合成データ市場規模とシェア
市場概要
| 調査期間 | 2020 - 2031 |
|---|---|
| 市場規模 (2026) | 0.71 十億米ドル |
| 市場規模 (2031) | 3.67 十億米ドル |
| 成長率 (2026 - 2031) | 38.96% CAGR |
| 最も急速に成長している市場 | アジア太平洋 |
| 最大市場 | 北米 |
| 市場集中度 | 中 |
主要プレーヤー *免責事項:主要選手の並び順不同 画像 © Mordor Intelligence。再利用にはCC BY 4.0の表示が必要です。 | |
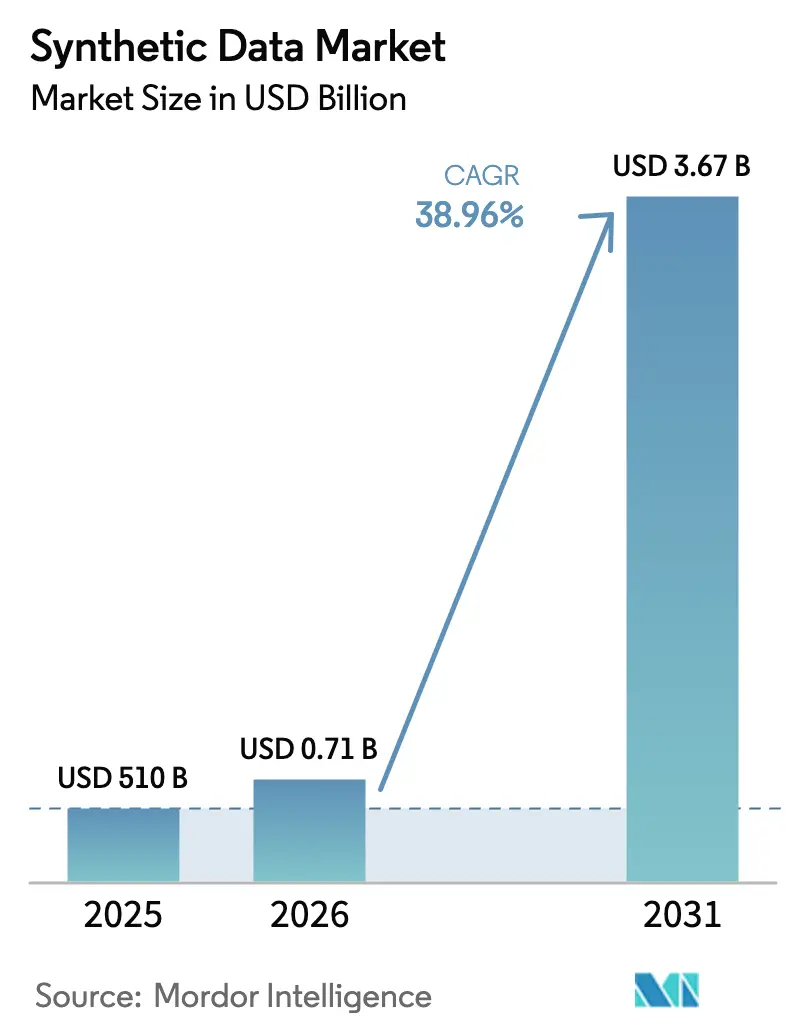
Mordor Intelligenceによる合成データ市場分析
2026年の合成データ市場規模は7億1,000万米ドルと推定され、2025年の5億1,000万米ドルから成長しており、2031年の予測は36億7,000万米ドルで、2026年〜2031年にかけて38.96%のCAGRで成長しています。この成長は、プライバシー優先の規制、生成AIワークロードの急増、および統計的に忠実なコンプライアントなデータセットに依存するデジタルトランスフォーメーションプロジェクトによってもたらされています。企業はマスキングツールから、EUのAI法および類似の規制に準拠しながら関係性を維持する高ユーティリティのレプリカへと移行しています。スケーラブルな生成エンジンと系譜追跡を組み合わせた技術サプライヤーは、ガバナンスチームが監査可能なアウトプットを求める中で予算シェアを獲得しています。同時に、製造業とモビリティにおける新たなデジタルツインの展開が合成データを活用した物理リッチなシミュレーションへの需要を深め、オープンデータ取引所の登場がソーシング上の摩擦を低減することで市場リーチを拡大しています。
主要レポートのポイント
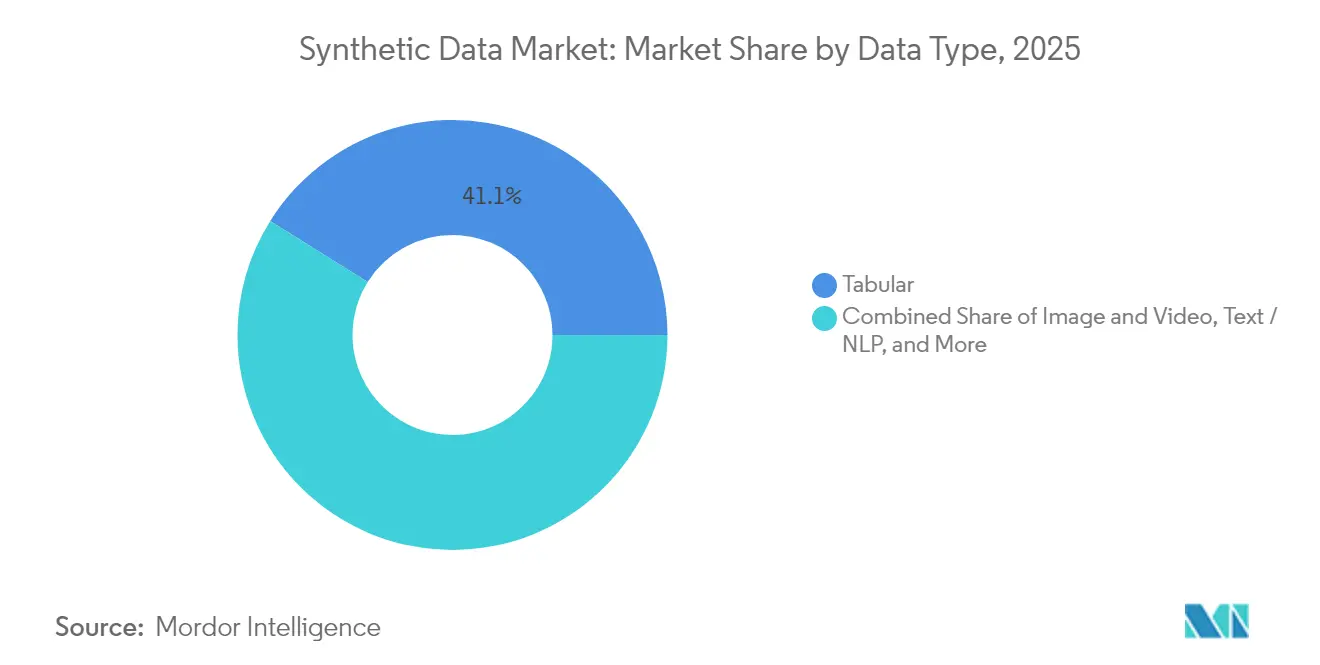
- データタイプ別では、表形式コンテンツが2025年の合成データ市場シェアの41.10%を占めました。画像・動画合成は2031年までに40.10%のCAGRで拡大する見込みです。
- 提供形態別では、完全合成ソリューションが2025年の合成データ市場規模の60.55%を占め、34.40%のCAGRで成長しています。
- 技術別では、敵対的生成ネットワーク(GAN)が2025年に37.75%の収益を獲得し、拡散モデルは2031年までに46.30%のCAGRで成長する見込みです。
- 展開モード別では、クラウド展開が2025年に66.80%の収益を占め、2031年までに28.60%のCAGRで上昇する見込みです。
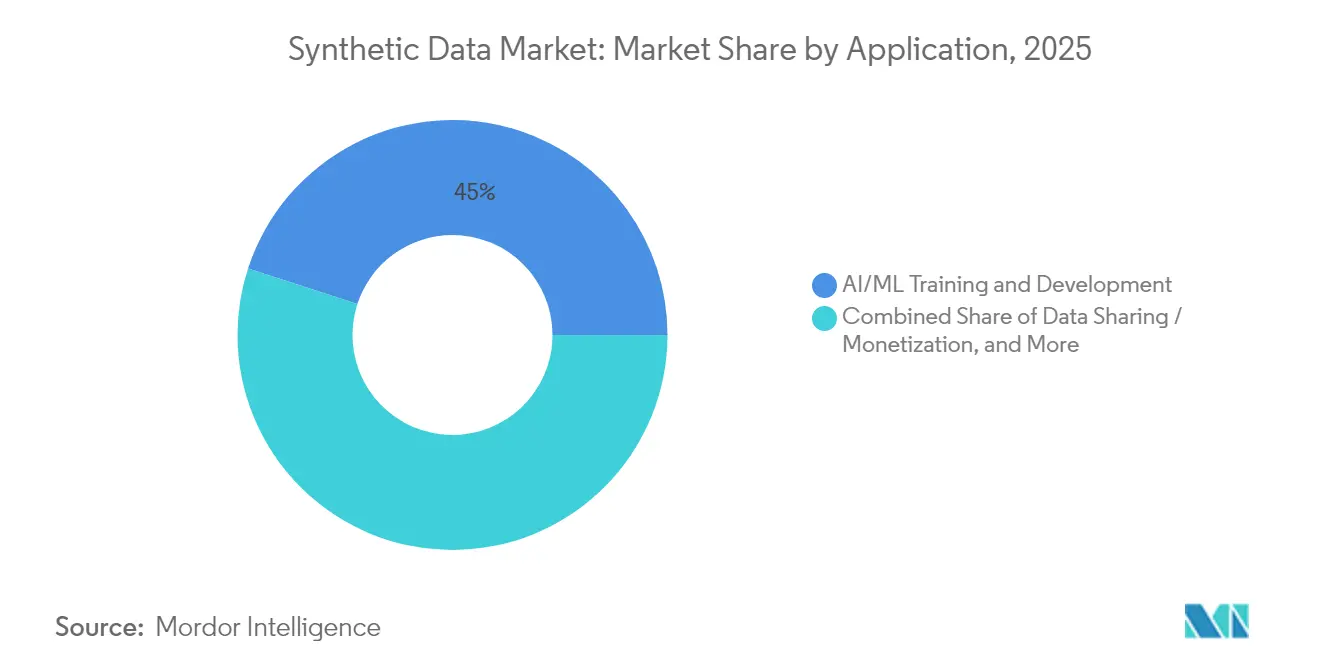
- アプリケーション別では、AI/MLトレーニングおよび開発が2025年収益の45.00%を占め、自律システムシミュレーションは2031年までに最速の44.95%のCAGRが見込まれています。
- エンドユーザー産業別では、BFSIが2025年収益の23.25%でトップとなり、自動車・輸送は2031年までに37.10%のCAGRで急増する見込みです。
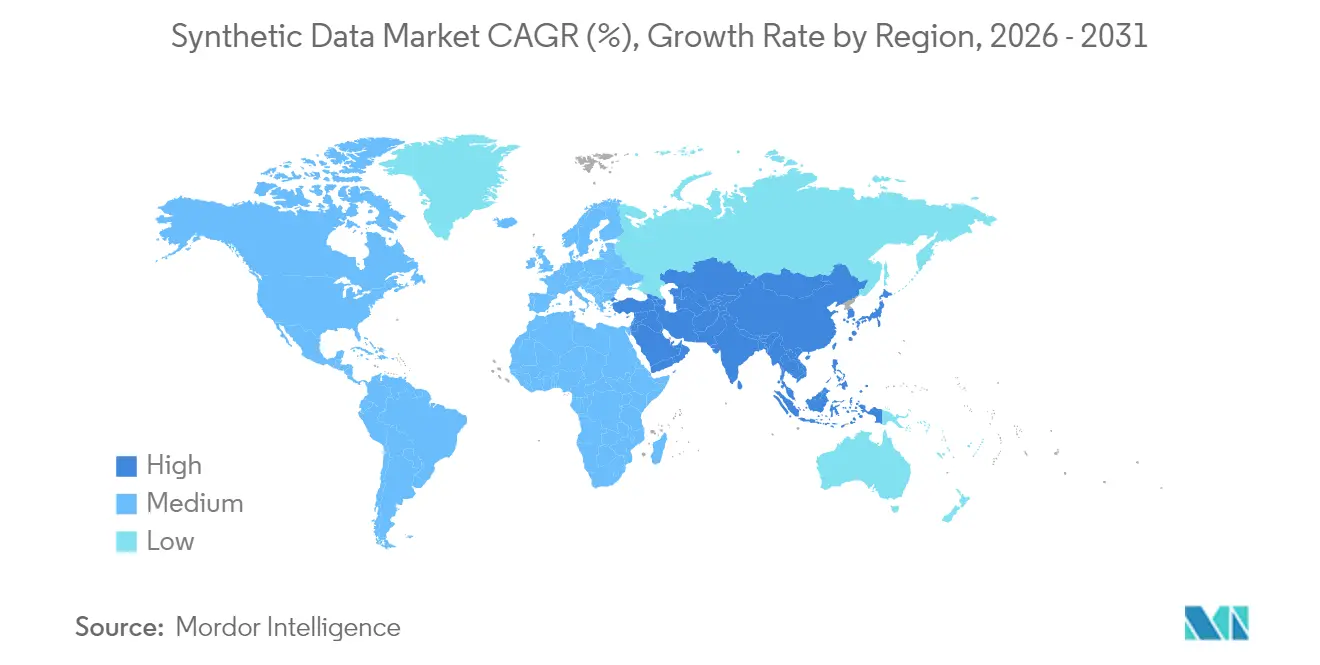
- 地域別では、北米が2025年に38.10%の収益を確保し、アジア太平洋地域が予測期間中に最高の31.10%のCAGRを記録する見込みです。
注記:本レポートの市場規模および予測値は、Mordor Intelligence の独自推定フレームワークを使用して算出され、2026年時点で入手可能な最新のデータと洞察に基づいて更新されています。
世界の合成データ市場のトレンドと洞察
ドライバーの影響分析*
| ドライバー | CAGRへの影響(〜%) | 地理的関連性 | 影響のタイムライン |
|---|---|---|---|
| プライバシー保護AIおよびデータ共有に向けた規制の推進 | +8.5% | EUおよび北米での早期採用を伴うグローバル | 中期(2〜4年) |
| スケーラブルな低バイアスデータセットを求める生成AIブーム | +12.2% | 北米およびアジア太平洋地域に集中するグローバル | 短期(2年以内) |
| データマスキングから高ユーティリティ合成レプリカへのシフト | +6.8% | 北米およびEU、アジア太平洋地域へ拡大 | 中期(2〜4年) |
| 差分プライバシーおよび準同型暗号化の統合 | +4.3% | 米国および中国の技術ハブが主導するグローバル | 長期(4年以上) |
| オープン合成データ取引所の台頭 | +3.7% | 北米およびEU、アジア太平洋地域でのパイロットプログラム | 長期(4年以上) |
| インダストリー4.0シミュレーションにおけるデジタルツインの収束 | +4.5% | ドイツおよび日本で強い世界の産業地域 | 中期(2〜4年) |
| 情報源: Mordor Intelligence | |||
スケーラブルな低バイアスデータセットを求める生成AIブーム
大規模な言語・ビジョンモデルには、膨大で多様なコーパスが必要です。アナリストは、2024年までに合成コンテンツがAIトレーニングデータの60%を供給すると推定しています。ハイパースケーラーはこれに対応しています。NVIDIA Corporationはダウンストリームパイプラインに供給するためにNemotron-4 340Bジェネレーターを設計し、データ取得コストとバイアスリスクを低減しました[1]NVIDIA Corporation、「Nemotron-4 340B:合成データ生成のための基盤モデル」、developer.nvidia.com。このブームはあらゆる業種に影響を与えていますが、実世界からのソーシングがコスト高になるか、プライバシー法によって禁止されているコンピュータビジョンおよび多言語NLPにおいて最も顕著です。合成拡張はシナリオカバレッジを拡大し、アノテーション予算を削減し、より迅速な実験を可能にします。
プライバシー保護AIおよびデータ共有に向けた規制の推進
EUのAI法は、個人データを処理する前に合成代替手段を検討することを組織に義務付けています。米国では、国土安全保障省が合成ジェネレーターのパイロットに170万米ドルを充当し、コンプライアントなデータ交換に対する連邦政府の関心を確認しました[2]米国国土安全保障省、「公募23-DN-004 合成データソリューション」、dhs.gov。中国の新しいラベリング規則も同様の意図を反映しています。合成データを早期に運用化した企業は罰金を回避し、国境を越えたコラボレーションを解放します。したがって、コンプライアンスは合成データをあれば便利なものから取締役会レベルの義務へと転換させます。
データマスキングから高ユーティリティ合成レプリカへのシフト
従来の匿名化は参照整合性を損なうことが多く、分析上の有用性を制限していました。新しいプラットフォームは統計的に忠実なレプリカを生成し、テスターが露出リスクなしにリアルなワークロードを実行できるようにします。SynthesizedのGoogle BigQueryへの組み込みは、生成がメインストリームのデータウェアハウス内に存在できることを示しています。ドイツの銀行は、テーブル間の関係を維持する合成スナップショットを採用した後、信用リスク分析が迅速化したと報告しています。このシフトは、コストのかかるアクセス制御からセルフサービスのデータ民主化へと予算を振り向けます。
インダストリー4.0シミュレーションにおけるデジタルツインの収束
産業企業はデジタルツインエンジンと合成センサーストリームを組み合わせて、予知保全のアルゴリズムをストレステストしています。Springerの研究では、合成テレメトリがデータギャップを埋めることで製品開発サイクルが10倍加速することが示されています[3]Springer、「デジタルツインと合成センサーストリーム」、link.springer.com。NVIDIA CorporationのOmniverseは物理リッチなシナリオを生成し、自動車サプライヤーやロボティクス企業が現実世界では危険または不可能なエッジケースを検証できるようにします。この組み合わせは安全性とコスト削減の両方をもたらします。
制約の影響分析*
| 制約 | CAGRへの影響(〜%) | 地理的関連性 | 影響のタイムライン |
|---|---|---|---|
| 再帰的に学習されたデータによるモデル崩壊リスク | -4.8% | 大規模言語モデル開発に特に影響するグローバル | 短期(2年以内) |
| ベンダー間での標準品質指標の欠如 | -3.2% | 米国およびEUでの標準化努力を伴うグローバル | 中期(2〜4年) |
| マルチモーダル基盤モデルの高い計算コスト | -5.1% | リソースが制約された市場で最も深刻なグローバル | 短期(2年以内) |
| 「非個人」合成データの未成熟な法的地位 | -2.9% | 新興市場での規制上の不確実性を伴うグローバル | 長期(4年以上) |
| 情報源: Mordor Intelligence | |||
再帰的に学習されたデータによるモデル崩壊リスク
研究では、自己生成コンテンツを繰り返し学習させるとデータの多様性が狭まり、バイアスが増幅されると警告しています。ベンダーは現在、有機的なフィードを混合し、フィードバックループを制限するためにジェネレーターの重みを固定しています。品質監査とアクティブラーニングパイプラインが新たなセーフガードとして台頭していますが、この問題は完全合成ワークフローに対する近期的なブレーキとして残っています。
マルチモーダル基盤モデルの高い計算コスト
最高水準の拡散エンジンは数千のGPUと数週間の実行時間を必要とします。月額費用は中小企業にとって6桁に達することがあり、実験の妨げとなっています。クラウドの従量課金サービスは参入を容易にしますが、スループットコストを解消するわけではありません。価格圧力はハードウェアの専門化とクライアント側チップへのフェデレーテッドオフロードを促進する可能性があります。
*当社の予測では、推進要因および抑制要因の影響を加算的ではなく方向性のあるものとして扱います。影響予測は、ベースライン成長、構成効果、および変数間の相互作用を反映しています。
セグメント分析
データタイプ別:ビジュアルコンテンツがイノベーションを牽引
画像・動画合成は2031年までに40.10%のCAGRで最速の成長を誇り、フォトリアリスティックなトレーニングデータセットを求める自律走行車開発とコンピュータビジョンアプリケーションを反映しています。表形式データは2025年に41.10%のシェアで市場リーダーシップを維持しており、構造化データのプライバシーソリューションを必要とする金融サービスおよびヘルスケアアプリケーションによって牽引されています。テキストおよびNLPアプリケーションは大規模言語モデルの進歩から恩恵を受け、音声合成はRightsifyのGramosynth等のプラットフォームを通じて著作権フリーの音楽生成で勢いを増しています。センサーおよび時系列データ合成はIoTおよび産業モニタリングの要件に対応しており、実世界のデータセットでは故障シナリオが稀な予知保全アプリケーションに特に価値があります。
マルチモーダル基盤モデルの台頭により、従来のデータタイプの境界が曖昧になっています。NVIDIA CorporationのCosmosのようなプラットフォームは、視覚、センサー、時間的モダリティにわたって物理ベースの合成データを同時に生成します。Applied Intuitionの150億米ドルの評価額は、自律システム向けビジュアル合成データアプリケーションへの投資家の信頼を反映しています。この収束により、複数のセンサーモダリティを同期させる必要があるロボティクスおよび自律走行車開発に特に価値のある、複雑な実世界のインタラクションを捉えるより高度なシミュレーション環境が実現します。
注記: 全個別セグメントのセグメントシェアはレポート購入時に入手可能


提供形態別:完全置換が優先される
完全合成パッケージが2025年収益の60.55%を占め、34.40%のCAGRで成長しています。企業は残留プライバシーリスクを排除し、ガバナンス構造を簡素化するために完全置換を選択します。ハイブリッドの代替手段は、わずかな実世界のアンカーがモデル精度を向上させる高忠実度の臨床または工学ワークフローに残っています。Tonic.ai Inc.のセキュアなレイクハウスは、非構造化フォーマット全体にわたる単一ペインの制御への需要を例示しており、統合されたツールチェーンへの市場移行を強調しています。
規制当局が生データ検査よりも統計的等価性テストを受け入れるにつれて、合成データ市場は承認タイムラインの短縮から恩恵を受けます。銀行および保険グループは、採用後のコンプライアンスレビュー時間の2桁削減を挙げています。系譜、バージョン管理、差分プライバシーチェックを自動化するベンダーは付加価値サービスをバンドルし、スイッチングコストを引き上げ、業界をプラットフォーム統合へと誘導しています。
技術別:拡散モデルが急増
GANは依然として2025年収益の37.75%を占めていますが、拡散エンジンは最速の46.30%のCAGRを記録しています。よりクリーンで多様なフレームを生成する能力により、エンターテインメントおよび先進製造における高解像度ビデオタスクに適しています。LLMベースのジェネレーターは表形式およびテキスト合成において強みを発揮し、列の相関関係を維持してダウンストリームモデルのF1スコアを向上させます。ルールベースのシミュレーターは、物理方程式がデータ駆動型のランダム性を凌駕する決定論的な産業制御において存続しています。
SiloFuseのような学術プロジェクトは、フェデレーテッド環境における拡散の適合性を実証しており、国境を越えた金融およびヘルスケアにおける重要なセールスポイントとなっています。ベンチマークでは、レガシーパイプラインと比較して欠陥率が30%低減することが明らかになっており、より高い計算費用にもかかわらずOEMがアップグレードする理由を説明しています。合成データ市場は、オーケストレーションロジックをジェネレーターアーキテクチャから切り離すベンダーに報いる明確な技術更新サイクルを示しています。
展開モード別:クラウドの優位性が継続
クラウド展開が2025年収益の66.80%を占め、2031年までに28.60%のCAGRで上昇する見込みです。企業は弾力的なGPUプールと管理されたコンプライアンスツールを好みます。AWS Bedrock、SynthesizedとのGoogle BigQuery、NVIDIA CorporationのDGX Cloudは、プロジェクトの立ち上げ時間を短縮するネイティブ生成APIをホストしています。オンプレミスのインストールは、厳格な主権義務に支配される防衛、中央銀行、公益事業にとって引き続き重要です。
レイテンシーに敏感なトレーディングデスクは、2ミリ秒未満で合成市場データを更新するエッジベースのマイクロジェネレーターを実験しています。一方、機密計算エンクレーブとリージョンピニングオプションは、パブリッククラウドにおける主権上の懸念を和らげています。コストが低下しセキュリティ機能が向上するにつれて、合成データ市場はクラウドファーストの展開にさらに傾いていますが、帯域幅またはポリシーの制約が続く場合はハイブリッドフットプリントが存続します。
アプリケーション別:自律システムが加速
AI/MLトレーニングが2025年支出の45.00%を占め、合成拡張がメインストリームの開発インプットとなったことを確認しています。自律システムシミュレーションは、規制当局が商業展開前に徹底的なシナリオテストを要求する中、最高の44.95%のCAGRを記録する見込みです。ソフトウェアテストチームは合成エッジケースを活用してバグを早期に発見し、不正分析部門は顧客記録を露出させることなく稀な攻撃パターンを複製します。
データ共有および収益化プラットフォームが新たな収益源として台頭しています。企業は匿名化されながらも有用なデータセットをパートナーに販売し、以前はサイロ化されていた資産から価値を引き出しています。ロボティクスでは、NVIDIA CorporationのIsaacパイプラインが数時間で数十万の動作軌跡を生成し、モデルの収束を加速させています。これらのダイナミクスは、合成データ市場を研究開発を超えて本番運用および商業データ製品へと拡大させています。
注記: 全個別セグメントのセグメントシェアはレポート購入時に入手可能
エンドユーザー産業別:自動車の変革
BFSIは合成データ市場規模において2025年収益の23.25%を占め、リスクモデリングおよび不正防止分析にレプリカを活用しています。自動車・輸送は、検証に数十億マイルの安全走行が必要なレベル4自律走行への競争に牽引され、37.10%のCAGRで成長すると予測されています。ヘルスケアは合成患者コホートを試験的に導入し、臨床試験の登録を合理化してプライバシーを保護しています。 小売業者はパーソナライゼーションエンジン向けに顧客ジャーニーを生成し、通信企業はネットワーク障害イベントをシミュレートして信頼性を強化しています。政府機関は機密特性を除去しながら戦略的有用性を維持するミッションプランニングデータセットを作成しています。合成データ市場は、実世界のデータが希少、機密性が高い、または収集コストが高いあらゆるセクターに浸透しています。
地域分析
北米は2025年収益の38.10%を獲得しました。Microsoft CorporationやMeta Platforms Inc.などのテック大手は、合成パイプラインに依存するAIインフラに数百億ドルを投資しており、連邦プログラムは国土安全保障のユースケースにおけるアプローチを検証しています。カリフォルニア州、テキサス州、オンタリオ州のクラスターはベンチャーキャピタルを引き付け、金融、ヘルスケア、防衛全体のイノベーションを促進する専門家の密なエコシステムを提供しています。
アジア太平洋地域は最速の31.10%のCAGRを示しています。中国のAI生成コンテンツラベリング法は、企業が実際のユーザーログの代わりに合成代替手段を生成することを奨励しており、日本のロボティクスリーダーは合成知覚データと工場自動化を組み合わせています。インドはデータローカライゼーション規則の中でテレヘルスプラットフォームを強化するために合成患者記録を活用し、韓国の半導体能力は地域内のモデルトレーニングをサポートしています。東南アジアは、金融包摂を拡大するためにプライバシーセーフな信用データを共有するフィンテック新興企業から恩恵を受けています。
欧州は規制上のリーダーシップと商業的モメンタムを融合させています。EUのAI法は合成ファーストの姿勢を正式化し、欧州委員会はデジタル金融のための方法を検証しました。ドイツのインダストリー4.0プロジェクトはデジタルツインと合成テレメトリを組み合わせてエネルギー使用を最適化しています。英国は規制上の独立性を活かして合理化された承認経路のパイロットを実施しています。北欧諸国は、持続可能性目標とAI成長を一致させながら、カーボンニュートラルな生成クラスターをホストするグリーンデータセンターに投資しています。その他の地域では、中東のスマートシティプログラムがモビリティとセキュリティのために合成データセットを統合し、アフリカのスタートアップは進化するプライバシー法をナビゲートしながらデータ不足を補うためにクラウドAPIを活用しています。

競争環境
合成データ市場は適度に集中しているものの、非常にダイナミックです。NVIDIA Corporationによる3億2,000万米ドルのGretel Labs Inc.買収は、ハードウェア、モデルオーケストレーション、プライバシーツールをエンドツーエンドのスタックに統合しました。SAS Instituteは銀行や保険会社が使用する分析スイートに生成機能を組み込むためにHazy Ltd.を買収しました。Applied Intuitionは自律走行向けのドメイン固有シミュレーションを提供するために150億米ドルの評価額で資本を調達し、垂直的な深さへのプレミアムを強調しています。
3つの競争アーキタイプが台頭しています。インフラリーダーはスケールで計算を収益化し、合成エンジンをバンドルします。垂直スペシャリストはドメインオントロジーと検証指標を調整します。プラットフォームインテグレーターは、異種ジェネレーターをエンタープライズデータファブリックに接続するガバナンスレイヤーに注力します。
IEEEワーキンググループは、基本生成機能を商品化し、競争をコンプライアンス自動化とリアルタイムオブザーバビリティへとシフトさせる可能性のある品質標準を起草しています。予測期間中、大企業が能力の幅を求めるにつれて買収が増加する可能性がありますが、オープンソースの拡散により新規参入者の障壁が低下し、合成データ市場の競争可能性が維持されます。
合成データ産業リーダー
MOSTLY AI Solutions MP GmbH
NVIDIA Corporation
Meta Platforms, Inc.
Amazon.com, Inc.
Microsoft Corporation
- *免責事項:主要選手の並び順不同

最近の産業動向
- 2025年4月:Tonic.ai Inc.がFabricateを買収し、非技術系スタッフが迅速にコンプライアントなデータセットを作成できる自然言語インターフェースを提供。
- 2025年3月:NVIDIA Corporationが3億2,000万米ドルでGretel Labs Inc.を買収し、プライバシー保護生成をクラウドAIサービスに統合。
- 2025年1月:NVIDIA CorporationがCosmos World Foundation Modelをリリースし、自律走行車とロボット向けのフォトリアリスティックな合成シーンを実現。Uberが最初のユーザーの一つ。
- 2025年1月:NVIDIA CorporationがOmniverseを生成物理AIで拡張し、Accenture、Microsoft Corporation、Siemensを早期採用者として追加。


研究方法のフレームワークとレポートの範囲
市場定義と主要カバレッジ
本調査では、合成データ市場を、AI/MLトレーニング、テストデータ管理、プライバシー保護、およびシミュレーションのために実際の情報を複製する統計的パターンを持つ人工データセットをアルゴリズム的に作成するソフトウェアプラットフォーム、クラウドサービス、およびAPIによって生成されるすべての商業収益として定義しています。
明確にするために、新しい統計的に代表的なデータを生成するのではなく、既存のレコードを単に匿名化するだけのレガシーデータマスキングユーティリティは除外しています。
セグメンテーション概要
- データタイプ別
- 表形式
- テキスト / NLP
- 画像・動画
- 音声
- センサー / 時系列
- 提供形態別
- 完全合成
- 部分合成 / ハイブリッド
- 技術別
- GAN
- 拡散モデル
- LLMベースのジェネレーター
- ルールベース / エージェントベースのシミュレーション
- 展開モード別
- クラウド
- オンプレミス
- アプリケーション別
- AI/MLトレーニングおよび開発
- データ共有 / 収益化
- ソフトウェアテストおよびDevOps
- 自律システムシミュレーション
- サイバーセキュリティおよび不正テスト
- エンドユーザー産業別
- BFSI
- ヘルスケアおよびライフサイエンス
- 小売・電子商取引
- 自動車・輸送
- 政府・防衛
- ITおよびITeS
- 産業・ロボティクス
- 地域別
- 北米
- 米国
- カナダ
- メキシコ
- 南米
- ブラジル
- アルゼンチン
- その他の南米
- 欧州
- ドイツ
- 英国
- フランス
- イタリア
- スペイン
- ロシア
- その他の欧州
- アジア太平洋
- 中国
- 日本
- インド
- 韓国
- オーストラリアおよびニュージーランド
- その他のアジア太平洋
- 中東・アフリカ
- 中東
- サウジアラビア
- アラブ首長国連邦
- トルコ
- その他の中東
- アフリカ
- 南アフリカ
- ナイジェリア
- エジプト
- その他のアフリカ
- 中東
- 北米
詳細な調査方法論とデータ検証
一次調査
Mordor Intelligenceのアナリストは、クラウドAIアーキテクト、BFSIおよびヘルスケアのチーフプライバシーオフィサー、北米、欧州、アジア太平洋の調達リーダーにインタビューを実施しました。
ライセンス価格帯、使用率、規制上のボトルネックに関する彼らの洞察により、二次データだけでは解決できなかった前提を精緻化することができました。
デスクリサーチ
OECDのAI政策オブザーバトリー、EUのGDPR執行トラッカー、米国経済分析局のソフトウェア支出表、IEEEエクスプロアにインデックスされた査読済みジャーナルなどのオープンソースを通じて潜在的な需要を規模化することから始めました。
D&Bフーバーズとダウジョーンズファクティバは指標的なベンダー収益を提供し、ITI評議会のホワイトペーパーは採用シグナルの検証に役立ちました。
異なるデータポイントを比較可能な指標に変換するために、値を2025年の定数ドルに正規化し、IMF平均を使用して通貨変動を調整し、すべての参照を内部リポジトリにアーカイブしました。
上記のリストは例示的なものであり、他の多くの二次インプットがデータ収集、検証、および明確化に役立てられました。
市場規模の算定と予測
トップダウンとボトムアップのブレンドを適用しました。エンタープライズAIソフトウェア支出が需要プールを形成し、セクター別の普及率がそれを合成データ収益に変換し、結果はサンプリングされたベンダーのロールアップと平均販売価格×数量テストと相互確認されました。
主要変数には、GPU時間コスト曲線、地域別コンプライアンス支出、アクティブなAIプロジェクト数、自律走行車1マイルあたりの合成画像量が含まれます。
多変量回帰がこれらのドライバーを2030年まで予測します。欠落しているマイクロデータは隣接する指標から補間され、レビュー中に調整されました。
データ検証と更新サイクル
承認前に異常スイープ、多段階ピアレビュー、独立したベンチマークとの分散チェックを実施しています。
モデルは毎年更新され、新しいプライバシー法などのイベントが需要を大幅に変化させる場合は中間更新が行われます。
Mordorの合成データベースラインが信頼性を持つ理由
企業が異なるスコープ、前提、更新頻度を採用するため、公表された推定値がしばしば乖離することを認識しています。
生成プラットフォーム収益に厳密に焦点を当て、モデルを毎年再調整することで、Mordor Intelligenceは過大評価と過小評価の両方を最小化しています。
ベンチマーク比較
| 市場規模 | 匿名化されたソース | 主要なギャップドライバー |
|---|---|---|
| 5億1,000万米ドル(2025年) | ||
| 3億米ドル(2023年) | グローバルコンサルタンシーA | 匿名化ソフトウェアと概念実証支出を含む |
| 2億9,000万米ドル(2024年) | 産業ジャーナルB | 地域較正なしに均一なCAGRを適用 |
これらの対比は、Mordor Intelligenceの厳格なスコープ選択、変数駆動型モデル、およびタイムリーな更新が、意思決定者が信頼できるバランスのとれた透明なベースラインを提供することを示しています。


レポートで回答される主要な質問
合成データ市場の2031年までの予測成長率は?
合成データ市場は2026年の7億1,000万米ドルから2031年までに36億7,000万米ドルに上昇すると予測されており、38.96%のCAGRを反映しています。
拡散モデルがGANよりもシェアを獲得しているのはなぜですか?
拡散エンジンはより高品質で安定した画像を生成し、GANベースのアプローチの成長を上回る46.30%のCAGRを牽引しています。
どの展開モードが支出を支配していますか?
クラウド展開は2025年収益の66.80%を占め、弾力的なGPUプールと統合されたコンプライアンスツールのおかげで28.60%のCAGRで拡大しています。
新しい規制は採用にどのような影響を与えますか?
EUのAI法などの規制は、個人データを処理する前に合成代替手段をテストすることを企業に要求しており、生成プラットフォームをコンプライアンスの必需品にしています。
どの産業業種が最速の成長を見込んでいますか?
自動車・輸送は、自律走行プログラムが安全性検証のために広範な合成シナリオカバレッジを必要とするため、37.10%のCAGRで成長する見込みです。
中小企業にとっての主な障壁は何ですか?
マルチモーダル基盤モデルの高い計算コストが最大の障壁であり、GPUを多用するワークロードにより月額クラウド費用が6桁に達しています。
最終更新日:




