Text-to-Speech Market Size and Share
Market Overview
| Study Period | 2020 - 2031 |
|---|---|
| Market Size (2026) | USD 4.36 Billion |
| Market Size (2031) | USD 7.92 Billion |
| Growth Rate (2026 - 2031) | 12.66% CAGR |
| Fastest Growing Market | Asia Pacific |
| Largest Market | North America |
| Market Concentration | Medium |
Major Players *Disclaimer: Major Players sorted in no particular order Image © Mordor Intelligence. Reuse requires attribution under CC BY 4.0. | |
Text-to-Speech Market Analysis by Mordor Intelligence
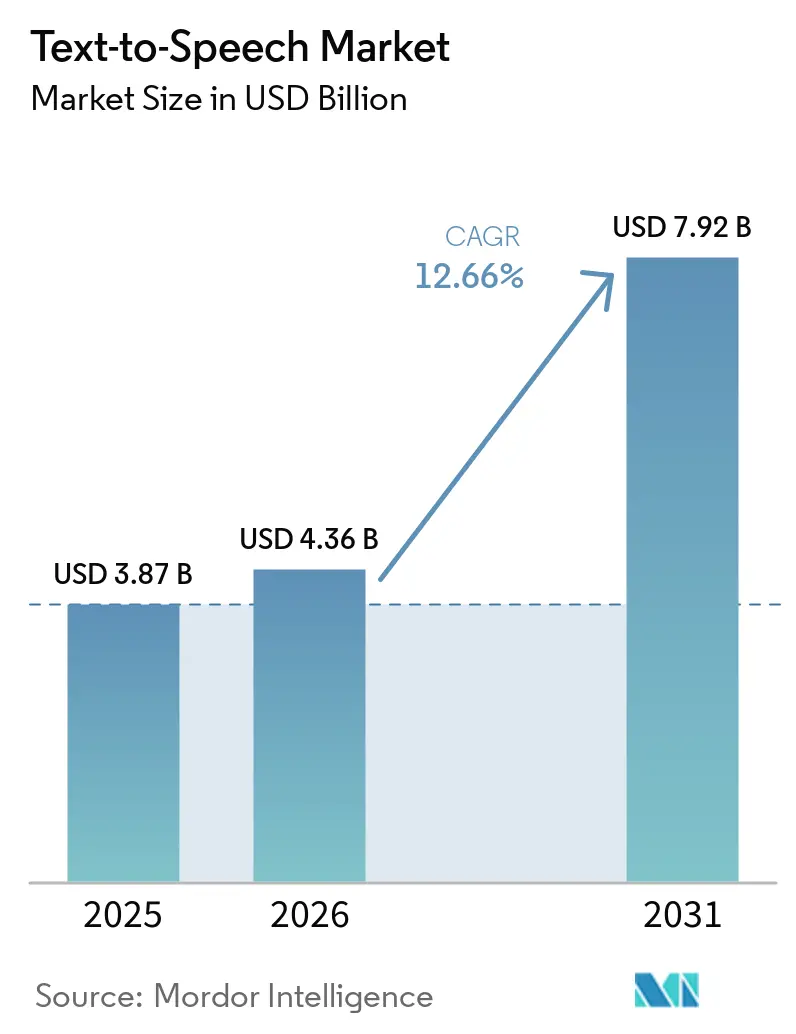
The Text-to-Speech market size is expected to grow from USD 3.87 billion in 2025 to USD 4.36 billion in 2026 and is forecast to reach USD 7.92 billion by 2031 at 12.66% CAGR over 2026-2031. This robust outlook for the Text-to-Speech market reflects how neural-network breakthroughs, stricter accessibility mandates, and maturing edge-AI hardware have elevated synthetic voice from a convenience feature to a core interface strategy. Enterprises are embedding branded voices into customer support, in-vehicle assistants, and adaptive learning tools, while hyperscale cloud platforms compete on language coverage and voice realism. Rising demand for data-private, low-latency speech on embedded chips is further widening the addressable Text-to-Speech market as automotive, industrial IoT, and healthcare devices require offline functionality. Meanwhile, licensing models for synthetic-voice IP have opened additional revenue avenues for vendors able to secure consented voice data and defend against cloning misuse.
Key Report Takeaways
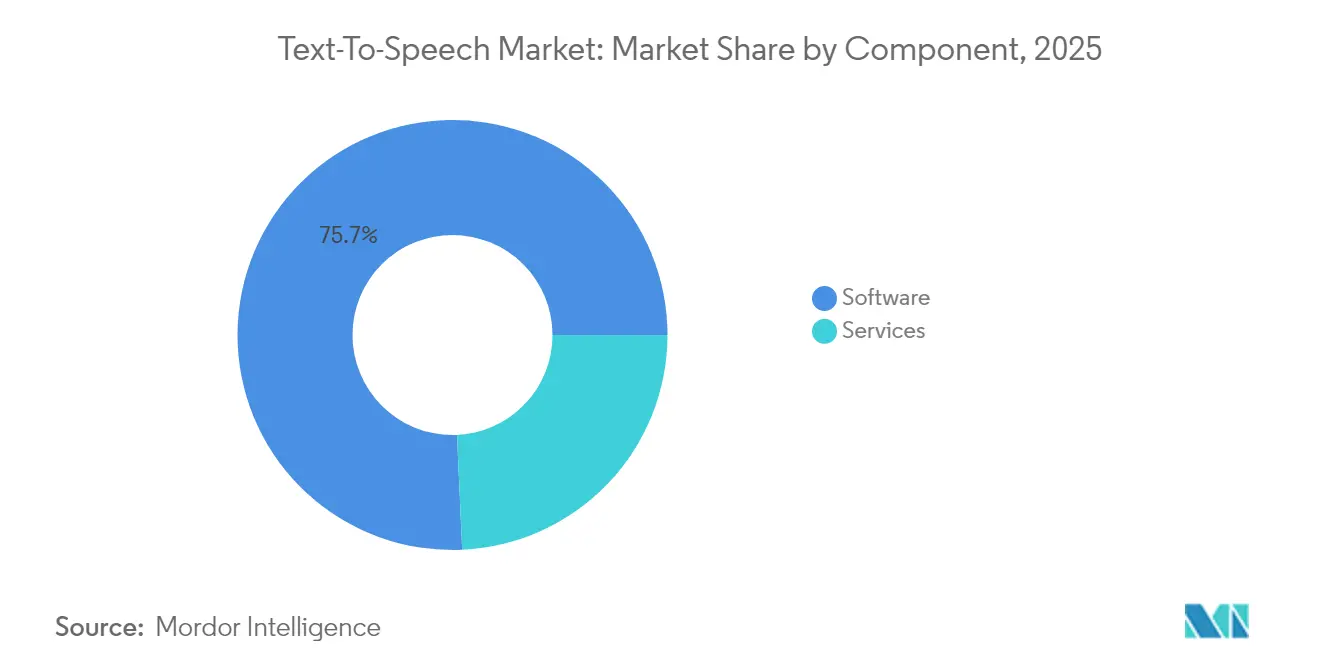
- By component, software retained 75.72% of the Text-to-Speech market share in 2025, whereas services are projected to expand at a 13.04% CAGR through 2031.
- By deployment mode, cloud solutions captured 63.35% of the Text-to-Speech market size in 2025, and edge-embedded offerings are growing fastest at 14.12% CAGR.
- By voice type, neural/AI voices led with a 67.18% revenue share in 2025 while outpacing all other types at a 15.08% CAGR.
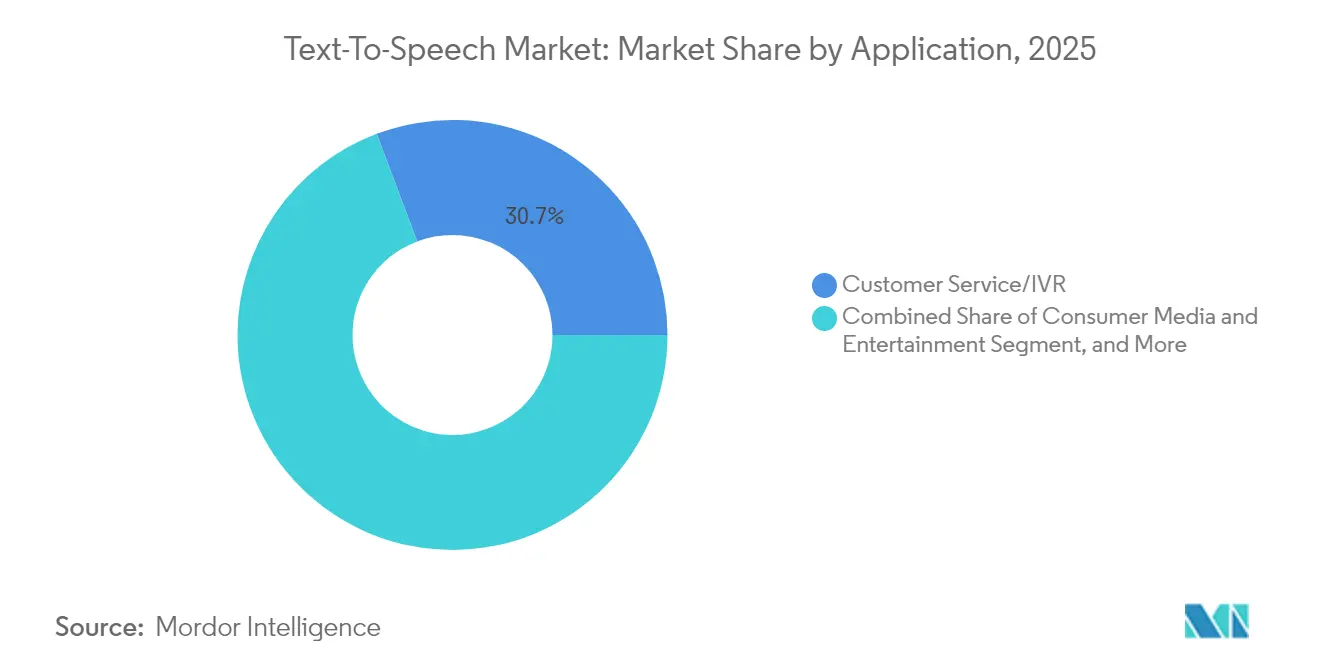
- By application, customer service/IVR accounted for 30.74% of the Text-to-Speech market size in 2025; automotive and transportation are advancing at 14.39% CAGR to 2031.
- By language, English held 51.83% share in 2025, and Hindi is projected to increase most rapidly at 13.42% CAGR.
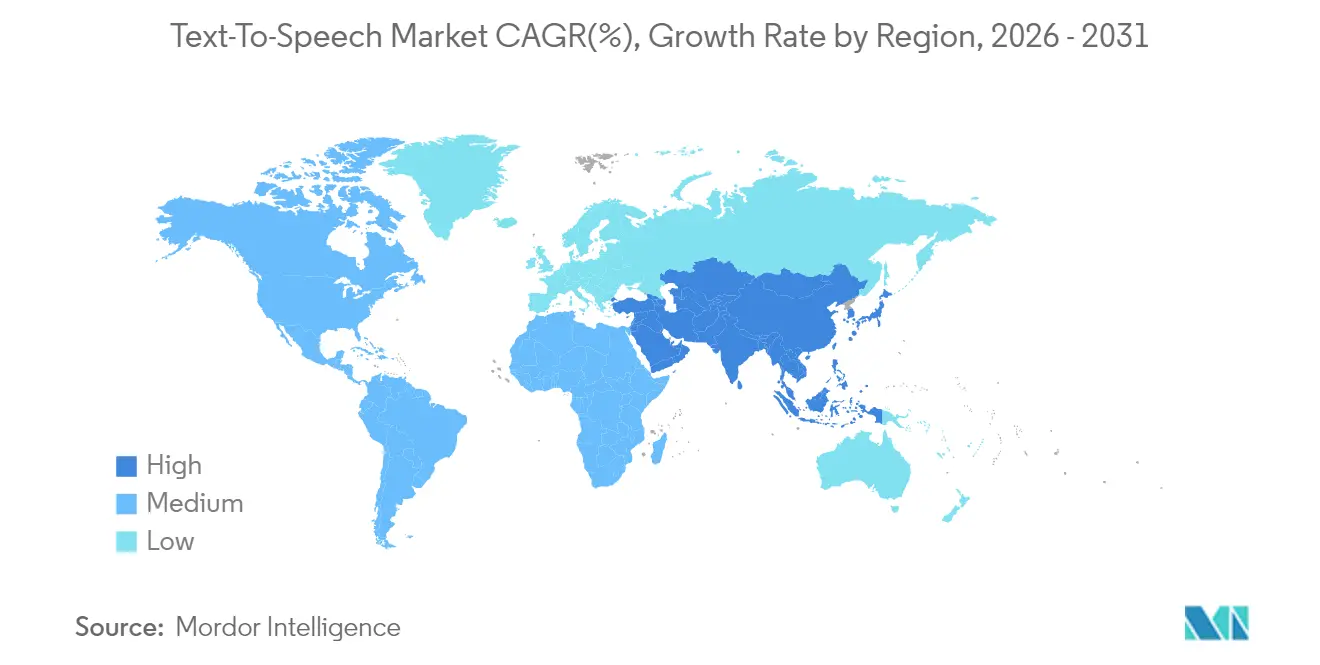
- By geography, North America dominated with 36.78% share in 2025; Asia-Pacific is the fastest-growing region at 14.86% CAGR to 2031.
Note: Market size and forecast figures in this report are generated using Mordor Intelligence’s proprietary estimation framework, updated with the latest available data and insights as of 2026.
Global Text-to-Speech Market Trends and Insights
Drivers Impact Analysis*
| Driver | % Impact on CAGR Forecast | Geographic Relevance | Impact Timeline |
|---|---|---|---|
| Voice-enabled devices and smart speakers proliferation | +2.8% | North America, Europe | Medium term (2-4 years) |
| Neural TTS delivers near-human quality | +3.1% | North America, Asia-Pacific | Short term (≤ 2 years) |
| E-learning and digital content expansion | +2.2% | Global; strong in Asia-Pacific | Medium term (2-4 years) |
| Digital accessibility mandates | +1.9% | North America, Europe | Long term (≥ 4 years) |
| Edge-AI accelerators for offline TTS | +2.4% | Global; early in automotive and industrial | Long term (≥ 4 years) |
| Synthetic-voice IP licensing | +1.5% | Developed markets | Medium term (2-4 years) |
| Source: Mordor Intelligence | |||
Proliferation of voice-enabled devices and smart speakers
Smart-speaker OEMs increasingly embed large language models that depend on natural-sounding output to regain shipment momentum after the Q1 2023 downturn. Amazon’s Alexa Teacher Model and Baidu’s ERNIE-powered assistants illustrate how compelling voices raise device engagement. Carmakers also benefit; Renault’s Reno companion uses emotive TTS to enrich in-vehicle interaction, highlighting growth in non-consumer electronics verticals. Edge-optimized models now power IoT sensors, thermostats, and wearables that must speak locally for privacy and uptime. Vendors able to compress neural voices without audible degradation are capturing new device design-wins.
Rapid improvements in neural TTS delivering near-human quality
Neural architectures allow prosody, pacing, and emotion to be modelled rather than concatenated, lifting naturalness in 20+ languages simultaneously. NICT’s 21-language system showed that quality does not have to fall when scale rises, while Microsoft’s February 2025 roll-out of 14 new HD voices, led by Indian characters Aarti and Arjun, underscores the commercial pivot toward culturally aware speech. Latency has dropped to real-time for most cloud APIs, letting brands deploy conversational support and interactive media without perceptible lag. As a result, neural speech is now the default specification in procurement cycles for call-center automation and streaming content dubbing.
Expansion of e-learning and digital content consumption
Digital classrooms in Asia-Pacific report generative-AI usage by 81% of students, driving demand for narration that adapts to dialect and learner preference. TTS platforms therefore offer personalised timbre and speaking rate profiles to improve retention. Multilingual voices help publishers reach audiences where voice-over talent is scarce, accelerating localisation pipelines and reducing cost per title. Educational institutions also commission proprietary “campus voices” that reinforce brand identity across LMS portals and accessibility tools, bolstering service revenue for TTS providers.
Mandates for digital accessibility (Section 508, WCAG)
Federal rules require that electronic documents and web interfaces remain usable by visually impaired individuals, directly translating to mandatory screen-reader and TTS support in software sold to US government entities. This regulatory push is also strengthening demand for assistive technology for visually impaired users across public-sector digital platforms and enterprise accessibility solutions. Similar expectations in European directives ensure that accessibility budgets remain funded despite broader IT spending cycles. Organisations frequently discover that better narration benefits all users, turning a compliance line-item into a broader UX upgrade. Consequently, procurement teams are weighting vendor roadmaps for complex document layout parsing and technical terminology pronunciation.
Restraints Impact Analysis*
| Restraint | % Impact on CAGR Forecast | Geographic Relevance | Impact Timeline |
|---|---|---|---|
| Accuracy limits for tonal and low-resource languages | -1.8% | Asia-Pacific, Africa | Medium term (2-4 years) |
| Data-privacy concerns in cloud TTS | -1.4% | Europe, North America | Short term (≤ 2 years) |
| Voice-cloning misuse erodes trust | -2.1% | Global | Short term (≤ 2 years) |
| Escalating GPU compute costs | -1.2% | Global | Medium term (2-4 years) |
| Source: Mordor Intelligence | |||
Rising voice-cloning/deep-fake misuse eroding user trust
The US Federal Trade Commission spotlighted cloning risks through its Voice Cloning Challenge, emphasising fraud scenarios that undermine biometric security. OpenAI’s ability to replicate a voice from a 15-second sample and research showing 95-97% attack success against speaker-ID systems highlight the technological gap between generation and detection. Legislative proposals such as the NO FAKES Act and Tennessee’s ELVIS Act foreshadow compliance costs for vendors that lack consent-verification pipelines, nudging enterprises toward providers with robust provenance controls.
Data-privacy concerns in cloud-based TTS
GDPR, CISA election-security advisories, and rising consumer awareness are motivating enterprises to process speech locally. Embedded assistants that never leave the device sidestep cross-border data-transfer rules and reduce breach exposure. Yet building and maintaining on-premise or edge stacks requires hardware budgets and specialised ML skills, slowing adoption for smaller firms. Hybrid deployment strategies have emerged, where sensitive sentences render on-device while non-critical text streams to the cloud, balancing privacy with cost efficiency.
*Our forecasts treat driver/restraint impacts as directional, not additive. The impact forecasts reflect baseline growth, mix effects, and variable interactions.
Segment Analysis
By Component: Services Growth Outpaces Software Dominance
Software maintained 75.72% share in 2025 as core engines and APIs underpin most deployments within the Text-to-Speech market. Nevertheless, services revenue is scaling at 13.04% CAGR as enterprises seek custom voices and multilingual roll-outs that demand phonetic tuning, cultural vetting, and ongoing quality assurance. These services often bundle usage analytics, helping clients track listener engagement and refine scripts. Outsourcing also mitigates the scarcity of in-house computational linguists, making specialised vendors indispensable.
The pivot toward service-led contracts illustrates a maturation point in the Text-to-Speech industry where differentiation moves from “does it talk” to “does it sound like us.” Custom voice projects encompass brand-tone workshops, accent calibration, and iterative neural-model retraining. Providers able to package these offerings with compliance tooling for consent and accessibility are capturing long-tail expansion budgets even among organisations that already licence generic TTS APIs.



By Deployment Mode: Edge Computing Disrupts Cloud Hegemony
Cloud delivery still contributed 63.35% of the Text-to-Speech market share in 2025 due to near-instant provisioning and frequent model updates. Edge-embedded deployments, however, are advancing at 14.12% CAGR, reflecting a structural pivot toward data sovereignty and real-time reliability. Automotive use cases typify the shift: in-cabin assistants must respond even when cellular coverage drops and must not send biometric audio off-board without consent.
Smaller models such as Nix-TTS demonstrate that high-fidelity speech can run on single-board computers, broadening applicability to smart appliances and medical instruments. Semiconductor vendors now ship neural-network inference accelerators that maintain under-100-millisecond latency, eliminating the perception gap between device and human conversation. For enterprises with intermittent connectivity or regulated data, the edge path offers compliance without sacrificing quality.
By Voice Type: Neural Networks Reshape Quality Expectations
Neural voices held 67.18% revenue share in 2025 and are expanding at 15.08% CAGR, decisively setting the tone for future-proof deployments in the Text-to-Speech market. Legacy concatenative methods remain for telephony prompts where predictable cadence matters, yet hybrid architectures now splice neural inflections onto unit-selection backbones to preserve deterministic pronunciation while adding warmth.
Neural pipelines learn speaker intent and adjust emphasis dynamically, delivering storytelling resonance that audiobook listeners reward with longer playtimes. Standardised benchmarks report double-digit MOS (Mean Opinion Score) improvements over previous waves, narrowing the perceptual gap to human narration. As GPU costs trend downward and quantisation improves, neural voices are expected to surpass 80% penetration well before 2030.
By Application: Automotive Acceleration Challenges IVR Leadership
Customer service/IVR recorded 30.74% of the Text-to-Speech market size in 2025, upheld by established integrations in contact-center platforms. Yet automotive assistants are clocking the fastest 14.39% CAGR, propelled by electric-vehicle dashboards that fuse navigation, infotainment, and climate control into voice-centric hubs. Drivers demand distraction-free interaction, and regulators endorse hands-free operation, aligning incentives toward premium in-cabin speech.
Media and entertainment providers continue to dub films and generate audiobooks with neural cast voices, but the strategic spotlight now tracks how mobility OEMs bind user loyalty to a friendly onboard persona. This cross-industry convergence expands total addressable voice hours, unlocking new royalties for IP-licensed synthetic voices.
By Language: Hindi Growth Reflects Localisation Imperative
English retained 51.83% usage in 2025, yet the pursuit of vernacular engagement is redirecting investment into under-served tongues. Hindi’s 13.42% CAGR underscores India’s digital-public-goods agenda, where government portals and fintech apps must serve massive non-English user bases. Chinese, Spanish, and German remain priority Tier-1 languages, but TTS providers now chase Tier-2 dialects where platform stickiness is high due to low prior competition.
Expanding into tonal and agglutinative languages challenges model architects with nuanced pitch contours and morphology. Vendors with curated local datasets and linguistic partnerships therefore stand to dominate niches that global generalists find hard to crack, sustaining a fragmented but opportunity-rich frontier inside the Text-to-Speech market.
Geography Analysis
North America anchored 36.78% of the Text-to-Speech market in 2025, propelled by Section 508 procurement filters that make voice output a checklist item for all federal-facing software.US-based cloud hyperscalers bundle TTS alongside broader AI suites, lowering entry barriers for startups to add speech. Meanwhile, privacy debates and FTC scrutiny of voice cloning push enterprises toward providers with transparent consent workflows. Venture-backed innovators cluster around Californian AI hubs, accelerating feature cadence and patent filings.
Asia-Pacific is on course for a 14.86% CAGR, the swiftest regional pace in the Text-to-Speech market, thanks to smartphone saturation and consumer comfort with voice as the primary input. China’s AI stimulus funds and India’s Digital Public Infrastructure projects require large-scale vernacular support, driving bulk API consumption. Korean and Japanese OEMs integrate neural voices into cars and smart-TVs, while Southeast Asian developers work with public-sector research labs to fill language-model gaps. The regional blueprint increasingly emphasises on-device speech due to patchy connectivity across rural districts and sovereignty laws over biometric data.
Europe continues steady adoption underpinned by GDPR and national accessibility statutes. Automotive suppliers in Germany embed local speech processing to meet in-vehicle safety mandates, and broadcasters in France and Spain invest in localisation to address multilingual audiences. Preference for on-premise deployment is higher than in other regions, reflecting cultural caution toward cloud storage of voice logs. Regulatory probes into AI transparency are likely to shape pan-EU technical standards that spill over into export markets.

Competitive Landscape
The Text-to-Speech market exhibits moderate fragmentation. Amazon, Google, and Microsoft leverage global cloud footprints and continuous model refreshes, while specialist vendors such as Cerence and iFlytek differentiate on automotive integration and native-language expertise. Regulatory pressure around voice cloning has raised entry thresholds; providers must now deliver consent verification, watermarking, and misuse monitoring to win enterprise contracts.[2]Federal Trade Commission, “The FTC Voice Cloning Challenge,” ftc.gov
Edge-first challengers optimise quantised neural networks for sub-1 W microcontrollers, targeting industrial IoT and medical devices that cannot rely on network connectivity. Patent portfolios are increasingly pivotal: Nvidia invests in voice-synthesis IP that it licenses to chip partners, creating royalty streams and defensive barriers. Growth-stage companies like ElevenLabs focus on creator economy tools, offering studio-quality cloning that appeals to podcasters and game designers but must navigate upcoming disclosure rules.
Strategic moves during 2024-2025 illustrate the race for language breadth and vertical depth. Microsoft released 27 new HD voices, including culturally tuned Indian personas, expanding its addressable base.[3]Microsoft Tech Community, “Azure AI Speech Text to Speech Feb 2025 Updates,” techcommunity.microsoft.comRenault’s collaboration with Cerence brought an emotive cockpit companion to its electric line-up, signaling OEM appetite for branded voices.[4]Cerence Inc., “Renault and Cerence Partner to Bring Generative AI to Renault 5 E-Tech,” cerence.comAppTek and Deluxe merged strengths to streamline media localisation workflows, underscoring how TTS now sits at the heart of content globalisation.
Text-to-Speech Industry Leaders
Amazon Web Services, Inc
IBM Corporation
Google LLC
Microsoft Corporation
Synthesys.io
- *Disclaimer: Major Players sorted in no particular order

Recent Industry Developments
- February 2025: Microsoft updated Azure AI Speech with 13 refreshed HD voices and 14 new HD voices, featuring Indian characters Aarti and Arjun to support regional deployments.
- January 2025: Consumer Reports released an AI Voice Cloning Report that found four of six companies lacked safeguards against non-consensual cloning, prompting renewed FTC interest.
- October 2024: Renault partnered with Cerence to embed the Reno companion in the Renault 5 E-Tech EV, delivering conversational, emotion-aware speech in-vehicle.
- July 2024: NICT unveiled a 21-language fast neural TTS system, proving multilingual scalability with high fidelity.


Research Methodology Framework and Report Scope
Market Definitions and Key Coverage
Our study defines the global text-to-speech (TTS) market as revenues generated from software and allied services that algorithmically convert written characters into intelligible, human-like audio across cloud, on-premise, and edge deployments.
Scope exclusion: hardware microphones, speech-to-text engines, and voice biometrics are not counted.
Segmentation Overview
- By Component
- Software
- Services
- By Deployment Mode
- Cloud-Based
- On-Premise
- Edge Embedded
- By Voice Type
- Neural/AI-based
- Standard Concatenative
- Hybrid
- By Application
- Consumer Media and Entertainment
- E-Learning and Education
- Accessibility for Visually Impaired
- Customer Service/IVR
- Automotive and Transportation
- Healthcare Assistive
- Robotics and IoT
- Other Applications
- By Language
- English
- Chinese
- Spanish
- Hindi
- German
- French
- Turkish
- Other Languages
- By Geography
- North America
- United States
- Canada
- Mexico
- South America
- Brazil
- Argentina
- Rest of South America
- Europe
- United Kingdom
- Germany
- France
- Italy
- Spain
- Russia
- Rest of Europe
- Asia-Pacific
- China
- India
- Japan
- South Korea
- Australia and New Zealand
- Rest of Asia-Pacific
- Middle East and Africa
- Middle East
- Saudi Arabia
- United Arab Emirates
- Turkey
- Rest of Middle East
- Africa
- South Africa
- Nigeria
- Rest of Africa
- Middle East
- North America
Detailed Research Methodology and Data Validation
Primary Research
We next interviewed cloud-platform architects, e-learning integrators, and assistive-technology distributors across North America, Europe, and Asia Pacific.
Their insights on average selling price movement, language-pack attach rates, and emerging automotive demand streams helped temper secondary estimates and clarify regional inflections.
Desk Research
Mordor analysts began with open datasets from bodies such as the International Telecommunication Union, World Health Organization, and OECD to gauge device bases, disability prevalence, and digital-service adoption.
Trade association white papers (for example, CTA smart speaker shipment tallies), W3C speech synthesis standards, and corporate 10-Ks enriched trend visibility.
Paid lenses from D&B Hoovers and Questel provided company revenue splits and patent velocity that anchor competitive intensity.
The sources cited illustrate our desk work; many further references supported data validation and gap filling.
Market-Sizing & Forecasting
A top-down model starts with worldwide internet-enabled device stock, applies observed TTS API penetration in key verticals, and then layers average voice-hour pricing to derive the value.
Select bottom-up checks, sampled supplier revenues and channel invoices, are run to reconcile totals before figures lock.
Variables tracked include smart speaker shipments, the visually impaired population using screen readers, the number of supported languages per vendor, cloud-platform price cuts, regulatory accessibility mandates, and in-car infotainment installs.
Multivariate regression projects each driver through the forecast period, and scenario analysis adjusts for currency swings and AI-chip supply constraints.
Where granular bottoms-up data are sparse, analyst judgment, reviewed by two peers, bridges the gap and is revisited each update cycle.
Data Validation & Update Cycle
Outputs face variance thresholds against independent indicators; any breach triggers re-work and expert callbacks.
A senior reviewer signs off, and the model refreshes yearly, with interim patches when material events, large fund-raises, or major regulation shifts the baseline.
Why Mordor's Text-to-Speech Market Baseline Earns Trust
Published estimates frequently diverge because firms choose different technology boundaries, currency years, and refresh cadences.
Key gap drivers here include whether SaaS usage fees or only perpetual licenses are tallied, how neural-voice premiums are treated, and the speed at which newly added low-resource languages are priced into growth curves.
Benchmark comparison
| Market Size | Anonymized source | Primary gap driver |
|---|---|---|
| USD 3.87 B (2025) | Mordor Intelligence | - |
| USD 4.00 B (2024) | Global Consultancy A | counts speech-to-text and dictation tools together, inflating base |
| USD 4.15 B (2024) | Industry Research Firm B | assumes uniform neural-voice pricing, ignoring freemium tiers |
| USD 4.55 B (2024) | Trade Journal C | applies single digit growth to legacy concatenative volumes, then adds neural CAGR without overlap checks |
Differences show why decision-makers rely on Mordor's disciplined scope setting, mixed-method sizing, and annual refresh to obtain a balanced, reproducible starting point for strategic planning.


Key Questions Answered in the Report
What is the current Text-to-Speech market size?
The Text-to-Speech Market size is expected to reach USD 4.36 billion in 2026 and grow at a CAGR of 12.66% to reach USD 7.92 billion by 2031.
What is the current Text-to-Speech Market size?
Services are expanding at a 13.04% CAGR as organisations outsource custom voice creation and multilingual deployment work.
Why is the automotive sector important for Text-to-Speech vendors?
Automakers need low-latency, on-device voices for safe, distraction-free interaction, making the sector the fastest-growing application at 14.39% CAGR.
How are regulations influencing adoption?
Section 508 and European accessibility laws mandate voice-enabled content, turning compliance into a consistent demand driver for enterprise TTS integration.
What risks does voice cloning pose to businesses?
Deep-fake speech can bypass biometric security and erode consumer trust, prompting regulators and enterprises to favour vendors with robust consent and detection mechanisms.
Will edge computing displace cloud TTS?
Edge deployments are rising at 14.12% CAGR, but hybrid models combining local privacy and cloud scalability are likely to coexist through 2031.
Page last updated on:






