Datenklassifizierungsmarkt Größe und Marktanteil
Marktübersicht
| Studienzeitraum | 2020 - 2031 |
|---|---|
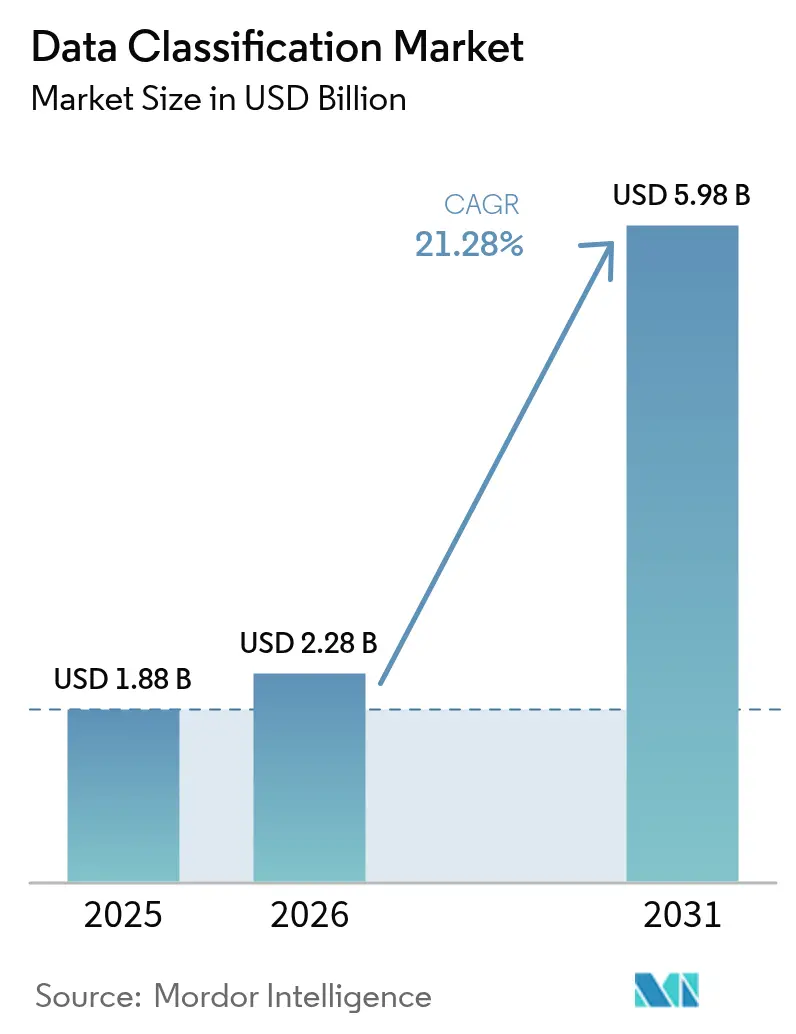
| Marktgröße (2026) | 2.28 Milliarden US-Dollar |
| Marktgröße (2031) | 5.98 Milliarden US-Dollar |
| Wachstumsrate (2026 - 2031) | 21.28% CAGR |
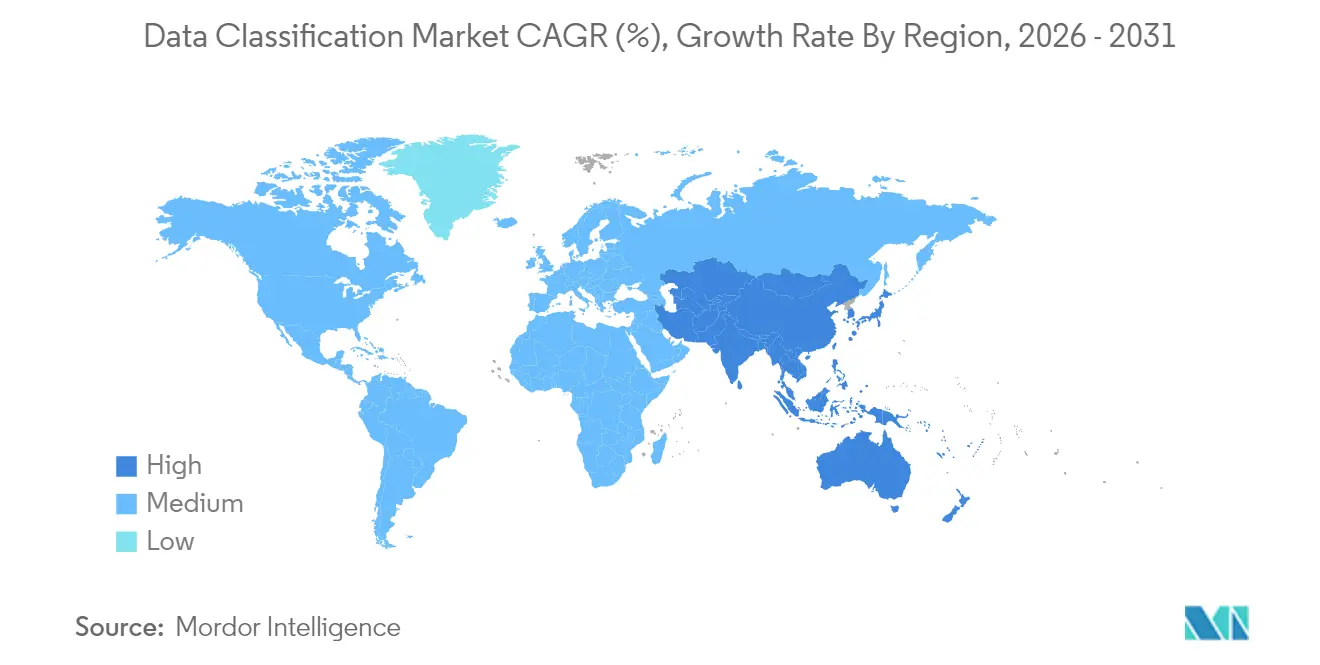
| Schnellstwachsender Markt | Asien-Pazifik |
| Größter Markt | Nordamerika |
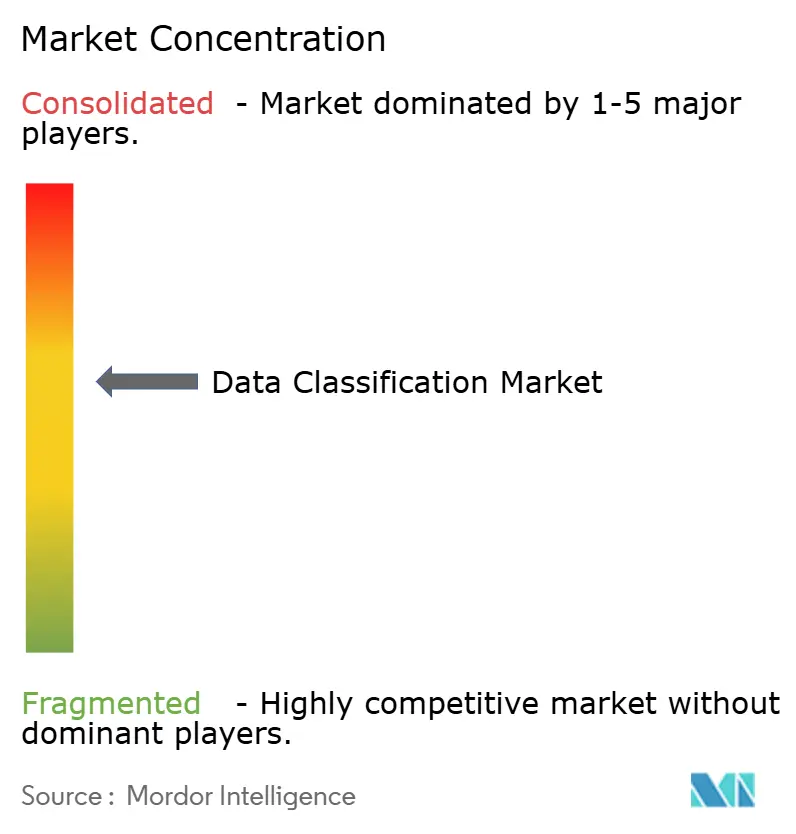
| Marktkonzentration | Mittel |
Hauptakteure *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. | |
Datenklassifizierungsmarkt Analyse von Mordor Intelligence
Die Größe des Datenklassifizierungsmarkts wird im Jahr 2026 auf USD 2,28 Milliarden geschätzt, ausgehend vom Wert des Jahres 2025 von USD 1,88 Milliarden, mit Prognosen für 2031 von USD 5,98 Milliarden, was einem Wachstum von 21,28 % CAGR über den Zeitraum 2026–2031 entspricht. Das rasante Datenwachstum, das auf täglich 328,77 Millionen TB neu erstellter Daten geschätzt wird, sowie strengere globale Datenschutzvorschriften veranlassen Unternehmen, KI-gestützte Echtzeit-Datenkennzeichnung einzuführen, die über hybride Cloud-Umgebungen skaliert. In Cloud-nativen Architekturen eingebettete KI-gestützte Klassifizierungsmaschinen erkennen nun sensible Informationen in unstrukturierten Repositories, während Initiativen zur souveränen Cloud im asiatisch-pazifischen Raum die regionale Nachfrage ankurbeln. Die zunehmende Bedrohungslage, bei der die durchschnittlichen Kosten eines Datenschutzvorfalls im Energiesektor im Jahr 2024 USD 4,78 Millionen erreichten, unterstreicht die Dringlichkeit automatisierter Governance zusätzlich. Investitionen von Hyperscalern wie AWS und Microsoft in regionale Rechenzentren verleihen dem Markt weiteren Schwung, indem sie die Latenz senken und Anforderungen an den Datenstandort erfüllen.
Wichtigste Erkenntnisse des Berichts
- Nach Komponente führte Software im Jahr 2025 mit einem Umsatzanteil von 67,92 %, während Dienstleistungen bis 2031 voraussichtlich mit einer CAGR von 23,62 % wachsen werden.
- Nach Klassifizierungsmethode entfielen im Jahr 2025 42,76 % des Marktanteils auf inhaltsbasierte Modelle; ML-gestützte Ansätze werden bis 2031 voraussichtlich mit einer CAGR von 22,44 % wachsen.
- Nach Unternehmensgröße hielten Großunternehmen im Jahr 2025 70,55 % des Marktanteils am Datenklassifizierungsmarkt, während das KMU-Segment mit einer CAGR von 23,29 % wachsen soll.
- Nach Anwendung entfielen im Jahr 2025 56,12 % des Marktanteils am Datenklassifizierungsmarkt auf Zugangskontrolle und IAM; Governance und Compliance verzeichnen eine CAGR von 22,91 %.
- Nach Branchenvertikale trug BFSI im Jahr 2025 einen Umsatzanteil von 35,12 % bei; Regierung und Verteidigung ist auf ein CAGR-Wachstum von 21,78 % ausgerichtet.
- Nach Geografie dominierte Nordamerika im Jahr 2025 mit einem Anteil von 40,62 %, doch der asiatisch-pazifische Raum wird bis 2031 voraussichtlich eine CAGR von 22,07 % verzeichnen.
Hinweis: Die Marktgrößen- und Prognosezahlen in diesem Bericht werden mithilfe des proprietären Schätzrahmens von Mordor Intelligence erstellt und mit den neuesten verfügbaren Daten und Erkenntnissen bis 2026 aktualisiert.
Globale Trends und Erkenntnisse zum Datenklassifizierungsmarkt
Analyse der Auswirkungen von Treibern*
| Treiber | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Ausweitung globaler Datenschutzvorschriften | +4.2% | Global, mit konzentrierter Auswirkung in der EU, Nordamerika und dem asiatisch-pazifischen Raum | Mittelfristig (2–4 Jahre) |
| Explosives Wachstum unstrukturierter Daten und Datenschutzverletzungsrisiko | +3.8% | Global, besonders ausgeprägt in Nordamerika und Europa | Kurzfristig (≤ 2 Jahre) |
| Nachfrage nach Cloud-nativer Datenklassifizierung | +3.5% | Asiatisch-pazifischer Raum als Kern, Ausstrahlungseffekte auf den Nahen Osten und Afrika sowie Lateinamerika | Mittelfristig (2–4 Jahre) |
| KI/ML-gestützte automatische Klassifizierung im Produktionseinsatz in großem Maßstab | +3.1% | Nordamerika und EU führend, rasante Übernahme im asiatisch-pazifischen Raum | Kurzfristig (≤ 2 Jahre) |
| Vertrauliche Datenverarbeitung durch Chipsets, die Inline-Kennzeichnung ermöglichen | +2.4% | Nordamerika und ausgewählte EU-Märkte | Langfristig (≥ 4 Jahre) |
| GenAI-Sicherheit erfordert feinkörnige Datenkennzeichnung | +2.7% | Global, mit früher Übernahme in regulierten Branchen | Mittelfristig (2–4 Jahre) |
| Quelle: Mordor Intelligence | |||
Ausweitung globaler Datenschutzvorschriften
Die europäischen DORA-Vorschriften und aktualisierte HIPAA-Standards verlagern die Compliance von geplanten Prüfungen hin zur kontinuierlichen Überprüfung und verpflichten Unternehmen, Klassifizierungslogik direkt in Datenverarbeitungsworkflows einzubetten[1]US-Bundesregister, "Sicherheits- und Datenschutzkontrollen für föderale Informationssysteme," federalregister.gov. Multinationale Unternehmen, die in mehreren Rechtsordnungen tätig sind, wenden häufig die strengste globale Anforderung als Ausgangspunkt an, was die Einführung einheitlicher Klassifizierungsarchitekturen beschleunigt. Finanzinstitute müssen Berichte zur Geldwäschebekämpfung innerhalb von Minuten vorlegen, was die Nachfrage nach richtliniengesteuerter Erkennung erhöht. Ähnlicher Druck entsteht durch lateinamerikanische Datensouveränitätsgesetze, die sich an der DSGVO orientieren. Zusammen verkürzen diese Vorschriften die Beschaffungszyklen und drängen selbst mittelgroße Unternehmen zu SaaS-basierten Tools, die Richtlinien automatisch aktualisieren.
Explosives Wachstum unstrukturierter Daten und Datenschutzverletzungsrisiko
Unstrukturierte Repositories wachsen jährlich um 62 %, was Sicherheitsteams blind gegenüber dem Inhaber sensibler Datensätze macht. Unternehmen berichten von übermäßigen Berechtigungen bei 82 % der Dateifreigaben, wodurch wertvolle Entwürfe und Kundendaten gefährdet werden. Energieversorger verzeichnen mittlerweile 1.100 wöchentliche Cyberangriffe, und Untersuchungen von Datenschutzverletzungen zeigen falsch klassifizierte Dokumente als Grundursache. Anwaltskanzleien sind ähnlichen Risiken ausgesetzt, da Mandantendateien ohne Kennzeichnung in gemeinsam genutzten Laufwerken liegen. KI-gestützte Mustererkennung wird zunehmend bevorzugt, da statische Regelwerke mit dynamischen Kollaborationsplattformen nicht Schritt halten können.
Nachfrage nach Cloud-nativer Datenklassifizierung
Vierundsechzig Prozent der australischen Organisationen testen Souveränitätsstrategien, und fast die Hälfte der Behörden im öffentlichen Sektor des asiatisch-pazifischen Raums plant, solche Kontrollen innerhalb eines Jahres einzuführen. Klassifizierungsmaschinen müssen über Multi-Cloud-Umgebungen hinweg betrieben werden und dabei lokale Anforderungen an den Datenstandort einhalten. Microsofts Partnerschaft im Wert von USD 1,5 Milliarden mit dem in den Vereinigten Arabischen Emiraten ansässigen Unternehmen G42 unterstreicht die regionale Rechenkapazitätserweiterung, die auf integrierte Kennzeichnung zur Trennung regulierter Workloads angewiesen ist. Die Einführung souveräner Cloud zwingt Unternehmen, duale Richtlinienebenen aufrechtzuerhalten: globale Standards und jurisdiktionsspezifische Tags. Anbieter, die diese Zuordnung automatisieren, erzielen eine klare Differenzierung.
KI/ML-gestützte automatische Klassifizierung im Produktionseinsatz in großem Maßstab
Unternehmen berichten nun von 96-prozentigen Verbesserungen der Datenqualität, nachdem sie maschinelles Lernen auf bestehende Erkennungspipelines aufgesetzt haben. Forcepoint integrierte das selbstlernende Modell von Getvisibility, um langwierige Regelerstellung zu eliminieren und die Genauigkeit durch Live-Feedback zu verbessern. Microsoft Purview bietet mehr als 200 integrierte Informationstypen, die Inhalte in Exchange, SharePoint und SQL-Assets automatisch kennzeichnen. Steigende Modellpräzision reduziert Fehlalarme, was wiederum den Helpdesk-Aufwand senkt und die Benutzerakzeptanz beschleunigt. KMU profitieren am meisten, da ihnen zuvor die Ressourcen für manuelle Anpassungen fehlten.
Analyse der Auswirkungen von Hemmnissen*
| Hemmnis | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Fehlende branchenübergreifende Taxonomiestandards | -2.1% | Global, mit besonderen Herausforderungen in Schwellenmärkten | Langfristig (≥ 4 Jahre) |
| Hohe Integrationskosten in veralteten IT-Umgebungen | -1.8% | Nordamerika und Europa mit etablierter IT-Infrastruktur | Mittelfristig (2–4 Jahre) |
| "Klassifizierungsrückstand" durch die Verbreitung synthetischer Daten | -1.5% | Global, konzentriert in KI-intensiven Branchen und Regionen | Mittelfristig (2–4 Jahre) |
| Homomorphe Verschlüsselung verzögert die Klartextprüfung | -1.2% | Nordamerika und EU führend bei der Einführung, selektiver Unternehmenseinsatz | Langfristig (≥ 4 Jahre) |
| Quelle: Mordor Intelligence | |||
Fehlende branchenübergreifende Taxonomiestandards
Finanzaufsichtsbehörden klassifizieren Risikodaten anders als Gesundheitsbehörden, was Anbieter zwingt, branchenspezifische Regelbibliotheken zu pflegen. Multinationale Unternehmen müssen die DSGVO-Terminologie mit Chinas Definition von „wichtigen Daten” in Einklang bringen, wenn sie Dateien übertragen. Diese Fragmentierung treibt den Aufwand für individuelle Programmierung in die Höhe, verstärkt Bedenken hinsichtlich der Anbieterabhängigkeit und verlangsamt Kaufentscheidungen. Branchenverbände erarbeiten offene Schema-Vorschläge, doch die Übernahme bleibt uneinheitlich. Infolgedessen erzielen Systemintegratoren erhebliche Einnahmen aus Zuordnungsworkshops und nicht aus reinen Softwarelizenzen.
Hohe Integrationskosten in veralteten IT-Umgebungen
Betreiber kritischer Infrastrukturen betreiben noch immer Systeme, die vor mehr als 20 Jahren in Betrieb genommen wurden und häufig keine modernen APIs besitzen[2]Thales Group, "Bericht zur Cybersicherheit kritischer Infrastrukturen," thalesgroup.com. Die Nachrüstung von Klassifizierung in solchen Umgebungen überschreitet häufig 18 Monate, während derer Compliance-Risiken ungelöst bleiben. KMU erleben ähnliche Reibungsverluste, da knappes Sicherheitspersonal den Tagesbetrieb mit Transformationsprojekten in Einklang bringen muss. Budgetverantwortliche verschieben Klassifizierungseinführungen manchmal bis zu geplanten umfassenderen ERP-Upgrades. Anbieter fördern nun agentenlose Konnektoren und vorgefertigte Pipelines, um diese Kosten zu senken, doch die Komplexität bleibt ein wesentliches Hemmnis.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Komponente: Dienstleistungen treiben das Wachstum über Softwarelizenzen hinaus
Software erzielte weiterhin den höchsten Umsatz und machte im Jahr 2025 67,92 % des Datenklassifizierungsmarkts aus. Der Lizenzverkauf konzentrierte sich auf Richtlinienmaschinen, Erkennungs-Crawler und SaaS-Dashboards. Dennoch skalieren professionelle und verwaltete Dienstleistungen mit einer CAGR von 23,62 %, da Unternehmen Orientierung benötigen, um langjährige Klassifizierungsrückstände abzubauen. Aufträge beginnen häufig mit Multi-Petabyte-Scans, die Rückstände bei der Behebung speisen und interne Ressourcen belasten. Anbieter verwalteter Dienste gleichen Qualifikationsmängel aus, indem sie Modell-Retraining, regulatorische Aktualisierungen und Ticket-Triage auf Abonnementbasis übernehmen. Diese Verträge können sich über mehrere Jahre erstrecken, was die Ausgaben von einmaligen Investitionsausgaben auf wiederkehrende Betriebsausgaben verlagert. Der Ansatz findet bei Vorständen Anklang, die vorhersehbare Budgets und prüfungsreife Nachweise anstreben. In monetären Begriffen könnten Dienstleistungen bis 2031 USD 2,16 Milliarden der Marktgröße des Datenklassifizierungsmarkts ausmachen, was ihre strategische Bedeutung widerspiegelt. Softwareanbieter bündeln daher Beratungskapazitäten in Premium-Tarifen, um Margen zu schützen.
Implementierungen der zweiten Generation setzen auf kontinuierliche Anpassung statt auf jährliche Gesundheitschecks. Servicepartner bauen DevSecOps-Pipelines auf, die eine Klassifizierung auslösen, sobald neue Daten in den Objektspeicher gelangen. Sie kodifizieren auch gemeinsame Taxonomien über Geschäftsbereiche hinweg, was die Onboarding-Zeiträume für Akquisitionen verkürzt. Der Trend erweitert den Datenklassifizierungsmarkt, da mittelgroße Unternehmen Expertise mieten können, anstatt knappe Spezialisten einzustellen. Anbieter-Marktplätze listen nun kuratierte Servicepakete auf, die auf ISO 27001, HIPAA oder PCI-Vorlagen abgestimmt sind, was die Einführung weiter demokratisiert. Da die Dienstleistungserlöse zunehmen, übernehmen Systemintegratoren Boutique-Beratungsunternehmen, um Domänenwissen zu stärken und Marktanteile zu sichern.
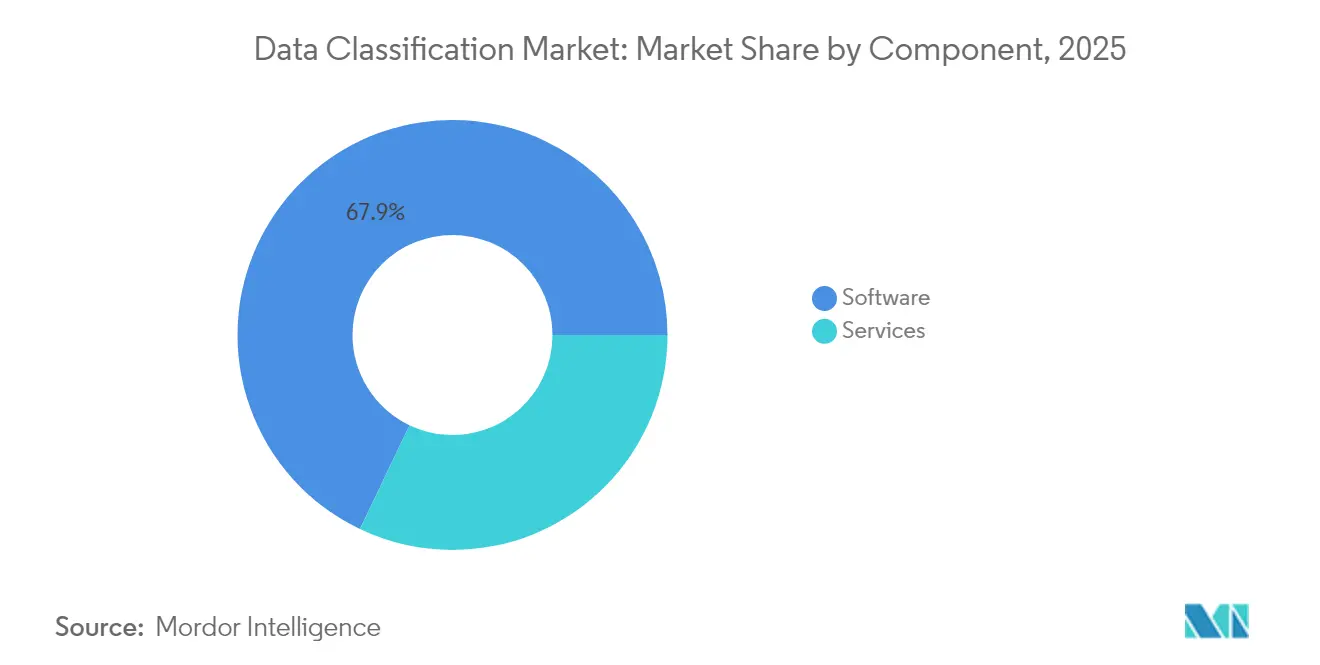
Notiz: Segmentanteile aller einzelnen Segmente sind nach dem Berichtskauf verfügbar


Nach Klassifizierungsmethode: Maschinelles Lernen definiert Genauigkeitsmaßstäbe neu
Die inhaltsbasierte Prüfung hielt im Jahr 2025 42,76 % der Ausgaben, indem sie reguläre Ausdrücke und Fingerprinting nutzte, um geistiges Eigentum zu kennzeichnen. Dennoch wachsen ML-gestützte und semantische Modelle mit einer CAGR von 22,44 %, indem sie Kontext aus Millionen gekennzeichneter Dokumente erlernen. Musterblindfähigkeiten, wie Transformer-Netzwerke, die Satzstrukturen analysieren, erhöhen die Trefferquoten und reduzieren Fehlalarme. Microsoft Purview trainiert auf globaler Telemetrie, was regelmäßige Modellaktualisierungen ohne Kundeneingriff ermöglicht. Digital Guardian schichtet kontextuelle Signale wie Standort und Gerätestatus über inhaltliche Hinweise, was eine risikogewichtete Kennzeichnung ermöglicht. Kombinierte Ansätze werden nun als vorkonfigurierte Pakete geliefert, sodass Administratoren neue Maschinen ohne Betriebsunterbrechung einführen können.
Frühe Anwender berichten, dass maschinelles Lernen die Produktivität der Prüfer um 35 % steigert, da weniger Elemente menschlicher Beurteilung bedürfen. Organisationen mit mehrsprachigen Archiven profitieren messbar, da semantische Modelle Sprachvarianz besser handhaben als manuelle Schlüsselwortlisten. Anbieter öffnen APIs zur Integration kundenspezifischer Ontologien und ermöglichen so maßgeschneiderte Genauigkeit ohne Neuentwicklung. Der Wandel stärkt den Datenklassifizierungsmarkt, da er eine ehemals elitäre Fähigkeit in ein SaaS-Standardmerkmal verwandelt. Trainingsdaten bleiben jedoch ein Engpass für Nischenbereiche, was einige Unternehmen dazu veranlasst, anonymisierte Korpora im Rahmen von Gegenseitigkeitsvereinbarungen zu teilen. Im Prognosezeitraum wird erwartet, dass die ML-Einführung die Zeit bis zur Wertschöpfung von Quartalen auf Wochen reduziert und ihre Rolle als Standardmethodik festigt.
Nach Unternehmensgröße: Cloud-native Plattformen demokratisieren Kennzeichnung auf Unternehmensebene
Großunternehmen trugen 2025 70,55 % des Umsatzes bei, bedingt durch regulatorische Exposition und Budgettiefe. Sie waren frühe Befürworter integrierter Governance-Suiten, die lokale Dateiserver und Multi-Cloud-Umgebungen umspannen. Dennoch stellen KMU nun das am schnellsten wachsende Segment mit einer CAGR von 23,29 % dar und profitieren von SaaS-Angeboten ohne Infrastrukturaufwand. Die meisten Plattformen werden innerhalb von Stunden bereitgestellt und erfordern nur leichtgewichtige Konnektoren für E-Mail, Zusammenarbeit und Objektspeicher. Abonnementtarife richten die Kosten am Verbrauch aus, was Einstiegspunkte für Unternehmen mit weniger als 500 Mitarbeitern erschwinglich macht. Auf Gesundheits-, Finanz- und Rechtsinhalte abgestimmte Vorlagen beschleunigen die Einführung, da KMU keine Vollzeit-Compliance-Beauftragten haben.
Bildungsressourcen, wie die von der Community geleiteten Workshops von Microsoft, senken die Hürden weiter, indem sie IT-Generalisten in der Verwaltung von Klassifizierungsrichtlinien schulen. Das PUZZLE-Framework bietet praktische Checklisten, mit denen KMU minimale tragfähige Sicherheit in Cloud-Workloads einbetten können. Branchenverbände verbreiten auch Open-Source-Regelpakete, damit Mitglieder ohne Ausgangspunkt starten können. Mit zunehmender Einführung sammeln Plattformanbieter Telemetrie, die die ML-Genauigkeit für alle Mandanten verbessert und ein Schwungrad schafft, das kleinere Unternehmen überproportional begünstigt. Das Muster motiviert Marktplätze, Nischenkonnektoren für Buchhaltungs-, Personal- und Kundenbeziehungssysteme aufzulisten, die im mittleren Marktsegment beliebt sind, und erweitert so die Abdeckung ohne individuelle Skripterstellung.
Nach Anwendung: Governance und Compliance rücken in den Mittelpunkt
Zugangskontrolle und IAM machten 2025 56,12 % der Ausgaben aus, da kennzeichnungsgesteuerte Berechtigungen das Rückgrat von Zero-Trust-Richtlinien bilden. E-Mail- und Mobilschutz folgten, da verteilte Belegschaften sensible Dokumente über Chat- und BYOD-Kanäle teilen. Das schnellste Wachstum mit einer CAGR von 22,91 % liegt in Governance- und Compliance-Dashboards, die Kennzahlen für Regulierungsbehörden und Vorstände aufbereiten. Diese Tools beziehen Daten aus der Klassifizierungstelemetrie, um Datenspeicherort, Aufbewahrung und Herkunft zu visualisieren. Sie exportieren maschinenlesbare Berichte für automatisierte Sicherungsportale und reduzieren die Prüfungsvorbereitung von Wochen auf Stunden. Die Fähigkeit wird unter nahezu in Echtzeit geltenden Offenlegungspflichten wie der Cybersicherheits-Vorfallsregel der SEC kritisch.
Integrationen mit Risikobewertungsmaschinen ermöglichen es Compliance-Teams, die Behebung nach Datenkritikalität statt nach Dateianzahl zu priorisieren. Erweiterte Dashboards betten prädiktive Analysen ein, die potenzielle Bußgelder schätzen, wenn falsch gekennzeichnete Datensätze eine Region verlassen. Daher verlagern sich Ausgabenmuster von punktuellen DLP-Plugins hin zu einheitlichen Plattformen mit integrierten Analysen. Anbieter positionieren Compliance-Module als produktgesteuerte Wachstumshebel und bieten Freemium-Lizenztarife an, die Risikobefunde aufzeigen und Upselling zu vollständig ausgestatteten Suiten fördern. Die daraus resultierende Transparenz fördert die Unterstützung durch Führungskräfte und erweitert den Datenklassifizierungsmarkt über die Sicherheitsabteilung hinaus.

Notiz: Segmentanteile aller einzelnen Segmente sind nach dem Berichtskauf verfügbar
Nach Branchenvertikale: Regierung und Verteidigung beschleunigen die Ausgabenentwicklung
BFSI erzielte 2025 35,12 % des Umsatzes, angetrieben durch Basel-III-Kapitalvorschriften und Verpflichtungen zur Geldwäschebekämpfung. Das Gesundheitswesen folgte, angetrieben durch die HIPAA-Modernisierung und den Vorstoß für elektronische Gesundheitsakten. Die schnellste Expansion mit einer CAGR von 21,78 % verzeichnen Regierung und Verteidigung, wo Zero-Trust-Anforderungen und Workflows für klassifizierte Informationen eine präzise Kennzeichnung erfordern. Das aktualisierte Informationssicherheitsprogramm des US-Verteidigungsministeriums verpflichtet Auftragnehmer, einheitliche Kennzeichnungsregeln für E-Mail, Kollaborationsplattformen und Cloud-Speicher anzuwenden. Validierungsfenster für Beschränkungen technischer Daten erstrecken sich nun auf 6 Jahre, was nachhaltige Dienstleistungserlöse sichert. Verteidigungsbehörden investieren auch in Inline-Kennzeichnung an Netzwerk-Gateways zur Unterstützung sicherer domänenübergreifender Lösungen.
Betreiber kritischer Infrastrukturen, wie Versorgungsunternehmen, die mit Smart-Grid-Analysen experimentieren, übernehmen zunehmend verteidigungsähnliche Praktiken, um staatlich geförderte Bedrohungen abzuwehren. Nationale Datenstrategien fordern souveräne Cloud-Einrichtungen, die wiederum eine durch Klassifizierungs-Tags durchgesetzte Mandantentrennung erfordern. Große Systemintegratoren bilden Joint Ventures mit Einrichtungen des öffentlichen Sektors, um Produkt-Roadmaps an Missionsbedürfnissen auszurichten. Da diese Verträge häufig inländisches Hosting vorschreiben, stärkt die Lokalisierung regionale SaaS-Präsenzen. Vertikale Spezialisierung wird daher zu einem Wettbewerbsvorteil und sichert stetige Zuflüsse in den Datenklassifizierungsmarkt.
Geografische Analyse
Nordamerika behauptete seine Führungsposition mit 40,62 % des Umsatzes im Jahr 2025, da strenge Vorschriften und eine frühe KI-Einführung Unternehmen dazu veranlassten, Erkennungsprogramme zu modernisieren. BigIDs Finanzierungsrunde über USD 60 Millionen im Jahr 2025 verdeutlicht den Risikokapitalhunger nach Lösungen, die Datenhygiene vor neuen SEC-Offenlegungsregeln automatisieren. Finanzinstitute setzen Kennzeichnung ein, um Intraday-Berichtspflichten zu erfüllen, während Gesundheitsdienstleister Tags in elektronische Patientenakten integrieren, um sich an die sich entwickelnden HIPAA-Erweiterungen anzupassen. Die Datenschutzgesetze der kanadischen Provinzen spiegeln die Bundesanforderungen wider und stärken eine konsistente Nachfrage. Mexikos Technologiecluster übernehmen Cloud-gehostete Plattformen, um die Datentransferklauseln des USMCA zu erfüllen, obwohl die Übernahme auf multinationale Tochtergesellschaften konzentriert ist.
Der asiatisch-pazifische Raum ist die am schnellsten wachsende Region mit einer CAGR von 22,07 %, was souveräne Cloud-Mandate und hohe Infrastrukturausgaben von Hyperscalern widerspiegelt. AWS verpflichtete sich zu USD 6 Milliarden für Malaysia und NTT zu USD 90 Millionen für Rechenzentren in Bangkok, was lokale Rechenkapazität schafft, die die Latenz für Richtlinienmaschinen reduziert. China schlägt vor, die Genehmigung für ausgehende Daten zu erleichtern, kennzeichnet jedoch viele Datensätze weiterhin als „wichtig”, was doppelte Kontrollen erzwingt. Japan und Südkorea setzen Klassifizierung in der 5G-Fertigung ein, um Geschäftsgeheimnisse zu schützen. Indiens IT-Dienstleistungsexporteure fordern mandantenfähige Kennzeichnung zur Trennung von Kundendaten, was den adressierbaren Pool von Cloud-Abonnenten erweitert.
Europa belegt einen soliden zweiten Platz nach Wert, angetrieben durch den Digitalen Betriebsresilienzakt, der bis 2025 kontinuierliche Kontrolltests erfordert. Deutschlands Industrie-4.0-Werke kennzeichnen Betriebsdaten, um geistiges Eigentum zu schützen und Sicherheitsprüfungen der Lieferkette zu erfüllen. Das Vereinigte Königreich balanciert die Post-Brexit-Angemessenheit mit inländischen Innovationsregeln, sodass Unternehmen grenzüberschreitende Datenflüsse unter dualen Richtlinien überwachen. Frankreich fördert souveräne Cloud-Zonen für öffentliche Workloads, während Italien den Schutz kritischer Infrastrukturen verschärft. Nordische Länder, frühe DSGVO-Anwender, pilotieren nun Chips für vertrauliche Datenverarbeitung, die Inline-Kennzeichnung ohne Klartextexposition ermöglichen, und positionieren die Region für Innovationen der nächsten Welle.

Wettbewerbslandschaft
Der Datenklassifizierungsmarkt weist eine moderate Fragmentierung auf, da Hyperscale-Cloud-Anbieter und spezialisierte Sicherheitsunternehmen um Plattformanteile konkurrieren. Microsoft Purview integriert Kennzeichnung über Azure, Microsoft 365 und SQL-Dienste und bietet eine zentrale Governance, die Großunternehmen anzieht. AWS, Google Cloud und IBM betten ähnliche Kontrollen in Speicher-APIs ein, was die Einführungshürden für Entwickler senkt. Spezialisierte Anbieter wie Varonis und BigID differenzieren sich durch tiefgehende Inhaltsanalysen und Datenschutz-Dashboards, die die Datenherkunft visualisieren. Aufstrebende Akteure wie Cyera konzentrieren sich auf Cloud-natives Datensicherheits-Positionsmanagement und ziehen rasche Finanzierungen an, was die Innovation beschleunigt.
Akquisitionsaktivitäten gestalten die Wettbewerbsdynamik um. Forcepoint erwarb Getvisibility, um selbstlernende Modelle mit seiner DLP-Maschine zu kombinieren und die Präzision über hybride Clouds zu verbessern. Capgemini kaufte Syniti, um Datenqualitätsdienste mit Governance-Beratung zu verbinden und das Mehrwertangebot zu erweitern. Snowflakes Übernahme von Reka AI und Databricks' Kauf von MosaicML verdeutlichen die Konvergenz von Analyse-, KI- und Kennzeichnungsfähigkeiten. Diese Schritte reagieren auf die Käuferpräferenz für konsolidierte Plattformen, die die Lizenzkomplexität reduzieren und Compliance-Nachweise integrieren.
Preismodelle entwickeln sich hin zu verbrauchsbasierten Tarifen, die an gescannte Terabytes und geschützte Nutzer geknüpft sind. Anbieter bündeln Starter-Kits mit vorgefertigten Taxonomien, um die Zeit bis zur Wertschöpfung zu beschleunigen. Kanalpartner entwickeln vertikale Beschleuniger, die Branchenvorschriften kodifizieren und so gebundene Ökosysteme schaffen. Wettbewerbsvorteile konzentrieren sich zunehmend auf nachweisbaren ROI, wobei Lieferanten Einsparungen bei Datenschutzverletzungskosten und Prüfungsressourcen vorweisen. Marktteilnehmer mit engen Punktlösungen stehen unter Druck, da Kunden sich um integrierte Suiten mit globalen Support-Netzwerken konsolidieren.
Marktführer im Bereich Datenklassifizierung
Amazon Web Services, Inc.
Boldon James Ltd (QinetiQ)
IBM Corporation
Microsoft Corporation
Broadcom Inc. (Symantec Corporation)
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Aktuelle Branchenentwicklungen
- April 2025: Kyndryl startete Datensicherheits-Positionsmanagement-Dienste mit Microsoft und lieferte automatisierte Erkennung und Klassifizierung, die die Betriebskosten um 31 % senken.
- April 2025: Forcepoint veröffentlichte seine Datensicherheits-Cloud-Plattform, die DSPM- und DDR-Funktionen kombiniert, um eine einheitliche Kontrolle über hybride Umgebungen zu ermöglichen.
- April 2025: Forcepoint schloss die Übernahme von Getvisibility ab und fügte seinem Sicherheits-Stack adaptive KI-gestützte Klassifizierung hinzu.
- März 2025: BigID sicherte sich eine Series-E-Finanzierung über USD 60 Millionen, um Datenhygiene- und Datenschutzfunktionen auszubauen.


Rahmen der Forschungsmethodik und Umfang des Berichts
Marktdefinitionen und wesentliche Abdeckung
Unsere Studie definiert den Markt für Datenklassifizierung als alle Softwareplattformen und zugehörigen professionellen oder verwalteten Dienstleistungen, die strukturierte, halbstrukturierte und unstrukturierte Daten in On-Premise-, Cloud- und Hybrid-Umgebungen kennzeichnen, beschriften und Handhabungsregeln durchsetzen. Laut Mordor Intelligence werden gebündelte Discovery-, Katalog-, Backup- oder umfassendere Sicherheits-Suites nur dann einbezogen, wenn das Klassifizierungsmodul separat bepreist und ausgewiesen wird.
Ausschluss aus dem Geltungsbereich: Tools, die hauptsächlich auf Datenerkennung, Katalogverwaltung oder Datensatzkennzeichnung für das Training von KI-Modellen ausgerichtet sind, liegen außerhalb dieses Geltungsbereichs.
Segmentierungsübersicht
- Nach Komponente
- Software
- Dienstleistungen
- Nach Klassifizierungsmethode
- Inhaltsbasiert
- Kontextbasiert
- Nutzer-/Rollenbasiert
- ML-gestützt und semantisch
- Nach Unternehmensgröße
- Großunternehmen
- Kleine und mittlere Unternehmen (KMU)
- Nach Anwendung
- Zugangskontrolle und IAM
- Governance und Compliance
- E-Mail- und Mobilschutz
- Nach Branchenvertikale
- BFSI
- Gesundheitswesen und Biowissenschaften
- Regierung und Verteidigung
- IT und Telekommunikation
- Energie und Versorgungsunternehmen
- Sonstige Branchenvertikalen
- Nach Geografie
- Nordamerika
- Vereinigte Staaten
- Kanada
- Mexiko
- Europa
- Deutschland
- Vereinigtes Königreich
- Frankreich
- Italien
- Spanien
- Übriges Europa
- Asiatisch-pazifischer Raum
- China
- Japan
- Indien
- Südkorea
- Australien
- Übriger asiatisch-pazifischer Raum
- Südamerika
- Brasilien
- Argentinien
- Übriges Südamerika
- Naher Osten und Afrika
- Naher Osten
- Saudi-Arabien
- Vereinigte Arabische Emirate
- Türkei
- Übriger Naher Osten
- Afrika
- Südafrika
- Ägypten
- Nigeria
- Übriges Afrika
- Naher Osten
- Nordamerika
Detaillierte Forschungsmethodik und Datenvalidierung
Primärforschung
Wir führten strukturierte Interviews mit Chief Information Security Officers in den Bereichen Banken, Gesundheitswesen, Telekommunikation und Behörden in Nordamerika, Europa und dem asiatisch-pazifischen Raum durch. Anschließend führten wir Umfragen mit Distributoren und Cybersicherheitsprüfern durch. Ihre Erkenntnisse zu Adoptionsauslösern, Pay-per-User-Spannen und der Geschwindigkeit der Cloud-Migration ermöglichten es den Mordor-Analysten, aus Desk-Research abgeleitete Annahmen zu korrigieren.
Desk Research
Unser Team begann mit offenen Quellen wie dem Vorfallsarchiv des US National Institute of Standards and Technology, der Datenbank für Sicherheitsverletzungen der European Union Agency for Cybersecurity, den Strafprotokollen der UK ICO und Volza-Versanddaten, die HS-Codes für Sicherheitssoftware kennzeichnen. Geschäftsberichte und 10-Ks offenbarten durchschnittliche Verkaufspreise und Seat-Penetration nach Branche, während D&B Hoovers, Dow Jones Factiva und Questel-Patentanalysen dabei halfen, Anbieterumfang und Innovation einzuschätzen. Die genannten Quellen sind illustrativ und nicht erschöpfend für den insgesamt gesichteten Quellenkorpus.
Marktgröße & Prognose
Ein Top-down-Ansatz verknüpft die Anzahl von Unternehmen in einzelnen Ländern und regulierte Daten-Workloads mit beobachteten Klassifizierungsdurchdringungsraten, die anschließend mit gemischten Lizenz- und Servicepreisen multipliziert werden. Lieferantenzusammenfassungen, Channel-Checks und anonymisierte Vertragswerte bieten eine Bottom-up-Plausibilitätsprüfung. Zu den wichtigsten Variablen zählen Nutzer-Seats unter Compliance-Vorgaben, unstrukturiertes Datenvolumen, durchschnittliche Lizenzkosten, Cloud-Speicheranteil, Häufigkeit regulatorischer Bußgelder und Wachstum des Sicherheitsbudgets. Eine multivariate Regression auf Basis dieser Treiber projiziert die Nachfrage bis 2030, während Szenarioanalysen strengere oder gelockerte Datenschutzregime testen. Lücken in der Bottom-up-Abdeckung werden durch regionale Preisstreuungen und Mittelpunktvolumina geschlossen.
Datenvalidierung & Aktualisierungszyklus
Modellergebnisse werden anhand von Varianzprüfungen gegen externe Ausgabenindizes und Anbietergewinne geprüft, bevor eine leitende Freigabe erfolgt. Berichte werden jährlich aktualisiert, mit Zwischenrevisionen bei größeren Sicherheitsverletzungen oder politischen Veränderungen, um sicherzustellen, dass Kunden stets die aktuellste Datenbasis erhalten.
Warum Mordors Datenklassifizierungs-Baseline Zuverlässigkeit gewährleistet
Veröffentlichte Schätzungen weichen häufig voneinander ab, da Herausgeber unterschiedliche Geltungsbereiche, Eingabevariablen und Aktualisierungsrhythmen wählen. Mordors disziplinierte Abgrenzungen, jährlich aktualisierte Treiber sowie die ausgewogene Abstimmung von Top-down- und Bottom-up-Ansätzen minimieren diese Verzerrungen für Entscheidungsträger.
Zu den wesentlichen Ursachen für Abweichungen zählen: Einige Studien erfassen ausschließlich Lösungsumsätze, andere extrapolieren aggressive Cloud-Seat-Kurven, und mehrere werden nur alle zwei Jahre aktualisiert, was zu Verzögerungen gegenüber sich schnell verändernden Datenschutzgesetzen führt.
Benchmark-Vergleich
| Marktgröße | Anonymisierte Quelle | Primärer Abweichungstreiber |
|---|---|---|
| USD 1,88 Mrd. (2025) | Mordor Intelligence | |
| USD 1,85 Mrd. (2024) | Global Consultancy A | Nur-Lösungen-Umfang und 35 % CAGR-Annahme |
| USD 1,66 Mrd. (2024) | Industry Research B | Schließt professionelle Dienstleistungen und drei aufstrebende Regionen aus |
Diese Kontraste zeigen, wie unser klar definierter Geltungsbereich, die Validierung auf Variablenebene und zeitnahe Aktualisierungen Mordor Intelligence zum verlässlichen Referenzpunkt für Planer und Investoren machen.


Im Bericht beantwortete Schlüsselfragen
Wie groß ist der Datenklassifizierungsmarkt derzeit?
Der Markt wird im Jahr 2026 auf USD 2,28 Milliarden geschätzt und soll bis 2031 USD 5,98 Milliarden erreichen, was einer CAGR von 21,28 % entspricht.
Welche Region wächst am schnellsten?
Der asiatisch-pazifische Raum verzeichnet das höchste Wachstum, wobei der Datenklassifizierungsmarkt bis 2031 voraussichtlich eine CAGR von 22,07 % aufweisen wird, bedingt durch souveräne Cloud-Mandate und Infrastrukturinvestitionen.
Welches Komponentensegment wächst am schnellsten?
Dienstleistungen wachsen mit einer CAGR von 23,62 %, da Organisationen professionelle Beratung benötigen, um KI-gestützte Kennzeichnung in hybriden Umgebungen einzuführen und zu pflegen.
Wie wirken sich Methoden des maschinellen Lernens auf die Einführung aus?
ML-gestützte Klassifizierung verbessert die Genauigkeit, reduziert Fehlalarme und verringert den manuellen Anpassungsaufwand, was kleineren Unternehmen den Zugang zu Schutz auf Unternehmensebene ermöglicht.
Welche Branchen investieren am stärksten?
BFSI führt bei den aktuellen Ausgaben dank strenger Vorschriften, während Regierung und Verteidigung mit einer CAGR von 21,78 % das schnellste Wachstum aufgrund nationaler Sicherheitsanforderungen verzeichnen.
Was ist ein wesentliches Hemmnis für eine breitere Einführung?
Die Integration von Klassifizierung in veraltete IT-Umgebungen bleibt kostspielig und zeitaufwendig, insbesondere für Betreiber kritischer Infrastrukturen, die noch immer veraltete Systeme betreiben.
Seite zuletzt aktualisiert am:




