データラベリング市場規模とシェア
市場概要
| 調査期間 | 2020 - 2031 |
|---|---|
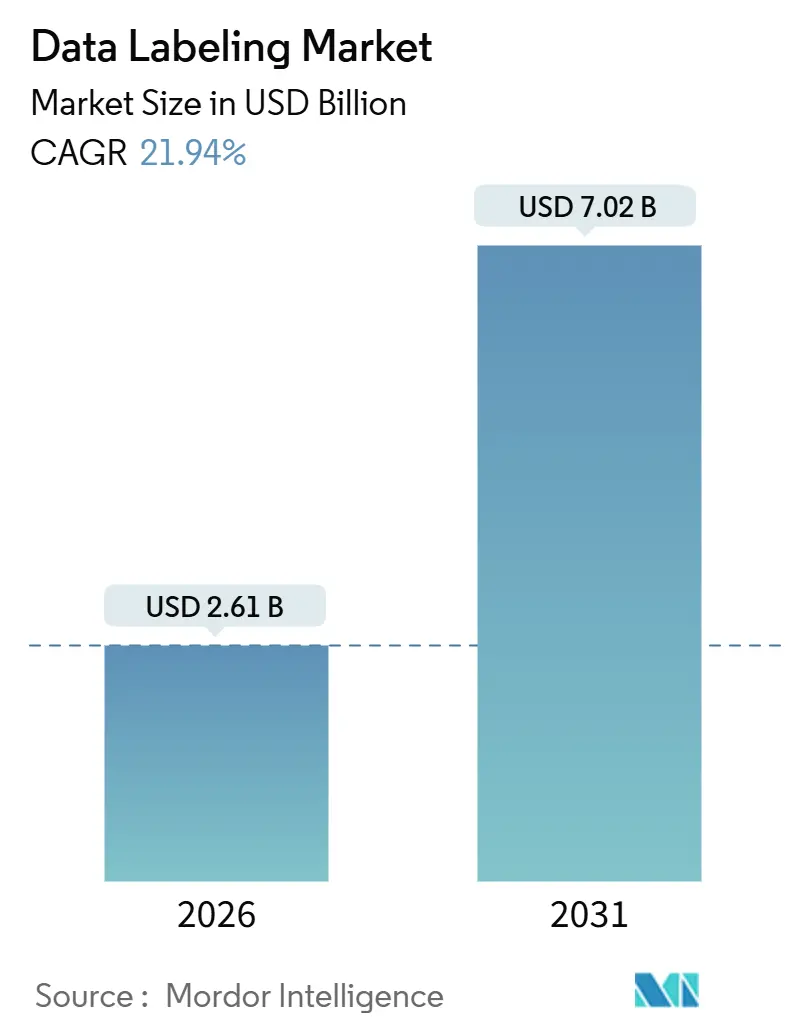
| 市場規模 (2026) | 2.61 十億米ドル |
| 市場規模 (2031) | 7.02 十億米ドル |
| 成長率 (2026 - 2031) | 21.94% CAGR |
| 最も急速に成長している市場 | アジア太平洋 |
| 最大市場 | 北米 |
| 市場集中度 | 中 |
主要プレーヤー *免責事項:主要選手の並び順不同 画像 © Mordor Intelligence。再利用にはCC BY 4.0の表示が必要です。 | |
Mordor Intelligenceによるデータラベリング市場分析
データラベリング市場規模は2026年に26億1,000万米ドルに達しており、2031年までに70億2,000万米ドルに拡大する見込みで、堅調な21.94%のCAGRを反映しています。この成長は、相互に絡み合う3つの触媒によって促進されています。幻覚を抑制する専門家監修コーパスを求めるファウンデーションモデル開発者、フレームレベルの3Dタグを必要とするセンサーフュージョンスタックを検証する自動車メーカー、そしてラベル付きの時系列障害データに依存する予知保全AIを拡張する産業企業です。2025年6月にMetaがScale AIに対して行った150億米ドルの出資は、ラベリングインフラを商品化されたサービスではなく戦略的な競争優位の源泉として位置づけることを明確にし、OpenAIとGoogleがアノテーションベンダーの多様化を進めるきっかけとなりました。自律システム向けの動画アノテーション、社内専門知識とアウトソーシング労働を融合したハイブリッド調達モデル、そしてラベル単価を引き下げる自己教師あり学習ラベリングパイプラインは、いずれもデータラベリング市場全体よりも速いペースで拡大しており、人間の専門家とモデル支援タグ付けを同期させるプラットフォームに成長の余地をもたらしています。北米は引き続き収益の中核を担っていますが、アジア太平洋地域の政策主導による産業AIへの取り組みが地域のダイナミクスを再形成しています。
主要レポートのポイント
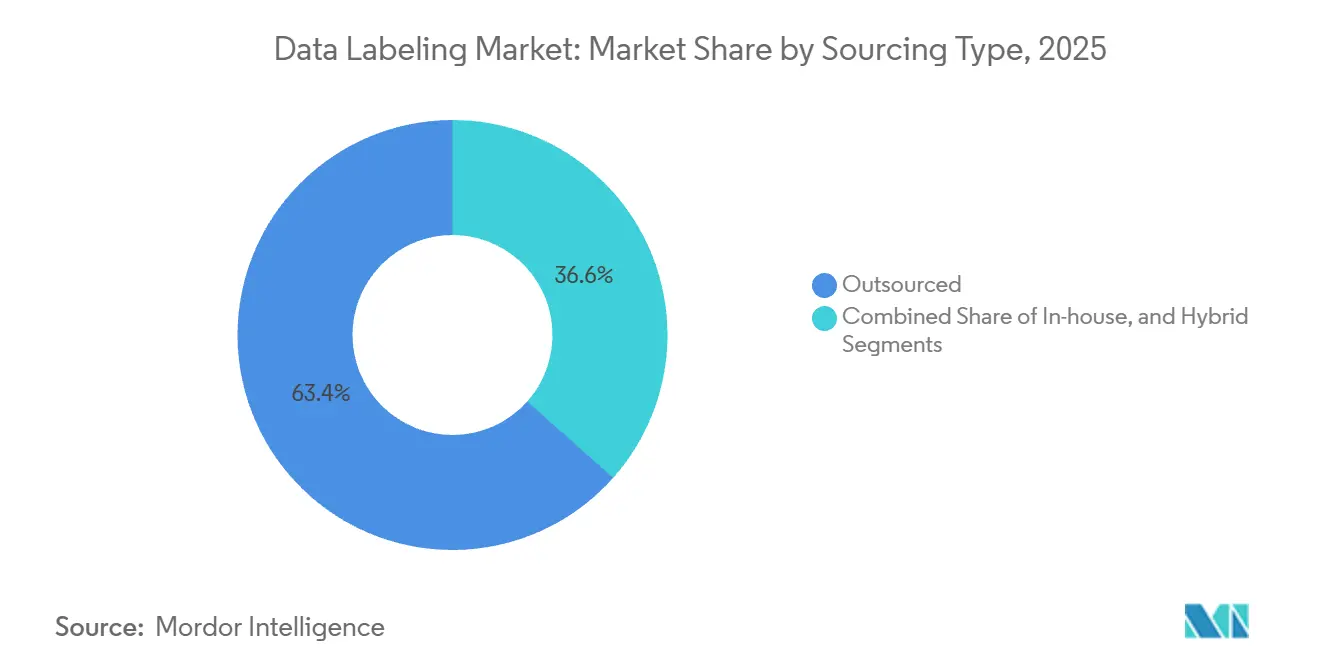
- 調達タイプ別では、アウトソーシングラベリングが2025年のデータラベリング市場シェアの63.43%をリードし、ハイブリッド調達は2031年にかけて22.48%のCAGRで拡大しています。
- データタイプ別では、画像データセットが2025年に36.26%のシェアを獲得し、動画アノテーションは2031年に向けて23.17%のCAGRで推移する見込みです。
- ラベリングアプローチ別では、手動ラベリングが2025年のデータラベリング市場規模の42.31%を占めていますが、自己教師あり学習およびプログラマティック手法は22.16%のCAGRで成長しています。
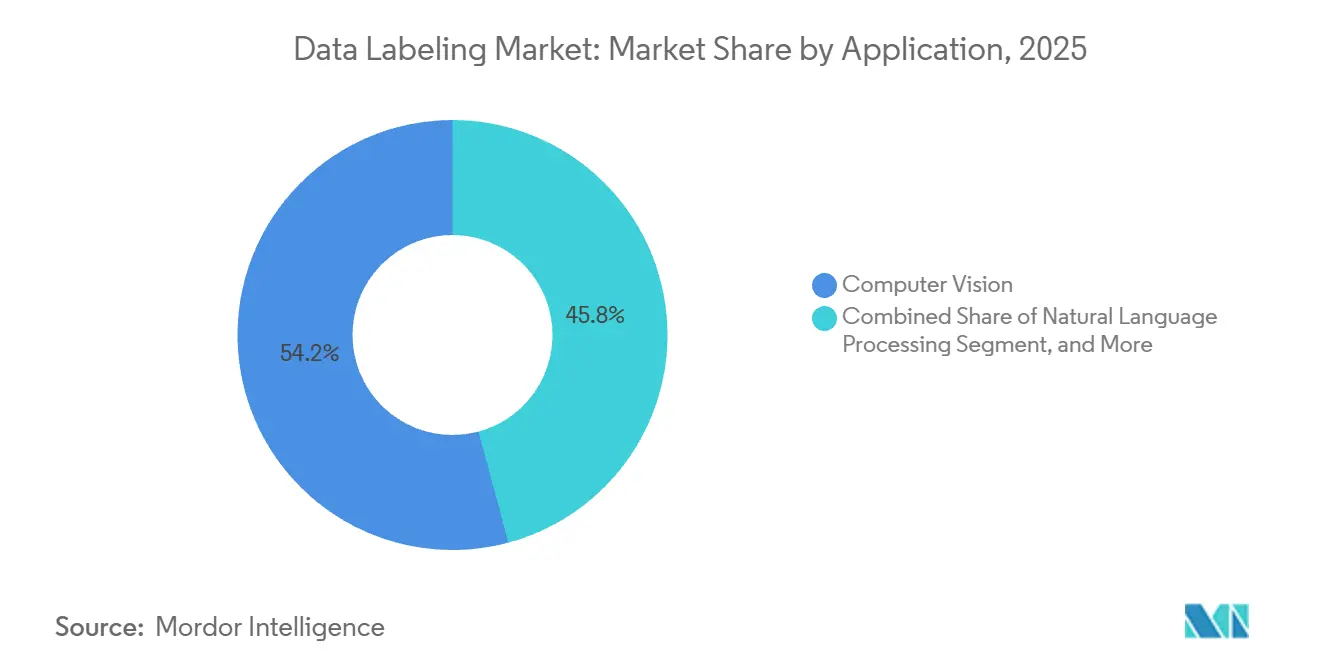
- アプリケーション別では、コンピュータビジョンアプリケーションが2025年に54.19%のシェアを占め、予知保全と品質保証は2031年にかけて最速の22.61%のCAGRを示しています。
- エンドユーザー産業別では、自動車・輸送が2025年に28.26%のシェアを保持し、産業・製造が22.84%のCAGRで最も速く成長しています。
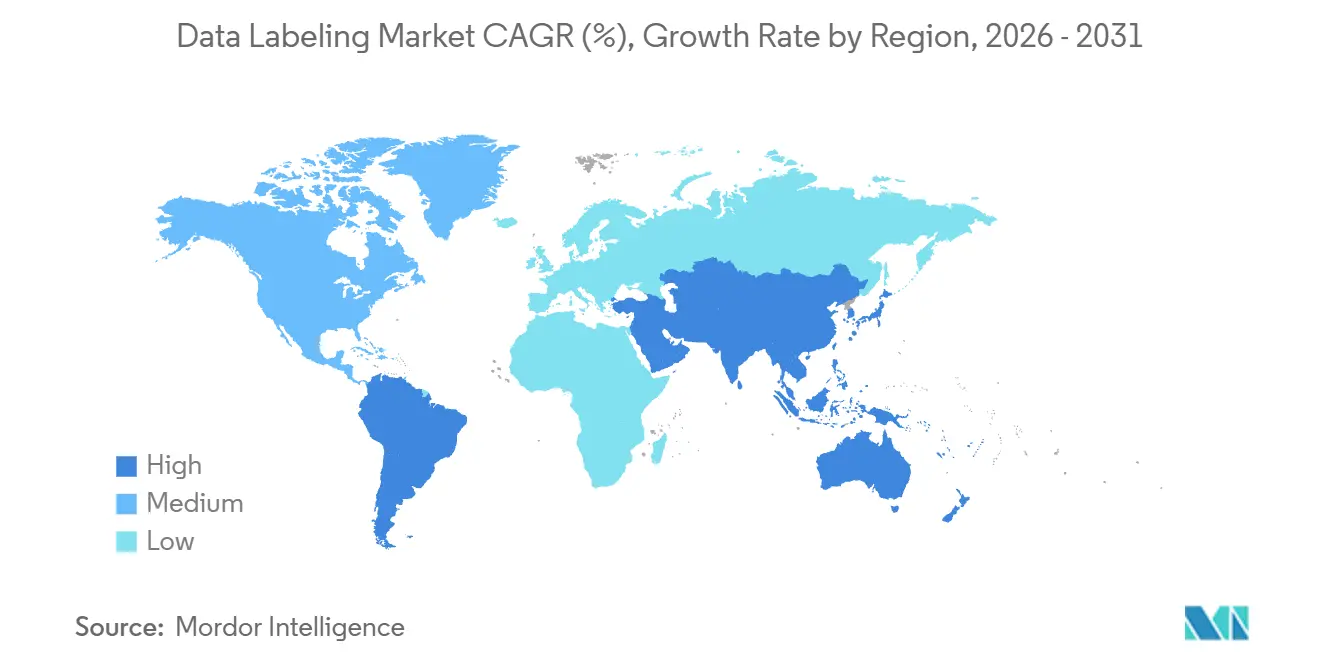
- 地域別では、北米が2025年の収益の31.13%を占めていますが、アジア太平洋地域が21.16%のCAGRで最も速く成長している地域です。
注:本レポートの市場規模および予測数値は、Mordor Intelligence 独自の推定フレームワークを使用して作成されており、2026年1月時点の最新の利用可能なデータとインサイトで更新されています。
グローバルデータラベリング市場のトレンドとインサイト
促進要因の影響分析*
| 促進要因 | CAGR予測への影響(概算%) | 地理的関連性 | 影響の時間軸 |
|---|---|---|---|
| ADASおよび自動運転ビジョンデータの急速な普及 | +5.2% | 北米、欧州、中国に集中したグローバル | 中期(2〜4年) |
| 生成AIブームによるマルチモーダルデータセット需要の拡大 | +6.8% | 北米とアジア太平洋地域が主導するグローバル | 短期(2年以内) |
| ビッグデータ機械学習パイプラインの進歩 | +3.1% | グローバル | 中期(2〜4年) |
| 医療画像AIの普及 | +2.9% | 北米、欧州、アジア太平洋 | 中期(2〜4年) |
| 合成データ検証のためのエッジマイクロラベリング | +1.7% | 北米と欧州で早期普及が進むグローバル | 長期(4年以上) |
| 規制主導の説明可能なAI出所メタデータ | +2.3% | 欧州、北米、中国 | 中期(2〜4年) |
| 情報源: Mordor Intelligence | |||
ADASおよび自動運転ビジョンデータの急速な普及
自動車センタースイートは現在、毎日テラバイト規模のマルチモーダルデータをストリーミングしており、データラベリング市場はレベル3およびレベル4の自律走行を実現するために精密なタグに依存しています。Waymoの公開データによると、車両の平均精度はトレーニングデータの10%使用時の29.7%から、全データ使用時の49.4%に向上しており、ラベルのスケールと地理的多様性が知覚精度に直接影響することが証明されています。日本のRoAD to L4イニシアチブと電気自動車充電インフラの整備は、地域固有のタグを必要とする新たなセンサーログを生み出すことになります。自動車メーカーは生データの量から1フレームあたりの品質へとシフトしており、同期されたLiDARカメララベリングツールと自動車グレードの検証ワークフローへの需要が高まっています。
生成AIブームによるマルチモーダルデータセット需要の拡大
ファウンデーションモデルの構築者は現在、幻覚を抑制しドメイン固有のチューニングを可能にする、より小規模で専門家によってラベル付けされたコーパスを好む傾向にあります。Scale AIは2024年の収益の90%が生成AIプロジェクトから生まれたことを公表しており、MetaによるScale AIへの150億米ドルの出資は出所が管理されたデータセットへのプレミアムを強調しています。中国の2026年1月のAIを20産業に統合する作業計画は、厳選された会話、対話、および指示追従コーパスへの需要を増幅させています。弁護士、医師、言語学者への賃金が現在1時間あたり60米ドルに達しており、供給を専門化層と汎用層に二極化させ、透明な監査証跡で両方のスキル層を管理するプラットフォームを優位に立たせています。
ビッグデータ機械学習パイプラインの進歩
企業は継続的インテグレーションワークフロー内でラベル付きデータセットのバージョン管理を行うケースが増えています。日本のAIブリッジングクラウドインフラは、ドメイン専門家のタグと不変の出所記録に依存する60日間の言語モデルプロジェクトに40〜80ノードを割り当てています。インドの2025年ロードマップは標準化された機械データプロトコルと国家デジタルバックボーンを求めており、品質指標をDevOpsダッシュボードに送り込むラベリングAPIへの需要を加速させています。[1]NITI Aayog、「製造業の再構想:先進製造業におけるインドのグローバルリーダーシップへのロードマップ」、niti.gov.in プログラマティックインジェスト、弱教師あり学習フック、ドリフト監視を提供するベンダーが従来のアノテーションショップを凌駕しつつあります。
医療画像AIの普及
世界中の放射線科および病理科は、規制当局がAIデバイスを承認する前に臨床医によって確認されたHIPAA準拠のデータセットを必要としています。米国食品医薬品局(FDA)は2024年以降、それぞれラベル付きグラウンドトゥルーススキャンを必要とする数十の画像アルゴリズムを承認しています。日本の研究機関である理化学研究所(RIKEN)は、透明な監査証跡を必要とする厳選された臨床データを用いてライフサイエンスのファウンデーションモデルをトレーニングしています。そのため、病院はループ内の放射線科医とISO認定品質システムを組み合わせたニッチなベンダーに目を向けています。
抑制要因の影響分析*
| 抑制要因 | CAGR予測への影響(概算%) | 地理的関連性 | 影響の時間軸 |
|---|---|---|---|
| 熟練アノテーターの不足と人件費の上昇 | -3.4% | 北米と欧州で深刻なグローバル | 短期(2年以内) |
| データプライバシーおよびデータ主権規制の強化 | -2.8% | 欧州、中国、北米でも台頭 | 中期(2〜4年) |
| ハイパースケールアノテーションのエネルギー使用に対するサステナビリティ圧力 | -0.9% | 欧州が主導するグローバル | 長期(4年以上) |
| 自己教師あり学習および弱教師あり学習による手動ラベリング支出の侵食 | -4.1% | 北米とアジア太平洋で早期採用が進むグローバル | 中期(2〜4年) |
| 情報源: Mordor Intelligence | |||
熟練アノテーターの不足と人件費の上昇
ドメイン専門家によるタグ付けへの転換は、人材のボトルネックを露呈させています。Scale AIは、クラウドソーシングの賃金水準への批判を受け、博士号レベルのアノテーターに1時間あたり30〜60米ドルを支払うようになり、ベンダー全体のコスト基準を引き上げています。インドのロードマップは、モジュール式の見習い制度とアノテーション認定のためのフロンティアテクノロジーインスティテュートを通じてスキルギャップに取り組んでいます。自動化は事前ラベリングを支援しますが、規制対象のユースケースでは人間による検証が依然として必須であり、賃金インフレが短期的にマージンの重荷となっています。
データプライバシーおよびデータ主権規制の強化
データローカライゼーション規則はデータラベリング市場を地域的なサイロに分断しています。EU AI法は出所メタデータとデータセットドキュメントを要求し、コンプライアンスのオーバーヘッドを増大させています。[2]欧州委員会、「人工知能に関する調和されたルールを定める規則の提案」、europa.eu 中国のガバナンスフレームワークは国境を越えたデータ転送を制限し、外国ベンダーに国内クラウドの設立を迫っています。これらの断片化した規制体制により、アノテーション企業はインフラを重複させ、地域の労働力を確保せざるを得なくなり、グローバルな規模の経済を抑制しています。
*当社の予測では、推進要因および抑制要因の影響を加算的ではなく方向性のあるものとして扱います。影響予測は、ベースライン成長、構成効果、および変数間の相互作用を反映しています。
セグメント分析
調達タイプ別:ハイブリッドモデルが管理とスケールのバランスを実現
ハイブリッド調達は2026年に22.48%のCAGRで大きな勢いを生み出しており、機密データを社内に保持しながら大量業務をベンダーに依存する企業によって牽引されています。アウトソーシングのシェアは2025年のデータラベリング市場シェアの63.43%を依然として占めていますが、知的財産への懸念の高まりとドメイン専門家の不足が予算を混合モデルへとシフトさせています。タスクを複雑さに応じてルーティングし、ロールベースのアクセスを適用し、リアルタイムの品質指標を表示するハイブリッドオーケストレーションツールがこの転換を支えています。アジア太平洋地域では、中国が2028年までに50,000の工場をデジタル化する計画により、企業が地域の工場レベルのチームと集中型プラットフォームを切り替えるにつれて、ハイブリッド調達がデフォルトとなるでしょう。北米全体では、防衛契約が機密データの国内処理を規定する一方で、商業用画像のオフショアタグ付けを許可しており、ハイブリッドワークフローを強化しています。
ハイブリッド戦略を採用する企業は、キューを分割することでターンアラウンドタイムを短縮しています。高感度ラベルはセキュアな内部クラスターに留まり、汎用のバウンディングボックスはオフショアベンダーに流れます。自動化されたポリシーエンジンがデータセットの系譜を追跡し、クリアランスレベルによってアノテーターを割り当て、スループットを制限することなくコンプライアンスを強化しています。ハイブリッドモデルを収益化するベンダーは、厳選された「マイクロデータセット」を複数の購入者に販売可能な繰り返し可能な資産として位置づけ、かつて不透明だったサービス収益をソフトウェアのようなマージンに転換し、データラベリング市場のアドレス可能な規模を拡大しています。
注記: 全セグメントの個別シェアはレポート購入後にご確認いただけます


データタイプ別:動画アノテーションが自律性を加速
動画アノテーションは、自律走行車、ロボティクス、スマートシティ監視によって推進され、2031年にかけて23.17%のCAGRが見込まれています。一方、静止画像は2025年の収益の36.26%を依然として占めており、フレームベースのコンピュータビジョンの定着した役割を示しています。連続ストリームは時間的に一貫したオブジェクトトラッキング、行動認識、シーンセグメンテーションを必要とし、ラベル単価と平均販売価格を引き上げています。LiDARおよび深度センサーのタグ付けに関するデータラベリング市場規模は比較的小さいものの、3Dポイントクラウドのバウンディングには専門的なツールと自動車グレードの精度が求められるため、プレミアム価格が設定されています。
具現化AIとスマートロボットを重視する中国の政策は、工場の組立ライン、倉庫物流、サービスロボットのインタラクションを捉えるマルチモーダルな動画LiDARデータセットへの需要を拡大するでしょう。北米のロボティクス新興企業も同様に、ビジョンベースの操作モデルを再トレーニングするためにアノテーション済みシーケンスをライセンス供与しています。補間支援バウンディングやモデル提案ポリゴンなどのワークフロー革新により手動作業は圧縮されますが、精度を保証するために検証段階は依然として人間中心のままです。
ラベリングアプローチ別:自己教師あり学習手法が効率的にスケール
手動ワークフローは2025年の収益の42.31%を依然として占めていますが、企業がコスト削減を追求する中で、自己教師あり学習およびプログラマティックアプローチが22.16%のCAGRで台頭しています。開発者はファウンデーションモデルを使用してフレームを事前ラベリングし、曖昧なスライスに人間をループさせることで、データセットあたりのエッジケースの総数を大幅に削減しています。小規模なゴールドラベルプールが自動化された疑似ラベルに情報を提供する半教師あり学習の拡張は、会話AIパイプラインを支配しています。弱教師あり学習ライブラリが成熟し、ダッシュボードがエンドツーエンドの出所を報告するにつれて、自動事前ラベリングに関連するデータラベリング市場規模は拡大すると予想されます。
しかし規制当局は監査可能性を義務付けています。日本のAI安全研究所は、説明可能なラベル生成ログを要求するガイダンスの草案を作成しており、ベンダーに高リスクの垂直市場での人間による監視の維持を求めています。その結果、最も強靭なプラットフォームは信頼度スコアリング、能動学習の優先順位付け、および可逆的なラベル履歴を統合し、純粋に手動のショップに対するマージン優位性を確保しながらコンプライアンスを確保しています。
アプリケーション別:予知保全が継続的な収益を牽引
コンピュータビジョンは2025年の支出の54.19%を維持していますが、工場がダウンタイムを防ぐためにセンサーデータを活用するにつれて、予知保全と品質保証は現在22.61%のCAGRを記録しています。振動、温度、音響信号の時系列タグ付けは、設備や運用体制が変化するたびにモデルを再トレーニングする必要があるため、安定したサブスクリプション型の需要を生み出しています。インドの国家ロードマップは、自律的なバッチリリースを引き起こすエージェンティックAIを重点項目として挙げており、ラベル付きセンサー障害タクソノミーと動画ベースの欠陥ライブラリを必要としています。これらの産業データセットに起因するデータラベリング市場規模は、OEMがラベリングコストを複数年のサービス契約に組み込むにつれて増加しています。
小売業者とコールセンターは引き続き自然言語処理と音声分析に投資していますが、産業用IoTパイプラインが成長をリードしています。ドメインオントロジー、エッジキャプチャSDK、クラウドサイドラベリングフックをバンドルするベンダーが工場展開を勝ち取っており、汎用プラットフォームよりも速く生の運用技術データをAI対応コーパスに変換しています。
注記: 全セグメントの個別シェアはレポート購入後にご確認いただけます
エンドユーザー産業別:産業製造が急成長
自動車企業はADASとフリートテレマティクスに牽引され、2025年の収益の28.26%を依然として生み出していますが、産業・製造顧客は2031年にかけて最速の22.84%のCAGRを示しています。中国の20のセクター別データセットと50,000の工場アップグレード計画は、金属、化学、消費者向け電子機器の垂直市場に大規模な需要を注入しています。[3]王晶晶、「中国、産業インターネットとAIの統合深化計画を発表」、国務院、english. 日本の半導体ルネサンスも同様に、ラベル付きフォトマスク画像、インライン検査スキャン、欠陥タクソノミーを必要としています。データラベリング市場は現在、生産デジタルツイン予算に直接組み込まれており、一度限りのパイロットから継続的な運用費用へと転換しています。
ヘルスケアとライフサイエンスは厳格なコンプライアンス要件を維持しており、専門ベンダーを育成しています。金融サービス企業は不正検知タグを優先し、農業ユーザーはドローンベースの作物ストレスラベルを要求しています。各垂直市場固有のオントロジーがプラットフォームのカスタマイズを促進しており、ドメインアドオンで補完された幅広いラベルオペレーションソフトウェアが社内の専用ツールを置き換えている理由を裏付けています。
地域分析
北米は2025年のデータラベリング市場収益の31.13%を占め、ハイパースケーラーへの投資、防衛契約、ファウンデーションモデルの研究開発によって支えられています。Scale AIの2024年5月の10億米ドルのシリーズF調達は投資家の信頼を強化し、Metaの2025年の出資はプロベナンスが豊富なデータセットの戦略的性質を浮き彫りにしました。情報・国家安全保障データセットに関する連邦調達は複数年契約をもたらし、景気循環的なテクノロジー支出を緩和しています。欧州のAI法はコンプライアンスのハードルを引き上げていますが、監査対応のラベルファイルを作成しEUデータ居住要件を維持できるベンダーを差別化しています。
アジア太平洋地域は21.16%のCAGRで最も速く成長しており、中国の産業インターネットロードマップ、インドの先進製造業ブループリント、日本のロボティクス拡大によって後押しされています。これらの政策的支援は、ローカライズされたアノテーション、多言語コーパス、セクター固有のタクソノミーへの地域需要を刺激しています。中国の国内クラウド義務は国内プラットフォームに優位性を与えていますが、合弁事業を形成するか国内データセンターを設立する外国ベンダーも成長セグメントにアクセスできます。東南アジア諸国は低コストの労働力を提供し、グローバルなハイブリッドワークフローを支えています。
中東・アフリカは依然として初期段階にあり、アラブ首長国連邦とサウジアラビアがスマートシティと自律モビリティのパイロットに資金を提供しており、控えめながらも戦略的なデータラベリングプロジェクトを生み出しています。南アフリカとケニアは英語圏のアウトソーシング業務を引き付けていますが、国内のAI需要の限界が地域の成長を抑制しています。ラテンアメリカの牽引力はブラジルを中心としており、電子商取引とアグリテック企業がタグ付けをアウトソーシングしていますが、通貨の変動性が国境を越えた取引を複雑にしています。

競合ランドスケープ
データラベリング市場は中程度に断片化しています。Scale AIはMetaによる150億米ドルの資金注入後に主導的な地位を確立し、厳選された専門家ラベル付きデータセットと2024年末までに14億米ドルに達すると予想される収益で注目を集めています。AppenとTELUS Internationalは、グローバルなクラウドプラットフォームとLionbridge AIなどの買収を通じてシェアを守っています。Labelbox、SuperAnnotate、V7 Labsを含む中立的なプラットフォームベンダーは、開発者エクスペリエンスと統合品質分析で競争しています。NVIDIAとDatabricks Venturesが支援するSuperAnnotateの3,600万米ドルのシリーズBは、企業がソフトウェアのみのモードとマネージドサービスモードを切り替えられるプラットフォーム中心のアプローチへの投資家の関心を示しています。
技術的差別化は現在、ファウンデーションモデルによる事前ラベリング、能動学習の優先順位付け、アノテーター間の一致度をリアルタイムで可視化する品質ダッシュボードに焦点が当たっています。データ主権のサポートを急ぐベンダーは欧州と中国に地域インスタンスを立ち上げており、小規模なブティックはISO 13485またはSOC 2認証を掲げることで規制対象セクターを獲得しています。汎用画像タグ付けでは価格圧力が続いていますが、医療画像、3D LiDAR、法的文書アノテーションなどの高付加価値セグメントはマージンを支えるプレミアム価格を維持しています。
Snorkel AIのようなスタートアップはプログラマティックラベリングを普及させ、ユーザーがヒューリスティックルールをエンコードしたり弱教師あり学習を活用したりできるようにしており、一方でDataloopのようなエッジ重視の参入者は合成データ検証のためのデバイス上マイクロラベリングを提供しています。企業がパイロットプロジェクトから本番規模のパイプラインへと移行するにつれて、勝者はハイブリッドクラウドとオンプレミスクラスター全体にわたって、インジェストからドリフト監視まで、フルスタックのラベルオペレーションを提供できる企業となるでしょう。
データラベリング産業リーダー
Appen Limited
TELUS International AI Inc.
Scale AI, Inc.
Amazon Mechanical Turk, Inc.
CloudFactory Limited
- *免責事項:主要選手の並び順不同

最近の業界動向
- 2026年1月:中国の工業情報化部が、2028年までに50,000件の産業インターネットアップグレードと標準化されたドメインデータセットを目標として、20のセクターにわたるAI統合を深化させる作業計画を発表しました。
- 2025年11月:中国が、大規模言語モデルを先進製造設備とAIエージェントと連携させる6点戦略を概説した産業AI ロードマップを公表しました。
- 2025年10月:インドのNITI Aayogが、AI搭載設計コパイロット、予知保全エージェント、認定ラベリングプロセスを優先する10年間の製造業ブループリントを発表しました。
- 2025年6月:MetaがScale AIに約150億米ドルを投資し、同社を290億米ドルと評価するとともに、28歳の最高経営責任者を新たな超知能研究所の責任者として招聘しました。


研究方法のフレームワークとレポートの範囲
市場定義と主要カバレッジ
本調査では、データラベリング市場を、機械学習モデルが学習、検証、またはファインチューニングできるようにテキスト、画像、動画、音声、ポイントクラウドファイルにタグを付けるプラットフォーム、マネージドサービス、およびブレンドされたヒューマンインザループワークフローから得られるすべての収益として定義しています。価値プールには、企業、研究機関、公的機関が支払う料金が含まれており、2025年の米ドル定価で表示されています。
スコープの除外:合成データジェネレーター、純粋なデータ分類ソフトウェア、および独立したモデルテストツールはこの境界の外に置かれています。
セグメンテーションの概要
- 調達タイプ別
- 社内
- アウトソーシング
- ハイブリッド
- データタイプ別
- テキスト
- 画像
- 動画
- 音声
- LiDAR・センサー
- ラベリングアプローチ別
- 手動
- 自動
- 半教師あり学習
- 自己教師あり学習・プログラマティック
- アプリケーション別
- コンピュータビジョン
- 自然言語処理
- 音声・オーディオ分析
- 予知保全・品質保証
- エンドユーザー産業別
- 自動車・輸送
- ヘルスケア・ライフサイエンス
- ITおよび通信
- 銀行・金融サービス・保険(BFSI)
- 小売・電子商取引
- 産業・製造
- 農業
- 政府・公共部門
- 地域別
- 北米
- 米国
- カナダ
- メキシコ
- 南米
- ブラジル
- アルゼンチン
- その他の南米
- 欧州
- 英国
- ドイツ
- フランス
- スペイン
- イタリア
- その他の欧州
- アジア太平洋
- 中国
- インド
- 日本
- オーストラリア
- 韓国
- その他のアジア太平洋
- 中東
- サウジアラビア
- アラブ首長国連邦
- トルコ
- その他の中東
- アフリカ
- 南アフリカ
- ケニア
- その他のアフリカ
- 北米
詳細な調査方法論とデータ検証
一次調査
Mordorのアナリストは次に、北米、欧州、アジア太平洋全体のプラットフォーム製品責任者、アウトソーシング担当役員、AIエンジニアリングリードと対話しました。これらの議論により、ワークフローの組み合わせ、自動化の比率、1,000ラベルあたりの現行価格が明確になり、デスクワークで残ったギャップを埋め、地域の採用曲線を調整するのに役立ちました。
デスクリサーチ
米国労働統計局、ユーロスタットのICT調査、OECDのAI政策オブザーバトリー、自律走行、医療画像、会話AIのセクター団体などの無料で入手可能なソースを通じて需要シグナルをマッピングしました。特許クラスターはQuestelで追跡し、企業収益の手がかりはD&B Hoovers、SEC 10-K、決算説明会から浮かび上がり、活動タイプ別の早期分類を提供しました。学術誌、NISTのAIリスクフレームワークのコメント、アノテーション労働契約を詳述した税関台帳がさらなるコンテキストを加えました。記載されているソースは例示的なものであり、多くの追加出版物がデータ収集と検証に情報を提供しました。
市場規模の算定と予測
企業のAIトレーニング予算、パブリッククラウドのGPU時間、ユースケースの普及率から再構築されたトップダウンプールがベースラインを形成し、サンプリングされたベンダーの請求書と平均販売価格に作業量を乗じたターゲットを絞ったボトムアップの積み上げによってクロスチェックされました。モデルを固定する5つの主要変数:自律走行1マイルあたりのアノテーション済みオブジェクト数、病院ベッドあたりのデジタル化された放射線スキャン数、合成対実データの拡張比率、ラベラーの時給、プラットフォーム自動化の普及率。多変量回帰がこれらの促進要因を2030年まで予測し、専門家との対話で検証されたシナリオオーバーレイが加えられています。
データ検証と更新サイクル
出力は分散スクリーン、ピアレビュー、異常チェックを経て承認されます。レポートは毎年更新され、新しいAI安全規則などの重要なイベントは中間更新を引き起こし、クライアントが最新の見解を受け取れるようにしています。
Mordorのデータラベリングベースラインが信頼性を持つ理由
各出版社の推計が異なるのは、それぞれが独自のスコープ、通貨処理、アップリフト要因を選択しているためです。
社内およびアウトソーシングの支出を捕捉し、プラットフォームライセンスを含め、12ヶ月ごとにインプットを見直すことで、Mordor Intelligenceは計画のためのより安定した基準を提供しています。
ベンチマーク比較
| 市場規模 | 匿名ソース | 主要なギャップ要因 |
|---|---|---|
| 65億米ドル | ||
| 48億9,000万米ドル | グローバルコンサルタントA | 社内プラットフォームとハイブリッド自動化収益ストリームを除外 |
| 48億7,000万米ドル | 地域コンサルタントB | ラベル単価に保守的な価格を適用し、LiDARデータフローを除外 |
この比較は、他社が対象範囲を狭めるか静的なコスト要因を固定しているのに対し、Mordorの厳格なスコープ、ライブの一次チェック、年次更新サイクルが、意思決定者が信頼できる透明で再現可能なベースラインをもたらすことを示しています。


レポートで回答される主要な質問
2031年のデータラベリング市場の予測値はいくらですか?
2026年から2031年にかけて21.94%のCAGRを反映し、70億2,000万米ドルに達すると予測されています。
データアノテーション需要が最も速く成長している地域はどこですか?
アジア太平洋地域が中国、インド、日本に牽引された21.16%のCAGRで最も高い勢いを示しています。
他よりも速く拡大しているデータタイプはどれですか?
動画アノテーションが自律走行車とロボティクスにより23.17%のCAGRで成長をリードしています。
ハイブリッド調達モデルが支持を集めている理由は何ですか?
企業は機密データに社内専門家を活用しながら、スケールのために外部ベンダーを組み合わせ、22.48%のCAGRで成長しながらコストと管理のバランスを実現しています。
継続的な繰り返しラベリング収益を生み出すと期待されているアプリケーション領域はどれですか?
産業環境における予知保全は、設備の進化に伴い継続的なセンサーの再タグ付けを必要とし、22.61%のCAGRで成長しています。
プライバシー規制はグローバルなラベリング戦略にどのような影響を与えていますか?
EU AI法や中国のデータガバナンス規則などの義務により、ベンダーは地域インフラを構築し、ローカライゼーション法に準拠するために個別のアノテーターのプールを維持することを余儀なくされています。
最終更新日:



