Marktgröße und Marktanteil für KI-Beschleuniger-Speicher
Marktübersicht
| Studienzeitraum | 2020 - 2031 |
|---|---|
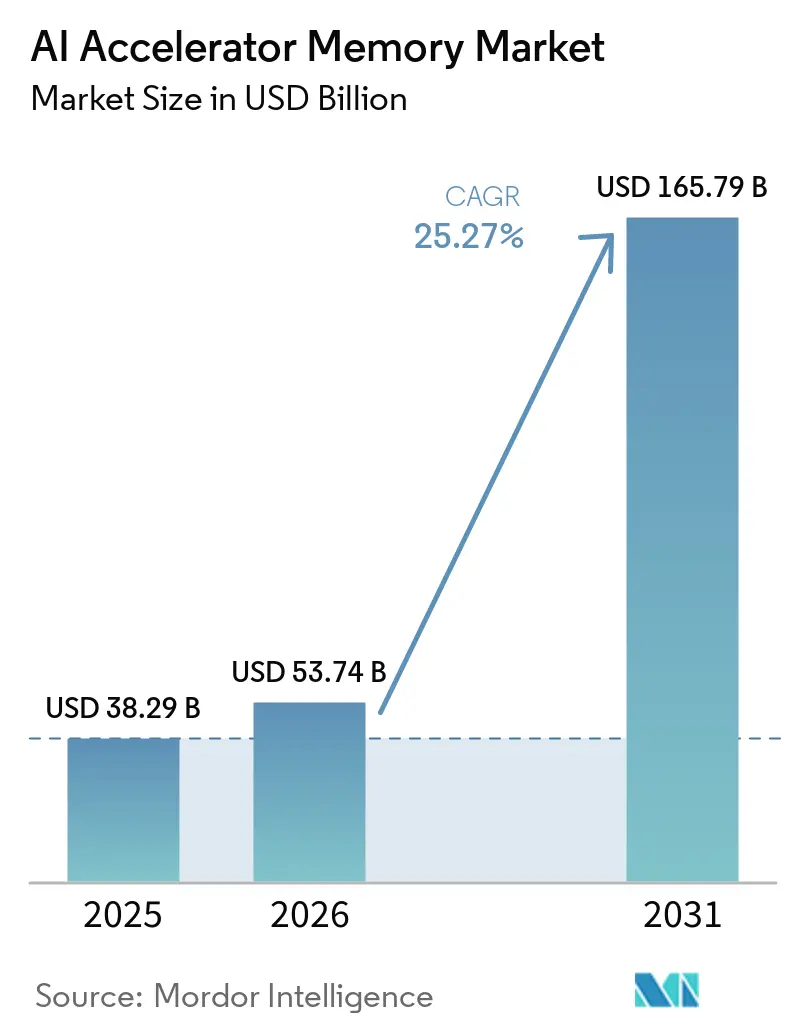
| Marktgröße (2026) | 53.74 Milliarden US-Dollar |
| Marktgröße (2031) | 165.79 Milliarden US-Dollar |
| Wachstumsrate (2026 - 2031) | 25.27% CAGR |
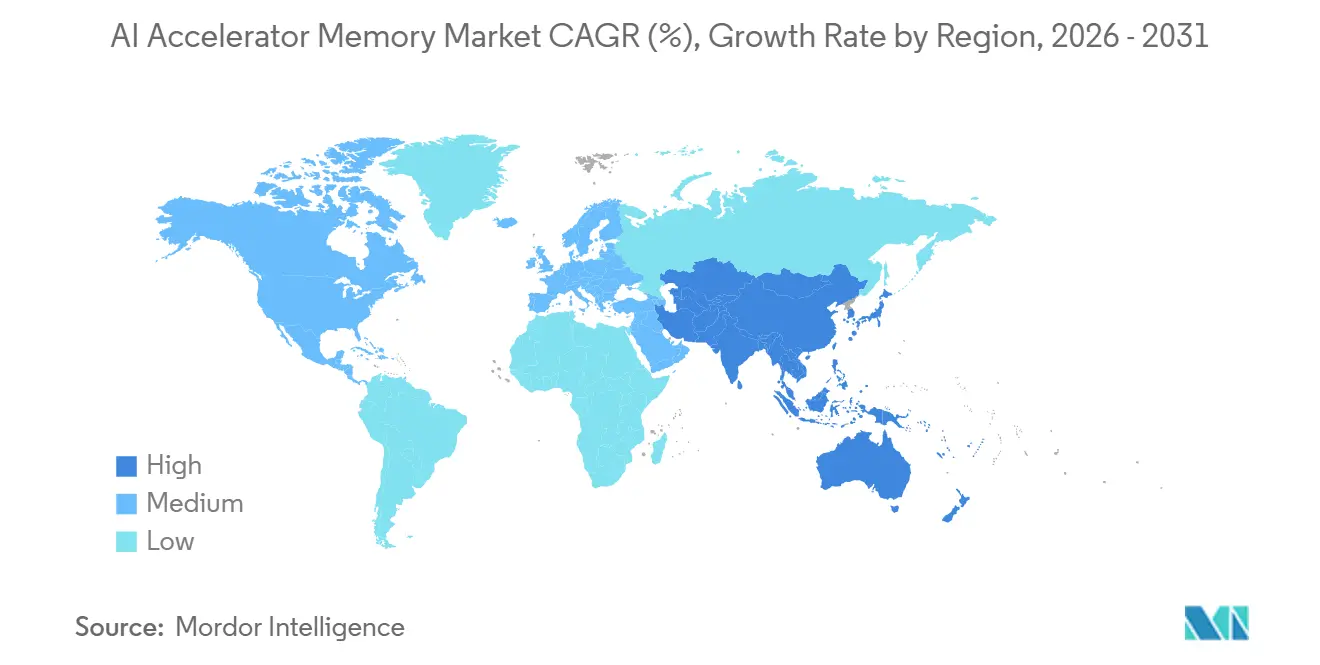
| Schnellstwachsender Markt | Asien-Pazifik |
| Größter Markt | Nordamerika |
| Marktkonzentration | Hoch |
Hauptakteure *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. | |
Analyse des KI-Beschleuniger-Speicher-Markts von Mordor Intelligence
Die Marktgröße für KI-Beschleuniger-Speicher wird voraussichtlich von 38,29 Milliarden USD im Jahr 2025 auf 53,74 Milliarden USD im Jahr 2026 wachsen und soll bis 2031 bei einer CAGR von 25,27 % über den Zeitraum 2026–2031 einen Wert von 165,79 Milliarden USD erreichen. Der KI-Beschleuniger-Speicher-Markt wird durch die Festigung von Hochbandbreitenspeicher in führenden Trainings- und Inferenz-Beschleunigern geprägt, was die Speicherarchitektur zu einer zentralen Designbeschränkung statt zu einer unterstützenden Komponente gemacht hat. Der KI-Beschleuniger-Speicher-Markt wird auch durch Hyperscale-Ausgaben gestützt, die weiterhin große KI-Server-Flotten, benutzerdefinierte Silizium-Programme und dichte Rack-Scale-Systeme mit hohem Speicherinhalt pro Beschleuniger bevorzugen. Lieferdisziplin ist ebenso wichtig, da die drei führenden DRAM-Anbieter Kapital, Ingenieuraufwand und Produktmix auf HBM-Produkte mit besseren Margen und stärkerer langfristiger Nachfragesichtbarkeit verlagert haben. Diese Verlagerung hat den KI-Beschleuniger-Speicher-Markt sowohl auf der Angebots- als auch auf der Nachfrageseite konzentrierter gemacht, da eine kleine Gruppe von Speicheranbietern und Hyperscale-Käufern nun die meisten Allokationsentscheidungen prägt. Die stärksten kurzfristigen Chancen sind an neuere HBM-Generationen, höhere Stapelhöhen und Edge-Inferenz-Plattformen geknüpft, während das Hauptrisiko im Tempo liegt, mit dem Verpackung, Wärmekontrolle und Qualifizierungskapazität mit der Nachfrage Schritt halten können.
Wichtigste Erkenntnisse des Berichts
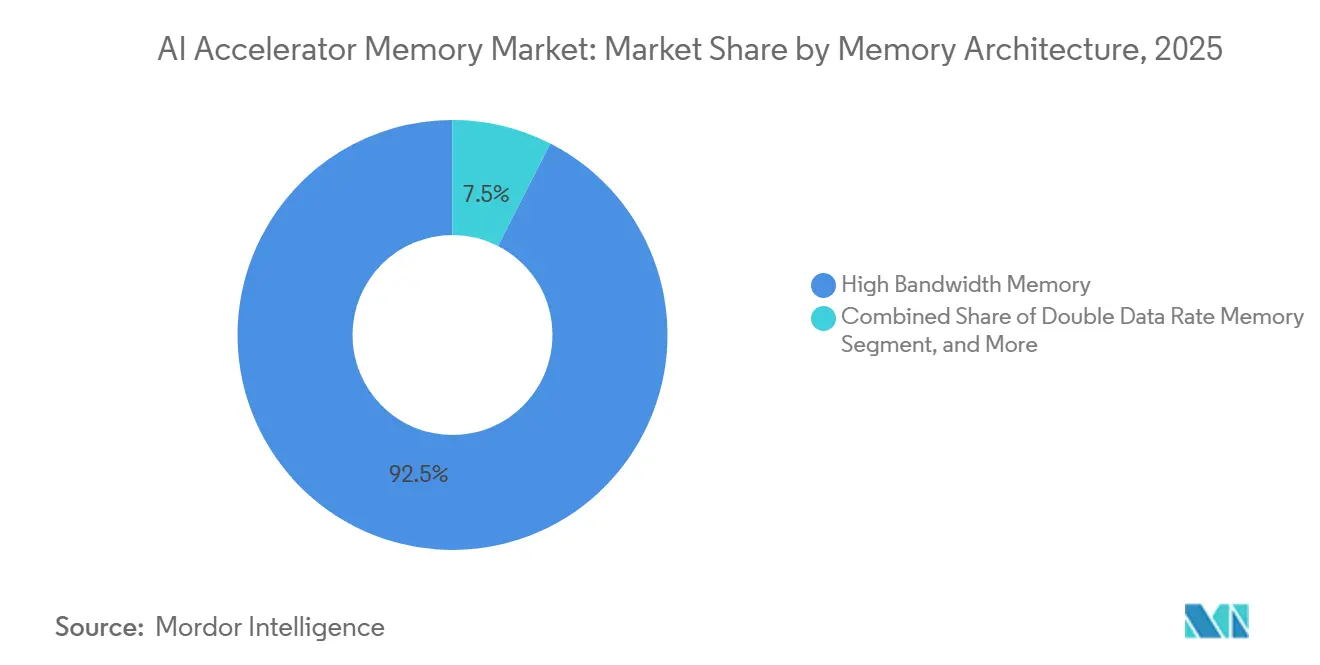
- Nach Speicherarchitektur führte Hochbandbreitenspeicher mit einem Anteil von 92,48 % im Jahr 2025 am KI-Beschleuniger-Speicher-Markt, während Niedrigenergie-Doppeldatenraten-Speicher bis 2031 voraussichtlich mit einer CAGR von 26,27 % wachsen wird.
- Nach Beschleuniger-Plattform hielten Datenzentrum-GPU-Beschleuniger im Jahr 2025 einen Anteil von 73,58 % am KI-Beschleuniger-Speicher-Markt, während benutzerdefinierte KI-ASICs und XPUs bis 2031 voraussichtlich die schnellste CAGR von 26,46 % verzeichnen werden.
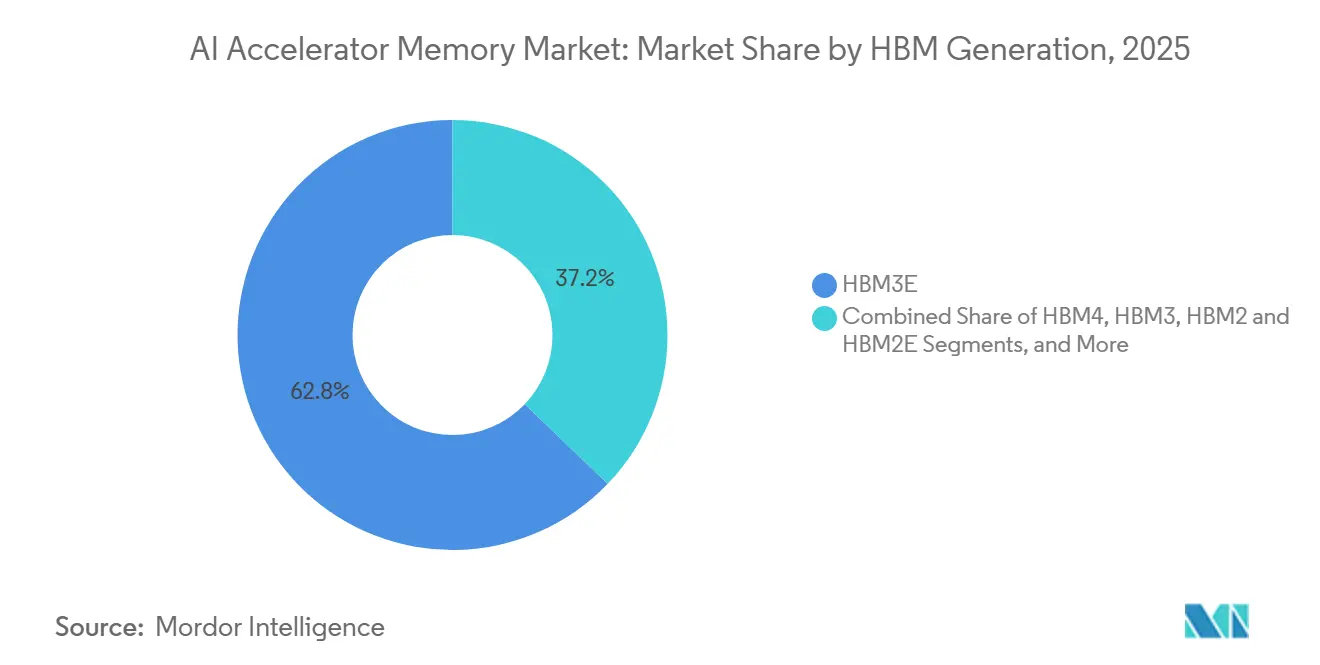
- Nach HBM-Generation entfiel auf HBM3E im Jahr 2025 ein Anteil von 62,84 %, während HBM4E und HBM der nächsten Generation bis 2031 voraussichtlich mit einer CAGR von 26,18 % wachsen werden.
- Nach HBM-Stapelhöhe dominierte 8-High im Jahr 2025 mit einem Anteil von 61,32 % am Markt für künstliche Intelligenz (KI)-Beschleuniger-Speicher, während 16-High bis 2031 voraussichtlich mit einer CAGR von 26,13 % wachsen wird.
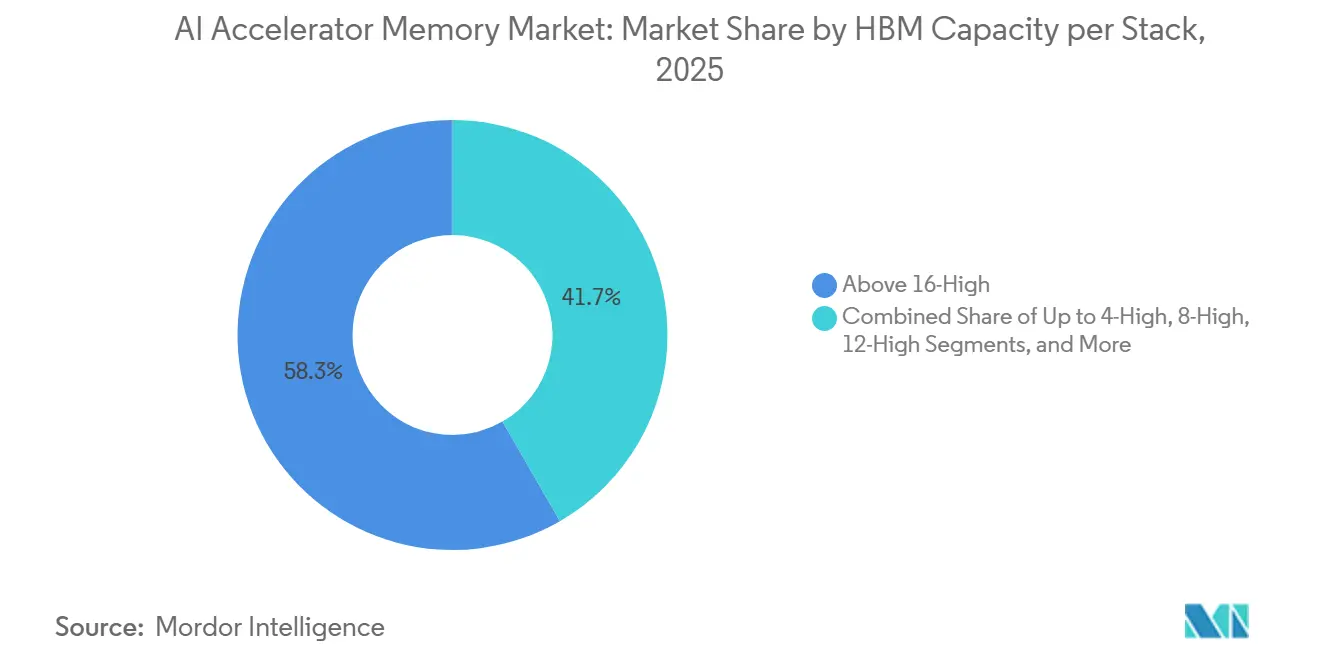
- Nach HBM-Kapazität pro Stapel hielt das Segment Über 16 GB bis 24 GB im Jahr 2025 einen Anteil von 58,33 % am KI-Beschleuniger-Speicher-Markt, während das Segment Über 36 GB bis 2031 voraussichtlich mit einer CAGR von 26,28 % wachsen wird.
- Nach Bereitstellungsplattform erfassten Hyperscale-Cloud und KI-Fabriken im Jahr 2025 einen Anteil von 73,87 %, während Edge-KI und Industriesysteme bis 2031 voraussichtlich die schnellste CAGR von 26,54 % verzeichnen werden.
- Nach Geografie hielt Nordamerika im Jahr 2025 einen Anteil von 48,12 % am KI-Beschleuniger-Speicher-Markt, während der asiatisch-pazifische Raum bis 2031 voraussichtlich mit einer CAGR von 26,19 % wachsen wird.
Hinweis: Die Marktgröße und Prognosezahlen in diesem Bericht werden mithilfe des proprietären Schätzungsrahmens von Mordor Intelligence erstellt und mit den neuesten verfügbaren Daten und Erkenntnissen vom Januar 2026 aktualisiert.
Globale Trends und Erkenntnisse zum KI-Beschleuniger-Speicher-Markt
Analyse der Treiberwirkung*
| Treiber | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Wachsende Einführung von HBM3E und HBM4 in KI-Beschleunigern | +6.2% | Global, am stärksten konzentriert in Nordamerika und dem asiatisch-pazifischen Raum | Kurzfristig (≤ 2 Jahre) |
| Steigende Rechendichte für KI-Training und -Inferenz | +5.1% | Global | Mittelfristig (2–4 Jahre) |
| Ausbau von KI-Flotten in Hyperscale-Rechenzentren | +4.3% | Nordamerika und Europa | Kurzfristig (≤ 2 Jahre) |
| Höherer Bandbreitenbedarf pro Watt in fortschrittlichen GPUs und ASICs | +3.0% | Global | Mittelfristig (2–4 Jahre) |
| Neuausrichtung des Angebots auf KI-Speicher-SKUs mit hohen Margen | +1.5% | Asiatisch-pazifischer Raum als Kern, Südkorea und Japan, Ausstrahlungseffekte auf Nordamerika | Kurzfristig (≤ 2 Jahre) |
| Wachsende Einführung von Chiplet-basierten KI-Architekturen | +1.1% | Global, frühe Gewinne in Nordamerika und dem asiatisch-pazifischen Raum | Langfristig (≥ 4 Jahre) |
| Quelle: Mordor Intelligence | |||
Wachsende Einführung von HBM3E und HBM4 in KI-Beschleunigern
Der KI-Beschleuniger-Speicher-Markt profitiert von jeder HBM-Generations-Aktualisierung, da höhere Leistung nun mit größerer Prozesskomplexität und höheren Verkaufspreisen einhergeht. SK hynix gab an, dass sein HBM3E bis zu 9,6 Gbps pro Pin und mehr als 1,23 TB/s Bandbreite erreicht, was unterstreicht, warum aktuelle KI-Beschleuniger weiterhin zu dichteren, schnelleren Speicherkonfigurationen tendieren. Samsung gab im Februar 2026 bekannt, dass es mit der Massenproduktion von HBM4 unter Verwendung eines 1c-DRAM-Prozesses und eines 4-nm-Logik-Basisdies begonnen hatte, was signalisiert, dass der Markt bereits begonnen hatte, zum nächsten Qualifizierungszyklus überzugehen. NVIDIA bestätigte im Juni 2026, dass Samsung, SK hynix und Micron alle qualifiziert wurden und die Produktion für seine Vera-Rubin-Plattform aufgenommen hatten, was die Unsicherheit hinsichtlich der Anbieterbereitschaft verringerte und die Versorgungsbasis für den nächsten Beschleuniger-Hochlauf erweiterte. Der KI-Beschleuniger-Speicher-Markt steigt daher nicht nur, weil die Stückzahlnachfrage steigt, sondern auch, weil jeder Übergang zu HBM4 und HBM4E das Umsatzwachstum an einen anspruchsvolleren und teureren Fertigungsweg knüpft.
Steigende Rechendichte für KI-Training und -Inferenz
Der KI-Beschleuniger-Speicher-Markt wird auch durch den stetigen Anstieg der pro Chip erforderlichen Speicherkapazität und Bandbreite sowohl für Training als auch für Inferenz vorangetrieben. Google stellte im April 2026 TPU 8i mit 288 GB HBM und 8.601 GB/s pro Chip vor und verdreifachte gleichzeitig den On-Chip-SRAM auf 384 MB, was zeigt, wie stark die Speicherintensität in einem Produktzyklus gestiegen ist.[1]Google Cloud Blog, "Technischer Tieftauchgang zu TPU 8t und TPU 8i," Google Cloud Blog, cloud.google.com NVIDIAs Vera-Rubin-Plattform setzte diese Richtung mit einer 576-GB-HBM4-Konfiguration pro Beschleuniger fort, was darauf hindeutet, dass Langkontext-Modelle und größere Arbeitsmengen die Mindestspeicheranforderungen weiterhin nach oben treiben. Die LPDDR6-Roadmap von JEDEC zeigte auch, dass selbst Edge-Systeme auf reichhaltigere Speicherfunktionen zusteuern, einschließlich der Unterstützung von Processing-in-Memory, was den breiteren Druck widerspiegelt, Datenbewegungen zu reduzieren und die lokale Inferenzeffizienz zu verbessern. Im KI-Beschleuniger-Speicher-Markt bedeutet dies, dass der Speicherinhalt pro Beschleuniger steigt, selbst wenn die Modelleffizienz verbessert wird, da längere Kontextfenster und komplexere Inferenz-Pipelines weiterhin zusätzliche Bandbreite und Kapazität verbrauchen.
Ausbau von KI-Flotten in Hyperscale-Rechenzentren
Der KI-Beschleuniger-Speicher-Markt ist nach wie vor eng mit dem Wachstum der Hyperscale-Infrastruktur verbunden, da große Cloud-Betreiber weiterhin die größten speicherintensiven Beschleuniger-Bereitstellungen ausmachen. Amazon gab im Februar 2026 bekannt, dass es 12 Milliarden USD in Louisiana für Cloud- und KI-Infrastruktur investieren würde, was den Umfang einzelner Projekte widerspiegelt, die nun auf Rechenzentrumsebene zugesagt werden. Google erweiterte seine TPU-Roadmap im Jahr 2026, und NVIDIA vertiefte seine mehrjährige Speicherpartnerschaft mit SK hynix, was zeigt, dass Compute-Plattform-Roadmaps und Speicherversorgungsplanung nun mehrere Zyklen im Voraus aufeinander abgestimmt werden. Rack-Scale-Systemdesigns intensivieren die Nachfrage ebenfalls, da jede Bereitstellung weit mehr HBM-Inhalt hinzufügt als eine herkömmliche Server-Aktualisierung. Dies hält den KI-Beschleuniger-Speicher-Markt einer kleinen Anzahl sehr großer Käufer ausgesetzt, deren Ausgabenpläne das verfügbare Angebot absorbieren können, bevor kleinere Unternehmenskunden Zugang erhalten.
Höherer Bandbreitenbedarf pro Watt in fortschrittlichen GPUs und ASICs
Der KI-Beschleuniger-Speicher-Markt wird nicht mehr ausschließlich durch Spitzenbandbreite angetrieben, da thermische und Leistungsgrenzen nun bestimmen, welche Speicherkonfigurationen in realen Bereitstellungen verwendet werden können. Marvell gab im Dezember 2024 bekannt, dass seine benutzerdefinierte HBM-Rechenarchitektur den Speicherschnittstellenverbrauch um 70 % reduzieren, 33 % mehr HBM-Stapel unterstützen und die Rechenfläche um 25 % vergrößern könnte, was unterstreicht, dass Energieeffizienz zum zentralen Element des Beschleuniger-Designs geworden ist. Samsungs LPDDR6-Programm und die LPDDR6-Roadmap von JEDEC weisen beide auf dieselbe Designpriorität am Edge hin: On-Device-KI benötigt höhere Speicherleistung ohne große Leistungseinbußen. Microns Edge-KI-Whitepaper verknüpfte die Speicherbandbreite auch direkt mit der Token-Generierungsgeschwindigkeit während der Dekodierung und verstärkte damit, warum Bandbreite pro Watt sowohl in großen als auch in kleinen KI-Systemen wichtig ist. Da Beschleuniger-Pakete höhere thermische Lasten und größere Stapelzahlen erreichen, werden Anbieter, die Leistung und Wärme effektiver verwalten, einen Preis- und Qualifizierungsvorteil im KI-Beschleuniger-Speicher-Markt behalten.
Analyse der Hemmnisauswirkung*
| Hemmnis | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Hohe thermische und Ausbeute-Einschränkungen auf Paketebene | -3.8% | Global, am akutesten in den Fertigungszentren des asiatisch-pazifischen Raums | Kurzfristig (≤ 2 Jahre) |
| Begrenzte qualifizierte Versorgungsbasis für fortschrittliches HBM | -2.6% | Global | Mittelfristig (2–4 Jahre) |
| Starke Abhängigkeit von fortschrittlicher Verpackungskapazität | -2.0% | Asiatisch-pazifischer Raum als Kern, Taiwan, Ausstrahlungseffekte auf Nordamerika | Mittelfristig (2–4 Jahre) |
| Exportkontrollen und Reibungsverluste bei der Lokalisierung der Lieferkette | -1.0% | Nordamerika und China | Langfristig (≥ 4 Jahre) |
| Quelle: Mordor Intelligence | |||
Hohe thermische und Ausbeute-Einschränkungen auf Paketebene
Der KI-Beschleuniger-Speicher-Markt steht vor einer erheblichen technischen Einschränkung: Das Wärmemanagement wird schwieriger, wenn die Schichtzahlen steigen und Logik-Dies in die Basisstruktur integriert werden. Samsungs HBM4-Hochlauf und der Übergang der Branche zu höheren Stapelhöhen zeigen, dass Speicheranbieter versuchen, die Dichte zu erhöhen und dabei innerhalb der Qualifizierungs- und Zuverlässigkeitsgrenzen zu bleiben.[2]Samsung Semiconductor Global Newsroom, "Samsung beginnt mit der Massenproduktion des branchenweit ersten 12-lagigen HBM3E-DRAM," Samsung Semiconductor Global Newsroom, news.samsungsemiconductor.com JEDEC-Standards bleiben wichtig, da die Kommerzialisierung davon abhängt, definierte thermische und Leistungsschwellen über aufeinanderfolgende Generationen hinweg zu erfüllen. Micron und Marvell hoben beide Speicherarchitekturänderungen hervor, die darauf abzielen, Datenbewegungen und Schnittstellenleistung zu reduzieren, und bestätigten damit, dass das Problem nicht auf das reine Angebotsvolumen beschränkt ist, sondern sich auf die Machbarkeit auf Paketebene erstreckt. Dies macht den Markt für künstliche Intelligenz (KI)-Beschleuniger-Speicher anfällig für langsamere als erwartete Hochläufe, wenn neue Stapelhöhen oder neue Logikprozesskombinationen die Ausbeuten unter kommerzielle Ziele drücken.
Begrenzte qualifizierte Versorgungsbasis für fortschrittliches HBM
Der KI-Beschleuniger-Speicher-Markt ist auch dadurch eingeschränkt, dass das fortschrittliche HBM-Angebot nach wie vor auf eine sehr kleine Gruppe qualifizierter Anbieter konzentriert ist. NVIDIAs Bestätigung vom Juni 2026, dass Samsung, SK hynix und Micron alle die Produktion für Vera Rubin aufgenommen hatten, unterstrich auch, dass sich die qualifizierte Versorgungsbasis erst jetzt innerhalb eines engen Feldes bestehender Marktführer verbreitert. Die Genehmigung von SK hynix im Februar 2026 für KRW 21,61 Billionen (ungefähr 16 Milliarden USD) für weitere Phasen des Yongin-Clusters zeigt, wie groß und wie langsam neue Kapazitätsverpflichtungen auf Fertigungsebene sind. Microns Ausstieg aus dem Verbraucherspeicher im Dezember 2025 verstärkte denselben Punkt, indem Ressourcen auf KI-orientierte Unternehmensspeicher umgeleitet wurden, anstatt die Kapazität auf breitere Endmärkte zu verteilen. In der Praxis kann der KI-Beschleuniger-Speicher-Markt angebotsknapp bleiben, selbst wenn die Nachfragesichtbarkeit stark ist, da Qualifizierungsvorlaufzeiten und Kapazitätserweiterungspläne sich viel langsamer bewegen als Beschleuniger-Bestellzyklen.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Speicherarchitektur: HBM dominiert, während LPDDR am Edge beschleunigt
HBM hielt im Jahr 2025 einen Anteil von 92,48 % am KI-Beschleuniger-Speicher-Markt nach Speicherarchitektur, was bestätigt, dass führende KI-Beschleuniger nach wie vor auf sehr hohe Bandbreite und dichten On-Package-Speicher angewiesen sind. Googles Ironwood-TPU setzte 8 Stapel HBM3E mit 7.370 GB/s pro Chip ein, und der spätere TPU 8i steigerte die Leistung auf 8.601 GB/s mit 288 GB pro Chip, was zeigt, warum HBM die Standard-Designwahl für Frontier-Systeme blieb. GDDR behielt eine Rolle in kostengünstigeren Inferenz-GPUs und Workstation-Karten, wo Systemdesigner weiterhin Leistung gegen Integrationskosten abwägen. DDR blieb auch für CPU-gebundene Funktionen in hybriden KI-Servern relevant, insbesondere wenn Beschleuniger neben breiterer Unternehmens-Compute-Infrastruktur eingesetzt werden. Im KI-Beschleuniger-Speicher-Markt spiegelt diese große Lücke zwischen HBM und dem Rest des Architekturmixes wider, wie stark die aktuelle Datenzentrum-KI von bandbreitenintensiven Beschleuniger-Paketen abhängt.
LPDDR ist das am schnellsten wachsende Teilsegment mit einer CAGR von 26,27 % von 2026 bis 2031, was darauf hindeutet, dass die nächste Nachfragewelle über die größten Rechenzentrumsbereitstellungen hinausgeht. JEDEC erklärte, dass seine LPDDR6-Roadmap Processing-in-Memory-Unterstützung hinzufügt und LPDDR in Rechenzentren und Edge-Anwendungsfälle erweitert, was auf eine breitere Rolle für Niedrigenergie-Speicher in KI-Systemen hindeutet, die lokale Inferenz und geringeren Energieverbrauch benötigen. Samsungs LPDDR6-Programm zielt auf KI-Edge-Systeme, KI-PCs, Rechenzentren und Automobil-Plattformen ab und bestätigt, dass Anbieter LPDDR als KI-Speicher-Wachstumsbereich und nicht nur als mobile Komponente behandeln. Micron verknüpfte die LPDDR-Bandbreite auch direkt mit der Token-Generierungsgeschwindigkeit in Edge-KI und machte den Speicherdurchsatz zu einem direkten Leistungshebel außerhalb der Hyperscale-Cloud. Der KI-Beschleuniger-Speicher-Markt teilt sich daher in einen Datenzentrum-HBM-Kern und eine schnell wachsende Edge-LPDDR-Schicht auf, wobei jede Architektur einem eigenen Bereitstellungsmodell dient.



Nach Beschleuniger-Plattform: GPU-Plattformen verankern Ausgaben, während benutzerdefiniertes Silizium beschleunigt
Datenzentrum-GPU-Beschleuniger erfassten im Jahr 2025 73,58 % der KI-Beschleuniger-Speicher-Marktgröße, was die installierte Basis und die Allokationsstärke der Mainstream-Trainings- und Inferenz-GPU-Plattformen widerspiegelt. NVIDIAs H100-, H200- und Blackwell-Familien hielten GPU-Plattformen im Mittelpunkt groß angelegter KI-Bereitstellungen, während AMD als bedeutender sekundärer Kundenweg für HBM-Angebot durch Plattformen wie MI455X im nächsten Zyklus verblieb. KI-SoCs, NPUs und APUs bedienten weiterhin mobile, Automobil- und eingebettete KI, aber ihr Speicherwert pro Einheit blieb niedriger als bei großen Datenzentrum-Beschleunigern. FPGA-basierte Beschleuniger waren weiterhin wichtig bei latenzempfindlichen Arbeitslasten, bei denen Anpassungsfähigkeit und deterministische Reaktionszeiten wichtig blieben. Dies ließ den KI-Beschleuniger-Speicher-Markt durch GPU-geführte Infrastruktur verankert, auch wenn andere Plattformtypen die Nachfragebasis erweiterten.
Benutzerdefinierte KI-ASICs und XPUs werden voraussichtlich bis 2031 mit einer CAGR von 26,46 % wachsen und sind damit das am schnellsten wachsende Plattformsegment im KI-Beschleuniger-Speicher-Markt. Broadcom gab im Februar 2026 bekannt, dass es mit dem Versand des ersten benutzerdefinierten 2-nm-Compute-SoC auf seiner 3,5D-XDSiP-Architektur mit Unterstützung für mehrere HBM-Stapel begonnen hatte, was zeigt, wie benutzerdefiniertes Silizium früher und schneller in fortschrittliche heterogene Verpackung übergeht.[3]Broadcom Inc., "Broadcom versendet 3,5D-Face-to-Face-Compute-SoC, der die KI-Revolution antreibt," Broadcom Investor Relations, investors.broadcom.com AWS Trainium, Google TPU 8 und Meta MTIA 500 zeigen, dass Hyperscaler ihre Speicheranforderungen zunehmend auf arbeitslastspezifische Bandbreiten- und Latenz-Ziele ausrichten, anstatt eine Standard-GPU-Vorlage zu akzeptieren. Marvells benutzerdefinierte HBM-Rechenarchitektur unterstützt auch mehr HBM-Stapel pro XPU mit geringerer Schnittstellenleistung, was maßgeschneiderte Speicherschnittstellen zu einem wettbewerbsfähigen Designmerkmal für benutzerdefinierte Beschleuniger macht. Da sich diese Verschiebung fortsetzt, wird der KI-Beschleuniger-Speicher-Markt eine breitere Mischung aus Qualifizierungspfaden und produktspezifischen HBM-Konfigurationen sehen als im vorherigen GPU-dominierten Zyklus.
Nach HBM-Generation: HBM3E führt aktuelle Bereitstellungen an, während HBM4E die nächste Architektur definiert
HBM3E entfiel im Jahr 2025 auf 62,84 % des KI-Beschleuniger-Speicher-Markts, was seine Rolle in der aktuellen Welle installierter Beschleuniger-Plattformen widerspiegelt. Es wurde in NVIDIA-Blackwell-GPUs, Googles Ironwood-TPU sowie AMD-MI300- und MI350-Serienprodukten eingesetzt und machte es zum kommerziellen Zentrum der aktuellen HBM-Nachfrage. SK hynix gab an, dass sein HBM3E mehr als 1,23 TB/s liefert, während Microns 24-GB-8-High-HBM3E in NVIDIA-H200-Systemen ebenfalls mehr als 1,2 TB/s überschritt, was erklärt, warum HBM3E die dominierende Brücke zwischen der heutigen Infrastruktur und den Plattformen von morgen blieb. HBM2 und HBM2E setzten ihren Rückgang fort, da neuere Bereitstellungen zunehmend höhere Bandbreite, größere Kapazität und stärkere Energieeffizienz erfordern. Der KI-Beschleuniger-Speicher-Markt stützte sich daher weiterhin auf HBM3E als führende kommerzielle Generation, während Käufer und Anbieter sich auf den nächsten Übergang vorbereiteten.
HBM4E und HBM der nächsten Generation werden voraussichtlich bis 2031 mit einer CAGR von 26,18 % wachsen und sind damit die am schnellsten wachsenden Generationsschichten im KI-Beschleuniger-Speicher-Markt. SK hynix lieferte im Juni 2026 12-lagige HBM4E-Muster mit 48-GB-Kapazität und berichtete von einer mehr als 20-prozentigen Verbesserung der Energieeffizienz gegenüber HBM4, was signalisiert, dass Anbieter sich bereits für Beschleuniger-Anforderungen nach Vera Rubin positionieren. Samsung brachte HBM4 auch in die Massenproduktion und beschleunigte das frühe HBM4E-Sampling, was darauf hindeutet, dass der nächste Zyklus davon abhängen wird, wie schnell Anbieter technologische Bereitschaft in stabile Volumenproduktion umwandeln. Die Verdoppelung der I/O-Anzahl und die Verwendung von Logikprozess-Basisdies erhöhen den Wert jedes Stapels, erhöhen aber auch die Belastung für Qualifizierung und Verpackung. Aus diesem Grund wird der KI-Beschleuniger-Speicher-Markt wahrscheinlich sehen, dass HBM4E das Premium-Ende der Nachfrage prägt, lange bevor die Kapazität einfach wird.
Nach HBM-Stapelhöhe: 8-High dominiert mit Mehrheitsanteil, während 16-High an Dynamik gewinnt
Die 8-High-Konfiguration hielt im Jahr 2025 einen Anteil von 61,32 % und war damit die größte Stapelhöhenkategorie im KI-Beschleuniger-Speicher-Markt. Dies spiegelte Reife, Ausbeute-Stabilität und die installierte Basis von HBM3E-Bereitstellungen in aktuellen KI-Server-Flotten wider. Die meisten H200- und Blackwell-B200-Generationssysteme waren auf 8-High-Stapel mit 24-GB-Kapazität ausgerichtet, was das Format über aktive Rollouts hinweg kommerziell dominant hielt. Das 12-High-Format expandierte durch Produkte wie Microns 36-GB-12-lagiges HBM3E, was bereits zeigte, dass Käufer bereit waren, höher zu gehen, wenn die zusätzliche Kapazität klare Arbeitslastgewinne unterstützte. Bis zu 4-High-Stapel blieben nur in Karten mit niedrigerer Leistung oder Legacy-Inferenz relevant, wo Kosteneffizienz wichtiger war als Speicherdichte.
Das 16-High-Segment wird voraussichtlich bis 2031 mit einer CAGR von 26,13 % wachsen und ist damit das am schnellsten wachsende Stapelhöhen-Tier im KI-Beschleuniger-Speicher-Markt. NVIDIAs Vera-Rubin-Plattform spezifiziert HBM4 in einer 16-High-Konfiguration mit 576 GB Gesamtkapazität pro Beschleuniger und schafft damit einen direkten Sog für dieses Format, wenn Bereitstellungen des nächsten Zyklus skalieren. SK hynix' HBM4E-Sampling und zukünftige HBM5-Arbeiten zeigen auch, dass Anbieter auf noch größere Stapeldichte drängen, aber jeder Schritt erhöht die Herausforderungen beim Ausdünnen, Bonden und bei der Wärme. Das bedeutet, dass kommerzielles Wachstum am oberen Ende nicht nur von der Beschleuniger-Nachfrage abhängt, sondern auch davon, wie schnell sich die Prozessstabilität bei fortschrittlichen Stapelhöhen verbessert. Der Markt für künstliche Intelligenz (KI)-Beschleuniger-Speicher wird daher wahrscheinlich seine größte installierte Basis in reifen Formaten behalten, während sein schnellstes Umsatzwachstum zu höheren Stapeln verlagert wird.
Nach HBM-Kapazität pro Stapel: Mittleres Segment 24 GB führt, während Ultra-Hochkapazität auf nächste Plattformen abzielt
Das Segment Über 16 GB bis 24 GB führte im Jahr 2025 mit einem Anteil von 58,33 % und stand damit im Mittelpunkt des KI-Beschleuniger-Speicher-Markts für Systeme der aktuellen Generation. Dieses Segment entsprach dem Kosten-Leistungs-Profil von Mainstream-KI-Server-Bereitstellungen, insbesondere dort, wo 8-High-HBM3E der praktische Standard blieb. Microns 24-GB-8-High-HBM3E in NVIDIA-H200-Systemen veranschaulicht, warum dieses Segment zum kommerziellen Sweet Spot für aktive Infrastrukturausbauten geworden ist. Der Bereich 8 GB bis 16 GB blieb für mittlere Inferenz- und FPGA-Einstellungen nützlich, erfüllte aber nicht mehr die Mindestkapazitätsanforderungen führender Produktions-KI-Arbeitslasten. Bis zu 8 GB verlor weiterhin an Relevanz, da Training und Langkontext-Inferenz den Kapazitätsboden wesentlich anhoben.
Das Segment Über 36 GB wird voraussichtlich bis 2031 mit einer CAGR von 26,28 % wachsen und ist damit das am schnellsten wachsende Kapazitätsband im KI-Beschleuniger-Speicher-Markt. SK hynix lieferte im Juni 2026 48-GB-HBM4E-Muster, und Samsungs HBM4E-Bemühungen konzentrierten sich ebenfalls auf 48-GB-Kapazität, was darauf hindeutet, dass Anbieter diese Kapazität nun als Kernziel für Beschleuniger-Programme der nächsten Generation betrachten. Steigende Kontextlängen, reichhaltigeres Agentenverhalten und größere multimodale Arbeitslasten erhöhen alle den Bedarf an größeren KV-Caches und größeren Speicherbudgets pro Stapel. Dieser Druck unterstützt eine Verlagerung hin zu Ultra-Hochkapazitäts-HBM, noch bevor es zum breiten Marktstandard wird. Infolgedessen wird der KI-Beschleuniger-Speicher-Markt voraussichtlich seine aktuelle Umsatzbasis im mittleren Kapazitätssegment beibehalten, während zukünftige Plattformdesigns die Nachfrage weiter nach oben ziehen.
Nach Bereitstellungsplattform: Hyperscale verankert Volumen, während Edge-KI die Nachfrage diversifiziert
Hyperscale-Cloud und KI-Fabriken hielten im Jahr 2025 einen Anteil von 73,87 % am KI-Beschleuniger-Speicher-Markt und waren damit mit großem Abstand das dominierende Bereitstellungsumfeld. Ein einzelnes NVIDIA-GB200-NVL72-Rack integriert mehr als 19 TB HBM3E über 72 Blackwell-GPUs und zeigt, wie das Rack-Scale-Systemdesign den Speicherbedarf weit über ein herkömmliches Serverformat hinaus multipliziert. Unternehmens- und On-Premise-Rechenzentren bildeten die nächste Nachfrageschicht, da Organisationen Inferenz-Cluster aufbauten, um Datenschutz- und Kontrollanforderungen zu erfüllen. Hochleistungsrechnen und Forschungssysteme blieben wichtig für wissenschaftliche KI und verteidigungsbezogene Anwendungsfälle, die nach wie vor auf dichte Beschleuniger-Cluster angewiesen sind. Netzwerk- und Telekommunikationsinfrastruktur erweiterte ebenfalls ihren Speicherbedarf, da KI-Arbeitslasten näher an den Netzwerk-Edge rückten.
Edge-KI und Industriesysteme werden voraussichtlich bis 2031 mit einer CAGR von 26,54 % wachsen und sind damit das am schnellsten wachsende Bereitstellungssegment im KI-Beschleuniger-Speicher-Markt. Microns Edge-KI-Whitepaper zeigte, dass die Speicherbandbreite die Inferenzlatenz und die Token-Generierungsgeschwindigkeit in kleineren Sprachmodellen direkt beeinflusst, was erklärt, warum Speicherdesign außerhalb der Cloud so wichtig ist. Samsungs LPDDR6-Positionierung für KI-PCs, Automobil- und Edge-Systeme weist auf dasselbe Nachfragemuster hin, bei dem lokale Inferenz stärkere Speicherleistung ohne das Kosten- und Leistungsprofil einer vollständigen HBM-Integration benötigt. Automobil-KI fügt auch Qualifizierungsanforderungen hinzu, die Designzyklen verlängern und die Speicherauswahl strategischer machen als bei Mainstream-Verbrauchergeräten. Das bedeutet, dass der KI-Beschleuniger-Speicher-Markt wertmäßig hyperscale-geführt bleiben wird, aber seine schnellste Diversifizierung von Edge-Systemen kommen wird, die mehr lokale Verarbeitung und strengere Bereitstellungskontrollen benötigen.
Geografische Analyse
Nordamerika hielt im Jahr 2025 einen Anteil von 48,12 % am KI-Beschleuniger-Speicher-Markt und behauptete seine Position als führendes regionales Nachfragezentrum. Der Vorsprung der Region resultierte aus der Konzentration von Hyperscale-Käufern, benutzerdefinierten Silizium-Programmen und großen KI-Server-Bereitstellungen und nicht allein aus der Speicherfertigungskapazität. Amazons Entscheidung vom Februar 2026, 12 Milliarden USD in Louisiana zu investieren, zeigte den Umfang einzelner Projektverpflichtungen, die weiterhin die regionale Hardware-Nachfrage prägen. Google erweiterte auch seine TPU-Roadmap im Jahr 2026 und festigte damit Nordamerikas Rolle als primäre Frühbereitstellungszone für speicherintensive Beschleuniger. Kanada unterstützte das regionale Wachstum durch günstige Strombedingungen für Rechenzentren, während Mexiko als Nearshore-Infrastrukturkorridor für zukünftige KI-Ausbauten Aufmerksamkeit erlangte.
Der asiatisch-pazifische Raum wird voraussichtlich bis 2031 mit einer CAGR von 26,19 % wachsen und ist damit die am schnellsten wachsende Region im KI-Beschleuniger-Speicher-Markt. Die Region spielt eine doppelte Rolle als Fertigungsbasis für fortschrittliches HBM und als aufstrebendes Zentrum der Nachfrage nach KI-Infrastruktur. Südkorea blieb durch die Fab-Netzwerke von SK hynix und Samsung zentral, während Microns Standort in Hiroshima einen wichtigen Produktionsknoten in der breiteren pazifischen Lieferkette hinzufügte. Die Genehmigung des Yongin-Clusters von SK hynix über KRW 21,61 Billionen (ungefähr 16 Milliarden USD) im Februar 2026 zeigte, wie stark die Region in zukünftige Speicherproduktion investiert. Japan trug fortschrittliche Verpackungsfähigkeiten bei, und Indien sowie Südostasien bauten weiterhin Nachfrage durch KI-Cloud-Expansion, KI-PC-Einführung und lokale Inferenz-Bereitstellungen auf.
Europa, Südamerika, der Nahe Osten und Afrika blieben im aktuellen Anteil kleiner, aber jeder fügte strategische Nachfrage für den Markt für künstliche Intelligenz (KI)-Beschleuniger-Speicher hinzu. Deutschland und das Vereinigte Königreich führten europäische KI-Server-Bereitstellungen an, während öffentliche Initiativen wie France 2030 weiterhin die inländische Rechenkapazität unterstützten. Das EU-KI-Gesetz förderte auch mehr lokale Infrastrukturplanung, da Compliance und Datenkontrolle nun beeinflussen, wo Unternehmens-KI-Arbeitslasten gehostet werden. Der Nahe Osten und Afrika gewannen durch souveräne KI-Cluster-Beschaffung in Saudi-Arabien und den Vereinigten Arabischen Emiraten an Bedeutung, unterstützt durch Exportrahmen und grenzüberschreitende Technologieabkommen. Südamerika befand sich noch früher in seinem Zyklus, aber Brasilien und Chile legten weiterhin den Grundstein für zukünftige regionale KI-Infrastrukturexpansion.

Wettbewerbslandschaft
Der KI-Beschleuniger-Speicher-Markt operierte im Jahr 2026 mit einer stark konzentrierten Angebotsstruktur, da die fortschrittliche HBM-Produktion auf SK hynix, Samsung Electronics und Micron Technology konzentriert blieb. Die Nachfrage war ebenfalls konzentriert, da NVIDIA, AMD und große Hyperscaler bestimmten, welche Speicheranbieter Qualifizierung und Allokation für die größten Beschleuniger-Programme erhielten. NVIDIA und SK hynix kündigten im Juni 2026 eine mehrjährige Technologiepartnerschaft an, um Speicher für KI-Fabriken voranzutreiben, was zeigte, wie eng Speicher-Roadmaps nun mit Plattform-Roadmaps verknüpft sind.[4]NVIDIA Investor Relations, "NVIDIA und SK hynix kündigen mehrjährige Technologiepartnerschaft zur Weiterentwicklung von Speicher für KI-Fabriken an," NVIDIA Investor Relations, investor.nvidia.com Samsung verfolgte einen anderen Weg, indem es die HBM4-Massenproduktion mit einem logikbasierten Die und einem stärker integrierten Fertigungsmodell vorantrieb, um seine Position im nächsten Qualifizierungszyklus zu verbessern. Micron stärkte seinen Fokus, indem es im Dezember 2025 aus dem Verbraucherspeicher ausstieg und Ressourcen auf KI-orientierten Unternehmensspeicher umleitete, wodurch sein Portfolio enger auf den KI-Beschleuniger-Speicher-Markt ausgerichtet wurde.
Benutzerdefinierte Silizium-Designer haben eine zweite Wettbewerbsschicht gebildet, die zunehmend Schnittstellendesign, Stapelanzahl und Qualifizierungsanforderungen im KI-Beschleuniger-Speicher-Markt beeinflusst. Broadcom begann im Februar 2026 mit dem Versand eines benutzerdefinierten 2-nm-Compute-SoC auf seiner 3,5D-XDSiP-Plattform und demonstrierte damit, dass benutzerdefinierte Beschleuniger schnell auf fortschrittliche HBM-Integration zusteuern. Marvells benutzerdefinierte HBM-Rechenarchitektur vom Dezember 2024 gab Hyperscalern eine Möglichkeit, mehr HBM-Stapel mit geringerer Schnittstellenleistung zu unterstützen, und verlagerte die Wettbewerbsdiskussion vom Angebotsvolumen zur Schnittstelleneffizienz. Google, AWS und Meta erweiterten diese benutzerdefinierte Designschicht weiterhin durch TPU-, Trainium- und MTIA-Programme, die auf arbeitslastspezifische Bandbreitenanforderungen zugeschnittenen Speicher nutzen. Das bedeutet, dass Anbieter, die produktspezifische HBM-Konfigurationen und schnellere Qualifizierungszyklen unterstützen können, einen Vorteil über die bloße Waferproduktion hinaus haben werden.
Eine dritte Wettbewerbsschicht liegt in Verpackung und Systemintegration, da der KI-Beschleuniger-Speicher-Markt mehr als nur DRAM-Fertigung erfordert. Fortschrittliche Verpackungspartner und foundry-gebundene Montagekapazität sind wichtig, da hochdichte HBM-Produkte ohne zuverlässiges Bonden und Paketdurchsatz nicht skalieren können. Deshalb umfasst die Anbieterstrategie nun Co-Engineering über Speicher, Logik, Verpackung und Plattformdesign hinaus, anstatt nur Komponentenversorgung zu verhandeln. Das Wettbewerbsfeld ist noch eng, wird aber zunehmend technischer, da Speicheranbieter, Beschleuniger-Designer und Verpackungspartner um eine Position im nächsten HBM-Übergang konkurrieren.
Marktführer im KI-Beschleuniger-Speicher-Bereich
SK hynix Inc.
Samsung Electronics Co., Ltd.
Micron Technology, Inc.
NVIDIA Corporation
Advanced Micro Devices, Inc.
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Aktuelle Branchenentwicklungen
- Juni 2026: NVIDIA Corporation und SK hynix Inc. kündigten eine mehrjährige Technologiepartnerschaft an, um Speicher der nächsten Generation für den globalen KI-Fabrik-Ausbau voranzutreiben, einschließlich HBM4 und zukünftiger Generationen. Die Vereinbarung baut auf Co-Engineering über die Blackwell- und Vera-Rubin-GPU-Plattformen auf und unterstützt die Versorgungsausrichtung für NVIDIAs Beschleuniger-Roadmap durch den Kapazitätshochlauf des Yongin-Clusters von SK hynix.
- Juni 2026: SK hynix Inc. lieferte 12-lagige HBM4E-Muster mit 48-GB-Kapazität, bis zu 16 Gbps pro Pin und mehr als 20 % Verbesserung der Energieeffizienz gegenüber HBM4 an mehrere Kunden und beschleunigte damit seinen ursprünglich geplanten H2-2026-Zeitplan. Das Unternehmen strebt die HBM4E-Massenproduktion im Jahr 2027 für KI-Beschleuniger-Plattformen nach Vera Rubin an.
- April 2026: Google LLC stellte die TPU-Familie der 8. Generation, TPU 8t und TPU 8i, auf der Google Cloud Next 2026 vor. Der TPU 8i trägt 288 GB HBM bei 8.601 GB/s pro Chip und 384 MB On-Chip-SRAM, das Dreifache der vorherigen Generation. Dies sind die ersten Google-Beschleuniger, die vollständig auf einem benutzerdefinierten Axion-ARM-CPU-Host gehostet werden.
- Februar 2026: Der Vorstand von SK hynix Inc. genehmigte KRW 21,61 Billionen (ungefähr 16 Milliarden USD) an neuen Anlageninvestitionen für die Phasen 2 bis 6 des Yongin-Halbleiterclusters, die bis Dezember 2030 laufen und auf eine Verdoppelung der DRAM-Waferkapazität auf ungefähr 1 Million Wafer pro Monat bis 2030 abzielen.


Umfang des globalen KI-Beschleuniger-Speicher-Marktberichts
Der KI-Beschleuniger-Speicher-Markt umfasst Speichertechnologien, -architekturen und -subsysteme, die speziell zur Unterstützung von Arbeitslasten in den Bereichen künstliche Intelligenz (KI), maschinelles Lernen, Hochleistungsrechnen (HPC) und beschleunigte Datenverarbeitung entwickelt wurden. KI-Beschleuniger-Speicherlösungen bieten die Bandbreiten-, Kapazitäts-, Latenz- und Energieeffizienz-Eigenschaften, die erforderlich sind, um zunehmend leistungsfähige KI-Beschleuniger mit großen Datenmengen zu versorgen und effizientes Training, Inferenz, Analytik, Simulation und generative KI-Operationen in Rechenzentren, Unternehmens-, Edge- und eingebetteten Rechenumgebungen zu ermöglichen.
Der KI-Beschleuniger-Speicher-Marktbericht ist segmentiert nach Speicherarchitektur (HBM, Grafik-Doppeldatenraten-Speicher, Niedrigenergie-Doppeldatenraten-Speicher, Doppeldatenraten-Speicher und andere spezialisierte Beschleuniger-Speicher), Beschleuniger-Plattform (Datenzentrum-GPU-Beschleuniger, benutzerdefinierte KI-ASICs und XPUs, KI-SoCs, NPUs und APUs, FPGA-basierte Beschleuniger, Datenverarbeitungseinheiten, SmartNICs und Netzwerkbeschleuniger sowie andere Beschleuniger-Plattformen), HBM-Generation (HBM2 und HBM2E, HBM3, HBM3E, HBM4 sowie HBM4E und HBM der nächsten Generation), HBM-Stapelhöhe (Bis zu 4-High, 8-High, 12-High, 16-High und Über 16-High), HBM-Kapazität pro Stapel (Bis zu 8 GB, 8 GB bis 16 GB, 16 GB bis 24 GB, 24 GB bis 36 GB und Über 36 GB), Bereitstellungsplattform (Hyperscale-Cloud und KI-Fabriken, Unternehmens- und On-Premise-Rechenzentren, Hochleistungsrechnen und Forschungssysteme, Netzwerk- und Telekommunikationsinfrastruktur, Edge-KI und Industriesysteme, KI-Workstations und KI-PCs sowie Automobil-KI und autonome Systeme) sowie Geografie (Nordamerika, Europa, asiatisch-pazifischer Raum, Südamerika sowie Naher Osten und Afrika). Die Marktprognosen werden in Wertangaben (USD) bereitgestellt.
| Hochbandbreitenspeicher (HBM) |
| Grafik-Doppeldatenraten-Speicher |
| Niedrigenergie-Doppeldatenraten-Speicher |
| Doppeldatenraten-Speicher |
| Andere spezialisierte Beschleuniger-Speicher |
| Datenzentrum-GPU-Beschleuniger |
| Benutzerdefinierte KI-ASICs und XPUs |
| KI-SoCs, NPUs und APUs |
| FPGA-basierte Beschleuniger |
| Datenverarbeitungseinheiten, SmartNICs und Netzwerkbeschleuniger |
| Andere Beschleuniger-Plattformen |
| HBM2 und HBM2E |
| HBM3 |
| HBM3E |
| HBM4 |
| HBM4E und HBM der nächsten Generation |
| Bis zu 4-High |
| 8-High |
| 12-High |
| 16-High |
| Über 16-High |
| Bis zu 8 GB |
| 8 GB bis 16 GB |
| 16 GB bis 24 GB |
| 24 GB bis 36 GB |
| Über 36 GB |
| Hyperscale-Cloud und KI-Fabriken |
| Unternehmens- und On-Premise-Rechenzentren |
| Hochleistungsrechnen und Forschungssysteme |
| Netzwerk- und Telekommunikationsinfrastruktur |
| Edge-KI und Industriesysteme |
| KI-Workstations und KI-PCs |
| Automobil-KI und autonome Systeme |
| Nordamerika | Vereinigte Staaten |
| Kanada | |
| Mexiko | |
| Europa | Deutschland |
| Vereinigtes Königreich | |
| Frankreich | |
| Italien | |
| Übriges Europa | |
| Asiatisch-pazifischer Raum | China |
| Japan | |
| Südkorea | |
| Indien | |
| Südostasien | |
| Übriger asiatisch-pazifischer Raum | |
| Südamerika | |
| Naher Osten und Afrika |
| Nach Speicherarchitektur | Hochbandbreitenspeicher (HBM) | |
| Grafik-Doppeldatenraten-Speicher | ||
| Niedrigenergie-Doppeldatenraten-Speicher | ||
| Doppeldatenraten-Speicher | ||
| Andere spezialisierte Beschleuniger-Speicher | ||
| Nach Beschleuniger-Plattform | Datenzentrum-GPU-Beschleuniger | |
| Benutzerdefinierte KI-ASICs und XPUs | ||
| KI-SoCs, NPUs und APUs | ||
| FPGA-basierte Beschleuniger | ||
| Datenverarbeitungseinheiten, SmartNICs und Netzwerkbeschleuniger | ||
| Andere Beschleuniger-Plattformen | ||
| Nach HBM-Generation | HBM2 und HBM2E | |
| HBM3 | ||
| HBM3E | ||
| HBM4 | ||
| HBM4E und HBM der nächsten Generation | ||
| Nach HBM-Stapelhöhe | Bis zu 4-High | |
| 8-High | ||
| 12-High | ||
| 16-High | ||
| Über 16-High | ||
| Nach HBM-Kapazität pro Stapel | Bis zu 8 GB | |
| 8 GB bis 16 GB | ||
| 16 GB bis 24 GB | ||
| 24 GB bis 36 GB | ||
| Über 36 GB | ||
| Nach Bereitstellungsplattform | Hyperscale-Cloud und KI-Fabriken | |
| Unternehmens- und On-Premise-Rechenzentren | ||
| Hochleistungsrechnen und Forschungssysteme | ||
| Netzwerk- und Telekommunikationsinfrastruktur | ||
| Edge-KI und Industriesysteme | ||
| KI-Workstations und KI-PCs | ||
| Automobil-KI und autonome Systeme | ||
| Nach Geografie | Nordamerika | Vereinigte Staaten |
| Kanada | ||
| Mexiko | ||
| Europa | Deutschland | |
| Vereinigtes Königreich | ||
| Frankreich | ||
| Italien | ||
| Übriges Europa | ||
| Asiatisch-pazifischer Raum | China | |
| Japan | ||
| Südkorea | ||
| Indien | ||
| Südostasien | ||
| Übriger asiatisch-pazifischer Raum | ||
| Südamerika | ||
| Naher Osten und Afrika | ||


Im Bericht beantwortete Schlüsselfragen
Wie hoch ist der aktuelle und prognostizierte Wert des KI-Beschleuniger-Speicher-Bereichs?
Der KI-Beschleuniger-Speicher-Markt belief sich im Jahr 2026 auf 53,74 Milliarden USD und soll bis 2031 einen Wert von 165,79 Milliarden USD erreichen, mit einer CAGR von 25,27 % über den Zeitraum 2026–2031.
Welche Speicherarchitektur führt heute KI-Beschleuniger-Bereitstellungen an?
Hochbandbreitenspeicher führte im Jahr 2025 mit einem Anteil von 92,48 %, da führende Trainings- und Inferenz-Beschleuniger nach wie vor sehr hohe On-Package-Bandbreite und dichte Speicherintegration erfordern.
Welche Beschleuniger-Plattform wächst bis 2031 am schnellsten?
Benutzerdefinierte KI-ASICs und XPUs werden voraussichtlich bis 2031 mit einer CAGR von 26,46 % wachsen, da Hyperscaler weiterhin Silizium für arbeitslastspezifische Speicher- und Bandbreitenanforderungen entwickeln.
Warum wird die Edge-Bereitstellung für die Speichernachfrage immer wichtiger?
Edge-KI und Industriesysteme werden voraussichtlich mit einer CAGR von 26,54 % wachsen, da lokale Inferenz geringere Latenz, stärkere Datenkontrolle und speichereffiziente Leistung außerhalb der Cloud benötigt.
Welche Region führt die Nachfrage an und welche Region wächst am schnellsten?
Nordamerika führte im Jahr 2025 mit einem Anteil von 48,12 %, während der asiatisch-pazifische Raum voraussichtlich am schnellsten mit einer CAGR von 26,19 % bis 2031 wachsen wird, da er Produktionsstärke mit steigender regionaler KI-Bereitstellung verbindet.
Was ist die Haupteinschränkung für das kurzfristige Wachstum?
Die Haupteinschränkung ist der langsame Hochlauf der fortschrittlichen HBM-Kapazität aufgrund thermischer Grenzen, Ausbeute-Druck, Qualifizierungszeitpläne und der engen Basis von Anbietern, die in der Lage sind, im großen Maßstab zu produzieren.
Seite zuletzt aktualisiert am:




