Marktgröße und Marktanteil für Spracherkennung
Marktübersicht
| Studienzeitraum | 2020 - 2031 |
|---|---|
| Marktgröße (2026) | 22.51 Milliarden US-Dollar |
| Marktgröße (2031) | 61.78 Milliarden US-Dollar |
| Wachstumsrate (2026 - 2031) | 22.38% CAGR |
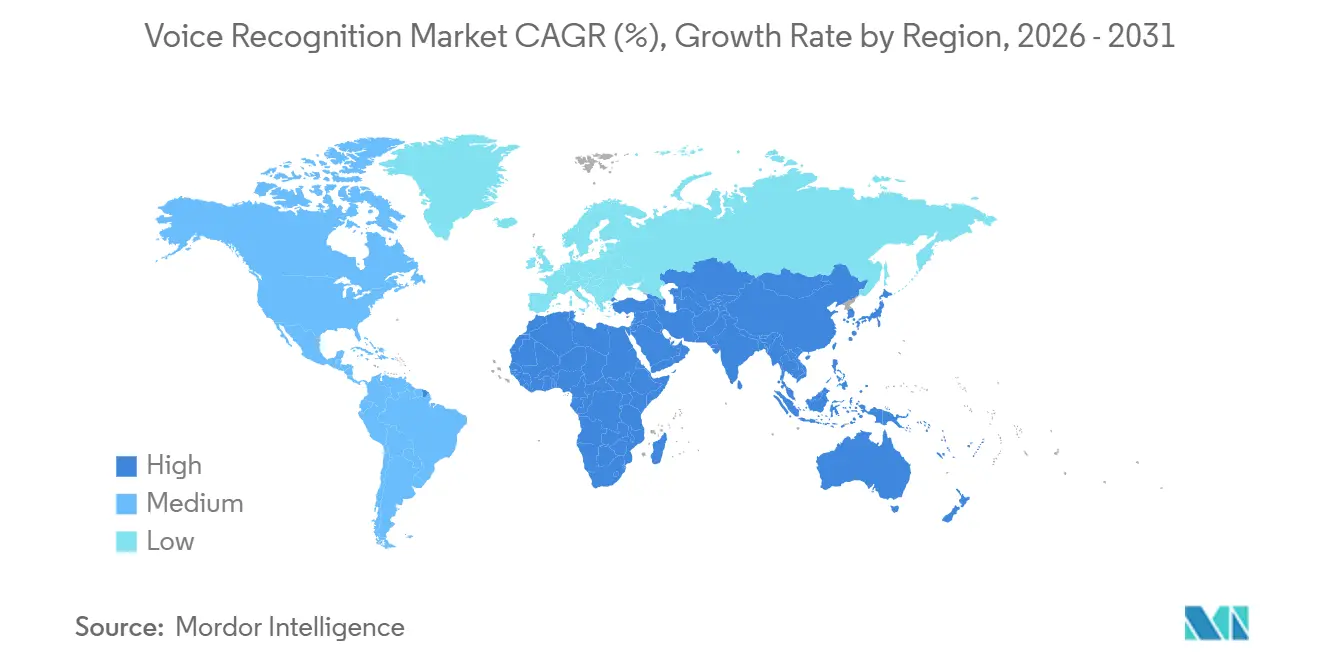
| Schnellstwachsender Markt | Afrika |
| Größter Markt | Asien-Pazifik |
| Marktkonzentration | Mittel |
Hauptakteure *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. | |
Marktanalyse für Spracherkennung von Mordor Intelligence
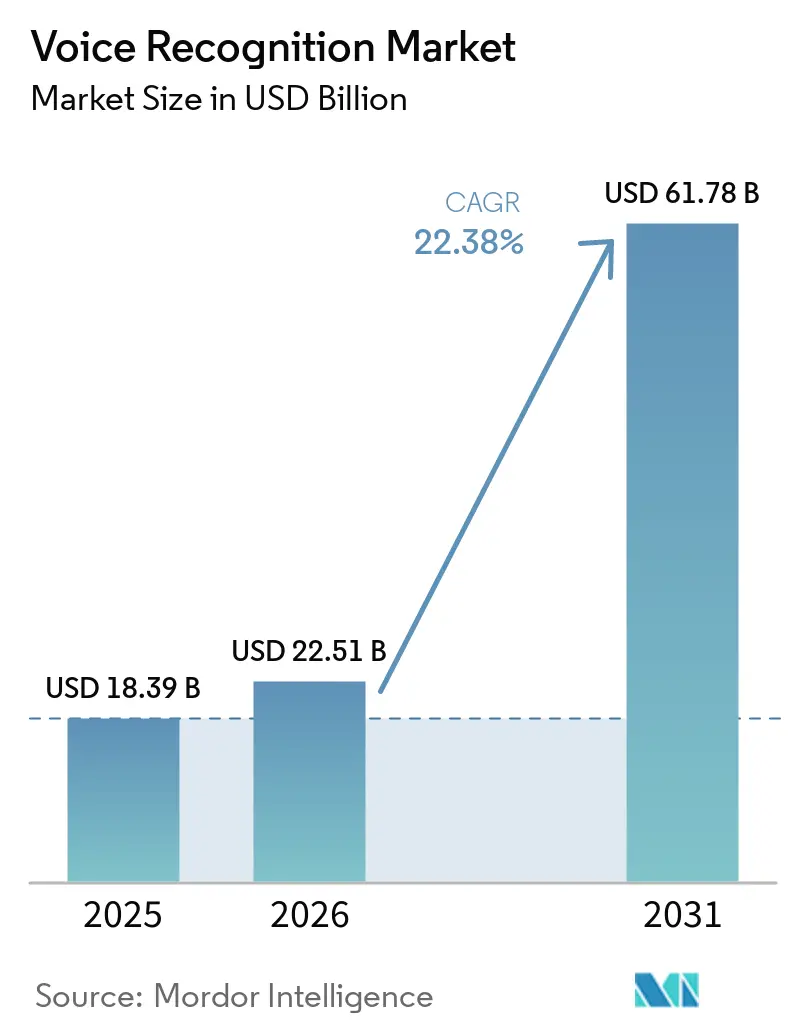
Die Marktgröße für Spracherkennung wird voraussichtlich im Jahr 2025 18,39 Milliarden USD, im Jahr 2026 22,51 Milliarden USD betragen und bis 2031 61,78 Milliarden USD erreichen, mit einer jährlichen Wachstumsrate (CAGR) von 22,38 % von 2026 bis 2031. Die Nachfrage beschleunigt sich, da öffentliche Sicherheitsvorschriften für Multimedia-Notrufdienste in Nordamerika, edge-native Sprach-KI-Chips in asiatischer Unterhaltungselektronik und die Umstellung europäischer Banken von wissensbasierter Authentifizierung auf Sprachbiometrie zusammentreffen. Anbieter verlagern Modelle von der Cloud auf Geräte, um Datenschutzvorschriften zu erfüllen, Latenzzeiten zu reduzieren und Übertragungsgebühren zu senken. Finanzinstitute und Krankenhäuser, die Modelle lokal betreiben, berichten nun von Authentifizierungs- und Dokumentationszyklen unter 50 Millisekunden, während Automobilhersteller Sprache in Cockpit-Betriebssysteme integrieren, um das Fahrerlebnis zu personalisieren. Venture-finanzierte Spezialisten erodieren den Marktanteil etablierter Anbieter, indem sie Domänenmodelle veröffentlichen, die allgemeine Engines in medizinischer, rechtlicher und mehrsprachiger Genauigkeit übertreffen.
Wichtigste Erkenntnisse des Berichts
- Nach Geografie führte Asien-Pazifik mit einem Marktanteil von 37,64 % im Markt für Spracherkennung im Jahr 2025, während Afrika bis 2031 die höchste CAGR von 23,46 % verzeichnen soll.
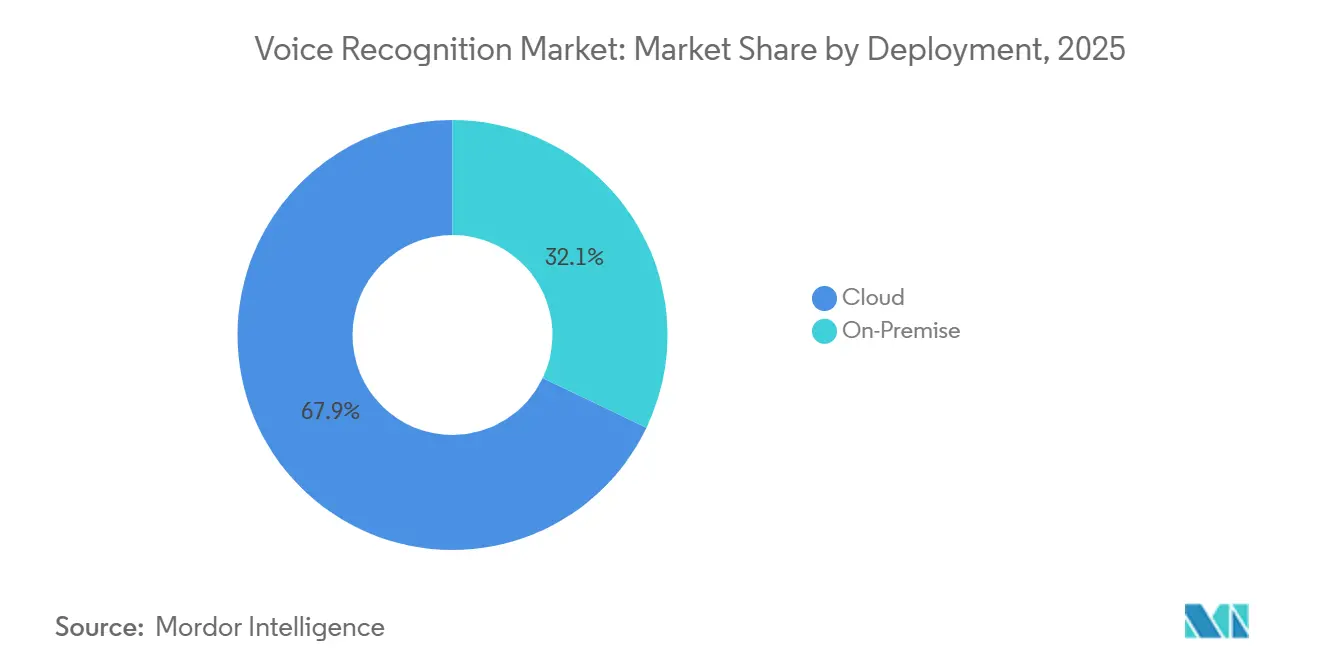
- Nach Bereitstellung erfasste die Cloud 67,91 % des Umsatzes im Jahr 2025; On-Premise-Lösungen werden voraussichtlich bis 2031 mit einer CAGR von 22,71 % wachsen.
- Nach Komponente entfielen Software und Software-Entwicklungskits auf 42,33 % des Marktanteils für Spracherkennung im Jahr 2025 und stellten die am schnellsten wachsende Komponente mit einer CAGR von 22,92 % dar.
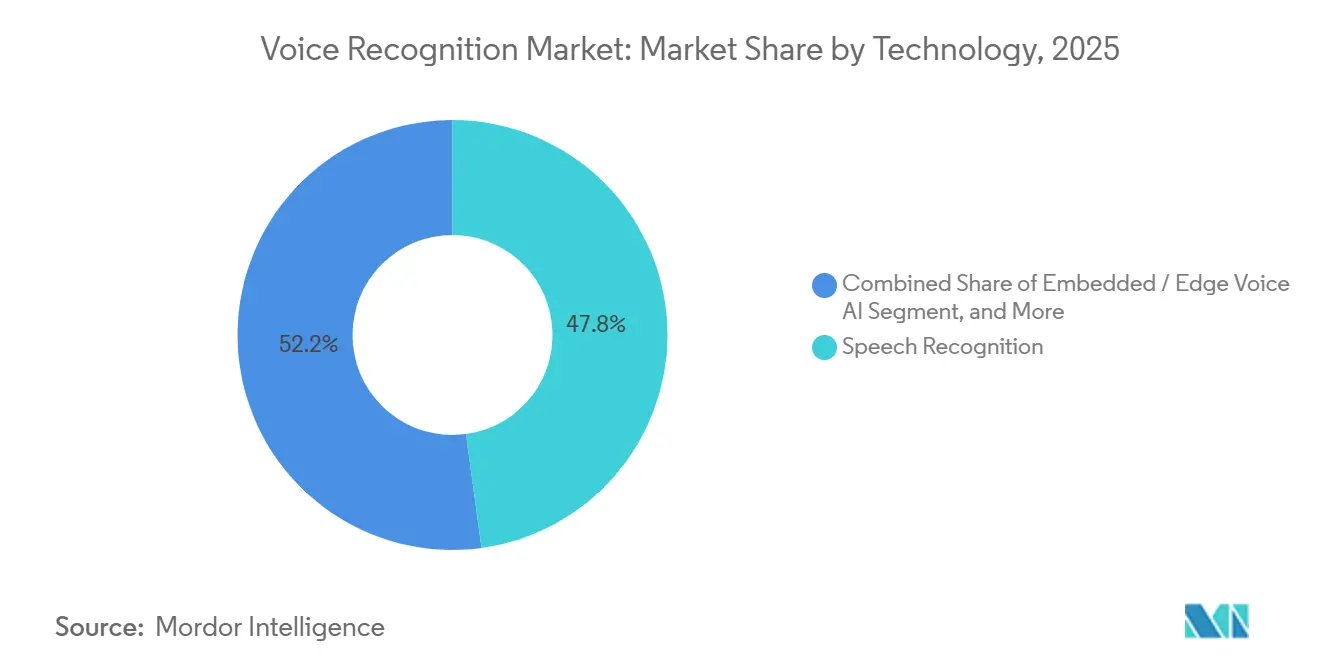
- Nach Technologie dominierte Spracherkennung mit 47,84 % des Umsatzes im Jahr 2025, während eingebettete und Edge-Sprach-KI voraussichtlich mit einer CAGR von 22,96 % wachsen wird.
- Nach Gerätetyp entfielen Smartphones und Tablets auf 39,17 % des Marktanteils für Spracherkennung im Jahr 2025, während Wearables bis 2031 mit einer CAGR von 23,33 % wachsen sollen.
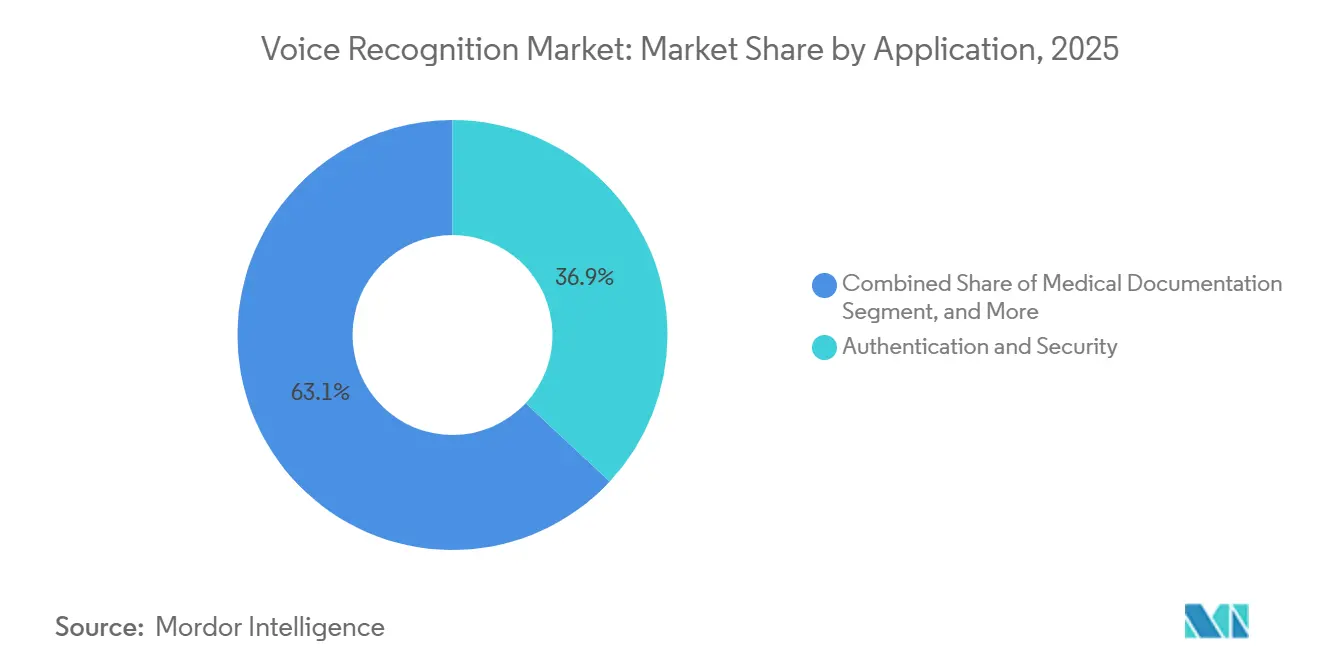
- Nach Anwendung entfielen Authentifizierung und Sicherheit auf 36,93 % des Umsatzes im Jahr 2025; medizinische Dokumentation wird voraussichtlich mit einer CAGR von 23,39 % wachsen.
- Nach Endnutzerbranche entfiel Unterhaltungselektronik auf 29,48 % des Marktanteils für Spracherkennung im Jahr 2025, während Gesundheitsdienstleister bis 2031 voraussichtlich mit einer CAGR von 23,94 % wachsen werden.
Hinweis: Die Marktgrößen- und Prognosezahlen in diesem Bericht werden mithilfe des proprietären Schätzrahmens von Mordor Intelligence erstellt und mit den neuesten verfügbaren Daten und Erkenntnissen bis 2026 aktualisiert.
Globale Trends und Erkenntnisse im Markt für Spracherkennung
Analyse der Treiberwirkung*
| Treiber | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Explosion von Sprach-KI-Chips in Edge-Geräten | +4.2% | Kernregion Asien-Pazifik, Ausstrahlungseffekte auf Nordamerika und Europa | Mittelfristig (2–4 Jahre) |
| Regulatorischer Druck für sprachgestützte Notrufe | +3.8% | Nordamerika, frühe Einführung in ausgewählten Märkten der Europäischen Union | Kurzfristig (≤ 2 Jahre) |
| Umstellung der Automobilhersteller auf eingebettete Sprach-Betriebssysteme | +3.5% | Global, konzentriert in China, Deutschland, Vereinigte Staaten | Mittelfristig (2–4 Jahre) |
| Einführung von Sprachbiometrie im Bereich Banken, Finanzdienstleistungen und Versicherungen | +3.1% | Europa und Nordamerika, Ausweitung auf Asien-Pazifik | Mittelfristig (2–4 Jahre) |
| Schnelles Wachstum des Sprachhandels | +2.9% | Nordamerika und Asien-Pazifik, in Europa noch in der Entstehungsphase | Kurzfristig (≤ 2 Jahre) |
| Edge-natives föderiertes Lernen | +2.6% | Global, angeführt von den Vereinigten Staaten, China, Israel | Langfristig (≥ 4 Jahre) |
| Quelle: Mordor Intelligence | |||
Explosion von Sprach-KI-Chips in Edge-Geräten in ganz Asien
Asiatische Regulierungsbehörden schreiben die Verarbeitung auf dem Gerät vor und drängen Halbleiterlieferanten dazu, neuronale Einheiten einzubetten, die eine Billion Operationen pro Sekunde ausführen können. China schreibt nun solche Chips in jedem im Inland verkauften Smartphone vor, was Marken im mittleren Preissegment zu anwendungsspezifischen integrierten Schaltkreisen von regionalen Lieferanten treibt. Indiens Jio Brain versorgt 450 Millionen Abonnenten mit Latenzen unter 200 Millisekunden in Hindi, Tamil, Telugu und Bengali und beweist, dass lokalisierte Edge-Modelle Cloud-Systeme in Regionen mit schlechter Konnektivität übertreffen. Südkorea verzeichnete zwischen 2023 und 2025 einen Anstieg der Einführung sprachgesteuerter Geräte um 34 Prozentpunkte, da Samsungs Exynos-Prozessoren dedizierte Sprachbeschleuniger erhielten. Japans NTT Docomo reduzierte die Transkriptionsverzögerung auf 80 Millisekunden, indem Modelle auf 5G-Basisstationen verlagert wurden. Unternehmen, die Cloud-Übertragungsgebühren um 60 % senken, erreichen die Amortisation in 18 Monaten, der Hälfte der historischen Norm.
Regulatorischer Druck für sprachgestützte Notrufe und Upgrades der Notfallleitstellen
Die Vereinigten Staaten investierten 15 Milliarden USD in die Modernisierung von Notrufzentralen und verlangen Echtzeit-Transkription und Multimedia-Verarbeitung.[1]Federal Communications Commission, "Next Generation 911," fcc.gov Kanada erließ 2024 parallele Richtlinien und beschleunigte die Einführung von Deepgram- und AssemblyAI-Engines in Zentren in Ontario und British Columbia. Der aktualisierte NENA-i3-Standard erfordert eine Adressextraktionsgenauigkeit von 98 % in lauten Umgebungen und zwingt Anbieter, ihre akustischen Modelle neu zu trainieren. Mexiko stellte 2,8 Milliarden MXN (165 Millionen USD) bereit, um Sprachbiometrie in Leitstellen zu integrieren und die Reaktionszeiten Anfang 2026 um 22 % zu verkürzen. Fahrzeugtelematik wird nun in 78 % der nordamerikanischen Fahrzeuge mit sprachaktiviertem Notruf ausgeliefert, gefördert durch Versicherungsrabatte.
Umstellung der Automobilhersteller auf eingebettete Sprach-Betriebssysteme zur Cockpit-Personalisierung
BMW integrierte einen Großsprachmodell-Assistenten von Cerence, der Kabineneinstellungen ausschließlich auf Basis von Gesprächshinweisen anpasst. Mercedes-Benz verarbeitet Befehle lokal auf NVIDIA-Drive-Orin-Chips, um den Dialogschwellenwert von 100 Millisekunden zu erfüllen. Die chinesischen Marken NIO und XPeng liefern 68 % ihrer Cockpits mit Sprach-Betriebssystemen aus, die Navigation, Zahlungen und Fahrzeug-zu-Infrastruktur-Kommunikation verwalten. SoundHounds Übernahme von Amelia kombiniert konversationelle KI mit Biometrie und ermöglicht die Fahrerauthentifizierung ohne Telefon. Teslas hauseigener Sprach-Stack entfernte separate digitale Signalprozessoren, senkte die Stücklistenkosten um 35 USD und erhöhte die Aktivierungswort-Genauigkeit auf 97 %.
Einführung von Sprachbiometrie im Banken-, Finanzdienstleistungs- und Versicherungsbereich zur Ablösung wissensbasierter Authentifizierung in Europa
Britische Ethikleitlinien empfahlen die Einführung multimodaler Biometrie, nachdem Betrug mit synthetischen Identitäten im Jahr 2024 1,3 Milliarden GBP überstieg. Europäische Banken, die Miteks Plattform nutzen, reduzierten die Verifizierung im Callcenter von 78 Sekunden auf 12 Sekunden und sparten 4,2 Millionen EUR (4,5 Millionen USD) pro Million Kunden. Bis 2024 hatte ein Drittel der Kreditgeber Sprachbiometrie eingesetzt, doppelt so viel wie 2022.[2]Europäische Bankenaufsichtsbehörde, "KI-Einführung im Bankwesen," eba.europa.eu Deutsche Standards verlangen nun Falschakzeptanzraten unter 0,1 %, was die Überführung von Pilotprojekten in die Vollproduktion in weniger als einem Jahr beschleunigt. Anbieter bemühen sich, Deepfake-Audio zu blockieren, und fügen Lebenderkennung und kanalübergreifende Prüfungen hinzu.
Analyse der Hemmnisse*
| Hemmnis | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Lücken bei der Erkennung von Akzenten und Dialekten in Afrika | -2.1% | Afrika, mit Sekundäreffekten in Asien-Pazifik und Südamerika | Langfristig (≥ 4 Jahre) |
| Datenschutzvorschriften zur Einschränkung der Cloud-Datenspeicherung | -1.8% | Europa und Nordamerika, Ausweitung auf Asien-Pazifik | Mittelfristig (2–4 Jahre) |
| Hohe Kosten für annotierte domänenspezifische Sprachkorpora | -1.5% | Global, besonders ausgeprägt in den Bereichen Gesundheitswesen und Rechtswesen | Mittelfristig (2–4 Jahre) |
| Rechnerische Latenz in ultraenergiearmen Wearables | -1.3% | Global, konzentriert in Unterhaltungselektronik und Gesundheits-Wearables | Kurzfristig (≤ 2 Jahre) |
| Quelle: Mordor Intelligence | |||
Lücken bei der Erkennung von Akzenten und Dialekten begrenzen die Einführung in Afrika
Mozillas Common Voice deckt nur 14 afrikanische Sprachen ab, weniger als 1 % der sprachlichen Vielfalt des Kontinents, was dazu führt, dass Modelle unzureichend trainiert sind. Das in Ghana ansässige Unternehmen Intron Health berichtet von 78 % Genauigkeit in Twi, aber 95 % in Englisch in Kliniken, was Sicherheitsbedenken aufwirft. Südafrikanische Systeme müssen zwischen 11 Amtssprachen wechseln, was zu Latenzspitzen von über 500 Millisekunden führt. Die Annotation von 1.000 Stunden Sprache kann bis zu 500.000 USD kosten und übersteigt damit das Umsatzpotenzial vieler lokaler Märkte.[3]Scale AI, "Preise und Dienstleistungen," scale.com Ägyptens Fünfjahres-Korpusinitiative finanziert nur 5.000 Stunden, sodass kommerzielle Produkte bis 2028 zurückbleiben werden.
Datenschutzvorschriften zur Einschränkung der Cloud-Speicherung von Sprachdaten
Artikel 9 der Datenschutz-Grundverordnung (DSGVO) behandelt Sprachdaten als sensible Daten und erfordert ausdrückliche Einwilligung und strenge Verarbeitungsbedingungen. Kaliforniens Delete Act zwingt Datenmakler, Aufzeichnungen innerhalb von 45 Tagen nach Anfrage zu löschen, was das longitudinale Modelltraining erschwert. Das Gesetz über künstliche Intelligenz der Europäischen Union schreibt Audits und Marktüberwachung nach der Markteinführung vor, die bis zu 2 Millionen EUR pro Einsatz kosten. Kanadas ausstehende Gesetzgebung begrenzt die Aufbewahrung auf 12 Monate ohne erneute Einwilligung, was bedeutet, dass Banken Kunden jährlich neu registrieren müssen. Unternehmen reagieren mit dem Wechsel zu föderiertem Lernen, aber das Training auf dem Gerät erhöht die Rechenlast um das Drei- bis Fünffache.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Bereitstellung: Cloud-Dominanz steht vor einem Comeback der On-Premise-Lösungen
Die Cloud-Bereitstellung hielt 67,91 % des Umsatzes im Jahr 2025 und hatte damit den größten Marktanteil für Spracherkennung unter den Bereitstellungsmodellen. On-Premise-Lösungen werden voraussichtlich bis 2031 jährlich um 22,71 % wachsen, da Banken und Krankenhäuser Authentifizierungszeiten unter 50 Millisekunden und eine strengere Kontrolle über sensible Daten anstreben. Hybride Setups leiten die Aktivierungswort-Erkennung nun lokal weiter, während komplexe Fragen an Cloud-Großsprachmodelle weitergeleitet werden, um Reaktionsfähigkeit und Kosten in Einklang zu bringen.
Die wirtschaftlichen Faktoren untermauern den Wandel. Unternehmen berichten von 40 % niedrigeren Übertragungsgebühren, nachdem sie die Inferenz auf Edge-Server verlagert haben, während sie die Cloud weiterhin für das Modell-Retraining nutzen. Regulatorische Auslöser verstärken den Trend, wobei 42 % der europäischen Unternehmen die biometrische Compliance als Haupttreiber für das lokale Hosting nennen. Infrastrukturanbieter erschließen daher neue Nachfrage nach Beschleunigern, die die Latenz komprimieren, ohne den Energiebedarf zu erhöhen, und drücken damit die Margen reiner Cloud-Anbieter.


Nach Komponente: Software wächst stark, während Hardware zur Massenware wird
Software und Software-Entwicklungskits erfassten 42,33 % des Umsatzes im Jahr 2025 und wachsen mit einer CAGR von 22,92 %, was die schnelle Skalierung von Programmierschnittstellen über Geräte hinweg widerspiegelt. Hardware machte 35,34 % aus, aber das Wachstum verlangsamt sich, da neuronale Smartphone-Engines diskrete Signalprozessorfunktionen übernehmen und 8–12 USD von der Stückliste jedes Geräts einsparen. Dienste rundeten den Mix mit 22,33 % ab, gestützt durch Integrations- und Domänenanpassungsarbeiten, die Unternehmen nicht standardisieren können.
Grundlagenmodelle beschleunigen den Vorsprung der Software. Das Feinabstimmen vortrainierter Netzwerke dauert jetzt Monate statt Jahre, und einmal lizenziert, sinken die inkrementellen Vertriebskosten gegen null. Hardware-Anbieter schwenken auf ultraenergiearme Sprachbeschleuniger um, die dauerhaft aktive Zuhörmodi auf Wearables ermöglichen, und positionieren sich als Wegbereiter der Software-Welle. Systemintegratoren bündeln unterdessen Datenverwaltung, Training und Compliance und strecken den Kundenumsatz weit über den ursprünglichen Vertrag hinaus.
Nach Technologie: Edge-KI gestaltet den Stack neu
Spracherkennung führte mit 47,84 % des Umsatzes im Jahr 2025, doch eingebettete Edge-KI hält mit dem Gesamtwachstum von 22,96 % Schritt, da Anbieter darum wetteifern, Cloud-Latenz zu eliminieren. Sprachbiometrie machte 29,20 % des Umsatzes aus, angetrieben durch Bankeneinführungen, die Betrug um 60 % reduzierten und die Callcenter-Verifizierung auf Sekunden verkürzten. Der Markt für Spracherkennung im Bereich Edge-KI wächst, da Smartphones, Autos und Ohrhörer Chips integrieren, die Modelle mit einer Billion Operationen auf dem Gerät ausführen.
Der Wettbewerb dreht sich nun um Energieeffizienz und Anti-Spoofing-Schutzmaßnahmen. RISC-V-Beschleuniger reduzieren die Inferenzlatenz um 35 % im Vergleich zu ARM und ermöglichen Echtzeit-Coaching in Ohrhörern ohne Überhitzung. Deepfake-Audio, das einen Sprecher aus 10-Sekunden-Proben imitiert, zwingt Anbieter, Lebenderkennung und Multi-Faktor-Fusion zu integrieren. Anbieter, die komprimierte akustische Modelle, föderiertes Lernen und robuste Spoofing-Abwehr kombinieren, sind am besten positioniert, um Marktanteile zu halten, wenn Genauigkeit zur Grundvoraussetzung wird.

Nach Gerätetyp: Wearables geben das Tempo vor
Smartphones und Tablets generierten 39,17 % des Umsatzes im Jahr 2025 und unterstreichen ihre fest verankerte Rolle als primäre Schnittstelle für Sprachdienste. Intelligente Lautsprecher und Displays folgten mit 24,58 %, da Sprachhandel im Wohnzimmer weiterhin beliebt blieb. Wearables, obwohl nur 14,92 % des Umsatzes im Jahr 2025, werden voraussichtlich mit einer CAGR von 23,33 % wachsen und alle anderen Geräte übertreffen, da Fitness-Tracker und Hörhilfen freihändige Interaktion und Gesundheitscoaching hinzufügen.
Energiebudgets bestimmen die Designentscheidungen. Dauerhaft aktive Zuhörmodelle, die auf Telefonen 500–800 mW verbrauchen, müssen für Armbänder mit 300-mAh-Akkus unter 200 mW fallen. Anbieter verwenden Kaskadendetektor-Systeme, die das vollständige Netzwerk nur bei hochzuverlässigen Auslösern aktivieren. Fahrzeuginfotainment, das 12,75 % des Umsatzes im Jahr 2025 ausmacht, profitiert von Unfallmeldepflichten, während Kioske und Kassensysteme (8,58 %) auf Sprache setzen, um Kassenvorgänge bei Arbeitskräftemangel zu vereinfachen.
Nach Anwendung: Medizinische Dokumentation macht einen Sprung nach vorne
Authentifizierung und Sicherheit blieben dominant und machten 36,93 % des Umsatzes im Jahr 2025 aus, da Banken Passwörter durch Stimmabdrücke ersetzten. Sprachsuche und -befehle, ein reifes Segment mit 28,45 %, wachsen stetig weiter, da konversationelle Agenten Smartphones im unteren Preissegment erreichen. Medizinische Dokumentation, nur 11,27 % im Jahr 2025, wird voraussichtlich mit einer CAGR von 23,39 % wachsen, der schnellsten unter den Anwendungen, da Umgebungsschreiber den Papierkram von Ärzten um 45 % reduzieren und neue Abrechnungscodes erschließen.
Transkription und Untertitelung machten 13,62 % aus und bedienen Medien-, Rechts- und Bildungskunden, die domänenspezifische Vokabulare benötigen. Virtuelle Assistenten und Chatbots machten 9,73 % aus, gestärkt durch Integrationen mit Echtzeit-Websuche, die veraltete Wissensprobleme lösen. Da sich Umgebungsintelligenz ausbreitet, müssen Anbieter das Vertrauen von Krankenhäusern gewinnen, indem sie bevorstehende Überprüfungen der Lebensmittel- und Arzneimittelbehörde bestehen, die bestimmte Dokumentationswerkzeuge als Medizinprodukte einstufen.
Nach Endnutzerbranche: Gesundheitsdienstleister beschleunigen die Einführung
Unterhaltungselektronik führte mit 29,48 % des Umsatzes im Jahr 2025, was die Smartphone-Sättigung und die Verbreitung intelligenter Lautsprecher widerspiegelt. Die Automobilindustrie folgte mit 18,72 %, wo softwaredefinierte Cockpits Sprache in den Vordergrund rücken. Gesundheitsdienstleister, nur 12,84 % im Jahr 2025, werden bis 2031 voraussichtlich mit 23,94 % wachsen, die schnellste Branchenexpansion, angetrieben durch Burnout-Entlastung, Genauigkeitsgewinne und Akkreditierungsanreize im Zusammenhang mit sprachbasierter Medikamentenabstimmung.
Banken und Finanzdienstleistungen trugen 14,36 % bei, da Regulierungsbehörden Biometrie zur Betrugskontrolle befürworten, während Telekommunikation (9,58 %) den Kundendienst mit Sprachanalyse automatisiert. Regierung und Verteidigung (7,21 %) integrieren Sprache in Notfallleitstellen und Grenzkontrollen. Einzel- und E-Commerce (4,93 %) setzt Bestellkioske ein, die Personalengpässe reduzieren, und Industrienutzer (2,88 %) verlassen sich auf Sprache für freihändige Inspektion und Bestandsaktualisierungen. Anbieter, die branchenspezifische Compliance- und Integrationshürden meistern, werden einen überproportionalen Anteil gewinnen.
Geografische Analyse
Asien-Pazifik hatte den größten Marktanteil für Spracherkennung im Jahr 2025 mit 37,64 % des globalen Umsatzes, da die Smartphone-Durchdringung in städtischen Gebieten Chinas und Indiens 80 % überstieg. Staatliche Vorschriften, dass jedes neue Mobiltelefon mit neuronalen On-Device-Engines ausgeliefert werden muss, beschleunigten die lokale Verarbeitung, während Jio Brain regionale Sprachunterstützung für 450 Millionen indische Abonnenten mit einer Latenz unter 200 Millisekunden integrierte. Südkorea verzeichnete den stärksten Einführungsanstieg unter den Mitgliedern der Organisation für wirtschaftliche Zusammenarbeit und Entwicklung und stieg zwischen 2023 und 2025 um 34 Punkte, nachdem Samsung dedizierte Sprachbeschleuniger in seine Exynos-Chips eingebettet hatte. Japanische Betreiber migrierten Modelle auf 5G-Basisstationen, reduzierten Transkriptionsverzögerungen auf 80 Millisekunden und ermöglichten Echtzeit-Übersetzung für den Kundendienst. Diese Fortschritte halten die Region auf Kurs, bis 2031 den größten absoluten Dollarbetrag hinzuzufügen.
Nordamerika belegte den zweiten Platz mit 28,53 % des Umsatzes im Jahr 2025, gestützt durch das 15-Milliarden-USD-Programm Next Generation 911 der Federal Communications Commission der Vereinigten Staaten, das bis Dezember 2025 78 % der Notrufzentralen mit Multimedia-Sprachverarbeitung ausrüstete. Kanada schrieb Sprache-zu-Text-Funktionen in Notfallzentren vor und reduzierte die durchschnittliche Anrufbearbeitungszeit in Ontario und British Columbia um 18 %. Der Bankensektor der Region registrierte 120 Millionen Kunden für Sprachbiometrie und senkte die jährlichen Authentifizierungskosten um 1,8 Milliarden USD. Europa folgte mit 19,27 %, verankert in der Banken-Compliance, die eine starke Kundenauthentifizierung erfordert, und in der Cockpit-Personalisierung in der Automobilindustrie unter Datenschutzvorschriften. On-Premise-Bereitstellungen wachsen am schnellsten in Deutschland und Frankreich, da Unternehmen biometrische Daten im Einklang mit der Datenschutz-Grundverordnung innerhalb nationaler Grenzen halten.
Afrika trug 7,18 % des Umsatzes im Jahr 2025 bei, wird aber voraussichtlich bis 2031 mit der höchsten CAGR von 23,46 % wachsen. Kenias M-Pesa fügte Swahili-Sprachbefehle hinzu und reduzierte die Transaktionszeit für ländliche Nutzer mit eingeschränkter Lesefähigkeit um 35 %. Nigeria schreibt nun vor, dass Mobilfunkbetreiber Kundendienst auf Hausa, Yoruba und Igbo anbieten müssen, um die 40 % der Abonnenten mit eingeschränkten Englischkenntnissen zu erreichen. Südafrikanische Banken reduzierten Kontomissbrauchsbetrug im ersten Halbjahr 2025 um 28 %, nachdem sie Stimmabdrücke zur Authentifizierung eingesetzt hatten. Begrenzte Netzwerkgeschwindigkeiten von 15–25 Mbps zwingen Anbieter, Modelle für eine Hin- und Rücklatenz von 300 Millisekunden zu optimieren, was leichtgewichtige Edge-Designs fördert, die zukünftige Gewinne im Marktanteil für Spracherkennung prägen werden.

Wettbewerbslandschaft
Der Markt für Spracherkennung ist mäßig konzentriert, wobei die fünf größten Anbieter etwa 45 % des Umsatzes im Jahr 2025 auf sich vereinen. Hyperscaler wie Apple, Google, Amazon, Microsoft und Baidu finanzieren Forschung aus Geräte- und Cloud-Gewinnpools und subventionieren die Sprachentwicklung, mit der kleinere Wettbewerber nicht leicht mithalten können. Apples vollständige On-Device-Verarbeitung von Siri stärkt seinen Ökosystem-Burggraben, während Googles Gemini-Integration Sprache in eine multimodale Schnittstelle verwandelt, die Text, Bilder und Video umfasst.
Spezialisten kontern mit Domänenmodellen und Geschwindigkeit. ElevenLabs erreichte nur 18 Monate nach der Gründung eine Bewertung von 1,1 Milliarden USD, indem es Sprachklonen anbot, das Medieninhalte mit nahezu menschlicher Wiedergabetreue lokalisiert. AssemblyAI und Deepgram sammelten 450 Millionen USD bzw. 155 Millionen USD ein, um mehrsprachige Engines zu trainieren, die bei verrauschtem Audio eine Genauigkeit von 95 % bei 40 % niedrigeren Inferenzkosten aufrechterhalten. SoundHounds Kauf von Amelia für 80 Millionen USD verband konversationelle KI mit Biometrie und ermöglicht es Automobilkunden, Fahrer zu authentifizieren und Infotainment ohne Telefonkopplung zu personalisieren. Scale AIs Finanzierungsrunde über 1 Milliarde USD finanziert die Generierung synthetischer Sprache, die Korpuskosten um 90 % senkt – ein Durchbruch für unterversorgte Sprachen.
Wettbewerbsstrategien divergieren nun entlang drei Achsen. Plattformanbieter bündeln Sprache in umfassendere KI-Suiten und verteidigen Marktanteile durch Integrationstiefe und regulatorische Compliance-Zertifizierungen. Edge-Spezialisten konzentrieren sich auf ultraenergiearme Chips und föderiertes Lernen, um Datenschutzvorschriften zu erfüllen, die die Cloud-Speicherung einschränken. Startups zielen auf Lücken in der Akzentabdeckung, insbesondere in Afrika und Südasien, wo der Markt für Spracherkennung wachsen kann, wenn ressourcenarme Sprachen erschwinglicher zu annotieren werden. Da die Basisgenauigkeit zur Massenware wird, verlagert sich der nachhaltige Wettbewerbsvorteil hin zu Energieeffizienz, Datenschutzgarantien und spezialisierten Vokabularen, die Premium-Branchen wie Gesundheitswesen und Finanzen erschließen.
Marktführer im Bereich Spracherkennung
Apple Inc.
Alphabet Inc.
Amazon.com Inc.
IBM Corporation
Samsung Electronics Co. Ltd.
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Aktuelle Branchenentwicklungen
- Februar 2026: Amazon startete Alexa+ für 9,99 USD pro Monat und fügte Großsprachmodell-Gespräche, biometrischen Checkout und personalisierte Medienempfehlungen hinzu.
- Januar 2026: Apple und Google einigten sich darauf, Gemini in Siri zu integrieren und Googles multimodale Engine mit On-Device-Datenschutzmaßnahmen zu kombinieren.
- Januar 2025: ElevenLabs erreichte eine Bewertung von 1,1 Milliarden USD nach einer Finanzierungsrunde, die seine Sprachklon-Plattform in den Bereichen Medien und Bildung erweiterte.
- Januar 2025: Baidu veröffentlichte Ernie Bot 4.5 Turbo, steigerte die Mandarin-Genauigkeit auf 98,2 % bei Expertenvokabularen und halbierte gleichzeitig die Latenz.


Berichtsumfang des globalen Marktes für Spracherkennung
Der Bericht über den Markt für Spracherkennung ist segmentiert nach Bereitstellung (Cloud und On-Premise), Komponente (Software/SDK, Hardware, Dienste), Technologie (Spracherkennung, Sprecher-/Sprachbiometrie, eingebettete / Edge-Sprach-KI), Gerätetyp (Smartphones und Tablets, intelligente Lautsprecher und Displays, Fahrzeuginfotainment und Telematik, Wearables, kommerzielle Kioske und Kassensysteme), Anwendung (Authentifizierung und Sicherheit, Sprachsuche und -befehle, Transkription und Untertitelung, virtuelle Assistenten und Chatbots, medizinische Dokumentation), Endnutzerbranche (Automobilindustrie, Banken und Finanzdienstleistungen, Telekommunikation, Gesundheitsdienstleister, Regierung und Verteidigung, Unterhaltungselektronik, Einzel- und E-Commerce, Industrie und Fertigung) und Geografie (Nordamerika, Südamerika, Europa, Asien-Pazifik, Naher Osten und Afrika). Die Marktprognosen werden in Werten (USD) angegeben.
| Cloud |
| On-Premise |
| Software / SDK |
| Hardware |
| Dienste |
| Spracherkennung |
| Sprecher- / Sprachbiometrie |
| Eingebettete / Edge-Sprach-KI |
| Smartphones und Tablets |
| Intelligente Lautsprecher und Displays |
| Fahrzeuginfotainment und Telematik |
| Wearables |
| Kommerzielle Kioske und Kassensysteme |
| Authentifizierung und Sicherheit |
| Sprachsuche und -befehle |
| Transkription und Untertitelung |
| Virtuelle Assistenten und Chatbots |
| Medizinische Dokumentation |
| Automobilindustrie |
| Banken und Finanzdienstleistungen |
| Telekommunikation |
| Gesundheitsdienstleister |
| Regierung und Verteidigung |
| Unterhaltungselektronik |
| Einzel- und E-Commerce |
| Industrie und Fertigung |
| Nordamerika | Vereinigte Staaten | |
| Kanada | ||
| Mexiko | ||
| Südamerika | Brasilien | |
| Argentinien | ||
| Übriges Südamerika | ||
| Europa | Vereinigtes Königreich | |
| Deutschland | ||
| Frankreich | ||
| Italien | ||
| Übriges Europa | ||
| Asien-Pazifik | China | |
| Japan | ||
| Indien | ||
| Südkorea | ||
| Übriges Asien-Pazifik | ||
| Naher Osten und Afrika | Naher Osten | Vereinigte Arabische Emirate |
| Saudi-Arabien | ||
| Übriger Naher Osten | ||
| Afrika | Südafrika | |
| Ägypten | ||
| Übriges Afrika | ||
| Nach Bereitstellung | Cloud | ||
| On-Premise | |||
| Nach Komponente | Software / SDK | ||
| Hardware | |||
| Dienste | |||
| Nach Technologie | Spracherkennung | ||
| Sprecher- / Sprachbiometrie | |||
| Eingebettete / Edge-Sprach-KI | |||
| Nach Gerätetyp | Smartphones und Tablets | ||
| Intelligente Lautsprecher und Displays | |||
| Fahrzeuginfotainment und Telematik | |||
| Wearables | |||
| Kommerzielle Kioske und Kassensysteme | |||
| Nach Anwendung | Authentifizierung und Sicherheit | ||
| Sprachsuche und -befehle | |||
| Transkription und Untertitelung | |||
| Virtuelle Assistenten und Chatbots | |||
| Medizinische Dokumentation | |||
| Nach Endnutzerbranche | Automobilindustrie | ||
| Banken und Finanzdienstleistungen | |||
| Telekommunikation | |||
| Gesundheitsdienstleister | |||
| Regierung und Verteidigung | |||
| Unterhaltungselektronik | |||
| Einzel- und E-Commerce | |||
| Industrie und Fertigung | |||
| Nach Geografie | Nordamerika | Vereinigte Staaten | |
| Kanada | |||
| Mexiko | |||
| Südamerika | Brasilien | ||
| Argentinien | |||
| Übriges Südamerika | |||
| Europa | Vereinigtes Königreich | ||
| Deutschland | |||
| Frankreich | |||
| Italien | |||
| Übriges Europa | |||
| Asien-Pazifik | China | ||
| Japan | |||
| Indien | |||
| Südkorea | |||
| Übriges Asien-Pazifik | |||
| Naher Osten und Afrika | Naher Osten | Vereinigte Arabische Emirate | |
| Saudi-Arabien | |||
| Übriger Naher Osten | |||
| Afrika | Südafrika | ||
| Ägypten | |||
| Übriges Afrika | |||


Im Bericht beantwortete Schlüsselfragen
Wie schnell werden die globalen Ausgaben für Spracherkennung zwischen 2026 und 2031 wachsen?
Der Markt für Spracherkennung wird voraussichtlich von 22,51 Milliarden USD im Jahr 2026 auf 61,78 Milliarden USD bis 2031 wachsen, was einer CAGR von 22,38 % entspricht.
Welche Region wird bis 2031 den größten neuen Umsatz hinzufügen?
Asien-Pazifik führt bereits mit 37,64 % des Umsatzes im Jahr 2025 und verzeichnet weiterhin die größten absoluten Zuwächse dank Smartphone-Sättigung und Edge-KI-Vorschriften.
Warum führen Krankenhäuser Sprachwerkzeuge so schnell ein?
Klinische Umgebungsintelligenz reduziert die Dokumentationszeit von Ärzten um 45 %, verbessert die Abrechnungsgenauigkeit und profitiert nun von dedizierten Abrechnungscodes, was eine CAGR von 23,94 % für Gesundheitsdienstleister antreibt.
Was treibt On-Premise-Bereitstellungen nach Jahren der Cloud-Dominanz an?
Datensouveränitätsgesetze und die Notwendigkeit einer Latenz unter 50 Millisekunden veranlassen Banken und Krankenhäuser, die Inferenz lokal zu halten, auch wenn das Modelltraining teilweise in der Cloud verbleibt.
Wie gehen Anbieter mit Datenschutzbedenken bezüglich gespeicherter Sprachdaten um?
Sie setzen föderiertes Lernen ein, sodass Modelle auf dem Gerät trainieren, nur Gradienten übertragen und Vorschriften einhalten, die die Aufbewahrung von Rohsprachdaten über definierte Zeiträume hinaus einschränken.
Welche Anwendung wird bis 2031 das schnellste Wachstum verzeichnen?
Medizinische Dokumentation wird voraussichtlich mit einer CAGR von 23,39 % wachsen, da Umgebungsschreiber die Erschöpfung von Klinikern lindern und neue Abrechnungsströme erschließen.
Seite zuletzt aktualisiert am:




