GPUインターコネクト市場規模とシェア
市場概要
| 調査期間 | 2020 - 2031 |
|---|---|
| 市場規模 (2026) | 89.43 十億米ドル |
| 市場規模 (2031) | 184.80 十億米ドル |
| 成長率 (2026 - 2031) | 15.62% CAGR |
| 最も急速に成長している市場 | アジア太平洋地域 |
| 最大市場 | 北米 |
| 市場集中度 | 中 |
主要プレーヤー *免責事項:主要選手の並び順不同 画像 © Mordor Intelligence。再利用にはCC BY 4.0の表示が必要です。 | |
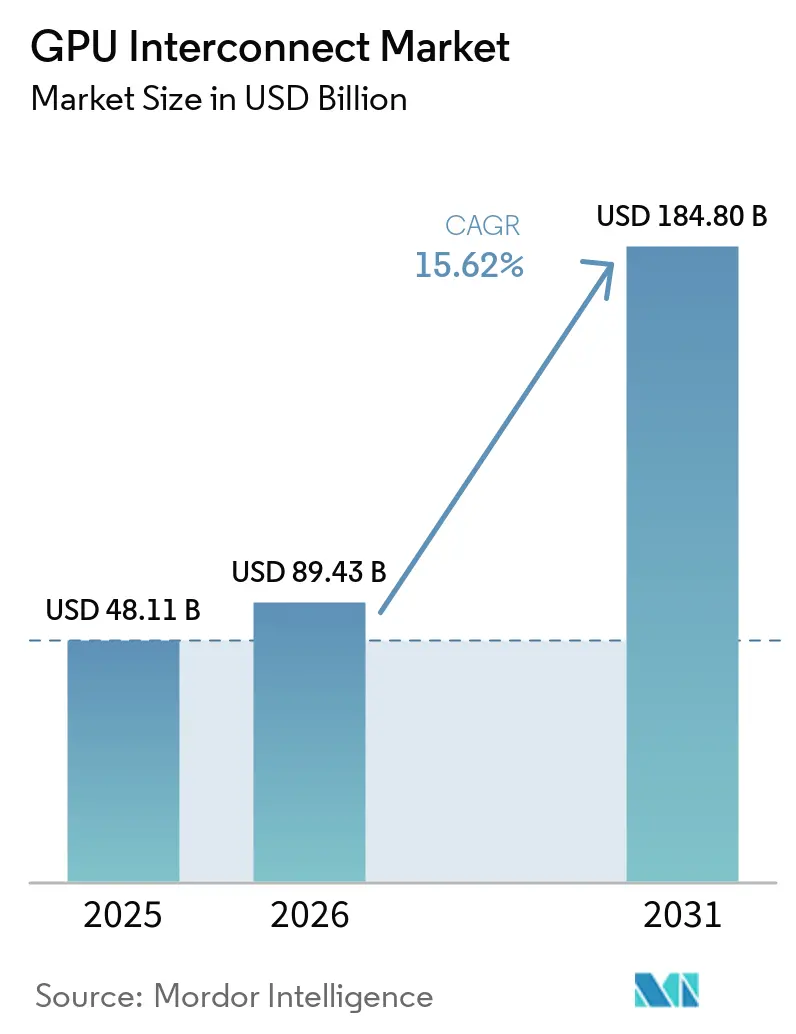
Mordor IntelligenceによるGPUインターコネクト市場分析
GPUインターコネクト市場規模は、2025年の481.1億米ドルから2026年には894.3億米ドルに拡大し、2031年までに1,848.0億米ドルに達する見込みで、2026年から2031年にかけてCAGR 15.62%で成長すると予測されています。ハイパースケーラーの支出およびラックスケールAIシステムへの移行により、インターコネクト設計は二次的なサーバーコンポーネントの選択ではなく、コアインフラストラクチャの意思決定事項となっています。バイヤーは現在、帯域幅、レイテンシ、ファブリック効率を使用可能なGPU出力の直接的な推進要因として捉えており、GPUインターコネクト市場における更新サイクルを短縮しています。光ネットワーキング、シリコンフォトニクス、より高密度なスイッチ設計も電力効率とスペース効率を向上させ、より大規模なAIクラスターの商業的根拠を広げています。競争は独自のスケールアップリンクに集中している一方、オープン標準およびイーサネットベースの設計はスケールアウト展開においてより多くの柔軟性を顧客に提供しています。GPUインターコネクト市場における最も強力な機会は、クラウドの拡大、ソブリンコンピュートプログラム、および企業向けAI展開によって牽引されており、これらはすべて統合リスクが低く、より優れた運用経済性を持つ高性能ファブリックを必要としています。
主要レポートのポイント
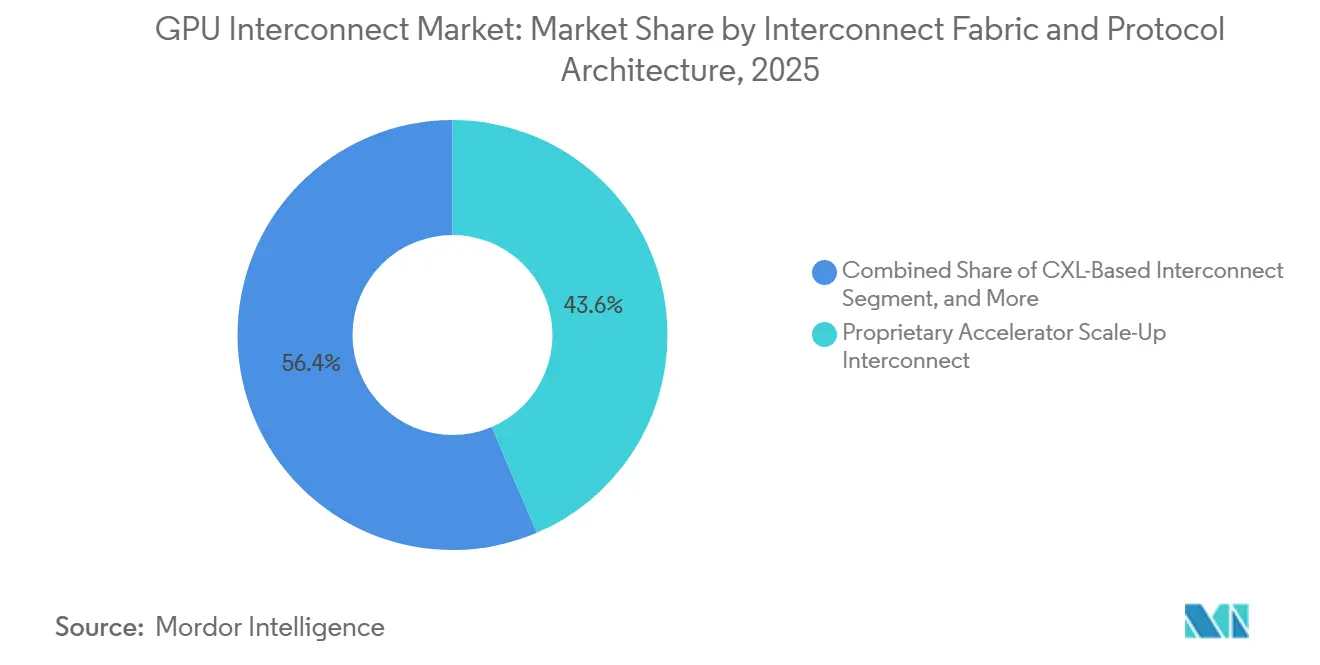
- インターコネクトファブリック別では、独自のアクセラレータースケールアップインターコネクトが2025年のGPUインターコネクト市場シェアの43.59%を占め、オープンアクセラレータースケールアップインターコネクトは2031年まで最も成長の速いファブリックセグメントであり続けると予測されています。
- 接続ドメイン別では、スケールアップ接続が2025年のグラフィックスプロセッシングユニット(GPU)インターコネクト市場規模の49.32%を占め、ポッド間およびキャンパスAI接続が2031年まで最も速く拡大すると予測されています。
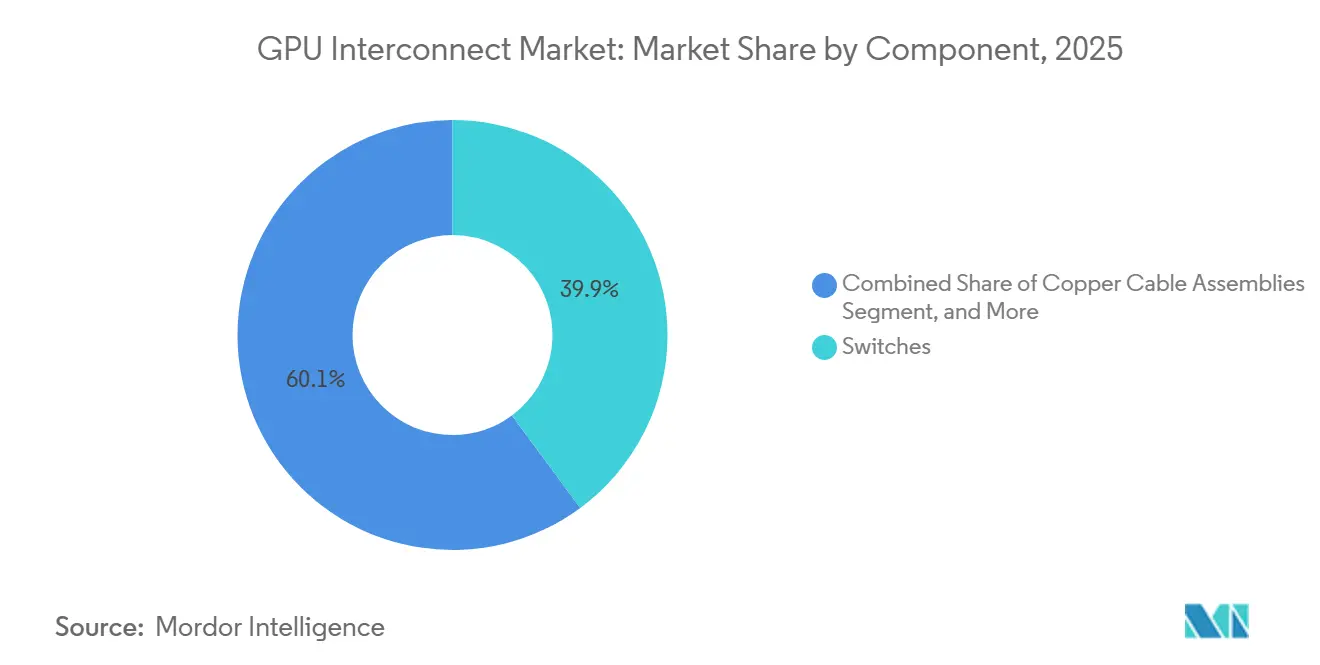
- コンポーネント別では、スイッチが2025年のGPUインターコネクト市場の39.87%のシェアを占め、光インターコネクトは2031年まで16.58%のCAGRで成長すると予測されています。
- エンドユーザー別では、ハイパースケーラーおよびTier-1クラウドサービスプロバイダーが2025年に68.84%のシェアを獲得し、AIネイティブクラウドプロバイダーおよびネオクラウドが2031年まで最も速い成長を記録すると予測されています。
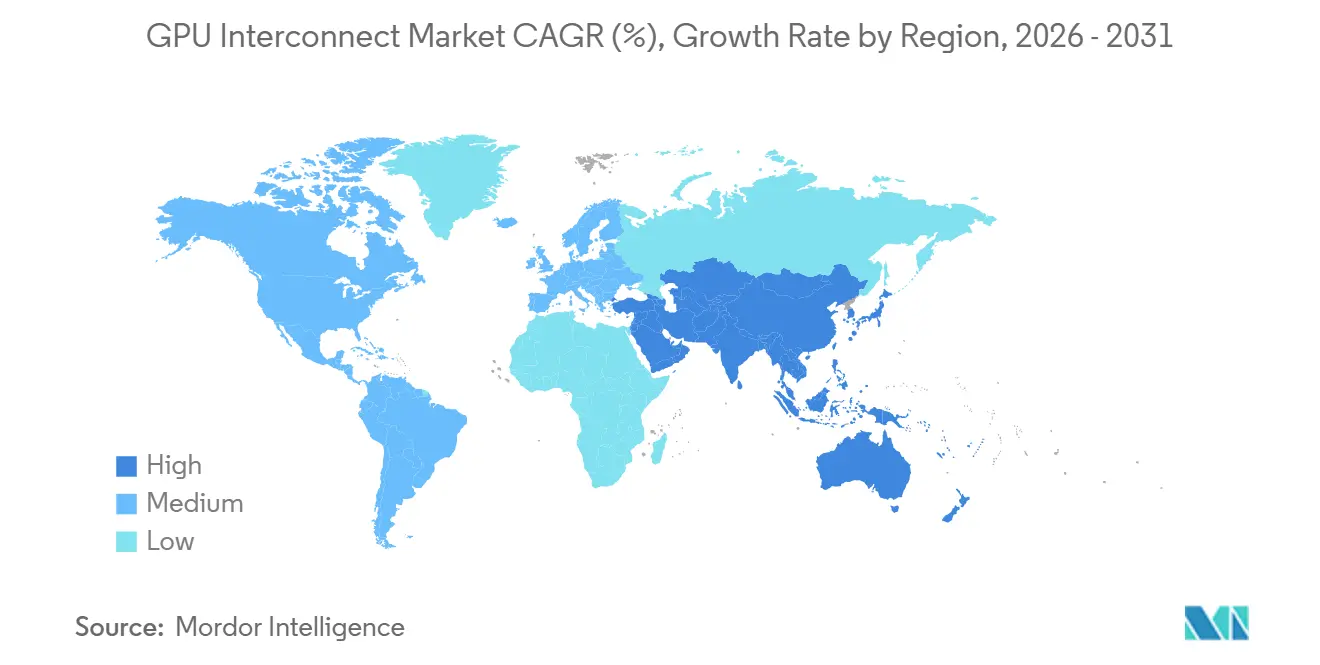
- 地域別では、北米が2025年のGPUインターコネクト市場の56.62%のシェアを占め、アジア太平洋地域が2031年まで16.44%のCAGRで成長すると予測されています。
注:本レポートの市場規模および予測数値は、Mordor Intelligence 独自の推定フレームワークを使用して作成されており、2026年1月時点の最新の利用可能なデータとインサイトで更新されています。
グローバルGPUインターコネクト市場のトレンドとインサイト
ドライバーの影響分析*
| ドライバー | (~)CAGR予測への影響(%) | 地理的関連性 | 影響のタイムライン |
|---|---|---|---|
| 生成AIクラスターの帯域幅需要の増大 | +4.5% | グローバル、北米およびアジア太平洋地域に集中 | 短期(2年以内) |
| コンピュートボトルネックからインターコネクトボトルネックへのシフト | +3.2% | グローバル | 中期(2~4年) |
| ハイパースケールデータセンターにおけるラックスケールGPUシステムの拡大 | +2.8% | 北米およびアジア太平洋地域が中心、欧州への波及あり | 中期(2~4年) |
| ベンダーロックインを低減するためのオープンインターコネクト標準の成長 | +2.1% | グローバル、北米および欧州での早期利益 | 中期(2~4年) |
| コパッケージドオプティクスおよびシリコンフォトニクスへの移行 | +1.6% | グローバル、北米および台湾での早期採用 | 長期(4年以上) |
| エンタープライズAIインフラにおけるCPU-GPU協調設計の需要 | +0.8% | 北米および欧州 | 中期(2~4年) |
| 情報源: Mordor Intelligence | |||
生成AIクラスターの帯域幅需要の増大
生成AIトレーニングは、集合通信タスクがネットワークファブリックを生のコンピュートが相殺できるよりもはるかに速く満たすため、GPUインターコネクト市場を押し上げ続けています。NVIDIAは、GB300 NVL72プラットフォームが72基のBlackwell Ultra GPU全体で130 TB/sの集約ラック内帯域幅を提供し、RubinのNVLink 6がGPUあたりの帯域幅を3.6 TB/sに引き上げると述べており、クラスター密度が増加するにつれて帯域幅要件がいかに急速に上昇しているかを強調しています。[1]NVIDIA Corporation、「NVIDIA GB300 NVL72 AIの推論性能と効率のために設計」、NVIDIA、nvidia.com モデルサイズが増大するにつれて、クラスター内の東西トラフィックは無視するには高コストになりすぎ、支出はサーバーの明細項目から専用ネットワークファブリック予算へとシフトしています。この変化は、多くのフロンティアオペレーターが従来のネットワーク更新習慣よりもアクセラレーター世代に合わせてファブリックのアップグレードを行うようになったため、GPUインターコネクト市場における交換サイクルを短縮しています。また、帯域幅の不足が実効稼働率を低下させ、大規模なコンピュート投資のリターンを弱める可能性があるため、数千のGPUを同時に稼働させ続けられる設計の商業的価値も高まっています。その結果、需要の成長はより多くのGPUによってだけでなく、はるかに高性能なファブリックでそれらを接続する必要性によっても牽引される市場となっています。
コンピュートボトルネックからインターコネクトボトルネックへのシフト
GPUインターコネクト市場は、大規模AIクラスター内でパフォーマンス上の問題が発生する場所のシフトからも恩恵を受けています。NVIDIAは、大規模なイーサネットベースのAIクラスターにおけるトポロジー対応スケジューリング、負荷分散、ネットワークチューニングを中心にSpectrum-Xを位置付けており、これはデプロイメント規模が拡大するにつれてスケーリングが効率的であり続けるかどうかをファブリックの動作が左右するようになったことを反映しています。十分な帯域幅を確保せずに強力なGPUキャパシティを確保したバイヤーは、分散トレーニングが資本支出から期待したスループットを提供しないことに気づいています。これにより、既存クラスター内に実際のアップグレードサイクルが生まれており、オペレーターは新しいアクセラレーターの購入を待たずにNIC、スイッチ、および関連する接続ハードウェアを追加しています。このパターンは、コンピュート購入のペースが顧客グループ間で不均一になった場合でも、GPUインターコネクト市場を支えています。また、インターコネクト需要が一度限りのGPU出荷イベントへの依存度が低くなり、継続的なクラスターチューニングとより密接に結びつくようになるため、スイッチ、NIC、DPUサプライヤーの立場も改善されます。
ハイパースケールデータセンターにおけるラックスケールGPUシステムの拡大
ラックスケールシステム設計は、展開されたAIシステムごとにより多くのファブリックを集中させることで、グラフィックスプロセッシングユニット(GPU)インターコネクト市場の収益構成を変えました。NVIDIAはGB300 NVL72をNVLinkネイティブ通信を中心に構築しており、そのアーキテクチャはより従来的なサーバーレベルの配置を、システム全体にわたって専用ファブリックハードウェアに依存する緊密に統合されたラックアプローチに置き換えています。4大クラウドオペレーターは合計で2026年の設備投資として7,250億米ドルを確認しており、その予算の大部分はAIコンピュートおよびネットワーキングインフラに向けられており、高密度インターコネクト展開への継続的な需要を支えています。これは、システム統合がボードレベルからラックレベルへと移行するにつれてコンテンツが増加するスイッチシリコン、光リンク、ファブリックコントローラー、およびその他のコンポーネントを提供するベンダーに有利です。また、ラックスケール採用が拡大するにつれて、その価値の一部が新しいスイッチおよび光レイヤーへとシフトするため、主に旧来のPCIe信号調整カテゴリーに縛られているサプライヤーにも圧力をかけています。実際には、ハイパースケーラーが孤立したアクセラレーターサーバーから統合されたAIファクトリー設計へと移行するにつれて、GPUインターコネクト市場は展開あたりの収益強度が高まっています。
ベンダーロックインを低減するためのオープンインターコネクト標準の成長
クラスター予算の増大に伴い、大規模バイヤーがより大きなサプライヤーの柔軟性を求めるようになっているため、オープン標準はGPUインターコネクト市場においてますます重要になっています。UALinkコンソーシアムは2026年4月にネットワーク内コンピュート、チップレット定義、および管理機能を含む2.0リリースを公開し、115社以上のメンバー企業が現在標準の策定に関与していると述べています。ウルトライーサネットコンソーシアムも2025年6月に仕様1.0を発表し、AIおよびHPCトラフィック向けにイーサネット上に構築されたオープンフレームワークをGPUインターコネクト市場のスケールアウト側に提供しました。UALink 1.0の評価ハードウェアは2026年後半に予定されていますが、商用シリコンはまだ後になると予想されており、採用はベンダーがコンソーシアム作業から展開可能な製品へとどれだけ迅速に移行できるかにかかっています。それでも、オープンフレームワークはすでに、企業やクラウドオペレーターにマルチベンダーGPUファブリックへの明確な道筋を提供することで購買行動を形成しています。長期的には、独自システムが近期において強力なリードを維持するとしても、GPUインターコネクト市場のスケールアップレイヤーにおける単一アーキテクチャへの依存度が低下するはずです。
抑制要因の影響分析*
| 抑制要因 | (~)CAGR予測への影響(%) | 地理的関連性 | 影響のタイムライン |
|---|---|---|---|
| 先進パッケージングおよび高速SerDes容量の限られた可用性 | -2.1% | グローバル、台湾の先進製造拠点に集中 | 中期(2~4年) |
| スケールアップGPUファブリックの高い総所有コスト | -1.4% | グローバル、中堅市場およびソブリンAI展開において深刻 | 中期(2~4年) |
| マルチベンダー採用を遅らせる独自エコシステムのロックイン | -0.9% | グローバル | 長期(4年以上) |
| ラックスケールにおける持続的な熱管理および電力供給の制約 | -0.7% | グローバル、既存施設およびコロケーション展開において深刻 | 中期(2~4年) |
| 情報源: Mordor Intelligence | |||
先進パッケージングおよび高速SerDes容量の限られた可用性
GPUインターコネクト市場は、AIセミコンダクタープログラム全体で先進パッケージング容量が依然として逼迫しているため、供給側の制限に直面しています。Epoch AIは、NVIDIA、Google、AMD、Amazonが2025年に金額ベースでグローバルなCoWoSパッケージング容量の90%以上を占めたと述べており、供給基盤のいかに多くが少数の非常に大規模なバイヤーによってすでに吸収されているかを強調しています。[2]Epoch AI、「先進パッケージングとHBMは、2025年のAIチップ生産においてロジックダイではなくボトルネックであった」、Epoch AI、epoch.ai これが重要なのは、インターコネクトASIC、先進光コンポーネント、および関連する高速シリコンがすべて、次世代AIハードウェアをサポートする同じ製造エコシステムをめぐって競合しているためです。ベンダーが設計スロットを獲得した場合でも、パッケージングとSerDesの供給が需要と同じペースでスケールしない場合、納品が顧客のスケジュールより遅れる可能性があります。これにより、GPUインターコネクト市場全体で出荷タイミングが不均一になり、特に顧客がアクセラレーター、スイッチ、光学機器、および補助接続デバイスの同期納品を必要とする場合、完全なクラスター展開が遅延する可能性があります。この制約は、先進パッケージングと高速ネットワーキングコンテンツの両方を同時に必要とするサプライヤーにとって最も深刻であり、チェーンの一部にギャップがあるとプログラム全体が遅延する可能性があります。
スケールアップGPUファブリックの高い総所有コスト
高性能スケールアップファブリックはスイッチASIC以上のものを必要とするため、総所有コストはGPUインターコネクト市場における明確な抑制要因となっています。高密度AIラックは多くの場合、液体冷却、専用電力供給、および施設のアップグレードを必要とし、単純なコンピュート購入を超えて全体的な運用コストを大幅に増加させます。このコスト負担は、最大のハイパースケーラーと同じ展開規模でインフラ支出を分散できないソブリンコンピュートプロジェクト、企業、および中規模クラウドオペレーターにとって最も重要です。UALinkは、よりオープンなサプライモデルでラックスケールのパフォーマンスを約束することでこの問題の一部に対処しようとしていますが、商用製品は2026年においてまだ評価段階を経ています。これらの製品が広く利用可能になるまで、GPUインターコネクト市場の多くのバイヤーは、最も高価な独自スケールアップシステムよりも、パフォーマンスの向上と冷却、統合、サイト改修コストの増加を比較検討し続けるでしょう。これは、一部の組織がより小さなクラスターサイズに留まるか、最も高価な独自スケールアップシステムよりもイーサネットベースの拡張パスを好むことを意味します。
*当社の予測では、推進要因および抑制要因の影響を加算的ではなく方向性のあるものとして扱います。影響予測は、ベースライン成長、構成効果、および変数間の相互作用を反映しています。
セグメント分析
インターコネクトファブリック/プロトコルアーキテクチャ別:独自のリーダーシップとより広範な標準化の推進
独自のアクセラレータースケールアップインターコネクトは2025年のGPUインターコネクト市場の43.59%を占め、オープンアクセラレータースケールアップインターコネクトは2031年まで最も成長の速いファブリックカテゴリーになると予測されています。このリーディングポジションは、ハイパースケーラー環境全体でNVLinkベースのラックスケールシステムが早期かつ広範に展開されたことによるもので、インターコネクトはオプションのアドオンではなく、完全なコンピュートアーキテクチャのコア部分としてパッケージ化されています。NVIDIAはNVLinkとNVSwitchをラックスケール設計アプローチに緊密に結びつけることでこのモデルを強化し、独自のスケールアップリンクを高密度AIインフラの中心に置き続けました。同時に、UALink 2.0リリースはネットワーク内コンピュート、チップレット、および管理機能を追加し、オープンスケールアップ設計にマルチベンダークラスターのより信頼性の高いロードマップを提供しました。これにより、GPUインターコネクト市場は近期において独自システムがトップエンドを支配し続ける一方、オープンフレームワークが後の採用に向けてより強固な技術基盤を構築するという構造になっています。
ネイティブPCIeベースインターコネクトは、コスト管理と広範な互換性が最高の帯域幅よりも重要視されることが多い異種推論サーバーにおいて、GPUインターコネクト産業で引き続き関連性を持っています。CXLベースインターコネクトも、共有メモリとプーリング機能が混合CPUおよびGPUワークロード全体のメモリボトルネックを軽減するのに役立つため、推論指向の設計で注目を集めています。Astera Labsは2026年にMicrosoft Azure関連ワークロード向けにLeo CXLメモリコントローラーを量産に移行し、CXLがクラウドインフラにおいてコンセプトから商用展開へと移行していることを示しました。イーサネットベースのスケールアウトファブリックは、大規模な既存ネットワークエコシステムと整合するため普及が進んでいる一方、InfiniBandは緊密に結合されたトレーニングパフォーマンスと確立された動作特性が依然として重視される場所で重要性を維持しています。したがって、GPUインターコネクト市場、独自のスケールアップシステムが最高密度のAIクラスターにおいて依然として最も強力な早期ポジションを占めているとはいえ、より混合されたファブリック環境へと移行しています。
注記: 個別セグメントのセグメントシェアはレポート購入時に入手可能


接続ドメイン別:スケールアップ収益が最大を維持しながらキャンパスリンクがより速く拡大
スケールアップ接続は2025年のGPUインターコネクト市場規模の49.32%を占め、ポッド間およびキャンパスAI接続は2031年まで他の接続ドメインよりも速く拡大すると予測されています。スケールアップが最大の収益ポジションを維持したのは、高密度ラックスケールシステムが展開されたユニットごとに直接大量のファブリックコンテンツを組み込み、インストールあたりのインターコネクト価値を高めているためです。NVIDIAはGB300 NVL72においてこのアプローチを中心に据えており、ラック自体がより従来的なルーズサーバー配置ではなく、高帯域幅の内部通信を中心に構築されています。この構造は、スイッチトレイ、内部リンク、および関連する接続ハードウェアの大きな部品表を支え、GPUインターコネクト市場の収益においてスケールアップを中心的な位置に保っています。また、緊密に統合されたAIシステムを選択するバイヤーが、アクセラレータープラットフォームを選択すると同時にインターコネクトアーキテクチャにコミットすることが多い理由も説明しています。
ポッド間およびキャンパスAI接続は、多くのAI展開が必要なすべてのコンピュートを1つの部屋や1つの建物に収めることができなくなっているため、より速く成長しています。オペレーターが電力、冷却、スペースの制約に対処するためにGPUキャパシティをより大きなキャンパスに分散させるにつれて、ポッド、クラスター、施設間の堅牢な光接続が必要になります。スケールアウト接続は、GPUがラック全体で予測可能な低レイテンシ通信を必要とするため、各クラスター内で引き続き重要であり、ノード内接続はPCIeまたはCXL接続に依存する混合CPUおよびGPUサーバーで引き続き重要です。GPU間パスのみを改善するオペレーターは、CPU-GPUパスが制約されたままであれば依然としてボトルネックに直面する可能性があり、パフォーマンスチューニングは複数のトラフィックレイヤーを同時にカバーする必要があることを意味します。これにより、GPUインターコネクト市場はクラスターサイズ、ワークロード設計、および物理的なデータセンターレイアウトに応じて異なるドメインが価値を得る、接続タイプ全体にわたって広範な市場を維持しています。
コンポーネント別:スイッチが最大の収益プールを保持しながら光学機器が最も速く成長
光インターコネクトは2026年から2031年にかけて16.58%のCAGRで成長すると予測されており、スイッチは2025年のGPUインターコネクト市場の39.87%を占めました。光学機器の成長は、コパッケージドオプティクスとシリコンフォトニクスへの移行によって牽引されており、特にクラスター密度の増加によりオペレーターがより要求の厳しいリンクで電力使用量を削減し信号品質を向上させる必要があるためです。NVIDIAは、Quantum-X800 InfiniBand CPOが2026年初頭に利用可能になり、Spectrum-X Ethernet Photonicsが2026年5月に生産に入ったと述べており、AIインフラにおける光スイッチングの意味のある商業的ステップを示しています。このシフトが重要なのは、光スケーリングがより大規模で電力効率の高いファブリックを可能にするためであり、GPUインターコネクト市場が孤立したアクセラレーターラックではなく、より大規模なAIファクトリーにサービスを提供するにつれてますます重要になっています。スイッチは、ラックレベルとクラスターレベルの両方の接続において中心的な役割を果たし続け、すべての高密度AI展開が大量のスイッチング容量を必要とするため、依然として最大の収益シェアを保持しています。
サプライヤーパイプラインは、GPUインターコネクト市場を中心にコンポーネントロードマップがいかに急速に進歩しているかも示しています。Aristaは2026年6月に7060XE7シリーズを発表し、ポートあたり1.6Tで64ポート、最大102.4 Tb/sの集約帯域幅を持ち、空冷および液冷の両構成でAIデータセンターにおける800Gネットワーキングを超える急速な移行を示しました。ネットワークインターフェースカードとDPUも重要性を増しており、高密度AIシステムは内部ファブリック帯域幅と並行してより強力な南北トラフィック処理を必要とし、NVIDIAはGB300ベースプラットフォーム向けにConnectX-8をポートあたり800 Gb/sで位置付けました。リタイマーと接続ICは、より高いレーン速度がボード、ケーブル、バックプレーン全体の信号整合性の課題を増大させるため、引き続き重要です。Astera Labsは2026年第1四半期に3億840万米ドルの収益を報告しながら、これらのカテゴリー全体でプレゼンスを拡大しました。銅ケーブルアセンブリは、コストと運用上の親しみやすさが重要な短距離リンクで引き続き機能していますが、GPUインターコネクト市場は光システムとそれをサポートするスイッチングプラットフォームに向けてより多くの成長を着実に向けています。
注記: 個別セグメントのセグメントシェアはレポート購入時に入手可能
エンドユーザー別:ハイパースケーラーが現在の需要をリードしながらネオクラウドが急速に拡大
ハイパースケーラーおよびTier-1クラウドサービスプロバイダーは2025年のGPUインターコネクト市場の68.84%を占め、AIネイティブクラウドプロバイダーおよびネオクラウドは2031年まで最も速く成長すると予測されています。この優位性は、Microsoft、Amazon、Google、MetaがAIトレーニングと推論の両方のためにインフラを展開する規模を反映しています。彼らの合計2026年設備投資コミットメントは7,250億米ドルに達し、その大部分はAIコンピュートとネットワーキングに向けられており、GPUインターコネクト市場に最も深く最も予測可能な支出基盤を提供しています。これらの顧客は新しいアーキテクチャを早期に採用するため、ラックスケールシステム、高帯域幅ファブリック、および先進光スイッチングの展開において中心的な役割を果たしてきました。一部のハイパースケーラーがネットワーキングスタックの一部を内部で設計する場合でも、その調達規模はサプライヤーエコシステム全体の製品ロードマップを形成し続けています。
AIネイティブクラウドプロバイダーとネオクラウドは、より新しいファブリックへのアクセスを企業および研究顧客への直接的な販売ポイントとして使用しているため、急速に拡大しています。NVIDIAは、CoreWeave、Lambda、Oracle Cloud InfrastructureがSpectrum-X Ethernet Photonicsの最初の採用者の中にあったと述べており、新しいクラウドプラットフォームがネットワーキングパフォーマンスと電力効率を使用してサービスを差別化していることを示しています。政府およびソブリンコンピュートプログラムもバイヤーベースを拡大しており、カナダは2026年4月に24億カナダドル(17.6億米ドル)の連邦支援でAIソブリンコンピュートインフラプログラムを開始しました。大企業、学術コンピューティングセンター、および通信関連の展開もさらなる需要を追加していますが、これらは最も高価な独自スケールアップシステムよりもコストを意識したスケールアウトファブリックを好むことが多いです。この拡大する顧客ミックスは、グラフィックスプロセッシングユニット(GPU)インターコネクト市場に、ハイパースケーラーの購入が総活動のはるかに大きなシェアを占めていた以前のアクセラレーターサイクルよりも大きな需要基盤を与えています。
地域分析
北米は2025年のGPUインターコネクト市場シェアの56.62%を占め、他のすべての地域セグメントを大きく上回っています。この地域は、米国における集中したハイパースケーラー投資と、NVIDIA、Broadcom、Arista Networks、Astera Labs、Credo Technology、Coherent、Lumentumを含むGPUインターコネクト市場を形成する多くの企業が本社を置くか、重要な商業活動を行っているという事実から恩恵を受けています。この地域はまた、ラックスケールAIインフラの最大の早期採用基盤であり続けており、製品発表がより広範なグローバル展開の前に北米での展開に結びつくことが多いことを意味します。大規模なクラウド設備投資がこのリードを強化しており、最大のオペレーターが2026年の主要予算をAIコンピュートおよびネットワーキングインフラに向けています。カナダも公共コンピュート投資を通じて地域需要を広げており、そのAIソブリンコンピュートインフラプログラムは2026年4月に24億カナダドル(17.6億米ドル)の連邦支援を追加しました。[3]カナダ政府、「カナダ、大規模AIスーパーコンピューティング能力構築のための国家イニシアチブを開始」、カナダ政府、canada.ca
アジア太平洋地域は2031年まで16.44%のCAGRで拡大すると予測されており、GPUインターコネクト市場において最も成長の速い地域となっています。この地域の成長は、ソブリンAIの野心、地域クラウドの構築、およびコンピュートインフラをより大きく制御しようとする国々における国内技術スタックの必要性によって支えられています。この地域はまた、アジア太平洋地域の複数の大手テクノロジーグループがUALinkコンソーシアムに参加しており、オープンスケールアップ標準が主要なプラットフォーム企業やハードウェア参加者から真の関心を集めていることを示しているため、重要です。この地域の推進力は、顧客がコスト、供給アクセス、および技術制御を比較検討するにつれて、地域製造エコシステムと代替インターコネクトアプローチへの需要の両方を支える可能性があります。GPUインターコネクト市場にとって、アジア太平洋地域は需要センターとしてだけでなく、将来の標準採用とコンポーネント調達パターンに影響を与えることができる地域としても重要になっています。
欧州は現在規模が小さいですが、データ主権規則とAIガバナンスフレームワークが地域コンピュートインフラへの需要を支え続けているため、戦略的に重要であり続けています。英国は2026年に、2030年までに展開予定の国家AIスーパーコンピューターに向けて7億5,000万ポンド(10.2億米ドル)を含む、AIハードウェア計画の下で11億ポンド(14億米ドル)を割り当てると述べました。南米は採用においてより早期の段階にあり、活動は大規模な国内ファブリックプログラムよりもハイパースケーラーのクラウド拡大と研究コンピューティングに密接に結びついています。中東およびアフリカの需要は絶対的な規模ではまだ小さいですが、ソブリンコンピュートへの関心が高まっており、グラフィックスプロセッシングユニット(GPU)インターコネクト市場に現在のハイパースケーラーコアを超えた別の長期的な地域成長パスを与えています。

競合環境
GPUインターコネクト市場は適度に集中しており、少数のサプライヤーによる独自スケールアップリンクと、より広範なベンダーグループで競争されるスケールアウトネットワーキングという分割構造を持っています。NVIDIAは独自スケールアップ接続において最も強力なポジションを保持しており、NVLinkとNVSwitchがラックスケールシステム設計に直接組み込まれているため、最高密度のAI展開において強力な優位性を持っています。スケールアウトネットワーキングでは、Broadcom、Marvell、Cisco、Arista Networksがイーサネットスイッチング、光接続、および関連するAIネットワーキングレイヤー全体で競合しており、フィールドはより広くなっています。[4]Arista Networks、「Arista、AIファブリック向け次世代1.6テラビットポートフォリオを発表」、Arista Networks、arista.com オープン標準グループも、スケールアップとスケールアウトの両方の環境でマルベンダーファブリックへの道筋を顧客に提供することで、将来の競争を形成しています。これは、GPUインターコネクト市場がトップエンドでは集中しているが、クラスター間スケーリングをサポートするより広範なネットワーキングレイヤーではよりオープンで競争的であることを意味します。
2026年のいくつかの企業行動は、GPUインターコネクト市場における競合環境がどのように進化しているかを示しています。NVIDIAはLumentumとCoherentにそれぞれ20億米ドルの戦略的投資を発表し、大規模な購入コミットメントとともに、コパッケージドオプティクスロードマップのための上流光供給を確保するための直接的な動きを示しました。次いでAristaが1.6T AIファブリック向けに7060XE7シリーズを発表し、イーサネット中心の競合他社がより遅い移行サイクルを待つのではなく、より高速なAIスイッチングに迅速に移行していることを示しました。Astera Labsは2026年6月に台湾での事業を拡大し、AIプラットフォームの検証と地域統合作業を深め、GPUインターコネクト市場をサポートする製造およびシステムアセンブリ基盤に近づいていることを反映しています。コンソーシアムへの参加も戦略的ツールとなっており、ベンダーはオープンスケールアップシリコンが広範な生産に達する前に将来のソケット決定に影響を与えようとしています。これらの動きは総じて、競争が孤立したコンポーネント発表だけでなく、供給アクセス、エコシステムポジション、およびアクセラレーターあたりのコンテンツ拡大を中心に展開されていることを示しています。
GPUインターコネクト市場には、ソフトウェア定義ファブリック管理、異種クラスター制御、および商業的に実証されたUALink準拠スイッチシリコンにおいてまだオープンスペースがあります。The Registerは、UALink評価ハードウェアが2026年後半に予定されており、商用シリコンはその後に続くと報告しており、市場にはまだ量産段階での完全に確立されたオープンスケールアップ製品セットが欠けていることを示しています。このギャップは既存企業に顧客関係を深める時間を与えますが、ロックインへの買い手の不満が高まる前に信頼性の高いオープン代替品を出荷できる挑戦者にも余地を生み出します。Oracleは、GPUクラウド展開において積極的であるにもかかわらず、このコンテキストではインターコネクトハードウェアの供給側設計者ではなく主にエンドユーザーであり続けているため、競合フィールドは依然として主にネットワーキング、半導体、および光ベンダーによって定義されています。
GPUインターコネクト産業リーダー
NVIDIA Corporation
Broadcom Inc.
Marvell Technology, Inc.
Advanced Micro Devices, Inc.
Astera Labs, Inc.
- *免責事項:主要選手の並び順不同

最近の産業動向
- 2026年6月:Arista Networksは、Broadcom Tomahawk 6シリコン上に構築された次世代1.6T AIネットワーキングポートフォリオである7060XE7シリーズを発表しました。ポートあたり1.6Tで64ポート、集約スイッチング容量102.4 Tb/sをサポートし、空冷および液冷の両構成に対応しています。空冷バリアントは2026年第4四半期、液冷バリアントは2027年第1四半期に予定されており、スケールアップおよびスケールアウトAIファブリック展開の両方に向けてポートフォリオを位置付けています。
- 2026年6月:Astera Labsは台湾での事業を拡大し、拡張されたクラウドスケール相互運用性ラボを設立し、AIプラットフォームプロバイダーおよび台湾システムメーカーとの統合を深めるためにエンジニアリングプレゼンスを拡大し、GB300世代のAIクラスター検証を目指しています。
- 2026年5月:NVIDIAは、台湾GTC、Computex 2026においてSpectrum-X Ethernet Photonicsが生産に入ったと発表し、200G SerDesテクノロジー上に構築された最大409.6 Tb/sの集約帯域幅を持つ世界初のCPOイーサネットスイッチとして位置付けました。CoreWeave、Lambda、Oracle Cloud Infrastructureが最初の採用者の中にあり、広範な提供は2026年後半に予定されています。
- 2026年4月:UALinkコンソーシアムは2.0リリースで4つの仕様を公開し、マルチワークロードAI展開向けにネットワーク内コンピュート、チップレット定義、および管理フレームワークを導入しました。現在115社以上のメンバー企業が標準を管理しています。


グローバルGPUインターコネクト市場レポートの範囲
GPUインターコネクト市場は、グラフィックスプロセッシングユニット(GPU)、アクセラレーター、CPU、メモリリソース、および分散コンピューティングインフラ間の高速通信とデータ交換を可能にするハードウェア、ソフトウェア、プロトコル、およびネットワーキング技術で構成されています。GPUインターコネクトソリューションは、ますます大規模かつ複雑なコンピュート環境全体でシームレスな通信を促進することにより、現代の人工知能(AI)、機械学習、高性能コンピューティング(HPC)、クラウドコンピューティング、およびデータ約型ワークロードの帯域幅、レイテンシ、スケーラビリティ、および効率要件に対応するように設計されています。
GPUインターコネクト市場レポートは、インターコネクトアーキテクチャ/プロトコルアーキテクチャ(ネイティブPCIeベースインターコネクト、CXLベースインターコネクト、独自アクセラレータースケールアップインターコネクト、オープンアクセラレータースケールアップインターコネクト、InfiniBandベーススケールアウトインターコネクト、およびイーサネットベーススケールアウトインターコネクト)、接続ドメイン(ノード内/サーバー内接続、スケールアップ接続、スケールアウト接続、およびポッド間/キャンパスAI接続)、コンポーネント(スイッチ、ネットワークインターフェースカードおよびDPU、リタイマー、リドライバー、および接続IC、銅ケーブルアセンブリ、および光インターコネクト)、エンドユーザー(ハイパースケーラーおよびTier-1クラウドサービスプロバイダー、AIネイティブクラウドプロバイダーおよびネオクラウド、大企業およびプライベートAIインフラオペレーター、政府、ソブリンAIプログラム、および国立研究所、学術およびHPC研究機関、ならびに通信、エッジクラウド、およびマネージドサービスプロバイダー)、地域(北米、欧州、アジア太平洋、南米、ならびに中東およびアフリカ)別にセグメント化されています。市場予測は金額ベース(米ドル)で提供されます。
| ネイティブPCIeベースインターコネクト |
| CXLベースインターコネクト |
| 独自アクセラレータースケールアップインターコネクト |
| オープンアクセラレータースケールアップインターコネクト |
| InfiniBandベーススケールアウトインターコネクト |
| イーサネットベーススケールアウトインターコネクト |
| ノード内/サーバー内接続 |
| スケールアップ接続 |
| スケールアウト接続 |
| ポッド間/キャンパスAI接続 |
| スイッチ |
| ネットワークインターフェースカードおよびDPU |
| リタイマー、リドライバー、および接続IC |
| 銅ケーブルアセンブリ |
| 光インターコネクト |
| ハイパースケーラーおよびTier-1クラウドサービスプロバイダー |
| AIネイティブクラウドプロバイダーおよびネオクラウド |
| 大企業およびプライベートAIインフラオペレーター |
| 政府、ソブリンAIプログラム、および国立研究所 |
| 学術およびHPC研究機関 |
| 通信、エッジクラウド、およびマネージドサービスプロバイダー |
| 北米 | 米国 |
| カナダ | |
| メキシコ | |
| 欧州 | ドイツ |
| 英国 | |
| フランス | |
| イタリア | |
| 欧州その他 | |
| アジア太平洋 | 中国 |
| 日本 | |
| 韓国 | |
| インド | |
| 東南アジア | |
| アジア太平洋その他 | |
| 南米 | |
| 中東およびアフリカ |
| インターコネクトファブリック/プロトコルアーキテクチャ別 | ネイティブPCIeベースインターコネクト | |
| CXLベースインターコネクト | ||
| 独自アクセラレータースケールアップインターコネクト | ||
| オープンアクセラレータースケールアップインターコネクト | ||
| InfiniBandベーススケールアウトインターコネクト | ||
| イーサネットベーススケールアウトインターコネクト | ||
| 接続ドメイン別 | ノード内/サーバー内接続 | |
| スケールアップ接続 | ||
| スケールアウト接続 | ||
| ポッド間/キャンパスAI接続 | ||
| コンポーネント別 | スイッチ | |
| ネットワークインターフェースカードおよびDPU | ||
| リタイマー、リドライバー、および接続IC | ||
| 銅ケーブルアセンブリ | ||
| 光インターコネクト | ||
| エンドユーザー別 | ハイパースケーラーおよびTier-1クラウドサービスプロバイダー | |
| AIネイティブクラウドプロバイダーおよびネオクラウド | ||
| 大企業およびプライベートAIインフラオペレーター | ||
| 政府、ソブリンAIプログラム、および国立研究所 | ||
| 学術およびHPC研究機関 | ||
| 通信、エッジクラウド、およびマネージドサービスプロバイダー | ||
| 地域別 | 北米 | 米国 |
| カナダ | ||
| メキシコ | ||
| 欧州 | ドイツ | |
| 英国 | ||
| フランス | ||
| イタリア | ||
| 欧州その他 | ||
| アジア太平洋 | 中国 | |
| 日本 | ||
| 韓国 | ||
| インド | ||
| 東南アジア | ||
| アジア太平洋その他 | ||
| 南米 | ||
| 中東およびアフリカ | ||


レポートで回答される主要な質問
GPUインターコネクト市場の現在の規模は?
GPUインターコネクト市場は2026年に894.3億米ドルに達し、15.62%のCAGRで2031年までに1,848億米ドルに達すると予測されています。
どのインターコネクトファブリックが現在の収益をリードしていますか?
独自アクセラレータースケールアップインターコネクトが2025年に43.59%のシェアでリードし、NVLinkベースアーキテクチャを中心とした早期ラックスケール展開によって支えられています。
どの接続ドメインが最も速く拡大していますか?
スケールアップ接続が2025年に最大のシェアを保持しましたが、クラスターがより大きなキャンパスに広がるにつれて、ポッド間およびキャンパスAI接続が2031年まで最も速く成長すると予測されています。
なぜ光インターコネクトがGPUクラスターで普及しているのですか?
光インターコネクトは、より高密度なAIシステムがより優れた電力効率、信号整合性、および高帯域幅スイッチングを必要とするため、16.58%のCAGRで成長すると予測されています。
現在、誰がGPUインターコネクトハードウェアを最も多く購入していますか?
ハイパースケーラーおよびTier-1クラウドサービスプロバイダーが2025年に68.84%のシェアで需要をリードし、非常に大規模なAIトレーニングおよび推論インフラプログラムによって牽引されています。
どの地域が最も強い成長見通しを示していますか?
北米が2025年に56.62%のシェアでリードし、アジア太平洋地域が2031年まで16.44%のCAGRで最も速い成長を記録すると予測されています。
最終更新日:




