Taille et Part du Marché des Mémoires pour Accélérateurs d'IA
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2020 - 2031 |
|---|---|
| Taille du Marché (2026) | 53.74 Milliards de dollars |
| Taille du Marché (2031) | 165.79 Milliards de dollars |
| Taux de croissance (2026 - 2031) | 25.27% CAGR |
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Amérique du Nord |
| Concentration du Marché | Élevé |
Acteurs majeurs
*Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. |
|
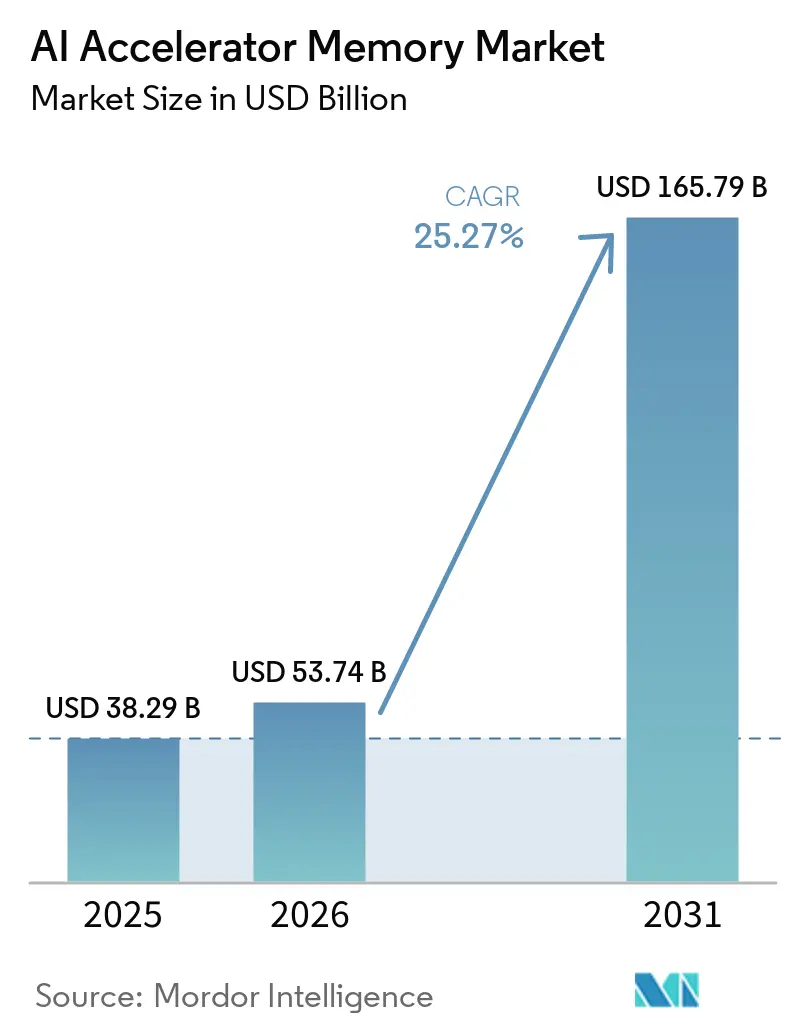
Analyse du Marché des Mémoires pour Accélérateurs d'IA par Mordor Intelligence
La taille du marché des mémoires pour accélérateurs d'IA devrait passer de 38,29 milliards USD en 2025 à 53,74 milliards USD en 2026 et devrait atteindre 165,79 milliards USD d'ici 2031, à un CAGR de 25,27 % sur la période 2026-2031. Le marché des mémoires pour accélérateurs d'IA est façonné par l'ancrage de la mémoire à haute bande passante au sein des principaux accélérateurs d'entraînement et d'inférence, ce qui a fait de l'architecture mémoire une contrainte de conception fondamentale plutôt qu'un composant secondaire. Le marché des mémoires pour accélérateurs d'IA est également porté par les dépenses hyperscale qui continuent de favoriser les grandes flottes de serveurs d'IA, les programmes de silicium personnalisé et les systèmes denses à l'échelle du rack avec un contenu mémoire élevé par accélérateur. La discipline d'approvisionnement est tout aussi importante, car les trois principaux fournisseurs de DRAM ont réorienté leurs capitaux, leurs efforts d'ingénierie et leur mix produit vers des produits HBM offrant de meilleures marges et une meilleure visibilité de la demande à long terme. Ce changement a rendu le marché des mémoires pour accélérateurs d'IA plus concentré tant du côté de l'offre que de la demande, un petit nombre de fournisseurs de mémoire et d'acheteurs hyperscale dictant désormais la plupart des décisions d'allocation. Les opportunités à court terme les plus solides sont liées aux nouvelles générations HBM, aux hauteurs de pile plus élevées et aux plateformes d'inférence en périphérie, tandis que le principal risque demeure la cadence à laquelle les capacités de packaging, de contrôle thermique et de qualification peuvent suivre la demande.
Points Clés du Rapport
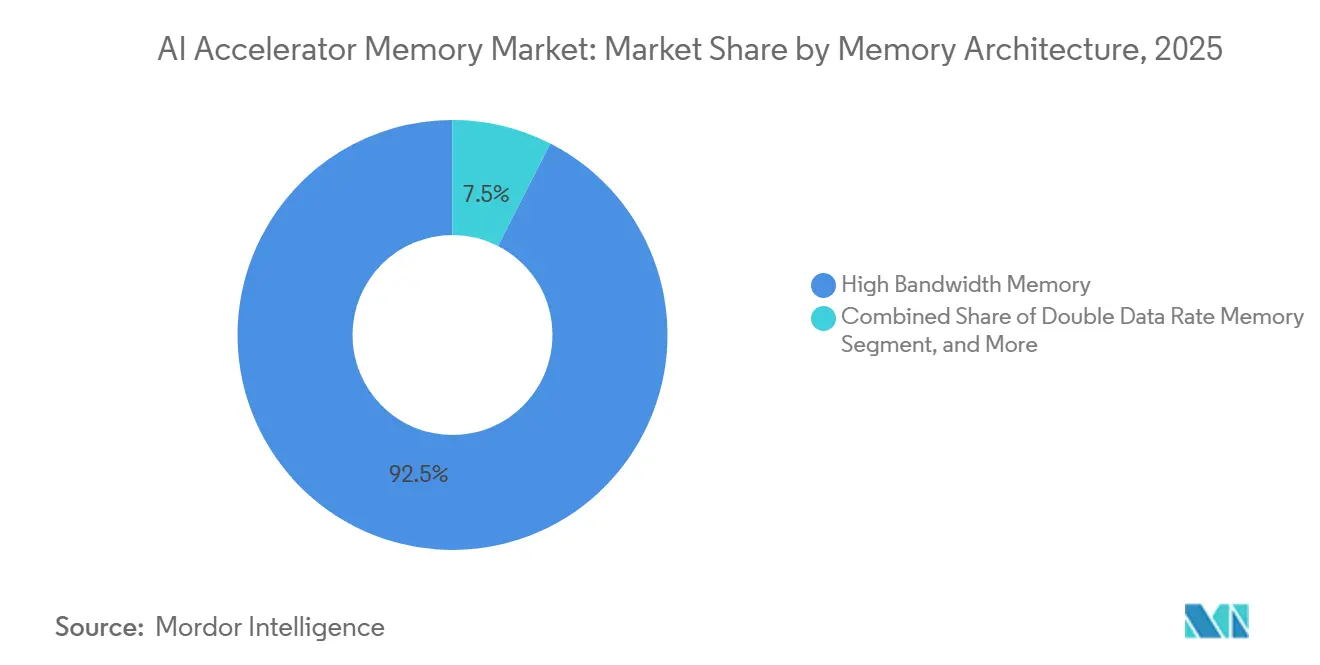
- Par architecture mémoire, la mémoire à haute bande passante (HBM) a dominé avec une part de 92,48 % en 2025 sur le marché des mémoires pour accélérateurs d'IA, tandis que la mémoire à double débit de données à faible consommation (LPDDR) devrait progresser à un CAGR de 26,27 % jusqu'en 2031.
- Par plateforme d'accélération, les accélérateurs GPU pour centres de données ont détenu une part de 73,58 % du marché des mémoires pour accélérateurs d'IA en 2025, tandis que les ASICs d'IA personnalisés et les XPUs devraient enregistrer le CAGR le plus rapide à 26,46 % jusqu'en 2031.
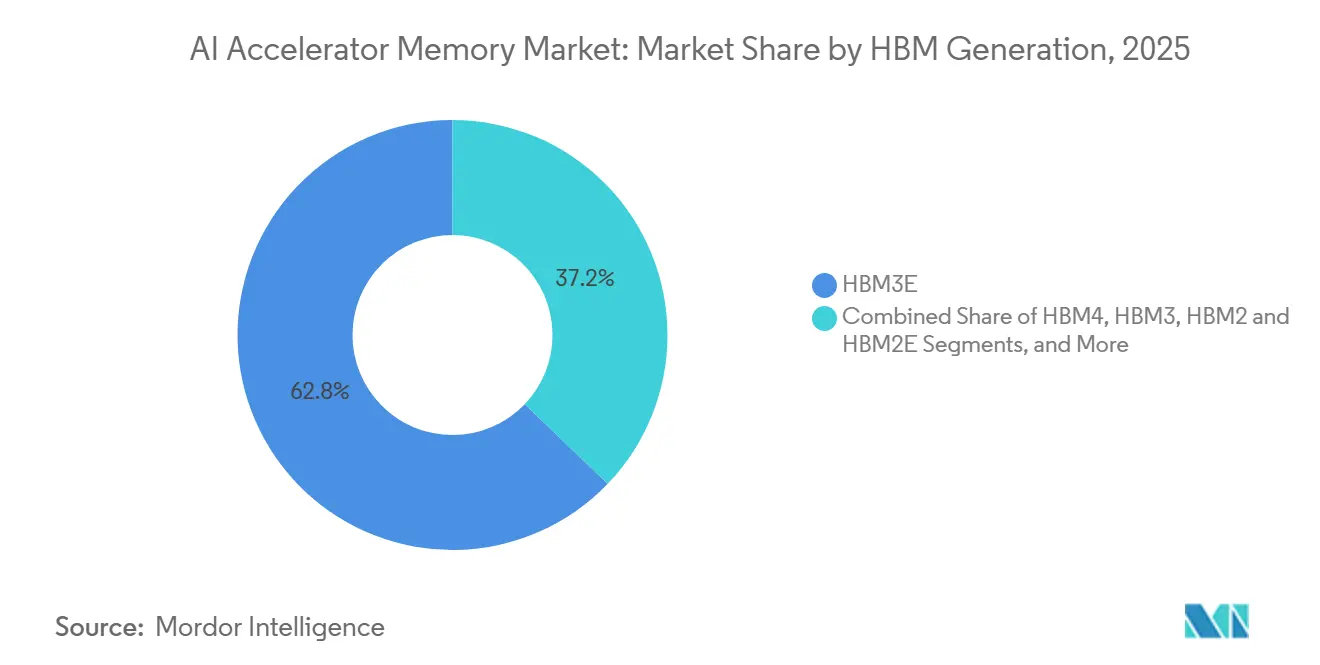
- Par génération HBM, la HBM3E a représenté 62,84 % de part en 2025, tandis que la HBM4E et la HBM de prochaine génération devraient progresser à un CAGR de 26,18 % jusqu'en 2031.
- Par hauteur de pile HBM, la configuration 8 couches a commandé 61,32 % de part en 2025 sur le marché des mémoires pour accélérateurs d'intelligence artificielle (IA), tandis que la configuration 16 couches devrait progresser à un CAGR de 26,13 % jusqu'en 2031.
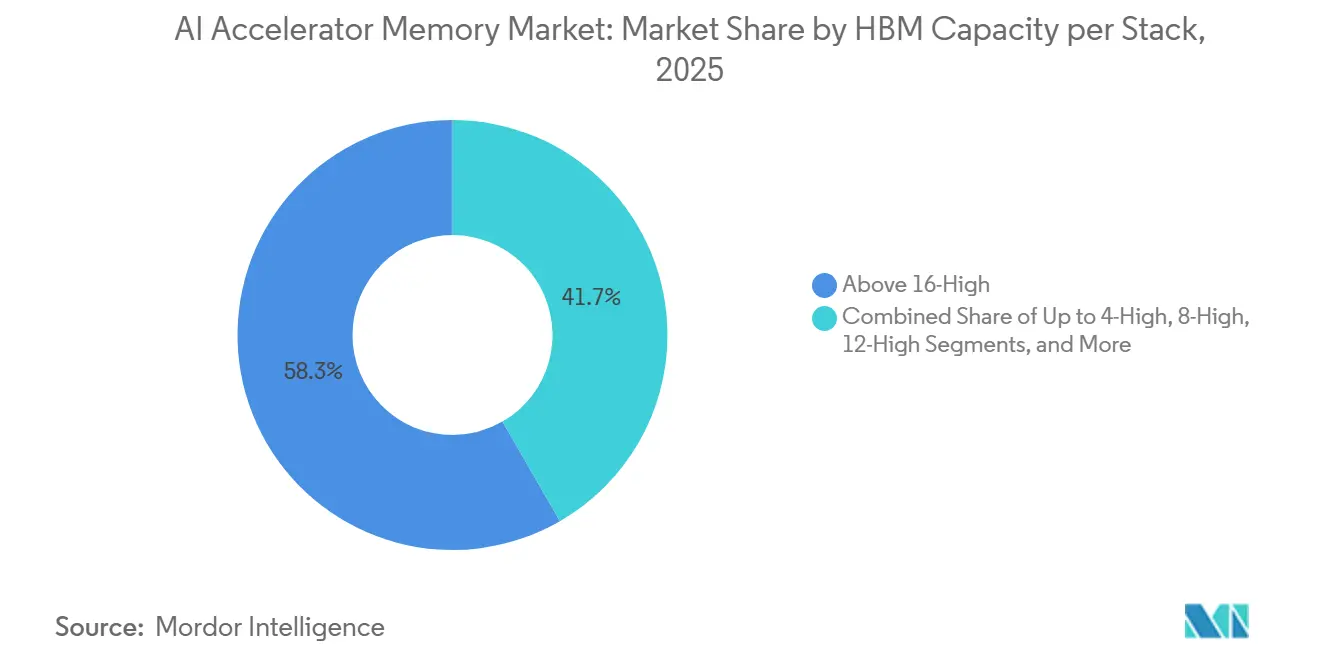
- Par capacité HBM par pile, le segment Au-dessus de 16 Go à 24 Go a détenu 58,33 % de part du marché des mémoires pour accélérateurs d'IA en 2025, tandis que le segment Au-dessus de 36 Go devrait croître à un CAGR de 26,28 % jusqu'en 2031.
- Par plateforme de déploiement, le cloud hyperscale et les usines d'IA ont capturé 73,87 % de part en 2025, tandis que les systèmes d'IA en périphérie et les systèmes industriels devraient afficher le CAGR le plus rapide à 26,54 % jusqu'en 2031.
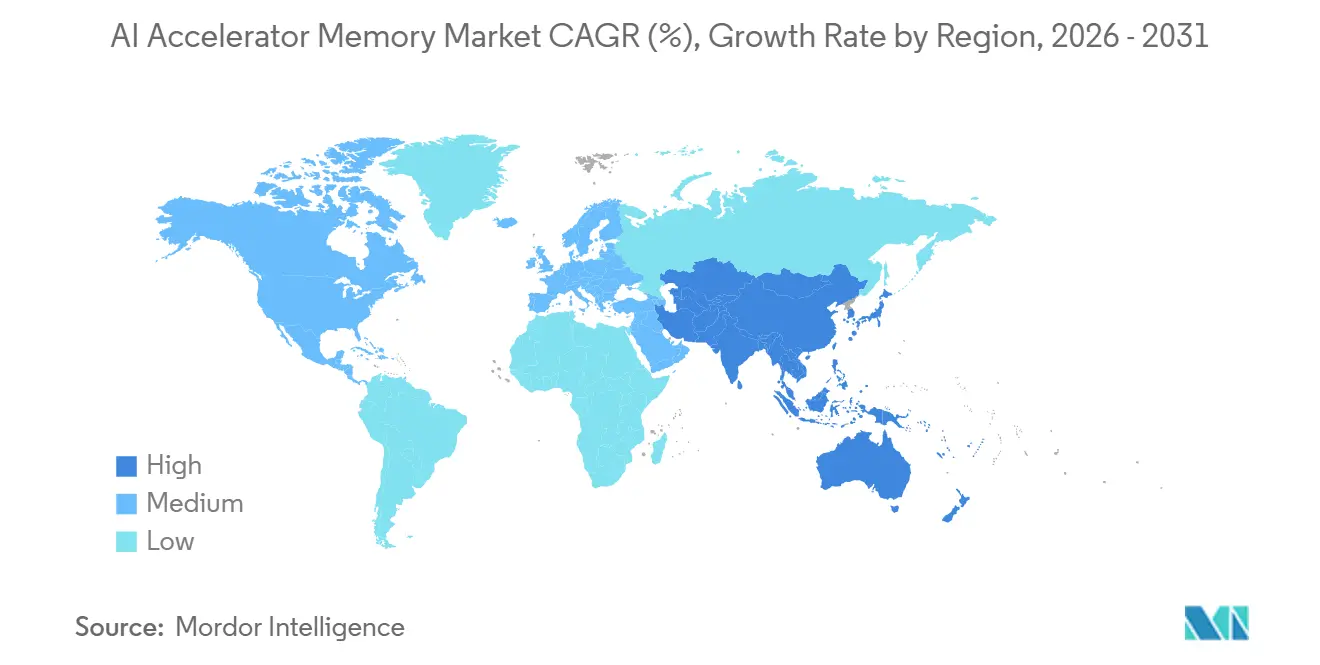
- Par géographie, l'Amérique du Nord a détenu 48,12 % de part du marché des mémoires pour accélérateurs d'IA en 2025, tandis que l'Asie-Pacifique devrait progresser à un CAGR de 26,19 % jusqu'en 2031.
Note : La taille du marché et les prévisions figurant dans ce rapport sont générées à l'aide du cadre d'estimation exclusif de Mordor Intelligence, mis à jour avec les dernières données et informations disponibles en janvier 2026.
Tendances et Perspectives du Marché Mondial des Mémoires pour Accélérateurs d'IA
Analyse de l'Impact des Moteurs*
| Moteur | (~) % d'Impact sur les Prévisions de CAGR | Pertinence Géographique | Horizon Temporel de l'Impact |
|---|---|---|---|
| Adoption Croissante de la HBM3E et de la HBM4 dans les Accélérateurs d'IA | +6.2% | Mondial, plus concentré en Amérique du Nord et en Asie-Pacifique | Court terme (≤ 2 ans) |
| Augmentation de la Densité de Calcul pour l'Entraînement et l'Inférence d'IA | +5.1% | Mondial | Moyen terme (2-4 ans) |
| Expansion des Flottes d'IA dans les Centres de Données Hyperscale | +4.3% | Amérique du Nord et Europe | Court terme (≤ 2 ans) |
| Demande Croissante de Bande Passante par Watt dans les GPU et ASICs Avancés | +3.0% | Mondial | Moyen terme (2-4 ans) |
| Réallocation de l'Offre vers les Références Mémoire IA à Haute Marge | +1.5% | Cœur Asie-Pacifique, Corée du Sud et Japon, débordement vers l'Amérique du Nord | Court terme (≤ 2 ans) |
| Adoption Croissante des Architectures d'IA à Base de Chiplets | +1.1% | Mondial, gains précoces en Amérique du Nord et en Asie-Pacifique | Long terme (≥ 4 ans) |
| Source: Mordor Intelligence | |||
Adoption Croissante de la HBM3E et de la HBM4 dans les Accélérateurs d'IA
Le marché des mémoires pour accélérateurs d'IA bénéficie de chaque mise à niveau de génération HBM, car des performances plus élevées s'accompagnent désormais d'une plus grande complexité de processus et de prix de vente plus élevés. SK hynix a déclaré que sa HBM3E atteignait jusqu'à 9,6 Gbps par broche et plus de 1,23 To/s de bande passante, soulignant pourquoi les accélérateurs d'IA actuels continuent d'évoluer vers des configurations mémoire plus denses et plus rapides. Samsung a annoncé en février 2026 avoir lancé la production en masse de la HBM4 en utilisant un processus DRAM 1c et une puce logique de base en 4 nm, signalant que le marché avait déjà commencé à basculer vers le prochain cycle de qualification. NVIDIA a confirmé en juin 2026 que Samsung, SK hynix et Micron avaient tous qualifié et lancé la production pour sa plateforme Vera Rubin, réduisant l'incertitude quant à la disponibilité des fournisseurs et élargissant la base d'approvisionnement pour la prochaine montée en puissance des accélérateurs. Le marché des mémoires pour accélérateurs d'IA progresse donc non seulement parce que la demande unitaire augmente, mais aussi parce que chaque transition vers la HBM4 et la HBM4E lie la croissance des revenus à un chemin de fabrication plus exigeant et plus coûteux.
Augmentation de la Densité de Calcul pour l'Entraînement et l'Inférence d'IA
Le marché des mémoires pour accélérateurs d'IA est également poussé par la hausse constante de la capacité mémoire et de la bande passante requises par puce, tant pour l'entraînement que pour l'inférence. Google a introduit le TPU 8i en avril 2026 avec 288 Go de HBM et 8 601 Go/s par puce, tout en triplant la SRAM sur puce à 384 Mo, démontrant à quel point l'intensité mémoire a augmenté en un seul cycle produit.[1]Google Cloud Blog, "Plongée technique dans le TPU 8t et le TPU 8i," Google Cloud Blog, cloud.google.com La plateforme Vera Rubin de NVIDIA a prolongé cette direction avec une configuration HBM4 de 576 Go par accélérateur, indiquant que les modèles à contexte long et les ensembles de travail plus importants continuent de faire monter les exigences minimales en mémoire. La feuille de route LPDDR6 de JEDEC a également montré que même les systèmes en périphérie évoluent vers des fonctions mémoire plus riches, notamment la prise en charge du traitement en mémoire, ce qui reflète une pression plus large pour réduire les déplacements de données et améliorer l'efficacité de l'inférence locale. Sur le marché des mémoires pour accélérateurs d'IA, cela signifie que le contenu mémoire par accélérateur augmente même lorsque l'efficacité des modèles s'améliore, car les fenêtres de contexte plus longues et les pipelines d'inférence plus complexes continuent de consommer davantage de bande passante et de capacité.
Expansion des Flottes d'IA dans les Centres de Données Hyperscale
Le marché des mémoires pour accélérateurs d'IA reste étroitement lié à la croissance des infrastructures hyperscale, les grands opérateurs cloud continuant de représenter les déploiements d'accélérateurs les plus gourmands en mémoire. Amazon a annoncé en février 2026 qu'il investirait 12 milliards USD en Louisiane pour des infrastructures cloud et d'IA, ce qui reflète l'ampleur des projets individuels désormais engagés au niveau des centres de données. Google a élargi sa feuille de route TPU en 2026, et NVIDIA a approfondi son partenariat mémoire pluriannuel avec SK hynix, ce qui montre que les feuilles de route des plateformes de calcul et la planification de l'approvisionnement en mémoire sont désormais alignées plusieurs cycles à l'avance. Les conceptions de systèmes à l'échelle du rack intensifient également la demande, car chaque déploiement ajoute beaucoup plus de contenu HBM qu'une actualisation de serveur conventionnelle. Cela maintient le marché des mémoires pour accélérateurs d'IA exposé à un petit nombre de très grands acheteurs dont les plans de dépenses peuvent absorber l'offre disponible avant que les clients entreprises plus petits n'y aient accès.
Demande Croissante de Bande Passante par Watt dans les GPU et ASICs Avancés
Le marché des mémoires pour accélérateurs d'IA n'est plus uniquement porté par la bande passante de pointe, car les limites thermiques et de puissance déterminent désormais quelles configurations mémoire peuvent être utilisées dans les déploiements réels. Marvell a annoncé en décembre 2024 que son architecture de calcul HBM personnalisée pouvait réduire la consommation d'énergie de l'interface mémoire de 70 %, prendre en charge 33 % de piles HBM supplémentaires et augmenter la surface de calcul de 25 %, soulignant que l'efficacité énergétique est devenue centrale dans la conception des accélérateurs. Le programme LPDDR6 de Samsung et la feuille de route LPDDR6 de JEDEC pointent tous deux vers la même priorité de conception en périphérie : l'IA embarquée a besoin de meilleures performances mémoire sans pénalités de puissance importantes. Le livre blanc de Micron sur l'IA en périphérie a également lié directement la bande passante mémoire à la vitesse de génération de jetons lors du décodage, renforçant l'importance de la bande passante par watt dans les grands comme dans les petits systèmes d'IA. À mesure que les packages d'accélérateurs approchent de charges thermiques plus élevées et d'un plus grand nombre de piles, les fournisseurs qui gèrent plus efficacement la puissance et la chaleur conserveront un avantage en termes de prix et de qualification sur le marché des mémoires pour accélérateurs d'IA.
Analyse de l'Impact des Freins*
| Frein | (~) % d'Impact sur les Prévisions de CAGR | Pertinence Géographique | Horizon Temporel de l'Impact |
|---|---|---|---|
| Contraintes Thermiques et de Rendement au Niveau du Package | -3.8% | Mondial, plus aigu dans les centres de fabrication d'Asie-Pacifique | Court terme (≤ 2 ans) |
| Base d'Approvisionnement Qualifiée Limitée pour la HBM Avancée | -2.6% | Mondial | Moyen terme (2-4 ans) |
| Forte Dépendance à la Capacité de Packaging Avancé | -2.0% | Cœur Asie-Pacifique, Taïwan, débordement vers l'Amérique du Nord | Moyen terme (2-4 ans) |
| Contrôles à l'Exportation et Frictions liées à la Localisation de la Chaîne d'Approvisionnement | -1.0% | Amérique du Nord et Chine | Long terme (≥ 4 ans) |
| Source: Mordor Intelligence | |||
Contraintes Thermiques et de Rendement au Niveau du Package
Le marché des mémoires pour accélérateurs d'IA est confronté à une contrainte technique importante : la gestion thermique devient plus difficile à mesure que le nombre de couches augmente et que les puces logiques sont intégrées dans la structure de base. La montée en puissance de la HBM4 de Samsung et l'évolution du secteur vers des hauteurs de pile plus élevées montrent que les fournisseurs de mémoire cherchent à augmenter la densité tout en restant dans les limites de qualification et de fiabilité.[2]Samsung Semiconductor Global Newsroom, "Samsung lance la production en masse de la première DRAM HBM3E à 12 couches de l'industrie," Samsung Semiconductor Global Newsroom, news.samsungsemiconductor.com Les normes JEDEC restent importantes car la commercialisation dépend du respect des seuils thermiques et de performance définis pour les générations successives. Micron et Marvell ont tous deux mis en avant des modifications d'architecture mémoire visant à réduire les déplacements de données et la consommation d'énergie de l'interface, confirmant que le problème ne se limite pas au volume brut d'approvisionnement mais s'étend à la faisabilité au niveau du package. Cela maintient le marché des mémoires pour accélérateurs d'intelligence artificielle (IA) vulnérable à des montées en puissance plus lentes que prévu chaque fois que de nouvelles hauteurs de pile ou de nouvelles combinaisons de processus logiques font chuter les rendements en dessous des objectifs commerciaux.
Base d'Approvisionnement Qualifiée Limitée pour la HBM Avancée
Le marché des mémoires pour accélérateurs d'IA est également contraint par le fait que l'approvisionnement en HBM avancée reste concentré parmi un très petit groupe de fournisseurs qualifiés. La confirmation par NVIDIA en juin 2026 que Samsung, SK hynix et Micron étaient tous entrés en production pour Vera Rubin a également souligné que la base d'approvisionnement qualifiée ne s'élargit que maintenant au sein d'un champ restreint de leaders existants. L'approbation par SK hynix en février 2026 de 21,61 billions KRW (environ 16 milliards USD) pour de nouvelles phases du cluster de Yongin montre l'ampleur et la lenteur des nouveaux engagements de capacité au niveau de la fabrication. La sortie de Micron de la mémoire grand public en décembre 2025 a renforcé le même point en réorientant les ressources vers la mémoire d'entreprise orientée IA plutôt que de répartir la capacité sur des marchés finaux plus larges. En pratique, le marché des mémoires pour accélérateurs d'IA peut rester contraint par l'offre même lorsque la visibilité de la demande est forte, car les délais de qualification et les calendriers d'expansion des capacités évoluent beaucoup plus lentement que les cycles de commande des accélérateurs.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des Segments
Par Architecture Mémoire : La HBM Domine Tandis que la LPDDR Accélère en Périphérie
La HBM a détenu 92,48 % de la part du marché des mémoires pour accélérateurs d'IA par architecture mémoire en 2025, ce qui confirme que les principaux accélérateurs d'IA dépendent encore d'une très haute bande passante et d'une mémoire dense intégrée dans le package. Le TPU Ironwood de Google a déployé 8 piles de HBM3E à 7 370 Go/s par puce, et le TPU 8i ultérieur a porté les performances à 8 601 Go/s avec 288 Go par puce, ce qui explique pourquoi la HBM est restée le choix de conception par défaut pour les systèmes de pointe. La GDDR a conservé un rôle dans les GPU d'inférence à moindre coût et les cartes de station de travail, où les concepteurs de systèmes équilibrent encore performance et coût d'intégration. La DDR est également restée pertinente pour les fonctions attachées au CPU dans les serveurs d'IA hybrides, notamment lorsque les accélérateurs sont déployés aux côtés d'une infrastructure de calcul d'entreprise plus large. Sur le marché des mémoires pour accélérateurs d'IA, cet écart important entre la HBM et le reste du mix d'architectures reflète à quel point l'IA actuelle des centres de données dépend des packages d'accélérateurs à forte intensité de bande passante.
La LPDDR est le sous-segment à la croissance la plus rapide, avec un CAGR de 26,27 % de 2026 à 2031, indiquant que la prochaine vague de demande s'étend au-delà des plus grands déploiements en centres de données. JEDEC a indiqué que sa feuille de route LPDDR6 ajoute la prise en charge du traitement en mémoire et étend la LPDDR aux centres de données et aux cas d'usage en périphérie, suggérant un rôle plus large pour la mémoire à faible consommation dans les systèmes d'IA nécessitant une inférence locale et une consommation d'énergie réduite. Le programme LPDDR6 de Samsung cible les systèmes d'IA en périphérie, les PC d'IA, les centres de données et les plateformes automobiles, confirmant que les fournisseurs traitent la LPDDR comme un domaine de croissance de la mémoire d'IA plutôt que comme un simple composant mobile. Micron a également lié directement la bande passante LPDDR à la vitesse de génération de jetons dans l'IA en périphérie, faisant du débit mémoire un levier de performance direct en dehors du cloud hyperscale. Le marché des mémoires pour accélérateurs d'IA se divise donc en un cœur HBM pour les centres de données et une couche LPDDR en périphérie à croissance rapide, chaque architecture servant un modèle de déploiement distinct.



Par Plateforme d'Accélération : Les Plateformes GPU Ancrent les Dépenses Tandis que le Silicium Personnalisé Accélère
Les accélérateurs GPU pour centres de données ont capturé 73,58 % de la taille du marché des mémoires pour accélérateurs d'IA en 2025, reflétant la base installée et la force d'allocation des plateformes GPU d'entraînement et d'inférence grand public. Les familles H100, H200 et Blackwell de NVIDIA ont maintenu les plateformes GPU au centre des déploiements d'IA à grande échelle, tandis qu'AMD est resté un itinéraire client secondaire significatif pour l'approvisionnement en HBM via des plateformes telles que la MI455X dans le prochain cycle. Les SoCs d'IA, les NPUs et les APUs ont continué à servir l'IA mobile, automobile et embarquée, mais leur valeur mémoire par unité est restée inférieure à celle des grands accélérateurs de centres de données. Les accélérateurs à base de FPGA ont encore eu leur importance dans les charges de travail sensibles à la latence où l'adaptabilité et les temps de réponse déterministes restaient importants. Cela a laissé le marché des mémoires pour accélérateurs d'IA ancré par une infrastructure menée par les GPU, même si d'autres types de plateformes ont élargi la base de demande.
Les ASICs d'IA personnalisés et les XPUs devraient croître à un CAGR de 26,46 % jusqu'en 2031, ce qui en fait le segment de plateforme à la croissance la plus rapide sur le marché des mémoires pour accélérateurs d'IA. Broadcom a déclaré en février 2026 avoir commencé à expédier le premier SoC de calcul personnalisé en 2 nm sur son architecture 3.5D XDSiP, avec prise en charge de plusieurs piles HBM, démontrant comment le silicium personnalisé évolue vers un packaging hétérogène avancé plus tôt et plus rapidement.[3]Broadcom Inc., "Broadcom expédie un SoC de calcul 3.5D face à face alimentant la révolution de l'IA," Relations Investisseurs Broadcom, investors.broadcom.com AWS Trainium, Google TPU 8 et Meta MTIA 500 indiquent que les hyperscalers conçoivent de plus en plus leurs besoins en mémoire autour de cibles de bande passante et de latence spécifiques aux charges de travail plutôt que d'accepter un modèle GPU standard. L'architecture de calcul HBM personnalisée de Marvell prend également en charge davantage de piles HBM par XPU avec une consommation d'énergie d'interface plus faible, ce qui fait des interfaces mémoire sur mesure un atout de conception compétitif pour les accélérateurs personnalisés. À mesure que cette évolution se poursuit, le marché des mémoires pour accélérateurs d'IA verra un mix plus large de chemins de qualification et de configurations HBM spécifiques aux produits qu'au cours du cycle précédent dominé par les GPU.
Par Génération HBM : La HBM3E Mène les Déploiements Actuels Tandis que la HBM4E Définit la Prochaine Architecture
La HBM3E a représenté 62,84 % du marché des mémoires pour accélérateurs d'IA en 2025, ce qui reflète son rôle dans la vague actuelle de plateformes d'accélérateurs installées. Elle a été déployée sur les GPU NVIDIA Blackwell, le TPU Google Ironwood et les produits des séries AMD MI300 et MI350, ce qui en fait le centre commercial de la demande HBM actuelle. SK hynix a indiqué que sa HBM3E délivre plus de 1,23 To/s, tandis que la HBM3E 24 Go 8 couches de Micron a également dépassé 1,2 To/s dans les systèmes NVIDIA H200, ce qui explique pourquoi la HBM3E est restée le pont dominant entre l'infrastructure d'aujourd'hui et les plateformes de demain. La HBM2 et la HBM2E ont continué à décliner à mesure que les nouveaux déploiements exigent de plus en plus une bande passante plus élevée, une plus grande capacité et une meilleure efficacité énergétique. Le marché des mémoires pour accélérateurs d'IA a donc continué à s'appuyer sur la HBM3E comme génération commerciale dominante pendant que les acheteurs et les fournisseurs se préparaient pour la prochaine transition.
La HBM4E et la HBM de prochaine génération devraient croître à un CAGR de 26,18 % jusqu'en 2031, ce qui en fait les couches générationnelles à la croissance la plus rapide sur le marché des mémoires pour accélérateurs d'IA. SK hynix a expédié des échantillons de HBM4E à 12 couches avec une capacité de 48 Go en juin 2026 et a rapporté une amélioration de l'efficacité énergétique de plus de 20 % par rapport à la HBM4, signalant que les fournisseurs se positionnent déjà pour les besoins des accélérateurs post-Vera Rubin. Samsung a également lancé la HBM4 en production de masse et accéléré l'échantillonnage précoce de la HBM4E, suggérant que le prochain cycle sera défini par la rapidité avec laquelle les fournisseurs convertissent la disponibilité technologique en production stable en volume. Le doublement du nombre d'entrées/sorties et l'utilisation de puces de base à processus logique augmentent la valeur de chaque pile, mais ils augmentent également la charge sur la qualification et le packaging. Pour cette raison, le marché des mémoires pour accélérateurs d'IA verra probablement la HBM4E façonner le haut de gamme de la demande bien avant que la capacité ne devienne aisée.
Par Hauteur de Pile HBM : La Configuration 8 Couches Commande la Majorité des Parts Tandis que la Configuration 16 Couches Prend de l'Élan
La configuration 8 couches a détenu une part de 61,32 % en 2025, ce qui en fait la plus grande catégorie de hauteur de pile sur le marché des mémoires pour accélérateurs d'IA. Cela reflétait la maturité, la stabilité du rendement et la base installée des déploiements HBM3E dans les flottes de serveurs d'IA actuelles. La plupart des systèmes de génération H200 et Blackwell B200 étaient alignés sur des piles 8 couches à 24 Go de capacité, ce qui a maintenu le format commercialement dominant dans les déploiements actifs. Le format 12 couches s'est développé à travers des produits tels que la HBM3E 36 Go à 12 couches de Micron, qui a déjà montré que les acheteurs étaient prêts à passer à des configurations plus élevées lorsque la capacité supplémentaire soutenait des gains de charge de travail clairs. Les piles jusqu'à 4 couches sont restées pertinentes uniquement dans les cartes d'inférence à faibles performances ou héritées où l'efficacité des coûts importait plus que la densité mémoire.
Le segment 16 couches devrait croître à un CAGR de 26,13 % jusqu'en 2031, ce qui en fait le niveau de hauteur de pile à la croissance la plus rapide sur le marché des mémoires pour accélérateurs d'IA. La plateforme Vera Rubin de NVIDIA spécifie la HBM4 dans une configuration 16 couches avec 576 Go de capacité totale par accélérateur, créant une demande directe pour ce format à mesure que les déploiements du prochain cycle se développent. L'échantillonnage de la HBM4E de SK hynix et les travaux futurs sur la HBM5 montrent également que les fournisseurs poussent vers une densité de pile encore plus grande, mais chaque étape soulève des défis d'amincissement, de liaison et de gestion thermique. Cela signifie que la croissance commerciale au haut de gamme dépendra non seulement de la demande des accélérateurs, mais aussi de la rapidité avec laquelle la stabilité des processus s'améliore aux hauteurs de pile avancées. Le marché des mémoires pour accélérateurs d'intelligence artificielle (IA) devrait donc maintenir sa plus grande base installée dans les formats matures, tandis que sa croissance de revenus la plus rapide se déplace vers des piles plus hautes.
Par Capacité HBM par Pile : Le Niveau Intermédiaire 24 Go Mène Tandis que la Très Haute Capacité Cible les Prochaines Plateformes
Le niveau Au-dessus de 16 Go à 24 Go a mené avec une part de 58,33 % en 2025, le plaçant au centre du marché des mémoires pour accélérateurs d'IA pour les systèmes de génération actuelle. Ce niveau correspondait au profil coût-performance des déploiements de serveurs d'IA grand public, notamment là où la HBM3E 8 couches est restée la norme pratique. La HBM3E 24 Go 8 couches de Micron utilisée dans les systèmes NVIDIA H200 illustre pourquoi ce niveau est devenu le point idéal commercial pour les déploiements d'infrastructure actifs. La plage 8 Go à 16 Go est restée utile pour l'inférence de milieu de gamme et les configurations FPGA, mais elle ne répondait plus aux exigences minimales de capacité des principales charges de travail d'IA en production. Jusqu'à 8 Go a continué à perdre de sa pertinence à mesure que l'entraînement et l'inférence à contexte long ont matériellement relevé le plancher de capacité.
Le segment Au-dessus de 36 Go devrait croître à un CAGR de 26,28 % jusqu'en 2031, ce qui en fait la bande de capacité à la croissance la plus rapide sur le marché des mémoires pour accélérateurs d'IA. SK hynix a expédié des échantillons de HBM4E 48 Go en juin 2026, et les efforts de Samsung sur la HBM4E se sont également concentrés sur une capacité de 48 Go, indiquant que les fournisseurs considèrent désormais cette capacité comme une cible centrale pour les programmes d'accélérateurs de prochaine génération. L'allongement des contextes, les comportements d'agents plus riches et les charges de travail multimodales plus importantes augmentent toutes le besoin de caches KV plus grands et de budgets mémoire par pile plus importants. Cette pression soutient un passage vers une HBM à très haute capacité avant même qu'elle ne devienne la norme du marché large. En conséquence, le marché des mémoires pour accélérateurs d'IA devrait maintenir sa base de revenus actuelle dans la capacité de niveau intermédiaire tandis que les conceptions de plateformes futures continuent de tirer la demande vers le haut.
Par Plateforme de Déploiement : L'Hyperscale Ancre le Volume Tandis que l'IA en Périphérie Diversifie la Demande
Le cloud hyperscale et les usines d'IA ont détenu 73,87 % de la part du marché des mémoires pour accélérateurs d'IA en 2025, ce qui en a fait le cadre de déploiement dominant de loin. Un seul rack NVIDIA GB200 NVL72 intègre plus de 19 To de HBM3E sur 72 GPU Blackwell, montrant comment la conception de systèmes à l'échelle du rack multiplie la demande de mémoire bien au-delà d'un format de serveur traditionnel. Les centres de données d'entreprise et sur site ont formé la prochaine couche de demande à mesure que les organisations construisaient des clusters d'inférence pour répondre aux exigences de résidence des données et de contrôle. Les systèmes de calcul haute performance et de recherche sont restés importants pour l'IA scientifique et les cas d'usage liés à la défense qui dépendent encore de clusters d'accélérateurs denses. Les infrastructures de réseau et de télécommunications ont également élargi leurs besoins en mémoire à mesure que les charges de travail d'IA se rapprochaient de la périphérie du réseau.
Les systèmes d'IA en périphérie et les systèmes industriels devraient croître à un CAGR de 26,54 % jusqu'en 2031, ce qui en fait le segment de déploiement à la croissance la plus rapide sur le marché des mémoires pour accélérateurs d'IA. Le livre blanc de Micron sur l'IA en périphérie a montré que la bande passante mémoire affecte directement la latence d'inférence et la vitesse de génération de jetons dans les modèles de langage plus petits, ce qui aide à expliquer pourquoi la conception mémoire est si importante en dehors du cloud. Le positionnement LPDDR6 de Samsung pour les PC d'IA, l'automobile et les systèmes en périphérie pointe vers le même schéma de demande, où l'inférence locale nécessite de meilleures performances mémoire sans le profil de coût et de puissance d'une intégration HBM complète. L'IA automobile ajoute également des exigences de qualification qui allongent les cycles de conception et rendent la sélection de la mémoire plus stratégique que dans les appareils grand public courants. Cela signifie que le marché des mémoires pour accélérateurs d'IA restera dominé par l'hyperscale en termes de valeur, mais sa diversification la plus rapide viendra des systèmes en périphérie qui ont besoin de plus de traitement local et de contrôles de déploiement plus stricts.
Analyse Géographique
L'Amérique du Nord a détenu 48,12 % du marché des mémoires pour accélérateurs d'IA en 2025, maintenant sa position de principal centre de demande régional. L'avance de la région provenait de la concentration des acheteurs hyperscale, des programmes de silicium personnalisé et des grands déploiements de serveurs d'IA plutôt que de la seule capacité de fabrication de mémoire. La décision d'Amazon en février 2026 d'investir 12 milliards USD en Louisiane a montré l'ampleur des engagements de projets individuels qui continuent de façonner la demande matérielle régionale. Google a également élargi sa feuille de route TPU en 2026, renforçant le rôle de l'Amérique du Nord comme principale zone de déploiement précoce pour les accélérateurs à forte intensité de mémoire. Le Canada a soutenu la croissance régionale grâce à des conditions d'alimentation électrique favorables pour les centres de données, tandis que le Mexique a attiré l'attention comme corridor d'infrastructure nearshore pour les futurs déploiements d'IA.
L'Asie-Pacifique devrait croître à un CAGR de 26,19 % jusqu'en 2031, ce qui en fait la région à la croissance la plus rapide sur le marché des mémoires pour accélérateurs d'IA. La région joue un double rôle en tant que base de fabrication pour la HBM avancée et centre de demande croissant pour l'infrastructure d'IA. La Corée du Sud est restée centrale grâce aux réseaux de fabrication de SK hynix et Samsung, tandis que le site de Hiroshima de Micron a ajouté un nœud de production important dans la chaîne d'approvisionnement du Pacifique élargi. L'approbation par SK hynix de 21,61 billions KRW (environ 16 milliards USD) pour le cluster de Yongin en février 2026 a montré à quel point la région investit massivement dans la production future de mémoire. Le Japon a apporté des capacités de packaging avancé, et l'Inde et l'Asie du Sud-Est ont continué à développer la demande grâce à l'expansion du cloud d'IA, à l'adoption des PC d'IA et aux déploiements d'inférence locale.
L'Europe, l'Amérique du Sud, le Moyen-Orient et l'Afrique sont restés plus modestes en termes de part actuelle, mais chacun a ajouté une demande stratégique pour le marché des mémoires pour accélérateurs d'intelligence artificielle (IA). L'Allemagne et le Royaume-Uni ont mené les déploiements de serveurs d'IA européens, tandis que des initiatives publiques telles que France 2030 ont continué à soutenir la capacité de calcul domestique. La loi européenne sur l'IA a également encouragé une planification d'infrastructure locale plus poussée, car la conformité et le contrôle des données influencent désormais l'hébergement des charges de travail d'IA d'entreprise. Le Moyen-Orient et l'Afrique ont gagné en importance grâce aux achats de clusters d'IA souverains en Arabie Saoudite et aux Émirats Arabes Unis, soutenus par des cadres d'exportation et des accords technologiques transfrontaliers. L'Amérique du Sud est restée plus tôt dans son cycle, mais le Brésil et le Chili ont continué à poser les bases d'une future expansion de l'infrastructure d'IA régionale.

Paysage Concurrentiel
Le marché des mémoires pour accélérateurs d'IA fonctionnait avec une structure d'approvisionnement très concentrée en 2026, car la production avancée de HBM restait concentrée chez SK hynix, Samsung Electronics et Micron Technology. La demande était également concentrée car NVIDIA, AMD et les grands hyperscalers déterminaient quels fournisseurs de mémoire recevaient la qualification et l'allocation pour les plus grands programmes d'accélérateurs. NVIDIA et SK hynix ont annoncé un partenariat technologique pluriannuel en juin 2026 pour faire progresser la mémoire pour les usines d'IA, ce qui a montré à quel point les feuilles de route mémoire sont désormais liées aux feuilles de route des plateformes.[4]Relations Investisseurs NVIDIA, "NVIDIA et SK hynix annoncent un partenariat technologique pluriannuel pour faire progresser la mémoire pour les usines d'IA," Relations Investisseurs NVIDIA, investor.nvidia.com Samsung a suivi une voie différente en poussant la production en masse de la HBM4 avec une puce logique et un modèle de fabrication plus intégré, visant à améliorer sa position dans le prochain cycle de qualification. Micron a renforcé sa concentration en quittant la mémoire grand public en décembre 2025 et en réorientant les ressources vers la mémoire d'entreprise orientée IA, alignant ainsi son portefeuille plus étroitement avec le marché des mémoires pour accélérateurs d'IA.
Les concepteurs de silicium personnalisé ont formé une deuxième couche concurrentielle, influençant de plus en plus la conception des interfaces, le nombre de piles et les exigences de qualification sur le marché des mémoires pour accélérateurs d'IA. Broadcom a commencé à expédier un SoC de calcul personnalisé en 2 nm sur sa plateforme 3.5D XDSiP en février 2026, démontrant que les accélérateurs personnalisés évoluent rapidement vers une intégration HBM avancée. L'architecture de calcul HBM personnalisée de Marvell de décembre 2024 a donné aux hyperscalers un moyen de prendre en charge davantage de piles HBM avec une consommation d'énergie d'interface plus faible, déplaçant la discussion concurrentielle du volume d'approvisionnement vers l'efficacité de l'interface. Google, AWS et Meta ont continué à développer cette couche de conception personnalisée via les programmes TPU, Trainium et MTIA qui exploitent la mémoire adaptée aux besoins de bande passante spécifiques aux charges de travail. Cela signifie que les fournisseurs capables de prendre en charge des configurations HBM spécifiques aux produits et des cycles de qualification plus rapides auront un avantage au-delà du simple débit de plaquettes.
Une troisième couche de concurrence réside dans le packaging et l'intégration système, car le marché des mémoires pour accélérateurs d'IA dépend de plus que la seule fabrication de DRAM. Les partenaires de packaging avancé et la capacité d'assemblage liée aux fonderies sont importants car les produits HBM à haute densité ne peuvent pas évoluer sans une liaison et un débit de package fiables. C'est pourquoi la stratégie des fournisseurs inclut désormais la co-ingénierie entre mémoire, logique, packaging et conception de plateforme plutôt que la simple négociation de l'approvisionnement en composants. Le champ concurrentiel est encore étroit, mais il devient de plus en plus technique à mesure que les fournisseurs de mémoire, les concepteurs d'accélérateurs et les partenaires de packaging cherchent à sécuriser une position dans la prochaine transition HBM.
Leaders du Secteur des Mémoires pour Accélérateurs d'IA
-
SK hynix Inc.
-
Samsung Electronics Co., Ltd.
-
Micron Technology, Inc.
-
NVIDIA Corporation
-
Advanced Micro Devices, Inc.
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Développements Récents du Secteur
- Juin 2026 : NVIDIA Corporation et SK hynix Inc. ont annoncé un partenariat technologique pluriannuel pour faire progresser la mémoire de prochaine génération pour le déploiement mondial des usines d'IA, couvrant la HBM4 et les générations futures. L'accord s'appuie sur la co-ingénierie des plateformes GPU Blackwell et Vera Rubin et soutient l'alignement de l'approvisionnement pour la feuille de route des accélérateurs de NVIDIA via la montée en puissance de la capacité du cluster de Yongin de SK hynix.
- Juin 2026 : SK hynix Inc. a expédié des échantillons de HBM4E à 12 couches, 48 Go de capacité, jusqu'à 16 Gbps par broche, avec une amélioration de l'efficacité énergétique de plus de 20 % par rapport à la HBM4, à plusieurs clients, avançant son calendrier initialement prévu pour le second semestre 2026. L'entreprise vise la production en masse de la HBM4E en 2027 pour les plateformes d'accélérateurs d'IA post-Vera Rubin.
- Avril 2026 : Google LLC a dévoilé la famille TPU de 8e génération, TPU 8t et TPU 8i, lors de Google Cloud Next 2026. Le TPU 8i embarque 288 Go de HBM à 8 601 Go/s par puce et 384 Mo de SRAM sur puce, soit le triple de la génération précédente. Ce sont les premiers accélérateurs Google hébergés entièrement sur un processeur hôte ARM Axion personnalisé.
- Février 2026 : Le conseil d'administration de SK hynix Inc. a approuvé 21,61 billions KRW (environ 16 milliards USD) en nouveaux investissements d'installations pour les phases 2 à 6 du cluster de semi-conducteurs de Yongin, s'étendant jusqu'en décembre 2030, visant à doubler la capacité de production de plaquettes DRAM à environ 1 million de plaquettes par mois d'ici 2030.


Périmètre du Rapport Mondial sur le Marché des Mémoires pour Accélérateurs d'IA
Le marché des mémoires pour accélérateurs d'IA comprend les technologies mémoire, les architectures et les sous-systèmes spécifiquement conçus pour prendre en charge les charges de travail d'intelligence artificielle (IA), d'apprentissage automatique, de calcul haute performance (HPC) et de traitement de données accéléré. Les solutions de mémoire pour accélérateurs d'IA fournissent les caractéristiques de bande passante, de capacité, de latence et d'efficacité énergétique nécessaires pour alimenter des accélérateurs d'IA de plus en plus puissants avec de grands volumes de données, permettant un entraînement, une inférence, des analyses, des simulations et des opérations d'IA générative efficaces dans les environnements de calcul des centres de données, d'entreprise, en périphérie et embarqués.
Le rapport sur le marché des mémoires pour accélérateurs d'IA est segmenté par architecture mémoire (HBM, mémoire graphique à double débit de données, mémoire à double débit de données à faible consommation, mémoire à double débit de données, et autres mémoires d'accélérateurs spécialisées), plateforme d'accélération (accélérateurs GPU pour centres de données, ASICs d'IA personnalisés et XPUs, SoCs d'IA, NPUs et APUs, accélérateurs à base de FPGA, unités de traitement de données, SmartNICs et accélérateurs réseau, et autres plateformes d'accélération), génération HBM (HBM2 et HBM2E, HBM3, HBM3E, HBM4, et HBM4E et HBM de prochaine génération), hauteur de pile HBM (jusqu'à 4 couches, 8 couches, 12 couches, 16 couches, et au-dessus de 16 couches), capacité HBM par pile (jusqu'à 8 Go, 8 Go à 16 Go, 16 Go à 24 Go, 24 Go à 36 Go, et au-dessus de 36 Go), plateforme de déploiement (cloud hyperscale et usines d'IA, centres de données d'entreprise et sur site, systèmes de calcul haute performance et de recherche, infrastructures de réseau et de télécommunications, systèmes d'IA en périphérie et systèmes industriels, stations de travail d'IA et PC d'IA, et IA automobile et systèmes autonomes), et géographie (Amérique du Nord, Europe, Asie-Pacifique, Amérique du Sud, et Moyen-Orient et Afrique). Les prévisions du marché sont fournies en termes de valeur (USD).
| Mémoire à Haute Bande Passante (HBM) |
| Mémoire Graphique à Double Débit de Données |
| Mémoire à Double Débit de Données à Faible Consommation |
| Mémoire à Double Débit de Données |
| Autres Mémoires d'Accélérateurs Spécialisées |
| Accélérateurs GPU pour Centres de Données |
| ASICs d'IA Personnalisés et XPUs |
| SoCs d'IA, NPUs et APUs |
| Accélérateurs à Base de FPGA |
| Unités de Traitement de Données, SmartNICs et Accélérateurs Réseau |
| Autres Plateformes d'Accélération |
| HBM2 et HBM2E |
| HBM3 |
| HBM3E |
| HBM4 |
| HBM4E et HBM de Prochaine Génération |
| Jusqu'à 4 Couches |
| 8 Couches |
| 12 Couches |
| 16 Couches |
| Au-dessus de 16 Couches |
| Jusqu'à 8 Go |
| 8 Go à 16 Go |
| 16 Go à 24 Go |
| 24 Go à 36 Go |
| Au-dessus de 36 Go |
| Cloud Hyperscale et Usines d'IA |
| Centres de Données d'Entreprise et sur Site |
| Systèmes de Calcul Haute Performance et de Recherche |
| Infrastructures de Réseau et de Télécommunications |
| Systèmes d'IA en Périphérie et Systèmes Industriels |
| Stations de Travail d'IA et PC d'IA |
| IA Automobile et Systèmes Autonomes |
| Amérique du Nord | États-Unis |
| Canada | |
| Mexique | |
| Europe | Allemagne |
| Royaume-Uni | |
| France | |
| Italie | |
| Reste de l'Europe | |
| Asie-Pacifique | Chine |
| Japon | |
| Corée du Sud | |
| Inde | |
| Asie du Sud-Est | |
| Reste de l'Asie-Pacifique | |
| Amérique du Sud | |
| Moyen-Orient et Afrique |
| Par Architecture Mémoire | Mémoire à Haute Bande Passante (HBM) | |
| Mémoire Graphique à Double Débit de Données | ||
| Mémoire à Double Débit de Données à Faible Consommation | ||
| Mémoire à Double Débit de Données | ||
| Autres Mémoires d'Accélérateurs Spécialisées | ||
| Par Plateforme d'Accélération | Accélérateurs GPU pour Centres de Données | |
| ASICs d'IA Personnalisés et XPUs | ||
| SoCs d'IA, NPUs et APUs | ||
| Accélérateurs à Base de FPGA | ||
| Unités de Traitement de Données, SmartNICs et Accélérateurs Réseau | ||
| Autres Plateformes d'Accélération | ||
| Par Génération HBM | HBM2 et HBM2E | |
| HBM3 | ||
| HBM3E | ||
| HBM4 | ||
| HBM4E et HBM de Prochaine Génération | ||
| Par Hauteur de Pile HBM | Jusqu'à 4 Couches | |
| 8 Couches | ||
| 12 Couches | ||
| 16 Couches | ||
| Au-dessus de 16 Couches | ||
| Par Capacité HBM par Pile | Jusqu'à 8 Go | |
| 8 Go à 16 Go | ||
| 16 Go à 24 Go | ||
| 24 Go à 36 Go | ||
| Au-dessus de 36 Go | ||
| Par Plateforme de Déploiement | Cloud Hyperscale et Usines d'IA | |
| Centres de Données d'Entreprise et sur Site | ||
| Systèmes de Calcul Haute Performance et de Recherche | ||
| Infrastructures de Réseau et de Télécommunications | ||
| Systèmes d'IA en Périphérie et Systèmes Industriels | ||
| Stations de Travail d'IA et PC d'IA | ||
| IA Automobile et Systèmes Autonomes | ||
| Par Géographie | Amérique du Nord | États-Unis |
| Canada | ||
| Mexique | ||
| Europe | Allemagne | |
| Royaume-Uni | ||
| France | ||
| Italie | ||
| Reste de l'Europe | ||
| Asie-Pacifique | Chine | |
| Japon | ||
| Corée du Sud | ||
| Inde | ||
| Asie du Sud-Est | ||
| Reste de l'Asie-Pacifique | ||
| Amérique du Sud | ||
| Moyen-Orient et Afrique | ||


Questions Clés Répondues dans le Rapport
Quelle est la valeur actuelle et prévisionnelle du marché des mémoires pour accélérateurs d'IA ?
Le marché des mémoires pour accélérateurs d'IA s'élevait à 53,74 milliards USD en 2026 et devrait atteindre 165,79 milliards USD d'ici 2031, avec un CAGR de 25,27 % sur la période 2026-2031.
Quelle architecture mémoire domine les déploiements d'accélérateurs d'IA aujourd'hui ?
La mémoire à haute bande passante a dominé avec une part de 92,48 % en 2025, car les principaux accélérateurs d'entraînement et d'inférence nécessitent encore une très haute bande passante intégrée dans le package et une intégration mémoire dense.
Quelle plateforme d'accélération connaît la croissance la plus rapide jusqu'en 2031 ?
Les ASICs d'IA personnalisés et les XPUs devraient progresser à un CAGR de 26,46 % jusqu'en 2031, les hyperscalers continuant à concevoir du silicium pour des besoins de mémoire et de bande passante spécifiques aux charges de travail.
Pourquoi le déploiement en périphérie devient-il plus important pour la demande de mémoire ?
Les systèmes d'IA en périphérie et les systèmes industriels devraient croître à un CAGR de 26,54 %, car l'inférence locale nécessite une latence plus faible, un meilleur contrôle des données et des performances efficaces en mémoire en dehors du cloud.
Quelle région mène la demande et quelle région se développe le plus rapidement ?
L'Amérique du Nord a mené avec une part de 48,12 % en 2025, tandis que l'Asie-Pacifique devrait croître le plus rapidement à un CAGR de 26,19 % jusqu'en 2031, car elle combine la force de production avec un déploiement d'IA régional croissant.
Quelle est la principale contrainte sur la croissance à court terme ?
La principale contrainte est la montée en puissance lente de la capacité HBM avancée en raison des limites thermiques, de la pression sur les rendements, des délais de qualification et de la base étroite de fournisseurs capables de produire à grande échelle.
Dernière mise à jour de la page le:




