Marktgröße und Marktanteil des KI-Rechenzentrums-GPU-Markts
Marktübersicht
| Studienzeitraum | 2020 - 2031 |
|---|---|
| Marktgröße (2026) | 45.04 Milliarden US-Dollar |
| Marktgröße (2031) | 90.46 Milliarden US-Dollar |
| Wachstumsrate (2026 - 2031) | 14.97% CAGR |
| Schnellstwachsender Markt | Asien-Pazifik |
| Größter Markt | Nordamerika |
| Marktkonzentration | Hoch |
Hauptakteure *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. | |
Analyse des KI-Rechenzentrums-GPU-Markts von Mordor Intelligence
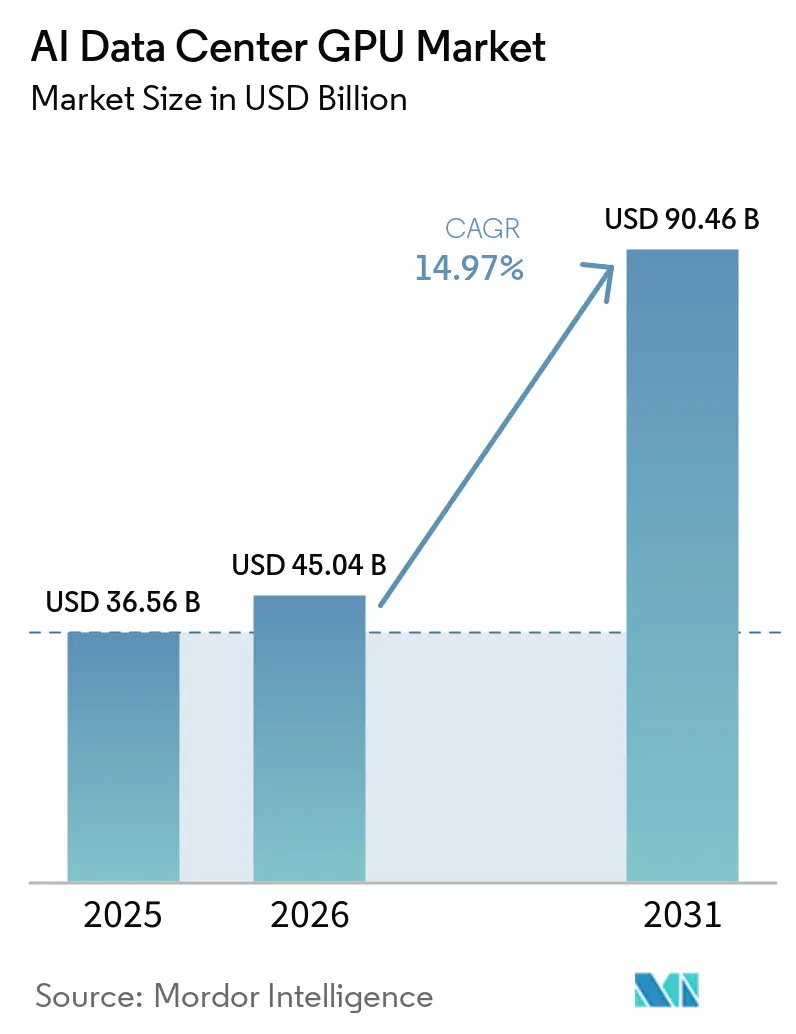
Die Marktgröße des KI-Rechenzentrums-GPU-Markts wird voraussichtlich von USD 36,56 Milliarden im Jahr 2025 auf USD 45,04 Milliarden im Jahr 2026 wachsen und soll bis 2031 bei einem CAGR von 14,97 % über 2026–2031 USD 90,46 Milliarden erreichen. Allein Hyperscaler planen, im Jahr 2026 mehr als USD 650 Milliarden in die KI-Infrastruktur zu investieren, wobei Alphabet Investitionsausgaben von USD 175–185 Milliarden anpeilt – fast das Doppelte seiner Ausgaben von 2025 –, um Kapazitätsengpässe zu beheben. Staatliche Initiativen erweitern die adressierbare Basis: Kanada stellte CAD 2 Milliarden (USD 1,48 Milliarden) für inländische Rechenkapazitäten bereit, während das Vereinigte Königreich GBP 500 Millionen (USD 630 Millionen) reservierte, um bis zu 1 Million GPU-Stunden pro Start-up zu gewähren. Gleichzeitig haben Exportkontrollen das Angebot in freundlichere Regionen umgeleitet, was die Dringlichkeit von Vorabkaufvereinbarungen der Hyperscaler erhöht und die Nachfragesichtbarkeit der Anbieter vertieft. Schließlich werden Hochbandbreitenspeicher und Nachrüstungen für Flüssigkühlung zu entscheidenden Faktoren, die Erneuerungszyklen beschleunigen und den Gesamtsystemwert trotz Komponenteninflation steigern.
Wichtigste Erkenntnisse des Berichts
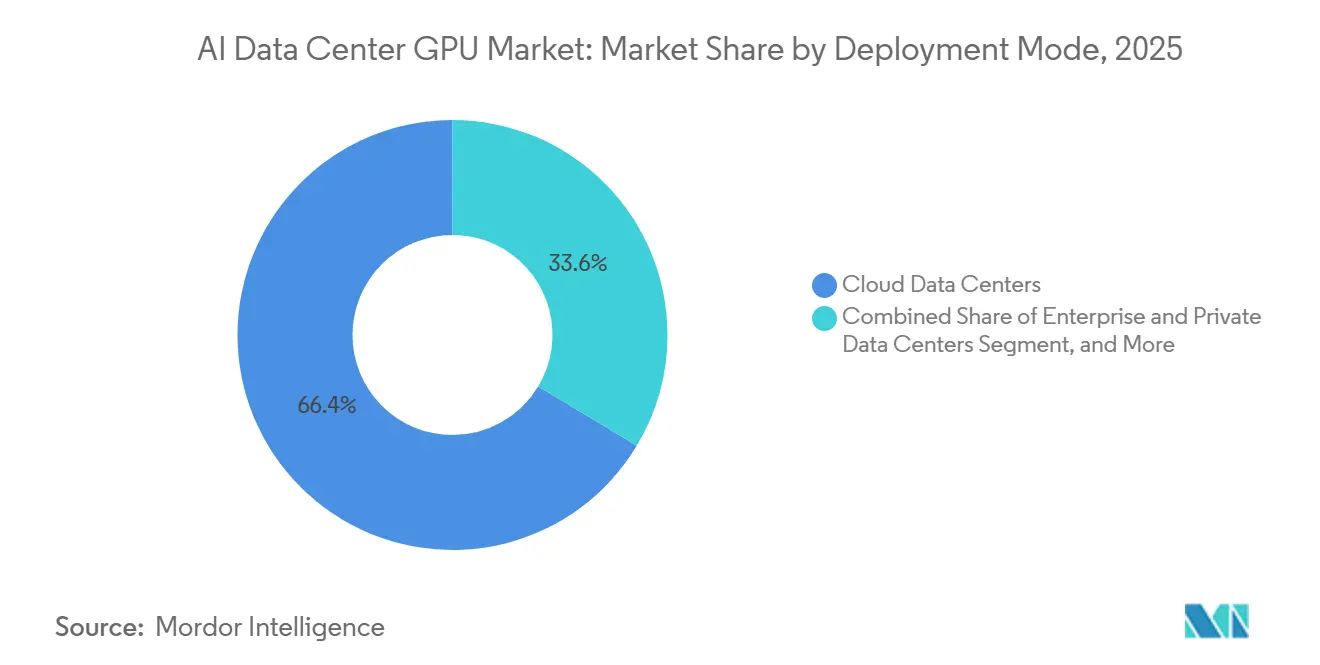
- Nach Bereitstellungsmodus führten Cloud-Rechenzentren mit einem Marktanteil von 66,38 % am KI-Rechenzentrums-GPU-Markt im Jahr 2025, während Edge-Rechenzentren bis 2031 voraussichtlich mit einem CAGR von 15,57 % wachsen werden.
- Nach GPU-Typ entfielen Inferenzbeschleuniger im Jahr 2025 auf einen Anteil von 54,23 % an der Marktgröße des KI-Rechenzentrums-GPU-Markts und sollen über 2026–2031 mit einem CAGR von 15,37 % wachsen.
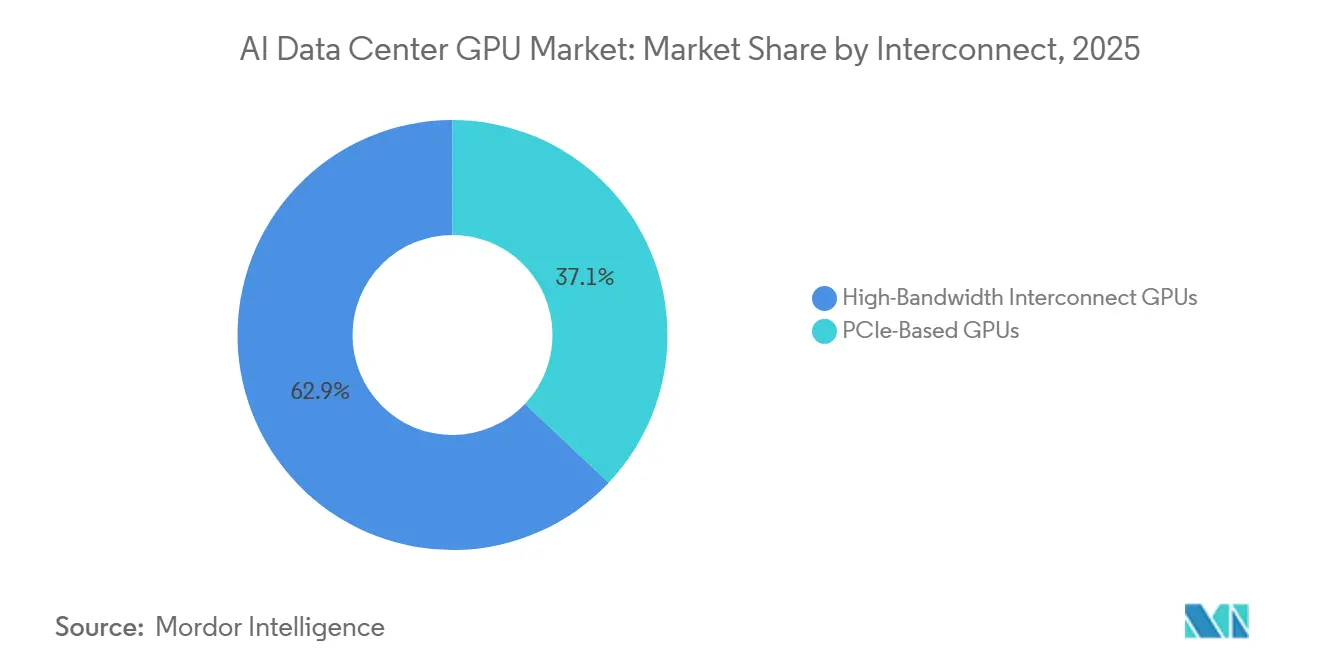
- Nach Verbindungsschnittstelle hielten Hochbandbreiten-Fabric-GPUs im Jahr 2025 einen Anteil von 62,94 % und werden voraussichtlich das schnellste Wachstum mit einem CAGR von 15,67 % zwischen 2026 und 2031 verzeichnen.
- Nach Endnutzer kontrollierten Hyperscaler und Cloud-Dienstanbieter 76,64 % des Umsatzes von 2025, während Regierungs- und Forschungseinrichtungen die am schnellsten wachsende Gruppe mit einem CAGR von 15,24 % bis 2031 darstellten.
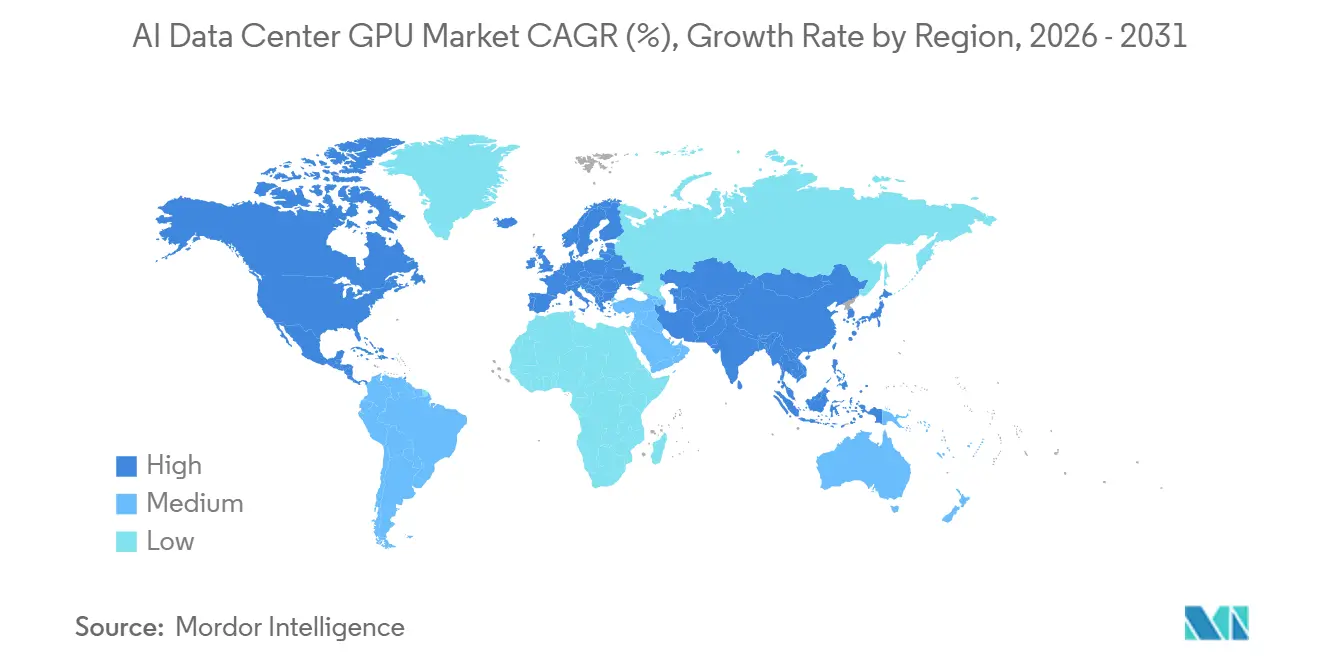
- Nach Geografie erfasste Nordamerika 37,50 % des Umsatzes im Jahr 2025, doch der asiatisch-pazifische Raum wird voraussichtlich das höchste regionale Wachstum mit einem CAGR von 15,97 % bis 2031 verzeichnen.
Hinweis: Die Marktgröße und Prognosezahlen in diesem Bericht werden mithilfe des proprietären Schätzungsrahmens von Mordor Intelligence erstellt und mit den neuesten verfügbaren Daten und Erkenntnissen vom Januar 2026 aktualisiert.
Globale Trends und Erkenntnisse des KI-Rechenzentrums-GPU-Markts
Analyse der Treiberwirkung*
| Treiber | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Explosives Wachstum der Größe generativer KI-Modelle | +3.8% | Global, am stärksten in Nordamerika und dem asiatisch-pazifischen Raum | Mittelfristig (2–4 Jahre) |
| Schnelle Einführung GPU-beschleunigter Cloud-Dienste | +3.2% | Global, angeführt von Nordamerika und Europa | Kurzfristig (≤2 Jahre) |
| GPU-Cluster im Rechenzentrumsmaßstab, die 100.000 Einheiten überschreiten | +2.6% | Hyperscale-Standorte in Nordamerika, Europa und dem asiatisch-pazifischen Raum | Mittelfristig (2–4 Jahre) |
| Standardisierung von MLPerf-Benchmarks bei der Beschaffung | +1.4% | Global | Langfristig (≥4 Jahre) |
| Aufstieg staatlicher KI-Initiativen in kleineren Volkswirtschaften | +2.1% | Europa, Kanada, Naher Osten und aufstrebende Märkte im asiatisch-pazifischen Raum | Mittelfristig (2–4 Jahre) |
| Nachrüstungen für Flüssigkühlung als Treiber von Erneuerungsverkäufen | +1.8% | Global, am frühesten in Nordamerika und Europa | Kurzfristig (≤2 Jahre) |
| Quelle: Mordor Intelligence | |||
Explosives Wachstum der Größe generativer KI-Modelle
Große Sprach- und multimodale Modelle überschreiten die Billionen-Parameter-Marke, und Nachtrainings-Skalierungsschritte wie Reinforcement Learning aus menschlichem Feedback, Erweiterung synthetischer Daten und Langkontext-Schlussfolgerung verbrauchen nun bis zu 30-mal so viel Rechenleistung wie der ursprüngliche Vortrainings-Durchlauf. Betreiber priorisieren daher GPUs mit enormem On-Package-Speicher; AMDs MI325X bietet 288 GB HBM3e und ermöglicht es einem einzelnen Server, ein Modell mit 1 Billion Parametern zu hosten und Verzögerungen durch knotenübergreifendes Sharding zu eliminieren. NVIDIAs Blackwell-Architektur verbessert die Kosten pro Million Token um das 15-Fache auf etwa USD 0,02 pro Million Token, wodurch Pay-as-you-go-API-Wirtschaftlichkeit im Unternehmensmaßstab realisierbar wird. Hyperscaler reagieren mit Rekord-Investitionsausgaben, und Vorauszahlungsverträge sichern sowohl Wafer-Starts als auch Slots für fortschrittliche Verpackung, was die Nachfrage effektiv vorverlagert und die Wachstumstrajektorie des KI-Rechenzentrums-GPU-Markts festigt.
Schnelle Einführung GPU-beschleunigter Cloud-Dienste
Die direkte Integration generativer KI in Produktivitätssoftware erweist sich als beständig und margenreich, was Cloud-Anbieter dazu veranlasst, beispiellose Mengen an GPUs zu reservieren. Microsoft verkaufte innerhalb von vier Monaten mehr als 8 Millionen bezahlte Gemini Enterprise-Lizenzen, während der Google Cloud-Umsatz im vierten Quartal 2025 auf der Grundlage von Gemini-Einführungen bei 2.800 Unternehmenskunden um 48 % im Jahresvergleich stieg. Diese Workloads amortisieren GPU-Flotten in weniger als zwei Jahren und verstärken eine aggressive Beschaffung. Parallele mehrjährige Lieferverträge, wie Microsofts Bestellung von 30.000 GPUs bei Nscale für einen 230-Megawatt-Standort in Norwegen, unterstreichen das Cashflow-Vertrauen, das dem KI-Rechenzentrums-GPU-Markt zugrunde liegt.
GPU-Cluster im Rechenzentrumsmaßstab, die den Schwellenwert von 100.000 GPUs überschreiten
Zweckgebundene KI-Fabriken entstehen, wobei einzelne Mieter Cluster von mehr als 100.000 GPUs einsetzen, um Grenzmodelle zu trainieren und Inferenz bei Gigawatt-Leistungshüllen bereitzustellen. Der Kauf von 50.000 NVIDIA B300 GPUs durch IREN Limited hebt seine installierte Basis auf 150.000 Einheiten und könnte bis Ende 2026 eine geschätzte annualisierte Umsatzlaufrate von USD 3,7 Milliarden generieren. Ähnliche Mega-Deployments drängen Anbieter zu integrierten Rack-Systemen. NVIDIAs Vera Rubin NVL72 beispielsweise verpackt 72 Rubin-GPUs und 36 Vera-CPUs mit 260 TB/s NVLink-Fabric, was wiederum den Ersatz älterer PCIe-only-Knoten beschleunigt und den Marktfußabdruck des KI-Rechenzentrums-GPU-Markts vergrößert.
Aufstieg staatlicher KI-Initiativen in kleineren Volkswirtschaften
Regierungen außerhalb der US-chinesischen Achse finanzieren inländische Rechencluster, um sensible Daten im Land zu halten und lokale KI-Ökosysteme zu kultivieren. Kanadas Programm für souveräne KI-Recheninfrastruktur wird bis zu CAD 1 Milliarde (USD 740 Millionen) in die Entwicklung kanadischer Supercomputer einbringen, auf die Forscher, die Industrie und die Regierung zu subventionierten Tarifen zugreifen können.[1]Innovation, Wissenschaft und Wirtschaftliche Entwicklung Kanada, "Programmhandbuch: Programm für souveräne KI-Recheninfrastruktur," canada.ca Die Sovereign AI Unit des Vereinigten Königreichs verpflichtete sich ebenfalls zu GBP 500 Millionen (USD 630 Millionen), um Zuteilungen von einer Million GPU-Stunden pro Start-up zu gewähren, und erwarb eine Kapitalbeteiligung am inländischen Hardware-Orchestrator Callosum. Diese Programme schaffen zusätzliche Nachfragepools jenseits der Hyperscaler-Budgets und erweitern den gesamten adressierbaren Markt für KI-Rechenzentrums-GPUs.
Analyse der Hemmnisauswirkung*
| Hemmnis | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Anhaltende Angebots-Nachfrage-Ungleichgewichte bei fortschrittlicher Verpackung | -2.4% | Global, am akutesten in Taiwan und Südkorea | Kurzfristig (≤2 Jahre) |
| Steigende Gesamtbetriebskosten für luftgekühlte Racks | -1.6% | Global, schwerwiegend in leistungsbeschränkten Regionen | Mittelfristig (2–4 Jahre) |
| Exportkontrollbeschränkungen für High-End-GPUs | -1.9% | China, Russland, Iran und südostasiatische Umschlaghäfen | Mittelfristig (2–4 Jahre) |
| Wachsende Präferenz für benutzerdefinierte KI-Beschleuniger gegenüber GPUs | -2.2% | Nordamerika und Europa, wo Hyperscaler dominieren | Langfristig (≥4 Jahre) |
| Quelle: Mordor Intelligence | |||
Anhaltende Angebots-Nachfrage-Ungleichgewichte bei fortschrittlicher Verpackung
Hochbandbreitenspeicher (HBM)-Stapel und CoWoS-Interposer bleiben chronisch knapp. HBM-Die-Flächen sind etwa 2,5-mal so groß wie die herkömmlicher DRAM-Chips, und die TSV-Komplexität erhöht die Fehlerquoten, was Lieferanten zwingt, Waferfläche für Ausbeuteverluste zu reservieren. Microns HBM-Produktion für 2026 ist bereits vorverkauft, Samsung verdreifacht den HBM-Umsatz und erhöht dennoch die Preise um hohe einstellige Prozentsätze, und TSMCs Erweiterung auf 9,5 Retikel-Limit wird die CoWoS-Kapazität erst 2027 nennenswert steigern. Die Knappheit verlangsamt die Volumenrampen von Rubin und MI400 und könnte Anbieter dazu zwingen, frühe Chargen den margenreichsten Käufern zuzuteilen, was den Zugang für kleinere Cloud- und Unternehmensnutzer verzögert.
Wachsende Präferenz für benutzerdefinierte KI-Beschleuniger gegenüber GPUs
Hyperscaler führen proprietäre ASICs ein, die für Inferenzökonomie optimiert sind. Microsofts Maia 200, gefertigt auf TSMCs 3-nm-Prozess und mit über 10 PFLOPS bei 4-Bit-Präzision, zielt auf einen 3-fachen Kosten-Leistungs-Vorteil gegenüber Amazons Trainium Gen3-Chips ab. Googles Ironwood TPU und Amazons Flotte von 500.000 Trainium2-Einheiten folgen demselben Ansatz.[2]Microsoft, "Maia 200: Der für Inferenz entwickelte KI-Beschleuniger," microsoft.com Während GPUs weiterhin flexibles Training und Multitask-Inferenz dominieren, könnte die ASIC-Durchdringung bei hochvolumiger, zweckgebundener Inferenz das langfristige Einheitenwachstum im KI-Rechenzentrums-GPU-Markt dämpfen.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Bereitstellungsmodus: Cloud dominiert, Edge beschleunigt
Cloud-Einrichtungen machten 2025 66,38 % des Umsatzes aus, verankert durch Multi-Gigawatt-Campusse, die flüssigkeitsgekühlte Rack-Pods mit jeweils mehr als 100.000 GPUs integrieren. Unternehmen verlassen sich auf diese zentralisierte Kapazität, um Rechenleistung über Tausende von Mietern zu amortisieren, aber steigende ausgehende Datengebühren und Datenschutzvorschriften drängen einige Workloads zurück in die eigene Infrastruktur oder in souveräne Zentren. Edge-Rechenzentren, obwohl noch eine Nische, sollen bis 2031 mit einem CAGR von 15,57 % wachsen, da autonome Fahrzeuge, Roboterzellen und industrielle Echtzeit-Inspektion eine Hin- und Rücklatenz von unter 10 Millisekunden erfordern.
Anbieter überarbeiten zunehmend ihre Software, um eine nahtlose Modellmigration über verschiedene Umgebungen hinweg zu ermöglichen. Beispielsweise spielt NVIDIAs BlueField-4 Datenverarbeitungseinheit (DPU)-Schicht eine entscheidende Rolle, indem sie Schlüssel-Wert-Caches vom Kern zur Edge tunnelt. Dieser Ansatz reduziert redundante GPU-Speicherzuweisungen erheblich und optimiert dadurch die Ressourcennutzung. Insgesamt treiben diese Fortschritte den KI-Rechenzentrums-GPU-Markt entlang einer zweigleisigen Skalierungstrajektorie voran. Einerseits verzeichnen Hyperscale-Hubs ein erhebliches Wachstum, während andererseits auch föderierte Mikro-Standorte expandieren, wenn auch von sehr unterschiedlichen Ausgangsniveaus. Diese Entwicklungen verdeutlichen die vielfältigen Strategien, die eingesetzt werden, um den sich wandelnden Anforderungen von KI-Workloads gerecht zu werden.



Nach GPU-Typ: Inferenz gewinnt Marktanteil, da das Nachtraining skaliert
Inferenzbeschleuniger machten 54,23 % des Umsatzes von 2025 aus und werden schneller wachsen als Training-GPUs, mit einem CAGR von 15,37 %, dank stetiger, tokenbasierter Monetarisierungsmodelle. Feinabstimmung, retrieval-augmented generation und Echtzeit-Personalisierung treiben kontinuierliche Inferenzzyklen an, die nun etwa zwei Drittel der Rechenausgaben von 2026 ausmachen. Training-GPUs bleiben für die Erstellung von Grenzmodellen unverzichtbar, aber ihr Anteil erodiert, da marginale Parametererhöhungen abnehmende Leistungsgewinne erzielen.
Hardware-Anbieter reagieren mit Pipelines für gemischte Präzision: NVIDIA Rubin enthält eine Transformer Engine der dritten Generation, und AMDs MI325X verdoppelt die HBM-Kapazität, um Billionen-Parameter-Interpreter auf einer einzigen Platine unterzubringen – beides Innovationen, die die Wirtschaftlichkeit weiter in Richtung Inferenz verschieben. Infolgedessen teilen Hyperscaler ihre Flotten zunehmend auf, indem sie die neuesten verbindungsreichen GPUs für das Training großer Batches reservieren und Inferenzcluster mit speicherdichten Karten auffüllen, die für Kosten pro Token optimiert sind.
Nach Verbindungsschnittstelle: Hochbandbreiten-Fabrics ermöglichen Rack-skalige Kohärenz
GPUs, die mit proprietären oder standardbasierten Hochbandbreiten-Fabrics ausgestattet sind, machten 2025 62,94 % des Umsatzes aus und sollen die höchste Wachstumsrate mit einem CAGR von 15,67 % aufrechterhalten. Die sechste Generation der NVLink-Technologie liefert 3,6 TB/s pro GPU und schafft, wenn sie in Vera Rubin NVL72-Racks eingesetzt wird, einen einheitlichen Speicherraum von 260 TB/s. Diese Konfiguration eliminiert effektiv den Overhead der Modellpartitionierung und verbessert dadurch Effizienz und Leistung.
Andererseits haben Ethernet-basierte Architekturen wie Spectrum-X bewiesen, dass offene Fabrics ebenfalls Skalierbarkeit erreichen können. Beispielsweise verbindet Supermicros Referenztopologie 32.768 GPUs über ein Netzwerk aus 512 Leaf-Switches, 512 Spine-Switches und 256 Superspine-Switches.[3]Super Micro Computer, "Vergleich von luftgekühlten und flüssigkeitsgekühlten NVIDIA GPU-Systemen," supermicro.com Während PCIe-only-Karten im Allgemeinen vorab kostengünstiger sind, begünstigen die Gesamtbetriebskosten häufig fabric-fähige Einheiten, wenn Faktoren wie Softwareentwicklungsaufwand und Trainingszeit berücksichtigt werden. Infolgedessen priorisieren Käufer zunehmend die Verbindungsbandbreite gegenüber der reinen Rechenleistung und erkennen sie als Schlüsselfaktor zur Senkung der Kosten pro Modell an.
Nach Endnutzer: Hyperscaler führen, Regierungen beschleunigen
Hyperscaler und Cloud-Dienstanbieter kontrollierten 76,64 % der Ausgaben von 2025 und nutzten ihre Bilanzkraft, um Angebote vorzubezahlen und frühzeitigen Zugang zu jeder Siliziumgeneration auszuhandeln. Diese Führungsposition wird sich so bald nicht auflösen, doch staatliche und akademische Programme werden die schnellste Expansion mit einem CAGR von 15,24 % verzeichnen, da Regierungen darum wetteifern, sensible Workloads zu lokalisieren. Kanadas Programm für souveräne KI-Recheninfrastruktur und der britische Isambard-AI-Supercomputer sind Beispiele für langfristige Finanzierungsstrukturen, die Multi-Petaflop-Flotten unterstützen.
Unternehmen nehmen eine hybride Mittelposition ein und nutzen öffentliche Cloud-Instanzen für stoßweises Training, während sie kritische Daten-Workflows über modulare Racks wie NVIDIA DGX Spark oder AMD-basierte MI325X-Blades vor Ort halten. Dieser Ansatz ermöglicht es Unternehmen, Skalierbarkeit und Kontrolle in Einklang zu bringen, eine effiziente Ressourcennutzung sicherzustellen und gleichzeitig sensible Daten zu schützen. Zusammen tragen diese Endnutzerdynamiken zur Entwicklung eines geschichteten Ökosystems bei, das den KI-Rechenzentrums-GPU-Markt unterstützt und sein Wachstum und seine Relevanz über den Kern-Hyperscaler-Zyklus hinaus ausdehnt.
Geografische Analyse
Nordamerika behielt 37,50 % des Umsatzes von 2025, gestützt durch die Nähe der Hauptsitze der führenden Cloud-Anbieter und reichliche Stromkapazitäten in Texas, dem Mittleren Westen und dem pazifischen Nordwesten. Die US-Politik begünstigt weiterhin die inländische Zuteilung: Exportkontrollrevisionen vom Januar 2026 verhängten einen Zoll von 25 % auf bestimmte ins Ausland versandte High-End-GPUs und sicherten damit effektiv das lokale Angebot. Mega-Mietverträge wie Applied Digitals 300-Megawatt-Deal bei Delta Forge 1 unterstreichen die langfristige Perspektive für den US-amerikanischen Bau. Europa folgt mit konzentriertem, aber strategischem Wachstum; Microsofts Vertrag über 30.000 Rubin-GPUs in Narvik, Norwegen, zeigt den Appetit auf kaltklima- und erneuerbar-betriebene Campusse, die steigende CO₂-Steuern abmildern. Das Vereinigte Königreich leitet GBP 500 Millionen (USD 630 Millionen) in seine Sovereign AI Unit und verpflichtet sich zu Zuschüssen von einer Million GPU-Stunden pro Start-up sowie direkten Kapitalbeteiligungen an Infrastruktur-Orchestrierungsunternehmen.
Der asiatisch-pazifische Raum soll mit einem CAGR von 15,97 % bis 2031 die schnellste regionale Expansion verzeichnen. Japans USD 12 Milliarden teurer souveräner GMI Cloud-Standort in Kagoshima zielt auf eine Kapazität von 1 Gigawatt ab und positioniert das Land als inländischen Fertigungsknotenpunkt für Robotik, autonome Fahrzeuge und KI-Workloads in der Schwerindustrie.[4]GMI Cloud, "GMI Cloud kündigt 1-GW-souveräne KI-Infrastruktur in Japan an, beschleunigt durch NVIDIA Vera Rubin NVL72™," gmicloud.ai China, das mit verschärften US-Exportregeln und Zollhürden bei der Einfuhr von NVIDIA H200-Chips konfrontiert ist, schwenkt auf hausgemachte Beschleuniger von Huawei, Cambricon und Biren um, obwohl Lücken bei Ausbeute und Software-Reife auf kurzfristige Leistungsrückstände hindeuten. Anderswo beschleunigt Indien die Genehmigungen für Multi-Megawatt-Campusse, während Samsung und SK Hynix in Südkorea HBM4-Linien hochfahren, um vorgelagert in der GPU-Lieferkette Wert zu schöpfen.
Südamerika, der Nahe Osten und Afrika halten kleinere Anteile, dienen aber als schnell folgende Ziele für kostengünstige erneuerbare Energie. Politische Änderungen im Mai 2025 öffneten Saudi-Arabien und die Vereinigten Arabischen Emirate für fortschrittliche GPU-Importe im Rahmen eines Validated End User-Rahmens und nutzten ihre umfangreichen Erdgas- und Solarressourcen, um wettbewerbsfähige Stromabnahmeverträge zu liefern. Obwohl diese Regionen die Größenordnung Nordamerikas oder des asiatisch-pazifischen Raums in absoluten Dollar-Beträgen nicht herausfordern werden, bieten sie inkrementelles Aufwärtspotenzial und geografische Risikodiversifizierung für Anbieter, die im KI-Rechenzentrums-GPU-Markt tätig sind.

Wettbewerbslandschaft
NVIDIA bleibt der dominante Lieferant im KI-Rechenzentrums-GPU-Markt mit einem Einheitenanteil von etwa 80 % und produziert wöchentlich fast 1.000 GB200 NVL72-Racks, die jeweils nahe USD 3 Millionen kosten. Diese Dominanz wird jedoch herausgefordert, da Hyperscaler zunehmend ASICs in ihre Betriebe integrieren, insbesondere für inferenzlastige Workloads. Unternehmen wie Microsoft, Google und Amazon nutzen ihre proprietären Technologien – wie Microsofts Maia 200, Googles Ironwood TPU und Amazons Trainium der dritten Generation –, um Leistungen zu erzielen, die GPUs bei eng definierten Workloads zu geringeren Stückkosten übertreffen oder ihnen ebenbürtig sind. Gleichzeitig gewinnt AMD an Boden, indem es sich auf das Rennen um Speicherkapazität konzentriert und MI325X-Platinen mit 288 GB HBM3e anbietet sowie MI400-Serien-Teile mit HBM4-Integration plant. Diese Strategie hat AMD ermöglicht, Positionen sowohl in Training- als auch in hochkapazitiven Inferenzclustern zu sichern. Darüber hinaus erschließen sich Start-ups wie Cerebras, Graphcore und SambaNova spezialisierte Nischen mit Wafer-Scale- oder Sparsity-optimierten Architekturen, obwohl ihnen das robuste CUDA-Software-Ökosystem fehlt, das NVIDIA einen Wettbewerbsvorteil verschafft.
Hardware-Integration hat sich als entscheidender Differenzierungsfaktor im Markt herausgestellt. Supermicro beispielsweise liefert über 100.000 GPUs pro Quartal und hat seit Mitte 2024 mehr als 2.000 flüssigkeitsgekühlte Racks ausgeliefert. Vertivs Übernahme von PurgeRite für USD 1 Milliarde hat seine Fähigkeiten im End-to-End-Flüssigkeitsmanagement für Thermalsysteme weiter gestärkt – ein Merkmal, das Betreiber anspricht, die hochdichte Deployments wie 150-Kilowatt-Racks verwalten. NVIDIA hat mit seinem Rubin-Launch auch einen umfassenden Ansatz verfolgt und eine Full-Stack-Lösung eingeführt, die sechs gemeinsam entwickelte Chips umfasst: GPU, CPU, NVLink-Switch, NIC, DPU und Ethernet-Switch, alle verwaltet durch seine Mission Control-Software. Diese Strategie ermutigt Kunden, schlüsselfertige Systeme zu übernehmen, anstatt sich für inkrementelle GPU-Upgrades zu entscheiden, und stärkt damit NVIDIAs Position im Markt.
Infolgedessen erstrecken sich die Markteintrittsbarrieren in der KI-Rechenzentrums-GPU-Branche nun über die Siliziumleistung hinaus auf Rack-Engineering, Einrichtungsintegration und Lebenszyklusdienstleistungen. Diese Faktoren tragen gemeinsam zu einer hochkonzentrierten Marktlandschaft bei. Die Wettbewerbsdynamik wird durch das Zusammenspiel etablierter Akteure wie NVIDIA und AMD, Hyperscaler, die interne Lösungen entwickeln, und aufstrebende Start-ups, die auf Nischenanwendungen abzielen, geprägt. Dieses geschichtete Ökosystem unterstreicht die Komplexität des Marktes, in dem Innovation in Hardware, Software und Systemintegration eine entscheidende Rolle bei der Bestimmung der Marktführerschaft und der Aufrechterhaltung des Wachstums im Prognosezeitraum spielt.
Marktführer der KI-Rechenzentrums-GPU-Branche
NVIDIA Corporation
Advanced Micro Devices, Inc.
Intel Corporation
Google LLC
Huawei Technologies Co., Ltd.
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Jüngste Branchenentwicklungen
- April 2026: Applied Digital unterzeichnete einen 15-jährigen Mietvertrag über 300 Megawatt mit einem US-amerikanischen Hyperscaler mit Investment-Grade-Rating auf seinem Delta Forge 1-Campus und brachte den gesamten vertraglich vereinbarten Mietumsatz auf über USD 23 Milliarden.
- April 2026: NVIDIA stellte die DGX SuperPOD-Referenz für Rubin-basierte Systeme vor, die das Vera Rubin NVL72-Rack mit 1.008 Rubin-GPUs und automatisierter Mission Control-Orchestrierung umfasst.
- April 2026: Kanada eröffnete das Programm für souveräne KI-Recheninfrastruktur und bietet bis zu CAD 1 Milliarde (USD 740 Millionen) für den Aufbau nationaler KI-Supercomputer unter strengen Datenhaltungsregeln an.
- März 2026: Global AI setzte 7.000 NVIDIA GB300 GPUs in seiner Einrichtung in Endicott, New York, ein und skizzierte einen Fahrplan, um bis 2029 eine Kapazität von 1 Gigawatt zu erreichen.


Globaler Berichtsumfang des KI-Rechenzentrums-GPU-Markts
Der KI-Rechenzentrums-GPU-Markt umfasst das globale Ökosystem von Grafikprozessoren (GPUs), die in Rechenzentren eingesetzt werden, um KI-Workloads zu unterstützen, einschließlich Modelltraining, Inferenz und Hochleistungsrechnen. Dieser Markt umfasst Hardware, zugehörige Verbindungstechnologien und Bereitstellungsinfrastrukturen, die für die groß angelegte KI-Verarbeitung optimiert sind.
Der Bericht zum KI-Rechenzentrums-GPU-Markt ist segmentiert nach Bereitstellungsmodus (Cloud-Rechenzentren, Unternehmens- und private Rechenzentren sowie Edge-Rechenzentren), GPU-Typ (Training-GPUs und Inferenz-GPUs), Verbindungsschnittstelle (PCIe-basierte GPUs und Hochbandbreiten-Verbindungs-GPUs), Endnutzer (Hyperscaler und Cloud-Dienstanbieter, Unternehmen sowie Regierungs- und Forschungseinrichtungen) und Geografie (Nordamerika, Europa, asiatisch-pazifischer Raum, Südamerika sowie Naher Osten und Afrika). Die Marktprognosen werden in Wertangaben (USD) bereitgestellt.
| Cloud-Rechenzentren |
| Unternehmens- und private Rechenzentren |
| Edge-Rechenzentren |
| Training-GPUs |
| Inferenz-GPUs |
| PCIe-basierte GPUs |
| Hochbandbreiten-Verbindungs-GPUs |
| Hyperscaler und Cloud-Dienstanbieter |
| Unternehmen |
| Regierungs- und Forschungseinrichtungen |
| Nordamerika | Vereinigte Staaten |
| Kanada | |
| Mexiko | |
| Europa | Vereinigtes Königreich |
| Deutschland | |
| Frankreich | |
| Italien | |
| Übriges Europa | |
| Asiatisch-pazifischer Raum | China |
| Japan | |
| Indien | |
| Südkorea | |
| Übriger asiatisch-pazifischer Raum | |
| Südamerika | |
| Naher Osten und Afrika |
| Nach Bereitstellungsmodus | Cloud-Rechenzentren | |
| Unternehmens- und private Rechenzentren | ||
| Edge-Rechenzentren | ||
| Nach GPU-Typ | Training-GPUs | |
| Inferenz-GPUs | ||
| Nach Verbindungsschnittstelle | PCIe-basierte GPUs | |
| Hochbandbreiten-Verbindungs-GPUs | ||
| Nach Endnutzer | Hyperscaler und Cloud-Dienstanbieter | |
| Unternehmen | ||
| Regierungs- und Forschungseinrichtungen | ||
| Nach Geografie | Nordamerika | Vereinigte Staaten |
| Kanada | ||
| Mexiko | ||
| Europa | Vereinigtes Königreich | |
| Deutschland | ||
| Frankreich | ||
| Italien | ||
| Übriges Europa | ||
| Asiatisch-pazifischer Raum | China | |
| Japan | ||
| Indien | ||
| Südkorea | ||
| Übriger asiatisch-pazifischer Raum | ||
| Südamerika | ||
| Naher Osten und Afrika | ||


Im Bericht beantwortete Schlüsselfragen
Welchen prognostizierten Wert wird der KI-Rechenzentrums-GPU-Markt im Jahr 2031 haben?
Die Marktgröße des KI-Rechenzentrums-GPU-Markts soll bis 2031 USD 90,46 Milliarden erreichen und wächst über 2026–2031 mit einem CAGR von 14,97 %.
Welcher Bereitstellungsmodus trägt heute den größten Umsatz bei?
Cloud-Rechenzentren machen 66,38 % des Umsatzes von 2025 aus und übertreffen damit Unternehmens-, private und Edge-Einrichtungen bei weitem.
Warum gewinnen Inferenz-GPUs Marktanteile gegenüber Training-GPUs?
Kontinuierliche Token-Generierung aus Feinabstimmung und Langkontext-Inferenz treibt nun den Großteil der Rechenausgaben an, was speicherdichte, inferenzoptimierte GPUs kostengünstiger macht als reine Training-Karten.
Wie beeinflussen Exportkontrollen das regionale Angebot?
US-Regeln verhängen Zölle, Mengenbeschränkungen und Einzelfallprüfungen für High-End-GPU-Exporte, lenken das Angebot zu inländischen Käufern und veranlassen China, sein eigenes Beschleuniger-Ökosystem zu beschleunigen.
Welche Rolle spielen Nachrüstungen für Flüssigkühlung im Markt?
Da die Rack-Leistungsdichten 150 Kilowatt überschreiten, verhindert Flüssigkühlung thermisches Drosseln, steigert den Durchsatz um zweistellige Prozentsätze und eröffnet einen lukrativen Erneuerungszyklus für Rack-Scale-Anbieter.
Welche Region wird bis 2031 voraussichtlich am schnellsten wachsen?
Der asiatisch-pazifische Raum soll den höchsten regionalen CAGR von 15,97 % verzeichnen, angeführt von staatlichen Investitionen in Japan, Indien und Südkorea.
Seite zuletzt aktualisiert am:




