United States Hadoop Market Size and Share
Market Overview
| Study Period | 2019 - 2030 |
|---|---|
| Forecast Data Period | 2025 - 2030 |
| Historical Data Period | 2019 - 2023 |
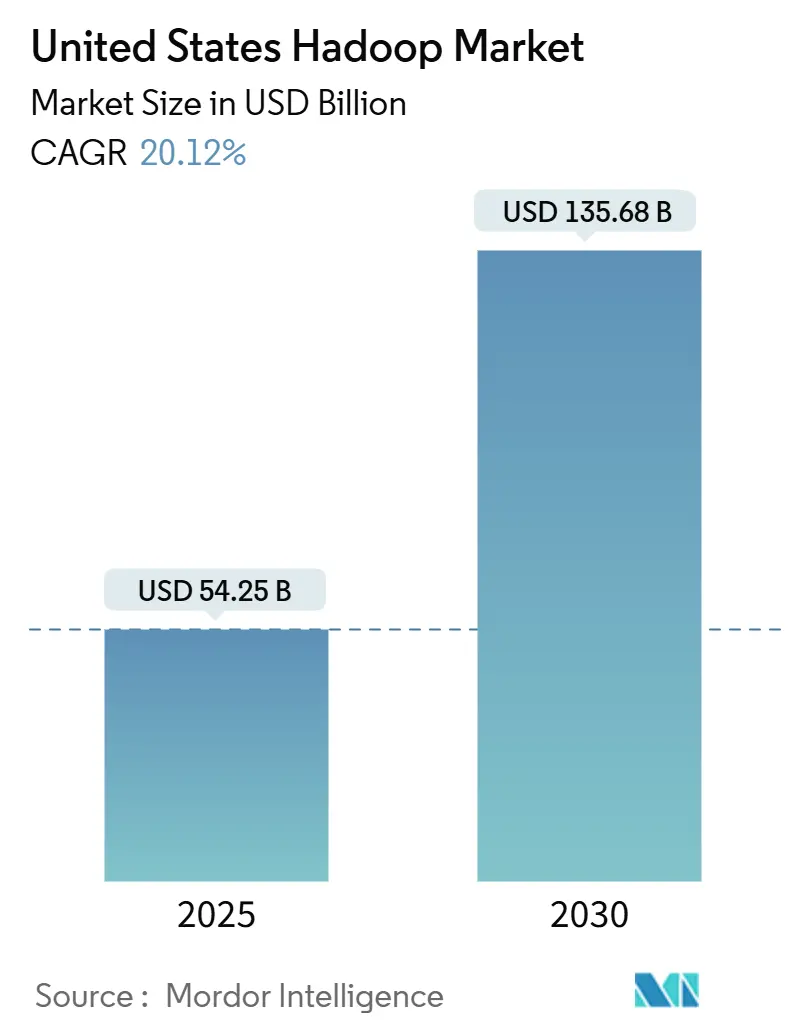
| Market Size (2025) | USD 54.25 Billion |
| Market Size (2030) | USD 135.68 Billion |
| Growth Rate (2025 - 2030) | 20.12% CAGR |
| Market Concentration | Medium |
Major Players *Disclaimer: Major Players sorted in no particular order Image © Mordor Intelligence. Reuse requires attribution under CC BY 4.0. | |
United States Hadoop Market Analysis by Mordor Intelligence
The United States Hadoop market size stands at USD 54.25 billion in 2025 and is projected to climb to USD 135.68 billion by 2030, translating into a sturdy 20.12% CAGR over the forecast horizon. Surging data volumes, aggressive digital-transformation programs, and the transition away from legacy data warehouses position the United States Hadoop market as indispensable infrastructure for enterprise-grade analytics. Software components remain central, yet cloud-delivered services are capturing budget as organizations seek managed clusters that scale on demand. Regionally, the South commands the largest spending pool while the West accelerates fastest, reflecting Silicon Valley’s innovation flywheel. Competitive rivalry stays intense as incumbents defend their share against cloud hyperscalers and lakehouse newcomers that promise simplified management and improved query speed.
Key Report Takeaways
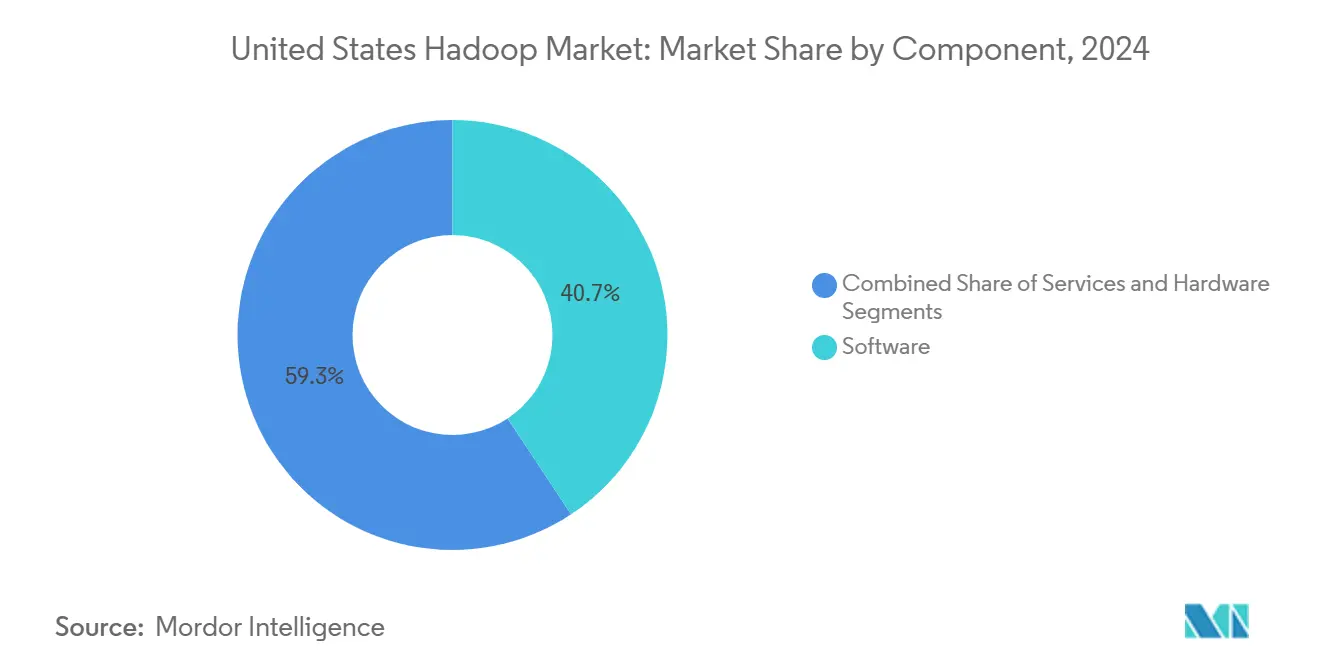
- By component, software commanded 40.7 % of the United States Hadoop market share in 2024, while services are advancing at a 20.92 % CAGR through 2030.
- By deployment model, on-premise solutions held 52.8 % of the United States Hadoop market size in 2024; cloud implementations are expanding at a 21.3 % CAGR to 2030.
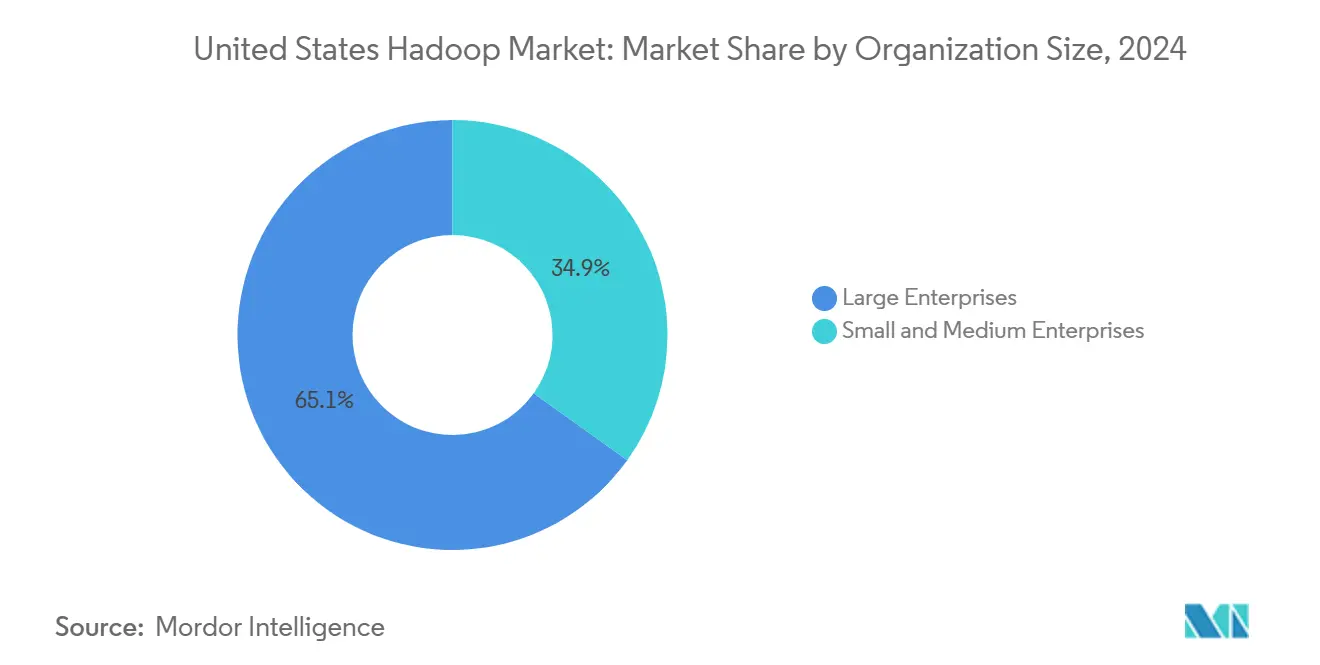
- By organization size, large enterprises accounted for a dominant 65.1 % share of the United States Hadoop market in 2024, whereas SMEs are forecast to post a 20.7 % CAGR through 2030.
- By end-user industry, IT and telecommunications controlled 30.02 % of spending in 2024 of the United States Hadoop market, while healthcare and life sciences are projected to grow at a 22.3 % CAGR through 2030.
- By region, the South led with 38.31 % revenue contribution of the United States Hadoop market in 2024; the West is pacing the field at a 21.5 % CAGR during the outlook period.
United States Hadoop Market Trends and Insights
Drivers Impact Analysis*
| Driver | (~) % Impact on CAGR Forecast | Geographic Relevance | Impact Timeline |
|---|---|---|---|
| Exploding enterprise data volumes and need for scalable processing | +4.2% | National, with concentration in South and West regions | Long term (≥ 4 years) |
| Shift toward cloud-based Hadoop-as-a-Service models | +3.8% | National, with early adoption in West and Northeast | Medium term (2-4 years) |
| Cost advantages over traditional EDW solutions | +2.9% | National, particularly in cost-sensitive SME segment | Medium term (2-4 years) |
| Integration of AI and ML workloads on Hadoop ecosystems | +3.5% | West and Northeast technology hubs | Long term (≥ 4 years) |
| Rising compliance analytics demand in regulated industries | +2.1% | National, with emphasis in BFSI and healthcare sectors | Medium term (2-4 years) |
| Edge and IoT data ingestion driving near-real-time Hadoop analytics | +1.8% | Manufacturing regions in Midwest and South | Long term (≥ 4 years) |
| Source: Mordor Intelligence | |||
Exploding Enterprise Data Volumes Require Scalable Processing
Digital channels, IoT sensors, and stringent record-keeping mandates are swelling data stores to petabyte scale, outstripping the throughput of conventional warehouses. An IBM survey found that 73% of U.S. companies logged annual data growth exceeding 40%.[1]IBM, “Enterprise Data Management Survey 2024,” ibm.com Hadoop’s distributed file system and parallelized computing capabilities enable firms to keep pace without rewriting schemas or re-architecting hardware. The ability to linearly add commodity nodes transforms capacity planning from a capital-expense gamble into an incremental exercise. As edge devices feed additional telemetry, centralized Hadoop clusters become the aggregator of choice for downstream analytics, predictive maintenance, and anomaly detection. Enterprises now treat scalable processing not as optional experimentation but as a core pillar of business continuity and competitive agility.
Cloud-Based Hadoop-as-a-Service Models Democratize Big-Data Adoption
Managed services such as Amazon EMR and Azure HDInsight lower the operational barrier by abstracting cluster provisioning, patching, and security hardening. AWS introduced serverless EMR in 2024, enabling workloads to scale automatically and bill only for the resources they consume.[2]Amazon Web Services, “Amazon EMR Serverless for Apache Spark,” amazon.com The service model resonates with organizations that lack deep Hadoop expertise, allowing data teams to focus on insights rather than infrastructure. Consumption-based pricing shifts budget from capital to operating expenditure, removing the sticker shock historically tied to on-premise builds. As multi-cloud strategies become more normalized, portability between providers improves, further widening the addressable market for the United States Hadoop market.
Cost Advantages Over Traditional Data-Warehouse Systems
Benchmarking by Oracle revealed total cost of ownership savings of 60–70 % when Hadoop replaces proprietary data-warehouse appliances at like-for-like scale. Open-source licensing eliminates platform fees, while commodity servers avert the premium commanded by specialized hardware. Schema-on-read design postpones data-model decisions until query time, shrinking ETL overhead and accelerating project launches. Enterprises with spiking data intake appreciate that scaling Hadoop requires purchasing additional nodes rather than forklift upgrades. For cost-sensitive SMEs, these economics unlock advanced analytics once reserved for deep-pocketed corporations, reinforcing the appeal of cloud-hosted delivery.
AI and ML Workload Integration within Hadoop Ecosystems
Machine learning pipelines thrive on vast labeled datasets that reside natively within Hadoop clusters. Google Cloud’s link between Vertex AI and Dataproc allows model training to execute adjacent to data, slashing transfer latency and egress charges. Frameworks like Spark MLlib and TensorFlow on YARN exploit distributed memory, accelerating algorithm convergence. Vendors are embedding AutoML, feature-engineering accelerators, and GPU scheduling to streamline experimentation. As use cases shift from retrospective dashboards to real-time pattern recognition, Hadoop emerges as the staging ground for iterative model development, evaluation, and deployment at scale.
Restraints Impact Analysis*
| Restraint | (~) % Impact on CAGR Forecast | Geographic Relevance | Impact Timeline |
|---|---|---|---|
| Acute shortage of Hadoop talent and steep learning curves | -2.8% | National, particularly acute in Midwest and South | Short term (≤ 2 years) |
| Increasing migration to cloud lakehouse platforms cannibalising on-prem Hadoop | -3.2% | National, with concentration in technology-forward regions | Medium term (2-4 years) |
| Persistent data-security and governance concerns | -1.9% | National, with emphasis in regulated industries | Medium term (2-4 years) |
| Legacy cluster technical debt and high maintenance costs | -2.1% | National, particularly in early adopter organizations | Long term (≥ 4 years) |
| Source: Mordor Intelligence | |||
Acute Shortage of Hadoop Talent
An IEEE study reported 68 % of enterprises struggle to hire qualified Hadoop professionals, with vacancies remaining open an average of 4.5 months. The ecosystem demands proficiency across HDFS, YARN, MapReduce, Spark, and security frameworks such as Ranger and Knox. Retraining database administrators often spans 12–18 months, hampering speed-to-deploy. Regional disparities exacerbate pressure: companies outside tier-one tech hubs face relocation premiums that dilute Hadoop’s cost savings. Bootcamps and university curricula are ramping but may not bridge the shortfall quickly, weighing on near-term expansion of the United States Hadoop market.
Cloud Lakehouse Migration Cannibalizes Traditional Hadoop Clusters
Unified platforms like Databricks and Snowflake collapse storage, analytics, and governance into a single service, challenging Hadoop’s multi-component complexity. Databricks’ lakehouse pitch of warehouse-grade performance atop open-format data lakes resonates with teams weary of tuning multiple engines.[3]Databricks, “Lakehouse Reference Architecture,” databricks.com Migration toolkits, discount credits, and performance benchmarks entice enterprises to re-platform instead of modernizing on-prem clusters. While many firms will adopt hybrid coexistence, new workloads may bypass Hadoop entirely, resulting in trimmed addressable spend over the mid-term.
*Our forecasts treat driver/restraint impacts as directional, not additive. The impact forecasts reflect baseline growth, mix effects, and variable interactions.
Segment Analysis
By Component: Services Build Momentum as Software Retains Core Position
Software remained dominant, capturing 40.7 % of spending within the United States Hadoop market in 2024 as enterprises renewed subscriptions for distribution support, security patches, and companion analytics modules. Vendors focused on feature hardening, deeper SQL compatibility, and cloud-native packaging to preserve installed bases.
Services, however, are scaling faster at a 20.92 % CAGR, reflecting executive preference for turnkey deployment, cluster tuning, and managed operations. Cloudera expanded its professional-services bench by 200 consultants in 2024 to meet this advisory demand. As regulatory obligations tighten, buyers lean on system integrators fluent in HIPAA, PCI-DSS, and FedRAMP to configure compliant pipelines. Hardware has narrowed to niche use cases such as ruggedized edge nodes, reinforcing the shift from capital expenditure to service-centric operating models within the United States Hadoop market.



By Deployment Model: Cloud Trajectory Challenges On-Premise Entitlements
On-premise estates still represented 52.8 % of the United States Hadoop market size in 2024, owing to sunk investment, data-sovereignty mandates, and low-latency application coupling. Financial institutions and public-sector agencies often maintain air-gapped clusters for audit and security reasons.
Cloud alternatives are accelerating at 21.3 % CAGR to 2030, propelled by serverless EMR, autoscaling HDInsight, and Google Dataproc custom-machine-type offerings. These services neutralize capacity-planning headaches and shrink lead times from months to hours. Hybrid blueprints, where sensitive datasets reside on-premise while burst workloads execute in the cloud, are emerging norms. The resulting architectural flexibility reinforces spending diversity across the United States Hadoop market.
By Organization Size: SMEs Narrow the Utilization Gap
Large enterprises held a 65.1% stake in 2024, leveraging deep data pools to run fraud detection, omnichannel personalization, and supply-chain optimization on multi-petabyte clusters. Dedicated platform teams enforce service-level objectives that keep Hadoop integral to mission-critical processes.
SMEs are the fastest-growing cohort, with a 20.7% CAGR, fueled by pay-as-you-go licensing and template-driven deployment wizards. Microsoft’s HDInsight Essentials targets smaller firms with predictable batch needs and limited staff. As SMBs digitize their front-office and back-office workflows, Hadoop becomes the analytical backbone that converts operational data into predictive insights, thereby broadening the penetration of the United States Hadoop market.
By End-User Industry: Healthcare Heads the Growth Leaderboard
IT and telecommunications providers accounted for 30.02% of total revenue in 2024, leveraging Hadoop for real-time network telemetry, customer-experience analytics, and billing-fraud mitigation. Latency tolerance has improved through Spark Streaming, sustaining the vertical’s appetite for distributed compute.
Healthcare and life sciences are poised to outpace their peers with a 22.3% CAGR, as genomic sequencing, clinical trial data fusion, and population health dashboards demand cost-efficient scaling. The FDA’s expanding stance on real-world evidence underscores the importance of compliance with verifiable data lineage. Pharmaceutical sponsors rely on Hadoop to ingest electronic health records, claims data, and wearable sensor feeds, reinforcing vertical-specific momentum within the United States' Hadoop market.
Geography Analysis
The South accounted for 38.31 % of national revenue in 2024, propelled by expansive data-center corridors in Texas, North Carolina, and Florida. Utility incentives, low energy costs, and pro-business tax regimes have lured hyperscalers and enterprise tenants alike. AWS added new US-East availability zones in North Carolina during 2025, improving regional latency and bolstering confidence in cloud-delivered Hadoop workloads.[4]Amazon Web Services, “US-East Region Expansion 2025,” amazon.com
The West is the pacesetter, with a 21.5% CAGR through 2030. Silicon Valley’s deep talent bench, coupled with venture backing, sustains a pipeline of data-engineering start-ups that standardize on Hadoop foundations. California privacy laws, such as the CPRA, heighten investment in governance tooling, indirectly boosting spend on metadata and security modules. Google’s Oregon and Nevada expansions prioritize high-memory instances tailored to big-data use cases, fortifying the regional cloud backbone.
Northeast and Midwest clusters together represent a sizeable share, anchored by New York’s financial-services concentration and the Great Lakes manufacturing belt. Chicago’s cloud-zone launches lower latency for Midwest customers, while New York fintechs use Hadoop to meet real-time risk and reporting requirements. Workforce availability and higher facility costs temper near-term acceleration, yet modernization grants and public-private innovation labs aim to sustain engagement with the United States Hadoop market.
Competitive Landscape
Competition blends legacy enterprise vendors, cloud hyperscalers, and specialist disruptors. Cloudera, IBM, and Oracle fortify portfolios through security certifications, GPU acceleration, and observability suites. Cloud providers leverage economies of scale to deliver managed Hadoop as an on-ramp into broader data-platform toolkits, intensifying price and performance jockeying. Market share concentration remains moderate; the top five suppliers collectively control about 45 % of revenue, fostering both consolidation plays and niche opportunities.
Emerging actors challenge incumbent mindshare. Databricks’ lakehouse model and Snowflake’s unstructured data processing siphon incremental workloads by offering single-platform simplicity. Patent filings around columnar caching, query federations, and Kubernetes-native deployment rose sharply in 2025, signaling a race for differentiated intellectual property.
Partnerships flourish as strategic currency. Oracle now supports multi-cloud deployments of its Big Data Service via AWS Direct Connect and Google Interconnect, aiding customers pursuing vendor diversity. IBM’s StreamSets buyout introduces automated data-pipeline design, shrinking onboarding friction. Cloudera’s USD 150 million infusion into AI-powered search interfaces aims to curb customer churn by embedding natural-language insights into its ecosystem. Collectively, these moves illustrate a market pivoting from raw throughput claims to outcome-focused value propositions within the United States Hadoop market.
United States Hadoop Industry Leaders
Cloudera, Inc.
Amazon Web Services, Inc.
Microsoft Corporation
IBM Corporation
Google LLC
- *Disclaimer: Major Players sorted in no particular order

Recent Industry Developments
- October 2025: Cloudera announced a USD 150 million investment to embed generative-AI querying and automated pipeline optimization into its flagship distribution.
- September 2025: Microsoft enabled GPU-accelerated clusters in Azure HDInsight for TensorFlow and PyTorch workloads.
- August 2025: Amazon Web Services debuted EMR Serverless for Apache Spark, removing cluster-management overhead.
- July 2025: IBM acquired StreamSets for USD 300 million to advance hybrid-cloud data-integration capabilities.
- June 2025: Oracle unveiled partnerships with Databricks and Snowflake, offering integrated lakehouse solutions.


United States Hadoop Market Report Scope
| Software |
| Hardware |
| Services |
| On-premise |
| Cloud |
| Hybrid |
| Large Enterprises |
| Small and Medium-Sized Enterprises |
| BFSI |
| Retail and Consumer Goods |
| Healthcare and Life Sciences |
| IT and Telecommunications |
| Manufacturing |
| Other End-User Industries |
| Northeast |
| Midwest |
| South |
| West |
| By Component | Software |
| Hardware | |
| Services | |
| By Deployment Model | On-premise |
| Cloud | |
| Hybrid | |
| By Organization Size | Large Enterprises |
| Small and Medium-Sized Enterprises | |
| By End-User Industry | BFSI |
| Retail and Consumer Goods | |
| Healthcare and Life Sciences | |
| IT and Telecommunications | |
| Manufacturing | |
| Other End-User Industries | |
| By Region | Northeast |
| Midwest | |
| South | |
| West |


Key Questions Answered in the Report
How large is the United States Hadoop market in 2025?
The United States Hadoop market size is USD 54.25 billion in 2025.
What CAGR is forecast for Hadoop spending in the United States through 2030?
Spending is projected to grow at a 20.12 % CAGR between 2025 and 2030.
Which U.S. region is expanding fastest for Hadoop deployments?
The West is forecast to post a 21.5 % CAGR, driven by Silicon Valley’s innovation ecosystem.
Which industry vertical is expected to grow most rapidly?
Healthcare and life sciences are projected to advance at a 22.3 % CAGR through 2030.
What is the main obstacle to broader Hadoop adoption?
A nationwide shortage of experienced Hadoop professionals is the leading constraint, adding hiring delays and cost.
How are cloud services influencing Hadoop uptake among SMEs?
Cloud-based Hadoop-as-a-Service offerings provide pay-as-you-go scalability and managed operations, enabling SMEs to adopt big-data analytics without heavy upfront capital.
Page last updated on:






