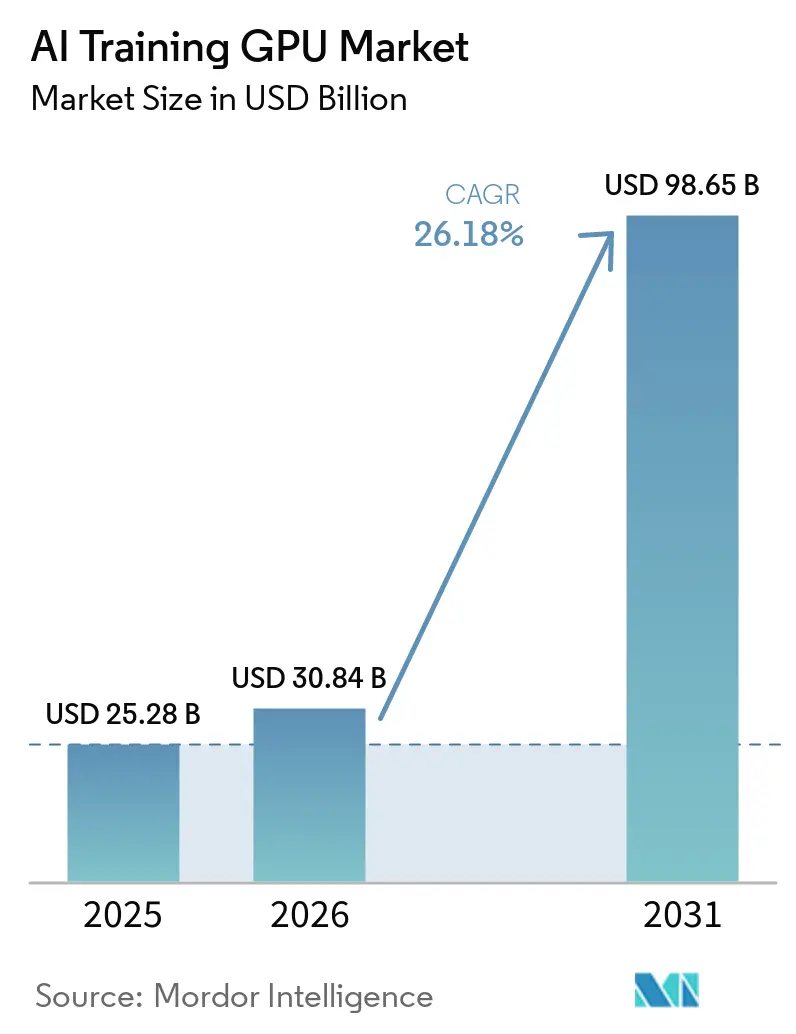
AI Training GPU Market Size and Share
Market Overview
| Study Period | 2020 - 2031 |
|---|---|
| Market Size (2026) | USD 30.84 Billion |
| Market Size (2031) | USD 98.65 Billion |
| Growth Rate (2026 - 2031) | 26.18% CAGR |
| Fastest Growing Market | Asia-Pacific |
| Largest Market | Asia-Pacific |
| Market Concentration | High |
Major Players *Disclaimer: Major Players sorted in no particular order Image © Mordor Intelligence. Reuse requires attribution under CC BY 4.0. | |
AI Training GPU Market Analysis by Mordor Intelligence
The AI Training GPU Market size is expected to grow from USD 25.28 billion in 2025 to USD 30.84 billion in 2026 and is forecast to reach USD 98.65 billion by 2031 at a 26.18% CAGR over 2026-2031. Record-setting capital‐expenditure plans by hyperscale cloud operators, government-backed sovereign AI programs, and the shift to high-bandwidth HBM3e memory are combining to lift unit demand and average selling prices. Hyperscalers accounted for more than two-thirds of 2025 revenue as training clusters scaled to tens of thousands of GPUs, while enterprises began bringing generative-AI workloads in-house to control intellectual-property risks and recurring API fees. Memory vendors captured outsized value because HBM3e modules added 40-50% to bill-of-materials costs, and packaging constraints extended lead times for new capacity. Government procurement, especially across Asia-Pacific, added a steady layer of baseline demand that partially offset the drag from export controls in China and parts of the Middle East.
Key Report Takeaways
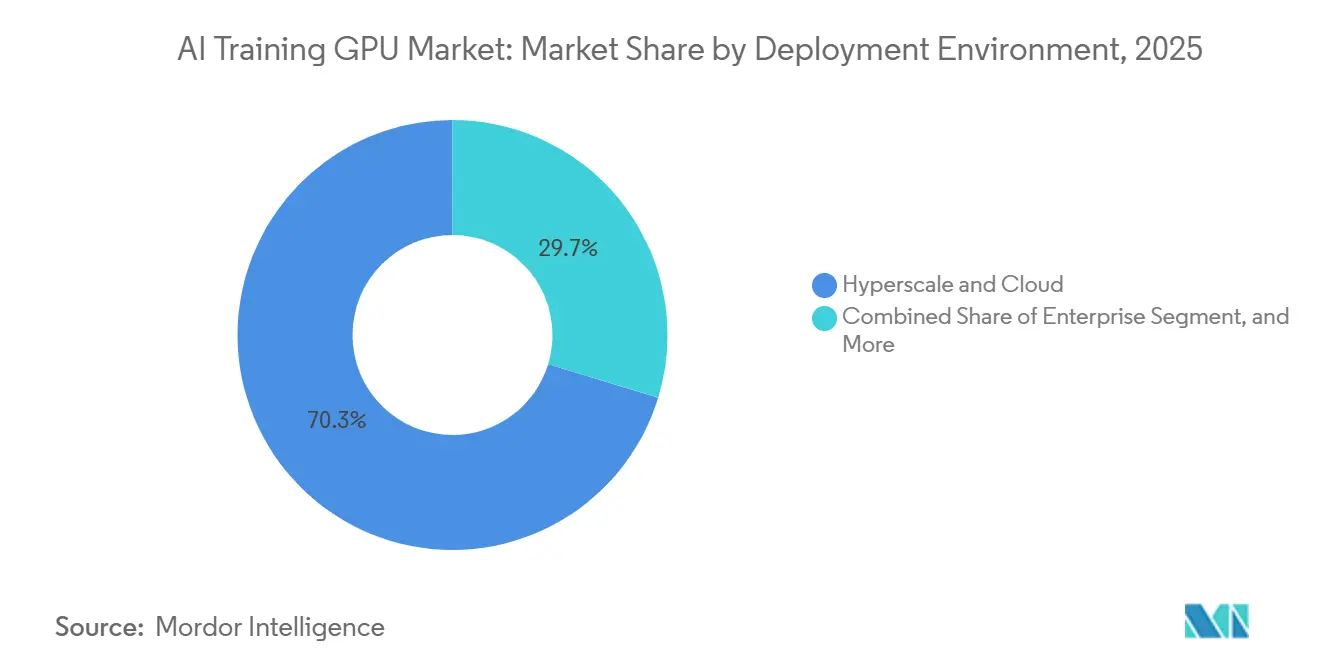
- By deployment environment, hyperscale and cloud installations led with 70.27% revenue share in 2025, while enterprise installations are projected to register the quickest expansion at a 26.71% CAGR through 2031.
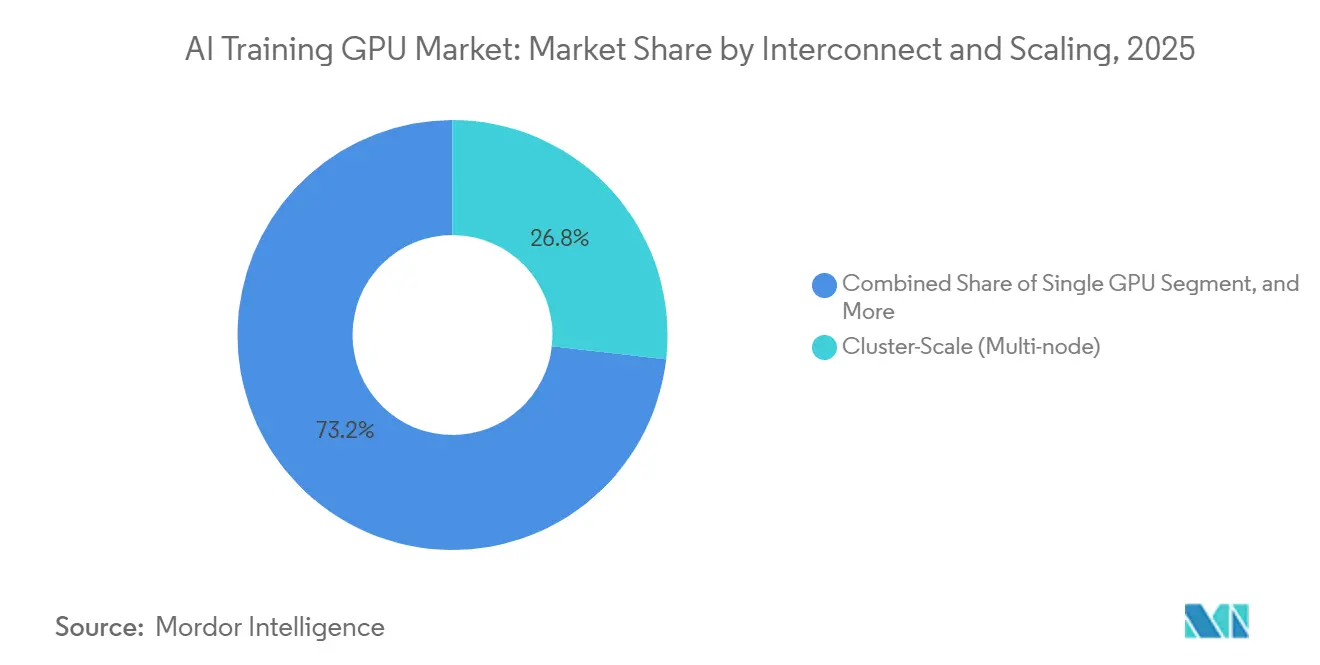
- By interconnect and scaling, cluster scale architectures held the top position with 56.33% of the AI Training GPU market share in 2025, and the same segment is also set to post the fastest growth at a 26.92% CAGR over the forecast period.
- By memory type, HBM-based GPUs dominated with 53.47% revenue share in 2025; within this category, HBM3e configurations are expected to grow the fastest with a CAGR of 26.98% as supply ramps and adoption broaden between 2026 and 2031.
- By end-use training workload, foundation-model and large-language-model training accounted for the largest slice at 49.72% of 2025 revenue and is likewise the fastest-expanding workload segment, with a projected 26.64% CAGR.
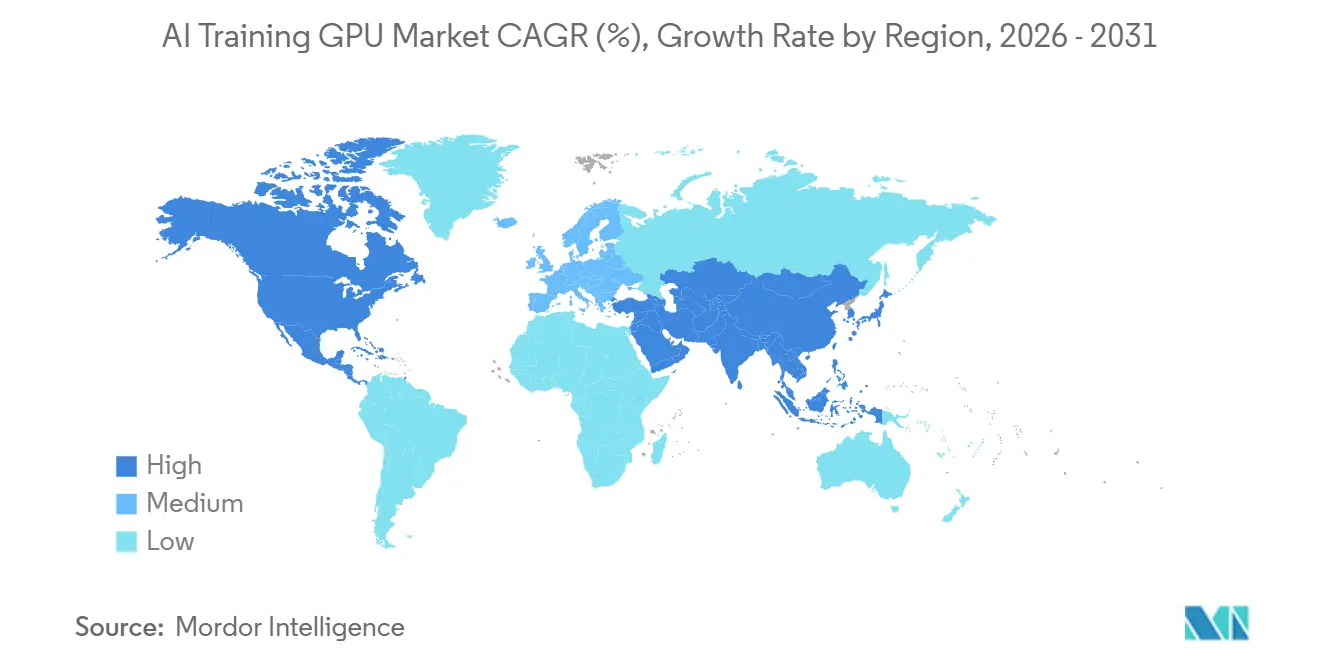
- By geography, Asia-Pacific generated the most revenue at 67.43% in 2025 and is forecast to remain the fastest growing region with a 26.59% CAGR through 2031.
Note: Market size and forecast figures in this report are generated using Mordor Intelligence’s proprietary estimation framework, updated with the latest available data and insights as of January 2026.
Global AI Training GPU Market Trends and Insights
Drivers Impact Analysis*
| Driver | (~) % Impact on CAGR Forecast | Geographic Relevance | Impact Timeline |
|---|---|---|---|
| Widespread Adoption of Generative AI in Enterprise Workloads | +7.2% | Global, concentration in North America and Europe | Medium term (2-4 years) |
| Rapid Scaling of Hyperscale AI Training Infrastructure Investments | +6.8% | Global, led by North America and Asia-Pacific | Short term (≤ 2 years) |
| Transition to Advanced HBM3 and HBM3e Memory Stacks Boosting GPU ASPs | +4.5% | Global | Short term (≤ 2 years) |
| Proliferation of Sovereign AI Initiatives Driving Government Procurement | +3.4% | Asia-Pacific core, spillover to Europe and Middle East | Long term (≥ 4 years) |
| Vendor-Neutral Open Interconnect Standards like NVLink-CXL Convergence | +2.1% | Global, early adoption in North America | Medium term (2-4 years) |
| Emergence of Liquid Cooling as a Standard for High-TDP Training GPUs | +1.8% | Global, leadership in hyperscale facilities | Medium term (2-4 years) |
| Source: Mordor Intelligence | |||
Widespread Adoption Of Generative AI In Enterprise Workloads
Enterprises moved training clusters on-premises in 2025 and 2026 to protect proprietary data, cut API-based inference charges, and fine-tune models on sector-specific corpora. Dell Technologies reported that more than 4,000 AI Factory customers have purchased 8-GPU to 32-GPU systems across healthcare, finance, and legal use cases. Professional-services firms installed NVIDIA GB300 NVL72 racks for internal projects, pushing enterprise demand from a negligible base in 2023 to high-single-digit market contribution by 2025. Three-year total cost of ownership per rack runs USD 2-5 million, yet organizations rationalize the spend against potential annual per-token fees that exceed USD 0.5 million under third-party billing models. The economics encourage hybrid architectures that keep sensitive workloads behind the firewall while bursting less-critical jobs to the cloud. GPU vendors that provide flexible licensing and multi-tenancy support are therefore winning incremental share.
Rapid Scaling Of Hyperscale AI Training Infrastructure Investments
Microsoft, Google, Amazon, Meta, and Oracle collectively signaled roughly USD 700 billion of capital outlays for AI infrastructure through 2027, with 40-50% earmarked for training clusters. Oracle and OpenAI’s Project Jupiter in Texas alone carries a USD 165 billion budget and plans to install more than 1 million GPUs before 2030. Capacity reservations now span multiple years, so utilization targets have risen into the 70-80% range, well above 2023 levels. Independent providers such as Applied Digital and IREN secured multi-billion-dollar lease commitments to furnish GPU-as-a-service capacity, confirming sustained hyperscale demand. The pivot to pre-purchased capacity compresses idle-time buffers and increases baseline consumption, driving consistent pull-through for GPU shipments across 2026-2028.
Transition To Advanced HBM3 And HBM3e Memory Stacks Boosting GPU ASPs
HBM comprises up to half of a training GPU’s bill of materials, and the move from HBM2e to HBM3e lifted per-unit ASPs by USD 8,000-12,000 between 2024 and early 2026. SK hynix started mass production of 12-high HBM3e packages in late 2025, and Samsung followed with 16-high stacks aimed at 2027 volume. Micron’s HBM3E Gen2, sampling in 2026, provides 1.5 TB/s bandwidth per stack, enabling GPUs to exceed 2 PFLOPS of sustained throughput. Tight supply and 12-18-month lead times keep pricing firm, and hyperscalers with multi-year contracts have already reserved the bulk of 2026 output, pushing smaller buyers onto a spot market that trades 30% above contract levels. Elevated memory prices, therefore, underpin revenue expansion even if logic-die costs moderate on mature process nodes.
Proliferation Of Sovereign AI Initiatives Driving Government Procurement
Governments allocated USD 15-20 billion to domestic AI compute during 2025-2026, seeking data sovereignty and national-security autonomy. India’s Rs 10,300 crore (USD 1.23 billion) IndiaAI Mission aims to deploy 10,000 GPUs to public institutions, while Japan has set aside JPY 2 trillion (USD 13.2 billion) to establish training hubs in Tokyo and Osaka. Canada committed CAD 890 million (USD 650 million) for sovereign clusters that guarantee local data residency.[1]Press Information Bureau, Government of India, “Press Information Bureau Homepage,” pib.gov.in Procurement rules emphasize domestic assembly and tech-transfer clauses, favoring regional silicon champions such as Huawei’s Ascend in China and Preferred Networks in Japan. Although these mandates add 3-5% annual demand, they fragment the supplier landscape and introduce specification divergence that global vendors must navigate.
Restraints Impact Analysis*
| Restraint | (~) % Impact on CAGR Forecast | Geographic Relevance | Impact Timeline |
|---|---|---|---|
| Persistent Supply-Chain Constraints in Advanced Packaging Capacity | -3.8% | Global, acute in Asia-Pacific | Short term (≤ 2 years) |
| Rising Total Cost of Ownership for Cluster-Scale GPU Deployments | -2.9% | Global, higher sensitivity in Europe | Medium term (2-4 years) |
| Geopolitical Export Controls on High-End GPUs to China and Middle East | -2.4% | China and Middle East, spillover to Southeast Asia | Long term (≥ 4 years) |
| Increasing Competition from Custom AI Accelerators and ASICs | -2.2% | North America and Europe | Medium term (2-4 years) |
| Source: Mordor Intelligence | |||
Persistent Supply-Chain Constraints In Advanced Packaging Capacity
TSMC’s CoWoS lines operated at full utilization in 2025 because GPU, HPC, and networking demand collectively exceeded capacity by roughly one-third. Lead times stretched to 12-18 months, forcing vendors to prioritize deliveries to hyperscalers with multiyear commitments and leaving enterprises with delays of up to nine months. Plans to boost CoWoS output by 50% during 2026 and to double it by 2028 are underway, but each new line costs USD 1-1.5 billion and requires lengthy equipment qualification.[2]TSMC, “CoWoS Capacity Expansion Plans,” investor.tsmc.com Competing approaches such as Samsung’s I-Cube and Intel’s Foveros have yet to reach third-party high-volume manufacturing, so tightness is unlikely to ease meaningfully before 2027. The bottleneck caps annual shipment growth at mid-30% even though potential demand supports 50-60%, granting hyperscalers with locked-in allocations a structural advantage.
Rising Total Cost Of Ownership For Cluster-Scale GPU Deployments
Electricity and cooling represent more than half of a training cluster’s three-year total cost, with regional power prices ranging from USD 0.10 to 0.30 per kWh. A 1,000-GPU installation running at 1.5 MW incurs USD 1.3-3.9 million in annual power fees before factoring in cooling retrofits. Direct-to-chip liquid systems now cost USD 0.5-1 million per MW of capacity. Networking further elevates outlays, a 10,000-GPU fabric built on 400 Gb/s InfiniBand needs more than 80,000 transceivers worth USD 40-60 million. These economics favor operators with cheap renewable or nuclear energy contracts and enough scale to amortize infrastructure, while mid-tier enterprises increasingly shift to GPU-as-a-service agreements that trade customization for lower up-front capital needs.
*Our forecasts treat driver/restraint impacts as directional, not additive. The impact forecasts reflect baseline growth, mix effects, and variable interactions.
Segment Analysis
By Deployment Environment: Hyperscale Dominance and Rising Enterprise Demand
Hyperscale and cloud installations accounted for 70.27% of 2025 revenue in the AI Training GPU market, reflecting routine deployments of clusters with more than 10,000 GPUs. Enterprises, however, are catching up, advancing at a 26.71% CAGR through 2031 as internal fine-tuning workloads grow. The AI Training GPU market size for enterprise buyers is forecast to expand steadily as more organizations weigh intellectual property control against cloud costs. Government and research institutions, supported by sovereign mandates, are layering incremental demand that diversifies the customer base.
Procurement patterns differ sharply. Hyperscalers lock in multi-year GPU and HBM supply, thereby capturing favorable pricing and guaranteed allocation during shortages. Enterprises often purchase spot inventory, which comes with 30% surcharges and longer lead times. Government tenders increasingly stipulate local assembly, steering contracts toward regional champions and limiting the addressable opportunity for export-constrained vendors. This bifurcation creates parallel supply chains that global suppliers must manage to sustain revenue growth without breaching licensing regimes.



By Memory Type: HBM3e Sustains Premium Valuation
HBM-equipped accelerators accounted for 53.47% of the 2025 value, significantly reducing the market share of GDDR products, which are now primarily used for legacy vision and recommendation models. The introduction of HBM3e into mass production led to a sharp increase in average selling prices, further solidifying the dominance of HBM-based cards in the AI Training GPU market with a CAGR of 26.98% over the forecast period. This segment is projected to maintain its leadership in the value mix through 2031. The HBM supply chain is controlled by three key suppliers, SK hynix, Samsung, and Micron, creating an oligopolistic market structure that ensures stable margins for these players.
While GDDR GPUs continue to serve smaller-parameter workloads, software development teams are increasingly preferring a unified HBM stack. This shift is driven by the need to avoid the complexities and inefficiencies associated with dual optimization flows. The anticipated sampling of HBM4 in late 2027 is expected to push per-package bandwidth to approximately 2 TB/s, reinforcing the trend of premium pricing in the market. Vendors that fail to secure sufficient HBM allocations risk losing market share, especially as transformer model sizes exceed 100 billion parameters. In such scenarios, memory bandwidth becomes the critical factor influencing training times, overtaking compute density in importance.
By Interconnect and Scaling: Cluster-Scale Architectures Lead Growth
Cluster-scale multi-node systems captured 56.33% of the market in 2025 and are projected to grow at an impressive 26.92% annually through 2031, making it the fastest-growing segment among scaling tiers. Single-GPU setups are losing relevance for training, as they are increasingly unable to meet the demands of modern AI workloads. Meanwhile, 8-GPU servers continue to serve as the standard enterprise building block, offering a balance of performance and scalability. Open-interconnect initiatives, such as UALink and the CXL 3.1 specification, are playing a pivotal role in commoditizing bandwidth and enabling heterogeneous accelerator pooling, which is critical for addressing the growing complexity of AI models.[3]CXL Consortium, “CXL 3.1 Specification Ratified,” computeexpresslink.org
The AI Training GPU market share for proprietary fabrics is expected to face pressure as hyperscalers increasingly adopt vendor-neutral switches. These switches not only reduce costs but also help prevent vendor lock-in, providing greater flexibility to enterprises. NVLink 5.0 remains the dominant interconnect within servers, delivering a high bandwidth of 1.8 TB/s per link. However, inter-node connectivity is gradually transitioning toward open standards that aim to achieve bandwidths of up to 1 TB/s. This shift toward open standards is anticipated to impact overall GPU solution gross margins slightly, with a potential reduction in profitability projected by 2028.
By End-Use Training Workload: Foundation Models Anchor Spending
Foundation and large-language models generated 49.72% of 2025 revenue and are on track to grow 26.64% annually through 2031 as conversational AI, code generation, and multimodal applications proliferate. Computer vision grows more slowly yet remains vital for autonomous systems and medical imaging, while speech and translation workloads hold a niche but stable slice. Recommendation systems, once hosted predominantly on GDDR GPUs, now increasingly migrate to HBM platforms as embedding tables balloon into trillion-parameter territory.
Specialized accelerators such as Google’s TPU v6e and Amazon’s Trainium family are increasingly adopted for specific internal workloads, particularly when their tailored designs offer performance or cost advantages. However, GPUs continue to maintain a competitive edge for rapid research iteration, largely due to their well-established, mature software ecosystems and highly adaptable architectures. This combination ensures that GPUs remain a critical component in the AI training landscape, securing a significant baseline demand even as custom silicon solutions gradually chip away at the discrete GPU market share within hyperscale accounts.
Geography Analysis
Asia-Pacific contributed 67.43% of global 2025 revenue and is forecast to sustain a 26.59% CAGR through 2031. China accelerated domestic adoption of accelerators after U.S. export controls, with Huawei's Ascend 910B and Biren BR104 capturing roughly one-quarter of internal demand. Japan’s JPY 2 trillion (USD 13.2 billion) program and India’s USD 1.23 billion mission underpin growth, while South Korea leverages memory-supply muscle to negotiate competitive bundle pricing. Singapore and Malaysia are emerging as regional data center hubs thanks to supportive policy frameworks, tax incentives, and access to subsea cables.
North America remains the epicenter of hyperscale outlays. Oracle and OpenAI’s USD 165 billion Project Jupiter in Texas and Microsoft’s expansion of Azure AI regions keep capital intensity high. Lower-cost hydroelectric, nuclear, and gas power enables favorable total-cost economics compared with Europe, where electricity can cost 3 times the U.S. average. Canada’s CAD 890 million (USD 650 million) sovereign compute project is building regional capacity, while Mexico is attracting nearshore investments for Spanish-language model training workloads.
Europe trails in absolute value yet is closing the gap through the EuroHPC Joint Undertaking’s EUR 7 billion (USD 7.5 billion) exascale initiative.[4]EuroHPC Joint Undertaking, “Funding for European Exascale Supercomputers,” eurohpc-ju.europa.eu Germany and France are adding 10,000-plus GPU clusters at national labs, and the United Kingdom’s GBP 500 million (USD 630 million) AI Research Resource ensures domestic access to training compute. Regulatory overhead from the EU AI Act may consolidate demand among larger institutions that can absorb compliance costs. Overall, geographic spending remains concentrated but increasingly balanced by sovereign-funded projects that diversify procurement.

Competitive Landscape
The top vendor held approximately 80% market share in 2025, highlighting the highly concentrated nature of the AI Training GPU market. However, hyperscalers are increasingly making inroads with proprietary chips. For instance, Google’s TPU v6e, Amazon’s Trainium2, and Microsoft’s Maia 100 collectively handled an estimated 15-20% of internal training workloads during 2025. Google exclusively trained Gemini 2.0 on TPUs, showcasing its ability to achieve performance parity with GPUs for specific architectures. Meanwhile, Amazon’s Trainium3, which is scheduled for a mid-2027 release, has already secured Meta as a key adopter, signaling growing interest in alternative solutions.
AMD’s MI350X began volume shipments in December 2025, targeting enterprise accounts that are actively seeking vendor diversification. Similarly, Intel’s Gaudi3 achieved PyTorch and TensorFlow certification in early 2026, addressing a critical gap in software compatibility and positioning itself as a viable competitor. Startups like Cerebras and SambaNova are focusing on niche segments, such as wafer-scale training and data-flow accelerators, respectively. However, despite their innovative approaches, widespread ecosystem adoption for these startups remains limited, as they face challenges in competing with established players.
Efforts to develop open interconnect standards, such as those led by the Ultra Accelerator Link consortium, along with industry shifts toward chiplet architectures, pose potential risks to incumbent players. These developments could erode gross margins by reducing the competitive advantage of tightly integrated fabrics. Patents filed during 2025-2026 emphasize advancements in disaggregated compute and memory tiles, creating opportunities for fabless companies to leverage outsourced packaging technologies. Despite these emerging trends, the incumbent’s leadership remains firmly anchored, supported by the widespread adoption of CUDA, a robust developer ecosystem, and well-established toolchains that continue to provide a significant competitive edge.
AI Training GPU Industry Leaders
NVIDIA Corporation
Advanced Micro Devices Inc.
Intel Corporation
Google LLC
Huawei Technologies Co., Ltd.
- *Disclaimer: Major Players sorted in no particular order

Recent Industry Developments
- April 2026: NVIDIA unveiled the Rubin architecture with HBM4 support and 3 PFLOPS of training throughput, with sampling planned for late 2026.
- March 2026: Oracle and OpenAI expanded Project Jupiter in Texas, raising capacity plans to more than 1 million GPUs by 2030.
- February 2026: SK hynix started mass shipments of 16-high HBM3e stacks offering 48 GB per package to hyperscale customers.
- January 2026: Amazon Web Services announced Trainium3, offering 6× the performance of Trainium2, aiming for a regionwide launch by mid-2027.


Global AI Training GPU Market Report Scope
The AI Training GPU Market refers to the global market for graphics processing units (GPUs) specifically designed and deployed for training artificial intelligence (AI) models. These GPUs are optimized for large-scale parallel computation, high memory bandwidth, and advanced interconnect capabilities, enabling efficient training of complex models such as large language models (LLMs), computer vision systems, and other deep learning architectures.
The AI Training GPU Market Report is Segmented by Deployment Environment (Hyperscale/Cloud, Enterprise, and Government and Research), Memory Type (HBM2e, HBM3, HBM3e, HBM4, and GDDR-based), Interconnect and Scaling (Single GPU, Multi-GPU Intra-node, and Cluster-Scale Multi-node), End-Use Training Workload (Foundation Models/LLM, Computer Vision, Speech/NLP, and Recommendation Systems), and Geography (North America, Europe, Asia-Pacific, South America, and Middle East, Africa). The Market Forecasts are Provided in Terms of Value (USD).
| Hyperscale / Cloud |
| Enterprise |
| Government and Research |
| HBM | HBM2e |
| HBM3 | |
| HBM3e | |
| HBM4 | |
| GDDR-based | Low-End Training / Legacy |
| Single GPU |
| Multi-GPU (Intra-node) |
| Cluster-Scale (Multi-node) |
| Foundation Models / LLM Training |
| Computer Vision Training |
| Speech / NLP Models |
| Recommendation Systems / Graph Models |
| North America | United States |
| Canada | |
| Mexico | |
| Europe | Germany |
| United Kingdom | |
| France | |
| Italy | |
| Rest of Europe | |
| Asia-Pacific | China |
| Japan | |
| South Korea | |
| India | |
| Southeast Asia | |
| Rest of Asia-Pacific | |
| South America | |
| Middle East | |
| Africa |
| By Deployment Environment | Hyperscale / Cloud | |
| Enterprise | ||
| Government and Research | ||
| By Memory Type | HBM | HBM2e |
| HBM3 | ||
| HBM3e | ||
| HBM4 | ||
| GDDR-based | Low-End Training / Legacy | |
| By Interconnect and Scaling | Single GPU | |
| Multi-GPU (Intra-node) | ||
| Cluster-Scale (Multi-node) | ||
| By End-Use Training Workload | Foundation Models / LLM Training | |
| Computer Vision Training | ||
| Speech / NLP Models | ||
| Recommendation Systems / Graph Models | ||
| By Geography | North America | United States |
| Canada | ||
| Mexico | ||
| Europe | Germany | |
| United Kingdom | ||
| France | ||
| Italy | ||
| Rest of Europe | ||
| Asia-Pacific | China | |
| Japan | ||
| South Korea | ||
| India | ||
| Southeast Asia | ||
| Rest of Asia-Pacific | ||
| South America | ||
| Middle East | ||
| Africa | ||


Key Questions Answered in the Report
What is the current and projected size of the AI Training GPU Market?
The AI Training GPU market size stands at USD 30.84 billion in 2026 and is projected to reach USD 98.65 billion by 2031, registering a 26.18% CAGR.
Which segment is expanding the fastest within AI training GPU deployments?
Cluster-scale multi-node systems are advancing at a 26.92% CAGR through 2031 as foundation-model training increasingly spans tens of thousands of GPUs.
Why are HBM-based GPUs absorbing most market value?
HBM3e memory delivers terabyte-scale bandwidth essential for transformer models, and its limited supply plus premium pricing drove HBM GPUs to 53.47% of 2025 market value.
How are sovereign AI mandates affecting procurement patterns?
Government programs in India, Japan, and Canada mandate domestic capacity and tech transfer, creating incremental demand while favoring regional silicon suppliers over export-constrained foreign vendors.
What challenges limit small and midsize enterprises from building on-premises training clusters?
High total cost of ownership, including power at USD 0.10-0.30 per kWh and expensive liquid-cooling retrofits, pushes many mid-tier firms toward GPU-as-a-service models despite customization trade-offs.
Which emerging technology could alter future GPU interconnect economics?
Vendor-neutral standards such as UALink and CXL 3.1 aim to commoditize GPU-to-GPU bandwidth, potentially trimming gross margins for proprietary interconnect suppliers by the end of the decade.
Page last updated on:






