United States Data Center GPU Market Size and Share
Market Overview
| Study Period | 2020 - 2031 |
|---|---|
| Forecast Data Period | 2026 - 2031 |
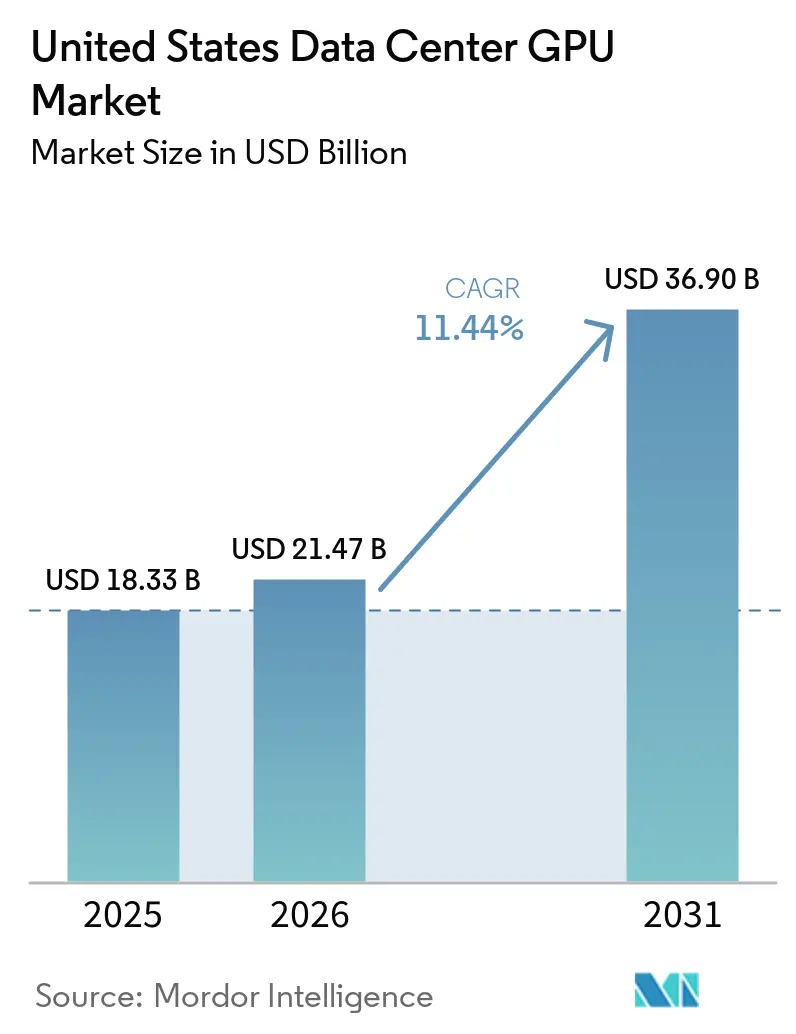
| Base Year Market Size (2025) | USD 18.33 Billion |
| Market Size (2026) | USD 21.47 Billion |
| Market Size (2031) | USD 36.90 Billion |
| Growth Rate (2026 - 2031) | 11.44% CAGR |
| Market Concentration | High |
Major Players *Disclaimer: Major Players sorted in no particular order Image © Mordor Intelligence. Reuse requires attribution under CC BY 4.0. | |
United States Data Center GPU Market Analysis by Mordor Intelligence
The United States data center GPU market size was valued at USD 18.33 billion in 2025 and estimated to grow from USD 21.47 billion in 2026 to reach USD 36.90 billion by 2031, at a CAGR of 11.44% during the forecast period (2026-2031). Rising model complexity is compressing refresh cycles to less than two years, creating structural demand for next-generation GPUs equipped with high-bandwidth memory and liquid cooling. Federal incentives worth USD 52 billion under the CHIPS and Science Act are reinforcing domestic capacity for packaging and assembly, while hyperscalers race to monetize sustained inference workloads through vertically integrated “AI factories”. Edge build-outs are accelerating as retail, manufacturing,, and autonomous-vehicle operators prioritize sub-50-millisecond response times. Meanwhile, export controls and substrate shortages are prompting multi-year capacity reservations and the emergence of secondary markets for lightly used GPUs.
Key Report Takeaways
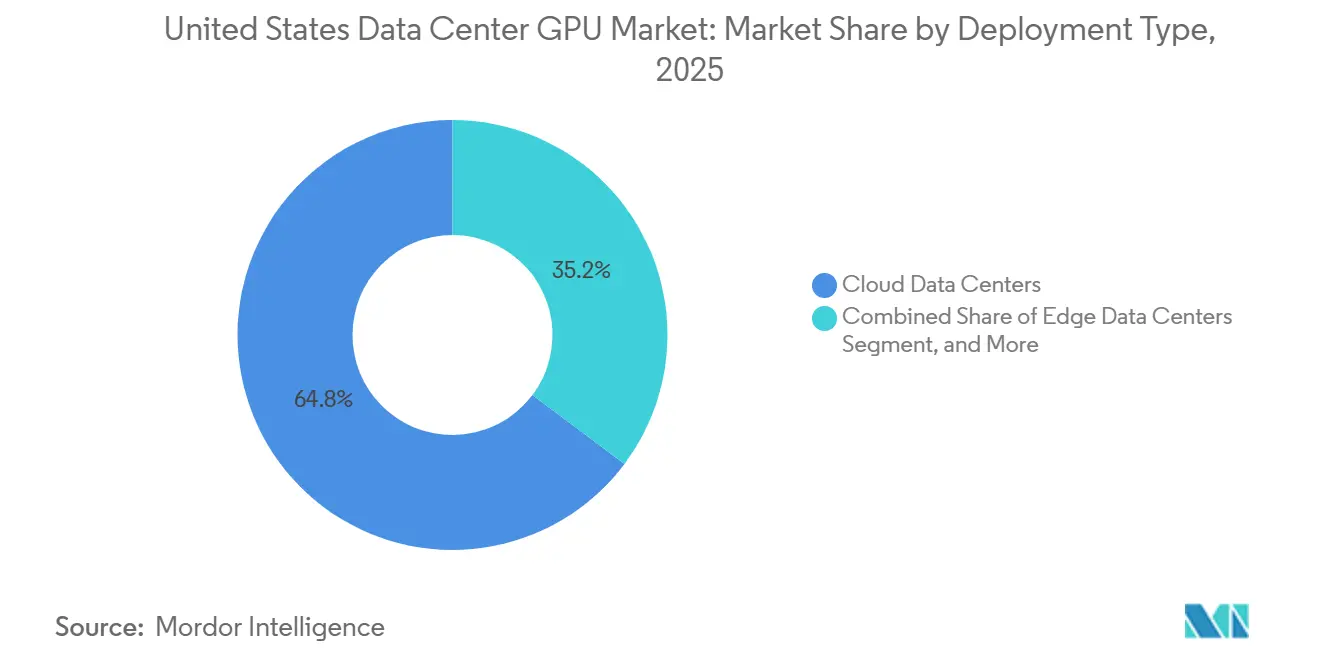
- By deployment type, cloud data centers led with 64.76% of the United States data center GPU market share in 2025, while edge facilities are projected to expand at a 12.89% CAGR through 2031.
- By GPU type, training devices accounted for 59.88% of the United States data center GPU market in 2025, and inference devices are expected to advance at a 12.77% CAGR through 2031.
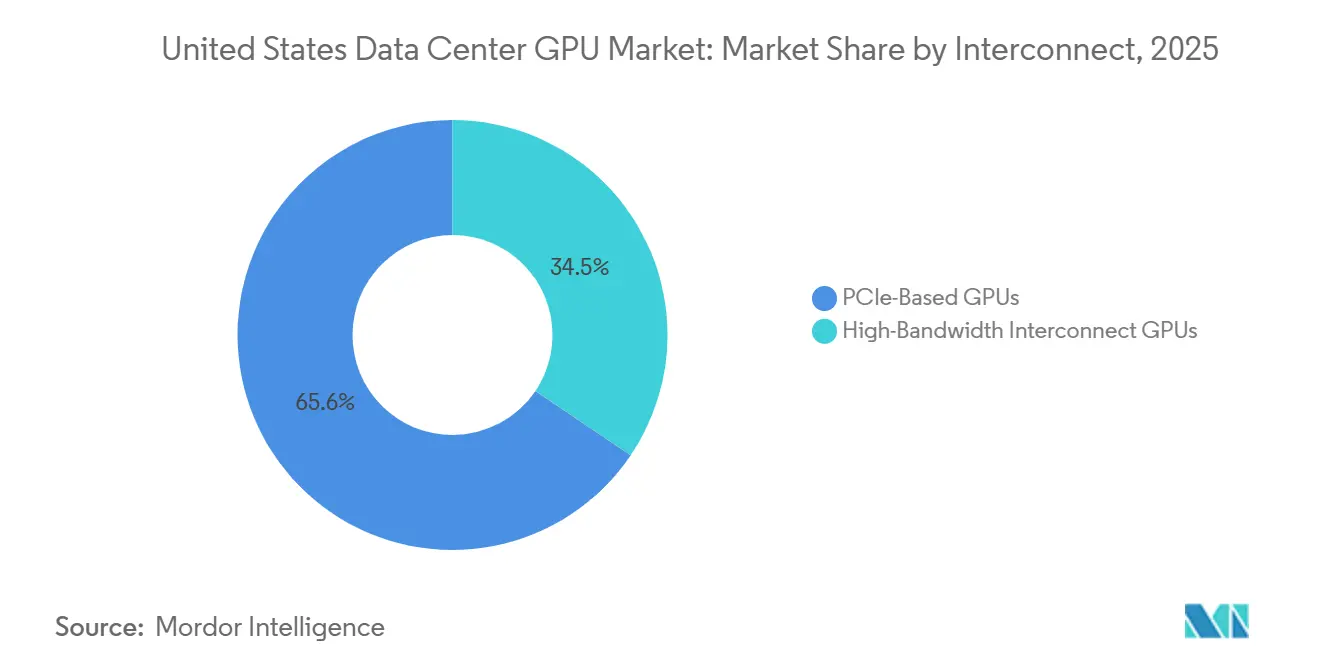
- By interconnect, PCIe devices held 65.55% share in 2025, and high-bandwidth interconnect GPUs are forecast to rise at a 13.23% CAGR through 2031.
- By workload, artificial intelligence and machine learning captured 60.99% revenue share in 2025, whereas data analytics is set to grow at a 12.73% CAGR between 2026 and 2031.
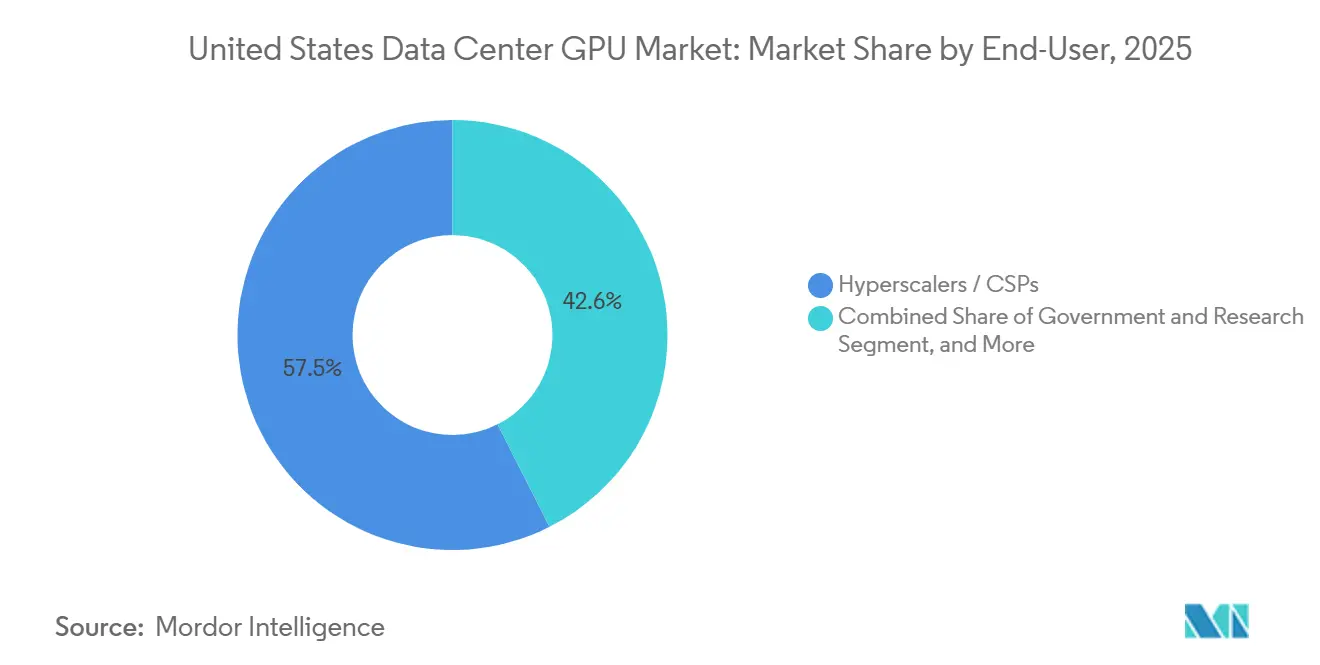
- By end-user, hyperscalers commanded 57.45% revenue share in 2025, and government plus research institutions exhibit the fastest projected growth at 13.11% CAGR to 2031
Note: Market size and forecast figures in this report are generated using Mordor Intelligence’s proprietary estimation framework, updated with the latest available data and insights as of January 2026.
United States Data Center GPU Market Trends and Insights
Drivers Impact Analysis*
| DRIVER | (~) % IMPACT ON CAGR FORECAST | GEOGRAPHIC RELEVANCE | IMPACT TIMELINE |
|---|---|---|---|
| Growing AI Model Complexity Driving GPU Refresh Cycles | +2.8% | Global, concentrated in Virginia, Oregon, Iowa, and Texas | Medium term (2-4 years) |
| Escalating Energy Efficiency Mandates Favoring Advanced GPUs | +2.1% | The United States federal and state jurisdictions | Long term (≥ 4 years) |
| Proliferation of Edge Inference Accelerating Low-Latency GPU Demand | +1.9% | The United States metro and industrial corridors | Short term (≤ 2 years) |
| Adoption of Cloud-Native HPC Workflows in Enterprise R&D | +1.6% | The United States pharmaceutical, automotive, and energy sectors | Medium term (2-4 years) |
| Emergence of Multi-Tenant GPU Virtualization Platforms | +1.4% | Global cloud providers and the United States enterprises | Short term (≤ 2 years) |
| United States Government Incentives for Domestic Semiconductor Capacity | +1.3% | Arizona, Texas, Ohio, New York | Long term (≥ 4 years) |
| Source: Mordor Intelligence | |||
Growing AI Model Complexity Driving GPU Refresh Cycles
Trillion-parameter transformers now demand rack-scale clusters with aggregate memory exceeding 10 TB, pushing hyperscalers to retire Hopper systems after roughly 18 months and to accelerate Blackwell and Rubin procurement cycles. NVIDIA’s Vera Rubin NVL72 couples 72 Rubin GPUs with 36 Vera CPUs, delivering a 3.6 TB/s interconnect that cuts GPU counts by one-quarter per petaflop. Continuous agentic workloads have shifted spending from one-time training bursts to always-on inference fleets, favoring reserved-instance contracts over spot pricing. OpenAI’s multi-year wafer-scale deal demonstrates how model providers can lock in capacity years in advance.[1]Timothy Prickett Klein, “Cerebras Inks Transformative $10 Billion Inference Deal With OpenAI,” Next Platform, nextplatform.com The result is a shortened refresh cadence that strengthens secondary markets for lightly used GPUs.
Escalating Energy Efficiency Mandates Favoring Advanced GPUs
The Environmental Protection Agency’s ENERGY STAR v4.0 caps idle power and targets PUE below 1.3, disadvantaging legacy Pascal and Volta cards. Department of Energy guidelines now require quarterly reporting of GPU utilization, nudging agencies toward Blackwell and Rubin devices that quadruple FP8 performance per watt. California Title 24, effective January 2026, mandates GPU fleet averages of 50 TFLOPS per kilowatt, a level only liquid-cooled Blackwell and AMD MI400 systems meet.[2]Alina Neacsu, “Equinix Expands AI Data Centers to Support GPU Workloads,” eeNews Europe, eenewseurope.com Colocation providers are retrofitting with direct-to-chip liquid cooling, raising rent premiums in Northern Virginia and Phoenix. Together, federal and state rules are splitting the market into legacy air-cooled sites and next-generation liquid-cooled campuses.
Proliferation of Edge Inference Accelerating Low-Latency GPU Demand
NVIDIA Jetson T4000 and IGX Thor platforms now deliver sub-10 ms response for autonomous vehicles and robotics.[3]NVIDIA Corporation, “NVIDIA Developer Blog,” nvidia.com Datavault AI’s 48,000-GPU fleet cut backhaul bandwidth costs by 60%, validating the economics of distributed inference. Private 5G networks in factories achieve latency of 50 ms or less for machine-vision workloads, which is incompatible with cloud round-trip times. TensorRT Edge-LLM compresses 7-billion-parameter models to 4-bit precision while maintaining 95% accuracy, enabling local device execution. Demand is rising for 16-32 GB GPUs within 50-150 W thermal envelopes, where NVIDIA L4 and AMD Radeon PRO W7000 compete.
Adoption of Cloud-Native HPC Workflows in Enterprise Research and Development
Pharma and automotive firms migrate CFD and molecular dynamics to cloud GPUs, slashing simulation times.[4]Microsoft, “Azure NCv6 Public Preview,” techcommunity.microsoft.com Roche’s March 2026 roll-out of 3,500 Blackwell GPUs, paired with Azure burst capacity, enables real-time protein folding. Microsoft Azure NCv6 offers fractional GPU instances, lowering entry costs for small enterprises. NSF’s Horizon supercomputer will provide 20 exaflops of AI performance when it launches in spring 2026. Hybrid orchestration across on-premise and cloud GPUs is becoming a standard R&D architecture.
Restraints Impact Analysis*
| RESTRAINT | (~) % IMPACT ON CAGR FORECAST | GEOGRAPHIC RELEVANCE | IMPACT TIMELINE |
|---|---|---|---|
| Supply Chain Constraints for Advanced Packaging Substrates | -1.8% | Taiwan, South Korea | Short term (≤ 2 years) |
| Rising Total Cost of Ownership Versus ASIC Alternatives for Inference | -1.5% | United States hyperscalers | Medium term (2-4 years) |
| Data Center Power and Cooling Bottlenecks in Legacy Facilities | -1.2% | Northern Virginia, Silicon Valley, Chicago | Long term (≥ 4 years) |
| Geopolitical Export Controls Limiting GPU Availability to Certain Users | -0.9% | United States | Medium term (2-4 years) |
| Source: Mordor Intelligence | |||
Supply Chain Constraints for Advanced Packaging Substrates
TSMC’s CoWoS capacity remains capped at around 30,000 wafers per month until at least 2027, slowing Blackwell and Rubin's output. SK hynix experienced HBM3e yield issues in 2025, delaying shipments by up to 12 weeks. ASML delivery backlogs limit advanced-node expansion despite multibillion-dollar fab projects. Micron entered HBM production in late 2025, yet early volumes are targeted at mobile rather than data center demand. Vendors therefore prioritize the highest-margin rack-scale systems, leaving mid-market enterprises with prolonged lead times.
Rising Total Cost of Ownership Versus ASIC Alternatives for Inference
Custom chips such as AWS Trainium2 and Google TPU v6 now deliver 2-3× lower cost per token than general-purpose GPUs on mature models.[5]Intel Corporation, “Intel Breaks Down Proprietary Walls to Bring Choice to Enterprise GenAI Market,” intel.com AWS benchmarks show 40% lower inference costs than Blackwell B200 for Llama models. Microsoft’s Maia 200 halves power draw per request. The economic crossover appears at roughly 10 billion monthly inferences, where ASIC amortization undercuts GPU rental. Consequently, GPUs risk erosion of their share in high-volume inference unless they evolve toward greater efficiency.
*Our forecasts treat driver/restraint impacts as directional, not additive. The impact forecasts reflect baseline growth, mix effects, and variable interactions.
Segment Analysis
By Deployment Type: Edge Outpaces Cloud Growth
Cloud data centers accounted for 64.76% of United States data center GPU revenue in 2025, yet edge data centers are forecast to grow at 12.89% annually through 2031, reflecting the migration of latency-sensitive inference workloads from centralized hyperscaler facilities to distributed edge sites. Hyperscalers such as AWS, Microsoft Azure, and Google Cloud continue to dominate capital expenditure.
NVIDIA's Omniverse on DGX Cloud, launched in February 2026 with optimized L40 GPUs for RTX rendering and low-latency streaming, targets industrial digitalization and digital twin workflows that require scalable GPU resources without customer infrastructure management, positioning cloud-managed GPU services as an on-ramp for enterprises hesitant to commit capital to on-premise clusters. Edge data centers, particularly those supporting autonomous vehicle fleets and smart manufacturing, are deploying ruggedized GPU servers with 50-150 watt thermal envelopes and passive cooling to operate in non-climate-controlled environments, a segment where NVIDIA Jetson and AMD Radeon PRO platforms compete on software ecosystem maturity and long-term supply commitments.



By GPU Type: Inference Gains Share as Training Peaks
Training GPUs commanded 59.88% of market share in 2025, yet inference GPUs are forecast to grow at 12.77% annually through 2031 as model providers shift capital from one-time pretraining toward multi-year inference fleets that serve continuous agentic workloads. The economic logic is straightforward: a trillion-parameter model requires USD 50-100 million and 10,000-20,000 GPUs for initial training, but serving that model at scale demands 5-10x more inference capacity over its operational lifetime, fundamentally altering the capital allocation calculus for hyperscalers and model builders. NVIDIA's Groq 3 LPX inference rack, integrating 256 language processing units with 128 gigabytes of on-chip SRAM and 40 petabytes per second of aggregate bandwidth, targets low-latency token generation for agentic reasoning workloads where sub-millisecond response times unlock premium pricing tiers.
Training GPUs remain essential for foundation model development and post-training fine-tuning, yet the cadence of new model releases is slowing GPT-5 and Llama 4 training runs are stretching to 12-18 months versus 6-9 months for prior generations, reducing the urgency of continuous training cluster expansion and allowing hyperscalers to amortize training infrastructure over longer periods. The emergence of test-time compute scaling, where models iteratively refine outputs during inference rather than relying solely on pretraining scale, is blurring the boundary between training and inference workloads and driving demand for hybrid GPU architectures that support both high-throughput batch training and low-latency interactive inference.
By Interconnect: High-Bandwidth Fabrics Enable Rack-Scale Systems
PCIe-based GPUs held 65.55% of market share in 2025, yet high-bandwidth interconnect GPUs are forecast to grow at 13.23% annually through 2031 as rack-scale clusters with NVLink, CXL, and UALink fabrics become the default architecture for trillion-parameter training and inference workloads. NVIDIA's NVLink 6, delivering 3.6 terabytes per second of chip-to-chip bandwidth in the Vera Rubin platform, enables 72-GPU clusters to function as a single logical device with unified memory addressing, eliminating the software complexity of explicit data movement across PCIe boundaries. AMD's Infinity Fabric, integrated into MI400-series GPUs with 2.8 terabytes per second of inter-GPU bandwidth, supports Meta's 6-gigawatt Helios rack platform, which scales to 432 gigabytes of HBM4 memory per GPU, and competes directly with NVIDIA's NVL72 architecture.
PCIe Gen5 adoption, with 32 gigatransfers per second per lane and 128 gigabytes per second of bidirectional bandwidth in x16 configurations, remains sufficient for inference workloads below 70 billion parameters and for single-GPU training of domain-specific models, sustaining demand for PCIe-based GPUs in enterprise and edge deployments. Intel's Gaudi 3 AI accelerator, integrating 24 ports of 200-gigabit Ethernet per device and targeting all-Ethernet fabrics for scale-out clusters, positions standard networking as a cost-effective alternative to proprietary interconnects for customers prioritizing vendor flexibility over peak bandwidth. Marvell's USD 540 million acquisition of XConn in January 2026, adding CXL and UALink controller IP, signals the emergence of open-standard high-bandwidth interconnects that challenge NVIDIA's NVLink ecosystem and enable multi-vendor GPU clusters.
By Workload Type: Analytics Gains as AI Matures
Artificial intelligence and machine learning workloads captured 60.99% of United States data center GPU revenue in 2025, yet data analytics is forecast to grow at 12.73% annually through 2031 as GPU-accelerated database engines displace CPU-only stacks in real-time query processing and business intelligence applications. High-performance computing workloads, encompassing non-AI scientific computing such as computational fluid dynamics and molecular dynamics, continue to rely on double-precision floating-point performance, where NVIDIA A100 and AMD MI250X GPUs maintain incumbency due to mature software ecosystems and validated application profiles.
The convergence of AI and analytics is creating hybrid workloads where GPU-accelerated SQL query engines invoke machine learning models inline during query execution, a pattern that Microsoft's Azure NCv6 virtual machine series explicitly targets by pairing NVIDIA RTX PRO 6000 GPUs with Intel Granite Rapids CPUs to avoid CPU bottlenecks in pre- and post-processing stages. NVIDIA's Velox and cuDF libraries, delivering 6x speedups on Apache Spark workloads compared to CPU-only execution, are enabling real-time analytics on terabyte-scale datasets that previously required overnight batch processing, a capability that justifies GPU adoption for data engineering teams beyond traditional AI practitioners.
By End-User: Government Procurement Accelerates
Hyperscalers and cloud service providers accounted for 57.45% of United States data center GPU revenue in 2025, yet government and research institutions are forecast to grow at 13.11% annually through 2031, driven by Department of Energy exascale procurements and National Science Foundation leadership-class computing initiatives. DOE's NERSC-10 "Doudna" supercomputer, a Dell-NVIDIA Vera Rubin system delivering over 10x the performance of the incumbent Perlmutter system, will serve approximately 11,000 researchers across climate modeling, materials science, and fusion energy simulations when it enters production in late 2026. DOE Idaho National Laboratory's Teton supercomputer, an HPE Cray EX 4000 system with 1,024 nodes and 20.8 petaflops of peak performance, entered production in January 2026 to support nuclear reactor modeling and grid resilience simulations.
Enterprises, encompassing Fortune 500 companies across pharmaceuticals, automotive, finance, and energy sectors, are adopting hybrid cloud architectures that combine on-premise GPU clusters for sensitive intellectual property with cloud-burst capacity for computationally intensive parameter sweeps, a model that requires seamless orchestration and consistent software stacks across heterogeneous environments. Roche's March 2026 deployment of over 3,500 NVIDIA Blackwell GPUs across United States and European facilities, integrated with Azure cloud-burst capacity, enables real-time protein folding and drug candidate screening, compressing discovery timelines from months to weeks.
Geography Analysis
Northern Virginia remains the world’s largest GPU hub, yet constrained grid interconnects are nudging deployments toward Phoenix, Salt Lake City, and Columbus. Phoenix gains additional pull from TSMC’s USD 165 billion fab and packaging campus that will alleviate CoWoS bottlenecks by 2028. Texas hosts megawatt-scale training clusters that exploit cheap wind and natural-gas power, while Ohio’s Intel fabs are slated to supply advanced-node logic dies for Gaudi accelerators after 2027.
Micron’s New York HBM expansion still earmarks early output for mobile, leaving data center buyers largely dependent on Asian suppliers through 2027. Emerging submarkets such as Reno benefit from favorable climates for air-side economization but face limited long-haul fiber, confining them to batch training rather than latency-critical inference. Federal agencies migrating from legacy sites under OMB M-25-03 will inject demand into modernized GPU-ready facilities across multiple states.
Overall, the United States data center GPU market enjoys geographic diversification that buffers supply-chain risk, with regional specialization in Arizona for packaging, Texas for power-intensive training, and Virginia for inference delivery mirroring earlier industrial patterns.
Competitive Landscape
NVIDIA retained a significant share of 2025 training revenue, yet competitive intensity is climbing. AMD’s MI400 won a USD 100 billion multi-year deal with Meta, marking the first large-scale displacement of NVIDIA in hyperscaler training environments. Intel Gaudi 3 targets enterprise inference with Ethernet fabrics that simplify scale-out clusters.
Cerebras secured a USD 10 billion wafer-scale agreement with OpenAI, validating non-GPU architectures for real-time inference. NVIDIA’s licensing of Groq LPU technology signals a pivot toward heterogeneous racks that combine GPUs for attention layers with specialized processors for token generation.
White-space opportunities persist in mid-range edge GPUs and in multi-tenant virtualization software, where idle capacity can be fractionally resold. As custom ASICs scale, GPUs must defend their share through deeper software ecosystems and continual energy-efficiency gains, shaping the next chapter of the United States data center GPU market.
United States Data Center GPU Industry Leaders
NVIDIA Corporation
Advanced Micro Devices, Inc.
Intel Corporation
Graphcore Ltd.
Cerebras Systems Inc.
- *Disclaimer: Major Players sorted in no particular order

Recent Industry Developments
- April 2026: NVIDIA introduced RTX PRO Server with 96 GB Blackwell GPUs and vGPU software, supporting up to 48 concurrent users per GPU.
- March 2026: NVIDIA invested USD 2 billion in Marvell to accelerate NVLink Fusion integration for heterogeneous clusters.
- March 2026: NVIDIA unveiled the Vera Rubin AI platform, projecting USD 1 trillion revenue through 2027.
- March 2026: Roche deployed 3,500 Blackwell GPUs across on-premises sites with Azure burst capacity for real-time protein folding.


United States Data Center GPU Market Report Scope
The United States Data Center GPU Market Report is Segmented by Deployment Type (Cloud Data Centers, Enterprise/Private Data Centers, and Edge Data Centers), GPU Type (Training GPUs, and Inference GPUs), Interconnect (PCIe-Based GPUs and High-Bandwidth Interconnect GPUs), Workload Type (AI and ML, HPC, Data Analytics, and Graphics and Visualization), and End-User (Hyperscalers/CSPs, Enterprises, and Government and Research). The Market Forecasts are Provided in Value (USD).
| Cloud Data Centers |
| Enterprise / Private Data Centers |
| Edge Data Centers |
| Training GPUs |
| Inference GPUs |
| PCIe-Based GPUs |
| High-Bandwidth Interconnect GPUs |
| Artificial Intelligence (AI) and Machine Learning (ML) |
| High-Performance Computing (HPC) (non-AI scientific computing) |
| Data Analytics (database acceleration, query processing) |
| Graphics and Visualization (VDI, rendering, digital twins) |
| Hyperscalers / Cloud Service Providers |
| Enterprises |
| Government and Research Institutions |
| By Deployment Type | Cloud Data Centers |
| Enterprise / Private Data Centers | |
| Edge Data Centers | |
| By GPU Type | Training GPUs |
| Inference GPUs | |
| By Interconnect | PCIe-Based GPUs |
| High-Bandwidth Interconnect GPUs | |
| By Workload Type | Artificial Intelligence (AI) and Machine Learning (ML) |
| High-Performance Computing (HPC) (non-AI scientific computing) | |
| Data Analytics (database acceleration, query processing) | |
| Graphics and Visualization (VDI, rendering, digital twins) | |
| By End-User | Hyperscalers / Cloud Service Providers |
| Enterprises | |
| Government and Research Institutions |


Key Questions Answered in the Report
What was the United States data center GPU market size in 2025, and how fast is it growing?
The United States data center GPU market size reached USD 18.33 billion in 2025 and is projected to reach USD 36.90 billion by 2031, with a 11.44% CAGR.
Which deployment type is expanding the quickest?
Edge data centers are the fastest growing, with a 12.89% CAGR forecast through 2031 as latency-sensitive inference shifts away from centralized cloud sites.
How is the market split between training and inference GPUs?
Training GPUs commanded 59.88% revenue share in 2025, while inference GPUs will grow faster at 12.77% CAGR as continuous serving workloads scale.
What factors most threaten future GPU supply?
Advanced packaging substrate shortages, notably CoWoS and HBM, are the most pressing supply constraint and could shave 1.8 percentage points off the CAGR forecast.
Which end-user group will outpace hyperscalers in growth?
Government and research institutions are expected to expand GPU spending at a 13.11% CAGR through 2031, faster than any commercial segment.
Page last updated on:






