Tamaño y Participación del Mercado de Datos Sintéticos
Visión General del Mercado
| Período de Estudio | 2020 - 2031 |
|---|---|
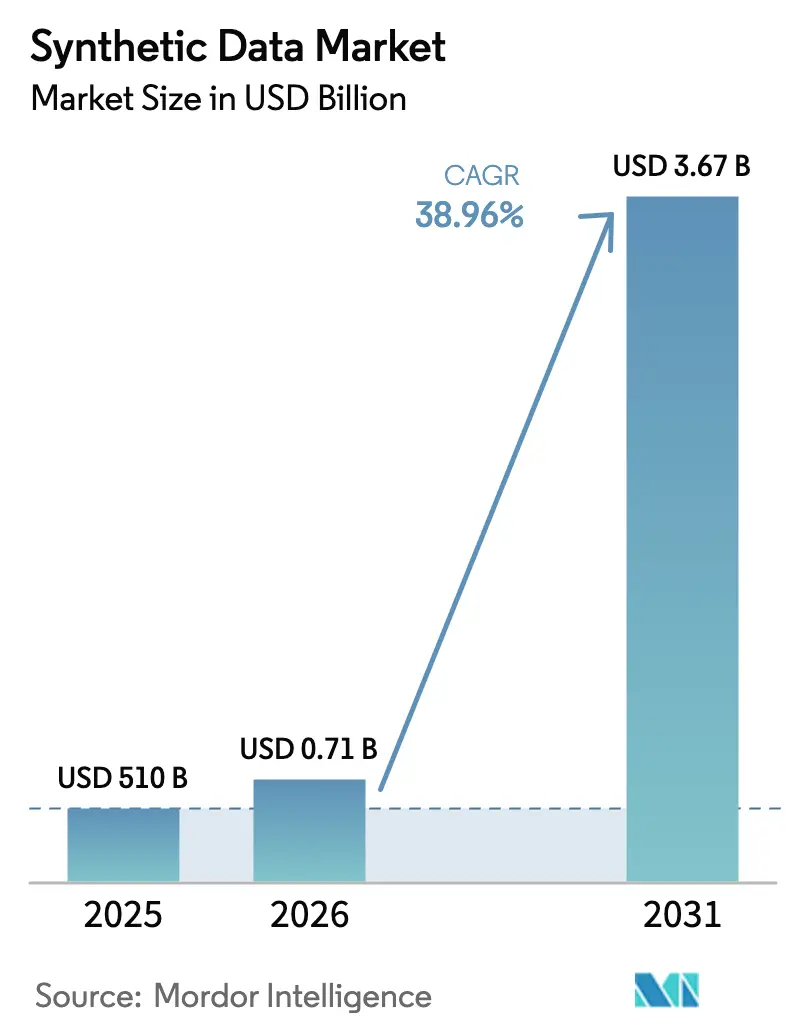
| Tamaño del Mercado (2026) | 0.71 Mil millones de dólares |
| Tamaño del Mercado (2031) | 3.67 Mil millones de dólares |
| Tasa de crecimiento (2026 - 2031) | 38.96% CAGR |
| Mercado de Crecimiento Más Rápido | Asia Pacífico |
| Mercado Más Grande | América del Norte |
| Concentración del Mercado | Medio |
Jugadores principales *Nota aclaratoria: los principales jugadores no se ordenaron de un modo en especial Imagen © Mordor Intelligence. El uso requiere atribución según CC BY 4.0. | |
Análisis del Mercado de Datos Sintéticos por Mordor Intelligence
El tamaño del mercado de datos sintéticos en 2026 se estima en USD 710 millones, creciendo desde el valor de 2025 de USD 510 millones con proyecciones para 2031 que muestran USD 3,67 mil millones, creciendo a una CAGR del 38,96% durante 2026-2031. Este crecimiento resulta de las regulaciones que priorizan la privacidad, las cargas de trabajo de IA generativa en aumento y los proyectos de transformación digital que dependen de conjuntos de datos conformes pero estadísticamente fieles. Las empresas están migrando de herramientas de enmascaramiento a réplicas de alta utilidad que mantienen las relaciones intactas mientras se alinean con la Ley de IA de la UE y normas similares. Los proveedores de tecnología que combinan motores de generación escalables con seguimiento de linaje ganan cuota de presupuesto a medida que los equipos de gobernanza exigen resultados auditables. Al mismo tiempo, los nuevos despliegues de gemelos digitales en manufactura y movilidad profundizan la demanda de simulaciones ricas en física impulsadas por datos sintéticos, y la llegada de intercambios de datos abiertos amplía el alcance del mercado al reducir la fricción en el aprovisionamiento.
Conclusiones Clave del Informe
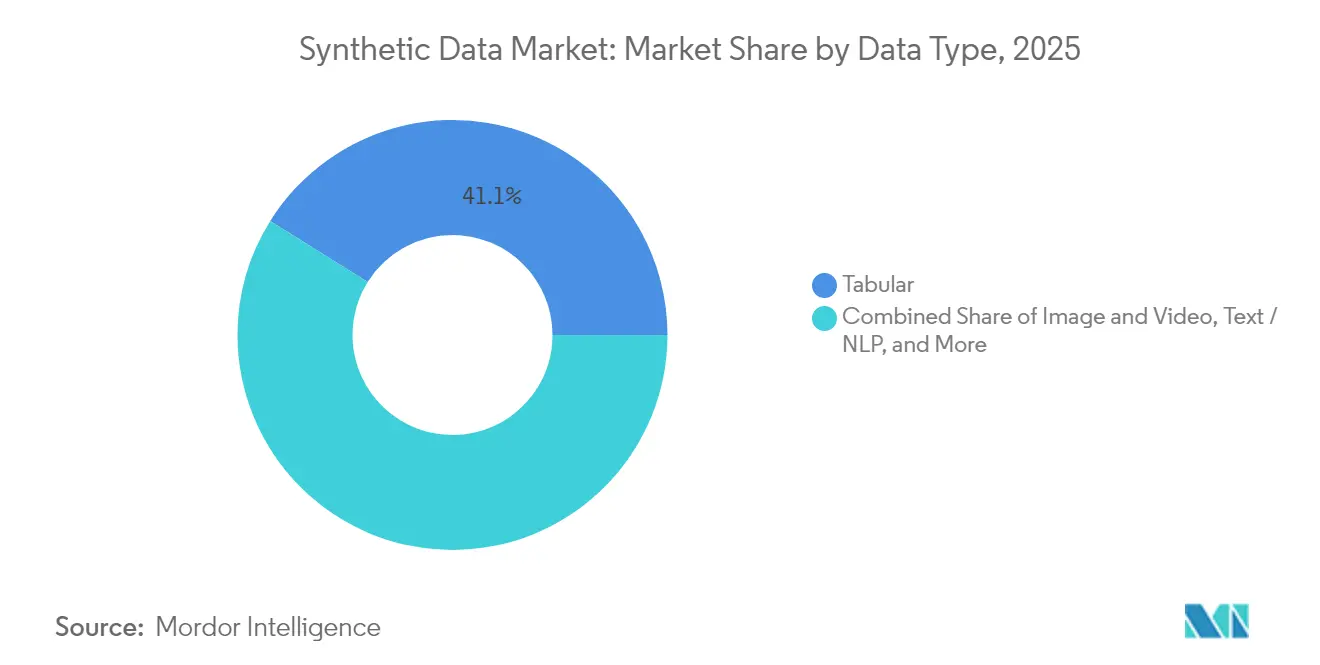
- Por tipo de datos, el contenido tabular representó el 41,10% de la participación del mercado de datos sintéticos en 2025; se prevé que la síntesis de imagen y video se expanda a una CAGR del 40,10% hasta 2031.
- Por oferta, las soluciones totalmente sintéticas representaron el 60,55% del tamaño del mercado de datos sintéticos en 2025 y avanzan a una CAGR del 34,40%.
- Por tecnología, las Redes Generativas Antagónicas capturaron el 37,75% de los ingresos en 2025, mientras que se proyecta que los Modelos de Difusión crezcan a una CAGR del 46,30% hasta 2031.
- Por modo de implementación, la implementación en la nube representó el 66,80% de los ingresos en 2025 y está previsto que aumente a una CAGR del 28,60% hasta 2031.
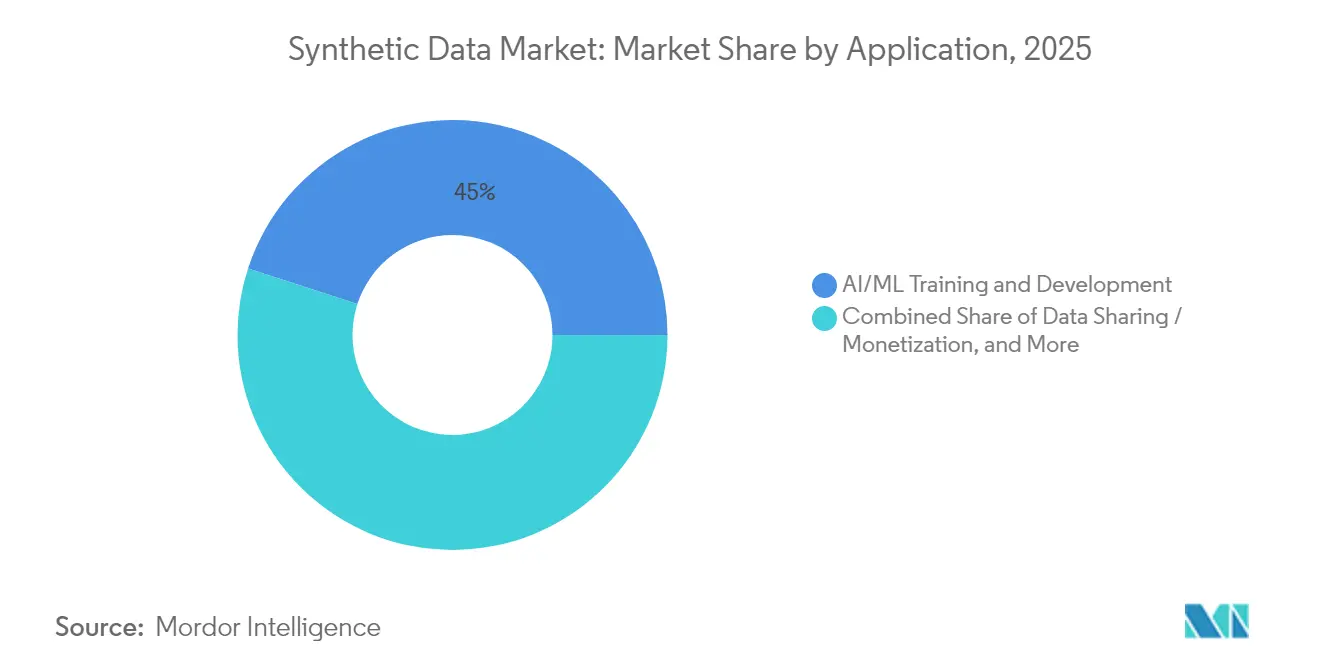
- Por aplicación, el entrenamiento y desarrollo de IA/ML representó el 45,00% de los ingresos de 2025, mientras que la simulación de sistemas autónomos está preparada para la CAGR más rápida del 44,95% hasta 2031.
- Por industria de usuario final, BFSI lideró con el 23,25% de los ingresos de 2025, mientras que se proyecta que el sector automotriz y de transporte aumente a una CAGR del 37,10% hasta 2031.
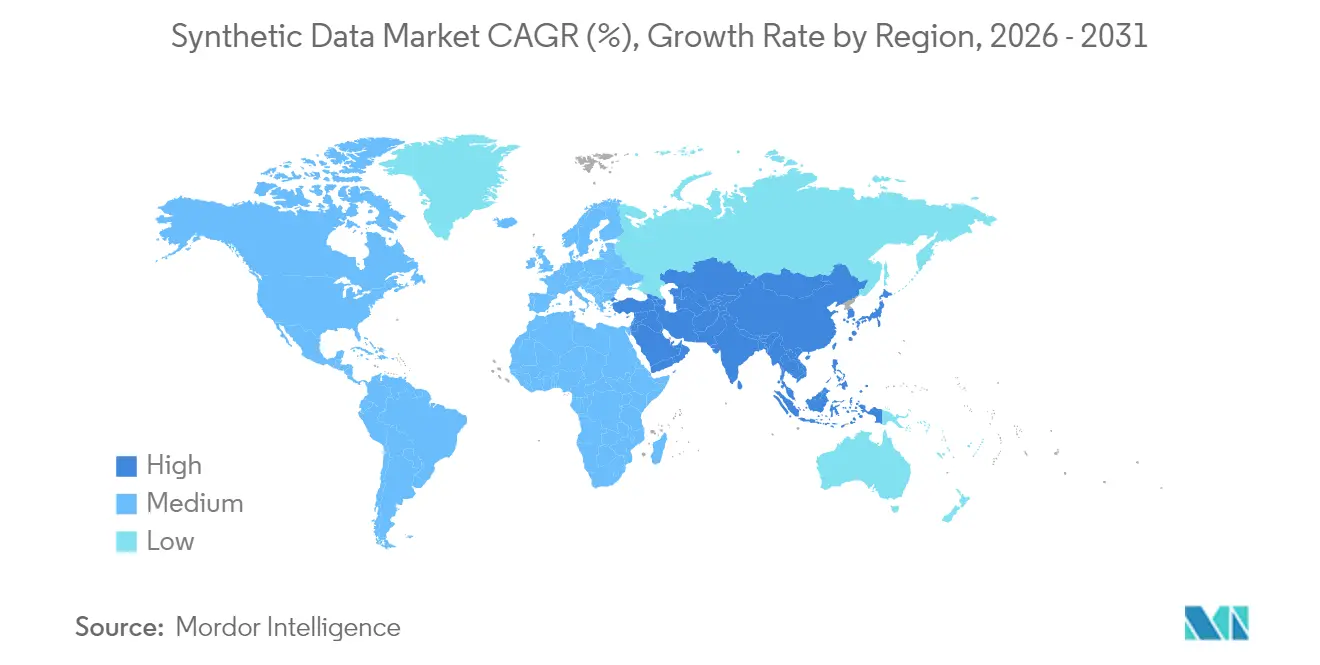
- Por geografía, América del Norte aseguró el 38,10% de los ingresos en 2025; se espera que Asia-Pacífico registre la CAGR más alta del 31,10% durante el período de pronóstico.
Nota: Las cifras de tamaño del mercado y previsión de este informe se generan utilizando el marco de estimación propietario de Mordor Intelligence, actualizado con los últimos datos e información disponibles a partir de 2026.
Tendencias e Información del Mercado Global de Datos Sintéticos
Análisis del Impacto de los Impulsores*
| Impulsor | (~) % de Impacto en el Pronóstico de CAGR | Relevancia Geográfica | Horizonte Temporal del Impacto |
|---|---|---|---|
| Impulso regulatorio para la IA que preserva la privacidad y el intercambio de datos | +8.5% | Global, con adopción temprana en la UE y América del Norte | Mediano plazo (2-4 años) |
| Auge de la IA generativa que demanda conjuntos de datos escalables con bajo sesgo | +12.2% | Global, concentrado en América del Norte y Asia-Pacífico | Corto plazo (≤ 2 años) |
| Transición del enmascaramiento de datos a réplicas sintéticas de alta utilidad | +6.8% | América del Norte y la UE, expandiéndose a Asia-Pacífico | Mediano plazo (2-4 años) |
| Integración de privacidad diferencial y cifrado homomórfico | +4.3% | Global, liderado por centros tecnológicos en EE. UU. y China | Largo plazo (≥ 4 años) |
| Surgimiento de intercambios de datos sintéticos abiertos | +3.7% | América del Norte y la UE, programas piloto en Asia-Pacífico | Largo plazo (≥ 4 años) |
| Convergencia de gemelos digitales en simulaciones de la Industria 4.0 | +4.5% | Regiones industriales globales, con fuerte presencia en Alemania y Japón | Mediano plazo (2-4 años) |
| Fuente: Mordor Intelligence | |||
Auge de la IA Generativa que Demanda Conjuntos de Datos Escalables con Bajo Sesgo
Los modelos de lenguaje y visión a gran escala requieren corpus vastos y diversos. Los analistas estiman que el contenido sintético suministrará el 60% de los datos de entrenamiento de IA para 2024. Los hiperescaladores están respondiendo: NVIDIA diseñó el generador Nemotron-4 340B para alimentar canalizaciones posteriores, reduciendo los costos de adquisición de datos y los riesgos de sesgo[1]NVIDIA, "Nemotron-4 340B: Un Modelo Fundacional para la Generación de Datos Sintéticos," developer.nvidia.com. El auge afecta a todos los sectores verticales, pero es más agudo en visión por computadora y PLN multilingüe, donde el aprovisionamiento en el mundo real puede ser costoso o estar prohibido por la ley de privacidad. La ampliación sintética expande la cobertura de escenarios, reduce los presupuestos de anotación y permite una experimentación más rápida.
Impulso Regulatorio para la IA que Preserva la Privacidad y el Intercambio de Datos
La Ley de IA de la UE obliga a las organizaciones a explorar sustitutos sintéticos antes de procesar datos personales. En los Estados Unidos, el Departamento de Seguridad Nacional destinó USD 1,7 millones para proyectos piloto de generadores sintéticos, confirmando el interés federal en el intercambio de datos conforme [2]Departamento de Seguridad Nacional de EE. UU., "Solicitud 23-DN-004 Soluciones de Datos Sintéticos," dhs.gov. Las nuevas normas de etiquetado de China reflejan una intención similar. Las empresas que operacionalizan los datos sintéticos de forma temprana evitan multas y desbloquean colaboraciones transfronterizas. El cumplimiento normativo, por tanto, transforma los datos sintéticos de algo deseable a un mandato a nivel de consejo directivo.
Transición del Enmascaramiento de Datos a Réplicas Sintéticas de Alta Utilidad
La anonimización tradicional a menudo rompe la integridad referencial, limitando la utilidad analítica. Las nuevas plataformas generan réplicas estadísticamente fieles, permitiendo a los evaluadores ejecutar cargas de trabajo realistas sin riesgo de exposición. La integración de Synthesized en Google BigQuery ilustra cómo la generación puede residir dentro de los almacenes de datos convencionales. Los bancos alemanes reportan un análisis de riesgo crediticio más rápido tras adoptar instantáneas sintéticas que mantienen intactas las relaciones entre tablas. Este cambio redirige el presupuesto desde costosos controles de acceso hacia la democratización de datos de autoservicio.
Convergencia de Gemelos Digitales en Simulaciones de la Industria 4.0
Las empresas industriales combinan motores de gemelos digitales con flujos de sensores sintéticos para someter a prueba de estrés los algoritmos de mantenimiento predictivo. La investigación de Springer muestra una aceleración de diez veces en los ciclos de desarrollo de productos cuando la telemetría sintética llena las brechas de datos [3]Springer, "Gemelos Digitales y Flujos de Sensores Sintéticos," link.springer.com. El Omniverse de NVIDIA genera escenarios ricos en física, permitiendo a los proveedores automotrices y a las empresas de robótica validar casos extremos que serían arriesgados o imposibles en el mundo real. La combinación ofrece tanto seguridad como ahorro de costos.
Análisis del Impacto de las Restricciones*
| Restricción | (~) % de Impacto en el Pronóstico de CAGR | Relevancia Geográfica | Horizonte Temporal del Impacto |
|---|---|---|---|
| Riesgo de colapso del modelo por datos entrenados de forma recursiva | -4.8% | Global, que afecta particularmente al desarrollo de modelos de lenguaje de gran escala | Corto plazo (≤ 2 años) |
| Falta de métricas de calidad estándar entre proveedores | -3.2% | Global, con esfuerzos de estandarización en EE. UU. y la UE | Mediano plazo (2-4 años) |
| Alto costo computacional para modelos fundacionales multimodales | -5.1% | Global, más agudo en mercados con recursos limitados | Corto plazo (≤ 2 años) |
| Estatus legal incipiente de los datos sintéticos "no personales" | -2.9% | Global, con incertidumbre regulatoria en mercados emergentes | Largo plazo (≥ 4 años) |
| Fuente: Mordor Intelligence | |||
Riesgo de Colapso del Modelo por Datos Entrenados de Forma Recursiva
Los estudios advierten que el entrenamiento repetido en contenido autogenerado reduce la diversidad de datos y amplifica el sesgo. Los proveedores ahora mezclan fuentes orgánicas y congelan los pesos del generador para limitar los bucles de retroalimentación. Las auditorías de calidad y las canalizaciones de aprendizaje activo son salvaguardas emergentes, aunque el problema sigue siendo un freno a corto plazo para los flujos de trabajo totalmente sintéticos.
Alto Costo Computacional para Modelos Fundacionales Multimodales
Los motores de difusión de primer nivel requieren miles de GPU y semanas de tiempo de ejecución. Las facturas mensuales pueden superar las seis cifras para las empresas más pequeñas, dificultando la experimentación. Los servicios de pago por uso en la nube facilitan la entrada, pero no eliminan los costos de rendimiento. La presión sobre los precios puede fomentar la especialización de hardware y la descarga federada a chips del lado del cliente.
*Nuestras previsiones consideran los impactos de impulsores y restricciones como direccionales, no aditivos. Las previsiones de impacto reflejan el crecimiento base, los efectos de mezcla y las interacciones entre variables.
Análisis de Segmentos
Por Tipo de Datos: El Contenido Visual Impulsa la Innovación
La síntesis de imagen y video registra el crecimiento más rápido con una CAGR del 40,10% hasta 2031, lo que refleja el desarrollo de vehículos autónomos y las aplicaciones de visión por computadora que demandan conjuntos de datos de entrenamiento fotorrealistas. Los datos tabulares mantienen el liderazgo del mercado con una participación del 41,10% en 2025, impulsados por aplicaciones de servicios financieros y salud que requieren soluciones de privacidad de datos estructurados. Las aplicaciones de texto y PLN se benefician de los avances en modelos de lenguaje de gran escala, mientras que la síntesis de audio gana impulso a través de plataformas como Gramosynth de Rightsify para la generación de música libre de derechos de autor. La síntesis de datos de sensores y series temporales aborda los requisitos de monitoreo industrial e IoT, particularmente valiosa para aplicaciones de mantenimiento predictivo donde los escenarios de fallo son escasos en conjuntos de datos del mundo real.
La aparición de modelos fundacionales multimodales está difuminando los límites tradicionales entre tipos de datos, con plataformas como Cosmos de NVIDIA que generan datos sintéticos basados en física a través de modalidades visuales, de sensores y temporales de forma simultánea. La valoración de USD 15 mil millones de Applied Intuition refleja la confianza de los inversores en las aplicaciones de datos sintéticos visuales para sistemas autónomos. Esta convergencia permite entornos de simulación más sofisticados que capturan interacciones complejas del mundo real, particularmente valiosos para el desarrollo de robótica y vehículos autónomos donde múltiples modalidades de sensores deben sincronizarse.



Por Oferta: Se Prefiere el Reemplazo Completo
Los paquetes totalmente sintéticos dominaron el 60,55% de los ingresos de 2025 y están creciendo a una CAGR del 34,40%. Las empresas eligen el reemplazo total para eliminar el riesgo residual de privacidad y simplificar las estructuras de gobernanza. Las alternativas híbridas permanecen para flujos de trabajo clínicos o de ingeniería de alta fidelidad donde pequeños anclajes en el mundo real mejoran la precisión del modelo. El lago de datos seguro de Tonic.ai ejemplifica la demanda de control unificado en formatos no estructurados, subrayando la migración del mercado hacia cadenas de herramientas consolidadas.
El mercado de datos sintéticos se beneficia a medida que los reguladores aceptan pruebas de equivalencia estadística en lugar de inspecciones de datos sin procesar, reduciendo los plazos de aprobación. Los grupos bancarios y de seguros citan reducciones de dos dígitos en las horas de revisión de cumplimiento tras la adopción. Los proveedores que automatizan el linaje, el versionado y las verificaciones de privacidad diferencial agrupan servicios de valor añadido, aumentando los costos de cambio y empujando a la industria hacia la consolidación de plataformas.
Por Tecnología: Los Modelos de Difusión se Disparan
Las GANs aún representan el 37,75% de los ingresos de 2025, pero los motores de difusión registran la CAGR más rápida del 46,30%. Su capacidad para producir fotogramas más limpios y diversos los posiciona para tareas de video de alta resolución en entretenimiento y manufactura avanzada. Los generadores basados en modelos de lenguaje de gran escala demuestran ser sólidos para la síntesis tabular y de texto, manteniendo las correlaciones entre columnas y mejorando las puntuaciones F1 de los modelos posteriores. Los simuladores basados en reglas persisten en el control industrial determinista donde las ecuaciones físicas superan a la aleatoriedad basada en datos.
Proyectos académicos como SiloFuse demuestran la idoneidad de la difusión para entornos federados, un argumento de venta clave en finanzas y salud transfronterizas. Los estudios comparativos revelan reducciones en la tasa de defectos del 30% frente a las canalizaciones heredadas, lo que explica por qué los fabricantes de equipos originales actualizan a pesar de las mayores facturas de cómputo. El mercado de datos sintéticos exhibe un ciclo claro de actualización tecnológica que recompensa a los proveedores que desacoplan la lógica de orquestación de la arquitectura del generador.
Por Modo de Implementación: La Dominancia de la Nube Continúa
Las implementaciones en la nube se apoderaron del 66,80% de los ingresos de 2025 y aumentarán a una CAGR del 28,60% hasta 2031. Las empresas favorecen los grupos de GPU elásticos y las herramientas de cumplimiento gestionadas. AWS Bedrock, Google BigQuery con Synthesized y el DGX Cloud de NVIDIA alojan API de generación nativas que acortan los tiempos de inicio de los proyectos. Las instalaciones locales siguen siendo críticas para la defensa, la banca central y los servicios públicos regidos por estrictos mandatos de soberanía.
Las mesas de operaciones sensibles a la latencia experimentan con microgeneradores basados en el borde que actualizan los datos sintéticos del mercado en menos de dos milisegundos. Mientras tanto, los enclaves de cómputo confidencial y las opciones de fijación regional moderan las preocupaciones de soberanía en la nube pública. A medida que los costos disminuyen y las características de seguridad mejoran, el mercado de datos sintéticos se inclina aún más hacia la implementación en la nube primero, aunque las huellas híbridas persisten donde existen restricciones de ancho de banda o de política.
Por Aplicación: Los Sistemas Autónomos se Aceleran
El entrenamiento de IA/ML representó el 45,00% del gasto de 2025, confirmando que la ampliación sintética se ha convertido en un insumo de desarrollo convencional. Se proyecta que la simulación de sistemas autónomos registre la CAGR más alta del 44,95% a medida que los reguladores exigen pruebas exhaustivas de escenarios antes del lanzamiento comercial. Los equipos de pruebas de software explotan casos extremos sintéticos para descubrir errores antes, y las unidades de análisis de fraude replican patrones de ataque raros sin exponer los registros de clientes.
Las plataformas de intercambio y monetización de datos emergen como nuevas fuentes de ingresos. Las empresas venden conjuntos de datos anonimizados pero útiles a socios, desbloqueando valor de activos anteriormente aislados. En robótica, la canalización Isaac de NVIDIA produce cientos de miles de trayectorias de movimiento en horas, acelerando la convergencia del modelo. Estas dinámicas amplían el mercado de datos sintéticos más allá de la investigación y el desarrollo hacia las operaciones de producción y los productos de datos comerciales.
Por Industria de Usuario Final: Transformación Automotriz
BFSI representó el 23,25% de los ingresos de 2025 en el tamaño del mercado de datos sintéticos, aprovechando las réplicas para el modelado de riesgos y el análisis antifraude. Se prevé que el sector automotriz y de transporte crezca a una CAGR del 37,10%, impulsado por la carrera hacia la autonomía de Nivel 4 que necesita miles de millones de millas de conducción segura para la validación. La salud pilota cohortes de pacientes sintéticos para agilizar la inscripción en ensayos clínicos y proteger la privacidad. Los minoristas fabrican recorridos de clientes para motores de personalización, y las empresas de telecomunicaciones simulan eventos de fallos de red para reforzar la fiabilidad. Las agencias gubernamentales elaboran conjuntos de datos de planificación de misiones que eliminan las características clasificadas pero mantienen la utilidad estratégica. El mercado de datos sintéticos penetra así en todos los sectores donde los datos del mundo real son escasos, sensibles o costosos de recopilar.
Análisis Geográfico
América del Norte capturó el 38,10% de los ingresos de 2025. Gigantes tecnológicos como Microsoft y Meta gastan decenas de miles de millones en infraestructura de IA que depende de canalizaciones sintéticas, y los programas federales validan el enfoque para casos de uso de seguridad nacional. Los clústeres en California, Texas y Ontario atraen capital de riesgo, proporcionando un denso ecosistema de especialistas que alimentan la innovación en finanzas, salud y defensa.
Asia-Pacífico muestra la CAGR más rápida del 31,10%. La ley de etiquetado de contenido generado por IA de China alienta a las empresas a generar alternativas sintéticas en lugar de registros de usuarios reales, y los líderes en robótica de Japón combinan datos de percepción sintéticos con automatización de fábricas. India aprovecha los registros de pacientes sintéticos para reforzar las plataformas de telesalud en medio de las normas de localización de datos, y la capacidad de semiconductores de Corea del Sur apoya el entrenamiento de modelos en la región. El Sudeste Asiático se beneficia de las empresas emergentes de tecnología financiera que comparten datos de crédito seguros para la privacidad con el fin de ampliar la inclusión financiera.
Europa combina el liderazgo regulatorio con el impulso comercial. La Ley de IA de la UE formaliza una postura sintética primero, y la Comisión Europea validó el método para las finanzas digitales. Los proyectos de Industrie 4.0 de Alemania combinan gemelos digitales y telemetría sintética para optimizar el uso de energía. El Reino Unido capitaliza su independencia regulatoria para pilotar vías de aprobación simplificadas. Los estados nórdicos invierten en centros de datos verdes que albergan clústeres de generación neutros en carbono, alineando los objetivos de sostenibilidad con el crecimiento de la IA. En otros lugares, los programas de ciudades inteligentes de Oriente Medio integran conjuntos de datos sintéticos para movilidad y seguridad, y las empresas emergentes africanas aprovechan las API en la nube para compensar la escasez de datos mientras navegan por las leyes de privacidad en evolución.

Panorama Competitivo
El mercado de datos sintéticos sigue siendo moderadamente concentrado pero altamente dinámico. La adquisición de Gretel por parte de NVIDIA por USD 320 millones fusiona hardware, orquestación de modelos y herramientas de privacidad en una pila de extremo a extremo. SAS Institute adquirió Hazy para integrar la generación dentro de los conjuntos analíticos utilizados por bancos y aseguradoras. Applied Intuition recaudó capital con una valoración de USD 15 mil millones para ofrecer simulación específica de dominio para la conducción autónoma, subrayando la prima por la profundidad vertical.
Emergen tres arquetipos competitivos. Los líderes de infraestructura monetizan el cómputo a escala y agrupan motores sintéticos. Los especialistas verticales adaptan ontologías de dominio y métricas de validación. Los integradores de plataformas se centran en las capas de gobernanza que conectan generadores dispares a los tejidos de datos empresariales.
Los grupos de trabajo del IEEE redactan estándares de calidad que podrían convertir en mercancía la funcionalidad de generación base y desplazar la rivalidad hacia la automatización del cumplimiento y la observabilidad en tiempo real. Durante el período de pronóstico, es probable que se produzcan adquisiciones a medida que las empresas más grandes busquen amplitud de capacidades, pero la difusión de código abierto reduce las barreras para los nuevos participantes, manteniendo el mercado de datos sintéticos en disputa.
Líderes de la Industria de Datos Sintéticos
MOSTLY AI Solutions MP GmbH
NVIDIA Corporation
Meta Platforms, Inc.
Amazon.com, Inc.
Microsoft Corporation
- *Nota aclaratoria: los principales jugadores no se ordenaron de un modo en especial

Desarrollos Recientes de la Industria
- Abril de 2025: Tonic.ai adquirió Fabricate para ofrecer interfaces de lenguaje natural que permiten al personal no técnico crear conjuntos de datos conformes rápidamente.
- Marzo de 2025: NVIDIA adquirió Gretel por USD 320 millones, integrando la generación que preserva la privacidad en sus servicios de IA en la nube.
- Enero de 2025: NVIDIA lanzó el Modelo Fundacional de Mundo Cosmos, que permite escenas sintéticas fotorrealistas para vehículos autónomos y robots, con Uber entre los primeros usuarios.
- Enero de 2025: NVIDIA amplió Omniverse con IA física generativa, añadiendo a Accenture, Microsoft y Siemens como primeros adoptantes.


Marco de la metodología de investigación y alcance del informe
Definiciones del Mercado y Cobertura Clave
Nuestro estudio define el mercado de datos sintéticos como todos los ingresos comerciales generados por plataformas de software, servicios en la nube y API que crean algorítmicamente conjuntos de datos artificiales cuyos patrones estadísticos replican información real para el entrenamiento de IA/ML, la gestión de datos de prueba, la preservación de la privacidad y la simulación.
Para mayor claridad, excluimos las utilidades heredadas de enmascaramiento de datos que simplemente anonimizan los registros existentes en lugar de generar datos nuevos y estadísticamente representativos.
Descripción General de la Segmentación
- Por Tipo de Datos
- Tabular
- Texto / PLN
- Imagen y Video
- Audio
- Sensor / Series Temporales
- Por Oferta
- Totalmente Sintético
- Parcialmente Sintético / Híbrido
- Por Tecnología
- GANs
- Modelos de Difusión
- Generadores Basados en Modelos de Lenguaje de Gran Escala
- Simulaciones Basadas en Reglas / Basadas en Agentes
- Por Modo de Implementación
- Nube
- Local
- Por Aplicación
- Entrenamiento y Desarrollo de IA/ML
- Intercambio / Monetización de Datos
- Pruebas de Software y DevOps
- Simulación de Sistemas Autónomos
- Pruebas de Ciberseguridad y Fraude
- Por Industria de Usuario Final
- BFSI
- Salud y Ciencias de la Vida
- Comercio Minorista y Comercio Electrónico
- Automotriz y Transporte
- Gobierno y Defensa
- TI y Servicios Habilitados por TI
- Industrial y Robótica
- Por Geografía
- América del Norte
- Estados Unidos
- Canadá
- México
- América del Sur
- Brasil
- Argentina
- Resto de América del Sur
- Europa
- Alemania
- Reino Unido
- Francia
- Italia
- España
- Rusia
- Resto de Europa
- Asia-Pacífico
- China
- Japón
- India
- Corea del Sur
- Australia y Nueva Zelanda
- Resto de Asia-Pacífico
- Oriente Medio y África
- Oriente Medio
- Arabia Saudita
- Emiratos Árabes Unidos
- Turquía
- Resto de Oriente Medio
- África
- Sudáfrica
- Nigeria
- Egipto
- Resto de África
- Oriente Medio
- América del Norte
Metodología de Investigación Detallada y Validación de Datos
Investigación Primaria
Los analistas de Mordor entrevistaron a arquitectos de IA en la nube, directores de privacidad en BFSI y salud, y responsables de adquisiciones en América del Norte, Europa y Asia-Pacífico.
Sus perspectivas sobre los niveles de precios de licencias, las tasas de uso y los cuellos de botella regulatorios nos permitieron refinar supuestos que los datos secundarios por sí solos no podían resolver.
Investigación Documental
Comenzamos dimensionando la demanda potencial a través de fuentes abiertas como el Observatorio de Políticas de IA de la OCDE, el rastreador de aplicación del RGPD de la UE, las tablas de gasto en software de la Oficina de Análisis Económico de los Estados Unidos y revistas revisadas por pares indexadas en IEEE Xplore.
D&B Hoovers y Dow Jones Factiva proporcionaron ingresos indicativos de proveedores, mientras que los documentos técnicos del Consejo ITI ayudaron a verificar las señales de adopción.
Para traducir puntos de datos dispares en métricas comparables, normalizamos los valores a dólares constantes de 2025, reconciliamos las fluctuaciones de divisas utilizando los promedios del FMI y archivamos cada referencia en un repositorio interno.
La lista anterior es ilustrativa; muchas otras fuentes secundarias informaron la recopilación, validación y aclaración de datos.
Dimensionamiento del Mercado y Pronóstico
Aplicamos una combinación de enfoque descendente y ascendente: el gasto en software de IA empresarial formó el grupo de demanda, las tasas de penetración por sector lo convirtieron en ingresos de datos sintéticos, y los resultados se verificaron cruzadamente con resúmenes de proveedores muestreados y pruebas de precio de venta promedio × volumen.
Las variables clave incluyen las curvas de costo por hora de GPU, el gasto en cumplimiento regional, los recuentos de proyectos de IA activos y los volúmenes de imágenes sintéticas por milla de vehículo autónomo.
Una regresión multivariante proyecta estos impulsores hasta 2030; los microdatos faltantes se interpolaron a partir de indicadores adyacentes y se reconciliaron durante la revisión.
Validación de Datos y Ciclo de Actualización
Ejecutamos barridos de anomalías, revisiones por pares de múltiples etapas y verificaciones de varianza contra puntos de referencia independientes antes de la aprobación.
Los modelos se actualizan cada año, con actualizaciones intermedias cuando eventos como nuevas leyes de privacidad desplazan materialmente la demanda.
Por Qué la Línea de Base de Datos Sintéticos de Mordor Merece Confianza
Reconocemos que las estimaciones publicadas a menudo divergen porque las empresas adoptan diferentes alcances, supuestos y cadencias de actualización.
Al centrarnos estrictamente en los ingresos de las plataformas de generación y al recalibrar nuestro modelo anualmente, Mordor minimiza tanto la sobreestimación como la subestimación.
Comparación de Referencia
| Tamaño del Mercado | Fuente anonimizada | Principal factor de diferencia |
|---|---|---|
| USD 0,51 mil millones (2025) | ||
| USD 0,30 mil millones (2023) | Consultora Global A | Incluye software de anonimización y gasto en pruebas de concepto |
| USD 0,29 mil millones (2024) | Revista de la Industria B | Aplica una CAGR uniforme sin calibración regional |
Estos contrastes muestran que la selección disciplinada del alcance de Mordor, el modelo impulsado por variables y la actualización oportuna ofrecen una línea de base equilibrada y transparente en la que los tomadores de decisiones pueden confiar.


Preguntas Clave Respondidas en el Informe
¿Cuál es el crecimiento proyectado del mercado de datos sintéticos hasta 2031?
Se prevé que el mercado de datos sintéticos aumente de USD 710 millones en 2026 a USD 3,67 mil millones en 2031, lo que refleja una CAGR del 38,96%.
¿Por qué los modelos de difusión están ganando participación frente a las GANs?
Los motores de difusión generan imágenes de mayor calidad y más estables, impulsando una CAGR del 46,30% que supera el crecimiento de los enfoques basados en GANs.
¿Qué modo de implementación domina el gasto?
La implementación en la nube representa el 66,80% de los ingresos de 2025 y se está expandiendo a una CAGR del 28,60% gracias a los grupos de GPU elásticos y las herramientas de cumplimiento integradas.
¿Cómo influyen las nuevas regulaciones en la adopción?
Normas como la Ley de IA de la UE exigen que las empresas prueben alternativas sintéticas antes de procesar datos personales, convirtiendo las plataformas de generación en una necesidad de cumplimiento.
¿Qué sector vertical de la industria está preparado para el crecimiento más rápido?
Se prevé que el sector automotriz y de transporte crezca a una CAGR del 37,10% porque los programas de conducción autónoma necesitan una amplia cobertura de escenarios sintéticos para la validación de seguridad.
¿Cuál es el principal obstáculo para las empresas más pequeñas?
Los altos costos computacionales para los modelos fundacionales multimodales siguen siendo la mayor barrera, con cargas de trabajo intensivas en GPU que elevan las facturas mensuales de la nube a territorio de seis cifras.
Última actualización de la página el:




