KI-Datenbeschriftungsmarkt Größe und Anteil
Marktübersicht
| Studienzeitraum | 2020 - 2031 |
|---|---|
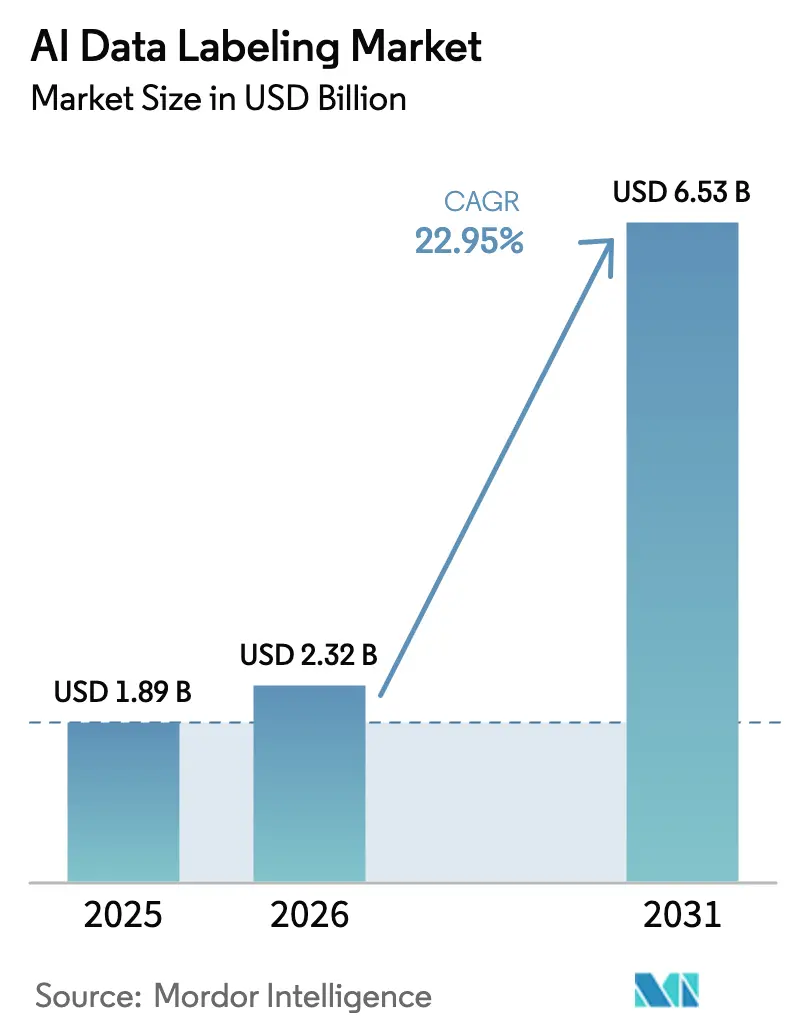
| Marktgröße (2026) | 2.32 Milliarden US-Dollar |
| Marktgröße (2031) | 6.53 Milliarden US-Dollar |
| Wachstumsrate (2026 - 2031) | 22.95% CAGR |
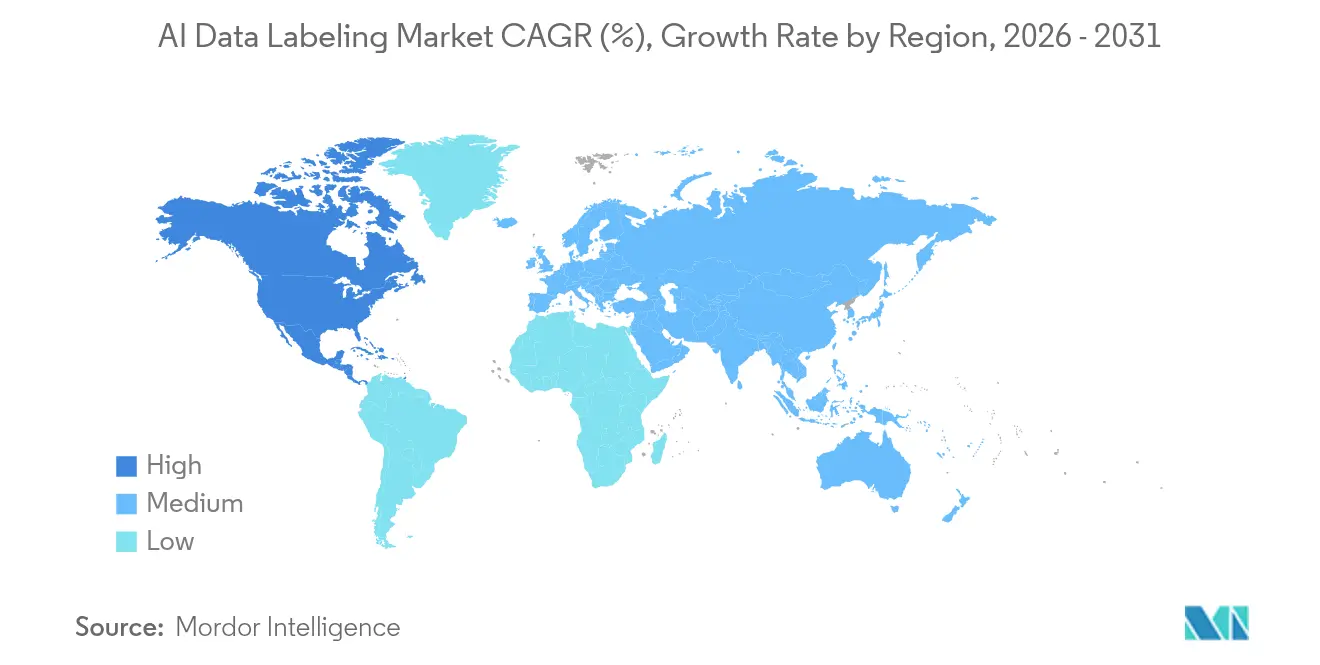
| Schnellstwachsender Markt | Asien-Pazifik |
| Größter Markt | Nordamerika |
| Marktkonzentration | Mittel |
Hauptakteure *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. | |
KI-Datenbeschriftungsmarkt Analyse von Mordor Intelligence
Die Größe des KI-Datenbeschriftungsmarkts im Jahr 2026 wird auf 2,32 Milliarden USD geschätzt, ausgehend vom Wert des Jahres 2025 von 1,89 Milliarden USD, mit Projektionen für 2031 von 6,53 Milliarden USD, was einem Wachstum von 22,95 % CAGR über den Zeitraum 2026–2031 entspricht. Die rasche Skalierung spiegelt wider, wie sich die Datenannotation von einem Kostenfaktor zu einer strategischen Fähigkeit entwickelt hat, die regulatorische Compliance, Modellausrichtung und unternehmerische Differenzierung unterstützt. Die sich intensivierende Entwicklung autonomer Fahrzeuge, steigende Unternehmensinvestitionen in generative KI und die Einführung rechtsverbindlicher Prüfanforderungen für Trainingsdaten sind die größten Rückenwinde. Ausgelagerte Plattformen, die Skalierbarkeit der Belegschaft mit automatisierter Qualitätssicherung verbinden, gewinnen weiterhin Marktanteile, während hybride Mensch-in-der-Schleife-Workflows die Beschriftungsproduktivität bei Bild-, Video- und Textressourcen steigern. Die geografische Expansion wird durch unterschiedliche Datenschutzregime und Talentangebot geprägt: Nordamerika hält die größte Nachfragebasis, der asiatisch-pazifische Raum verzeichnet das stärkste Wachstum und Europa legt Wert auf nachvollziehbare Herkunftsnachweise.
Wichtigste Erkenntnisse des Berichts
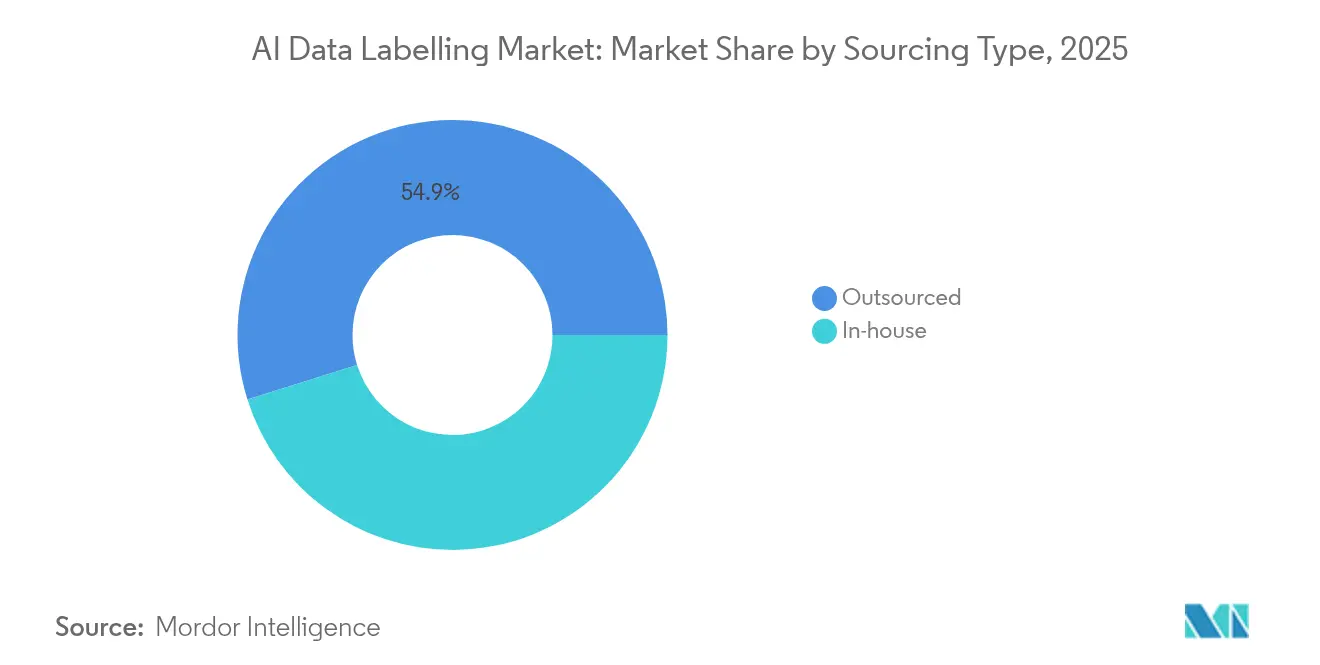
- Nach Beschaffungstyp erfasste die Auslagerung im Jahr 2025 einen Anteil von 54,85 % am KI-Datenbeschriftungsmarkt; interne Betriebe hinken beim Wachstum hinterher, da ausgelagerte Dienste bis 2031 mit einer CAGR von 28,37 % expandieren.
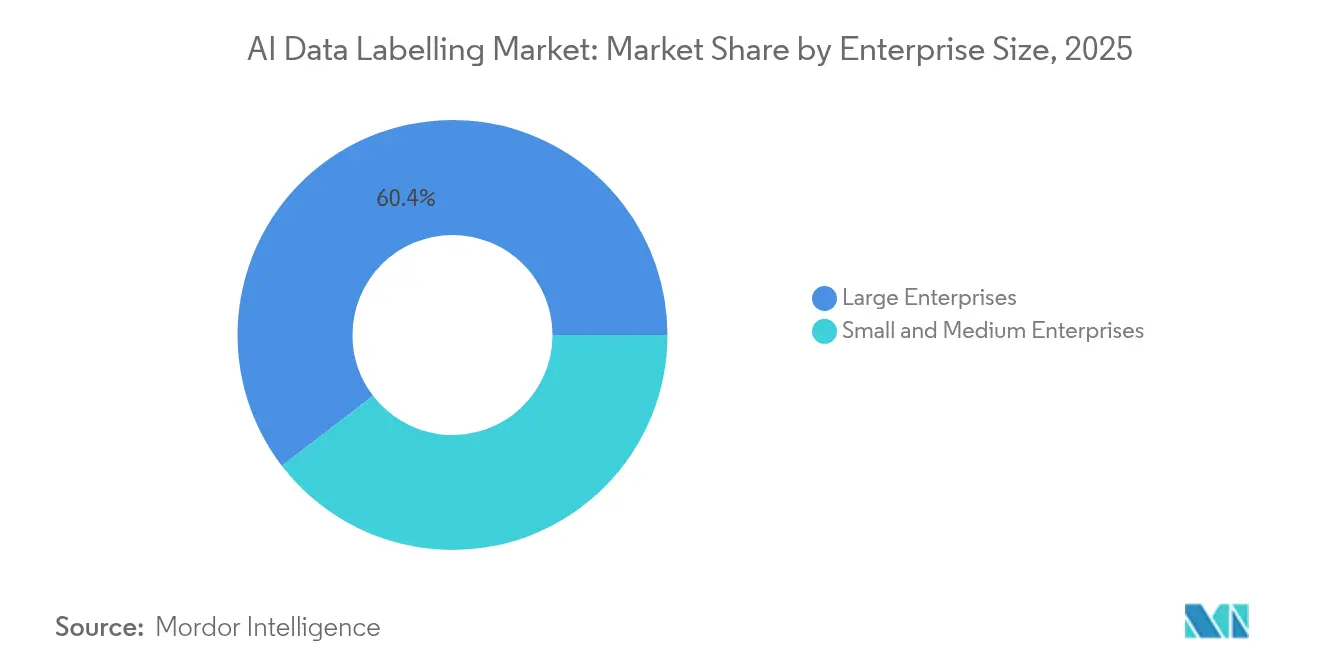
- Nach Unternehmensgröße hielten Großunternehmen im Jahr 2025 einen Anteil von 60,40 % an der Größe des KI-Datenbeschriftungsmarkts, während KMU die schnellste CAGR von 26,42 % bis 2031 verzeichnen.
- Nach Datentyp führte die Textannotation mit 27,30 % des Umsatzes im Jahr 2025; Video wird voraussichtlich bis 2031 mit einer CAGR von 31,18 % wachsen.
- Nach Beschriftungsmethode behielten manuelle Workflows im Jahr 2025 einen Anteil von 78,10 %; halbüberwachte und Mensch-in-der-Schleife-Methoden beschleunigen sich mit einer CAGR von 33,15 %.
- Nach Endnutzerbranche hielten Automobil und Mobilität im Jahr 2025 einen Marktanteil von 23,10 %; das Gesundheitswesen wächst mit einer CAGR von 24,63 % dank politischer Unterstützung für Marktplätze für medizinische Bildgebung.
- Nach Region dominierte Nordamerika im Jahr 2025 mit einem Anteil von 34,70 %, während der asiatisch-pazifische Raum mit einer CAGR von 23,35 % bis 2031 die am schnellsten wachsende Region ist.
Hinweis: Die Marktgrößen- und Prognosezahlen in diesem Bericht werden mithilfe des proprietären Schätzrahmens von Mordor Intelligence erstellt und mit den neuesten verfügbaren Daten und Erkenntnissen bis 2026 aktualisiert.
Globale KI-Datenbeschriftungsmarkt Trends und Einblicke
Analyse der Auswirkungen von Treibern*
| Treiber | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Verbreitung vernetzter und autonomer Fahrzeuge | +6.2% | Nordamerika, China, EU | Mittelfristig (2–4 Jahre) |
| Unternehmens-KI- und Big-Data-Initiativen | +5.8% | Nordamerika, asiatisch-pazifischer Raum | Kurzfristig (≤ 2 Jahre) |
| Generative KI-RLHF-Datenpipelines | +4.1% | Nordamerika, EU, Ausweitung auf den asiatisch-pazifischen Raum | Mittelfristig (2–4 Jahre) |
| Verschärfung der KI-Governance-Gesetze | +3.7% | EU, Nordamerika, Ausstrahlungseffekte auf den asiatisch-pazifischen Raum | Langfristig (≥ 4 Jahre) |
| Edge-KI-Silizium für kontinuierliches Lernen | +2.9% | Globale Früheinführung in Nordamerika, asiatisch-pazifischer Raum | Langfristig (≥ 4 Jahre) |
| Synthetische Datensätze, die Mikro-Ground-Truth erfordern | +2.3% | Globale Technologiezentren | Mittelfristig (2–4 Jahre) |
| Quelle: Mordor Intelligence | |||
Steigende Verbreitung vernetzter und autonomer Fahrzeuge
Level-4- und Level-5-Programme erfordern hochdichte LiDAR-Punktwolken-, 3D-Quader- und zeitliche Videobeschriftungen, die regionale Fahrbesonderheiten erfassen. Automobil-OEMs legen Wert auf Inferenzeffizienz, sodass Annotationsrichtlinien nun Objektgrößen-Priors und Verdeckungsmetadaten enthalten, die Modellparameter komprimieren, ohne die Wahrnehmungsgenauigkeit zu beeinträchtigen. Sicherheitsregulatoren in China und der EU verlangen Herkunftsnachweise, wodurch konforme Beschriftungspipelines zu Wettbewerbsvorteilen werden, die Anbieter mit integrierten Dokumentations-Workflows bevorzugen[2]Quelle: BasicAI, "Fortgeschrittene 3D-LiDAR-Annotationstechniken für autonomes Fahren," basic.ai.
Verbreitung von Unternehmens-KI- und Big-Data-Initiativen
Finanzdienstleister, Einzelhändler und Telekommunikationsbetreiber erweitern proprietäre Dokument- und Interaktionsdatensätze, die domänenspezifische Kennzeichnung benötigen, um prädiktive Risikoanalysen, Next-Best-Action-Engines und hyperpersonalisiertes Marketing zu erschließen. Verstärkendes Lernen aus menschlichem Feedback (RLHF) vervielfacht die Nachfrage nach qualifizierten Prüfern, die die Hilfsbereitschaft von Modellen bewerten, und gestaltet Service-Level-Vereinbarungen rund um fachliche Tiefe statt Annotationsvolumen um.
Entstehung generativer KI-RLHF-Datenpipelines
RLHF-Aufgaben – einschließlich offener vergleichender Bewertung, Identifizierung von Sicherheitsauslösern und Erkennung von Widersprüchen – erzielen Premiumpreise und erfordern längere Einarbeitungszeiten der Belegschaft. Anbieter, die die Kapazitäten zur Deckung der Nachfrage ausbauen, investieren in Evaluatorenschulungsprogramme und statistische Fehlervorhersagemodelle, die Inkonsistenzen vor der Kundenprüfung erkennen. Apple-Forscher zeigten, dass Vorhersagealgorithmen 65–75 % der wahrscheinlichen Fehler markieren können, was neue Qualitätsbenchmarks setzt.
Verschärfung der KI-Governance-Gesetze mit Forderung nach nachvollziehbaren Ground-Truth-Daten
Das EU-KI-Gesetz und das Leitlinienpaket der französischen CNIL verlangen eine klare Offenlegung von Datenquellen, Einwilligungsstatus und Annotationsprotokollen während des gesamten Modell-Lebenszyklus. Vergleichbare Regeln der Monetary Authority of Singapore schaffen sektorspezifische Verpflichtungen für Finanzinstitute. Anbieter, die mit detaillierten Prüfpfaden, rollenbasierter Zugriffskontrolle und verschlüsselten Beschriftungsumgebungen ausgestattet sind, erlangen den Status bevorzugter Anbieter für grenzüberschreitende Einsätze.
Analyse der Auswirkungen von Hemmnissen*
| Hemmnis | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Datenschutz- und IP-Sicherheitsbedenken | −2.8% | EU, Nordamerika | Kurzfristig (≤ 2 Jahre) |
| Mangel an Fachexperten für Annotationen | −2.1% | Globale Hochqualifikationsdomänen | Mittelfristig (2–4 Jahre) |
| Steigende Lohnkosteninflation | −1.7% | Nordamerika, Westeuropa | Kurzfristig (≤ 2 Jahre) |
| Commoditisierungsdruck durch synthetische Daten | −1.4% | Globale Technologiezentren | Mittelfristig (2–4 Jahre) |
| Quelle: Mordor Intelligence | |||
Datenschutz- und IP-Sicherheitsbedenken
Obligatorische Datenlokalisierungsgesetze und Zero-Trust-Anbieterprüfungen erhöhen den Aufwand für verteilte Belegschaften. Unternehmen, die medizinische Scans oder Finanztransaktionen verarbeiten, schränken den Fernzugriff ein und zwingen Anbieter dazu, souveräne Clouds und On-Premise-Workbenches einzurichten, die Verschlüsselungs-, Schlüsselverwaltungs- und Prüfprotokoll-Anforderungen erfüllen. Die zusätzlichen Investitionen erhöhen die Kosten und verlangsamen das Onboarding.
Mangel an Fachexperten für Annotationen
Medizinische Bildgebung, rechtliche Vertragsanalyse und Grenzfälle beim autonomen Fahren erfordern Annotatoren mit fortgeschrittenen Qualifikationen und längeren Schulungszyklen. Die durchschnittliche Betriebszugehörigkeit von Prüfern auf mittlerem Niveau in wichtigen Zentren wie Indien beträgt 12–18 Monate, was die Fluktuation und die Kosten für Nachschulungen erhöht. Hybride KI-gestützte Werkzeuge gleichen Volumenlücken aus, aber die menschliche Validierung bleibt für die Erkennung von Verzerrungen und Leistungsgarantien unerlässlich[1]Quelle: NIST, "Ansätze zur Bewertung von Mensch-in-der-Schleife für KI-Systeme," nist.gov.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Beschaffungstyp: Dominanz der Auslagerung beschleunigt sich
Ausgelagerte Anbieter generierten im Jahr 2025 einen Anteil von 54,85 % am KI-Datenbeschriftungsmarkt, da Unternehmen Geschwindigkeit und regulatorische Sicherheit priorisierten. Die CAGR des Segments von 28,37 % bis 2031 positioniert es als den wichtigsten Beitragenden zum inkrementellen Umsatz innerhalb des KI-Datenbeschriftungsmarkts. Hybridverträge kombinieren nun Offshore-Belegschaften mit Onshore-Prüfknoten, um Souveränitätsklauseln zu erfüllen, und schaffen eine zweistufige Kostenstruktur, die Plattformanbieter begünstigt.
Interne Teams bestehen für proprietäre oder hochsensible Projekte fort, können jedoch nicht mit der Werkzeugbreite und den Compliance-Zertifizierungen spezialisierter Anbieter mithalten. Da synthetische Daten-Workflows reifen, integrieren Unternehmen externe Partner für die Mikro-Ground-Truth-Verifizierung statt für die vollständige Beschriftung, was die Nachfrage auch dann aufrechthält, wenn das Gesamtannotationsvolumen sinkt.



Nach Datentyp: Videobeschriftung entwickelt sich zum Wachstumsführer
Die CAGR der Videoannotation von 31,18 % macht sie zum am schnellsten wachsenden Segment des KI-Datenbeschriftungsmarkts. Autonome Fahrzeugstacks erfordern 4K-Mehrkamera-Feeds, die mit LiDAR-Netzen verknüpft sind, was den durchschnittlichen Projektwert im Vergleich zu herkömmlichen Bildsätzen erhöht. Textressourcen liefern weiterhin einen Umsatzanteil von 27,30 %, angetrieben durch die Abstimmung konversationeller KI und Dokumentenintelligenzprogramme, aber der Preisdruck ist stärker, da automatisiertes Musterabgleichen große Teile der Daten vorab beschriften kann.
3D-Punktwolkenaufgaben mit LiDAR und Radar weisen hohe Eintrittsbarrieren aufgrund spezialisierter Werkzeuge und fortgeschrittener geometrischer Kenntnisse auf. Audioprojekte gewinnen durch Sprachbiometrie und Call-Center-Automatisierung an Dynamik, bleiben jedoch ein einstelliges Umsatzsegment. Multimodale Mandate, die Text-, Bild-, Video- und Sensorströme synchronisieren, unterstützen neue gebündelte Angebote, die Anbieter mit vollständigen Orchestrierungsfähigkeiten belohnen.
Nach Beschriftungsmethode: Halbüberwachte Revolution beschleunigt sich
Die manuelle Annotation behielt im Jahr 2025 einen Anteil von 78,10 % an der Gesamtgröße des KI-Datenbeschriftungsmarkts und unterstreicht den anhaltenden Bedarf an menschlichem Urteilsvermögen in sicherheitskritischen Kontexten. Dennoch liefern halbüberwachte und Mensch-in-der-Schleife-Methoden eine CAGR von 33,15 % und setzen eine neue Produktivitätsbasis im gesamten KI-Datenbeschriftungsmarkt. Aktive Lernabfragestrategien reduzieren nun redundante Stichproben um 30–40 %, was die Zykluszeiten verkürzt, ohne die Trefferquote zu beeinträchtigen.
Automatisierte Beschriftungsmaschinen übernehmen einfache Begrenzungsrahmen- oder Stimmungsklassifizierungsaufgaben, übergeben jedoch mehrdeutige Fälle an Fachprüfer. Große Sprachmodelle generieren zunehmend Erstbeschriftungen für Nischentaxonomien, die Menschen verfeinern. Anbieter differenzieren sich durch statistische Qualitätskontrollen – wie Inter-Annotator-Übereinstimmungsbewertung und Stichprobenprüfungen – die das Vertrauen aufrechterhalten und gleichzeitig den Durchsatz skalieren.
Nach Unternehmensgröße: KMU-Einführung beschleunigt die digitale Transformation
Großunternehmen halten im Jahr 2025 einen Marktanteil von 60,40 % an der Größe des KI-Datenbeschriftungsmarkts aufgrund komplexer Projekte im Bereich autonomes Fahren, medizinische Bildgebung und Verteidigung. Dennoch wachsen KMU mit einer CAGR von 26,42 %, da Pay-as-you-go-Cloud-Werkzeuge die Eintrittsbarrieren senken. Branchenspezifische Vorlagen ermöglichen es kleineren Einzelhändlern, Versicherern und Herstellern, Modelle mit begrenztem internem Personal für maschinelles Lernen aufzubauen, und erweitern die Nachfragebasis für standardisierte Annotationspipelines.
Hybride Abonnementpakete bündeln Beschriftungsguthaben mit Modellbewertungs-Dashboards und reduzieren die Beschaffungsreibung für Finanz- und Compliance-Stakeholder. Wachstumsstarke mittelgroße Unternehmen setzen auf ausgelagerte Mikrotask-Modelle, die sich an saisonale Volumina anpassen, während sie zentrale Testdatensätze intern für die Governance behalten. Weiterbildungszuschüsse regionaler Regierungen fördern die KMU-Beteiligung im gesamten KI-Datenbeschriftungsmarkt zusätzlich.
Nach Endnutzerbranche: Gesundheitswesen führt die Wachstumstransformation an
Der Marktanteil des Gesundheitswesens und der Biowissenschaften verzeichnet bis 2031 eine CAGR von 24,63 % und übertrifft damit alle anderen Branchen innerhalb der KI-Datenbeschriftungsbranche. Von der FDA unterstützte Bildgebungsrepositorien beschleunigen die Algorithmusvalidierung und fördern die Nachfrage nach pixelgenauer Organsegmentierung, Läsionsabgrenzung und multimodaler Omics-Fusion. Automobil und Mobilität behält mit 23,10 % im Jahr 2025 den größten Umsatzanteil, aber regulatorische Unfallsicherheitsprüfungen treiben kontinuierliche Datensatz-Aktualisierungen an, die die Ausgaben aufrechterhalten.
Finanzinstitute intensivieren Anti-Betrugs- und KYC-Workflows, die Dokumentenbeschriftung und Transaktionsgraph-Annotation erfordern. Industrielle Robotik nutzt visionsbasierte Fehlererkennung, die auf ausgewogener Klassenverteilung beruht, während Telekommunikationsanbieter Netzwerkereignisprotokolle annotieren, um selbstoptimierende RAN-Controller zu speisen. Der spezifische Compliance-Code jeder Branche fördert maßgeschneiderte Service-Level-Vereinbarungen, die Spezialisierung und Preissetzungsmacht im gesamten KI-Datenbeschriftungsmarkt stärken.
Geografische Analyse
Nordamerika generierte im Jahr 2025 34,70 % des Umsatzes und bleibt die größte Käufergruppe des KI-Datenbeschriftungsmarkts. Scale AIs mehrjähriger Thunderforge-Verteidigungsauftrag unterstreicht die staatliche Nachfrage nach hochsicheren Annotationspipelines. Die Ökosysteme des Gesundheitswesens und des autonomen Fahrens in den Vereinigten Staaten stärken das Volumen, während die grenzüberschreitende Automobillieferkette Kanadas zweisprachige Bild- und Textprojekte antreibt. Mexikos Nearshore-Zentren gewinnen Überlaufarbeiten, die Kosten und Nähe ausbalancieren, obwohl CCPA und sektorspezifische Datenschutzmandate Anbieter dazu zwingen, sichere inländische Infrastruktur einzusetzen. Steigende Vergütungskosten lösen eine Nearshore-Expansion aus, aber US-amerikanische Käufer schätzen weiterhin inländische souveräne Clouds für streng geheime Workloads.
Der asiatisch-pazifische Raum liefert die schnellste regionale CAGR von 23,35 % bis 2031 und steigert seinen Beitrag zum KI-Datenbeschriftungsmarkt jedes Jahr. China investiert 45 Milliarden USD in KI-Infrastruktur und schreibt Inhaltsbeschriftungsstandards vor, die die Skalierung inländischer Anbieter stimulieren. Indiens Annotationsbelegschaft übersteigt 450.000 Prüfer und bedient globale Verträge, während sie die einheimische Modellentwicklung verankert. Japan konzentriert sich auf die Bildgebung für chirurgische Roboter und Radiologieannotation und generiert hochmargige Nachfrage nach medizinisch zertifizierten Fachleuten. Südkoreas aufstrebendes KI-Grundgesetz positioniert Telekommunikations- und Automobilkonzerne dazu, umfangreiche Multi-Sensor-Datensätze auszulagern. ASEAN-Finanzzentren setzen auf KI-Risikomanagement-Frameworks, und Australien zielt auf Präzisionslandwirtschafts-Visionsdatensätze ab, die die Dürreprognose unterstützen.
Europa verzeichnet stabiles Wachstum im mittleren Zehnerbereich, da DSGVO, das EU-KI-Gesetz und CNIL-Leitlinien Herkunftsprüfungen institutionalisieren. Lokale Anbieter setzen datenschutzwahrende Annotationssandboxen mit On-Premise-Rechenleistung ein, um strenge Regeln für personenbezogene Daten zu erfüllen. Deutschland ist Vorreiter bei der Beschriftung für industrielle Robotik, während der britische Finanzdienstleistungssektor trotz datentransferrechtlicher Komplexitäten nach dem Brexit Datensätze zur Ausrichtung konversationeller KI in Auftrag gibt. Nordische Regierungen finanzieren KI-Programme für nachhaltige Energie, die Satellitenbildannotation erfordern, und Südeuropa profitiert von Tourismus-Analyseprojekten. In allen Mitgliedstaaten beeinflussen Lieferables zur Vorurteilsminderung und Erklärbarkeitsberichte die Anbieterauswahllisten und stärken die compliance-getriebene Prämie der Region.

Wettbewerbslandschaft
Der KI-Datenbeschriftungsmarkt weist eine moderate Fragmentierung auf: Kein einzelner Anbieter kontrolliert mehr als ein Fünftel der globalen Ausgaben, doch Skalierungsakteure wie Scale AI, Appen und iMerit üben Einkaufshebel über Werkzeug-Ökosysteme aus. Scale AIs Bewertung von 14 Milliarden USD beruht auf der integrierten Plattformbreite, von RLHF-Workflows bis hin zur sicheren Enklave-Bereitstellung, unterstützt durch Bundesverträge, die eine kontinuierliche Penetrationstestzertifizierung erfordern. Appen erweitert automatisierte Qualitätsprüfungsfähigkeiten, um Margen zu schützen, während die Lohnkosten steigen, und iMerit nutzt domänenspezifische Mentorenprogramme, um Gesundheits- und Geospatial-Projekte zu sichern.
Plattformeinsteiger differenzieren sich durch die Fusion von Annotations- und Bewertungs-Dashboards, die es Kunden ermöglichen, Datenvorverarbeitung, Beschriftung, Testset-Kuratierung und laufende Modellgesundheitsüberwachung über eine einzige Schnittstelle zu orchestrieren. Qualitätssicherungsmaschinen, die statistische Stichproben und automatisches Triagieren von Grenzfällen nutzen, reduzieren Überarbeitungszyklen um 15–25 %. Etablierte Technologiegiganten betten Beschriftungsmodule in ihre Cloud-KI-Suiten ein, was die Integration strafft, aber bei Multi-Cloud-Nutzern Bedenken hinsichtlich der Neutralität aufwirft.
Pioniere der programmatischen Beschriftung wie Snorkel AI setzen auf schwache Überwachungsframeworks, die es Datenwissenschaftlern ermöglichen, Heuristiken zu kodifizieren, anstatt Millionen von Beispielen manuell zu beschriften. Anbieter synthetischer Daten arbeiten mit Beschriftungsspezialisten für Stichprobenprüfungen zusammen, was zeigt, dass menschliche Aufsicht dort unverzichtbar bleibt, wo Sicherheit und Vorurteile auf dem Spiel stehen. Regulatorische Vorschriften verlangen unveränderliche Prüfpfade, Verschlüsselung im Ruhezustand und rollenbasierte Zugriffskontrollen, die kleinere Wettbewerber kaum finanzieren können, was den Markt in Richtung einer Hantelstruktur aus großen Full-Stack-Plattformen und Nischen-Domänenexperten treibt.
Führende Unternehmen der KI-Datenbeschriftungsbranche
Appen Limited
Scale AI Inc.
Amazon Web Services
Google LLC
CloudFactory Ltd.
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Aktuelle Branchenentwicklungen
- März 2025: Scale AI sicherte sich einen mehrere Millionen USD umfassenden Vertrag mit dem Verteidigungsministerium im Rahmen des Thunderforge-Programms zur Unterstützung der KI-gestützten operativen Planung in Partnerschaft mit Anduril und Microsoft.
- Februar 2025: Die französische CNIL veröffentlichte detaillierte KI-Compliance-Empfehlungen, die eine ausdrückliche Offenlegung von Trainingsdatenquellen und Annotationsstandards erfordern, was die Nachfrage nach nachvollziehbaren Beschriftungspipelines erhöht.
- Dezember 2024: iSoftStone erschien auf der „Karte der Branche für künstliche Intelligenz und Datenannotation” der China Academy of Information and Communications Technology und bestätigte damit den Plattformausbau des Unternehmens in mehreren Städten.
- April 2024: Bayer und Google Cloud starteten eine Zusammenarbeit zum Aufbau generativer KI-Radiologiewerkzeuge unter Verwendung kuratierter medizinischer Bildbeschriftungen in Googles Vertex-AI-Umgebung.


Rahmen der Forschungsmethodik und Umfang des Berichts
Marktdefinitionen und wichtige Abdeckung
Mordor Intelligence definiert den KI-Datenbeschriftungsmarkt als den Umsatz, der durch Dienste erzielt wird, die rohe digitale Ressourcen – einschließlich Bilder, Video, Text, Audio und 3D-Punktwolken – kennzeichnen, klassifizieren oder anreichern, sodass die resultierenden beschrifteten Datensätze Modelle für maschinelles Lernen trainieren oder validieren können. Der Verkauf reiner Softwareplattformen wird nur dann erfasst, wenn er mit Pro-Asset-Beschriftungsdiensten gebündelt ist; eigenständige Lizenzgebühren, Engines für synthetische Daten und Rohdatenerfassungsaktivitäten sind ausgeschlossen.
Ausschluss aus dem Umfang: Eigenständige Lizenzen für Annotationswerkzeuge, Generierung synthetischer Daten und Datenvermittlungsumsätze liegen außerhalb unserer Marktgrenzen.
Segmentierungsübersicht
- Nach Beschaffungstyp
- Intern
- Ausgelagert
- Nach Datentyp
- Text
- Bild
- Audio
- Video
- 3D-Punktwolke
- Nach Beschriftungsmethode
- Manuell
- Automatisch
- Halbüberwacht / Mensch-in-der-Schleife
- Nach Unternehmensgröße
- Kleine und mittlere Unternehmen
- Großunternehmen
- Nach Endnutzerbranche
- Automobil und Mobilität
- Gesundheitswesen und Biowissenschaften
- Einzelhandel und E-Commerce
- BFSI
- IT und Telekommunikation
- Industrie und Robotik
- Sonstige (Landwirtschaft, Medien usw.)
- Nach Geografie
- Nordamerika
- Vereinigte Staaten
- Kanada
- Mexiko
- Südamerika
- Brasilien
- Argentinien
- Übriges Südamerika
- Europa
- Vereinigtes Königreich
- Deutschland
- Frankreich
- Italien
- Spanien
- Nordische Länder
- Übriges Europa
- Naher Osten und Afrika
- GCC
- Israel
- Südafrika
- Übriger Naher Osten und Afrika
- Asiatisch-pazifischer Raum
- China
- Indien
- Japan
- Südkorea
- ASEAN
- Australien
- Neuseeland
- Übriger asiatisch-pazifischer Raum
- Nordamerika
Detaillierte Forschungsmethodik und Datenvalidierung
Primärforschung
Wir befragen Leiter der Datenwissenschaft bei Entwicklern autonomer Fahrzeuge, Chief Compliance Officers im Bereich Gesundheits-KI und Anbieter von Annotationsdiensten im asiatisch-pazifischen Raum, um Preispunkte, Asset-Level-Durchsatz und Ablehnungsraten aus der Schreibtischarbeit zu testen. Regionale Käuferbefragungen verankern zudem aufkommende Ausgabenmuster bei KMU im Vergleich zu Großunternehmen.
Schreibtischforschung
Unsere Analysten beginnen damit, Handelsstatistiken und regulatorische Einreichungen aus Quellen wie der jährlichen Erhebung des US Census Service, Eurostat-IKT-Statistiken, dem Japan Electronics and Information Technology Industries Association und Patentanalysen über Questel zu kompilieren. Ergänzende Eingaben stammen aus SEC 10-Ks, Investoren-Decks von Anbietern und Spezialportalen wie WSTS (Chip-Volumina, die die Datensatznachfrage antreiben) und Dow Jones Factiva-Nachrichtenarchiven. Diese Quellen klären Projektpipelines, Stückkosten und Auslagerungsintensität in den Endnutzersektoren. Die Liste ist indikativ; zahlreiche weitere Veröffentlichungen fließen in die Evidenzbasis ein.
Marktgrößenbestimmung und Prognose
Ein Top-down-Nachfragepoolaufbau, der globale KI-Projektzahlen, durchschnittliche beschriftete Asset-Volumina und geltende Preise pro Asset verknüpft, wird durch selektive Bottom-up-Lieferantenaufstellungen gegengeprüft. Zu den Schlüsselvariablen gehören Millionen-Bild-Äquivalente pro Modelliteration, ausgelagerter Projektanteil, Kostensteigerung durch EU-KI-Gesetz-Dokumentation, Aktualisierungshäufigkeit generativer KI-Datensätze und durchschnittlicher Annotationslohn in wichtigen Zentren. Multivariate Regression, unterstützt durch expertenvalidierte Annahmen, projiziert jeden Treiber bis 2030; die Ergebnisse werden angepasst, wenn Bottom-up-Summen über ein internes Varianzband hinaus abweichen.
Datenvalidierung und Aktualisierungszyklus
Ergebnisse durchlaufen Anomalieprüfungen, Peer-Review und Managementgenehmigung. Wir aktualisieren das Modell jährlich und geben Zwischenrevisionen heraus, wenn wesentliche Ereignisse – wie Finanzierungsspitzen, regulatorische Entscheidungen oder wichtige Vertragsabschlüsse – die Ausgangsbasis verschieben. Vor jeder Kundenlieferung erfolgt ein neuer Analysedurchgang, um die Aktualität zu gewährleisten.
Warum Mordors KI-Datenbeschriftungs-Ausgangsbasis verlässlich ist
Die in der Branche veröffentlichten Schätzungen weichen oft voneinander ab, weil Unternehmen unterschiedliche Umsatzkörbe, Preisannahmen und Aktualisierungsrhythmen wählen. Unser disziplinierter Umfang, aktualisierte Variablen und transparente Neukalibrierung machen den Unterschied.
Zu den wichtigsten Lückenursachen gehören, ob Datenerfassungsgebühren mit der Beschriftung gebündelt sind, wie synthetische Daten behandelt werden und in welchem Rhythmus durchschnittliche Verkaufspreise für Währungs- oder Lohninflation neu berechnet werden.
Benchmark-Vergleich
| Marktgröße | Anonymisierte Quelle | Primärer Lückentreiber |
|---|---|---|
| 1,89 Mrd. USD | ||
| 4,89 Mrd. USD | Globale Unternehmensberatung A | Kombiniert Erfassungs- und Beschriftungsgebühren sowie Werkzeuglizenzierung; begrenzte Aufschlüsselung nach Beschaffungstyp |
| 4,87 Mrd. USD | Fachzeitschrift B | Fügt Umsätze von Crowdsourcing-Plattformen und KI-Trainingsdatensatzverkäufe hinzu; geografischer Umfang unklar |
Diese Kontraste zeigen, dass Mordor Intelligence eine ausgewogene, klar abgegrenzte Ausgangsbasis liefert, die Entscheidungsträger auf explizite Variablen und wiederholbare Schritte zurückverfolgen können, was Kunden ein größeres situatives Vertrauen gibt.


Im Bericht beantwortete Schlüsselfragen
Wie groß ist der KI-Datenbeschriftungsmarkt derzeit?
Die Größe des KI-Datenbeschriftungsmarkts beträgt im Jahr 2026 2,32 Milliarden USD mit einer Prognose, bis 2031 6,53 Milliarden USD zu erreichen.
Welche Region führt den KI-Datenbeschriftungsmarkt an?
Nordamerika hält den größten Anteil von 34,70 % aufgrund der frühen Unternehmenseinführung, obwohl der asiatisch-pazifische Raum mit einer CAGR von 23,35 % das schnellste Wachstum verzeichnet.
Warum wächst die Videoannotation schneller als andere Datentypen?
Die Entwicklung autonomer Fahrzeuge und KI für die Überwachung erfordern hochauflösende Mehrfachrahmen-Beschriftung, was eine CAGR von 31,18 % für Videoprojekte antreibt.
Wie wirken sich verschärfte Vorschriften auf die Nachfrage nach Datenbeschriftung aus?
Regelwerke wie das EU-KI-Gesetz schreiben nachvollziehbare Herkunftsnachweise für Trainingsdaten vor und veranlassen Unternehmen, Anbieter mit zertifizierten Qualitäts- und Datenschutzkontrollen zu beauftragen.
Was ist RLHF und warum ist es für die Beschriftung wichtig?
Verstärkendes Lernen aus menschlichem Feedback richtet große Sprachmodelle an der Benutzerabsicht aus; es stützt sich auf qualifizierte Annotatoren, die Modellausgaben prüfen und bewerten, was eine Nachfrage nach Premiumdienstleistungen schafft.
Setzen KMU KI-Datenbeschriftungsdienste ein?
Ja, KMU verzeichnen eine CAGR von 26,42 %, da cloudbasierte Plattformen und vorgefertigte Vorlagen die technischen und kostenbezogenen Hürden für den Start von KI-Projekten senken.
Seite zuletzt aktualisiert am:



