Taille et part du marché de la bioinformatique
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2020 - 2031 |
|---|---|
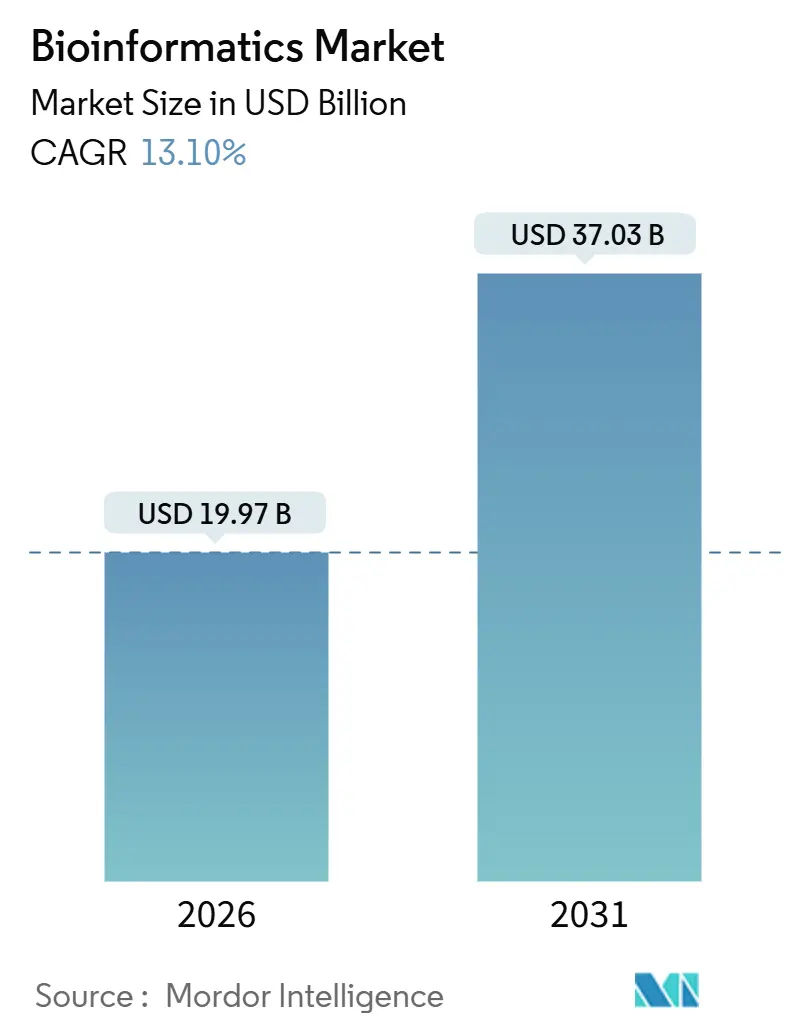
| Taille du Marché (2026) | 19.97 Milliards de dollars |
| Taille du Marché (2031) | 37.03 Milliards de dollars |
| Taux de croissance (2026 - 2031) | 13.10% CAGR |
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Amérique du Nord |
| Concentration du Marché | Moyen |
Acteurs majeurs *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. | |
Analyse du marché de la bioinformatique par Mordor Intelligence
La taille du marché de la bioinformatique est estimée à 19,97 milliards USD en 2026, et devrait atteindre 37,03 milliards USD d'ici 2031, avec un CAGR de 13,10 % au cours de la période de prévision (2026-2031).
Un pipeline en expansion d'études multi-omiques, une pression réglementaire croissante en faveur des diagnostics de précision et le pivot du secteur pharmaceutique vers une R&D centrée sur les données continuent de repositionner les plateformes de bioinformatique, qui passent d'outils tactiques à une infrastructure d'entreprise. Les hyperscalers du cloud intègrent des services optimisés pour la génomique qui font passer les dépenses d'investissement vers des modèles basés sur la consommation, tandis que l'analytique de proximité des instruments réduit la latence et les coûts de sortie des données dans les laboratoires cliniques. Les fournisseurs qui combinent des algorithmes natifs à l'IA avec un calcul élastique captent la plus grande part des nouveaux déploiements, même si les lacunes en matière de cybersécurité et de main-d'œuvre tempèrent la scalabilité à court terme. Le paysage concurrentiel qui en résulte est défini par la convergence : les fabricants d'instruments de séquençage, les organisations de recherche sous contrat et les start-ups logicielles se disputent désormais la même pile analytique.
Points clés du rapport
- Par produits et services, les plateformes de bioinformatique ont dominé avec une part de revenus de 48,1 % en 2025, tandis que les services de bioinformatique progressent à un CAGR de 14,1 % jusqu'en 2031.
- Par application, la génomique et la transcriptomique ont représenté 34,6 % de la taille du marché de la bioinformatique en 2025, tandis que la protéomique et la métabolomique devraient se développer à un CAGR de 14,43 % jusqu'en 2031.
- Par utilisateur final, les entreprises pharmaceutiques et biotechnologiques ont représenté 40,2 % de la part du marché de la bioinformatique en 2025 ; les organisations de recherche sous contrat constituent le segment à la croissance la plus rapide avec un CAGR de 13,98 % jusqu'en 2031.
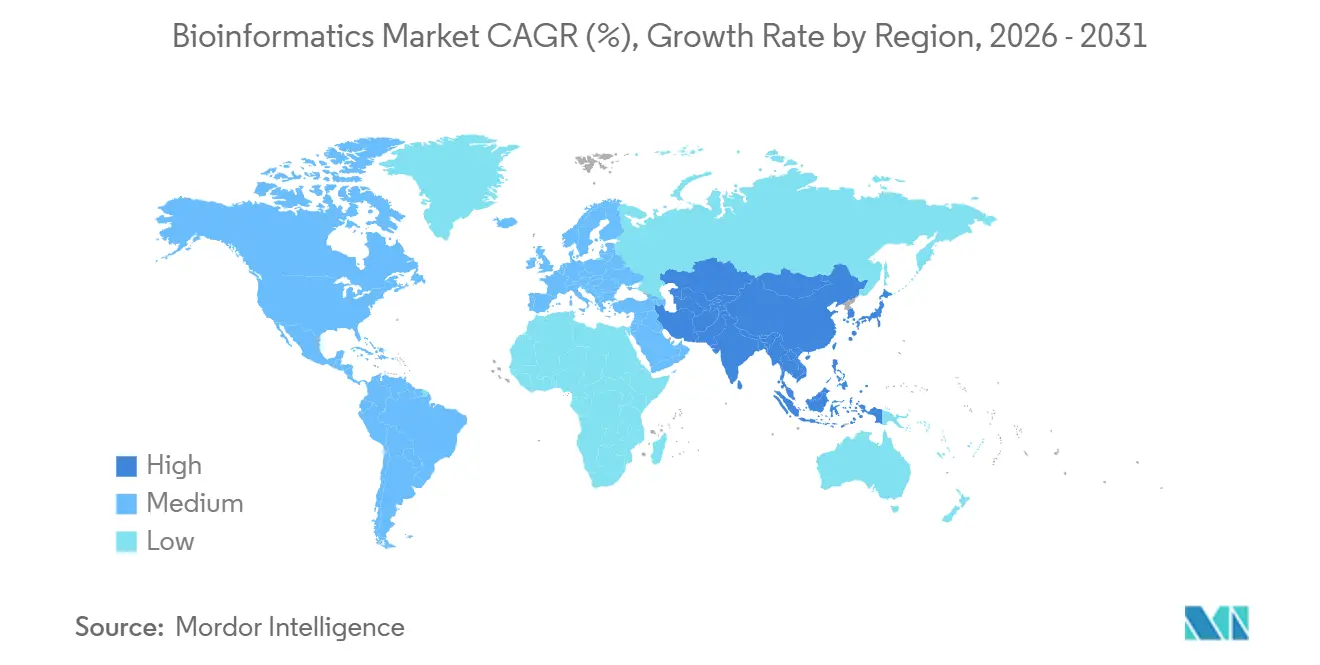
- Par géographie, l'Amérique du Nord détenait une part de 39,4 % en 2025, mais l'Asie-Pacifique devrait enregistrer un CAGR de 14,89 % jusqu'en 2031.
Note : La taille du marché et les prévisions figurant dans ce rapport sont générées à l'aide du cadre d'estimation exclusif de Mordor Intelligence, mis à jour avec les dernières données et informations disponibles en janvier 2026.
Tendances et perspectives du marché mondial de la bioinformatique
Analyse de l'impact des moteurs*
| Moteur | (~) % d'impact sur les prévisions de CAGR | Pertinence géographique | Horizon temporel d'impact |
|---|---|---|---|
| Explosion des volumes de données multi-omiques | +2.8% | Mondial, pic en Amérique du Nord et en Chine | Court terme (≤ 2 ans) |
| Médecine de précision et diagnostics compagnons | +2.5% | Amérique du Nord, Europe, Japon | Moyen terme (2-4 ans) |
| Transition pharma-biotech vers une R&D centrée sur les données | +2.2% | Mondial, porté par l'Amérique du Nord et l'Europe | Moyen terme (2-4 ans) |
| Initiatives génomiques financées par les gouvernements | +1.9% | Amérique du Nord, Royaume-Uni, Chine, Inde | Long terme (≥ 4 ans) |
| Traitement en périphérie ou à proximité des instruments | +1.6% | Amérique du Nord, Europe, cœur de l'Asie-Pacifique | Court terme (≤ 2 ans) |
| Places de marché de modèles d'IA | +1.4% | Mondial, adoption précoce en Amérique du Nord | Moyen terme (2-4 ans) |
| Source: Mordor Intelligence | |||
Explosion des volumes de données multi-omiques
Le débit de séquençage a dépassé 20 pétabases par instrument et par an, mais l'infrastructure de stockage et de calcul est à la traîne par rapport à la demande, créant des goulots d'étranglement que les plateformes de bioinformatique doivent résoudre. Le coût du séquençage d'un génome humain est tombé en dessous de 200 USD en 2024, mais l'analyse en aval coûte désormais trois à cinq fois ce montant, ce qui stimule les investissements dans les algorithmes de compression et l'apprentissage fédéré qui traitent les données in situ. Les commanditaires pharmaceutiques intègrent de plus en plus des ensembles de données génomiques, transcriptomiques, protéomiques et métabolomiques provenant de cohortes de patients identiques, un flux de travail qui dépend de clusters GPU et d'un stockage d'objets optimisé pour des charges de travail à l'échelle du pétaoctet. Des fournisseurs de cloud tels qu'AWS, Google Cloud et Microsoft Azure répondent avec des pipelines gérés qui accélèrent l'appel de variants et l'annotation. Les appareils de périphérie intégrés dans les séquenceurs minimisent davantage les frais de transfert de données en gérant l'appel de bases et l'analyse primaire localement. Ensemble, ces dynamiques soutiennent des dépenses à deux chiffres en calcul élastique, même si les coûts de séquençage par échantillon diminuent.
Adoption de la médecine de précision et des diagnostics compagnons
Les approbations réglementaires pour les diagnostics compagnons ont augmenté en 2025 par rapport à 2024, renforçant ainsi la nécessité de pipelines capables de détecter des altérations génomiques complexes avec une précision de niveau clinique. Les thérapies agnostiques de la tumeur ciblant les fusions NTRK et les signatures MSI-élevées nécessitent des panels interrogeant plus de 300 gènes, ce qui fait évoluer la demande des tests monogéniques vers le profilage complet. L'Agence européenne des médicaments a finalisé en 2024 des orientations qui imposent une validation analytique sur des cohortes ethniques diverses, incitant à l'expansion des ensembles de données de référence et des algorithmes tenant compte de l'ethnicité. Le Japon a ajouté des codes de remboursement pour la surveillance par biopsie liquide en 2025, catalysant l'adoption d'outils qui suivent la dynamique de l'ADN tumoral circulant. Collectivement, ces politiques ancrent les dépenses de bioinformatique en oncologie, tout en se répercutant sur la cardiologie et les maladies rares à mesure que les payeurs reconnaissent la valeur pharmacoéconomique des thérapeutiques stratifiées.
Transition pharma-biotech vers une R&D centrée sur les données
Les pipelines pharmaceutiques s'appuient désormais sur la génération d'hypothèses in silico pour raccourcir les cycles en laboratoire humide. La publication en accès libre par AlphaFold de 200 millions de structures protéiques a démontré que des années de cristallographie peuvent être compressées en quelques heures de temps GPU, accélérant la conception de médicaments guidée par la structure. La découverte d'anticorps bénéficie particulièrement de modèles génératifs entraînés sur des données de répertoire immunitaire qui proposent des liants avec une développabilité prédite, réduisant considérablement les pools de candidats. Les grands commanditaires élargissent donc leurs unités d'IA internes tout en s'associant à des fournisseurs qui proposent des flux de travail de prédiction de structure clés en main. Les organisations de recherche sous contrat développent des capacités similaires auprès de plusieurs clients, convertissant l'infrastructure en services facturables et stimulant l'adoption parmi les start-ups biotechnologiques à ressources limitées.
Initiatives génomiques financées par les gouvernements
Le programme NIH All of Us a publié des séquences de génome entier pour 245 000 participants en 2025, créant la plus grande cohorte ethniquement diverse pour la recherche en médecine de précision [1]National Institutes of Health, "Mise à jour du programme de recherche All of Us," nih.gov. La Biobanque du Royaume-Uni a ajouté des couches protéomiques et métabolomiques pour 50 000 volontaires, produisant des ensembles de données intégrés que les laboratoires académiques exploitent pour les biomarqueurs cardiovasculaires. Le Centre national de données génomiques de Chine stocke désormais plus de 10 pétaoctets de données de séquençage, permettant la construction de génomes de référence spécifiques à la population qui améliorent l'interprétation des variants pour les cohortes asiatiques. Le projet Genome India a terminé le séquençage de 10 000 individus, posant les bases d'études d'optimisation des doses qui réduisent les effets indésirables liés aux allèles CYP2C19 et CYP2D6. Ces initiatives à grande échelle stimulent la construction de clouds nationaux et alimentent des partenariats analytiques transfrontaliers.
Analyse de l'impact des freins*
| Frein | (~) % d'impact sur les prévisions de CAGR | Pertinence géographique | Horizon temporel d'impact |
|---|---|---|---|
| Pénurie de bioinformaticiens qualifiés | -1.8% | Mondial, aiguë en Amérique du Nord et en Europe | Moyen terme (2-4 ans) |
| Normes de données fragmentées | -1.4% | Mondial, perturbateur dans les essais multi-sites | Long terme (≥ 4 ans) |
| Risques liés à la cybersécurité et à la confidentialité des données génomiques | -1.2% | Mondial, forte pression réglementaire en Occident | Court terme (≤ 2 ans) |
| Hausse des frais de sortie du cloud et de stockage à long terme | -1.0% | Mondial, aiguë pour les projets à l'échelle de la population | Moyen terme (2-4 ans) |
| Source: Mordor Intelligence | |||
Pénurie de bioinformaticiens qualifiés
Les programmes académiques ont diplômé environ 8 500 biologistes computationnels en 2025, contre une demande industrielle de plus de 15 000 nouvelles recrues, creusant un déficit de talents qui fait grimper les salaires au-delà de 150 000 USD pour les professionnels en milieu de carrière [2]Bureau of Labor Statistics des États-Unis, "Perspectives professionnelles pour les scientifiques en bioinformatique," bls.gov. Les entreprises lancent des formations internes pour perfectionner les biologistes moléculaires en Python et R, tandis que les fournisseurs de plateformes intègrent des interfaces sans code pour élargir l'utilisabilité. Les viviers de talents offshore en Inde et en Europe de l'Est offrent un soulagement partiel, bien que les contraintes de fuseau horaire et de souveraineté des données limitent les flux de travail impliquant des informations de santé protégées.
Risques liés à la cybersécurité et à la confidentialité des données génomiques
Les attaques par rançongiciel ciblant les ensembles de données génomiques ont augmenté de manière significative d'une année sur l'autre en 2025, obligeant les laboratoires à mettre à niveau leurs architectures de confiance zéro et à se conformer à une application plus stricte de la HIPAA et du RGPD. Les primes d'assurance pour la couverture cybernétique ont fortement augmenté, et certains payeurs exigent désormais des tests de pénétration externes comme condition préalable au remboursement des tests génomiques. Le chiffrement au repos et l'analyse fédérée atténuent l'exposition mais ajoutent des coûts supplémentaires qui réduisent les marges des centres de diagnostic plus petits.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des segments
Par produits et services : les plateformes dominent tandis que les services cloud s'accélèrent
Les plateformes ont représenté 48,1 % du marché de la bioinformatique en 2025, portées par des flux de travail d'analyse de séquences étroitement couplés aux instruments Illumina et Oxford Nanopore. Dans cette catégorie, le déploiement cloud basé sur la consommation gagne des parts de marché à mesure que les laboratoires migrent des clusters sur site en cours d'amortissement. Les services progressent à un CAGR de 14,1 % jusqu'en 2031 en convertissant les dépenses d'investissement en charges d'exploitation variables et en regroupant des cadres de conformité qui satisfont aux exigences CLIA et CE-IVDR. L'analyse de séquences reste au cœur du dispositif, mais les modules d'intégration multi-omiques et de gestion des connaissances regroupent désormais des bases de données graphiques et des moteurs d'exploration de texte qui font émerger les informations sur les voies métaboliques plus rapidement que la curation manuelle. Les fournisseurs de plateformes qui ne peuvent pas fournir à la fois des bases de code cloud et de périphérie font face à des pressions de consolidation, comme en témoignent les récentes fusions de niveau intermédiaire.
Les services de bioinformatique captent une part croissante des dépenses des petites biotechs et des laboratoires académiques qui manquent d'équipes computationnelles internes. Les hyperscalers amplifient cette tendance en intégrant des boîtes à outils génomiques — AWS HealthOmics, API Google Cloud Life Sciences — dans des offres cloud plus larges, souvent tarifées en dessous du coût pour stimuler la consommation de stockage et de calcul. En conséquence, la taille du marché de la bioinformatique attribuable aux licences logicielles autonomes est en déclin, même si les dépenses globales augmentent. Les frais d'abonnement et par échantillon remplacent les revenus matériels ponctuels, alignant les incitations des fournisseurs sur les volumes de données des clients. Les outils de gestion des connaissances monétisent toujours la qualité de la curation, mais les ressources en accès libre érodent leur pouvoir de fixation des prix, déplaçant l'accent vers des algorithmes propriétaires qui s'intègrent aux cahiers de laboratoire électroniques et aux systèmes d'information de laboratoire.
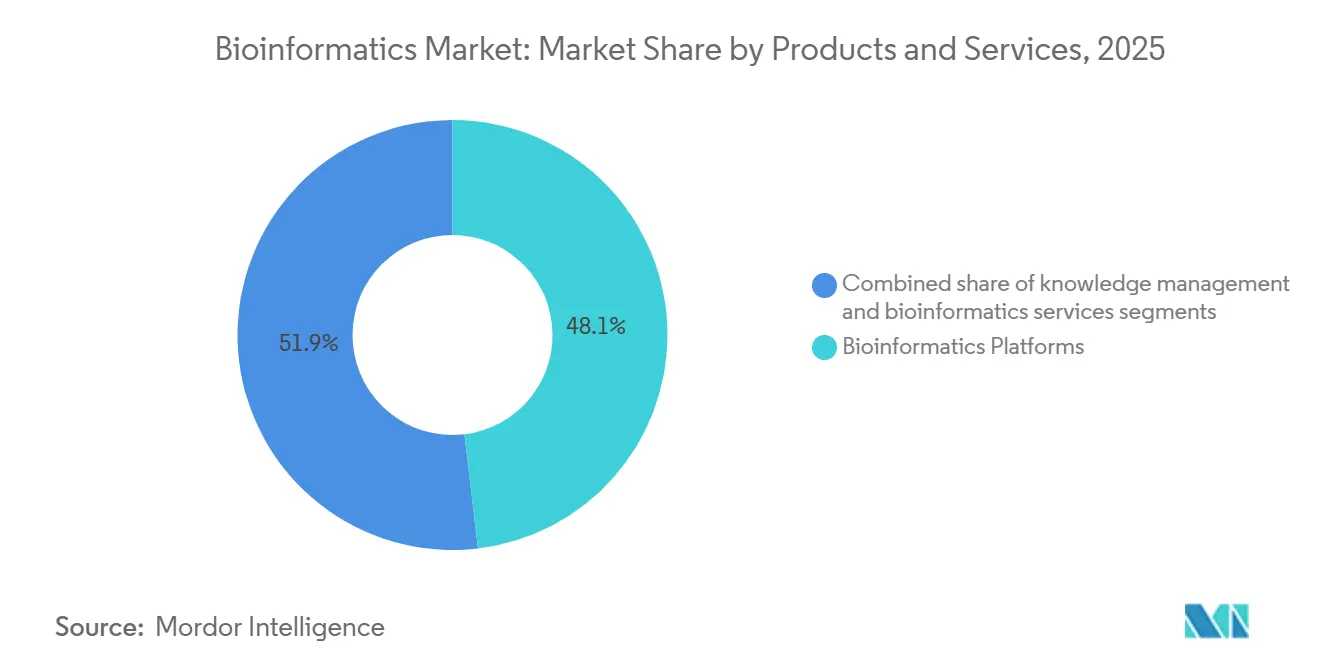
Note: Les parts de segments de tous les segments individuels sont disponibles à l'achat du rapport


Par application : la protéomique émerge comme leader de la croissance
La génomique et la transcriptomique détenaient 34,6 % de la taille du marché de la bioinformatique en 2025, ancrées par les programmes de séquençage nationaux et les diagnostics en oncologie. La protéomique et la métabolomique enregistrent cependant un CAGR de 14,43 % jusqu'en 2031, portées par les avancées en spectrométrie de masse qui quantifient plus de 10 000 protéines par échantillon. Les techniques spatiales superposent les signaux moléculaires sur l'architecture tissulaire, stimulant la demande de visualisation accélérée par GPU. Les pipelines de découverte de médicaments intègrent des algorithmes de prédiction de structure avec la chimie générative pour réduire les délais précliniques, tandis que la génomique microbienne gagne en urgence à mesure que les gouvernements surveillent la résistance aux antimicrobiens.
Les cas d'usage de la médecine de précision passent de la recherche à la clinique, avec des étiquettes pharmacogénomiques approuvées par la FDA dépassant 400 en 2025. La génomique agricole et environnementale progresse également à mesure que les régulateurs évaluent les cultures éditées par CRISPR pour les effets hors cible. Le séquençage unicellulaire associe l'imagerie et l'omique, produisant des ensembles de données à l'échelle du téraoctet qui nécessitent une analytique en temps réel et un calcul en périphérie. Collectivement, ces applications émergentes rééquilibrent les portefeuilles des fournisseurs et réduisent la dépendance aux revenus mono-omiques.
Par utilisateur final : les ORC capitalisent sur la vague d'externalisation
Les entreprises pharmaceutiques et biotechnologiques ont généré 40,2 % de la demande en 2025, déployant des clouds privés qui intègrent les données expérimentales aux soumissions réglementaires. Les organisations de recherche sous contrat dépassent les autres groupes avec un CAGR de 13,98 %, tirant parti d'une infrastructure partagée pour amortir le calcul entre les commanditaires et fournir des rapports analytiques clés en main. Les instituts académiques et de recherche restent influents mais perdent des parts à mesure que le financement par subventions plafonne.
Les laboratoires cliniques et de diagnostic intègrent des pipelines réglementés conformes aux listes de contrôle CLIA et CAP, une démarche qui élève la demande de moteurs d'interprétation de variants validés. Les entreprises de tests agri-génomiques et environnementaux, bien que de niche, connaissent une croissance rapide à mesure que les semenciers mettent en œuvre la sélection génomique. Les acquisitions d'ORC de fournisseurs de plateformes, comme l'achat en 2024 par IQVIA d'une division génomique, illustrent l'intégration verticale qui capture plus de valeur par échantillon.
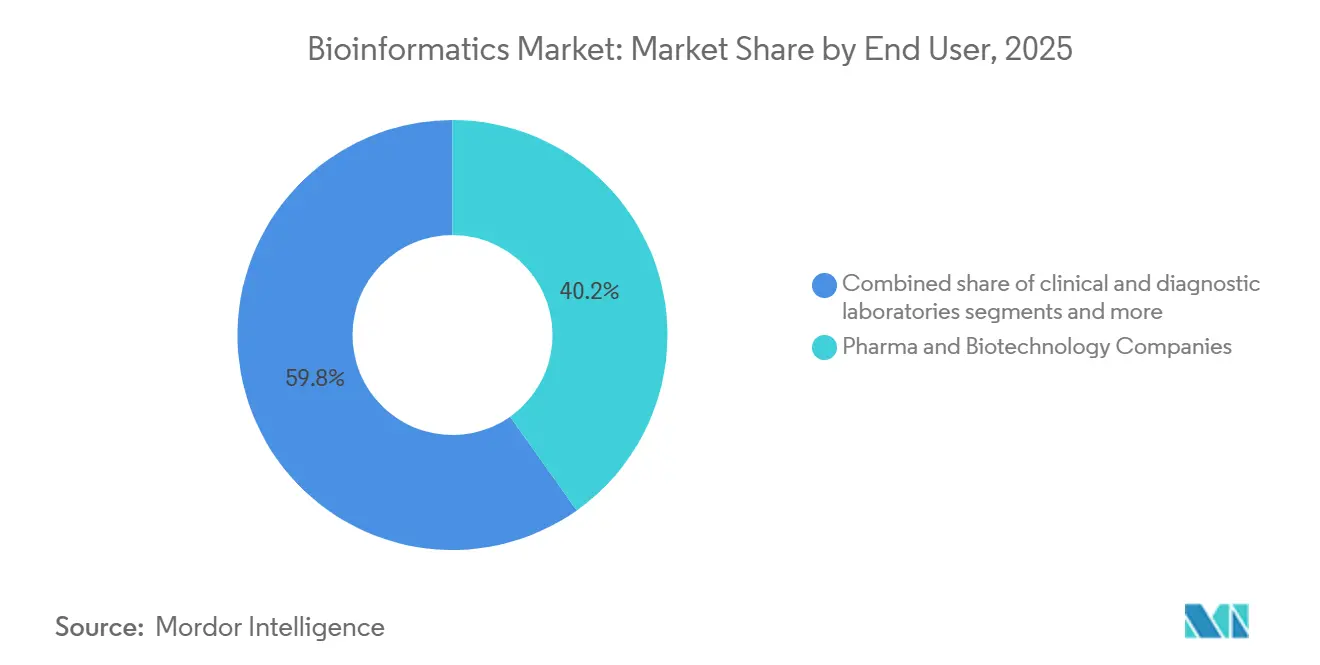
Note: Les parts de segments de tous les segments individuels sont disponibles à l'achat du rapport
Analyse géographique
L'Amérique du Nord a représenté 39,4 % du marché de la bioinformatique en 2025, soutenue par une dense concentration de sièges sociaux pharmaceutiques, de centres académiques et de financements en capital-risque. Les orientations de la FDA publiées en 2024 ont renforcé les normes de validité clinique pour les tests de séquençage de nouvelle génération, prolongeant les cycles de développement tout en augmentant la complexité globale de l'analyse des données. Les réseaux d'onco-précision du Canada déploient des plateformes fédérées conformes aux lois provinciales sur la protection de la vie privée, et les producteurs de biosimilaires du Mexique adoptent des outils de bioinformatique pour les protocoles de comparabilité, diversifiant la demande régionale.
La région Asie-Pacifique devrait se développer à un CAGR de 14,89 % jusqu'en 2031, l'écosystème génomique parrainé par l'État chinois augmentant sa capacité de séquençage et intégrant verticalement les plateformes analytiques [3]BGI Genomics, "Présentation aux relations investisseurs," bgi.com. L'Inde incube des start-ups qui localisent les pipelines pour les haplotypes sud-asiatiques, et le Japon élargit le remboursement pour les panels de plus de 500 gènes, poussant les hôpitaux à adopter des logiciels de niveau clinique. L'Australie et la Corée du Sud investissent dans des programmes nationaux de médecine de précision qui associent le cloud computing à des centres de données souverains, garantissant la conformité avec les lois nationales sur la cybersécurité.
Le règlement européen sur les dispositifs de diagnostic in vitro, applicable depuis 2024, oblige les logiciels utilisés dans les diagnostics à obtenir la certification CE-IVDR, augmentant les coûts de conformité des fournisseurs. Le Centre national du génome d'Allemagne centralise les flux de travail sur les maladies rares, tandis que le Royaume-Uni intègre le séquençage du génome entier au Service national de santé, imposant des délais d'exécution inférieurs à 14 jours. Le marché d'Amérique du Sud est centré sur les projets pilotes de pharmacogénomique du Brésil et les programmes de génomique des cultures d'Argentine, tandis que le Moyen-Orient et l'Afrique restent naissants, les Émirats arabes unis et l'Arabie saoudite finançant le séquençage à grande échelle dans le cadre de leurs agendas de diversification économique.

Paysage réglementaire
La bioinformatique utilisée dans les flux de travail cliniques réglementés est de plus en plus considérée comme un logiciel pouvant éclairer la prise de décision diagnostique. Aux États-Unis, la FDA maintient sa supervision des tests de profilage tumoral par séquençage de nouvelle génération sous le code produit PZM (21 CFR 866.6080), où les logiciels et algorithmes de bioinformatique associés s'inscrivent dans un contexte réglementaire de Classe II lorsqu'ils sont utilisés pour soutenir l'aide à la décision clinique et le reporting. En janvier 2026, la FDA a mis à jour les lignes directrices relatives aux logiciels d'aide à la décision clinique, clarifiant quelles fonctions sont exclues de la définition du dispositif au titre de la section 520(o)(1)(E) du FD&C Act, ce qui affecte la manière dont les fournisseurs intègrent l'analytique dans les applications destinées aux cliniciens.
Du côté des données et de l'interopérabilité, le programme de certification en informatique de santé de l'ONC a établi USCDI Version 3 comme référence obligatoire pour l'informatique de santé certifiée à partir du 1er janvier 2026, renforçant les exigences relatives aux éléments de données standardisés consommés par les systèmes de bioinformatique et de médecine de précision en aval. L'ONC a également fait progresser son Standards Version Advancement Process (SVAP) avec le cycle 2026, incluant le guide d'implémentation HL7 FHIR US Core STU 9.0.0 pour une incorporation volontaire à partir du 29 août 2026, afin de soutenir un échange de données basé sur des API plus cohérent vers les environnements analytiques. Dans l'UE, le Règlement (UE) 2025/327 (Espace européen des données de santé, EHDS) est entré en vigueur le 26 mars 2025, formalisant les règles d'accès aux données de santé électroniques et leur utilisation secondaire pour la recherche et la médecine personnalisée ; le Règlement d'exécution de la Commission (UE) 2026/771 (publié le 7 avril 2026) a établi le Conseil de l'EHDS pour coordonner une application cohérente entre les États membres.
Analyse de la chaîne de valeur
La chaîne de valeur de la bioinformatique commence par la génération de données multi-omiques en amont (séquençage et spectrométrie de masse) et se poursuit par le traitement primaire, l'analytique, l'interprétation et la livraison des résultats dans les systèmes de recherche et cliniques. Les fournisseurs d'instruments et de tests intègrent de plus en plus l'analytique proche de l'instrument ou intégrée (incluant le basecalling, l'alignement, l'appel de variants et le contrôle qualité), tandis que les hyperscalers cloud fournissent une orchestration de pipelines gérée, du calcul élastique et des environnements conformes qui réduisent le besoin pour les laboratoires de maintenir des clusters sur site. Un goulot d'étranglement récurrent se situe entre le stockage et le calcul, où les contraintes d'E/S et les étapes répétées de décompression et de formatage ralentissent l'analyse à grande échelle, ce qui stimule la demande pour des formats de données optimisés, des moteurs de workflow et des architectures réduisant les déplacements de données.
Les acteurs intermédiaires comprennent les fournisseurs de plateformes, les prestataires de services de bioinformatique et les CRO qui standardisent les pipelines pour les essais multi-sites et le reporting réglementé, les contrôles de cybersécurité et de confidentialité devenant des exigences intégrées plutôt que des ajouts. En aval, les résultats alimentent des couches de gestion des connaissances et des systèmes cliniques ou d'entreprise, où les normes d'interopérabilité, telles que les échanges alignés sur FHIR dans les environnements informatiques de santé, influencent la manière dont les résultats sont opérationnalisés. De plus en plus, les modèles de données fédérés maintiennent les données génomiques sensibles en place tout en permettant l'interrogation et l'analyse inter-ensembles de données, réduisant les frictions liées aux transferts transfrontaliers et s'alignant avec les contraintes de souveraineté des données, y compris les efforts de l'industrie pour construire des ensembles de données fédérés mondiaux pour des génomes complets à haute fidélité. L'infrastructure des ensembles de données financés publiquement et la gouvernance de l'accès façonnent également le débit et la reproductibilité pour les utilisateurs académiques et translationnels, créant une dépendance à une gestion stable des données et un accès évolutif au calcul.
Paysage concurrentiel
Les cinq premiers fournisseurs, Illumina, Thermo Fisher Scientific, QIAGEN, Agilent Technologies et Roche, détenaient une part majoritaire en 2025, indiquant une concentration modérée. Illumina poursuit sa stratégie d'intégration verticale, couplant l'accélération DRAGEN aux ventes d'instruments pour générer 450 millions USD de revenus logiciels récurrents. Thermo Fisher poursuit une expansion horizontale, acquérant des solutions ponctuelles et les intégrant dans une plateforme cloud qui couvre de la préparation des échantillons à l'interprétation des variants.
Les perturbateurs comprennent des entreprises axées sur l'IA telles qu'Insitro et Recursion, qui commercialisent des piles analytiques propriétaires initialement construites pour la découverte interne de médicaments. La boîte à outils BioNeMo de NVIDIA permet aux entreprises pharmaceutiques d'entraîner des modèles de fondation sur des données locales, réduisant la dépendance aux plateformes tierces. Des organismes de normalisation comme GA4GH publient des API ouvertes qui pourraient commoditiser l'alignement de routine et l'appel de variants, intensifiant la concurrence par les prix.
Leaders du secteur de la bioinformatique
Illumina Inc.
Thermo Fischer Scientific
Qiagen NV
Agilent Technologies
F. Hoffmann-La Roche Ltd.
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Opportunités de marché et perspectives d'avenir
Une opportunité à court terme réside dans l'expansion clinique des flux de travail multi-omiques et oncologiques qui nécessitent une analytique validée et de bout en bout plutôt que des outils autonomes. Les systèmes hospitaliers et les services de santé nationaux traduisent la biopsie liquide et le séquençage à large panel en parcours de routine, ce qui accroît la demande pour des plateformes combinant des pipelines spécifiques aux tests, le contrôle qualité, l'interprétation des variants et un reporting auditable. En 2026, SOPHiA GENETICS a élargi les signaux d'adoption clinique, avec le Mount Sinai Health System adoptant la plateforme SOPHiA DDM pour le NGS oncologique, et un partenariat avec Synnovis pour soutenir les tests de biopsie liquide ctDNA à travers le NHS England (visant environ 7 000 tests annuels). Ces déploiements favorisent les fournisseurs capables d'opérationnaliser des flux de travail réglementés sur plusieurs sites tout en respectant les exigences de confidentialité et de sécurité.
L'interopérabilité et l'accès conforme aux données pour usage secondaire restent également un domaine d'opportunité ciblé, à mesure que les réglementations sur les données de santé et les référentiels de certification renforcent le lien entre les systèmes de données cliniques et les piles de bioinformatique. Dans l'UE, le cadre EHDS offre une voie structurée pour l'utilisation transorganisationnelle des données dans la recherche et la médecine personnalisée, augmentant la valeur des plateformes conçues pour le consentement, la gouvernance et l'analyse fédérée. Aux États-Unis, les référentiels de certification de l'ONC (USCDI v3 à partir de janvier 2026) et les avancées FHIR pilotées par le SVAP renforcent les incitations à acquérir des systèmes capables de consommer des données cliniques standardisées et de restituer des résultats traçables, en particulier lorsque l'analytique nécessite des contrôles de cycle de vie et une auditabilité. Les fournisseurs et prestataires de services qui livrent des pipelines validés, une traçabilité des données et des environnements de collaboration préservant la confidentialité sont positionnés pour capter les dépenses à mesure que les organisations consolident des flux de travail fragmentés en infrastructure d'entreprise.
Développements récents du secteur
- Juin 2026 : Thermo Fisher Scientific a introduit de nouvelles plateformes de spectrométrie de masse Orbitrap lors de l'ASMS 2026, notamment l'Orbitrap Tribrid Apex. Une protéomique à plus haut débit augmente les exigences en aval pour des pipelines de bioinformatique robustes, accélérant la demande pour des logiciels d'analyse, de visualisation et d'interprétation évolutifs dans la biopharma et la recherche translationnelle.
- Mai 2026 : Illumina a annoncé une solution de recherche sur la maladie résiduelle moléculaire (MRD) basée sur le séquençage du génome entier, en accès anticipé. La MRD basée sur le WGS repousse les volumes de données et la complexité analytique au-delà des panels ciblés, augmentant l'importance de l'alignement optimisé, de l'appel de variants et de l'analytique longitudinale au sein de plateformes de bioinformatique intégrées.
- Février 2025 : QIAGEN a acquis Bioinformatics Solutions Inc. (BSI) pour renforcer ses capacités en analyse de données de protéomique et de spectrométrie de masse. L'accord a élargi la capacité de QIAGEN à fournir une analytique multi-omique intégrée et a soutenu les ventes croisées auprès des laboratoires exécutant à la fois des flux de séquençage et de protéomique.


Cadre de la méthodologie de recherche et portée du rapport
Définition et couverture du marché
Ce marché couvre les revenus générés par les logiciels de bioinformatique, les plateformes, les outils de gestion des connaissances et les services analytiques payants utilisés pour stocker, traiter, visualiser et interpréter les données biologiques provenant de domaines tels que la génomique, la transcriptomique, la protéomique et la métabolomique, à travers les principales régions.
Exclusions du périmètre : nous excluons les instruments de séquençage et le matériel de laboratoire, ainsi que le calcul ou le stockage cloud génériques vendus sans couche de flux de travail bioinformatique.
Aperçu de la segmentation
- Par produits et services
- Outils de gestion des connaissances
- Plateformes de bioinformatique
- Plateformes d'analyse de séquences
- Plateformes d'alignement de séquences
- Plateformes de manipulation de séquences
- Plateformes d'analyse structurelle et fonctionnelle
- Plateformes d'intégration multi-omiques
- Services de bioinformatique
- Services de séquençage et de génération de données
- Construction et gestion de bases de données
- Services d'analyse et d'interprétation des données
- Bioinformatique en tant que service natif du cloud
- Par application
- Génomique et transcriptomique
- Protéomique et métabolomique
- Découverte et développement de médicaments
- Génomique microbienne (métagénomique et résistance aux antimicrobiens)
- Médecine de précision et personnalisée
- Autres applications
- Par utilisateur final
- Entreprises pharmaceutiques et biotechnologiques
- Instituts académiques et de recherche
- Laboratoires cliniques et de diagnostic
- Organisations de recherche sous contrat (ORC)
- Autres utilisateurs finaux
- Géographie
- Amérique du Nord
- États-Unis
- Canada
- Mexique
- Europe
- Allemagne
- Royaume-Uni
- France
- Italie
- Espagne
- Reste de l'Europe
- Asie-Pacifique
- Chine
- Japon
- Inde
- Corée du Sud
- Australie
- Reste de l'Asie-Pacifique
- Moyen-Orient et Afrique
- CCG
- Afrique du Sud
- Reste du Moyen-Orient et de l'Afrique
- Amérique du Sud
- Brésil
- Argentine
- Reste de l'Amérique du Sud
- Amérique du Nord
Sources de données, dimensionnement du marché et validation
Recherche documentaire
La recherche documentaire a été utilisée pour cartographier le bassin de demande et construire des hypothèses pratiques et reproductibles. Nous nous sommes appuyés sur des sources scientifiques et sanitaires publiques telles que NCBI (NIH), le National Human Genome Research Institute, les indicateurs de santé et d'innovation de l'OCDE, les séries macroéconomiques de la Banque mondiale, et des sources comme l'OMS pour des signaux plus larges sur les soins de santé.
Pour relier l'activité scientifique aux dépenses, nous avons également examiné les rapports annuels d'entreprises, les présentations de résultats, les annonces réglementaires et de financement, les articles évalués par des pairs et les publications d'associations qui traitent des volumes de séquençage, de l'adoption multi-omique et des charges de travail en bioinformatique. Le cas échéant, nous avons utilisé des abonnements payants limités aux données financières et de renseignement d'entreprises, aux actualités et données financières, ainsi qu'aux bases de données de brevets pour recouper l'exposition aux revenus et l'orientation technologique. Les sources documentaires listées ici ne sont pas exhaustives, et nous avons examiné d'autres documents publics pour la collecte de données, la validation et la clarification si nécessaire.
Entretiens primaires et enquêtes
Le travail primaire s'est concentré sur la confirmation de ce qui est réellement payé en bioinformatique, et de ce qui est inclus dans des postes adjacents comme les services de laboratoire ou les dépenses cloud. Nous avons échangé avec un panel de fournisseurs de solutions, d'équipes de services, de responsables de recherche et de fonctions achats à travers l'APAC, l'EMEA et les Amériques, afin que les hypothèses sur la tarification, le calendrier d'adoption et le mix de cas d'usage puissent être corrigées puis retestées.
Répartition des répondants au travail de terrain de la recherche primaire
| Type d'entreprise | Poste du répondant | Région |
|---|---|---|
| Premier rang : 27 % | Dirigeants (CXO) : 12 % | APAC : 38 % |
| Rang intermédiaire : 59 % | Responsables fonctionnels/d'unité : 43 % | EMEA : 35 % |
| Acteurs plus petits : 14 % | Managers : 45 % | Amériques : 27 % |
Dimensionnement et prévisions du marché
Le dimensionnement commence par une construction descendante où les dépenses adressables en bioinformatique sont reconstruites à partir de l'activité de recherche et clinique multi-omique, puis filtrées à travers les taux d'adoption et de monétisation pour les plateformes, outils et services payants. Une fois cette forme établie, nous utilisons des vérifications ascendantes sélectives pour nous assurer que les totaux ne dérivent pas, incluant des répartitions de revenus échantillonnées à partir de dépôts publics, des fourchettes de prix par poste ou d'abonnement issues d'entretiens, et des approximations volume x prix moyen pour les flux de travail couramment achetés.
Les principales entrées utilisées dans le modèle incluent les signaux de débit de séquençage et multi-omique, la part des projets utilisant la génomique et la transcriptomique par rapport à la protéomique et la métabolomique, le glissement du mix entre outils déployés sur site et dans le cloud, la progression typique des prix de licence et d'abonnement, et le mix des utilisateurs finaux entre biopharma, instituts académiques et autres groupes de clients. Lorsque les données ascendantes manquaient pour des géographies plus petites ou des applications de niche, nous avons combler les lacunes en utilisant des ratios d'adoption par procuration ancrés sur le financement de la recherche et l'intensité des publications, ces ratios ayant ensuite été testés auprès d'experts.
Pour les prévisions, une analyse de scénarios a été utilisée avec une couche de régression multivariée où la croissance est liée à des indicateurs tels que l'orientation du financement de la recherche, les tendances de la capacité de séquençage installée et les modèles de consommation logicielle. Les hypothèses n'ont été finalisées qu'après convergence des retours primaires sur ce à quoi ressemblent un cycle d'achat normal et le comportement de renouvellement pour les utilisateurs finaux à la fin de la période de prévision.
Validation des données et cycle de mise à jour
Les résultats ont été validés par triangulation avec des signaux indépendants, tels que l'intensité de la recherche régionale, les calendriers d'adoption multi-omique connus, et les glissements observés entre les dépenses en plateformes et en services. Si un résultat par pays ou par application semblait hors norme, nous avons revérifié les moteurs, puis effectué un second examen pour confirmer la logique des unités, le traitement des devises et l'alignement des années.
Avant validation finale, le classeur complet est examiné par étapes afin que les erreurs soient détectées tôt et que les hypothèses restent cohérentes entre les régions et les utilisateurs finaux. Le rapport est actualisé annuellement, et des mises à jour intermédiaires sont effectuées lorsque des événements importants modifient le comportement de dépense ou la tarification. Avant la livraison, un analyste effectue un nouveau passage afin que les clients reçoivent la vue la plus récente.
Estimation du marché mondial de la bioinformatique par Mordor Intelligence comparée à d'autres estimations publiées
Les différentes tailles publiées pour la bioinformatique ne correspondent pas toujours car les éléments inclus et l'année mesurée ne sont pas les mêmes, ce qui modifie le calcul avant même le début des prévisions. L'écart provient également de la manière dont la tarification est traitée entre logiciels, plateformes et services, ainsi que de la vitesse d'adoption supposée dans les régions à forte croissance.
Les instruments de séquençage et le matériel de laboratoire se situent hors du périmètre de Mordor Intelligence, ce qui peut faire paraître certains totaux plus larges de l'informatique des sciences de la vie plus élevés lorsque ces revenus adjacents sont comptés ensemble. Des écarts apparaissent également lorsqu'une source utilise une année de base différente, applique une expansion des prix plus agressive pour les abonnements logiciels, ou convertit les devises selon un calendrier différent, et nous avons observé clairement ces effets lors de la réconciliation des mêmes régions et mix d'utilisateurs finaux.
Comparaison de référence
| Source | Taille du marché | Lacunes dans la méthodologie de recherche |
|---|---|---|
| Mordor Intelligence | 19,97 milliards USD (2026) | |
| Éditeur sectoriel A | 18,69 milliards USD (2025) | Utilise une année de dimensionnement antérieure et une configuration d'année de base différente, ce qui déplace le bassin de revenus initial et peut sous-estimer la progression liée à l'adoption multi-omique récente et aux changements de tarification. |
| Cabinet de conseil mondial B | 31,74 milliards USD (2025) | Rapporte une valeur 2025 plus importante qui reflète probablement des inclusions plus larges et des hypothèses d'escalade de prix plus rapides pour les logiciels et services, ce qui augmente les totaux avant l'application des vérifications d'adoption régionale. |
L'écart dans le tableau s'explique principalement par ce qui est compté comme revenu de bioinformatique, l'année utilisée pour la taille déclarée, et la manière dont la croissance des prix est appliquée aux dépenses axées sur le logiciel. En maintenant les entrées liées à des signaux d'activité observables et en répétant le même alignement des années et les mêmes règles de périmètre à travers les régions, l'estimation finale reste pratique à auditer et cohérente à mettre à jour.


Questions clés auxquelles répond le rapport
À quel rythme le marché de la bioinformatique devrait-il croître jusqu'en 2031 ?
Le marché de la bioinformatique devrait se développer de 19,97 milliards USD en 2026 à 37,03 milliards USD d'ici 2031, enregistrant un CAGR de 13,1 %.
Quelle catégorie de produits contribue actuellement le plus aux revenus ?
Les plateformes de bioinformatique ont contribué à hauteur de 48,1 % du chiffre d'affaires total en 2025, reflétant leur rôle central dans l'analyse de séquences et l'intégration multi-omiques.
Pourquoi les organisations de recherche sous contrat gagnent-elles des parts de marché ?
Les ORC développent l'infrastructure de bioinformatique auprès de plusieurs commanditaires, réduisant les coûts par projet et atteignant un CAGR projeté de 13,98 % de la demande jusqu'en 2031.
Pourquoi la médecine de précision est-elle importante pour la croissance du marché de la bioinformatique ?
La médecine de précision dépend de la traduction des données génomiques en actions cliniques, et les plateformes de bioinformatique fournissent l'analytique qui permet cette traduction.
Quelle région connaîtra la croissance la plus rapide d'ici 2031 ?
L'Asie-Pacifique devrait croître à un CAGR de 14,89 %, portée par les initiatives gouvernementales de génomique à grande échelle en Chine, en Inde et au Japon.
Comment les fournisseurs répondent-ils aux préoccupations en matière de sécurité des données ?
Les fournisseurs déploient des architectures de confiance zéro, un traitement local en périphérie et une analyse fédérée pour se conformer à la HIPAA et au RGPD tout en réduisant l'exposition aux attaques par rançongiciel.
Dernière mise à jour de la page le:




