Marktgröße und -anteil für Data Wrangling
Marktübersicht
| Studienzeitraum | 2020 - 2031 |
|---|---|
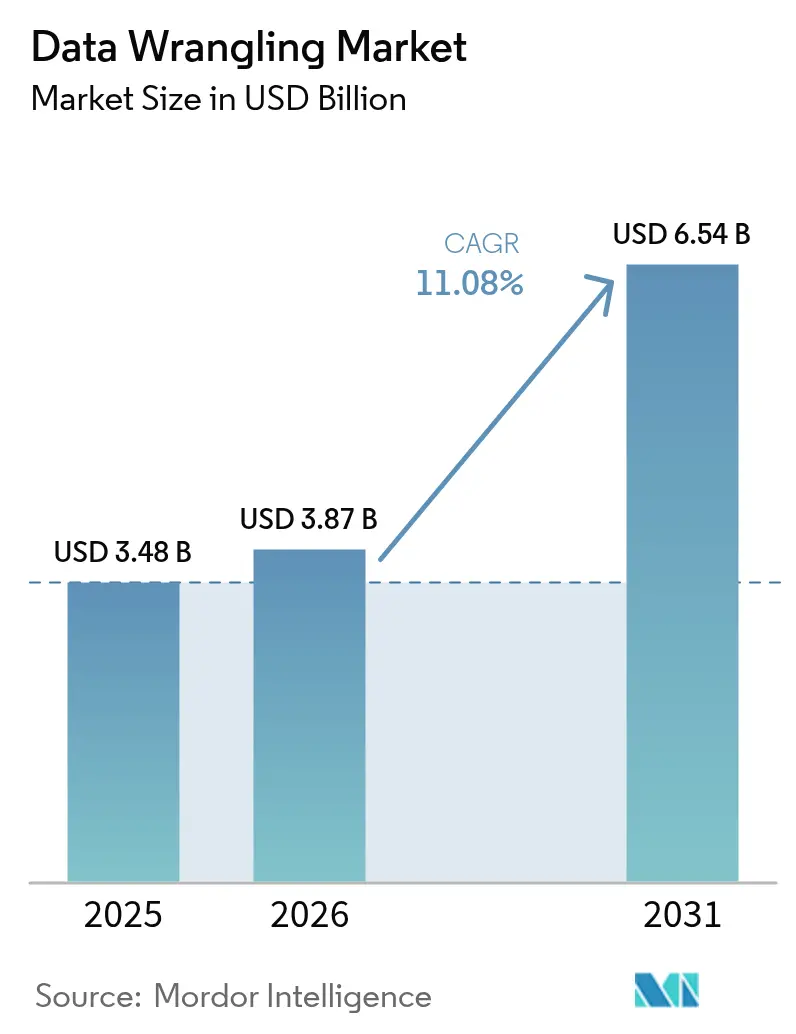
| Marktgröße (2026) | 3.87 Milliarden US-Dollar |
| Marktgröße (2031) | 6.54 Milliarden US-Dollar |
| Wachstumsrate (2026 - 2031) | 11.08% CAGR |
| Schnellstwachsender Markt | Asien-Pazifik |
| Größter Markt | Nordamerika |
| Marktkonzentration | Mittel |
Hauptakteure *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. | |
Marktanalyse für Data Wrangling von Mordor Intelligence
Die Marktgröße für Data Wrangling wird voraussichtlich von 3,48 Milliarden USD im Jahr 2025 auf 3,87 Milliarden USD im Jahr 2026 wachsen und soll bis 2031 bei einer CAGR von 11,08 % über den Zeitraum 2026–2031 6,54 Milliarden USD erreichen. Im Prognosezeitraum werden das beschleunigte Wachstum der Unternehmensdaten, die steigende Nachfrage nach Echtzeitanalysen und der Wechsel von traditionellen ETL-Suiten zu KI-gestützten Aufbereitungsplattformen die wichtigsten Wachstumstreiber bleiben. Anbieter integrieren generative KI, Low-Code-Transformationsabläufe und Lakehouse-Konnektoren, um die Zeit bis zur Erkenntnisgewinnung zu verkürzen und Self-Service in Finanz-, Marketing- und Betriebsteams zu unterstützen. Die Wettbewerbsintensität steigt, da Hyperscale-Cloud-Anbieter native Wrangling-Funktionen integrieren, was reine Datenvorbereitung-Unternehmen zwingt, sich durch domänenspezifische Automatisierung und multimodale Unterstützung zu differenzieren. Neue Vorschriften, die robuste Governance-Rahmenwerke und Herkunftsberichte vorschreiben, verstärken den Adoptionsschwung zusätzlich, auch wenn steigende Rechenkosten Unternehmen zu hybriden Bereitstellungsmodellen drängen.
Wichtigste Erkenntnisse des Berichts
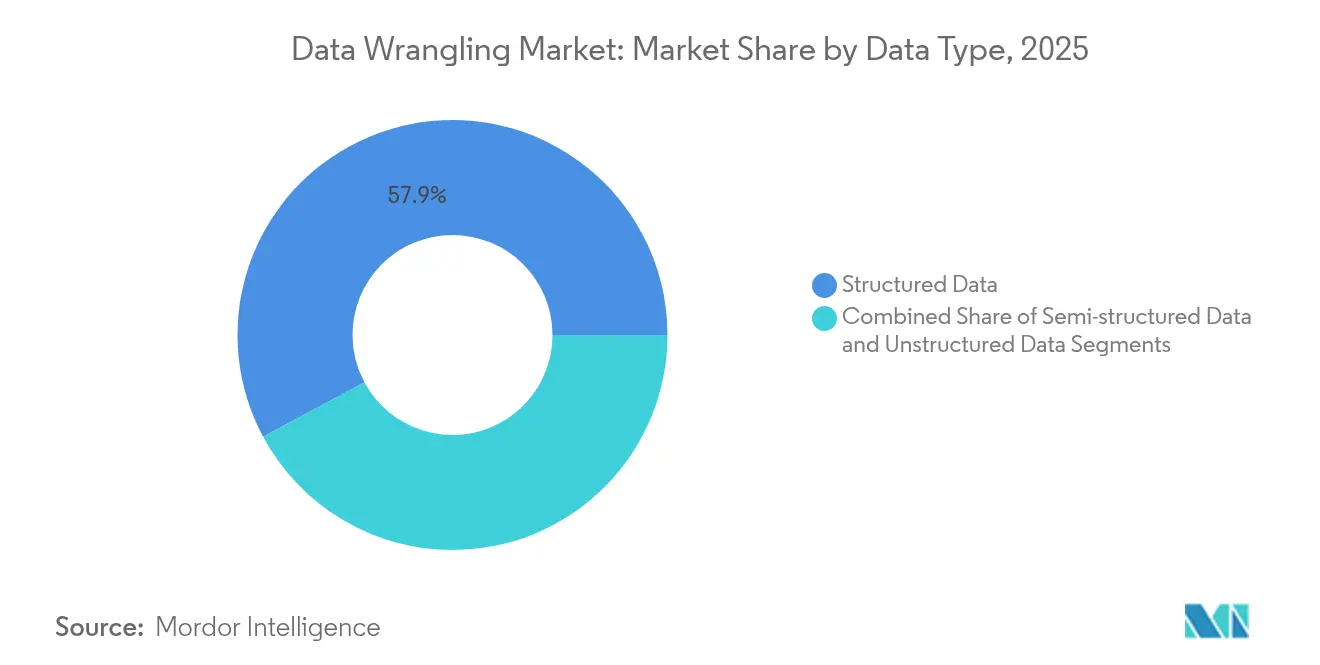
- Nach Datentyp behielten strukturierte Formate im Jahr 2025 einen Marktanteil von 57,85 % am Markt für Data Wrangling, während unstrukturierte Formate bis 2031 voraussichtlich mit einer CAGR von 12,32 % wachsen werden.
- Nach Komponente erzielte Software im Jahr 2025 68,85 % des Umsatzes; Dienstleistungen stellen die am schnellsten wachsende Komponente mit einer CAGR von 12,45 % bis 2031 dar.
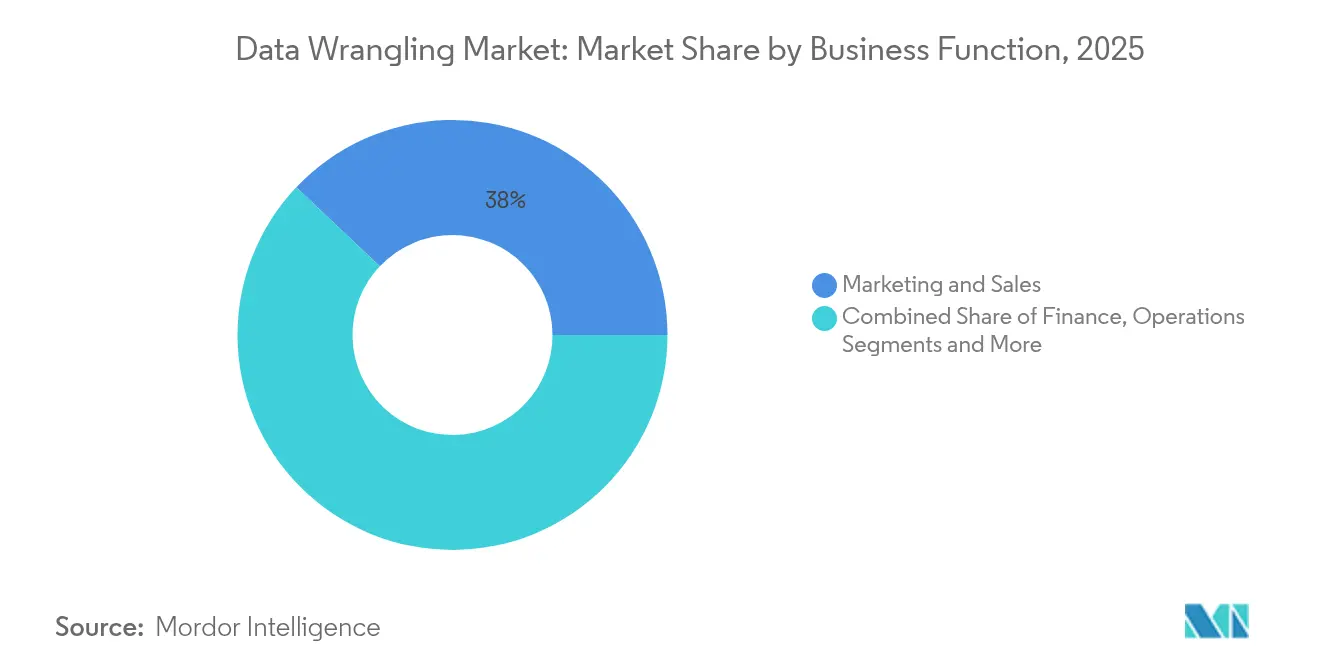
- Nach Geschäftsfunktion führte Marketing und Vertrieb mit einem Anteil von 37,95 % am Markt für Data Wrangling im Jahr 2025, während Finanzen voraussichtlich mit einer CAGR von 11,98 % wachsen werden.
- Nach Endnutzerbranche hielt IT und Telekommunikation im Jahr 2025 einen Anteil von 27,35 % am Markt für Data Wrangling, und BFSI wächst mit einer CAGR von 11,42 %.
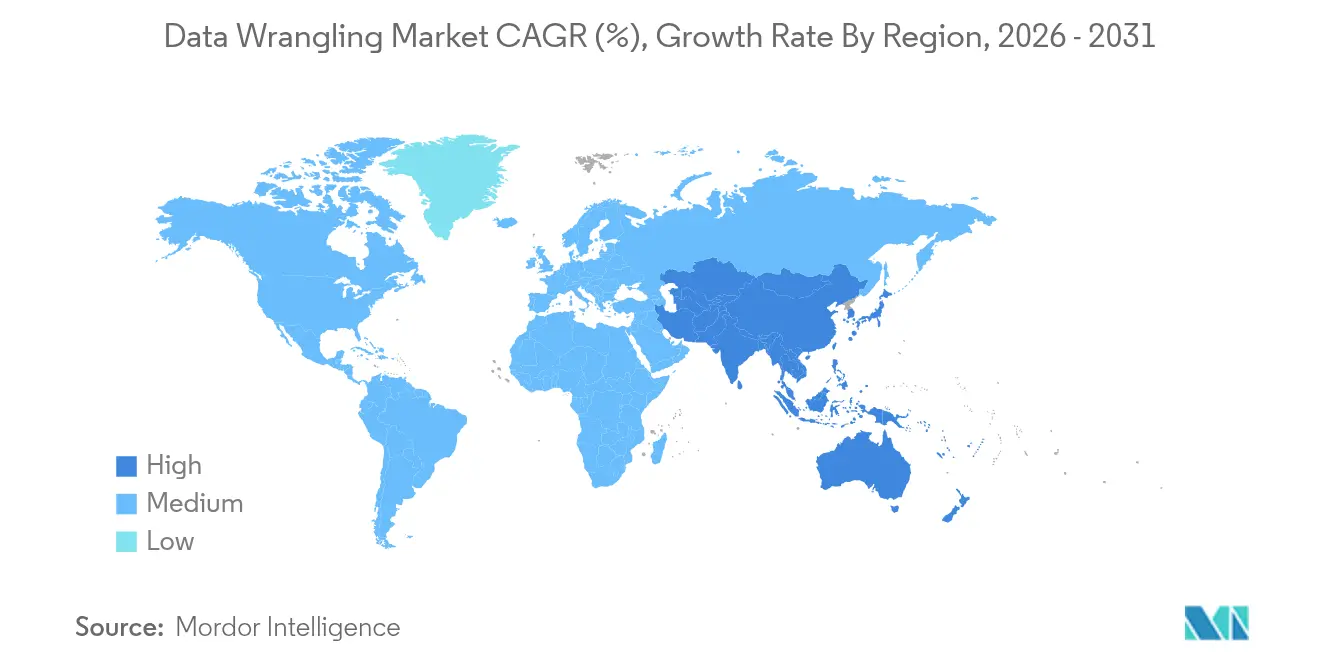
- Nach Geografie dominierte Nordamerika im Jahr 2025 mit einem Umsatzanteil von 37,10 %, während Asien-Pazifik bis 2031 eine CAGR von 11,75 % verzeichnen soll.
Hinweis: Die Marktgrößen- und Prognosezahlen in diesem Bericht werden mithilfe des proprietären Schätzrahmens von Mordor Intelligence erstellt und mit den neuesten verfügbaren Daten und Erkenntnissen bis 2026 aktualisiert.
Globale Trends und Erkenntnisse im Markt für Data Wrangling
Analyse der Auswirkungen von Treibern*
| Treiber | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Steigende globale Datenvolumina | +2.8% | Global | Langfristig (≥ 4 Jahre) |
| Fortschritte in der KI-gesteuerten Automatisierung | +2.1% | Nordamerika, EU, APAC | Mittelfristig (2–4 Jahre) |
| Wachsende Nachfrage nach Self-Service-Analysen | +1.9% | Global | Kurzfristig (≤ 2 Jahre) |
| Strengere Qualitäts- und Governance-Vorschriften | +1.7% | EU, Nordamerika | Mittelfristig (2–4 Jahre) |
| Momentum bei der Migration zu Lakehouse-Architekturen | +1.4% | APAC, Naher Osten und Afrika | Mittelfristig (2–4 Jahre) |
| Aufstieg von No-Code-LLM-Copiloten | +1.2% | Nordamerika, EU | Kurzfristig (≤ 2 Jahre) |
| Quelle: Mordor Intelligence | |||
Wachsende Datenvolumina in allen Branchen
McKinsey schätzt, dass die globalen Ausgaben für Rechenzentren bis 2030 6,7 Billionen USD erreichen werden, wovon 5,2 Billionen USD direkt auf KI-Workloads entfallen. Edge-Geräte, 5G-Rollouts und die Digitalisierung von Fertigungslinien treiben die Datenerzeugung voran, die die Kapazität veralteter ETL-Systeme übersteigt. Asien-Pazifik veranschaulicht diesen Trend mit 12.206 MW operativer Rechenzentrums-Leistung und 14.338 MW in der Entwicklung im Jahr 2024. Unternehmen wechseln daher zu Plattformen, die in der Lage sind, vielfältige, hochfrequente Datenströme in lokalen Rechtsgebieten zu verarbeiten, die Datensouveränitätsvorschriften auferlegen.
Fortschritte in KI- und Big-Data-Technologien zur Ermöglichung von Automatisierung
Anbieter wie Alteryx haben generative Assistenten integriert, die Transformationsschritte empfehlen und Zusammenfassungen in natürlicher Sprache erstellen. Gartners Taxonomie für agentische Analysen aus dem Jahr 2025 verweist auf autonome Pipelines, die sich selbst bei Schema-Abweichungen korrigieren und die Rechenzuweisung optimieren. Databricks beschleunigte diesen Trend durch die Übernahme von Lilac AI und fügte seinem Lakehouse-Stack eine LLM-basierte Datenqualitätsbewertung hinzu. Während KI die Produktivität steigert, dämpfen Organisationen die Einführung mit hybriden Bereitstellungsstrategien, die Kostenspitzen beim Rechnen abmildern.
Steigende Nachfrage nach Self-Service-Datenvorbereitung bei Geschäftsanwendern
Fallstudien aus dem Einzelhandel zeigen, dass 54 % der Unternehmen durch Datenanalyse-Initiativen mindestens 10 % Gewinnzuwachs erzielten, aber dennoch auf fragmentierte Datensilos stoßen, die Self-Service behindern. Programme für Citizen-Data-Scientists und eingebettete Wrangling-Module in BI-Suiten statten Finanz- und Merchandising-Teams mit Point-and-Click-Oberflächen aus. Gartner prognostiziert, dass bis 2027 mehr als die Hälfte der Chief Data and Analytics Officers in Datenkompetenzprogramme investieren wird, was verdeutlicht, dass die Förderung von Soft Skills genauso wichtig ist wie die Auswahl der richtigen Werkzeuge.
Strengere Vorschriften zur Datenqualität und Governance
BCBS 239 und die DSGVO erhöhen den Bedarf an Herkunftsnachweisen, Rückverfolgbarkeit und prüfungssicheren Transformationen. Die jüngsten RDARR-Überprüfungen der Europäischen Zentralbank haben anhaltende Lücken bei der Risikodatenaggregation aufgezeigt, was Banken dazu veranlasst, Unternehmensplattformen einzuführen, die die Regeldurchsetzung automatisieren. Gesundheitsdienstleister setzen De-Identifizierungsroutinen ein, um die HIPAA-Anforderungen zu erfüllen und gleichzeitig granulare klinische Attribute für Forschungszwecke zu erhalten.
Analyse der Auswirkungen von Hemmnissen*
| Hemmnis | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Geringes Bewusstsein für Data-Wrangling-Werkzeuge bei KMU | -1.8% | Schwellenmärkte | Mittelfristig (2–4 Jahre) |
| Sicherheitsbedingte Datenzugangsbeschränkungen | -1.2% | EU, APAC | Langfristig (≥ 4 Jahre) |
| Mangel an Cloud-Datentechnik-Fachkräften | -1.1% | Nordamerika, EU | Mittelfristig (2–4 Jahre) |
| Steigende Cloud-Rechenkosten | -0.9% | Global | Kurzfristig (≤ 2 Jahre) |
| Quelle: Mordor Intelligence | |||
Geringes Bewusstsein für Data-Wrangling-Werkzeuge bei KMU
KMU machen 98,9 % aller Unternehmen in Zentral- und Westasien aus, doch mangelnde digitale Kompetenzen und Budgetbeschränkungen lassen viele auf Tabellenkalkulationen angewiesen sein[1]Asiatische Entwicklungsbank, "Asia SME Monitor 2022," adb.org . Politische Gremien befürworten Ausbildungssubventionen und Cloud-Gutscheine zur Ausweitung der Nutzung, während Anbieter Freemium-Stufen und lokale Wiederverkäuferpartnerschaften verfolgen, um dieses preissensible Segment zu erschließen.
Steigende Cloud-Rechenkosten für durch generative KI erweiterte Wrangling-Workloads
IBM meldete zwischen 2023 und 2025 einen Anstieg der Rechenausgaben um 89 %, was 70 % der Führungskräfte dazu veranlasste, KI-Projekte zu verzögern. Unternehmen vergleichen nun die Gesamtbetriebskosten bei Hyperscalern, setzen parametereffiziente Modelle ein und speichern Zwischenergebnisse zwischen, um die Ausgaben zu begrenzen. Diese Maßnahmen dämpfen, aber beseitigen nicht die Nachfrage nach KI-reichen Vorbereitungspipelines und erhalten die langfristige Wachstumstrajektorie des Marktes für Data Wrangling.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Datentyp: Unstrukturierte Volumina eröffnen neue Horizonte
Strukturierte Daten trugen im Jahr 2025 2,01 Milliarden USD zur Marktgröße für Data Wrangling bei, was einem Umsatzanteil von 57,85 % entspricht. Relationale Tabellen bleiben für die Transaktionsintegrität und das Kernberichtswesen unverzichtbar. Dennoch müssen moderne Pipelines Protokolle, Clickstreams und Sensordaten in Data-Warehouse- und Lakehouse-Umgebungen zusammenführen. SQL-zentrierte visuelle Builder, die automatisch Herkunftskarten erstellen, helfen Unternehmen, die Governance aufrechtzuerhalten, wenn die Zeilenzahlen steigen.
Das Segment der unstrukturierten Daten soll zwischen 2026 und 2031 bei einer CAGR von 12,32 % – dem höchsten Tempo unter den Datentypen – einen inkrementellen Umsatz von 1,19 Milliarden USD hinzufügen. LLM-gestützte Klassifizierung und Computer-Vision-Fähigkeiten erschließen Erkenntnisse aus Verträgen, technischen Zeichnungen und Videoframes. Anbieter differenzieren sich durch integrierte Vektorindizierung, multimodale Metadatenextraktion und datenschutzbewusste Schwärzungsmodule, die grenzüberschreitende Vorschriften einhalten.



Nach Komponente: Dienstleistungen expandieren mit zunehmender Projektkomplexität
Software-Werkzeuge hielten im Jahr 2025 68,85 % des Marktes für Data Wrangling, was 2,4 Milliarden USD an Lizenz- und Abonnementgebühren entspricht. Cloud-native Suiten verbinden Vorbereitung, Katalogisierung und Governance in einem einzigen Arbeitsbereich. Anbieter festigen die Kundenbindung, indem sie Vorbereitungsfunktionen in Analyse- oder ML-Workloads bündeln und Data Wrangling zu einem Workflow statt einer eigenständigen Aufgabe machen.
Der Dienstleistungsumsatz, der voraussichtlich jährlich um 12,45 % wachsen wird, spiegelt die Nachfrage nach Architekturdesign, Migration und verwalteten Betriebsleistungen wider. Die Zusammenarbeit von Deloitte mit Databricks bei Data as a Service für das Bankwesen unterstreicht den Mehrwert, den Expertenpartner bei Modernisierungsinitiativen bieten. Da Lakehouses und verteilte Fabrics reifen, lagern viele Unternehmen die Pipeline-Überwachung an Spezialisten aus, die rund um die Uhr Support im Rahmen ergebnisbasierter Verträge leisten.
Nach Geschäftsfunktion: Finanzen beschleunigen Technologieausgaben
Marketing und Vertrieb erfasste im Jahr 2025 37,95 % des Marktanteils für Data Wrangling, was 1,32 Milliarden USD entspricht, angetrieben durch Omnichannel-Aktivierung und Personalisierungsanforderungen. Plattform-Roadmaps fügen Reverse-ETL-Konnektoren hinzu, die saubere Attribute zurück an Kampagnen-Engines übertragen und nahezu Echtzeit-Segmentierung sowie A/B-Tests ermöglichen.
Finanz-Workloads werden bis 2031 mit einer CAGR von 11,98 % steigen, da Regulierungsbehörden die Berichtsanforderungen verschärfen und Finanzvorstände eine kontinuierliche Buchführung anstreben. Regelgesteuerte Abstimmungsvorlagen, Anomalieerkennung und sofortige Aggregationsfunktionen reduzieren Monatsabschlusszyklen von Tagen auf Stunden. Prüfungssichere Herkunftsnachweise und unveränderliche Datenqualitätsmetriken positionieren Anbieter für nachhaltiges Wachstum in Treasury-, Risiko- und Controllerteams.
Nach Endnutzerbranche: BFSI führt bei compliance-getriebenem Einsatz
IT und Telekommunikation trugen im Jahr 2025 0,95 Milliarden USD zum Markt für Data Wrangling bei. Diese Unternehmen betreiben massive Infrastruktur-Footprints und agieren als frühe Anwender von Daten-Governance-Rahmenwerken. Ihre Erfahrungen fließen in Best Practices ein, die später von anderen Branchen übernommen werden.
BFSI-Implementierungen werden alle anderen Sektoren übertreffen und bis 2031 jährlich um 11,42 % wachsen. Basel-konforme Berechnungen wie Liquiditäts- und Kreditwertanpassungen erfordern granulare, hochfrequente Datenströme, die veraltete ETL-Systeme nicht bewältigen können. Banken wenden sich an Wrangling-Engines, die verschachtelte XML-Handelsdateien analysieren, sie mit Referenzdaten anreichern und Herkunftsnachweise für Aufsichtsbehörden bereitstellen. Versicherungsgesellschaften nutzen ähnliche Pipelines für Solvenzanalysen, Katastrophenmodellierung und ESG-Offenlegungen.
Geografische Analyse
Nordamerika hielt im Jahr 2025 37,10 % des globalen Umsatzes, was auf eine tiefe Cloud-Durchdringung, etablierte Hyperscale-Rechenzentrumsnetzwerke und anhaltende Risikokapitalfinanzierung für KI-first-Plattformen zurückzuführen ist. Unternehmen in den Vereinigten Staaten treiben den Großteil der Ausgaben voran, veranschaulicht durch Microsofts Cloud-Umsatz von 42,4 Milliarden USD im ersten Quartal 2025 und den 80-prozentigen Kundenzuwachs bei Fabric. Kanada orientiert sich an Kompetenz- und Regulierungsrahmen, während Mexikos Fertigungscluster lokale Lakehouse-Implementierungen einsetzen, um Datensouveränitätsgesetzen zu entsprechen. Kostendruck treibt viele Unternehmen zu workload-bewusstem Tiering, das häufig abgerufene Datensätze auf schnellem Objektspeicher hält und kalte Daten lokal archiviert.
Asien-Pazifik soll eine CAGR von 11,75 % verzeichnen und ist damit das am schnellsten wachsende Gebiet für den Markt für Data Wrangling. Regionale Unternehmen profitieren von einem operativen Rechenzentrums-Footprint von 12.206 MW, einer wachsenden 5G-Nutzerbasis und souveränen Cloud-Angeboten in China, Indien und Indonesien. Lokale Anbieter arbeiten mit globalen Plattformen zusammen, um gebietsansässige Edge-Lösungen anzubieten, die Latenz- und Regulierungsanforderungen erfüllen. Starke E-Commerce- und Fintech-Ökosysteme in Singapur und Hongkong erfordern Echtzeit-Customer-360-Lösungen und verstärken den Bedarf an skalierbaren Vorbereitungs-Engines.
Europa verfügt über ein reifes, aber regulierungsintensives Umfeld, in dem die DSGVO und operationelle Risikovorgaben die Beschaffungskriterien bestimmen. Deutsche Automobilhersteller setzen digitale Zwillinge ein, die Anlagentelemetrie mit ERP-Daten verbinden. Banken im Vereinigten Königreich treiben die Automatisierung von Herkunftsnachweisen voran, um die Erwartungen der Prudential Regulation Authority zu erfüllen. Südamerika sowie der Nahe Osten und Afrika bleiben unterdessen noch jung, aber vielversprechend. Brasiliens Open-Banking-Initiative stimuliert API-Verkehr, der standardisiert werden muss, und Saudi-Arabiens Cloud-first-Direktiven erhöhen die Nachfrage nach lokalisierten Datenfabrics, die kulturelle und rechtliche Anforderungen in Einklang bringen.

Wettbewerbslandschaft
Der Markt für Data Wrangling umfasst eine Mischung aus breit aufgestellten Cloud-Suiten und spezialisierten Anbietern, was zu einer moderaten Machtkonzentration führt. Microsoft, IBM und Oracle bündeln Vorbereitung mit angrenzenden Analyse- und Governance-Modulen und nutzen dabei bestehende Unternehmensverträge und globale Vertriebsnetzwerke. Alteryx und Informatica konkurrieren durch intuitive Benutzeroberflächen und sofort einsatzbereite Konnektoren, die auf Fachabteilungsanalysten ausgerichtet sind. Databricks und Snowflake positionieren ihre Lakehouse- und Cloud-Datenplattform-Ökosysteme als Rückgrat für KI-native Transformationsabläufe, wobei Databricks bis Juli 2025 einen annualisierten Umsatz von 3,7 Milliarden USD und ein Wachstum von 50 % im Jahresvergleich erreichte.
Strategische Deals unterstreichen den Wettlauf um die Integration von KI und Governance. ServiceNow übernahm Data.world im Mai 2025, um Katalogisierung und Workflow-Orchestrierung zu integrieren[3]ServiceNow Pressemitteilung, "ServiceNow schließt Übernahme von data.world ab," servicenow.com. Databricks folgte mit Lilac AI, um die LLM-zentrierte Datenqualitätsbewertung zu stärken. Auch Partnerschaften nehmen zu; Databricks schloss sich im April 2025 mit BladeBridge zusammen, um Warehouse-zu-Lakehouse-Migrationen zu optimieren. Anbieter-Roadmaps umfassen nun Vektorspeicher, fein abgestimmte Sprachmodelle und kostenorientierte Orchestrierung, die automatisch zwischen Spark-, Photon- oder SQL-Engines wählt.
Der Preiswettbewerb steigt, da Hyperscaler die Speicher- und Rechentarife für langfristige Analyse-Cluster senken und damit die Margen für eigenständige Anbieter unter Druck setzen. Dennoch hält die Differenzierung durch vertikalisierte Vorlagen, Datenverträge und eingebettete Qualitätsprüfungen das Feld lebendig. Der nächste Wettbewerbsbereich wird sich wahrscheinlich auf autonome Agenten konzentrieren, die Pipelines nicht nur vorbereiten, sondern auch kontinuierlich überwachen und auf der Grundlage von Geschäftsregeländerungen anpassen.
Marktführer im Bereich Data Wrangling
Alteryx, Inc.
Oracle Corporation
Teradata Corporation
SAS Institute Inc.
Altair Engineering Inc.
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Jüngste Branchenentwicklungen
- Juni 2025: Microsoft meldete einen Gesamtumsatz von 70,1 Milliarden USD und einen Cloud-Umsatz von 42,4 Milliarden USD, ein Anstieg von 22 % im Jahresvergleich, was die Nachfrage nach KI- und Datendiensten unterstreicht.
- Mai 2025: ServiceNow schloss die Übernahme von data.world ab und fügte dem Workflow Data Fabric erweiterte Katalog- und Governance-Funktionen hinzu.
- April 2025: Databricks kooperierte mit BladeBridge, um über 20 veraltete Data Warehouses mithilfe KI-gesteuerter Werkzeuge auf Lakehouse-Architektur zu migrieren.
- März 2025: Microsoft meldete einen rekordverdächtigen vierteljährlichen Cloud-Umsatz von über 42 Milliarden USD, wobei die Einführung von Microsoft Fabric im Jahresvergleich um 80 % stieg.


Berichtsumfang des globalen Marktes für Data Wrangling
Data Wrangling wird als der Prozess der Vorbereitung von Rohdaten für die Analyse durch Bereinigung, Anordnung und Konvertierung in das erforderliche Format definiert. Data Wrangling, auch bekannt als Datenbereinigung oder Datenmunging, hilft Organisationen, komplexere Daten in kürzerer Zeit zu verarbeiten, genauere Ergebnisse zu erzielen und bessere Entscheidungen zu treffen.
Der Markt für Data Wrangling ist segmentiert nach Komponente (Werkzeug, Dienstleistung), Bereitstellung (cloudbasiert, vor Ort), Unternehmenstyp (groß, klein und mittelgroß), Endnutzerbranche (IT und Telekommunikation, Einzelhandel, Regierung, BFSI und Gesundheitswesen) sowie Geografie (Nordamerika, Europa, Asien-Pazifik, Lateinamerika sowie Naher Osten und Afrika).
Die Marktgrößen und Prognosen werden in Wertangaben (USD) für alle oben genannten Segmente bereitgestellt.
| Strukturierte Daten |
| Halbstrukturierte Daten |
| Unstrukturierte Daten |
| Software | Self-Service-Datenvorbereitungsplattformen |
| Eingebettete Vorbereitungsmodule in BI/KI-Suiten | |
| Dienstleistungen | Verwaltete Dienste |
| Professionelle Dienste / Beratungsdienstleistungen |
| Finanzen |
| Marketing und Vertrieb |
| Betrieb |
| Personalwesen |
| Recht und Compliance |
| IT und Telekommunikation |
| BFSI |
| Einzelhandel und E-Commerce |
| Gesundheitswesen |
| Regierung und öffentlicher Sektor |
| Sonstige Endnutzerbranchen |
| Nordamerika | Vereinigte Staaten | |
| Kanada | ||
| Mexiko | ||
| Europa | Deutschland | |
| Vereinigtes Königreich | ||
| Frankreich | ||
| Italien | ||
| Spanien | ||
| Übriges Europa | ||
| Asien-Pazifik | China | |
| Japan | ||
| Indien | ||
| Südkorea | ||
| Australien | ||
| Übriges Asien-Pazifik | ||
| Südamerika | Brasilien | |
| Argentinien | ||
| Übriges Südamerika | ||
| Naher Osten und Afrika | Naher Osten | Saudi-Arabien |
| Vereinigte Arabische Emirate | ||
| Türkei | ||
| Übriger Naher Osten | ||
| Afrika | Südafrika | |
| Ägypten | ||
| Nigeria | ||
| Übriges Afrika | ||
| Nach Datentyp | Strukturierte Daten | ||
| Halbstrukturierte Daten | |||
| Unstrukturierte Daten | |||
| Nach Komponente | Software | Self-Service-Datenvorbereitungsplattformen | |
| Eingebettete Vorbereitungsmodule in BI/KI-Suiten | |||
| Dienstleistungen | Verwaltete Dienste | ||
| Professionelle Dienste / Beratungsdienstleistungen | |||
| Nach Geschäftsfunktion | Finanzen | ||
| Marketing und Vertrieb | |||
| Betrieb | |||
| Personalwesen | |||
| Recht und Compliance | |||
| Nach Endnutzerbranche | IT und Telekommunikation | ||
| BFSI | |||
| Einzelhandel und E-Commerce | |||
| Gesundheitswesen | |||
| Regierung und öffentlicher Sektor | |||
| Sonstige Endnutzerbranchen | |||
| Nach Geografie | Nordamerika | Vereinigte Staaten | |
| Kanada | |||
| Mexiko | |||
| Europa | Deutschland | ||
| Vereinigtes Königreich | |||
| Frankreich | |||
| Italien | |||
| Spanien | |||
| Übriges Europa | |||
| Asien-Pazifik | China | ||
| Japan | |||
| Indien | |||
| Südkorea | |||
| Australien | |||
| Übriges Asien-Pazifik | |||
| Südamerika | Brasilien | ||
| Argentinien | |||
| Übriges Südamerika | |||
| Naher Osten und Afrika | Naher Osten | Saudi-Arabien | |
| Vereinigte Arabische Emirate | |||
| Türkei | |||
| Übriger Naher Osten | |||
| Afrika | Südafrika | ||
| Ägypten | |||
| Nigeria | |||
| Übriges Afrika | |||


Im Bericht beantwortete Schlüsselfragen
Wie groß ist der aktuelle Markt für Data Wrangling?
Der Markt für Data Wrangling erreichte im Jahr 2026 3,87 Milliarden USD und soll bis 2031 bei einer CAGR von 11,08 % auf 6,54 Milliarden USD wachsen.
Welche Region führt den Markt für Data Wrangling an?
Nordamerika führte im Jahr 2025 mit einem Umsatzanteil von 37,10 %, unterstützt durch eine tiefe Cloud-Nutzung und ein reifes Analyse-Ökosystem.
Welche Komponente wächst am schnellsten?
Dienstleistungen sind die am schnellsten wachsende Komponente mit einer CAGR von 12,45 %, da Unternehmen Expertenunterstützung für komplexe Transformationsprojekte suchen.
Warum investiert der BFSI-Sektor stark in Data Wrangling?
Strengere Vorschriften wie BCBS 239 erfordern eine robuste Risikoatenaggregation und Echtzeit-Berichterstattung, was die schnelle Einführung im Bank- und Versicherungswesen vorantreibt.
Wie wirken sich steigende Rechenkosten auf die Einführung aus?
Steigende Cloud-Ausgaben drängen Organisationen zu hybriden Implementierungen und parametereffizienten Modellen, doch die langfristige Wachstumstrajektorie bleibt intakt.
Welche Wettbewerbsmaßnahmen prägen den Markt?
Jüngste Übernahmen wie ServiceNow–data.world und Databricks–Lilac AI verdeutlichen einen Wandel hin zu integrierter Governance und KI-gestützter Qualitätsanalyse.
Seite zuletzt aktualisiert am:




