Taille et part du marché du marquage de données
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2020 - 2031 |
|---|---|
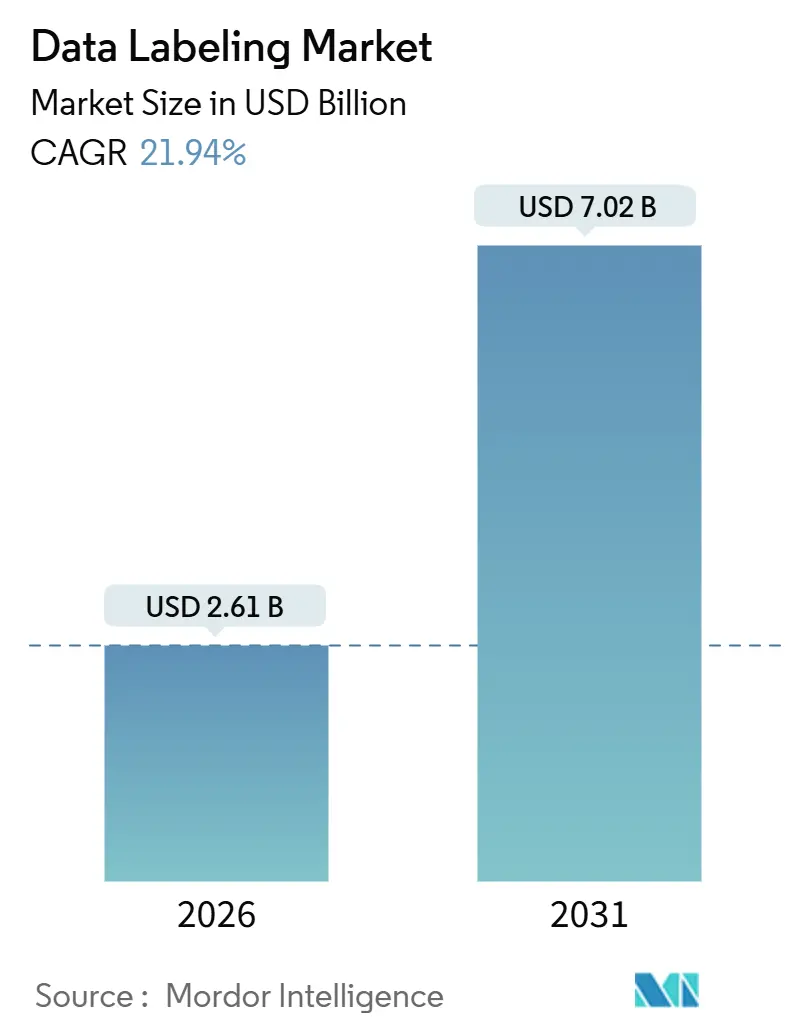
| Taille du Marché (2026) | 2.61 Milliards de dollars |
| Taille du Marché (2031) | 7.02 Milliards de dollars |
| Taux de croissance (2026 - 2031) | 21.94% CAGR |
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Amérique du Nord |
| Concentration du Marché | Moyen |
Acteurs majeurs *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. | |
Analyse du marché du marquage de données par Mordor Intelligence
La taille du marché du marquage de données s'établit à 2,61 milliards USD en 2026 et devrait atteindre 7,02 milliards USD d'ici 2031, reflétant un TCAC robuste de 21,94 %. Cette hausse est alimentée par trois catalyseurs interdépendants. Les développeurs de modèles de fondation à la recherche de corpus organisés par des experts pour réduire les hallucinations, les constructeurs automobiles validant des architectures de fusion de capteurs nécessitant des étiquettes 3D au niveau de l'image, et les entreprises industrielles déployant à grande échelle des IA de maintenance prédictive dépendant de données de séries temporelles de pannes étiquetées. L'investissement de 15 milliards USD de Meta dans Scale AI en juin 2025 a cristallisé l'infrastructure de marquage comme un avantage stratégique plutôt qu'un service banalisé, incitant OpenAI et Google à diversifier leurs fournisseurs d'annotation. L'annotation vidéo pour les systèmes autonomes, les modèles d'approvisionnement hybrides combinant expertise interne et main-d'œuvre externalisée, et les pipelines de marquage auto-supervisé réduisant les coûts par étiquette se développent tous plus rapidement que le marché du marquage de données dans son ensemble, créant des opportunités pour les plateformes qui synchronisent les spécialistes humains et le marquage assisté par modèle. L'Amérique du Nord reste l'ancre des revenus, mais la dynamique régionale est remodelée par la politique asiatique en faveur de l'IA industrielle.
Principaux enseignements du rapport
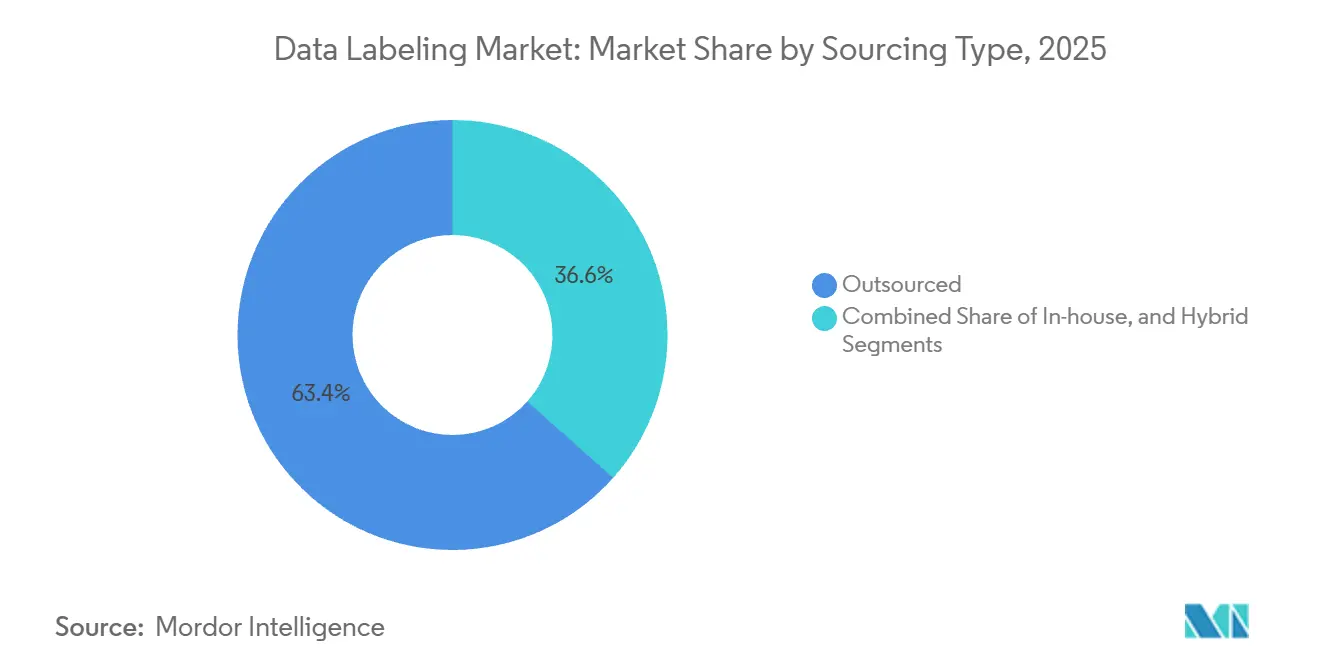
- Par type d'approvisionnement, le marquage externalisé a dominé avec 63,43 % de la part du marché du marquage de données en 2025, tandis que l'approvisionnement hybride progresse à un TCAC de 22,48 % jusqu'en 2031.
- Par type de données, les jeux de données d'images ont capturé une part de 36,26 % en 2025 ; l'annotation vidéo est en passe d'atteindre un TCAC de 23,17 % d'ici 2031.
- Par approche de marquage, le marquage manuel représentait 42,31 % de la taille du marché du marquage de données en 2025, mais les techniques auto-supervisées et programmatiques croissent à un TCAC de 22,16 %.
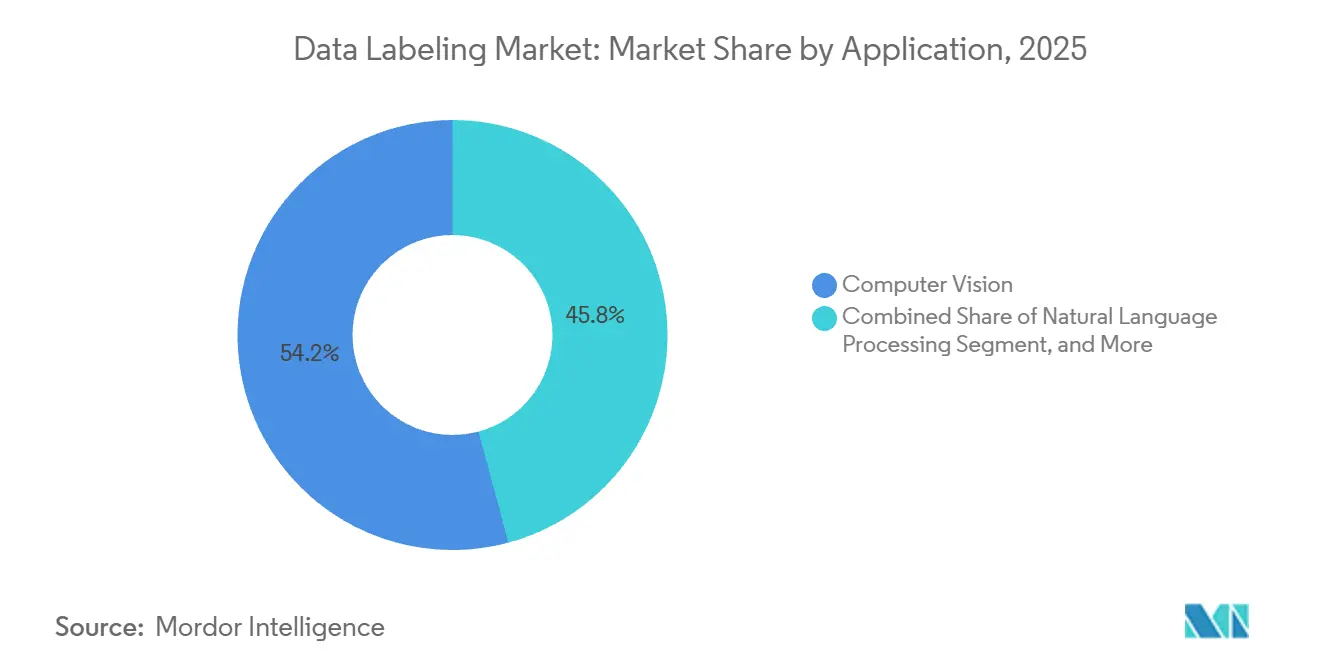
- Par application, les applications de vision par ordinateur commandaient une part de 54,19 % en 2025, tandis que la maintenance prédictive et l'assurance qualité affichaient le TCAC le plus rapide à 22,61 % jusqu'en 2031.
- Par secteur d'utilisation final, l'automobile et le transport détenaient une part de 28,26 % en 2025 ; l'industrie et la fabrication est le secteur à la croissance la plus rapide avec un TCAC de 22,84 %.
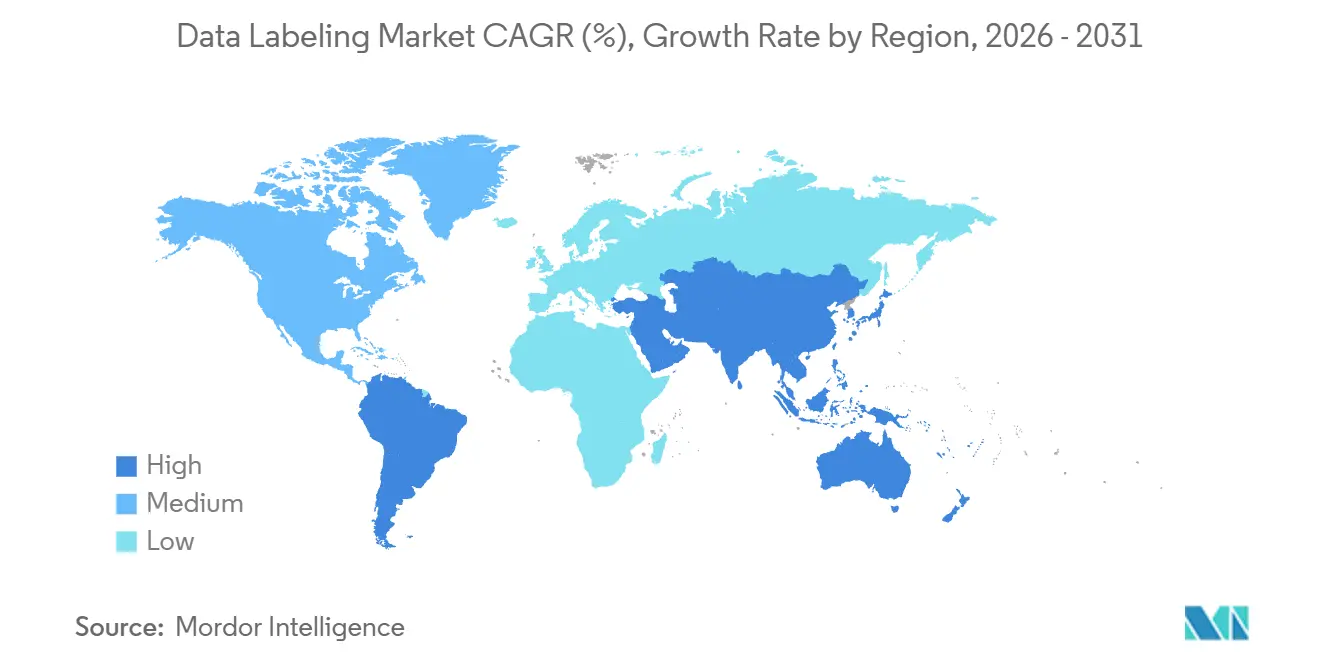
- Par géographie, l'Amérique du Nord a contribué à hauteur de 31,13 % des revenus en 2025, mais la région Asie-Pacifique est la région à la croissance la plus rapide avec un TCAC de 21,16 %.
Note : La taille du marché et les prévisions figurant dans ce rapport sont générées à l'aide du cadre d'estimation exclusif de Mordor Intelligence, mis à jour avec les dernières données et informations disponibles en janvier 2026.
Tendances et perspectives mondiales du marché du marquage de données
Analyse de l'impact des moteurs*
| Moteur | (~) % d'impact sur les prévisions de TCAC | Pertinence géographique | Horizon temporel d'impact |
|---|---|---|---|
| Adoption rapide des données de vision pour les ADAS et la conduite autonome | +5.2% | Mondial, concentré en Amérique du Nord, en Europe et en Chine | Moyen terme (2 à 4 ans) |
| Essor de l'IA générative stimulant la demande de jeux de données multimodaux | +6.8% | Mondial, porté par l'Amérique du Nord et l'Asie-Pacifique | Court terme (≤ 2 ans) |
| Avancées dans les pipelines d'apprentissage automatique sur les mégadonnées | +3.1% | Mondial | Moyen terme (2 à 4 ans) |
| Adoption de l'IA en imagerie médicale | +2.9% | Amérique du Nord, Europe, Asie-Pacifique | Moyen terme (2 à 4 ans) |
| Micro-marquage en périphérie pour la validation de données synthétiques | +1.7% | Mondial, adoption précoce en Amérique du Nord et en Europe | Long terme (≥ 4 ans) |
| Métadonnées de provenance pour l'IA explicable imposées par la réglementation | +2.3% | Europe, Amérique du Nord, Chine | Moyen terme (2 à 4 ans) |
| Source: Mordor Intelligence | |||
Adoption rapide des données de vision pour les ADAS et la conduite autonome
Les ensembles de capteurs automobiles diffusent désormais des téraoctets de données multimodales chaque jour, et le marché du marquage de données dépend d'étiquettes précises pour débloquer l'autonomie de niveau 3 et de niveau 4. La publication publique de Waymo a montré que la précision moyenne des véhicules passait de 29,7 % avec 10 % des données d'entraînement à 49,4 % avec la totalité des données, prouvant que l'échelle des étiquettes et la diversité géographique influencent directement la précision de la perception. L'initiative japonaise RoAD to L4 et le déploiement des infrastructures de recharge pour véhicules électriques généreront de nouveaux journaux de capteurs nécessitant des étiquettes spécifiques à chaque région. Les équipementiers passent du volume brut à la qualité par image, ce qui accroît la demande d'outils de marquage LiDAR-caméra synchronisés et de flux de validation de qualité automobile.
Essor de l'IA générative stimulant la demande de jeux de données multimodaux
Les concepteurs de modèles de fondation privilégient désormais des corpus plus petits, expertement étiquetés, qui suppriment les hallucinations et permettent un ajustement spécifique au domaine. Scale AI a révélé que 90 % de ses revenus de 2024 provenaient de projets d'IA générative, et la participation de 15 milliards USD de Meta souligne la prime accordée aux jeux de données contrôlés en termes de provenance. Le plan de travail de janvier 2026 de la Chine visant à intégrer l'IA dans 20 secteurs amplifie le besoin de corpus conversationnels, de dialogue et de suivi d'instructions organisés. Les salaires plus élevés pour les avocats, les médecins et les linguistes atteignant désormais 60 USD de l'heure bifurquent l'offre en niveaux spécialisés et banalisés, favorisant les plateformes qui gèrent les deux catégories de compétences avec des pistes d'audit transparentes.
Avancées dans les pipelines d'apprentissage automatique sur les mégadonnées
Les entreprises versionnent de plus en plus les jeux de données étiquetés dans des flux d'intégration continue. L'infrastructure cloud de passerelle IA du Japon alloue 40 à 80 nœuds pour des projets de modèles de langage de 60 jours qui reposent sur des étiquettes d'experts du domaine et des enregistrements de provenance immuables. La feuille de route 2025 de l'Inde prévoit des protocoles standardisés de données machine et des dorsales numériques nationales, accélérant la demande d'API de marquage qui intègrent des métriques de qualité dans les tableaux de bord DevOps.[1]NITI Aayog, "Réimaginer la fabrication : la feuille de route de l'Inde vers le leadership mondial dans la fabrication avancée", niti.gov.in Les fournisseurs proposant une ingestion programmatique, des hooks de supervision faible et une surveillance de la dérive supplantent les ateliers d'annotation traditionnels.
Adoption de l'IA en imagerie médicale
Les services de radiologie et de pathologie du monde entier ont besoin de jeux de données conformes à la HIPAA vérifiés par des cliniciens avant que les régulateurs n'approuvent les dispositifs d'IA. La FDA américaine a approuvé des dizaines d'algorithmes d'imagerie depuis 2024, chacun nécessitant des scans de vérité terrain étiquetés. L'agence de recherche japonaise RIKEN entraîne des modèles de fondation en sciences de la vie sur des données cliniques organisées nécessitant des pistes d'audit transparentes. Les hôpitaux se tournent donc vers des fournisseurs de niche qui combinent des radiologues dans la boucle avec des systèmes de qualité certifiés ISO.
Analyse de l'impact des freins*
| Frein | (~) % d'impact sur les prévisions de TCAC | Pertinence géographique | Horizon temporel d'impact |
|---|---|---|---|
| Pénurie d'annotateurs qualifiés et hausse des coûts de main-d'œuvre | -3.4% | Mondial, aigu en Amérique du Nord et en Europe | Court terme (≤ 2 ans) |
| Exigences croissantes en matière de confidentialité des données et de souveraineté | -2.8% | Europe, Chine, émergent en Amérique du Nord | Moyen terme (2 à 4 ans) |
| Pression environnementale sur la consommation énergétique de l'annotation à grande échelle | -0.9% | Mondial, porté par l'Europe | Long terme (≥ 4 ans) |
| Apprentissage auto-supervisé et faiblement supervisé réduisant les dépenses en marquage manuel | -4.1% | Mondial, adoption précoce en Amérique du Nord et en Asie-Pacifique | Moyen terme (2 à 4 ans) |
| Source: Mordor Intelligence | |||
Pénurie d'annotateurs qualifiés et hausse des coûts de main-d'œuvre
Le pivot vers le marquage par des experts du domaine a mis en évidence un goulot d'étranglement des talents. Scale AI paie désormais entre 30 et 60 USD de l'heure à des annotateurs de niveau doctorat après des critiques sur ses taux de rémunération participatifs, élevant les coûts de référence chez tous les fournisseurs. La feuille de route de l'Inde s'attaque au déficit de compétences grâce à des apprentissages modulaires et à un Institut des technologies de pointe pour la certification en annotation. Bien que l'automatisation aide au pré-marquage, la validation humaine reste obligatoire pour les cas d'usage réglementés, maintenant l'inflation salariale comme un frein à court terme sur les marges.
Exigences croissantes en matière de confidentialité des données et de souveraineté
Les règles de localisation des données découpent le marché du marquage de données en silos régionaux. La loi européenne sur l'IA exige des métadonnées de provenance et une documentation des jeux de données, augmentant les charges de conformité.[2]Commission européenne, "Proposition de règlement établissant des règles harmonisées sur l'intelligence artificielle", europa.eu Le cadre de gouvernance de la Chine restreint les transferts transfrontaliers, poussant les fournisseurs étrangers à créer des clouds domestiques. Ces régimes fragmentés obligent les entreprises d'annotation à dupliquer les infrastructures et à maintenir des effectifs locaux, modérant les économies d'échelle mondiales.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des segments
Par type d'approvisionnement : les modèles hybrides équilibrent contrôle et échelle
L'approvisionnement hybride a généré un élan substantiel en 2026, croissant à un TCAC de 22,48 %, porté par des entreprises qui conservent les données sensibles en interne mais s'appuient sur des fournisseurs pour les travaux à fort volume. La part externalisée dominait encore avec 63,43 % de la part du marché du marquage de données en 2025, mais les préoccupations croissantes en matière de propriété intellectuelle et la rareté des experts du domaine font évoluer les budgets vers des modèles mixtes. Les outils d'orchestration hybride qui acheminent les tâches par complexité, appliquent un contrôle d'accès basé sur les rôles et affichent des métriques de qualité en temps réel sous-tendent ce pivot. En Asie-Pacifique, le plan de la Chine visant à numériser 50 000 usines d'ici 2028 fera de l'approvisionnement hybride une option par défaut, les entreprises alternant entre des équipes locales au niveau des usines et des plateformes centralisées. En Amérique du Nord, les contrats de défense stipulent le traitement domestique des données classifiées tout en permettant que les images commerciales soient étiquetées à l'étranger, renforçant les flux de travail hybrides.
Les entreprises adoptant des stratégies hybrides réduisent les délais d'exécution en divisant les files d'attente. Les étiquettes hautement sensibles restent sur des clusters internes sécurisés, tandis que les boîtes englobantes banalisées sont confiées à des fournisseurs offshore. Les moteurs de politique automatisés suivent désormais la lignée des jeux de données et affectent les annotateurs selon leur niveau d'habilitation, renforçant la conformité sans réduire le débit. Les fournisseurs monétisant les modèles hybrides positionnent des « micro-jeux de données » organisés comme des actifs réutilisables vendus à plusieurs acheteurs, convertissant des revenus de services autrefois opaques en marges similaires à celles des logiciels et élargissant le marché adressable du marquage de données.



Par type de données : l'annotation vidéo accélère l'autonomie
L'annotation vidéo est en passe d'atteindre un TCAC de 23,17 % d'ici 2031, portée par les véhicules autonomes, la robotique et la surveillance des villes intelligentes. En revanche, les images statiques représentaient encore 36,26 % des revenus de 2025, témoignant du rôle ancré de la vision par ordinateur basée sur les images. Les flux continus nécessitent un suivi d'objets temporellement cohérent, une reconnaissance d'actions et une segmentation de scènes, augmentant la complexité par étiquette et le prix de vente moyen. La taille du marché du marquage de données pour le marquage LiDAR et des capteurs de profondeur, bien que comparativement modeste, commande des tarifs premium car délimiter des nuages de points 3D exige des outils spécialisés et une précision de qualité automobile.
Les politiques chinoises mettant l'accent sur l'IA incarnée et les robots intelligents élargiront la demande de jeux de données vidéo-LiDAR multimodaux capturant les lignes d'assemblage en usine, la logistique d'entrepôt et les interactions des robots de service. Les startups de robotique nord-américaines concèdent également sous licence des séquences annotées pour réentraîner des modèles de manipulation basés sur la vision. Les innovations de flux de travail telles que les délimitations assistées par interpolation et les polygones suggérés par le modèle réduisent l'effort manuel, mais les étapes de vérification restent centrées sur l'humain pour garantir la précision.
Par approche de marquage : les techniques auto-supervisées s'adaptent efficacement
Les flux de travail manuels représentaient encore 42,31 % des revenus de 2025, mais les approches auto-supervisées et programmatiques progressent à un TCAC de 22,16 % alors que les entreprises cherchent à réduire les coûts. Les développeurs pré-étiquettent désormais les images à l'aide de modèles de fondation, puis font intervenir des humains sur les tranches ambiguës, réduisant considérablement le nombre total de cas limites par jeu de données. L'expansion semi-supervisée, où un petit pool d'étiquettes de référence informe des pseudo-étiquettes automatisées, domine les pipelines d'IA conversationnelle. La taille du marché du marquage de données liée au pré-marquage automatique devrait s'élargir à mesure que les bibliothèques de supervision faible arrivent à maturité et que les tableaux de bord rapportent la provenance de bout en bout.
Les régulateurs imposent néanmoins l'auditabilité. L'Institut japonais de sécurité de l'IA a rédigé des orientations exigeant des journaux explicables de génération d'étiquettes, poussant les fournisseurs à maintenir une supervision humaine pour les secteurs à haut risque. Par conséquent, les plateformes les plus résilientes intègrent la notation de confiance, la priorisation par apprentissage actif et des historiques d'étiquettes réversibles, garantissant la conformité tout en débloquant des avantages de marge par rapport aux ateliers purement manuels.
Par application : la maintenance prédictive génère des revenus récurrents
La vision par ordinateur a conservé 54,19 % des dépenses de 2025, mais la maintenance prédictive et l'assurance qualité affichent désormais un TCAC de 22,61 % alors que les usines exploitent les données de capteurs pour éviter les temps d'arrêt. Le marquage de séries temporelles pour les signaux de vibration, de température et acoustiques crée une demande régulière de type abonnement, car les modèles doivent être réentraînés chaque fois que les équipements ou les régimes d'exploitation changent. En Inde, la feuille de route nationale met en avant une IA agentique qui déclenche une libération autonome des lots, nécessitant des taxonomies de pannes de capteurs étiquetées et des bibliothèques de défauts basées sur la vidéo. La taille du marché du marquage de données attribuée à ces jeux de données industriels augmente à mesure que les équipementiers intègrent les coûts de marquage dans des accords de service pluriannuels.
Les détaillants et les centres d'appels continuent d'investir dans le traitement du langage naturel et l'analyse de la parole, mais les pipelines IoT industriels mènent la croissance. Les fournisseurs qui regroupent des ontologies de domaine, des SDK de capture en périphérie et des hooks de marquage côté cloud remportent les déploiements en usine, car ils transforment les données brutes de technologie opérationnelle en corpus prêts pour l'IA plus rapidement que les plateformes génériques.
Par secteur d'utilisation final : l'industrie manufacturière en plein essor
Les entreprises automobiles ont encore généré 28,26 % des revenus de 2025, portées par les ADAS et la télématique de flotte, mais les clients industriels et manufacturiers affichent le TCAC le plus rapide à 22,84 % jusqu'en 2031. Le plan de la Chine pour 20 jeux de données sectoriels et 50 000 usines modernisées injecte une demande à grande échelle dans les secteurs des métaux, de la chimie et de l'électronique grand public.[3]Wang Jingjing, "La Chine dévoile un plan pour approfondir l'intégration de l'internet industriel et de l'IA", Conseil d'État, english. La renaissance des semi-conducteurs au Japon nécessite également des images de photomasques étiquetées, des scans d'inspection en ligne et des taxonomies de défauts. Le marché du marquage de données s'intègre désormais directement dans les budgets de jumeaux numériques de production, passant de projets pilotes ponctuels à des dépenses opérationnelles récurrentes.
La santé et les sciences de la vie maintiennent des exigences de conformité strictes, favorisant les fournisseurs spécialisés. Les entreprises de services financiers privilégient les étiquettes de détection de fraude, tandis que les utilisateurs agricoles demandent des étiquettes de stress des cultures basées sur des drones. L'ontologie unique de chaque secteur vertical entraîne une personnalisation des plateformes, soulignant pourquoi les logiciels d'opérations d'étiquetage larges complétés par des modules complémentaires de domaine supplantent les outils internes sur mesure.
Analyse géographique
L'Amérique du Nord commandait 31,13 % des revenus du marché du marquage de données en 2025, ancrée par les investissements des hyperscalers, les contrats de défense et la R&D sur les modèles de fondation. La série F de 1 milliard USD de Scale AI en mai 2024 a renforcé la confiance des investisseurs, tandis que la participation de Meta en 2025 a mis en évidence la nature stratégique des jeux de données riches en provenance. Les marchés publics fédéraux pour les jeux de données de renseignement et de sécurité nationale génèrent des accords pluriannuels qui amortissent les dépenses technologiques cycliques. La loi européenne sur l'IA soulève des obstacles de conformité mais différencie également les fournisseurs capables de produire des fichiers d'étiquettes prêts pour l'audit et de maintenir la résidence des données dans l'UE.
L'Asie-Pacifique est la région à la croissance la plus rapide, avec un TCAC de 21,16 %, stimulée par la feuille de route de l'internet industriel de la Chine, le plan de fabrication avancée de l'Inde et l'expansion de la robotique au Japon. Ces soutiens politiques stimulent la demande régionale d'annotation localisée, de corpus multilingues et de taxonomies sectorielles spécifiques. Les mandats de cloud domestique en Chine donnent un avantage aux plateformes locales, mais les fournisseurs étrangers qui forment des coentreprises ou établissent des centres de données locaux peuvent toujours accéder aux segments de croissance. Les nations d'Asie du Sud-Est ajoutent une capacité de main-d'œuvre à faible coût, alimentant les flux de travail hybrides mondiaux.
Le Moyen-Orient et l'Afrique restent naissants, avec les Émirats arabes unis et l'Arabie saoudite finançant des projets pilotes de villes intelligentes et de mobilité autonome qui génèrent des projets de marquage de données modestes mais stratégiques. L'Afrique du Sud et le Kenya attirent des travaux d'externalisation en anglais ; cependant, la demande domestique limitée en IA tempère la croissance régionale. La traction de l'Amérique latine se concentre sur le Brésil, où les entreprises de commerce électronique et d'agritech externalisent le marquage, bien que la volatilité des devises complique les engagements transfrontaliers.

Paysage concurrentiel
Le marché du marquage de données est modérément fragmenté. Scale AI occupe une position de leader après l'apport de 15 milliards USD de Meta, attirant l'attention grâce à des jeux de données organisés et étiquetés par des experts, avec des revenus attendus atteignant 1,4 milliard USD d'ici fin 2024. Appen et TELUS International défendent leurs parts via des plateformes participatives mondiales et des acquisitions telles que Lionbridge AI. Les fournisseurs de plateformes neutres, notamment Labelbox, SuperAnnotate et V7 Labs, se différencient par l'expérience développeur et l'analyse de qualité intégrée. La série B de 36 millions USD de SuperAnnotate, soutenue par NVIDIA et Databricks Ventures, illustre l'appétit des investisseurs pour les approches centrées sur les plateformes qui permettent aux entreprises d'alterner entre les modes logiciel uniquement et service géré.
La différenciation technologique pivote désormais sur le pré-marquage par modèle de fondation, la priorisation par apprentissage actif et les tableaux de bord de qualité qui visualisent l'accord inter-annotateurs en temps réel. Les fournisseurs cherchant à soutenir la souveraineté des données ont déployé des instances régionales en Europe et en Chine, tandis que les boutiques spécialisées plus petites gagnent des secteurs réglementés en mettant en avant les certifications ISO 13485 ou SOC 2. La pression sur les prix persiste dans le marquage d'images banalisé, mais les segments à haute valeur ajoutée - imagerie médicale, LiDAR 3D et annotation de documents juridiques - commandent des tarifs premium qui soutiennent les marges.
Des startups comme Snorkel AI popularisent le marquage programmatique, permettant aux utilisateurs d'encoder des règles heuristiques ou d'exploiter la supervision faible, tandis que des entrants axés sur la périphérie comme Dataloop proposent un micro-marquage sur appareil pour la validation de données synthétiques. À mesure que les entreprises passent de projets pilotes à des pipelines à l'échelle de la production, les gagnants seront ceux qui offrent des opérations d'étiquetage complètes, de l'ingestion à la surveillance de la dérive, sur des clouds hybrides et des clusters sur site.
Leaders du secteur du marquage de données
Appen Limited
TELUS International AI Inc.
Scale AI, Inc.
Amazon Mechanical Turk, Inc.
CloudFactory Limited
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Développements récents du secteur
- Janvier 2026 : le ministère chinois de l'Industrie et des Technologies de l'information a publié un plan de travail pour approfondir l'intégration de l'IA dans 20 secteurs, ciblant 50 000 mises à niveau de l'internet industriel et des jeux de données de domaine standardisés d'ici 2028.
- Novembre 2025 : la Chine a publié une feuille de route pour l'IA industrielle décrivant une stratégie en six points reliant les grands modèles de langage aux équipements de fabrication avancée et aux agents d'IA.
- Octobre 2025 : le NITI Aayog de l'Inde a publié un plan directeur de fabrication sur 10 ans qui donne la priorité aux copilotes de conception alimentés par l'IA, aux agents de maintenance prédictive et aux processus de marquage certifiés.
- Juin 2025 : Meta a investi près de 15 milliards USD dans Scale AI, valorisant l'entreprise à 29 milliards USD et recrutant son directeur général de 28 ans pour diriger un nouveau laboratoire de superintelligence.


Cadre de la méthodologie de recherche et portée du rapport
Définitions du marché et couverture principale
Notre étude définit le marché du marquage de données comme l'ensemble des revenus générés par les plateformes, les services gérés et les flux de travail hybrides avec humain dans la boucle qui étiquettent des fichiers texte, image, vidéo, audio et nuage de points afin que les modèles d'apprentissage automatique puissent apprendre, valider ou affiner. Le pool de valeur comprend les frais payés par les entreprises, les laboratoires de recherche et les agences publiques et est exprimé en dollars américains constants de 2025.
Exclusion du périmètre : les générateurs de données synthétiques, les logiciels de classification de données purs et les outils de test de modèles autonomes sont exclus de ce périmètre.
Aperçu de la segmentation
- Par type d'approvisionnement
- Interne
- Externalisé
- Hybride
- Par type de données
- Texte
- Image
- Vidéo
- Audio
- LiDAR / Capteur
- Par approche de marquage
- Manuel
- Automatique
- Semi-supervisé
- Auto-supervisé / Programmatique
- Par application
- Vision par ordinateur
- Traitement du langage naturel
- Analyse de la parole et de l'audio
- Maintenance prédictive et assurance qualité
- Par secteur d'utilisation final
- Automobile et transport
- Santé et sciences de la vie
- Informatique et télécommunications
- Banque, services financiers et assurance
- Commerce de détail et commerce électronique
- Industrie et fabrication
- Agriculture
- Gouvernement et secteur public
- Par géographie
- Amérique du Nord
- États-Unis
- Canada
- Mexique
- Amérique du Sud
- Brésil
- Argentine
- Reste de l'Amérique du Sud
- Europe
- Royaume-Uni
- Allemagne
- France
- Espagne
- Italie
- Reste de l'Europe
- Asie-Pacifique
- Chine
- Inde
- Japon
- Australie
- Corée du Sud
- Reste de l'Asie-Pacifique
- Moyen-Orient
- Arabie saoudite
- Émirats arabes unis
- Turquie
- Reste du Moyen-Orient
- Afrique
- Afrique du Sud
- Kenya
- Reste de l'Afrique
- Amérique du Nord
Méthodologie de recherche détaillée et validation des données
Recherche primaire
Les analystes de Mordor ont ensuite échangé avec des responsables produit de plateformes, des dirigeants de l'externalisation et des responsables d'ingénierie IA en Amérique du Nord, en Europe et en Asie-Pacifique. Ces discussions ont clarifié les combinaisons de flux de travail, les ratios d'automatisation et les prix courants par millier d'étiquettes, nous aidant à combler les lacunes laissées par le travail de bureau et à aligner les courbes d'adoption régionales.
Recherche documentaire
Nous avons cartographié les signaux de demande à travers des sources librement disponibles telles que le Bureau américain des statistiques du travail, les enquêtes TIC d'Eurostat, l'Observatoire des politiques d'IA de l'OCDE et les organismes sectoriels pour la conduite autonome, l'imagerie médicale et l'IA conversationnelle. Les clusters de brevets ont été tracés avec Questel, tandis que les indices de revenus des entreprises ont émergé de D&B Hoovers, des formulaires 10-K de la SEC et des appels aux résultats, fournissant des premières ventilations par type d'activité. Les revues académiques, les commentaires sur le cadre de gestion des risques IA du NIST et les registres douaniers détaillant les contrats de travail d'annotation ont apporté un contexte supplémentaire. Les sources listées sont illustratives ; de nombreuses publications supplémentaires ont informé la collecte et la validation des données.
Dimensionnement du marché et prévisions
Un pool descendant reconstruit à partir des budgets d'entraînement IA des entreprises, des heures GPU sur cloud public et de la prévalence des cas d'usage a formé la base de référence, qui a été recoupée par des factures de fournisseurs échantillonnées et le prix de vente moyen multiplié par les volumes de travaux, une consolidation ascendante ciblée. Cinq variables clés ancrent le modèle : les objets annotés par mile autonome, les scans de radiologie numérisés par lit d'hôpital, les ratios d'augmentation synthétique-réel, le salaire horaire des annotateurs et la pénétration de l'automatisation des plateformes. Une régression multivariée projette ces moteurs jusqu'en 2030, avec des superpositions de scénarios validées lors d'appels d'experts.
Validation des données et cycle de mise à jour
Les résultats passent par des contrôles de variance, une révision par les pairs et des vérifications d'anomalies avant validation. Les rapports sont actualisés annuellement, et les événements importants, comme les nouvelles règles de sécurité de l'IA, déclenchent des mises à jour intermédiaires, garantissant que les clients reçoivent notre dernière analyse.
Pourquoi la base de référence du marquage de données de Mordor est-elle fiable
Les estimations des différents éditeurs divergent car chacun sélectionne son propre périmètre, son traitement des devises et ses facteurs de majoration.
En capturant les dépenses internes et externalisées, y compris les licences de plateformes, et en révisant les données tous les douze mois, Mordor Intelligence offre une base de référence plus stable pour la planification.
Comparaison de référence
| Taille du marché | Source anonymisée | Principal facteur d'écart |
|---|---|---|
| 6,5 milliards USD | ||
| 4,89 milliards USD | Consultance mondiale A | Omet les plateformes internes et les flux de revenus d'automatisation hybride |
| 4,87 milliards USD | Consultance régionale B | Applique un prix par étiquette conservateur et exclut les flux de données LiDAR |
La comparaison montre que les autres réduisent l'univers ou bloquent des facteurs de coût statiques, tandis que le périmètre discipliné de Mordor, les vérifications primaires en direct et le cycle de mise à jour annuel produisent une base de référence transparente et reproductible sur laquelle les décideurs peuvent s'appuyer.


Questions clés auxquelles le rapport répond
Quelle est la valeur projetée du marché du marquage de données en 2031 ?
Il est prévu qu'il atteigne 7,02 milliards USD, reflétant un TCAC de 21,94 % de 2026 à 2031.
Quelle région connaît la croissance la plus rapide en matière de demande d'annotation de données ?
L'Asie-Pacifique affiche le dynamisme le plus élevé avec un TCAC de 21,16 % porté par la Chine, l'Inde et le Japon.
Quel type de données se développe plus rapidement que les autres ?
L'annotation vidéo mène la croissance avec un TCAC de 23,17 % en raison des véhicules autonomes et de la robotique.
Pourquoi les modèles d'approvisionnement hybrides gagnent-ils du terrain ?
Les entreprises combinent des experts internes pour les données sensibles avec des fournisseurs externes pour l'échelle, atteignant un équilibre entre coût et contrôle tout en croissant à un TCAC de 22,48 %.
Quel domaine d'application devrait générer des revenus de marquage récurrents et stables ?
La maintenance prédictive dans les environnements industriels, croissant à un TCAC de 22,61 %, nécessite un ré-étiquetage continu des capteurs à mesure que les équipements évoluent.
Comment les réglementations sur la confidentialité affectent-elles les stratégies mondiales de marquage ?
Des mandats tels que la loi européenne sur l'IA et les règles de gouvernance des données de la Chine obligent les fournisseurs à établir des infrastructures régionales et à maintenir des pools d'annotateurs séparés pour se conformer aux lois de localisation.
Dernière mise à jour de la page le:



