Voice Recognition Market Size and Share
Market Overview
| Study Period | 2020 - 2031 |
|---|---|
| Market Size (2026) | USD 22.51 Billion |
| Market Size (2031) | USD 61.78 Billion |
| Growth Rate (2026 - 2031) | 22.38% CAGR |
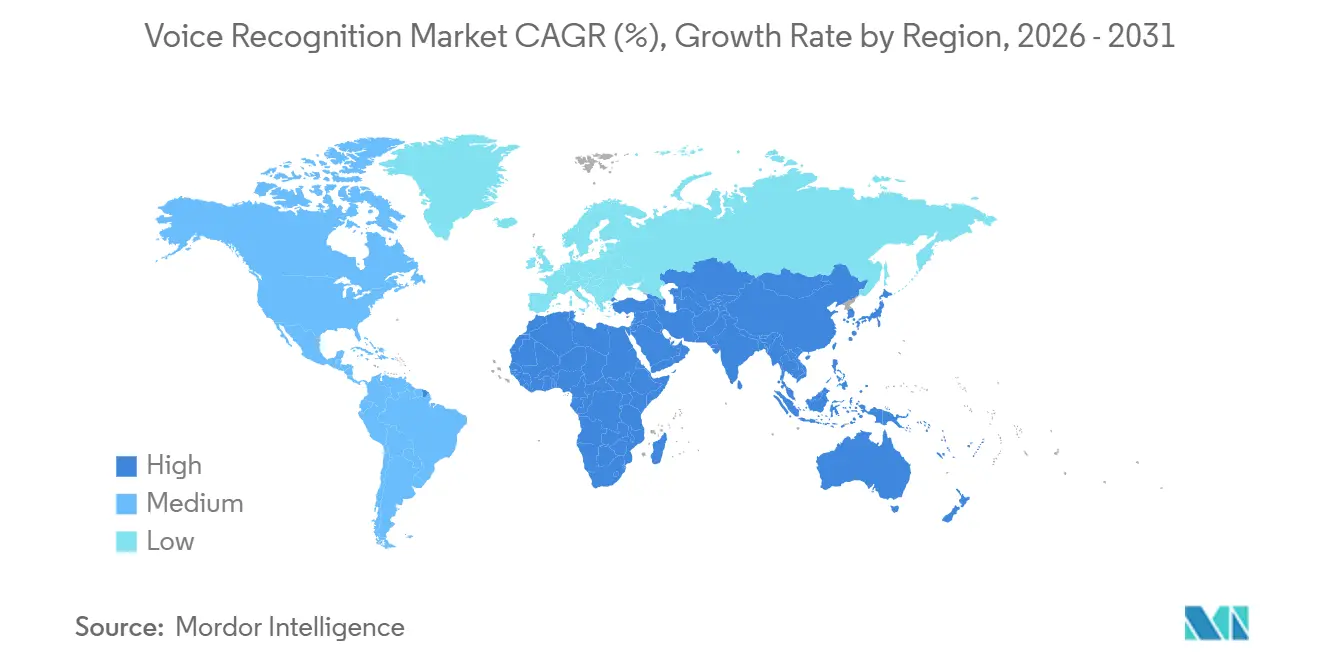
| Fastest Growing Market | Africa |
| Largest Market | Asia Pacific |
| Market Concentration | Medium |
Major Players *Disclaimer: Major Players sorted in no particular order Image © Mordor Intelligence. Reuse requires attribution under CC BY 4.0. | |
Voice Recognition Market Analysis by Mordor Intelligence
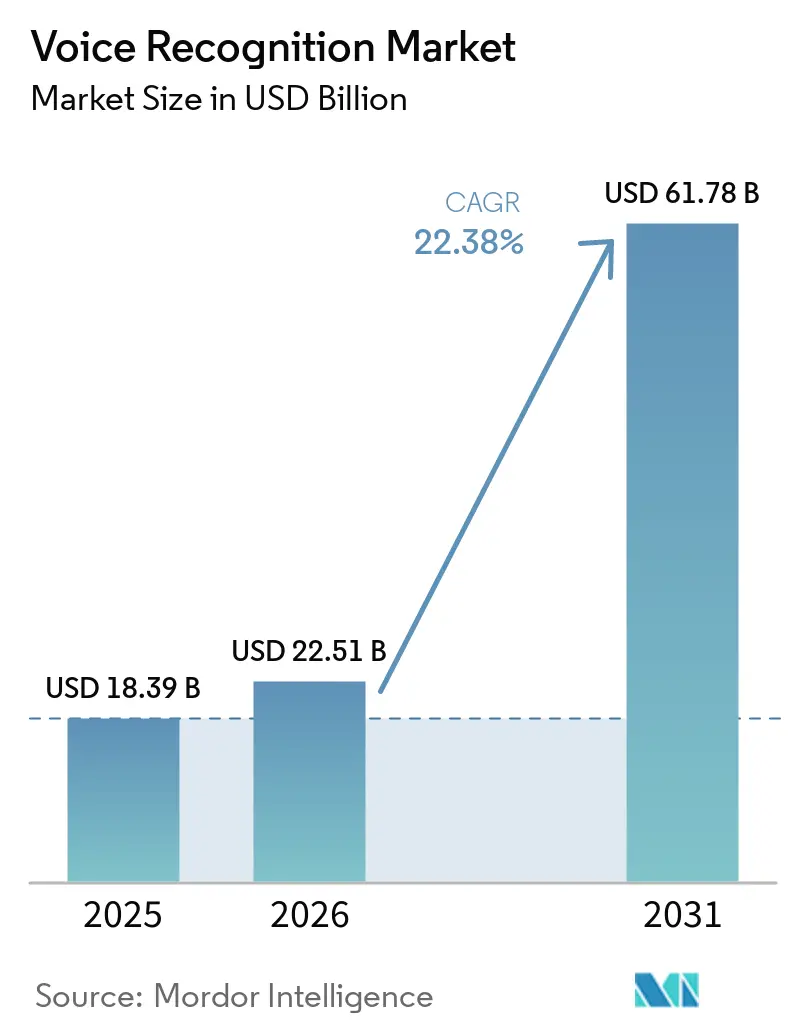
The Voice Recognition Market size is projected to be USD 18.39 billion in 2025, USD 22.51 billion in 2026, and reach USD 61.78 billion by 2031, growing at a CAGR of 22.38% from 2026 to 2031. Demand is accelerating as public-safety mandates for multimedia 911 services in North America, edge-native voice artificial intelligence chips in Asian consumer electronics, and European banks’ shift from knowledge-based authentication to voice biometrics converge. Vendors are moving models from the cloud to devices to meet privacy rules, reduce latency, and trim egress fees. Financial institutions and hospitals that run models locally now report authentication and documentation cycles under 50 milliseconds, while automotive original equipment manufacturers are embedding voice into cockpit operating systems to personalize in-car experiences. Venture-funded specialists are eroding incumbents’ market share by releasing domain models that outperform general-purpose engines on medical, legal, and multilingual accuracy.
Key Report Takeaways
- By geography, Asia-Pacific led with 37.64% of the voice recognition market share in 2025, while Africa is projected to record the highest CAGR of 23.46% through 2031.
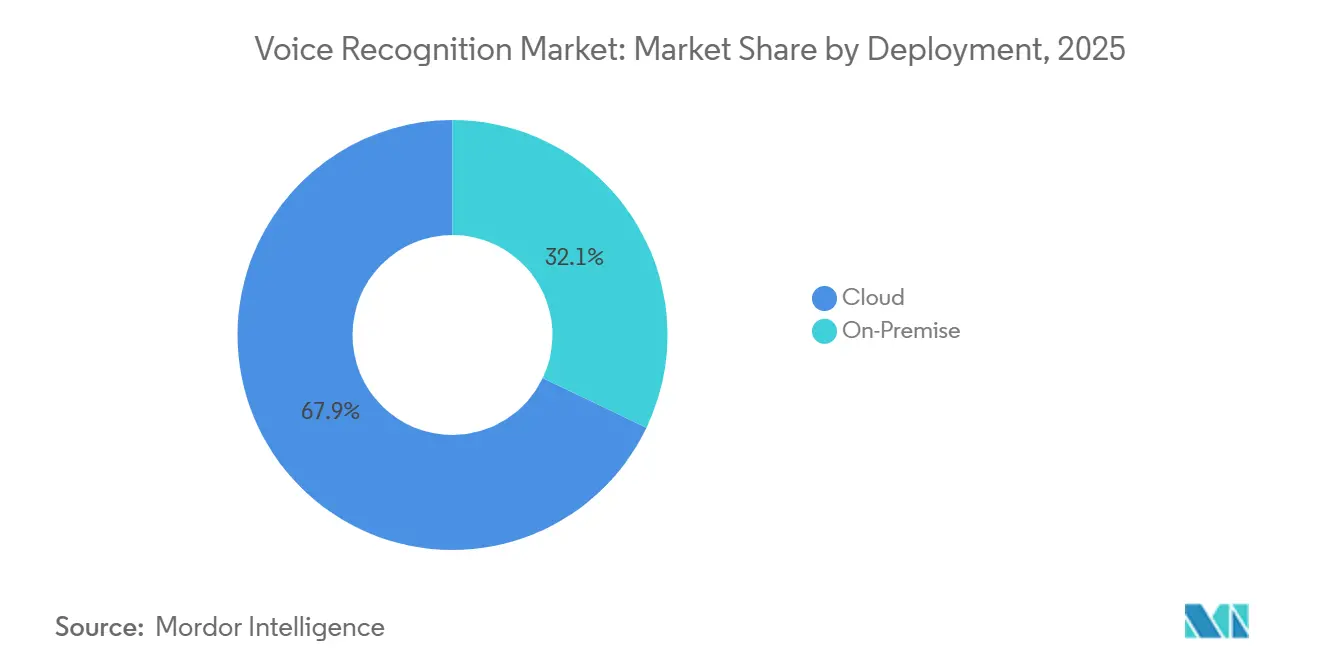
- By deployment, cloud captured 67.91% of 2025 revenue; on-premise solutions are forecast to expand at a 22.71% CAGR to 2031.
- By component, software and software development kits accounted for 42.33% of the voice recognition market share in 2025 and represented the fastest-growing component, with a 22.92% CAGR.
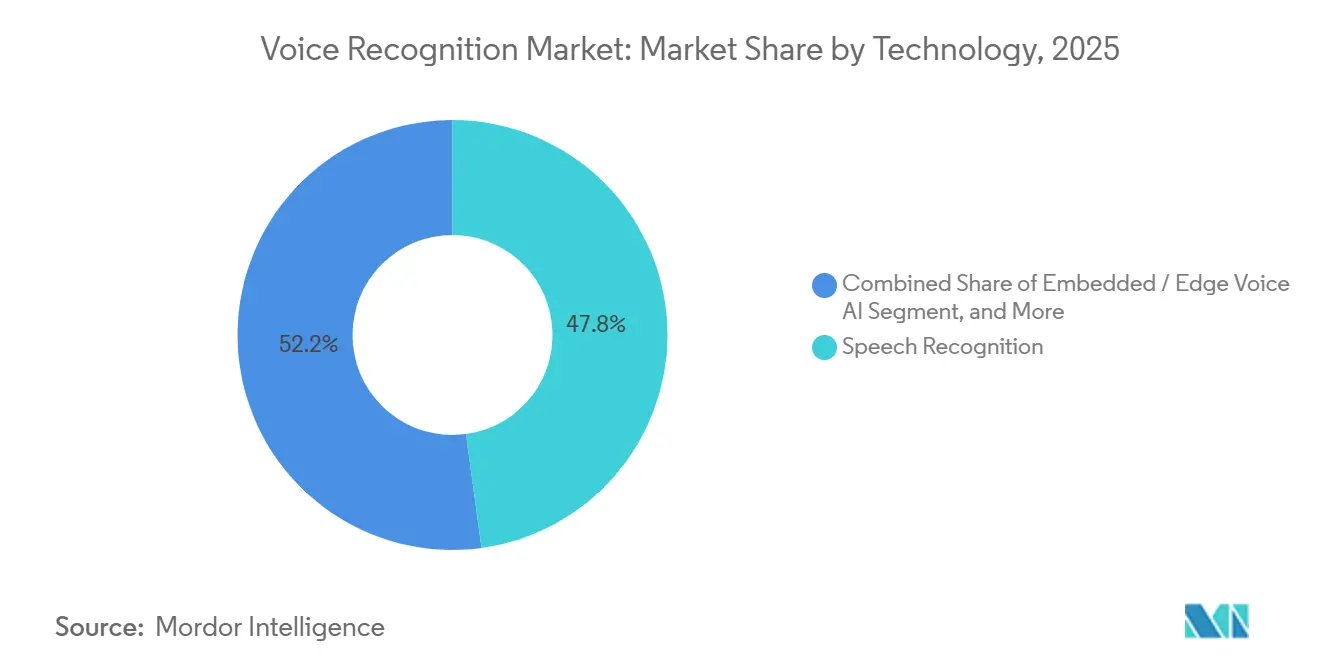
- By technology, speech recognition commanded 47.84% of 2025 revenue, whereas embedded and edge voice artificial intelligence is expected to grow at a 22.96% CAGR.
- By device type, smartphones and tablets accounted for 39.17% of the voice recognition market share in 2025, while wearables are set to increase at a 23.33% CAGR through 2031.
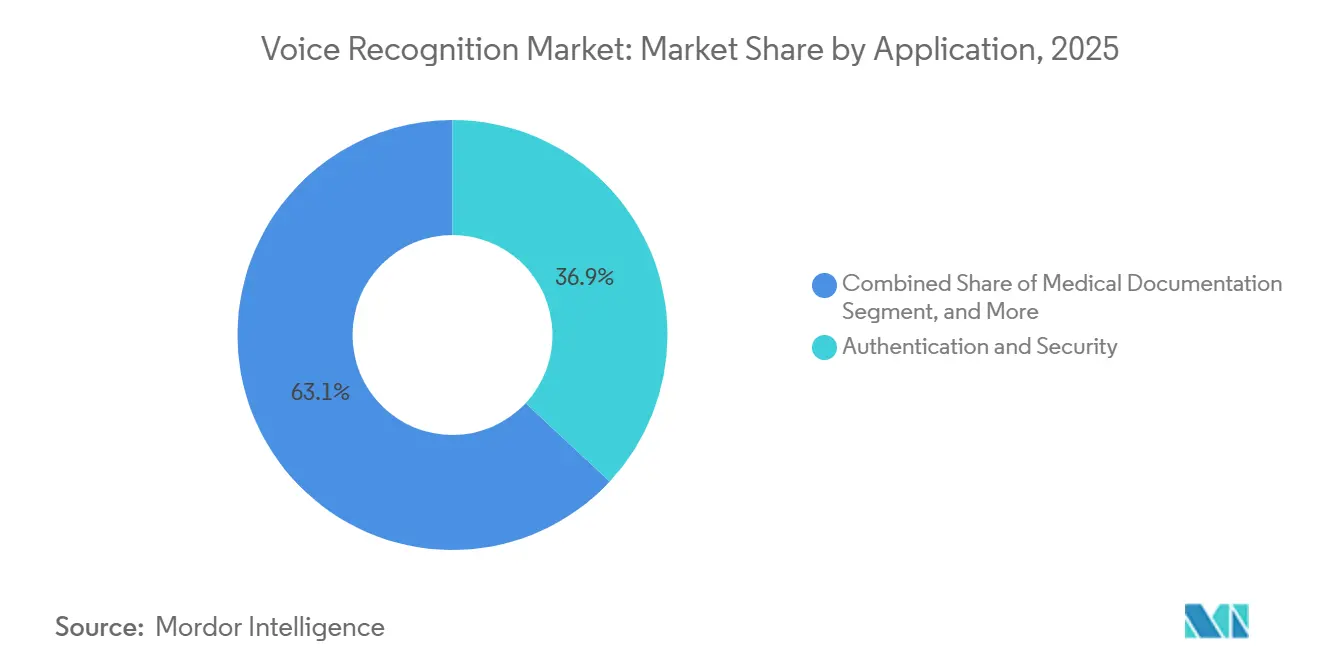
- By application, authentication and security accounted for 36.93% of 2025 revenue; medical documentation is forecast to grow at a 23.39% CAGR.
- By end-user vertical, consumer electronics accounted for 29.48% of the voice recognition market share in 2025, whereas healthcare providers are projected to grow at a 23.94% CAGR through 2031.
Note: Market size and forecast figures in this report are generated using Mordor Intelligence’s proprietary estimation framework, updated with the latest available data and insights as of 2026.
Global Voice Recognition Market Trends and Insights
Drivers Impact Analysis*
| Driver | (~) % Impact on CAGR Forecast | Geographic Relevance | Impact Timeline |
|---|---|---|---|
| Explosion of Voice-AI Chips in Edge Devices | +4.2% | Asia-Pacific core, spill-over to North America and Europe | Medium term (2-4 years) |
| Regulatory Push for Voice-Enabled 911 | +3.8% | North America, early adoption in select European Union markets | Short term (≤ 2 years) |
| Automotive OEM Shift to Embedded Voice OS | +3.5% | Global, concentrated in China, Germany, United States | Medium term (2-4 years) |
| BFSI Adoption of Voice Biometrics | +3.1% | Europe and North America, expanding to Asia-Pacific | Medium term (2-4 years) |
| Rapid Growth of Voice Commerce | +2.9% | North America and Asia-Pacific, nascent in Europe | Short term (≤ 2 years) |
| Edge-Native Federated Learning | +2.6% | Global, led by United States, China, Israel | Long term (≥ 4 years) |
| Source: Mordor Intelligence | |||
Explosion of Voice-AI Chips in Edge Devices Across Asia
Asian regulators mandate on-device processing, pushing semiconductor suppliers to embed neural units capable of executing a trillion operations per second. China now requires such chips in every smartphone sold domestically, driving mid-tier brands toward application-specific integrated circuits from regional suppliers. India’s Jio Brain serves 450 million subscribers with sub-200-millisecond latencies in Hindi, Tamil, Telugu, and Bengali, proving that localized edge models outperform cloud systems in low-connectivity regions. South Korea saw a 34-point increase in voice-enabled device adoption from 2023-2025 as Samsung’s Exynos processors added dedicated voice accelerators. Japan’s NTT Docomo reduced transcription delay to 80 milliseconds by pushing models to 5G base stations. Enterprises cutting cloud egress fees by 60% reach payback in 18 months, half the historical norm.
Regulatory Push for Voice-Enabled 911 and Emergency Dispatch Upgrades
The United States invested USD 15 billion to modernize public-safety answering points, requiring real-time transcription and multimedia handling.[1]Federal Communications Commission, “Next Generation 911,” fcc.gov Canada issued parallel directives in 2024, accelerating the adoption of Deepgram and AssemblyAI engines across Ontario and British Columbia centers. The updated NENA i3 standard requires 98% address-extraction accuracy in noisy settings, forcing vendors to retrain their acoustic models. Mexico allocated MXN 2.8 billion (USD 165 million) to embed voice biometrics in dispatch centers, trimming response times by 22% in early 2026. Automotive telematics now ships with voice-activated emergency calling in 78% of North American vehicles, encouraged by insurance discounts.
Automotive OEM Shifts to Embedded Voice OS for Cockpit Personalization
BMW integrated a large-language-model assistant from Cerence that adjusts cabin settings solely from conversational cues. Mercedes-Benz processes commands locally on NVIDIA Drive Orin chips to meet the 100-millisecond dialogue threshold. Chinese brands NIO and XPeng ship 68% of their cockpits with voice-operating systems that manage navigation, payments, and vehicle-to-infrastructure chat. SoundHound’s acquisition of Amelia combines conversational artificial intelligence with biometrics, enabling driver authentication without phones. Tesla’s in-house voice stack removed separate digital signal processors, shaving USD 35 off the bill of materials and raising wake-word accuracy to 97%.
BFSI Adoption of Voice Biometrics to Replace Knowledge-Based Authentication in Europe
United Kingdom ethics guidance urged the adoption of multimodal biometrics after synthetic-identity fraud topped GBP 1.3 billion in 2024. European banks using Mitek’s platform cut call-center verification from 78 seconds to 12 seconds, saving EUR 4.2 million (USD 4.5 million) per million customers. By 2024, one-third of lenders had deployed voice biometrics, double the 2022 level.[2]European Banking Authority, “AI Adoption in Banking,” eba.europa.eu German standards now require false-acceptance rates below 0.1%, accelerating pilots to full production in under a year. Vendors scramble to block deepfake audio, adding liveness and cross-channel checks.
Restraints Impact Analysis*
| Restraint | (~) % Impact on CAGR Forecast | Geographic Relevance | Impact Timeline |
|---|---|---|---|
| Accent and Dialect Recognition Gaps in Africa | -2.1% | Africa, with secondary effects in Asia-Pacific and South America | Long term (≥ 4 years) |
| Privacy Regulations Limiting Cloud Retention | -1.8% | Europe and North America, expanding to Asia-Pacific | Medium term (2-4 years) |
| High Cost of Annotated Domain Speech Corpora | -1.5% | Global, acute in healthcare and legal verticals | Medium term (2-4 years) |
| Computational Latency in Ultra-Low-Power Wearables | -1.3% | Global, concentrated in consumer electronics and healthcare wearables | Short term (≤ 2 years) |
| Source: Mordor Intelligence | |||
Accent and Dialect Recognition Gaps Limiting Adoption in Africa
Mozilla’s Common Voice covers only 14 African languages, less than 1% of the continent’s linguistic variety, leaving models under-trained. Ghana-based Intron Health reports 78% accuracy in Twi but 95% in English in clinics, raising safety concerns. South African systems must code-switch among 11 official languages, resulting in latency spikes exceeding 500 milliseconds. Annotating 1,000 hours of speech can cost up to USD 500,000, outstripping many local markets’ revenue potential.[3]Scale AI, “Pricing and Services,” scale.com Egypt’s five-year corpus initiative funds only 5,000 hours, so commercial products will lag until 2028.
Privacy Regulations Restricting Cloud Voice Data Retention
GDPR Article 9 treats voice data as sensitive data, requiring explicit consent and strict processing conditions. California’s Delete Act forces data brokers to erase recordings within 45 days of request, complicating longitudinal model training. The European Union Artificial Intelligence Act imposes audits and post-market surveillance that add as much as EUR 2 million per deployment. Canada’s pending law caps retention at 12 months without renewed consent, meaning banks must annually re-enroll clients. Enterprises respond by shifting to federated learning, but on-device training raises compute loads three-to-five-fold.
*Our forecasts treat driver/restraint impacts as directional, not additive. The impact forecasts reflect baseline growth, mix effects, and variable interactions.
Segment Analysis
By Deployment: Cloud Dominance Faces On-Premise Revival
Cloud deployment held 67.91% of 2025 revenue, giving it the largest voice recognition market share among deployment models. On-premise solutions are forecast to grow at 22.71% annually through 2031 as banks and hospitals chase sub-50-millisecond authentication and tighter control over sensitive data. Hybrid setups now route wake-word detection locally while forwarding complex questions to cloud large-language models, balancing responsiveness with cost.
The economics underpin the shift. Enterprises report 40% lower egress fees after moving inference to edge servers while still tapping the cloud for model retraining. Regulatory triggers amplify the trend, with 42% of European firms citing biometric compliance as the chief driver for local hosting. Infrastructure vendors, therefore, capture new demand for accelerators that compress latency without ballooning power budgets, squeezing the margins of pure-play cloud providers.


By Component: Software Surges as Hardware Commoditizes
Software and software development kits captured 42.33% of 2025 revenue and are advancing at a 22.92% CAGR, reflecting the rapid scaling of application programming interfaces across devices. Hardware accounted for 35.34%, but growth is slowing as smartphone neural engines absorb discrete digital-signal-processor functions, trimming USD 8-12 from each device’s bill of materials. Services rounded out the mix at 22.33%, buoyed by integration and domain-tuning work that enterprises cannot commoditize.
Foundation models accelerate software’s edge. Fine-tuning pretrained networks now takes months instead of years, and once licensed, incremental distribution costs fall toward zero. Hardware vendors pivot to ultra-low-power voice accelerators that enable always-listening modes on wearables, positioning themselves as enablers of the software wave. Meanwhile, system integrators bundle data governance, training, and compliance, stretching customer lifetime revenue well beyond the initial contract.
By Technology: Edge AI Recasts the Stack
Speech recognition led with 47.84% of 2025 revenue, yet embedded edge artificial intelligence is matching the overall 22.96% growth as vendors race to eliminate cloud latency. Voice biometrics accounted for 29.20% of sales, propelled by banking rollouts that cut fraud by 60% and reduced call-center verification to seconds. The voice recognition market for edge AI is growing as smartphones, cars, and earbuds integrate chips that run trillion-operation models on the device.
Competitive dynamics now hinge on power efficiency and anti-spoof safeguards. RISC-V accelerators slice inference latency by 35% compared to ARM, enabling real-time coaching in earbuds without overheating shells. Deepfake audio that mimics a speaker from 10-second samples pushes suppliers to layer liveness detection and multi-factor fusion. Vendors that combine compressed acoustic models, federated learning, and robust spoof defenses are best positioned to retain share as accuracy becomes table stakes.

By Device Type: Wearables Set the Pace
Smartphones and tablets generated 39.17% of 2025 revenue, underscoring their entrenched role as the primary interface for voice services. Smart speakers and displays followed at 24.58% as voice commerce remained sticky in the living room. Wearables, though only 14.92% of 2025 sales, are forecast to expand at a 23.33% CAGR, outpacing all other devices as fitness trackers and hearables add hands-free interaction and health coaching.
Power budgets dictate design choices. Always-listening models that consume 500-800 mW on phones must fall below 200 mW for wristbands with 300 mAh batteries. Vendors use cascade detectors that wake the full network only on high-confidence triggers. Automotive infotainment, which accounts for 12.75% of 2025 revenue, benefits from crash-notification mandates, while kiosks and point-of-sale terminals (8.58%) rely on voice to reduce checkout friction amid labor shortages.
By Application: Medical Documentation Leaps Ahead
Authentication and security remained dominant, accounting for 36.93% of 2025 revenue, as banks replaced passwords with voiceprints. Voice search and command, a mature segment at 28.45%, continues to grow steadily as conversational agents reach lower-tier smartphones. Medical documentation, just 11.27% in 2025, is projected to rise at a 23.39% CAGR, the quickest among applications, as ambient scribes cut physician paperwork 45% and unlock new reimbursement codes.
Transcription and captioning accounted for 13.62%, serving media, legal, and education clients that demand domain-specific vocabularies. Virtual assistants and chatbots accounted for 9.73%, strengthened by integrations with real-time web search that solve stale-knowledge pain points. As ambient intelligence spreads, vendors must win hospital trust by passing upcoming Food and Drug Administration reviews that classify certain documentation tools as medical devices.
By End-User Vertical: Healthcare Providers Accelerate Adoption
Consumer electronics led with 29.48% of 2025 revenue, mirroring smartphone saturation and smart-speaker proliferation. Automotive followed at 18.72%, where software-defined cockpits push voice to the fore. Healthcare providers, only 12.84% in 2025, are forecast to grow at 23.94% through 2031, the fastest vertical expansion, driven by burnout relief, accuracy gains, and accreditation incentives tied to voice-based medication reconciliation.
Banking and financial services contributed 14.36% as regulators endorse biometrics for fraud control, while telecommunications (9.58%) automates customer care with speech analytics. Government and defense (7.21%) integrate voice in emergency dispatch and border checks. Retail and e-commerce (4.93%) deploy ordering kiosks that reduce staffing gaps, and industrial users (2.88%) rely on voice for hands-free inspection and inventory updates. Vendors that navigate industry-specific compliance and integration hurdles will capture a disproportionate share.
Geography Analysis
Asia-Pacific accounted for the largest voice recognition market share in 2025, with 37.64% of global revenue, as smartphone penetration exceeded 80% in urban China and India. Government mandates that every new handset ship with on-device neural engines accelerated local processing, while Jio Brain integrated regional language support for 450 million Indian subscribers at sub-200-millisecond latency. South Korea recorded the sharpest adoption jump among Organisation for Economic Co-operation and Development members, rising 34 points between 2023 and 2025 after Samsung embedded dedicated voice accelerators in its Exynos chips. Japanese operators migrated models to 5G base stations, reducing transcription delays to 80 milliseconds and enabling real-time translation for customer service. These advances keep the region on track to add the most absolute dollars through 2031.
North America ranked second with 28.53% of 2025 revenue, buoyed by the United States Federal Communications Commission’s USD 15 billion Next Generation 911 program, which equipped 78% of public safety answering points with multimedia voice-handling by December 2025. Canada mandated voice-to-text capabilities in emergency centers, cutting average call handling times by 18% across Ontario and British Columbia. The region’s banking sector enrolled 120 million customers in voice biometrics, lowering annual authentication costs by USD 1.8 billion. Europe followed with 19.27%, anchored in banking compliance that requires strong customer authentication and in automotive cockpit personalization under privacy rules. On-premise deployments are rising fastest in Germany and France as enterprises keep biometric data within national borders for General Data Protection Regulation alignment.
Africa contributed 7.18% of 2025 revenue, yet is projected to grow at the highest CAGR of 23.46% through 2031. Kenya’s M-Pesa added Swahili voice commands, reducing transaction time by 35% for rural users with limited literacy. Nigeria now requires mobile operators to provide Hausa, Yoruba, and Igbo customer service, widening reach to the 40% of subscribers with limited English proficiency. South African banks cut account-takeover fraud by 28% in the first half of 2025 after deploying voiceprints for authentication. Limited network speeds of 15-25 Mbps force vendors to optimize models for 300-millisecond round-trip latency, spurring lightweight edge designs that will shape future gains in voice recognition market share.

Competitive Landscape
The voice recognition market remains moderately concentrated, with the top five vendors accounting for roughly 45% of 2025 revenue. Hyperscalers such as Apple, Google, Amazon, Microsoft, and Baidu fund research from device and cloud profit pools, cross-subsidizing voice development that smaller rivals cannot easily match. Apple’s full-on-device processing of Siri hardens its ecosystem moat, while Google’s Gemini integration turns voice into a multimodal interface spanning text, images, and video.
Specialists counter with domain models and speed. ElevenLabs reached a USD 1.1 billion valuation only 18 months after launch by offering voice cloning that localizes media content at near-human fidelity. AssemblyAI and Deepgram raised USD 450 million and USD 155 million, respectively, to train multilingual engines that sustain 95% accuracy on noisy audio at 40% lower inference cost. SoundHound’s USD 80 million purchase of Amelia fused conversational artificial intelligence with biometrics, enabling automotive clients to authenticate drivers and personalize infotainment without phone pairing. Scale AI’s USD 1 billion round finances synthetic speech generation that slashes corpus costs by 90%, a breakthrough for underserved languages.
Competitive strategies now diverge along three axes. Platform players bundle voice into broader artificial intelligence suites, defending share through integration depth and regulatory compliance certifications. Edge specialists focus on ultra-low-power chips and federated learning to satisfy privacy mandates that restrict cloud storage. Startups target gaps in accent coverage, especially in Africa and South Asia, where the voice recognition market can expand as low-resource languages become more affordable to annotate. As baseline accuracy commoditizes, sustainable advantage shifts toward power efficiency, privacy guarantees, and specialized vocabularies that unlock premium verticals such as healthcare and finance.
Voice Recognition Industry Leaders
Apple Inc.
Alphabet Inc.
Amazon.com Inc.
IBM Corporation
Samsung Electronics Co. Ltd.
- *Disclaimer: Major Players sorted in no particular order

Recent Industry Developments
- February 2026: Amazon launched Alexa+ at USD 9.99 per month, adding large-language-model conversations, biometric checkout, and personalized media recommendations.
- January 2026: Apple and Google agreed to embed Gemini in Siri, combining Google’s multimodal engine with on-device privacy safeguards.
- January 2025: ElevenLabs reached a USD 1.1 billion valuation after a funding round that expanded its voice-cloning platform across media and education.
- January 2025: Baidu released Ernie Bot 4.5 Turbo, pushing Mandarin accuracy to 98.2% on expert vocabularies while halving latency.


Global Voice Recognition Market Report Scope
The Voice Recognition Market Report is Segmented by Deployment (Cloud, and On-Premise), Component (Software/SDK, Hardware, Services), Technology (Speech Recognition, Speaker/Voice Biometrics, Embedded / Edge Voice AI), Device Type (Smartphones and Tablets, Smart Speakers and Displays, Automotive Infotainment and Telematics, Wearables, Commercial Kiosks and POS), Application (Authentication and Security, Voice Search and Command, Transcription and Captioning, Virtual Assistants and Chatbots, Medical Documentation), End-User Vertical (Automotive, Banking and Financial Services, Telecommunications, Healthcare Providers, Government and Defence, Consumer Electronics, Retail and E-Commerce, Industrial and Manufacturing), and Geography (North America, South America, Europe, Asia-Pacific, Middle East and Africa). The Market Forecasts are Provided in Terms of Value (USD).
| Cloud |
| On-Premise |
| Software / SDK |
| Hardware |
| Services |
| Speech Recognition |
| Speaker / Voice Biometrics |
| Embedded / Edge Voice AI |
| Smartphones and Tablets |
| Smart Speakers and Displays |
| Automotive Infotainment and Telematics |
| Wearables |
| Commercial Kiosks and POS |
| Authentication and Security |
| Voice Search and Command |
| Transcription and Captioning |
| Virtual Assistants and Chatbots |
| Medical Documentation |
| Automotive |
| Banking and Financial Services |
| Telecommunications |
| Healthcare Providers |
| Government and Defence |
| Consumer Electronics |
| Retail and E-Commerce |
| Industrial and Manufacturing |
| North America | United States | |
| Canada | ||
| Mexico | ||
| South America | Brazil | |
| Argentina | ||
| Rest of South America | ||
| Europe | United Kingdom | |
| Germany | ||
| France | ||
| Italy | ||
| Rest of Europe | ||
| Asia Pacific | China | |
| Japan | ||
| India | ||
| South Korea | ||
| Rest of Asia Pacific | ||
| Middle East and Africa | Middle East | United Arab Emirates |
| Saudi Arabia | ||
| Rest of Middle East | ||
| Africa | South Africa | |
| Egypt | ||
| Rest of Africa | ||
| By Deployment | Cloud | ||
| On-Premise | |||
| By Component | Software / SDK | ||
| Hardware | |||
| Services | |||
| By Technology | Speech Recognition | ||
| Speaker / Voice Biometrics | |||
| Embedded / Edge Voice AI | |||
| By Device Type | Smartphones and Tablets | ||
| Smart Speakers and Displays | |||
| Automotive Infotainment and Telematics | |||
| Wearables | |||
| Commercial Kiosks and POS | |||
| By Application | Authentication and Security | ||
| Voice Search and Command | |||
| Transcription and Captioning | |||
| Virtual Assistants and Chatbots | |||
| Medical Documentation | |||
| By End-User Vertical | Automotive | ||
| Banking and Financial Services | |||
| Telecommunications | |||
| Healthcare Providers | |||
| Government and Defence | |||
| Consumer Electronics | |||
| Retail and E-Commerce | |||
| Industrial and Manufacturing | |||
| By Geography | North America | United States | |
| Canada | |||
| Mexico | |||
| South America | Brazil | ||
| Argentina | |||
| Rest of South America | |||
| Europe | United Kingdom | ||
| Germany | |||
| France | |||
| Italy | |||
| Rest of Europe | |||
| Asia Pacific | China | ||
| Japan | |||
| India | |||
| South Korea | |||
| Rest of Asia Pacific | |||
| Middle East and Africa | Middle East | United Arab Emirates | |
| Saudi Arabia | |||
| Rest of Middle East | |||
| Africa | South Africa | ||
| Egypt | |||
| Rest of Africa | |||


Key Questions Answered in the Report
How fast will global spending on voice recognition grow between 2026 and 2031?
The voice recognition market is projected to expand from USD 22.51 billion in 2026 to USD 61.78 billion by 2031, reflecting a 22.38% CAGR.
Which region will add the most new revenue through 2031?
Asia-Pacific already leads with 37.64% of 2025 revenue and continues to add the largest absolute gains thanks to smartphone saturation and edge artificial intelligence mandates.
Why are hospitals adopting voice tools so rapidly?
Ambient clinical intelligence reduces physician documentation time by 45%, improves billing accuracy, and now benefits from dedicated reimbursement codes, driving a 23.94% CAGR for healthcare providers.
What is driving on-premise deployments after years of cloud dominance?
Data-sovereignty laws and the need for sub-50-millisecond latency push banks and hospitals to keep inference local, even as model training remains partly in the cloud.
How are vendors addressing privacy concerns around stored voice data?
They deploy federated learning so models train on device, transmit only gradients, and comply with regulations that restrict raw voice retention beyond defined periods.
Which application will see the fastest growth to 2031?
Medical documentation is forecast to climb at a 23.39% CAGR as ambient scribes ease clinician burnout and secure new reimbursement streams.
Page last updated on:






