Taille et part du marché de la collecte et de l'étiquetage de données
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2020 - 2031 |
|---|---|
| Taille du Marché (2026) | 2.67 Milliards de dollars |
| Taille du Marché (2031) | 10.92 Milliards de dollars |
| Taux de croissance (2026 - 2031) | 32.59% CAGR |
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Amérique du Nord |
| Concentration du Marché | Moyen |
Acteurs majeurs *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. | |
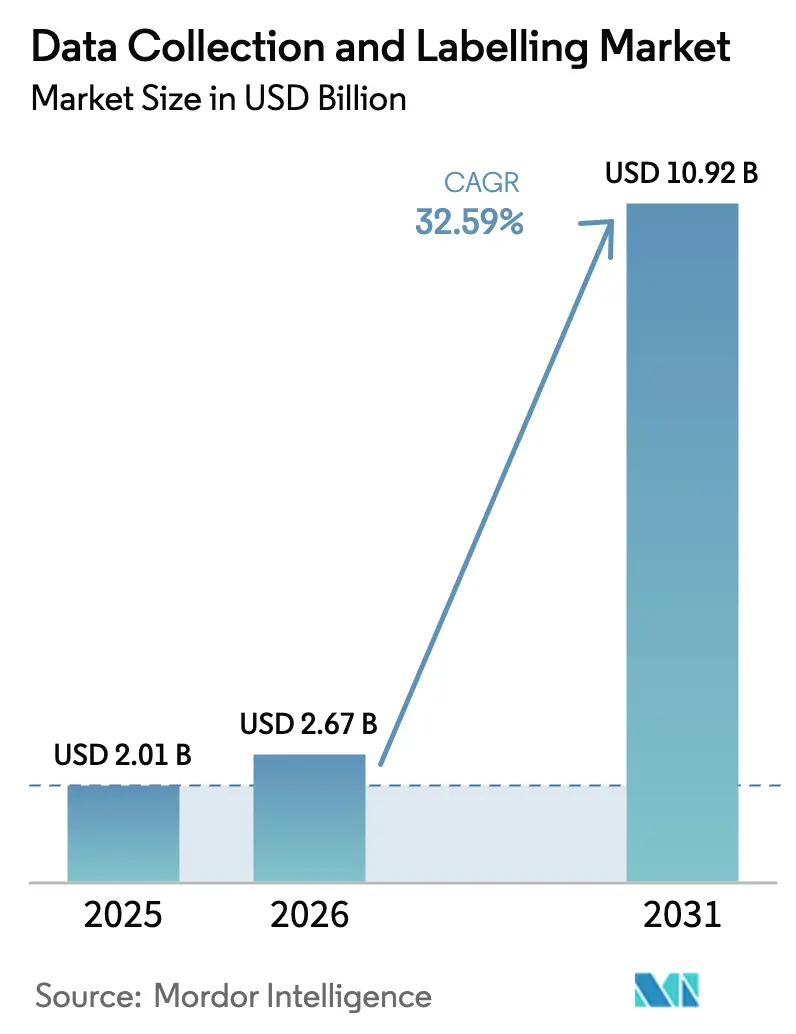
Analyse du marché de la collecte et de l'étiquetage de données par Mordor Intelligence
La taille du marché de la collecte et de l'étiquetage de données était évaluée à 2,01 milliards USD en 2025 et devrait croître de 2,67 milliards USD en 2026 pour atteindre 10,92 milliards USD d'ici 2031, à un TCAC de 32,59 % au cours de la période de prévision (2026-2031). La demande incessante de données d'entraînement de haute qualité et multi-domaines est alimentée par les modèles de fondation multimodaux, le pivot vers des pipelines d'apprentissage continu et les délais réglementaires de conformité qui approchent rapidement. Le pré-étiquetage assisté par l'IA générative gère désormais les tâches routinières avec des gains de vitesse multipliés par 20, libérant les rares experts humains pour les cas limites complexes. La génération de données synthétiques, les règles de localisation des données axées sur la confidentialité et la hausse des coûts liés à l'épuisement des annotateurs remodèlent les stratégies d'approvisionnement. L'élan commercial est le plus fort en Amérique du Nord, mais l'Asie-Pacifique connaît la croissance la plus rapide, la Chine et l'Inde développant leurs capacités nationales malgré des lois strictes sur la souveraineté des données. La rivalité concurrentielle est intense, car les niches de « petites données » spécifiques à un domaine, telles que l'imagerie médicale, commandent encore des prix premium même si les niveaux d'automatisation globaux augmentent.
Principaux enseignements du rapport
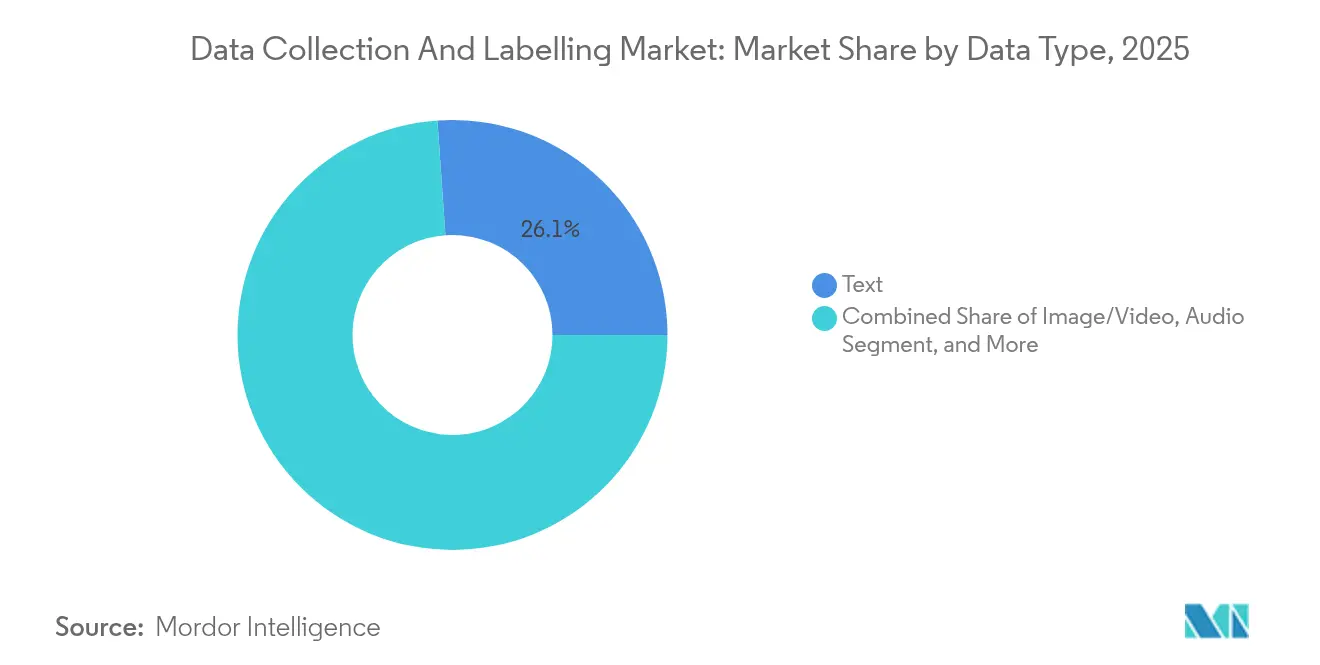
- Par type de données, l'annotation de texte a dominé avec une part de revenus de 26,12 % du marché de la collecte et de l'étiquetage de données en 2025, tandis que les flux de fusion de capteurs devraient se développer à un TCAC de 35,42 % jusqu'en 2031.
- Par secteur d'utilisation finale, le segment automobile et mobilité détenait 22,05 % de la part du marché de la collecte et de l'étiquetage de données en 2025, tandis que le secteur de la santé devrait enregistrer le TCAC le plus rapide de 34,89 % jusqu'en 2031.
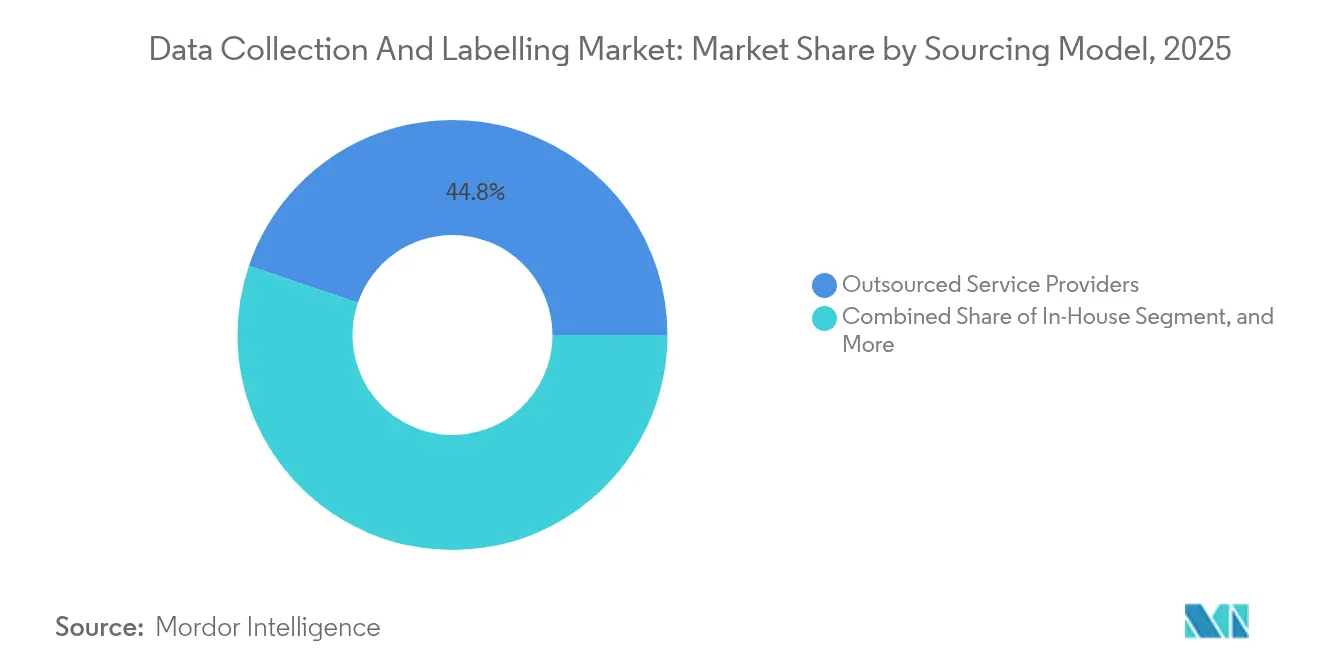
- Par modèle d'approvisionnement, les prestataires de services externalisés ont capturé 44,78 % du marché de la collecte et de l'étiquetage de données en 2025, mais la génération de données synthétiques devrait croître de 36,2 % par an.
- Par type d'annotation, les flux de travail manuels avec intervention humaine représentaient encore 49,45 % de la taille du marché de la collecte et de l'étiquetage de données en 2025, mais les approches entièrement automatisées progressent à un TCAC de 34,95 %.
- L'Amérique du Nord représentait 39,92 % du marché de la collecte et de l'étiquetage de données en 2025, tandis que l'Asie-Pacifique est la géographie à la croissance la plus rapide avec un TCAC de 35,65 %.
Remarque : Les chiffres de la taille du marché et des prévisions de ce rapport sont générés à l’aide du cadre d’estimation propriétaire de Mordor Intelligence, mis à jour avec les données et analyses les plus récentes disponibles en 2026.
Tendances et Analyses du Marché
Analyse de l'Impact des Moteurs sur le Marché de la Collecte et de l'Étiquetage de Données*
| Moteur | (~) % d'impact sur les prévisions de TCAC | Pertinence géographique | Calendrier d'impact |
|---|---|---|---|
| Essor des modèles de fondation multimodaux | +8.2% | Amérique du Nord, Chine | Moyen terme (2-4 ans) |
| Passage aux pipelines d'apprentissage continu | +7.1% | États-Unis, UE, Asie-Pacifique | Long terme (≥ 4 ans) |
| Pré-étiquetage assisté par l'IA générative | +6.8% | Amérique du Nord, UE | Court terme (≤ 2 ans) |
| Délais de conformité réglementaire rapides (Loi européenne sur l'IA, Déclaration des droits en matière d'IA des États-Unis) | +5.3% | UE, Amérique du Nord | Court terme (≤ 2 ans) |
| Besoins verticaux en « petites données » dans l'imagerie médicale et géospatiale | +4.7% | Marchés développés | Moyen terme (2-4 ans) |
| Source: Mordor Intelligence | |||
L'essor des modèles de fondation multimodaux stimule la demande de jeux de données multi-domaines
Les modèles de fondation multimodaux nécessitent des jeux de données massifs et diversifiés qui mêlent texte, images, audio, vidéo et flux de capteurs, suscitant une nouvelle demande sur l'ensemble du marché de la collecte et de l'étiquetage de données [1]Anas Awadalla et al., "MINT-1T : Mise à l'échelle des données multimodales open source par 10×," arXiv, arxiv.org. Des corpus de référence tels que MINT-1T ont multiplié par 10 les données multimodales open source et illustrent la nouvelle base de référence pour l'entraînement de l'IA moderne. Les fournisseurs capables d'orchestrer des flux de travail d'annotation multi-médias remportent désormais des contrats premium, car les clients exigent des étiquettes étroitement alignées entre les modalités. Les investisseurs considèrent cette capacité comme une infrastructure essentielle, comme en témoigne le tour de financement de 1 milliard USD de Scale AI en 2024. Les premiers adoptants dans la conduite autonome, les assistants vocaux et la robotique catalysent la croissance des volumes, tandis que les prestataires de soins de santé développent des jeux de données de fusion imagerie-texte pour les modèles de diagnostic. À mesure que ces cas d'usage arrivent à maturité, le marché de la collecte et de l'étiquetage de données devrait connaître des afflux de volumes soutenus sur plusieurs années.
L'IA centrée sur les données transforme l'annotation statique en pipelines d'apprentissage continu
Les entreprises sont passées de la création ponctuelle de jeux de données à une itération perpétuelle de la qualité des données, modifiant fondamentalement les modèles commerciaux au sein du marché de la collecte et de l'étiquetage de données [2]Matei Zaharia, "Que peut apprendre l'IA centrée sur les données de l'ingénierie des données et du ML ?" arXiv, arxiv.org . Les fournisseurs de plateformes proposent désormais le contrôle de version des jeux de données en flux continu, l'orchestration automatisée des pipelines et l'optimisation des boucles de rétroaction dans le cadre des cadres DataOps émergents. Les pipelines d'apprentissage continu élèvent la demande d'annotation, car la télémétrie des modèles entrants révèle constamment de nouveaux modes de défaillance nécessitant un ré-étiquetage ciblé. Les prestataires de services capables d'associer une exécution rapide à des pistes d'audit détaillées remportent des contrats sensibles à la conformité. Ce moteur à long terme soutient des engagements à revenus récurrents plutôt que des projets sporadiques, renforçant la visibilité de la croissance du marché de la collecte et de l'étiquetage de données.
Le pré-étiquetage assisté par l'IA générative accélère la productivité de l'annotation
Les grands modèles de langage tels que GPT-4 pré-étiquettent désormais les données avec un accord de 88,4 % avec la vérité terrain et des gains de vitesse multipliés par 20, transformant les économies unitaires. Les flux de travail hybrides acheminent les cas routiniers vers des algorithmes tout en réservant l'effort humain aux ambiguïtés, réduisant les heures manuelles jusqu'à 90,6 % dans les jeux de données biologiques. L'amélioration de la productivité permet aux fournisseurs de gérer des volumes croissants sans expansion linéaire des effectifs, renforçant la compétitivité des prix. À mesure que les outils d'IA arrivent à maturité, les acheteurs en entreprise s'attendent de plus en plus à une automatisation intégrée, faisant de la sophistication de la pile technologique un qualificatif décisif sur l'ensemble du marché de la collecte et de l'étiquetage de données.
Les délais de conformité réglementaire accélèrent les investissements dans la gouvernance des données
L'article 10 de la Loi européenne sur l'IA, en vigueur depuis 2024, impose la documentation de la provenance des jeux de données et des contrôles rigoureux de gouvernance des données pour les systèmes d'IA à haut risque [3]Parlement européen et Conseil, "Règlement – UE – 2024/1689," eur-lex.europa.eu . Des dispositions similaires figurent dans le plan directeur de la Déclaration des droits en matière d'IA des États-Unis, obligeant les entreprises à budgétiser le suivi de la traçabilité, les audits de biais et les contrôles continus d'assurance qualité. Les fournisseurs proposant des outils prêts à la conformité et des environnements d'annotation sécurisés sur site captent des engagements premium. Ces obligations augmentent les coûts de changement et allongent la durée des contrats, offrant au marché de la collecte et de l'étiquetage de données un vent arrière ancré dans la réglementation tout au long de la décennie.
Analyse de l'Impact des Freins sur le Marché de la Collecte et de l'Étiquetage de Données*
| Frein | (≈) % d'impact sur les prévisions de TCAC | Pertinence géographique | Calendrier d'impact |
|---|---|---|---|
| Hausse des coûts unitaires due à l'épuisement des annotateurs et à la dégradation de la qualité | -3.9% | Philippines, Kenya, pôles mondiaux | Moyen terme (2-4 ans) |
| Restrictions sur les transferts de données transfrontaliers | -2.8% | Chine, UE, Inde | Long terme (≥ 4 ans) |
| La substitution par des données synthétiques réduit les dépenses traditionnelles | -2.1% | Marchés à forte orientation technologique | Moyen terme (2-4 ans) |
| Source: Mordor Intelligence | |||
L'épuisement des annotateurs et la dégradation de la qualité font augmenter les coûts unitaires
La répétitivité élevée des tâches et les délais serrés ont accru le taux de rotation dans les principaux pôles d'externalisation, faisant monter les salaires et menaçant la cohérence de la qualité. Les prestataires font désormais tourner les travailleurs plus fréquemment et intègrent une surveillance de la qualité basée sur l'IA, mais ces mesures d'atténuation gonflent les bases de coûts. Si elles ne sont pas traitées, l'escalade des dépenses de main-d'œuvre pourrait éroder les marges et ralentir l'adoption, en particulier parmi les PME sensibles aux prix sur le marché de la collecte et de l'étiquetage de données.
Les restrictions sur les transferts de données transfrontaliers fragmentent les opérations mondiales
Le Règlement chinois sur la gestion de la sécurité des données de réseau et la Loi indienne sur la protection des données personnelles numériques imposent des obligations strictes de localisation et d'évaluation de la sécurité. Les examens d'adéquation du RGPD de l'UE ajoutent une complexité supplémentaire. Les entreprises d'annotation doivent construire des centres de traitement régionaux, investir dans le chiffrement et naviguer dans des audits redondants, augmentant les coûts fixes. Les fournisseurs plus petits manquant de ressources peuvent se retirer des juridictions restreintes, resserrant l'offre et prolongeant les délais de réalisation des projets au sein du marché de la collecte et de l'étiquetage de données.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des Segments du Marché de la Collecte et de l'Étiquetage de Données
Par type de données :
les flux de fusion de capteurs accélèrent les applications futuresL'annotation de texte est restée la plus grande tranche du marché de la collecte et de l'étiquetage de données avec une part de revenus de 26,12 % en 2025, soutenue par la montée en puissance des pipelines d'entraînement des grands modèles de langage. Les flux de fusion de capteurs, cependant, progressent rapidement avec un TCAC de 35,42 %, car les robots autonomes, les équipements de fabrication intelligente et les systèmes avancés d'aide à la conduite fusionnent les données LiDAR, radar, caméra et inertielles. L'étiquetage d'images et de vidéos conserve son élan dans la détection des défauts de fabrication et l'analyse des rayons de vente au détail, tandis que les jeux de données d'imagerie médicale 3D tels que M3D élargissent les horizons de l'IA en santé. L'annotation audio bénéficie des applications d'expérience client à commande vocale, et les tâches de séries temporelles tabulaires soutiennent les modèles de risque en finance et en télécommunications.
La complexité de la fusion de capteurs, impliquant la synchronisation temporelle et la calibration spatiale, commande des prix premium, augmentant sa contribution aux revenus malgré un nombre absolu de tâches plus faible. Les fournisseurs déployant des routines de validation automatisées et des simulateurs basés sur la physique réduisent les taux de reprise et se différencient dans les appels d'offres concurrentiels. Une collaboration étroite entre les équipes d'annotation et les ingénieurs en matériel de capteurs devient indispensable, cimentant les offres de services intégrés comme un avantage concurrentiel sur le marché de la collecte et de l'étiquetage de données.



Par secteur d'utilisation finale :
la santé dépasse les références de croissanceL'automobile et la mobilité représentaient 22,05 % du marché de la collecte et de l'étiquetage de données en 2025, portés par des jeux de données à l'échelle du pétaoctet pour la conduite autonome. Les mises à jour réglementaires continues telles que les règles de validation ADAS 2026 d'Euro-NCAP soutiennent les pipelines de génération de données. La santé devrait enregistrer le TCAC le plus rapide de 34,89 %, propulsée par l'imagerie haute résolution, la structuration des notes cliniques et la découverte de médicaments augmentée par l'IA. La taille du marché de la collecte et de l'étiquetage de données pour la seule imagerie médicale est appelée à augmenter fortement, car l'annotation experte en radiologie reste non substituable en raison des considérations de responsabilité.
Les agences gouvernementales développent la classification, la détection des menaces et les chatbots de services aux citoyens, tandis que les institutions BFSI affinent les modèles d'analyse de la fraude nécessitant un étiquetage équilibré du taux de faux positifs. Les plateformes de commerce électronique de détail améliorent la couverture de la taxonomie des produits et les performances de recherche visuelle. L'agriculture exploite l'imagerie par drone pour la prédiction des rendements et la surveillance des ravageurs, et les opérateurs de télécommunications constituent des corpus linguistiques spécifiques à leur domaine pour optimiser les opérations réseau. Chaque secteur vertical élargit l'ouverture de la demande, mais la croissance se répartit inégalement, offrant aux fournisseurs spécialisés la possibilité d'exceller dans des niches au sein du secteur de la collecte et de l'étiquetage de données.
Par modèle d'approvisionnement :
la génération synthétique remet en question la domination de l'externalisationLes prestataires de services externalisés détenaient 44,78 % du marché de la collecte et de l'étiquetage de données en 2025, soutenus par leur échelle, leurs viviers de talents multilingues et leurs installations certifiées ISO. Pourtant, la génération de données synthétiques, qui progresse à un TCAC de 36,2 %, déstabilise les flux de travail établis. Les environnements de simulation fabriquent des événements de conduite rares, et les réseaux antagonistes génératifs comblent les lacunes dans les classes médicales sous-représentées. Les entreprises mélangent de plus en plus les données synthétiques et réelles, réduisant les volumes d'annotation pour les scénarios routiniers tout en réservant l'effort humain à la validation.
La capacité d'annotation interne se renforce là où la sensibilité des données ou la protection de la propriété intellectuelle est primordiale, notamment parmi les contractants de la défense et les hôpitaux de premier rang. La production participative reste pertinente pour les tâches grand public à longue traîne nécessitant une nuance culturelle, telles que l'analyse des sentiments dans les dialectes, bien que le risque de variance de qualité nécessite des couches de révision avancées. Les modèles de services hybrides combinant l'augmentation synthétique, le pré-étiquetage assisté par l'IA et des installations sécurisées sur site émergent comme la nouvelle norme sur le marché de la collecte et de l'étiquetage de données.
Par type d'annotation :
l'automatisation gagne du terrain malgré la supervision humaineLes processus manuels avec intervention humaine représentaient encore 49,45 % des revenus de 2025, soulignant la valeur durable du jugement contextuel des experts. Les boucles semi-supervisées et d'apprentissage actif réduisent désormais le nombre d'annotations de plus de 60 % sans perte mesurable de précision dans les études de référence. Les pipelines automatisés affichant un TCAC de 34,95 % s'appuient sur des étiqueteurs alimentés par des modèles de fondation pour le marquage en première passe, alimentant les validateurs humains via des files d'attente d'exceptions. Les outils d'IA centrés sur les données enregistrent les métadonnées de provenance, automatisent le score de consensus et signalent la dérive pour le ré-étiquetage, réduisant les délais de cycle et renforçant les rapports de conformité.
À mesure que la précision algorithmique s'améliore, l'annotation entièrement automatisée pénétrera les domaines routiniers tels que la détection de boîtes englobantes dans les images de rayons de vente au détail, mais les interprétations médicales ou juridiques complexes maintiendront les humains indispensables. Les fournisseurs équilibrant une automatisation rentable avec une escalade rapide vers des experts captureront les opportunités à plus forte marge sur l'ensemble du marché de la collecte et de l'étiquetage de données.
Analyse géographique
Marché de la Collecte et de l'Étiquetage de Données en Amérique du Nord
L'Amérique du Nord a dominé le marché de la collecte et de l'étiquetage de données avec une part de 39,92 % en 2025, soutenue par un financement en capital-risque solide, des écosystèmes d'IA matures et des taux d'adoption élevés en entreprise. Des initiatives telles que le projet Thunderforge de l'Unité d'Innovation de Défense des États-Unis signalent une demande gouvernementale pour des pipelines d'étiquetage sécurisés et critiques pour les missions diu.mil. Le cluster d'innovation Scale AI du Canada a investi 96 millions USD dans 22 projets, renforçant davantage l'infrastructure régionale. Le lien entre le monde académique et l'industrie dans la région maintient un leadership technique, mais la hausse des coûts de main-d'œuvre stimule l'adoption de l'automatisation assistée par l'IA.
Marché de la Collecte et de l'Étiquetage de Données en Asie-Pacifique
L'Asie-Pacifique est le territoire à la croissance la plus rapide avec un CAGR de 35,65 %, portée par des déploiements d'IA à grande échelle et des mandats régionaux de résidence des données. La réglementation chinoise sur la gestion de la sécurité des données de réseau, en vigueur depuis 2025, exige des évaluations annuelles des risques, ce qui incite à la création d'installations d'annotation sur le territoire national. La loi indienne sur la protection des données personnelles numériques impose un consentement explicite et des évaluations de sécurité, générant une demande pour des prestataires nationaux conformes. Les marchés de l'ASEAN exploitent des viviers de crowdsourcing multilingues pour attirer des acheteurs mondiaux, tandis que le Japon et la Corée du Sud investissent dans l'annotation de haute précision pour la robotique et l'inspection de semi-conducteurs.
Marché de la Collecte et de l'Étiquetage de Données en Europe
L'Europe affiche une croissance régulière soutenue par des impératifs de gouvernance des données dictés par les politiques. L'accent mis par la loi européenne sur l'IA sur la transparence accroît la demande de documentation d'étiquetage prête pour l'audit. Les projets du Service numérique gouvernemental ont démontré des gains d'efficacité substantiels grâce à la catégorisation basée sur l'apprentissage automatique des contenus du secteur public. Les prestataires offrant des environnements sécurisés et conformes au RGPD pratiquent des tarifs premium, tandis que les collaborations de recherche régionales stimulent l'innovation dans les techniques d'annotation préservant la confidentialité.
Paysage concurrentiel
La concurrence est fragmentée. Scale AI, Appen et TELUS International ancrent le haut de gamme du marché de la collecte et de l'étiquetage de données, chacun se développant par le biais de partenariats stratégiques. L'alliance d'OpenAI en 2024 avec Scale AI étend le support d'affinage en entreprise, soulignant la valeur des services intégrés données-modèles. TaskUs s'est associé à V7, reliant une communauté d'annotateurs forte de 670 000 personnes à des outils avancés d'infrastructure de données.
La différenciation technologique s'intensifie. Les fournisseurs déploient des moteurs d'apprentissage actif, des détecteurs d'erreurs d'étiquetage et des modèles de fondation spécifiques à un domaine pour améliorer la productivité et la qualité. La capacité en données synthétiques est un champ de bataille croissant ; les entreprises combinant des pipelines réels et simulés commercialisent un biais réduit et une meilleure couverture des cas limites. Les secteurs de la santé, du droit et des sciences valorisent les experts certifiés, incitant les nouveaux entrants à constituer des réseaux de talents ciblés.
Les investisseurs continuent de soutenir les plateformes axées sur l'échelle. Le tour de table Série F de 1 milliard USD de Scale AI à une valorisation de 13,8 milliards USD a mis en évidence la confiance dans l'économie de l'infrastructure de données. Le partenariat de Labelbox en 2024 avec Handshake élargit l'accès à des annotateurs spécialisés pour gérer des charges de travail complexes d'apprentissage automatique. TELUS Digital a obtenu la reconnaissance de NelsonHall pour l'excellence de l'annotation de données automobiles. Dans l'ensemble, l'intensité concurrentielle devrait rester élevée à mesure que l'automatisation comprime les marges et que les acheteurs exigent des solutions de bout en bout prêtes à la conformité sur l'ensemble du marché de la collecte et de l'étiquetage de données.
Leaders du secteur de la collecte et de l'étiquetage de données
Appen Limited
Alegion Inc.
Cogito Tech
iMerit Technology
SuperAnnotate AI Inc.
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier
Entreprises Couvertes dans ce Rapport sur le Marché de la Collecte et de l'Étiquetage de Données
- Appen
- TELUS International AI Data (Lionbridge AI)
- iMerit
- CloudFactory
- Scale AI
- SuperAnnotate
- Sama
- Labelbox
- Alegion
- Cognizant (Servian)
- Defined.ai
- Cogito Tech
- V7
- Kili Technology
- Keymakr
- Deepen AI
- Playment
- Trilldata
- Tasq.ai
- Shaip

Développements Récents dans le Secteur du Marché de la Collecte et de l'Étiquetage de Données
- Janvier 2025 : Le Règlement chinois sur la gestion de la sécurité des données de réseau est entré en vigueur, imposant des évaluations annuelles des risques pour les entreprises à forte intensité de données et incitant à la construction d'installations d'annotation régionales Rödl & Partner.
- Décembre 2024 : Labelbox a formé une alliance stratégique avec Handshake pour accéder à des talents spécialisés en IA pour des tâches d'étiquetage complexes Labelbox.
- Octobre 2024 : TELUS Digital a été nommé leader dans le rapport sur les services CX de NelsonHall pour les secteurs des hautes technologies et de l'automobile, citant de solides capacités d'annotation de données ADAS TELUS Digital.
- Août 2024 : Singtel et Nscale se sont associés pour libérer la capacité GPU en Europe et en Asie du Sud-Est, atténuant les goulots d'étranglement de calcul pour les charges de travail d'annotation à forte intensité de données Nscale.


Portée du rapport mondial sur le marché de la collecte et de l'étiquetage de données
Le secteur de la collecte et de l'étiquetage de données est un secteur qui implique la collecte, le traitement et l'annotation de données, qui sont ensuite utilisées pour entraîner des modèles d'apprentissage automatique (ML) et des systèmes d'intelligence artificielle (IA). La recherche examine également les facteurs de croissance sous-jacents et les principaux fournisseurs du secteur, qui contribuent tous à soutenir les estimations du marché et les taux de croissance tout au long de la période anticipée. Les estimations et projections du marché sont basées sur les facteurs de l'année de base et ont été obtenues par des approches descendantes et ascendantes.
Le marché de la collecte et de l'étiquetage de données est segmenté par type de données (texte, image/vidéo et audio), par secteur d'utilisation finale (automobile, gouvernement, santé, BFSI, commerce de détail et commerce électronique et autres secteurs d'utilisation finale) et par géographie (Amérique du Nord, Europe, Asie-Pacifique, Amérique du Sud et Moyen-Orient et Afrique). Le dimensionnement et les prévisions du marché sont fournis en termes de valeur (USD) pour tous les segments ci-dessus.
Aperçu de la Segmentation
| Texte |
| Image/Vidéo |
| Audio |
| Nuage de points 3D |
| Flux de capteurs et de fusion |
| Tabulaire/Séries temporelles |
| Automobile et mobilité |
| Gouvernement et secteur public |
| Santé et sciences de la vie |
| BFSI |
| Commerce de détail et commerce électronique |
| Agriculture |
| Informatique et télécommunications |
| Autres secteurs d'utilisation finale |
| Interne |
| Prestataires de services externalisés |
| Plateformes de production participative |
| Génération de données synthétiques |
| Manuel (avec intervention humaine) |
| Semi-supervisé / Apprentissage actif |
| Entièrement automatisé |
| Amérique du Nord | États-Unis | |
| Canada | ||
| Mexique | ||
| Europe | Allemagne | |
| Royaume-Uni | ||
| France | ||
| Italie | ||
| Espagne | ||
| Russie | ||
| Reste de l'Europe | ||
| Asie-Pacifique | Chine | |
| Inde | ||
| Japon | ||
| Corée du Sud | ||
| Australie et Nouvelle-Zélande | ||
| Reste de l'Asie-Pacifique | ||
| Moyen-Orient et Afrique | Moyen-Orient | Émirats arabes unis |
| Arabie saoudite | ||
| Turquie | ||
| Reste du Moyen-Orient | ||
| Afrique | Afrique du Sud | |
| Nigéria | ||
| Égypte | ||
| Reste de l'Afrique | ||
| Amérique du Sud | Brésil | |
| Argentine | ||
| Reste de l'Amérique du Sud | ||
| Par type de données | Texte | ||
| Image/Vidéo | |||
| Audio | |||
| Nuage de points 3D | |||
| Flux de capteurs et de fusion | |||
| Tabulaire/Séries temporelles | |||
| Par secteur d'utilisation finale | Automobile et mobilité | ||
| Gouvernement et secteur public | |||
| Santé et sciences de la vie | |||
| BFSI | |||
| Commerce de détail et commerce électronique | |||
| Agriculture | |||
| Informatique et télécommunications | |||
| Autres secteurs d'utilisation finale | |||
| Par modèle d'approvisionnement | Interne | ||
| Prestataires de services externalisés | |||
| Plateformes de production participative | |||
| Génération de données synthétiques | |||
| Par type d'annotation | Manuel (avec intervention humaine) | ||
| Semi-supervisé / Apprentissage actif | |||
| Entièrement automatisé | |||
| Par géographie | Amérique du Nord | États-Unis | |
| Canada | |||
| Mexique | |||
| Europe | Allemagne | ||
| Royaume-Uni | |||
| France | |||
| Italie | |||
| Espagne | |||
| Russie | |||
| Reste de l'Europe | |||
| Asie-Pacifique | Chine | ||
| Inde | |||
| Japon | |||
| Corée du Sud | |||
| Australie et Nouvelle-Zélande | |||
| Reste de l'Asie-Pacifique | |||
| Moyen-Orient et Afrique | Moyen-Orient | Émirats arabes unis | |
| Arabie saoudite | |||
| Turquie | |||
| Reste du Moyen-Orient | |||
| Afrique | Afrique du Sud | ||
| Nigéria | |||
| Égypte | |||
| Reste de l'Afrique | |||
| Amérique du Sud | Brésil | ||
| Argentine | |||
| Reste de l'Amérique du Sud | |||


Questions clés auxquelles le rapport répond
Quelle est la taille actuelle du marché de la collecte et de l'étiquetage de données ?
La taille du marché de la collecte et de l'étiquetage de données a atteint 2,67 milliards USD en 2026 et devrait atteindre 10,92 milliards USD d'ici 2031.
Quelle région est en tête du marché de la collecte et de l'étiquetage de données ?
L'Amérique du Nord est en tête avec une part de marché de 39,92 % en 2025, reflétant des investissements profonds dans l'IA et des écosystèmes d'infrastructure de données matures.
Quel segment se développe le plus rapidement au sein du marché de la collecte et de l'étiquetage de données ?
Les flux de données de fusion de capteurs devraient croître à un TCAC de 35,42 %, portés par les systèmes autonomes et les applications IoT.
Comment les données synthétiques affectent-elles les services d'annotation traditionnels ?
Les moteurs de données synthétiques progressent à un TCAC de 36,2 % et devraient fournir la majorité des jeux de données d'entraînement, réduisant la demande d'étiquetage manuel routinier tout en créant de nouveaux besoins de validation.
Quel impact la Loi européenne sur l'IA a-t-elle sur les opérations d'étiquetage de données ?
La Loi européenne sur l'IA impose une gouvernance stricte des données et un suivi de la provenance, incitant les entreprises à investir dans des flux de travail d'annotation conformes et stimulant la demande pour des prestataires de services prêts pour l'audit.
Dernière mise à jour de la page le:




