Taille et part du marché des données synthétiques
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2020 - 2031 |
|---|---|
| Taille du Marché (2026) | 0.71 Milliards de dollars |
| Taille du Marché (2031) | 3.67 Milliards de dollars |
| Taux de croissance (2026 - 2031) | 38.96% CAGR |
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Amérique du Nord |
| Concentration du Marché | Moyen |
Acteurs majeurs *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. | |
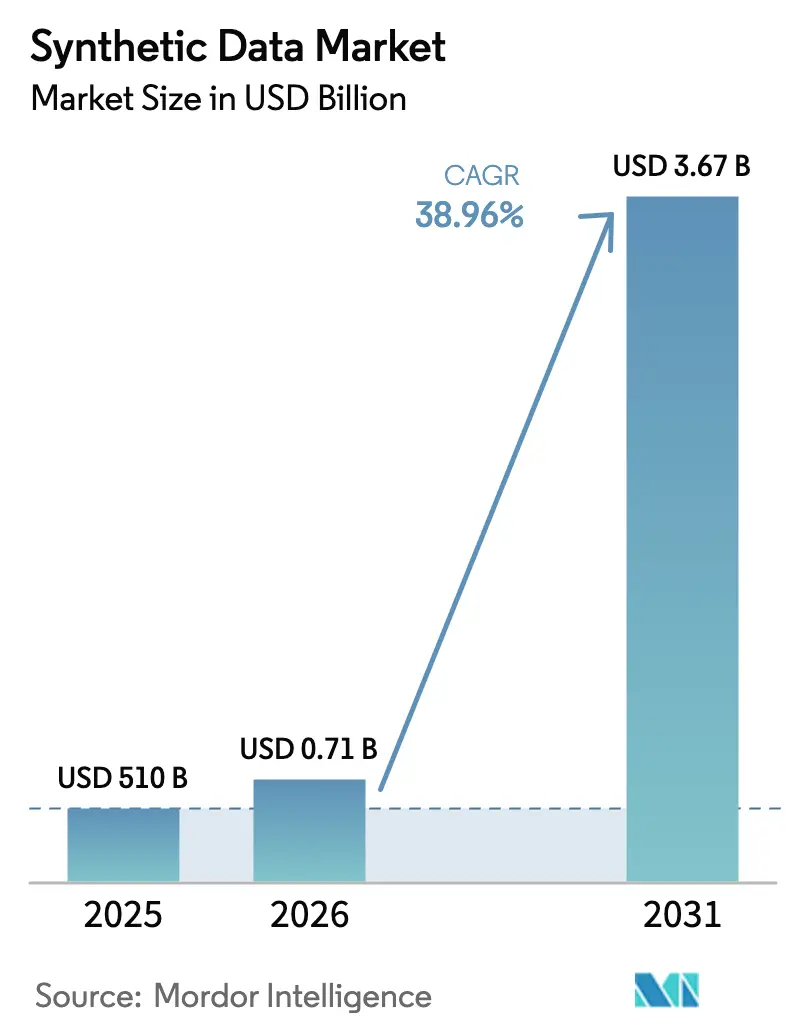
Analyse du marché des données synthétiques par Mordor Intelligence
La taille du marché des données synthétiques en 2026 est estimée à 710 millions USD, en hausse par rapport à la valeur de 2025 de 510 millions USD, avec des projections pour 2031 indiquant 3,67 milliards USD, croissant à un TCAC de 38,96 % sur la période 2026-2031. Cette croissance résulte des réglementations axées sur la protection de la vie privée, de la montée en puissance des charges de travail d'IA générative et des projets de transformation numérique qui s'appuient sur des ensembles de données conformes mais statistiquement fidèles. Les entreprises migrent des outils de masquage vers des répliques à haute utilité qui préservent les relations tout en s'alignant sur la loi européenne sur l'IA et des règles similaires. Les fournisseurs de technologie qui combinent des moteurs de génération évolutifs avec le suivi de la traçabilité remportent des parts de budget, car les équipes de gouvernance exigent des résultats auditables. Parallèlement, les nouveaux déploiements de jumeaux numériques dans la fabrication et la mobilité approfondissent la demande de simulations riches en physique alimentées par des données synthétiques, et l'émergence d'échanges de données ouvertes élargit la portée du marché en réduisant les frictions d'approvisionnement.
Principaux enseignements du rapport
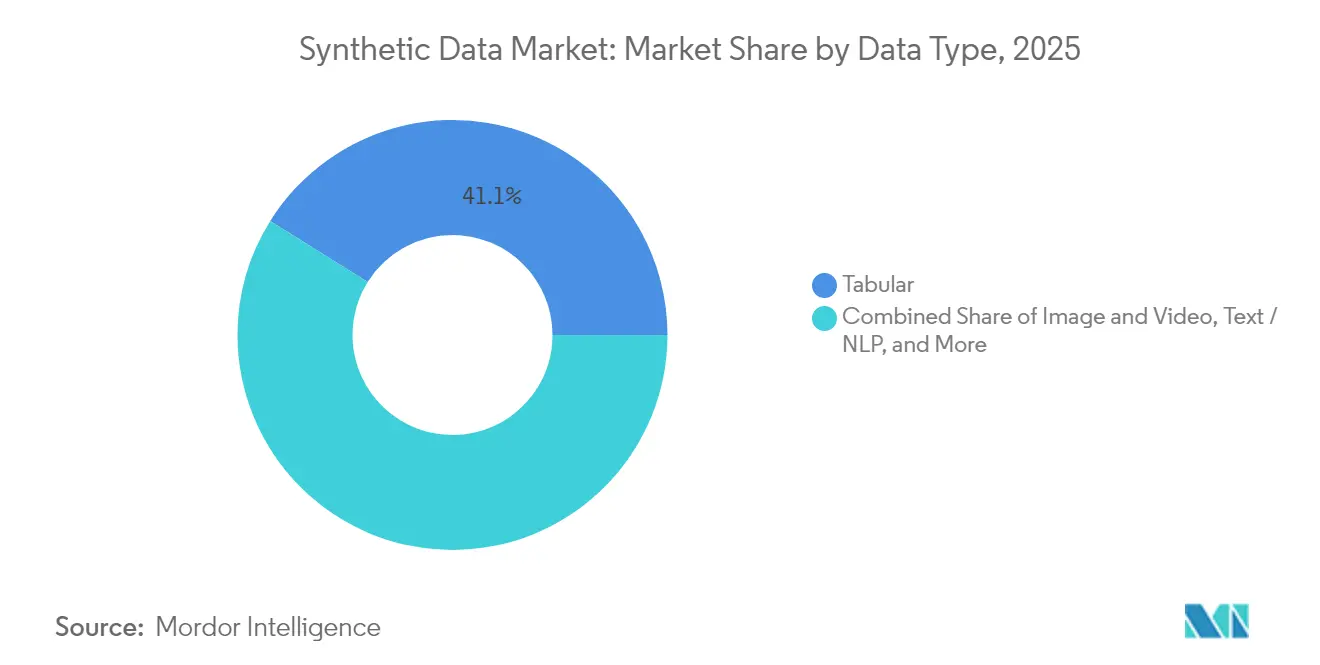
- Par type de données, le contenu tabulaire détenait 41,10 % de la part du marché des données synthétiques en 2025 ; la synthèse d'images et de vidéos devrait se développer à un TCAC de 40,10 % jusqu'en 2031.
- Par offre, les solutions entièrement synthétiques représentaient 60,55 % de la taille du marché des données synthétiques en 2025 et progressent à un TCAC de 34,40 %.
- Par technologie, les réseaux antagonistes génératifs ont capturé 37,75 % des revenus en 2025, tandis que les modèles de diffusion devraient croître à un TCAC de 46,30 % jusqu'en 2031.
- Par mode de déploiement, le déploiement cloud représentait 66,80 % des revenus en 2025 et devrait progresser à un TCAC de 28,60 % jusqu'en 2031.
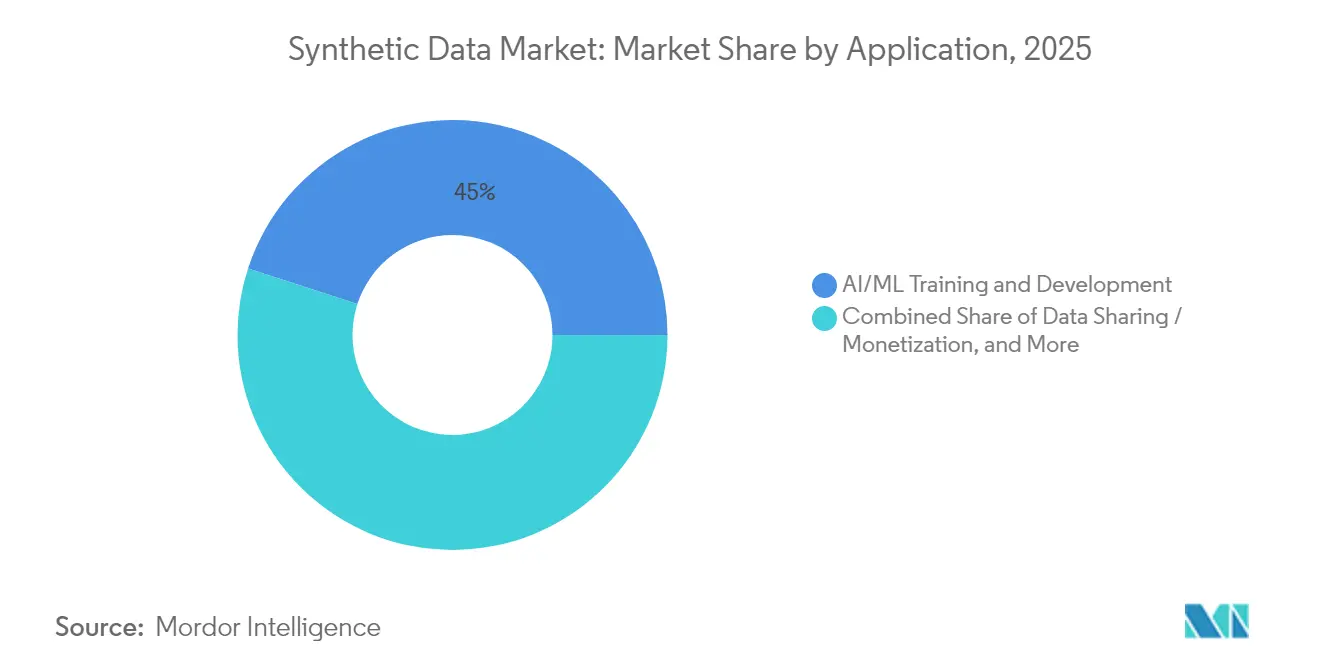
- Par application, la formation et le développement IA/ML représentaient 45,00 % des revenus de 2025, tandis que la simulation de systèmes autonomes est positionnée pour le TCAC le plus rapide de 44,95 % jusqu'en 2031.
- Par secteur d'utilisation final, le BFSI était en tête avec 23,25 % des revenus de 2025, tandis que l'automobile et le transport devraient progresser à un TCAC de 37,10 % jusqu'en 2031.
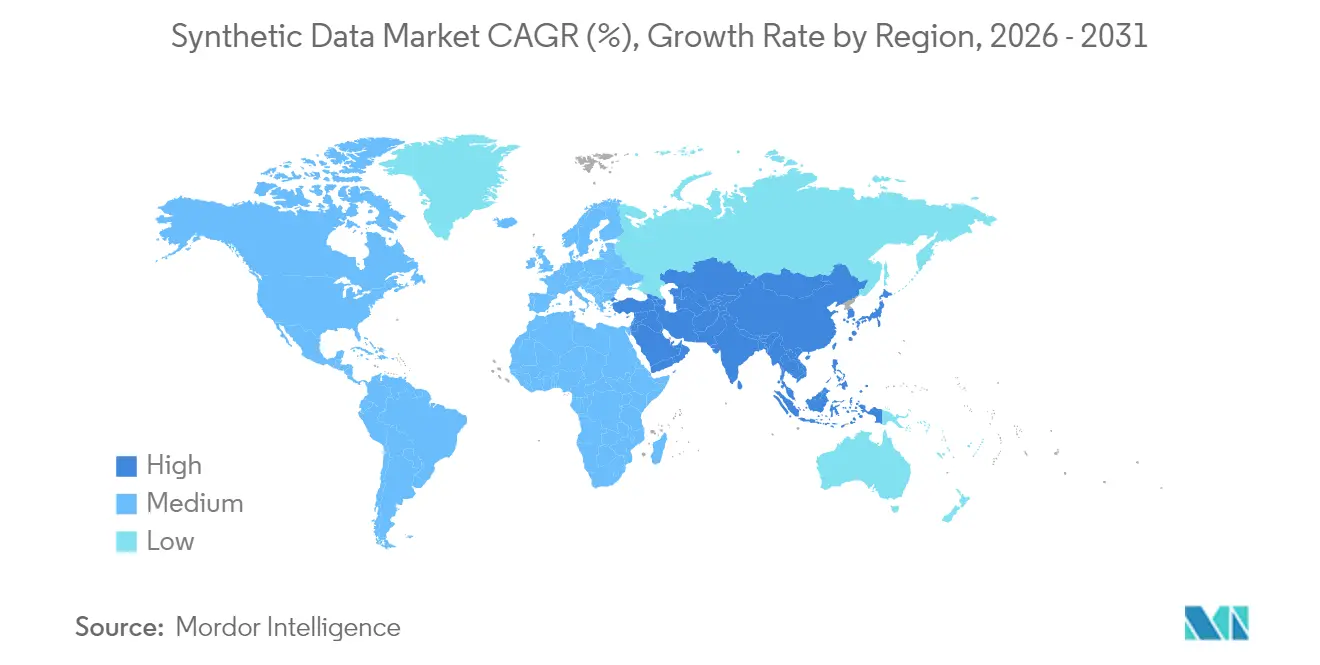
- Par géographie, l'Amérique du Nord a sécurisé 38,10 % des revenus en 2025 ; l'Asie-Pacifique devrait afficher le TCAC le plus élevé de 31,10 % sur la période de prévision.
Remarque : Les chiffres de la taille du marché et des prévisions de ce rapport sont générés à l’aide du cadre d’estimation propriétaire de Mordor Intelligence, mis à jour avec les données et analyses les plus récentes disponibles en 2026.
Tendances et perspectives mondiales du marché des données synthétiques
Analyse de l'impact des moteurs*
| Moteur | (~) % d'impact sur les prévisions de TCAC | Pertinence géographique | Calendrier d'impact |
|---|---|---|---|
| Pression réglementaire en faveur de l'IA préservant la vie privée et du partage des données | +8.5% | Mondial, avec adoption précoce dans l'UE et en Amérique du Nord | Moyen terme (2-4 ans) |
| Essor de l'IA générative exigeant des ensembles de données évolutifs à faible biais | +12.2% | Mondial, concentré en Amérique du Nord et en Asie-Pacifique | Court terme (≤ 2 ans) |
| Passage du masquage des données aux répliques synthétiques à haute utilité | +6.8% | Amérique du Nord et UE, expansion vers l'Asie-Pacifique | Moyen terme (2-4 ans) |
| Intégration de la confidentialité différentielle et du chiffrement homomorphe | +4.3% | Mondial, dirigé par les pôles technologiques aux États-Unis et en Chine | Long terme (≥ 4 ans) |
| Émergence d'échanges de données synthétiques ouvertes | +3.7% | Amérique du Nord et UE, programmes pilotes en Asie-Pacifique | Long terme (≥ 4 ans) |
| Convergence des jumeaux numériques dans les simulations de l'Industrie 4.0 | +4.5% | Régions industrielles mondiales, forte présence en Allemagne et au Japon | Moyen terme (2-4 ans) |
| Source: Mordor Intelligence | |||
Essor de l'IA générative exigeant des ensembles de données évolutifs à faible biais
Les modèles de langage et de vision à grande échelle nécessitent de vastes corpus diversifiés. Les analystes estiment que le contenu synthétique fournira 60 % des données d'entraînement de l'IA d'ici 2024. Les hyperscalers réagissent : NVIDIA a conçu le générateur Nemotron-4 340B pour alimenter les pipelines en aval, réduisant les coûts d'acquisition de données et les risques de biais[1]NVIDIA, "Nemotron-4 340B : un modèle de fondation pour la génération de données synthétiques," developer.nvidia.com. L'essor touche tous les secteurs verticaux, mais est le plus aigu en vision par ordinateur et en NLP multilingue, où l'approvisionnement en données réelles peut être coûteux ou interdit par la législation sur la vie privée. L'augmentation synthétique élargit la couverture des scénarios, réduit les budgets d'annotation et permet une expérimentation plus rapide.
Pression réglementaire en faveur de l'IA préservant la vie privée et du partage des données
La loi européenne sur l'IA oblige les organisations à explorer des substituts synthétiques avant de traiter des données personnelles. Aux États-Unis, le Département de la sécurité intérieure a réservé 1,7 million USD pour des projets pilotes de générateurs synthétiques, confirmant l'intérêt fédéral pour l'échange de données conformes[2]Département de la sécurité intérieure des États-Unis, "Appel d'offres 23-DN-004 Solutions de données synthétiques," dhs.gov. Les nouvelles règles d'étiquetage de la Chine reflètent une intention similaire. Les entreprises qui opérationnalisent les données synthétiques tôt évitent les amendes et débloquent des collaborations transfrontalières. La conformité fait donc passer les données synthétiques d'un atout facultatif à un mandat au niveau du conseil d'administration.
Passage du masquage des données aux répliques synthétiques à haute utilité
L'anonymisation traditionnelle brise souvent l'intégrité référentielle, limitant l'utilité analytique. Les nouvelles plateformes génèrent des répliques statistiquement fidèles, permettant aux testeurs d'exécuter des charges de travail réalistes sans risquer d'exposition. L'intégration de Synthesized dans Google BigQuery illustre comment la génération peut s'intégrer dans les entrepôts de données courants. Les banques allemandes signalent une analyse du risque de crédit plus rapide après avoir adopté des instantanés synthétiques qui préservent les relations entre les tables. Ce changement redirige le budget des contrôles d'accès coûteux vers la démocratisation des données en libre-service.
Convergence des jumeaux numériques dans les simulations de l'Industrie 4.0
Les entreprises industrielles associent les moteurs de jumeaux numériques à des flux de capteurs synthétiques pour tester les algorithmes de maintenance prédictive. La recherche de Springer montre une accélération décuplée des cycles de développement de produits lorsque la télémétrie synthétique comble les lacunes de données[3]Springer, "Jumeaux numériques et flux de capteurs synthétiques," link.springer.com. L'Omniverse de NVIDIA génère des scénarios riches en physique, permettant aux équipementiers automobiles et aux entreprises de robotique de valider des cas limites qui seraient risqués ou impossibles dans le monde réel. La combinaison offre à la fois sécurité et économies de coûts.
Analyse de l'impact des contraintes*
| Contrainte | (~) % d'impact sur les prévisions de TCAC | Pertinence géographique | Calendrier d'impact |
|---|---|---|---|
| Risque d'effondrement du modèle dû à des données entraînées de manière récursive | -4.8% | Mondial, affectant particulièrement le développement des grands modèles de langage | Court terme (≤ 2 ans) |
| Absence de métriques de qualité standardisées entre les fournisseurs | -3.2% | Mondial, avec des efforts de normalisation aux États-Unis et dans l'UE | Moyen terme (2-4 ans) |
| Coût de calcul élevé pour les modèles de fondation multimodaux | -5.1% | Mondial, le plus aigu dans les marchés à ressources limitées | Court terme (≤ 2 ans) |
| Statut juridique naissant des données synthétiques « non personnelles » | -2.9% | Mondial, avec une incertitude réglementaire dans les marchés émergents | Long terme (≥ 4 ans) |
| Source: Mordor Intelligence | |||
Risque d'effondrement du modèle dû à des données entraînées de manière récursive
Des études avertissent que l'entraînement répété sur du contenu auto-généré réduit la diversité des données et amplifie les biais. Les fournisseurs mélangent désormais des flux organiques et figent les poids du générateur pour limiter les boucles de rétroaction. Les audits de qualité et les pipelines d'apprentissage actif constituent des garde-fous émergents, mais le problème reste un frein à court terme sur les flux de travail entièrement synthétiques.
Coût de calcul élevé pour les modèles de fondation multimodaux
Les moteurs de diffusion de premier rang nécessitent des milliers de GPU et des semaines de temps d'exécution. Les factures mensuelles peuvent dépasser six chiffres pour les petites entreprises, entravant l'expérimentation. Les services cloud à la demande facilitent l'entrée mais n'éliminent pas les coûts de débit. La pression sur les prix pourrait encourager la spécialisation matérielle et la délocalisation fédérée vers des puces côté client.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des segments
Par type de données : le contenu visuel stimule l'innovation
La synthèse d'images et de vidéos affiche la croissance la plus rapide avec un TCAC de 40,10 % jusqu'en 2031, reflétant le développement de véhicules autonomes et les applications de vision par ordinateur exigeant des ensembles de données d'entraînement photoréalistes. Les données tabulaires maintiennent leur leadership sur le marché avec une part de 41,10 % en 2025, portées par les services financiers et les applications de santé nécessitant des solutions de confidentialité des données structurées. Les applications de texte et de NLP bénéficient des avancées des grands modèles de langage, tandis que la synthèse audio prend de l'élan grâce à des plateformes comme Gramosynth de Rightsify pour la génération de musique libre de droits. La synthèse de données de capteurs et de séries temporelles répond aux exigences de l'IoT et de la surveillance industrielle, particulièrement précieuse pour les applications de maintenance prédictive où les scénarios de défaillance sont rares dans les ensembles de données du monde réel.
L'émergence de modèles de fondation multimodaux estompe les frontières traditionnelles entre les types de données, avec des plateformes comme Cosmos de NVIDIA générant simultanément des données synthétiques basées sur la physique à travers les modalités visuelles, de capteurs et temporelles. La valorisation de 15 milliards USD d'Applied Intuition reflète la confiance des investisseurs dans les applications de données synthétiques visuelles pour les systèmes autonomes. Cette convergence permet des environnements de simulation plus sophistiqués qui capturent des interactions complexes du monde réel, particulièrement précieux pour le développement de la robotique et des véhicules autonomes où plusieurs modalités de capteurs doivent être synchronisées.



Par offre : le remplacement complet est préféré
Les offres entièrement synthétiques ont dominé 60,55 % des revenus de 2025 et croissent à un TCAC de 34,40 %. Les entreprises choisissent le remplacement total pour éliminer le risque résiduel de confidentialité et simplifier les structures de gouvernance. Les alternatives hybrides subsistent pour les flux de travail cliniques ou d'ingénierie à haute fidélité où de légères ancres du monde réel améliorent la précision du modèle. Le lac de données sécurisé de Tonic.ai illustre la demande d'un contrôle centralisé sur les formats non structurés, soulignant la migration du marché vers des chaînes d'outils consolidées.
Le marché des données synthétiques bénéficie du fait que les régulateurs acceptent les tests d'équivalence statistique plutôt que les inspections de données brutes, réduisant les délais d'approbation. Les groupes bancaires et d'assurance citent des réductions à deux chiffres des heures de révision de conformité après adoption. Les fournisseurs qui automatisent la traçabilité, la gestion des versions et les contrôles de confidentialité différentielle regroupent des services à valeur ajoutée, augmentant les coûts de changement et poussant le secteur vers la consolidation des plateformes.
Par technologie : les modèles de diffusion en plein essor
Les GAN représentent encore 37,75 % des revenus de 2025, mais les moteurs de diffusion affichent le TCAC le plus rapide de 46,30 %. Leur capacité à produire des images plus nettes et plus diversifiées les positionne pour les tâches vidéo haute résolution dans le divertissement et la fabrication avancée. Les générateurs basés sur les grands modèles de langage s'avèrent efficaces pour la synthèse tabulaire et textuelle, préservant les corrélations entre colonnes et améliorant les scores F1 des modèles en aval. Les simulateurs basés sur des règles persistent dans le contrôle industriel déterministe où les équations physiques priment sur le caractère aléatoire piloté par les données.
Des projets académiques comme SiloFuse démontrent l'adéquation de la diffusion aux environnements fédérés, un argument de vente clé dans la finance et la santé transfrontalières. Les benchmarks révèlent des réductions du taux de défauts de 30 % par rapport aux pipelines hérités, ce qui explique pourquoi les équipementiers mettent à niveau malgré des factures de calcul plus élevées. Le marché des données synthétiques présente un cycle de renouvellement technologique clair qui récompense les fournisseurs qui découplent la logique d'orchestration de l'architecture du générateur.
Par mode de déploiement : la domination du cloud se poursuit
Les déploiements cloud ont capturé 66,80 % des revenus de 2025 et progresseront à un TCAC de 28,60 % jusqu'en 2031. Les entreprises privilégient les pools de GPU élastiques et les outils de conformité gérés. AWS Bedrock, Google BigQuery avec Synthesized et le DGX Cloud de NVIDIA hébergent des API de génération natives qui raccourcissent les délais de démarrage des projets. Les installations sur site restent essentielles pour la défense, les banques centrales et les services publics régis par des mandats stricts de souveraineté.
Les salles de marché sensibles à la latence expérimentent des micro-générateurs périphériques qui actualisent les données de marché synthétiques en moins de deux millisecondes. Pendant ce temps, les enclaves de calcul confidentiel et les options d'ancrage régional tempèrent les préoccupations de souveraineté dans le cloud public. À mesure que les coûts diminuent et que les fonctionnalités de sécurité s'améliorent, le marché des données synthétiques s'oriente davantage vers un déploiement axé sur le cloud, bien que les empreintes hybrides persistent là où les contraintes de bande passante ou de politique subsistent.
Par application : les systèmes autonomes s'accélèrent
La formation IA/ML a représenté 45,00 % des dépenses de 2025, confirmant que l'augmentation synthétique est devenue une contribution standard au développement. La simulation de systèmes autonomes devrait afficher le TCAC le plus élevé de 44,95 % car les régulateurs exigent des tests de scénarios exhaustifs avant le déploiement commercial. Les équipes de test logiciel exploitent les cas limites synthétiques pour détecter les bogues plus tôt, et les unités d'analyse de la fraude reproduisent des schémas d'attaque rares sans exposer les dossiers des clients.
Les plateformes de partage et de monétisation des données émergent comme de nouveaux flux de revenus. Les entreprises vendent des ensembles de données anonymisés mais utiles à leurs partenaires, débloquant de la valeur à partir d'actifs auparavant cloisonnés. En robotique, le pipeline Isaac de NVIDIA produit des centaines de milliers de trajectoires de mouvement en quelques heures, accélérant la convergence des modèles. Ces dynamiques élargissent le marché des données synthétiques au-delà de la recherche et du développement vers les opérations de production et les produits de données commerciales.
Par secteur d'utilisation final : la transformation automobile
Le BFSI détenait 23,25 % des revenus de 2025 dans la taille du marché des données synthétiques, exploitant les répliques pour la modélisation des risques et l'analyse anti-fraude. L'automobile et le transport devraient croître à un TCAC de 37,10 %, portés par la course vers l'autonomie de niveau 4 qui nécessite des milliards de kilomètres de conduite sûre pour la validation. La santé pilote des cohortes de patients synthétiques pour rationaliser le recrutement dans les essais cliniques et protéger la vie privée. Les détaillants fabriquent des parcours clients pour les moteurs de personnalisation, et les entreprises de télécommunications simulent des événements de panne réseau pour renforcer la fiabilité. Les agences gouvernementales élaborent des ensembles de données de planification de mission qui suppriment les caractéristiques classifiées tout en maintenant l'utilité stratégique. Le marché des données synthétiques pénètre ainsi tous les secteurs où les données du monde réel sont rares, sensibles ou coûteuses à collecter.
Analyse géographique
L'Amérique du Nord a capturé 38,10 % des revenus de 2025. Des géants technologiques tels que Microsoft et Meta dépensent des dizaines de milliards en infrastructure d'IA qui repose sur des pipelines synthétiques, et des programmes fédéraux valident l'approche pour les cas d'usage de la sécurité intérieure. Les pôles en Californie, au Texas et en Ontario attirent le capital-risque, fournissant un écosystème dense de spécialistes qui alimentent l'innovation dans la finance, la santé et la défense.
L'Asie-Pacifique affiche le TCAC le plus rapide de 31,10 %. La loi chinoise sur l'étiquetage des contenus générés par l'IA encourage les entreprises à générer des alternatives synthétiques plutôt que de vrais journaux d'utilisateurs, et les leaders de la robotique au Japon associent des données de perception synthétiques à l'automatisation des usines. L'Inde exploite des dossiers de patients synthétiques pour renforcer les plateformes de télésanté dans le contexte des règles de localisation des données, et la capacité en semi-conducteurs de la Corée du Sud soutient l'entraînement des modèles dans la région. L'Asie du Sud-Est bénéficie des start-ups fintech qui partagent des données de crédit respectueuses de la vie privée pour élargir l'inclusion financière.
L'Europe allie leadership réglementaire et dynamisme commercial. La loi européenne sur l'IA formalise une approche privilégiant le synthétique, et la Commission européenne a validé la méthode pour la finance numérique. Les projets Industrie 4.0 de l'Allemagne combinent jumeaux numériques et télémétrie synthétique pour optimiser la consommation d'énergie. Le Royaume-Uni capitalise sur son indépendance réglementaire pour piloter des voies d'approbation simplifiées. Les États nordiques investissent dans des centres de données verts qui hébergent des clusters de génération neutres en carbone, alignant les objectifs de durabilité avec la croissance de l'IA. Ailleurs, les programmes de villes intelligentes au Moyen-Orient intègrent des ensembles de données synthétiques pour la mobilité et la sécurité, et les start-ups africaines exploitent les API cloud pour compenser la rareté des données tout en naviguant dans l'évolution des lois sur la vie privée.

Paysage concurrentiel
Le marché des données synthétiques reste modérément concentré mais très dynamique. L'acquisition de Gretel par NVIDIA pour 320 millions USD fusionne le matériel, l'orchestration des modèles et les outils de confidentialité en une pile de bout en bout. SAS Institute a racheté Hazy pour intégrer la génération dans les suites analytiques utilisées par les banques et les assureurs. Applied Intuition a levé des fonds à une valorisation de 15 milliards USD pour fournir des simulations spécifiques à un domaine pour la conduite autonome, soulignant la prime accordée à la profondeur verticale.
Trois archétypes concurrentiels émergent. Les leaders de l'infrastructure monétisent le calcul à grande échelle et regroupent les moteurs synthétiques. Les spécialistes verticaux adaptent les ontologies de domaine et les métriques de validation. Les intégrateurs de plateformes se concentrent sur les couches de gouvernance qui connectent des générateurs disparates aux structures de données d'entreprise.
Les groupes de travail de l'IEEE élaborent des normes de qualité qui pourraient commoditiser la fonctionnalité de génération de base et déplacer la rivalité vers l'automatisation de la conformité et l'observabilité en temps réel. Sur la période de prévision, des acquisitions sont probables car les grandes entreprises cherchent à élargir leurs capacités, mais la diffusion open source réduit les barrières pour les nouveaux entrants, maintenant le marché des données synthétiques contestable.
Leaders du secteur des données synthétiques
MOSTLY AI Solutions MP GmbH
NVIDIA Corporation
Meta Platforms, Inc.
Amazon.com, Inc.
Microsoft Corporation
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Développements récents du secteur
- Avril 2025 : Tonic.ai a acquis Fabricate pour fournir des interfaces en langage naturel permettant au personnel non technique de créer rapidement des ensembles de données conformes.
- Mars 2025 : NVIDIA a acquis Gretel pour 320 millions USD, intégrant la génération préservant la vie privée dans ses services d'IA cloud.
- Janvier 2025 : NVIDIA a lancé le modèle de fondation mondial Cosmos, permettant des scènes synthétiques photoréalistes pour les véhicules autonomes et les robots, avec Uber parmi les premiers utilisateurs.
- Janvier 2025 : NVIDIA a étendu Omniverse avec l'IA physique générative, ajoutant Accenture, Microsoft et Siemens comme premiers adoptants.


Cadre de la méthodologie de recherche et portée du rapport
Définitions du marché et couverture principale
Notre étude définit le marché des données synthétiques comme l'ensemble des revenus commerciaux générés par les plateformes logicielles, les services cloud et les API qui créent algorithmiquement des ensembles de données artificielles dont les modèles statistiques reproduisent des informations réelles pour la formation IA/ML, la gestion des données de test, la préservation de la vie privée et la simulation.
Par souci de clarté, nous excluons les utilitaires de masquage de données hérités qui se contentent d'anonymiser les enregistrements existants plutôt que de générer de nouvelles données statistiquement représentatives.
Aperçu de la segmentation
- Par type de données
- Tabulaire
- Texte / NLP
- Image et vidéo
- Audio
- Capteur / Séries temporelles
- Par offre
- Entièrement synthétique
- Partiellement synthétique / Hybride
- Par technologie
- GAN
- Modèles de diffusion
- Générateurs basés sur les grands modèles de langage
- Simulations basées sur des règles / basées sur des agents
- Par mode de déploiement
- Cloud
- Sur site
- Par application
- Formation et développement IA/ML
- Partage / Monétisation des données
- Tests logiciels et DevOps
- Simulation de systèmes autonomes
- Cybersécurité et tests de fraude
- Par secteur d'utilisation final
- BFSI
- Santé et sciences de la vie
- Commerce de détail et e-commerce
- Automobile et transport
- Gouvernement et défense
- TI et services TI
- Industrie et robotique
- Par géographie
- Amérique du Nord
- États-Unis
- Canada
- Mexique
- Amérique du Sud
- Brésil
- Argentine
- Reste de l'Amérique du Sud
- Europe
- Allemagne
- Royaume-Uni
- France
- Italie
- Espagne
- Russie
- Reste de l'Europe
- Asie-Pacifique
- Chine
- Japon
- Inde
- Corée du Sud
- Australie et Nouvelle-Zélande
- Reste de l'Asie-Pacifique
- Moyen-Orient et Afrique
- Moyen-Orient
- Arabie saoudite
- Émirats arabes unis
- Turquie
- Reste du Moyen-Orient
- Afrique
- Afrique du Sud
- Nigéria
- Égypte
- Reste de l'Afrique
- Moyen-Orient
- Amérique du Nord
Méthodologie de recherche détaillée et validation des données
Recherche primaire
Les analystes de Mordor ont interrogé des architectes cloud-IA, des responsables de la protection de la vie privée dans le BFSI et la santé, ainsi que des responsables des achats en Amérique du Nord, en Europe et en Asie-Pacifique.
Leurs informations sur les niveaux de tarification des licences, les ratios d'utilisation et les obstacles réglementaires nous ont permis d'affiner des hypothèses que les données secondaires seules ne pouvaient pas résoudre.
Recherche documentaire
Nous avons commencé par dimensionner la demande potentielle à partir de sources ouvertes telles que l'Observatoire des politiques d'IA de l'OCDE, le suivi de l'application du RGPD de l'UE, les tableaux de dépenses logicielles du Bureau d'analyse économique des États-Unis et des revues évaluées par des pairs indexées dans IEEE Xplore.
D&B Hoovers et Dow Jones Factiva ont fourni des revenus indicatifs des fournisseurs, tandis que les livres blancs du Conseil ITI ont aidé à vérifier les signaux d'adoption.
Pour traduire des points de données disparates en métriques comparables, nous avons normalisé les valeurs en dollars constants de 2025, réconcilié les fluctuations de devises en utilisant les moyennes du FMI et archivé chaque référence dans un référentiel interne.
La liste ci-dessus est illustrative ; de nombreuses autres sources secondaires ont alimenté la collecte, la validation et la clarification des données.
Dimensionnement du marché et prévisions
Nous avons appliqué une combinaison descendante et ascendante : les dépenses en logiciels d'IA d'entreprise ont formé le bassin de demande, les taux de pénétration par secteur l'ont converti en revenus de données synthétiques, et les résultats ont été recoupés avec des agrégations de fournisseurs échantillonnés et des tests de prix de vente moyen × volume.
Les variables clés comprennent les courbes de coût des heures GPU, les dépenses de conformité régionales, le nombre de projets d'IA actifs et les volumes d'images synthétiques par kilomètre de véhicule autonome.
Une régression multivariée projette ces moteurs jusqu'en 2030 ; les micro-données manquantes ont été interpolées à partir d'indicateurs adjacents et réconciliées lors de la révision.
Validation des données et cycle de mise à jour
Nous effectuons des balayages d'anomalies, des révisions par les pairs en plusieurs étapes et des vérifications de variance par rapport à des benchmarks indépendants avant validation.
Les modèles sont actualisés chaque année, avec des mises à jour intermédiaires lorsque des événements tels que de nouvelles lois sur la vie privée modifient matériellement la demande.
Pourquoi la base de référence des données synthétiques de Mordor est fiable
Nous reconnaissons que les estimations publiées divergent souvent parce que les entreprises adoptent des portées, des hypothèses et des cadences de mise à jour différentes.
En nous concentrant strictement sur les revenus des plateformes de génération et en recalibrant notre modèle annuellement, Mordor minimise à la fois la surestimation et la sous-estimation.
Comparaison de référence
| Taille du marché | Source anonymisée | Principal facteur d'écart |
|---|---|---|
| 0,51 milliard USD (2025) | ||
| 0,30 milliard USD (2023) | Consultance mondiale A | Inclut les logiciels d'anonymisation et les dépenses de preuve de concept |
| 0,29 milliard USD (2024) | Journal sectoriel B | Applique un TCAC uniforme sans calibration régionale |
Ces contrastes montrent que la sélection rigoureuse de la portée, le modèle piloté par les variables et l'actualisation en temps opportun de Mordor fournissent une base de référence équilibrée et transparente sur laquelle les décideurs peuvent s'appuyer.


Questions clés auxquelles le rapport répond
Quelle est la croissance projetée du marché des données synthétiques jusqu'en 2031 ?
Le marché des données synthétiques devrait passer de 710 millions USD en 2026 à 3,67 milliards USD d'ici 2031, reflétant un TCAC de 38,96 %.
Pourquoi les modèles de diffusion gagnent-ils des parts sur les GAN ?
Les moteurs de diffusion génèrent des images de meilleure qualité et plus stables, entraînant un TCAC de 46,30 % qui dépasse la croissance des approches basées sur les GAN.
Quel mode de déploiement domine les dépenses ?
Le déploiement cloud représente 66,80 % des revenus de 2025 et se développe à un TCAC de 28,60 % grâce aux pools de GPU élastiques et aux outils de conformité intégrés.
Comment les nouvelles réglementations influencent-elles l'adoption ?
Des règles telles que la loi européenne sur l'IA obligent les entreprises à tester des alternatives synthétiques avant de traiter des données personnelles, faisant des plateformes de génération une nécessité de conformité.
Quel secteur vertical est positionné pour la croissance la plus rapide ?
L'automobile et le transport devraient croître à un TCAC de 37,10 % car les programmes de conduite autonome nécessitent une couverture étendue de scénarios synthétiques pour la validation de la sécurité.
Quel est le principal obstacle pour les petites entreprises ?
Les coûts de calcul élevés pour les modèles de fondation multimodaux restent la plus grande barrière, avec des charges de travail intensives en GPU poussant les factures cloud mensuelles à six chiffres.
Dernière mise à jour de la page le:




