Text-to-Speech-Marktgröße und Marktanteil
Marktübersicht
| Studienzeitraum | 2020 - 2031 |
|---|---|
| Marktgröße (2026) | 4.36 Milliarden US-Dollar |
| Marktgröße (2031) | 7.92 Milliarden US-Dollar |
| Wachstumsrate (2026 - 2031) | 12.66% CAGR |
| Schnellstwachsender Markt | Asien-Pazifik |
| Größter Markt | Nordamerika |
| Marktkonzentration | Mittel |
Hauptakteure *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. | |
Text-to-Speech-Marktanalyse von Mordor Intelligence
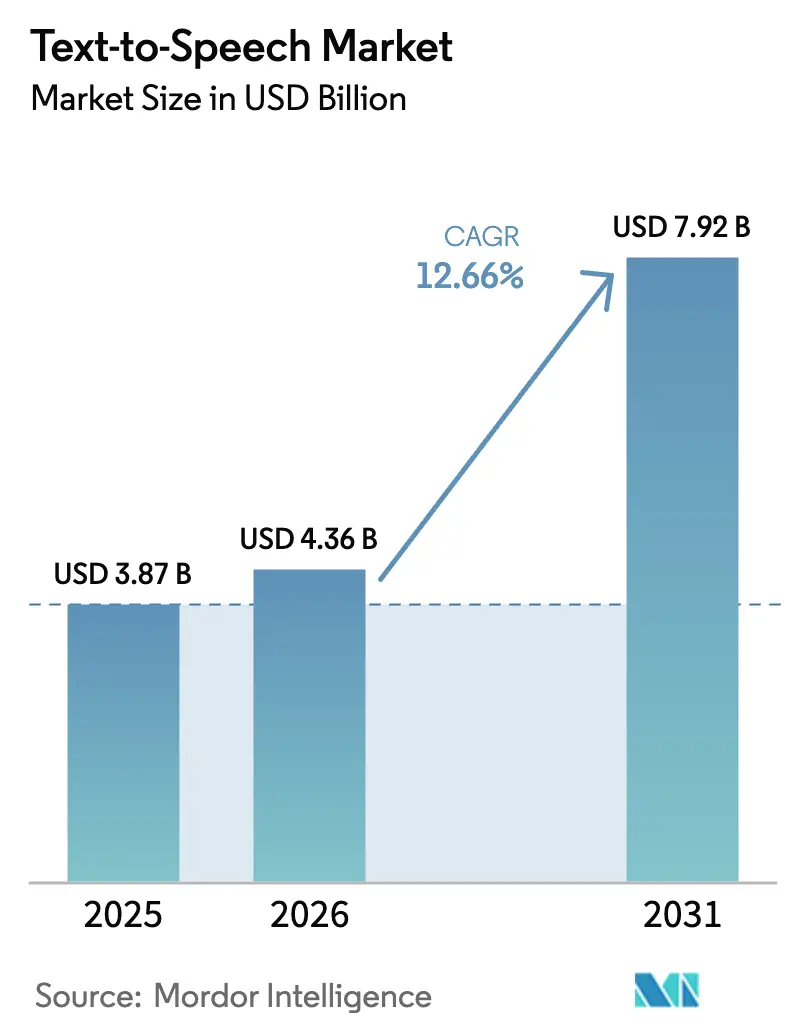
Die Größe des Text-to-Speech-Marktes wird voraussichtlich von USD 3,87 Milliarden im Jahr 2025 auf USD 4,36 Milliarden im Jahr 2026 wachsen und bis 2031 bei einem CAGR von 12,66 % über 2026–2031 USD 7,92 Milliarden erreichen. Dieser robuste Ausblick für den Text-to-Speech-Markt spiegelt wider, wie Durchbrüche bei neuronalen Netzen, strengere Barrierefreiheitsvorschriften und ausgereifte Edge-KI-Hardware synthetische Sprache von einem Komfortmerkmal zu einer zentralen Schnittstellenstrategie erhoben haben. Unternehmen betten Markensprachen in den Kundensupport, Fahrzeugassistenten und adaptive Lernwerkzeuge ein, während hyperscale Cloud-Plattformen beim Sprachumfang und der Sprachrealistik konkurrieren. Die steigende Nachfrage nach datenschutzkonformer, latenzarmer Sprachausgabe auf eingebetteten Chips erweitert den adressierbaren Text-to-Speech-Markt weiter, da Automobil-, Industrie-IoT- und Gesundheitsgeräte eine Offline-Funktionalität benötigen. Gleichzeitig haben Lizenzmodelle für synthetische Sprach-IP zusätzliche Einnahmequellen für Anbieter eröffnet, die in der Lage sind, zustimmungsbasierte Sprachdaten zu sichern und sich gegen den Missbrauch durch Klonen zu verteidigen.
Wichtigste Erkenntnisse des Berichts
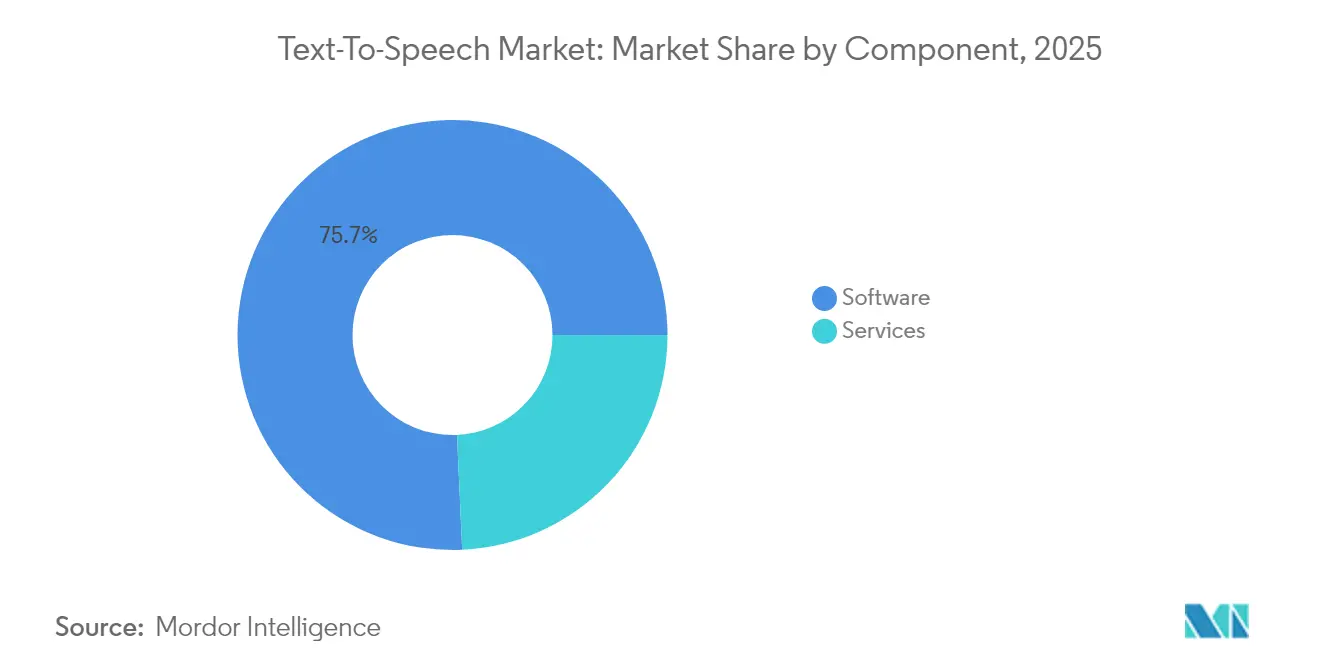
- Nach Komponente behielt Software im Jahr 2025 einen Anteil von 75,72 % am Text-to-Speech-Markt, während Dienstleistungen bis 2031 voraussichtlich mit einem CAGR von 13,04 % wachsen werden.
- Nach Bereitstellungsmodus erfassten Cloud-Lösungen im Jahr 2025 63,35 % der Text-to-Speech-Marktgröße, und Edge-eingebettete Angebote wachsen am schnellsten mit einem CAGR von 14,12 %.
- Nach Sprachtyp führten neuronale/KI-Stimmen mit einem Umsatzanteil von 67,18 % im Jahr 2025 und übertrafen alle anderen Typen mit einem CAGR von 15,08 %.
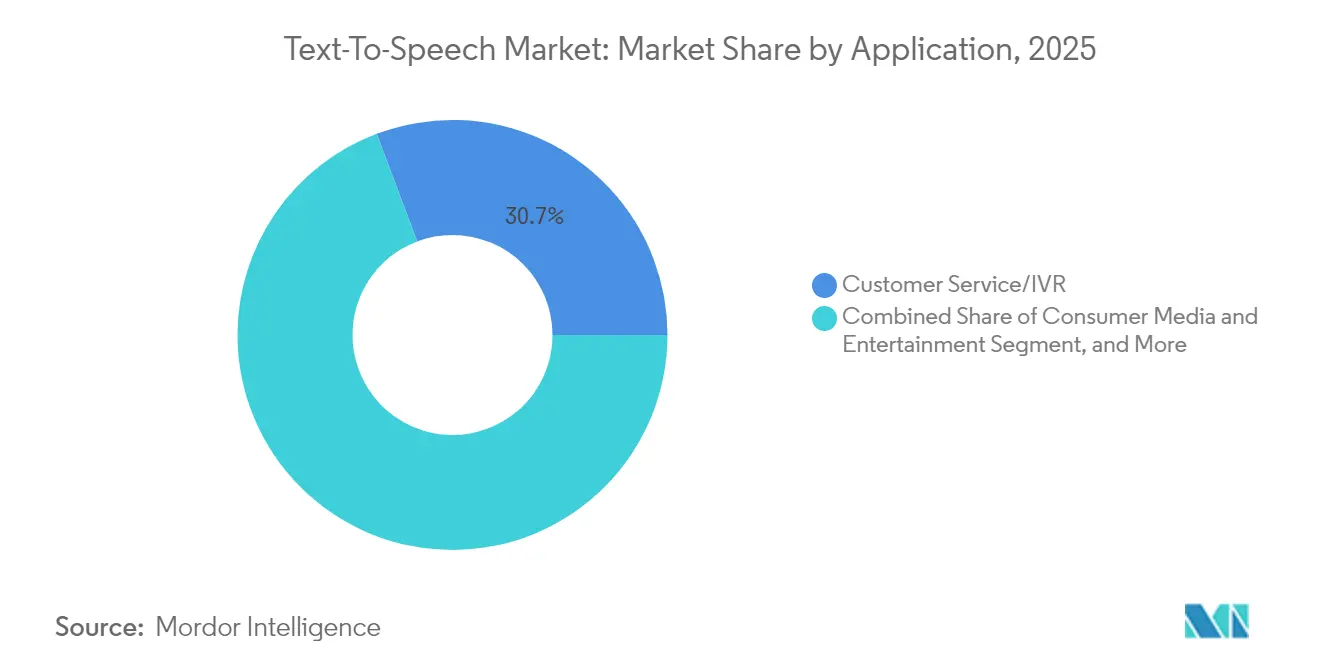
- Nach Anwendung entfiel auf Kundendienst/IVR im Jahr 2025 ein Anteil von 30,74 % an der Text-to-Speech-Marktgröße; Automobil und Transport entwickeln sich bis 2031 mit einem CAGR von 14,39 % weiter.
- Nach Sprache hielt Englisch im Jahr 2025 einen Anteil von 51,83 %, und Hindi wird voraussichtlich mit einem CAGR von 13,42 % am schnellsten wachsen.
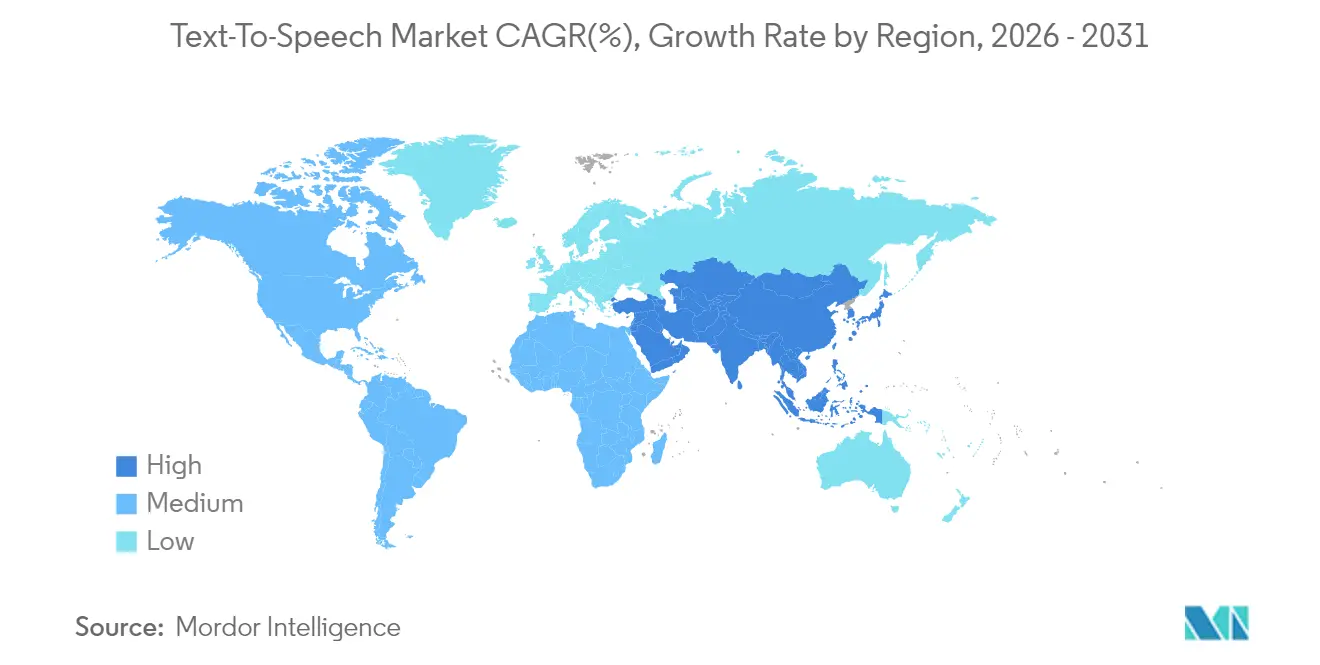
- Nach Geografie dominierte Nordamerika mit einem Anteil von 36,78 % im Jahr 2025; Asien-Pazifik ist die am schnellsten wachsende Region mit einem CAGR von 14,86 % bis 2031.
Hinweis: Die Marktgrößen- und Prognosezahlen in diesem Bericht werden mithilfe des proprietären Schätzrahmens von Mordor Intelligence erstellt und mit den neuesten verfügbaren Daten und Erkenntnissen bis 2026 aktualisiert.
Globale Text-to-Speech-Markttrends und Erkenntnisse
Analyse der Treiberwirkung*
| Treiber | Prozentualer Einfluss auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Wirkung |
|---|---|---|---|
| Verbreitung sprachgesteuerter Geräte und intelligenter Lautsprecher | +2.8% | Nordamerika, Europa | Mittelfristig (2–4 Jahre) |
| Neuronale Sprachsynthese liefert nahezu menschliche Qualität | +3.1% | Nordamerika, Asien-Pazifik | Kurzfristig (≤ 2 Jahre) |
| Expansion von E-Learning und digitalen Inhalten | +2.2% | Global; stark in Asien-Pazifik | Mittelfristig (2–4 Jahre) |
| Vorschriften zur digitalen Barrierefreiheit | +1.9% | Nordamerika, Europa | Langfristig (≥ 4 Jahre) |
| Edge-KI-Beschleuniger für Offline-Sprachsynthese | +2.4% | Global; früh im Automobil- und Industriebereich | Langfristig (≥ 4 Jahre) |
| Lizenzierung von synthetischer Sprach-IP | +1.5% | Entwickelte Märkte | Mittelfristig (2–4 Jahre) |
| Quelle: Mordor Intelligence | |||
Verbreitung sprachgesteuerter Geräte und intelligenter Lautsprecher
Hersteller intelligenter Lautsprecher betten zunehmend große Sprachmodelle ein, die auf natürlich klingende Ausgabe angewiesen sind, um nach dem Rückgang im ersten Quartal 2023 wieder Schwung bei den Auslieferungen zu gewinnen. Amazons Alexa Teacher Model und Baidus ERNIE-gestützte Assistenten veranschaulichen, wie überzeugende Stimmen das Gerätengagement steigern. Auch Automobilhersteller profitieren davon; Renaults Reno-Begleiter nutzt emotionale Sprachsynthese, um die Interaktion im Fahrzeug zu bereichern, was das Wachstum in Nicht-Unterhaltungselektronik-Segmenten unterstreicht. Edge-optimierte Modelle treiben jetzt IoT-Sensoren, Thermostate und Wearables an, die aus Datenschutz- und Verfügbarkeitsgründen lokal sprechen müssen. Anbieter, die neuronale Stimmen ohne hörbare Qualitätsverluste komprimieren können, gewinnen neue Designaufträge für Geräte.
Schnelle Verbesserungen bei der neuronalen Sprachsynthese, die nahezu menschliche Qualität liefert
Neuronale Architekturen ermöglichen die Modellierung von Prosodie, Tempo und Emotion anstelle von Konkatenation, was die Natürlichkeit in mehr als 20 Sprachen gleichzeitig verbessert. Das 21-Sprachen-System des NICT zeigte, dass die Qualität nicht sinken muss, wenn der Umfang steigt, während Microsofts Einführung von 14 neuen HD-Stimmen im Februar 2025, angeführt von den indischen Charakteren Aarti und Arjun, den kommerziellen Schwenk hin zu kulturell bewusster Sprache unterstreicht. Die Latenz ist für die meisten Cloud-APIs auf Echtzeit gesunken, sodass Marken konversationellen Support und interaktive Medien ohne wahrnehmbare Verzögerung einsetzen können. Infolgedessen ist neuronale Sprache nun die Standardspezifikation in Beschaffungszyklen für die Automatisierung von Callcentern und das Synchronisieren von Streaming-Inhalten.
Expansion von E-Learning und dem Konsum digitaler Inhalte
Digitale Klassenzimmer in Asien-Pazifik berichten von einer Nutzung generativer KI durch 81 % der Studierenden, was die Nachfrage nach Erzählungen antreibt, die sich an Dialekt und Lernerpräferenz anpassen. TTS-Plattformen bieten daher personalisierte Klangfarben- und Sprechgeschwindigkeitsprofile zur Verbesserung der Behaltensleistung an. Mehrsprachige Stimmen helfen Verlagen, Zielgruppen zu erreichen, wo Synchronsprecher rar sind, was Lokalisierungspipelines beschleunigt und die Kosten pro Titel senkt. Bildungseinrichtungen beauftragen auch eigene „Campus-Stimmen”, die die Markenidentität über LMS-Portale und Barrierefreiheitswerkzeuge hinweg stärken, was den Dienstleistungsumsatz für TTS-Anbieter steigert.
Vorschriften zur digitalen Barrierefreiheit (Section 508, WCAG)
Bundesvorschriften verlangen, dass elektronische Dokumente und Weboberflächen für sehbehinderte Personen nutzbar bleiben, was sich direkt in eine verpflichtende Unterstützung von Screenreadern und Text-to-Speech in Software niederschlägt, die an US-Regierungsbehörden verkauft wird. Dieser regulatorische Druck stärkt zudem die Nachfrage nach Hilfstechnologien für sehbehinderte Nutzer auf digitalen Plattformen des öffentlichen Sektors sowie nach Barrierefreiheitslösungen für Unternehmen. Ähnliche Anforderungen in europäischen Richtlinien stellen sicher, dass Budgets für Barrierefreiheit trotz allgemeiner IT-Ausgabenzyklen finanziert bleiben. Organisationen stellen häufig fest, dass eine bessere Sprachausgabe allen Nutzern zugutekommt und so einen Compliance-Posten in eine umfassendere Verbesserung der Nutzererfahrung verwandelt. Infolgedessen gewichten Beschaffungsteams die Anbieter-Roadmaps für das Parsen komplexer Dokumentlayouts und die Aussprache von Fachterminologie stärker.
Analyse der Hemmnisswirkung*
| Hemmnis | Prozentualer Einfluss auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Wirkung |
|---|---|---|---|
| Genauigkeitsgrenzen bei tonalen und ressourcenarmen Sprachen | -1.8% | Asien-Pazifik, Afrika | Mittelfristig (2–4 Jahre) |
| Datenschutzbedenken bei Cloud-basierter Sprachsynthese | -1.4% | Europa, Nordamerika | Kurzfristig (≤ 2 Jahre) |
| Missbrauch von Stimmklonen untergräbt das Vertrauen | -2.1% | Global | Kurzfristig (≤ 2 Jahre) |
| Steigende GPU-Rechenkosten | -1.2% | Global | Mittelfristig (2–4 Jahre) |
| Quelle: Mordor Intelligence | |||
Zunehmender Missbrauch von Stimmklonen und Deep-Fakes, der das Nutzervertrauen untergräbt
Die US-amerikanische Federal Trade Commission hat Klonrisiken durch ihre Voice Cloning Challenge hervorgehoben und dabei Betrugsszenarien betont, die die biometrische Sicherheit untergraben. OpenAIs Fähigkeit, eine Stimme aus einer 15-Sekunden-Probe zu replizieren, und Forschungsergebnisse, die eine Angriffserfolgsrate von 95–97 % gegen Sprecher-ID-Systeme zeigen, verdeutlichen die technologische Lücke zwischen Erzeugung und Erkennung. Gesetzgebungsvorschläge wie der NO FAKES Act und Tennessees ELVIS Act lassen Compliance-Kosten für Anbieter erahnen, denen es an Zustimmungsverifizierungspipelines mangelt, und drängen Unternehmen zu Anbietern mit robusten Herkunftskontrollen.
Datenschutzbedenken bei Cloud-basierter Sprachsynthese
Die DSGVO, CISA-Wahlsicherheitsempfehlungen und ein wachsendes Verbraucherbewusstsein motivieren Unternehmen dazu, Sprache lokal zu verarbeiten. Eingebettete Assistenten, die das Gerät nie verlassen, umgehen grenzüberschreitende Datenübertragungsregeln und reduzieren das Risiko von Datenpannen. Der Aufbau und die Wartung von On-Premise- oder Edge-Stacks erfordert jedoch Hardware-Budgets und spezialisierte ML-Kenntnisse, was die Einführung für kleinere Unternehmen verlangsamt. Es haben sich hybride Bereitstellungsstrategien herausgebildet, bei denen sensible Sätze auf dem Gerät verarbeitet werden, während unkritischer Text in die Cloud gestreamt wird, um Datenschutz und Kosteneffizienz in Einklang zu bringen.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Komponente: Wachstum der Dienstleistungen übertrifft die Dominanz der Software
Software hielt im Jahr 2025 einen Anteil von 75,72 %, da Kernmaschinen und APIs die meisten Bereitstellungen im Text-to-Speech-Markt unterstützen. Dennoch skaliert der Dienstleistungsumsatz mit einem CAGR von 13,04 %, da Unternehmen individuelle Stimmen und mehrsprachige Einführungen anstreben, die phonetische Abstimmung, kulturelle Prüfung und laufende Qualitätssicherung erfordern. Diese Dienstleistungen bündeln häufig Nutzungsanalysen, die Kunden helfen, das Zuhörerengagement zu verfolgen und Skripte zu verfeinern. Outsourcing mildert auch den Mangel an internen Computerlinguisten und macht spezialisierte Anbieter unverzichtbar.
Der Schwenk hin zu dienstleistungsgeführten Verträgen veranschaulicht einen Reifepunkt in der Text-to-Speech-Branche, bei dem sich die Differenzierung von „spricht es” zu „klingt es wie wir” verlagert. Individuelle Stimmenprojekte umfassen Markenton-Workshops, Akzentkalibration und iteratives Neutraining neuronaler Modelle. Anbieter, die diese Angebote mit Compliance-Tools für Zustimmung und Barrierefreiheit bündeln können, erschließen sich Long-Tail-Expansionsbudgets selbst bei Organisationen, die bereits generische TTS-APIs lizenzieren.
Notiz: Segmentanteile aller einzelnen Segmente sind nach dem Berichtskauf verfügbar


Nach Bereitstellungsmodus: Edge Computing stört die Cloud-Hegemonie
Die Cloud-Bereitstellung trug im Jahr 2025 aufgrund der nahezu sofortigen Bereitstellung und häufiger Modellaktualisierungen noch immer 63,35 % des Text-to-Speech-Marktanteils bei. Edge-eingebettete Bereitstellungen entwickeln sich jedoch mit einem CAGR von 14,12 % weiter, was einen strukturellen Schwenk hin zu Datensouveränität und Echtzeitzuverlässigkeit widerspiegelt. Automobil-Anwendungsfälle verdeutlichen den Wandel: Fahrzeuginterne Assistenten müssen auch dann reagieren, wenn die Mobilfunkabdeckung abbricht, und dürfen biometrische Audiodaten ohne Zustimmung nicht nach außen senden.
Kleinere Modelle wie Nix-TTS zeigen, dass hochwertige Sprache auf Einplatinencomputern laufen kann, was die Anwendbarkeit auf intelligente Haushaltsgeräte und medizinische Instrumente ausweitet. Halbleiteranbieter liefern jetzt Inferenzbeschleuniger für neuronale Netze, die eine Latenz von unter 100 Millisekunden aufrechterhalten und die Wahrnehmungslücke zwischen Gerät und menschlichem Gespräch beseitigen. Für Unternehmen mit intermittierender Konnektivität oder regulierten Daten bietet der Edge-Pfad Compliance ohne Qualitätseinbußen.
Nach Sprachtyp: Neuronale Netze gestalten Qualitätserwartungen neu
Neuronale Stimmen hielten im Jahr 2025 einen Umsatzanteil von 67,18 % und expandieren mit einem CAGR von 15,08 %, was den Ton für zukunftssichere Bereitstellungen im Text-to-Speech-Markt entscheidend vorgibt. Ältere konkatenative Methoden bleiben für Telefonansagen bestehen, bei denen ein vorhersehbarer Rhythmus wichtig ist, doch hybride Architekturen fügen jetzt neuronale Intonationen in Unit-Selection-Grundgerüste ein, um deterministische Aussprache beizubehalten und gleichzeitig Wärme hinzuzufügen.
Neuronale Pipelines erlernen die Sprecherabsicht und passen die Betonung dynamisch an, was eine erzählerische Resonanz liefert, die Hörbuchhörer mit längeren Wiedergabezeiten belohnen. Standardisierte Benchmarks berichten von zweistelligen MOS-Verbesserungen (Mean Opinion Score) gegenüber früheren Generationen, was die Wahrnehmungslücke zur menschlichen Erzählung verringert. Da GPU-Kosten sinken und die Quantisierung sich verbessert, wird erwartet, dass neuronale Stimmen weit vor 2030 eine Durchdringung von über 80 % erreichen.
Nach Anwendung: Automobil-Beschleunigung fordert die IVR-Führung heraus
Kundendienst/IVR verzeichnete im Jahr 2025 einen Anteil von 30,74 % an der Text-to-Speech-Marktgröße, gestützt durch etablierte Integrationen in Contact-Center-Plattformen. Dennoch verzeichnen Fahrzeugassistenten den schnellsten CAGR von 14,39 %, angetrieben durch Elektrofahrzeug-Dashboards, die Navigation, Infotainment und Klimasteuerung in sprachzentrierte Hubs integrieren. Fahrer fordern ablenkungsfreie Interaktion, und Regulierungsbehörden befürworten den Freisprechbetrieb, was die Anreize für hochwertige Fahrzeuginnenraumsprache ausrichtet.
Medien- und Unterhaltungsanbieter synchronisieren weiterhin Filme und erstellen Hörbücher mit neuronalen Besetzungsstimmen, doch der strategische Fokus verfolgt nun, wie Mobilitäts-OEMs die Nutzerbindung an eine freundliche bordeigene Persona knüpfen. Diese branchenübergreifende Konvergenz erweitert die gesamten adressierbaren Sprachstunden und erschließt neue Lizenzgebühren für IP-lizenzierte synthetische Stimmen.
Notiz: Segmentanteile aller einzelnen Segmente sind nach dem Berichtskauf verfügbar
Nach Sprache: Hindi-Wachstum spiegelt den Lokalisierungsimperativ wider
Englisch behielt im Jahr 2025 eine Nutzung von 51,83 %, doch das Streben nach regionalsprachlichem Engagement lenkt Investitionen in unterversorgte Sprachen um. Hindis CAGR von 13,42 % unterstreicht Indiens Agenda für digitale öffentliche Güter, bei der Regierungsportale und Fintech-Apps massive nicht-englischsprachige Nutzerbasen bedienen müssen. Chinesisch, Spanisch und Deutsch bleiben vorrangige Tier-1-Sprachen, aber TTS-Anbieter verfolgen nun Tier-2-Dialekte, bei denen die Plattformbindung aufgrund geringer bisheriger Konkurrenz hoch ist.
Die Expansion in tonale und agglutinierende Sprachen stellt Modellarchitekten vor Herausforderungen durch nuancierte Tonhöhenkonturen und Morphologie. Anbieter mit kuratierten lokalen Datensätzen und linguistischen Partnerschaften sind daher in der Lage, Nischen zu dominieren, die globale Generalisten nur schwer knacken können, und erhalten eine fragmentierte, aber chancenreiche Grenze innerhalb des Text-to-Speech-Marktes aufrecht.
Geografische Analyse
Nordamerika verankerte im Jahr 2025 36,78 % des Text-to-Speech-Marktes, angetrieben durch Section-508-Beschaffungsfilter, die die Sprachausgabe zu einem Pflichtpunkt für alle bundesbehördennahen Software machen. In den USA ansässige Cloud-Hyperscaler bündeln Sprachsynthese mit umfassenderen KI-Suiten und senken so die Einstiegshürden für Startups, die Sprache hinzufügen möchten. Gleichzeitig drängen Datenschutzdebatten und die FTC-Kontrolle von Stimmklonen Unternehmen zu Anbietern mit transparenten Zustimmungsworkflows. Venture-finanzierte Innovatoren konzentrieren sich um kalifornische KI-Hubs und beschleunigen den Funktionsrhythmus und die Patentanmeldungen.
Asien-Pazifik ist auf dem Weg zu einem CAGR von 14,86 %, dem schnellsten regionalen Tempo im Text-to-Speech-Markt, dank Smartphone-Sättigung und der Vertrautheit der Verbraucher mit Sprache als primärer Eingabe. Chinas KI-Fördermittel und Indiens Projekte zur digitalen öffentlichen Infrastruktur erfordern umfangreiche Unterstützung für Regionalsprachen und treiben den Massen-API-Verbrauch an. Koreanische und japanische OEMs integrieren neuronale Stimmen in Autos und Smart-TVs, während südostasiatische Entwickler mit öffentlichen Forschungslabors zusammenarbeiten, um Sprachmodelllücken zu schließen. Der regionale Ansatz betont zunehmend die Sprachverarbeitung auf dem Gerät aufgrund lückenhafter Konnektivität in ländlichen Gebieten und Souveränitätsgesetzen über biometrische Daten.
Europa setzt die stetige Einführung fort, gestützt durch die DSGVO und nationale Barrierefreiheitsgesetze. Automobilzulieferer in Deutschland betten lokale Sprachverarbeitung ein, um fahrzeuginterne Sicherheitsvorschriften zu erfüllen, und Rundfunkanstalten in Frankreich und Spanien investieren in Lokalisierung, um mehrsprachige Zielgruppen anzusprechen. Die Präferenz für On-Premise-Bereitstellung ist höher als in anderen Regionen, was die kulturelle Vorsicht gegenüber der Cloud-Speicherung von Sprachprotokollen widerspiegelt. Regulatorische Untersuchungen zur KI-Transparenz werden wahrscheinlich gesamteuropäische technische Standards prägen, die auf Exportmärkte ausstrahlen.

Wettbewerbslandschaft
Der Text-to-Speech-Markt weist eine moderate Fragmentierung auf. Amazon, Google und Microsoft nutzen globale Cloud-Präsenzen und kontinuierliche Modellaktualisierungen, während spezialisierte Anbieter wie Cerence und iFlytek sich durch Automobilintegration und muttersprachliche Expertise differenzieren. Der regulatorische Druck rund um das Stimmklonen hat die Einstiegsschwellen erhöht; Anbieter müssen nun Zustimmungsverifizierung, Wasserzeichen und Missbrauchsüberwachung liefern, um Unternehmensverträge zu gewinnen.[2]Federal Trade Commission, "Die FTC Voice Cloning Challenge," ftc.gov
Edge-first-Herausforderer optimieren quantisierte neuronale Netze für Mikrocontroller mit unter 1 W und zielen auf industrielle IoT- und Medizingeräte ab, die nicht auf Netzwerkkonnektivität angewiesen sein können. Patentportfolios werden zunehmend entscheidend: Nvidia investiert in Sprachsynthese-IP, die es an Chip-Partner lizenziert, und schafft so Lizenzgebührenströme und Abwehrbarrieren. Wachstumsunternehmen wie ElevenLabs konzentrieren sich auf Werkzeuge für die Creator Economy und bieten studioqualitatives Klonen an, das Podcaster und Spieledesigner anspricht, muss aber bevorstehende Offenlegungsregeln navigieren.
Strategische Schritte in den Jahren 2024–2025 veranschaulichen das Rennen um Sprachbreite und vertikale Tiefe. Microsoft veröffentlichte 27 neue HD-Stimmen, darunter kulturell abgestimmte indische Personas, und erweiterte damit seine adressierbare Basis.[3]Microsoft Tech Community, "Azure AI Speech Text to Speech Feb 2025 Updates," techcommunity.microsoft.comRenaults Zusammenarbeit mit Cerence brachte einen emotionalen Cockpit-Begleiter in seine Elektrofahrzeug-Reihe und signalisierte den OEM-Appetit auf Markenstimmen.[4]Cerence Inc., "Renault and Cerence Partner to Bring Generative AI to Renault 5 E-Tech," cerence.comAppTek und Deluxe bündelten ihre Stärken zur Optimierung von Medien-Lokalisierungs-Workflows und unterstrichen damit, wie die Sprachsynthese nun im Mittelpunkt der Inhaltsglobalisierung steht.
Marktführer im Text-to-Speech-Bereich
Amazon Web Services, Inc
IBM Corporation
Google LLC
Microsoft Corporation
Synthesys.io
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Aktuelle Branchenentwicklungen
- Februar 2025: Microsoft aktualisierte Azure AI Speech mit 13 aufgefrischten HD-Stimmen und 14 neuen HD-Stimmen, darunter die indischen Charaktere Aarti und Arjun zur Unterstützung regionaler Bereitstellungen.
- Januar 2025: Consumer Reports veröffentlichte einen KI-Stimmklon-Bericht, der feststellte, dass vier von sechs Unternehmen keine Schutzmaßnahmen gegen nicht einvernehmliches Klonen hatten, was erneutes FTC-Interesse auslöste.
- Oktober 2024: Renault kooperierte mit Cerence, um den Reno-Begleiter in den Renault 5 E-Tech Elektrowagen einzubetten und konversationelle, emotionsbewusste Sprache im Fahrzeug zu liefern.
- Juli 2024: NICT stellte ein 21-sprachiges schnelles neuronales TTS-System vor und bewies mehrsprachige Skalierbarkeit mit hoher Wiedergabetreue.


Rahmen der Forschungsmethodik und Umfang des Berichts
Marktdefinitionen und wichtige Abdeckung
Unsere Studie definiert den globalen Text-to-Speech-Markt (TTS) als Umsätze, die aus Software und zugehörigen Dienstleistungen generiert werden, die geschriebene Zeichen algorithmisch in verständliche, menschenähnliche Audiodaten über Cloud-, On-Premise- und Edge-Bereitstellungen umwandeln.
Ausschluss aus dem Umfang: Hardware-Mikrofone, Sprache-zu-Text-Engines und Stimmbiometrie werden nicht berücksichtigt.
Segmentierungsübersicht
- Nach Komponente
- Software
- Dienstleistungen
- Nach Bereitstellungsmodus
- Cloud-basiert
- On-Premise
- Edge-Eingebettet
- Nach Sprachtyp
- Neural/KI-basiert
- Standard-Konkatenativ
- Hybrid
- Nach Anwendung
- Verbrauchermedien und Unterhaltung
- E-Learning und Bildung
- Barrierefreiheit für Sehbehinderte
- Kundendienst/IVR
- Automobil und Transport
- Gesundheitliche Assistenz
- Robotik und IoT
- Weitere Anwendungen
- Nach Sprache
- Englisch
- Chinesisch
- Spanisch
- Hindi
- Deutsch
- Französisch
- Türkisch
- Weitere Sprachen
- Nach Geografie
- Nordamerika
- Vereinigte Staaten
- Kanada
- Mexiko
- Südamerika
- Brasilien
- Argentinien
- Übriges Südamerika
- Europa
- Vereinigtes Königreich
- Deutschland
- Frankreich
- Italien
- Spanien
- Russland
- Übriges Europa
- Asien-Pazifik
- China
- Indien
- Japan
- Südkorea
- Australien und Neuseeland
- Übriger Asien-Pazifik-Raum
- Naher Osten und Afrika
- Naher Osten
- Saudi-Arabien
- Vereinigte Arabische Emirate
- Türkei
- Übriger Naher Osten
- Afrika
- Südafrika
- Nigeria
- Übriges Afrika
- Naher Osten
- Nordamerika
Detaillierte Forschungsmethodik und Datenvalidierung
Primärforschung
Anschließend befragten wir Cloud-Plattform-Architekten, E-Learning-Integratoren und Anbieter von Assistenztechnologien in Nordamerika, Europa und Asien-Pazifik.
Ihre Erkenntnisse zu Bewegungen beim durchschnittlichen Verkaufspreis, Sprachpaket-Attach-Raten und aufkommenden Automobil-Nachfrageströmen halfen dabei, Sekundärschätzungen zu moderieren und regionale Inflektionen zu klären.
Desk Research
Mordor-Analysten begannen mit offenen Datensätzen von Institutionen wie der Internationalen Fernmeldeunion, der Weltgesundheitsorganisation und der OECD, um Gerätegrundlagen, Prävalenz von Behinderungen und die Einführung digitaler Dienste zu bewerten.
Weißbücher von Handelsverbänden (zum Beispiel CTA-Lieferzahlen für intelligente Lautsprecher), W3C-Standards für Sprachsynthese und Unternehmens-10-Ks bereicherten die Trendsichtbarkeit.
Kostenpflichtige Datenquellen von D&B Hoovers und Questel lieferten Unternehmenserlösaufteilungen und Patentgeschwindigkeit, die die Wettbewerbsintensität verankern.
Die zitierten Quellen veranschaulichen unsere Desk-Research-Arbeit; viele weitere Referenzen unterstützten die Datenvalidierung und Lückenfüllung.
Marktgrößenbestimmung und Prognose
Ein Top-down-Modell beginnt mit dem weltweiten Bestand an internetfähigen Geräten, wendet die beobachtete TTS-API-Durchdringung in wichtigen Branchen an und schichtet dann durchschnittliche Sprachstundenpreise auf, um den Wert abzuleiten.
Ausgewählte Bottom-up-Prüfungen, Stichproben von Lieferantenumsätzen und Kanalrechnungen, werden durchgeführt, um Gesamtsummen abzugleichen, bevor Zahlen festgeschrieben werden.
Zu den verfolgten Variablen gehören Lieferungen intelligenter Lautsprecher, die sehbehinderte Bevölkerung, die Screenreader nutzt, die Anzahl der unterstützten Sprachen pro Anbieter, Preissenkungen bei Cloud-Plattformen, regulatorische Barrierefreiheitsvorschriften und Installationen von Fahrzeug-Infotainmentsystemen.
Multivariate Regression projiziert jeden Treiber über den Prognosezeitraum, und Szenarioanalysen passen sich an Währungsschwankungen und Engpässe bei der KI-Chip-Versorgung an.
Wo granulare Bottom-up-Daten spärlich sind, überbrückt das Analystenurteil, das von zwei Kollegen überprüft wird, die Lücke und wird in jedem Aktualisierungszyklus erneut geprüft.
Datenvalidierung und Aktualisierungszyklus
Ergebnisse unterliegen Varianzschwellen gegenüber unabhängigen Indikatoren; jede Überschreitung löst Nacharbeiten und Expertenrückrufe aus.
Ein leitender Prüfer gibt sein Einverständnis, und das Modell wird jährlich aktualisiert, mit Zwischenaktualisierungen, wenn wesentliche Ereignisse, große Kapitalerhöhungen oder wichtige regulatorische Änderungen die Ausgangsbasis verschieben.
Warum Mordors Text-to-Speech-Markt-Ausgangsbasis Vertrauen verdient
Veröffentlichte Schätzungen weichen häufig voneinander ab, weil Unternehmen unterschiedliche Technologiegrenzen, Währungsjahre und Aktualisierungsrhythmen wählen.
Wichtige Treiber für Abweichungen sind hier, ob SaaS-Nutzungsgebühren oder nur Dauerlizenzgebühren gezählt werden, wie neuronale Stimmenprämien behandelt werden und wie schnell neu hinzugefügte ressourcenarme Sprachen in Wachstumskurven eingepreist werden.
Benchmarkvergleich
| Marktgröße | Anonymisierte Quelle | Primärer Treiber für Abweichungen |
|---|---|---|
| USD 3,87 Mrd. (2025) | ||
| USD 4,00 Mrd. (2024) | Globales Beratungsunternehmen A | zählt Sprache-zu-Text- und Diktierwerkzeuge zusammen und bläht so die Basis auf |
| USD 4,15 Mrd. (2024) | Branchenforschungsunternehmen B | setzt einheitliche neuronale Stimmenpreise voraus und ignoriert Freemium-Stufen |
| USD 4,55 Mrd. (2024) | Fachzeitschrift C | wendet einstelliges Wachstum auf veraltete konkatenative Volumina an und addiert dann den neuronalen CAGR ohne Überschneidungsprüfungen |
Die Unterschiede zeigen, warum Entscheidungsträger auf Mordors disziplinierte Umfangsbestimmung, gemischte Methodik zur Größenbestimmung und jährliche Aktualisierung angewiesen sind, um einen ausgewogenen, reproduzierbaren Ausgangspunkt für die strategische Planung zu erhalten.


Im Bericht beantwortete Schlüsselfragen
Wie groß ist der aktuelle Text-to-Speech-Markt?
Die Größe des Text-to-Speech-Marktes wird voraussichtlich im Jahr 2026 USD 4,36 Milliarden erreichen und mit einem CAGR von 12,66 % wachsen, um bis 2031 USD 7,92 Milliarden zu erreichen.
Wie groß ist der aktuelle Text-to-Speech-Markt?
Dienstleistungen expandieren mit einem CAGR von 13,04 %, da Organisationen die Erstellung individueller Stimmen und mehrsprachige Bereitstellungsarbeiten auslagern.
Warum ist der Automobilsektor für Text-to-Speech-Anbieter wichtig?
Automobilhersteller benötigen latenzarme, geräteinterne Stimmen für eine sichere, ablenkungsfreie Interaktion, was den Sektor zur am schnellsten wachsenden Anwendung mit einem CAGR von 14,39 % macht.
Wie beeinflussen Vorschriften die Einführung?
Section 508 und europäische Barrierefreiheitsgesetze schreiben sprachfähige Inhalte vor und machen Compliance zu einem beständigen Nachfragetreiber für die Unternehmens-TTS-Integration.
Welche Risiken birgt das Stimmklonen für Unternehmen?
Deep-Fake-Sprache kann biometrische Sicherheit umgehen und das Verbrauchervertrauen untergraben, was Regulierungsbehörden und Unternehmen dazu veranlasst, Anbieter mit robusten Zustimmungs- und Erkennungsmechanismen zu bevorzugen.
Wird Edge Computing die Cloud-Sprachsynthese verdrängen?
Edge-Bereitstellungen steigen mit einem CAGR von 14,12 %, aber hybride Modelle, die lokalen Datenschutz und Cloud-Skalierbarkeit kombinieren, werden bis 2031 wahrscheinlich nebeneinander bestehen.
Seite zuletzt aktualisiert am:




