Größe und Marktanteil des Marktes für Synthetische Daten
Marktübersicht
| Studienzeitraum | 2020 - 2031 |
|---|---|
| Marktgröße (2026) | 0.71 Milliarden US-Dollar |
| Marktgröße (2031) | 3.67 Milliarden US-Dollar |
| Wachstumsrate (2026 - 2031) | 38.96% CAGR |
| Schnellstwachsender Markt | Asien-Pazifik |
| Größter Markt | Nordamerika |
| Marktkonzentration | Mittel |
Hauptakteure *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. | |
Analyse des Marktes für Synthetische Daten von Mordor Intelligence
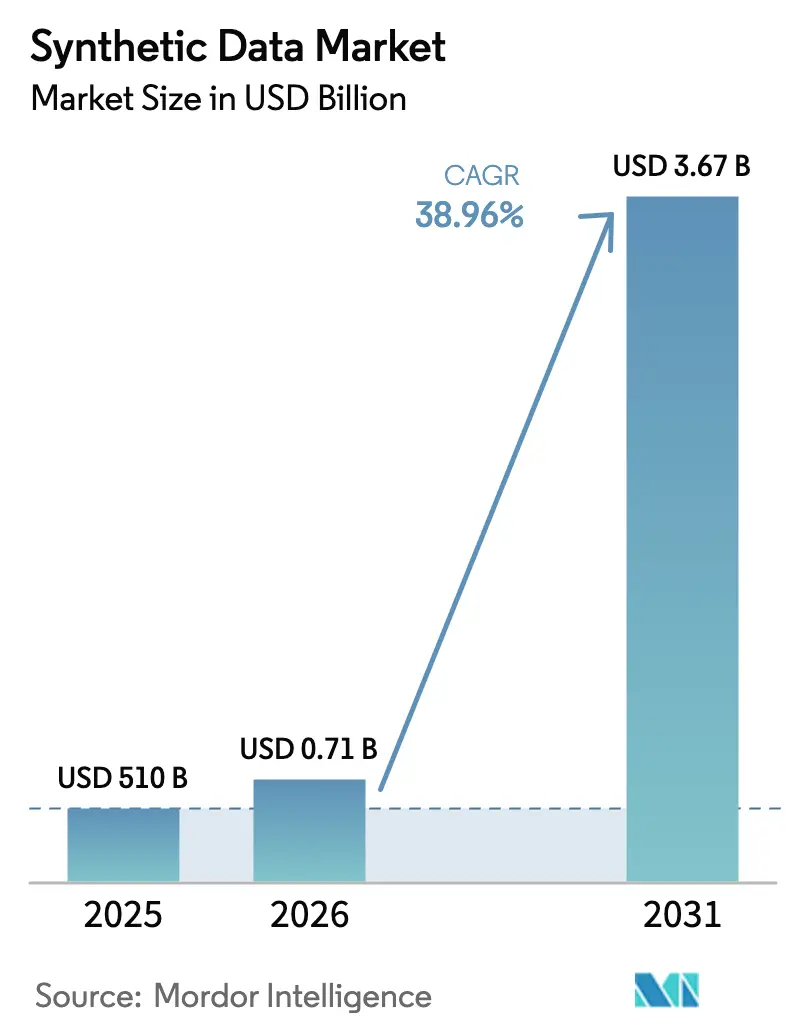
Die Größe des Marktes für synthetische Daten wird im Jahr 2026 auf 710 Millionen USD geschätzt, ausgehend von einem Wert von 510 Millionen USD im Jahr 2025, mit Projektionen für 2031, die 3,67 Milliarden USD zeigen, und einem Wachstum von 38,96 % CAGR über den Zeitraum 2026–2031. Dieses Wachstum resultiert aus datenschutzorientierten Vorschriften, steigenden generativen KI-Workloads und digitalen Transformationsprojekten, die auf konforme, aber statistisch zuverlässige Datensätze angewiesen sind. Unternehmen migrieren von Maskierungstools zu hochnützlichen Replikaten, die Beziehungen intakt halten und gleichzeitig dem EU-KI-Gesetz und ähnlichen Regelungen entsprechen. Technologieanbieter, die skalierbare Generierungsmaschinen mit Herkunftsverfolgung kombinieren, gewinnen Budgetanteile, da Governance-Teams prüfbare Ausgaben fordern. Gleichzeitig vertiefen neue Digitaler-Zwilling-Implementierungen in der Fertigung und Mobilität die Nachfrage nach physikintensiven Simulationen, die durch synthetische Daten angetrieben werden, und die Entstehung offener Datenaustauschplattformen erweitert die Marktreichweite durch die Verringerung von Beschaffungsreibungen.
Wichtigste Erkenntnisse des Berichts
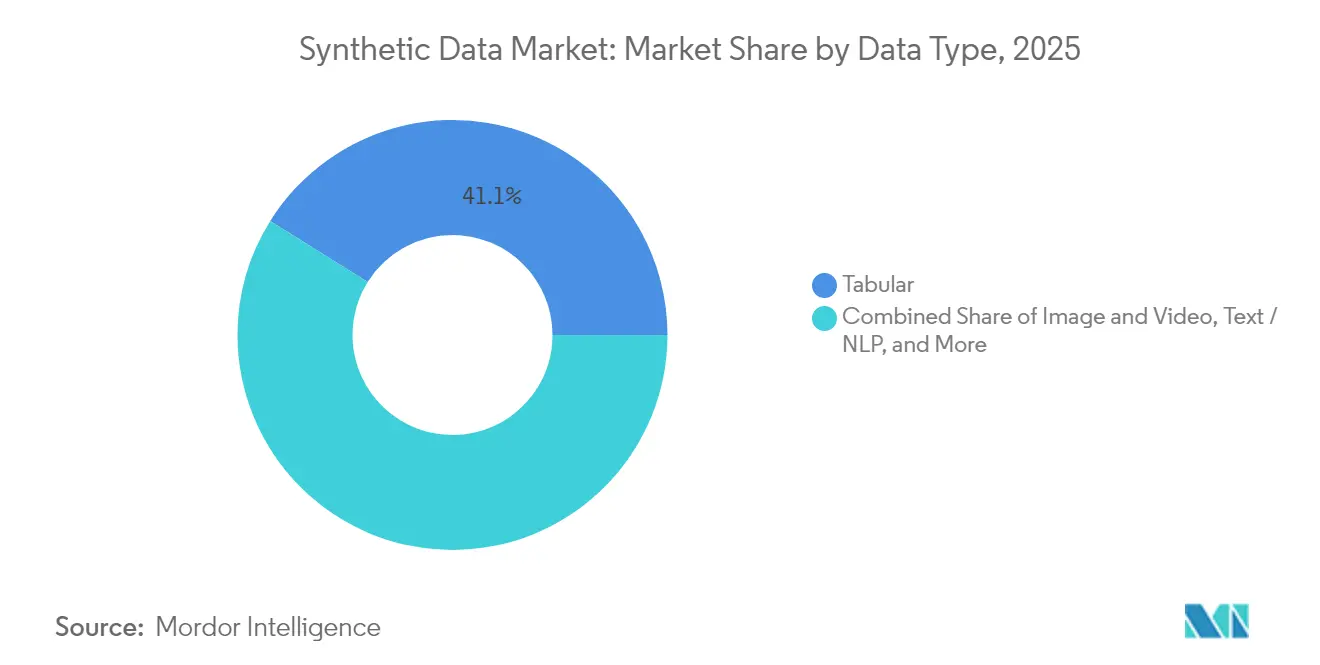
- Nach Datentyp hielt tabellarischer Inhalt im Jahr 2025 einen Marktanteil von 41,10 % am Markt für synthetische Daten; die Bild- und Videosynthese wird voraussichtlich bis 2031 mit einer CAGR von 40,10 % wachsen.
- Nach Angebot dominierten vollständig synthetische Lösungen im Jahr 2025 mit 60,55 % der Marktgröße für synthetische Daten und wachsen mit einer CAGR von 34,40 %.
- Nach Technologie erfassten Generative Adversarial Networks im Jahr 2025 37,75 % des Umsatzes, während Diffusionsmodelle bis 2031 voraussichtlich mit einer CAGR von 46,30 % wachsen werden.
- Nach Bereitstellungsmodus entfiel im Jahr 2025 ein Umsatzanteil von 66,80 % auf die Cloud-Bereitstellung, die bis 2031 mit einer CAGR von 28,60 % steigen soll.
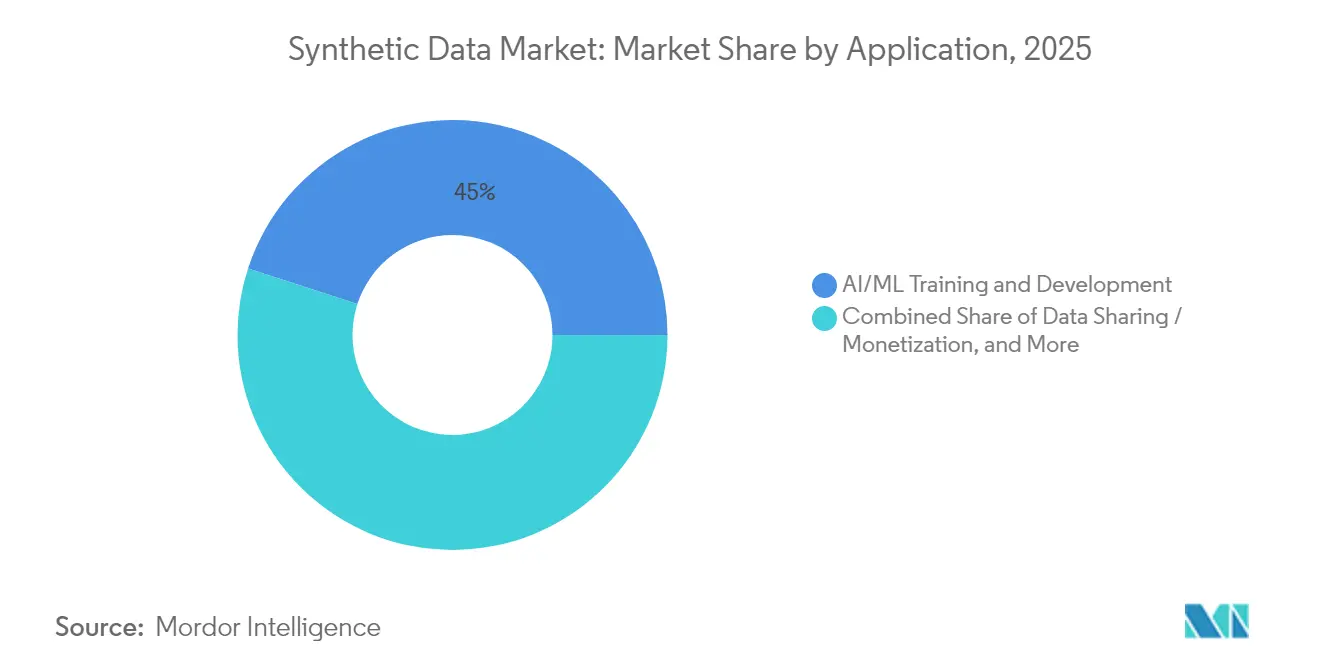
- Nach Anwendung repräsentierte KI/ML-Training und -Entwicklung im Jahr 2025 45,00 % des Umsatzes, während die Simulation autonomer Systeme die schnellste CAGR von 44,95 % bis 2031 verzeichnen dürfte.
- Nach Endnutzerbranche führte BFSI mit 23,25 % des Umsatzes im Jahr 2025, während Automobil und Transport voraussichtlich bis 2031 mit einer CAGR von 37,10 % stark wachsen wird.
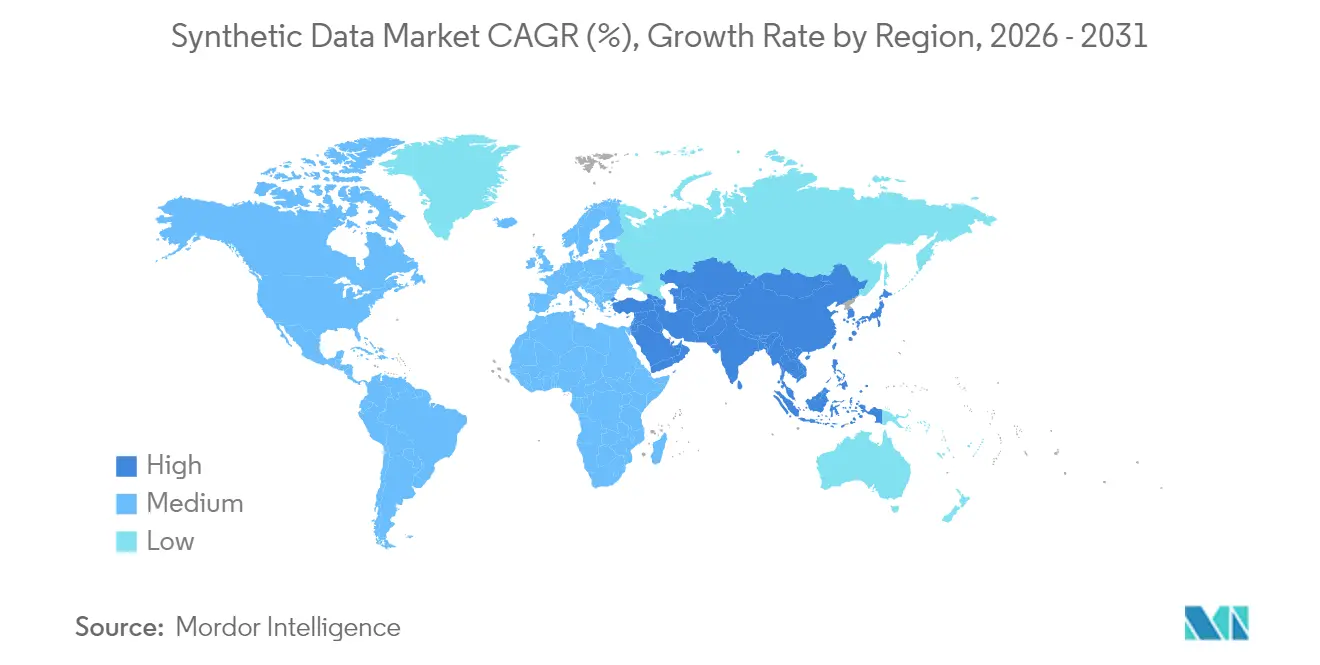
- Nach Geografie sicherte sich Nordamerika im Jahr 2025 38,10 % des Umsatzes; Asien-Pazifik wird voraussichtlich die höchste CAGR von 31,10 % über den Prognosezeitraum verzeichnen.
Hinweis: Die Marktgrößen- und Prognosezahlen in diesem Bericht werden mithilfe des proprietären Schätzrahmens von Mordor Intelligence erstellt und mit den neuesten verfügbaren Daten und Erkenntnissen bis 2026 aktualisiert.
Globale Trends und Erkenntnisse im Markt für Synthetische Daten
Analyse der Treiberwirkung*
| Treiber | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Regulatorischer Druck für datenschutzwahrende KI und Datenaustausch | +8.5% | Global, mit früher Einführung in der EU und Nordamerika | Mittelfristig (2–4 Jahre) |
| Boom der generativen KI mit Nachfrage nach skalierbaren, verzerrungsarmen Datensätzen | +12.2% | Global, konzentriert in Nordamerika und Asien-Pazifik | Kurzfristig (≤ 2 Jahre) |
| Wechsel von Datenmaskierung zu hochnützlichen synthetischen Replikaten | +6.8% | Nordamerika und EU, Ausweitung auf Asien-Pazifik | Mittelfristig (2–4 Jahre) |
| Integration von differenziellem Datenschutz und homomorpher Verschlüsselung | +4.3% | Global, angeführt von Technologiezentren in den USA und China | Langfristig (≥ 4 Jahre) |
| Entstehung offener synthetischer Datenaustauschplattformen | +3.7% | Nordamerika und EU, Pilotprogramme in Asien-Pazifik | Langfristig (≥ 4 Jahre) |
| Konvergenz digitaler Zwillinge in Industrie-4.0-Simulationen | +4.5% | Globale Industrieregionen, stark in Deutschland und Japan | Mittelfristig (2–4 Jahre) |
| Quelle: Mordor Intelligence | |||
Boom der Generativen KI mit Nachfrage nach Skalierbaren, Verzerrungsarmen Datensätzen
Groß angelegte Sprach- und Bildmodelle benötigen umfangreiche, vielfältige Korpora. Analysten schätzen, dass synthetische Inhalte bis 2024 60 % der KI-Trainingsdaten liefern werden. Hyperscaler reagieren darauf: NVIDIA hat den Nemotron-4-340B-Generator entwickelt, um nachgelagerte Pipelines zu versorgen, was die Datenerfassungskosten und Verzerrungsrisiken reduziert[1]NVIDIA, "Nemotron-4 340B: Ein Grundlagenmodell für die Generierung synthetischer Daten," developer.nvidia.com. Der Boom betrifft alle Branchen, ist jedoch am stärksten in Computer Vision und mehrsprachigem NLP ausgeprägt, wo die Beschaffung aus der realen Welt teuer oder durch Datenschutzgesetze verboten sein kann. Synthetische Augmentierung erweitert die Szenarioabdeckung, reduziert Annotationsbudgets und ermöglicht schnellere Experimente.
Regulatorischer Druck für Datenschutzwahrende KI und Datenaustausch
Das EU-KI-Gesetz verpflichtet Organisationen, synthetische Alternativen zu prüfen, bevor personenbezogene Daten verarbeitet werden. In den Vereinigten Staaten stellte das Ministerium für Innere Sicherheit 1,7 Millionen USD für Pilotprojekte mit synthetischen Generatoren bereit und bestätigte damit das föderale Interesse an konformem Datenaustausch[2]US-Ministerium für Innere Sicherheit, "Ausschreibung 23-DN-004 Lösungen für Synthetische Daten," dhs.gov. Chinas neue Kennzeichnungsregeln spiegeln ähnliche Absichten wider. Unternehmen, die synthetische Daten frühzeitig operationalisieren, vermeiden Bußgelder und erschließen grenzüberschreitende Kooperationen. Compliance verschiebt synthetische Daten daher von einem Nice-to-have zu einem Mandat auf Vorstandsebene.
Wechsel von Datenmaskierung zu Hochnützlichen Synthetischen Replikaten
Herkömmliche Anonymisierung bricht häufig die referenzielle Integrität und schränkt den analytischen Nutzen ein. Neue Plattformen generieren statistisch zuverlässige Replikate, die es Testern ermöglichen, realistische Workloads auszuführen, ohne ein Expositionsrisiko einzugehen. Die Integration von Synthesized in Google BigQuery veranschaulicht, wie die Generierung innerhalb gängiger Data Warehouses stattfinden kann. Deutsche Banken berichten von schnelleren Kreditrisikoanalysen nach der Einführung synthetischer Snapshots, die tabellenübergreifende Beziehungen intakt halten. Dieser Wandel lenkt das Budget von kostspieligen Zugriffskontrollen hin zur Self-Service-Datendemokratisierung um.
Konvergenz Digitaler Zwillinge in Industrie-4.0-Simulationen
Industrieunternehmen verbinden Digitaler-Zwilling-Engines mit synthetischen Sensorströmen, um Algorithmen für die vorausschauende Wartung zu testen. Springer-Forschungen zeigen eine zehnfache Beschleunigung der Produktentwicklungszyklen, wenn synthetische Telemetrie Datenlücken füllt[3]Springer, "Digitale Zwillinge und Synthetische Sensorströme," link.springer.com. NVIDIAs Omniverse generiert physikintensive Szenarien und ermöglicht es Automobilzulieferern und Robotikunternehmen, Grenzfälle zu validieren, die in der realen Welt riskant oder unmöglich wären. Die Kombination liefert sowohl Sicherheit als auch Kosteneinsparungen.
Analyse der Hemmnisauswirkungen*
| Hemmnis | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Risiko des Modellzusammenbruchs durch rekursiv trainierte Daten | -4.8% | Global, besonders relevant für die Entwicklung großer Sprachmodelle | Kurzfristig (≤ 2 Jahre) |
| Mangel an standardisierten Qualitätsmetriken bei Anbietern | -3.2% | Global, mit Standardisierungsbemühungen in den USA und der EU | Mittelfristig (2–4 Jahre) |
| Hohe Rechenkosten für multimodale Grundlagenmodelle | -5.1% | Global, am stärksten in ressourcenbeschränkten Märkten | Kurzfristig (≤ 2 Jahre) |
| Ungeklärter Rechtsstatus "nicht-personenbezogener" synthetischer Daten | -2.9% | Global, mit regulatorischer Unsicherheit in Schwellenmärkten | Langfristig (≥ 4 Jahre) |
| Quelle: Mordor Intelligence | |||
Risiko des Modellzusammenbruchs durch Rekursiv Trainierte Daten
Studien warnen, dass wiederholtes Training auf selbst generierten Inhalten die Datenvielfalt einschränkt und Verzerrungen verstärkt. Anbieter mischen nun organische Feeds und frieren Generatorgewichte ein, um Rückkopplungsschleifen zu begrenzen. Qualitätsprüfungen und Pipelines für aktives Lernen entstehen als Schutzmaßnahmen, doch das Problem bleibt ein kurzfristiges Hemmnis für vollständig synthetische Workflows.
Hohe Rechenkosten für Multimodale Grundlagenmodelle
Erstklassige Diffusionsmaschinen erfordern Tausende von GPUs und wochenlange Laufzeiten. Monatliche Rechnungen können für kleinere Unternehmen sechsstellige Beträge erreichen, was Experimente erschwert. Cloud-Pay-as-you-go-Dienste erleichtern den Einstieg, beseitigen jedoch keine Durchsatzkosten. Der Preisdruck könnte zur Hardwarespezialisierung und zur föderalen Auslagerung auf clientseitige Chips führen.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Datentyp: Visuelle Inhalte Treiben Innovation
Die Bild- und Videosynthese verzeichnet mit einer CAGR von 40,10 % bis 2031 das schnellste Wachstum, was die Entwicklung autonomer Fahrzeuge und Computer-Vision-Anwendungen widerspiegelt, die fotorealistische Trainingsdatensätze erfordern. Tabellarische Daten behalten mit einem Anteil von 41,10 % im Jahr 2025 die Marktführerschaft, angetrieben durch Finanzdienstleistungs- und Gesundheitsanwendungen, die strukturierte Datenschutzlösungen benötigen. Text- und NLP-Anwendungen profitieren von Fortschritten bei großen Sprachmodellen, während die Audiosynthese durch Plattformen wie Rightsifys Gramosynth für urheberrechtsfreie Musikgenerierung an Dynamik gewinnt. Die Synthese von Sensor- und Zeitreihendaten adressiert IoT- und industrielle Überwachungsanforderungen, besonders wertvoll für Anwendungen zur vorausschauenden Wartung, bei denen Ausfallszenarien in realen Datensätzen selten sind.
Die Entstehung multimodaler Grundlagenmodelle verwischt traditionelle Datentypgrenzen, wobei Plattformen wie NVIDIAs Cosmos physikbasierte synthetische Daten über visuelle, sensorische und zeitliche Modalitäten gleichzeitig generieren. Die Bewertung von Applied Intuition in Höhe von 15 Milliarden USD spiegelt das Vertrauen der Investoren in visuelle synthetische Datenanwendungen für autonome Systeme wider. Diese Konvergenz ermöglicht anspruchsvollere Simulationsumgebungen, die komplexe reale Interaktionen erfassen, besonders wertvoll für die Entwicklung von Robotik und autonomen Fahrzeugen, bei denen mehrere Sensormodalitäten synchronisiert werden müssen.



Nach Angebot: Vollständiger Ersatz Bevorzugt
Vollständig synthetische Pakete dominierten im Jahr 2025 mit 60,55 % des Umsatzes und wachsen mit einer CAGR von 34,40 %. Unternehmen wählen den vollständigen Ersatz, um Restdatenschutzrisiken zu eliminieren und Governance-Strukturen zu vereinfachen. Hybride Alternativen bleiben für hochpräzise klinische oder technische Workflows bestehen, bei denen geringfügige reale Anker die Modellgenauigkeit verbessern. Tonic.ais sicheres Lakehouse veranschaulicht die Nachfrage nach einer einheitlichen Steuerung über unstrukturierte Formate hinweg und unterstreicht die Marktmigration hin zu konsolidierten Toolchains.
Der Markt für synthetische Daten profitiert, da Regulierungsbehörden statistische Äquivalenztests gegenüber rohen Dateninspektionen akzeptieren, was die Genehmigungszeiträume verkürzt. Bank- und Versicherungsgruppen berichten von zweistelligen Reduzierungen der Compliance-Prüfungsstunden nach der Einführung. Anbieter, die Herkunft, Versionierung und Prüfungen des differenziellen Datenschutzes automatisieren, bündeln Mehrwertdienste, erhöhen die Wechselkosten und drängen die Branche zur Plattformkonsolidierung.
Nach Technologie: Diffusionsmodelle auf dem Vormarsch
GANs machen im Jahr 2025 noch immer 37,75 % des Umsatzes aus, aber Diffusionsmaschinen verzeichnen die schnellste CAGR von 46,30 %. Ihre Fähigkeit, sauberere und vielfältigere Frames zu erzeugen, positioniert sie für hochauflösende Videoaufgaben in der Unterhaltung und der fortgeschrittenen Fertigung. LLM-basierte Generatoren erweisen sich als stark für die tabellarische und Textsynthese, da sie Spaltenkorrelationen beibehalten und nachgelagerte Modell-F1-Scores verbessern. Regelbasierte Simulatoren bleiben in der deterministischen industriellen Steuerung bestehen, wo Physikgleichungen datengetriebene Zufälligkeit übertrumpfen.
Akademische Projekte wie SiloFuse demonstrieren die Eignung von Diffusion für föderierte Umgebungen, ein wichtiges Verkaufsargument im grenzüberschreitenden Finanz- und Gesundheitswesen. Benchmarks zeigen Fehlerquotenreduzierungen von 30 % gegenüber Legacy-Pipelines, was erklärt, warum OEMs trotz höherer Rechenkosten aufrüsten. Der Markt für synthetische Daten weist einen klaren Technologie-Erneuerungszyklus auf, der Anbieter belohnt, die Orchestrierungslogik von der Generatorarchitektur entkoppeln.
Nach Bereitstellungsmodus: Cloud-Dominanz Setzt Sich Fort
Cloud-Bereitstellungen sicherten sich im Jahr 2025 66,80 % des Umsatzes und werden bis 2031 mit einer CAGR von 28,60 % steigen. Unternehmen bevorzugen elastische GPU-Pools und verwaltete Compliance-Tools. AWS Bedrock, Google BigQuery mit Synthesized und NVIDIAs DGX Cloud hosten native Generierungs-APIs, die Projektanlaufzeiten verkürzen. On-Premise-Installationen bleiben für Verteidigung, Zentralbanken und Versorgungsunternehmen, die strengen Souveränitätsmandaten unterliegen, unverzichtbar.
Latenzempfindliche Handelsabteilungen experimentieren mit Edge-basierten Mikrogeneratoren, die synthetische Marktdaten in unter zwei Millisekunden aktualisieren. Gleichzeitig mildern Enklaven für vertrauliches Computing und Optionen zur Regionsfixierung Souveränitätsbedenken in der öffentlichen Cloud. Da die Kosten sinken und die Sicherheitsfunktionen verbessert werden, neigt der Markt für synthetische Daten weiter zur Cloud-First-Bereitstellung, obwohl hybride Footprints dort bestehen bleiben, wo Bandbreiten- oder Richtlinienbeschränkungen fortbestehen.
Nach Anwendung: Autonome Systeme Beschleunigen
KI/ML-Training dominierte im Jahr 2025 mit 45,00 % der Ausgaben und bestätigt, dass synthetische Augmentierung zu einem Mainstream-Entwicklungsinput geworden ist. Die Simulation autonomer Systeme wird voraussichtlich die höchste CAGR von 44,95 % verzeichnen, da Regulierungsbehörden vor der kommerziellen Einführung umfangreiche Szenariotests fordern. Software-Testteams nutzen synthetische Grenzfälle, um Fehler früher zu entdecken, und Betrugsanalyseeinheiten replizieren seltene Angriffsmuster, ohne Kundendaten preiszugeben.
Plattformen für Datenaustausch und Monetarisierung entstehen als neue Einnahmequellen. Unternehmen verkaufen anonymisierte, aber nützliche Datensätze an Partner und erschließen so Wert aus zuvor isolierten Vermögenswerten. In der Robotik produziert NVIDIAs Isaac-Pipeline in Stunden Hunderttausende von Bewegungstrajektorien und beschleunigt die Modellkonvergenz. Diese Dynamiken erweitern den Markt für synthetische Daten über Forschung und Entwicklung hinaus in den Produktionsbetrieb und kommerzielle Datenprodukte.
Nach Endnutzerbranche: Transformation im Automobilsektor
BFSI hielt im Jahr 2025 23,25 % des Umsatzes im Markt für synthetische Daten und nutzte Replikate für Risikomodellierung und Anti-Betrugs-Analysen. Automobil und Transport werden voraussichtlich mit einer CAGR von 37,10 % wachsen, angetrieben durch den Wettlauf zur Level-4-Autonomie, die Milliarden sicherer Fahrkilometer zur Validierung benötigt. Das Gesundheitswesen erprobt synthetische Patientenkohorten, um die Einschreibung in klinische Studien zu optimieren und die Privatsphäre zu schützen. Einzelhändler erstellen Kundenpfade für Personalisierungsmaschinen, und Telekommunikationsunternehmen simulieren Netzwerkausfälle, um die Zuverlässigkeit zu stärken. Regierungsbehörden erstellen Datensätze für die Missionsplanung, die klassifizierte Merkmale entfernen, aber den strategischen Nutzen erhalten. Der Markt für synthetische Daten dringt somit in jeden Sektor vor, in dem reale Daten knapp, sensibel oder teuer zu erfassen sind.
Geografische Analyse
Nordamerika erfasste im Jahr 2025 38,10 % des Umsatzes. Technologiegiganten wie Microsoft und Meta investieren Dutzende von Milliarden in KI-Infrastruktur, die auf synthetische Pipelines angewiesen ist, und föderale Programme validieren den Ansatz für Anwendungsfälle der inneren Sicherheit. Cluster in Kalifornien, Texas und Ontario ziehen Risikokapital an und bieten ein dichtes Ökosystem von Spezialisten, das Innovationen in den Bereichen Finanzen, Gesundheit und Verteidigung vorantreibt.
Asien-Pazifik verzeichnet die schnellste CAGR von 31,10 %. Chinas Gesetz zur Kennzeichnung KI-generierter Inhalte ermutigt Unternehmen, synthetische Alternativen anstelle echter Nutzerprotokolle zu generieren, und Robotikführer in Japan kombinieren synthetische Wahrnehmungsdaten mit Fabrikautomatisierung. Indien nutzt synthetische Patientenakten zur Stärkung von Telemedizin-Plattformen inmitten von Datenlokalisierungsregeln, und Südkoreas Halbleiterkapazität unterstützt das regionale Modelltraining. Südostasien profitiert von Fintech-Startups, die datenschutzsichere Kreditdaten teilen, um die finanzielle Inklusion zu erweitern.
Europa verbindet regulatorische Führerschaft mit kommerziellem Schwung. Das EU-KI-Gesetz formalisiert eine Synthetic-First-Haltung, und die Europäische Kommission hat die Methode für den digitalen Finanzbereich validiert. Deutschlands Industrie-4.0-Projekte kombinieren digitale Zwillinge und synthetische Telemetrie zur Optimierung des Energieverbrauchs. Das Vereinigte Königreich nutzt seine regulatorische Unabhängigkeit, um vereinfachte Genehmigungswege zu erproben. Nordische Staaten investieren in grüne Rechenzentren, die CO₂-neutrale Generierungscluster beherbergen und Nachhaltigkeitsziele mit KI-Wachstum in Einklang bringen. Andernorts integrieren Smart-City-Programme im Nahen Osten synthetische Datensätze für Mobilität und Sicherheit, und afrikanische Start-ups nutzen Cloud-APIs, um Datenknappheit auszugleichen und gleichzeitig sich entwickelnde Datenschutzgesetze zu navigieren.

Wettbewerbslandschaft
Der Markt für synthetische Daten bleibt mäßig konzentriert, aber hochdynamisch. NVIDIAs Übernahme von Gretel für 320 Millionen USD verbindet Hardware, Modellorchestrierung und Datenschutz-Tools zu einem End-to-End-Stack. SAS Institute kaufte Hazy, um die Generierung in Analysepakete zu integrieren, die von Banken und Versicherern genutzt werden. Applied Intuition sammelte Kapital bei einer Bewertung von 15 Milliarden USD, um domänenspezifische Simulationen für autonomes Fahren zu liefern, was die Prämie für vertikale Tiefe unterstreicht.
Drei Wettbewerbsarchetypen entstehen. Infrastrukturführer monetarisieren Rechenleistung im großen Maßstab und bündeln synthetische Engines. Vertikalspezialisten passen Domänenontologien und Validierungsmetriken an. Plattformintegratoren konzentrieren sich auf Governance-Schichten, die disparate Generatoren mit unternehmensweiten Datenfabrics verbinden.
IEEE-Arbeitsgruppen erarbeiten Qualitätsstandards, die die Basisgenerierungsfunktionalität zur Ware machen und den Wettbewerb in Richtung Compliance-Automatisierung und Echtzeit-Beobachtbarkeit verlagern könnten. Im Prognosezeitraum sind Übernahmen wahrscheinlich, da größere Unternehmen nach Fähigkeitsbreite suchen, aber Open-Source-Diffusion senkt die Eintrittsbarrieren für neue Marktteilnehmer und hält den Markt für synthetische Daten wettbewerbsfähig.
Marktführer im Bereich Synthetischer Daten
MOSTLY AI Solutions MP GmbH
NVIDIA Corporation
Meta Platforms, Inc.
Amazon.com, Inc.
Microsoft Corporation
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Jüngste Branchenentwicklungen
- April 2025: Tonic.ai erwarb Fabricate, um natürlichsprachliche Schnittstellen bereitzustellen, die es nicht-technischem Personal ermöglichen, schnell konforme Datensätze zu erstellen.
- März 2025: NVIDIA erwarb Gretel für 320 Millionen USD und integrierte datenschutzwahrende Generierung in seine Cloud-KI-Dienste.
- Januar 2025: NVIDIA veröffentlichte das Cosmos World Foundation Model, das fotorealistische synthetische Szenen für autonome Fahrzeuge und Roboter ermöglicht, wobei Uber zu den ersten Nutzern gehörte.
- Januar 2025: NVIDIA erweiterte Omniverse um generative physikalische KI und gewann Accenture, Microsoft und Siemens als frühe Anwender.


Rahmen der Forschungsmethodik und Umfang des Berichts
Marktdefinitionen und wichtige Abdeckung
Unsere Studie definiert den Markt für synthetische Daten als alle kommerziellen Umsätze, die durch Softwareplattformen, Cloud-Dienste und APIs generiert werden, die algorithmisch künstliche Datensätze erstellen, deren statistische Muster reale Informationen für KI/ML-Training, Testdatenmanagement, Datenschutz und Simulation replizieren.
Der Klarheit halber schließen wir veraltete Datenmaskierungstools aus, die lediglich vorhandene Datensätze anonymisieren, anstatt neue, statistisch repräsentative Daten zu generieren.
Segmentierungsübersicht
- Nach Datentyp
- Tabellarisch
- Text / NLP
- Bild und Video
- Audio
- Sensor / Zeitreihen
- Nach Angebot
- Vollständig Synthetisch
- Teilweise Synthetisch / Hybrid
- Nach Technologie
- GANs
- Diffusionsmodelle
- LLM-basierte Generatoren
- Regelbasierte / Agentenbasierte Simulationen
- Nach Bereitstellungsmodus
- Cloud
- On-Premise
- Nach Anwendung
- KI/ML-Training und -Entwicklung
- Datenaustausch / Monetarisierung
- Softwaretests und DevOps
- Simulation Autonomer Systeme
- Cybersicherheit und Betrugstests
- Nach Endnutzerbranche
- BFSI
- Gesundheitswesen und Biowissenschaften
- Einzelhandel und E-Commerce
- Automobil und Transport
- Regierung und Verteidigung
- IT und ITeS
- Industrie und Robotik
- Nach Geografie
- Nordamerika
- Vereinigte Staaten
- Kanada
- Mexiko
- Südamerika
- Brasilien
- Argentinien
- Übriges Südamerika
- Europa
- Deutschland
- Vereinigtes Königreich
- Frankreich
- Italien
- Spanien
- Russland
- Übriges Europa
- Asien-Pazifik
- China
- Japan
- Indien
- Südkorea
- Australien und Neuseeland
- Übriges Asien-Pazifik
- Naher Osten und Afrika
- Naher Osten
- Saudi-Arabien
- Vereinigte Arabische Emirate
- Türkei
- Übriger Naher Osten
- Afrika
- Südafrika
- Nigeria
- Ägypten
- Übriges Afrika
- Naher Osten
- Nordamerika
Detaillierte Forschungsmethodik und Datenvalidierung
Primärforschung
Mordor-Analysten befragten Cloud-KI-Architekten, Chief Privacy Officers in BFSI und im Gesundheitswesen sowie Beschaffungsverantwortliche in Nordamerika, Europa und Asien-Pazifik.
Ihre Erkenntnisse zu Lizenzpreisstufen, Nutzungsquoten und regulatorischen Engpässen ermöglichten es uns, Annahmen zu verfeinern, die Sekundärdaten allein nicht auflösen konnten.
Desk-Research
Wir begannen mit der Schätzung der potenziellen Nachfrage durch offene Quellen wie das OECD-KI-Politikobservatorium, den EU-DSGVO-Durchsetzungs-Tracker, die Softwareausgabentabellen des US-Wirtschaftsanalysebüros und von IEEE Xplore indexierte, von Fachleuten begutachtete Zeitschriften.
D&B Hoovers und Dow Jones Factiva lieferten indikative Anbieterumsätze, während Weißbücher des ITI Council halfen, Einführungssignale zu verifizieren.
Um disparate Datenpunkte in vergleichbare Metriken umzuwandeln, normalisierten wir Werte auf konstante US-Dollar von 2025, glichen Währungsschwankungen mithilfe von IWF-Durchschnittswerten ab und archivierten jede Referenz in einem internen Repository.
Die obige Liste ist illustrativ; viele weitere Sekundärquellen flossen in die Datenerhebung, -validierung und -klärung ein.
Marktgrößenbestimmung und Prognose
Wir wendeten eine Kombination aus Top-down- und Bottom-up-Ansatz an: Unternehmens-KI-Softwareausgaben bildeten den Nachfragepool, Penetrationsraten nach Sektor wandelten diesen in Umsätze mit synthetischen Daten um, und die Ergebnisse wurden mit Stichproben von Anbieter-Rollups und Tests des durchschnittlichen Verkaufspreises × Volumen abgeglichen.
Zu den Schlüsselvariablen gehören GPU-Stundenkostenkurven, regionale Compliance-Ausgaben, aktive KI-Projektzahlen und synthetische Bildvolumina pro autonomer Fahrzeugmeile.
Eine multivariate Regression projiziert diese Treiber bis 2030; fehlende Mikrodaten wurden aus benachbarten Indikatoren interpoliert und während der Überprüfung abgeglichen.
Datenvalidierung und Aktualisierungszyklus
Wir führen Anomalie-Sweeps, mehrstufige Peer-Reviews und Varianzprüfungen gegen unabhängige Benchmarks durch, bevor wir die Freigabe erteilen.
Modelle werden jährlich aktualisiert, mit Zwischenaktualisierungen, wenn Ereignisse wie neue Datenschutzgesetze die Nachfrage wesentlich verschieben.
Warum Mordors Baseline für Synthetische Daten Zuverlässigkeit Gebietet
Wir erkennen an, dass veröffentlichte Schätzungen häufig abweichen, weil Unternehmen unterschiedliche Umfänge, Annahmen und Aktualisierungsrhythmen verwenden.
Indem wir uns strikt auf den Umsatz von Generierungsplattformen konzentrieren und unser Modell jährlich neu kalibrieren, minimiert Mordor sowohl Über- als auch Unterschätzungen.
Benchmarkvergleich
| Marktgröße | Anonymisierte Quelle | Primärer Unterschiedstreiber |
|---|---|---|
| 0,51 Mrd. USD (2025) | ||
| 0,30 Mrd. USD (2023) | Globale Unternehmensberatung A | Umfasst Anonymisierungssoftware und Proof-of-Concept-Ausgaben |
| 0,29 Mrd. USD (2024) | Branchenjournal B | Wendet eine einheitliche CAGR ohne regionale Kalibrierung an |
Diese Kontraste zeigen, dass Mordors disziplinierte Umfangsauswahl, das variablengetriebene Modell und die zeitnahe Aktualisierung eine ausgewogene, transparente Baseline liefern, auf die Entscheidungsträger sich verlassen können.


Im Bericht beantwortete Schlüsselfragen
Wie hoch ist das prognostizierte Wachstum des Marktes für synthetische Daten bis 2031?
Der Markt für synthetische Daten wird voraussichtlich von 710 Millionen USD im Jahr 2026 auf 3,67 Milliarden USD bis 2031 steigen, was einer CAGR von 38,96 % entspricht.
Warum gewinnen Diffusionsmodelle Marktanteile gegenüber GANs?
Diffusionsmaschinen erzeugen qualitativ hochwertigere und stabilere Bilder und treiben damit eine CAGR von 46,30 % an, die das Wachstum GAN-basierter Ansätze übertrifft.
Welcher Bereitstellungsmodus dominiert die Ausgaben?
Die Cloud-Bereitstellung macht 66,80 % des Umsatzes im Jahr 2025 aus und expandiert mit einer CAGR von 28,60 % dank elastischer GPU-Pools und integrierter Compliance-Tools.
Wie beeinflussen neue Vorschriften die Einführung?
Regelungen wie das EU-KI-Gesetz verpflichten Unternehmen, synthetische Alternativen zu testen, bevor personenbezogene Daten verarbeitet werden, was Generierungsplattformen zu einer Compliance-Notwendigkeit macht.
Welche Endnutzerbranche ist für das schnellste Wachstum positioniert?
Automobil und Transport wird voraussichtlich mit einer CAGR von 37,10 % wachsen, da Programme für autonomes Fahren eine umfangreiche synthetische Szenarioabdeckung für die Sicherheitsvalidierung benötigen.
Was ist das größte Hindernis für kleinere Unternehmen?
Hohe Rechenkosten für multimodale Grundlagenmodelle bleiben die größte Barriere, da GPU-intensive Workloads die monatlichen Cloud-Rechnungen in den sechsstelligen Bereich treiben.
Seite zuletzt aktualisiert am:




