In-Memory-Datenbankmarkt Größe und Anteil
Marktübersicht
| Studienzeitraum | 2020 - 2031 |
|---|---|
| Marktgröße (2026) | 8.05 Milliarden US-Dollar |
| Marktgröße (2031) | 15.31 Milliarden US-Dollar |
| Wachstumsrate (2026 - 2031) | 13.72% CAGR |
| Schnellstwachsender Markt | Asien-Pazifik |
| Größter Markt | Asien-Pazifik |
| Marktkonzentration | Mittel |
Hauptakteure *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. | |
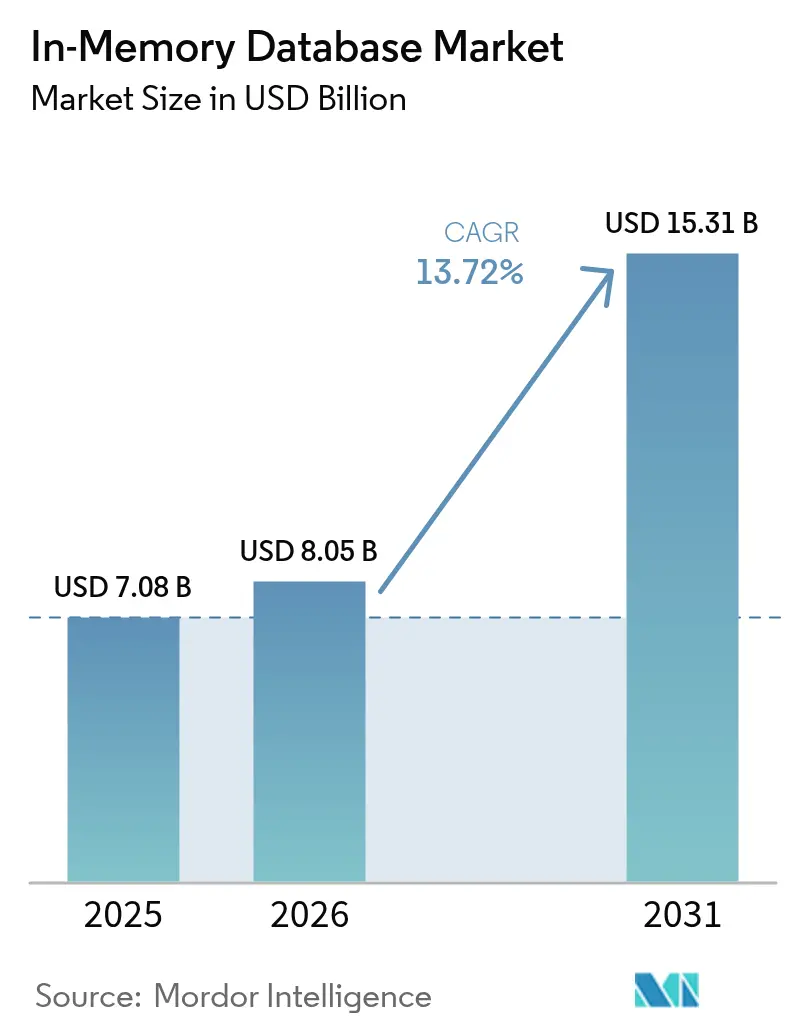
In-Memory-Datenbankmarkt Analyse von Mordor Intelligence
Die Größe des In-Memory-Datenbankmarkts wird voraussichtlich von USD 7,08 Milliarden im Jahr 2025 auf USD 8,05 Milliarden im Jahr 2026 wachsen und bis 2031 bei einer CAGR von 13,72 % über den Zeitraum 2026–2031 USD 15,31 Milliarden erreichen. Anforderungen an Sub-Millisekunden-Leistung durch cloud-native Microservices, KI-Inferenz-Engines und Streaming-Analyseplattformen trieben Unternehmen weiterhin in Richtung speicherzentrierter Architekturen. Sinkende DRAM-Preise und die Einführung CXL-basierter persistenter Speichermodule haben die Gesamtbetriebskosten gesenkt und mehr Workloads zur Migration von festplattengestützten Systemen veranlasst. Edge-Deployments in vernetzten Fahrzeugen und industriellen IoT-Anlagen weiteten die Nachfrage zusätzlich aus, da lokale Verarbeitung Netzwerklatenznachteile vermeidet. Die Wettbewerbsdynamik blieb fließend, da traditionelle Anbieter ihre Integrationen mit Hyperscale-Clouds vertieften, während Open-Source-Forks an Dynamik gewannen und Käufern neue Wege zur Vermeidung von Anbieterabhängigkeit eröffneten.
Wichtigste Erkenntnisse des Berichts
- Nach Verarbeitungstyp führte die Online-Transaktionsverarbeitung (OLTP) mit einem Anteil von 44,85 % am In-Memory-Datenbankmarkt im Jahr 2025, während die hybride Transaktions-/Analyseverarbeitung (HTAP) bis 2031 voraussichtlich mit einer CAGR von 20,68 % wachsen wird.
- Nach Bereitstellungsmodus behielten On-Premise-Installationen im Jahr 2025 einen Umsatzanteil von 55,15 %; Edge- und eingebettete Deployments werden bis 2031 voraussichtlich mit einer CAGR von 22,55 % wachsen.
- Nach Datenmodell erfasste relationales SQL im Jahr 2025 einen Anteil von 59,95 %, während Multi-Modell-Plattformen zwischen 2026 und 2031 eine CAGR von 19,6 % erzielen werden.
- Nach Unternehmensgröße hielten Großunternehmen im Jahr 2025 einen Anteil von 70,15 % an der Größe des In-Memory-Datenbankmarkts; kleine und mittlere Unternehmen werden bis 2031 die schnellste CAGR von 17,7 % verzeichnen.
- Nach Anwendung entfiel auf die Echtzeit-Transaktionsverarbeitung im Jahr 2025 ein Anteil von 39,75 % an der Größe des In-Memory-Datenbankmarkts, während KI/ML-Modell-Serving bis 2031 voraussichtlich mit einer CAGR von 23,1 % wachsen wird.
- Nach Endbenutzerbranche dominierte BFSI mit einem Umsatzanteil von 27,95 % im Jahr 2025; Gesundheitswesen und Biowissenschaften sind bis 2031 auf eine CAGR von 17,4 % ausgerichtet.
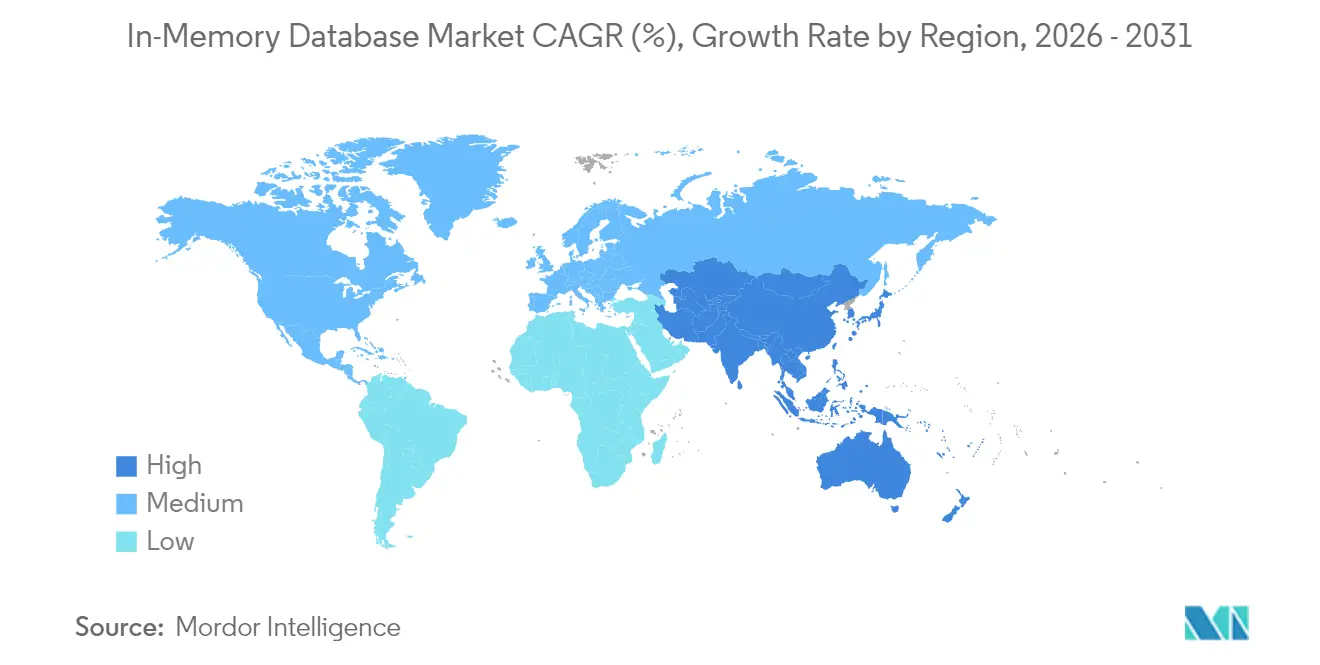
- Nach Geografie entfielen auf Asien-Pazifik im Jahr 2025 31,95 % des globalen Umsatzes, und die Region bleibt mit einer CAGR von 16,65 % bis 2031 die am schnellsten wachsende Region.
Hinweis: Die Marktgrößen- und Prognosezahlen in diesem Bericht werden mithilfe des proprietären Schätzrahmens von Mordor Intelligence erstellt und mit den neuesten verfügbaren Daten und Erkenntnissen bis 2026 aktualisiert.
Globale Trends und Erkenntnisse zum In-Memory-Datenbankmarkt
Analyse der Auswirkungen von Treibern*
| Treiber | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Cloud-native Microservices mit Anforderungen an Sub-Millisekunden-Latenz | +3.2% | Global, mit Schwerpunkt in Nordamerika und der EU | Kurzfristig (≤ 2 Jahre) |
| Sinkende DRAM- und persistente Speicher-USD/GB-Preise, die die TCO-Lücke gegenüber Festplatten vergrößern | +2.8% | Global, frühe Einführung in Fertigungszentren im Asien-Pazifik-Raum | Mittelfristig (2–4 Jahre) |
| Einführung von Streaming-Analysen in BFSI und Telekommunikation für Betrug und Netzwerk-QoS | +2.1% | Nordamerika und EU-Finanzzentren, Telekommunikationsinfrastruktur im Asien-Pazifik-Raum | Kurzfristig (≤ 2 Jahre) |
| HTAP-Architekturen zur Beschleunigung von KI/ML-Modell-Serving im Gesundheitswesen | +1.9% | Global, mit regulierungsgetriebenem Einsatz in der EU und Nordamerika | Mittelfristig (2–4 Jahre) |
| Edge-Computing-Anwendungsfälle (vernetzte Fahrzeuge, IIoT) mit Anforderungen an eingebettete In-Memory-Datenbanken | +2.4% | Asien-Pazifik-Fertigung, nordamerikanische Automobilkorridore | Langfristig (≥ 4 Jahre) |
| Quelle: Mordor Intelligence | |||
Cloud-native Microservices mit Anforderungen an Sub-Millisekunden-Latenz
Die Einführung cloud-nativer Architekturen veränderte die Leistungsgrundlagen, da containerisierte Microservices Datenzugriff in Mikrosekunden benötigten. Sitzungsspeicher, Personalisierungs-Engines und Hochfrequenzhandelsplattformen wechselten von festplattengestützten Datenbanken zu speicherzentrierten Speichern, da jede Millisekunde Verzögerung die Konversionsraten oder Handelsgewinne senkte. Dragonfly demonstrierte 6,43 Millionen Operationen pro Sekunde auf AWS Graviton3E-Silizium und verdeutlichte damit die Leistungsobergrenze, die nun von Datenbankebenen erwartet wird.[1]DragonflyDB, "2024 New Year, New Number," dragonflydb.io Finanzinstitute und digitale Handelsbetreiber, die Monolithen auf verteilte Systeme migrierten, sahen, wie sich Verbesserungen der Reaktionszeit in greifbare Umsatzgewinne übersetzten, was die kurzfristige Bedeutung dieses Treibers unterstrich.
Sinkende DRAM- und persistente Speicherkosten vergrößern die TCO-Lücke
Die globalen Spotpreise für DDR4- und DDR5-Module sanken weiter, während Samsungs CXL Memory Module Hybrid-Prototyp DRAM-ähnliche Latenz mit Persistenz zeigte und ein überzeugendes Kostenprofil schuf. Hyperscale-Betreiber bündelten Speicher über Racks hinweg, reduzierten ungenutzten Kapazitätsüberschuss und Backup-Zyklen. Unternehmen richteten ihre Roadmaps auf In-Memory-Deployments aus, da der Aufpreis gegenüber SSD-Arrays schrumpfte, insbesondere bei Analyse-Workloads mit engen SLA-Fenstern. Der Effekt ist in Fertigungszentren im Asien-Pazifik-Raum sichtbar, wo große Historian-Datensätze für Echtzeit-Digital-Twin-Analysen in den Speicher verschoben werden.
Einführung von Streaming-Analysen in BFSI und Telekommunikation
Banken setzten Streaming-Betrugserkennung ein, die Millionen von Kartenautorisierungen pro Sekunde mit Aerospikes In-Memory-Engine verarbeitete. Telekommunikationsanbieter, die 5G einführten, überwachten Protokolle des Funkzugangsnetzes in Echtzeit, um die Servicequalität aufrechtzuerhalten, und nutzten dabei Vektorsuchen auf MongoDB zur Erkennung von Anomalien. Vorschriften in Nordamerika und Europa verlangten Echtzeit-Meldungen verdächtiger Aktivitäten, was die Einführungskurve dieses Treibers steil nach oben trieb.
HTAP-Architekturen zur Beschleunigung von KI/ML-Modell-Serving
Die hybride Transaktions-/Analyseverarbeitung beseitigte ETL-Verzögerungen, indem Schreibvorgänge und Analysen im selben Speicherpool vereint wurden. Oracle bettete große Sprachmodelle in HeatWave GenAI ein, sodass Patientenakten für klinische Entscheidungen abgefragt und bewertet werden konnten, ohne Daten zu verschieben. Gesundheitsdienstleister übernahmen HTAP-Speicher, um Vorhersagen während Konsultationen bereitzustellen, was die Ergebnisse verbesserte und den Infrastrukturaufwand senkte, was ein nachhaltiges mittelfristiges Wachstum unterstützte.
Analyse der Auswirkungen von Hemmnissen*
| Hemmnis | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Bedenken hinsichtlich Anbieterabhängigkeit bei proprietären In-Memory-Formaten | -1.8% | Global, insbesondere Multi-Cloud-Unternehmen betreffend | Kurzfristig (≤ 2 Jahre) |
| Komplexität des Hochverfügbarkeitsdesigns für Cluster mit mehr als 40 TB | -1.2% | Unternehmensdeployments in Nordamerika und der EU | Mittelfristig (2–4 Jahre) |
| Datensouveränitätsgesetze (z. B. China CSL, EU-DSGVO), die die globale Replikation einschränken | -0.9% | EU, China, mit Auswirkungen auf multinationale Deployments | Langfristig (≥ 4 Jahre) |
| Quelle: Mordor Intelligence | |||
Bedenken hinsichtlich Anbieterabhängigkeit bei proprietären Formaten
Die Lizenzänderung von Redis im Jahr 2024 verstärkte die Skepsis der Käufer gegenüber proprietären Formaten und veranlasste AWS, Google und Oracle, den Valkey-Fork unter der Linux Foundation zu unterstützen. Unternehmen, die mehrjährige Datenbankprojekte budgetierten, berücksichtigten Ausstiegskosten, was die Kaufzyklen verlangsamte. Zur Risikominderung setzten einige auf mehrschichtige Datenbank-Orchestrierungsebenen, aber diese Abstraktionen führten zu Latenzeinbußen, die die Geschwindigkeitsgewinne durch den Speicher teilweise aufhoben.
Komplexität des Hochverfügbarkeitsdesigns für große Cluster
Cluster mit mehr als 40 TB stießen auf Protokoll-Overhead, der die Replikat-Synchronisierungszeiten verschlechterte. Der Gossip-Ansatz von Redis Cluster skalierte quadratisch, während Dragonflys alternative Orchestrierung Verbesserungen zeigte, aber dennoch aufwendige Überwachungsskripte erforderte. Workloads im Finanzdienstleistungsbereich, die eine Verfügbarkeit von fünf Neunen erfordern, zögerten, die größten Datensätze vollständig in den Speicher zu migrieren, und entschieden sich für hybride Ebenen, die die Spitzenleistung verringerten.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Verarbeitungstyp: HTAP entwickelt sich zur einheitlichen Architektur
Das OLTP-Segment hielt im Jahr 2025 einen Anteil von 44,85 % am In-Memory-Datenbankmarkt und unterstreicht die anhaltende Abhängigkeit von hochintegren Transaktions-Workloads in den Bereichen Bankwesen, E-Commerce und ERP-Systeme. Die Nachfrage blieb bestehen, da geschäftskritische Datensätze weiterhin ACID-Konformität erforderten, wobei Unternehmen einen Leistungsaufschlag für Sub-Millisekunden-Commits zahlten. OLAP-Deployments bedienten etablierte Business-Intelligence-Frontends, wuchsen jedoch langsam, da sich Analysen auf flexiblere Engines verlagerten.
HTAP stieg mit einer prognostizierten CAGR von 20,68 % von 2026 bis 2031, da Unternehmen nach Einfachheit auf einer einzigen Plattform suchten. GridGains Plattform zeigte bis zu 1.000-fache Geschwindigkeitssteigerungen gegenüber festplattenbasierten Systemen bei gleichzeitiger Beibehaltung der ANSI SQL-99-Unterstützung. Echtzeit-Risikoberechnungen und Supply-Chain-Zwillinge benötigten gleichzeitigen Lese-/Schreibzugriff, was HTAP zur bevorzugten Architektur machte. Die Konvergenz erschloss zusätzliche Budgets aus Abteilungen, die zuvor zwischen Betrieb und Analyse getrennt waren, und trieb den In-Memory-Datenbankmarkt in Richtung einheitlicher Designs.
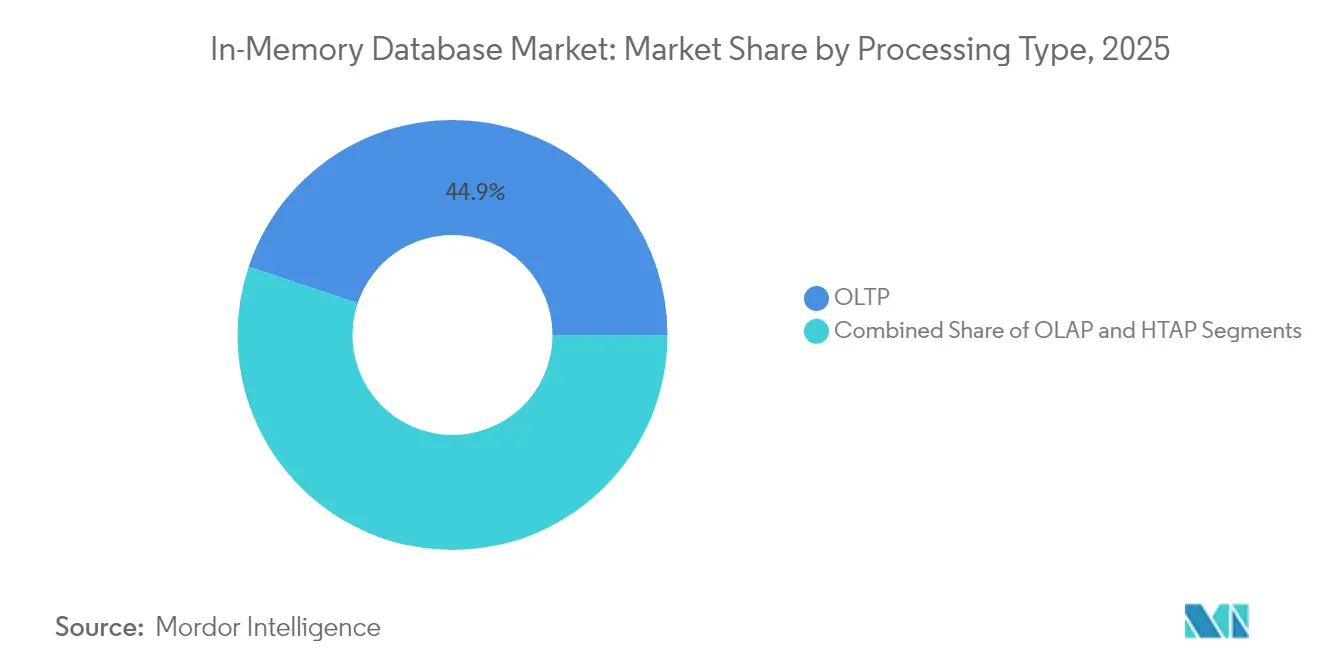
Notiz: Segmentanteile aller einzelnen Segmente sind nach dem Berichtskauf verfügbar


Nach Bereitstellungsmodus: Edge-Computing treibt eingebettetes Wachstum voran
On-Premise-Installationen erfassten 55,15 % des Umsatzes im Jahr 2025, da regulierte Sektoren volle Kontrolle über den Datenstandort und maßgeschneiderte Hochverfügbarkeitsarchitekturen erforderten. Ältere Unternehmenssoftware-Stacks, die eng mit On-Premise-Datenbanken integriert waren, verankerten die Ausgaben, auch als öffentliche Clouds reiften. Cloud-Deployments haben sich dennoch weiterentwickelt, da digital-native Unternehmen verwaltete Dienste übernahmen, um die Infrastrukturverwaltung zu vermeiden.
Edge- und eingebettete Deployments zeigten eine CAGR-Prognose von 22,55 %, angetrieben durch vernetzte Fahrzeuge und IIoT-Gateways. Moderne Fahrzeuge erzeugen jährlich rund 300 TB, was eine fahrzeuginterne Verarbeitung für autonome Funktionen erfordert. TDengine erzielte eine 10-fache Komprimierung gegenüber Elasticsearch bei Smart-Vehicle-Telemetrie und reduzierte die Bandbreite für vorgelagerte Übertragungen. Hersteller wandten ähnliche Strategien auf Produktionslinien an, um Defekte sofort zu erkennen. Der Wandel signalisierte, dass Leistungsgewinne, die einst Rechenzentren vorbehalten waren, nun am Edge unverzichtbar sind und den Marktfußabdruck des In-Memory-Datenbankmarkts erweitern.
Nach Datenmodell: Multi-Modell-Architekturen gewinnen an Bedeutung
Relationale SQL-Engines behielten im Jahr 2025 einen Umsatzanteil von 59,95 %, da jahrzehntelanger Anwendungscode und Entwicklerkenntnisse an das Modell gebunden blieben. Unternehmen zögerten, Kernsysteme neu zu schreiben, was die relationale Vorherrschaft bewahrte, auch als neue Anwendungsfälle entstanden. NoSQL-Kategorien – Schlüssel-Wert, Dokument, Graph – adressierten flexible Schemata, bedienten jedoch engere Workloads.
Multi-Modell-Plattformen prognostizieren eine CAGR von 19,6 %, da KI-Workloads einheitlichen Speicher für strukturierte Datensätze, Vektoren und unstrukturierten Text erfordern. Hazelcast fügte Vektorsuche neben traditionellen Schlüssel-Wert-APIs hinzu. Die Konsolidierung verschiedener Datentypen in einem einzigen Speicherpool senkte die Betriebskomplexität und Latenz und ermöglichte konversationelle KI, Betrugsgraphen und Empfehlungs-Pipelines. Diese Dynamik wird voraussichtlich den In-Memory-Datenbankmarkt über heterogene Datenlandschaften hinweg ausweiten.

Notiz: Segmentanteile aller einzelnen Segmente sind nach dem Berichtskauf verfügbar
Nach Unternehmensgröße: KMU beschleunigen die Cloud-Einführung
Großunternehmen machten im Jahr 2025 70,15 % des Umsatzes aus, bedingt durch die Kapitalintensität von Deployments im Petabyte-Maßstab und strenge SLA-Anforderungen. Globale Banken, Telekommunikationsanbieter und Luft- und Raumfahrtunternehmen investierten in redundante Cluster mit Terabytes an DRAM, um die Geschäftskontinuität aufrechtzuerhalten. Ihre Budgetkapazität schützte sie vor hohen Kosten pro Gigabyte.
Kleine und mittlere Unternehmen werden voraussichtlich über verwaltete Dienste mit einer CAGR von 17,7 % wachsen. AWS führte Aurora DSQL ein, um verteilte SQL-Semantik mit In-Memory-ähnlicher Leistung zu kombinieren. Durch die Auslagerung von Skalierung und Patches an Cloud-Anbieter erhielten Startups Zugang zu Latenz auf Unternehmensniveau für Mikro-SaaS-Produkte ohne Personalaufwand. Die Valkey-Unterstützung von ElastiCache senkte die Lizenzkosten und beschleunigte die Demokratisierung des In-Memory-Datenbankmarkts unter budgetbeschränkten Unternehmen.
Nach Anwendung: KI/ML-Modell-Serving treibt Innovation voran
Die Echtzeit-Transaktionsverarbeitung behielt im Jahr 2025 mit 39,75 % den größten Anteil, wobei Aktienhandel, Zahlungs-Gateways und Bestandssysteme auf sofortige Commits angewiesen waren. Operative Analysen lieferten Dashboards für Fertigung und IT-Beobachtbarkeit, verlangsamten sich jedoch, da neuere KI-Anwendungsfälle Ausgaben auf sich zogen.
KI/ML-Modell-Serving wird voraussichtlich mit einer CAGR von 23,1 % wachsen, da Unternehmen Vektorindizes und Einbettungen direkt in Datenbanken für Inferenz integrieren. Microsoft schlug Managed Retention Memory vor, um die Latenz bei der Ausführung großer Sprachmodelle zu reduzieren. Das Muster integriert Inferenz innerhalb der Transaktionsschicht und eliminiert WAN-Hops zwischen Modellservern und Quelldaten. Hybride Workloads, die ACID-Updates mit Vektorähnlichkeitssuchen kombinieren, werden voraussichtlich den inkrementellen Umsatz des In-Memory-Datenbankmarkts dominieren.
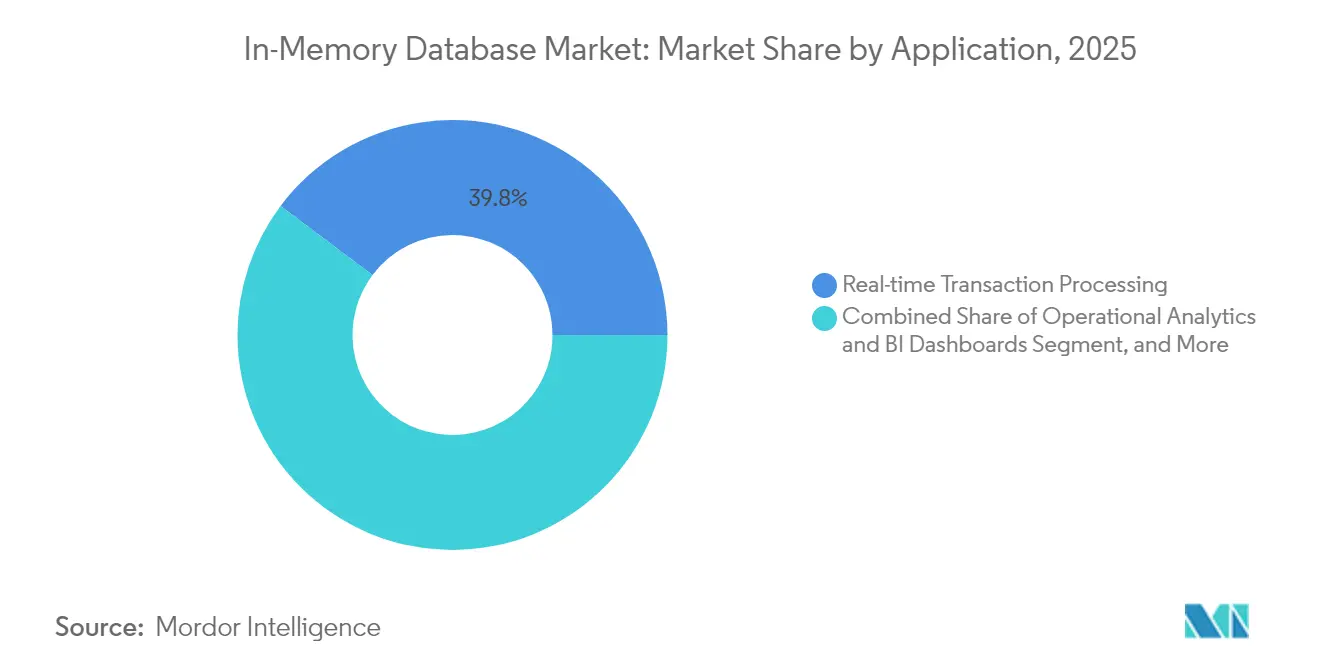
Notiz: Segmentanteile aller einzelnen Segmente sind nach dem Berichtskauf verfügbar
Nach Endbenutzerbranche: Gesundheitswesen führt die digitale Transformation an
BFSI erzielte im Jahr 2025 27,95 % des Umsatzes, was die frühe Einführung für Hochfrequenzhandel und Betrugsprävention widerspiegelt. Regulatorische Mandate für Echtzeit-Berichterstattung und strenge RTO-Anforderungen sicherten anhaltende Investitionen. Telekommunikation setzt In-Memory-Analysen für Netzwerkorchestrierung und Kundenerfahrungs-Einblicke ein und hält einen stabilen Anteil aufrecht.
Gesundheitswesen und Biowissenschaften zeigen eine CAGR-Prognose von 17,4 %. Corti veröffentlichte spezialisierte KI-Infrastruktur, die sofortigen Zugriff auf Patientendaten für diagnostische Unterstützung erfordert. Anbieter elektronischer Gesundheitsakten integrierten HTAP-Datenbanken, um klinische Entscheidungsalgorithmen zu speisen, was die Pflegequalität und Betriebseffizienz verbesserte. Die Fertigung investierte in vorausschauende Wartung, und der Einzelhandel nutzte Personalisierungs-Engines, was die gesamte In-Memory-Datenbankbranche diversifiziert hielt.
Geografische Analyse
Asien-Pazifik verzeichnete im Jahr 2025 den größten regionalen Umsatz mit 31,95 % und behielt eine CAGR-Prognose von 16,65 % bei. Nationale Industrie-4.0-Programme in China, Japan und Indien förderten die Fabrikautomatisierung, die In-Memory-Historian-Datenbanken für Sub-Sekunden-MES-Feedback-Schleifen erforderte. General Motors verknüpfte mehr als 100.000 Betriebstechnologieverbindungen in seinem MES-4.0-Rollout und veranschaulichte damit den Umfang von Edge-Deployments. Lokale Anbieter wie Nautilus Technologies entwickelten fortschrittliche einheimische relationale Engines und reduzierten die Abhängigkeit von ausländischem geistigem Eigentum.
Nordamerika bildete einen reifen, aber innovationsreichen Markt, der auf Finanzdienstleistungen, Hyperscale-Clouds und Forschung und Entwicklung im Bereich autonomer Fahrzeuge ausgerichtet war. Oracle und Google vertieften ihre Partnerschaft, um Oracle-Datenbankdienste nativ auf Google Cloud auszuführen und Enterprise-SQL-Fähigkeiten mit KI-Beschleunigern zu verbinden. Die Risikokapitalfinanzierung der Region unterstützte aufstrebende Akteure wie Dragonfly und intensivierte den Wettbewerbswandel.
Europa priorisierte die Einhaltung der Datensouveränität gemäß der DSGVO, förderte die Einführung hybrider Clouds und bevorzugte On-Premise-Cluster in Kombination mit verwalteten Diensten in lokalen Rechenzentren. Oracle erweiterte die Database@Azure-Abdeckung auf weitere EU-Regionen, um Anforderungen an den Datenstandort zu erfüllen. Der Kontinent verzeichnete auch Gesundheitsdeployments von HTAP-Datenbanken zur Unterstützung von KI-Diagnostik unter strengen Datenschutzrahmen.
Der Nahe Osten und Afrika investierten in Smart-City-Glasfaser und 5G-Backbones, was zu Pilot-IIoT-Deployments führte, die Echtzeit-Analysen erfordern. Südamerika gewann an Dynamik im Bergbau und im digitalen Bankwesen, wo Betrugserkennung mit geringer Latenz speicherzentrierte Systeme mit Aufpreis rechtfertigte. Obwohl die absoluten Ausgaben in diesen beiden Regionen bescheiden blieben, erweiterte das zweistellige Wachstum die globale Diversität des In-Memory-Datenbankmarkts.

Regulatorisches Umfeld
Die Einführung und Bereitstellungsentscheidungen von In-Memory-Datenbanken werden durch grenzüberschreitende Handelskontrollen für Halbleiter und KI-Governance-Regeln geprägt, die den Zugang zu leistungsstarker Rechen- und Speicherinfrastruktur beeinflussen, die zum Betrieb latenzsensibler Datenbankcluster verwendet wird. Im Januar 2026 überarbeitete das US-Handelsministerium, Bureau of Industry and Security (BIS), die Richtlinien zur Lizenzprüfung für fortschrittliche Computertechnik, die nach China exportiert wird, und verschärfte damit die Compliance-Anforderungen für führende Beschleuniger, die üblicherweise in Rechenzentren zusammen mit speicherzentrierten Datenbankebenen eingesetzt werden.
In Europa ist die Regulierung zunehmend mit KI-gesteuerten Arbeitslasten verknüpft, die datenbankinterne Vektorsuche und HTAP nutzen, um Modell-Serving und Echtzeitentscheidungen zu unterstützen. Das EU-KI-Gesetz (Verordnung (EU) 2024/1689), das im Juni 2024 verabschiedet wurde, schuf einen harmonisierten Rahmen für KI-Systeme und verstärkte den Bedarf an starker Datenverwaltung, Prüfbarkeit und Datenschutzkontrollen in Datenbankarchitekturen, die regulierte Anwendungsfälle unterstützen, insbesondere im Gesundheitswesen, im BFSI-Sektor und im öffentlichen Sektor.
Wertschöpfungskettenanalyse
Die Wertschöpfungskette von In-Memory-Datenbanken umfasst Hardware- und Infrastruktureingaben (DRAM, persistenter Speicher, CPUs, Netzwerktechnik wie RDMA-fähige Fabrics und Serverplattformen), Plattformsoftware (proprietäre und Open-Source-In-Memory-Engines, Clustering, Replikation und HTAP-Komponenten), Cloud- und Edge-Bereitstellungsmodelle (verwaltete Datenbankdienste, eingebettete Laufzeitumgebungen und Orchestrierungsebenen) sowie die Anwendungsintegration in BFSI, Telekommunikation, Fertigung/IIoT, Einzelhandel und Gesundheitswesen. On-Premise-Implementierungen bleiben in regulierten Branchen verankert, die Kontrolle über Datenresidenz und Hochverfügbarkeitsdesign erfordern, während Hyperscaler und Unternehmenssoftwareanbieter sich durch verwaltete Angebote, native Integrationen mit KI-Toolchains und Ökosystem-Konnektoren differenzieren.
Vorgelagerte Halbleiterengpässe beeinflussen die Wirtschaftlichkeit der Skalierung speicherzentrierter Architekturen, da knappe Angebote bei High-End-Speicher und fortschrittlicher Verpackungstechnik die Serververfügbarkeit und die Kosten pro GB auf Infrastrukturebene beeinträchtigen. Branchenkommentare Ende 2024 bis 2025 wiesen auf fortschrittliche Verpackungstechnik (zum Beispiel CoWoS-Klasse-Kapazität) und knapper werdendes HBM-Angebot als Engpässe für KI-Hardware hin, was wiederum die Erneuerungszyklen von Unternehmen für speicherdichte Systeme prägt, auf denen In-Memory-Datenbanken laufen. Nachgelagert bündeln Implementierungspartner und Systemintegratoren Referenzarchitekturen für SAP, Oracle und Cloud-native Stacks, und Käufer bewerten zunehmend Governance- und Lizenzierungsmodelle (einschließlich der Dynamik des Valkey-Forks nach Änderungen der Redis-Lizenzierung) als Teil langfristiger Beschaffungsentscheidungen.
Wettbewerbslandschaft
Der In-Memory-Datenbankmarkt blieb mäßig fragmentiert, wobei SAP, Oracle, Microsoft und IBM breite Unternehmenssuiten nutzten, um ihre Marktstellung zu behaupten. Ihre Roadmaps integrieren In-Datenbank-Vektorspeicher und ML-Beschleuniger und entsprechen damit den Kundenwünschen nach einheitlichen Plattformen. Die Lizenzänderung von Redis veranlasste Hyperscaler, Valkey zu unterstützen, was zeigt, wie Governance-Modelle Wettbewerbsgrenzen neu gestalten können.
Spezialisierte Anbieter wie Aerospike und Hazelcast konkurrierten mit vorhersehbarer, niedriger Latenz im großen Maßstab und niedrigeren Gesamtkosten pro Gigabyte. Aerospikes Erfolg bei PayPal bewies die Fähigkeit, Echtzeit-Betrugssignale auf Standard-Hardware zu verarbeiten. Hazelcast veröffentlichte Platform 5.5 mit erweiterten Konnektoren, die KI-Pipeline-Integrationen vereinfachten.[4]Hazelcast, "Announcing Hazelcast Platform 5.5 Release," hazelcast.com Dragonfly positionierte sich als direkter Ersatz für Redis mit überlegener Einzelkern-Effizienz und forderte Platzhirsche in der Entwicklergemeinschaft heraus.
Strategische Allianzen beschleunigten sich. Oracles Vereinbarung mit Google Cloud vom April 2025 ermöglichte es Unternehmen, Datenbanken und KI-Toolchains ohne Cross-Cloud-Egress-Gebühren zu konsolidieren. AWS gründete eine agentische KI-Gruppe, um die Modellentwicklung enger mit In-Memory-Datendiensten zu verknüpfen. Die Markteintrittsbarrieren stiegen in Bezug auf Ökosystemtiefe und integrierte KI-Funktionen, was den Anteil bei Anbietern konsolidierte, die sowohl transaktionale Exzellenz als auch Vektorsuche nativ anbieten können.
Marktführer im In-Memory-Datenbankbereich
IBM Corporation
Microsoft Corporation
Oracle Corporation
SAP SE
TIBCO Software Inc.
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Marktchancen und Zukunftsaussichten
An der Schnittstelle zwischen KI-optimierten Infrastrukturaufrüstungen und Datenbankarchitekturen, die operative Daten, Vektoren und Streaming-Funktionen nah an der Rechenleistung halten, entsteht ein Freiraum. Jüngste Infrastrukturmaßnahmen zeigen, wie Anbieter größere Speicherkapazitäten und geringere Konkurrenz für schreibintensive Arbeitslasten anstreben: Im Mai 2026 kündigte HPE den HPE Compute Scale-up Server 3250 für In-Memory-Datenbankanwendungsfälle an, der bis zu 48 TB Speicher unterstützt, und im Juli 2026 führte Oracle In-Memory Transaction Table- und Commit-Cache-Funktionen in Oracle AI Database 26ai auf Exadata ein, um Transaktionsabfragen und die Commit-Verarbeitung zu beschleunigen. Diese Produktaktualisierungen entsprechen Unternehmensmustern, bei denen Modell-Serving, Betrugserkennung und Echtzeit-Personalisierung näher am transaktionalen Systemkern ablaufen.
Angebotsseitige Investitionen in fortschrittlichen Speicher und Verpackungstechnik unterstützen zudem eine kosteneffizientere Skalierung speicherzentrierter Stacks, insbesondere für HTAP und KI-/ML-Modell-Serving. Im Juli 2026 gab SK Hynix einen Investitionsplan über 100 Billionen KRW in der Region Chungcheong bekannt, der fortschrittliche Verpackungstechnik (P&T7) und eine neue NAND-Anlage (M17) umfasst, und Samsung Electronics sowie SK Hynix kommunizierten einen umfassenderen, staatlich unterstützten Plan rund um einen groß angelegten Chip-Fertigungsknotenpunkt in Südkorea. Für Anbieter von In-Memory-Datenbanken und Cloud-Anbieter stärken diese Investitionen das Argument für den Einsatz dichterer, speicherreicherer Instanztypen und Appliances in verschiedenen Regionen, während datensouveränitätsbedingte Einschränkungen die Nachfrage nach hybriden Bereitstellungen und lokalen, regionalen verwalteten Diensten in Europa und Teilen des asiatisch-pazifischen Raums aufrechterhalten.
Aktuelle Branchenentwicklungen
- Juli 2026: Oracle führte In-Memory Transaction Table- und Commit-Cache-Funktionen innerhalb von Oracle AI Database 26ai auf Exadata ein, mit dem Ziel schnellerer Transaktionsabfragen und Commit-Verarbeitung durch Hochleistungs-Interconnects. Das Update untermauert Oracles Vorstoß in Richtung KI-optimierter Datenbankinfrastruktur, bei der In-Memory-Beschleunigungsfunktionen zusammen mit Exadata gebündelt werden, um gemischte OLTP- und KI-Arbeitslasten zu bedienen.
- Mai 2026: HPE kündigte den HPE Compute Scale-up Server 3250 an, der für In-Memory-Datenbankbereitstellungen positioniert ist und auf Intel Xeon 6-Prozessoren basiert, mit Unterstützung von bis zu 48 TB Speicher. Durch die Erweiterung der adressierbaren Obergrenze für speicherdichte Konfigurationen unterstützt die Markteinführung größere In-Memory-Cluster und die Konsolidierung latenzsensibler Unternehmensarbeitslasten.
- Mai 2025: AWS gab die allgemeine Verfügbarkeit von Amazon Aurora DSQL bekannt, um verteilte SQL-Skalierbarkeit mit Leistungsmerkmalen im In-Memory-Stil bereitzustellen. Die Veröffentlichung erweitert die Optionen für verwaltete Dienste für Teams, die latenzarme Semantik wünschen, ohne große lokale Speicherkapazitäten zu betreiben und abzustimmen.


Rahmen der Forschungsmethodik und Umfang des Berichts
Marktdefinition und Abdeckung
Der Markt für In-Memory-Datenbanken umfasst Software und zugehörige Dienstleistungen, bei denen der primäre Arbeitsdatensatz im RAM gehalten wird, um sehr geringe Latenz für Transaktionen, Analysen, Caching und gemischte Arbeitslasten in Unternehmens- und Cloud-Umgebungen zu erzielen.
Umfangsausschlüsse: Wir schließen universelle Speicherhardware und nicht verwandte Datenbank-Tools aus, die nicht wesentlich auf In-Memory-Verarbeitung als Kerntreiber des Werts angewiesen sind.
Übersicht der Segmentierung
- Nach Verarbeitungstyp
- OLTP
- OLAP
- Hybride Transaktions-/Analyseverarbeitung (HTAP)
- Nach Bereitstellungsmodus
- On-Premise
- Cloud
- Edge/Eingebettet
- Nach Datenmodell
- Relational (SQL)
- NoSQL (Schlüssel-Wert, Dokument, Graph)
- Multi-Modell
- Nach Unternehmensgröße
- Kleine und mittlere Unternehmen (KMU)
- Großunternehmen
- Nach Anwendung
- Echtzeit-Transaktionsverarbeitung
- Operative Analysen und BI-Dashboards
- KI/ML-Modell-Serving
- Caching und Sitzungsspeicher
- Nach Endbenutzerbranche
- BFSI
- Telekommunikation und IT
- Einzelhandel und E-Commerce
- Gesundheitswesen und Biowissenschaften
- Fertigung und industrielles IoT
- Medien und Unterhaltung
- Regierung und Verteidigung
- Sonstige (Energie, Bildung usw.)
- Nach Geografie
- Nordamerika
- Vereinigte Staaten
- Kanada
- Mexiko
- Europa
- Deutschland
- Frankreich
- Vereinigtes Königreich
- Nordische Länder
- Übriges Europa
- Asien-Pazifik
- China
- Taiwan
- Südkorea
- Japan
- Indien
- Übriger Asien-Pazifik-Raum
- Südamerika
- Brasilien
- Mexiko
- Argentinien
- Übriges Südamerika
- Naher Osten und Afrika
- Naher Osten
- Saudi-Arabien
- Vereinigte Arabische Emirate
- Türkei
- Übriger Naher Osten
- Afrika
- Südafrika
- Übriges Afrika
- Naher Osten
- Nordamerika
Datenquellen, Marktdimensionierung und Validierung
Sekundärforschung
Die Sekundärarbeit beginnt mit dem Aufbau der Faktenbasis rund um Datenbankeinführung und IT-Ausgabenmuster und wird dann auf Lösungen eingegrenzt, bei denen In-Memory-Verarbeitung ein bestimmendes Merkmal ist. Wir haben öffentliche Quellen wie US-SEC-Einreichungen, Jahresberichte und Investorenpräsentationen sowie Dokumentationen und Preisseiten von Cloud-Anbietern herangezogen, die helfen, Bereitstellungsmuster und gängige Arbeitslastmischungen zu validieren.
Um die Eingaben fundiert zu halten, haben wir auch nicht kostenpflichtige Indikatoren des US Bureau of Economic Analysis für den Kontext digitaler Investitionen, makroökonomische Reihen der Weltbank und der OECD zur länderübergreifenden Normalisierung sowie ITU-Konnektivitätsstatistiken zur Infrastrukturbereitschaft verwendet. Wir haben peer-reviewte Systeme- und Datenbankfachzeitschriften genutzt, um technische Einführungsaussagen auf Plausibilität zu prüfen. Patentdatenbanken und ein Nachrichten- und Finanzabonnement wurden selektiv eingesetzt, um Produkteinführungen, Fusionen und Übernahmen sowie Funktionsverschiebungen zu verfolgen, die beeinflussen, was als In-Memory-Datenbank gegenüber angrenzenden Caching- oder Analyseebenen gezählt wird. Diese Quellen sind nicht erschöpfend, und wir haben viele weitere öffentliche Referenzen zur Datenerhebung, Validierung und Klärung beim Aufbau des Modells verwendet.
Primärinterviews und Umfragen
Die Primärarbeit konzentrierte sich darauf zu prüfen, was Käufer tatsächlich für latenzsensible Arbeitslasten einsetzen und wie Lizenz-, Abonnement- und verwaltete Servicepreise in realen Geschäften gestaltet werden. Wir sprachen mit einer Mischung aus Softwareanbietern, Cloud- und Vertriebspartnern sowie Unternehmensnutzern in wichtigen Regionen, um Lücken aus Sekundärdaten zu schließen und anschließend Annahmen zu Einführung, Preisgestaltung und Upgrade-Zyklen zu triangulieren.
Verteilung der Befragten der primären Feldforschung
| Unternehmenstyp | Position des Befragten | Region |
|---|---|---|
| Top-Tier: 29 % | CXOs: 19 % | APAC: 45 % |
| Mid-Tier: 51 % | Funktions-/Bereichsleiter: 25 % | EMEA: 29 % |
| Kleinere Akteure: 20 % | Manager: 56 % | Amerika: 26 % |
Marktdimensionierung & Prognose
Die Dimensionierung erfolgt nach Top-down- und Bottom-up-Logik, wobei die Top-down-Sicht die adressierbaren Ausgaben rekonstruiert, indem Unternehmensdatenbank- und Datenplattform-Budgets auf In-Memory-Anwendungsfälle abgebildet werden, und anschließend regionale und branchenspezifische Einführungssignale angewendet werden. Sobald der Nachfragepool gebildet ist, wird er anhand von Bottom-up-Näherungen aus stichprobenartigen Preis- und Volumenprüfungen, Partner-Feedback zu Bereitstellungszahlen und selektiven Umsatzaufteilungen der Lieferanten korrigiert, um die Gesamtsummen realistisch zu halten.
Zu den wichtigsten Modelleingaben gehören die Verteilung von Cloud- gegenüber On-Premise-Bereitstellungen, durchschnittliche Vertragswerte nach Unternehmensgröße, der Anteil transaktionaler gegenüber analytischer Arbeitslasten (einschließlich HTAP), Zeitpunkte für Verlängerungen und Upgrades sowie die Geschwindigkeit, mit der speicherintensive Architekturen für Echtzeitanwendungsfälle übernommen werden. Wo direkte Volumenindikatoren fehlen, werden Lücken durch Proxy-Variablen behandelt, die in Gesprächen belegbar sind, wie zum Beispiel die Anwendungsdurchdringung in BFSI und Telekommunikation sowie die Verlagerung hin zu verwalteten Datenbankdiensten.
Prognosen werden mittels Szenarioanalyse erstellt, unterstützt durch Trendglättung bei Einführungs- und Preispfaden, und anschließend anhand der Erwartungen der Befragten zum Tempo der Cloud-Migration, zum Wachstum von KI- und Streaming-Arbeitslasten sowie zur Preissensibilität überprüft. Die endgültige Reihe bleibt wiederholbar, indem jeder Schritt an einen kleinen Satz messbarer Eingaben und klar formulierter Annahmen gekoppelt wird.
Datenvalidierung & Aktualisierungszyklus
Die Validierung erfolgt in mehreren Durchgängen, beginnend mit Einzelprüfungen von Preisgestaltung, Einführung und regionaler Aufteilung, gefolgt von Abweichungsprüfungen gegenüber unabhängigen Signalen wie der Richtung des Cloud-Verbrauchs, Trends bei Unternehmenssoftwareausgaben und gemeldeten leistungsgetriebenen Upgrade-Zyklen. Wenn eine Eingabe zu einem ungewöhnlichen Sprung in einer Region oder Branche führt, wird sie markiert, von einem anderen Analysten überprüft und dann mit einer neuen Sekundärquelle oder einem erneuten Kontakt mit einem relevanten Befragten neu geprüft.
Das Modell und die Erzählung werden vor der Freigabe überprüft, damit die endgültigen Zahlen mit dem angegebenen Umfang und den Definitionen übereinstimmen. Berichte werden jährlich aktualisiert, und Zwischenaktualisierungen erfolgen, wenn wesentliche Ereignisse eintreten, wie größere Produktänderungen oder Verschiebungen in den Bereitstellungsmodellen. Vor der Auslieferung führen wir einen abschließenden Durchgang durch, damit die Marktzahlen die neuesten verfügbaren Informationen widerspiegeln.
Vergleich der Marktdimensionierung von In-Memory-Datenbanken durch Mordor Intelligence mit anderen veröffentlichten Schätzungen
Veröffentlichte Marktwerte für In-Memory-Datenbanken können voneinander abweichen, da jeder Herausgeber eigene Entscheidungen darüber trifft, was gezählt wird, welches Jahr als Basisjahr gilt und wie Umsätze aus cloud-verwalteten Datenbanken behandelt werden. Unterschiede zeigen sich auch, wenn sich ein Modell stärker auf anbieterseitige Umsatzberichte stützt, während ein anderes stärker auf Käufer-Einführungssignale setzt.
Die Hauptlücke ergibt sich daraus, ob angrenzende Ebenen wie In-Memory-Datengitter, Caching-Dienste und breitere In-Memory-Computing-Stacks in die Gesamtsumme eingerechnet werden, wobei Mordor Intelligence nur In-Memory-Datenbankumsätze zählt, die an Datenbankbereitstellungen und zugehörige Dienstleistungen innerhalb des definierten Umfangs gebunden sind, und dann Prognosen ab dem Basisjahr 2026 unter Verwendung regionaler Einführungs- und Preisprüfungen erstellt.
Benchmark-Vergleich
| Quelle | Marktgröße | Lücken in der Forschungsmethodik |
|---|---|---|
| Mordor Intelligence | 8,05 Mrd. USD (2026) | |
| Globale Beratungsgesellschaft A | 6,66 Mrd. USD (2025) | Verwendet ein anderes Basisjahr und eine breitere Bündelung verwandter Dienstleistungen in der Kategoriedefinition, was verändern kann, was als Datenbankumsatz gegenüber Plattform-Add-ons gezählt wird, und dann den Ausgangspunkt für den Prognosepfad verändert. |
| Branchenverlag B | 3,90 Mrd. USD (2024) | Beginnt mit einem früheren Jahr und einem kleineren Adoptionspool und wendet oft langsamere Wachstumsannahmen für cloud-verwaltete Bereitstellungen an, was den Anteil der Ausgaben, die sich in Richtung Abonnement- und verbrauchsbasierte Preisgestaltung verschieben, unterschätzen kann. |
Insgesamt betrachtet lässt sich die Spanne hauptsächlich durch Entscheidungen zum Umfang und zur Jahresauswahl erklären, gefolgt davon, wie Cloud-Umsätze in Marktwert umgerechnet werden. Indem die Einschlüsse explizit gehalten und die Prognose an Einführung, Bereitstellungsmix und Preisentwicklung gekoppelt wird, bleibt die endgültige Zahl nachvollziehbar an klaren, wiederholbaren und überprüfbaren Schritten.


Im Bericht beantwortete Schlüsselfragen
Wie hoch ist der aktuelle Wert des In-Memory-Datenbankmarkts?
Der In-Memory-Datenbankmarkt wurde im Jahr 2026 auf USD 8,05 Milliarden bewertet und wird bis 2031 voraussichtlich USD 15,31 Milliarden erreichen.
Welche Region führt das Wachstum des In-Memory-Datenbankmarkts an?
Asien-Pazifik führte im Jahr 2025 mit einem Umsatzanteil von 31,95 % und wird bis 2031 voraussichtlich eine CAGR von 16,65 % erzielen.
Warum sind HTAP-Architekturen für KI-Workloads wichtig?
HTAP vereint Transaktions- und Analyseverarbeitung und ermöglicht Echtzeit-Inferenz ohne ETL-Verzögerungen, wie Oracle HeatWave GenAI zeigt.
Wie wirken sich sinkende DRAM-Preise auf die Einführung aus?
Niedrigere USD/GB-Preise und neue persistente Speicheroptionen senken die Gesamtbetriebskosten und machen In-Memory-Deployments wirtschaftlich rentabel.
Welche Herausforderungen begrenzen sehr große In-Memory-Cluster?
Die Hochverfügbarkeitsarchitektur wird bei mehr als 40 TB komplex, da Clustering-Protokolle Leistungs-Overhead verursachen.
Seite zuletzt aktualisiert am:




