AIアクセラレータメモリ市場規模とシェア
市場概要
| 調査期間 | 2020 - 2031 |
|---|---|
| 市場規模 (2026) | 53.74 十億米ドル |
| 市場規模 (2031) | 165.79 十億米ドル |
| 成長率 (2026 - 2031) | 25.27% CAGR |
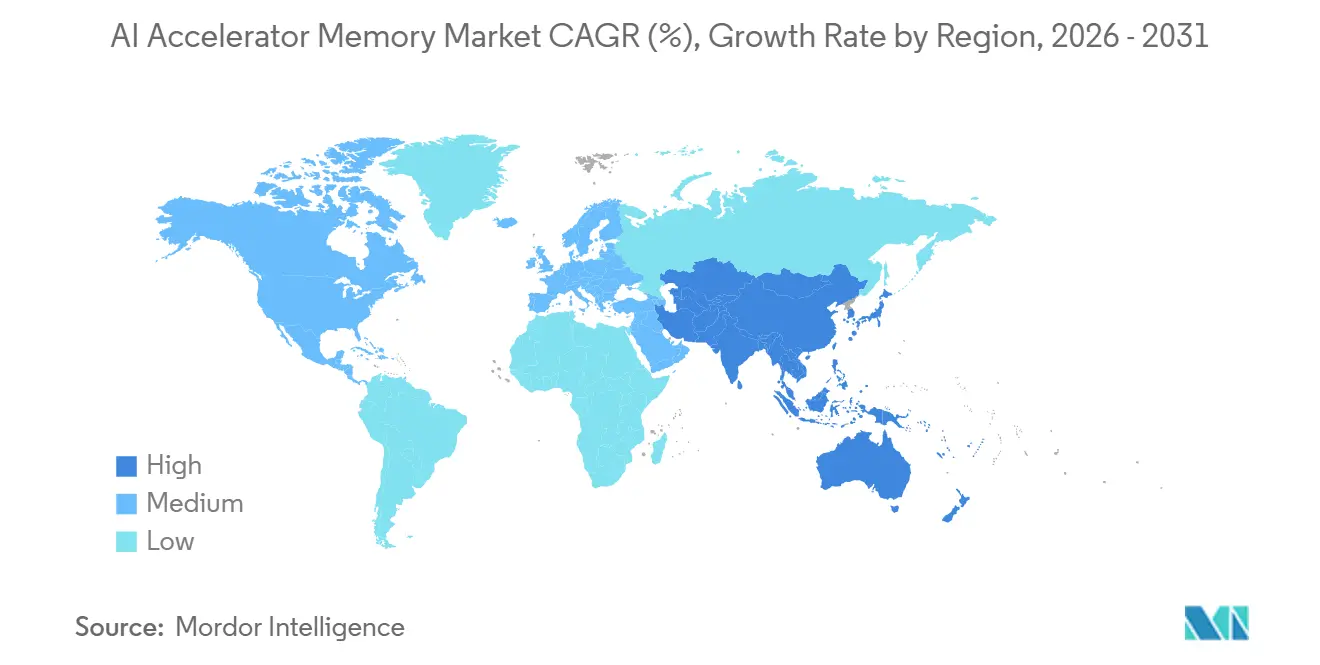
| 最も急速に成長している市場 | アジア太平洋地域 |
| 最大市場 | 北米 |
| 市場集中度 | 高 |
主要プレーヤー *免責事項:主要選手の並び順不同 画像 © Mordor Intelligence。再利用にはCC BY 4.0の表示が必要です。 | |
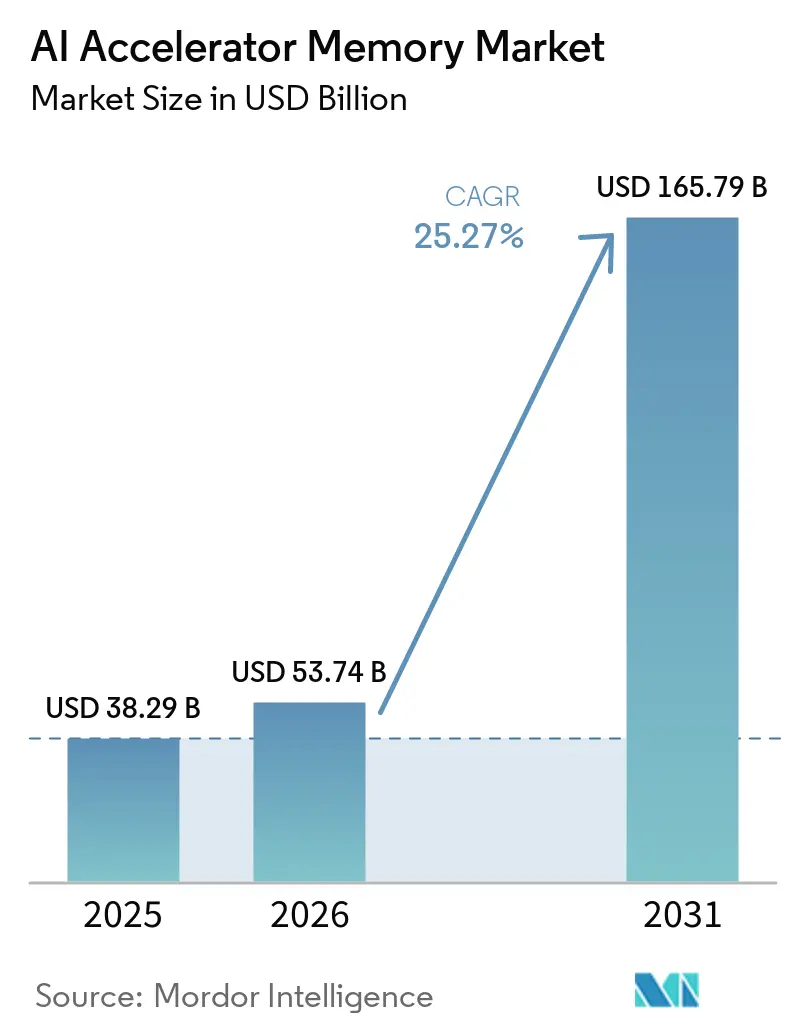
Mordor IntelligenceによるAIアクセラレータメモリ市場分析
AIアクセラレータメモリ市場規模は、2025年の382.9 ビリオン 米ドルから2026年には537.4 ビリオン 米ドルへと成長し、2026年から2031年にかけてCAGR 25.27%で2031年までに1,657.9 ビリオン 米ドルに達すると予測されています。AIアクセラレータメモリ市場は、主要なトレーニングおよび推論アクセラレータ全体にわたる高帯域幅メモリのロックインによって形成されており、メモリアーキテクチャはサポートコンポーネントではなくコア設計上の制約となっています。AIアクセラレータメモリ市場はまた、大規模なAIサーバーフリート、カスタムシリコンプログラム、およびアクセラレータあたりの高いメモリ搭載量を持つ高密度ラックスケールシステムを引き続き優先するハイパースケール支出によっても押し上げられています。供給規律も同様に重要であり、3大DRAMサプライヤーは、より高いマージンと長期的な需要の視認性が高いHBM製品に向けて資本、エンジニアリング努力、および製品ミックスをシフトさせています。このシフトにより、AIアクセラレータメモリ市場は供給側と需要側の両方でより集中化しており、少数のメモリベンダーとハイパースケールバイヤーが現在ほとんどの割り当て決定を形成しています。最も強い近期の機会は、新しいHBMジェネレーション、より高いスタック高さ、およびエッジ推論プラットフォームに結びついており、主なリスクはパッケージング、熱制御、および資格認定能力が需要に追いつくペースにあります。
主要レポートのポイント
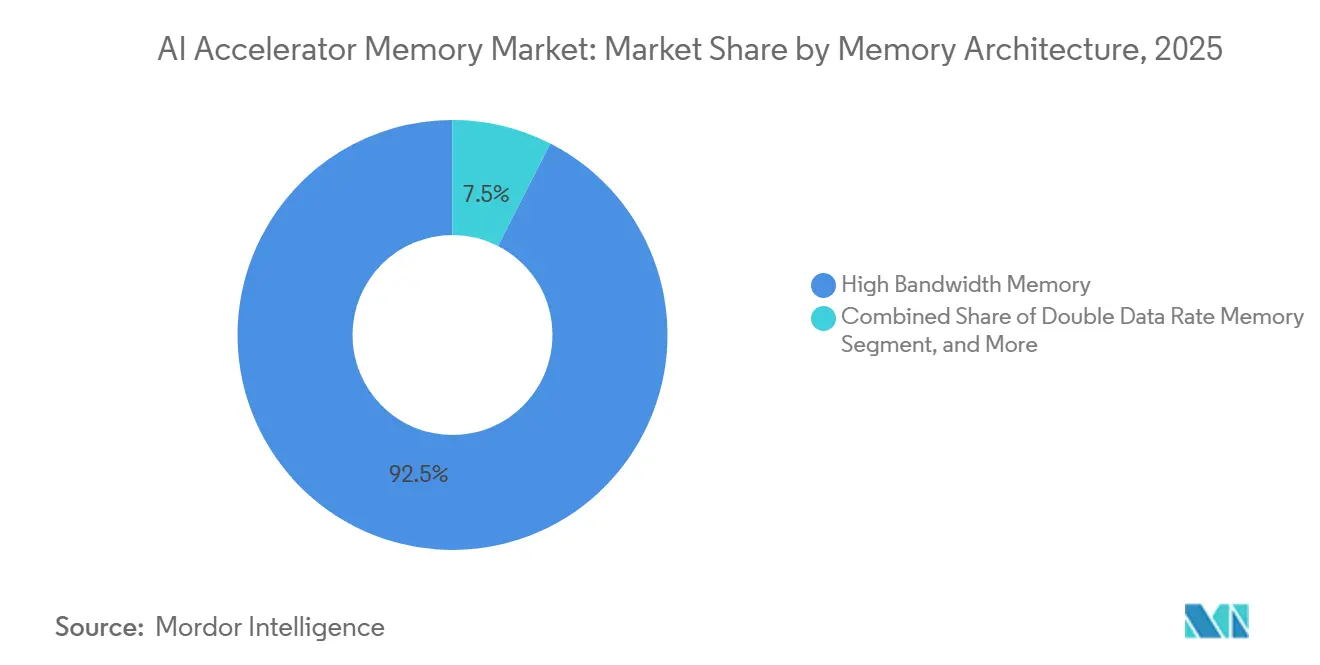
- メモリアーキテクチャ別では、高帯域幅メモリが2025年のAIアクセラレータメモリ市場において92.48%のシェアでリードし、低消費電力ダブルデータレートメモリは2031年までCAGR 26.27%で拡大すると予測されています。
- アクセラレータプラットフォーム別では、データセンターGPUアクセラレータが2025年のAIアクセラレータメモリ市場において73.58%のシェアを保持し、カスタムAI ASICおよびXPUは2031年までCAGR 26.46%で最速の成長を記録すると予測されています。
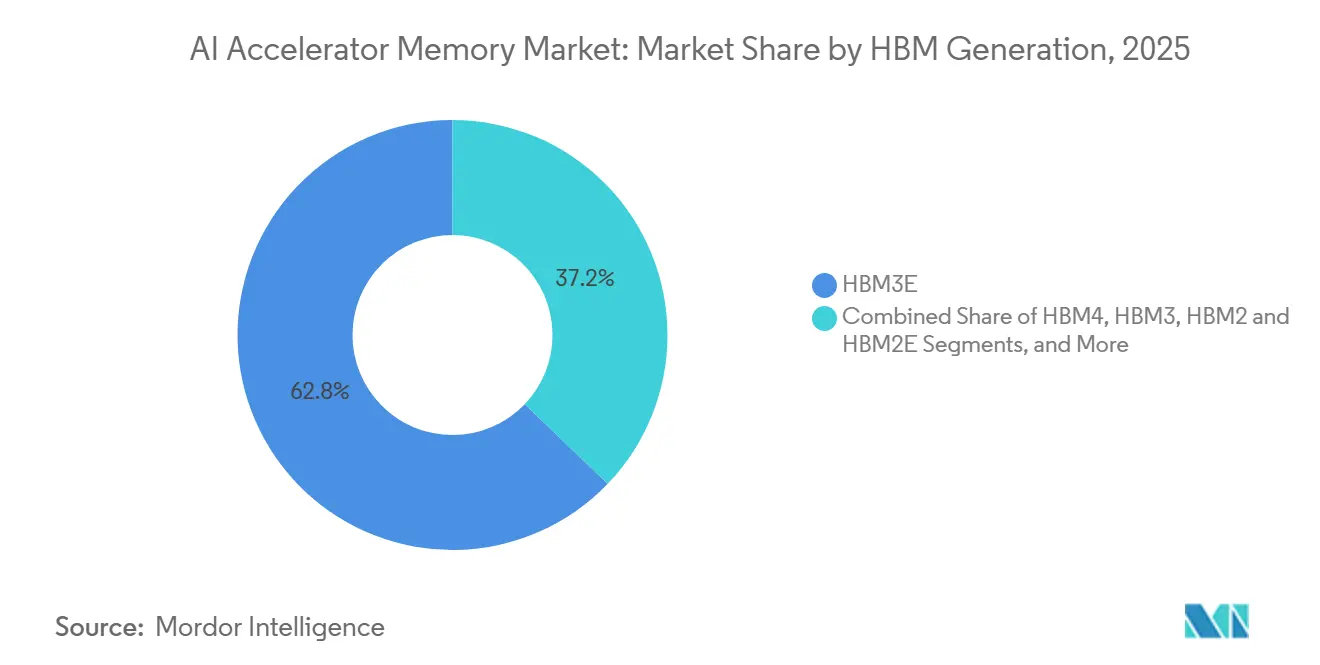
- HBMジェネレーション別では、HBM3Eが2025年に62.84%のシェアを占め、HBM4EおよびネクストジェネレーションHBMは2031年までCAGR 26.18%で進展すると予測されています。
- HBMスタック高さ別では、8-Highが2025年に人工知能(AI)アクセラレータメモリ市場において61.32%のシェアを占め、16-Highは2031年までCAGR 26.13%で拡大すると予測されています。
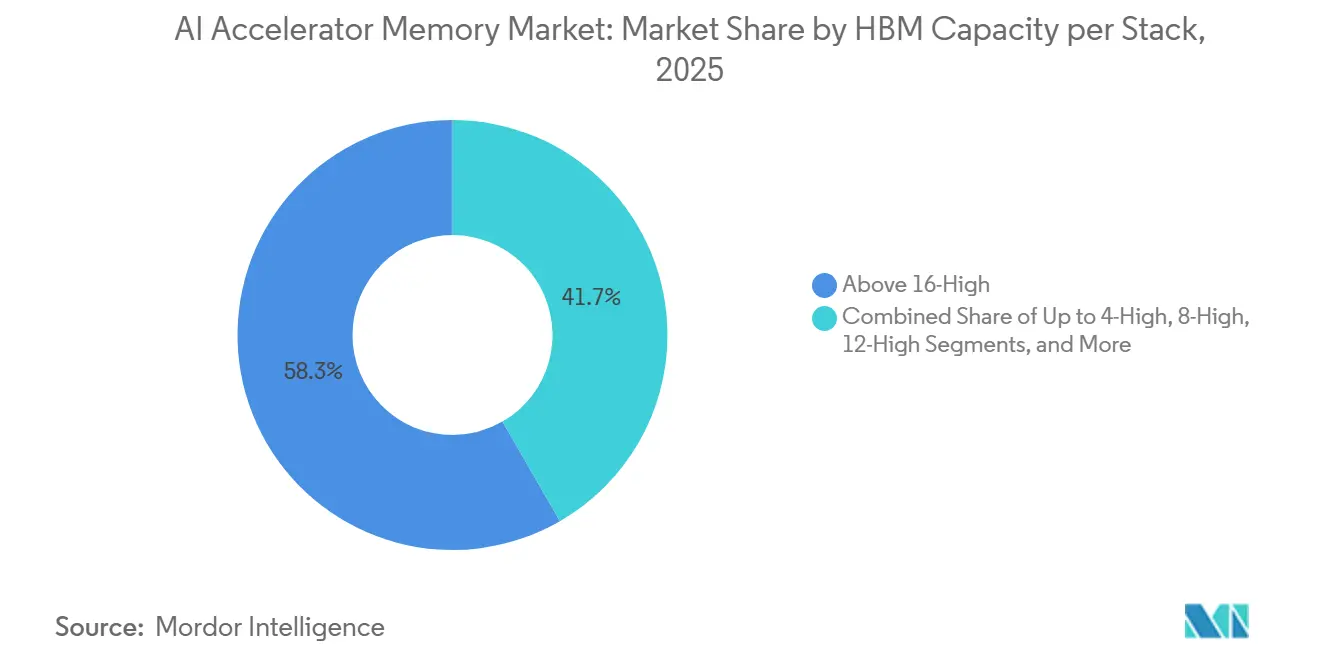
- スタックあたりHBM容量別では、16 GBを超え24 GB以下の層が2025年のAIアクセラレータメモリ市場において58.33%のシェアを保持し、36 GB超の層は2031年までCAGR 26.28%で成長すると予測されています。
- デプロイメントプラットフォーム別では、ハイパースケールクラウドおよびAIファクトリーが2025年に73.87%のシェアを獲得し、エッジAIおよび産業システム2031年までCAGR 26.54%で最速の成長を記録すると予測されています。
- 地域別では、北米が2025年のAIアクセラレータメモリ市場において48.12%のシェアを保持し、アジア太平洋地域は2031年までCAGR 26.19%で拡大すると予測されています。
注:本レポートの市場規模および予測数値は、Mordor Intelligence 独自の推定フレームワークを使用して作成されており、2026年1月時点の最新の利用可能なデータとインサイトで更新されています。
グローバルAIアクセラレータメモリ市場のトレンドとインサイト
ドライバーインパクト分析*
| ドライバー | (〜)CAGRへの影響(%) | 地理的関連性 | 影響タイムライン |
|---|---|---|---|
| AIアクセラレータにおけるHBM3EおよびHBM4の採用拡大 | +6.2% | グローバル、北米およびアジア太平洋地域に最も集中 | 短期(2年以内) |
| AIトレーニングおよび推論コンピュート密度の上昇 | +5.1% | グローバル | 中期(2〜4年) |
| ハイパースケールデータセンターAIフリートの拡大 | +4.3% | 北米およびヨーロッパ | 短期(2年以内) |
| 先進GPUおよびASICにおけるワットあたりの帯域幅需要の増加 | +3.0% | グローバル | 中期(2〜4年) |
| 高マージンAIメモリSKUへの供給再配分 | +1.5% | アジア太平洋地域中心、韓国および日本、北米への波及 | 短期(2年以内) |
| チップレットベースAIアーキテクチャの採用拡大 | +1.1% | グローバル、北米およびアジア太平洋地域での早期利益 | 長期(4年以上) |
| 情報源: Mordor Intelligence | |||
AIアクセラレータにおけるHBM3EおよびHBM4の採用拡大
AIアクセラレータメモリ市場は、HBMジェネレーションのアップグレードごとに恩恵を受けています。より高い性能は現在、より大きなプロセスの複雑さとより高い販売価格を伴うためです。SK hynixは、そのHBM3Eがピンあたり最大9.6 Gbpsおよび1.23 TB/s以上の帯域幅を達成したと述べており、現在のAIアクセラレータがより高密度で高速なメモリ構成に移行し続ける理由を強調しています。Samsungは2026年2月、1c DRAMプロセスと4 nmロジックベースダイを使用したHBM4の量産を開始したと発表し、市場がすでに次の資格認定サイクルへのシフトを開始していることを示しました。NVIDIAは2026年6月、Samsung、SK hynix、およびMicronがすべてVera Rubinプラットフォームの資格認定を取得し量産に入ったことを確認し、ベンダーの準備に関する不確実性を低減し、次のアクセラレータ立ち上げに向けた供給基盤を拡大しました。したがって、AIアクセラレータメモリ市場は、ユニット需要が増加しているだけでなく、HBM4およびHBM4Eへの各移行が収益成長をより要求が高くより高価な製造パスに結びつけるため、上昇しています。
AIトレーニングおよび推論コンピュート密度の上昇
AIアクセラレータメモリ市場はまた、トレーニングと推論の両方においてチップあたりに必要なメモリ容量と帯域幅の着実な増加によっても押し上げられています。Googleは2026年4月にTPU 8iを発表し、チップあたり288 GBのHBMと8,601 GB/sを搭載し、オンチップSRAMを384 MBに3倍増加させ、1製品サイクルでメモリ集約度がいかに上昇したかを示しました。[1]Google Cloud Blog、「TPU 8tおよびTPU 8iテクニカルディープダイブ」、Google Cloud Blog、cloud.google.com NVIDIAのVera Rubinプラットフォームは、アクセラレータあたり576 GBのHBM4構成でその方向性を延長し、長コンテキストモデルとより大きなワーキングセットが依然として最小メモリ要件を上方に押し上げていることを示しています。JEDECのLPDDR6ロードマップはまた、エッジシステムでさえプロセッシングインメモリサポートを含むより豊富なメモリ機能に向かっていることを示しており、データ移動を削減しローカル推論効率を改善するための広範な圧力を反映しています。AIアクセラレータメモリ市場において、これはモデル効率が改善されても、より長いコンテキストウィンドウとより複雑な推論パイプラインが追加の帯域幅と容量を消費し続けるため、アクセラレータあたりのメモリ搭載量が増加していることを意味します。
ハイパースケールデータセンターAIフリートの拡大
AIアクセラレータメモリ市場は、大規模クラウドオペレーターが最大のメモリ集約型アクセラレータデプロイメントを引き続き担っているため、ハイパースケールインフラストラクチャの成長と密接に結びついています。Amazonは2026年2月、クラウドおよびAIインフラストラクチャのためにルイジアナ州に120 ビリオン 米ドルを投資すると発表し、データセンターレベルで現在コミットされている個々のプロジェクトの規模を反映しています。Googleは2026年にTPUロードマップを拡大し、NVIDIAはSK hynixとの複数年にわたるメモリパートナーシップを深化させ、コンピュートプラットフォームロードマップとメモリ供給計画が現在複数サイクル先まで整合されていることを示しています。ラックスケールシステム設計も需要を強化します。各デプロイメントは従来のサーバー更新よりもはるかに多くのHBMコンテンツを追加するためです。これにより、AIアクセラレータメモリ市場は、その支出計画が小規模なエンタープライズ顧客がアクセスを得る前に利用可能な供給を吸収できる少数の非常に大規模なバイヤーにさらされ続けます。
先進GPUおよびASICにおけるワットあたりの帯域幅需要の増加
AIアクセラレータメモリ市場は、熱および電力の制限が実際のデプロイメントで使用できるメモリ構成を形成するため、もはやピーク帯域幅だけによって駆動されていません。Marvellは2024年12月、そのカスタムHBMコンピュートアーキテクチャがメモリインターフェース電力を70%削減し、33%多くのHBMスタックをサポートし、コンピュート面積を25%増加させることができると発表し、電力効率がアクセラレータ設計の中心となっていることを強調しました。SamsungのLPDDR6プログラムとJEDECのLPDDR6ロードマップはどちらも、エッジでの同じ設計優先事項を示しており、デバイス上のAIは大きな電力ペナルティなしに高いメモリパフォーマンスを必要としています。MicronのエッジAIホワイトペーパーもまた、デコード中のトークン生成速度にメモリ帯域幅を直接結びつけ、大規模および小規模のAIシステム全体でワットあたりの帯域幅が重要である理由を強化しました。アクセラレータパッケージがより高い熱負荷とより大きなスタック数に近づくにつれて、電力と熱をより効果的に管理するサプライヤーはAIアクセラレータメモリ市場において価格設定と資格認定の優位性を維持するでしょう。
制約インパクト分析*
| 制約 | (〜)CAGRへの影響(%) | 地理的関連性 | 影響タイムライン |
|---|---|---|---|
| パッケージレベルの熱および歩留まり制約 | -3.8% | グローバル、アジア太平洋地域の製造ハブで最も深刻 | 短期(2年以内) |
| 先進HBMの限られた資格認定済み供給基盤 | -2.6% | グローバル | 中期(2〜4年) |
| 先進パッケージング能力への強い依存 | -2.0% | アジア太平洋地域中心、台湾、北米への波及 | 中期(2〜4年) |
| 輸出規制とサプライチェーンのローカライゼーション摩擦 | -1.0% | 北米および中国 | 長期(4年以上) |
| 情報源: Mordor Intelligence | |||
パッケージレベルの熱および歩留まり制約
AIアクセラレータメモリ市場は重大な技術的制約に直面しています。層数が増加しロジックダイがベース構造に統合されるにつれて、熱管理がより困難になります。SamsungのHBM4立ち上げと業界のより高いスタック高さへの移行は、メモリベンダーが資格認定と信頼性の限界内に留まりながら密度を高めようとしていることを示しています。[2]Samsung Semiconductor Global Newsroom、「Samsungが業界初の12層HBM3E DRAMの量産を開始」、Samsung Semiconductor Global Newsroom、news.samsungsemiconductor.com JEDEC標準は、商業化が連続する世代にわたって定義された熱およびパフォーマンスの閾値を満たすことに依存しているため、依然として重要です。MicronとMarvellはどちらも、データ移動とインターフェース電力を削減することを目的としたメモリアーキテクチャの変更を強調し、問題が単純な供給量に限定されず、パッケージレベルの実現可能性にまで及ぶことを確認しました。これにより、人工知能(AI)アクセラレータメモリ市場は、新しいスタック高さや新しいロジックプロセスの組み合わせが歩留まりを商業目標以下に押し下げるたびに、予想より遅い立ち上げに対して脆弱なままとなります。
先進HBMの限られた資格認定済み供給基盤
AIアクセラレータメモリ市場はまた、先進HBM供給が依然として非常に少数の資格認定済みベンダーに集中しているという事実によっても制約されています。NVIDIAの2026年6月の確認、すなわちSamsung、SK hynix、およびMicronがすべてVera Rubin向けの量産に入ったという事実は、資格認定済み供給基盤が既存のリーダーの狭い分野の中でようやく拡大しつつあることも強調しました。SK hynixの2026年2月の龍仁クラスターフェーズ向けの21.61兆韓国ウォン(約160 ビリオン 米ドル)の追加設備投資承認は、製造レベルでの新規能力コミットメントがいかに大規模でいかに遅いかを示しています。Micronの2025年12月のコンシューマーメモリからの撤退は、リソースをAI指向のエンタープライズメモリに向け直すことで同じ点を強化し、より広いエンドマーケットに能力を分散させるのではなく、AIアクセラレータメモリ市場により密接にポートフォリオを整合させました。実際には、AIアクセラレータメモリ市場は、資格認定のリードタイムと能力拡張スケジュールがアクセラレータの注文サイクルよりもはるかに遅く動くため、需要の視認性が強い場合でも供給制約のままである可能性があります。
*当社の予測では、推進要因および抑制要因の影響を加算的ではなく方向性のあるものとして扱います。影響予測は、ベースライン成長、構成効果、および変数間の相互作用を反映しています。
セグメント分析
メモリアーキテクチャ別:HBMがエッジでLPDDRが加速する中で支配
HBMは2025年のメモリアーキテクチャ別AIアクセラレータメモリ市場シェアの92.48%を保持し、主要なAIアクセラレータが依然として非常に高い帯域幅と高密度のオンパッケージメモリに依存していることを確認しました。GoogleのIronwood TPUはチップあたり7,370 GB/sで8スタックのHBM3Eをデプロイし、後のTPU 8iはチップあたり288 GBで8,601 GB/sにパフォーマンスを向上させ、HBMがフロンティアシステムのデフォルト設計選択であり続ける理由を示しました。GDDRは、システム設計者が依然としてパフォーマンスと統合コストのバランスを取る低コスト推論GPUおよびワークステーションカードでの役割を維持しました。DDRはまた、アクセラレータがより広いエンタープライズコンピュートインフラストラクチャと並んでデプロイされる場合に特に、ハイブリッドAIサーバーのCPU接続機能にも関連性を維持しました。AIアクセラレータメモリ市場において、HBMとアーキテクチャミックスの残りの部分との間のこの大きなギャップは、現在のデータセンターAIが帯域幅集約型アクセラレータパッケージにいかに強く依存しているかを反映しています。
LPDDRは最も成長の速いサブセグメントであり、2026年から2031年にかけてCAGR 26.27%を示し、次の需要の波が最大のデータセンターデプロイメントを超えて拡大していることを示しています。JEDECは、そのLPDDR6ロードマップがプロセッシングインメモリサポートを追加し、LPDDRをデータセンターおよびエッジのユースケースに拡張すると述べており、ローカル推論と低エネルギー消費を必要とするAIシステムにおける低消費電力メモリのより広い役割を示唆しています。SamsungのLPDDR6プログラムはAIエッジシステム、AI PC、データセンター、および自動車プラットフォームを対象としており、サプライヤーがLPDDRを単なるモバイルコンポーネントではなくAIメモリ成長分野として扱っていることを確認しています。MicronもまたエッジAIにおけるトークン生成速度にLPDDR帯域幅を直接結びつけ、ハイパースケールクラウド外でのメモリスループットを直接的なパフォーマンスレバーとしています。したがって、AIアクセラレータメモリ市場はデータセンターHBMコアと急成長するエッジLPDDR層に分割されており、各アーキテクチャが異なるデプロイメントモデルに対応しています。
注記: 個別セグメントのセグメントシェアはレポート購入時に入手可能


アクセラレータプラットフォーム別:GPUプラットフォームが支出を固定しカスタムシリコンが加速
データセンターGPUアクセラレータは2025年のAIアクセラレータメモリ市場規模の73.58%を獲得し、主流のトレーニングおよび推論GPUプラットフォームのインストールベースと割り当て強度を反映しています。NVIDIAのH100、H200、およびBlackwellファミリーはGPUプラットフォームを大規模AIデプロイメントの中心に置き続け、AMDは次のサイクルでMI455Xなどのプラットフォームを通じてHBM供給の重要なセカンダリ顧客ルートとして残りました。AI SoC、NPU、およびAPUはモバイル、自動車、および組み込みAIに引き続き対応しましたが、ユニットあたりのメモリ価値は大規模データセンターアクセラレータよりも低いままでした。FPGAベースのアクセラレータは、適応性と決定論的応答時間が依然として重要レイテンシ敏感なワークロードで引き続き重要でした。これにより、他のプラットフォームタイプが需要基盤を拡大しても、AIアクセラレータメモリ市場はGPU主導のインフラストラクチャに固定されたままでした。
カスタムAI ASICおよびXPUは2031年までCAGR 26.46%で成長すると予測されており、AIアクセラレータメモリ市場で最も成長の速いプラットフォームセグメントとなっています。Broadcomは2026年2月、複数のHBMスタックをサポートする3.5D XDSiPアーキテクチャ上で最初の2 nmカスタムコンピュートSoCの出荷を開始したと述べ、カスタムシリコンがより早くより速く先進的なヘテロジニアスパッケージングに移行していることを示しました。[3]Broadcom Inc.、「BroadcomがAI革命を推進する3.5Dフェイスツーフェイスコンピュートシステムオンチップを出荷」、Broadcom投資家向け情報、investors.broadcom.com AWS Trainium、Google TPU 8、およびMeta MTIA 500は、ハイパースケーラーが標準GPUテンプレートを受け入れるのではなく、ワークロード固有の帯域幅とレイテンシ目標に合わせてメモリニーズを設計していることを示しています。MarvellのカスタムHBMコンピュートアーキテクチャもまた、より低いインターフェース電力でXPUあたりより多くのHBMスタックをサポートし、カスタムアクセラレータの競争的な設計機能としてカスタマイズされたメモリインターフェースを実現しています。このシフトが続くにつれて、AIアクセラレータメモリ市場は、以前のGPU支配サイクルよりも広い資格認定パスとプロダクト固有のHBM構成のミックスを見ることになるでしょう。
HBMジェネレーション別:HBM3Eが現在のデプロイメントをリードしHBM4Eが次のアーキテクチャを定義
HBM3Eは2025年のAIアクセラレータメモリ市場の62.84%を占め、現在のインストール済みアクセラレータプラットフォームの波におけるその役割を反映しています。NVIDIA Blackwell GPU、Google Ironwood TPU、およびAMD MI300およびMI350シリーズ製品全体にデプロイされ、現在のHBM需要の商業的中心となっています。SK hynixはそのHBM3Eが1.23 TB/s以上を提供すると述べ、MicronのNVIDIA H200システムにおける24 GB 8-High HBM3Eも1.2 TB/s以上を超え、HBM3Eが今日のインフラストラクチャと明日のプラットフォームの間の主要な商業的橋渡しであり続ける理由を説明しています。HBM2およびHBM2Eは、新しいデプロイメントがより高い帯域幅、より大きな容量、およびより強力な電力効率を必要とするにつれて引き続き減少しました。したがって、AIアクセラレータメモリ市場は、バイヤーとサプライヤーが次の引き渡しに備える中、HBM3Eを主要な商業ジェネレーションとして引き続き依存しました。
HBM4EおよびネクストジェネレーションHBMは2031年までCAGR 26.18%で成長すると予測されており、AIアクセラレータメモリ市場で最も急速に上昇するジェネレーション層となっています。SK hynixは2026年6月に48 GB容量の12層HBM4Eサンプルを出荷し、HBM4比で20%以上の電力効率改善を報告し、サプライヤーがすでにVera Rubin後のアクセラレータニーズに向けてポジショニングしていることを示しました。SamsungもHBM4を量産に移行し、早期HBM4Eサンプリングを加速させ、次のサイクルがサプライヤーが技術的準備を安定した量産出力に変換する速さによって定義されることを示唆しています。I/O数の倍増とロジックプロセスベースダイの使用は各スタックの価値を高めますが、資格認定とパッケージングへの負担も高めます。そのため、AIアクセラレータメモリ市場では、容量が容易になるずっと前にHBM4Eがプレミアム需要の端を形成する可能性が高いでしょう。
注記: 個別セグメントのセグメントシェアはレポート購入時に入手可能
HBMスタック高さ別:8-Highが過半数シェアを占め16-Highが勢いを増す
8-High構成は2025年に61.32%のシェアを保持し、AIアクセラレータメモリ市場で最大のスタック高さカテゴリとなりました。これは、現在のAIサーバーフリートにおけるHBM3Eデプロイメントの成熟度、歩留まりの安定性、およびインストールベースを反映しています。ほとんどのH200およびBlackwell B200ジェネレーションシステムは24 GB容量の8-Highスタックに整合しており、アクティブな展開全体でフォーマットを商業的に支配的に保ちました。12-Highフォーマットは、Micronの36 GB 12層HBM3Eなどの製品を通じて拡大し、追加容量が明確なワークロードの利益をサポートする場合にバイヤーがより高いものに移行する意欲があることをすでに示しました。4-High以下のスタックは、コスト効率がメモリ密度よりも重要な低パフォーマンスまたはレガシー推論カードでのみ関連性を維持しました。
16-Highセグメントは2031年までCAGR 26.13%で成長すると予測されており、AIアクセラレータメモリ市場で最も成長の速いスタック高さ層となっています。NVIDIAのVera Rubinプラットフォームは、アクセラレータあたり576 GBの総容量を持つ16-High構成でHBM4を指定し、次サイクルのデプロイメントが拡大するにつれてこのフォーマットへの直接的な引きを生み出しています。SK hynixのHBM4Eサンプリングと将来のHBM5の取り組みもまた、サプライヤーがさらに大きなスタック密度に向けて推進していることを示していますが、各ステップは薄化、ボンディング、および熱の課題を高めます。つまり、高端での商業的成長は、アクセラレータ需要だけでなく、先進スタック高さでのプロセス安定性がいかに速く改善するかにも依存します。したがって、人工知能(AI)アクセラレータメモリ市場は、最大のインストールベースを成熟したフォーマットに維持しながら、最速の収益成長がより高いスタックにシフトする可能性が高いでしょう。
HBMスタックあたり容量別:中間層24 GBがリードし超高容量が次のプラットフォームを標的に
16 GBを超え24 GB以下の層は2025年に58.33%のシェアでリードし、現行世代システムのAIアクセラレータメモリ市場の中心に位置しました。この層は、特に8-High HBM3Eが実用的な標準であり続けた主流AIサーバーデプロイメントのコストパフォーマンスプロファイルに一致しました。NVIDIA H200システムで使用されるMicronの24 GB 8-High HBM3Eは、この層がアクティブなインフラストラクチャ構築の商業的スイートスポットとなった理由を示しています。8 GBから16 GBの範囲は中間推論およびFPGA設定に有用でしたが、主要な本番AIワークロードの最小容量要件を満たさなくなりました。8 GB以下は、トレーニングと長コンテキスト推論が容量フロアを大幅に引き上げるにつれて関連性を失い続けました。
36 GB超の層は2031年までCAGR 26.28%で成長すると予測されており、AIアクセラレータメモリ市場で最も成長の速い容量帯となっています。SK hynixは2026年6月に48 GB HBM4Eサンプルを出荷し、SamsungのHBM4Eの取り組みも48 GB容量を中心としており、サプライヤーが現在この容量を次世代アクセラレータプログラムのコアターゲットとして見ていることを示しています。コンテキスト長の増加、より豊かなエージェント動作、およびより大きなマルチモーダルワークロードはすべて、より大きなKVキャッシュとより大きなスタックあたりメモリバジェットの必要性を高めています。この圧力は、広範な市場標準となる前でも超高容量HBMへのシフトを支持します。その結果、AIアクセラレータメモリ市場は、将来のプラットフォーム設計が需要を上方に引き続ける中、中間層容量での現在の収益基盤を維持すると予想されます。
注記: 個別セグメントのセグメントシェアはレポート購入時に入手可能
デプロイメントプラットフォーム別:ハイパースケールが量を固定しエッジAIが需要を多様化
ハイパースケールクラウドおよびAIファクトリーは2025年のAIアクセラレータメモリ市場シェアの73.87%を保持し、大きな差をつけて支配的なデプロイメント設定となりました。単一のNVIDIA GB200 NVL72ラックは72台のBlackwell GPU全体で19 TB以上のHBM3Eを統合し、ラックスケールシステム設計が従来のサーバーフォーマットをはるかに超えてメモリ需要を倍増させる方法を示しています。エンタープライズおよびオンプレミスデータセンターは、組織がデータ居住地と制御要件を満たすために推論クラスターを構築するにつれて、次の需要層を形成しました。高性能コンピューティングおよび研究システムは、依然として高密度アクセラレータクラスターに依存する科学AIおよび防衛関連のユースケースにとって重要であり続けました。ネットワーキングおよびテレコミュニケーションインフラストラクチャもまた、AIワークロードがネットワークエッジに近づくにつれてメモリニーズを拡大しました。
エッジAIおよび産業システムは2031年までCAGR 26.54%で成長すると予測されており、AIアクセラレータメモリ市場で最も成長の速いデプロイメントセグメントとなっています。MicronのエッジAIホワイトペーパーは、メモリ帯域幅が小規模言語モデルにおける推論レイテンシとトークン生成速度に直接影響することを示し、クラウド外でのメモリ設計の重要性を説明しています。SamsungのAI PC、自動車、およびエッジシステム向けLPDDR6ポジショニングは同じ需要パターンを示しており、ローカル推論がフルHBM統合のコストと電力プロファイルなしにより強力なメモリパフォーマンスを必要としています。自動車AIもまた、設計サイクルを長くし、主流のコンシューマーデバイスよりもメモリ選択をより戦略的にする資格認定要件を追加します。これは、AIアクセラレータメモリ市場が価値の面ではハイパースケール主導のままであるが、最速の多様化はより多くのローカル処理とより厳格なデプロイメント制御を必要とするエッジシステムから来ることを意味します。
地域分析
北米は2025年のAIアクセラレータメモリ市場の48.12%を保持し、主要な地域需要センターとしての地位を維持しました。この地域のリードは、メモリ製造能力だけでなく、ハイパースケールバイヤー、カスタムシリコンプログラム、および大規模AIサーバーデプロイメントの集中から来ています。Amazonの2026年2月のルイジアナ州への120 ビリオン 米ドル投資決定は、地域のハードウェア需要を形成し続ける単一プロジェクトコミットメントの規模を示しました。Googleもまた2026年にTPUロードマップを拡大し、北米がメモリ集約型アクセラレータの主要な早期デプロイメントゾーンとしての役割を強化しました。カナダはデータセンターに有利な電力条件を通じて地域成長を支援し、メキシコは将来のAI構築のためのニアショアインフラストラクチャコリドーとして注目を集めました。
アジア太平洋地域は2031年までCAGR 26.19%で成長すると予測されており、AIアクセラレータメモリ市場で最も成長の速い地域となっています。この地域は、先進HBMの製造基盤とAIインフラストラクチャの需要の高まりの中心という二重の役割を果たしています。韓国はSK hynixとSamsungのファブネットワークを通じて中心的な役割を維持し、MicronのHiroshimaサイトはより広い太平洋サプライチェーンに重要な生産ノードを追加しました。SK hynixの2026年2月の龍仁クラスター承認における21.61兆韓国ウォン(約160 ビリオン 米ドル)は、この地域が将来のメモリ出力にいかに大きく投資しているかを示しました。日本は先進パッケージング能力を提供し、インドおよび東南アジアはAIクラウドの拡大、AI PCの採用、およびローカル推論デプロイメントを通じて需要を構築し続けました。
ヨーロッパ、南米、中東、およびアフリカは現在のシェアでは小さいままでしたが、それぞれが人工知能(AI)アクセラレータメモリ市場に戦略的な需要を追加しました。ドイツとイギリスがヨーロッパのAIサーバーデプロイメントをリードし、フランス2030などの公的イニシアチブが国内コンピュート能力の支援を継続しました。EU AI法もまた、コンプライアンスとデータ制御がエンタープライズAIワークロードのホスト場所に影響を与えるため、より多くのローカルインフラストラクチャ計画を促進しました。中東およびアフリカは、輸出フレームワークと国境を越えた技術協定に支えられたサウジアラビアとUAEにおけるソブリンAIクラスター調達を通じて重要性を増しました。南米はサイクルの早い段階にありましたが、ブラジルとチリは将来の地域AIインフラストラクチャ拡大の基盤を引き続き構築しました。

競合環境
AIアクセラレータメモリ市場は2026年に高度に集中した供給構造で運営されました。先進HBM生産がSK hynix、Samsung Electronics、およびMicron Technologyに集中していたためです。需要もまた集中していました。NVIDIA、AMD、および大規模ハイパースケーラーが、最大のアクセラレータプログラムの資格認定と割り当てを受けるメモリサプライヤーを形成したためです。NVIDIAとSK hynixは2026年6月にAIファクトリー向けメモリを進化させるための複数年にわたる技術パートナーシップを発表し、メモリロードマップがプラットフォームロードマップといかに密接に結びついているかを示しました。[4]NVIDIA投資家向け情報、「NVIDIAとSK hynixがAIファクトリー向けメモリを進化させる複数年技術パートナーシップを発表」、NVIDIA投資家向け情報、investor.nvidia.com Samsungはロジックベースダイとより統合された製造モデルでHBM4量産を推進することで異なる道を追求し、次の資格認定サイクルでの地位改善を目指しました。Micronは2025年12月にコンシューマーメモリから撤退し、リソースをAI指向のエンタープライズメモリに向け直すことで焦点を強化し、AIアクセラレータメモリ市場とのポートフォリオの整合をより密接にしました。
カスタムシリコン設計者は第二の競争層を形成し、AIアクセラレータメモリ市場においてインターフェース設計、スタック数、および資格認定要件にますます影響を与えています。Broadcomは2026年2月に3.5D XDSiPプラットフォーム上で2 nmカスタムコンピュートSoCの出荷を開始し、カスタムアクセラレータが先進HBM統合に向けて急速に移行していることを示しました。Marvellの2024年12月のカスタムHBMコンピュートアーキテクチャは、ハイパースケーラーにより低いインターフェース電力でより多くのHBMスタックをサポートする方法を提供し、競争的な議論を供給量からインターフェース効率にシフトさせました。Google、AWS、およびMetaは、ワークロード固有の帯域幅ニーズに合わせたメモリを活用するTPU、Trainium、およびMTIAプログラムを通じてこのカスタム設計層を拡大し続けました。これは、プロダクト固有のHBM構成とより速い資格認定サイクルをサポートできるサプライヤーが、単純なウェーハ出力を超えた優位性を持つことを意味します。
競争の第三の層はパッケージングとシステム統合にあります。AIアクセラレータメモリ市場はDRAM製造だけに依存しているわけではないためです。高密度HBM製品は信頼性の高いボンディングとパッケージスループットなしにはスケールできないため、先進パッケージングパートナーとファウンドリ連携の組み立て能力が重要です。そのため、サプライヤー戦略には、コンポーネント供給の交渉だけでなく、メモリ、ロジック、パッケージング、およびプラットフォーム設計にわたる共同エンジニアリングが含まれるようになりました。競争フィールドはまだ狭いですが、メモリベンダー、アクセラレータ設計者、およびパッケージングパートナーが次のHBM移行での地位確保を競うにつれて、ますます技術的になっています。
AIアクセラレータメモリ業界リーダー
SK hynix Inc.
Samsung Electronics Co., Ltd.
Micron Technology, Inc.
NVIDIA Corporation
Advanced Micro Devices, Inc.
- *免責事項:主要選手の並び順不同

最近の業界動向
- 2026年6月:NVIDIA CorporationとSK hynix Inc.は、HBM4および将来のジェネレーションをカバーするグローバルAIファクトリー構築のための次世代メモリを進化させる複数年技術パートナーシップを発表しました。この合意はBlackwellおよびVera Rubin GPUプラットフォーム全体の共同エンジニアリングに基づいており、SK hynixの龍仁クラスター能力立ち上げを通じてNVIDIAのアクセラレータロードマップの供給整合をサポートします。
- 2026年6月:SK hynix Inc.は、12層HBM4Eサンプル(48 GB容量、ピンあたり最大16 Gbps、HBM4比20%以上の電力効率改善)を複数の顧客に出荷し、当初予定していた2026年下半期のスケジュールを前倒ししました。同社はVera Rubin後のAIアクセラレータプラットフォーム向けに2027年のHBM4E量産を目標としています。
- 2026年4月:Google LLCはGoogle Cloud Next 2026で第8世代TPUファミリー、TPU 8tおよびTPU 8iを発表しました。TPU 8iはチップあたり8,601 GB/sで288 GBのHBMと384 MBのオンチップSRAMを搭載し、前世代の3倍です。これらはカスタムAxion ARM CPUホスト上に完全にホストされた最初のGoogleアクセラレータです。
- 2026年2月:SK hynix Inc.の取締役会は、2030年12月まで続く龍仁半導体クラスターのフェーズ2から6のための新規設備投資として21.61兆韓国ウォン(約160 ビリオン 米ドル)を承認し、2030年までにDRAMウェーハ能力を月約100万枚に倍増させることを目標としています。


グローバルAIアクセラレータメモリ市場レポートスコープ
AIアクセラレータメモリ市場は、人工知能(AI)、機械学習、高性能コンピューティング(HPC)、および加速データ処理ワークロードをサポートするために特別に設計されたメモリ技術、アーキテクチャ、およびサブシステムで構成されています。AIアクセラレータメモリソリューションは、データセンター、エンタープライズ、エッジ、および組み込みコンピューティング環境全体で効率的なトレーニング、推論、分析、シミュレーション、および生成AI操作を可能にするために、ますます強力なAIアクセラレータに大量のデータを供給するために必要な帯域幅、容量、レイテンシ、および電力効率特性を提供します。
AIアクセラレータメモリ市場レポートは、メモリアーキテクチャ(HBM、グラフィックスダブルデータレートメモリ、低消費電力ダブルデータレートメモリ、ダブルデータレートメモリ、およびその他の特殊アクセラレータメモリ)、アクセラレータプラットフォーム(データセンターGPUアクセラレータ、カスタムAI ASICおよびXPU、AI SoC、NPU、およびAPU、FPGAベースアクセラレータ、データ処理ユニット、スマートNIC、およびネットワーキングアクセラレータ、およびその他のアクセラレータプラットフォーム)、HBMジェネレーション(HBM2およびHBM2E、HBM3、HBM3E、HBM4、およびHBM4EおよびネクストジェネレーションHBM)、HBMスタック高さ(4-High以下、8-High、12-High、16-High、および16-High超)、スタックあたりHBM容量(8 GB以下、8 GBから16 GB、16 GBから24 GB、24 GBから36 GB、および36 GB超)、デプロイメントプラットフォーム(ハイパースケールクラウドおよびAIファクトリー、エンタープライズおよびオンプレミスデータセンター、高性能コンピューティングおよび研究システム、ネットワーキングおよびテレコミュニケーションインフラストラクチャ、エッジAIおよび産業システム、AIワークステーションおよびAI PC、および自動車AIおよび自律システム)、および地域(北米、ヨーロッパ、アジア太平洋、南米、および中東・アフリカ)別にセグメント化されています。市場予測は金額(米ドル)ベースで提供されます。
| 高帯域幅メモリ(HBM) |
| グラフィックスダブルデータレートメモリ |
| 低消費電力ダブルデータレートメモリ |
| ダブルデータレートメモリ |
| その他の特殊アクセラレータメモリ |
| データセンターGPUアクセラレータ |
| カスタムAI ASICおよびXPU |
| AI SoC、NPU、およびAPU |
| FPGAベースアクセラレータ |
| データ処理ユニット、スマートNIC、およびネットワーキングアクセラレータ |
| その他のアクセラレータプラットフォーム |
| HBM2およびHBM2E |
| HBM3 |
| HBM3E |
| HBM4 |
| HBM4EおよびネクストジェネレーションHBM |
| 4-High以下 |
| 8-High |
| 12-High |
| 16-High |
| 16-High超 |
| 8 GB以下 |
| 8 GBから16 GB |
| 16 GBから24 GB |
| 24 GBから36 GB |
| 36 GB超 |
| ハイパースケールクラウドおよびAIファクトリー |
| エンタープライズおよびオンプレミスデータセンター |
| 高性能コンピューティングおよび研究システム |
| ネットワーキングおよびテレコミュニケーションインフラストラクチャ |
| エッジAIおよび産業システム |
| AIワークステーションおよびAI PC |
| 自動車AIおよび自律システム |
| 北米 | 米国 |
| カナダ | |
| メキシコ | |
| ヨーロッパ | ドイツ |
| イギリス | |
| フランス | |
| イタリア | |
| その他のヨーロッパ | |
| アジア太平洋 | 中国 |
| 日本 | |
| 韓国 | |
| インド | |
| 東南アジア | |
| その他のアジア太平洋 | |
| 南米 | |
| 中東・アフリカ |
| メモリアーキテクチャ別 | 高帯域幅メモリ(HBM) | |
| グラフィックスダブルデータレートメモリ | ||
| 低消費電力ダブルデータレートメモリ | ||
| ダブルデータレートメモリ | ||
| その他の特殊アクセラレータメモリ | ||
| アクセラレータプラットフォーム別 | データセンターGPUアクセラレータ | |
| カスタムAI ASICおよびXPU | ||
| AI SoC、NPU、およびAPU | ||
| FPGAベースアクセラレータ | ||
| データ処理ユニット、スマートNIC、およびネットワーキングアクセラレータ | ||
| その他のアクセラレータプラットフォーム | ||
| HBMジェネレーション別 | HBM2およびHBM2E | |
| HBM3 | ||
| HBM3E | ||
| HBM4 | ||
| HBM4EおよびネクストジェネレーションHBM | ||
| HBMスタック高さ別 | 4-High以下 | |
| 8-High | ||
| 12-High | ||
| 16-High | ||
| 16-High超 | ||
| スタックあたりHBM容量別 | 8 GB以下 | |
| 8 GBから16 GB | ||
| 16 GBから24 GB | ||
| 24 GBから36 GB | ||
| 36 GB超 | ||
| デプロイメントプラットフォーム別 | ハイパースケールクラウドおよびAIファクトリー | |
| エンタープライズおよびオンプレミスデータセンター | ||
| 高性能コンピューティングおよび研究システム | ||
| ネットワーキングおよびテレコミュニケーションインフラストラクチャ | ||
| エッジAIおよび産業システム | ||
| AIワークステーションおよびAI PC | ||
| 自動車AIおよび自律システム | ||
| 地域別 | 北米 | 米国 |
| カナダ | ||
| メキシコ | ||
| ヨーロッパ | ドイツ | |
| イギリス | ||
| フランス | ||
| イタリア | ||
| その他のヨーロッパ | ||
| アジア太平洋 | 中国 | |
| 日本 | ||
| 韓国 | ||
| インド | ||
| 東南アジア | ||
| その他のアジア太平洋 | ||
| 南米 | ||
| 中東・アフリカ | ||


レポートで回答される主要な質問
AIアクセラレータメモリ分野の現在および予測される価値は?
AIアクセラレータメモリ市場は2026年に537.4 ビリオン 米ドルに達し、2026年から2031年にかけてCAGR 25.27%で成長し、2031年までに1,657.9 ビリオン 米ドルに達すると予測されています。
現在のAIアクセラレータデプロイメントをリードするメモリアーキテクチャは?
高帯域幅メモリは2025年に92.48%のシェアでリードしました。主要なトレーニングおよび推論アクセラレータが依然として非常に高いオンパッケージ帯域幅と高密度メモリ統合を必要としているためです。
2031年まで最も速く成長するアクセラレータプラットフォームは?
カスタムAI ASICおよびXPUは、ハイパースケーラーがワークロード固有のメモリと帯域幅ニーズに合わせてシリコンを設計し続けるため、2031年までCAGR 26.46%で拡大すると予測されています。
エッジデプロイメントがメモリ需要においてより重要になっている理由は?
エッジAIおよび産業システムは、ローカル推論がより低いレイテンシ、より強力なデータ制御、およびクラウド外でのメモリ効率の高いパフォーマンスを必要とするため、CAGR 26.54%で成長すると予測されています。
需要をリードする地域と最も速く拡大している地域は?
北米は2025年に48.12%のシェアでリードし、アジア太平洋地域は生産力と地域AIデプロイメントの増加を組み合わせているため、2031年までCAGR 26.19%で最速の成長が予測されています。
近期成長の主な制約は?
主な制約は、熱制限、歩留まり圧力、資格認定タイムライン、および大規模生産が可能なサプライヤーの狭い基盤による先進HBM能力の遅い立ち上げです。
最終更新日:




