Taille et part du marché des interconnexions GPU
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2020 - 2031 |
|---|---|
| Taille du Marché (2026) | 89.43 Milliards de dollars |
| Taille du Marché (2031) | 184.80 Milliards de dollars |
| Taux de croissance (2026 - 2031) | 15.62% CAGR |
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Amérique du Nord |
| Concentration du Marché | Moyen |
Acteurs majeurs *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. | |
Analyse du marché des interconnexions GPU par Mordor Intelligence
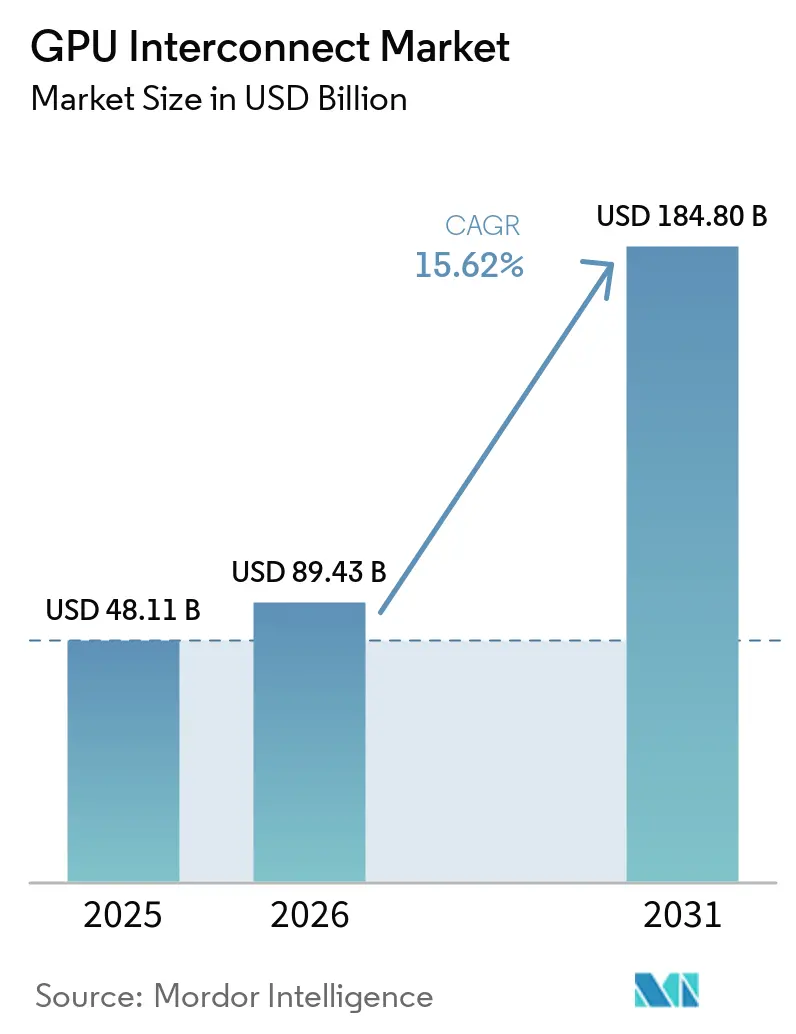
La taille du marché des interconnexions GPU devrait passer de 48,11 milliards USD en 2025 à 89,43 milliards USD en 2026 et atteindre 184,80 milliards USD d'ici 2031, avec un CAGR de 15,62 % sur la période 2026-2031. Les dépenses des hyperscalers et l'évolution vers des systèmes d'IA à l'échelle du rack ont fait de la conception des interconnexions une décision d'infrastructure centrale plutôt qu'un choix de composant serveur secondaire. Les acheteurs considèrent désormais la bande passante, la latence et l'efficacité du fabric comme des moteurs directs de la production GPU utilisable, ce qui raccourcit les cycles de renouvellement sur le marché des interconnexions GPU. La mise en réseau optique, la photonique sur silicium et les conceptions de commutateurs plus denses améliorent également l'efficacité énergétique et spatiale, élargissant ainsi l'intérêt commercial pour les clusters d'IA plus importants. La concurrence reste concentrée dans les liens propriétaires de montée en charge, tandis que les standards ouverts et les conceptions basées sur Ethernet offrent aux clients plus de flexibilité dans les déploiements de montée en puissance. Les opportunités les plus importantes sur le marché des interconnexions GPU émergent, portées par l'expansion du cloud, les programmes de calcul souverain et les déploiements d'IA en entreprise, qui nécessitent tous des fabrics plus performants avec un risque d'intégration réduit et une meilleure économie d'exploitation.
Points clés du rapport
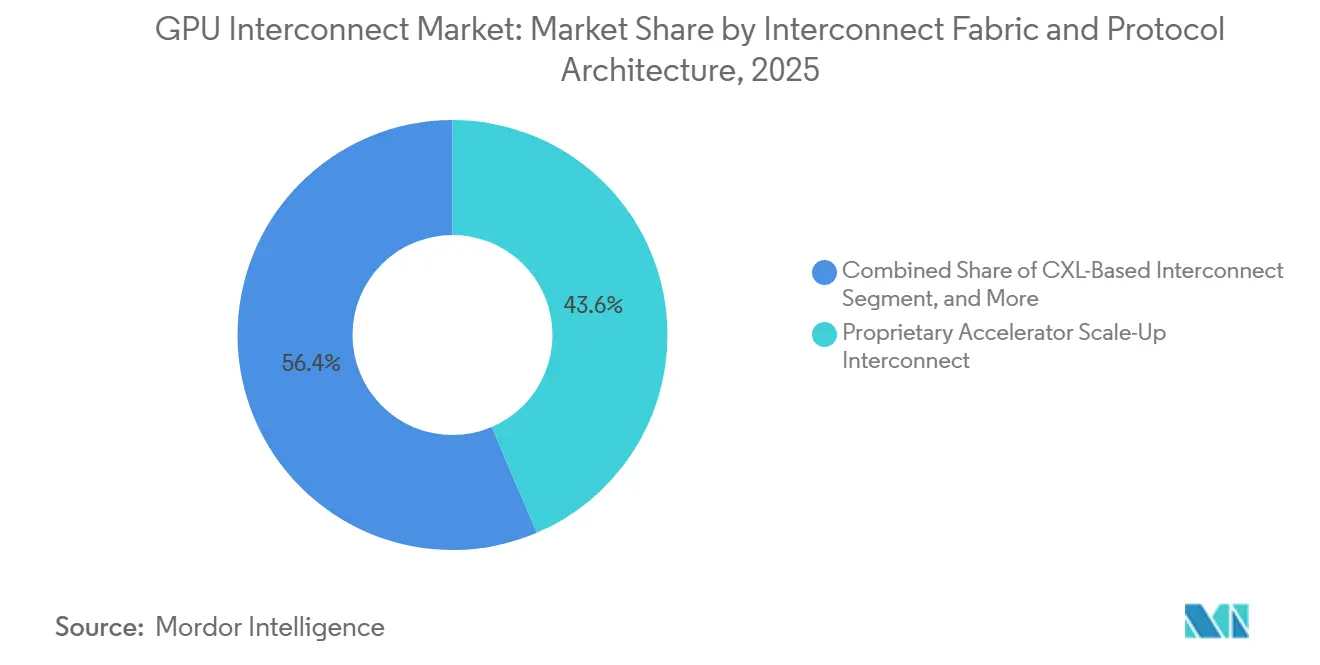
- Par fabric d'interconnexion, l'interconnexion propriétaire de montée en charge des accélérateurs détenait 43,59 % de la part du marché des interconnexions GPU en 2025, tandis que l'interconnexion ouverte de montée en charge des accélérateurs devrait rester le segment de fabric à la croissance la plus rapide jusqu'en 2031.
- Par domaine de connectivité, la connectivité de montée en charge représentait 49,32 % de la taille du marché des interconnexions d'unités de traitement graphique (GPU) en 2025, tandis que la connectivité inter-pod et campus IA devrait connaître la croissance la plus rapide jusqu'en 2031.
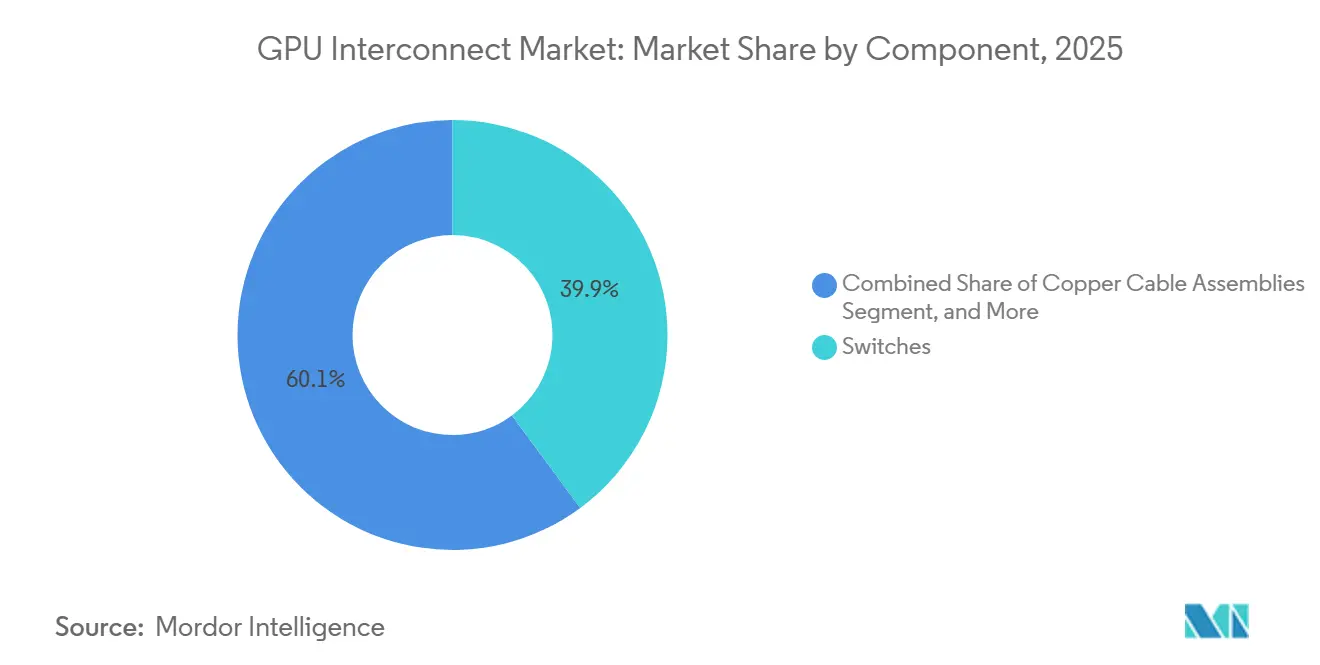
- Par composant, les commutateurs détenaient 39,87 % de la part du marché des interconnexions GPU en 2025, tandis que les interconnexions optiques devraient croître à un CAGR de 16,58 % jusqu'en 2031.
- Par utilisateur final, les hyperscalers et les fournisseurs de services cloud de niveau 1 ont capturé 68,84 % de la part en 2025, tandis que les fournisseurs de cloud natifs IA et les neoclouds devraient enregistrer la croissance la plus rapide jusqu'en 2031.
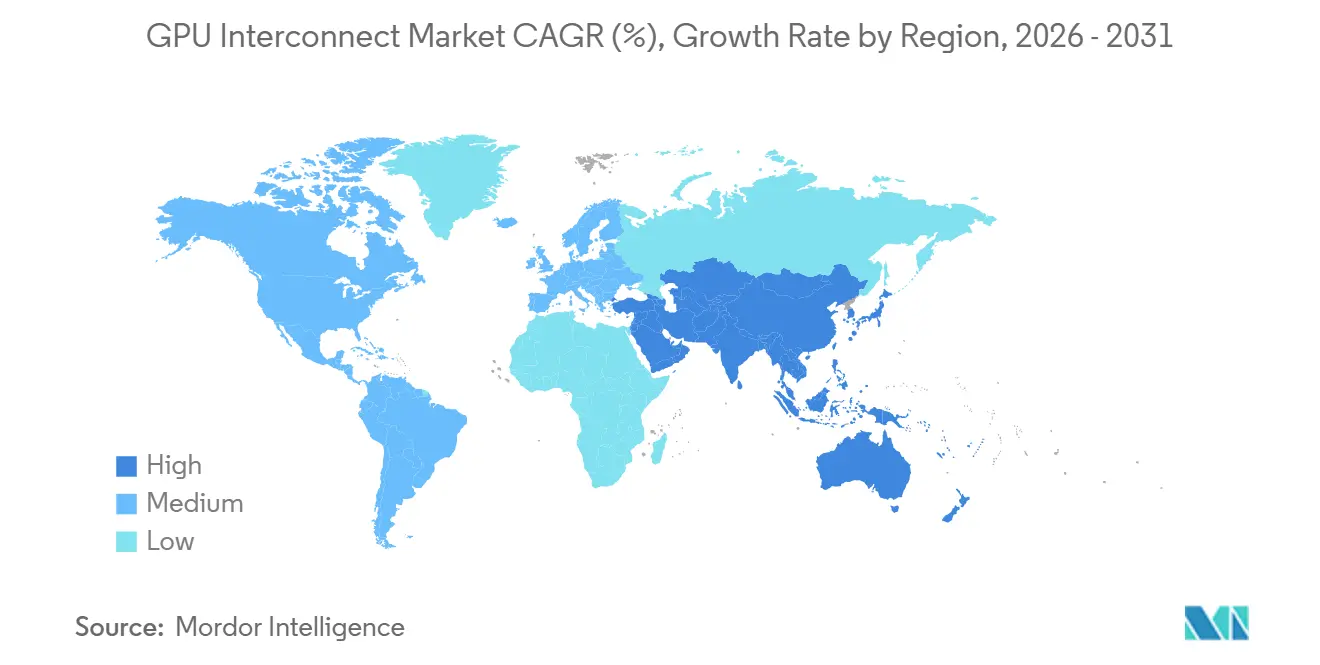
- Par géographie, l'Amérique du Nord détenait 56,62 % de la part du marché des interconnexions GPU en 2025, tandis que l'Asie-Pacifique devrait croître à un CAGR de 16,44 % jusqu'en 2031.
Note : La taille du marché et les prévisions figurant dans ce rapport sont générées à l'aide du cadre d'estimation exclusif de Mordor Intelligence, mis à jour avec les dernières données et informations disponibles en janvier 2026.
Tendances et perspectives mondiales du marché des interconnexions GPU
Analyse de l'impact des moteurs*
| Moteur | (~) % d'impact sur les prévisions de CAGR | Pertinence géographique | Horizon temporel de l'impact |
|---|---|---|---|
| Demande croissante de bande passante pour les clusters d'IA générative | +4.5% | Mondial, concentré en Amérique du Nord et en Asie-Pacifique | Court terme (≤ 2 ans) |
| Passage des goulots d'étranglement de calcul aux goulots d'étranglement d'interconnexion | +3.2% | Mondial | Moyen terme (2-4 ans) |
| Expansion des systèmes GPU à l'échelle du rack dans les centres de données hyperscale | +2.8% | Amérique du Nord et Asie-Pacifique en cœur, avec des retombées vers l'Europe | Moyen terme (2-4 ans) |
| Croissance des standards d'interconnexion ouverts pour réduire la dépendance aux fournisseurs | +2.1% | Mondial, avec des gains précoces en Amérique du Nord et en Europe | Moyen terme (2-4 ans) |
| Transition vers l'optique co-packagée et la photonique sur silicium | +1.6% | Mondial, avec une adoption précoce en Amérique du Nord et à Taïwan | Long terme (≥ 4 ans) |
| Demande de co-conception CPU-GPU dans l'infrastructure d'IA en entreprise | +0.8% | Amérique du Nord et Europe | Moyen terme (2-4 ans) |
| Source: Mordor Intelligence | |||
Demande croissante de bande passante pour les clusters d'IA générative
L'entraînement de l'IA générative continue de faire progresser le marché des interconnexions GPU, car les tâches de communication collective saturent le fabric réseau bien plus vite que le calcul brut ne peut compenser. NVIDIA a indiqué que sa plateforme GB300 NVL72 délivre 130 To/s de bande passante agrégée intra-rack sur 72 GPU Blackwell Ultra, et que NVLink 6 pour Rubin portera la bande passante par GPU à 3,6 To/s, soulignant la rapidité avec laquelle les exigences en bande passante augmentent à mesure que la densité des clusters s'accroît.[1]NVIDIA Corporation, "NVIDIA GB300 NVL72 Conçu pour la performance et l'efficacité du raisonnement IA," NVIDIA, nvidia.com À mesure que la taille des modèles augmente, le trafic est-ouest au sein du cluster devient trop coûteux pour être ignoré, déplaçant les dépenses d'un poste serveur vers un budget de fabric réseau dédié. Ce changement raccourcit les cycles de remplacement sur le marché des interconnexions GPU, car de nombreux opérateurs de pointe alignent désormais les mises à niveau du fabric plus étroitement avec les générations d'accélérateurs qu'avec les habitudes traditionnelles de renouvellement réseau. Cela augmente également la valeur commerciale des conceptions capables de maintenir des milliers de GPU occupés simultanément, car tout déficit de bande passante peut réduire l'utilisation effective et affaiblir les rendements sur les grands investissements en calcul. Il en résulte un marché où la croissance de la demande est portée non seulement par davantage de GPU, mais aussi par la nécessité de les connecter avec des fabrics beaucoup plus performants.
Passage des goulots d'étranglement de calcul aux goulots d'étranglement d'interconnexion
Le marché des interconnexions GPU bénéficie également d'un déplacement des problèmes de performance au sein des grands clusters d'IA. NVIDIA a positionné Spectrum-X autour de la planification tenant compte de la topologie, de l'équilibrage de charge et du réglage réseau pour les grands clusters d'IA basés sur Ethernet, ce qui reflète la manière dont le comportement du fabric détermine désormais si la mise à l'échelle reste efficace à mesure que la taille du déploiement augmente. Les acheteurs qui ont sécurisé une forte capacité GPU sans l'associer à une bande passante suffisante constatent que l'entraînement distribué ne délivre pas le débit attendu de leurs dépenses en capital. Cela a créé un cycle de mise à niveau pratique au sein des clusters existants, où les opérateurs ajoutent des cartes d'interface réseau, des commutateurs et du matériel de connectivité associé sans attendre un nouvel achat d'accélérateur. Ce schéma soutient le marché des interconnexions GPU même lorsque le rythme d'achat de calcul devient irrégulier entre les groupes de clients. Il améliore également la position des fournisseurs de commutateurs, de cartes d'interface réseau et de DPU, car la demande d'interconnexions devient moins dépendante d'un événement ponctuel d'expédition de GPU et davantage liée au réglage continu des clusters.
Expansion des systèmes GPU à l'échelle du rack dans les centres de données hyperscale
La conception de systèmes à l'échelle du rack a modifié la composition des revenus du marché des interconnexions d'unités de traitement graphique (GPU) en concentrant davantage de fabric au sein de chaque système d'IA déployé. NVIDIA a construit le GB300 NVL72 autour d'une communication native NVLink, et cette architecture remplace un agencement serveur plus conventionnel par une approche rack étroitement intégrée qui dépend d'un matériel de fabric dédié sur l'ensemble du système. Les quatre plus grands opérateurs cloud ont confirmé des dépenses en capital combinées pour 2026 de 725 milliards USD, une large part de ce budget étant dirigée vers l'infrastructure de calcul IA et de mise en réseau, ce qui soutient la demande continue de déploiements d'interconnexions denses. Cela favorise les fournisseurs qui proposent du silicium de commutation, des liens optiques, des contrôleurs de fabric et d'autres composants dont le contenu augmente à mesure que l'intégration des systèmes passe du niveau carte au niveau rack. Cela exerce également une pression sur les fournisseurs principalement liés aux anciennes catégories de conditionnement de signal PCIe, car une partie de cette valeur se déplace vers les nouvelles couches de commutation et optiques à mesure que l'adoption à l'échelle du rack s'étend. En pratique, le marché des interconnexions GPU connaît une intensité de revenus plus élevée par déploiement, les hyperscalers passant de serveurs d'accélérateurs isolés à des conceptions d'usines d'IA intégrées.
Croissance des standards d'interconnexion ouverts pour réduire la dépendance aux fournisseurs
Les standards ouverts prennent une importance croissante sur le marché des interconnexions GPU, car les grands acheteurs recherchent une plus grande flexibilité de fournisseurs face à des budgets de clusters en hausse. Le Consortium UALink a publié sa version 2.0 en avril 2026 avec des fonctionnalités de calcul en réseau, de définition de chiplet et de gestion, et le groupe a indiqué que 115 entreprises membres ou plus participent désormais à l'élaboration du standard. L'Ultra Ethernet Consortium a également lancé la Spécification 1.0 en juin 2025, fournissant au côté montée en puissance du marché des interconnexions GPU un cadre ouvert basé sur Ethernet pour le trafic IA et HPC. Le matériel d'évaluation pour UALink 1.0 est attendu au second semestre 2026, mais le silicium commercial est encore attendu plus tard, ce qui signifie que l'adoption dépendra de la rapidité avec laquelle les fournisseurs pourront passer des travaux du consortium à des produits déployables. Même ainsi, les cadres ouverts façonnent déjà le comportement d'achat en offrant aux entreprises et aux opérateurs cloud une voie plus claire vers des fabrics GPU multi-fournisseurs. À terme, cela devrait rendre le marché des interconnexions GPU moins dépendant d'une architecture unique dans la couche de montée en charge, même si les systèmes propriétaires maintiennent une forte avance à court terme.
Analyse de l'impact des freins*
| Frein | (~) % d'impact sur les prévisions de CAGR | Pertinence géographique | Horizon temporel de l'impact |
|---|---|---|---|
| Disponibilité limitée des capacités d'encapsulation avancée et de SerDes haute vitesse | -2.1% | Mondial, concentré autour des pôles de fabrication avancée à Taïwan | Moyen terme (2-4 ans) |
| Coût total de possession élevé pour les fabrics GPU de montée en charge | -1.4% | Mondial, aigu dans les déploiements d'IA souverains et de marché intermédiaire | Moyen terme (2-4 ans) |
| Verrouillage des écosystèmes propriétaires ralentissant l'adoption multi-fournisseurs | -0.9% | Mondial | Long terme (≥ 4 ans) |
| Contraintes thermiques et d'alimentation persistantes à l'échelle du rack | -0.7% | Mondial, aigu dans les déploiements en environnement existant et en colocation | Moyen terme (2-4 ans) |
| Source: Mordor Intelligence | |||
Disponibilité limitée des capacités d'encapsulation avancée et de SerDes haute vitesse
Le marché des interconnexions GPU est encore confronté à une limite côté offre, car la capacité d'encapsulation avancée reste tendue dans les programmes de semi-conducteurs IA. Epoch AI a indiqué que NVIDIA, Google, AMD et Amazon représentaient ensemble plus de 90 % de la capacité mondiale d'encapsulation CoWoS en valeur en 2025, soulignant dans quelle mesure la base d'approvisionnement est déjà absorbée par un petit groupe de très grands acheteurs.[2]Epoch AI, "L'encapsulation avancée et la HBM, et non les puces logiques, étaient les goulots d'étranglement de la production de puces IA en 2025," Epoch AI, epoch.ai Cela est important car les ASIC d'interconnexion, les composants optiques avancés et le silicium haute vitesse associé sont tous en concurrence pour le même écosystème de fabrication qui soutient le matériel IA de nouvelle génération. Même lorsqu'un fournisseur remporte un créneau de conception, les livraisons peuvent encore être en retard sur les calendriers des clients si l'approvisionnement en encapsulation et en SerDes ne s'adapte pas au même rythme que la demande. Cela crée des délais d'expédition irréguliers sur le marché des interconnexions GPU et peut retarder le déploiement complet des clusters, en particulier lorsque les clients ont besoin d'une livraison synchronisée d'accélérateurs, de commutateurs, d'optiques et de dispositifs de connectivité associés. Le frein est le plus sévère pour les fournisseurs qui ont besoin à la fois d'une encapsulation avancée et d'un contenu réseau haute vitesse en même temps, car tout écart dans une partie de la chaîne peut ralentir l'ensemble du programme.
Coût total de possession élevé pour les fabrics GPU de montée en charge
Le coût total de possession constitue un autre frein évident sur le marché des interconnexions GPU, car les fabrics de montée en charge haute performance nécessitent bien plus que le seul ASIC de commutation. Les racks d'IA denses nécessitent souvent un refroidissement liquide, une alimentation électrique spécialisée et des mises à niveau des installations, ce qui augmente considérablement le coût d'exploitation total au-delà d'un simple achat de calcul. Ce fardeau de coûts est le plus important pour les projets de calcul souverain, les entreprises et les opérateurs cloud de taille moyenne qui ne peuvent pas répartir les dépenses d'infrastructure sur la même échelle de déploiement que les plus grands hyperscalers. UALink tente de résoudre une partie de ce problème en promettant des performances à l'échelle du rack avec un modèle d'approvisionnement plus ouvert, mais les produits commerciaux sont encore en phase d'évaluation en 2026. Jusqu'à ce que ces produits soient largement disponibles, de nombreux acheteurs sur le marché des interconnexions GPU continueront à peser les gains de performance par rapport aux coûts plus élevés de refroidissement, d'intégration et de réaménagement des sites. Cela signifie que certaines organisations s'en tiendront à des tailles de clusters plus petites ou privilégieront des voies d'expansion basées sur Ethernet plutôt que les systèmes propriétaires de montée en charge les plus coûteux.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des segments
Par fabric d'interconnexion / architecture de protocole : le leadership propriétaire face à une poussée plus large vers les standards
L'interconnexion propriétaire de montée en charge des accélérateurs détenait 43,59 % du marché des interconnexions GPU en 2025, tandis que l'interconnexion ouverte de montée en charge des accélérateurs devrait être la catégorie de fabric à la croissance la plus rapide jusqu'en 2031. Cette position dominante est due au déploiement précoce et étendu des systèmes rack-scale basés sur NVLink dans les environnements hyperscalers, où l'interconnexion est intégrée comme un élément central de l'architecture de calcul complète plutôt qu'un module optionnel. NVIDIA a renforcé ce modèle en liant étroitement NVLink et NVSwitch à son approche de conception rack-scale, ce qui a maintenu les liens propriétaires de montée en charge au cœur de l'infrastructure IA haute densité. Dans le même temps, la version UALink 2.0 a ajouté des fonctionnalités de calcul en réseau, de chiplet et de gestion, offrant aux conceptions de montée en charge ouvertes une feuille de route plus crédible pour les clusters multi-fournisseurs. Cela laisse le marché des interconnexions GPU avec une structure à court terme où les systèmes propriétaires dominent encore le haut de gamme, tandis que les cadres ouverts construisent une base technique plus solide pour une adoption ultérieure.
L'interconnexion native basée sur PCIe reste pertinente dans le secteur des interconnexions GPU pour les serveurs d'inférence hétérogènes, où le contrôle des coûts et la large compatibilité importent souvent davantage que la bande passante maximale possible. L'interconnexion basée sur CXL attire également l'attention dans les conceptions orientées inférence, car les fonctionnalités de mémoire partagée et de mise en commun peuvent aider à réduire les goulots d'étranglement mémoire dans les charges de travail mixtes CPU et GPU. Astera Labs a mis son contrôleur de mémoire CXL Leo en production en volume pour les charges de travail liées à Microsoft Azure en 2026, démontrant que CXL passe du concept au déploiement commercial dans l'infrastructure cloud. Les fabrics de montée en puissance basés sur Ethernet gagnent du terrain car ils s'alignent sur les grands écosystèmes réseau installés, tandis qu'InfiniBand reste important là où les performances d'entraînement étroitement couplées et le comportement opérationnel établi ont encore du poids. Le marché des interconnexions GPU évolue donc vers un environnement de fabric plus mixte, même si les systèmes propriétaires de montée en charge occupent encore la position initiale la plus forte dans les clusters d'IA à plus haute densité.



Par domaine de connectivité : les revenus de la montée en charge restent les plus importants tandis que les liens campus se développent plus rapidement
La connectivité de montée en charge représentait 49,32 % de la taille du marché des interconnexions GPU en 2025, tandis que la connectivité inter-pod et campus IA devrait se développer plus rapidement que les autres domaines de connectivité jusqu'en 2031. La montée en charge a maintenu la plus grande position en termes de revenus car les systèmes rack-scale denses intègrent un contenu de fabric significatif directement dans chaque unité déployée, augmentant ainsi la valeur des interconnexions par installation. NVIDIA a centré cette approche dans le GB300 NVL72, où le rack lui-même est construit autour d'une communication interne à haute bande passante plutôt qu'un agencement de serveurs plus conventionnel. Cette structure soutient une large nomenclature pour les plateaux de commutation, les liens internes et le matériel de connectivité associé, ce qui maintient la montée en charge au cœur des revenus sur le marché des interconnexions GPU. Cela explique également pourquoi les acheteurs qui choisissent des systèmes d'IA étroitement intégrés s'engagent souvent dans une architecture d'interconnexion en même temps qu'ils choisissent la plateforme d'accélérateur.
La connectivité inter-pod et campus IA croît plus rapidement car de nombreux déploiements d'IA ne peuvent plus faire tenir toute la capacité de calcul requise dans une seule salle ou un seul bâtiment. À mesure que les opérateurs répartissent la capacité GPU sur des campus plus grands pour répondre aux contraintes d'alimentation, de refroidissement et d'espace, ils ont besoin d'une connectivité optique robuste entre les pods, les clusters et les installations. La connectivité de montée en puissance reste importante au sein de chaque cluster car les GPU ont encore besoin d'une communication prévisible à faible latence entre les racks, tandis que la connectivité intra-nœud continue d'être importante dans les serveurs mixtes CPU et GPU qui s'appuient sur une connexion PCIe ou CXL. Les opérateurs qui n'améliorent que le chemin GPU à GPU peuvent encore faire face à des goulots d'étranglement si le chemin CPU à GPU reste contraint, ce qui signifie que l'optimisation des performances doit couvrir plusieurs couches de trafic simultanément. Cela maintient le marché des interconnexions GPU large à travers les types de connectivité, avec différents domaines gagnant en valeur selon la taille du cluster, la conception de la charge de travail et la disposition physique du centre de données.
Par composant : les commutateurs détiennent le plus grand pool de revenus tandis que l'optique croît le plus rapidement
Les interconnexions optiques devraient croître à un CAGR de 16,58 % de 2026 à 2031, tandis que les commutateurs détenaient 39,87 % du marché des interconnexions GPU en 2025. La croissance optique est portée par l'évolution vers l'optique co-packagée et la photonique sur silicium, notamment à mesure que la densité des clusters pousse les opérateurs à réduire la consommation d'énergie et à améliorer la qualité du signal sur des liens plus exigeants. NVIDIA a indiqué que le Quantum-X800 InfiniBand CPO est devenu disponible début 2026, et que Spectrum-X Ethernet Photonics est entré en production en mai 2026, marquant une étape commerciale significative pour la commutation optique dans l'infrastructure IA. Ce changement est important car la mise à l'échelle optique permet des fabrics plus grands et plus économes en énergie, ce qui devient de plus en plus important à mesure que le marché des interconnexions GPU sert de plus grandes usines d'IA plutôt que des racks d'accélérateurs isolés. Les commutateurs détenaient encore la plus grande part des revenus car ils restent centraux à la connectivité au niveau du rack et du cluster, et chaque déploiement d'IA dense nécessite une capacité de commutation substantielle.
Le pipeline de fournisseurs montre également à quelle vitesse les feuilles de route des composants progressent autour du marché des interconnexions GPU. Arista a présenté la série 7060XE7 en juin 2026 avec 64 ports à 1,6 T par port et jusqu'à 102,4 Tb/s de bande passante agrégée, signalant une évolution rapide au-delà du réseau 800G dans les centres de données IA. Les cartes d'interface réseau et les DPU gagnent également en importance car les systèmes d'IA denses ont besoin d'une gestion plus robuste du trafic nord-sud aux côtés de la bande passante du fabric interne, et NVIDIA a positionné ConnectX-8 à 800 Gb/s par port pour les plateformes basées sur GB300. Les retimers et les circuits intégrés de connectivité restent importants car des vitesses de voie plus élevées augmentent les défis d'intégrité du signal sur les cartes, les câbles et les plans de fond. Astera Labs a déclaré 308,4 millions USD de revenus au T1 2026 tout en élargissant sa présence dans ces catégories. Les assemblages de câbles en cuivre servent encore les liens à courte portée où le coût et la familiarité opérationnelle importent, mais le marché des interconnexions GPU oriente régulièrement davantage de croissance vers les systèmes optiques et les plateformes de commutation qui les soutiennent.
Par utilisateur final : les hyperscalers dominent la demande actuelle tandis que les neoclouds se développent rapidement
Les hyperscalers et les fournisseurs de services cloud de niveau 1 représentaient 68,84 % du marché des interconnexions GPU en 2025, tandis que les fournisseurs de cloud natifs IA et les neoclouds sont en passe de connaître la croissance la plus rapide jusqu'en 2031. Cette domination reflète l'échelle à laquelle Microsoft, Amazon, Google et Meta déploient l'infrastructure pour l'entraînement et l'inférence IA. Leurs engagements combinés de dépenses en capital pour 2026 ont atteint 725 milliards USD, une large part étant destinée au calcul IA et à la mise en réseau, fournissant au marché des interconnexions GPU sa base de dépenses la plus profonde et la plus prévisible. Ces clients adoptent également les nouvelles architectures tôt, c'est pourquoi ils ont été au cœur du déploiement des systèmes rack-scale, des fabrics à haute bande passante et de la commutation optique avancée. Même lorsque certains hyperscalers conçoivent des parties de leur pile réseau en interne, leur échelle d'approvisionnement continue de façonner les feuilles de route des produits dans l'ensemble de l'écosystème des fournisseurs.
Les fournisseurs de cloud natifs IA et les neoclouds se développent rapidement car ils utilisent l'accès à des fabrics plus récents comme argument de vente direct auprès des clients entreprises et de recherche. NVIDIA a indiqué que CoreWeave, Lambda et Oracle Cloud Infrastructure figuraient parmi les premiers adoptants de Spectrum-X Ethernet Photonics, ce qui montre comment les nouvelles plateformes cloud utilisent les performances réseau et l'efficacité énergétique pour différencier leurs services. Les programmes gouvernementaux et de calcul souverain élargissent également la base d'acheteurs, et le Canada a lancé son Programme d'infrastructure de calcul souverain IA en avril 2026 avec 2,4 milliards CAD (1,76 milliard USD) de soutien fédéral. Les grandes entreprises, les centres de calcul académiques et les déploiements liés aux télécommunications ajoutent une demande supplémentaire, bien qu'ils préfèrent souvent des fabrics de montée en puissance économiques plutôt que les systèmes propriétaires de montée en charge les plus coûteux. Cet élargissement du mix de clients donne au marché des interconnexions d'unités de traitement graphique (GPU) une base de demande plus large qu'elle ne l'était lors des cycles d'accélérateurs précédents, lorsque les achats des hyperscalers représentaient une part bien plus importante de l'activité totale.
Analyse géographique
L'Amérique du Nord détenait 56,62 % de la part du marché des interconnexions GPU en 2025, la plaçant bien en avance sur tous les autres segments régionaux. La région bénéficie d'investissements hyperscalers concentrés aux États-Unis et du fait que de nombreuses entreprises qui façonnent le marché des interconnexions GPU, notamment NVIDIA, Broadcom, Arista Networks, Astera Labs, Credo Technology, Coherent et Lumentum, y ont leur siège social ou y exercent des activités commerciales significatives. La région reste également la plus grande base d'adoption précoce pour l'infrastructure d'IA rack-scale, ce qui signifie que les lancements de produits se traduisent souvent par des déploiements nord-américains avant des déploiements mondiaux plus larges. Les grandes dépenses en capital cloud renforcent cette avance, les plus grands opérateurs dirigeant d'importants budgets 2026 vers l'infrastructure de calcul IA et de mise en réseau. Le Canada contribue également à élargir la demande régionale grâce à des investissements publics en calcul, et son Programme d'infrastructure de calcul souverain IA a ajouté 2,4 milliards CAD (1,76 milliard USD) de soutien fédéral en avril 2026.[3]Gouvernement du Canada, "Le Canada lance une initiative nationale pour développer une grande capacité de supercalcul IA," Gouvernement du Canada, canada.ca
L'Asie-Pacifique devrait se développer à un CAGR de 16,44 % jusqu'en 2031, ce qui en fait la géographie à la croissance la plus rapide sur le marché des interconnexions GPU. La croissance dans la région est soutenue par les ambitions d'IA souveraine, les constructions cloud locales et la nécessité de piles technologiques nationales dans les pays cherchant un plus grand contrôle sur l'infrastructure de calcul. La région est également importante car plusieurs grands groupes technologiques d'Asie-Pacifique font partie du Consortium UALink, indiquant que les standards ouverts de montée en charge attirent un intérêt réel de la part des grandes entreprises de plateformes et des participants matériels. Cette poussée régionale est susceptible de soutenir à la fois les écosystèmes de fabrication locaux et la demande d'approches d'interconnexion alternatives, à mesure que les clients évaluent le coût, l'accès à l'approvisionnement et le contrôle technologique. Pour le marché des interconnexions GPU, l'Asie-Pacifique devient importante non seulement en tant que centre de demande, mais aussi en tant que région pouvant influencer l'adoption future des standards et les schémas d'approvisionnement en composants.
L'Europe est plus petite aujourd'hui, mais elle reste stratégiquement importante car les règles de souveraineté des données et les cadres de gouvernance de l'IA continuent de soutenir la demande d'infrastructure de calcul régionale. Le Royaume-Uni a annoncé en 2026 qu'il allouerait 1,1 milliard GBP (1,4 milliard USD), dans le cadre de son plan matériel IA, dont 750 millions GBP (1,02 milliard USD) pour un supercalculateur national IA dont le déploiement est prévu d'ici 2030. L'Amérique du Sud reste en phase d'adoption plus précoce, avec une activité davantage liée à l'expansion du cloud hyperscaler et au calcul de recherche qu'à de grands programmes de fabric nationaux. La demande au Moyen-Orient et en Afrique est encore plus faible en termes absolus, mais l'intérêt pour le calcul souverain augmente, ce qui offre au marché des interconnexions d'unités de traitement graphique (GPU) une autre voie de croissance régionale à long terme au-delà du cœur hyperscaler actuel.

Paysage concurrentiel
Le marché des interconnexions GPU est modérément concentré et présente une structure divisée, avec des liens propriétaires de montée en charge parmi un petit nombre de fournisseurs, tandis que la mise en réseau de montée en puissance est disputée par un groupe de fournisseurs plus large. NVIDIA détient la position la plus forte dans la connectivité propriétaire de montée en charge car NVLink et NVSwitch sont intégrés directement dans sa conception de système rack-scale, ce qui lui confère un avantage puissant dans les déploiements d'IA à plus haute densité. Dans la mise en réseau de montée en puissance, le champ est plus large, avec Broadcom, Marvell, Cisco et Arista Networks en concurrence sur la commutation Ethernet, la connectivité optique et les couches de mise en réseau IA associées.[4]Arista Networks, "Arista présente son portefeuille 1,6 Térabit de nouvelle génération pour les fabrics IA," Arista Networks, arista.com Les groupes de standards ouverts façonnent également la concurrence future en offrant aux clients une voie vers des fabrics multi-fournisseurs dans les environnements de montée en charge et de montée en puissance. Cela signifie que le marché des interconnexions GPU est concentré au sommet, mais plus ouvert et compétitif dans les couches de mise en réseau plus larges qui soutiennent la mise à l'échelle de cluster à cluster.
Plusieurs actions d'entreprises en 2026 montrent comment le paysage concurrentiel évolue sur le marché des interconnexions GPU. NVIDIA a annoncé des investissements stratégiques de 2 milliards USD chacun dans Lumentum et Coherent, ainsi que de grands engagements d'achat, ce qui montre une démarche directe pour sécuriser l'approvisionnement optique en amont pour sa feuille de route d'optique co-packagée. Arista a ensuite présenté la série 7060XE7 pour les fabrics IA 1,6 T, signalant que les concurrents centrés sur Ethernet évoluent rapidement vers une commutation IA à plus haute vitesse plutôt que d'attendre un cycle de migration plus lent. Astera Labs a étendu ses opérations à Taïwan en juin 2026 pour approfondir la validation des plateformes IA et le travail d'intégration locale, reflétant la manière dont les fournisseurs se rapprochent de la base de fabrication et d'assemblage de systèmes qui soutient le marché des interconnexions GPU. La participation aux consortiums est également devenue un outil stratégique, les fournisseurs cherchant à influencer les futures décisions de socket avant que le silicium de montée en charge ouvert n'atteigne une production large. Ensemble, ces mouvements montrent que la concurrence est désormais centrée sur l'accès à l'approvisionnement, la position dans l'écosystème et l'expansion du contenu par accélérateur plutôt que sur des lancements de composants isolés.
Il reste encore de l'espace ouvert sur le marché des interconnexions GPU pour la gestion de fabric définie par logiciel, le contrôle de cluster hétérogène et le silicium de commutation conforme à UALink commercialement éprouvé. The Register a rapporté que le matériel d'évaluation UALink est attendu au second semestre 2026, et que le silicium commercial suivra plus tard, indiquant que le marché manque encore d'un ensemble de produits de montée en charge ouverts pleinement établis en volume. Cet écart donne aux acteurs en place plus de temps pour approfondir les relations avec les clients, mais il crée également de la place pour les challengers capables de livrer des alternatives ouvertes crédibles avant que la frustration des acheteurs face au verrouillage ne s'accroisse. Oracle, bien qu'actif dans les déploiements cloud GPU, reste principalement un utilisateur final dans ce contexte plutôt qu'un concepteur côté offre de matériel d'interconnexion, de sorte que le champ concurrentiel est encore défini principalement par les fournisseurs de mise en réseau, de semi-conducteurs et d'optique.
Leaders du secteur des interconnexions GPU
NVIDIA Corporation
Broadcom Inc.
Marvell Technology, Inc.
Advanced Micro Devices, Inc.
Astera Labs, Inc.
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Développements récents du secteur
- Juin 2026 : Arista Networks a présenté la série 7060XE7, un portefeuille de mise en réseau IA 1,6 T de nouvelle génération basé sur le silicium Broadcom Tomahawk 6, supportant 64 ports à 1,6 T par port et une capacité de commutation agrégée de 102,4 Tb/s, en configurations refroidies par air et par liquide. Les variantes refroidies par air sont prévues pour le T4 2026 et les variantes refroidies par liquide pour le T1 2027, positionnant le portefeuille pour les déploiements de fabric IA de montée en charge et de montée en puissance.
- Juin 2026 : Astera Labs a étendu ses opérations à Taïwan, établissant un laboratoire d'interopérabilité à l'échelle cloud élargi et développant sa présence en ingénierie pour approfondir l'intégration avec les fournisseurs de plateformes IA et les fabricants de systèmes taïwanais, ciblant la validation de clusters IA pour la génération GB300.
- Mai 2026 : NVIDIA a annoncé que Spectrum-X Ethernet Photonics est désormais en production au GTC de Taïwan, Computex 2026, le présentant comme le premier commutateur Ethernet CPO au monde basé sur la technologie SerDes 200G avec jusqu'à 409,6 Tb/s de bande passante agrégée. CoreWeave, Lambda et Oracle Cloud Infrastructure figuraient parmi les premiers adoptants, et la disponibilité générale est prévue pour le second semestre 2026.
- Avril 2026 : Le Consortium UALink a publié quatre spécifications dans sa version 2.0, introduisant des cadres de calcul en réseau, de définition de chiplet et de gestion pour les déploiements IA multi-charges de travail, avec 115 entreprises membres ou plus gouvernant désormais le standard.


Périmètre du rapport mondial sur le marché des interconnexions GPU
Le marché des interconnexions GPU comprend le matériel, les logiciels, les protocoles et les technologies de mise en réseau qui permettent une communication à haute vitesse et un échange de données entre les unités de traitement graphique (GPU), les accélérateurs, les CPU, les ressources mémoire et l'infrastructure de calcul distribué. Les solutions d'interconnexion GPU sont conçues pour répondre aux exigences de bande passante, de latence, d'évolutivité et d'efficacité des charges de travail modernes d'intelligence artificielle (IA), d'apprentissage automatique, de calcul haute performance (HPC), de cloud computing et de traitement intensif des données, en facilitant une communication transparente dans des environnements de calcul de plus en plus grands et complexes.
Le rapport sur le marché des interconnexions GPU est segmenté par architecture d'interconnexion/architecture de protocole (interconnexion native basée sur PCIe, interconnexion basée sur CXL, interconnexion propriétaire de montée en charge des accélérateurs, interconnexion ouverte de montée en charge des accélérateurs, interconnexion de montée en puissance basée sur InfiniBand et interconnexion de montée en puissance basée sur Ethernet), domaine de connectivité (connectivité intra-nœud/intra-serveur, connectivité de montée en charge, connectivité de montée en puissance et connectivité inter-pod/campus IA), composant (commutateurs, cartes d'interface réseau et DPU, retimers, redrivers et circuits intégrés de connectivité, assemblages de câbles en cuivre et interconnexions optiques), utilisateur final (hyperscalers et fournisseurs de services cloud de niveau 1, fournisseurs de cloud natifs IA et neoclouds, grandes entreprises et opérateurs d'infrastructure IA privée, gouvernement, programmes d'IA souveraine et laboratoires de recherche nationaux, institutions académiques et de recherche HPC, et fournisseurs de télécommunications, de cloud en périphérie et de services gérés), et géographie (Amérique du Nord, Europe, Asie-Pacifique, Amérique du Sud et Moyen-Orient et Afrique). Les prévisions du marché sont fournies en termes de valeur (USD).
| Interconnexion native basée sur PCIe |
| Interconnexion basée sur CXL |
| Interconnexion propriétaire de montée en charge des accélérateurs |
| Interconnexion ouverte de montée en charge des accélérateurs |
| Interconnexion de montée en puissance basée sur InfiniBand |
| Interconnexion de montée en puissance basée sur Ethernet |
| Connectivité intra-nœud/intra-serveur |
| Connectivité de montée en charge |
| Connectivité de montée en puissance |
| Connectivité inter-pod/campus IA |
| Commutateurs |
| Cartes d'interface réseau et DPU |
| Retimers, redrivers et circuits intégrés de connectivité |
| Assemblages de câbles en cuivre |
| Interconnexions optiques |
| Hyperscalers et fournisseurs de services cloud de niveau 1 |
| Fournisseurs de cloud natifs IA et neoclouds |
| Grandes entreprises et opérateurs d'infrastructure IA privée |
| Gouvernement, programmes d'IA souveraine et laboratoires de recherche nationaux |
| Institutions académiques et de recherche HPC |
| Fournisseurs de télécommunications, de cloud en périphérie et de services gérés |
| Amérique du Nord | États-Unis |
| Canada | |
| Mexique | |
| Europe | Allemagne |
| Royaume-Uni | |
| France | |
| Italie | |
| Reste de l'Europe | |
| Asie-Pacifique | Chine |
| Japon | |
| Corée du Sud | |
| Inde | |
| Asie du Sud-Est | |
| Reste de l'Asie-Pacifique | |
| Amérique du Sud | |
| Moyen-Orient et Afrique |
| Par fabric d'interconnexion/architecture de protocole | Interconnexion native basée sur PCIe | |
| Interconnexion basée sur CXL | ||
| Interconnexion propriétaire de montée en charge des accélérateurs | ||
| Interconnexion ouverte de montée en charge des accélérateurs | ||
| Interconnexion de montée en puissance basée sur InfiniBand | ||
| Interconnexion de montée en puissance basée sur Ethernet | ||
| Par domaine de connectivité | Connectivité intra-nœud/intra-serveur | |
| Connectivité de montée en charge | ||
| Connectivité de montée en puissance | ||
| Connectivité inter-pod/campus IA | ||
| Par composant | Commutateurs | |
| Cartes d'interface réseau et DPU | ||
| Retimers, redrivers et circuits intégrés de connectivité | ||
| Assemblages de câbles en cuivre | ||
| Interconnexions optiques | ||
| Par utilisateur final | Hyperscalers et fournisseurs de services cloud de niveau 1 | |
| Fournisseurs de cloud natifs IA et neoclouds | ||
| Grandes entreprises et opérateurs d'infrastructure IA privée | ||
| Gouvernement, programmes d'IA souveraine et laboratoires de recherche nationaux | ||
| Institutions académiques et de recherche HPC | ||
| Fournisseurs de télécommunications, de cloud en périphérie et de services gérés | ||
| Par géographie | Amérique du Nord | États-Unis |
| Canada | ||
| Mexique | ||
| Europe | Allemagne | |
| Royaume-Uni | ||
| France | ||
| Italie | ||
| Reste de l'Europe | ||
| Asie-Pacifique | Chine | |
| Japon | ||
| Corée du Sud | ||
| Inde | ||
| Asie du Sud-Est | ||
| Reste de l'Asie-Pacifique | ||
| Amérique du Sud | ||
| Moyen-Orient et Afrique | ||


Questions clés auxquelles le rapport répond
Quelle est la taille actuelle du marché des interconnexions GPU ?
Le marché des interconnexions GPU a atteint 89,43 milliards USD en 2026 et devrait atteindre 184,8 milliards USD d'ici 2031 à un CAGR de 15,62 %.
Quel fabric d'interconnexion domine les revenus actuels ?
L'interconnexion propriétaire de montée en charge des accélérateurs était en tête avec 43,59 % de part en 2025, soutenue par le déploiement précoce rack-scale autour des architectures basées sur NVLink.
Quel domaine de connectivité se développe le plus rapidement ?
La connectivité de montée en charge détenait la plus grande part en 2025, mais la connectivité inter-pod et campus IA devrait croître le plus rapidement jusqu'en 2031, à mesure que les clusters se répandent sur des campus plus grands.
Pourquoi les interconnexions optiques gagnent-elles du terrain dans les clusters GPU ?
Les interconnexions optiques devraient croître à un CAGR de 16,58 % car les systèmes d'IA plus denses ont besoin d'une meilleure efficacité énergétique, d'une meilleure intégrité du signal et d'une commutation à plus haute bande passante.
Qui achète le plus de matériel d'interconnexion GPU aujourd'hui ?
Les hyperscalers et les fournisseurs de services cloud de niveau 1 dominaient la demande avec 68,84 % de part en 2025, portés par de très grands programmes d'infrastructure d'entraînement et d'inférence IA.
Quelle région présente les meilleures perspectives de croissance ?
L'Amérique du Nord était en tête avec 56,62 % de part en 2025, tandis que l'Asie-Pacifique devrait afficher la croissance la plus rapide à un CAGR de 16,44 % jusqu'en 2031.
Dernière mise à jour de la page le:




