Größe und Marktanteil des Markts für Datenerfassung und -kennzeichnung
Marktübersicht
| Studienzeitraum | 2020 - 2031 |
|---|---|
| Marktgröße (2026) | 2.67 Milliarden US-Dollar |
| Marktgröße (2031) | 10.92 Milliarden US-Dollar |
| Wachstumsrate (2026 - 2031) | 32.59% CAGR |
| Schnellstwachsender Markt | Asien-Pazifik |
| Größter Markt | Nordamerika |
| Marktkonzentration | Mittel |
Hauptakteure *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. | |
Analyse des Markts für Datenerfassung und -kennzeichnung von Mordor Intelligence
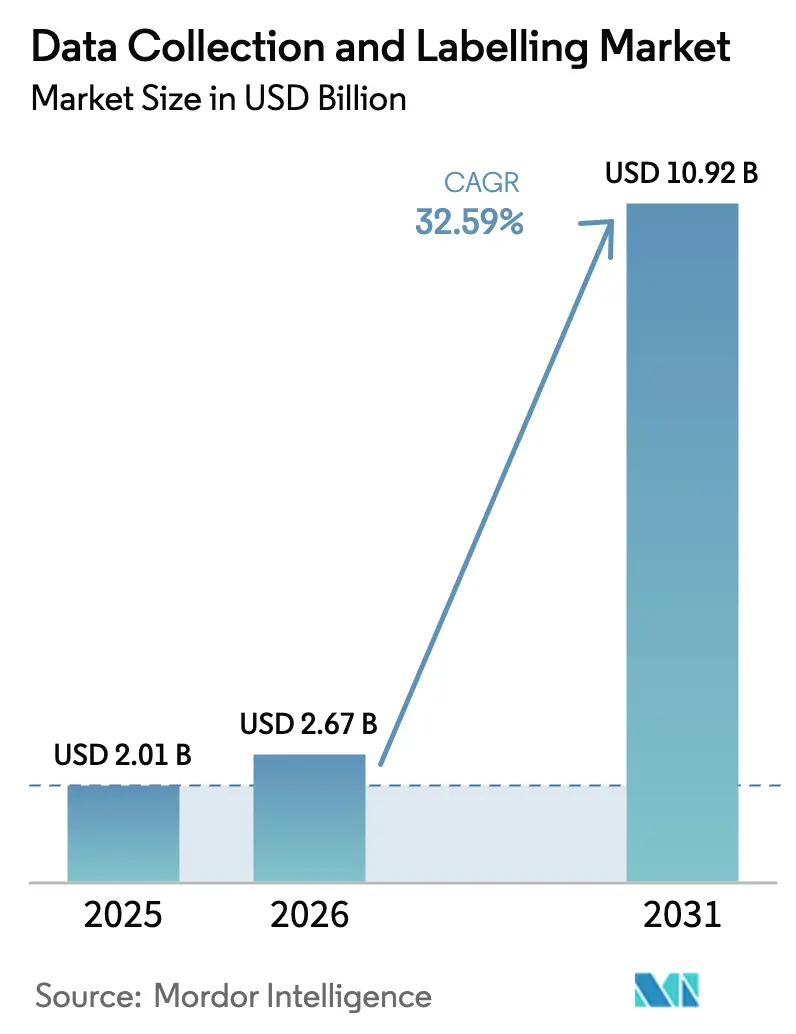
Die Marktgröße für Datenerfassung und -kennzeichnung wurde im Jahr 2025 auf 2,01 Milliarden USD geschätzt und soll von 2,67 Milliarden USD im Jahr 2026 auf 10,92 Milliarden USD bis 2031 wachsen, bei einer CAGR von 32,59 % während des Prognosezeitraums (2026–2031). Die unaufhörliche Nachfrage nach hochwertigen, domänenübergreifenden Trainingsdaten wird durch multimodale Grundlagenmodelle, den Schwenk hin zu kontinuierlichen Lernpipelines und schnell nahende regulatorische Compliance-Fristen angetrieben. KI-gestützte Vorannotierung auf Basis generativer KI übernimmt nun Routineaufgaben mit 20-fachen Geschwindigkeitsgewinnen und entlastet knappe menschliche Experten für komplexe Randfälle. Synthetische Datengenerierung, datenschutzzentrierte Datenlokalisierungsregeln und steigende Kosten durch Annotator-Burnout gestalten die Beschaffungsstrategien neu. Die kommerzielle Dynamik ist in Nordamerika am stärksten, doch der asiatisch-pazifische Raum wächst am schnellsten, da China und Indien trotz strenger Datensouveränitätsgesetze inländische Kapazitäten aufbauen. Der Wettbewerbsdruck ist intensiv, da domänenspezifische „Small-Data”-Nischen wie die medizinische Bildgebung weiterhin Premiumpreise erzielen, obwohl das Gesamtautomatisierungsniveau steigt.
Wichtigste Erkenntnisse des Berichts
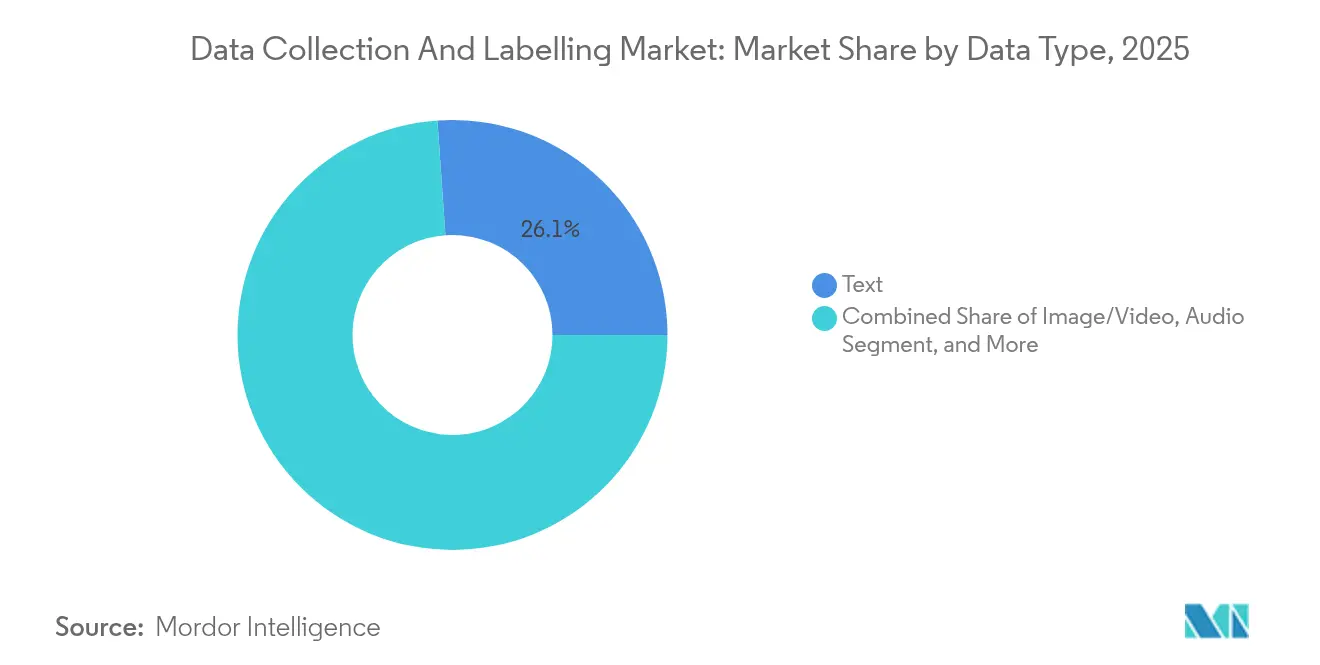
- Nach Datentyp führte die Textannotation im Jahr 2025 mit einem Umsatzanteil von 26,12 % im Markt für Datenerfassung und -kennzeichnung, während Sensorfusions-Datenströme bis 2031 voraussichtlich mit einer CAGR von 35,42 % wachsen werden.
- Nach Endverbrauchsbranche hielt das Segment Automobil und Mobilität im Jahr 2025 einen Marktanteil von 22,05 % am Markt für Datenerfassung und -kennzeichnung, während das Gesundheitswesen voraussichtlich die schnellste CAGR von 34,89 % bis 2031 verzeichnen wird.
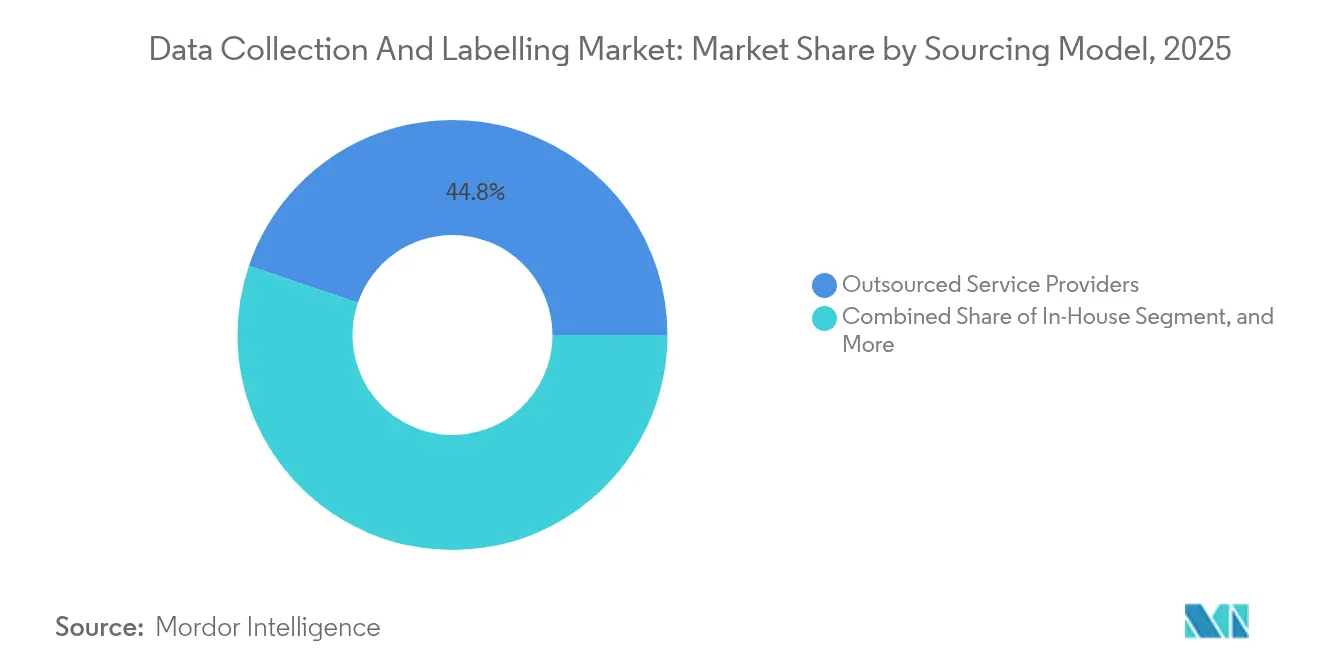
- Nach Beschaffungsmodell erfassten ausgelagerte Dienstleister im Jahr 2025 44,78 % des Markts für Datenerfassung und -kennzeichnung, während die synthetische Datengenerierung voraussichtlich jährlich um 36,2 % wachsen wird.
- Nach Annotationstyp machten manuelle Mensch-in-der-Schleife-Workflows im Jahr 2025 noch 49,45 % der Marktgröße für Datenerfassung und -kennzeichnung aus, während vollständig automatisierte Ansätze mit einer CAGR von 34,95 % voranschreiten.
- Nordamerika dominierte den Markt für Datenerfassung und -kennzeichnung im Jahr 2025 mit einem Anteil von 39,92 %, während der asiatisch-pazifische Raum mit einer CAGR von 35,65 % die am schnellsten wachsende Region ist.
Hinweis: Die Marktgrößen- und Prognosezahlen in diesem Bericht werden mithilfe des proprietären Schätzrahmens von Mordor Intelligence erstellt und mit den neuesten verfügbaren Daten und Erkenntnissen bis 2026 aktualisiert.
Markttrends und Einblicke
Analyse der Treiber-Auswirkungen auf den Markt für Datenerfassung und -kennzeichnung*
| Treiber | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Anstieg multimodaler Grundlagenmodelle | +8.2% | Nordamerika, China | Mittelfristig (2–4 Jahre) |
| Wechsel zu kontinuierlichen Lernpipelines | +7.1% | USA, EU, asiatisch-pazifischer Raum | Langfristig (≥ 4 Jahre) |
| Vorannotierung mit generativer KI-Unterstützung | +6.8% | Nordamerika, EU | Kurzfristig (≤ 2 Jahre) |
| Schnelle Compliance-Fristen (EU-KI-Gesetz, US-KI-Rechtecharta) | +5.3% | EU, Nordamerika | Kurzfristig (≤ 2 Jahre) |
| Vertikaler „Small-Data”-Bedarf in der medizinischen Bildgebung und Geospatial-Analyse | +4.7% | Entwickelte Märkte | Mittelfristig (2–4 Jahre) |
| Quelle: Mordor Intelligence | |||
Anstieg multimodaler Grundlagenmodelle treibt die Nachfrage nach domänenübergreifenden Datensätzen an
Multimodale Grundlagenmodelle erfordern massive, vielfältige Datensätze, die Text, Bilder, Audio, Video und Sensordatenströme kombinieren, und entfachen eine neue Nachfrage im gesamten Markt für Datenerfassung und -kennzeichnung [1]Anas Awadalla et al., "MINT-1T: Skalierung offener multimodaler Daten um das 10-Fache," arXiv, arxiv.org. Wegweisende Korpora wie MINT-1T haben offene multimodale Daten um das 10-Fache skaliert und veranschaulichen den neuen Ausgangspunkt für das Training moderner KI. Anbieter, die medienübergreifende Annotationsworkflows orchestrieren können, gewinnen nun Premiumverträge, da Kunden eng aufeinander abgestimmte Labels über alle Modalitäten hinweg benötigen. Investoren betrachten diese Fähigkeit als Kerninfrastruktur, wie die Finanzierungsrunde von Scale AI in Höhe von 1 Milliarde USD im Jahr 2024 belegt. Frühe Anwender in den Bereichen autonomes Fahren, Sprachassistenten und Robotik katalysieren das Volumenwachstum, während Gesundheitsdienstleister Bild-Text-Fusionsdatensätze für diagnostische Modelle ausbauen. Mit der Reifung dieser Anwendungsfälle werden im Markt für Datenerfassung und -kennzeichnung nachhaltige mehrjährige Volumenzuflüsse erwartet.
Datenzentrierte KI wandelt statische Annotation in kontinuierliche Lernpipelines um
Unternehmen haben sich von der einmaligen Datensatzerstellung hin zur kontinuierlichen Datenqualitätsiteration verlagert und damit die kommerziellen Modelle im Markt für Datenerfassung und -kennzeichnung grundlegend verändert [2]Matei Zaharia, "Was kann datenzentrierte KI von Daten- und ML-Engineering lernen?" arXiv, arxiv.org . Plattformanbieter bieten nun Streaming-Datensatz-Versionskontrolle, automatisierte Pipeline-Orchestrierung und Feedback-Schleifen-Optimierung im Rahmen aufkommender DataOps-Frameworks an. Kontinuierliche Lernpipelines erhöhen den Annotationsbedarf, da eingehende Modelltelemetrie ständig neue Fehlermodi aufdeckt, die eine gezielte Neukennzeichnung erfordern. Dienstleister, die schnelle Durchlaufzeiten mit detaillierten Prüfpfaden kombinieren können, gewinnen compliance-sensible Verträge. Dieser langfristige Treiber unterstützt wiederkehrende Umsatzengagements anstelle sporadischer Projekte und stärkt die Wachstumssichtbarkeit des Markts für Datenerfassung und -kennzeichnung.
Vorannotierung mit generativer KI-Unterstützung steigert die Annotationsproduktivität
Große Sprachmodelle wie GPT-4 kennzeichnen Daten nun mit einer Übereinstimmung von 88,4 % mit der Ground Truth und 20-fachen Geschwindigkeitsgewinnen vor und transformieren damit die Stückkosten. Hybride Workflows leiten Routinefälle an Algorithmen weiter, während menschliche Arbeit für Mehrdeutigkeiten reserviert wird, was den manuellen Aufwand in biologischen Datensätzen um bis zu 90,6 % reduziert. Der Produktivitätszuwachs ermöglicht es Anbietern, steigende Volumina ohne lineares Personalwachstum zu bewältigen und die Preiswettbewerbsfähigkeit zu stärken. Mit der Reifung von KI-Tools erwarten Unternehmenskäufer zunehmend integrierte Automatisierung, was die technische Stack-Kompetenz zu einem entscheidenden Qualifikationsmerkmal im gesamten Markt für Datenerfassung und -kennzeichnung macht.
Regulatorische Compliance-Fristen beschleunigen Investitionen in die Datenverwaltung
Artikel 10 des EU-KI-Gesetzes, das seit 2024 in Kraft ist, schreibt eine dokumentierte Datensatzherkunft und strenge Datenverwaltungskontrollen für KI-Hochrisikosysteme vor [3]Europäisches Parlament und Rat, "Verordnung – EU – 2024/1689," eur-lex.europa.eu . Ähnliche Bestimmungen finden sich im Entwurf der US-KI-Rechtecharta und verpflichten Unternehmen, Budgets für Herkunftsverfolgung, Bias-Audits und kontinuierliche Qualitätssicherungsprüfungen einzuplanen. Anbieter, die compliance-fähige Tools und sichere On-Premise-Annotationsumgebungen anbieten, gewinnen Premiumaufträge. Diese Verpflichtungen erhöhen die Wechselkosten und verlängern die Vertragslaufzeiten, was dem Markt für Datenerfassung und -kennzeichnung bis zum Ende des Jahrzehnts einen regulatorisch verankerten Rückenwind verleiht.
Analyse der Hemmnisse-Auswirkungen auf den Markt für Datenerfassung und -kennzeichnung*
| Hemmnis | (≈) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Steigende Stückkosten durch Annotator-Burnout und Qualitätsverfall | -3.9% | Philippinen, Kenia, globale Zentren | Mittelfristig (2–4 Jahre) |
| Beschränkungen beim grenzüberschreitenden Datentransfer | -2.8% | China, EU, Indien | Langfristig (≥ 4 Jahre) |
| Substitution durch synthetische Daten reduziert traditionelle Ausgaben | -2.1% | Technologieorientierte Märkte | Mittelfristig (2–4 Jahre) |
| Quelle: Mordor Intelligence | |||
Annotator-Burnout und Qualitätsverfall erhöhen die Stückkosten
Hohe Aufgabenwiederholung und enge Fristen haben die Fluktuation in den wichtigsten Outsourcing-Zentren erhöht, die Löhne nach oben getrieben und die Qualitätskonsistenz gefährdet. Anbieter rotieren Mitarbeiter nun häufiger und integrieren KI-basierte Qualitätsüberwachung, doch diese Gegenmaßnahmen erhöhen die Kostenbasis. Wenn keine Abhilfe geschaffen wird, könnten steigende Arbeitskosten die Margen erodieren und die Akzeptanz verlangsamen, insbesondere bei preissensiblen kleinen und mittleren Unternehmen im Markt für Datenerfassung und -kennzeichnung.
Beschränkungen beim grenzüberschreitenden Datentransfer fragmentieren den globalen Betrieb
Chinas Verordnung zur Verwaltung der Netzwerkdatensicherheit und Indiens Gesetz zum Schutz digitaler personenbezogener Daten erlegen strenge Lokalisierungs- und Sicherheitsbewertungspflichten auf. DSGVO-Angemessenheitsprüfungen der EU erhöhen die Komplexität zusätzlich. Annotationsunternehmen müssen regionale Verarbeitungszentren aufbauen, in Verschlüsselung investieren und doppelte Audits bewältigen, was die Fixkosten erhöht. Kleinere Anbieter ohne ausreichende Ressourcen könnten sich aus eingeschränkten Rechtsgebieten zurückziehen, das Angebot verknappen und die Projektvorlaufzeiten im Markt für Datenerfassung und -kennzeichnung verlängern.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse des Marktes für Datenerfassung und -kennzeichnung
Nach Datentyp:
Sensorfusions-Datenströme beschleunigen zukünftige AnwendungenDie Textannotation blieb mit einem Umsatzanteil von 26,12 % im Jahr 2025 das größte Segment des Markts für Datenerfassung und -kennzeichnung, getragen durch steigende Trainingspipelines für große Sprachmodelle. Sensorfusions-Datenströme eilen jedoch mit einer CAGR von 35,42 % voraus, da autonome Roboter, Smart-Factory-Anlagen und fortschrittliche Fahrerassistenzsysteme LiDAR-, Radar-, Kamera- und Inertialdaten fusionieren. Die Bild- und Videokennzeichnung behält ihre Dynamik in der Erkennung von Fertigungsfehlern und der Analyse von Einzelhandelsregalen, während dreidimensionale medizinische Bildgebungsdatensätze wie M3D die Horizonte der Gesundheits-KI erweitern. Die Audioannotation profitiert von sprachgesteuerten Kundenerfahrungsanwendungen, und tabellarische Zeitreihentasks unterstützen Risikomodelle in Finanzen und Telekommunikation.
Die Komplexität der Sensorfusion, die Zeitsynchronisation und räumliche Kalibrierung umfasst, erzielt Premiumpreise und erhöht ihren Umsatzbeitrag trotz geringerer absoluter Auftragszahlen. Anbieter, die automatisierte Validierungsroutinen und physikbasierte Simulatoren einsetzen, senken die Nachbearbeitungsquoten und differenzieren sich in Wettbewerbsausschreibungen. Die enge Zusammenarbeit zwischen Annotationsteams und Sensorhardware-Ingenieuren wird unverzichtbar und festigt integrierte Serviceangebote als Wettbewerbsvorteil im Markt für Datenerfassung und -kennzeichnung.



Nach Endverbrauchsbranche:
Gesundheitswesen übertrifft WachstumsbenchmarksAutomobil und Mobilität machten im Jahr 2025 22,05 % des Markts für Datenerfassung und -kennzeichnung aus, angetrieben durch Datensätze im Petabyte-Maßstab für autonomes Fahren. Laufende regulatorische Aktualisierungen wie die ADAS-Validierungsregeln von Euro-NCAP für 2026 erhalten die Datengenerierungspipelines aufrecht. Das Gesundheitswesen soll mit der schnellsten CAGR von 34,89 % wachsen, angetrieben durch hochauflösende Bildgebung, Strukturierung klinischer Notizen und KI-gestützte Arzneimittelentdeckung. Die Marktgröße für Datenerfassung und -kennzeichnung allein für die medizinische Bildgebung wird stark ansteigen, da die Annotation durch Experten in der Radiologie aufgrund von Haftungserwägungen nicht ersetzbar bleibt.
Regierungsbehörden erweitern Klassifizierungs-, Bedrohungserkennungs- und Bürgerservice-Chatbots, während BFSI-Institutionen Betrugsanalysemodelle verfeinern, die eine ausgewogene Kennzeichnung der Falsch-Positiv-Rate erfordern. Einzelhandels-E-Commerce-Plattformen verbessern die Produkttaxonomieabdeckung und die Leistung der visuellen Suche. Die Landwirtschaft nutzt UAV-Bilder für Ertragsvorhersagen und Schädlingsüberwachung, und Telekommunikationsanbieter kuratieren domänenspezifische Sprachkorpora zur Optimierung des Netzwerkbetriebs. Jede Branche erweitert den Nachfragehorizont, aber das Wachstum verteilt sich ungleichmäßig, was spezialisierten Anbietern Raum gibt, in Nischen der Branche für Datenerfassung und -kennzeichnung zu glänzen.
Nach Beschaffungsmodell:
Synthetische Generierung stellt die Dominanz des Outsourcings in FrageAusgelagerte Dienstleister hielten im Jahr 2025 44,78 % des Markts für Datenerfassung und -kennzeichnung, gestützt durch Skalierung, mehrsprachige Talentpools und ISO-zertifizierte Einrichtungen. Doch die synthetische Datengenerierung, die mit einer CAGR von 36,2 % skaliert, destabilisiert etablierte Workflows. Simulationsumgebungen erzeugen seltene Fahrereignisse, und generative adversarielle Netzwerke füllen Lücken in unterrepräsentierten medizinischen Klassen. Unternehmen kombinieren zunehmend synthetische und reale Daten, reduzieren Annotationsvolumina für Routineszenarien und reservieren menschliche Arbeit für die Validierung.
Interne Annotationskapazitäten werden dort gestärkt, wo Datensensibilität oder IP-Schutz von größter Bedeutung sind, insbesondere bei Verteidigungsunternehmen und führenden Krankenhäusern. Crowdsourcing bleibt für Long-Tail-Verbraucheraufgaben relevant, die kulturelle Nuancen erfordern, wie z. B. Stimmungsanalyse über Dialekte hinweg, obwohl das Qualitätsvarianzrisiko fortschrittliche Überprüfungsebenen erfordert. Hybride Servicemodelle, die synthetische Augmentierung, KI-gestützte Vorannotierung und sichere On-Shore-Einrichtungen kombinieren, entwickeln sich zum neuen Standard im Markt für Datenerfassung und -kennzeichnung.
Nach Annotationstyp:
Automatisierung gewinnt an Dynamik bei menschlicher AufsichtManuelle Mensch-in-der-Schleife-Prozesse machten im Jahr 2025 noch 49,45 % des Umsatzes aus und unterstreichen den anhaltenden Wert des fachkundigen Kontexturteilsvermögens. Halbüberwachte und aktive Lernschleifen reduzieren die Annotationszahlen nun um über 60 %, ohne messbare Genauigkeitsverluste in Benchmark-Studien. Automatisierte Pipelines mit einer CAGR von 34,95 % stützen sich auf Grundlagenmodell-gestützte Kennzeichner für die Erstmarkierung und speisen menschliche Validatoren über Ausnahme-Warteschlangen. Datenzentrierte KI-Tools protokollieren Herkunftsmetadaten, automatisieren die Konsensberechnung und markieren Drift zur Neukennzeichnung, was Zykluszeiten verkürzt und die Compliance-Berichterstattung stärkt.
Mit verbesserter algorithmischer Genauigkeit wird die vollständig automatisierte Annotation in Routinedomänen wie der Bounding-Box-Erkennung in Einzelhandelsregalbildern vordringen, doch komplexe medizinische oder rechtliche Interpretationen werden Menschen unverzichtbar halten. Anbieter, die kosteneffiziente Automatisierung mit schneller Experteneskalation verbinden, werden die margenreichsten Chancen im Markt für Datenerfassung und -kennzeichnung nutzen.
Geografische Analyse
Markt für Datenerfassung und -kennzeichnung in Nordamerika
Nordamerika dominierte den Markt für Datenerfassung und -kennzeichnung mit einem Anteil von 39,92 % im Jahr 2025, gestützt durch robuste Risikokapitalfinanzierung, ausgereifte KI-Ökosysteme und hohe Adoptionsraten in Unternehmen. Initiativen wie das Thunderforge-Projekt der US Defense Innovation Unit signalisieren staatliche Nachfrage nach sicheren, unternehmenskritischen Kennzeichnungs-Pipelines diu.mil. Kanadas Scale AI-Innovationscluster investierte 96 Millionen USD in 22 Projekte und erweiterte damit die regionale Infrastruktur weiter. Das akademisch-industrielle Netzwerk der Region sichert die technologische Führungsposition, doch steigende Arbeitskosten treiben die Einführung KI-gestützter Automatisierung voran.
Markt für Datenerfassung und -kennzeichnung im asiatisch-pazifischen Raum
Der asiatisch-pazifische Raum ist das am schnellsten wachsende Gebiet mit einer CAGR von 35,65 %, angetrieben durch groß angelegte KI-Implementierungen und regionale Datenschutzvorschriften zur Datenspeicherung im Inland. Chinas Verordnung zur Verwaltung der Netzwerkdatensicherheit, die 2025 in Kraft tritt, schreibt jährliche Risikobewertungen vor und veranlasst die Einrichtung von Annotationseinrichtungen im Inland. Indiens Gesetz zum Schutz digitaler personenbezogener Daten schreibt ausdrückliche Einwilligung und Sicherheitsbewertungen vor und erzeugt Nachfrage nach konformen inländischen Anbietern. ASEAN-Märkte nutzen mehrsprachige Crowdsourcing-Pools, um globale Auftraggeber anzuziehen, während Japan und Südkorea in hochpräzise Annotation für Robotik und Halbleiterinspektion investieren.
Markt für Datenerfassung und -kennzeichnung in Europa
Europa verzeichnet ein stetiges Wachstum, das durch politisch bedingte Anforderungen an die Datenverwaltung untermauert wird. Der Fokus des EU-KI-Gesetzes auf Transparenz steigert die Nachfrage nach prüfungsfähiger Kennzeichnungsdokumentation. Projekte des Government Digital Service haben erhebliche Effizienzgewinne durch auf maschinellem Lernen basierende Kategorisierung von Inhalten des öffentlichen Sektors nachgewiesen. Anbieter, die sichere, DSGVO-konforme Umgebungen anbieten, erzielen Premiumpreise, während regionale Forschungskooperationen Innovationen bei datenschutzwahrenden Annotationstechniken vorantreiben.
Wettbewerbslandschaft
Der Wettbewerb ist fragmentiert. Scale AI, Appen und TELUS International verankern das obere Ende des Markts für Datenerfassung und -kennzeichnung, wobei jedes Unternehmen durch strategische Partnerschaften expandiert. OpenAIs Allianz mit Scale AI aus dem Jahr 2024 erweitert die Unterstützung für das unternehmensweite Fine-Tuning und unterstreicht den Wert integrierter Daten-Modell-Dienste. TaskUs hat sich mit V7 zusammengetan und verbindet eine Annotator-Community von 670.000 Personen mit fortschrittlichen Dateninfrastruktur-Tools.
Die technologische Differenzierung nimmt zu. Anbieter setzen aktive Lernmaschinen, Label-Fehlerdetektoren und domänenspezifische Grundlagenmodelle ein, um Produktivität und Qualität zu steigern. Synthetische Datenkapazität ist ein wachsendes Schlachtfeld; Unternehmen, die reale und simulierte Pipelines kombinieren, vermarkten geringere Verzerrungen und überlegene Abdeckung von Randfällen. Gesundheits-, Rechts- und Wissenschaftssektoren schätzen zertifizierte Experten, was neue Marktteilnehmer dazu veranlasst, gezielte Talentnetze aufzubauen.
Investoren unterstützen weiterhin skalierungsgetriebene Plattformen. Scale AIs Series-F-Runde in Höhe von 1 Milliarde USD bei einer Bewertung von 13,8 Milliarden USD unterstrich das Vertrauen in die Dateninfrastrukturökonomie. Labelboxs Partnerschaft mit Handshake aus dem Jahr 2024 erweitert den Zugang zu spezialisierten Annotatoren für komplexe maschinelle Lernarbeitslasten. TELUS Digital erhielt die NelsonHall-Anerkennung für hervorragende Datenkennzeichnung im Automobilbereich. Insgesamt dürfte die Wettbewerbsintensität hoch bleiben, da Automatisierung die Margen komprimiert und Käufer End-to-End-Lösungen mit Compliance-Bereitschaft im Markt für Datenerfassung und -kennzeichnung fordern.
Marktführer in der Branche für Datenerfassung und -kennzeichnung
Appen Limited
Alegion Inc.
Cogito Tech
iMerit Technology
SuperAnnotate AI Inc.
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert
Im Bericht erfasste Unternehmen im Markt für Datenerfassung und -kennzeichnung
- Appen
- TELUS International AI Data (Lionbridge AI)
- iMerit
- CloudFactory
- Scale AI
- SuperAnnotate
- Sama
- Labelbox
- Alegion
- Cognizant (Servian)
- Defined.ai
- Cogito Tech
- V7
- Kili Technology
- Keymakr
- Deepen AI
- Playment
- Trilldata
- Tasq.ai
- Shaip

Jüngste Branchenentwicklungen im Markt für Datenerfassung und -kennzeichnung
- Januar 2025: Chinas Verordnung zur Verwaltung der Netzwerkdatensicherheit trat in Kraft und verpflichtet datenintensive Unternehmen zu jährlichen Risikobewertungen und veranlasst den Aufbau regionaler Annotationseinrichtungen – Rödl & Partner.
- Dezember 2024: Labelbox schloss eine strategische Allianz mit Handshake, um spezialisierte KI-Talente für komplexe Kennzeichnungsaufgaben zu erschließen – Labelbox.
- Oktober 2024: TELUS Digital wurde in NelsonHalls CX-Services-Bericht für Hochtechnologie und Automobil als führendes Unternehmen genannt und dabei für seine starken ADAS-Datenkennzeichnungsfähigkeiten ausgezeichnet – TELUS Digital.
- August 2024: Singtel und Nscale haben eine Partnerschaft geschlossen, um GPU-Kapazitäten in Europa und Südostasien zu erschließen und Rechenengpässe für datenintensive Annotationsarbeitslasten zu beseitigen – Nscale.


Globaler Berichtsumfang des Markts für Datenerfassung und -kennzeichnung
Die Branche für Datenerfassung und -kennzeichnung ist ein Sektor, der das Sammeln, Verarbeiten und Annotieren von Daten umfasst, die dann zum Training von Modellen des maschinellen Lernens (ML) und Systemen der künstlichen Intelligenz (KI) verwendet werden. Die Forschung untersucht auch die zugrunde liegenden Wachstumstreiber und bedeutende Branchenanbieter, die alle zur Unterstützung von Marktschätzungen und Wachstumsraten während des prognostizierten Zeitraums beitragen. Die Marktschätzungen und -prognosen basieren auf den Faktoren des Basisjahres und wurden durch Top-down- und Bottom-up-Ansätze ermittelt.
Der Markt für Datenerfassung und -kennzeichnung ist segmentiert nach Datentyp (Text, Bild/Video und Audio), nach Endverbrauchsbranche (Automobil, Regierung, Gesundheitswesen, BFSI, Einzelhandel & E-Commerce und andere Endverbrauchsbranchen) sowie nach Geografie (Nordamerika, Europa, asiatisch-pazifischer Raum, Südamerika sowie Naher Osten und Afrika). Die Marktgrößen und -prognosen werden in Wertangaben (USD) für alle oben genannten Segmente bereitgestellt.
Überblick über die Segmentierung
| Text |
| Bild/Video |
| Audio |
| Dreidimensionale Punktwolke |
| Sensor- und Fusionsdatenströme |
| Tabellarische Daten/Zeitreihen |
| Automobil und Mobilität |
| Regierung und öffentlicher Sektor |
| Gesundheitswesen und Biowissenschaften |
| BFSI |
| Einzelhandel und E-Commerce |
| Landwirtschaft |
| IT und Telekommunikation |
| Sonstige Endverbrauchsbranchen |
| Intern |
| Ausgelagerte Dienstleister |
| Crowdsourcing-Plattformen |
| Synthetische Datengenerierung |
| Manuell (Mensch in der Schleife) |
| Halbüberwacht / Aktives Lernen |
| Vollständig automatisiert |
| Nordamerika | Vereinigte Staaten | |
| Kanada | ||
| Mexiko | ||
| Europa | Deutschland | |
| Vereinigtes Königreich | ||
| Frankreich | ||
| Italien | ||
| Spanien | ||
| Russland | ||
| Übriges Europa | ||
| Asiatisch-pazifischer Raum | China | |
| Indien | ||
| Japan | ||
| Südkorea | ||
| Australien und Neuseeland | ||
| Übriger asiatisch-pazifischer Raum | ||
| Naher Osten und Afrika | Naher Osten | Vereinigte Arabische Emirate |
| Saudi-Arabien | ||
| Türkei | ||
| Übriger Naher Osten | ||
| Afrika | Südafrika | |
| Nigeria | ||
| Ägypten | ||
| Übriges Afrika | ||
| Südamerika | Brasilien | |
| Argentinien | ||
| Übriges Südamerika | ||
| Nach Datentyp | Text | ||
| Bild/Video | |||
| Audio | |||
| Dreidimensionale Punktwolke | |||
| Sensor- und Fusionsdatenströme | |||
| Tabellarische Daten/Zeitreihen | |||
| Nach Endverbrauchsbranche | Automobil und Mobilität | ||
| Regierung und öffentlicher Sektor | |||
| Gesundheitswesen und Biowissenschaften | |||
| BFSI | |||
| Einzelhandel und E-Commerce | |||
| Landwirtschaft | |||
| IT und Telekommunikation | |||
| Sonstige Endverbrauchsbranchen | |||
| Nach Beschaffungsmodell | Intern | ||
| Ausgelagerte Dienstleister | |||
| Crowdsourcing-Plattformen | |||
| Synthetische Datengenerierung | |||
| Nach Annotationstyp | Manuell (Mensch in der Schleife) | ||
| Halbüberwacht / Aktives Lernen | |||
| Vollständig automatisiert | |||
| Nach Geografie | Nordamerika | Vereinigte Staaten | |
| Kanada | |||
| Mexiko | |||
| Europa | Deutschland | ||
| Vereinigtes Königreich | |||
| Frankreich | |||
| Italien | |||
| Spanien | |||
| Russland | |||
| Übriges Europa | |||
| Asiatisch-pazifischer Raum | China | ||
| Indien | |||
| Japan | |||
| Südkorea | |||
| Australien und Neuseeland | |||
| Übriger asiatisch-pazifischer Raum | |||
| Naher Osten und Afrika | Naher Osten | Vereinigte Arabische Emirate | |
| Saudi-Arabien | |||
| Türkei | |||
| Übriger Naher Osten | |||
| Afrika | Südafrika | ||
| Nigeria | |||
| Ägypten | |||
| Übriges Afrika | |||
| Südamerika | Brasilien | ||
| Argentinien | |||
| Übriges Südamerika | |||


Im Bericht beantwortete Schlüsselfragen
Wie groß ist der aktuelle Markt für Datenerfassung und -kennzeichnung?
Die Marktgröße für Datenerfassung und -kennzeichnung erreichte im Jahr 2026 einen Wert von 2,67 Milliarden USD und soll bis 2031 auf 10,92 Milliarden USD ansteigen.
Welche Region führt den Markt für Datenerfassung und -kennzeichnung an?
Nordamerika führte im Jahr 2025 mit einem Marktanteil von 39,92 % und spiegelt damit tiefe KI-Investitionen und ausgereifte Dateninfrastruktur-Ökosysteme wider.
Welches Segment wächst innerhalb des Markts für Datenerfassung und -kennzeichnung am schnellsten?
Sensorfusions-Datenströme sollen mit einer CAGR von 35,42 % wachsen, angetrieben durch autonome Systeme und IoT-Anwendungen.
Wie wirkt sich synthetische Datengenerierung auf traditionelle Annotationsdienstleistungen aus?
Synthetische Daten-Engines skalieren mit einer CAGR von 36,2 % und sollen voraussichtlich den Großteil der Trainingsdatensätze liefern, wodurch die routinemäßige manuelle Kennzeichnungsnachfrage sinkt und gleichzeitig neue Validierungsanforderungen entstehen.
Welche Auswirkungen hat das EU-KI-Gesetz auf den Betrieb der Datenkennzeichnung?
Das EU-KI-Gesetz schreibt strenge Datenverwaltung und Herkunftsverfolgung vor und veranlasst Unternehmen, in konforme Annotationsworkflows zu investieren, was die Nachfrage nach prüfungsfähigen Dienstleistern steigert.
Seite zuletzt aktualisiert am:




