Tamaño y Participación del Mercado de Recopilación y Etiquetado de Datos
Visión General del Mercado
| Período de Estudio | 2020 - 2031 |
|---|---|
| Tamaño del Mercado (2026) | 2.67 Mil millones de dólares |
| Tamaño del Mercado (2031) | 10.92 Mil millones de dólares |
| Tasa de crecimiento (2026 - 2031) | 32.59% CAGR |
| Mercado de Crecimiento Más Rápido | Asia Pacífico |
| Mercado Más Grande | América del Norte |
| Concentración del Mercado | Medio |
Jugadores principales *Nota aclaratoria: los principales jugadores no se ordenaron de un modo en especial Imagen © Mordor Intelligence. El uso requiere atribución según CC BY 4.0. | |
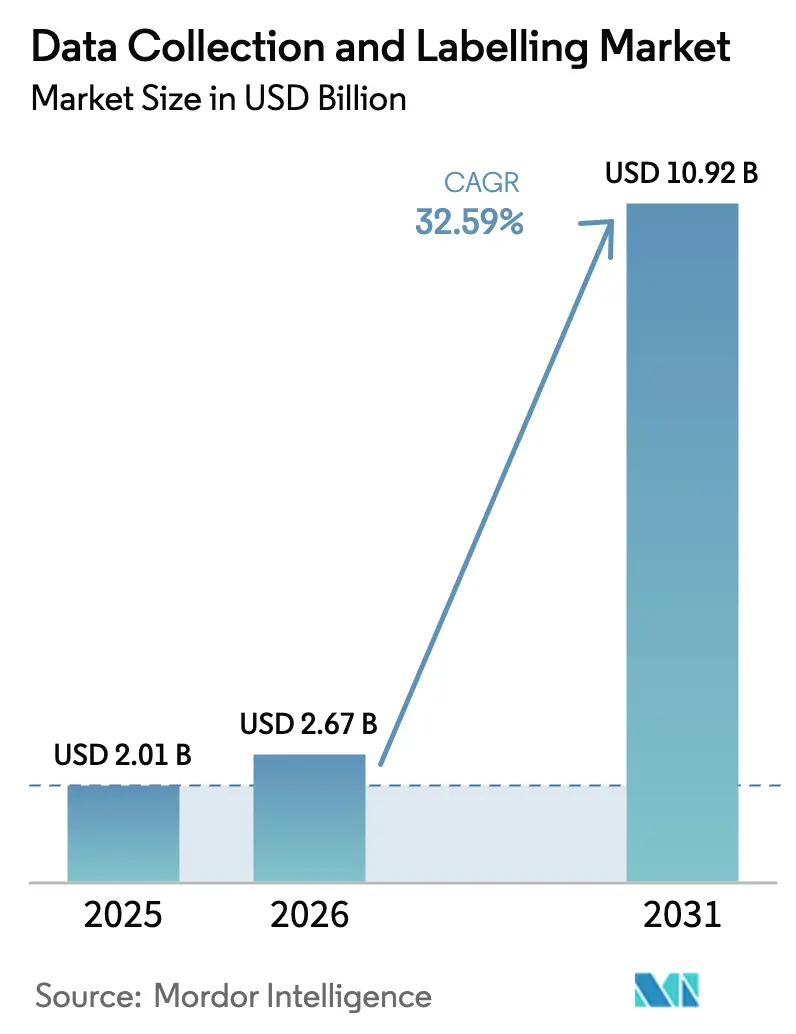
Análisis del Mercado de Recopilación y Etiquetado de Datos por Mordor Intelligence
El tamaño del mercado de recopilación y etiquetado de datos fue valorado en USD 2,01 mil millones en 2025 y se estima que crecerá desde USD 2,67 mil millones en 2026 hasta alcanzar USD 10,92 mil millones en 2031, a una CAGR del 32,59% durante el período de pronóstico (2026-2031). La demanda incesante de datos de entrenamiento de alta calidad y múltiples dominios es impulsada por los modelos fundacionales multimodales, el giro hacia las canalizaciones de aprendizaje continuo y los plazos de cumplimiento normativo que se aproximan rápidamente. El preetiquetado asistido por inteligencia artificial generativa ahora gestiona tareas rutinarias con ganancias de velocidad de 20 veces, liberando a los escasos expertos humanos para casos límite complejos. La generación de datos sintéticos, las normas de localización de datos centradas en la privacidad y el aumento de los costos por agotamiento de los anotadores están reformulando las estrategias de abastecimiento. El impulso comercial es más fuerte en América del Norte, aunque Asia-Pacífico está escalando más rápido a medida que China e India desarrollan capacidad doméstica a pesar de las estrictas leyes de soberanía de datos. La rivalidad competitiva es intensa porque los nichos de "datos pequeños" específicos de dominio, como la imagen médica, siguen teniendo precios premium aunque los niveles generales de automatización estén aumentando.
Conclusiones Clave del Informe
- Por tipo de datos, la anotación de texto lideró con una participación de ingresos del 26,12% del mercado de recopilación y etiquetado de datos en 2025, mientras que se prevé que los flujos de fusión de sensores se expandan a una CAGR del 35,42% hasta 2031.
- Por industria de uso final, el segmento automotriz y de movilidad mantuvo el 22,05% de la participación del mercado de recopilación y etiquetado de datos en 2025, mientras que se proyecta que el sector sanitario registre la CAGR más rápida del 34,89% hasta 2031.
- Por modelo de abastecimiento, los proveedores de servicios externalizados capturaron el 44,78% del mercado de recopilación y etiquetado de datos en 2025, pero se espera que la generación de datos sintéticos crezca un 36,2% anualmente.
- Por tipo de anotación, los flujos de trabajo manuales con intervención humana aún representaron el 49,45% del tamaño del mercado de recopilación y etiquetado de datos en 2025, aunque los enfoques totalmente automatizados avanzan a una CAGR del 34,95%.
- América del Norte concentró el 39,92% del mercado de recopilación y etiquetado de datos en 2025, mientras que Asia-Pacífico es la geografía de más rápido crecimiento con una CAGR del 35,65%.
Nota: Las cifras de tamaño del mercado y previsión de este informe se generan utilizando el marco de estimación propietario de Mordor Intelligence, actualizado con los últimos datos e información disponibles a partir de 2026.
Tendencias e Información del Mercado
Análisis del Impacto de los Impulsores del Mercado de Recopilación y Etiquetado de Datos*
| Impulsor | (~) % de Impacto en el Pronóstico de CAGR | Relevancia Geográfica | Plazo de Impacto |
|---|---|---|---|
| Auge de los modelos fundacionales multimodales | +8.2% | América del Norte, China | Mediano plazo (2-4 años) |
| Transición hacia canalizaciones de aprendizaje continuo | +7.1% | EE. UU., UE, Asia-Pacífico | Largo plazo (≥ 4 años) |
| Preetiquetado asistido por inteligencia artificial generativa | +6.8% | América del Norte, UE | Corto plazo (≤ 2 años) |
| Plazos de cumplimiento acelerados (Ley de IA de la UE, Declaración de Derechos de IA de EE. UU.) | +5.3% | UE, América del Norte | Corto plazo (≤ 2 años) |
| Necesidades verticales de "datos pequeños" en imagen médica y geoespacial | +4.7% | Mercados desarrollados | Mediano plazo (2-4 años) |
| Fuente: Mordor Intelligence | |||
El Auge de los Modelos Fundacionales Multimodales Impulsa la Demanda de Conjuntos de Datos Multidominios
Los modelos fundacionales multimodales requieren conjuntos de datos masivos y diversos que combinan texto, imágenes, audio, video y flujos de sensores, encendiendo una nueva demanda en todo el mercado de recopilación y etiquetado de datos [1]Anas Awadalla et al., "MINT-1T: Escalando Datos Multimodales de Código Abierto 10×," arXiv, arxiv.org. Corpus de referencia como MINT-1T escalaron los datos multimodales de código abierto 10 veces e ilustran la nueva línea base para el entrenamiento de inteligencia artificial moderna. Los proveedores capaces de orquestar flujos de trabajo de anotación multimedia ahora ganan contratos premium porque los clientes requieren etiquetas estrechamente alineadas entre modalidades. Los inversores consideran esta capacidad como infraestructura central, como lo evidencia la ronda de financiación de USD 1.000 millones de Scale AI en 2024. Los primeros adoptantes en conducción autónoma, asistentes de voz y robótica están catalizando el crecimiento en volumen, mientras que los proveedores de atención médica amplían los conjuntos de datos de fusión imagen-texto para modelos de diagnóstico. A medida que estos casos de uso maduran, se espera que el mercado de recopilación y etiquetado de datos experimente entradas de volumen sostenidas durante varios años.
La IA Centrada en Datos Transforma la Anotación Estática en Canalizaciones de Aprendizaje Continuo
Las empresas han pasado de la creación puntual de conjuntos de datos hacia la iteración perpetua de calidad de datos, alterando fundamentalmente los modelos comerciales dentro del mercado de recopilación y etiquetado de datos [2]Matei Zaharia, "¿Qué puede aprender la IA centrada en datos de la ingeniería de datos y aprendizaje automático?" arXiv, arxiv.org . Los proveedores de plataformas ahora ofrecen control de versiones de conjuntos de datos en tiempo real, orquestación automatizada de canalizaciones y optimización de bucles de retroalimentación bajo los marcos emergentes de DataOps. Las canalizaciones de aprendizaje continuo elevan la demanda de anotación porque la telemetría entrante de los modelos revela constantemente nuevos modos de fallo que requieren reetiquetado específico. Los proveedores de servicios que pueden combinar una respuesta rápida con registros de auditoría detallados están ganando contratos sensibles al cumplimiento normativo. Este impulsor a largo plazo respalda compromisos de ingresos recurrentes en lugar de proyectos esporádicos, fortaleciendo la visibilidad de crecimiento del mercado de recopilación y etiquetado de datos.
El Preetiquetado Asistido por Inteligencia Artificial Generativa Acelera la Productividad de la Anotación
Los grandes modelos de lenguaje como GPT-4 ahora preetiquetan datos con un 88,4% de concordancia con la verdad de referencia y ganancias de velocidad de 20 veces, transformando la economía unitaria. Los flujos de trabajo híbridos dirigen los casos rutinarios a los algoritmos mientras reservan el esfuerzo humano para las ambigüedades, reduciendo las horas manuales hasta en un 90,6% en conjuntos de datos biológicos. El aumento de productividad permite a los proveedores gestionar volúmenes crecientes sin una expansión lineal de la fuerza laboral, reforzando la competitividad en precios. A medida que las herramientas de inteligencia artificial maduran, los compradores empresariales esperan cada vez más automatización integrada, convirtiendo la sofisticación del conjunto tecnológico en un calificador decisivo en todo el mercado de recopilación y etiquetado de datos.
Los Plazos de Cumplimiento Normativo Aceleran las Inversiones en Gobernanza de Datos
El Artículo 10 de la Ley de IA de la UE, vigente desde 2024, exige la documentación de la procedencia de los conjuntos de datos y controles rigurosos de gobernanza de datos para los sistemas de inteligencia artificial de alto riesgo [3]Parlamento Europeo y Consejo, "Reglamento – UE – 2024/1689," eur-lex.europa.eu . Disposiciones similares aparecen en el anteproyecto de la Declaración de Derechos de IA de EE. UU., obligando a las empresas a presupuestar el seguimiento del linaje, las auditorías de sesgo y las verificaciones continuas de garantía de calidad. Los proveedores que ofrecen herramientas listas para el cumplimiento normativo y entornos de anotación seguros en las instalaciones están captando compromisos premium. Estas obligaciones elevan los costos de cambio y prolongan la duración de los contratos, otorgando al mercado de recopilación y etiquetado de datos un viento de cola anclado en la regulación durante la década.
Análisis del Impacto de las Restricciones del Mercado de Recopilación y Etiquetado de Datos*
| Restricción | (≈) % de Impacto en el Pronóstico de CAGR | Relevancia Geográfica | Plazo de Impacto |
|---|---|---|---|
| Aumento de los costos unitarios por agotamiento de los anotadores y deterioro de la calidad | -3.9% | Filipinas, Kenia, centros globales | Mediano plazo (2-4 años) |
| Restricciones a la transferencia transfronteriza de datos | -2.8% | China, UE, India | Largo plazo (≥ 4 años) |
| La sustitución por datos sintéticos reduce el gasto tradicional | -2.1% | Mercados tecnológicamente avanzados | Mediano plazo (2-4 años) |
| Fuente: Mordor Intelligence | |||
El Agotamiento de los Anotadores y el Deterioro de la Calidad Elevan los Costos Unitarios
La alta repetición de tareas y los plazos ajustados han elevado la rotación en los principales centros de externalización, impulsando los salarios al alza y amenazando la consistencia de la calidad. Los proveedores ahora rotan a los trabajadores con mayor frecuencia e incorporan monitoreo de calidad basado en inteligencia artificial, pero estas medidas de mitigación inflan las bases de costos. Si no se abordan, el aumento de los gastos laborales podría erosionar los márgenes y ralentizar la adopción, particularmente entre las pequeñas y medianas empresas sensibles al precio en el mercado de recopilación y etiquetado de datos.
Las Restricciones a la Transferencia Transfronteriza de Datos Fragmentan las Operaciones Globales
Las Regulaciones de Gestión de Seguridad de Datos de Red de China y la Ley de Protección de Datos Personales Digitales de India imponen estrictas obligaciones de localización y evaluación de seguridad. Las revisiones de adecuación del RGPD de la UE añaden mayor complejidad. Las empresas de anotación deben construir centros de procesamiento regionales, invertir en cifrado y navegar por auditorías duplicadas, elevando los costos fijos. Los proveedores más pequeños que carecen de recursos pueden abandonar las jurisdicciones restringidas, reduciendo la oferta y prolongando los plazos de entrega de los proyectos dentro del mercado de recopilación y etiquetado de datos.
*Nuestras previsiones consideran los impactos de impulsores y restricciones como direccionales, no aditivos. Las previsiones de impacto reflejan el crecimiento base, los efectos de mezcla y las interacciones entre variables.
Análisis de Segmentos del Mercado de Recopilación y Etiquetado de Datos
Por Tipo de Datos:
Los Flujos de Fusión de Sensores Aceleran las Aplicaciones FuturasLa anotación de texto siguió siendo la mayor porción del mercado de recopilación y etiquetado de datos con una participación de ingresos del 26,12% en 2025, sostenida por el auge de las canalizaciones de entrenamiento de grandes modelos de lenguaje. Sin embargo, los flujos de fusión de sensores avanzan rápidamente con una CAGR del 35,42% a medida que los robots autónomos, los equipos de fábricas inteligentes y los sistemas avanzados de asistencia al conductor fusionan datos de LiDAR, radar, cámara e inercia. El etiquetado de imágenes y videos mantiene su impulso en la detección de defectos de fabricación y el análisis de estantes en el comercio minorista, mientras que los conjuntos de datos de imágenes médicas en 3D como M3D amplían los horizontes de la inteligencia artificial en la atención médica. La anotación de audio se beneficia de las aplicaciones de experiencia del cliente habilitadas por voz, y las tareas de series temporales tabulares respaldan los modelos de riesgo en finanzas y telecomunicaciones.
La complejidad de la fusión de sensores, que implica sincronización temporal y calibración espacial, exige precios premium, elevando su contribución a los ingresos a pesar de un menor número absoluto de trabajos. Los proveedores que implementan rutinas de validación automatizada y simuladores basados en física reducen las tasas de retrabajo y se diferencian en licitaciones competitivas. La estrecha colaboración entre los equipos de anotación y los ingenieros de hardware de sensores se vuelve indispensable, consolidando las ofertas de servicios integrados como una ventaja competitiva en el mercado de recopilación y etiquetado de datos.
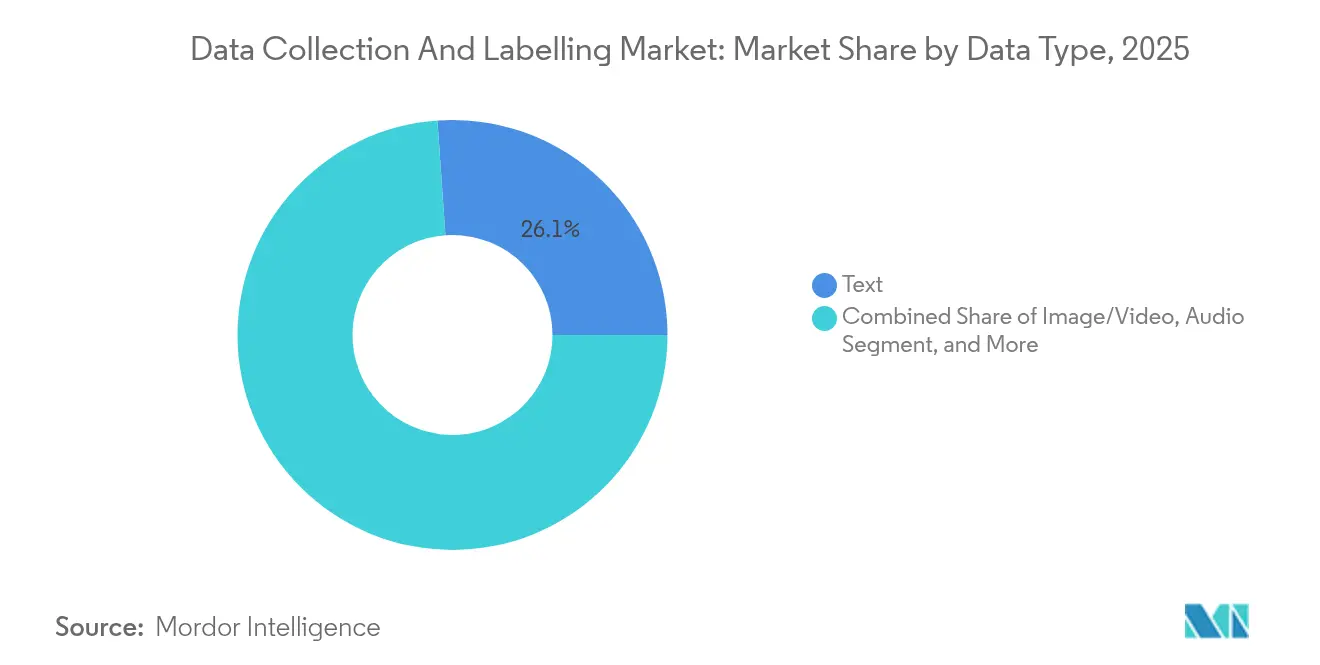
Nota: Las participaciones de todos los segmentos individuales están disponibles con la compra del informe


Por Industria de Uso Final:
El Sector Sanitario Supera los Parámetros de CrecimientoEl sector automotriz y de movilidad representó el 22,05% del mercado de recopilación y etiquetado de datos en 2025, impulsado por conjuntos de datos a escala de petabytes para la conducción autónoma. Las actualizaciones normativas continuas, como las reglas de validación de sistemas avanzados de asistencia al conductor de Euro-NCAP para 2026, sostienen las canalizaciones de generación de datos. Se prevé que el sector sanitario registre la CAGR más rápida del 34,89%, impulsado por imágenes de alta resolución, estructuración de notas clínicas y descubrimiento de fármacos asistido por inteligencia artificial. El tamaño del mercado de recopilación y etiquetado de datos solo para imagen médica está destinado a crecer pronunciadamente, ya que la anotación experta en radiología sigue siendo insustituible debido a consideraciones de responsabilidad.
Las agencias gubernamentales amplían los chatbots de clasificación, detección de amenazas y servicios al ciudadano, mientras que las instituciones del sector bancario, financiero, de seguros e inversiones refinan los modelos de análisis de fraude que requieren un etiquetado equilibrado de la tasa de falsos positivos. Las plataformas de comercio electrónico minorista elevan la cobertura de taxonomía de productos y el rendimiento de la búsqueda visual. La agricultura aprovecha las imágenes de vehículos aéreos no tripulados para la predicción de rendimiento y el monitoreo de plagas, y los operadores de telecomunicaciones curan corpus de lenguaje específicos del dominio para optimizar las operaciones de red. Cada sector vertical amplía el espectro de demanda, pero el crecimiento se distribuye de manera desigual, dando a los proveedores especializados espacio para destacar en nichos dentro de la industria de recopilación y etiquetado de datos.
Por Modelo de Abastecimiento:
La Generación Sintética Desafía el Dominio de la ExternalizaciónLos proveedores de servicios externalizados mantuvieron el 44,78% del mercado de recopilación y etiquetado de datos en 2025, respaldados por escala, grupos de talento multilingüe e instalaciones certificadas por ISO. Sin embargo, la generación de datos sintéticos, que escala a una CAGR del 36,2%, está desestabilizando los flujos de trabajo establecidos. Los entornos de simulación fabrican eventos de conducción poco frecuentes, y las redes generativas adversariales llenan los vacíos en las clases médicas subrepresentadas. Las empresas combinan cada vez más datos sintéticos y reales, reduciendo los volúmenes de anotación para escenarios rutinarios mientras reservan el esfuerzo humano para la validación.
La capacidad de anotación interna se está fortaleciendo donde la sensibilidad de los datos o la protección de la propiedad intelectual son primordiales, especialmente entre los contratistas de defensa y los hospitales de primer nivel. La externalización colectiva sigue siendo relevante para las tareas de consumo de larga cola que requieren matices culturales, como el análisis de sentimientos en dialectos, aunque el riesgo de varianza de calidad requiere capas de revisión avanzadas. Los modelos de servicio híbridos que combinan el aumento sintético, el preetiquetado asistido por inteligencia artificial y las instalaciones seguras en tierra están emergiendo como el nuevo estándar en todo el mercado de recopilación y etiquetado de datos.
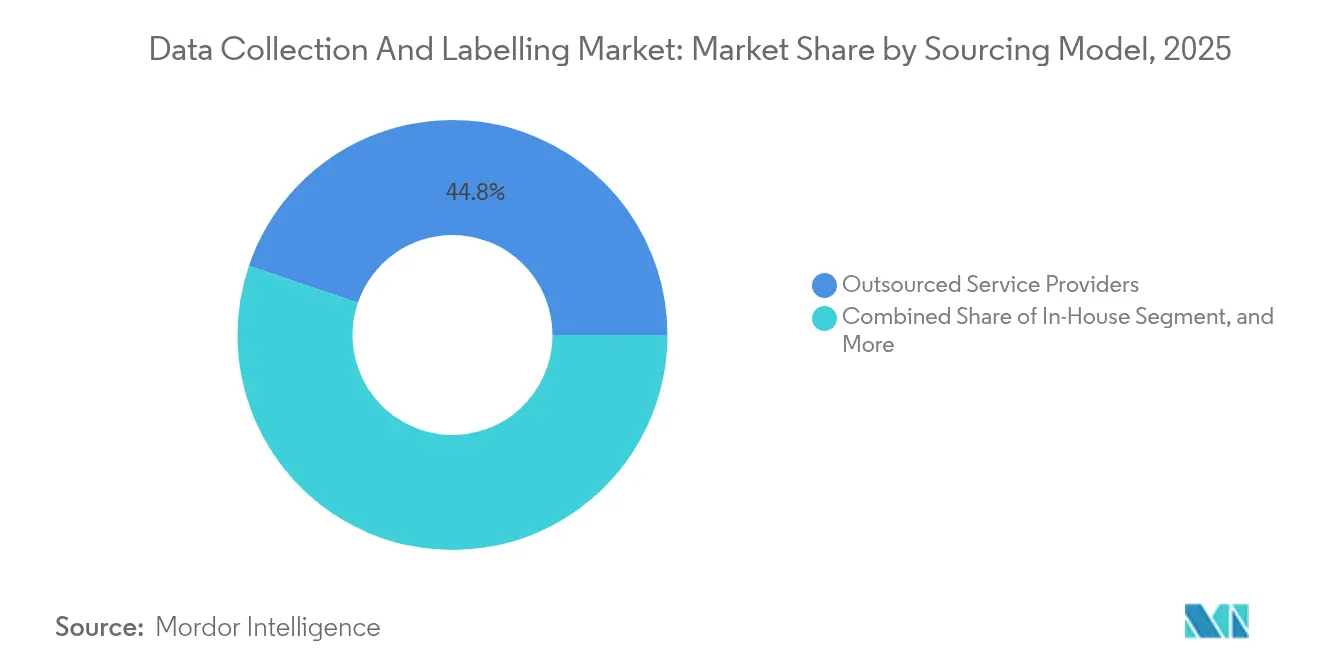
Nota: Las participaciones de todos los segmentos individuales están disponibles con la compra del informe
Por Tipo de Anotación:
La Automatización Gana Impulso en Medio de la Supervisión HumanaLos procesos manuales con intervención humana aún representaron el 49,45% de los ingresos de 2025, subrayando el valor perdurable del juicio contextual experto. Los bucles semisupervisados y de aprendizaje activo ahora reducen los recuentos de anotación en más del 60% sin pérdida medible de precisión en estudios de referencia. Las canalizaciones automatizadas que registran una CAGR del 34,95% se basan en etiquetadores impulsados por modelos fundacionales para el etiquetado de primer paso, alimentando a los validadores humanos a través de colas de excepciones. Las herramientas de inteligencia artificial centradas en datos registran metadatos de procedencia, automatizan la puntuación de consenso y señalan la deriva para el reetiquetado, reduciendo los tiempos de ciclo y reforzando los informes de cumplimiento normativo.
A medida que mejora la precisión algorítmica, la anotación totalmente automatizada penetrará en dominios rutinarios como la detección de cuadros delimitadores en imágenes de estantes minoristas, aunque las interpretaciones médicas o legales intrincadas mantendrán a los humanos como indispensables. Los proveedores que equilibren la automatización rentable con una escalada experta rápida capturarán las oportunidades de mayor margen en todo el mercado de recopilación y etiquetado de datos.
Análisis Geográfico
Mercado de Recopilación y Etiquetado de Datos en América del Norte
América del Norte dominó el mercado de recopilación y etiquetado de datos con una participación del 39,92% en 2025, respaldada por una sólida financiación de capital de riesgo, ecosistemas de inteligencia artificial maduros y altas tasas de adopción empresarial. Iniciativas como el proyecto Thunderforge de la Unidad de Innovación de Defensa de los Estados Unidos señalan la demanda gubernamental de canalizaciones de etiquetado seguras y de misión crítica en diu.mil. El clúster de innovación Scale AI de Canadá invirtió 96 millones de USD en 22 proyectos, ampliando aún más la infraestructura regional. El nexo académico-industrial de la región sostiene el liderazgo técnico, pero el aumento de los costes laborales impulsa la adopción de la automatización asistida por inteligencia artificial.
Mercado de Recopilación y Etiquetado de Datos en Asia-Pacífico
Asia-Pacífico es el territorio de más rápido crecimiento con una CAGR del 35,65%, impulsado por implementaciones de inteligencia artificial a gran escala y mandatos regionales de residencia de datos. Las Regulaciones de Gestión de Seguridad de Datos de Red de China, vigentes desde 2025, exigen evaluaciones de riesgo anuales, lo que impulsa la creación de instalaciones de anotación en territorio nacional. La Ley de Protección de Datos Personales Digitales de India impone el consentimiento explícito y evaluaciones de seguridad, generando demanda de proveedores domésticos conformes. Los mercados de la ASEAN aprovechan grupos de crowdsourcing multilingüe para atraer compradores globales, mientras que Japón y Corea del Sur invierten en anotación de alta precisión para robótica e inspección de semiconductores.
Mercado de Recopilación y Etiquetado de Datos en Europa
Europa exhibe un crecimiento constante sustentado por imperativos de gobernanza de datos impulsados por políticas. El enfoque de la Ley de Inteligencia Artificial de la UE en la transparencia incrementa la demanda de documentación de etiquetado lista para auditorías. Los proyectos del Servicio Digital del Gobierno han demostrado ganancias sustanciales de eficiencia a partir de la categorización basada en aprendizaje automático de contenido del sector público. Los proveedores que ofrecen entornos seguros y alineados con el RGPD obtienen precios premium, mientras que las colaboraciones de investigación regionales impulsan la innovación en técnicas de anotación que preservan la privacidad.
Panorama Competitivo
La competencia está fragmentada. Scale AI, Appen y TELUS International anclan el extremo superior del mercado de recopilación y etiquetado de datos, cada uno expandiéndose a través de asociaciones estratégicas. La alianza de OpenAI con Scale AI en 2024 amplía el soporte de ajuste fino empresarial, subrayando el valor de los servicios integrados de datos y modelos. TaskUs se asoció con V7, vinculando una comunidad de anotadores de 670.000 personas a herramientas avanzadas de infraestructura de datos.
La diferenciación tecnológica se está intensificando. Los proveedores implementan motores de aprendizaje activo, detectores de errores de etiquetado y modelos fundacionales específicos del dominio para elevar la productividad y la calidad. La capacidad de datos sintéticos es un campo de batalla emergente; las empresas que combinan canalizaciones reales y simuladas comercializan menor sesgo y una cobertura superior de casos límite. Los sectores sanitario, legal y científico valoran a los expertos certificados, lo que lleva a los nuevos participantes a construir redes de talento específicas.
Los inversores continúan respaldando plataformas impulsadas por escala. La ronda Serie F de USD 1.000 millones de Scale AI a una valoración de USD 13.800 millones destacó la confianza en la economía de la infraestructura de datos. La asociación de Labelbox con Handshake en 2024 amplía el acceso a anotadores especializados para gestionar cargas de trabajo complejas de aprendizaje automático. TELUS Digital obtuvo el reconocimiento de NelsonHall por la excelencia en la anotación de datos automotrices. En general, es probable que la intensidad competitiva se mantenga alta a medida que la automatización comprime los márgenes y los compradores exigen soluciones integrales y listas para el cumplimiento normativo en todo el mercado de recopilación y etiquetado de datos.
Líderes de la Industria de Recopilación y Etiquetado de Datos
Appen Limited
Alegion Inc.
Cogito Tech
iMerit Technology
SuperAnnotate AI Inc.
- *Nota aclaratoria: los principales jugadores no se ordenaron de un modo en especial
Empresas del Mercado de Recopilación y Etiquetado de Datos Cubiertas en este Informe
- Appen
- TELUS International AI Data (Lionbridge AI)
- iMerit
- CloudFactory
- Scale AI
- SuperAnnotate
- Sama
- Labelbox
- Alegion
- Cognizant (Servian)
- Defined.ai
- Cogito Tech
- V7
- Kili Technology
- Keymakr
- Deepen AI
- Playment
- Trilldata
- Tasq.ai
- Shaip

Desarrollo Reciente de la Industria en el Mercado de Recopilación y Etiquetado de Datos
- Enero de 2025: Las Regulaciones de Gestión de Seguridad de Datos de Red de China entraron en vigor, obligando a las evaluaciones de riesgo anuales para las empresas con uso intensivo de datos y promoviendo la construcción de instalaciones de anotación regionales Rödl & Partner.
- Diciembre de 2024: Labelbox formó una alianza estratégica con Handshake para acceder a talento especializado en inteligencia artificial para tareas de etiquetado complejas Labelbox.
- Octubre de 2024: TELUS Digital fue nombrado líder en el informe de Servicios de Experiencia del Cliente de NelsonHall para alta tecnología y automotriz, citando sólidas capacidades de anotación de datos de sistemas avanzados de asistencia al conductor TELUS Digital.
- Agosto de 2024: Singtel y Nscale se asociaron para desbloquear capacidad de unidades de procesamiento gráfico en Europa y el Sudeste Asiático, aliviando los cuellos de botella de cómputo para las cargas de trabajo de anotación con uso intensivo de datos Nscale.


Alcance del Informe Global del Mercado de Recopilación y Etiquetado de Datos
La industria de recopilación y etiquetado de datos es un sector que implica la recopilación, el procesamiento y la anotación de datos, que luego se utilizan para entrenar modelos de aprendizaje automático (ML) y sistemas de inteligencia artificial (IA). La investigación también examina los factores de crecimiento subyacentes y los principales proveedores del sector, todos los cuales ayudan a respaldar las estimaciones del mercado y las tasas de crecimiento durante el período previsto. Las estimaciones y proyecciones del mercado se basan en los factores del año base y se obtienen mediante enfoques descendentes y ascendentes.
El mercado de recopilación y etiquetado de datos está segmentado por tipo de datos (texto, imagen/video y audio), por industria de uso final (automotriz, gobierno, atención médica, sector bancario, financiero, de seguros e inversiones, comercio minorista y comercio electrónico y otras industrias de uso final) y por geografía (América del Norte, Europa, Asia-Pacífico, América del Sur y Oriente Medio y África). El dimensionamiento y los pronósticos del mercado se proporcionan en términos de valor (USD) para todos los segmentos anteriores.
Resumen de la Segmentación
| Texto |
| Imagen/Video |
| Audio |
| Nube de Puntos 3D |
| Flujos de Sensores y Fusión |
| Tabular/Series Temporales |
| Automotriz y Movilidad |
| Gobierno y Sector Público |
| Atención Médica y Ciencias de la Vida |
| Sector Bancario, Financiero, de Seguros e Inversiones |
| Comercio Minorista y Comercio Electrónico |
| Agricultura |
| Tecnología de la Información y Telecomunicaciones |
| Otras Industrias de Uso Final |
| Interno |
| Proveedores de Servicios Externalizados |
| Plataformas de Externalización Colectiva |
| Generación de Datos Sintéticos |
| Manual (con Intervención Humana) |
| Semisupervisado / Aprendizaje Activo |
| Totalmente Automatizado |
| América del Norte | Estados Unidos | |
| Canadá | ||
| México | ||
| Europa | Alemania | |
| Reino Unido | ||
| Francia | ||
| Italia | ||
| España | ||
| Rusia | ||
| Resto de Europa | ||
| Asia-Pacífico | China | |
| India | ||
| Japón | ||
| Corea del Sur | ||
| Australia y Nueva Zelanda | ||
| Resto de Asia-Pacífico | ||
| Oriente Medio y África | Oriente Medio | Emiratos Árabes Unidos |
| Arabia Saudita | ||
| Turquía | ||
| Resto de Oriente Medio | ||
| África | Sudáfrica | |
| Nigeria | ||
| Egipto | ||
| Resto de África | ||
| América del Sur | Brasil | |
| Argentina | ||
| Resto de América del Sur | ||
| Por Tipo de Datos | Texto | ||
| Imagen/Video | |||
| Audio | |||
| Nube de Puntos 3D | |||
| Flujos de Sensores y Fusión | |||
| Tabular/Series Temporales | |||
| Por Industria de Uso Final | Automotriz y Movilidad | ||
| Gobierno y Sector Público | |||
| Atención Médica y Ciencias de la Vida | |||
| Sector Bancario, Financiero, de Seguros e Inversiones | |||
| Comercio Minorista y Comercio Electrónico | |||
| Agricultura | |||
| Tecnología de la Información y Telecomunicaciones | |||
| Otras Industrias de Uso Final | |||
| Por Modelo de Abastecimiento | Interno | ||
| Proveedores de Servicios Externalizados | |||
| Plataformas de Externalización Colectiva | |||
| Generación de Datos Sintéticos | |||
| Por Tipo de Anotación | Manual (con Intervención Humana) | ||
| Semisupervisado / Aprendizaje Activo | |||
| Totalmente Automatizado | |||
| Por Geografía | América del Norte | Estados Unidos | |
| Canadá | |||
| México | |||
| Europa | Alemania | ||
| Reino Unido | |||
| Francia | |||
| Italia | |||
| España | |||
| Rusia | |||
| Resto de Europa | |||
| Asia-Pacífico | China | ||
| India | |||
| Japón | |||
| Corea del Sur | |||
| Australia y Nueva Zelanda | |||
| Resto de Asia-Pacífico | |||
| Oriente Medio y África | Oriente Medio | Emiratos Árabes Unidos | |
| Arabia Saudita | |||
| Turquía | |||
| Resto de Oriente Medio | |||
| África | Sudáfrica | ||
| Nigeria | |||
| Egipto | |||
| Resto de África | |||
| América del Sur | Brasil | ||
| Argentina | |||
| Resto de América del Sur | |||


Preguntas Clave Respondidas en el Informe
¿Cuál es el tamaño actual del mercado de recopilación y etiquetado de datos?
El tamaño del mercado de recopilación y etiquetado de datos alcanzó USD 2,67 mil millones en 2026 y se prevé que aumente a USD 10,92 mil millones en 2031.
¿Qué región lidera el mercado de recopilación y etiquetado de datos?
América del Norte lideró con una participación de mercado del 39,92% en 2025, lo que refleja una profunda inversión en inteligencia artificial y ecosistemas maduros de infraestructura de datos.
¿Qué segmento se está expandiendo más rápidamente dentro del mercado de recopilación y etiquetado de datos?
Se proyecta que los flujos de datos de fusión de sensores crezcan a una CAGR del 35,42%, impulsados por sistemas autónomos y aplicaciones de IoT.
¿Cómo están afectando los datos sintéticos a los servicios de anotación tradicionales?
Los motores de datos sintéticos están escalando a una CAGR del 36,2% y se espera que suministren la mayoría de los conjuntos de datos de entrenamiento, reduciendo la demanda rutinaria de etiquetado manual mientras crean nuevas necesidades de validación.
¿Qué impacto tiene la Ley de IA de la UE en las operaciones de etiquetado de datos?
La Ley de IA de la UE exige una estricta gobernanza de datos y seguimiento de la procedencia, lo que lleva a las empresas a invertir en flujos de trabajo de anotación conformes y aumentando la demanda de proveedores de servicios listos para auditoría.
Última actualización de la página el:




