Tamaño y Participación del Mercado de Etiquetado de Datos
Visión General del Mercado
| Período de Estudio | 2020 - 2031 |
|---|---|
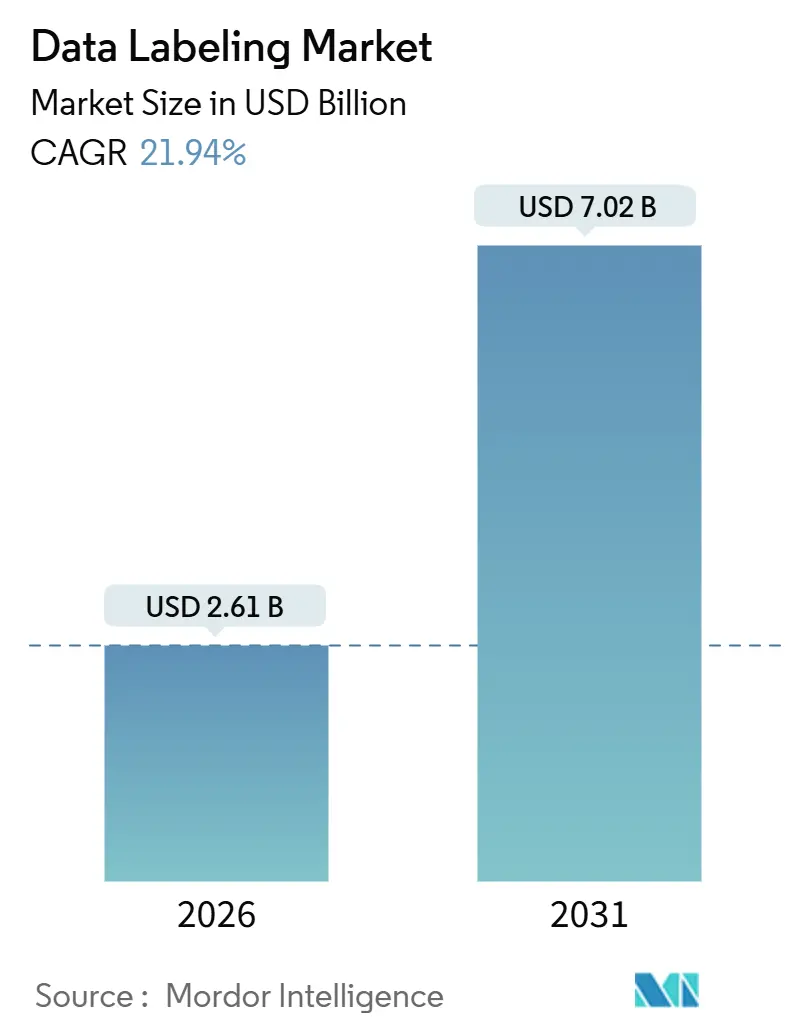
| Tamaño del Mercado (2026) | 2.61 Mil millones de dólares |
| Tamaño del Mercado (2031) | 7.02 Mil millones de dólares |
| Tasa de crecimiento (2026 - 2031) | 21.94% CAGR |
| Mercado de Crecimiento Más Rápido | Asia Pacífico |
| Mercado Más Grande | América del Norte |
| Concentración del Mercado | Medio |
Jugadores principales *Nota aclaratoria: los principales jugadores no se ordenaron de un modo en especial Imagen © Mordor Intelligence. El uso requiere atribución según CC BY 4.0. | |
Análisis del Mercado de Etiquetado de Datos por Mordor Intelligence
El tamaño del mercado de etiquetado de datos se sitúa en USD 2,61 mil millones en 2026 y se proyecta que alcance USD 7,02 mil millones en 2031, reflejando una sólida CAGR del 21,94%. Este crecimiento está impulsado por tres catalizadores interrelacionados. Los desarrolladores de modelos fundacionales que buscan corpus curados por expertos para reducir alucinaciones, los fabricantes de automóviles que validan pilas de fusión de sensores que requieren etiquetas 3D a nivel de fotograma, y las empresas industriales que escalan la IA de mantenimiento predictivo que depende de datos de series temporales de fallos etiquetados. La inversión de USD 15 mil millones de Meta en Scale AI en junio de 2025 cristalizó la infraestructura de etiquetado como una ventaja estratégica en lugar de un servicio mercantilizado, impulsando a OpenAI y Google a diversificar sus proveedores de anotación. La anotación de video para sistemas autónomos, los modelos de abastecimiento híbrido que combinan la experiencia interna con la mano de obra externalizada, y los flujos de trabajo de etiquetado autosupervisado que reducen los costos por etiqueta están todos expandiéndose más rápido que el mercado de etiquetado de datos en general, creando espacio para plataformas que sincronizan especialistas humanos y etiquetado asistido por modelos. América del Norte sigue siendo el ancla de ingresos, pero el impulso de Asia Pacífico impulsado por políticas para la IA industrial está remodelando la dinámica regional.
Conclusiones Clave del Informe
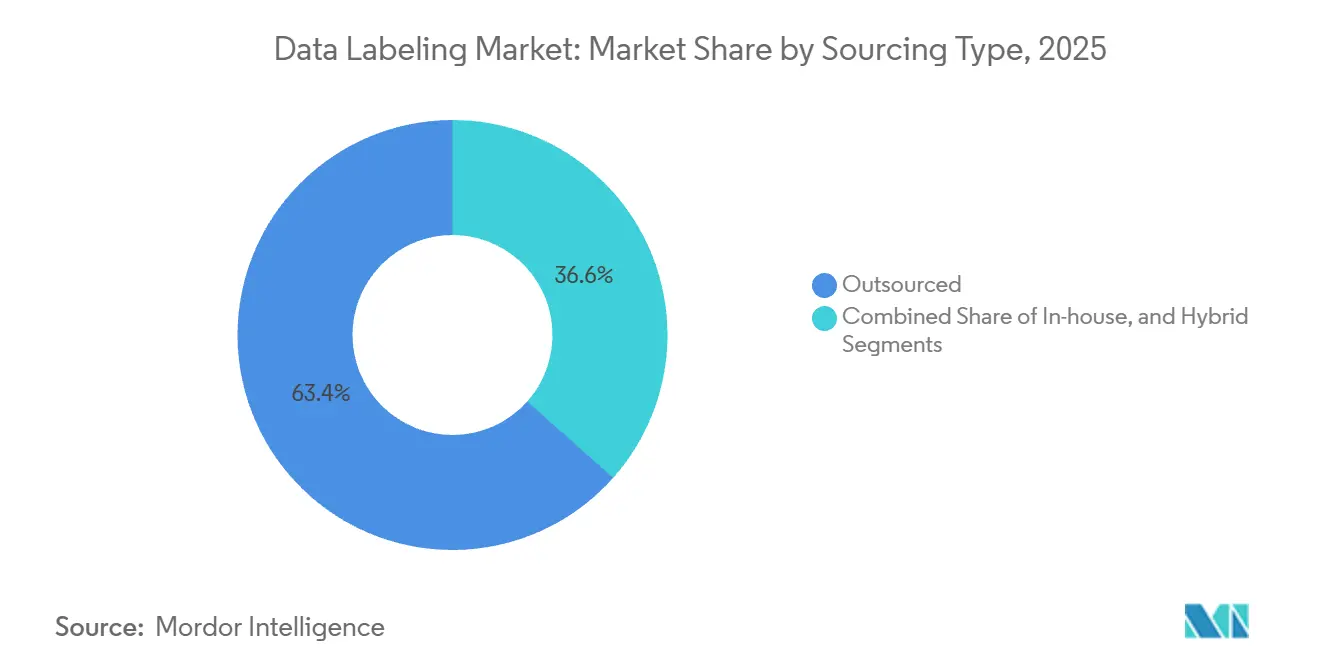
- Por tipo de abastecimiento, el etiquetado externalizado lideró con el 63,43% de la participación del mercado de etiquetado de datos en 2025, mientras que el abastecimiento híbrido avanza a una CAGR del 22,48% hasta 2031.
- Por tipo de datos, los conjuntos de datos de imágenes capturaron una participación del 36,26% en 2025; la anotación de video está en camino de alcanzar una CAGR del 23,17% hasta 2031.
- Por enfoque de etiquetado, el etiquetado manual representó el 42,31% del tamaño del mercado de etiquetado de datos en 2025, aunque las técnicas autosupervisadas y programáticas están creciendo a una CAGR del 22,16%.
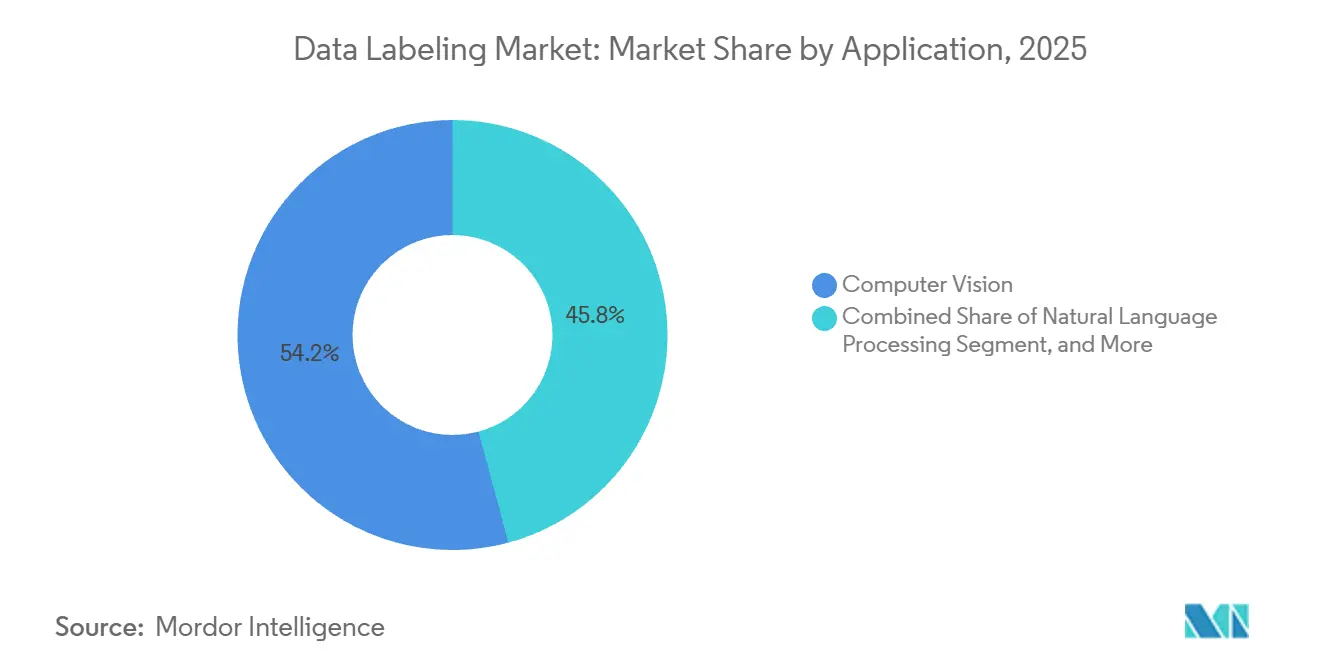
- Por aplicación, las aplicaciones de visión por computadora comandaron una participación del 54,19% en 2025, mientras que el mantenimiento predictivo y el aseguramiento de la calidad mostraron la CAGR más rápida del 22,61% hasta 2031.
- Por industria de usuario final, el sector automotriz y de transporte mantuvo una participación del 28,26% en 2025; el sector industrial y de manufactura es el de más rápido crecimiento con una CAGR del 22,84%.
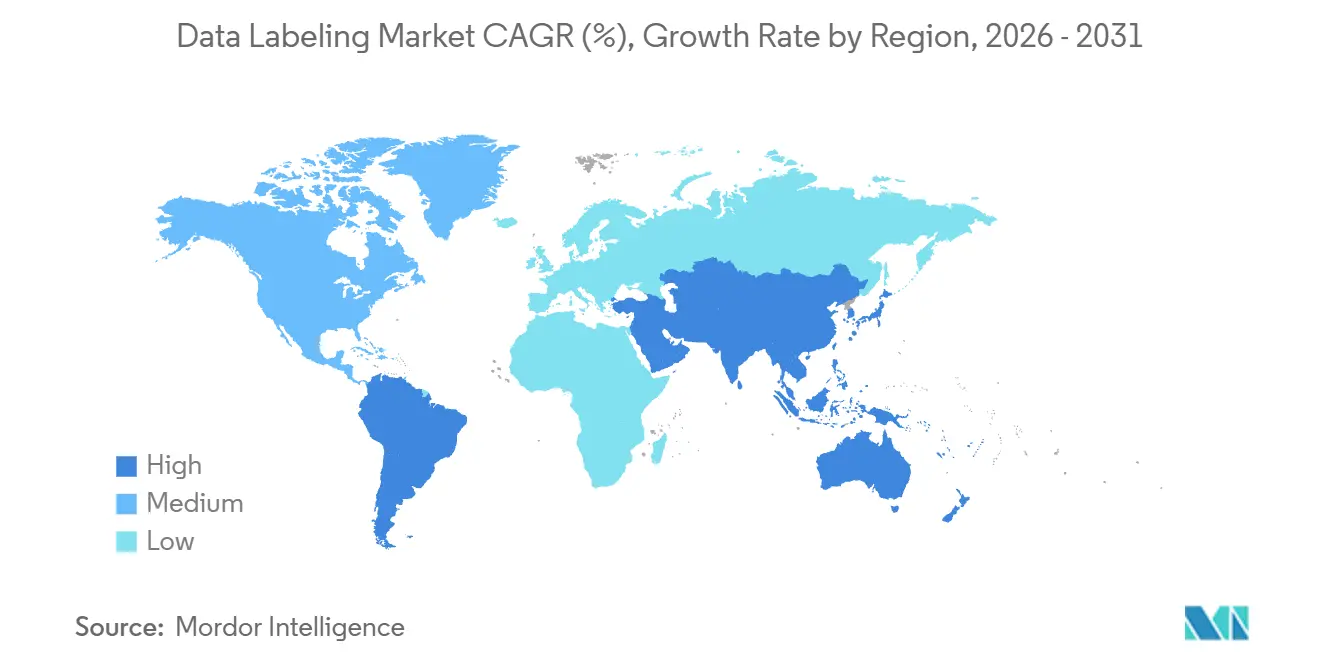
- Por geografía, América del Norte contribuyó con el 31,13% de los ingresos en 2025, pero Asia Pacífico es la región de más rápido crecimiento con una CAGR del 21,16%.
Nota: Las cifras del tamaño del mercado y los pronósticos de este informe se generan utilizando el marco de estimación patentado de Mordor Intelligence, actualizado con los datos y conocimientos más recientes disponibles a partir de enero de 2026.
Tendencias e Información del Mercado Global de Etiquetado de Datos
Análisis del Impacto de los Impulsores*
| Impulsor | (~) % de Impacto en el Pronóstico de CAGR | Relevancia Geográfica | Horizonte Temporal del Impacto |
|---|---|---|---|
| Rápida Adopción de ADAS y Datos de Visión para la Conducción Autónoma | +5.2% | Global, con foco en América del Norte, Europa y China | Mediano plazo (2-4 años) |
| Auge de la IA Generativa que Impulsa la Demanda de Conjuntos de Datos Multimodales | +6.8% | Global, liderado por América del Norte y Asia Pacífico | Corto plazo (≤ 2 años) |
| Avances en Flujos de Trabajo de Aprendizaje Automático de Grandes Datos | +3.1% | Global | Mediano plazo (2-4 años) |
| Adopción de IA en Imágenes Médicas | +2.9% | América del Norte, Europa, Asia Pacífico | Mediano plazo (2-4 años) |
| Microetiquetado en el Borde para Validación de Datos Sintéticos | +1.7% | Global, adopción temprana en América del Norte y Europa | Largo plazo (≥ 4 años) |
| Metadatos de Procedencia de IA Explicable Impulsados por la Regulación | +2.3% | Europa, América del Norte, China | Mediano plazo (2-4 años) |
| Fuente: Mordor Intelligence | |||
Rápida Adopción de ADAS y Datos de Visión para la Conducción Autónoma
Los conjuntos de sensores automotrices ahora transmiten terabytes de datos multimodales cada día, y el mercado de etiquetado de datos depende de etiquetas precisas para desbloquear la autonomía de Nivel 3 y Nivel 4. La publicación pública de Waymo mostró que la precisión promedio del vehículo aumentó del 29,7% con el 10% de los datos de entrenamiento al 49,4% con datos completos, lo que demuestra que la escala de etiquetas y la diversidad geográfica influyen directamente en la precisión de la percepción. La iniciativa RoAD to L4 de Japón y su desarrollo de infraestructura de carga de vehículos eléctricos generarán nuevos registros de sensores que necesitan etiquetas específicas de la región. Los fabricantes de equipos originales están pasando del volumen bruto a la calidad por fotograma, aumentando la demanda de herramientas de etiquetado sincronizado LiDAR-cámara y flujos de trabajo de validación de grado automotriz.
Auge de la IA Generativa que Impulsa la Demanda de Conjuntos de Datos Multimodales
Los constructores de modelos fundacionales ahora prefieren corpus más pequeños y etiquetados por expertos que suprimen las alucinaciones y permiten el ajuste específico del dominio. Scale AI reveló que el 90% de sus ingresos de 2024 provino de proyectos de IA generativa, y la participación de USD 15 mil millones de Meta subraya la prima sobre los conjuntos de datos con procedencia controlada. El plan de trabajo de China de enero de 2026 para integrar la IA en 20 industrias amplifica la necesidad de corpus conversacionales, de diálogo y de seguimiento de instrucciones curados. Los salarios más altos para abogados, médicos y lingüistas que ahora alcanzan USD 60 por hora están bifurcando la oferta en niveles especializados y de productos básicos, favoreciendo a las plataformas que gestionan ambas bandas de habilidades con pistas de auditoría transparentes.
Avances en Flujos de Trabajo de Aprendizaje Automático de Grandes Datos
Las empresas cada vez más versionan los conjuntos de datos etiquetados dentro de los flujos de trabajo de integración continua. La Infraestructura de Nube de Puente de IA de Japón asigna 40-80 nodos para proyectos de modelos de lenguaje de 60 días que dependen de etiquetas de expertos en el dominio y registros de procedencia inmutables. La hoja de ruta de India para 2025 exige protocolos estandarizados de datos de máquinas y columnas vertebrales digitales nacionales, acelerando la demanda de API de etiquetado que envían métricas de calidad a los paneles de DevOps.[1]NITI Aayog, "Reimaginando la Manufactura: Hoja de Ruta de India hacia el Liderazgo Global en Manufactura Avanzada," niti.gov.in Los proveedores que ofrecen ingesta programática, ganchos de supervisión débil y monitoreo de deriva están desplazando a los talleres de anotación heredados.
Adopción de IA en Imágenes Médicas
Los departamentos de radiología y patología de todo el mundo necesitan conjuntos de datos conformes con HIPAA verificados por médicos antes de que los reguladores aprueben los dispositivos de IA. La FDA de los Estados Unidos ha aprobado docenas de algoritmos de imágenes desde 2024, cada uno de los cuales requiere escaneos de verdad fundamental etiquetados. La agencia de investigación de Japón, RIKEN, está entrenando modelos fundacionales de ciencias de la vida con datos clínicos curados que requieren pistas de auditoría transparentes. Por lo tanto, los hospitales están recurriendo a proveedores especializados que combinan radiólogos en el ciclo con sistemas de calidad certificados por ISO.
Análisis del Impacto de las Restricciones*
| Restricción | (~) % de Impacto en el Pronóstico de CAGR | Relevancia Geográfica | Horizonte Temporal del Impacto |
|---|---|---|---|
| Escasez de Anotadores Calificados y Aumento de los Costos Laborales | -3.4% | Global, agudo en América del Norte y Europa | Corto plazo (≤ 2 años) |
| Escalada de Mandatos de Privacidad de Datos y Soberanía | -2.8% | Europa, China, emergente en América del Norte | Mediano plazo (2-4 años) |
| Presión de Sostenibilidad sobre el Uso de Energía en la Anotación a Hiperescala | -0.9% | Global, liderado por Europa | Largo plazo (≥ 4 años) |
| Aprendizaje Autosupervisado y Débilmente Supervisado que Erosiona el Gasto en Etiquetado Manual | -4.1% | Global, adopción temprana en América del Norte y Asia Pacífico | Mediano plazo (2-4 años) |
| Fuente: Mordor Intelligence | |||
Escasez de Anotadores Calificados y Aumento de los Costos Laborales
El giro hacia el etiquetado por expertos en el dominio ha expuesto un cuello de botella de talento. Scale AI ahora paga USD 30-60 por hora a anotadores de nivel doctoral tras las críticas a sus tarifas de pago colaborativo, elevando los costos base en todos los proveedores. La hoja de ruta de India aborda la brecha de habilidades a través de aprendizajes modulares y un Instituto de Tecnología de Frontera para la certificación de anotación. Si bien la automatización ayuda al preetiquetado, la validación humana sigue siendo obligatoria para los casos de uso regulados, manteniendo la inflación salarial como un lastre a corto plazo sobre los márgenes.
Escalada de Mandatos de Privacidad de Datos y Soberanía
Las reglas de localización de datos dividen el mercado de etiquetado de datos en silos regionales. La Ley de IA de la UE exige metadatos de procedencia y documentación de conjuntos de datos, aumentando la carga de cumplimiento.[2]Comisión Europea, "Propuesta de Reglamento por el que se establecen normas armonizadas sobre inteligencia artificial," europa.eu El marco de gobernanza de China restringe las transferencias transfronterizas, lo que obliga a los proveedores extranjeros a establecer nubes domésticas. Estos regímenes fragmentados obligan a las empresas de anotación a duplicar la infraestructura y retener mano de obra local, moderando las economías de escala globales.
*Nuestras previsiones consideran los impactos de impulsores y restricciones como direccionales, no aditivos. Las previsiones de impacto reflejan el crecimiento base, los efectos de mezcla y las interacciones entre variables.
Análisis de Segmentos
Por Tipo de Abastecimiento: Los Modelos Híbridos Equilibran el Control y la Escala
El abastecimiento híbrido generó un impulso sustancial en 2026, creciendo a una CAGR del 22,48%, impulsado por empresas que mantienen los datos sensibles internamente pero dependen de proveedores para el trabajo de alto volumen. El segmento externalizado todavía dominó con el 63,43% de la participación del mercado de etiquetado de datos en 2025, pero las crecientes preocupaciones sobre la propiedad intelectual y la escasez de expertos en el dominio están desplazando los presupuestos hacia modelos mixtos. Las herramientas de orquestación híbrida que enrutan las tareas por complejidad, aplican el acceso basado en roles y muestran métricas de calidad en tiempo real sustentan este giro. En Asia Pacífico, el plan de China de digitalizar 50.000 fábricas para 2028 hará del abastecimiento híbrido un estándar predeterminado a medida que las empresas alternan entre equipos locales a nivel de planta y plataformas centralizadas. En América del Norte, los contratos de defensa estipulan el manejo doméstico de datos clasificados mientras permiten que las imágenes comerciales sean etiquetadas en el extranjero, reforzando los flujos de trabajo híbridos.
Las empresas que adoptan estrategias híbridas reducen los tiempos de respuesta dividiendo las colas. Las etiquetas de alta sensibilidad permanecen en clústeres internos seguros, mientras que los cuadros delimitadores de productos básicos fluyen hacia proveedores en el extranjero. Los motores de políticas automatizadas ahora rastrean el linaje de los conjuntos de datos y asignan anotadores por nivel de autorización, reforzando el cumplimiento sin reducir el rendimiento. Los proveedores que monetizan los modelos híbridos posicionan los "microconjuntos de datos" curados como activos repetibles vendidos a múltiples compradores, convirtiendo los ingresos de servicios opacos en márgenes similares a los del software y expandiendo el mercado de etiquetado de datos direccionable.



Por Tipo de Datos: La Anotación de Video Acelera la Autonomía
La anotación de video está proyectada para una CAGR del 23,17% hasta 2031, impulsada por vehículos autónomos, robótica y vigilancia de ciudades inteligentes. En contraste, las imágenes estáticas todavía capturaron el 36,26% de los ingresos de 2025, evidenciando el papel arraigado de la visión por computadora basada en fotogramas. Las transmisiones continuas requieren seguimiento de objetos temporalmente consistente, reconocimiento de acciones y segmentación de escenas, aumentando la complejidad por etiqueta y el precio de venta promedio. El tamaño del mercado de etiquetado de datos para el etiquetado de LiDAR y sensores de profundidad, aunque comparativamente pequeño, exige tarifas premium porque delimitar nubes de puntos 3D requiere herramientas especializadas y precisión de grado automotriz.
Las políticas chinas que enfatizan la IA incorporada y los robots inteligentes expandirán la demanda de conjuntos de datos multimodales de video-LiDAR que capturan líneas de ensamblaje de fábricas, logística de almacenes e interacciones de robots de servicio. Las empresas emergentes de robótica de América del Norte también licencian secuencias anotadas para reentrenar modelos de manipulación basados en visión. Las innovaciones en el flujo de trabajo, como el delimitado asistido por interpolación y los polígonos sugeridos por modelos, comprimen el esfuerzo manual, pero las etapas de verificación siguen siendo centradas en el ser humano para garantizar la precisión.
Por Enfoque de Etiquetado: Las Técnicas Autosupervisadas Escalan Eficientemente
Los flujos de trabajo manuales todavía representaron el 42,31% de los ingresos de 2025, aunque los enfoques autosupervisados y programáticos están aumentando a una CAGR del 22,16% a medida que las empresas buscan reducir costos. Los desarrolladores ahora preetiquetan fotogramas usando modelos fundacionales, luego involucran a humanos en segmentos ambiguos, reduciendo drásticamente los casos límite totales por conjunto de datos. La expansión semisupervisada, donde un pequeño grupo de etiquetas de referencia informa pseudoetiquetas automatizadas, domina los flujos de trabajo de IA conversacional. Se espera que el tamaño del mercado de etiquetado de datos vinculado al preetiquetado automático se amplíe a medida que maduren las bibliotecas de supervisión débil y los paneles reporten la procedencia de extremo a extremo.
Sin embargo, los reguladores exigen auditabilidad. El Instituto de Seguridad de IA de Japón ha elaborado orientaciones que requieren registros explicables de generación de etiquetas, lo que obliga a los proveedores a mantener la supervisión humana para los sectores de alto riesgo. En consecuencia, las plataformas más resilientes integran puntuación de confianza, priorización de aprendizaje activo e historiales de etiquetas reversibles, garantizando el cumplimiento mientras desbloquean ventajas de margen sobre los talleres puramente manuales.
Por Aplicación: El Mantenimiento Predictivo Impulsa Ingresos Recurrentes
La visión por computadora retuvo el 54,19% del gasto de 2025, pero el mantenimiento predictivo y el aseguramiento de la calidad ahora registran una CAGR del 22,61% a medida que las fábricas aprovechan los datos de sensores para evitar tiempos de inactividad. El etiquetado de series temporales para señales de vibración, temperatura y acústica crea una demanda constante similar a la de suscripción porque los modelos deben reentrenarse cada vez que cambian los equipos o los regímenes operativos. En India, la hoja de ruta nacional destaca la IA agéntica que activa la liberación autónoma de lotes, lo que requiere taxonomías de fallos de sensores etiquetadas y bibliotecas de defectos basadas en video. El tamaño del mercado de etiquetado de datos atribuido a estos conjuntos de datos industriales está aumentando a medida que los fabricantes de equipos originales incorporan los costos de etiquetado en acuerdos de servicio plurianuales.
Los minoristas y los centros de llamadas continúan invirtiendo en procesamiento de lenguaje natural y análisis de voz, pero los flujos de trabajo de IoT industrial lideran el crecimiento. Los proveedores que agrupan ontologías de dominio, SDK de captura en el borde y ganchos de etiquetado en la nube están ganando implementaciones en fábricas, ya que traducen datos de tecnología operativa bruta en corpus listos para IA más rápido que las plataformas genéricas.
Por Industria de Usuario Final: La Manufactura Industrial Surge
Las empresas automotrices todavía generaron el 28,26% de los ingresos de 2025, impulsadas por ADAS y la telemática de flotas, aunque los clientes industriales y de manufactura exhiben la CAGR más rápida del 22,84% hasta 2031. El plan de China para 20 conjuntos de datos sectoriales y 50.000 plantas actualizadas inyecta demanda a gran escala en los sectores de metales, productos químicos y electrónica de consumo.[3]Wang Jingjing, "China Presenta Plan para Profundizar la Integración de Internet Industrial e IA," Consejo de Estado, english. El renacimiento de los semiconductores de Japón también necesita imágenes de fotomáscaras etiquetadas, escaneos de inspección en línea y taxonomías de defectos. El mercado de etiquetado de datos ahora se integra directamente en los presupuestos de gemelos digitales de producción, pasando de proyectos piloto únicos a gastos operativos recurrentes.
La salud y las ciencias de la vida mantienen necesidades de cumplimiento estrictas, fomentando proveedores especializados. Las empresas de servicios financieros priorizan las etiquetas de detección de fraude, mientras que los usuarios agrícolas solicitan etiquetas de estrés de cultivos basadas en drones. La ontología única de cada sector impulsa la personalización de la plataforma, lo que subraya por qué el software amplio de operaciones de etiquetado complementado con complementos de dominio está desplazando a las herramientas internas a medida.
Análisis Geográfico
América del Norte comandó el 31,13% de los ingresos del mercado de etiquetado de datos en 2025, anclada por inversiones de hiperescaladores, contratos de defensa e I+D de modelos fundacionales. La Serie F de USD 1 mil millones de Scale AI en mayo de 2024 reforzó la confianza de los inversores, mientras que la participación de Meta en 2025 destacó la naturaleza estratégica de los conjuntos de datos ricos en procedencia. La contratación federal para conjuntos de datos de inteligencia y seguridad nacional genera acuerdos plurianuales que amortiguan el gasto tecnológico cíclico. La Ley de IA de Europa eleva los obstáculos de cumplimiento, pero también diferencia a los proveedores que pueden producir archivos de etiquetas listos para auditoría y mantener la residencia de datos en la UE.
Asia Pacífico es el escalador más rápido, con una CAGR del 21,16%, impulsado por la hoja de ruta de internet industrial de China, el plan de manufactura avanzada de India y la expansión de la robótica de Japón. Estos respaldos de política estimulan la demanda regional de anotación localizada, corpus multilingües y taxonomías específicas del sector. Los mandatos de nube doméstica en China dan ventaja a las plataformas locales, aunque los proveedores extranjeros que forman empresas conjuntas o establecen centros de datos locales aún pueden acceder a segmentos de crecimiento. Las naciones del Sudeste Asiático añaden capacidad de mano de obra de bajo costo, alimentando flujos de trabajo híbridos globales.
Oriente Medio y África siguen siendo incipientes, con los Emiratos Árabes Unidos y Arabia Saudita financiando proyectos piloto de ciudad inteligente y movilidad autónoma que generan proyectos de etiquetado de datos modestos pero estratégicos. Sudáfrica y Kenia atraen trabajo de externalización en inglés; sin embargo, la limitada demanda doméstica de IA modera el crecimiento regional. La tracción de América Latina se centra en Brasil, donde las empresas de comercio electrónico y tecnología agrícola externalizan el etiquetado, aunque la volatilidad cambiaria complica los compromisos transfronterizos.

Panorama Competitivo
El mercado de etiquetado de datos está moderadamente fragmentado. Scale AI ocupa una posición de liderazgo tras la infusión de USD 15 mil millones de Meta, captando atención a través de conjuntos de datos curados y etiquetados por expertos con ingresos esperados de USD 1,4 mil millones para finales de 2024. Appen y TELUS International defienden su participación a través de plataformas colaborativas globales y adquisiciones como Lionbridge AI. Los proveedores de plataformas neutrales, incluidos Labelbox, SuperAnnotate y V7 Labs, compiten en experiencia del desarrollador y análisis de calidad integrado. La Serie B de USD 36 millones de SuperAnnotate, respaldada por NVIDIA y Databricks Ventures, ilustra el apetito de los inversores por enfoques centrados en plataformas que permiten a las empresas alternar entre modos de solo software y servicio gestionado.
La diferenciación tecnológica ahora gira en torno al preetiquetado con modelos fundacionales, la priorización de aprendizaje activo y los paneles de calidad que visualizan el acuerdo entre anotadores en tiempo real. Los proveedores que compiten por apoyar la soberanía de datos han puesto en marcha instancias regionales en Europa y China, mientras que las boutiques más pequeñas ganan sectores regulados presumiendo de certificaciones ISO 13485 o SOC 2. La presión de precios persiste en el etiquetado de imágenes mercantilizado, pero los segmentos de alto valor —imágenes médicas, LiDAR 3D y anotación de documentos legales— exigen tarifas premium que sostienen los márgenes.
Las empresas emergentes como Snorkel AI popularizan el etiquetado programático, permitiendo a los usuarios codificar reglas heurísticas o aprovechar la supervisión débil, mientras que los participantes enfocados en el borde como Dataloop ofrecen microetiquetado en el dispositivo para la validación de datos sintéticos. A medida que las empresas pasan de proyectos piloto a flujos de trabajo a escala de producción, los ganadores serán aquellos que ofrezcan operaciones de etiquetado de pila completa, desde la ingesta hasta el monitoreo de deriva, en nubes híbridas y clústeres locales.
Líderes de la Industria de Etiquetado de Datos
Appen Limited
TELUS International AI Inc.
Scale AI, Inc.
Amazon Mechanical Turk, Inc.
CloudFactory Limited
- *Nota aclaratoria: los principales jugadores no se ordenaron de un modo en especial

Desarrollos Recientes de la Industria
- Enero de 2026: El Ministerio de Industria y Tecnología de la Información de China publicó un plan de trabajo para profundizar la integración de la IA en 20 sectores, con el objetivo de realizar 50.000 actualizaciones de internet industrial y conjuntos de datos de dominio estandarizados para 2028.
- Noviembre de 2025: China publicó una hoja de ruta de IA industrial que describe una estrategia de seis puntos que vincula los grandes modelos de lenguaje con equipos de manufactura avanzada y agentes de IA.
- Octubre de 2025: El NITI Aayog de India emitió un plan de manufactura a 10 años que prioriza los copilotos de diseño impulsados por IA, los agentes de mantenimiento predictivo y los procesos de etiquetado certificados.
- Junio de 2025: Meta invirtió casi USD 15 mil millones en Scale AI, valorando la empresa en USD 29 mil millones y reclutando a su director ejecutivo de 28 años para dirigir un nuevo laboratorio de superinteligencia.


Marco de la metodología de investigación y alcance del informe
Definiciones del Mercado y Cobertura Clave
Nuestro estudio define el mercado de etiquetado de datos como todos los ingresos obtenidos de plataformas, servicios gestionados y flujos de trabajo combinados de humano en el ciclo que etiquetan archivos de texto, imagen, video, audio y nube de puntos para que los modelos de aprendizaje automático puedan aprender, validar o ajustar. El conjunto de valor incluye las tarifas pagadas por empresas, laboratorios de investigación y agencias públicas y se expresa en dólares estadounidenses constantes de 2025.
Exclusión del alcance: los generadores de datos sintéticos, el software puro de clasificación de datos y las herramientas independientes de prueba de modelos quedan fuera de este límite.
Descripción General de la Segmentación
- Por Tipo de Abastecimiento
- Interno
- Externalizado
- Híbrido
- Por Tipo de Datos
- Texto
- Imagen
- Video
- Audio
- LiDAR / Sensor
- Por Enfoque de Etiquetado
- Manual
- Automático
- Semisupervisado
- Autosupervisado / Programático
- Por Aplicación
- Visión por Computadora
- Procesamiento de Lenguaje Natural
- Análisis de Voz y Audio
- Mantenimiento Predictivo y Aseguramiento de la Calidad
- Por Industria de Usuario Final
- Automotriz y Transporte
- Salud y Ciencias de la Vida
- TI y Telecomunicaciones
- Banca, Servicios Financieros y Seguros
- Comercio Minorista y Comercio Electrónico
- Industrial y Manufactura
- Agricultura
- Gobierno y Sector Público
- Por Geografía
- América del Norte
- Estados Unidos
- Canadá
- México
- América del Sur
- Brasil
- Argentina
- Resto de América del Sur
- Europa
- Reino Unido
- Alemania
- Francia
- España
- Italia
- Resto de Europa
- Asia Pacífico
- China
- India
- Japón
- Australia
- Corea del Sur
- Resto de Asia Pacífico
- Oriente Medio
- Arabia Saudita
- Emiratos Árabes Unidos
- Turquía
- Resto de Oriente Medio
- África
- Sudáfrica
- Kenia
- Resto de África
- América del Norte
Metodología de Investigación Detallada y Validación de Datos
Investigación Primaria
Los analistas de Mordor luego hablaron con jefes de producto de plataformas, ejecutivos de externalización y líderes de ingeniería de IA en América del Norte, Europa y Asia Pacífico. Estas discusiones aclararon las combinaciones de flujos de trabajo, las proporciones de automatización y los precios vigentes por mil etiquetas, ayudándonos a cerrar las brechas dejadas por el trabajo de escritorio y alinear las curvas de adopción regional.
Investigación Documental
Mapeamos las señales de demanda a través de fuentes disponibles libremente, como la Oficina de Estadísticas Laborales de los Estados Unidos, las encuestas de TIC de Eurostat, el Observatorio de Políticas de IA de la OCDE y los organismos sectoriales de conducción autónoma, imágenes médicas e IA conversacional. Los grupos de patentes se rastrearon con Questel, mientras que las pistas de ingresos de las empresas surgieron de D&B Hoovers, los formularios 10-K de la SEC y las llamadas de resultados, proporcionando divisiones tempranas por tipo de actividad. Las revistas académicas, los comentarios del Marco de Riesgo de IA del NIST y los registros aduaneros que detallan los contratos de mano de obra de anotación añadieron más contexto. Las fuentes enumeradas son ilustrativas; muchas publicaciones adicionales informaron la recopilación y validación de datos.
Dimensionamiento del Mercado y Pronóstico
Un conjunto de datos descendente reconstruido a partir de presupuestos de entrenamiento de IA empresarial, horas de GPU en la nube pública y prevalencia de casos de uso formó la línea de base, que se verificó mediante facturas de proveedores muestreadas y el precio de venta promedio multiplicado por los volúmenes de trabajo, una consolidación ascendente específica. Cinco variables clave anclan el modelo: objetos anotados por milla autónoma, escaneos de radiología digitalizados por cama hospitalaria, proporciones de aumento sintético a real, salario por hora del anotador y penetración de automatización de la plataforma. La regresión multivariante proyecta estos impulsores hasta 2030, con superposiciones de escenarios verificadas en llamadas con expertos.
Validación de Datos y Ciclo de Actualización
Los resultados pasan por controles de varianza, revisión por pares y verificaciones de anomalías antes de la aprobación. Los informes se actualizan anualmente, y los eventos materiales, como las nuevas reglas de seguridad de IA, desencadenan actualizaciones intermedias, lo que garantiza que los clientes reciban nuestra visión más reciente.
Por Qué la Línea de Base de Etiquetado de Datos de Mordor Merece Confianza
Las estimaciones entre los editores divergen porque cada uno selecciona su propio alcance, tratamiento de divisas y factores de incremento.
Al capturar el gasto interno y externalizado, incluidas las licencias de plataforma, y revisar los insumos cada doce meses, Mordor Intelligence ofrece un ancla más estable para la planificación.
Comparación de referencia
| Tamaño del Mercado | Fuente anónima | Principal factor de diferencia |
|---|---|---|
| USD 6,5 mil millones | ||
| USD 4,89 mil millones | Consultora Global A | Omite plataformas internas y flujos de ingresos de automatización híbrida |
| USD 4,87 mil millones | Consultora Regional B | Aplica un precio conservador por etiqueta y excluye los flujos de datos LiDAR |
La comparación muestra que otros reducen el universo o bloquean factores de costo estáticos, mientras que el alcance disciplinado de Mordor, las verificaciones primarias en tiempo real y el ciclo de actualización anual producen una línea de base transparente y repetible en la que los tomadores de decisiones pueden confiar.


Preguntas Clave Respondidas en el Informe
¿Cuál es el valor proyectado del mercado de etiquetado de datos en 2031?
Se prevé que alcance USD 7,02 mil millones, reflejando una CAGR del 21,94% de 2026 a 2031.
¿Qué región está creciendo más rápido en la demanda de anotación de datos?
Asia Pacífico muestra el mayor impulso con una CAGR del 21,16% impulsada por China, India y Japón.
¿Qué tipo de datos se está expandiendo más rápido que los demás?
La anotación de video lidera el crecimiento con una CAGR del 23,17% debido a los vehículos autónomos y la robótica.
¿Por qué los modelos de abastecimiento híbrido están ganando terreno?
Las empresas combinan expertos internos para datos sensibles con proveedores externos para escalar, logrando un equilibrio de costo y control mientras crecen a una CAGR del 22,48%.
¿Qué área de aplicación se espera que genere ingresos de etiquetado recurrentes y constantes?
El mantenimiento predictivo en entornos industriales, que crece a una CAGR del 22,61%, requiere un reetiquetado continuo de sensores a medida que los equipos evolucionan.
¿Cómo están afectando las regulaciones de privacidad a las estrategias globales de etiquetado?
Mandatos como la Ley de IA de la UE y las reglas de gobernanza de datos de China obligan a los proveedores a establecer infraestructuras regionales y mantener grupos de anotadores separados para cumplir con las leyes de localización.
Última actualización de la página el:



