Taille et part du marché du traitement intelligent de documents
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2020 - 2031 |
|---|---|
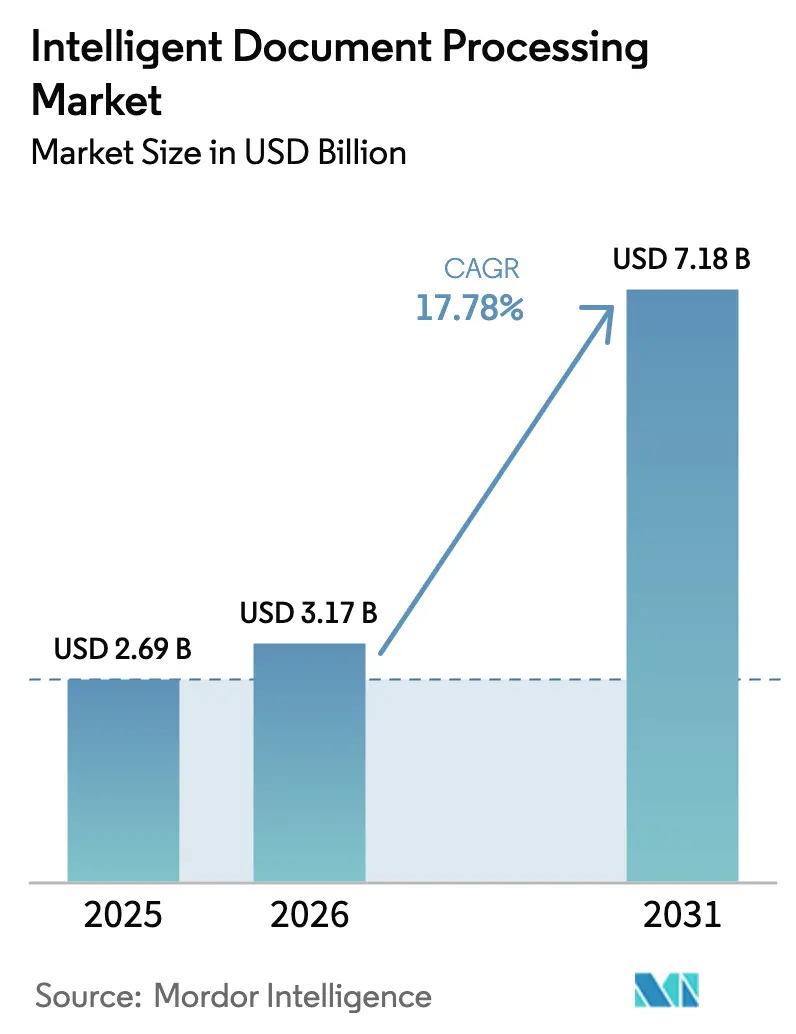
| Taille du Marché (2026) | 3.17 Milliards de dollars |
| Taille du Marché (2031) | 7.18 Milliards de dollars |
| Taux de croissance (2026 - 2031) | 17.78% CAGR |
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Amérique du Nord |
| Concentration du Marché | Moyen |
Acteurs majeurs *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. | |
Analyse du marché du traitement intelligent de documents par Mordor Intelligence
La taille du marché du traitement intelligent de documents en 2026 est estimée à 3,17 milliards USD, en hausse par rapport à la valeur de 2025 de 2,69 milliards USD, avec des projections pour 2031 affichant 7,18 milliards USD, croissant à un TCAC de 17,78 % sur la période 2026-2031. La croissance repose sur le passage rapide à l'automatisation pilotée par l'IA, l'expansion de l'adoption du cloud et les exigences réglementaires croissantes en matière de traitement direct des sinistres dans le secteur de l'assurance. Les entreprises réagissent également à la hausse des volumes de documents générés par l'IA, ce qui accroît les dépenses en matière de détection des fraudes, tandis que les limites des systèmes de reconnaissance optique de caractères traditionnels continuent de freiner les initiatives numériques. Les fournisseurs dotés de modèles adaptés verticalement gagnent du terrain, car les acheteurs recherchent une précision prête à l'emploi et un délai de rentabilisation plus court. Parallèlement, la prolifération du travail à distance intègre les flux de travail documentaires sans contact dans les opérations essentielles, mettant davantage l'accent sur les plateformes cloud évolutives pouvant être mises à jour en temps réel.
Points clés du rapport
- Par composant, les plateformes logicielles ont dominé avec 62,55 % de la part du marché du traitement intelligent de documents en 2025, tandis que les services devraient se développer à un TCAC de 19,15 % jusqu'en 2031.
- Par mode de déploiement, les solutions cloud ont capturé 74,10 % de la part des revenus en 2025 et continuent de croître le plus rapidement à un TCAC de 21,85 % jusqu'en 2031.
- Par taille d'entreprise, les grandes entreprises détenaient 64,35 % de la part du marché du traitement intelligent de documents en 2025, tandis que les petites et moyennes entreprises progressent à un TCAC de 19,35 % jusqu'en 2031.
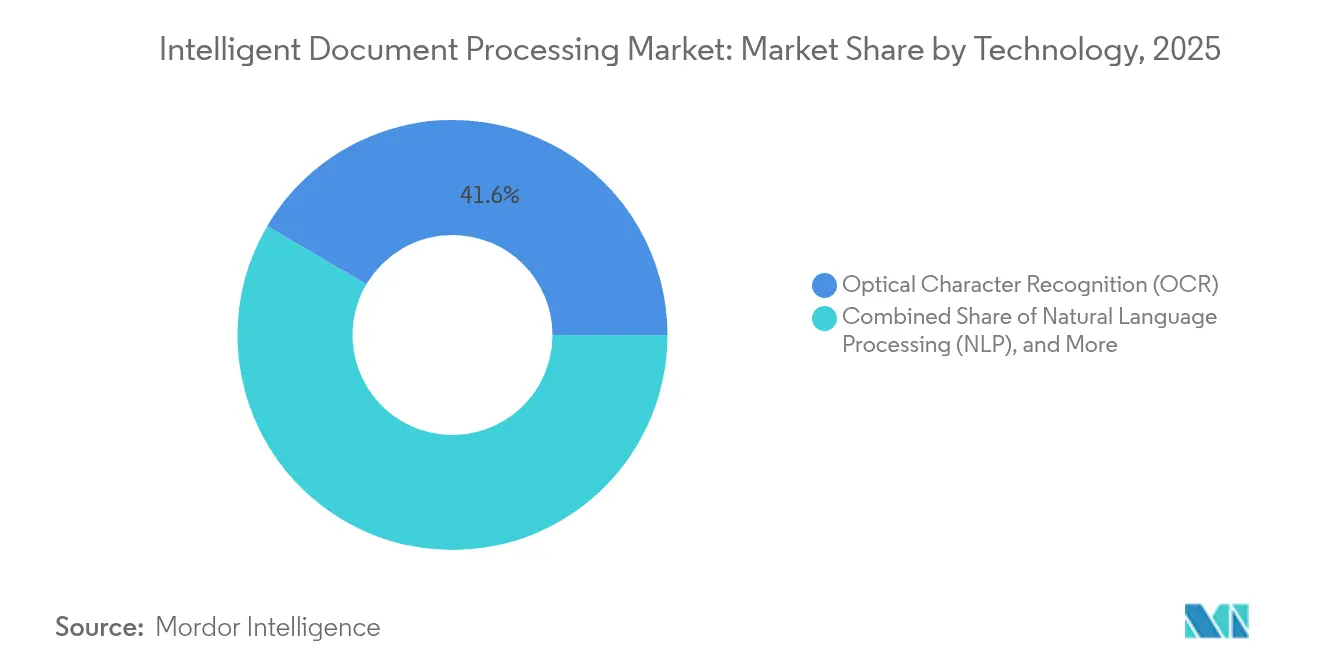
- Par technologie, la reconnaissance optique de caractères représentait 41,55 % de la taille du marché du traitement intelligent de documents en 2025, mais le traitement du langage naturel mène le peloton avec un TCAC de 22,95 % jusqu'en 2031.
- Par secteur d'utilisation final, la banque, les services financiers et l'assurance représentaient une part de 5,25 % de la taille du marché du traitement intelligent de documents en 2025, tandis que la santé et les sciences de la vie devraient progresser à un TCAC de 20,95 % jusqu'en 2031.
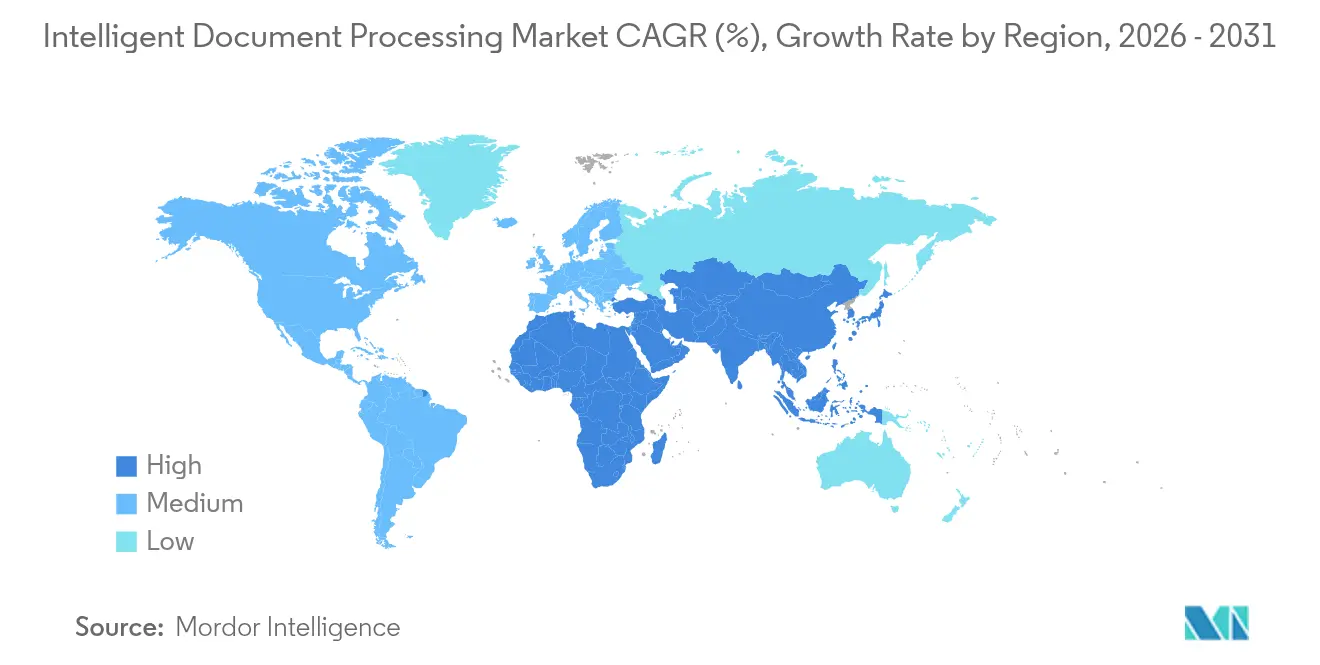
- Par géographie, l'Amérique du Nord a dominé avec 35,55 % de la part des revenus en 2025 ; l'Asie-Pacifique est la région à la croissance la plus rapide avec un TCAC de 19,75 % jusqu'en 2031.
Remarque : Les chiffres de la taille du marché et des prévisions de ce rapport sont générés à l’aide du cadre d’estimation propriétaire de Mordor Intelligence, mis à jour avec les données et analyses les plus récentes disponibles en 2026.
Tendances et perspectives mondiales du marché du traitement intelligent de documents
Analyse de l'impact des moteurs*
| Moteur | (~) % d'impact sur les prévisions de TCAC | Pertinence géographique | Calendrier d'impact |
|---|---|---|---|
| Investissements croissants dans la transformation numérique | +4.2% | Mondial ; Asie-Pacifique en tête | Moyen terme (2 à 4 ans) |
| Passage vers des plateformes de traitement intelligent de documents natives du cloud | +3.8% | Amérique du Nord et UE en cœur, expansion vers l'Asie-Pacifique | Court terme (≤ 2 ans) |
| Demande croissante d'automatisation du travail à distance | +2.9% | Mondial, accéléré après la COVID | Court terme (≤ 2 ans) |
| Émergence d'accélérateurs de traitement intelligent de documents spécifiques à l'industrie | +2.1% | Amérique du Nord et UE en premier, déploiement mondial | Moyen terme (2 à 4 ans) |
| Pression réglementaire des assurances pour le traitement direct des sinistres | +1.8% | Zones réglementaires d'Amérique du Nord et de l'UE | Long terme (≥ 4 ans) |
| Documents générés par l'IA augmentant les dépenses de détection des fraudes | +1.4% | Mondial, concentré dans les pôles financiers | Moyen terme (2 à 4 ans) |
| Source: Mordor Intelligence | |||
Investissements croissants dans la transformation numérique
Les entreprises citant des contraintes de main-d'œuvre lors des conférences téléphoniques sur les résultats sont 45 % plus susceptibles d'évoquer les avantages de l'automatisation, soulignant comment l'adoption du marché du traitement intelligent de documents découle désormais de la différenciation concurrentielle plutôt que de la réduction des coûts. Les premiers adoptants signalent également que les projets réussis révèlent des flux de travail adjacents propices à l'automatisation, créant un effet d'entraînement d'effets de réseau de données et d'optimisation continue des processus. L'implication est claire : les pionniers acquièrent un avantage lié à la courbe d'apprentissage que les entrants tardifs peinent à égaler.
Passage vers des plateformes de traitement intelligent de documents natives du cloud
Les déploiements cloud ont capturé 74,80 % de la part en 2024 et se développent à un TCAC de 22,20 % parce que les organisations privilégient la mise à l'échelle élastique et les actualisations rapides des modèles plutôt que le contrôle de l'infrastructure. Les architectures axées sur les API permettent un traitement en temps réel dans les opérations mondiales où les exigences de conformité localisées nécessitent un réentraînement et un redéploiement rapides des modèles. Les entreprises européennes, soumises aux obligations du RGPD, se tournent vers les fournisseurs cloud offrant des contrôles dynamiques de résidence des données et des pistes d'audit instantanées, transformant le traitement intelligent de documents natif du cloud d'une préférence informatique en un prérequis pour l'expansion transfrontalière [1]DocuWare, "Conformité au RGPD grâce à la gestion intelligente des documents," docuware.com.
Demande croissante d'automatisation du travail à distance
Les modèles de travail hybrides poussent les entreprises à repenser les processus à forte intensité documentaire pour une gestion asynchrone. Environ 75 % des employés s'appuient désormais sur des outils d'IA qui améliorent la productivité du service client de 14 %, renforçant le passage du marché du traitement intelligent de documents vers des flux de travail sans contact. Dans le secteur de la santé, la synthèse automatisée réduit de 50 % le temps de traitement des dossiers médicaux selon UiPath. Les organismes publics en bénéficient également : le guide GenAI du Département de la sécurité intérieure des États-Unis décrit comment l'automatisation à distance améliore les niveaux de service même dans des environnements fortement réglementés.
Émergence d'accélérateurs de traitement intelligent de documents spécifiques à l'industrie
Les accélérateurs adaptés à un domaine surpassent régulièrement les plateformes génériques. Les modèles de santé spécialisés atteignent une précision de 98 % et réduisent les cycles de déploiement de plusieurs mois à quelques semaines. Un fabricant de premier plan a atteint 90 % de traitement sans contact des bons de livraison en 2 semaines, dégageant 5 millions EUR (5,5 millions USD) d'économies annuelles grâce à des modèles personnalisés et des vocabulaires préentraînés. Les fournisseurs cultivant une expertise verticale approfondie peuvent pratiquer des prix premium tout en offrant un retour sur investissement mesurable que les directeurs financiers valident aisément.
Analyse de l'impact des freins*
| Frein | (~) % d'impact sur les prévisions de TCAC | Pertinence géographique | Calendrier d'impact |
|---|---|---|---|
| Réglementations complexes et fragmentées en matière de confidentialité des données | -2.1% | UE RGPD en cœur, expansion mondiale | Long terme (≥ 4 ans) |
| Pénurie de données d'entraînement annotées | -1.8% | Mondial, aiguë dans les secteurs verticaux spécialisés | Moyen terme (2 à 4 ans) |
| Contrôle croissant de la comptabilité carbone sur l'inférence de grands modèles | -1.2% | Mandats ESG de l'UE et de l'Amérique du Nord | Long terme (≥ 4 ans) |
| Débauchage de talents faisant grimper le coût total de possession | -0.9% | Pôles technologiques mondiaux, focus sur la Silicon Valley | Court terme (≤ 2 ans) |
| Source: Mordor Intelligence | |||
Réglementations complexes et fragmentées en matière de confidentialité des données
Le RGPD et les lois similaires obligent les entreprises à jongler avec des règles de consentement divergentes, des exigences de résidence et des demandes de droit à l'oubli, prolongeant les déploiements de traitement intelligent de documents et gonflant les budgets de conformité. Les multinationales maintiennent souvent des pipelines distincts pour différentes régions, compliquant la gouvernance des modèles et faisant monter les coûts de maintenance. Les fournisseurs dotés de boîtes à outils de conformité éprouvées acquièrent ainsi un avantage concurrentiel, tandis que les nouveaux entrants sans ressources juridiques font face à des barrières à l'entrée plus élevées.
Pénurie de données d'entraînement annotées
L'annotation spécifique à un secteur vertical nécessite des professionnels certifiés dans le domaine, ce qui fait monter les coûts d'étiquetage et allonge les délais de développement. Les dossiers médicaux, les contrats juridiques et les documents de détection des fraudes ne peuvent souvent pas être mis en commun entre entreprises en raison des contraintes de confidentialité, obligeant chaque organisation à constituer des ensembles de données propriétaires [2]BytePlus, "Solutions sécurisées d'étiquetage de données pour les secteurs réglementés," byteplus.com. Ceux qui disposent de vastes référentiels de documents internes et d'équipes d'étiquetage sécurisées peuvent maintenir des performances de modèle supérieures, tandis que les acteurs plus petits peuvent avoir besoin d'externaliser à des services spécialisés d'étiquetage de données répondant à des normes de sécurité strictes.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des segments
Par composant : les services s'accélèrent malgré la domination des logiciels
Les logiciels ont conservé 62,55 % de la part du marché du traitement intelligent de documents en 2025, mais les revenus des services progressent à un TCAC de 19,15 % à mesure que les entreprises découvrent que le succès repose sur la refonte des processus et la gestion du changement, et pas seulement sur les licences. Après la mise en œuvre, de nombreuses organisations externalisent l'ajustement et la surveillance continus des modèles à des partenaires de services gérés, transformant la complexité opérationnelle en opportunité d'abonnement.
Le marché du traitement intelligent de documents valorise de plus en plus les engagements basés sur les résultats plutôt que les licences traditionnelles par poste. Les éditeurs de plateformes cultivent désormais des alliances avec des intégrateurs de systèmes capables de gérer la cartographie de la conformité, la réingénierie des flux de travail et la formation des utilisateurs à grande échelle. À mesure que davantage d'entreprises adoptent des cadres de gouvernance matures, les services devraient représenter une part croissante de la valeur totale des contrats.




Par mode de déploiement : la suprématie du cloud s'accélère
Les offres cloud contrôlaient 74,10 % des revenus en 2025, avec une adoption se développant à un TCAC de 21,85 %, cimentant un pivot architectural décisif. La taille du marché du traitement intelligent de documents liée aux abonnements cloud devrait s'élargir davantage à mesure que les multinationales s'appuient sur une orchestration centralisée des modèles couplée à des points de terminaison d'inférence localisés.
Les systèmes sur site persistent là où les règles de souveraineté des données ou les architectures à isolation physique sont obligatoires, notamment dans la défense et certains organismes du secteur public. Les architectures hybrides gagnent en faveur : le prétraitement sensible reste dans les centres de données locaux, tandis que l'entraînement des modèles et l'analyse en masse résident dans le cloud. Les fournisseurs capables d'assembler ces environnements sans pénalités de latence sont en position de gagner des parts de marché.
Par taille d'entreprise : l'élan de croissance des PME défie la domination des grandes entreprises
Les grandes entreprises contrôlent encore 64,35 % des revenus ; cependant, les PME enregistrent un TCAC de 19,35 %, signalant une tendance à la démocratisation. Les places de marché cloud proposent désormais des packs de traitement intelligent de documents d'entrée de gamme tarifés pour des budgets plus modestes, permettant aux exportateurs de taille moyenne d'automatiser les factures, les connaissements et les formulaires de conformité presque du jour au lendemain.
Les PME dépassent souvent les acteurs établis en adoptant des modèles verticaux préentraînés et des interfaces low-code, réduisant les cycles de déploiement de plusieurs mois à quelques jours. À l'inverse, les entreprises du Fortune 1000 continuent de dominer les projets complexes et multi-juridictionnels nécessitant une gouvernance en couches et une intégration dans des suites ERP héritées. La coexistence de PME agiles et de conglomérats soumis à la conformité injecte des exigences diverses qui poussent les fournisseurs à innover sur l'ensemble du spectre prix-performance.
Par technologie : le traitement du langage naturel perturbe l'hégémonie de la reconnaissance optique de caractères
La reconnaissance optique de caractères détient encore 41,55 % de la part, mais le traitement du langage naturel se développe à un TCAC de 22,95 % à mesure que les entreprises passent de la reconnaissance de caractères à la compréhension sémantique. La taille du marché du traitement intelligent de documents attribuable au traitement du langage naturel augmente parce que l'extraction contextuelle alimente l'automatisation de bout en bout sans validation manuelle.
En parallèle, les modules de vision par ordinateur et d'analyse de mise en page aident à décoder les formulaires complexes et les fichiers multimédias, tandis que les ensembles d'apprentissage profond poussent la précision des documents standard à 99,56 %. Les fournisseurs investissant dans des piles multimodales acquièrent un avantage décisif car les acheteurs exigent de plus en plus une couverture sur une seule plateforme pour les entrées structurées, semi-structurées et non structurées.
Par secteur d'utilisation final : la transformation de la santé s'accélère
La banque, les services financiers et l'assurance détenaient une part de 5,25 % en 2025, reflétant les premiers investissements dans les cas d'usage de connaissance du client, de sinistres et de traitement des prêts. Pourtant, la santé et les sciences de la vie devraient croître à un TCAC de 20,95 % à mesure que les régulateurs approuvent les mandats d'autorisation préalable électronique et que les modèles de soins basés sur la valeur imposent des cycles de documentation plus rapides.
Les détaillants et les plateformes de commerce électronique exploitent le traitement intelligent de documents pour un intégration rapide et une visibilité de la chaîne d'approvisionnement, tandis que les fabricants favorisent la logistique sans papier et les rapports de contrôle qualité. Ces gains spécifiques aux secteurs révèlent que le marché du traitement intelligent de documents n'est plus confiné aux institutions financières à forte intensité documentaire, mais se diffuse dans des secteurs qui considèrent les données non structurées comme une réserve d'efficacité latente.
Analyse géographique
L'Amérique du Nord a représenté 35,55 % des revenus en 2025, lui conférant la plus grande part du marché du traitement intelligent de documents. La pénétration profonde du SaaS, l'abondance de talents qualifiés en IA et des cadres réglementaires matures maintiennent les dépenses des entreprises à un niveau élevé, notamment dans les services financiers, l'assurance et la santé. Les hyperscalers cloud raccourcissent les cycles de déploiement et réduisent les coûts de possession, tandis que les programmes de relance fédéraux canalisent de nouveaux financements vers des projets d'automatisation du secteur public. Collectivement, ces facteurs assurent la position de leader de l'Amérique du Nord, même si les régions à croissance plus rapide comblent l'écart.
L'Asie-Pacifique devrait afficher un TCAC de 19,75 % jusqu'en 2031, le rythme le plus rapide parmi toutes les régions. La Chine a réservé 2,1 milliards USD pour des investissements en IA générative qui sous-tendent des déploiements d'automatisation documentaire à grande échelle. Les gouvernements d'Inde, de Singapour et d'Australie utilisent des allègements fiscaux et des crédits cloud pour pousser les entreprises vers des flux de travail sans papier, et les fournisseurs cloud locaux s'associent à des spécialistes du traitement intelligent de documents pour satisfaire des règles strictes de résidence des données. Les petites et moyennes entreprises adoptent des outils axés sur le mobile et pilotés par API pour rationaliser les factures et les documents commerciaux, tandis que les banques régionales déploient le traitement intelligent de documents pour des vérifications de connaissance du client en temps réel à mesure que les règles de lutte contre le blanchiment d'argent se renforcent.
L'Europe reste influente grâce à la demande induite par le RGPD pour des contrôles de confidentialité intégrés, bien que son taux de croissance soit inférieur à celui de l'Asie-Pacifique. Les entreprises privilégient les plateformes cloud offrant une résidence des données configurable et des pistes d'audit automatisées, mais les systèmes sur site prévalent encore dans la défense et certains segments de l'administration publique. L'Amérique du Sud et le Moyen-Orient et l'Afrique en sont à des stades plus précoces, mais les agendas de modernisation stimulent des projets pilotes qui associent des packs linguistiques préentraînés à une tarification à l'usage. Les fournisseurs doivent donc équilibrer des déploiements cloud rapides dans les régions à forte croissance avec des capacités de conformité approfondies dans les juridictions matures pour saisir pleinement l'opportunité de taille du marché mondial du traitement intelligent de documents.

Paysage concurrentiel
Le marché du traitement intelligent de documents reste modérément fragmenté, avec plus de 60 fournisseurs actifs. Aucune entreprise ne détient une part écrasante, mais les fournisseurs de premier rang — ABBYY, UiPath et IBM — s'appuient sur de larges portefeuilles et d'importants programmes partenaires pour remporter des mandats mondiaux. Les hyperscalers cloud tels que Microsoft, Google et Amazon intègrent la compréhension documentaire dans leurs piles d'IA plus larges, exerçant une pression sur les prix des spécialistes tout en élevant les attentes des clients en matière d'intégration transparente avec les services cloud existants.
L'orientation stratégique dérive de l'étendue horizontale vers la profondeur verticale. Les fournisseurs proposant des modèles linguistiques spécifiques à la santé ou des accélérateurs de sinistres d'assurance remportent régulièrement des contrats sur la vitesse de mise en œuvre et la précision, même lorsque leur reconnaissance optique de caractères de base est comparable aux alternatives génériques. Dans le même temps, des initiatives open source comme Docling d'IBM favorisent un écosystème de modules complémentaires pilotés par la communauté, permettant aux fournisseurs de niveau intermédiaire d'améliorer leurs capacités sans repartir de zéro.
Les start-ups armées d'architectures basées sur les transformeurs et d'outils low-code trouvent des espaces vierges dans le segment des PME, où la facilité d'utilisation l'emporte sur les listes de fonctionnalités exhaustives. Pendant ce temps, les acteurs établis consolident leurs positions grâce à des coentreprises avec des intégrateurs de systèmes et des consortiums industriels, visant à verrouiller des ensembles de données propriétaires et des certifications de conformité que les nouveaux entrants ne peuvent pas facilement reproduire.
Leaders du secteur du traitement intelligent de documents
IBM Corporation
UiPath Inc.
OpenText Corporation
ABBYY Solutions Ltd.
Automation Anywhere, Inc.
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Développements récents du secteur
- Mars 2025 : IBM a fait don de trois projets open source — Docling, Data Prep Kit et BeeAI — à la Fondation Linux, renforçant la collaboration communautaire autour de l'IA documentaire.
- Février 2025 : IBM a publié Granite 3.2 avec une compréhension visuelle multimodale des documents et un ensemble de données dédié à l'ajustement par instruction, DocFM.
- Octobre 2024 : UiPath a intégré Anthropic Claude dans ses modules Autopilot et Clipboard AI, améliorant la précision de l'extraction de données non structurées.
- Juin 2024 : Affinda a levé 10 millions USD pour développer des outils d'automatisation documentaire par IA destinés aux flux de travail de back-office à volume élevé.


Cadre de la méthodologie de recherche et portée du rapport
Définitions du marché et couverture principale
Notre étude traite le marché du traitement intelligent de documents comme l'ensemble des plateformes logicielles et des services gérés qui ingèrent des documents semi-structurés ou non structurés, appliquent des techniques d'IA telles que la reconnaissance optique de caractères, le traitement du langage naturel et les classificateurs d'apprentissage automatique, et renvoient des données propres aux systèmes et flux de travail métier en aval. Selon Mordor Intelligence, il comptabilise les revenus des fournisseurs provenant des licences, des abonnements et du support à la mise en œuvre dans tous les secteurs et régions.
Exclusion du périmètre : les scanners matériels autonomes, les suites larges de gestion documentaire sans extraction IA intégrée et les services purs de saisie manuelle de données ne sont pas couverts.
Aperçu de la segmentation
- Par composant
- Logiciels (plateforme et SDK)
- Services (mise en œuvre, gérés)
- Par mode de déploiement
- Cloud
- Sur site
- Par taille d'entreprise
- Grandes entreprises
- Petites et moyennes entreprises (PME)
- Par technologie
- Reconnaissance optique de caractères (ROC)
- Traitement du langage naturel (TLN)
- Apprentissage automatique et apprentissage profond
- Vision par ordinateur
- Par secteur d'utilisation final
- Banque, services financiers et assurance
- Gouvernement et secteur public
- Santé et sciences de la vie
- Commerce de détail et e-commerce
- Fabrication et logistique
- Autres secteurs (télécommunications, énergie, juridique)
- Par géographie
- Amérique du Nord
- États-Unis
- Canada
- Mexique
- Amérique du Sud
- Brésil
- Argentine
- Reste de l'Amérique du Sud
- Europe
- Allemagne
- Royaume-Uni
- France
- Italie
- Espagne
- Russie
- Reste de l'Europe
- Asie-Pacifique
- Chine
- Japon
- Inde
- Corée du Sud
- Australie et Nouvelle-Zélande
- Reste de l'Asie-Pacifique
- Moyen-Orient et Afrique
- Moyen-Orient
- Arabie saoudite
- Émirats arabes unis
- Turquie
- Reste du Moyen-Orient
- Afrique
- Afrique du Sud
- Nigéria
- Égypte
- Reste de l'Afrique
- Moyen-Orient
- Amérique du Nord
Méthodologie de recherche détaillée et validation des données
Recherche primaire
Les analystes de Mordor ont échangé avec des chefs de produit de traitement intelligent de documents, des consultants en automatisation et des responsables informatiques de banques, d'assureurs et d'hôpitaux en Amérique du Nord, en Europe et en Asie-Pacifique. Leurs éclairages sur les écarts de prix, le rythme d'adoption du cloud et les délais de projet ont comblé les lacunes et ancré les hypothèses clés.
Recherche documentaire
Nous avons collecté des indicateurs de dépenses auprès du Bureau of Labor Statistics des États-Unis, d'Eurostat et des ensembles de données de l'OCDE qui suivent les investissements en automatisation de bureau, et nous avons examiné des études du NASSCOM, de l'AIIM et du Forum économique mondial quantifiant les volumes mondiaux de factures et de sinistres. Les rapports annuels 10-K des entreprises, les dépôts auprès de la SEC, les analyses de brevets Questel et les journaux d'expédition Volza ont aidé à tester les répartitions des revenus des fournisseurs. Des sources payantes telles que D&B Hoovers et Dow Jones Factiva ont complété l'intelligence concurrentielle. Les sources citées sont illustratives, et de nombreuses autres ont alimenté la collecte, la validation et la clarification des données.
Dimensionnement du marché et prévisions
Notre modèle combine une approche descendante et ascendante. En partant des volumes mondiaux documentés de factures, de connaissements et de sinistres, nous appliquons des taux de pénétration du traitement intelligent de documents par secteur et les prix d'abonnement en vigueur pour dimensionner la demande. Nous corroborons ensuite les totaux avec des agrégations d'échantillons de fournisseurs et des vérifications de canaux. Des variables telles que la part de migration vers le cloud, la prime de l'IA générative, les pages par transaction, la fréquence d'audit et les budgets d'automatisation des grandes entreprises alimentent une prévision par régression multivariée et analyse de scénarios jusqu'en 2030. Les écarts ascendants sont comblés par consensus d'experts avant finalisation.
Validation des données et cycle de mise à jour
Les résultats passent des contrôles d'anomalies et de variance par rapport aux références externes de dépenses et aux divulgations trimestrielles des fournisseurs. Les conclusions font l'objet d'une révision par les pairs en plusieurs étapes avant validation. Les rapports sont actualisés annuellement, avec des mises à jour intermédiaires déclenchées par des événements significatifs, afin que les clients disposent toujours de la vue la plus récente.
Pourquoi la base de référence du traitement intelligent de documents de Mordor mérite confiance
Les estimations publiées divergent souvent parce que les entreprises choisissent des règles d'inclusion, des courbes de prix et des cadences d'actualisation différentes.
Les principaux facteurs d'écart comprennent la prise en compte ou non des revenus des services, le traitement des primes de l'IA générative et l'intégration ou non des outils adjacents de gestion documentaire dans les totaux. Le périmètre de Mordor reste strictement centré sur les plateformes d'extraction activées par l'IA et applique une conversion de devise uniforme pour 2025.
Comparaison de référence
| Taille du marché | Source anonymisée | Principal facteur d'écart |
|---|---|---|
| 2,69 milliards USD (2025) | ||
| 2,30 milliards USD (2024) | Consultance mondiale A | Exclut les revenus des services gérés et ne comptabilise que les licences logicielles de base |
| 1,10 milliard USD (2022) | Consultance régionale B | Utilise une année de base plus ancienne et omet les plateformes natives du cloud lancées après 2022 |
| 7,89 milliards USD (2024) | Association sectorielle C | Regroupe des suites plus larges de gestion documentaire et de gestion de contenu d'entreprise, gonflant les totaux |
Ces différences montrent comment notre sélection rigoureuse du périmètre, notre ensemble de variables transparent et notre cycle d'actualisation annuel offrent aux décideurs une base de référence équilibrée et fiable.


Questions clés auxquelles le rapport répond
Quelle est la taille actuelle du marché du traitement intelligent de documents ?
Le marché est évalué à 3,17 milliards USD en 2026 et devrait atteindre 7,18 milliards USD d'ici 2031.
Quel mode de déploiement connaît la croissance la plus rapide dans le traitement intelligent de documents ?
Les modèles cloud se développent à un TCAC de 21,85 %, reflétant la demande de mise à l'échelle élastique et de mises à jour rapides des modèles.
Pourquoi les petites et moyennes entreprises adoptent-elles le traitement intelligent de documents si rapidement ?
Les plateformes natives du cloud avec des modèles préentraînés suppriment les lourdes barrières à la mise en œuvre, permettant aux PME de déployer une automatisation documentaire avancée sans grandes équipes informatiques.
Quel segment technologique perturbe la reconnaissance optique de caractères traditionnelle ?
Le traitement du langage naturel croît à un TCAC de 22,95 % parce qu'il ajoute une compréhension contextuelle à la simple extraction de texte.
Comment les réglementations sur la confidentialité des données influencent-elles les projets de traitement intelligent de documents ?
Des règles fragmentées comme le RGPD nécessitent souvent des pipelines de traitement distincts et un stockage localisé des données, augmentant à la fois le temps de déploiement et les coûts de conformité continus.
Quelles régions présentent les meilleures opportunités de croissance ?
L'Asie-Pacifique est en tête avec un TCAC de 19,75 % à mesure que les gouvernements et les entreprises accélèrent les initiatives de transformation numérique.
Dernière mise à jour de la page le:




