Taille et parts du marché de la synthèse vocale
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2020 - 2031 |
|---|---|
| Taille du Marché (2026) | 4.36 Milliards de dollars |
| Taille du Marché (2031) | 7.92 Milliards de dollars |
| Taux de croissance (2026 - 2031) | 12.66% CAGR |
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Amérique du Nord |
| Concentration du Marché | Moyen |
Acteurs majeurs *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. | |
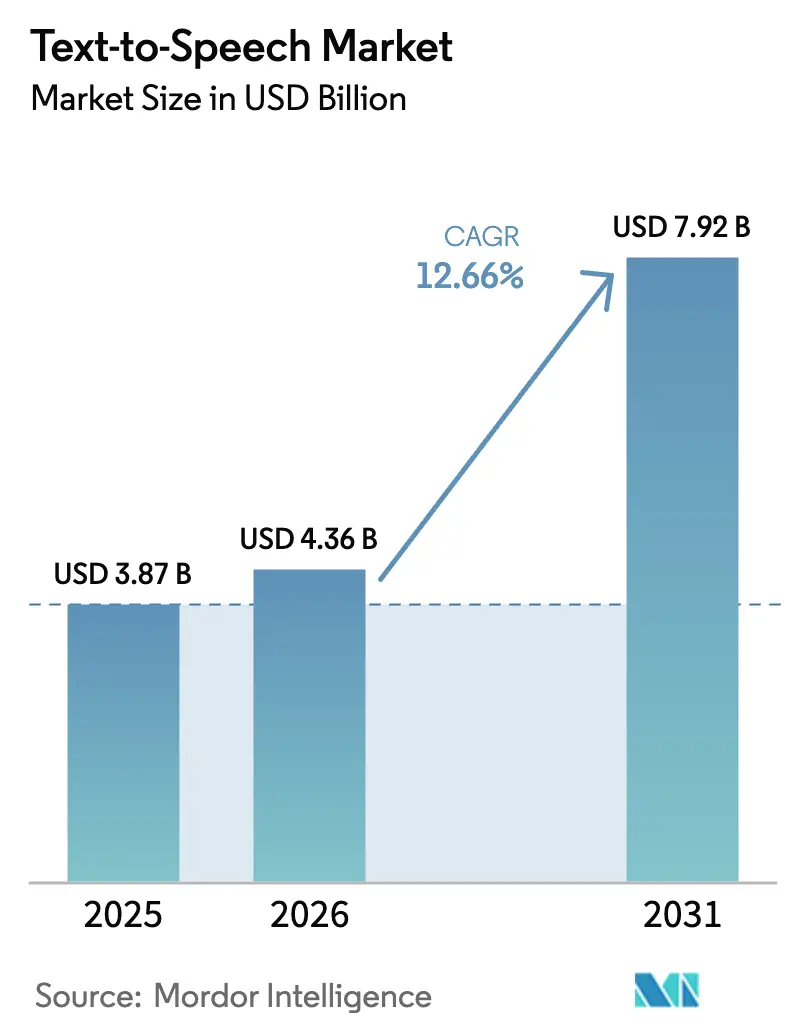
Analyse du marché de la synthèse vocale par Mordor Intelligence
La taille du marché de la synthèse vocale devrait passer de 3,87 milliards USD en 2025 à 4,36 milliards USD en 2026 et devrait atteindre 7,92 milliards USD d'ici 2031, avec un CAGR de 12,66 % sur la période 2026-2031. Ces perspectives robustes pour le marché de la synthèse vocale reflètent la manière dont les avancées des réseaux de neurones, les mandats d'accessibilité plus stricts et la maturité du matériel d'IA en périphérie ont élevé la voix synthétique du statut de fonctionnalité pratique à celui de stratégie d'interface centrale. Les entreprises intègrent des voix de marque dans le support client, les assistants embarqués et les outils d'apprentissage adaptatif, tandis que les plateformes cloud hyperscale se disputent la couverture linguistique et le réalisme vocal. La demande croissante de synthèse vocale privée et à faible latence sur des puces embarquées élargit davantage le marché adressable de la synthèse vocale, les dispositifs automobiles, industriels IoT et de santé nécessitant une fonctionnalité hors ligne. Par ailleurs, les modèles de licence pour la propriété intellectuelle de voix synthétiques ont ouvert de nouvelles sources de revenus pour les fournisseurs capables de sécuriser des données vocales consenties et de se défendre contre les abus de clonage.
Principaux enseignements du rapport
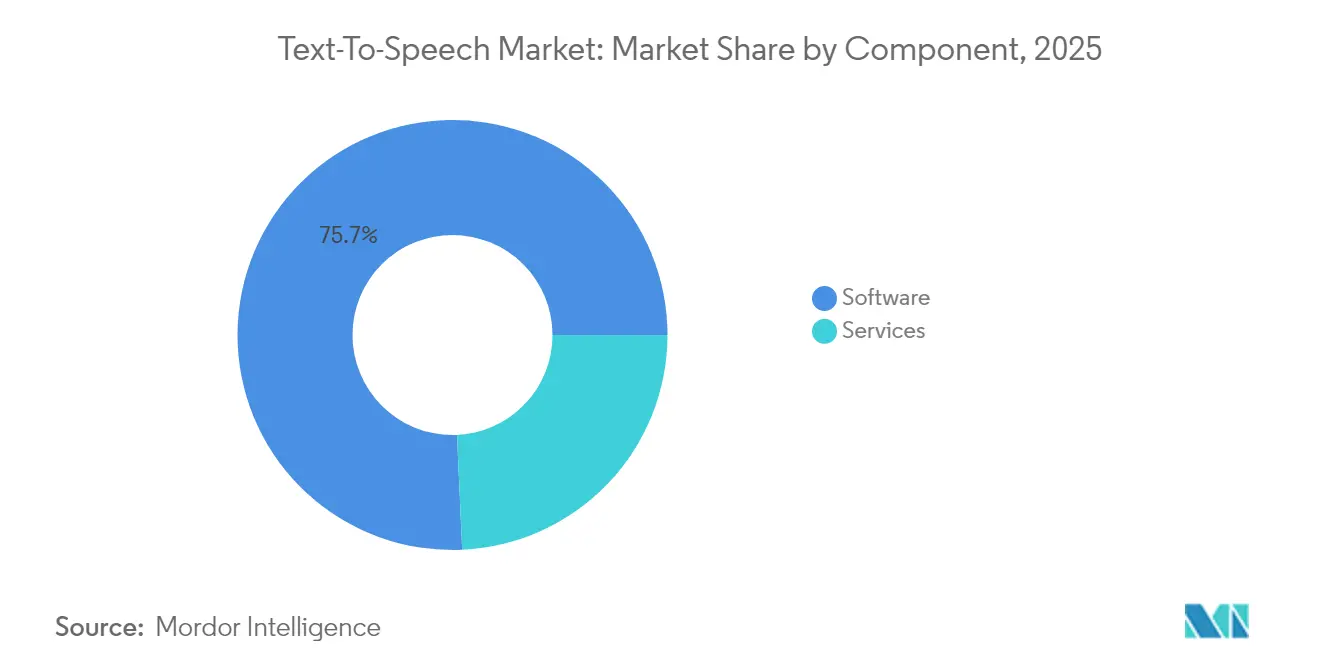
- Par composant, les logiciels ont conservé 75,72 % des parts du marché de la synthèse vocale en 2025, tandis que les services devraient se développer à un CAGR de 13,04 % jusqu'en 2031.
- Par mode de déploiement, les solutions cloud ont capturé 63,35 % de la taille du marché de la synthèse vocale en 2025, et les offres intégrées en périphérie connaissent la croissance la plus rapide avec un CAGR de 14,12 %.
- Par type de voix, les voix neuronales/IA ont dominé avec une part de revenus de 67,18 % en 2025, tout en surpassant tous les autres types avec un CAGR de 15,08 %.
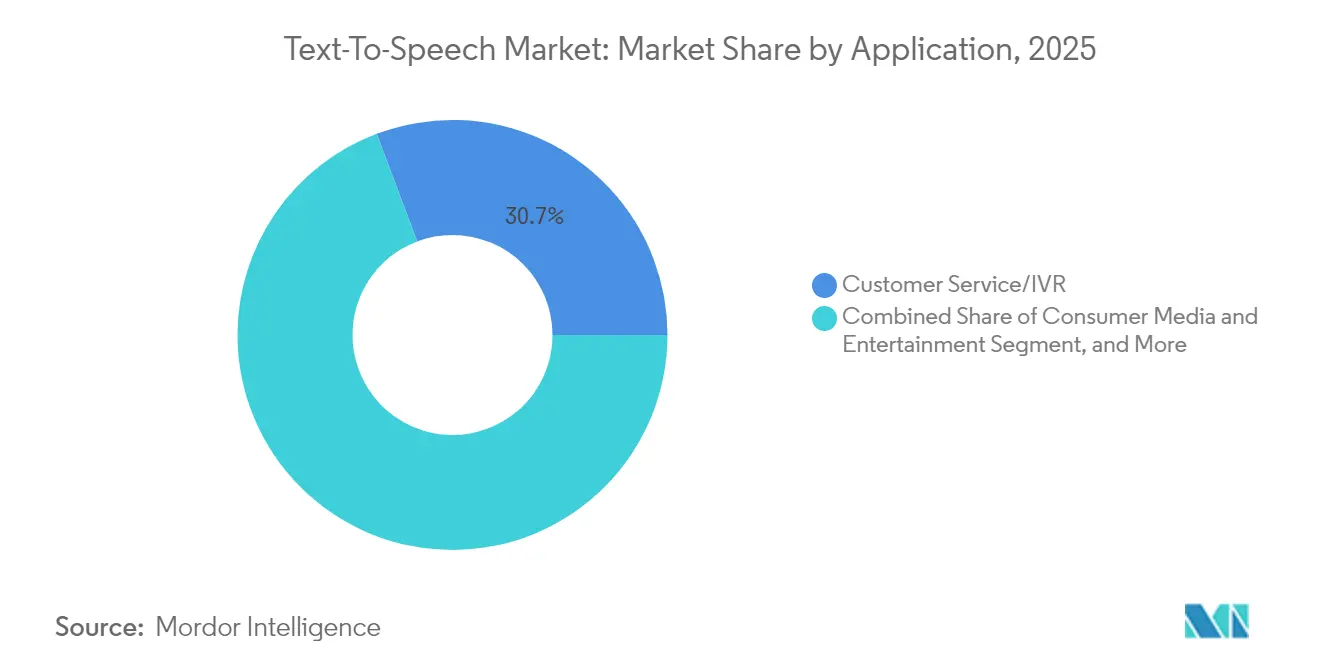
- Par application, le service client/SVI a représenté 30,74 % de la taille du marché de la synthèse vocale en 2025 ; l'automobile et le transport progressent à un CAGR de 14,39 % jusqu'en 2031.
- Par langue, l'anglais détenait une part de 51,83 % en 2025, et l'hindi devrait croître le plus rapidement avec un CAGR de 13,42 %.
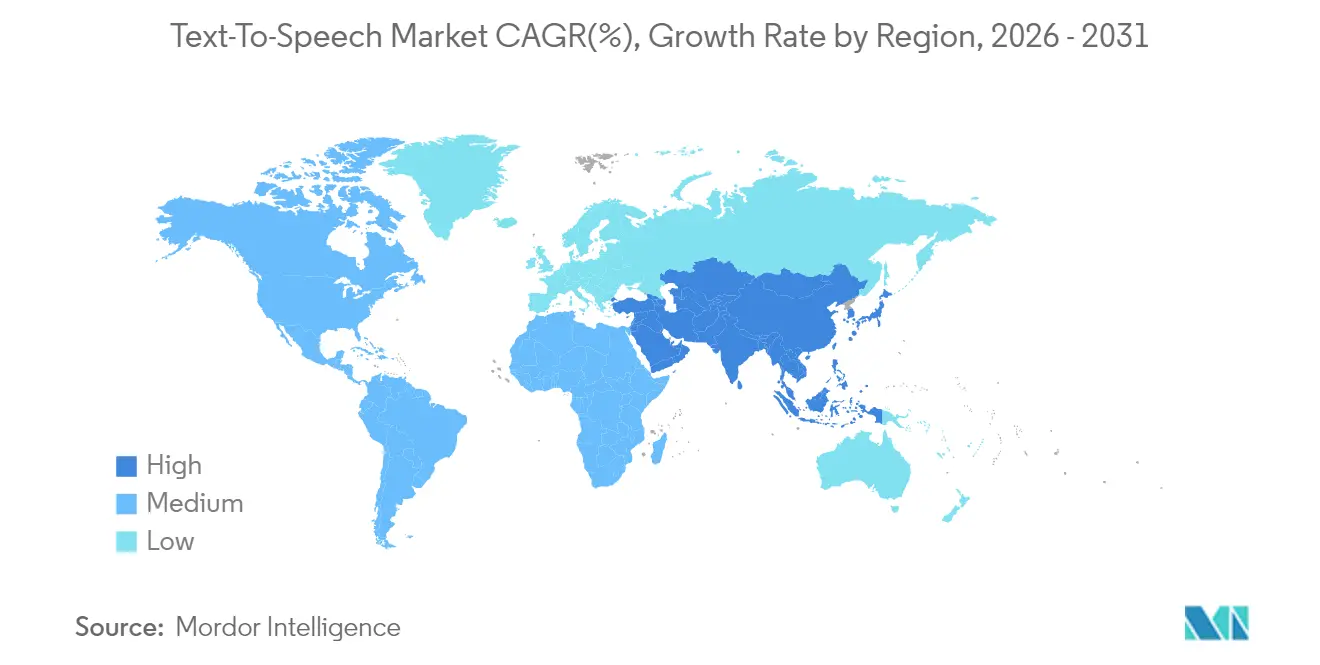
- Par géographie, l'Amérique du Nord a dominé avec une part de 36,78 % en 2025 ; l'Asie-Pacifique est la région à la croissance la plus rapide avec un CAGR de 14,86 % jusqu'en 2031.
Remarque : Les chiffres de la taille du marché et des prévisions de ce rapport sont générés à l’aide du cadre d’estimation propriétaire de Mordor Intelligence, mis à jour avec les données et analyses les plus récentes disponibles en 2026.
Tendances et perspectives mondiales du marché de la synthèse vocale
Analyse de l'impact des moteurs*
| Moteur | % d'impact sur les prévisions de CAGR | Pertinence géographique | Horizon temporel de l'impact |
|---|---|---|---|
| Prolifération des appareils à commande vocale et des enceintes intelligentes | +2.8% | Amérique du Nord, Europe | Moyen terme (2 à 4 ans) |
| La synthèse vocale neuronale offre une qualité quasi humaine | +3.1% | Amérique du Nord, Asie-Pacifique | Court terme (≤ 2 ans) |
| Expansion de l'e-learning et du contenu numérique | +2.2% | Mondial ; fort en Asie-Pacifique | Moyen terme (2 à 4 ans) |
| Mandats d'accessibilité numérique | +1.9% | Amérique du Nord, Europe | Long terme (≥ 4 ans) |
| Accélérateurs d'IA en périphérie pour la synthèse vocale hors ligne | +2.4% | Mondial ; en phase précoce dans l'automobile et l'industrie | Long terme (≥ 4 ans) |
| Licence de propriété intellectuelle de voix synthétiques | +1.5% | Marchés développés | Moyen terme (2 à 4 ans) |
| Source: Mordor Intelligence | |||
Prolifération des appareils à commande vocale et des enceintes intelligentes
Les fabricants d'enceintes intelligentes intègrent de plus en plus des grands modèles de langage qui dépendent d'une sortie au son naturel pour regagner l'élan des expéditions après le ralentissement du premier trimestre 2023. Le modèle Alexa Teacher de Amazon et les assistants propulsés par ERNIE de Baidu illustrent comment des voix convaincantes augmentent l'engagement des appareils. Les constructeurs automobiles en bénéficient également ; le compagnon Reno de Renault utilise une synthèse vocale émotionnelle pour enrichir l'interaction en habitacle, soulignant la croissance dans les secteurs verticaux hors électronique grand public. Les modèles optimisés pour la périphérie alimentent désormais les capteurs IoT, les thermostats et les appareils portables qui doivent fonctionner localement pour des raisons de confidentialité et de disponibilité. Les fournisseurs capables de compresser les voix neuronales sans dégradation audible captent de nouvelles opportunités de conception d'appareils.
Améliorations rapides de la synthèse vocale neuronale offrant une qualité quasi humaine
Les architectures neuronales permettent de modéliser la prosodie, le rythme et l'émotion plutôt que de les concaténer, améliorant le naturel dans plus de 20 langues simultanément. Le système en 21 langues du NICT a montré que la qualité n'a pas à diminuer lorsque l'échelle augmente, tandis que le déploiement par Microsoft en février 2025 de 14 nouvelles voix HD, menées par les personnages indiens Aarti et Arjun, souligne le pivot commercial vers une parole culturellement adaptée. La latence a chuté au temps réel pour la plupart des API cloud, permettant aux marques de déployer un support conversationnel et des médias interactifs sans délai perceptible. En conséquence, la synthèse vocale neuronale est désormais la spécification par défaut dans les cycles d'approvisionnement pour l'automatisation des centres d'appels et le doublage de contenus en streaming.
Expansion de l'e-learning et de la consommation de contenu numérique
Les salles de classe numériques en Asie-Pacifique rapportent une utilisation de l'IA générative par 81 % des étudiants, stimulant la demande de narration qui s'adapte au dialecte et aux préférences de l'apprenant. Les plateformes de synthèse vocale proposent donc des profils de timbre et de débit de parole personnalisés pour améliorer la rétention. Les voix multilingues aident les éditeurs à atteindre des publics où les talents de doublage sont rares, accélérant les pipelines de localisation et réduisant le coût par titre. Les établissements d'enseignement commandent également des « voix de campus » propriétaires qui renforcent l'identité de marque sur les portails LMS et les outils d'accessibilité, stimulant les revenus de services pour les fournisseurs de synthèse vocale.
Mandats d'accessibilité numérique (Section 508, WCAG)
Les réglementations fédérales exigent que les documents électroniques et les interfaces web restent utilisables par les personnes malvoyantes, ce qui se traduit directement par une obligation de prise en charge des lecteurs d'écran et de la synthèse vocale dans les logiciels vendus aux entités gouvernementales américaines. Cette impulsion réglementaire renforce également la demande de technologies d'assistance pour les utilisateurs malvoyants sur les plateformes numériques du secteur public et les solutions d'accessibilité en entreprise. Des attentes similaires dans les directives européennes garantissent que les budgets consacrés à l'accessibilité restent financés malgré les cycles plus larges de dépenses informatiques. Les organisations découvrent fréquemment qu'une meilleure narration bénéficie à l'ensemble des utilisateurs, transformant ainsi un poste de conformité en une amélioration plus large de l'expérience utilisateur. Par conséquent, les équipes d'approvisionnement accordent davantage de poids aux feuilles de route des fournisseurs en matière d'analyse de mises en page de documents complexes et de prononciation de terminologie technique.
Analyse de l'impact des freins*
| Frein | % d'impact sur les prévisions de CAGR | Pertinence géographique | Horizon temporel de l'impact |
|---|---|---|---|
| Limites de précision pour les langues tonales et à faibles ressources | -1.8% | Asie-Pacifique, Afrique | Moyen terme (2 à 4 ans) |
| Préoccupations relatives à la confidentialité des données dans la synthèse vocale cloud | -1.4% | Europe, Amérique du Nord | Court terme (≤ 2 ans) |
| L'abus du clonage vocal érode la confiance | -2.1% | Mondial | Court terme (≤ 2 ans) |
| Coûts de calcul GPU croissants | -1.2% | Mondial | Moyen terme (2 à 4 ans) |
| Source: Mordor Intelligence | |||
Abus croissant du clonage vocal et des hypertrucages érodant la confiance des utilisateurs
La Commission fédérale du commerce des États-Unis a mis en lumière les risques de clonage à travers son défi sur le clonage vocal, soulignant les scénarios de fraude qui compromettent la sécurité biométrique. La capacité d'OpenAI à reproduire une voix à partir d'un échantillon de 15 secondes et des recherches montrant un taux de succès d'attaque de 95 à 97 % contre les systèmes d'identification des locuteurs mettent en évidence l'écart technologique entre la génération et la détection. Des propositions législatives telles que la loi NO FAKES et la loi ELVIS du Tennessee présagent des coûts de conformité pour les fournisseurs qui ne disposent pas de pipelines de vérification du consentement, poussant les entreprises vers des prestataires dotés de contrôles de provenance robustes.
Préoccupations relatives à la confidentialité des données dans la synthèse vocale basée sur le cloud
Le RGPD, les avis de sécurité électorale de la CISA et la sensibilisation croissante des consommateurs incitent les entreprises à traiter la parole localement. Les assistants embarqués qui ne quittent jamais l'appareil contournent les règles de transfert de données transfrontalières et réduisent l'exposition aux violations. Pourtant, la construction et la maintenance de piles sur site ou en périphérie nécessitent des budgets matériels et des compétences spécialisées en apprentissage automatique, ralentissant l'adoption pour les petites entreprises. Des stratégies de déploiement hybrides ont émergé, où les phrases sensibles sont traitées sur l'appareil tandis que le texte non critique est transmis au cloud, équilibrant confidentialité et efficacité des coûts.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des segments
Par composant : la croissance des services dépasse la domination des logiciels
Les logiciels ont maintenu une part de 75,72 % en 2025, les moteurs de base et les API sous-tendant la plupart des déploiements sur le marché de la synthèse vocale. Néanmoins, les revenus des services progressent à un CAGR de 13,04 % alors que les entreprises recherchent des voix personnalisées et des déploiements multilingues qui exigent un réglage phonétique, une vérification culturelle et une assurance qualité continue. Ces services intègrent souvent des analyses d'utilisation, aidant les clients à suivre l'engagement des auditeurs et à affiner les scripts. L'externalisation atténue également la pénurie de linguistes computationnels internes, rendant les fournisseurs spécialisés indispensables.
Le pivot vers des contrats axés sur les services illustre un point de maturité dans le secteur de la synthèse vocale où la différenciation passe de « est-ce qu'il parle » à « est-ce qu'il nous ressemble ». Les projets de voix personnalisées englobent des ateliers sur le ton de la marque, le calibrage de l'accent et le réentraînement itératif des modèles neuronaux. Les fournisseurs capables de regrouper ces offres avec des outils de conformité pour le consentement et l'accessibilité captent des budgets d'expansion à longue traîne, même parmi les organisations qui disposent déjà de licences d'API de synthèse vocale génériques.



Par mode de déploiement : l'informatique en périphérie perturbe l'hégémonie du cloud
La livraison cloud a encore contribué à 63,35 % des parts du marché de la synthèse vocale en 2025 grâce à un provisionnement quasi instantané et à des mises à jour fréquentes des modèles. Les déploiements intégrés en périphérie progressent cependant à un CAGR de 14,12 %, reflétant un pivot structurel vers la souveraineté des données et la fiabilité en temps réel. Les cas d'usage automobiles illustrent ce changement : les assistants en habitacle doivent répondre même lorsque la couverture cellulaire est absente et ne doivent pas envoyer d'audio biométrique hors du véhicule sans consentement.
Des modèles plus petits tels que Nix-TTS démontrent qu'une synthèse vocale haute fidélité peut fonctionner sur des ordinateurs monocarte, élargissant l'applicabilité aux appareils électroménagers intelligents et aux instruments médicaux. Les fabricants de semi-conducteurs livrent désormais des accélérateurs d'inférence de réseaux de neurones qui maintiennent une latence inférieure à 100 millisecondes, éliminant l'écart de perception entre l'appareil et la conversation humaine. Pour les entreprises avec une connectivité intermittente ou des données réglementées, la voie périphérique offre la conformité sans sacrifier la qualité.
Par type de voix : les réseaux de neurones redéfinissent les attentes en matière de qualité
Les voix neuronales détenaient une part de revenus de 67,18 % en 2025 et se développent à un CAGR de 15,08 %, établissant décisivement le ton pour les déploiements pérennes sur le marché de la synthèse vocale. Les méthodes concaténatives héritées subsistent pour les invites de téléphonie où une cadence prévisible est importante, mais les architectures hybrides intègrent désormais des inflexions neuronales sur des bases de sélection d'unités pour préserver une prononciation déterministe tout en ajoutant de la chaleur.
Les pipelines neuronaux apprennent l'intention du locuteur et ajustent l'emphase de manière dynamique, offrant une résonance narrative que les auditeurs de livres audio récompensent par des durées de lecture plus longues. Des benchmarks standardisés rapportent des améliorations à deux chiffres du MOS (score d'opinion moyen) par rapport aux vagues précédentes, réduisant l'écart perceptuel avec la narration humaine. Alors que les coûts des GPU baissent et que la quantification s'améliore, les voix neuronales devraient dépasser 80 % de pénétration bien avant 2030.
Par application : l'accélération automobile défie le leadership du SVI
Le service client/SVI a enregistré 30,74 % de la taille du marché de la synthèse vocale en 2025, soutenu par des intégrations établies dans les plateformes de centres de contact. Pourtant, les assistants automobiles affichent le CAGR le plus rapide à 14,39 %, propulsés par les tableaux de bord de véhicules électriques qui fusionnent navigation, infodivertissement et contrôle climatique en des hubs centrés sur la voix. Les conducteurs exigent une interaction sans distraction, et les régulateurs approuvent le fonctionnement mains libres, alignant les incitations vers une synthèse vocale premium en habitacle.
Les fournisseurs de médias et de divertissement continuent de doubler des films et de générer des livres audio avec des voix de distribution neuronales, mais les projecteurs stratégiques suivent désormais la manière dont les équipementiers de mobilité fidélisent les utilisateurs à un personnage embarqué convivial. Cette convergence intersectorielle élargit le total des heures vocales adressables, débloquant de nouvelles redevances pour les voix synthétiques sous licence de propriété intellectuelle.
Par langue : la croissance de l'hindi reflète l'impératif de localisation
L'anglais a conservé 51,83 % d'utilisation en 2025, mais la recherche d'un engagement vernaculaire réoriente les investissements vers des langues peu desservies. Le CAGR de 13,42 % de l'hindi souligne l'agenda des biens publics numériques de l'Inde, où les portails gouvernementaux et les applications de technologie financière doivent servir de massifs bassins d'utilisateurs non anglophones. Le chinois, l'espagnol et l'allemand restent des langues prioritaires de niveau 1, mais les fournisseurs de synthèse vocale ciblent désormais les dialectes de niveau 2 où la fidélité à la plateforme est élevée en raison d'une faible concurrence antérieure.
L'expansion vers les langues tonales et agglutinantes met au défi les architectes de modèles avec des contours de hauteur tonale nuancés et une morphologie complexe. Les fournisseurs disposant de jeux de données locaux organisés et de partenariats linguistiques sont donc bien placés pour dominer des niches que les généralistes mondiaux trouvent difficiles à pénétrer, maintenant une frontière fragmentée mais riche en opportunités au sein du marché de la synthèse vocale.
Analyse géographique
L'Amérique du Nord a ancré 36,78 % du marché de la synthèse vocale en 2025, propulsée par les filtres d'approvisionnement de la Section 508 qui font de la sortie vocale un élément de liste de contrôle pour tous les logiciels destinés au secteur fédéral. Les hyperscalers cloud basés aux États-Unis regroupent la synthèse vocale avec des suites d'IA plus larges, abaissant les barrières à l'entrée pour les startups souhaitant ajouter la parole. Pendant ce temps, les débats sur la confidentialité et le contrôle de la Commission fédérale du commerce sur le clonage vocal poussent les entreprises vers des fournisseurs dotés de flux de travail de consentement transparents. Les innovateurs soutenus par du capital-risque se regroupent autour des pôles d'IA californiens, accélérant le rythme des fonctionnalités et les dépôts de brevets.
L'Asie-Pacifique est en voie d'atteindre un CAGR de 14,86 %, le rythme régional le plus rapide sur le marché de la synthèse vocale, grâce à la saturation des smartphones et à l'aisance des consommateurs avec la voix comme principal mode de saisie. Les fonds de stimulus pour l'IA en Chine et les projets d'infrastructure publique numérique de l'Inde nécessitent un support vernaculaire à grande échelle, stimulant la consommation d'API en volume. Les équipementiers coréens et japonais intègrent des voix neuronales dans les voitures et les téléviseurs intelligents, tandis que les développeurs d'Asie du Sud-Est travaillent avec des laboratoires de recherche du secteur public pour combler les lacunes des modèles linguistiques. Le modèle régional met de plus en plus l'accent sur la synthèse vocale sur appareil en raison d'une connectivité inégale dans les zones rurales et des lois sur la souveraineté des données biométriques.
L'Europe poursuit une adoption régulière soutenue par le RGPD et les lois nationales sur l'accessibilité. Les fournisseurs automobiles en Allemagne intègrent le traitement vocal local pour répondre aux mandats de sécurité en habitacle, et les diffuseurs en France et en Espagne investissent dans la localisation pour s'adresser à des publics multilingues. La préférence pour le déploiement sur site est plus élevée que dans d'autres régions, reflétant une prudence culturelle à l'égard du stockage cloud des journaux vocaux. Les enquêtes réglementaires sur la transparence de l'IA sont susceptibles de façonner des normes techniques paneuropéennes qui se répercuteront sur les marchés d'exportation.

Paysage concurrentiel
Le marché de la synthèse vocale présente une fragmentation modérée. Amazon, Google et Microsoft s'appuient sur des empreintes cloud mondiales et des actualisations continues des modèles, tandis que des fournisseurs spécialisés tels que Cerence et iFlytek se différencient par leur intégration automobile et leur expertise en langues natives. La pression réglementaire autour du clonage vocal a relevé les seuils d'entrée ; les fournisseurs doivent désormais proposer la vérification du consentement, le filigranage et la surveillance des abus pour remporter des contrats d'entreprise.[2]Commission fédérale du commerce, "Le défi de la Commission fédérale du commerce sur le clonage vocal," ftc.gov
Les challengers axés sur la périphérie optimisent les réseaux de neurones quantifiés pour les microcontrôleurs de moins de 1 W, ciblant l'IoT industriel et les dispositifs médicaux qui ne peuvent pas s'appuyer sur la connectivité réseau. Les portefeuilles de brevets sont de plus en plus essentiels : Nvidia investit dans la propriété intellectuelle de synthèse vocale qu'il concède sous licence à ses partenaires de puces, créant des flux de redevances et des barrières défensives. Les entreprises en phase de croissance comme ElevenLabs se concentrent sur les outils de l'économie créative, offrant un clonage de qualité studio qui séduit les podcasteurs et les concepteurs de jeux, mais qui doit naviguer dans les règles de divulgation à venir.
Les mouvements stratégiques de 2024-2025 illustrent la course à l'étendue linguistique et à la profondeur verticale. Microsoft a publié 27 nouvelles voix HD, dont des personnages indiens culturellement adaptés, élargissant sa base adressable.[3]Communauté technique Microsoft, "Mises à jour de la synthèse vocale Azure AI Speech de février 2025," techcommunity.microsoft.comLa collaboration de Renault avec Cerence a apporté un compagnon de cockpit émotionnel à sa gamme électrique, signalant l'appétit des équipementiers pour des voix de marque.[4]Cerence Inc., "Renault et Cerence s'associent pour apporter l'IA générative à la Renault 5 E-Tech," cerence.comAppTek et Deluxe ont fusionné leurs forces pour rationaliser les flux de travail de localisation des médias, soulignant comment la synthèse vocale se trouve désormais au cœur de la mondialisation du contenu.
Leaders du secteur de la synthèse vocale
Amazon Web Services, Inc
IBM Corporation
Google LLC
Microsoft Corporation
Synthesys.io
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Développements récents du secteur
- Février 2025 : Microsoft a mis à jour Azure AI Speech avec 13 voix HD actualisées et 14 nouvelles voix HD, avec les personnages indiens Aarti et Arjun pour soutenir les déploiements régionaux.
- Janvier 2025 : Consumer Reports a publié un rapport sur le clonage vocal par IA qui a révélé que quatre entreprises sur six manquaient de protections contre le clonage non consenti, suscitant un regain d'intérêt de la Commission fédérale du commerce.
- Octobre 2024 : Renault s'est associé à Cerence pour intégrer le compagnon Reno dans la Renault 5 E-Tech électrique, offrant une synthèse vocale conversationnelle et sensible aux émotions en habitacle.
- Juillet 2024 : le NICT a dévoilé un système de synthèse vocale neuronale rapide en 21 langues, prouvant l'évolutivité multilingue avec une haute fidélité.


Cadre de la méthodologie de recherche et portée du rapport
Définitions du marché et couverture principale
Notre étude définit le marché mondial de la synthèse vocale comme les revenus générés par les logiciels et les services associés qui convertissent algorithmiquement des caractères écrits en audio intelligible et semblable à la voix humaine sur des déploiements cloud, sur site et en périphérie.
Exclusion du périmètre : les microphones matériels, les moteurs de reconnaissance vocale et la biométrie vocale ne sont pas comptabilisés.
Aperçu de la segmentation
- Par composant
- Logiciels
- Services
- Par mode de déploiement
- Basé sur le cloud
- Sur site
- Intégré en périphérie
- Par type de voix
- Neuronal/basé sur l'IA
- Concaténatif standard
- Hybride
- Par application
- Médias grand public et divertissement
- E-learning et éducation
- Accessibilité pour les malvoyants
- Service client/SVI
- Automobile et transport
- Assistance médicale
- Robotique et IoT
- Autres applications
- Par langue
- Anglais
- Chinois
- Espagnol
- Hindi
- Allemand
- Français
- Turc
- Autres langues
- Par géographie
- Amérique du Nord
- États-Unis
- Canada
- Mexique
- Amérique du Sud
- Brésil
- Argentine
- Reste de l'Amérique du Sud
- Europe
- Royaume-Uni
- Allemagne
- France
- Italie
- Espagne
- Russie
- Reste de l'Europe
- Asie-Pacifique
- Chine
- Inde
- Japon
- Corée du Sud
- Australie et Nouvelle-Zélande
- Reste de l'Asie-Pacifique
- Moyen-Orient et Afrique
- Moyen-Orient
- Arabie saoudite
- Émirats arabes unis
- Turquie
- Reste du Moyen-Orient
- Afrique
- Afrique du Sud
- Nigéria
- Reste de l'Afrique
- Moyen-Orient
- Amérique du Nord
Méthodologie de recherche détaillée et validation des données
Recherche primaire
Nous avons ensuite interrogé des architectes de plateformes cloud, des intégrateurs d'e-learning et des distributeurs de technologies d'assistance en Amérique du Nord, en Europe et en Asie-Pacifique.
Leurs observations sur l'évolution du prix de vente moyen, les taux d'attachement des packs linguistiques et les flux de demande automobile émergents ont contribué à tempérer les estimations secondaires et à clarifier les inflexions régionales.
Recherche documentaire
Les analystes de Mordor ont commencé par des ensembles de données ouverts provenant d'organismes tels que l'Union internationale des télécommunications, l'Organisation mondiale de la santé et l'OCDE pour évaluer les bases d'appareils, la prévalence du handicap et l'adoption des services numériques.
Les livres blancs des associations professionnelles (par exemple, les données d'expédition d'enceintes intelligentes de la CTA), les normes de synthèse vocale du W3C et les rapports annuels 10-K des entreprises ont enrichi la visibilité des tendances.
Les sources payantes de D&B Hoovers et Questel ont fourni des répartitions des revenus des entreprises et la vélocité des brevets qui ancrent l'intensité concurrentielle.
Les sources citées illustrent notre travail documentaire ; de nombreuses autres références ont soutenu la validation des données et le comblement des lacunes.
Dimensionnement du marché et prévisions
Un modèle descendant part du parc mondial d'appareils connectés à Internet, applique le taux de pénétration observé des API de synthèse vocale dans les principaux secteurs verticaux, puis superpose le prix moyen par heure vocale pour dériver la valeur.
Des vérifications ascendantes sélectives, échantillonnant les revenus des fournisseurs et les factures des canaux, sont effectuées pour réconcilier les totaux avant le verrouillage des chiffres.
Les variables suivies comprennent les expéditions d'enceintes intelligentes, la population malvoyante utilisant des lecteurs d'écran, le nombre de langues prises en charge par fournisseur, les baisses de prix des plateformes cloud, les mandats réglementaires d'accessibilité et les installations d'infodivertissement en voiture.
La régression multivariée projette chaque moteur sur la période de prévision, et l'analyse de scénarios s'ajuste aux fluctuations monétaires et aux contraintes d'approvisionnement en puces d'IA.
Lorsque les données ascendantes granulaires sont rares, le jugement des analystes, examiné par deux pairs, comble l'écart et est révisé à chaque cycle de mise à jour.
Validation des données et cycle de mise à jour
Les résultats font face à des seuils de variance par rapport à des indicateurs indépendants ; tout dépassement déclenche une révision et des rappels d'experts.
Un réviseur senior valide, et le modèle est actualisé annuellement, avec des mises à jour intermédiaires lorsque des événements importants, des levées de fonds importantes ou des changements réglementaires majeurs modifient la base de référence.
Pourquoi la base de référence du marché de la synthèse vocale de Mordor mérite-t-elle confiance
Les estimations publiées divergent fréquemment parce que les entreprises choisissent des limites technologiques, des années de référence monétaires et des cadences d'actualisation différentes.
Les principaux facteurs d'écart ici comprennent la question de savoir si les frais d'utilisation SaaS ou uniquement les licences perpétuelles sont comptabilisés, la manière dont les primes de voix neuronales sont traitées, et la vitesse à laquelle les langues à faibles ressources nouvellement ajoutées sont intégrées dans les courbes de croissance.
Comparaison de référence
| Taille du marché | Source anonymisée | Principal facteur d'écart |
|---|---|---|
| 3,87 milliards USD (2025) | ||
| 4,00 milliards USD (2024) | Consultance mondiale A | comptabilise ensemble les outils de reconnaissance vocale et de dictée, gonflant la base |
| 4,15 milliards USD (2024) | Cabinet de recherche sectorielle B | suppose une tarification uniforme des voix neuronales, ignorant les niveaux freemium |
| 4,55 milliards USD (2024) | Revue professionnelle C | applique une croissance à un chiffre aux volumes concaténatifs hérités, puis ajoute le CAGR neuronal sans vérifications de chevauchement |
Ces différences montrent pourquoi les décideurs s'appuient sur la définition rigoureuse du périmètre, le dimensionnement par méthodes mixtes et l'actualisation annuelle de Mordor pour obtenir un point de départ équilibré et reproductible pour la planification stratégique.


Questions clés auxquelles le rapport répond
Quelle est la taille actuelle du marché de la synthèse vocale ?
La taille du marché de la synthèse vocale devrait atteindre 4,36 milliards USD en 2026 et croître à un CAGR de 12,66 % pour atteindre 7,92 milliards USD d'ici 2031.
Quelle est la taille actuelle du marché de la synthèse vocale ?
Les services se développent à un CAGR de 13,04 % alors que les organisations externalisent la création de voix personnalisées et les travaux de déploiement multilingue.
Pourquoi le secteur automobile est-il important pour les fournisseurs de synthèse vocale ?
Les constructeurs automobiles ont besoin de voix à faible latence et sur appareil pour une interaction sûre et sans distraction, faisant du secteur l'application à la croissance la plus rapide avec un CAGR de 14,39 %.
Comment les réglementations influencent-elles l'adoption ?
La Section 508 et les lois européennes sur l'accessibilité imposent des contenus à commande vocale, transformant la conformité en un moteur de demande constant pour l'intégration de la synthèse vocale en entreprise.
Quels risques le clonage vocal pose-t-il aux entreprises ?
La parole hypertrucage peut contourner la sécurité biométrique et éroder la confiance des consommateurs, incitant les régulateurs et les entreprises à privilégier les fournisseurs dotés de mécanismes robustes de consentement et de détection.
L'informatique en périphérie va-t-elle supplanter la synthèse vocale cloud ?
Les déploiements en périphérie progressent à un CAGR de 14,12 %, mais les modèles hybrides combinant confidentialité locale et évolutivité cloud devraient coexister jusqu'en 2031.
Dernière mise à jour de la page le:




