計算生物学市場規模およびシェア
市場概要
| 調査期間 | 2020 - 2031 |
|---|---|
| 市場規模 (2026) | 8.17 十億米ドル |
| 市場規模 (2031) | 14.89 十億米ドル |
| 成長率 (2026 - 2031) | 12.78% CAGR |
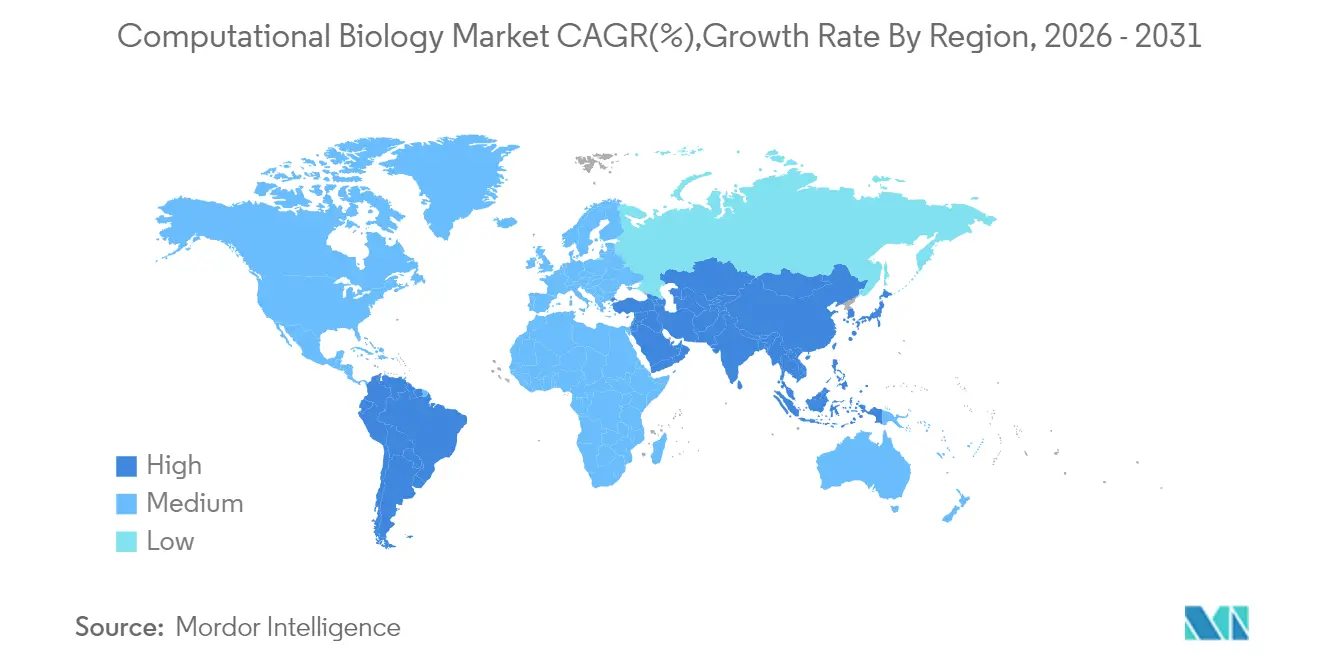
| 最も急速に成長している市場 | アジア太平洋 |
| 最大市場 | 北米 |
| 市場集中度 | 中 |
主要プレーヤー *免責事項:主要選手の並び順不同 画像 © Mordor Intelligence。再利用にはCC BY 4.0の表示が必要です。 | |
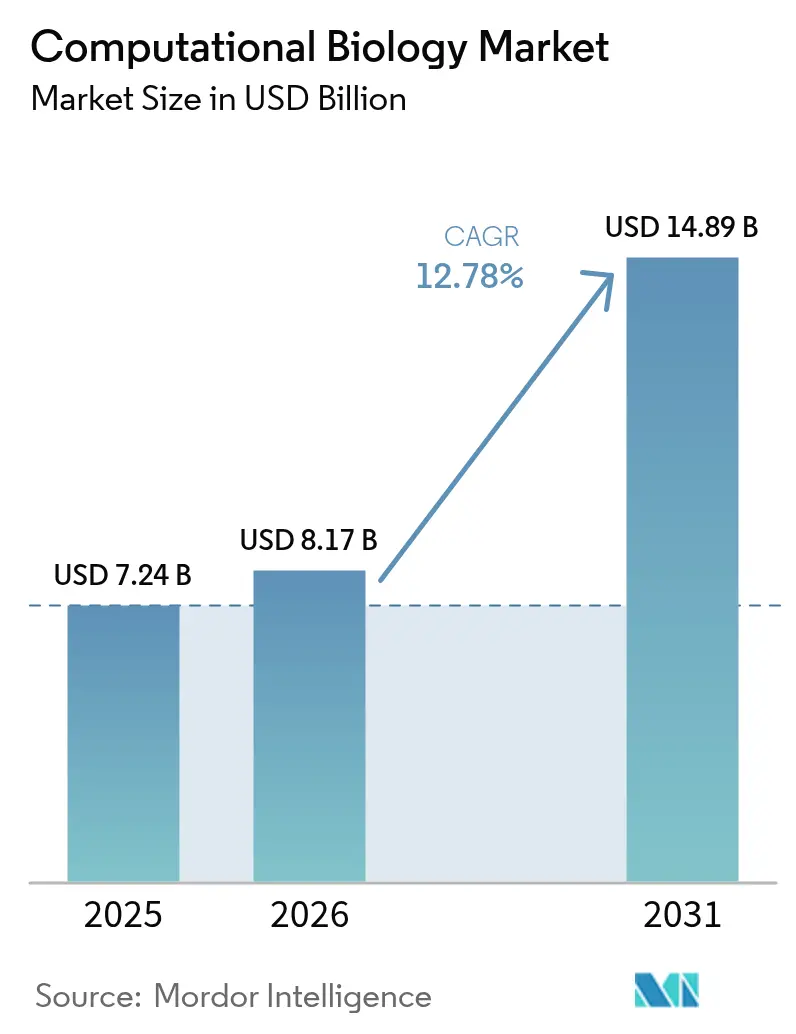
Mordor Intelligenceによる計算生物学市場分析
2026年の計算生物学市場規模は81億7,000万米ドルと推定され、2025年の72億4,000万米ドルから成長し、2031年には148億9,000万米ドルに達する見通しで、2026年から2031年にかけて12.78%のCAGRで成長します。この見通しは、トランスフォーマーベースのゲノム言語モデル、合成生物学デジタルツイン、およびAIの広範な普及が計算生物学市場のあらゆる用途層をいかに形成しているかを示しています。マルチオミクスデータセットの急増、契約研究サービスへの継続的なシフト、およびスケーラブルなクラウドインフラへの需要が引き続き需要を牽引しています。北米は成熟したバイオテク規制により計算生物学市場の中心であり続けていますが、アジア太平洋地域のスーパーコンピュータへの投資と拡大する医薬品製造基盤が同地域を次の成長エンジンとして位置づけています。一方、シーメンスによるDotmaticsの51億米ドルの買収などの戦略的買収は、計算生物学市場内でのプラットフォーム統合の激化を反映しています。
主要レポートのポイント
- 用途別では、細胞・生物シミュレーションが2025年の計算生物学市場シェアの32.10%を占め、創薬・疾患モデリングは2031年にかけて15.33%のCAGRで成長すると予測されています。
- ツール別では、データベースが2025年の計算生物学市場規模の最大シェアである35.95%を保持しましたが、分析ソフトウェアおよびサービスは2031年にかけて14.49%のCAGRで拡大すると見込まれています。
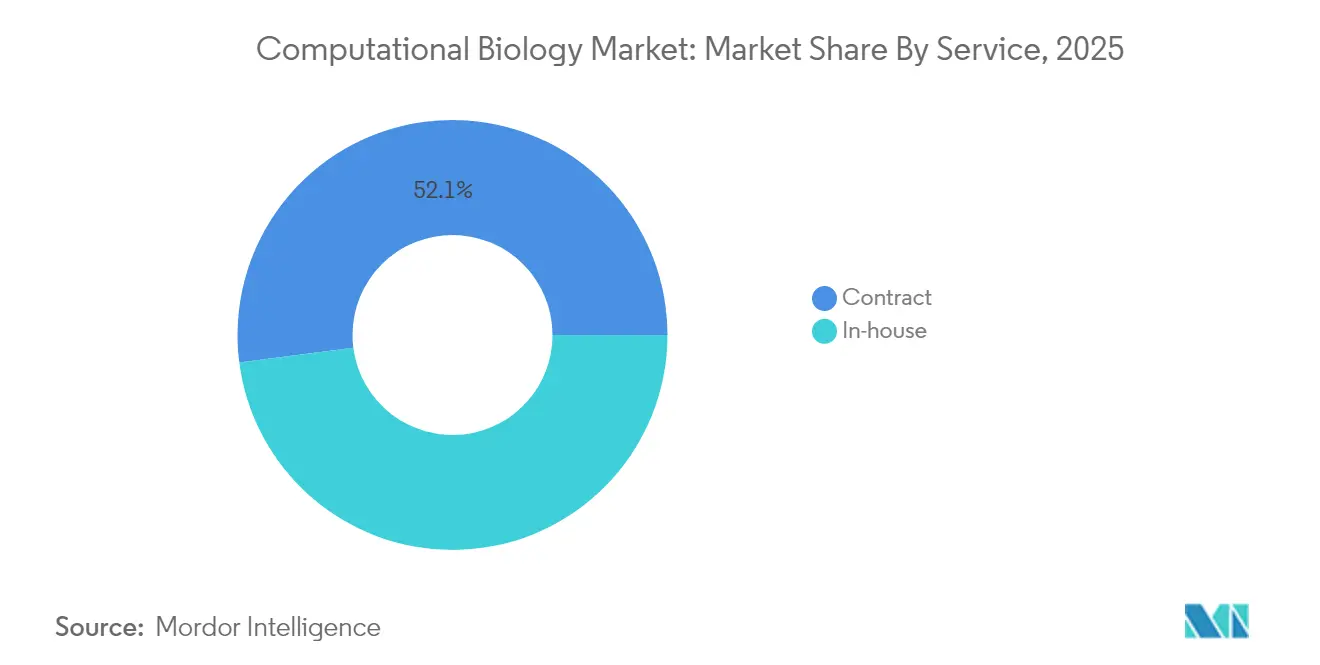
- サービスモデル別では、契約形態が2025年の計算生物学市場シェアの52.05%を占め、2031年にかけて15.72%のCAGRで拡大すると予測されています。
- エンドユーザー別では、学術機関が2025年に44.10%の収益シェアを維持し、産業・商業ユーザーは2031年にかけて14.27%のCAGRを記録すると予測されています。
- 地域別では、北米が2025年の計算生物学市場シェアの42.30%をリードし、アジア太平洋地域は2031年にかけて最速の16.02%のCAGR見通しを示しています。
注記:本レポートの市場規模および予測値は、Mordor Intelligence の独自推定フレームワークを使用して算出され、2026年時点で入手可能な最新のデータと洞察に基づいて更新されています。
グローバル計算生物学市場のトレンドとインサイト
ドライバーの影響分析*
| ドライバー | (~)CAGRへの影響(%) | 地理的関連性 | 影響の時間軸 |
|---|---|---|---|
| オミクスデータ量の増加と バイオインフォマティクス研究 | +2.8% | グローバル、北米とEUに集中 | 中期(2~4年) |
| 創薬・疾患モデリングにおける 利用の加速 | +3.1% | グローバル、北米主導、APACへ拡大 | 短期(2年以内) |
| 臨床薬理ゲノミクスおよび 薬物動態研究の拡大 | +1.9% | 北米とEU、APACで新興 | 中期(2~4年) |
| 迅速なアノテーションを可能にする トランスフォーマーベースのゲノム言語モデル | +2.2% | グローバル、研究機関による早期採用 | 短期(2年以内) |
| インシリコワークフロー向けの 合成生物学デジタルツイン | +1.7% | 北米とEU、APACでパイロット実施 | 長期(4年以上) |
| オープンソースの単一細胞 系譜追跡アルゴリズム | +1.5% | グローバル、学術主導で産業界が採用 | 中期(2~4年) |
| 情報源: Mordor Intelligence | |||
オミクスデータ量の増加とバイオインフォマティクス研究
テラバイト規模の単一細胞RNAシーケンシング、マルチオミクス統合、およびシーケンシングコストの低下が計算生物学市場へのデータフローを拡大し続けています。シーケンシングの進歩によりRNA-seqコストが50〜70%削減され、精密医療データセットへのアクセスが広がっています。大規模言語モデルは現在、一般的なデータ要素マッピングの94%を自動化し、相互運用性を推進しています。[1]Rodney Alan Long、Jordan Klebanoff、Vince D. Calhoun、「新しいAI支援データ標準が生物医学研究における相互運用性を加速する」、medRxiv、medrxiv.orgその結果生じるデータネットワーク効果は、最大のリポジトリを管理するステークホルダーにとってのファーストムーバー優位性を強化します。したがって、クラウドバイオインフォマティクスプラットフォームは、オンプレミスの高性能コンピューティングを持たない組織にとって必須のインフラとなっています。
創薬・疾患モデリングにおける利用の加速
ESM-3などのタンパク質言語モデルは進化プロセスをシミュレートし、数年前には達成できなかったペースで新規タンパク質候補を生成しています。Model MedicinesのGALILEOに代表されるハイブリッドAI・量子システムは、現在100%のヒット率を持つ抗ウイルススクリーニングを実現しています。[2]Model Medicines Communications Team、「創薬の未来:ハイブリッドAIと量子コンピューティングの変曲点となる2025年」、Model Medicines、modelmedicines.comデジタルツインにより研究者は数百万件の仮想実験を実施でき、仮説検証サイクルを短縮し、ウェットラボコストを削減しています。47万9,000件の試験を含む機械学習ベンチマークは、試験設計最適化のための前例のないトレーニングデータを提供しています。RecursionとExscientiaの6億8,800万米ドルの合併などのM&A活動は、既存企業がこれらのAI優位性を内部化しプラットフォームを統合しようと競い合っていることを示しています。
臨床薬理ゲノミクスおよび薬物動態研究の拡大
先制的薬理ゲノミクス検査により、精神科における薬物有害反応が34.1%、入院が41.2%削減されました。[3]Maria Skokou、Konstantinos Tziomalos、Georgios Papazisis、「精神科における先制的薬理ゲノミクスの臨床実装」、eBioMedicine、thelancet.com実世界のパネルでは、患者の60.4%が少なくとも1つのアクション可能な処方を受けています。UCLAは34万2,000人のバイオバンクを活用してスタチンの有効性を調節する156の遺伝子を特定し、遺伝的多様性が投与精度を向上させることを証明しました。AI強化PK/PDモデルは現在、集団特異的変異を考慮しており、アジア太平洋地域での薬理ゲノミクス採用が増加するにつれてこれが必要条件となっています。
迅速なアノテーションを可能にするトランスフォーマーベースのゲノム言語モデル
オープンソースのタンパク質モデルは、汎用GPUのみを使用してAlphaFoldクラスの性能を発揮します。JanusDNAなどの双方向DNA基盤モデルは、専用ハードウェアなしに100万塩基対を処理します。LoRAなどのパラメータ効率的なファインチューニング手法は、下流の予測精度を維持または向上させながらトレーニングコストを削減します。これらの進歩により高度な分析が民主化され、参入障壁が低下し、計算生物学市場は従来のバイオインフォマティクスセンターをはるかに超えて拡大しています。
制約要因の影響分析*
| 制約要因 | (~)CAGRへの影響(%) | 地理的関連性 | 影響の時間軸 |
|---|---|---|---|
| 学際的人材の不足 | -1.8% | グローバル、北米とEUで深刻 | 短期(2年以内) |
| 相互運用性と データ標準化のギャップ | -1.2% | グローバル、特に国境を越えた協力 | 中期(2~4年) |
| クラウドおよびコンピューティングコストの上昇 | -0.9% | グローバル、コスト敏感な市場で最も強い影響 | 短期(2年以内) |
| バイオセキュリティおよびデュアルユース 規制上の精査 | -0.7% | 主に北米とEU、世界的に拡大 | 長期(4年以上) |
| 情報源: Mordor Intelligence | |||
学際的人材の不足
生物学、ソフトウェアエンジニアリング、統計学の専門知識を持つ人材への需要が供給を上回っています。ライフサイエンス雇用主は2030年までに35%の人材不足を予測しており、採用需要は年率11.75%で成長すると予測されています。特に、この分野に参入するテック大手と競合する中規模バイオテク企業では、給与インフレとプロジェクト遅延が生じています。スキルベースの採用、見習い制度、および異業種からの採用が暫定的な緩和策となっています。
相互運用性とデータ標準化のギャップ
マトリックスおよび分析メタデータ標準(MAMS)が単一細胞データセットの整合を始めているものの、広範な調和は依然として困難です。セマンティックマッピングツールは非構造化医療記録を統合できますが、実装の負担がその採用を遅らせています。フェデレーテッドラーニングのパイロットはプライバシーを保護しますが、依然として規制上の不確実性に直面しており、多国間研究は手動データクリーニングに依存しています。
*当社の予測では、推進要因および抑制要因の影響を加算的ではなく方向性のあるものとして扱います。影響予測は、ベースライン成長、構成効果、および変数間の相互作用を反映しています。
セグメント分析
用途別:創薬・疾患モデリングが次世代ワークフローを牽引
創薬・疾患モデリングはすでに最速の15.33%のCAGRを記録しており、細胞・生物シミュレーションは2025年の計算生物学市場規模の32.10%のシェアを維持しています。AI強化された標的同定とリード最適化により、Insilico Medicineなどの企業はインシリコで数百万の化合物をスクリーニングできます。前臨床チームはゲノム、プロテオーム、メタボロームのデータセットを統合して化合物から臨床への成功確率を高めています。臨床試験業務は97.9%の適格性スクリーニング精度を達成する検索拡張システムを活用し、採用のボトルネックを削減しています。増加する研究者がデジタルツインを活用して仮想用量反応試験を実施し、ウェットラボのタイムラインを短縮しています。その結果、計算生物学市場はR&Dのあらゆる段階でより深い製薬業界の関与を経験しています。
ヒト身体シミュレーションソフトウェアは高ポテンシャルのサブセグメントとして浮上しています。スタンフォード大学のAI駆動「仮想細胞」は、統合されたマルチオミクスおよび生物物理モデルが個別化治療戦略のための経路摂動をマッピングできることを示しています。この発展により計算生物学市場は最前線の精密医療臨床医にまで拡大しています。デジタルツインの精度が向上するにつれ、保険会社はコンピュータ最適化治療計画の償還モデルの評価を開始しており、下流の収益源としての潜在的機会を示しています。

注記: 全個別セグメントのセグメントシェアはレポート購入時に入手可能


ツール別:分析ソフトウェアがAI統合を加速
データベースは依然として計算生物学市場シェアの35.95%を占めていますが、分析ソフトウェアおよびサービスは14.49%のCAGRで最速の成長を示しています。タンパク質およびゲノム言語モデルにより、組織は静的アーカイブの維持よりも分析能力への投資を促されています。ベンダーはゲノム、プロテオーム、臨床ストリームを融合するマルチモーダルデータパイプラインを組み込んでいます。このシフトはまた、学術・産業コンソーシアムがオープンソーススタックを共同開発することを促進しており、標準GPUでのBoltz-1のAlphaFold相当の精度は、コミュニティイノベーションが広範な採用を促進することを示しています。
オンプレミスの高性能コンピューティングは機密データセットの処理において依然として重要ですが、クラウドコストの曲線とマネージドサービスの成熟が移行を促進しています。プロバイダーは自動スケーリングアルゴリズムとセキュリティ認証で差別化しています。データベースの既存企業はリポジトリの上に分析レイヤーを構築してインストールベースを守ろうとしています。その結果、競争は激化しますが全体的なソフトウェア品質が向上し、計算生物学市場の持続的な成長を支えています。
サービス別:契約モデルが成長を主導
契約研究サービスはシェアと成長速度の両方でリードしており、2025年に52.05%、CAGRは15.72%の見通しで、製薬会社が複雑なインシリコワークフローをアウトソーシングしています。CROはゲノム分析、AIモデル開発、仮想スクリーニングを統合サブスクリプションにバンドルするようになっています。社内チームはコアとなるIP集約型アルゴリズムを維持しつつ、計算集約型シミュレーションについては外部とパートナーシップを結んでいます。
ハイブリッドサービスフレームワークが普及しています。企業はオンプレミスでデータガバナンスノードを維持しながら、ピーク時のワークロードにはクラウドベースのCROプラットフォームにバーストしています。戦略的アライアンスはリスクを分散させ、クライアントは使用量ベースの料金を支払い、プロバイダーは規制サポートを含むサービスレベル契約を保証します。採用が増加するにつれ、計算生物学市場は従来の創薬バリューチェーンにさらに統合されています。
注記: 全個別セグメントのセグメントシェアはレポート購入時に入手可能
エンドユーザー別:産業界の採用が加速
学術機関は2025年に収益の44.10%を管理していましたが、産業ユーザーは2031年にかけて14.27%のCAGRで勢いを増しています。シーケンシングコストの低下、検証済みAIパイプライン、および緊急の治療タイムラインが製薬業界の採用を促進しています。エンタープライズバイヤーは監査証跡を組み込み、GxP規制に準拠したターンキーソリューションを求めています。
学術機関は知識エンジンとして残り、後に商業的にライセンスされるアルゴリズムを先駆けています。予算制限に対抗するため、大学はテクノロジーベンダーが共著権と早期フィードバックアクセスと引き換えにコンピューティングクレジットを提供するパートナーシップモデルを拡大しています。この共生関係は計算生物学産業のイノベーションファネルを維持しています。
地域分析
2025年収益の42.30%を占める北米は、深いバイオテクベンチャーキャピタル、成熟した規制当局との関与、および密度の高い人材プールから恩恵を受けています。FDAの進化するAIフレームワークは、地元企業に多くの同業他社よりも明確な商業化経路を提供しています。Thermo Fisher Scientificの20億米ドルの複数年にわたる国内投資はインフラのスケーラビリティへの信頼を示していますが、人材不足とクラウドコストの上昇が加速を抑制しています。
アジア太平洋地域は最高の16.02%のCAGRを記録しています。各国政府はエクサフロップスーパーコンピュータに資金を提供しており、韓国の計画は2025年までの稼働を目標としており、中国の分散型国家センターはすでにマルチオミクスプロジェクトを推進しています。地域の医薬品製造が急成長し、遺伝的多様性研究プログラムが地域集団に合わせたAIモデルを調整し、他では入手できないエッジケースデータ資産を生み出しています。分散型臨床試験パイロットとmRNAプラットフォームの構築が計算生物学市場能力への長期的な需要を強化しています。
欧州は国境を越えたコンソーシアムと強固なデータプライバシー保護に支えられ、安定した成長を維持しています。倫理的AIイニシアチブはコンプライアンスの負担を増加させますが、支払者と規制当局の間の信頼も醸成しています。デジタルツインパイロットは資源利用を最適化するという公衆衛生目標と一致しています。一方、ラテンアメリカ、アフリカ、中東はインターネットインフラとバイオインフォマティクスカリキュラムの拡大とともに進歩しています。多国籍製薬グループとのパートナーシップが地域の資金ギャップを補い、計算生物学における段階的ながら持続的な市場浸透を確保しています。

競合環境
計算生物学市場は適度に断片化されていますが、M&Aの明確なトレンドを示しています。シーメンスによるDotmaticsの51億米ドルの買収はラボインフォマティクスと産業用デジタルツインオファリングを統合しており、エンドツーエンドのスタックへのバイヤーの欲求を反映しています。DanaherはGeneDataをポートフォリオに加え、同じ論理を反映しています。IlluminaはNVIDIAと協力してGPU駆動のオミクス分析を加速しており、テクノロジーとバイオテクの融合の例となっています。
スタートアップはオープンソースコミュニティを活用して実力以上の存在感を示しています。EvolutionaryScaleは既存企業の独自化学と直接競合するタンパク質生成AIを商業化するために1億4,200万米ドルを調達しました。ハイブリッド量子古典モデルと系譜追跡アルゴリズムを巡る特許出願はIP競争の激化を示唆しています。競争上の成功は、キュレートされたデータセット、スケーラブルなコンピューティング、および切り替えコストを最小化する統合ワークフローへのアクセスにかかっています。
大手ベンダーはサブスクリプションライセンスとデータネットワーク効果によるエコシステムロックインを追求しています。中堅プレーヤーは単一細胞分析、デジタルツインエンジン、または薬理ゲノミクスツールキットなどの垂直特化によって差別化しています。精度、規制コンプライアンス、および納期速度が依然として決定的な購買要因であるため、価格競争は抑制されています。
計算生物学産業リーダー
Dassault Systèmes SE
Schrödinger Inc.
Certara
Simulation Plus Inc.
Illumina Inc.
- *免責事項:主要選手の並び順不同

最近の業界動向
- 2025年6月:IlluminaはSomaLogicを最大4億2,500万米ドルで買収し、プロテオミクスおよびバイオマーカー能力を拡大し、マルチオミクスポートフォリオを拡充しました。
- 2025年4月:シーメンスはDotmaticsの51億米ドルの買収を完了し、R&Dインフォマティクスと産業用デジタルツインフレームワークを統合しました。
- 2025年2月:Illuminaはコンステレーションマッピングリードと5塩基シーケンシングソリューションをリリースし、2026年の商業展開を予定しています。
- 2025年1月:IlluminaはNVIDIAとパートナーシップを締結し、GPUを使用してマルチオミクスデータパイプラインを加速し、より迅速な治療薬発見を目指しています。


研究方法のフレームワークとレポートの範囲
市場定義と主要カバレッジ
本調査では、計算生物学市場を、創薬、疾患モデリング、ゲノミクス、プロテオミクスのワークフローにわたって生物学的・化学的・臨床データセットを解析するために、数理モデリング、データ分析、シミュレーション技術を活用するすべてのソフトウェアプラットフォーム、インフラツール、および専門データベースと定義する。Mordor Intelligenceによれば、収益は、ホスティングモデルや商業ティアに関わらず、ベンダーがエンドユーザーにソリューションまたはサービスをライセンス供与もしくはプロビジョニングした時点で計上される。
スコープ除外:収益化されたサポートなしに配布される学術フリーウェアおよびオープンソースコードは計上対象外とする。
セグメンテーション概要
- 用途別
- 細胞・生物シミュレーション
- 計算ゲノミクス
- 計算プロテオミクス
- 薬理ゲノミクス
- その他のシミュレーション(トランスクリプトミクス/メタボロミクス)
- 創薬・疾患モデリング
- 標的同定
- 標的検証
- リード探索
- リード最適化
- 前臨床薬物開発
- 薬物動態
- 薬力学
- 臨床試験
- 第I相
- 第II相
- 第III相
- ヒト身体シミュレーションソフトウェア
- 細胞・生物シミュレーション
- ツール別
- データベース
- インフラ(ハードウェア)
- 分析ソフトウェアおよびサービス
- サービス別
- 社内
- 契約
- エンドユーザー別
- 学術機関
- 産業・商業
- 地域別
- 北米
- 米国
- カナダ
- メキシコ
- 欧州
- ドイツ
- 英国
- フランス
- イタリア
- スペイン
- その他の欧州
- アジア太平洋
- 中国
- 日本
- インド
- オーストラリア
- 韓国
- その他のアジア太平洋
- 中東・アフリカ
- GCC
- 南アフリカ
- その他の中東・アフリカ
- 南米
- ブラジル
- アルゼンチン
- その他の南米
- 北米
詳細な調査方法論とデータ検証
一次調査
Mordorのアナリストはその後、北米、欧州、およびアジア太平洋の主要拠点において、ソフトウェアアーキテクト、CROバイオインフォマティシャン、学術コアファシリティディレクター、および調達担当者にインタビューを実施した。協議を通じて、支出範囲、標準的な価格帯、ハイパフォーマンスコンピューティングクラスターの採用曲線、および新興のAI対応ワークフローが検証され、二次情報源では定量化できなかったモデルの前提条件を精緻化することが可能となった。
デスクリサーチ
まず、米国NIH予算表、FDA臨床試験レジストリ、EurostatのR&D支出ファイル、中国科学技術省のプロジェクトカタログ、およびQuestelプラットフォームの特許件数などの公開情報を通じて、対応可能な支出の全体像をマッピングした。これらは、資金提供を受けた研究がどの程度、有償の計算ツール需要に転換し得るかを示すものである。補足的なインプットとして、企業の10-K、投資家向け資料、PubMedにインデックスされた査読済み学術誌、International Society for Computational Biologyなどの協会ポータル、およびDow Jones Factivaを通じて収集したキュレーション済みニュースフローを活用した。デスクレビューは事実的な骨格を構築する一方で、直接的なアウトリーチを要するデータの空白を明らかにした。このリストは例示的なものであり、中間的な確認と明確化には他にも多くの参考資料が活用されている。
市場規模の算定と予測
公開されているライフサイエンスR&D支出額、次世代シーケンシングの実行量、および現行のライセンス普及率を基準とするトップダウン構造により、2025年の初期値を確定する。サンプリングされた平均販売価格とインストールベースの積によるサプライヤーの積み上げ、クラウド利用料に関するチャネルチェック、および専用ハードウェアの輸入統計が選択的なボトムアップの照合として機能し、合計値を整合させる。追跡する主要変数には、a) 資金提供を受けたゲノミクスプロジェクト、b) ゲノムあたりのコスト動向、c) インシリコ実験あたりの平均計算時間、d) バイオロジクスパイプライン数、e) 官民AI連携の発表件数、f) バイオファーマクラスターへのサーバーGPU出荷数が含まれる。予測には多変量回帰とシナリオ分析を組み合わせた手法を採用し、5年間の見通しを確定する前に、ウェイトを専門家のコンセンサスに対してストレステストする。サプライヤーデータの残余ギャップは、地域固有の使用係数を用いた保守的な補間によって補完される。
データ検証と更新サイクル
アウトプットは三層のレビューを経る:過去系列との差異チェック、代替データシグナルとのクロス比較、およびシニアアナリストによる監査。モデルは年次で更新され、資金調達の急変、大型M&A、または破壊的な規制変更が生じた場合には中間スイープが実施される。最終的な公開前スイープにより、クライアントが常に最新の見解を受け取れるよう保証される。
Mordorの計算生物学ベースラインが信頼性を持つ理由
公表された推計値がしばしば乖離するのは、各社が市場を異なる形で定義したり、異なる基準年で通貨換算を行ったり、未検証の成長プレミアムを組み込んだりするためである。
主なギャップ要因としては、無償の学術ソフトウェアを計上するかどうか、ハイブリッドクラウドサブスクリプションの年換算方法、および大規模なバイオインフォマティクススイートにバンドルされたツールをアンバンドルするかどうかが挙げられる。Mordorのスコープは収益化されていないフリーウェアを除外し、透明性のある2025年通貨ベースラインを適用し、採用率を12ヶ月ごとに再ベンチマークすることで、更新サイクルが長期化した場合に生じ得る過大・過小評価を防止している。
ベンチマーク比較
| 市場規模 | 匿名化されたソース | 主なギャップ要因 |
|---|---|---|
| USD 7.24 B(2025年) | Mordor Intelligence | - |
| USD 5.90 B(2024年) | Global Consultancy A | ソフトウェアプラットフォーム収益のみを含み、インフラおよびデータベース層を除外 |
| USD 7.18 B(2025年) | Industry Association B | 一部の政府資金によるオープンソースプロジェクトを有償相当として計上 |
| USD 9.13 B(2025年) | Regional Consultancy C | 隣接するバイオインフォマティクスサービスを集計し、総価値を過大評価 |
要約すると、Mordor Intelligenceが採用する厳格なスコープ定義、二重チェックされた変数、および適時の更新サイクルにより、意思決定者は他所で一般的に見られる楽観的な過大計上や保守的な過小評価の双方を回避した、バランスのとれた追跡可能なベースラインを得ることができる。


レポートで回答される主要な質問
計算生物学市場の現在の規模はどのくらいですか?
計算生物学市場は2026年に81億7,000万米ドルを生み出し、2031年までに148億9,000万米ドルに達する軌道にあります。
最も急速に拡大している用途分野はどこですか?
創薬・疾患モデリングは、AI対応の標的同定とデジタルツインワークフローに牽引され、2031年にかけて最高の15.33%のCAGRを記録しています。
契約研究サービスが急速に成長している理由は何ですか?
製薬会社はデータ集約型モデリングを専門のCROにアウトソーシングしており、契約サービスに52.05%のシェアと15.72%の成長率をもたらしています。
将来の成長に最も貢献する地域はどこですか?
アジア太平洋地域は政府のスーパーコンピュータプロジェクトと急速に拡大する医薬品製造により16.02%のCAGRでリードしています。
計算生物学プラットフォームのより広範な採用を妨げているものは何ですか?
学際的人材の不足、クラウドコンピューティングコストの上昇、および進化するバイオセキュリティ規制が主な制約要因です。
最終更新日:




