GPU-Datenbankmarkt Größe und Anteil
Marktübersicht
| Studienzeitraum | 2020 - 2031 |
|---|---|
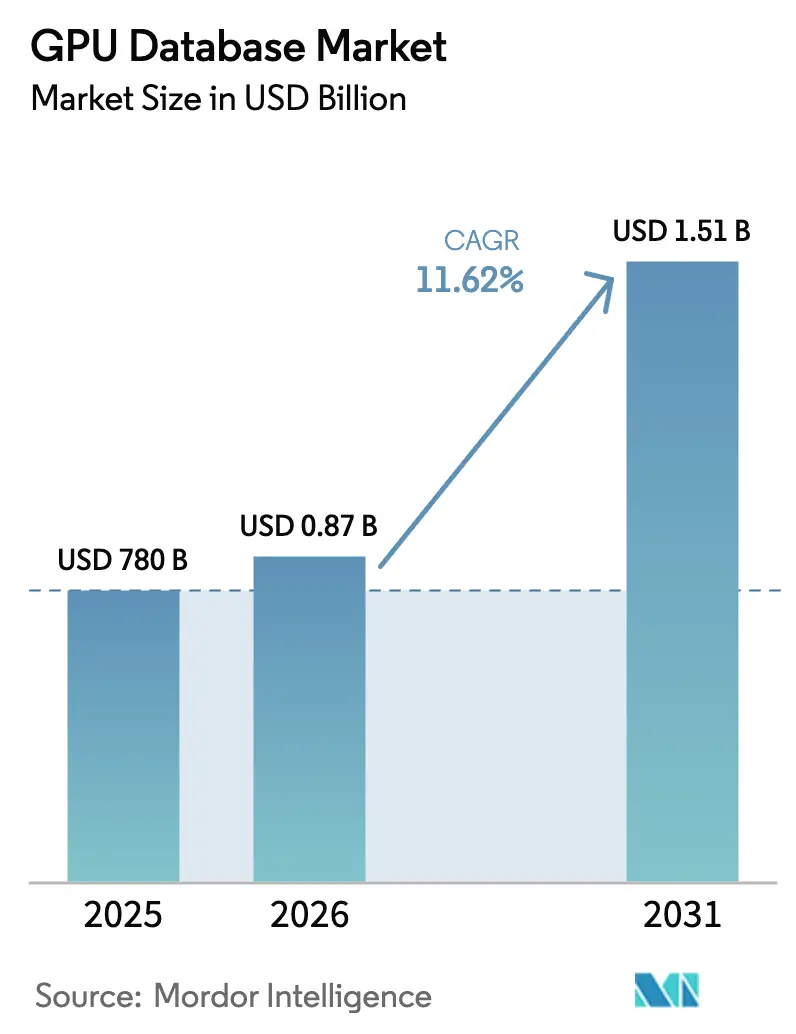
| Marktgröße (2026) | 0.87 Milliarden US-Dollar |
| Marktgröße (2031) | 1.51 Milliarden US-Dollar |
| Wachstumsrate (2026 - 2031) | 11.62% CAGR |
| Schnellstwachsender Markt | Asien-Pazifik |
| Größter Markt | Nordamerika |
| Marktkonzentration | Mittel |
Hauptakteure *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. | |
GPU-Datenbankmarkt Analyse von Mordor Intelligence
Die Größe des GPU-Datenbankmarkts im Jahr 2026 wird auf USD 870,64 Millionen geschätzt, ausgehend vom Wert des Jahres 2025 von USD 780 Millionen, mit Projektionen für 2031 von USD 1,51 Milliarden, was einem Wachstum von 11,62 % CAGR über 2026–2031 entspricht. Unternehmen setzen auf diese Plattformen, um Echtzeit-Analysen, Vektorsuche für die Inferenz großer Sprachmodelle (LLM) und hybride transaktionale / analytische Arbeitslasten zu unterstützen, die ETL-Verzögerungen beseitigen. Nordamerikanische Hyperscaler skalieren mandantenfähige GPU-Cluster, asiatisch-pazifische Regierungen subventionieren KI-Infrastruktur, und Anbieter von Hochbandbreitenspeicher (HBM) melden weiterhin ausverkaufte Kapazitäten bis 2025[1]Anton Shilov, „SK Hynix, Micron melden ausverkaufte HBM-Kapazität bis 2025,” AnandTech, anandtech.com. Die Wettbewerbsdynamik konzentriert sich auf das NVIDIA CUDA-Ökosystem, aber alternative Beschleuniger wie Groq-LPUs und quelloffene SQL-Engines, die auf Apache Arrow laufen, haben begonnen, die Leistungserwartungen neu zu definieren. Der Margendruck durch einen 500%igen Anstieg der HBM-Preise sowie der Mangel an CUDA-Fachkräften hält kleinere Anbieter auf vertikale Nischen fokussiert, in denen die Wechselkosten hoch bleiben.
Wichtigste Erkenntnisse des Berichts
- Nach Komponente führten Lösungen mit einem Anteil von 67,90 % am GPU-Datenbankmarkt im Jahr 2025, während Dienste mit einer CAGR von 35,2 % bis 2031 das schnellste Wachstum verzeichneten.
- Nach Bereitstellungsmodell entfiel auf die Cloud ein Anteil von 77,60 % an der GPU-Datenbankmarktgröße im Jahr 2025 und sie expandiert mit einer CAGR von 33,1 % bis 2031.
- Nach Endnutzerbranche hielt BFSI im Jahr 2025 einen Umsatzanteil von 25,00 %; Gesundheitswesen und Biowissenschaften sollen zwischen 2026 und 2031 mit einer CAGR von 28,4 % wachsen.
- Nach Anwendung hielt Echtzeit-Analyse einen Anteil von 29,70 % an der GPU-Datenbankmarktgröße im Jahr 2025, während Betrugserkennung und Risikoanalyse die höchste prognostizierte CAGR von 31,5 % bis 2031 verzeichnet.
- Nach Datenmodell erfassten spaltenorientierte Engines einen Anteil von 44,10 % an der GPU-Datenbankmarktgröße im Jahr 2025, während Vektor- / Dokumentdatenbanken mit einer CAGR von 38,9 % bis 2031 voranschreiten.
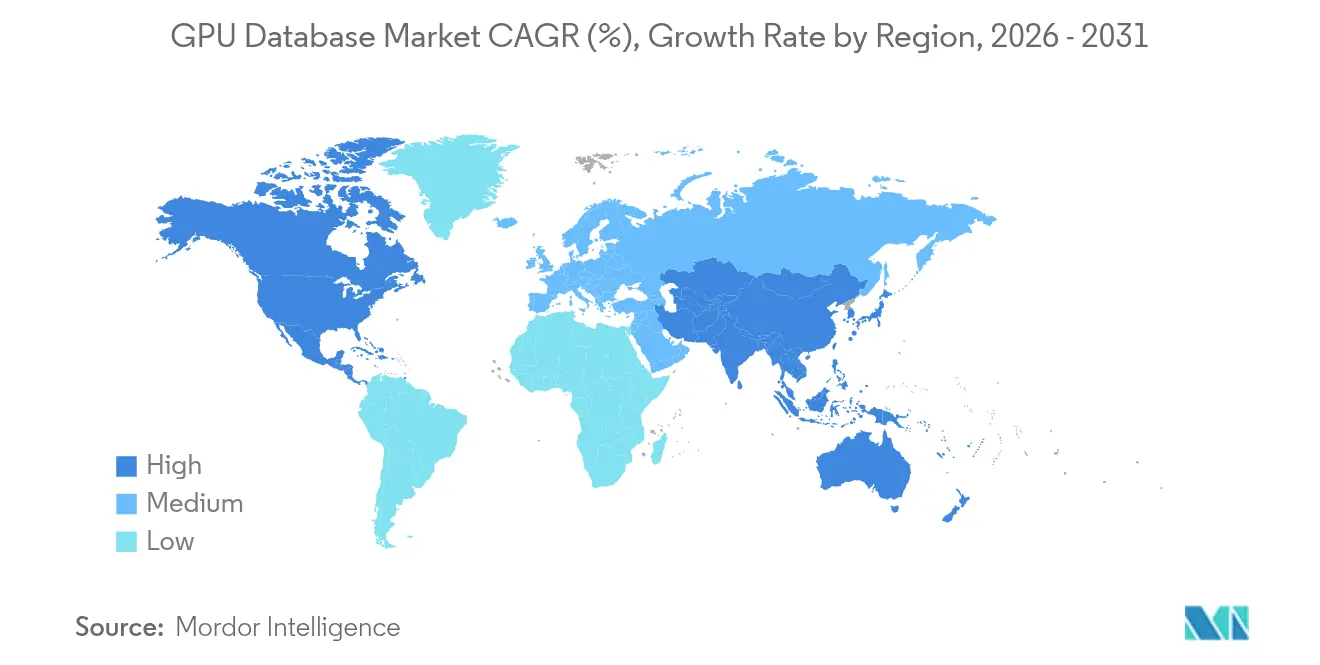
- Nach Geografie behielt Nordamerika im Jahr 2025 einen GPU-Datenbankmarktanteil von 41,10 %; der asiatisch-pazifische Raum soll im Prognosezeitraum mit einer CAGR von 26,2 % expandieren.
Hinweis: Die Marktgrößen- und Prognosezahlen in diesem Bericht werden mithilfe des proprietären Schätzrahmens von Mordor Intelligence erstellt und mit den neuesten verfügbaren Daten und Erkenntnissen bis 2026 aktualisiert.
Globale GPU-Datenbankmarkt Trends und Erkenntnisse
Analyse der Treiberwirkung*
| Treiber | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Steigende Nachfrage nach Echtzeit-Analysen | +3.2% | Global | Kurzfristig (≤ 2 Jahre) |
| Verbreitung von KI/ML-Arbeitslasten mit Bedarf an GPU-Beschleunigung | +4.1% | Nordamerika und asiatisch-pazifischer Raum | Mittelfristig (2–4 Jahre) |
| Explosives Wachstum der LLM-Inferenz, das die Einführung von Vektorsuche-Datenbanken ankurbelt | +2.8% | Global, konzentriert in den USA und China | Kurzfristig (≤ 2 Jahre) |
| Konvergenz von analytischer und transaktionaler Verarbeitung (HTAP) auf GPUs | +1.9% | Nordamerika und EU | Langfristig (≥ 4 Jahre) |
| Reifung quelloffener GPU-SQL-Engines | +1.3% | Global | Mittelfristig (2–4 Jahre) |
| Edge-Cloud-GPU-Marktplätze senken Einstiegshürden | +0.9% | Asiatisch-pazifischer Raum als Kern, Ausweitung auf MEA | Langfristig (≥ 4 Jahre) |
| Quelle: Mordor Intelligence | |||
Steigende Nachfrage nach Echtzeit-Analysen
Finanzinstitute lösen nächtliche Batch-Routinen zugunsten kontinuierlicher Analysen auf, die Betrug innerhalb von Millisekunden erkennen. Der Einsatz eines NVIDIA DGX SuperPOD durch BNY Mellon ermöglicht eine sofortige Risikobewertung über USD 48 Billionen an verwahrten Vermögenswerten. Compliance-Teams profitieren von einer Echtzeittransparenz bei anomalen Transaktionen, und kundenorientierte Anwendungen personalisieren Angebote in Echtzeit. GPU-Datenbanken nehmen Zeitreihendatenströme parallel auf und führen Millionen gleichzeitiger Aggregationen durch, die CPU-Systeme sequenziell in die Warteschlange stellen. Edge-Architekturen erhöhen die Ausfallsicherheit, indem sie latenzempfindliche Risikoprüfungen lokal durchführen, bevor sie mit Cloud-Analysen synchronisiert werden. Diese Gewinne stärken den Unternehmenshunger nach skalierbaren GPU-Clustern trotz knappem HBM-Angebot und steigenden Stromkosten.
Verbreitung von KI / ML-Arbeitslasten mit Bedarf an GPU-Beschleunigung
Die Integration von CUDA-Bibliotheken durch Databricks zeigt, wie gemeinsam lokalisierter Speicher und Rechenleistung den Datenübertragungsaufwand für generative KI-Pipelines eliminieren. Gesundheitsdienstleister verwenden Vektoreinbettungen zur Triage medizinischer Bilder; das SLIViT-Modell der UCLA erreichte auf NVIDIA T4- und V100-GPUs Genauigkeit auf Expertenniveau. Matrixoperationen, die die Modellinferenz dominieren, sind auf die Tausenden von Kernen einer modernen GPU ausgerichtet und ermöglichen Echtzeit-Radiologieberichte und Arzneimittelentdeckungssimulationen. Da reasoning-zentrierte Modelle die Anforderungen an die Speicherbandbreite auf über 3 TB/s treiben, genießen GPU-Datenbanken, die mit On-Package-HBM integriert sind, einen strukturellen Vorteil gegenüber DDR-gebundenen CPU-Appliances. Unternehmen weisen daher einen wachsenden Anteil ihrer KI-Budgets für das Training und die Inferenz in der Datenbank zu.
Explosives Wachstum der LLM-Inferenz, das die Einführung von Vektorsuche-Datenbanken ankurbelt
E-Commerce-Unternehmen setzen Vektordatenbanken ein, um Produkte mit der Nutzerabsicht abzugleichen. Ein SaaS-Einzelhändler auf Zilliz Cloud führt semantische Suchen über Milliarden von Bewertungen durch, um Empfehlungen zu verfeinern. Die Ähnlichkeitssuche skaliert mit der Anzahl der Einbettungsdimensionen, und GPU-Parallelismus hält die Latenz innerhalb interaktiver Schwellenwerte. Der auf Milvus basierende konversationelle Einkaufsassistent von FARFETCH veranschaulicht, wie RAG-Architekturen Browsing-Sitzungen in Echtzeit personalisieren. Da Unternehmens-Chatbots von der Schlüsselwortsuche zu Einbettungsabfragen wechseln, integrieren GPU-native Vektorindizes transaktionale Datensätze, um Empfehlungen während einer Sitzung zu aktualisieren. Die gegenseitige Befruchtung unstrukturierter und strukturierter Datenquellen führt zu höheren Konversionsraten und weniger Warenkorbabbrüchen.
Konvergenz von analytischer und transaktionaler Verarbeitung (HTAP) auf GPUs
GPU-Cluster führen ACID-konforme Schreibvorgänge durch und beantworten gleichzeitig analytische Joins, wodurch die historische Trennung zwischen OLTP und OLAP aufgehoben wird. Benchmark-Forschung zu GPU-OLTP-Engines zeigt Tausende paralleler Commits pro Sekunde neben komplexen Vier-Wege-Joins. Einzelhändler kalibrieren Preise auf Basis sofortiger Bestandsaufnahmen neu, und Logistikmanager leiten Flotten mithilfe von Live-Telematik um. Die Eliminierung von ETL-Kopien reduziert den Infrastrukturaufwand und begrenzt Fehler bei der Datenaktualität. Langfristig senkt dieser Trend die Gesamtbetriebskosten und verankert den GPU-Datenbankmarkt als Standardwahl für geschäftskritische Arbeitslasten.
Analyse der Hemmnisauswirkungen*
| Hemmnis | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Hohe Implementierungskosten und Integrationskomplexit | -2.7% | Global, akut in Schwellenmärkten | Kurzfristig (≤ 2 Jahre) |
| Mangel an qualifizierten CUDA / OpenCL-Datenbankfachkräften | -1.8% | Global, konzentriert im asiatisch-pazifischen Raum | Mittelfristig (2–4 Jahre) |
| Volatilität der GPU-Lieferkette und Zuteilung an KI-Trainingscluster | -1.4% | Global | Kurzfristig (≤ 2 Jahre) |
| Unreife Standards für persistentes GPU-Speichermanagement | -0.9% | Global | Langfristig (≥ 4 Jahre) |
| Quelle: Mordor Intelligence | |||
Hohe Implementierungskosten und Integrationskomplexität
Eine einzelne NVIDIA H100 kostet im Einzelhandel rund USD 40.000, und Unternehmensbereitstellungen erfordern oft Dutzende von Einheiten sowie redundante InfiniBand-Fabrics. Oracles Kauf von NVIDIA-Inventar im Wert von USD 40 Milliarden für eine OpenAI-Einrichtung unterstreicht die Kapitalintensität in großem Maßstab[2]Mike O'Connor, „Oracle gibt USD 40 Milliarden für NVIDIA-Chips für OpenAI aus,” Data Center Dynamics, datacenterdynamics.com. Facility-Teams müssen die Stromverteilung und Flüssigkühlung aufrüsten, um 700 W pro Karte zu bewältigen. Auf der Softwareseite stehen Datenbankadministratoren vor einer steilen Lernkurve beim Abstimmen von CUDA-Kerneln für Indexaufbau und Shuffle-Operationen. Mittelständische Unternehmen kompensieren Kapitalhürden über Cloud-Instanzen, doch wiederkehrende Rechenkosten können die On-Premises-Abschreibung übersteigen, wenn Arbeitslasten kontinuierlich laufen.
Mangel an qualifizierten CUDA / OpenCL-Datenbankfachkräften
Die globale Nachfrage nach Ingenieuren, die sowohl relationale Optimierung als auch GPU-Thread-Scheduling beherrschen, übersteigt das Angebot bei weitem. Viele Unternehmen im asiatisch-pazifischen Raum berichten von sechsmonatigen Verzögerungen bei der Besetzung von Führungspositionen. AMDs Erweiterung von ROCm auf Windows und Linux zielt darauf ab, den Talentpool zu vergrößern, indem gängige KI-Frameworks unterstützt werden. Die Beherrschung von Warp-Level-Parallelismus und einheitlichem Speicher bleibt jedoch außerhalb führender Forschungsuniversitäten selten. Begrenztes Personal verlangsamt Migrationszeitpläne und erhöht das Bereitstellungsrisiko, was einige Unternehmen dazu veranlasst, verwaltete GPU-Datenbankdienste trotz höherer Betriebskosten einzusetzen.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Komponente: Lösungen treiben den Markt an, während Dienste beschleunigen
Lösungsangebote dominierten den Umsatz und hielten im Jahr 2025 einen GPU-Datenbankmarktanteil von 67,90 %, da Unternehmen vorgefertigte SQL-, Vektor- und Graph-Engines bevorzugten, die für CUDA-Kerne optimiert sind. Dieses Segment soll bis 2031 mit 35,2 % wachsen, da Proof-of-Concept-Piloten in geschäftskritische Produktion übergehen. Anbieter konkurrieren durch die Lieferung konvergierter Datenmodelle innerhalb einheitlicher Laufzeitumgebungen, die es einem einzigen Cluster ermöglichen, Zeitreihenüberwachung parallel zur semantischen Suche zu bedienen. Quelloffene Projekte wie Apache Gluten liefern 23,45-fache SparkSQL-Beschleunigungen, reduzieren Lizenzausgaben und erweitern die Akzeptanz bei kostenempfindlichen Nutzern. Kleinere Entwickler integrieren REST-APIs für No-Code-Analysen, um Fachabteilungsteams ohne SQL-Kenntnisse anzusprechen.
Dienste machen den verbleibenden Anteil aus, verzeichnen aber vergleichbares Wachstum, da Unternehmen mit Integrationskomplexität konfrontiert sind. GPU-Schema-Design, Speicheroptimierung und Index-Partitionierung erfordern Beratungsleistungen, die oft die Lizenzgebühren übersteigen. Systemintegratoren bündeln Migrationsfahrpläne, CUDA-Schulungsworkshops und 24/7-Leistungsüberwachung, was den Gesamtvertragswert stärkt. Da mandantenfähige Compliance-Audits strenger werden, zertifizieren Managed-Service-Anbieter Cluster für SOC 2 und ISO 27001, um Finanz- und Gesundheitsarbeitslasten zu sichern. Zusammen bilden Lösungen und Dienste die Grundlage des wachsenden GPU-Datenbankmarkts, da Nutzer schlüsselfertige Beschleunigung ohne Einbußen bei der Governance fordern.
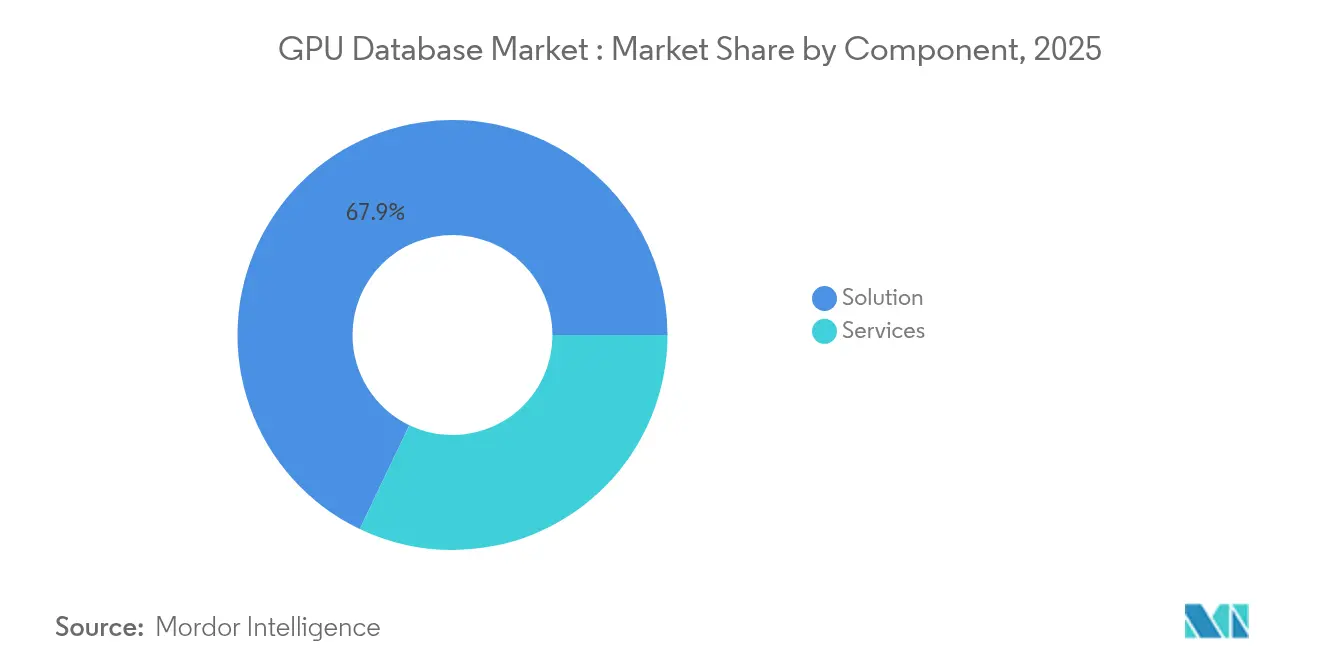
Notiz: Segmentanteile aller einzelnen Segmente sind nach dem Berichtskauf verfügbar


Nach Bereitstellungsmodell: Cloud-Dominanz mit aufkommenden hybriden Architekturen
Die Cloud-Bereitstellung hielt im Jahr 2025 einen Anteil von 77,60 % an der GPU-Datenbankmarktgröße, was die Hyperscaler-Investitionen widerspiegelt, die eine sofortige Bereitstellung von Hunderten von H100-Einheiten auf Stundenbasis ermöglichen. Dasselbe Modell soll jährlich um 33,1 % wachsen, da Unternehmen Investitionsausgaben vermeiden und geografische Redundanz nutzen. Anbieter wie Oracle planen 130.000 Blackwell-GPUs in mehreren Regionen, um den steigenden Inferenzverkehr zu bewältigen. Verbrauchsbasierte Preisgestaltung passt sich an stoßartige KI-Pipelines an und ermöglicht es Data-Science-Teams, Cluster für Experimente hochzufahren und nach der Modellvalidierung wieder abzubauen.
Hybride Muster entstehen nun, da Organisationen Cloud-Training mit Edge-Inferenz kombinieren, um Latenz und Datensouveränitätsrisiken zu reduzieren. NVIDIA DGX Cloud Lepton stellt elastische GPU-Pools bereit, während Edge-Knoten Echtzeit-Scoring auf lokalen Replikaten ausführen. Telekommunikationsbetreiber nutzen 5G-Netzwerke, um Merkmalsvektoren an regionale Kerne zurückzusenden, die Modelle über Nacht neu kalibrieren. Stark regulierte Branchen halten personenbezogene Daten lokal und übertragen anonymisierte Einbettungen in die Cloud, um Datenschutzvorschriften zu erfüllen. Diese hybriden Designs veranschaulichen, wie der GPU-Datenbankmarkt sich an diverse Arbeitslastvermittlungen anpasst.
Nach Endnutzerbranche: BFSI-Führung mit Transformation im Gesundheitswesen
Banken, Broker und Versicherer hielten gemeinsam im Jahr 2025 einen Anteil von 25,00 % am GPU-Datenbankmarkt und stützten sich auf Streaming-Analysen für Mikrosekunden-Handelsabgleich und Basel-III-Liquiditätsberechnungen. Algorithmische Händler archivieren Orderbücher direkt im GPU-Speicher, um Muster in volatilen Sitzungen wiederzugeben. Der regulatorische Druck für Echtzeit-Stresstests verankert GPU-Engines weiter in Treasury-Operationen und sichert lange Ersatzzyklen.
Akteure aus dem Gesundheitswesen und den Biowissenschaften treiben die schnellste Expansion mit einer CAGR von 28,4 % voran, da Radiologie-, Genomik- und Arzneimittelentdeckungs-Workflows auf GPU-native Datenspeicher migrieren. Die autonome Bildgebungssuite von GE HealthCare verarbeitet CT-Schichten an Bord und erstellt während der Patientenuntersuchungen Diagnoseberichte. Krankenhäuser bündeln dann de-identifizierte Bilder in nationalen Forschungsclouds, wo kohortübergreifende Analysen klinische Studien beschleunigen. Da sich Vergütungsmodelle auf ergebnisbasierte Kennzahlen verlagern, bilden GPU-Datenbanken die Grundlage für Echtzeit-Dashboards, die die Behandlungswirksamkeit in der Bevölkerung überwachen.
Nach Anwendung: Echtzeit-Analyse als Fundament mit Beschleunigung der Betrugserkennung
Echtzeit-Analyse hielt im Jahr 2025 einen Anteil von 29,70 % an der GPU-Datenbankmarktgröße, da IT-Teams schnelle Dashboards und Anomaliemeldungen für IoT-Telemetrie und Clickstream-Daten priorisierten. Streaming-Pipelines nutzen fensterbasierte Joins über Milliarden von Ereignissen, um Bestandsumlagerungen in Sekunden auszulösen. GPU-Beschleunigung verkürzt Berichtsaktualisierungszyklen von Minuten auf Millisekunden und ermöglicht kontinuierliche Intelligenz.
Betrugserkennung und Risikoanalyse wächst bis 2031 mit einer CAGR von 31,5 % und nutzt Graph-Traversal und Vektorähnlichkeit, um verdächtige Muster beim Entstehen zu erkennen. Zahlungsabwickler führen bei jedem Karteneinsatz Gradient-Boosted-Trees mit 70 Merkmalen aus und lehnen betrügerische Versuche ab, bevor die Autorisierung abgeschlossen ist. Telekommunikationsanbieter vergleichen SIM-Tausch-Anfragen mit historischen Einbettungen, um Social-Engineering-Angriffe zu erkennen. Da Angriffsflächen größer werden, erfordern Zero-Trust-Richtlinien nahezu sofortige Urteile, und GPU-Engines liefern den erforderlichen Rechenspielraum.
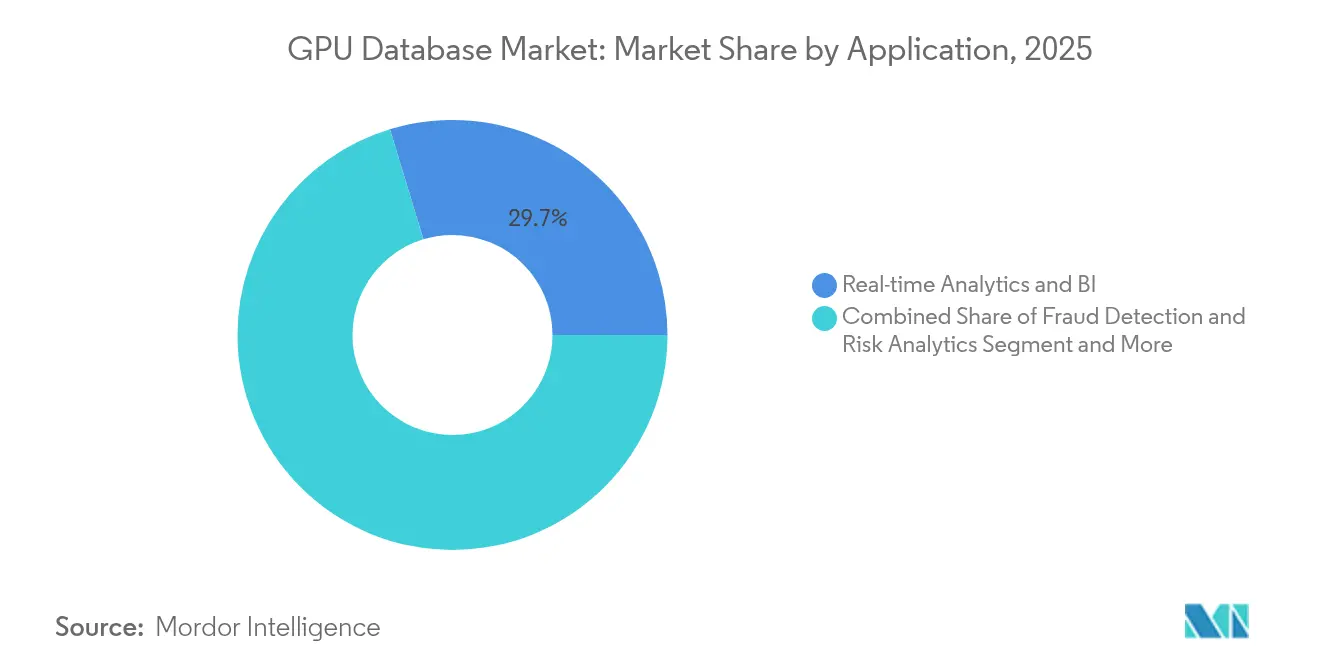
Notiz: Segmentanteile aller einzelnen Segmente sind nach dem Berichtskauf verfügbar
Nach Datenmodell: Stabilität spaltenorientierter Speicher mit Revolution der Vektordatenbanken
Spaltenorientierte Engines behielten im Jahr 2025 einen GPU-Datenbankmarktanteil von 44,10 %, da spaltenorientierte Komprimierung und scanfreundliche Layouts effizient auf die GPU-Speicherbandbreite abgebildet werden. Heavy.AI und SQream optimieren Prädikat-Pushdown und Wörterbuchkodierung, um einen Durchsatz von mehreren TB pro Sekunde auf HBM-Stacks aufrechtzuerhalten. Finanz- und Telekommunikationsbetreiber bleiben bei der vertrauten SQL-Syntax und nutzen gleichzeitig massiv parallele Scans für Ad-hoc-Analysen.
Vektor- / Dokumentdatenbanken verzeichnen den stärksten Anstieg mit einer CAGR von 38,9 %, angetrieben durch den LLM-Einsatz. Milvus, Qdrant und Weaviate indizieren Milliarden von 768-dimensionalen Einbettungen für semantische Suchen, die traditionelle B-Baum-Strukturen nicht bewältigen können. Die GPU-Datenbankbranche integriert nun Algorithmen für approximative nächste Nachbarn mit ACID-Konformität, damit Chatbots Kontext abrufen können, während Benutzersitzungen aktualisiert werden. Aufkommende Multi-Modell-Engines schichten spaltenorientierte Tabellen über Vektorindizes und bieten Entwicklern eine einzige API für Metriken, Protokolle und Einbettungen.
Geografische Analyse
Nordamerika erzielte im Jahr 2025 mit einem Anteil von 41,10 % den größten Umsatzanteil, gestützt auf den Ausbau von Hyperscalern, Wall-Street-Handelsvolumina und frühe KI-Bereitstellungen im Gesundheitswesen. Unternehmen in den Vereinigten Staaten profitieren von der Nähe zum NVIDIA-Entwicklerökosystem und zu Risikokapital, das GPU-Beschleunigungspiloten finanziert. Kanadas KI-Strategie des öffentlichen Sektors finanziert edge-fähige GPU-Knoten für Smart-City-Verkehrsflüsse und stärkt die regionale Nachfrage.
Der asiatisch-pazifische Raum zeigt mit 26,2 % bis 2031 die höchste Wachstumsrate, da Indien, China und südostasiatische Volkswirtschaften inländische KI-Lieferketten subventionieren. Die IndiaAI-Mission gewährt Cloud-Guthaben, die die GPU-Zugriffskosten auf INR 67 (USD 0,77) pro Stunde senken und Pilotprojekte in Fintech und Agrar-Tech ankurbeln. Chinesische Smartphone-Hersteller wie Xiaomi bauen 10.000-GPU-Cluster zusammen, um multimodale Assistenten trotz Exportbeschränkungen zu verfeinern. Start-ups in Singapur und Korea nutzen regionale GPU-Marktplätze, um in Nebenzeiten ungenutzte Beschleuniger zu mieten und die Gesamtkosten für Experimente zu senken.
Europa hält eine stetige Akzeptanz aufrecht und balanciert DSGVO-Anforderungen mit dem Bedarf an Echtzeit-Analysen in der Fertigung und Energie. Nationale Rahmenwerke wie GAIA-X fördern souveräne Cloud-Zonen und drängen GPU-Anbieter zur Zertifizierung für Datenresidenz-Compliance. Unterdessen digitalisieren der Nahe Osten und Afrika Ölfelder und Logistikkorridore und setzen GPU-Datenbanken für satellitengestütztes Asset-Tracking ein. Südamerikanische Bergbauunternehmen verarbeiten hyperspektrale Bilder lokal, um Cloud-Bandbreitengebühren zu reduzieren, und nutzen hybride Konferenzen für CUDA-Schulungen. Zusammen diversifizieren diese Regionen den Fußabdruck des GPU-Datenbankmarkts und schützen ihn vor Schocks in einzelnen Regionen.

Wettbewerbslandschaft
Der Markt bleibt mäßig konsolidiert rund um NVIDIAs CUDA-Burggraben, der ausgereifte Bibliotheken, Treiber-Support und eine große Entwicklerbasis bereitstellt. Heavy.AI, Kinetica und SQream bündeln proprietäre Kernel, die Warp-Scheduling nutzen, um einen Abfragedurchsatz von über 100 GB/s zu übertreffen. Ihre langjährige Optimierungskompetenz erhöht die Wechselkosten und sichert Fortune-500-Verträge. Oracle und Microsoft integrieren GPU-Beschleunigung in Mainstream-Datenbanken, was die durchschnittlichen Verkaufspreise drückt und spezialisierte Anbieter dazu drängt, sich durch fortschrittliche Datenmodelle zu differenzieren.
Disruptoren fordern die Orthodoxie mit neuen Chips und offenen Lizenzen heraus. Groqs Logic Processing Unit wirbt mit 18-fach schnellerer Inferenz und verleitet Teams dazu, CUDA ganz zu umgehen. Apache Gluten und Arrow liefern Kompilierzeit-Optimierungen, die proprietäre Leistung annähern, während der Code transparent bleibt, und ziehen die Aufmerksamkeit kostensensibler Cloud-Natives auf sich. Patentanmeldungen zeigen einen Anstieg bei GPU-residenten Pufferverwaltungs- und dynamischen NVLink-Routing-Technologien, was ein Wettrüsten bei den F&E-Ausgaben signalisiert.
Strategische Schritte beschleunigen die Konsolidierung. AMD erwarb ZT Systems für USD 4,9 Milliarden, um Server-Design mit Instinct-GPU-Roadmaps zu integrieren. NVIDIA erwägt Berichten zufolge Lepton AI, um in die Workload-Orchestrierung einzusteigen. Weißer Fleck verbleibt am Netzwerk-Edge, wo energieeffiziente Beschleuniger und domänenspezifische Kernel Drohnenflotten, Einzelhandelskiosken und autonomen Lagern dienen. Insgesamt halten diese Dynamiken den GPU-Datenbankmarkt im Wandel und stärken gleichzeitig die Eintrittsbarrieren für Späteinsteiger.
GPU-Datenbankbranche Marktführer
Heavy.AI (OmniSci)
Kinetica DB Inc.
SQream Technologies
NVIDIA
Brytlyt Ltd.
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Jüngste Branchenentwicklungen
- Juni 2025: AMD erwarb Brium, um das KI-Software-Ökosystem zu stärken und NVIDIAs CUDA-Dominanz herauszufordern, was AMDs vierte Akquisition in zwei Jahren im Rahmen einer Strategie zur Verbesserung des Inferenzdurchsatzes markiert.
- Mai 2025: Oracle kündigte eine Investition von USD 40 Milliarden in NVIDIA-Chips für das Texas-Rechenzentrum von OpenAI an und unterstreicht damit die Rekordnachfrage nach großmaßstäblichen GPU-Clustern.
- Mai 2025: AMD stellte die Radeon AI PRO R9700 mit 32 GB GDDR6 und 1.531 KI-TOPS vor, die im Juli 2025 für professionelle Beschleunigungsarbeitslasten ausgeliefert wird.
- März 2025: AMD schloss die Übernahme von ZT Systems für USD 4,9 Milliarden ab, um das KI-Infrastrukturangebot für GPU-Datenbankbereitstellungen zu stärken.


Rahmen der Forschungsmethodik und Umfang des Berichts
Marktdefinitionen und wichtige Abdeckung
Unsere Studie definiert den GPU-Datenbankmarkt als lizenzierte Software und zugehörige verwaltete Dienste, die Datenbankarbeitslasten hauptsächlich auf Grafikprozessoren ausführen und massiv parallele Echtzeit-Analysen auf strukturierten, halbstrukturierten und Vektordaten in jeder Bereitstellung liefern.
Bare-Metal-GPU-Server, CPU-gebundene Datenbanken und Beschleuniger, die ausschließlich für die Grafikdarstellung verwendet werden, sind nicht abgedeckt.
Segmentierungsübersicht
- Nach Komponente
- Lösung
- GPU-SQL-Engines
- GPU-Vektordatenbanken
- GPU-Graph-Datenbanken
- Sonstige
- Dienste
- Lösung
- Nach Bereitstellungsmodell
- Cloud
- On-Premises
- Nach Endnutzerbranche
- BFSI
- IT und Telekommunikation
- Einzelhandel und E-Commerce
- Gesundheitswesen und Biowissenschaften
- Regierung und Verteidigung
- Sonstige Branchen
- Nach Anwendung
- Echtzeit-Analyse und BI
- Betrugserkennung und Risikoanalyse
- Geospatiale und IoT-Analyse
- Empfehlung und Personalisierung
- Infrastrukturüberwachung und Protokollanalyse
- Nach Datenmodell
- Spaltenorientierter Speicher
- Dokument / Vektor
- Graph
- Multi-Modell
- Nach Geografie
- Nordamerika
- Vereinigte Staaten
- Kanada
- Mexiko
- Südamerika
- Brasilien
- Argentinien
- Übriges Südamerika
- Europa
- Vereinigtes Königreich
- Deutschland
- Frankreich
- Italien
- Spanien
- Nordische Länder
- Übriges Europa
- Naher Osten und Afrika
- Naher Osten
- Saudi-Arabien
- Vereinigte Arabische Emirate
- Türkei
- Übriger Naher Osten
- Afrika
- Südafrika
- Ägypten
- Nigeria
- Übriges Afrika
- Naher Osten
- Asiatisch-pazifischer Raum
- China
- Indien
- Japan
- Südkorea
- ASEAN
- Australien
- Neuseeland
- Übriger asiatisch-pazifischer Raum
- Nordamerika
Detaillierte Forschungsmethodik und Datenvalidierung
Primärforschung
Mordor-Analysten sprechen mit Cloud-Architekten, Dateningenieuren in BFSI und Einzelhandel sowie Systemintegratoren in Nordamerika, Europa und dem asiatisch-pazifischen Raum. Ihre Erkenntnisse bestätigen aktuelle Lizenzpreise, Bereitstellungsumfang und Schwachstellen, die Lehrbücher übersehen.
Sekundärforschung
Wir sichten öffentliche Datensätze wie UN-Comtrade-Handelsprotokoll, OECD Digital Economy Outlook, Eurostat-Cloud-Umfragen und Rechenzentrumsstatistiken der US-amerikanischen Energieinformationsbehörde, um das globale GPU-Angebot und die Nutzung zu verankern. Patentübersichten von Questel sowie begutachtete Artikel kartieren aufkommende Beschleunigungstechniken, während Unternehmens-10-Ks und Investorenpräsentationen Umsatzaufteilungen zwischen Software und Diensten offenbaren. Weitere öffentliche Aufzeichnungen und kostenpflichtige Feeds vervollständigen unseren Evidenzstapel.
Marktgrößenbestimmung und Prognose
Wir beginnen von oben nach unten und multiplizieren vierteljährliche GPU-Lieferungen mit Attach-Raten und dem beobachteten Anteil, der für Datenbankarbeitslasten aufgewendet wird. Stichprobenartige Anbieterumsätze und Cloud-Abrechnungen liefern Bottom-up-Überprüfungen. Treibervariablen umfassen GPU-Preistrends, aktive Vektorsuche-Instanzen, Wachstum von Echtzeit-Analyseabfragen, Cloud-GPU-Stunden und die Einführung von KI in Unternehmen. Eine multivariate Regression projiziert jeden Treiber bis 2030, wobei Interview-Feedback die Szenariogewichtungen leitet. Wo Anbieter-Rollups quelloffene Installationen verfehlen, schließen kalibrierte Faktoren die Lücke.
Datenvalidierung und Aktualisierungszyklus
Modelle bestehen Varianzprüfungen, Peer-Review und Genehmigung durch leitende Mitarbeiter. Wir aktualisieren die Zahlen jedes Jahr und veröffentlichen Anpassungen, wenn GPU-Lieferungen um mehr als fünf Prozent schwanken oder wegweisende Markteinführungen die Preisgestaltung neu definieren.
Warum Mordors GPU-Datenbankbasis Vertrauen verdient
Veröffentlichte Zahlen weichen ab, weil Herausgeber unterschiedliche Umfänge, Währungen oder Aktualisierungsgeschwindigkeiten wählen.
Indem wir Gesamtwerte in verifizierten Lieferdaten verankern und Lizenzverhältnisse mit aktuellen Nutzern gegenseitig prüfen, balancieren wir bei Mordor Intelligence Breite mit Realität.
Benchmark-Vergleich
| Marktgröße | Anonymisierte Quelle | Primärer Lückentreiber |
|---|---|---|
| USD 0,78 Mrd. (2025) | ||
| USD 0,55 Mrd. (2024) | Globale Unternehmensberatung A | Lässt Dienstleistungsumsätze und Cloud-Abonnements aus |
| USD 0,46 Mrd. (2023) | Fachzeitschrift B | Älteres Basisjahr, nur On-Premises |
| USD 0,51 Mrd. (2023) | Branchenverband C | Anbieterbefragung ohne Prüfung |
Diese Kontraste zeigen, wie Mordors disziplinierter Umfang, aktuellere Daten und mehrstufige Prüfungen die ausgewogene, transparente Grundlage liefern, die Entscheidungsträger benötigen.


Im Bericht beantwortete Schlüsselfragen
Was ist die aktuelle Bewertung des GPU-Datenbankmarkts?
Der GPU-Datenbankmarkt steht im Jahr 2026 bei USD 870,64 Millionen und soll bis 2031 USD 1,51 Milliarden erreichen.
Welches Bereitstellungsmodell dominiert die GPU-Datenbankakzeptanz?
Die Cloud-Bereitstellung führt mit einem Umsatzanteil von 77,60 % im Jahr 2025, dank der GPU-Verfügbarkeit von Hyperscalern und nutzungsbasierter Preisgestaltung.
Warum wachsen Vektordatenbanken so schnell?
LLM-Inferenz und semantische Suche erfordern hochdimensionale Ähnlichkeitsabfragen, die GPUs effizient verarbeiten, was Vektor- / Dokumentdatenbanken auf eine CAGR von 38,9 % treibt.
Welche Endnutzerbranche expandiert am schnellsten?
Gesundheitswesen und Biowissenschaften zeigen mit einer CAGR von 28,4 % das höchste Wachstum aufgrund von GPU-beschleunigter diagnostischer Bildgebung und Genomik-Arbeitslasten.
Was sind die wichtigsten Adoptionshürden?
Hohe Hardwarekosten und ein Mangel an qualifizierten CUDA-Fachkräften verlangsamen die Einführung, insbesondere in Schwellenmärkten.
Wie beeinflusst HTAP die GPU-Datenbanknachfrage?
Durch die Zusammenführung von transaktionaler und analytischer Verarbeitung in einer Engine beseitigt HTAP ETL-Verzögerungen und positioniert GPUs als Kernplattform für Echtzeit-Entscheidungsfindung.
Seite zuletzt aktualisiert am:




