Taille et part du marché de l'étiquetage des données par IA
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2020 - 2031 |
|---|---|
| Taille du Marché (2026) | 2.32 Milliards de dollars |
| Taille du Marché (2031) | 6.53 Milliards de dollars |
| Taux de croissance (2026 - 2031) | 22.95% CAGR |
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Amérique du Nord |
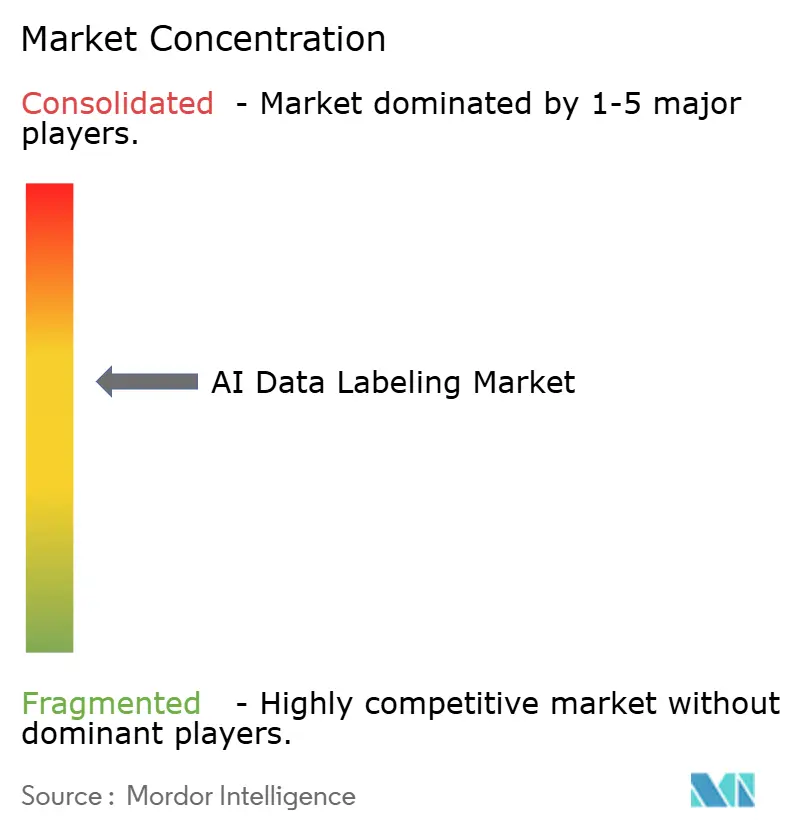
| Concentration du Marché | Moyen |
Acteurs majeurs *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. | |
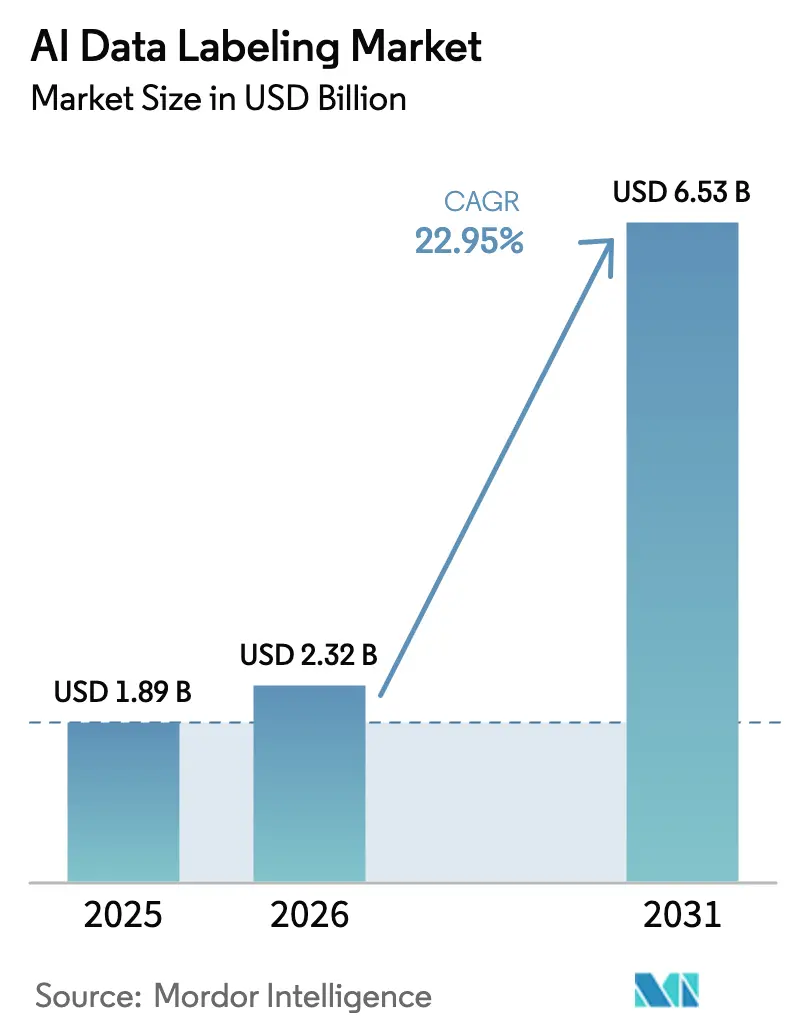
Analyse du marché de l'étiquetage des données par IA par Mordor Intelligence
La taille du marché de l'étiquetage des données par IA en 2026 est estimée à 2,32 milliards USD, en hausse par rapport à la valeur de 2025 de 1,89 milliard USD, avec des projections pour 2031 indiquant 6,53 milliards USD, croissant à un TCAC de 22,95 % sur la période 2026-2031. Cette montée en puissance rapide reflète la façon dont l'annotation de données est passée d'un centre de coûts à une capacité stratégique qui sous-tend la conformité réglementaire, l'alignement des modèles et la différenciation des entreprises. L'intensification du développement des véhicules autonomes, la hausse des investissements des entreprises dans l'IA générative et le déploiement d'exigences d'audit juridiquement contraignantes pour les données d'entraînement constituent les principaux facteurs favorables. Les plateformes externalisées qui combinent l'évolutivité de la main-d'œuvre avec l'assurance qualité automatisée continuent de gagner des parts de marché, tandis que les flux de travail hybrides avec intervention humaine dans la boucle améliorent la productivité de l'étiquetage sur les ressources image, vidéo et texte. L'expansion géographique est façonnée par des régimes de confidentialité divergents et la disponibilité des talents : l'Amérique du Nord maintient la plus grande base de demande, l'Asie-Pacifique affiche la croissance la plus forte et l'Europe met l'accent sur la traçabilité vérifiable.
Principaux enseignements du rapport
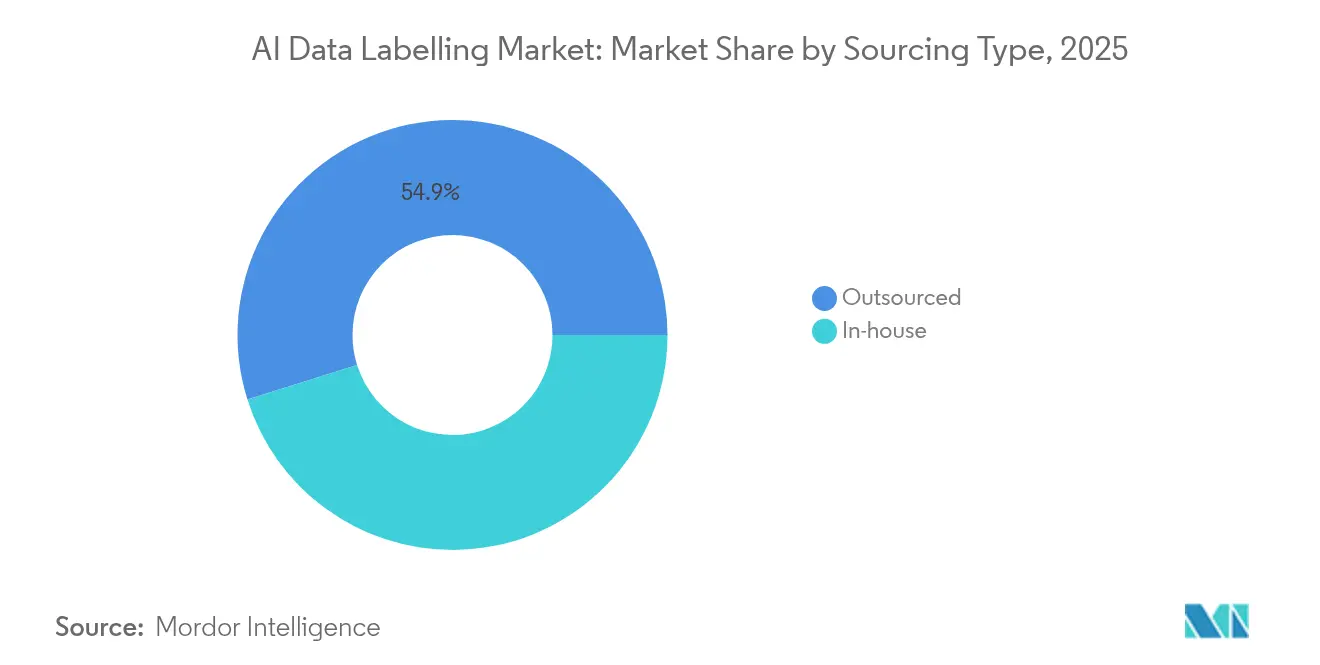
- Par type d'approvisionnement, l'externalisation a capturé 54,85 % de la part du marché de l'étiquetage des données par IA en 2025 ; les opérations internes accusent un retard de croissance alors que les services externalisés se développent à un TCAC de 28,37 % jusqu'en 2031.
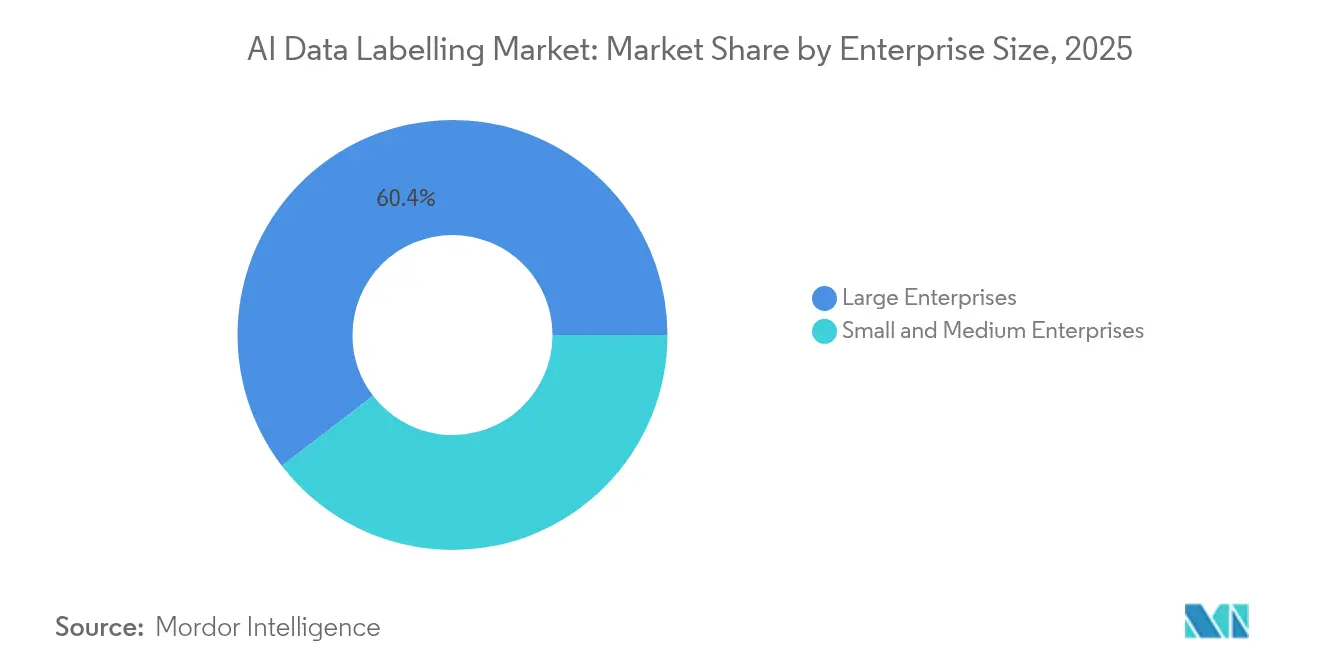
- Par taille d'entreprise, les grandes entreprises détenaient 60,40 % de la taille du marché de l'étiquetage des données par IA en 2025, tandis que les PME affichent le TCAC le plus rapide de 26,42 % jusqu'en 2031.
- Par type de données, l'annotation de texte était en tête avec 27,30 % du chiffre d'affaires 2025 ; la vidéo devrait progresser à un TCAC de 31,18 % jusqu'en 2031.
- Par méthode d'étiquetage, les flux de travail manuels ont conservé une part de 78,10 % en 2025 ; les méthodes semi-supervisées et avec intervention humaine dans la boucle s'accélèrent à un TCAC de 33,15 %.
- Par secteur d'utilisation final, l'automobile et la mobilité détenaient 23,10 % de part de marché en 2025 ; la santé progresse à un TCAC de 24,63 % grâce au soutien des politiques en faveur des marchés d'imagerie médicale.
- Par région, l'Amérique du Nord commandait 34,70 % de part en 2025, tandis que l'Asie-Pacifique est la région à la croissance la plus rapide avec un TCAC de 23,35 % jusqu'en 2031.
Remarque : Les chiffres de la taille du marché et des prévisions de ce rapport sont générés à l’aide du cadre d’estimation propriétaire de Mordor Intelligence, mis à jour avec les données et analyses les plus récentes disponibles en 2026.
Tendances et perspectives mondiales du marché de l'étiquetage des données par IA
Analyse de l'impact des facteurs moteurs*
| Facteur | Impact (~) % sur les prévisions de TCAC | Pertinence géographique | Horizon temporel de l'impact |
|---|---|---|---|
| Pénétration des véhicules connectés et autonomes | +6.2% | Amérique du Nord, Chine, UE | Moyen terme (2 à 4 ans) |
| Initiatives d'IA d'entreprise et de mégadonnées | +5.8% | Amérique du Nord, Asie-Pacifique | Court terme (≤ 2 ans) |
| Pipelines de données RLHF pour l'IA générative | +4.1% | Amérique du Nord, UE, expansion vers l'Asie-Pacifique | Moyen terme (2 à 4 ans) |
| Renforcement des lois sur la gouvernance de l'IA | +3.7% | UE, Amérique du Nord, répercussions vers l'Asie-Pacifique | Long terme (≥ 4 ans) |
| Puces d'IA embarquée pour l'apprentissage continu | +2.9% | Adoption précoce mondiale en Amérique du Nord et en Asie-Pacifique | Long terme (≥ 4 ans) |
| Jeux de données synthétiques nécessitant une vérité terrain micro | +2.3% | Pôles technologiques mondiaux | Moyen terme (2 à 4 ans) |
| Source: Mordor Intelligence | |||
Hausse de la pénétration des véhicules connectés et autonomes
Les programmes de niveau 4 et de niveau 5 exigent des étiquettes de nuage de points LiDAR haute densité, de cuboïdes 3D et de vidéo temporelle qui capturent les particularités de conduite régionales. Les équipementiers automobiles mettent l'accent sur l'efficacité de l'inférence, de sorte que les directives d'annotation intègrent désormais des a priori sur la taille des objets et des métadonnées d'occlusion qui compriment les paramètres du modèle sans éroder la précision de la perception. Les régulateurs de sécurité en Chine et dans l'UE exigent des preuves de provenance, transformant les pipelines d'étiquetage conformes en boucliers concurrentiels qui favorisent les fournisseurs disposant de flux de travail de documentation intégrés[2]Source : BasicAI, « Techniques avancées d'annotation LiDAR 3D pour la conduite autonome », basic.ai.
Prolifération des initiatives d'IA d'entreprise et de mégadonnées
Les opérateurs des services financiers, du commerce de détail et des télécommunications développent des jeux de données propriétaires de documents et d'interactions qui nécessitent un balisage spécifique au domaine pour exploiter les analyses prédictives du risque, les moteurs de prochaine meilleure action et le marketing hyperpersonnalisé. L'apprentissage par renforcement à partir de retours humains (RLHF) multiplie la demande d'évaluateurs qualifiés qui notent l'utilité des modèles, remodelant les accords de niveau de service autour de la profondeur thématique plutôt que du volume d'annotation.
Émergence des pipelines de données RLHF pour l'IA générative
Les tâches RLHF — notamment le classement comparatif en format libre, l'identification des déclencheurs de sécurité et la détection des contradictions — commandent des tarifs premium et des délais de montée en compétences plus longs. Les fournisseurs qui développent leur capacité pour répondre à la demande investissent dans des programmes de formation des évaluateurs et des modèles statistiques de prédiction des erreurs qui détectent les incohérences avant la révision par le client. Des chercheurs d'Apple ont montré que des algorithmes prédictifs peuvent signaler 65 à 75 % des erreurs probables, ancrant de nouveaux référentiels de qualité.
Renforcement des lois sur la gouvernance de l'IA exigeant une vérité terrain vérifiable
La loi européenne sur l'IA et le paquet de directives de la CNIL française exigent une divulgation claire des sources de données, du statut de consentement et des protocoles d'annotation tout au long du cycle de vie des modèles. Des règles comparables de l'Autorité monétaire de Singapour créent des obligations sectorielles spécifiques pour les institutions financières. Les fournisseurs équipés de pistes d'audit granulaires, de contrôles d'accès basés sur les rôles et d'environnements d'étiquetage chiffrés obtiennent le statut de fournisseur privilégié pour les déploiements transfrontaliers.
Analyse de l'impact des facteurs limitants*
| Facteur limitant | Impact (~) % sur les prévisions de TCAC | Pertinence géographique | Horizon temporel de l'impact |
|---|---|---|---|
| Préoccupations relatives à la confidentialité des données et à la sécurité de la propriété intellectuelle | −2.8% | UE, Amérique du Nord | Court terme (≤ 2 ans) |
| Pénurie d'annotateurs experts | −2.1% | Domaines à haute qualification mondiale | Moyen terme (2 à 4 ans) |
| Hausse de l'inflation des coûts de main-d'œuvre | −1.7% | Amérique du Nord, Europe occidentale | Court terme (≤ 2 ans) |
| Pression de banalisation due aux données synthétiques | −1.4% | Pôles technologiques mondiaux | Moyen terme (2 à 4 ans) |
| Source: Mordor Intelligence | |||
Préoccupations relatives à la confidentialité des données et à la sécurité de la propriété intellectuelle
Les lois obligatoires de localisation des données et les audits des fournisseurs à confiance zéro augmentent les frais généraux pour les effectifs distribués. Les entreprises traitant des scanners médicaux ou des transactions financières limitent l'accès à distance, poussant les fournisseurs à déployer des clouds souverains et des postes de travail sur site conformes aux mandats de chiffrement, de gestion des clés et de journaux d'audit. L'investissement supplémentaire augmente les coûts et ralentit l'intégration.
Pénurie d'annotateurs experts
L'imagerie médicale, l'analyse de contrats juridiques et les cas limites de la conduite autonome nécessitent des annotateurs dotés de qualifications avancées et de cycles de formation plus longs. La durée moyenne de service des évaluateurs de niveau intermédiaire dans les principaux pôles tels que l'Inde est de 12 à 18 mois, ce qui entraîne une rotation et des dépenses de recyclage élevées. Les outils hybrides assistés par IA compensent les lacunes en volume, mais la validation humaine reste essentielle pour la détection des biais et les garanties de performance[1]Source : NIST, « Approches d'évaluation avec intervention humaine dans la boucle pour les systèmes d'IA », nist.gov.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des segments
Par type d'approvisionnement : la domination de l'externalisation s'accélère
Les fournisseurs externalisés ont généré 54,85 % de la part du marché de l'étiquetage des données par IA en 2025, les entreprises ayant privilégié la rapidité et l'assurance réglementaire. Le TCAC de 28,37 % du segment jusqu'en 2031 le positionne comme le principal contributeur aux revenus incrémentaux au sein du marché de l'étiquetage des données par IA. Les contrats hybrides associent désormais des effectifs offshore à des nœuds d'audit onshore pour satisfaire aux clauses de souveraineté, créant une structure de coûts à deux niveaux qui ancre les fournisseurs de plateformes.
Les équipes internes persistent pour les projets propriétaires ou hautement sensibles, mais peinent à égaler l'étendue des outils et les certifications de conformité atteintes par les fournisseurs spécialisés. À mesure que les flux de travail de données synthétiques arrivent à maturité, les entreprises intègrent des partenaires externes pour la vérification de la micro-vérité terrain plutôt que pour l'étiquetage à grande échelle, maintenant la demande même lorsque les volumes d'annotation globaux diminuent.



Par type de données : l'étiquetage vidéo émerge comme leader de la croissance
Le TCAC de 31,18 % de l'annotation vidéo en fait la tranche à expansion la plus rapide du marché de l'étiquetage des données par IA. Les systèmes de véhicules autonomes nécessitent des flux multi-caméras 4K assemblés avec des maillages LiDAR, élevant la valeur moyenne des projets par rapport aux ensembles d'images traditionnels. Les ressources textuelles représentent toujours 27,30 % de la part des revenus, portées par l'ajustement de l'IA conversationnelle et les programmes d'intelligence documentaire, mais la compression des prix est plus marquée car la correspondance automatisée de modèles peut pré-étiqueter de grandes fractions de données.
Les tâches de nuage de points 3D impliquant le LiDAR et le radar présentent des barrières à l'entrée élevées en raison des outils spécialisés et des connaissances géométriques avancées. Les projets audio gagnent en dynamique grâce à la biométrie vocale et à l'automatisation des centres d'appels, mais restent un segment à revenus à un chiffre. Les mandats multimodaux qui synchronisent les flux de texte, d'image, de vidéo et de capteurs sous-tendent de nouvelles offres groupées qui récompensent les fournisseurs dotés de capacités d'orchestration complète.
Par méthode d'étiquetage : la révolution semi-supervisée s'accélère
L'annotation manuelle a maintenu une part de 78,10 % en 2025 dans la taille globale du marché de l'étiquetage des données par IA, soulignant le besoin continu de jugement humain dans les contextes critiques pour la sécurité. Néanmoins, les méthodes semi-supervisées et avec intervention humaine dans la boucle affichent un TCAC de 33,15 % et établissent un nouveau référentiel de productivité sur l'ensemble du marché de l'étiquetage des données par IA. Les stratégies de requête par apprentissage actif réduisent désormais les échantillons redondants de 30 à 40 %, réduisant les délais de cycle sans éroder le rappel.
Les moteurs d'étiquetage automatisé gèrent les tâches simples de boîte englobante ou de classification des sentiments, mais transfèrent les instances ambiguës à des évaluateurs experts. Les grands modèles de langage génèrent de plus en plus des étiquettes de premier passage pour des taxonomies de niche, que les humains affinent. Les fournisseurs se différencient grâce à des contrôles de qualité statistiques — tels que le score d'accord inter-annotateurs et les audits par échantillonnage — qui maintiennent la confiance tout en augmentant le débit.
Par taille d'entreprise : l'adoption par les PME accélère la transformation numérique
Les grandes entreprises commandent 60,40 % de la taille du marché de l'étiquetage des données par IA en 2025, portées par des projets complexes de conduite autonome, d'imagerie médicale et de défense. Pourtant, les PME progressent à un TCAC de 26,42 % grâce aux outils cloud à la demande qui abaissent les barrières à l'entrée. Les modèles spécifiques à l'industrie permettent aux petits détaillants, assureurs et fabricants de déployer des modèles avec un personnel interne limité en apprentissage automatique, élargissant la base de demande pour les pipelines d'annotation standardisés.
Les offres d'abonnement hybrides regroupent des crédits d'étiquetage avec des tableaux de bord d'évaluation des modèles, réduisant les frictions d'approvisionnement pour les parties prenantes financières et de conformité. Les entreprises de taille intermédiaire à forte croissance adoptent des modèles de micro-tâches externalisées qui s'adaptent aux volumes saisonniers, tout en conservant en interne les jeux de données de test de base pour la gouvernance. Les subventions de perfectionnement des gouvernements régionaux catalysent davantage la participation des PME sur l'ensemble du marché de l'étiquetage des données par IA.
Par secteur d'utilisation final : la santé mène la transformation de la croissance
La part de marché de la santé et des sciences de la vie affiche un TCAC de 24,63 % jusqu'en 2031, dépassant tous les autres secteurs verticaux au sein du secteur de l'étiquetage des données par IA. Les référentiels d'imagerie soutenus par la FDA accélèrent la validation des algorithmes, suscitant une demande de segmentation d'organes au niveau des pixels, de délimitation des lésions et de fusion multimodale des données omiques. L'automobile et la mobilité conservent la plus grande part des revenus à 23,10 % en 2025, mais les audits réglementaires de sécurité en cas de collision entraînent des actualisations continues des jeux de données qui soutiennent les dépenses.
Les institutions financières intensifient les flux de travail anti-fraude et de connaissance du client nécessitant l'étiquetage de documents et l'annotation de graphes de transactions. La robotique industrielle utilise la détection de défauts basée sur la vision qui dépend d'une distribution équilibrée des classes, tandis que les opérateurs de télécommunications annotent les journaux d'événements réseau pour alimenter les contrôleurs RAN auto-optimisants. Le code de conformité distinct de chaque secteur vertical entraîne des accords de niveau de service sur mesure qui renforcent la spécialisation et le pouvoir de fixation des prix sur l'ensemble du marché de l'étiquetage des données par IA.
Analyse géographique
L'Amérique du Nord a généré 34,70 % des revenus de 2025 et reste le plus grand groupe d'acheteurs du marché de l'étiquetage des données par IA. Le contrat pluriannuel Thunderforge de Scale AI pour le ministère de la Défense souligne la demande fédérale de pipelines d'annotation à haute assurance. Les écosystèmes de santé et de conduite autonome des États-Unis renforcent les volumes, tandis que la chaîne d'approvisionnement automobile transfrontalière du Canada alimente des projets d'image et de texte bilingues. Les pôles nearshore du Mexique remportent les travaux de débordement qui équilibrent coût et proximité, bien que les mandats de confidentialité de la CCPA et sectoriels spécifiques poussent les fournisseurs à déployer une infrastructure nationale sécurisée. La hausse des coûts de rémunération déclenche une expansion nearshore, mais les acheteurs américains valorisent toujours les clouds souverains nationaux pour les charges de travail top secrètes.
L'Asie-Pacifique affiche le TCAC régional le plus rapide de 23,35 % jusqu'en 2031, augmentant sa contribution au marché de l'étiquetage des données par IA chaque année. La Chine investit 45 milliards USD dans l'infrastructure d'IA et impose des normes d'étiquetage de contenu qui stimulent l'échelle des fournisseurs nationaux. La main-d'œuvre d'annotation de l'Inde dépasse 450 000 évaluateurs, servant des contrats mondiaux tout en ancrant le développement de modèles indigènes. Le Japon se concentre sur la vision des robots chirurgicaux et l'annotation en radiologie, générant une demande à haute marge pour des professionnels certifiés médicalement. La loi de base sur l'IA naissante de la Corée du Sud positionne les conglomérats de télécommunications et d'automobile pour externaliser de vastes jeux de données multi-capteurs. Les pôles financiers de l'ASEAN adoptent des cadres de gestion des risques liés à l'IA, et l'Australie cible des jeux de données de vision pour l'agriculture de précision qui soutiennent la prédiction de la sécheresse.
L'Europe maintient une croissance stable à deux chiffres moyens alors que le RGPD, la loi européenne sur l'IA et les directives de la CNIL institutionnalisent les audits de provenance. Les fournisseurs locaux déploient des bacs à sable d'annotation préservant la confidentialité avec des calculs sur site pour satisfaire aux règles strictes sur les données personnelles. L'Allemagne est pionnière dans l'étiquetage de la robotique industrielle, tandis que le secteur des services financiers du Royaume-Uni commande des jeux de données d'alignement de l'IA conversationnelle malgré les complexités de transfert de données après le Brexit. Les gouvernements nordiques financent des programmes d'IA pour l'énergie durable qui nécessitent l'annotation d'images satellitaires, et l'Europe du Sud bénéficie de projets d'analyse du tourisme. Dans tous les États membres, les livrables d'atténuation des biais et les rapports d'explicabilité influencent les listes restreintes de fournisseurs, renforçant la prime axée sur la conformité de la région.
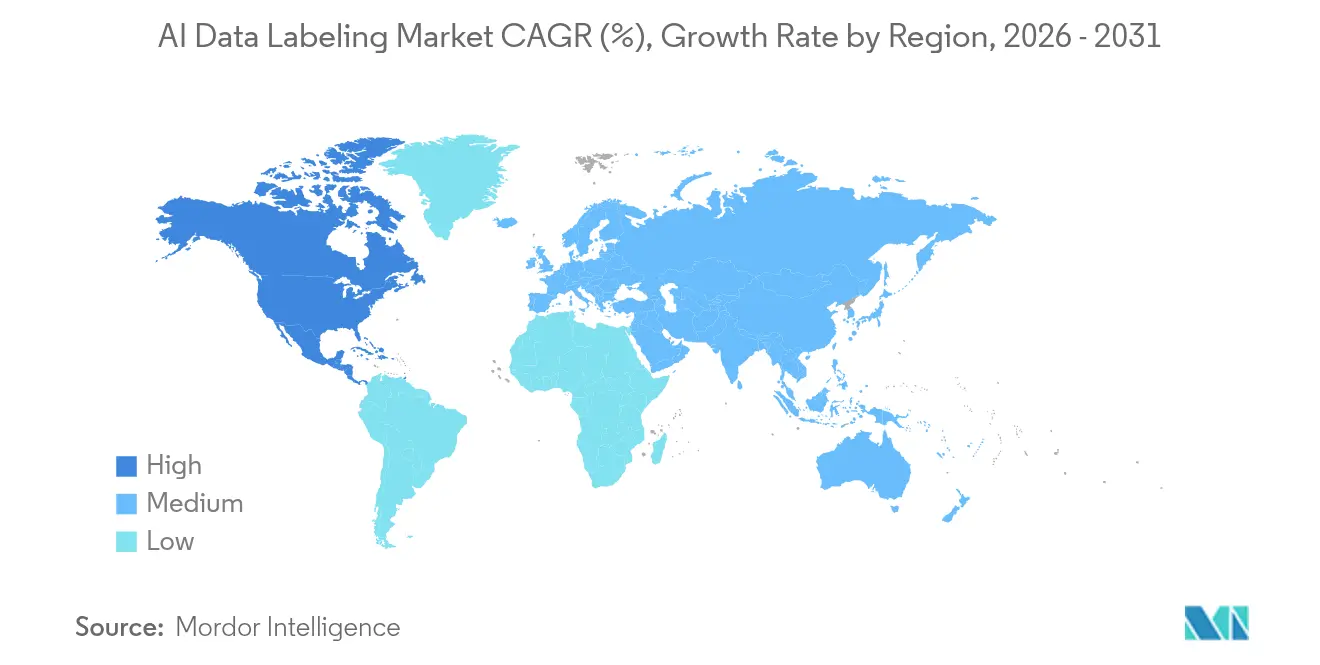

Paysage concurrentiel
Le marché de l'étiquetage des données par IA présente une fragmentation modérée : aucun fournisseur ne contrôle plus d'un cinquième des dépenses mondiales, mais les acteurs d'envergure tels que Scale AI, Appen et iMerit exercent un pouvoir d'achat sur les écosystèmes d'outils. La valorisation de 14 milliards USD de Scale AI repose sur l'étendue de sa plateforme intégrée, des flux de travail RLHF au déploiement en enclave sécurisée, soutenue par des contrats fédéraux qui exigent une certification continue de test de pénétration. Appen élargit ses capacités de contrôle qualité automatisé pour protéger les marges à mesure que les coûts de main-d'œuvre augmentent, tandis qu'iMerit s'appuie sur des programmes de mentorat de domaine pour sécuriser des projets de santé et de géospatial.
Les entrants sur les plateformes se différencient en fusionnant les tableaux de bord d'annotation et d'évaluation, permettant aux clients d'orchestrer le prétraitement des données, l'étiquetage, la constitution des jeux de test et la surveillance continue de la santé des modèles depuis une interface unique. Les moteurs d'assurance qualité qui utilisent l'échantillonnage statistique et le tri automatique des cas limites réduisent les cycles de révision de 15 à 25 %. Les grands acteurs technologiques établis intègrent des modules d'étiquetage dans leurs suites d'IA cloud, renforçant l'intégration mais soulevant des préoccupations de neutralité parmi les utilisateurs multi-cloud.
Les pionniers de l'étiquetage programmatique tels que Snorkel AI défendent des cadres de supervision faible qui permettent aux scientifiques des données de codifier des heuristiques plutôt que d'étiqueter manuellement des millions d'exemples. Les fournisseurs de données synthétiques s'associent à des spécialistes de l'étiquetage pour la vérification par sondage, illustrant que la supervision humaine reste indispensable lorsque la sécurité et les biais sont en jeu. La réglementation impose des pistes d'audit immuables, un chiffrement au repos et un accès basé sur les rôles que les concurrents plus petits peinent à financer, poussant le marché vers une structure en haltère composée de grandes plateformes complètes et d'experts de niche dans des domaines spécifiques.
Leaders du secteur de l'étiquetage des données par IA
Appen Limited
Scale AI Inc.
Amazon Web Services
Google LLC
CloudFactory Ltd.
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Développements récents du secteur
- Mars 2025 : Scale AI a obtenu un contrat pluriannuel de plusieurs millions de dollars du ministère de la Défense dans le cadre du programme Thunderforge pour soutenir la planification opérationnelle assistée par IA en partenariat avec Anduril et Microsoft.
- Février 2025 : La CNIL française a publié des recommandations détaillées de conformité à l'IA exigeant la divulgation explicite des sources de données d'entraînement et des normes d'annotation, augmentant la demande de pipelines d'étiquetage vérifiables.
- Décembre 2024 : iSoftStone est apparu sur la « Carte du secteur de l'annotation des données d'intelligence artificielle » de l'Académie chinoise des technologies de l'information et des communications, validant le déploiement de la plateforme multi-villes de l'entreprise.
- Avril 2024 : Bayer et Google Cloud ont lancé une collaboration pour développer des outils de radiologie basés sur l'IA générative en utilisant des étiquettes d'images médicales organisées sur l'environnement Vertex AI de Google.


Cadre de la méthodologie de recherche et portée du rapport
Définitions du marché et couverture principale
Mordor Intelligence définit le marché de l'étiquetage des données par IA comme les revenus générés par les services qui balisent, classifient ou enrichissent des ressources numériques brutes, notamment des images, des vidéos, du texte, de l'audio et des nuages de points 3D, afin que les jeux de données étiquetés résultants puissent entraîner ou valider des modèles d'apprentissage automatique. Les ventes de plateformes logicielles pures sont suivies uniquement lorsqu'elles sont associées à des services d'étiquetage par ressource ; les frais de licence autonomes, les moteurs de données synthétiques et les activités de collecte de données brutes sont exclus.
Exclusion du périmètre : les licences d'outils d'annotation autonomes, la génération de données synthétiques et les revenus de courtage de données se situent en dehors de notre périmètre de marché.
Aperçu de la segmentation
- Par type d'approvisionnement
- Interne
- Externalisé
- Par type de données
- Texte
- Image
- Audio
- Vidéo
- Nuage de points 3D
- Par méthode d'étiquetage
- Manuelle
- Automatique
- Semi-supervisée / Avec intervention humaine dans la boucle
- Par taille d'entreprise
- Petites et moyennes entreprises
- Grandes entreprises
- Par secteur d'utilisation final
- Automobile et mobilité
- Santé et sciences de la vie
- Commerce de détail et commerce électronique
- Banque, services financiers et assurance
- Informatique et télécommunications
- Industrie et robotique
- Autres (agriculture, médias, etc.)
- Par géographie
- Amérique du Nord
- États-Unis
- Canada
- Mexique
- Amérique du Sud
- Brésil
- Argentine
- Reste de l'Amérique du Sud
- Europe
- Royaume-Uni
- Allemagne
- France
- Italie
- Espagne
- Pays nordiques
- Reste de l'Europe
- Moyen-Orient et Afrique
- CCG
- Israël
- Afrique du Sud
- Reste du Moyen-Orient et de l'Afrique
- Asie-Pacifique
- Chine
- Inde
- Japon
- Corée du Sud
- ASEAN
- Australie
- Nouvelle-Zélande
- Reste de l'Asie-Pacifique
- Amérique du Nord
Méthodologie de recherche détaillée et validation des données
Recherche primaire
Nous interrogeons des responsables de la science des données chez des développeurs de véhicules autonomes, des directeurs de la conformité dans le domaine de l'IA en santé et des fournisseurs de services d'annotation en Asie-Pacifique pour tester les points de prix, le débit au niveau des ressources et les taux de rejet issus du travail documentaire. Des enquêtes auprès des acheteurs régionaux ancrent davantage les tendances de dépenses émergentes parmi les PME par rapport aux grandes entreprises.
Recherche documentaire
Nos analystes commencent par compiler des statistiques commerciales et des dépôts réglementaires provenant de sources telles que l'enquête annuelle du Service du recensement des États-Unis, les statistiques TIC d'Eurostat, l'Association japonaise de l'industrie de l'électronique et des technologies de l'information, et des analyses de brevets accessibles via Questel. Des données complémentaires proviennent des formulaires 10-K déposés auprès de la SEC, des présentations aux investisseurs des fournisseurs et de portails spécialisés tels que WSTS (volumes de puces stimulant la demande de jeux de données) et les archives de presse Dow Jones Factiva. Ces sources clarifient les pipelines de projets, les coûts unitaires et l'intensité de l'externalisation dans les secteurs d'utilisation final. La liste est indicative ; de nombreuses autres publications alimentent la base de preuves.
Dimensionnement du marché et prévisions
Une construction descendante du bassin de demande, reliant le nombre mondial de projets d'IA, les volumes moyens de ressources étiquetées et le prix courant par ressource, est recoupée par des agrégations ascendantes sélectives de fournisseurs. Les variables clés comprennent les équivalents en millions d'images par itération de modèle, la part des projets externalisés, la majoration des coûts de documentation liée à la loi européenne sur l'IA, la fréquence d'actualisation des jeux de données d'IA générative et le salaire moyen d'annotation dans les principaux pôles. Une régression multivariée, soutenue par des hypothèses validées par des experts, projette chaque facteur jusqu'en 2030 ; les résultats sont ajustés lorsque les totaux ascendants s'écartent au-delà d'une bande de variance interne.
Validation des données et cycle de mise à jour
Les résultats passent des contrôles d'anomalies, une révision par les pairs et une approbation de la direction. Nous actualisons le modèle annuellement, en émettant des révisions intermédiaires lorsque des événements importants, tels que des pics de financement, des décisions réglementaires ou des attributions de contrats majeurs, modifient la base de référence. Une nouvelle analyse par un analyste précède chaque livraison client pour garantir l'actualité.
Pourquoi la base de référence de Mordor Intelligence pour l'étiquetage des données par IA est-elle fiable
Les estimations publiées dans le secteur divergent souvent parce que les entreprises choisissent différents compartiments de revenus, hypothèses de prix et rythmes de mise à jour. Notre périmètre discipliné, nos variables actualisées et notre recalibrage transparent font la différence.
Les principaux facteurs d'écart comprennent la question de savoir si les frais de collecte de données sont regroupés avec l'étiquetage, la façon dont les données synthétiques sont traitées et la cadence à laquelle les prix de vente moyens sont recalculés pour tenir compte de l'inflation monétaire ou salariale.
Comparaison de référence
| Taille du marché | Source anonymisée | Principal facteur d'écart |
|---|---|---|
| 1,89 milliard USD | ||
| 4,89 milliards USD | Consultance mondiale A | Combine les frais de collecte et d'étiquetage ainsi que les licences d'outils ; ventilations limitées par type d'approvisionnement |
| 4,87 milliards USD | Revue spécialisée B | Ajoute les revenus des plateformes de crowdsourcing et les ventes de jeux de données d'entraînement d'IA ; périmètre géographique peu clair |
Ces contrastes montrent que Mordor Intelligence fournit une base de référence équilibrée et clairement délimitée que les décideurs peuvent relier à des variables explicites et à des étapes reproductibles, offrant aux clients une plus grande confiance situationnelle.


Questions clés auxquelles le rapport répond
Quelle est la taille actuelle du marché de l'étiquetage des données par IA ?
La taille du marché de l'étiquetage des données par IA est de 2,32 milliards USD en 2026, avec une prévision d'atteindre 6,53 milliards USD d'ici 2031.
Quelle région est en tête du marché de l'étiquetage des données par IA ?
L'Amérique du Nord détient la plus grande part de 34,70 % en raison de l'adoption précoce par les entreprises, bien que l'Asie-Pacifique enregistre la croissance la plus rapide avec un TCAC de 23,35 %.
Pourquoi l'annotation vidéo croît-elle plus vite que les autres types de données ?
Le développement des véhicules autonomes et l'IA de surveillance nécessitent un étiquetage haute résolution multi-images, entraînant un TCAC de 31,18 % pour les projets vidéo.
Comment le renforcement des réglementations affecte-t-il la demande d'étiquetage des données ?
Des régimes tels que la loi européenne sur l'IA imposent une traçabilité vérifiable des données d'entraînement, incitant les entreprises à contracter des fournisseurs dotés de contrôles de qualité et de confidentialité certifiés.
Qu'est-ce que le RLHF et pourquoi est-il important pour l'étiquetage ?
L'apprentissage par renforcement à partir de retours humains aligne les grands modèles de langage sur l'intention de l'utilisateur ; il repose sur des annotateurs qualifiés pour examiner et noter les sorties des modèles, créant une demande de services premium.
Les PME adoptent-elles des services d'étiquetage des données par IA ?
Oui, les PME affichent un TCAC de 26,42 % car les plateformes cloud et les modèles prédéfinis réduisent les barrières techniques et financières au lancement de projets d'IA.
Dernière mise à jour de la page le:



