Taille et Part du Marché de la Biologie Computationnelle
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2020 - 2031 |
|---|---|
| Taille du Marché (2026) | 8.17 Milliards de dollars |
| Taille du Marché (2031) | 14.89 Milliards de dollars |
| Taux de croissance (2026 - 2031) | 12.78% CAGR |
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Amérique du Nord |
| Concentration du Marché | Moyen |
Acteurs majeurs *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. | |
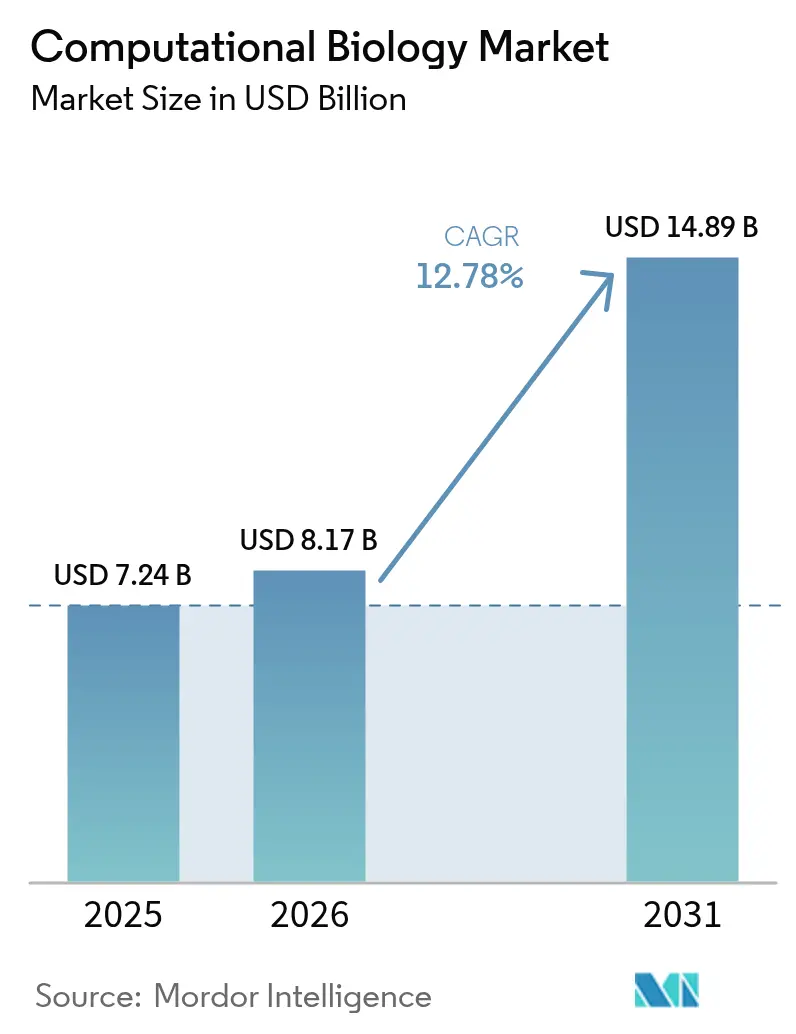
Analyse du Marché de la Biologie Computationnelle par Mordor Intelligence
La taille du marché de la biologie computationnelle en 2026 est estimée à 8,17 milliards USD, en hausse par rapport à la valeur de 2025 de 7,24 milliards USD, avec des projections pour 2031 indiquant 14,89 milliards USD, croissant à un TCAC de 12,78 % sur la période 2026-2031. Ces perspectives signalent comment les modèles de langage génomique basés sur les transformeurs, les jumeaux numériques de biologie synthétique et l'adoption plus large de l'IA façonnent désormais chaque couche applicative du marché de la biologie computationnelle. Une forte augmentation des ensembles de données multi-omiques, les évolutions continues vers les services de recherche sous contrat et le besoin d'une infrastructure cloud évolutive continuent d'alimenter la demande. L'Amérique du Nord ancre toujours le marché de la biologie computationnelle grâce à une réglementation biotechnologique mature, mais les investissements en supercalculateurs de l'Asie-Pacifique et l'expansion de sa base de fabrication pharmaceutique positionnent la région comme le prochain moteur de croissance. Par ailleurs, des acquisitions stratégiques telles que l'opération de 5,1 milliards USD de Siemens pour Dotmatics reflètent une consolidation croissante des plateformes au sein du marché de la biologie computationnelle.
Principaux Enseignements du Rapport
- Par application, la simulation cellulaire et biologique représentait 32,10 % de la part du marché de la biologie computationnelle en 2025, tandis que la découverte de médicaments et la modélisation des maladies devraient croître à un TCAC de 15,33 % jusqu'en 2031.
- Par outil, les bases de données détenaient la plus grande part de 35,95 % de la taille du marché de la biologie computationnelle en 2025 ; cependant, les logiciels d'analyse et les services devraient se développer à un TCAC de 14,49 % jusqu'en 2031.
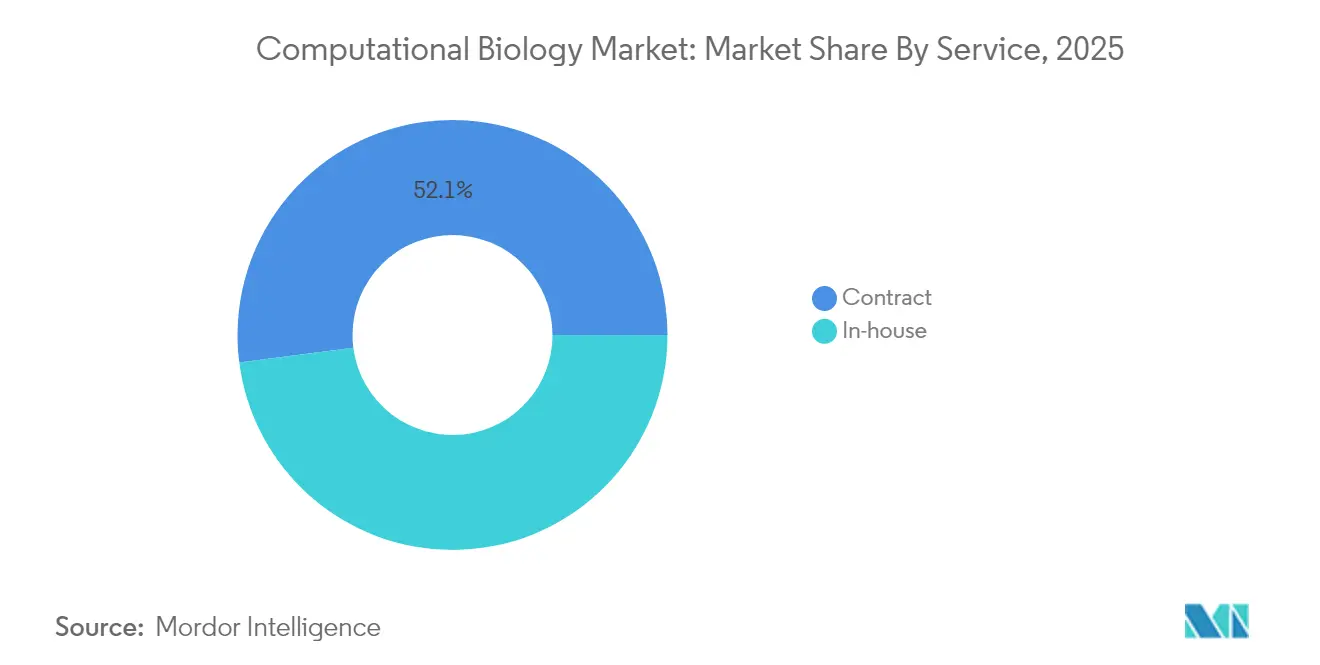
- Par modèle de service, les arrangements contractuels représentaient 52,05 % de la part du marché de la biologie computationnelle en 2025 et devraient progresser à un TCAC de 15,72 % jusqu'en 2031.
- Par utilisateur final, le secteur académique a conservé une part de revenus de 44,10 % en 2025, tandis que les utilisateurs industriels et commerciaux devraient afficher un TCAC de 14,27 % jusqu'en 2031.
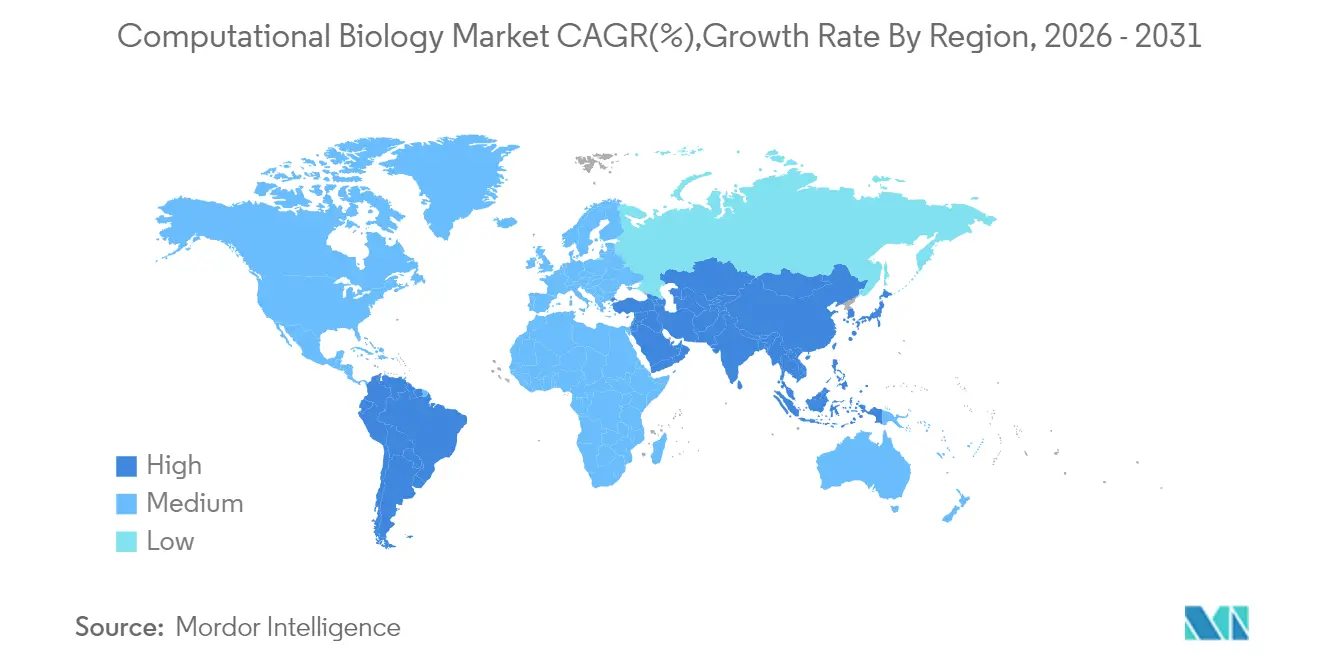
- Par région, l'Amérique du Nord était en tête avec une part de marché de la biologie computationnelle de 42,30 % en 2025 ; la région Asie-Pacifique affiche les perspectives de TCAC les plus rapides à 16,02 % jusqu'en 2031.
Remarque : Les chiffres de la taille du marché et des prévisions de ce rapport sont générés à l’aide du cadre d’estimation propriétaire de Mordor Intelligence, mis à jour avec les données et analyses les plus récentes disponibles en 2026.
Tendances et Perspectives Mondiales du Marché de la Biologie Computationnelle
Analyse de l'Impact des Facteurs Moteurs*
| Facteur Moteur | (~) % d'Impact sur les Prévisions de TCAC | Pertinence Géographique | Horizon Temporel de l'Impact |
|---|---|---|---|
| Volume croissant de données omiques et de recherche en bioinformatique | +2.8% | Mondial, concentré en Amérique du Nord et dans l'UE | Moyen terme (2 à 4 ans) |
| Utilisation accélérée dans la découverte de médicaments et la modélisation des maladies | +3.1% | Mondial, porté par l'Amérique du Nord, en expansion vers l'APAC | Court terme (≤ 2 ans) |
| Expansion des études cliniques de pharmacogénomique et de pharmacocinétique | +1.9% | Amérique du Nord et UE, émergent en APAC | Moyen terme (2 à 4 ans) |
| Modèles de langage génomique basés sur les transformeurs permettant une annotation rapide | +2.2% | Mondial, adoption précoce par les instituts de recherche | Court terme (≤ 2 ans) |
| Jumeaux numériques de biologie synthétique pour les flux de travail in silico | +1.7% | Amérique du Nord et UE, projets pilotes en APAC | Long terme (≥ 4 ans) |
| Algorithmes open source de traçage de lignée cellulaire unique | +1.5% | Mondial, portés par le milieu académique avec adoption industrielle | Moyen terme (2 à 4 ans) |
| Source: Mordor Intelligence | |||
Volume croissant de données omiques et de recherche en bioinformatique
Le séquençage de l'ARN unicellulaire à l'échelle du téraoctet, l'intégration multi-omique et la baisse des coûts de séquençage continuent d'élargir les flux de données vers le marché de la biologie computationnelle. Les avancées en matière de séquençage ont réduit les coûts du séquençage ARN de 50 à 70 %, élargissant l'accès aux ensembles de données de médecine de précision. Les grands modèles de langage automatisent désormais 94 % de la cartographie des éléments de données courants, favorisant l'interopérabilité.[1]Rodney Alan Long, Jordan Klebanoff et Vince D. Calhoun, « Une nouvelle norme de données assistée par l'IA accélère l'interopérabilité dans la recherche biomédicale », medRxiv, medrxiv.orgLes effets de réseau de données qui en résultent renforcent les avantages du premier entrant pour les parties prenantes contrôlant les plus grands référentiels. Les plateformes de bioinformatique cloud sont donc devenues une infrastructure obligatoire pour les organisations ne disposant pas de capacités de calcul haute performance sur site.
Utilisation accélérée dans la découverte de médicaments et la modélisation des maladies
Les modèles de langage protéique, tels qu'ESM-3, simulent des processus évolutifs, créant de nouveaux candidats protéiques à un rythme que les développeurs de médicaments n'auraient pu atteindre il y a quelques années. Les systèmes hybrides IA-quantique, illustrés par le GALILEO de Model Medicines, atteignent désormais un taux de réussite de 100 % dans les criblages antiviraux.[2]Équipe de communication de Model Medicines, « L'avenir de la découverte de médicaments : 2025 comme année d'inflexion pour l'IA hybride et l'informatique quantique », Model Medicines, modelmedicines.comLes jumeaux numériques permettent aux chercheurs d'effectuer des millions d'expériences virtuelles, comprimant ainsi les cycles de test d'hypothèses et réduisant les coûts de laboratoire humide. Un référentiel d'apprentissage automatique de 479 000 essais fournit des données d'entraînement sans précédent pour l'optimisation de la conception des essais. L'activité de fusions et acquisitions, telle que la fusion Recursion-Exscientia à 688 millions USD, montre que les acteurs établis s'empressent d'internaliser ces avantages de l'IA et de consolider leurs plateformes.
Expansion des études cliniques de pharmacogénomique et de pharmacocinétique
Les tests pharmacogénomiques préemptifs ont réduit les réactions indésirables aux médicaments psychiatriques de 34,1 % et les hospitalisations de 41,2 %.[3]Maria Skokou, Konstantinos Tziomalos et Georgios Papazisis, « Mise en œuvre clinique de la pharmacogénomique préemptive en psychiatrie », eBioMedicine, thelancet.com Les panels en conditions réelles montrent que 60,4 % des patients reçoivent au moins une prescription exploitable. L'UCLA a exploité une biobanque de 342 000 personnes pour identifier 156 gènes modulant l'efficacité des statines, prouvant que la diversité génétique améliore la précision des dosages. Les modèles PK/PD améliorés par l'IA tiennent désormais compte des variants spécifiques aux populations, une exigence à mesure que l'adoption de la pharmacogénomique en région Asie-Pacifique progresse.
Modèles de langage génomique basés sur les transformeurs permettant une annotation rapide
Les modèles protéiques open source offrent des performances comparables à AlphaFold tout en ne nécessitant que des GPU grand public. Les modèles de fondation d'ADN bidirectionnels, tels que JanusDNA, traitent 1 million de paires de bases sans matériel spécialisé. Les méthodes d'ajustement fin à efficacité paramétrique, telles que LoRA, réduisent les coûts d'entraînement tout en maintenant ou en améliorant la précision des prédictions en aval. Ces avancées démocratisent l'analyse avancée et abaissent les barrières à l'entrée, étendant le marché de la biologie computationnelle bien au-delà des centres de bioinformatique traditionnels.
Analyse de l'Impact des Facteurs Limitants*
| Facteur Limitant | (~) % d'Impact sur les Prévisions de TCAC | Pertinence Géographique | Horizon Temporel de l'Impact |
|---|---|---|---|
| Pénurie de talents multidisciplinaires | -1.8% | Mondial, aiguë en Amérique du Nord et dans l'UE | Court terme (≤ 2 ans) |
| Lacunes en matière d'interopérabilité et de normalisation des données | -1.2% | Mondial, notamment dans les collaborations transfrontalières | Moyen terme (2 à 4 ans) |
| Hausse des coûts cloud et de calcul | -0.9% | Mondial, effet le plus fort dans les marchés sensibles aux coûts | Court terme (≤ 2 ans) |
| Contrôle réglementaire en matière de biosécurité et de double usage | -0.7% | Principalement Amérique du Nord et UE, en expansion mondiale | Long terme (≥ 4 ans) |
| Source: Mordor Intelligence | |||
Pénurie de talents multidisciplinaires
La demande de professionnels ayant une expertise en biologie, en génie logiciel et en statistiques dépasse l'offre. Les employeurs des sciences de la vie anticipent un déficit de 35 % d'ici 2030, avec une demande d'embauche projetée à un taux annuel de 11,75 %. L'inflation salariale et les retards de projets s'ensuivent, en particulier pour les biotechs de taille moyenne qui rivalisent avec les géants technologiques entrant dans le domaine. L'embauche basée sur les compétences, les apprentissages et le recrutement intersectoriel sont des stratégies d'atténuation provisoires.
Lacunes en matière d'interopérabilité et de normalisation des données
Bien que les normes de métadonnées matricielles et d'analyse (MAMS) commencent à aligner les ensembles de données unicellulaires, une harmonisation large reste difficile à atteindre. Les outils de cartographie sémantique peuvent intégrer des dossiers de santé non structurés ; cependant, les charges de mise en œuvre ralentissent leur adoption. Les projets pilotes d'apprentissage fédéré protègent la vie privée mais se heurtent encore à une incertitude réglementaire, laissant les études multinationales dépendantes du nettoyage manuel des données.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des Segments
Par Application : La découverte de médicaments et la modélisation des maladies alimentent les flux de travail de nouvelle génération
La découverte de médicaments et la modélisation des maladies affichent déjà le TCAC le plus rapide à 15,33 %, tandis que la simulation cellulaire et biologique conservait une part de 32,10 % de la taille du marché de la biologie computationnelle en 2025. L'identification de cibles et l'optimisation des leads améliorées par l'IA permettent à des entreprises comme Insilico Medicine de cribler des millions de composés in silico. Les équipes précliniques intègrent désormais des ensembles de données génomiques, protéomiques et métabolomiques pour augmenter les chances de succès du composé jusqu'à la clinique. Les opérations d'essais cliniques utilisent des systèmes à récupération augmentée atteignant une précision de 97,9 % dans le criblage d'éligibilité, réduisant ainsi les goulots d'étranglement du recrutement. Un nombre croissant de chercheurs exploitent les jumeaux numériques pour mener des études virtuelles de réponse à la dose, réduisant ainsi les délais de laboratoire humide. Par conséquent, le marché de la biologie computationnelle connaît un engagement pharmaceutique plus profond à chaque étape de la R&D.
Le logiciel de simulation du corps humain émerge comme un sous-segment à fort potentiel. La « cellule virtuelle » pilotée par l'IA de Stanford illustre comment des modèles multi-omiques et biophysiques intégrés peuvent cartographier les perturbations des voies pour des stratégies thérapeutiques individualisées. Ce développement étend le marché de la biologie computationnelle aux cliniciens de médecine de précision en première ligne. À mesure que la fidélité des jumeaux numériques augmente, les assureurs commencent à évaluer des modèles de remboursement pour les plans de traitement optimisés par ordinateur, indiquant des opportunités potentielles pour des flux de revenus en aval.




Par Outil : Les logiciels d'analyse accélèrent l'intégration de l'IA
Les bases de données représentent toujours 35,95 % de la part du marché de la biologie computationnelle, mais les logiciels d'analyse et les services affichent la croissance la plus rapide à un TCAC de 14,49 %. Les modèles de langage protéique et génomique incitent les organisations à investir dans la capacité analytique plutôt qu'à maintenir des archives statiques. Les fournisseurs intègrent des pipelines de données multimodaux fusionnant des flux génomiques, protéomiques et cliniques. Ce changement encourage également les consortiums académiques-industriels à co-développer des piles open source ; la précision comparable à AlphaFold de Boltz-1 sur des GPU standard souligne comment l'innovation communautaire favorise une adoption plus large.
Le calcul haute performance sur site reste important pour le traitement des ensembles de données sensibles ; cependant, les courbes de coûts cloud et la maturité des services gérés encouragent la migration. Les fournisseurs se différencient par des algorithmes de mise à l'échelle automatique et des certifications de sécurité. Les acteurs établis dans les bases de données réagissent en construisant des couches analytiques au-dessus des référentiels pour défendre leur base installée. L'effet net accroît la concurrence tout en améliorant la qualité globale des logiciels, soutenant une croissance soutenue du marché de la biologie computationnelle.
Par Service : Les modèles contractuels dominent la croissance
Les services de recherche sous contrat dominent à la fois en part et en dynamique — 52,05 % en 2025 et un TCAC prévu de 15,72 % — alors que les entreprises pharmaceutiques externalisent des flux de travail in silico complexes. Les ORC regroupent désormais l'analyse génomique, le développement de modèles d'IA et le criblage virtuel dans des abonnements unifiés. Les équipes internes conservent les algorithmes essentiels à forte intensité de propriété intellectuelle mais s'associent à l'externe pour les simulations à forte intensité de calcul.
Les cadres de services hybrides gagnent du terrain. Les entreprises maintiennent des nœuds de gouvernance des données sur site tout en faisant appel à des plateformes ORC basées sur le cloud pour les charges de travail de pointe. Les alliances stratégiques distribuent les risques : les clients paient des frais basés sur l'utilisation, tandis que les fournisseurs garantissent des accords de niveau de service incluant un soutien réglementaire. À mesure que l'adoption augmente, le marché de la biologie computationnelle s'intègre davantage dans les chaînes de valeur traditionnelles du développement de médicaments.
Par Utilisateur Final : L'adoption industrielle s'accélère
Le secteur académique contrôlait 44,10 % des revenus en 2025, mais les utilisateurs industriels ont capté l'élan avec un TCAC de 14,27 % jusqu'en 2031. La baisse des coûts de séquençage, les pipelines d'IA validés et les délais thérapeutiques urgents stimulent l'adoption pharmaceutique. Les acheteurs d'entreprise recherchent des solutions clés en main intégrant des pistes d'audit et conformes aux réglementations BPx.
Les établissements académiques restent des moteurs de connaissance, pionniers d'algorithmes ensuite licenciés commercialement. Pour contrer les contraintes budgétaires, les universités développent des modèles de partenariat où les fournisseurs de technologie accordent des crédits de calcul en échange d'une co-signature et d'un accès anticipé aux retours. Cette symbiose maintient les entonnoirs d'innovation pour le secteur de la biologie computationnelle.
Analyse Géographique
L'Amérique du Nord, représentant 42,30 % des revenus de 2025, bénéficie d'un capital-risque biotechnologique profond, d'un engagement réglementaire mature et d'un vivier de talents dense. Le cadre évolutif de la FDA en matière d'IA offre aux entreprises locales un chemin de commercialisation plus direct que beaucoup de leurs homologues. L'investissement domestique pluriannuel de 2 milliards USD de Thermo Fisher souligne la confiance dans l'évolutivité des infrastructures ; néanmoins, les pénuries de main-d'œuvre et la hausse des coûts cloud tempèrent l'accélération.
L'Asie-Pacifique affiche le TCAC le plus élevé à 16,02 %. Les gouvernements financent des supercalculateurs exaflops — le plan de la Corée du Sud vise un lancement d'ici 2025 — tandis que les centres nationaux distribués de la Chine propulsent déjà des projets multi-omiques. La fabrication pharmaceutique régionale est en plein essor, et les programmes de recherche sur la diversité génétique adaptent les modèles d'IA aux populations locales, créant des actifs de données de cas limites indisponibles ailleurs. Les projets pilotes d'essais cliniques décentralisés et le développement de plateformes ARNm renforcent la demande à long terme pour les capacités du marché de la biologie computationnelle.
L'Europe maintient une croissance régulière, ancrée par des consortiums transfrontaliers et de solides garanties en matière de protection des données. Les initiatives d'IA éthique augmentent les charges de conformité, mais favorisent également la confiance parmi les payeurs et les régulateurs. Les projets pilotes de jumeaux numériques s'alignent sur les objectifs de santé publique pour optimiser l'utilisation des ressources. Pendant ce temps, l'Amérique latine, l'Afrique et le Moyen-Orient progressent à mesure que l'infrastructure internet et les programmes de bioinformatique se développent. Les partenariats avec des groupes pharmaceutiques multinationaux compensent les lacunes de financement locales, assurant une pénétration de marché progressive mais persistante en biologie computationnelle.

Paysage Concurrentiel
Le marché de la biologie computationnelle reste modérément fragmenté, mais affiche une tendance claire aux fusions et acquisitions. L'acquisition de Dotmatics par Siemens pour 5,1 milliards USD intègre l'informatique de laboratoire aux offres de jumeaux numériques industriels, reflétant le désir des acheteurs de disposer de piles de bout en bout. Danaher a intégré Genedata dans son portefeuille, suivant la même logique. Illumina collabore avec NVIDIA pour accélérer l'analyse omique propulsée par GPU, un exemple de convergence technologie-biotechnologie.
Les start-ups s'appuient sur les communautés open source pour peser au-delà de leur taille. EvolutionaryScale a levé 142 millions USD pour commercialiser une IA générant des protéines qui concurrence directement les chimies propriétaires des acteurs établis. Les dépôts de brevets autour des modèles hybrides quantiques-classiques et des algorithmes de traçage de lignée suggèrent une intensification des batailles de propriété intellectuelle. Le succès concurrentiel dépendra de l'accès à des ensembles de données organisés, d'un calcul évolutif et de flux de travail intégrés minimisant les coûts de changement.
Les grands fournisseurs poursuivent le verrouillage de l'écosystème par le biais de licences par abonnement et d'effets de réseau de données. Les acteurs de niveau intermédiaire se différencient par une spécialisation verticale — analytique unicellulaire, moteurs de jumeaux numériques ou boîtes à outils de pharmacogénomique. La concurrence par les prix est atténuée car la précision, la conformité réglementaire et la rapidité d'exécution restent des facteurs d'achat décisifs.
Leaders du Secteur de la Biologie Computationnelle
Dassault Systèmes SE
Schrödinger Inc.
Certara
Simulation Plus Inc.
Illumina Inc.
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Développements Récents du Secteur
- Juin 2025 : Illumina a acquis SomaLogic pour un montant pouvant atteindre 425 millions USD afin d'élargir ses capacités en protéomique et en biomarqueurs, agrandissant ainsi son portefeuille multi-omique.
- Avril 2025 : Siemens a finalisé le rachat de Dotmatics pour 5,1 milliards USD, fusionnant l'informatique de R&D avec les cadres de jumeaux numériques industriels.
- Février 2025 : Illumina a publié des lectures cartographiées par constellation et des solutions de séquençage à 5 bases, prévues pour un déploiement commercial en 2026.
- Janvier 2025 : Illumina s'est associée à NVIDIA pour accélérer les pipelines de données multi-omiques à l'aide de GPU, ciblant une découverte thérapeutique plus rapide.


Cadre de la méthodologie de recherche et portée du rapport
Définitions du marché et périmètre de couverture
Notre étude définit le marché de la biologie computationnelle comme l'ensemble des plateformes logicielles, des outils d'infrastructure et des bases de données spécialisées qui déploient des techniques de modélisation mathématique, d'analyse de données et de simulation pour interroger des ensembles de données biologiques, chimiques et cliniques dans le cadre des flux de travail liés à la découverte de médicaments, à la modélisation des maladies, à la génomique et à la protéomique. Selon Mordor Intelligence, les revenus sont comptabilisés au moment où un fournisseur concède sous licence ou met à disposition une solution ou un service à un utilisateur final, indépendamment du modèle d'hébergement ou du niveau commercial.
Exclusion du périmètre : Les logiciels académiques gratuits et les codes open source distribués sans support monétisé ne sont pas comptabilisés.
Aperçu de la segmentation
- Par Application
- Simulation Cellulaire et Biologique
- Génomique Computationnelle
- Protéomique Computationnelle
- Pharmacogénomique
- Autres Simulations (Transcriptomique/Métabolomique)
- Découverte de Médicaments et Modélisation des Maladies
- Identification des Cibles
- Validation des Cibles
- Découverte de Leads
- Optimisation des Leads
- Développement Préclinique de Médicaments
- Pharmacocinétique
- Pharmacodynamique
- Essais Cliniques
- Phase I
- Phase II
- Phase III
- Logiciels de Simulation du Corps Humain
- Simulation Cellulaire et Biologique
- Par Outil
- Bases de Données
- Infrastructure (Matériel)
- Logiciels d'Analyse et Services
- Par Service
- Interne
- Contrat
- Par Utilisateur Final
- Académiques
- Industrie et Commerciaux
- Par Géographie
- Amérique du Nord
- États-Unis
- Canada
- Mexique
- Europe
- Allemagne
- Royaume-Uni
- France
- Italie
- Espagne
- Reste de l'Europe
- Asie-Pacifique
- Chine
- Japon
- Inde
- Australie
- Corée du Sud
- Reste de l'Asie-Pacifique
- Moyen-Orient et Afrique
- CCG
- Afrique du Sud
- Reste du Moyen-Orient et de l'Afrique
- Amérique du Sud
- Brésil
- Argentine
- Reste de l'Amérique du Sud
- Amérique du Nord
Méthodologie de recherche détaillée et validation des données
Recherche primaire
Les analystes de Mordor ont ensuite interrogé des architectes logiciels, des bioinformaticiens de CRO, des directeurs de centres de ressources académiques et des responsables des achats en Amérique du Nord, en Europe et dans les principaux pôles d'Asie-Pacifique. Les discussions ont permis de valider les fourchettes de dépenses, les niveaux de prix typiques, les courbes d'adoption des clusters de calcul haute performance et les flux de travail émergents basés sur l'IA, nous permettant d'affiner les hypothèses du modèle que les sources secondaires ne pouvaient pas quantifier.
Recherche documentaire
Nous avons d'abord cartographié l'univers des dépenses adressables à partir de sources publiques telles que les tableaux budgétaires du NIH des États-Unis, les registres d'essais cliniques de la FDA, les fichiers de dépenses en R&D d'Eurostat, les catalogues de projets du ministère chinois des Sciences et les comptages de brevets issus de la plateforme Questel. Ces sources permettent d'établir dans quelle mesure la recherche financée peut se traduire par une demande payante d'outils computationnels. Des données complémentaires proviennent des rapports 10-K des entreprises, des présentations aux investisseurs, des revues à comité de lecture indexées sur PubMed, des portails d'associations tels que l'International Society for Computational Biology, et des flux d'actualités sélectionnés via Dow Jones Factiva. L'examen documentaire a constitué une ossature factuelle tout en mettant en évidence les lacunes de données nécessitant une démarche directe. Cette liste est illustrative ; de nombreuses autres références ont alimenté les vérifications et clarifications intermédiaires.
Dimensionnement du marché et prévisions
Une construction descendante ancrée sur les dépenses de R&D en sciences du vivant divulguées publiquement, les volumes de séquençage de nouvelle génération et les taux de pénétration des licences en vigueur établit la valeur initiale de 2025. Les agrégations fournisseurs de prix de vente moyens échantillonnés multipliés par la base installée, les vérifications des canaux sur les frais d'utilisation du cloud et les statistiques d'importation pour le matériel dédié servent de miroirs ascendants sélectifs, permettant de réconcilier les totaux. Les variables clés suivies comprennent : a) les projets de génomique financés, b) les tendances du coût par génome, c) les heures de calcul moyennes par expérience in silico, d) les comptages de pipelines de produits biologiques, e) les annonces de partenariats public-privé en matière d'IA, et f) les expéditions de GPU serveur vers les clusters biopharma. Les prévisions utilisent une régression multivariée combinée à une analyse de scénarios, avec des pondérations soumises à des tests de résistance par rapport au consensus d'experts avant que les perspectives à cinq ans ne soient arrêtées. Les lacunes résiduelles dans les données fournisseurs sont comblées par une interpolation prudente à l'aide de coefficients d'utilisation spécifiques à chaque région.
Cycle de validation des données et de mise à jour
Les résultats passent par un examen en trois couches : vérifications des écarts par rapport aux séries historiques, comparaison croisée avec d'autres signaux de données et audits par des analystes seniors. Le modèle est actualisé annuellement, et une révision intermédiaire est déclenchée en cas de chocs de financement, d'opérations de M&A majeures ou de changements réglementaires perturbateurs ; une révision finale avant publication garantit que les clients reçoivent toujours la vue la plus récente.
Pourquoi la base de référence de Mordor en biologie computationnelle inspire confiance
Les estimations publiées divergent souvent parce que les entreprises définissent le marché différemment, convertissent les devises sur des années de base distinctes ou intègrent des primes de croissance non vérifiées.
Les principaux facteurs d'écart incluent la prise en compte ou non des logiciels académiques gratuits, la méthode d'annualisation des abonnements cloud hybrides, et la question de savoir si les outils intégrés dans des suites bioinformatiques plus larges sont dissociés. Le périmètre de Mordor exclut les logiciels gratuits non monétisés, applique une base de référence de change transparente pour 2025 et réévalue les taux d'adoption tous les douze mois, évitant ainsi les surestimations ou sous-estimations qui peuvent survenir lorsque les cycles d'actualisation s'allongent.
Comparaison de référence
| Taille du marché | Source anonymisée | Principal facteur d'écart |
|---|---|---|
| 7,24 Md USD (2025) | Mordor Intelligence | - |
| 5,90 Md USD (2024) | Global Consultancy A | Inclut uniquement les revenus des plateformes logicielles ; omet les couches d'infrastructure et de bases de données |
| 7,18 Md USD (2025) | Industry Association B | Comptabilise certains projets open source financés par des fonds publics comme des équivalents payants |
| 9,13 Md USD (2025) | Regional Consultancy C | Agrège des services bioinformatiques adjacents, gonflant la valeur totale |
En résumé, la définition rigoureuse du périmètre, les variables vérifiées deux fois et la cadence de mise à jour régulière employées par Mordor Intelligence fournissent aux décideurs une base de référence équilibrée et traçable, évitant à la fois les surestimations optimistes et les sous-estimations conservatrices courantes ailleurs.


Questions Clés Répondues dans le Rapport
Quelle est la taille actuelle du marché de la biologie computationnelle ?
Le marché de la biologie computationnelle génère 8,17 milliards USD en 2026 et est en bonne voie pour atteindre 14,89 milliards USD d'ici 2031.
Quel domaine d'application se développe le plus rapidement ?
La découverte de médicaments et la modélisation des maladies affichent le TCAC le plus élevé à 15,33 % jusqu'en 2031, portées par l'identification de cibles assistée par l'IA et les flux de travail de jumeaux numériques.
Pourquoi les services de recherche sous contrat connaissent-ils une croissance rapide ?
Les entreprises pharmaceutiques externalisent la modélisation à forte intensité de données à des ORC spécialisées, conférant aux services contractuels une part de 52,05 % et un taux de croissance de 15,72 %.
Quelle région contribuera le plus à la croissance future ?
L'Asie-Pacifique est en tête avec un TCAC de 16,02 % grâce aux projets gouvernementaux de supercalculateurs et à l'expansion rapide de la fabrication pharmaceutique.
Qu'est-ce qui freine l'adoption plus large des plateformes de biologie computationnelle ?
Une pénurie de talents multidisciplinaires, la hausse des coûts de calcul cloud et l'évolution des réglementations en matière de biosécurité constituent les principales contraintes.
Dernière mise à jour de la page le:




