AI Inference GPU Market Size and Share
Market Overview
| Study Period | 2020 - 2031 |
|---|---|
| Market Size (2026) | USD 14.87 Billion |
| Market Size (2031) | USD 57.29 Billion |
| Growth Rate (2026 - 2031) | 30.97% CAGR |
| Fastest Growing Market | Asia-Pacific |
| Largest Market | Asia-Pacific |
| Market Concentration | Medium |
Major Players *Disclaimer: Major Players sorted in no particular order Image © Mordor Intelligence. Reuse requires attribution under CC BY 4.0. | |
AI Inference GPU Market Analysis by Mordor Intelligence
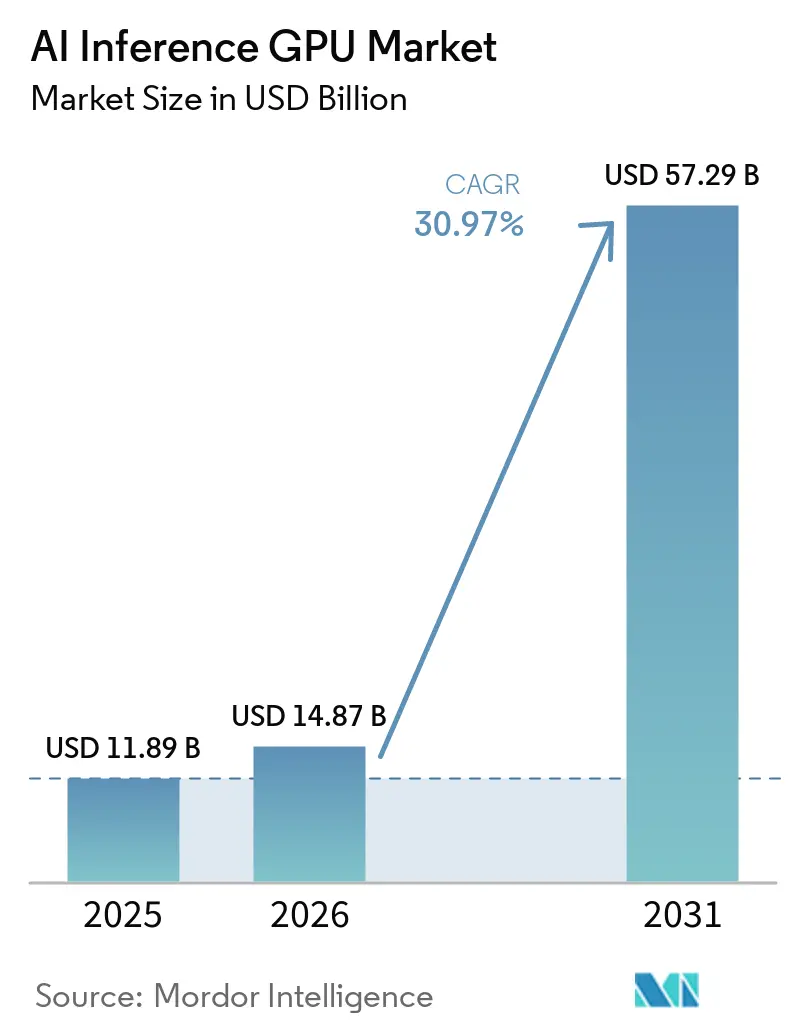
The AI inference GPU market size is projected to expand from USD 11.89 billion in 2025 and USD 14.87 billion in 2026 to USD 57.29 billion by 2031, registering a CAGR of 30.97% between 2026 and 2031. Rising production-scale deployments of generative AI models are shifting capital toward inference clusters, where throughput-per-watt and total cost of ownership now outweigh raw training speed in data-center investment decisions. Meta Platforms disclosed operating more than 600,000 NVIDIA H100 GPUs in fiscal 2025, with a large share dedicated to inference workloads that support Llama-based recommendation and content-moderation services. Export controls that limit shipments of advanced GPUs to China have accelerated the rollout of domestic alternatives, such as Huawei's Ascend 910C and Alibaba's Hanguang 800, heightening regional competition. Hyperscale operators are simultaneously adopting open-source inference compilers.
Key Report Takeaways
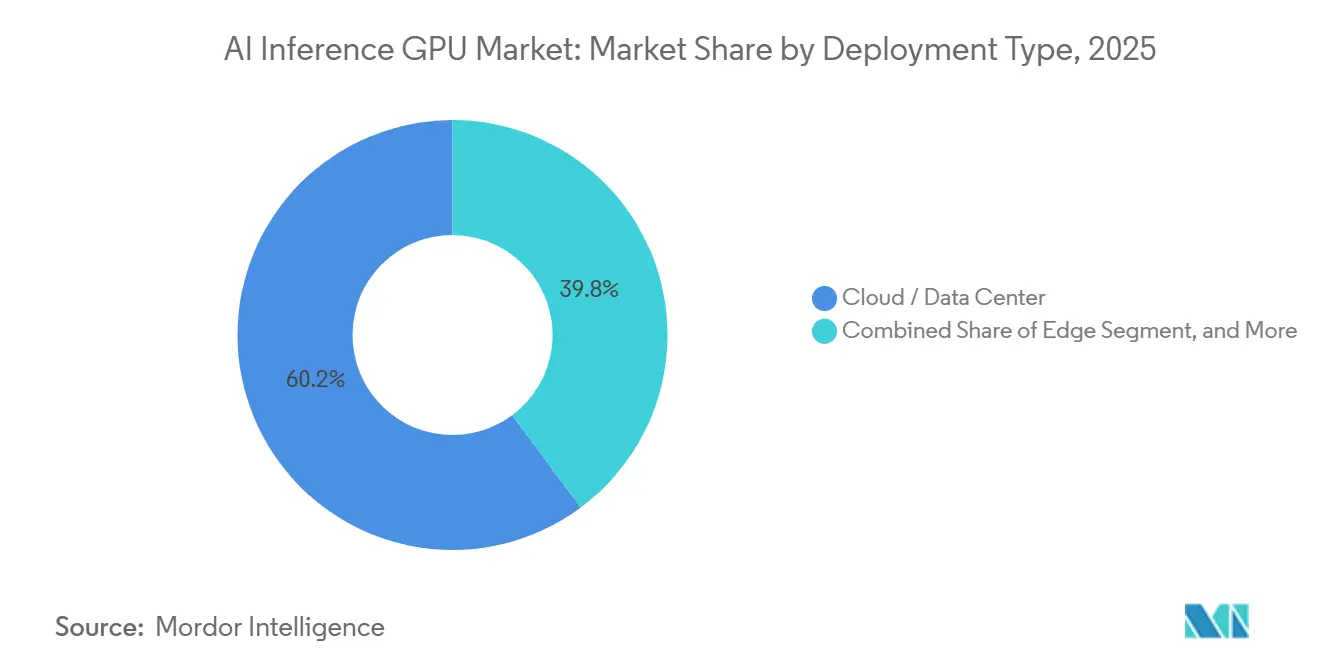
- By deployment type, cloud and data-center deployments led with 60.17% of the AI inference GPU market share in 2025.
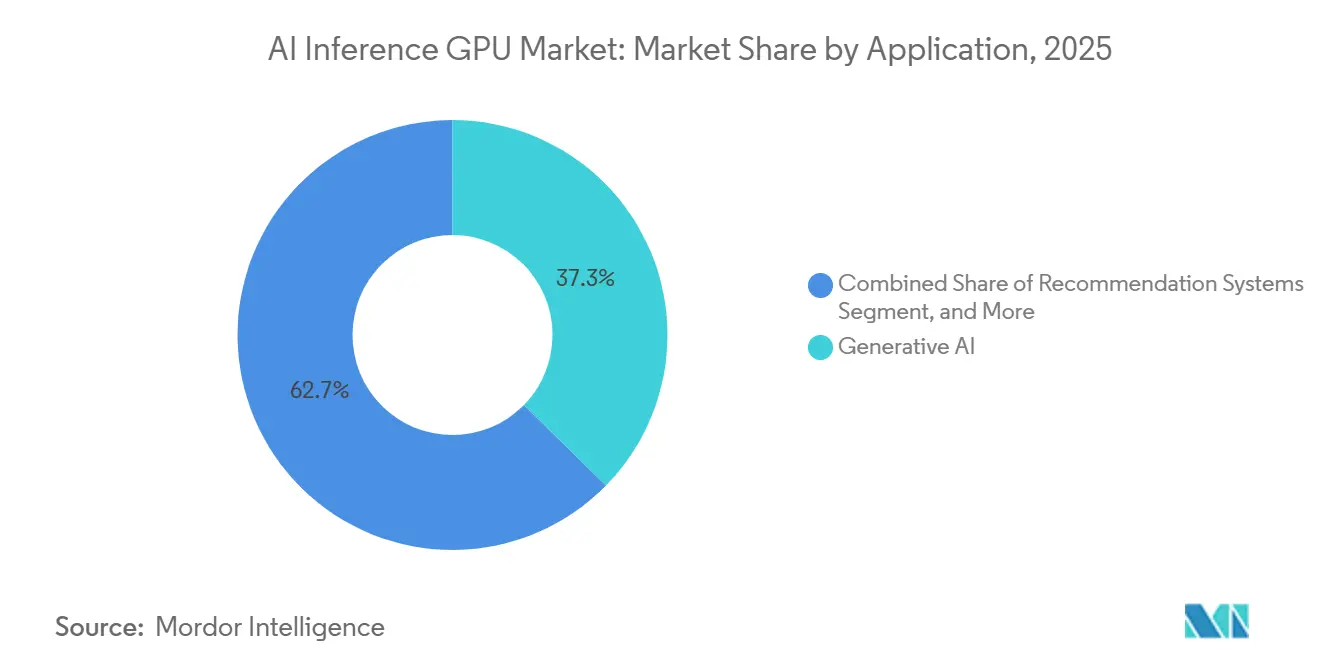
- By application, generative AI accounted for 37.34% of the AI inference GPU market in 2025 and is advancing at a 31.75% CAGR through 2031.
- By form factor, PCIe GPUs held 50.44% of the AI inference GPU market in 2025, while embedded modules are projected to grow at a 31.78% CAGR through 2031.
- By application, generative AI accounted for 3in 2025 and is advancing at a 31.75% CAGR through 2031.ugh 2031.
Note: Market size and forecast figures in this report are generated using Mordor Intelligence’s proprietary estimation framework, updated with the latest available data and insights as of January 2026.
Global AI Inference GPU Market Trends and Insights
Drivers Impact Analysis*
| DRIVER | (~) % IMPACT ON CAGR FORECAST | GEOGRAPHIC RELEVANCE | IMPACT TIMELINE |
|---|---|---|---|
| Surging Demand for Generative AI Services in Hyperscale Data Centers | +8.5% | Global, concentrated in North America and Asia-Pacific | Medium term (2–4 years) |
| Rapid Proliferation of Recommendation Engines in E-commerce Platforms | +6.2% | Global, led by Asia-Pacific and North America | Short term (≤ 2 years) |
| Expansion of Computer Vision across Industrial Automation Lines | +5.8% | Europe and Asia-Pacific manufacturing hubs | Medium term (2–4 years) |
| Growing Adoption of Conversational AI in Customer Support Operations | +4.9% | Global, early traction in North America and Europe | Short term (≤ 2 years) |
| Emergence of Transformer-Pruning Optimized Inference GPUs | +3.7% | Global, driven by hyperscale operators | Long term (≥ 4 years) |
| Availability of Open-Source Inference Compilers Lowering TCO | +2.6% | Global | Medium term (2–4 years) |
| Source: Mordor Intelligence | |||
Surging Demand for Generative AI Services in Hyperscale Data Centers
Hyperscale clouds are provisioning inference clusters that now exceed the scale of their training systems, reflecting the reality that a single large language model serves millions of concurrent users. Microsoft Azure added 120,000 NVIDIA H200 NVL GPUs in late 2025 to support GitHub Copilot and Azure OpenAI endpoints, which processed more than 50 billion API calls in December 2025.[1]Microsoft, “Azure Expands H200 Fleet,” news.microsoft.com Oracle Cloud Infrastructure reported 99.95% uptime for GPU inference workloads after adopting liquid-cooled rack designs that keep junction temperatures below 75 °C. AWS introduced Inferentia 3 custom silicon in March 2026, delivering triple the throughput of Inferentia 2, yet NVIDIA Blackwell NVL remains ahead in mixed-precision workloads that exploit FP8 and INT4 quantization. Meta revealed that inference infrastructure consumed USD 18 billion of its USD 40 billion 2025 capital budget, underscoring the strategic priority of owning rather than leasing capacity. As latency targets for conversational AI tighten from 500 milliseconds in 2024 to less than 200 milliseconds in 2026, demand for GPUs with high-bandwidth memory and low-latency interconnects continues to accelerate.
Rapid Proliferation of Recommendation Engines in E-commerce Platforms
Real-time personalization now operates at sub-10-millisecond latency, forcing retailers to adopt inference GPUs that manage sparse embeddings and dynamic features without batch delays. Amazon Personalize increased inference throughput in 2025 as merchants migrated from CPU-based collaborative filtering to GPU-accelerated deep learning models.[2]Amazon, “Amazon Personalize 2025 Annual Report,” sec.gov Alibaba Cloud’s Hanguang 800 chip cut recommendation latency from 35 milliseconds to 12 milliseconds on Taobao and Tmall, reducing per-query energy consumption by 60% during the 2025 Singles’ Day peak. Shopify integrated NVIDIA TensorRT-LLM in September 2025, enabling product-discovery models to adapt to inventory changes within 5 minutes and boosting conversion rates for pilot merchants. ByteDance stated that TikTok Shop processes 400 million product impressions per hour on NVIDIA A100 and H100 GPUs, with inference costs representing less than 0.02% of gross merchandise value due to aggressive model pruning.
Expansion of Computer Vision across Industrial Automation Lines
Manufacturers are installing inference GPUs at inspection points to detect defects at speeds exceeding human visual inspection. BMW Group deployed NVIDIA Jetson AGX Orin modules at 47 plants in 2025, lowering false-positive rates on paint flaws to below 0.5%.[3]BMW Group, “Sustainability Report 2025,” bmw.com Siemens’ Simatic AI platform, built on Intel Gaudi 3 accelerators, reduced unplanned downtime in semiconductor fabs by 18% by predicting failures 72 hours in advance. Bosch Rexroth integrated AMD Instinct MI300A into ctrlX controllers in late 2025 to ensure a 10-millisecond closed-loop response for high-speed robotics. Cognex upgraded In-Sight vision systems with embedded accelerators and achieved 99.7% uptime in high-vibration zones, a four-point improvement over prior external-compute designs. Edge deployment dominates because industrial protocols cannot tolerate the jitter introduced by cloud round-trips.
Growing Adoption of Conversational AI in Customer Support Operations
Enterprises are offloading tier-1 support to generative AI agents that resolve issues autonomously, shrinking average handle time and freeing human agents for escalations. Salesforce's Einstein GPT resolved 35% of customer-service cases without human intervention across pilots in telecommunications and finance, running inference on mixed NVIDIA H100 and AMD MI300X fleets.[4]Salesforce, “Q1 FY 2026 Earnings Call Transcript,” salesforce.com ServiceNow’s Now Assist, powered by fine-tuned Llama 3, lowered mean time to resolution for IT service workflows by incorporating retrieval-augmented generation. Microsoft Dynamics 365 Copilot processed more than 2 billion support interactions in Q4 2025, with inference costs dropping 40% after adopting INT8 quantization and speculative decoding. Regulated sectors prefer on-premises inference to avoid data-egress fees; JPMorgan Chase operates a private cloud with over 10,000 NVIDIA H100 GPUs to keep customer data in-house.
Restraints Impact Analysis*
| RESTRAINT | (~) % IMPACT ON CAGR FORECAST | GEOGRAPHIC RELEVANCE | IMPACT TIMELINE |
|---|---|---|---|
| High Up-Front Capital Cost of High-End Inference GPUs | -4.3% | Global, acute impact on mid-tier enterprises in emerging markets | Short term (≤ 2 years) |
| Power and Cooling Constraints in Edge Deployments | -3.8% | Global, especially remote and industrial edge sites | Medium term (2–4 years) |
| Supply-Chain Volatility for Advanced Packaging Substrates | -2.9% | Global, concentrated in Asia-Pacific semiconductor hubs | Medium term (2–4 years) |
| Rising Competition from RISC-V and Custom ASIC AI Accelerators | -2.1% | Global, early adoption in hyperscale and sovereign AI projects | Long term (≥ 4 years) |
| Source: Mordor Intelligence | |||
High Up-Front Capital Cost of High-End Inference GPUs
List prices for NVIDIA H200 NVL units exceed USD 40,000, creating a significant barrier for mid-tier enterprises that lack venture debt or cloud credits. Dell Technologies stated that AI-optimized server average selling prices rose 35% year over year due to high-bandwidth memory and liquid-cooling requirements.[5]Dell Technologies, “Q4 FY 2026 Earnings Highlights,” dell.com Supermicro reported 16-week lead times for GPU servers and required 50% deposits, extending deliveries into late 2026. Equinix data shows AI inference racks consume 25 kilowatts on average, driving a premium in colocation charges. NVIDIA’s DGX Cloud subscription at USD 5.50 per GPU-hour offers an alternative, but ownership remains cost-effective only when utilization stays above 60%.
Power and Cooling Constraints in Edge Deployments
Edge sites often cap racks at 500 watts, forcing developers to trade model complexity for thermal headroom. Qualcomm’s Snapdragon X Elite platform delivers 45 TOPS of INT8 performance inside a 15-watt envelope suitable for fanless kiosks. The NVIDIA Jetson AGX Orin can reach 60 watts under peak loads and requires active cooling after 30 minutes, limiting its use in sealed outdoor enclosures. International Electrotechnical Commission studies show performance drop when junction temperatures exceed 85 °C, a common challenge in unventilated industrial environments. Intel Xeon 6 processors integrate AMX tiles, delivering 2 TFLOPS of INT8 inference within existing CPU thermal envelopes, eliminating the need for discrete GPUs in some latency-sensitive edge applications.
*Our forecasts treat driver/restraint impacts as directional, not additive. The impact forecasts reflect baseline growth, mix effects, and variable interactions.
Segment Analysis
By Deployment Type: Cloud Dominance Anchored by Hyperscale Operators
Cloud and data-center installations held 60.17% of the AI inference GPU market share in 2025 as hyperscalers pooled resources to serve billions of daily API calls. Microsoft Azure’s addition of 120,000 H200 NVL units in late 2025 enabled 50 billion GitHub Copilot calls in a single month, underscoring the throughput criteria that dominate procurement decisions. Meta’s USD 18 billion allocation to inference infrastructure further illustrates the pivot from training to serving.
Edge deployments, advancing at 31.53% CAGR, gain traction where latency budgets deny round-trip cloud processing. Tesla’s Full-Self-Driving computer processes 2,300 camera frames per second on custom accelerators, demonstrating the deterministic performance edge applications demand. Industrial automation similarly favors on-device inference to meet control-loop timing requirements, but strict power envelopes constrain GPU selection to sub-60-watt modules, such as the Jetson AGX Orin. The AI inference GPU market thus bifurcates between power-rich hyperscale facilities and constrained edge sites.



By Form Factor: PCIe Compatibility Sustains Leadership amid SXM Gains
PCIe boards captured 50.44% of the AI inference GPU market size in 2025, owing to drop-in compatibility with existing servers. Dell reported that 68% of PowerEdge AI shipments used PCIe GPUs, and Supermicro cited 92% utilization rates thanks to flexible mix-and-match configurations. PCIe 5.0’s 128 GB s⁻¹ bandwidth is sufficient for most inference jobs that lack the all-to-all traffic of distributed training.
SXM and OAM modules are gaining in large clusters where inter-GPU bandwidth matters more than modularity. NVIDIA Blackwell NVL integrates 72 GPUs per rack with a 1.8 TB/s NVLink Switch fabric, enabling trillion-parameter model inference. Meta’s Grand Teton server uses OAM to achieve 40% higher energy efficiency than PCIe equivalents. Embedded modules, forecast at a 31.78% CAGR, fit power-constrained edge devices; Jetson Orin NX delivers 100 TOPS INT8 inference inside a 100 mm × 87 mm footprint, broadening deployment options in autonomous robots and smart-city cameras.
By Application: Generative AI Drives Broad-Based Adoption
Generative AI held a 37.34% share of the AI inference GPU market size in 2025 and is expanding at a 31.75% CAGR through 2031, reflecting its rapid integration into customer-facing workflows and content pipelines. Salesforce reported that Einstein GPT autonomously resolved 35% of service tickets, highlighting how token-generation workloads favor GPUs with high-bandwidth memory over FLOPS-centric designs. Adobe Firefly processed more than 10 billion image-generation calls in 2025, running on NVIDIA H100 and AMD MI300X fleets distributed across AWS and Azure regions. Token streaming is predominantly memory-bound, so operators standardize on GPUs that ship with at least 192 GB of HBM3 or HBM3E. OpenAI’s adoption of Cerebras wafer-scale engines underscores the premium placed on memory locality for trillion-parameter models.
Computer-vision inference, growing at a 28.3% CAGR, remains essential for industrial automation, autonomous vehicles, and robotic inspection. BMW’s deployment of NVIDIA Jetson AGX Orin modules across 47 plants cut false-positive defect rates below 0.5%. Recommendation engines continue to migrate from collaborative filtering to transformer architectures, as evidenced by Alibaba Cloud’s Hanguang 800 reduction of latency from 35 ms to 12 ms during the 2025 Singles’ Day surge. Conversational AI increasingly overlaps with generative AI; ServiceNow uses retrieval-augmented generation to drive a drop in mean time to resolution. Together, these workloads sustain demand diversity that buffers the AI inference GPU market against single-segment slowdowns.
Geography Analysis
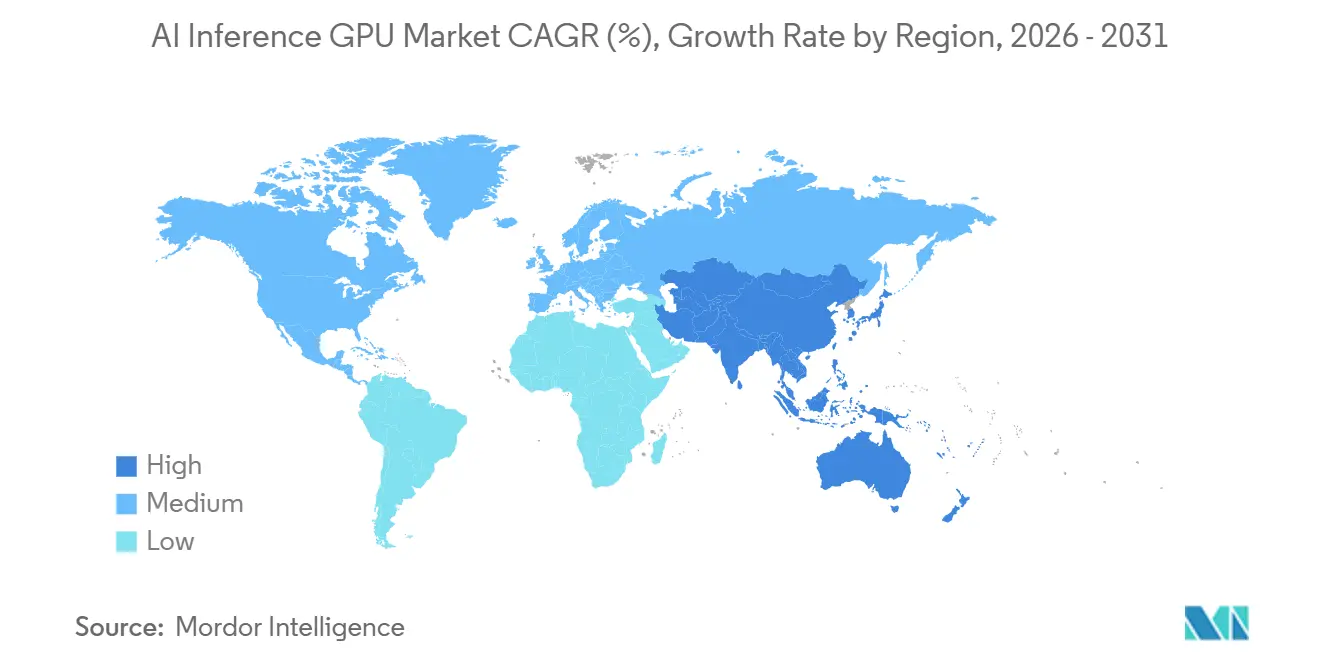
Asia-Pacific accounted for 69.52% of revenue in 2025 and is forecast to grow at a 31.92% CAGR through 2031, supported by sovereign AI programs, hyperscale partnerships, and aggressive data center expansion. Huawei shipped more than 50,000 Ascend 910C accelerators in 2025 after export restrictions limited NVIDIA H100 availability. Reliance Jio and NVIDIA formed a joint venture in September 2025 to install 100,000 H100 GPUs by mid-2027, anchoring India’s push for enterprise AI services. Singapore and Thailand approved new liquid-cooled campuses in 2026, adding 800 megawatts of capacity that will open to GPU tenants in 2027.
The demand for AI inference GPUs in North America is driven by hyperscale cloud providers and regulated enterprises that prefer on-premises inference to meet data-sovereignty mandates. AWS released Inferentia 3 in July 2025 and reported 40% lower latency for Stable Diffusion pipelines after migrating to TensorRT optimization. JPMorgan Chase operates a private cloud with more than 10,000 NVIDIA H100 GPUs, underscoring the bank’s preference for owned infrastructure for compliance-sensitive workloads. Canadian energy firms started pilot deployments of Groq language-processing units in early 2026 for real-time well-log interpretation, signaling rising interest in deterministic-latency silicon.
Europe's AI Act adds documentation and transparency obligations, lengthening deployment cycles. Siemens showed compliance is achievable; its Gaudi 3-based Simatic AI platform reduced semiconductor-fab downtime by 18% while meeting mandated risk-assessment disclosures. France and Germany earmarked EUR 2 billion (USD 2.18 billion) for sovereign inference cloud programs that will come online in 2028, indicating pent-up demand once regulatory clarity improves.

Competitive Landscape
The AI inference GPU market remains moderately concentrated: NVIDIA controlled a significant share of data-center inference shipments in 2025, yet custom ASICs and alternative GPU vendors are eroding that dominance. Cerebras secured a USD 15 billion, multi-year supply agreement with OpenAI to deliver wafer-scale CS-3 engines that stream 1 million tokens per second, eliminating PCIe bottlenecks. Groq won a USD 1.5 billion contract with Saudi Arabia’s Public Investment Fund to roll out deterministic-latency processors optimized for Arabic language-model serving. AMD’s MI350X, shipping to Microsoft Azure and Oracle Cloud in March 2026, integrates 288 GB of HBM3E to address context windows with more than 100 billion parameters.
Vertical integration is intensifying. Google disclosed TPU v7 in December 2025, delivering a 2.5× inference throughput bump over TPU v6 while cutting per-query costs by 35%. Amazon, Microsoft, and Meta are each funding internal silicon teams to reduce reliance on third-party GPUs. Edge inference exhibits lower concentration; Qualcomm, Intel, Imagination Technologies, and multiple RISC-V startups compete under 100-watt envelopes where power efficiency trumps peak throughput.
Open-source compilers such as TensorRT, ONNX Runtime, and Apache TVM level the playing field, allowing smaller vendors to rival NVIDIA’s optimization head start. AWS cut Stable Diffusion latency 40% after adopting TensorRT in early 2025. Owing to these dynamics, price competition is expected to sharpen from 2027 as wafer-scale capacity increases and packaging constraints ease.
AI Inference GPU Industry Leaders
NVIDIA Corporation
Advanced Micro Devices, Inc.
Intel Corporation
Qualcomm Technologies, Inc.
Samsung Electronics Co., Ltd.
- *Disclaimer: Major Players sorted in no particular order

Recent Industry Developments
- April 2026: Imagination Technologies announced that its IMG Series 4 neural-network accelerator has achieved ISO 26262 ASIL-D certification, enabling its use in automotive perception systems that require functional-safety compliance. Pilot integrations with Tier-1 suppliers started in Q2 2026.
- March 2026: NVIDIA Corporation launched its Blackwell Ultra inference platform, featuring 144 GPUs per rack with NVLink Switch delivering 3.6 TB s⁻¹ aggregate bandwidth and liquid cooling that lowers power draw 25% versus air-cooled Blackwell NVL setups.
- March 2026: Tenstorrent secured USD 200 million in Series D funding led by Samsung Catalyst Fund to scale production of Grayskull and Wormhole inference processors, and announced design wins with Japanese and South Korean telecom operators.
- February 2026: AMD announced the MI355X inference accelerator with 384 GB of HBM3E and FP6 quantization support, shipping first units to Microsoft Azure and Meta Platforms in March 2026.


Global AI Inference GPU Market Report Scope
The AI Inference GPU Market Report is Segmented by Deployment Type (Cloud/Data Center, Edge, and Embedded/On-Device), Form Factor (PCIe GPUs, SXM/OAM GPUs, and Embedded Modules), Application (Generative AI, Computer Vision, Recommendation Systems, Autonomous Systems, and NLP/Conversational AI), and Geography (North America, Europe, Asia-Pacific, South America, and Middle East and Africa). The Market Forecasts are Provided in Terms of Value (USD).
| Cloud / Data Center |
| Edge |
| Embedded / On-Device |
| PCIe GPUs |
| SXM / OAM GPUs |
| Embedded Modules |
| Generative AI |
| Computer Vision |
| Recommendation Systems |
| Autonomous Systems |
| NLP / Conversational AI |
| North America | United States |
| Canada | |
| Mexico | |
| Europe | Germany |
| United Kingdom | |
| France | |
| Italy | |
| Rest of Europe | |
| Asia-Pacific | China |
| Japan | |
| South Korea | |
| India | |
| Southeast Asia | |
| Rest of Asia-Pacific | |
| South America | |
| Middle East and Africa |
| By Deployment Type | Cloud / Data Center | |
| Edge | ||
| Embedded / On-Device | ||
| By Form Factor | PCIe GPUs | |
| SXM / OAM GPUs | ||
| Embedded Modules | ||
| By Application | Generative AI | |
| Computer Vision | ||
| Recommendation Systems | ||
| Autonomous Systems | ||
| NLP / Conversational AI | ||
| By Geography | North America | United States |
| Canada | ||
| Mexico | ||
| Europe | Germany | |
| United Kingdom | ||
| France | ||
| Italy | ||
| Rest of Europe | ||
| Asia-Pacific | China | |
| Japan | ||
| South Korea | ||
| India | ||
| Southeast Asia | ||
| Rest of Asia-Pacific | ||
| South America | ||
| Middle East and Africa | ||


Key Questions Answered in the Report
How large will the AI inference GPU market be by 2031?
The AI inference GPU market size is forecast to reach USD 57.29 billion by 2031, expanding at a 30.97% CAGR from 2026 to 2031.
Which application area is growing fastest in AI inference GPUs?
Generative AI remains the fastest-growing segment, advancing at a 31.75% CAGR as enterprises embed large language models into customer-facing tools.
Why do hyperscale operators prefer PCIe GPUs for inference?
PCIe cards retain 50.44% of AI inference GPU market share because they drop into existing servers and reach 92% utilization in mixed-workload clusters.
What factors limit AI inference at the network edge?
Tight 500-watt rack budgets and limited cooling capacity constrain edge deployments, pushing vendors toward low-power modules such as Qualcomm Snapdragon X Elite at 15 watts.
How are export controls influencing regional market dynamics?
U.S. restrictions on advanced GPU exports to China spurred domestic accelerators such as Huawei's Ascend 910C and Alibaba's Hanguang 800, reinforcing Asia-Pacifics 69.52% revenue share.
Which companies lead custom AI inference silicon development?
Cerebras, Groq, and Tenstorrent headline the custom-ASIC wave, securing multi-billion-dollar contracts for deterministic-latency or wafer-scale inference engines.
Page last updated on:






