Tamanho e Participação do Mercado de Dados Sintéticos
Visão Geral do Mercado
| Período de Estudo | 2020 - 2031 |
|---|---|
| Tamanho do Mercado (2026) | 0.71 Bilhões de dólares |
| Tamanho do Mercado (2031) | 3.67 Bilhões de dólares |
| Taxa de crescimento (2026 - 2031) | 38.96% CAGR |
| Mercado de Crescimento Mais Rápido | Ásia-Pacífico |
| Maior Mercado | América do Norte |
| Concentração do Mercado | Médio |
Principais jogadores *Isenção de responsabilidade: Principais participantes classificados em nenhuma ordem específica Imagem © Mordor Intelligence. O reuso requer atribuição conforme CC BY 4.0. | |
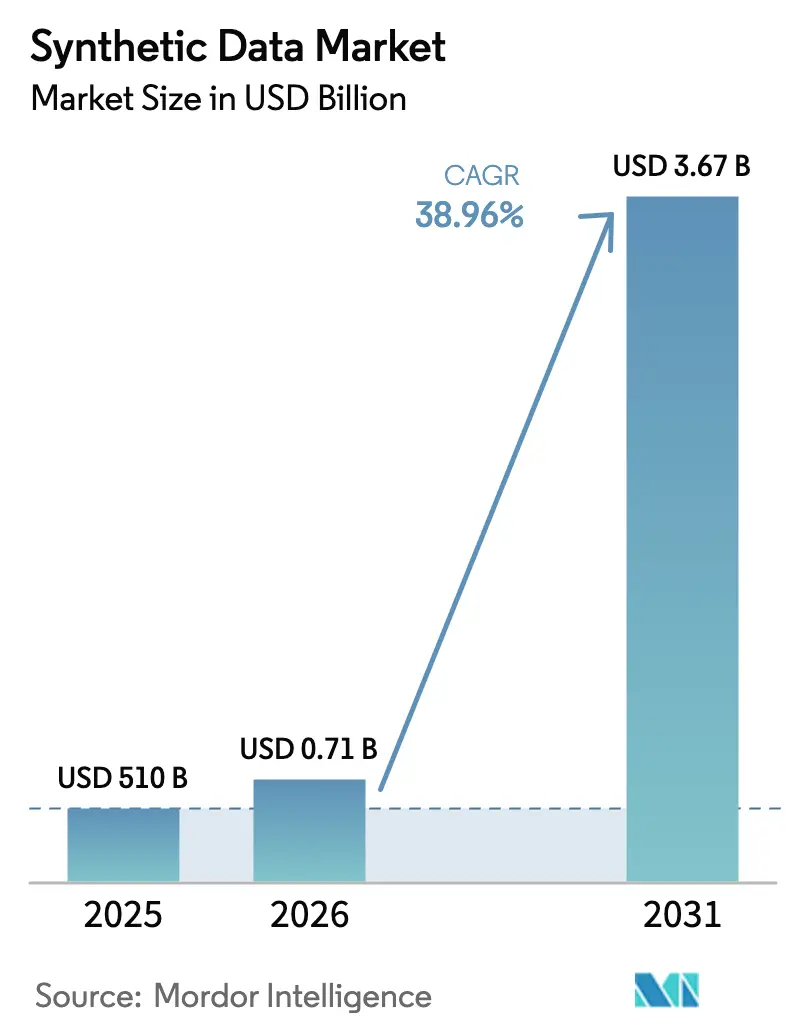
Análise do Mercado de Dados Sintéticos por Mordor Intelligence
O tamanho do mercado de dados sintéticos em 2026 é estimado em USD 710 milhões, crescendo a partir do valor de 2025 de USD 510 milhões, com projeções para 2031 mostrando USD 3,67 bilhões, crescendo a um CAGR de 38,96% no período de 2026 a 2031. Esse crescimento resulta de regulamentações que priorizam a privacidade, cargas de trabalho de IA generativa em expansão e projetos de transformação digital que dependem de conjuntos de dados em conformidade, porém estatisticamente fiéis. As empresas estão migrando de ferramentas de mascaramento para réplicas de alta utilidade que mantêm os relacionamentos intactos, ao mesmo tempo em que se alinham com a Lei de IA da UE e normas similares. Os fornecedores de tecnologia que combinam mecanismos de geração escaláveis com rastreamento de linhagem conquistam participação orçamentária à medida que as equipes de governança exigem resultados auditáveis. Ao mesmo tempo, novas implantações de gêmeos digitais em manufatura e mobilidade aprofundam a demanda por simulações ricas em física impulsionadas por dados sintéticos, e o surgimento de mercados abertos de dados sintéticos amplia o alcance do mercado ao reduzir a fricção no fornecimento.
Principais Conclusões do Relatório
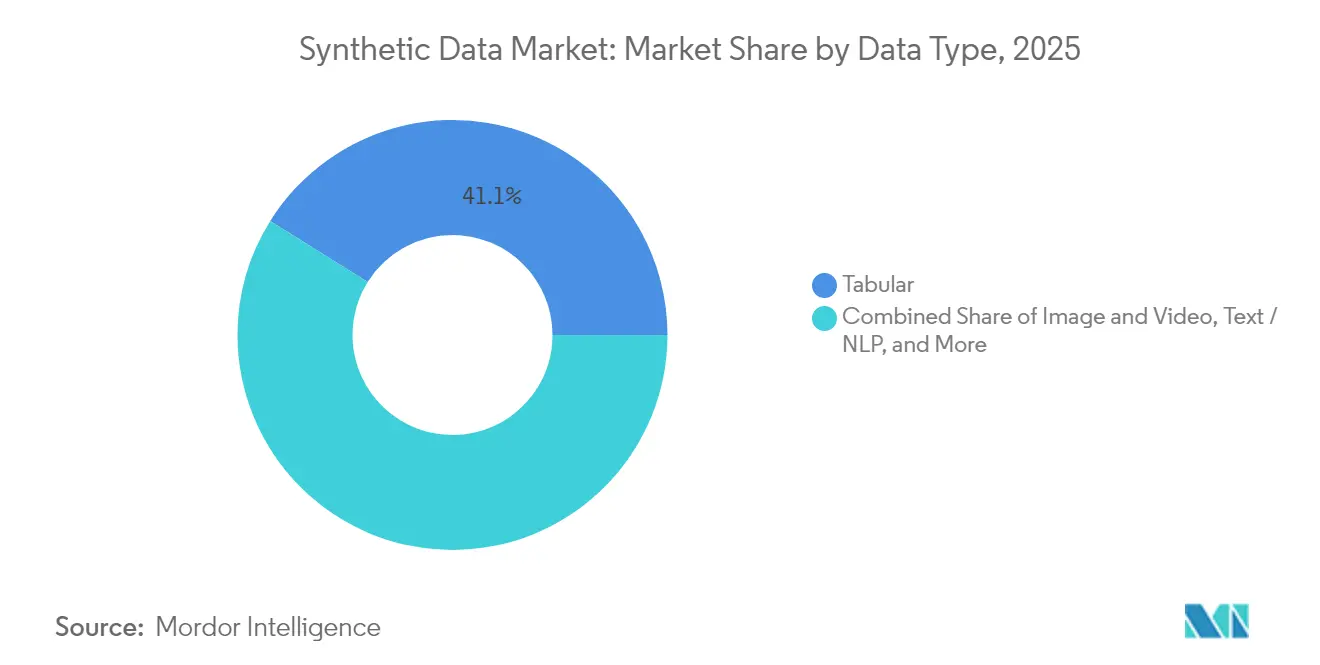
- Por tipo de dados, o conteúdo tabular detinha 41,10% da participação do mercado de dados sintéticos em 2025; a síntese de imagem e vídeo tem previsão de expansão a um CAGR de 40,10% até 2031.
- Por oferta, as soluções totalmente sintéticas representavam 60,55% do tamanho do mercado de dados sintéticos em 2025 e estão avançando a um CAGR de 34,40%.
- Por tecnologia, as Redes Adversariais Generativas capturaram 37,75% da receita em 2025, enquanto os Modelos de Difusão têm projeção de crescimento a um CAGR de 46,30% até 2031.
- Por modo de implantação, a implantação em nuvem representou 66,80% da receita em 2025 e deve crescer a um CAGR de 28,60% até 2031.
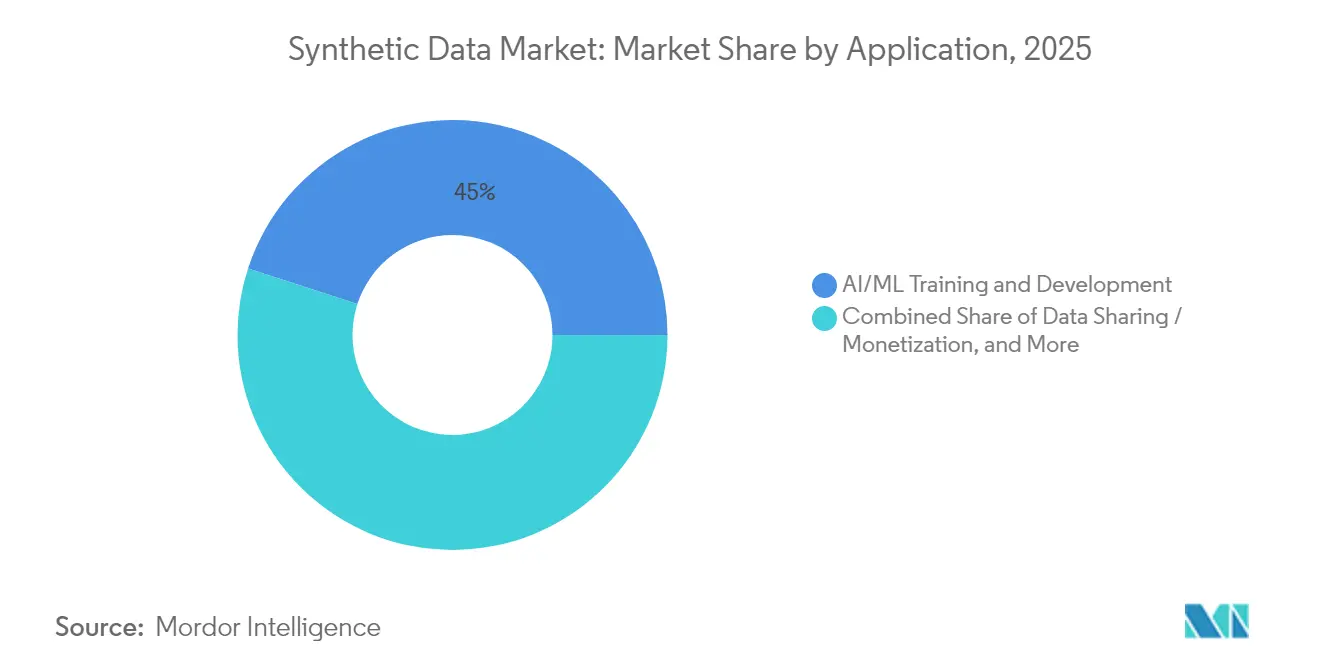
- Por aplicação, o treinamento e desenvolvimento de IA/ML representou 45,00% da receita de 2025, enquanto a simulação de sistemas autônomos está posicionada para o CAGR mais rápido de 44,95% até 2031.
- Por setor do usuário final, o BFSI liderou com 23,25% da receita de 2025, enquanto o setor automotivo e de transporte tem projeção de crescimento a um CAGR de 37,10% até 2031.
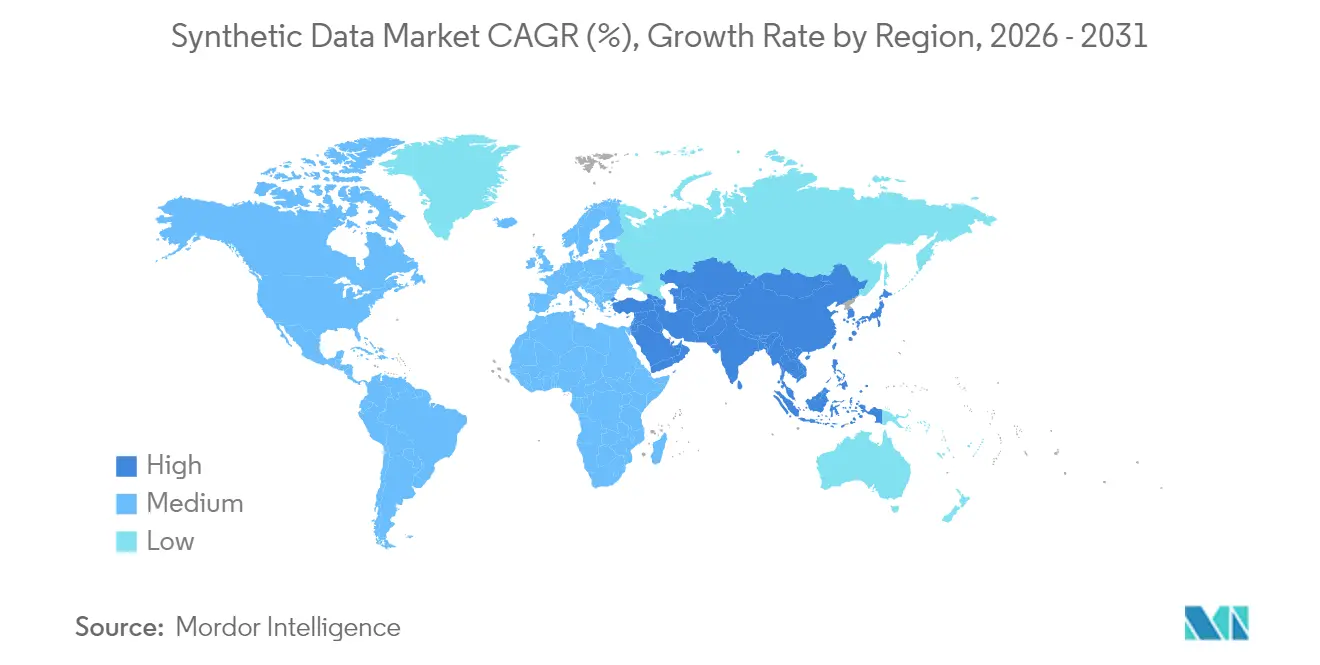
- Por geografia, a América do Norte assegurou 38,10% da receita em 2025; a Ásia-Pacífico deve registrar o maior CAGR de 31,10% ao longo do período de previsão.
Nota: Os números de tamanho de mercado e previsão neste relatório são gerados usando a estrutura de estimativa proprietária da Mordor Intelligence, atualizada com os dados e insights mais recentes disponíveis até 2026.
Tendências e Perspectivas do Mercado Global de Dados Sintéticos
Análise de Impacto dos Impulsionadores*
| Impulsionador | (~) % de Impacto na Previsão do CAGR | Relevância Geográfica | Prazo de Impacto |
|---|---|---|---|
| Pressão regulatória para IA que preserva a privacidade e compartilhamento de dados | +8.5% | Global, com adoção antecipada na UE e na América do Norte | Médio prazo (2 a 4 anos) |
| Expansão da IA generativa exigindo conjuntos de dados escaláveis e com baixo viés | +12.2% | Global, concentrado na América do Norte e na Ásia-Pacífico | Curto prazo (≤ 2 anos) |
| Migração do mascaramento de dados para réplicas sintéticas de alta utilidade | +6.8% | América do Norte e UE, expandindo-se para a Ásia-Pacífico | Médio prazo (2 a 4 anos) |
| Integração de privacidade diferencial e criptografia homomórfica | +4.3% | Global, liderado por centros tecnológicos nos EUA e na China | Longo prazo (≥ 4 anos) |
| Surgimento de mercados abertos de dados sintéticos | +3.7% | América do Norte e UE, programas-piloto na Ásia-Pacífico | Longo prazo (≥ 4 anos) |
| Convergência de gêmeos digitais em simulações da Indústria 4.0 | +4.5% | Regiões industriais globais, forte na Alemanha e no Japão | Médio prazo (2 a 4 anos) |
| Fonte: Mordor Intelligence | |||
Expansão da IA Generativa Exigindo Conjuntos de Dados Escaláveis e com Baixo Viés
Modelos de linguagem e visão em larga escala requerem corpora vastos e diversificados. Analistas estimam que o conteúdo sintético fornecerá 60% dos dados de treinamento de IA até 2024. Os hiperescaladores estão respondendo: a NVIDIA projetou o gerador Nemotron-4 340B para alimentar pipelines downstream, reduzindo custos de aquisição de dados e riscos de viés[1]NVIDIA, "Nemotron-4 340B: Um Modelo Fundacional para Geração de Dados Sintéticos," developer.nvidia.com. A expansão atinge todos os setores, mas é mais aguda em visão computacional e PLN multilíngue, onde o fornecimento de dados do mundo real pode ser caro ou proibido pela legislação de privacidade. O aumento sintético amplia a cobertura de cenários, reduz orçamentos de anotação e permite experimentação mais rápida.
Pressão Regulatória para IA que Preserva a Privacidade e Compartilhamento de Dados
A Lei de IA da UE obriga as organizações a explorar substitutos sintéticos antes de processar dados pessoais. Nos Estados Unidos, o Departamento de Segurança Interna reservou USD 1,7 milhão para projetos-piloto de geradores sintéticos, confirmando o interesse federal em troca de dados em conformidade [2]Departamento de Segurança Interna dos EUA, "Solicitação 23-DN-004 Soluções de Dados Sintéticos," dhs.gov. As novas regras de rotulagem da China ecoam intenção semelhante. As empresas que operacionalizam dados sintéticos antecipadamente evitam multas e desbloqueiam colaborações transfronteiriças. A conformidade, portanto, transforma os dados sintéticos de um diferencial desejável em um mandato de nível de conselho.
Migração do Mascaramento de Dados para Réplicas Sintéticas de Alta Utilidade
A anonimização tradicional frequentemente quebra a integridade referencial, limitando a utilidade analítica. As novas plataformas geram réplicas estatisticamente fiéis, permitindo que os testadores executem cargas de trabalho realistas sem risco de exposição. A integração da Synthesized ao Google BigQuery ilustra como a geração pode residir dentro de armazéns de dados convencionais. Bancos alemães relatam análises de risco de crédito mais rápidas após adotar instantâneos sintéticos que mantêm os relacionamentos entre tabelas intactos. Essa migração redireciona o orçamento de controles de acesso onerosos para a democratização de dados em autoatendimento.
Convergência de Gêmeos Digitais em Simulações da Indústria 4.0
Empresas industriais combinam mecanismos de gêmeos digitais com fluxos sintéticos de sensores para testar algoritmos de manutenção preditiva sob estresse. Pesquisas da Springer mostram aceleração de dez vezes nos ciclos de desenvolvimento de produtos quando a telemetria sintética preenche lacunas de dados [3]Springer, "Gêmeos Digitais e Fluxos Sintéticos de Sensores," link.springer.com. O Omniverse da NVIDIA gera cenários ricos em física, permitindo que fornecedores automotivos e empresas de robótica validem casos extremos que seriam arriscados ou impossíveis no mundo real. A combinação proporciona tanto segurança quanto economia de custos.
Análise de Impacto das Restrições*
| Restrição | (~) % de Impacto na Previsão do CAGR | Relevância Geográfica | Prazo de Impacto |
|---|---|---|---|
| Risco de colapso de modelo a partir de dados treinados recursivamente | -4.8% | Global, afetando particularmente o desenvolvimento de LLMs | Curto prazo (≤ 2 anos) |
| Falta de métricas de qualidade padronizadas entre fornecedores | -3.2% | Global, com esforços de padronização nos EUA e na UE | Médio prazo (2 a 4 anos) |
| Alto custo computacional para modelos fundacionais multimodais | -5.1% | Global, mais agudo em mercados com recursos limitados | Curto prazo (≤ 2 anos) |
| Status legal incipiente de dados sintéticos "não pessoais" | -2.9% | Global, com incerteza regulatória em mercados emergentes | Longo prazo (≥ 4 anos) |
| Fonte: Mordor Intelligence | |||
Risco de Colapso de Modelo a partir de Dados Treinados Recursivamente
Estudos alertam que o treinamento repetido em conteúdo autogerado reduz a diversidade dos dados e amplifica o viés. Os fornecedores agora mesclam feeds orgânicos e congelam os pesos do gerador para limitar os ciclos de retroalimentação. Auditorias de qualidade e pipelines de aprendizado ativo estão surgindo como salvaguardas, mas o problema permanece como um freio de curto prazo nos fluxos de trabalho totalmente sintéticos.
Alto Custo Computacional para Modelos Fundacionais Multimodais
Os mecanismos de difusão de ponta requerem milhares de GPUs e semanas de tempo de execução. As contas mensais podem ultrapassar seis dígitos para empresas menores, dificultando a experimentação. Os serviços de nuvem com pagamento por uso facilitam a entrada, mas não eliminam os custos de throughput. A pressão sobre os preços pode incentivar a especialização de hardware e o descarregamento federado para chips do lado do cliente.
*Nossas previsões tratam os impactos dos impulsionadores e restrições como direcionais, e não aditivos. As previsões de impacto refletem o crescimento de base, os efeitos de composição e as interações entre variáveis.
Análise de Segmentos
Por Tipo de Dados: O Conteúdo Visual Impulsiona a Inovação
A síntese de Imagem e Vídeo lidera o crescimento mais rápido com um CAGR de 40,10% até 2031, refletindo o desenvolvimento de veículos autônomos e aplicações de visão computacional que demandam conjuntos de dados de treinamento fotorrealistas. Os dados tabulares mantêm a liderança de mercado com 41,10% de participação em 2025, impulsionados por aplicações de serviços financeiros e saúde que requerem soluções de privacidade de dados estruturados. As aplicações de Texto e PLN se beneficiam dos avanços em modelos de linguagem de grande porte, enquanto a síntese de áudio ganha impulso por meio de plataformas como o Gramosynth da Rightsify para geração de música livre de direitos autorais. A síntese de dados de Sensores e Séries Temporais atende aos requisitos de monitoramento de IoT e industrial, particularmente valiosa para aplicações de manutenção preditiva onde cenários de falha são raros em conjuntos de dados do mundo real.
O surgimento de modelos fundacionais multimodais está borrando as fronteiras tradicionais entre tipos de dados, com plataformas como o Cosmos da NVIDIA gerando dados sintéticos baseados em física em modalidades visuais, de sensores e temporais simultaneamente. A avaliação de USD 15 bilhões da Applied Intuition reflete a confiança dos investidores em aplicações de dados sintéticos visuais para sistemas autônomos. Essa convergência permite ambientes de simulação mais sofisticados que capturam interações complexas do mundo real, particularmente valiosos para o desenvolvimento de robótica e veículos autônomos onde múltiplas modalidades de sensores devem ser sincronizadas.



Por Oferta: Substituição Completa é Preferida
Os pacotes totalmente sintéticos dominaram 60,55% da receita de 2025 e estão crescendo a um CAGR de 34,40%. As empresas optam pela substituição total para eliminar o risco residual de privacidade e simplificar as estruturas de governança. As alternativas híbridas permanecem para fluxos de trabalho clínicos ou de engenharia de alta fidelidade, onde pequenas âncoras do mundo real melhoram a precisão do modelo. O data lakehouse seguro da Tonic.ai exemplifica a demanda por controle em painel único em formatos não estruturados, sublinhando a migração do mercado em direção a cadeias de ferramentas consolidadas.
O mercado de dados sintéticos se beneficia à medida que os reguladores aceitam testes de equivalência estatística em vez de inspeções de dados brutos, reduzindo os prazos de aprovação. Grupos bancários e de seguros citam reduções de dois dígitos nas horas de revisão de conformidade após a adoção. Os fornecedores que automatizam linhagem, versionamento e verificações de privacidade diferencial agrupam serviços de valor agregado, aumentando os custos de migração e impulsionando o setor em direção à consolidação de plataformas.
Por Tecnologia: Modelos de Difusão em Ascensão
As GANs ainda representam 37,75% da receita de 2025, mas os mecanismos de difusão registram o CAGR mais rápido de 46,30%. Sua capacidade de produzir quadros mais limpos e diversificados os posiciona para tarefas de vídeo de alta resolução em entretenimento e manufatura avançada. Os geradores baseados em LLM se mostram fortes para síntese tabular e de texto, retendo correlações de colunas e aumentando as pontuações F1 dos modelos downstream. Os simuladores baseados em regras persistem no controle industrial determinístico, onde as equações físicas superam a aleatoriedade orientada por dados.
Projetos acadêmicos como o SiloFuse demonstram a adequação da difusão para ambientes federados, um ponto de venda fundamental em finanças e saúde transfronteiriças. Os benchmarks revelam reduções de 30% na taxa de defeitos em comparação com pipelines legados, explicando por que os fabricantes de equipamentos originais fazem upgrades apesar das contas computacionais mais altas. O mercado de dados sintéticos exibe um ciclo claro de atualização tecnológica que recompensa os fornecedores que desacoplam a lógica de orquestração da arquitetura do gerador.
Por Modo de Implantação: Domínio da Nuvem Continua
As implantações em nuvem conquistaram 66,80% da receita de 2025 e crescerão a um CAGR de 28,60% até 2031. As empresas favorecem pools de GPU elásticos e ferramentas de conformidade gerenciadas. O AWS Bedrock, o Google BigQuery com Synthesized e o DGX Cloud da NVIDIA hospedam APIs de geração nativas que reduzem os tempos de inicialização de projetos. As instalações locais permanecem críticas para defesa, bancos centrais e concessionárias regidas por mandatos rígidos de soberania.
Mesas de negociação sensíveis à latência experimentam microgeradores baseados em borda que atualizam dados sintéticos de mercado em menos de dois milissegundos. Enquanto isso, enclaves de computação confidencial e opções de fixação de região atenuam as preocupações de soberania na nuvem pública. À medida que os custos diminuem e os recursos de segurança melhoram, o mercado de dados sintéticos se inclina ainda mais para a implantação em nuvem em primeiro lugar, embora as pegadas híbridas persistam onde restrições de largura de banda ou de política se mantêm.
Por Aplicação: Sistemas Autônomos Aceleram
O treinamento de IA/ML representou 45,00% dos gastos de 2025, confirmando que o aumento sintético se tornou um insumo de desenvolvimento convencional. A simulação de sistemas autônomos tem projeção de registrar o maior CAGR de 44,95% à medida que os reguladores exigem testes exaustivos de cenários antes da implantação comercial. As equipes de teste de software exploram casos extremos sintéticos para descobrir bugs mais cedo, e as unidades de análise de fraude replicam padrões de ataque raros sem expor registros de clientes.
As plataformas de compartilhamento e monetização de dados surgem como novos fluxos de receita. As empresas vendem conjuntos de dados anonimizados, porém úteis, a parceiros, desbloqueando valor de ativos anteriormente isolados. Em robótica, o pipeline Isaac da NVIDIA produz centenas de milhares de trajetórias de movimento em horas, acelerando a convergência do modelo. Essas dinâmicas ampliam o mercado de dados sintéticos além da pesquisa e desenvolvimento para operações de produção e produtos de dados comerciais.
Por Setor do Usuário Final: Transformação Automotiva
O BFSI detinha 23,25% da receita de 2025 no tamanho do mercado de dados sintéticos, aproveitando réplicas para modelagem de risco e análise antifraude. O setor automotivo e de transporte tem previsão de crescimento a um CAGR de 37,10%, impulsionado pela corrida em direção à autonomia de Nível 4, que necessita de bilhões de quilômetros de direção segura para validação. A saúde realiza projetos-piloto com coortes sintéticas de pacientes para agilizar o recrutamento em ensaios clínicos e proteger a privacidade. Os varejistas fabricam jornadas de clientes para mecanismos de personalização, e as empresas de telecomunicações simulam eventos de falha de rede para fortalecer a confiabilidade. As agências governamentais elaboram conjuntos de dados de planejamento de missões que removem características classificadas, mas mantêm a utilidade estratégica. O mercado de dados sintéticos, portanto, penetra em todos os setores onde os dados do mundo real são escassos, sensíveis ou caros de coletar.
Análise Geográfica
A América do Norte capturou 38,10% da receita de 2025. Gigantes da tecnologia como Microsoft e Meta gastam dezenas de bilhões em infraestrutura de IA que depende de pipelines sintéticos, e programas federais validam a abordagem para casos de uso de segurança interna. Clusters na Califórnia, Texas e Ontário atraem capital de risco, proporcionando um ecossistema denso de especialistas que alimentam a inovação em finanças, saúde e defesa.
A Ásia-Pacífico apresenta o CAGR mais rápido de 31,10%. A lei de rotulagem de conteúdo gerado por IA da China incentiva as empresas a gerar alternativas sintéticas em vez de registros reais de usuários, e os líderes em robótica no Japão combinam dados sintéticos de percepção com automação de fábricas. A Índia aproveita registros sintéticos de pacientes para fortalecer plataformas de telessaúde em meio a regras de localização de dados, e a capacidade de semicondutores da Coreia do Sul apoia o treinamento de modelos na região. O Sudeste Asiático se beneficia de startups de fintech que compartilham dados de crédito seguros para a privacidade a fim de expandir a inclusão financeira.
A Europa combina liderança regulatória com impulso comercial. A Lei de IA da UE formaliza uma postura sintética em primeiro lugar, e a Comissão Europeia validou o método para finanças digitais. Os projetos Industrie 4.0 da Alemanha combinam gêmeos digitais e telemetria sintética para otimizar o uso de energia. O Reino Unido capitaliza a independência regulatória para projetos-piloto de caminhos de aprovação simplificados. Os países nórdicos investem em centros de dados verdes que hospedam clusters de geração com neutralidade de carbono, alinhando metas de sustentabilidade com o crescimento da IA. Em outros lugares, os programas de cidades inteligentes do Oriente Médio integram conjuntos de dados sintéticos para mobilidade e segurança, e startups africanas acessam APIs de nuvem para compensar a escassez de dados enquanto navegam por leis de privacidade em evolução.

Cenário Competitivo
O mercado de dados sintéticos permanece moderadamente concentrado, porém altamente dinâmico. A aquisição de USD 320 milhões da Gretel pela NVIDIA funde hardware, orquestração de modelos e ferramentas de privacidade em uma pilha de ponta a ponta. O SAS Institute adquiriu a Hazy para incorporar a geração em suítes analíticas usadas por bancos e seguradoras. A Applied Intuition captou capital a uma avaliação de USD 15 bilhões para fornecer simulação específica de domínio para direção autônoma, sublinhando o prêmio pela profundidade vertical.
Três arquétipos competitivos emergem. Os líderes de infraestrutura monetizam a computação em escala e agrupam mecanismos sintéticos. Os especialistas verticais adaptam ontologias de domínio e métricas de validação. Os integradores de plataforma se concentram em camadas de governança que conectam geradores díspares a estruturas de dados empresariais.
Os grupos de trabalho do IEEE elaboram padrões de qualidade que poderiam tornar a funcionalidade de geração base uma commodity e deslocar a rivalidade para automação de conformidade e observabilidade em tempo real. Ao longo do período de previsão, aquisições são prováveis à medida que empresas maiores buscam amplitude de capacidades, mas a difusão de código aberto reduz as barreiras para novos entrantes, mantendo o mercado de dados sintéticos contestável.
Líderes do Setor de Dados Sintéticos
MOSTLY AI Solutions MP GmbH
NVIDIA Corporation
Meta Platforms, Inc.
Amazon.com, Inc.
Microsoft Corporation
- *Isenção de responsabilidade: Principais participantes classificados em nenhuma ordem específica

Desenvolvimentos Recentes do Setor
- Abril de 2025: A Tonic.ai adquiriu a Fabricate para fornecer interfaces em linguagem natural que permitem que funcionários não técnicos criem conjuntos de dados em conformidade rapidamente.
- Março de 2025: A NVIDIA adquiriu a Gretel por USD 320 milhões, integrando a geração que preserva a privacidade em seus serviços de IA em nuvem.
- Janeiro de 2025: A NVIDIA lançou o Modelo Fundacional de Mundo Cosmos, permitindo cenas sintéticas fotorrealistas para veículos autônomos e robôs, com a Uber entre os primeiros usuários.
- Janeiro de 2025: A NVIDIA expandiu o Omniverse com IA física generativa, adicionando Accenture, Microsoft e Siemens como primeiros adotantes.


Estrutura da metodologia de pesquisa e escopo do relatório
Definições de Mercado e Cobertura Principal
Nosso estudo define o mercado de dados sintéticos como toda a receita comercial gerada por plataformas de software, serviços em nuvem e APIs que criam algoritmicamente conjuntos de dados artificiais cujos padrões estatísticos replicam informações reais para treinamento de IA/ML, gestão de dados de teste, preservação de privacidade e simulação.
Para maior clareza, excluímos utilitários legados de mascaramento de dados que meramente anonimizam registros existentes em vez de gerar dados novos e estatisticamente representativos.
Visão Geral da Segmentação
- Por Tipo de Dados
- Tabular
- Texto / PLN
- Imagem e Vídeo
- Áudio
- Sensor / Séries Temporais
- Por Oferta
- Totalmente Sintético
- Parcialmente Sintético / Híbrido
- Por Tecnologia
- GANs
- Modelos de Difusão
- Geradores Baseados em LLM
- Simulações Baseadas em Regras / Baseadas em Agentes
- Por Modo de Implantação
- Nuvem
- Local
- Por Aplicação
- Treinamento e Desenvolvimento de IA/ML
- Compartilhamento / Monetização de Dados
- Teste de Software e DevOps
- Simulação de Sistemas Autônomos
- Teste de Cibersegurança e Fraude
- Por Setor do Usuário Final
- BFSI
- Saúde e Ciências da Vida
- Varejo e Comércio Eletrônico
- Automotivo e Transporte
- Governo e Defesa
- TI e ITeS
- Industrial e Robótica
- Por Geografia
- América do Norte
- Estados Unidos
- Canadá
- México
- América do Sul
- Brasil
- Argentina
- Restante da América do Sul
- Europa
- Alemanha
- Reino Unido
- França
- Itália
- Espanha
- Rússia
- Restante da Europa
- Ásia-Pacífico
- China
- Japão
- Índia
- Coreia do Sul
- Austrália e Nova Zelândia
- Restante da Ásia-Pacífico
- Oriente Médio e África
- Oriente Médio
- Arábia Saudita
- Emirados Árabes Unidos
- Turquia
- Restante do Oriente Médio
- África
- África do Sul
- Nigéria
- Egito
- Restante da África
- Oriente Médio
- América do Norte
Metodologia de Pesquisa Detalhada e Validação de Dados
Pesquisa Primária
Os analistas da Mordor Intelligence entrevistaram arquitetos de IA em nuvem, diretores de privacidade em BFSI e saúde, e responsáveis por aquisições na América do Norte, Europa e Ásia-Pacífico.
Suas percepções sobre faixas de preços de licenças, índices de uso e gargalos regulatórios nos permitiram refinar premissas que os dados secundários por si só não conseguiam resolver.
Pesquisa Documental
Começamos dimensionando a demanda potencial por meio de fontes abertas, como o Observatório de Políticas de IA da OCDE, o rastreador de aplicação do RGPD da UE, as tabelas de gastos com software do Departamento de Análise Econômica dos Estados Unidos e periódicos revisados por pares indexados no IEEE Xplore.
O D&B Hoovers e o Dow Jones Factiva forneceram receitas indicativas de fornecedores, enquanto os white papers do ITI Council ajudaram a verificar os sinais de adoção.
Para traduzir pontos de dados díspares em métricas comparáveis, normalizamos os valores para dólares constantes de 2025, reconciliamos as variações cambiais usando as médias do FMI e arquivamos cada referência em um repositório interno.
A lista acima é ilustrativa; muitos outros insumos secundários informaram a coleta, validação e esclarecimento de dados.
Dimensionamento de Mercado e Previsão
Aplicamos uma combinação de abordagem de cima para baixo e de baixo para cima: os gastos com software de IA empresarial formaram o pool de demanda, as taxas de penetração por setor o converteram em receita de dados sintéticos, e os resultados foram verificados em relação a consolidações de fornecedores amostrados e testes de preço médio de venda × volume.
As principais variáveis incluem curvas de custo por hora de GPU, despesas regionais de conformidade, contagens de projetos de IA ativos e volumes de imagens sintéticas por quilômetro de veículo autônomo.
Uma regressão multivariada projeta esses impulsionadores até 2030; os microdados ausentes foram interpolados a partir de indicadores adjacentes e reconciliados durante a revisão.
Validação de Dados e Ciclo de Atualização
Realizamos varreduras de anomalias, revisões por pares em múltiplos estágios e verificações de variância em relação a benchmarks independentes antes da aprovação.
Os modelos são atualizados a cada ano, com atualizações intermediárias quando eventos como novas leis de privacidade alteram materialmente a demanda.
Por que a Linha de Base de Dados Sintéticos da Mordor Inspira Confiabilidade
Reconhecemos que as estimativas publicadas frequentemente divergem porque as empresas adotam diferentes escopos, premissas e cadências de atualização.
Ao focar estritamente na receita de plataformas de geração e ao recalibrar nosso modelo anualmente, a Mordor minimiza tanto a superestimação quanto a subestimação.
Comparação de Benchmarks
| Tamanho do Mercado | Fonte anonimizada | Principal fator de divergência |
|---|---|---|
| USD 0,51 B (2025) | ||
| USD 0,30 B (2023) | Consultoria Global A | Inclui software de anonimização e gastos com prova de conceito |
| USD 0,29 B (2024) | Periódico do Setor B | Aplica CAGR uniforme sem calibração regional |
Esses contrastes mostram que a seleção disciplinada de escopo, o modelo orientado por variáveis e a atualização oportuna da Mordor fornecem uma linha de base equilibrada e transparente na qual os tomadores de decisão podem confiar.


Principais Perguntas Respondidas no Relatório
Qual é o crescimento projetado do mercado de dados sintéticos até 2031?
O mercado de dados sintéticos tem previsão de crescer de USD 710 milhões em 2026 para USD 3,67 bilhões até 2031, refletindo um CAGR de 38,96%.
Por que os modelos de difusão estão ganhando participação em relação às GANs?
Os mecanismos de difusão geram imagens de maior qualidade e mais estáveis, impulsionando um CAGR de 46,30% que supera o crescimento das abordagens baseadas em GANs.
Qual modo de implantação domina os gastos?
A implantação em nuvem representa 66,80% da receita de 2025 e está se expandindo a um CAGR de 28,60% graças a pools de GPU elásticos e ferramentas de conformidade integradas.
Como as novas regulamentações influenciam a adoção?
Normas como a Lei de IA da UE exigem que as empresas testem alternativas sintéticas antes de processar dados pessoais, tornando as plataformas de geração uma necessidade de conformidade.
Qual setor vertical está posicionado para o crescimento mais rápido?
O setor automotivo e de transporte deve crescer a um CAGR de 37,10% porque os programas de direção autônoma necessitam de ampla cobertura sintética de cenários para validação de segurança.
Qual é o principal obstáculo para empresas menores?
Os altos custos computacionais para modelos fundacionais multimodais permanecem a maior barreira, com cargas de trabalho intensivas em GPU elevando as contas mensais de nuvem para a casa dos seis dígitos.
Página atualizada pela última vez em:




