AI Training Dataset Market Size and Share
Market Overview
| Study Period | 2020 - 2031 |
|---|---|
| Market Size (2026) | USD 11.91 Billion |
| Market Size (2031) | USD 49.82 Billion |
| Growth Rate (2026 - 2031) | 33.14% CAGR |
| Fastest Growing Market | Asia-Pacific |
| Largest Market | North America |
| Market Concentration | Low |
Major Players *Disclaimer: Major Players sorted in no particular order Image © Mordor Intelligence. Reuse requires attribution under CC BY 4.0. | |
AI Training Dataset Market Analysis by Mordor Intelligence
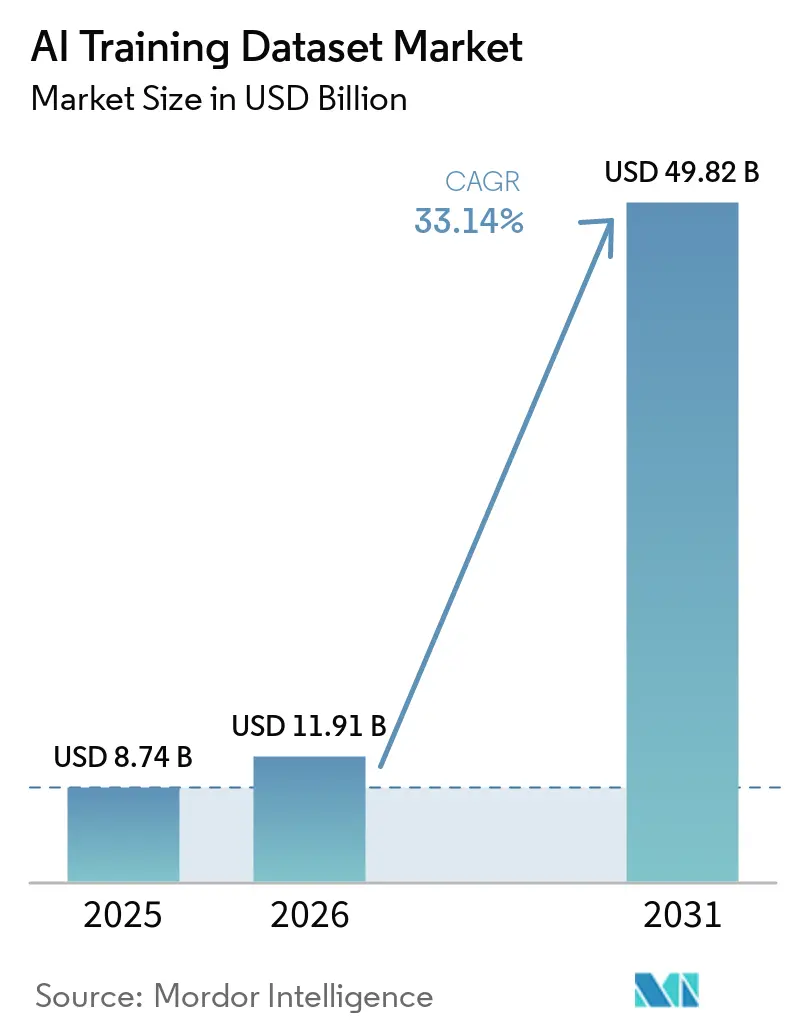
The AI training dataset market size is expected to grow from USD 8.74 billion in 2025 to USD 11.91 billion in 2026 and is forecast to reach USD 49.82 billion by 2031 at 33.14% CAGR over 2026-2031. The AI training dataset market is expanding as large language models at the frontier require larger volumes of curated text, images, videos, and multimodal inputs to support pretraining, tuning, and evaluation. Buyers are also moving away from passive data collection toward tightly managed annotation, verification, and provenance workflows, as model performance now depends more on data quality than on raw volume alone. Post-training alignment methods, especially reinforcement learning from human feedback, are pushing providers to build deeper expert networks and to implement stronger quality controls for preference and evaluation data. The AI training dataset market is also facing rising pressure from synthetic content contamination and a shortage of expert labor, widening the gap between large-scale providers and smaller vendors. Competition is therefore shifting toward multimodal quality systems, domain expertise, rights-cleared content access, and secure delivery models that can meet enterprise compliance expectations.
Key Report Takeaways
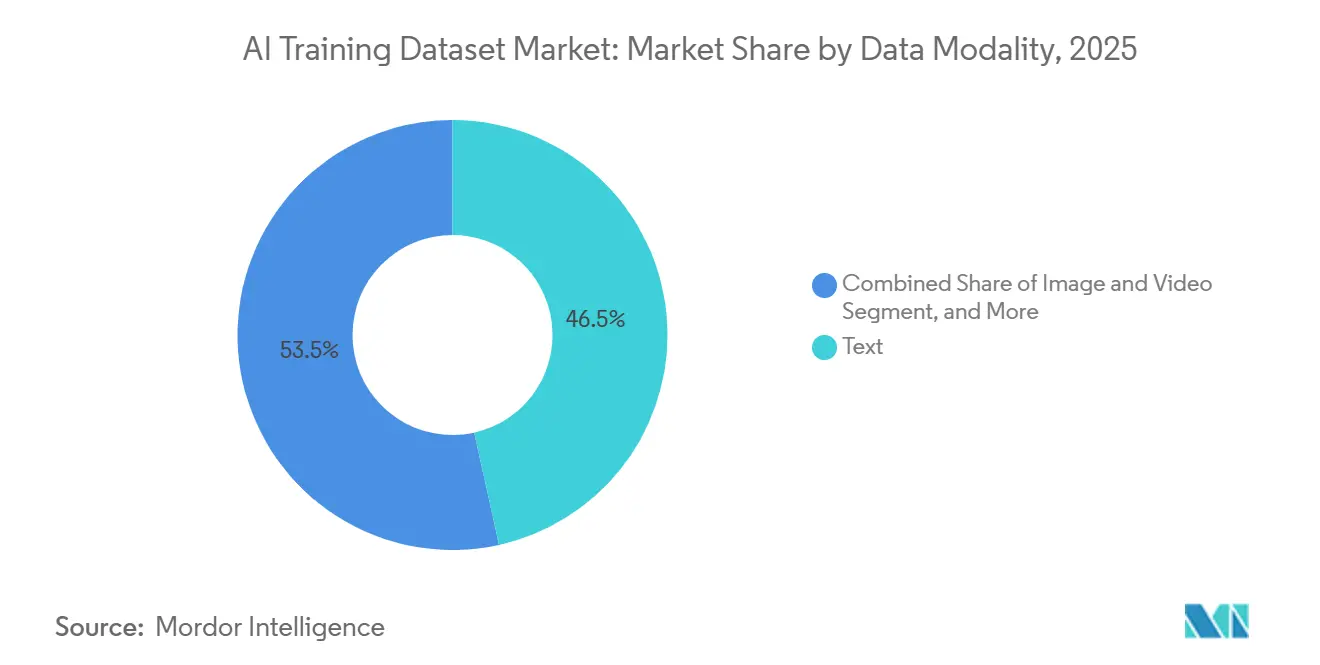
- By data modality, text data held 46.53% share of the AI training dataset market in 2025, while video data is forecast to grow at a 33.94% CAGR through 2031.
- By dataset offering, off-the-shelf datasets accounted for 46.84% of the market share in 2025, while custom dataset creation is projected to expand at a 33.74% CAGR through 2031.
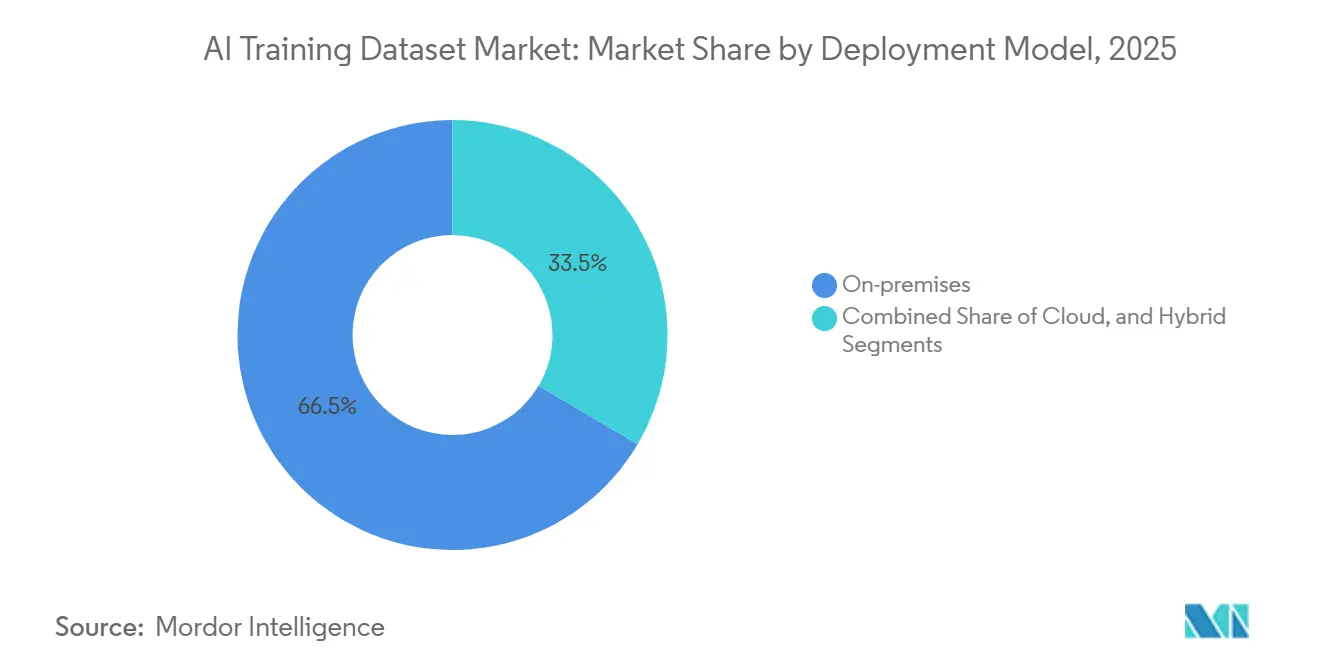
- By deployment model, on-premises deployment held 66.52% share of the artificial intelligence training dataset market in 2025, while cloud deployment is projected to grow at a 33.71% CAGR through 2031.
- By end-user industry, IT and telecommunications retained 31.27% share of the AI training dataset market in 2025, while healthcare is expected to advance at a 34.74% CAGR through 2031.
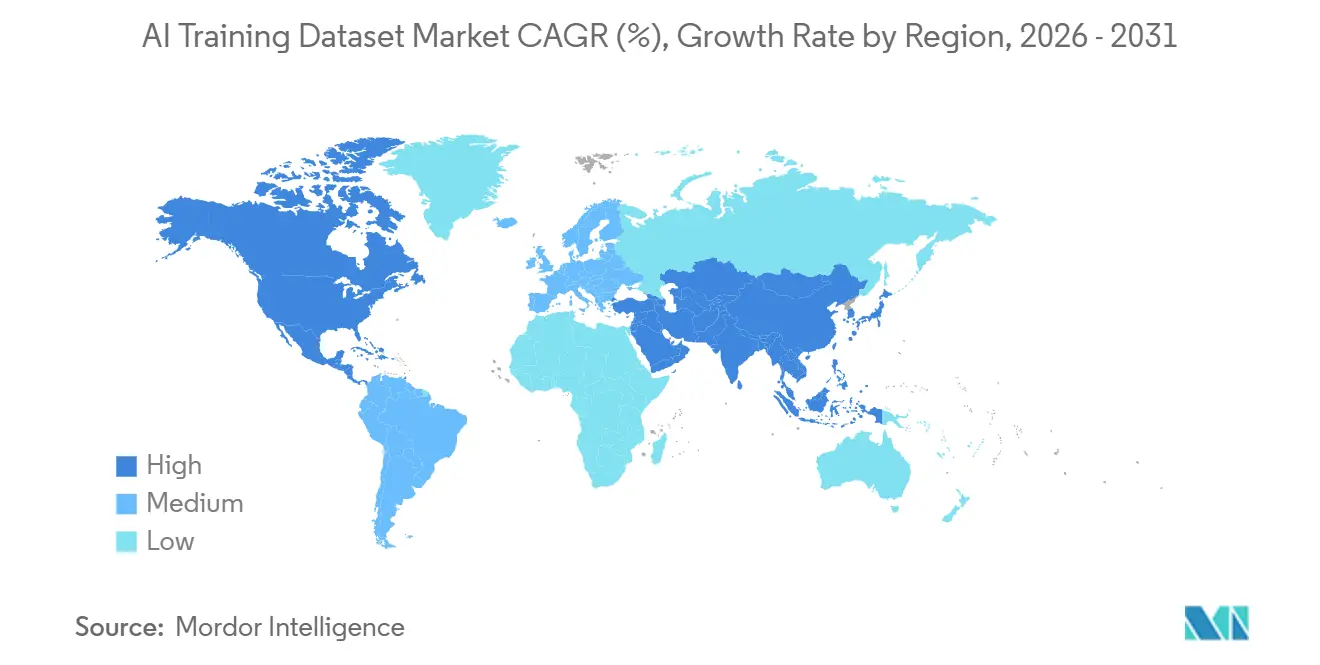
- By geography, North America accounted for 34.11% share of the artificial intelligence training dataset market in 2025, while Asia-Pacific is projected to grow at a 34.14% CAGR through 2031.
Note: Market size and forecast figures in this report are generated using Mordor Intelligence’s proprietary estimation framework, updated with the latest available data and insights as of January 2026.
Global AI Training Dataset Market Trends and Insights
Drivers Impact Analysis*
| Driver | (~) % Impact on CAGR Forecast | Geographic Relevance | Impact Timeline |
|---|---|---|---|
| Expansion Of Multimodal LLMs And Generative AI Workloads | +9.5% | Global | Short term (≤ 2 years) |
| Rising Demand For Domain-Specific Datasets In Regulated Workflows | +7.0% | North America and Europe, spill-over to APAC | Medium term (2-4 years) |
| Greater Use Of Synthetic And Simulated Data | +5.8% | Global | Short term (≤ 2 years) |
| Scaling Of Physical AI And Autonomous Systems | +4.5% | North America and APAC | Medium term (2-4 years) |
| Shift Toward Post-Training Preference, Agent Trajectory, And Evaluation Data | +3.2% | Global, with concentration in North America | Short term (≤ 2 years) |
| Growth Of Rights-Cleared Licensed Content Markets | +2.1% | North America and Europe | Medium term (2-4 years) |
| Source: Mordor Intelligence | |||
Expansion of Multimodal LLMs and Generative AI Workloads
The spread of multimodal large language models has changed what buyers expect from the AI training dataset market. Providers now need to supply synchronized text-image pairs, time-aligned video-audio sequences, and other records that preserve meaning across modalities rather than within a single data type alone. This has raised the value of datasets that can support both training and evaluation for image reasoning, video understanding, and cross-modal retrieval. The scaling challenge is visible in the MINT-1T release, which expanded open-source multimodal data by combining PDFs, HTML, and arXiv material into a 1.02 trillion-token corpus. The same demand is carried into agentic systems, where models need interaction traces, task demonstrations, and environment feedback beyond static labels. As a result, the artificial intelligence training dataset market is seeing faster growth in complex annotation and cross-modal quality assurance than in basic labeling volume.
Rising Demand for Domain-Specific Datasets in Regulated Workflows
The AI training dataset market is gaining momentum as regulated workflows require general-purpose corpora that are not sufficient. Healthcare, legal, and financial use cases require data that is de-identified, traceable, and labeled by qualified reviewers, which increases the value of suppliers that already operate in controlled environments. PhysioNet expanded on that pattern in 2025 with releases such as ER-REASON, which demonstrated ongoing institutional demand for research-grade clinical reasoning datasets under governed access terms. This is one reason healthcare is the fastest-growing end-user segment through 2031, as AI developers need annotated clinical notes, medical imaging, and structured records that can support high-stakes applications. The cost profile is also different from general data work because expert review, de-identification, and audit documentation are built into delivery rather than added later. That keeps margins firmer for providers embedded in regulated workflows and makes domain access a durable advantage in the artificial intelligence training dataset market.
Greater Use of Synthetic and Simulated Data
Synthetic data is becoming a larger part of the AI training dataset market because it can expand coverage, protect privacy, and speed development where real-world examples are scarce. MIT researchers reported that more than 60% of the data used in AI training in 2024 was synthetic, indicating how quickly the practice has moved into mainstream workflows.[1] Adam Zewe, “3 Questions: The Pros and Cons of Synthetic Data in AI,” MIT News, news.mit.edu At the same time, synthetic generation is not a full substitute for verified human-created material because repeated training on self-generated data can narrow distributional coverage and weaken edge-case performance. Research presented at ICML 2025 found that a 20-30% floor of verified human-generated examples is needed to avoid that type of degradation. This is pushing frontier labs to treat synthetic data as a complement that improves scale and scenario coverage, not as a stand-alone source of truth. The artificial intelligence training dataset market, therefore, benefits from suppliers that can blend synthetic generation with provenance controls, verification pipelines, and selective human oversight.
Scaling of Physical AI and Autonomous Systems
Physical AI is creating a distinct growth path in the AI training dataset market because robots, autonomous systems, and industrial machines require sensor-rich data that web corpora cannot provide. NVIDIA describes physical AI as systems that must perceive, reason, and act in real-world settings, which means training requires synchronized camera feeds, motion traces, force data, and state trajectories. The scale now required is visible in NVIDIA's Open Physical AI Dataset, which includes 15 TB of data and more than 320,000 robotic trajectories for robotics and autonomous vehicle development. Scale AI and Universal Robots moved in the same direction in 2026 by launching the UR AI Trainer to capture high-fidelity industrial data directly from deployed hardware. This makes physical AI data one of the hardest product categories to replicate because collection quality depends on hardware access, workflow integration, and synchronized capture. That combination is giving specialized providers a stronger position in the artificial intelligence training dataset market as industrial and robotics use cases expand.
Restraints Impact Analysis*
| Restraint | (~) % Impact on CAGR Forecast | Geographic Relevance | Impact Timeline |
|---|---|---|---|
| Data Privacy, Sovereignty, And Compliance Burdens | -3.5% | Global, concentrated in Europe and APAC | Medium term (2-4 years) |
| High Cost Of Expert Annotation And Quality Assurance | -2.0% | Global | Short term (≤ 2 years) |
| Training-Data Contamination From AI-Generated Web Content | -1.5% | Global | Short term (≤ 2 years) |
| Fragmented Licensing Provenance And Chain-Of-Custody Requirements | -0.8% | North America and Europe | Medium term (2-4 years) |
| Source: Mordor Intelligence | |||
Data Privacy, Sovereignty, and Compliance Burdens
Privacy and compliance rules remain the most structural restraint on the AI training dataset market. The EU AI Act enters full enforcement on August 2, 2026, and requires high-risk AI systems to use datasets that are relevant, representative, and documented with strong traceability. Those obligations interact with GDPR data minimization rules, which can limit the amount of personal information that may be retained in training corpora. That tension increases project costs because providers need localized workflows, stronger documentation, and more legal review before data can move into production. It is especially difficult in healthcare, finance, and public-sector deployments, where representativeness and privacy must be demonstrated simultaneously. The AI training dataset market will continue to grow, but providers that cannot support provenance, localization, and auditability will face a narrower addressable customer base.[2]“AI Act | Shaping Europe's Digital Future,” European Commission, digital-strategy.ec.europa.eu
High Cost of Expert Annotation and Quality Assurance
The AI training dataset market is also constrained by the rising cost of expert annotation and review. As model development moves toward clinical, legal, coding, and reasoning tasks, buyers need data labeled by specialized professionals rather than broad labor pools. That makes supply harder to scale and keeps unit economics challenging for mid-sized developers that cannot fund large expert networks. AfterQuery's April 2026 fundraiser and its network of nearly 100,000 verified professionals demonstrated that investor attention is now centered on expert-curated reasoning datasets. Quality assurance adds another layer, as errors in preference data or domain labels can weaken post-training performance even when the annotation volume is high. Research from ETH Zurich also shows that more efficient active learning can reduce that burden, but those gains mainly favor teams with the tooling and process maturity to use it well.
*Our forecasts treat driver/restraint impacts as directional, not additive. The impact forecasts reflect baseline growth, mix effects, and variable interactions.
Segment Analysis
By Data Modality: Text Dominates While Video Scales Rapidly
Text data accounted for 46.53% of the AI training dataset in 2025, making it the largest modality. That lead reflected continued demand for pretraining corpora, instruction-tuning datasets, and evaluation material for large language models across both frontier and enterprise development programs. The structure of LLM training still favors text because pretraining, supervised fine-tuning, and alignment each require distinct text assets, and each step imposes higher quality thresholds than the one before. This has kept demand steady for licensed corpora, specialist instruction sets, multilingual material, and human preference data. NVIDIA's HelpSteer3-Preference release in 2025 illustrated that shift by providing more than 40,000 human-annotated preference pairs across STEM, coding, and multilingual tasks under a CC-BY-4.0 license. In practice, this means the AI training dataset market continues to rely on text as the foundation for model capabilities, even as other modalities gain ground.
Audio and speech data remain stable because voice interfaces, multilingual recognition, and low-resource language initiatives still require labeled speech and paralinguistic features. Multimodal data is gaining importance as developers increasingly combine text with image, audio, and structured context inside a single training flow. Video data is the fastest-growing modality, with a 33.94% CAGR through 2031, driven by clip-level alignment, dense captioning, and temporally ordered events for vision-language and physical AI systems. The supply challenge is more severe in video than in static-image work because action boundaries, scene changes, and synchronized instructions all require precise timing and review. MINT-1T demonstrated the scale of infrastructure needed to train competitive multimodal models, pushing open-source multimodal corpora to far larger token volumes than earlier datasets. As a result, the AI training dataset industry is moving toward a model in which text remains foundational, while video becomes the primary driver of higher-value annotation demand.



By Dataset Offering: Custom Creation Gains Ground Against Off-The-Shelf Incumbency
Off-the-shelf datasets accounted for 46.84% of the AI training dataset market in 2025, maintaining their leading position across offering types. Buyers favored this model when speed, cost control, and standard use cases mattered more than deep customization. Catalog-based procurement is still useful for early model development, testing, and generalized training tasks where common benchmarks and broad corpora are acceptable. That advantage is reinforced by the maturing marketplace layer, where structured metadata and standardized license terms reduce procurement friction. The launch of licensing structures for AI training content in 2025, including the Copyright Licensing Agency's Generative AI Training License, reflected the move toward more formalized exchange models. This helps the AI training dataset market maintain a large standardized supply channel even as enterprise requirements become more specific.
Custom dataset creation is the fastest-growing offering, with a 33.74% CAGR through 2031, because regulated and domain-heavy buyers need corpora that catalog products that are rarely provided by cataloging systems. Healthcare, BFSI, government, and other high-scrutiny users want bespoke datasets with documented provenance, compliance support, and bias review that can fit a defined workflow. Rights-cleared content is part of that shift, as shown by the New York Times licensing agreement with Amazon in May 2025 for AI training access to newsroom archives and affiliated properties. This creates a more split revenue structure inside the AI training dataset market, with high-volume standard products on one side and lower-volume, higher-margin custom work on the other. It also favors providers that can combine expert annotation, legal clearance, and audit-ready documentation within a single delivery model. The AI training dataset industry is therefore moving toward a more layered commercial structure rather than a single dominant procurement format.
By Deployment Model: On-Premises Incumbency and Cloud Acceleration
On-premises deployment accounted for 66.52% of the market in 2025, making it the largest deployment model in the AI training dataset market. This reflected the strong preference among healthcare systems, financial institutions, government agencies, and defense users to keep sensitive corpora under direct control. In these environments, physical custody, internal access controls, and auditable movement of files are often as important as the annotation outcome itself. Those requirements support established providers that can offer secure infrastructure, custom workflows, and long-term governance support. The model also creates a barrier for smaller vendors because secure pipelines, review environments, and quality systems require meaningful upfront investment. For that reason, the AI training dataset market has continued to see on-premises demand remain strong even as cloud workflows improve.
Cloud deployment is the fastest-growing model, with a 33.71% CAGR through 2031, because buyers need flexible capacity for bursty post-training and evaluation cycles. Preference data, agent interaction traces, and iterative review tasks often arrive in large batches, making elastic cloud delivery more attractive for teams under compressed deadlines. Hybrid deployment is also gaining traction because many multinational customers want sensitive production data to stay on-premises, while less sensitive preparation and large-scale processing run in cloud environments. That mix is a practical response to both privacy rules andthe need for model development to speed. It also means the AI training dataset market is not moving away from on-premises systems as much as it is building a more flexible split between secure residency and scalable execution. The AI training dataset market will likely continue to favor vendors that can support on-premises, cloud, and hybrid models without forcing customers into a single operating model.
By End-User Industry: IT Anchors Demand While Healthcare Leads Growth
IT and telecommunications retained 31.27% share in 2025, making the sector the largest end-user base in the AI training dataset market. Demand stayed high because telecom and IT buyers continue to fund network anomaly detection, customer support automation, cybersecurity training data, and model evaluation at scale. These users also tend to have more mature AI stacks, which lets them procure large dataset volumes and enforce tighter quality standards than many other industries. The sector, therefore, anchors recurring demand for text, multimodal, and post-training data across the AI training dataset market. Manufacturing and industrial demand is also becoming more visible as robotics and physical AI programs require force, motion, sensor, and video records that generic annotation services cannot easily supply. Government and defense remain important emerging buyers because benchmark creation, safety testing, and advanced model evaluation increasingly require controlled curation processes tied to security and policy objectives.
Healthcare is the fastest-growing end-user segment, with a 34.74% CAGR through 2031, giving it the most aggressive expansion profile in the AI training dataset market. Growth is being driven by demand for annotated medical imaging, de-identified electronic health records, and clinical reasoning corpora that can support diagnostic, workflow, and decision-support systems. The supply side is constrained by HIPAA Safe Harbor requirements, review standards, and the need for physician or specialist validation, which keeps pricing and margins firmer than in general-purpose data work. BFSI and retail and e-commerce also remain material demand pools because they need privacy-preserving fraud datasets, product recognition inputs, and recommendation training data. This mix gives the AI training dataset market a broad customer base, but the strongest revenue growth is shifting toward sectors where domain expertise and compliance are part of the product itself. That is why healthcare is likely to increase its importance faster than most other end-user categories during the forecast period.
Geography Analysis
North America accounted for 34.11% of the AI training dataset market share in 2025, driven by frontier AI labs, hyperscaler infrastructure, and enterprise buyers prioritizing expert-annotated, rights-cleared data. The U.S. leads demand with high-spend users in healthcare, financial services, and defense, deploying advanced models. Scale AI's 2025-2026 office expansion highlighted providers growing near major enterprise AI hubs.[3]“Expanding Our Presence with New Offices Around the World,” Scale AI, scale.com Canada supports demand with autonomous vehicle development and bilingual NLP work, while Mexico offers cost-efficient labor for U.S.-linked annotation programs.
Asia-Pacific is projected to grow at a 34.14% CAGR, the fastest in the market, through 2031. Government-backed AI programs in China, India, and South Korea drive demand across manufacturing, healthcare, smart cities, and autonomous systems. India combines a large annotation labor pool with growing expert-level workflows in medical, legal, and reasoning data. China boosts demand through public and private AI investments, while Japan and South Korea focus on automotive, semiconductor, and precision manufacturing AI programs requiring sensors and multimodal data.
Europe's AI training dataset market is shaped by compliance-driven procurement rather than annotation volume. The EU AI Act's Article 10 pushes developers toward documented, auditable, and bias-examined datasets for high-risk applications, favoring specialist European providers. AI Verse's EUR 5 million (USD 5.3 million) January 2026 funding reflects interest in synthetic computer vision data amid compliance needs. South America, led by Brazil, sees emerging demand for fintech and agritech that requires local text and geospatial data. The Middle East and Africa are at early stages, with Qatar, Saudi Arabia, and the UAE advancing domestic data procurement and the development of unstructured data.

Competitive Landscape
The AI training dataset market is fragmented, with pure-play data providers, hyperscaler-adjacent platforms, and expert-network companies competing for share. Buyers now prioritize neutrality, provenance controls, expert access, compliance support, and scalable post-training data delivery over labeling capacity. Meta's June 2025 USD 14 billion investment in Scale AI highlighted vertical integration in the data supply chain but raised concerns among enterprise customers about supplier neutrality. This has increased demand for provider diversification and scrutiny of ownership structures.
Competition is shifting from labor-heavy annotation to AI-driven data curation and quality control. Providers are adopting automated pre-labeling, workflow orchestration, and review systems to reduce timelines while maintaining quality. Labelbox's February 2026 acquisition of Upcraft automated expert recruitment, while Handshake's January 2026 acquisition of Cleanlab added label-auditing technology to flag errors without a second reviewer. Quality verification has become a key differentiator, especially in expert-reviewed and high-risk use cases.
Opportunities are strongest in physical AI data infrastructure, sovereign AI data environments, and expert-led post-training datasets. Encord's USD 60 million Series C in February 2026 demonstrated confidence in multimodal data management for robotics and autonomous systems. NVIDIA's March 2025 acquisition of Gretel Labs and release of its Open Physical AI Dataset signaled growing hardware vendor activity in the market.[4]Katie Washabaugh, “NVIDIA Unveils Open Physical AI Dataset to Advance Robotics and Autonomous Vehicle Development,” NVIDIA Blog, blogs.nvidia.com Companies combining secure infrastructure, expert supervision, and scalable workflows are poised to lead. The market remains competitive, with workflow depth and data defensibility defining the strongest suppliers over raw annotation capacity.
AI Training Dataset Industry Leaders
Scale AI, Inc.
Appen Limited
Innodata Inc.
Samasource Impact Sourcing, Inc.
iMerit Technology Services Private Limited
- *Disclaimer: Major Players sorted in no particular order

Recent Industry Developments
- April 2026: AfterQuery Inc. raised USD 30 million in a Series A round led by Altos Ventures at a USD 300 million valuation. The company, which utilizes nearly 100,000 verified professionals to build expert reasoning datasets across finance, healthcare, law, and software engineering, reported an annual recurring revenue run rate exceeding USD 100 million just 14 months post-founding, signaling that structured, expert-curated AI training data commands substantial enterprise value.
- March 2026: Universal Robots and Scale AI launched the UR AI Trainer at GTC 2026, an imitation learning system that captures high-fidelity, synchronized, multimodal industrial data using Direct Torque Control and force feedback. With over 100,000 global deployments as the foundation for data collection, the partnership plans to release a large-scale industrial robotics dataset later in 2026.
- February 2026: Scale AI launched RL Environments, a suite of simulated environments for training and evaluating AI agents for tool, computer, and coding workflows. Nearly 50% of Scale AI's new data training projects now involve RL environments, marking a rapid industry pivot from static labeled datasets toward agent-trajectory and evaluation data.
- February 2026: Labelbox acquired Upcraft, an AI-powered agentic automation startup, to integrate agent technology into its Alignerr network of over 1 million domain experts. The acquisition targets automating expert recruitment and engagement workflows to accelerate the delivery of high-quality training data to over 80% of leading U.S. AI labs.


Global AI Training Dataset Market Report Scope
The AI Training Dataset Market refers to the global industry focused on the creation, collection, curation, licensing, and distribution of datasets used to train, validate, and fine-tune artificial intelligence (AI) and machine learning (ML) models. These datasets are essential for enabling AI systems to learn patterns, improve accuracy, and perform tasks such as natural language understanding, computer vision, speech recognition, and multimodal reasoning across various applications.
The AI Training Dataset Market Report is Segmented by Data Modality (Text, Image and Video, Audio and Speech, and Multimodal and Sensor-Rich Data), Dataset Offering (Off-the-Shelf Datasets, Custom Dataset Creation, and Dataset Marketplaces and Licensed Exchanges), Deployment (On-premises, Cloud, and Hybrid), End-User Industry (IT and Telecom, Automotive and Modality, Healthcare and Life Sciences, BFSI, Retail and E-commerce, Government and Defense, Media and Entertainment, and Manufacturing and Industrial), and Geography (North America, South America, Europe, Asia-Pacific, and Middle East and Africa). The Market Forecasts are Provided in Terms of Value (USD).
| Text |
| Image and Video |
| Audio and Speech |
| Multimodal and Sensor-Rich Data |
| Off-the-Shelf Datasets |
| Custom Dataset Creation |
| Dataset Marketplaces and Licensed Exchanges |
| On-premises |
| Cloud |
| Hybrid |
| IT and Telecom |
| Automotive and Mobility |
| Healthcare and Life Sciences |
| BFSI |
| Retail and E-commerce |
| Government and Defense |
| Media and Entertainment |
| Manufacturing and Industrial |
| North America | United States | |
| Canada | ||
| Mexico | ||
| South America | Brazil | |
| Argentina | ||
| Rest of South America | ||
| Europe | United Kingdom | |
| Germany | ||
| France | ||
| Italy | ||
| Spain | ||
| Rest of Europe | ||
| Asia-Pacific | China | |
| Japan | ||
| India | ||
| South Korea | ||
| Rest of Asia-Pacific | ||
| Middle East and Africa | Middle East | United Arab Emirates |
| Saudi Arabia | ||
| Rest of Middle East | ||
| Africa | South Africa | |
| Egypt | ||
| Rest of Africa | ||
| By Data Modality | Text | ||
| Image and Video | |||
| Audio and Speech | |||
| Multimodal and Sensor-Rich Data | |||
| By Dataset Offering | Off-the-Shelf Datasets | ||
| Custom Dataset Creation | |||
| Dataset Marketplaces and Licensed Exchanges | |||
| By Deployment Model | On-premises | ||
| Cloud | |||
| Hybrid | |||
| By End-User Industry | IT and Telecom | ||
| Automotive and Mobility | |||
| Healthcare and Life Sciences | |||
| BFSI | |||
| Retail and E-commerce | |||
| Government and Defense | |||
| Media and Entertainment | |||
| Manufacturing and Industrial | |||
| By Geography | North America | United States | |
| Canada | |||
| Mexico | |||
| South America | Brazil | ||
| Argentina | |||
| Rest of South America | |||
| Europe | United Kingdom | ||
| Germany | |||
| France | |||
| Italy | |||
| Spain | |||
| Rest of Europe | |||
| Asia-Pacific | China | ||
| Japan | |||
| India | |||
| South Korea | |||
| Rest of Asia-Pacific | |||
| Middle East and Africa | Middle East | United Arab Emirates | |
| Saudi Arabia | |||
| Rest of Middle East | |||
| Africa | South Africa | ||
| Egypt | |||
| Rest of Africa | |||


Key Questions Answered in the Report
What is the size outlook for the AI training dataset sector through 2031?
The AI training dataset market was valued at USD 8.74 billion in 2025, stands at USD 11.91 billion in 2026, and is forecast to reach USD 49.82 billion by 2031 at a 33.14% CAGR.
Which data modality leads current demand for AI training datasets?
Text data led with a 46.53% share in 2025 because pretraining, instruction tuning, and alignment workflows still depend heavily on high-quality text corpora.
Which dataset type is growing fastest for enterprise AI development?
Custom dataset creation is the fastest-growing offering, with a 33.74% CAGR through 2031, as regulated buyers need domain-specific, traceable, and compliant corpora.
Why is healthcare becoming such an important buyer of training data?
Healthcare is projected to grow at a 34.74% CAGR because AI tools need annotated medical imaging, de-identified records, and clinical reasoning datasets that can support high-stakes use cases.
Why does North America currently lead while Asia-Pacific grows faster?
North America held 34.11% share in 2025 due to frontier labs and hyperscaler infrastructure, while Asia-Pacific is expected to grow at a 34.14% CAGR because of government-backed AI programs and strong annotation capacity.
What is changing competition among dataset providers most rapidly?
Competition is shifting toward multimodal quality systems, expert-led post-training data, secure deployment, and data provenance, with acquisitions and funding increasingly focused on automation and quality control.
Page last updated on:






