardware-Teilnehmern wecken. Dieser regionale Schub wird voraussichtlich sowohl lokale Fertigungsökosysteme als auch die Nachfrage nach alternativen Interconnect-Ansätzen unterstützen, da Kunden Kosten, Versorgungszugang und Technologiekontrolle abwägen. Für den GPU Interconnect Markt wird Asien-Pazifik nicht nur als Nachfragezentrum, sondern auch als Region wichtig, die zukünftige Standardseinführung und Komponentenbeschaffungsmuster beeinflussen kann.
Europa ist heute kleiner, bleibt aber strategisch wichtig, da Datensouveränitätsregeln und KI-Governance-Rahmen weiterhin die Nachfrage nach regionaler Recheninfrastruktur unterstützen. Das Vereinigte Königreich gab 2026 bekannt, dass es im Rahmen seines KI-Hardware-Plans GBP 1,1 Milliarden (USD 1,4 Milliarden) bereitstellen wird, darunter GBP 750 Millionen (USD 1,02 Milliarden) für einen nationalen KI-Supercomputer, der bis 2030 eingesetzt werden soll. Südamerika befindet sich noch früher in der Einführungsphase, wobei die Aktivitäten stärker mit der Hyperscaler-Cloud-Expansion und dem Forschungsrechnen als mit großen inländischen Fabric-Programmen verbunden sind. Die Nachfrage im Nahen Osten und in Afrika ist in absoluten Zahlen noch geringer, aber das Interesse an souveränem Rechnen nimmt zu, was dem Grafikprozessor (GPU) Interconnect Markt einen weiteren langfristigen regionalen Wachstumspfad über den aktuellen Hyperscaler-Kern hinaus bietet.

Wettbewerbslandschaft
Der GPU Interconnect Markt ist mäßig konzentriert und weist eine gespaltene Struktur auf, mit proprietären Scale-up-Links bei einer kleinen Anzahl von Anbietern, während Scale-out-Vernetzung über eine breitere Anbietergruppe hinweg umkämpft ist. NVIDIA hält die stärkste Position bei proprietärer Scale-up-Konnektivität, da NVLink und NVSwitch direkt in sein Rack-Scale-Systemdesign eingebettet sind, was ihm einen starken Vorteil bei den dichtesten KI-Deployments verschafft. Im Scale-out-Netzwerkbereich ist das Feld breiter, mit Broadcom, Marvell, Cisco und Arista Networks, die über Ethernet-Switching, optische Konnektivität und verwandte KI-Netzwerkschichten konkurrieren.[4]Arista Networks, "Arista stellt nächste Generation des 1,6-Terabit-Portfolios für KI-Fabrics vor," Arista Networks, arista.com Offene Standardsgruppen prägen auch den zukünftigen Wettbewerb, indem sie Kunden einen Weg zu Multi-Vendor-Fabrics sowohl in Scale-up- als auch in Scale-out-Umgebungen bieten. Das bedeutet, dass der GPU Interconnect Markt an der Spitze konzentriert ist, aber in den breiteren Netzwerkschichten, die die Cluster-zu-Cluster-Skalierung unterstützen, offener und wettbewerbsfähiger ist.
Mehrere Unternehmensaktionen im Jahr 2026 zeigen, wie sich die Wettbewerbslandschaft im GPU Interconnect Markt entwickelt. NVIDIA kündigte strategische Investitionen von jeweils USD 2 Milliarden in Lumentum und Coherent sowie große Kaufverpflichtungen an, was einen direkten Schritt zur Sicherung der vorgelagerten optischen Versorgung für seine Co-Packaged-Optics-Roadmap zeigt. Arista stellte dann die 7060XE7-Serie für 1,6T-KI-Fabrics vor, was signalisiert, dass Ethernet-zentrierte Wettbewerber schnell in höhergeschwindigkeitiges KI-Switching einsteigen, anstatt auf einen langsameren Migrationszyklus zu warten. Astera Labs erweiterte im Juni 2026 seine Taiwan-Aktivitäten, um die KI-Plattformvalidierung und lokale Integrationsarbeit zu vertiefen, was widerspiegelt, wie Anbieter näher an die Fertigungs- und Systemmontage-Basis rücken, die den GPU Interconnect Markt unterstützt. Die Konsortiumsteilnahme ist auch zu einem strategischen Instrument geworden, da Anbieter versuchen, zukünftige Socket-Entscheidungen zu beeinflussen, bevor offenes Scale-up-Silizium die breite Produktion erreicht. Zusammen zeigen diese Schritte, dass der Wettbewerb nun auf Versorgungszugang, Ökosystemposition und Inhaltserweiterung pro Accelerator ausgerichtet ist und nicht mehr auf isolierte Komponenteneinführungen allein.
Im GPU Interconnect Markt gibt es noch offenen Raum für softwaredefinierten Fabric-Management, heterogene Cluster-Steuerung und kommerziell bewährtes UALink-konformes Switch-Silizium. The Register berichtete, dass UALink-Evaluierungshardware in der zweiten Hälfte des Jahres 2026 erwartet wird und kommerzielles Silizium später folgen wird, was darauf hindeutet, dass dem Markt noch ein vollständig etabliertes offenes Scale-up-Produktset in großem Volumen fehlt. Diese Lücke gibt Platzhirschen mehr Zeit, Kundenbeziehungen zu vertiefen, schafft aber auch Raum für Herausforderer, die glaubwürdige offene Alternativen liefern können, bevor die Käuferfrustration über Abhängigkeit wächst. Oracle bleibt trotz aktiver Beteiligung an GPU-Cloud-Deployments in diesem Kontext primär ein Endnutzer und kein angebotsseitiger Designer von Interconnect-Hardware, sodass das Wettbewerbsfeld weiterhin hauptsächlich von Netzwerk-, Halbleiter- und optischen Anbietern definiert wird.
Branchenführer im GPU Interconnect Markt
NVIDIA Corporation
Broadcom Inc.
Marvell Technology, Inc.
Advanced Micro Devices, Inc.
Astera Labs, Inc.
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Aktuelle Branchenentwicklungen
- Juni 2026: Arista Networks stellte die 7060XE7-Serie vor, ein nächste Generation 1,6T-KI-Netzwerkportfolio, das auf Broadcom Tomahawk 6-Silizium aufgebaut ist und 64 Ports bei 1,6T pro Port sowie eine aggregierte Switching-Kapazität von 102,4 Tb/s unterstützt, in sowohl luftgekühlten als auch flüssiggekühlten Konfigurationen. Luftgekühlte Varianten sind für das vierte Quartal 2026 und flüssiggekühlte Varianten für das erste Quartal 2027 geplant, was das Portfolio sowohl für Scale-up- als auch für Scale-out-KI-Fabric-Deployments positioniert.
- Juni 2026: Astera Labs erweiterte seine Taiwan-Aktivitäten, richtete ein erweitertes Cloud-Scale-Interoperabilitätslabor ein und vergrößerte die Ingenieurspräsenz, um die Integration mit KI-Plattformanbietern und taiwanesischen Systemherstellern zu vertiefen, mit dem Ziel der KI-Cluster-Validierung für die GB300-Generation.
- Mai 2026: NVIDIA gab bekannt, dass Spectrum-X Ethernet Photonics nun auf dem Taiwan GTC, Computex 2026, in Produktion ist, und bezeichnete es als den weltweit ersten CPO-Ethernet-Switch, der auf 200G-SerDes-Technologie mit bis zu 409,6 Tb/s aggregierter Bandbreite aufgebaut ist. CoreWeave, Lambda und Oracle Cloud Infrastructure gehörten zu den ersten Anwendern, und eine breite Verfügbarkeit ist für die zweite Hälfte des Jahres 2026 geplant.
- April 2026: Das UALink-Konsortium veröffentlichte vier Spezifikationen in seiner Version 2.0 und führte In-Network-Computing-, Chiplet-Definitions- und Verwaltbarkeits-Frameworks für Multi-Workload-KI-Deployments ein, wobei nun 115 oder mehr Mitgliedsunternehmen den Standard mitgestalten.


Umfang des globalen GPU Interconnect Marktberichts
Der GPU Interconnect Markt umfasst Hardware, Software, Protokolle und Netzwerktechnologien, die eine Hochgeschwindigkeitskommunikation und den Datenaustausch zwischen Grafikprozessoren (GPUs), Acceleratoren, CPUs, Speicherressourcen und verteilter Recheninfrastruktur ermöglichen. GPU Interconnect-Lösungen sind darauf ausgelegt, die Bandbreiten-, Latenz-, Skalierbarkeits- und Effizienzanforderungen moderner künstlicher Intelligenz (KI), maschinellen Lernens, Hochleistungsrechnens (HPC), Cloud-Computings und datenintensiver Workloads zu erfüllen, indem sie eine nahtlose Kommunikation in zunehmend großen und komplexen Rechenumgebungen ermöglichen.
Der GPU Interconnect Marktbericht ist segmentiert nach Interconnect-Architektur/Protokollarchitektur (natives PCIe-basiertes Interconnect, CXL-basiertes Interconnect, proprietäres Accelerator-Scale-up-Interconnect, offenes Accelerator-Scale-up-Interconnect, InfiniBand-basiertes Scale-out-Interconnect und Ethernet-basiertes Scale-out-Interconnect), Konnektivitätsdomäne (Intra-Node/Intra-Server-Konnektivität, Scale-up-Konnektivität, Scale-out-Konnektivität und Inter-Pod/Campus-KI-Konnektivität), Komponente (Switches, Netzwerkschnittstellenkarten und DPUs, Retimer, Redriver und Konnektivitäts-ICs, Kupferkabelbaugruppen und optische Interconnects), Endnutzer (Hyperscaler und Tier-1-Cloud-Dienstleister, KI-native Cloud-Anbieter und Neoclouds, große Unternehmen und private KI-Infrastrukturbetreiber, Regierung, souveräne KI-Programme und nationale Forschungslabore, akademische und HPC-Forschungseinrichtungen sowie Telekommunikation, Edge-Cloud und Managed-Service-Anbieter) und Geografie (Nordamerika, Europa, Asien-Pazifik, Südamerika sowie Naher Osten und Afrika). Die Marktprognosen werden in Wertangaben (USD) bereitgestellt.
| Natives PCIe-basiertes Interconnect |
| CXL-basiertes Interconnect |
| Proprietäres Accelerator-Scale-up-Interconnect |
| Offenes Accelerator-Scale-up-Interconnect |
| InfiniBand-basiertes Scale-out-Interconnect |
| Ethernet-basiertes Scale-out-Interconnect |
| Intra-Node/Intra-Server-Konnektivität |
| Scale-up-Konnektivität |
| Scale-out-Konnektivität |
| Inter-Pod/Campus-KI-Konnektivität |
| Switches |
| Netzwerkschnittstellenkarten und DPUs |
| Retimer, Redriver und Konnektivitäts-ICs |
| Kupferkabelbaugruppen |
| Optische Interconnects |
| Hyperscaler und Tier-1-Cloud-Dienstleister |
| KI-native Cloud-Anbieter und Neoclouds |
| Große Unternehmen und private KI-Infrastrukturbetreiber |
| Regierung, souveräne KI-Programme und nationale Forschungslabore |
| Akademische und HPC-Forschungseinrichtungen |
| Telekommunikation, Edge-Cloud und Managed-Service-Anbieter |
| Nordamerika | Vereinigte Staaten |
| Kanada | |
| Mexiko | |
| Europa | Deutschland |
| Vereinigtes Königreich | |
| Frankreich | |
| Italien | |
| Übriges Europa | |
| Asien-Pazifik | China |
| Japan | |
| Südkorea | |
| Indien | |
| Südostasien | |
| Übriges Asien-Pazifik | |
| Südamerika | |
| Naher Osten und Afrika |
| Nach Interconnect-Fabric/Protokollarchitektur | Natives PCIe-basiertes Interconnect | |
| CXL-basiertes Interconnect | ||
| Proprietäres Accelerator-Scale-up-Interconnect | ||
| Offenes Accelerator-Scale-up-Interconnect | ||
| InfiniBand-basiertes Scale-out-Interconnect | ||
| Ethernet-basiertes Scale-out-Interconnect | ||
| Nach Konnektivitätsdomäne | Intra-Node/Intra-Server-Konnektivität | |
| Scale-up-Konnektivität | ||
| Scale-out-Konnektivität | ||
| Inter-Pod/Campus-KI-Konnektivität | ||
| Nach Komponente | Switches | |
| Netzwerkschnittstellenkarten und DPUs | ||
| Retimer, Redriver und Konnektivitäts-ICs | ||
| Kupferkabelbaugruppen | ||
| Optische Interconnects | ||
| Nach Endnutzer | Hyperscaler und Tier-1-Cloud-Dienstleister | |
| KI-native Cloud-Anbieter und Neoclouds | ||
| Große Unternehmen und private KI-Infrastrukturbetreiber | ||
| Regierung, souveräne KI-Programme und nationale Forschungslabore | ||
| Akademische und HPC-Forschungseinrichtungen | ||
| Telekommunikation, Edge-Cloud und Managed-Service-Anbieter | ||
| Nach Geografie | Nordamerika | Vereinigte Staaten |
| Kanada | ||
| Mexiko | ||
| Europa | Deutschland | |
| Vereinigtes Königreich | ||
| Frankreich | ||
| Italien | ||
| Übriges Europa | ||
| Asien-Pazifik | China | |
| Japan | ||
| Südkorea | ||
| Indien | ||
| Südostasien | ||
| Übriges Asien-Pazifik | ||
| Südamerika | ||
| Naher Osten und Afrika | ||


Im Bericht beantwortete Schlüsselfragen
Wie groß ist der GPU Interconnect Markt derzeit?
Der GPU Interconnect Markt erreichte im Jahr 2026 USD 89,43 Milliarden und wird voraussichtlich bis 2031 bei einer CAGR von 15,62 % USD 184,8 Milliarden erreichen.
Welches Interconnect-Fabric führt den aktuellen Umsatz an?
Proprietäres Accelerator-Scale-up-Interconnect führte im Jahr 2025 mit einem Anteil von 43,59 %, unterstützt durch frühe Rack-Scale-Deployments rund um NVLink-basierte Architekturen.
Welche Konnektivitätsdomäne expandiert am schnellsten?
Scale-up-Konnektivität hielt im Jahr 2025 den größten Anteil, aber Inter-Pod- und Campus-KI-Konnektivität wird bis 2031 voraussichtlich am schnellsten wachsen, da sich Cluster über größere Campusse ausbreiten.
Warum gewinnen optische Interconnects in GPU-Clustern an Bedeutung?
Optische Interconnects werden voraussichtlich mit einer CAGR von 16,58 % wachsen, da dichtere KI-Systeme bessere Energieeffizienz, Signalintegrität und Hochbandbreiten-Switching benötigen.
Wer kauft heute am meisten GPU Interconnect-Hardware?
Hyperscaler und Tier-1-Cloud-Dienstleister führten die Nachfrage im Jahr 2025 mit einem Anteil von 68,84 % an, angetrieben durch sehr große KI-Training- und Inferenzinfrastrukturprogramme.
Welche Region zeigt die stärksten Wachstumsaussichten?
Nordamerika führte im Jahr 2025 mit einem Anteil von 56,62 %, während Asien-Pazifik bis 2031 voraussichtlich das schnellste Wachstum mit einer CAGR von 16,44 % verzeichnen wird.
Seite zuletzt aktualisiert am:




