Marktgröße und Marktanteil für große Sprachmodelle (LLM)
Marktübersicht
| Studienzeitraum | 2020 - 2031 |
|---|---|
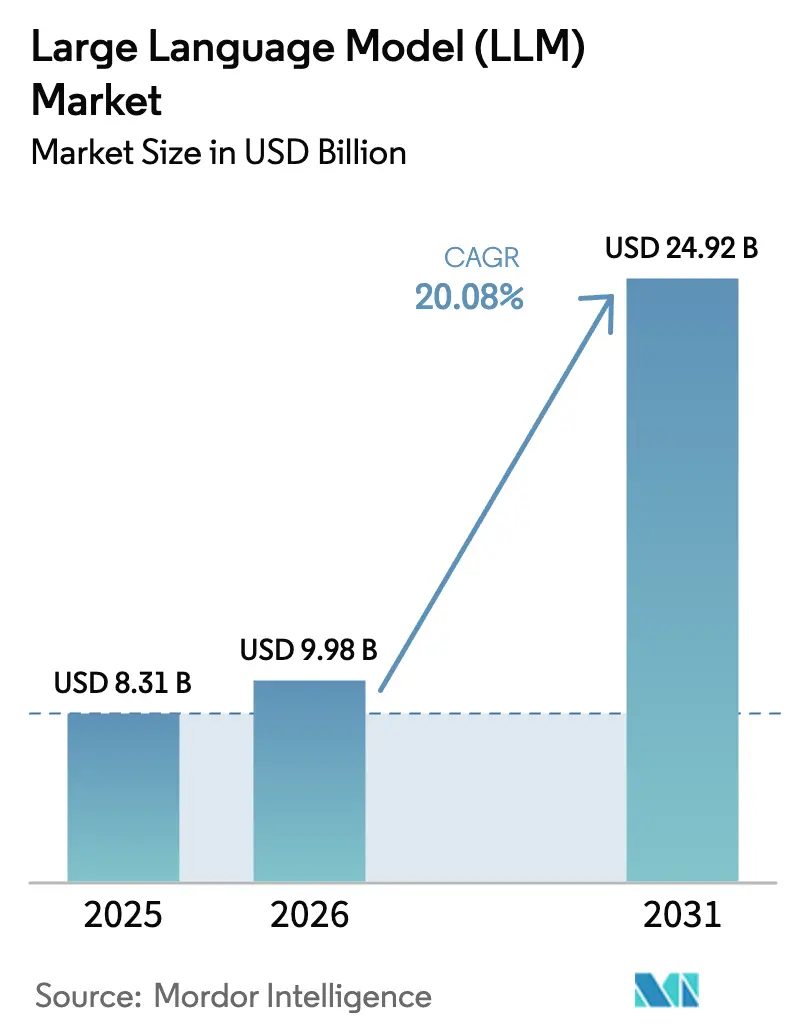
| Marktgröße (2026) | 9.98 Milliarden US-Dollar |
| Marktgröße (2031) | 24.92 Milliarden US-Dollar |
| Wachstumsrate (2026 - 2031) | 20.08% CAGR |
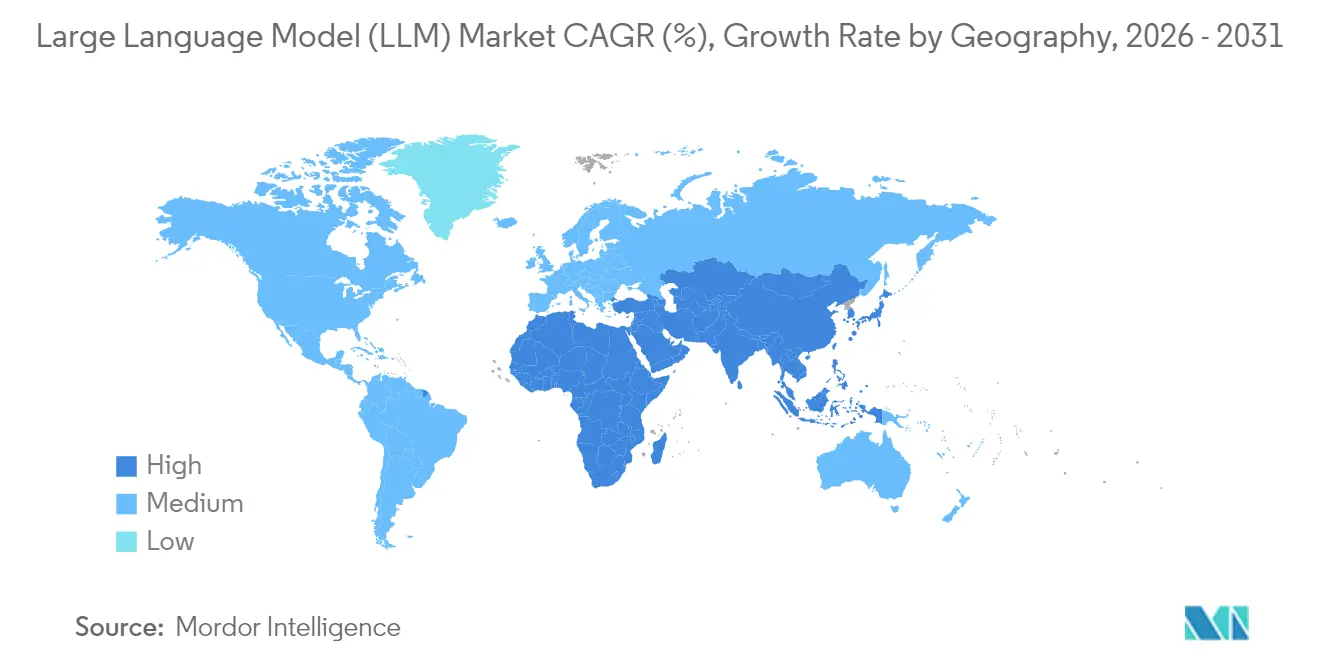
| Schnellstwachsender Markt | Asien-Pazifik |
| Größter Markt | Nordamerika |
| Marktkonzentration | Mittel |
Hauptakteure *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. | |
Marktanalyse für große Sprachmodelle (LLM) von Mordor Intelligence
Die Marktgröße für große Sprachmodelle wurde im Jahr 2025 auf 8,31 Milliarden USD geschätzt und soll von 9,98 Milliarden USD im Jahr 2026 auf 24,92 Milliarden USD bis 2031 wachsen, bei einer CAGR von 20,08 % während des Prognosezeitraums (2026–2031). GPU-Innovationen wie Nvidias Blackwell-Plattform und AWS Trainium2 senken die Gesamtbetriebskosten und beseitigen Skalierungshürden, was Unternehmen jeder Größe dazu veranlasst, interne oder verwaltete Initiativen für große Sprachmodelle zu erproben.[1]Nvidia Corporation, "NVIDIA Blackwell-Plattform erscheint, um eine neue Ära des Rechnens einzuläuten," nvidianews.nvidia.com Multimodale Architekturen, die Text, Bild und Audio in einer einzigen Pipeline verarbeiten, wechseln von Forschungslaboren zu kommerziellen Angeboten und weiten die Akzeptanz über konversationelle KI hinaus auf Design, Diagnostik und Werbung aus. Nationale KI-Regulierungen drängen Käufer zu regional trainierten oder On-Premise-Bereitstellungen, während domänenspezifische APIs im Bank- und Gesundheitswesen generische Modelle verdrängen, indem sie das Halluzinationsrisiko senken und die Compliance erleichtern. Für den Edge optimierte kleine Sprachmodelle gestalten die Geräte-Roadmaps für Smartphone-, Wearable- und industrielle OEMs neu und eröffnen neue Einnahmequellen für Chiphersteller und Anbieter von Inferenz als Dienstleistung. Zusammen deuten diese Kräfte auf ein Jahrzehnt hin, in dem sich der Markt für große Sprachmodelle von konzentrierten Cloud-Workloads zu einem gestuften, allgegenwärtigen Intelligenznetz entwickelt.
Wichtigste Erkenntnisse des Berichts
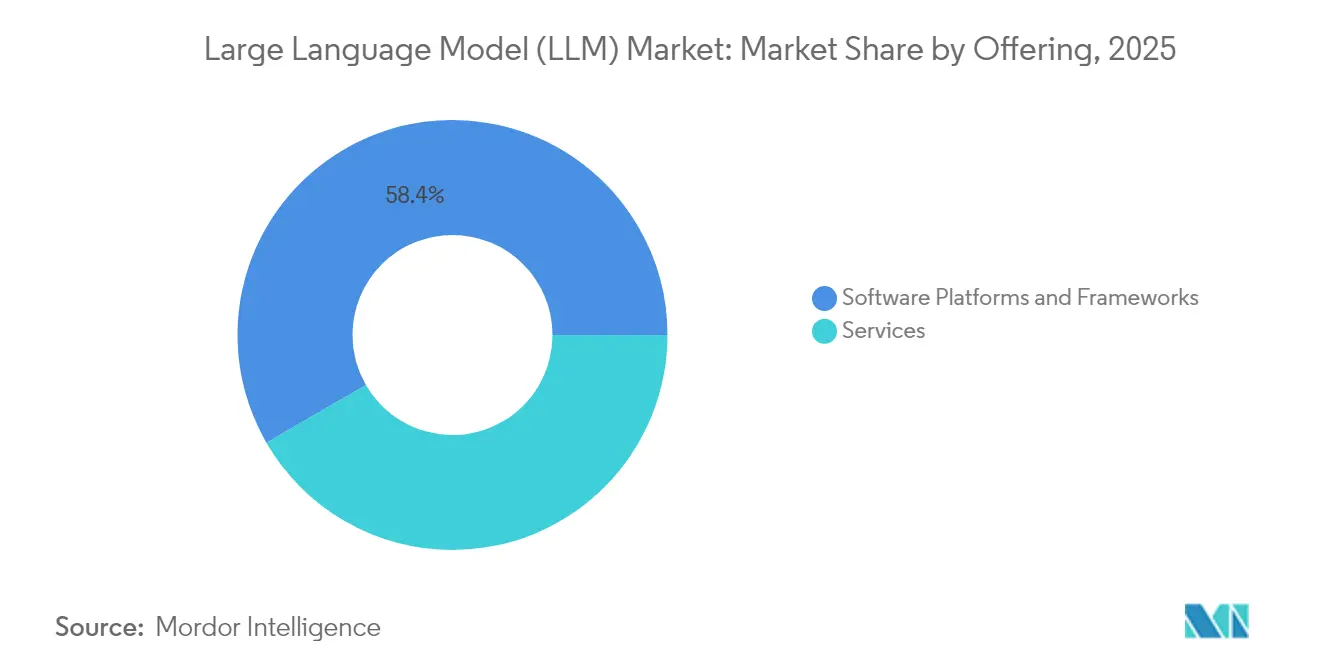
- Nach Angebot hielten Softwareplattformen im Jahr 2025 einen Marktanteil von 58,35 % am Markt für große Sprachmodelle; Dienstleistungen sollen bis 2031 mit einer CAGR von 24,26 % wachsen.
- Nach Bereitstellung führten On-Premise-Lösungen mit 51,85 % der Marktgröße für große Sprachmodelle im Jahr 2025, während Edge- und Gerätebereitstellungen mit einer CAGR von 27,25 % bis 2031 voranschreiten.
- Nach Modellgröße erfassten Modelle mit weniger als 100 Milliarden Parametern im Jahr 2025 einen Marktanteil von 69,20 % am Markt für große Sprachmodelle; Modelle mit mehr als 300 Milliarden Parametern sollen mit einer CAGR von 29,05 % wachsen.
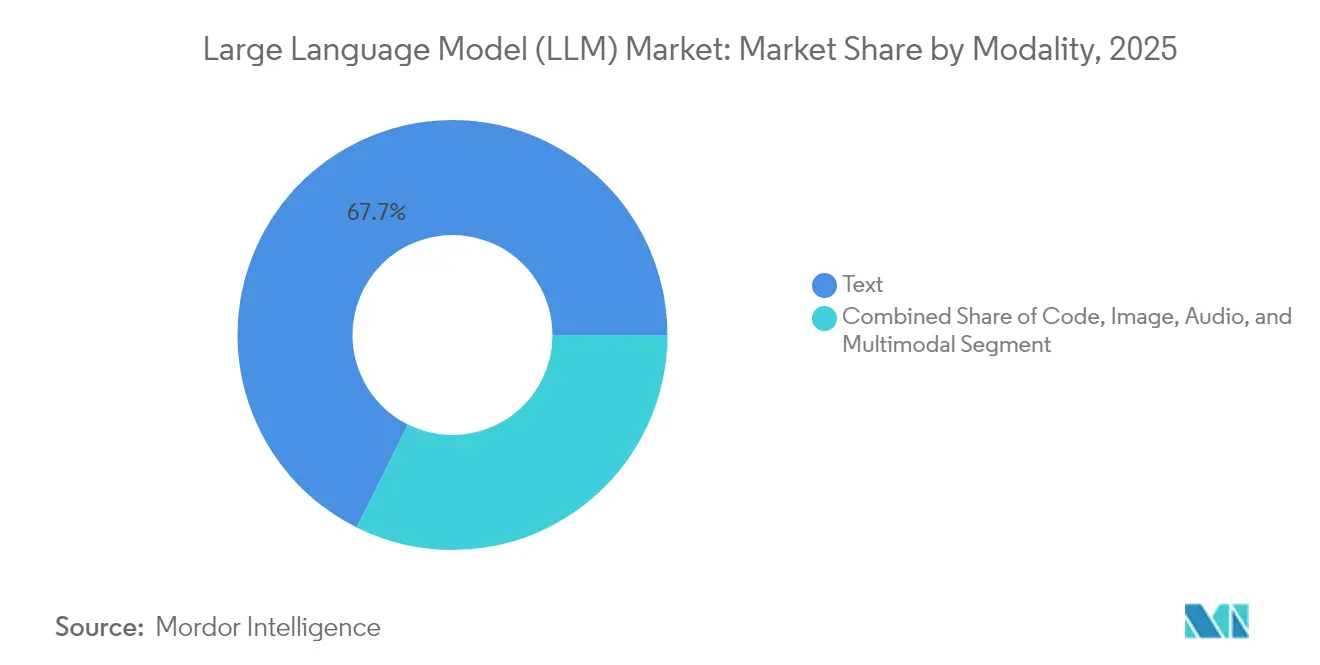
- Nach Modalität erzielten textbasierte Modelle im Jahr 2025 einen Umsatzanteil von 67,65 %; multimodale Modelle sollen bis 2031 eine CAGR von 28,95 % verzeichnen.
- Nach Anwendung hielten Chatbots und virtuelle Assistenten im Jahr 2025 einen Marktanteil von 26,35 % am Markt für große Sprachmodelle, während Code-Generierungstools mit einer CAGR von 24,75 % skalieren werden.
- Nach Endnutzerbranche führte der Einzel- und E-Commerce-Handel im Jahr 2025 mit einem Umsatzanteil von 26,75 %; das Gesundheitswesen wird bis 2031 mit einer CAGR von 25,95 % wachsen.
- Nach Geografie entfielen auf Nordamerika 31,70 % des Umsatzes im Jahr 2025, während der asiatisch-pazifische Raum zwischen 2026 und 2031 eine CAGR von 31,40 % anstrebt.
Hinweis: Die Marktgrößen- und Prognosezahlen in diesem Bericht werden mithilfe des proprietären Schätzrahmens von Mordor Intelligence erstellt und mit den neuesten verfügbaren Daten und Erkenntnissen bis 2026 aktualisiert.
Globale Trends und Erkenntnisse im Markt für große Sprachmodelle (LLM)
Analyse der Treiberwirkung*
| Treiber | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Schneller Kostenrückgang bei GPU-Rechenleistung durch Nvidia Blackwell und AWS Trainium2 | +5.2% | Global, mit Schwerpunkt in Nordamerika und Ostasien | Mittelfristig (2–4 Jahre) |
| Unternehmenstaugliche, domänenspezifische LLM-APIs im BFSI- und Gesundheitsbereich (Nordamerika) | +4.3% | Nordamerika, mit Ausstrahlungseffekten auf Europa | Kurzfristig (≤ 2 Jahre) |
| Nationale KI-Richtlinien, die lokales Training erzwingen (z. B. Chinas Interimsmassnahmen 2024) | +3.1% | China, EU, mit globalen Auswirkungen | Mittelfristig (2–4 Jahre) |
| SaaS-Upselling-Möglichkeit durch eingebettete LLM-Funktionen (europäisches CRM/ERP) | +2.8% | Europa, Nordamerika | Kurzfristig (≤ 2 Jahre) |
| Starker Anstieg der Nachfrage nach multimodalen Inhalten durch globale Werbetech-Agenturen | +2.5% | Global, mit Schwerpunkt in Nordamerika und Europa | Mittelfristig (2–4 Jahre) |
| Für den Edge optimierte kleine Sprachmodelle (weniger als 2 Milliarden Parameter) für Smartphones | +3.7% | Global, mit früher Akzeptanz im asiatisch-pazifischen Raum | Langfristig (≥ 4 Jahre) |
| Quelle: Mordor Intelligence | |||
Schneller Kostenrückgang bei GPU-Rechenleistung durch Nvidia Blackwell und AWS Trainium2
Nvidias Blackwell-Familie, die 2024 vorgestellt wurde, senkt die Gesamtbetriebskosten für umfangreiches Training und Inferenz um bis zu das 25-Fache gegenüber der Vorgängergeneration und reduziert sowohl Investitionsausgaben als auch Energieverbrauch. AWS Trainium2 erweitert diese Einsparungen auf verwaltete Clouds und bietet mittelständischen Softwareanbietern einen kostengünstigen Weg zur Experimentierung mit Billionen-Parameter-Modellen. Die daraus resultierende Kapitaleffizienz beseitigt einen historischen Burggraben, den große Hyperscaler genossen, und ermöglicht es regionalen Anbietern und Open-Source-Konsortien, wettbewerbsfähige Checkpoints zu veröffentlichen. Die Kostenelastizität verstärkt auch die Experimentierfreude bei parametereffizienten Feinabstimmungsansätzen, die die Genauigkeit verbessern, ohne Hardware-Upgrades als Einzelposten zu erfordern. Insgesamt beschleunigen diese wirtschaftlichen Faktoren die Einführung in Sektoren von der Präzisionsfertigung bis zur personalisierten Bildung und vergrößern den adressierbaren Markt für große Sprachmodelle.
Unternehmenstaugliche, domänenspezifische LLM-APIs im BFSI- und Gesundheitsbereich
Banken integrieren finanzoptimierte Modelle für die Kreditrisikobewertung, die Sanktionsprüfung und individuelle Kundenberatung, wodurch manuelle Prüfzyklen verkürzt und gleichzeitig Prüfstandards eingehalten werden. Gesundheitsnetzwerke erproben klinisch ausgerichtete Assistenten, die medizinische Notizen und Fachliteratur analysieren, um diagnostische Entscheidungen, die Patientenaufnahme und die Arzneimittelentwicklung zu verbessern. Anbieter legen Wert auf eine enge Prompt-Verankerung und retrieval-augmentierte Generierung, um Halluzinationen zu unterdrücken und regulatorische Anforderungen zu erfüllen. Abonnementmodelle, die Token oder Ergebnisse abrechnen, passen zu bestehenden Beschaffungsnormen und erleichtern Verkaufszyklen. Angesichts strenger Datenschutzvorschriften in beiden Branchen verdrängen diese spezialisierten APIs allgemeine Modelle und festigen ein Premium-Segment im Markt für große Sprachmodelle.
Nationale KI-Richtlinien, die lokales Training erzwingen
Chinas Interimsmassnahmen und der EU-KI-Act erfordern eine Risikoklassifizierung, Sicherheitsmeldungen und in vielen Fällen lokales Modelltraining für die digitale Strategie.[3]Europäische Kommission, "Regulierungsrahmen für KI," digital-strategy.ec.europa.eu Unternehmen wägen nun die jurisdiktionale Fragmentierung gegen Effizienz ab und tendieren zu souveränen Clouds oder On-Premise-Clustern, um proprietäre Daten zu schützen. Systemintegratoren reagieren mit der Einrichtung regionaler Modell-Hubs, die häufig von Telekommunikationsunternehmen oder staatlichen Fonds mitfinanziert werden, um sprachliche Abdeckung und schnellere behördliche Genehmigungen zu gewährleisten. Der Wandel bringt neue regionale Marktführer hervor und untergräbt die These, dass ein einziges Modell alle Anforderungen erfüllt, die das frühe Wachstum des Marktes für große Sprachmodelle dominierte. Gleichzeitig erzeugt lokales Training kulturell abgestimmte Ergebnisse, was die Nutzerakzeptanz in Sektoren wie öffentliche Dienste und Rundfunkmedien verbessert.
SaaS-Upselling-Möglichkeit durch eingebettete LLM-Funktionen
CRM-, ERP- und Arbeitsplattformen integrieren generative Funktionen – automatisches E-Mail-Verfassen, Zusammenfassung von Geschäftsrisiken, Abstimmung von Finanzabschlüssen – direkt in ihre bestehenden Oberflächen. Anbieter haben begonnen, von der Preisgestaltung pro Nutzer zu nutzungsbasierten Stufen überzugehen, die den Wert besser mit dem Rechenverbrauch in Einklang bringen.[4]Europäische Kommission, "Regulierungsrahmen für KI," digital-strategy.ec.europa.eu Upselling-Strategien beruhen auf der Nutzung von Kundendaten, die bereits im SaaS-Stack vorhanden sind, und liefern kontextreiche Antworten, die Wettbewerber nur schwer replizieren können. Für Käufer minimiert das Modell den Integrationsaufwand und realisiert den Mehrwert innerhalb von Wochen, was zur Umschichtung von Budgets führt, die zuvor für eigenständige KI-Pilotprojekte reserviert waren. Diese Dynamik erweitert den gesamten adressierbaren Markt für große Sprachmodelle über KI-Teams hinaus auf Entscheidungsträger in den Geschäftsbereichen.
Analyse der Hemmnisse*
| Hemmnis | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Steigende Inferenz-Energiekosten (0,12 USD/1.000 Token), die die Akzeptanz bei kleinen und mittleren Unternehmen einschränken (Südamerika) | -2.1% | Südamerika, Afrika, Südostasien | Kurzfristig (≤ 2 Jahre) |
| Hohe Compliance-Aufwände durch den EU-KI-Act für Hochrisikoanwendungen | -1.8% | Europäische Union, mit globalen Auswirkungen auf Unternehmen, die EU-Märkte bedienen | Mittelfristig (2–4 Jahre) |
| Mangel an mehrsprachigen Trainingsdaten für afrikanische Sprachen | -1.3% | Afrika, mit globalen Auswirkungen auf inklusive KI | Langfristig (≥ 4 Jahre) |
| Kontrolle der H100-GPU-Versorgung durch Hyperscaler, die On-Premise-HPC einschränkt | -1.9% | Global, mit besonderem Einfluss auf Schwellenmärkte | Mittelfristig (2–4 Jahre) |
| Quelle: Mordor Intelligence | |||
Steigende Inferenz-Energiekosten, die die Akzeptanz bei kleinen und mittleren Unternehmen einschränken
Der Betrieb eines Assistenten mit 20 Milliarden Parametern kann mehrere Kilowattstunden pro Million Token verbrauchen, was in Regionen mit Netzwerktarifen über 0,10 USD/kWh Stromkosten von 0,12 USD für je 1.000 verarbeitete Token entspricht. Für kleine E-Commerce- oder Logistikunternehmen mit knappen Margen in Brasilien oder Kenia untergräbt diese Rechnung den ROI. Cloud-Anbieter verlagern ultraeffiziente Kühlung und erneuerbare Energien an ihre Standorte, doch die Weitergaberaten bleiben volatil. Energiebewusste Compiler und Sparsity-Techniken entstehen, erreichen jedoch selten die Produktionsreife bei den Budgets, die für IT-Teams kleiner und mittlerer Unternehmen typisch sind. Bis sich die Inferenzdichte verbessert, werden viele kleinere Unternehmen bei veralteten Chatbots bleiben und damit einen Teil des kurzfristigen Marktes für große Sprachmodelle begrenzen.
Hohe Compliance-Aufwände durch den EU-KI-Act für Hochrisikoanwendungen
Der EU-KI-Act, der im Februar 2025 in Kraft trat, stuft viele LLM-Bereitstellungen in den Bereichen Kreditwürdigkeitsprüfung, Personalwesen oder medizinische Unterstützung als hochriskant ein und löst damit obligatorische Folgenabschätzungen, menschliche Aufsichtsschleifen und öffentliche Register aus. Strafen von bis zu 35 Millionen EUR oder 7 % des weltweiten Umsatzes erhöhen die Aufmerksamkeit auf Vorstandsebene. Dokumentationspflichten verlangsamen Veröffentlichungszyklen und erfordern neue Werkzeuge für die Nachverfolgung von Datensätzen, Erklärbarkeit und Bias-Überwachung. Große Unternehmen können die Kosten über Produktlinien amortisieren, während Start-ups mit verzögertem Markteintritt konfrontiert sind und in weniger regulierte Rechtsgebiete gedrängt werden. Insgesamt schmälern diese Reibungsverluste das regionale Wachstum im Markt für große Sprachmodelle.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Angebot: Softwareplattformen treiben die Unternehmensadoption voran
Softwareplattformen machten 58,35 % des Umsatzes im Jahr 2025 aus und dienten als Gerüst für Experimente, Prompt-Verkettung und Feinabstimmungs-Workflows. Funktionspakete, die Tokenisierung, Vektorsuche und Sicherheitsfilter abstrahieren, ermöglichen es Entwicklern, generative Funktionen ohne tiefes Modellwissen zu integrieren. Im Prognosezeitraum werden Beratungs- und Feinabstimmungsdienstleistungen mit einer CAGR von 24,26 % wachsen, da Unternehmen Unterstützung bei der Ausrichtung von Ausgaben auf Markentonalität, Risikorichtlinien und Latenzbudgets suchen. Verwaltete Inferenzpläne skalieren ebenfalls und ermöglichen es Unternehmen, Aufrufe basierend auf Echtzeit-Kostenkurven über GPUs, ASICs und CPUs zu verteilen. Diese Dienstleistungsschicht treibt den Markt für große Sprachmodelle in Richtung eines Dienstleistungsparadigmas.
Die wachsende Nachfrage nach schlüsselfertigen vertikalen Stacks veranlasst Plattformunternehmen, regulatorische Voreinstellungen, Domänenvokabulare und Benchmark-Dashboards hinzuzufügen. Vertragsmodelle bündeln zunehmend Lizenzen, Nutzungsanalysen und Compliance-Berichte, was den Beschaffungsnormen in Finanz- und Gesundheitswesen entspricht. Unabhängige Softwareanbieter integrieren diese Plattformen und fördern ein Partnerökosystem, das die Kanalreichweite verbreitert. Infolgedessen belohnt der Markt für große Sprachmodelle insbesondere Anbieter, die offene Werkzeuge mit kuratierten Datenverbindungen und robusten Governance-Funktionen kombinieren.
Notiz: Segmentanteile aller einzelnen Segmente sind nach dem Berichtskauf verfügbar


Nach Bereitstellung: Edge-Computing gestaltet die KI-Architektur neu
On-Premise-Installationen dominierten 51,85 % der Ausgaben im Jahr 2025, da Banken, Krankenhäuser und Behörden Datensouveränität und Latenzkontrolle priorisierten. Vorschriften, die eine landesinterne Datenverarbeitung erfordern, verlagerten Budgets weiter in Richtung privater Cluster und souveräner Clouds. Die schnellste Dynamik liegt jedoch am Edge, wo quantisierte 4-GB-Checkpoints nun auf Flaggschiff-Smartphones und industriellen Steuerungen Platz finden. Mit einer CAGR von 27,25 % bis 2031 beseitigt Edge-Inferenz Hin- und Rücklaufverzögerungen und reduziert die Bandbreitenlast – geschätzt bei autonomen Inspektionsdrohnen und Wearables für den Außendienst. Frühe Pilotprojekte in Südkorea und Indien demonstrieren Reaktionszeiten unter 100 Millisekunden auf mobilen SoCs mit 6 W und markieren ein neues Kapitel für den Markt für große Sprachmodelle.
Hybride Topologien kristallisieren sich heraus: Hochpräzisions-Prompts werden in der Cloud initiiert, während risikoarme Fortsetzungen auf dem Gerät stattfinden, was Cloud-Egress-Gebühren erheblich senkt. Chiphersteller liefern NPUs, die für 4-Bit-Transformer optimiert sind, und Firmware-Updates ermöglichen es OEMs, nach dem Kauf wertsteigernde Sprachagenten bereitzustellen. Zusammen verwischen diese Trends die Grenze zwischen Cloud und Produkt und verbreiten die Intelligenz des Marktes für große Sprachmodelle im gesamten Gerätestapel.
Nach Modellgröße: Parametereffizienz treibt Innovation voran
Unternehmen bevorzugten Modelle mit weniger als 100 Milliarden Parametern, die 69,20 % des Umsatzes im Jahr 2025 erfassten und typischerweise komfortabel auf Acht-GPU-Clustern laufen. Parametereffizientes Design reduziert Token, während Kontextfenster erhalten bleiben, wie die rekurrente Architektur von xLSTM 7B zeigt, die schnelle Inferenz auf handelsüblichen Servern bietet. Solche Footprints entsprechen Kostengrenzen in der Kontaktcenter-Automatisierung oder im Versicherungs-Chat und halten den Markt für große Sprachmodelle für mittelständische Unternehmen zugänglich.
Am anderen Extrem werden Modelle mit mehr als 300 Milliarden Parametern eine CAGR von 29,05 % verzeichnen, angetrieben durch komplexe Schlussfolgerungen, wissenschaftliche Entdeckungen und multimodale Kompositionsanwendungsfälle. Forschungsallianzen zwischen Pharmariesen und Cloud-Plattformen zielen darauf ab, Trainingspläne mit Curriculum-Lernen und synthetischen Daten zu komprimieren und Durchbrüche bei der Proteinfaltung und im Materialdesign voranzutreiben. Da die Werkzeuge zur Destillation von Wissen aus diesen Giganten in kleinere Serving-Heads reifen, kaskadiert der an der Spitze geschaffene Wert in alltägliche Geschäftsanwendungen und erweitert den gesamten Markt für große Sprachmodelle.
Nach Modalität: Multimodale Fähigkeiten erweitern den Anwendungsbereich
Textbasierte Architekturen erzielten 67,65 % des Einkommens im Jahr 2025 und trieben Zusammenfassung, Wissensmanagement und konversationellen Support voran. Kundenbindungsteams, Werbeagenturen und Kliniker benötigen jedoch zunehmend Modelle, die Diagramme, Bilder und Wellenformen zusammen mit Text verarbeiten. Multimodale Stacks werden bis 2031 mit einer CAGR von 28,95 % wachsen, angetrieben durch Innovationen bei visuellen Token und gemeinsamen Einbettungsräumen. Immobilien-Apps beschreiben Immobilienfotos nun in mehreren Sprachen, und Radiologie-Assistenten vergleichen Bildgebung mit Patientenakten, um Anomalien zu kennzeichnen, und eröffnen neue Wege im Markt für große Sprachmodelle.
Audioergänzte Eingaben steigern die Genauigkeit bei der Qualitätssicherung in Callcentern, und Geste-zu-Code-Prototypen deuten auf einen bevorstehenden Schnittstellenwandel hin. Anbieter, die die modalitätsübergreifende Ausrichtung und Latenzoptimierung beherrschen, gewinnen einen Wettbewerbsvorteil, da Datenpipelines und Bewertungsprotokolle deutlich komplexer werden als rein textbasierte Varianten. Folglich bestimmt die technische Tiefe im multimodalen Vortraining zunehmend die Marktführerschaft im Markt für große Sprachmodelle.
Notiz: Segmentanteile aller einzelnen Segmente sind nach dem Berichtskauf verfügbar
Nach Anwendung: Code-Generierung steigert die Entwicklerproduktivität
Chatbots und virtuelle Assistenten führten die Nachfrage im Jahr 2025 mit einem Anteil von 26,35 % an und automatisierten erstklassigen Support, HR-Helpdesks und virtuelle Concierge-Dienste. Sie bleiben ein Einstiegspunkt, aber Software-Teams verzeichnen den steilsten Anstieg. Code-Generierungs- und Überprüfungstools werden mit einer CAGR von 24,75 % wachsen, Sprints durch automatische Funktionsvorschläge beschleunigen, Sicherheitslücken aufdecken und Testsuiten erstellen. Teams, die LLM-Paarprogrammierer einsetzen, berichten von weniger übertragenen Fehlern und engeren Veröffentlichungszyklen, was einen greifbaren ROI für Finanzvorstände demonstriert und den Trichter des Marktes für große Sprachmodelle erweitert.
Über Code hinaus integrieren Content-Erstellungs-Pipelines Text-, Layout- und Vertonungsgenerierung unter einer Orchestrierungsschicht. Autonome Agenten verbinden Retrieval-, Reasoning- und Aktions-APIs, um komplexe Workflows wie die Triage von Versicherungsansprüchen oder die Behandlung von Ausnahmen in der Lieferkette zu navigieren. Diese aufkommenden Muster unterstreichen einen Wandel von einmaligen Prompts zur mehrstufigen Orchestrierung und vertiefen den Wert, der vom Markt für große Sprachmodelle erfasst wird.
Nach Endnutzerbranche: Innovationen im Gesundheitswesen treiben das Wachstum voran
Einzel- und E-Commerce-Handel erfasste 26,75 % des Umsatzes im Jahr 2025 und nutzte Echtzeit-Produkt-Q&A, Werbetexte und dynamisches Such-Reranking. Finanzinstitute schwenkten auf Anti-Betrugs-Analysen und kontextuelle Kundenberatung um und trieben Cross-Selling voran, ohne den Personalbestand zu erhöhen. Das Gesundheitswesen wird jedoch bis 2031 eine CAGR von 25,95 % verzeichnen, da klinische LLMs diagnostisches Denken, Literatursynthese und personalisierte Entlassungsanweisungen unterstützen. Frühe Pilotprojekte zeigen reduzierte Wiederaufnahmeraten, wenn Entlassungsnotizen automatisch an das Leseverständnis der Patienten angepasst werden, was direkte Ergebnisauswirkungen beweist und die Ausgaben im Markt für große Sprachmodelle stärkt.
Biowissenschaftliche Forscher speisen Laborprotokolle, Omics- und Patentkorpora in feinabgestimmte Modelle ein, um die Zielidentifizierung zu beschleunigen. Regierungs- und Verteidigungseinrichtungen experimentieren mit mehrsprachiger Geheimdienstzusammenfassung, während Bildungsanbieter adaptives Tutoring testen, das Konzepterklärungen mit sokratischem Fragen verbindet. In all diesen Branchen sind Datenschutzprotokolle und Prüfpfade zu Standardbestandteilen von Ausschreibungschecklisten geworden, was Anbieter dazu drängt, Governance-Grundelemente tief in das Produktdesign einzubetten.
Geografische Analyse
Nordamerika trug 31,70 % des Umsatzes im Jahr 2025 bei, gestützt durch Risikokapitalfinanzierung, universitäre Talentpools und Cloud-GPU-Versorgung. Unternehmen dort waren Erstanwender bei der Bereitstellung domänenspezifischer Assistenten für Vermögensverwaltung, onkologische Entscheidungsunterstützung und juristische Recherche. Datenschutzgesetze auf Staatsebene und die bundesstaatliche Aufmerksamkeit für algorithmische Voreingenommenheit treiben die Nachfrage nach Erklärbarkeitsmodulen an, doch die Gesamtpolitik bleibt innovationsfreundlich. Die kontinuierliche Einführung KI-fähiger Rechenzentren durch Hyperscaler unterstützt den regionalen Durchsatz und stellt sicher, dass der Markt für große Sprachmodelle einen bedeutenden nordamerikanischen Kern behält.
Der asiatisch-pazifische Raum wird die schnellste CAGR von 31,40 % verzeichnen, da Regierungen souveräne Modellinitiativen subventionieren und sprachliche Vielfalt lokale Checkpoints fördert. Chinas Interimsmassnahmen schreiben inländisches Training vor und stimulieren das Design inländischer Beschleuniger und Cloud-Dienste. Japan fördert wirkungsstarke KI im Rahmen seiner Digitalen Gartenstrategie 2025, während Indiens IndiaAI-Mission öffentliche Datensätze und GPU-Guthaben für Start-ups öffnet. Für den Edge optimierte kleine Sprachmodelle finden in smartphone-zentrierten Märkten wie Indonesien und den Philippinen Anklang, erweitern die ländliche Abdeckung und vergrößern den Markt für große Sprachmodelle.
Europa balanciert Ambitionen mit Vorsicht unter dem EU-KI-Act. Unternehmen verfolgen hybride Bereitstellungen, um Datenresidenz mit Skalierbarkeit in Einklang zu bringen, und nutzen private Cluster für sensible Workloads und öffentliche Clouds für Spitzenlastkapazitäten. Spanien, Frankreich und Italien bauen KI-fähige Serverfarmen aus, die häufig mit erneuerbaren Energien betrieben werden, um Nachhaltigkeitsziele zu erfüllen. Die SaaS-Upselling-Welle ist hier ausgeprägt, wobei ERP-Anbieter mehrsprachige Chat- und Rechnungsabstimmungsfunktionen integrieren, die lokale Prüfstandards erfüllen. Insgesamt fragmentieren unterschiedliche nationale Durchsetzungsregime die Markteinführungspläne, erzeugen aber auch Nachfrage nach Beratungs- und Compliance-Tools und halten den regionalen Markt für große Sprachmodelle auf einem stabilen Wachstumskurs.

Wettbewerbslandschaft
Die fünf größten Anbieter kontrollieren zusammen mehr als 85 % des Umsatzes, gestützt durch integrierte Stacks, die von Silizium bis Software reichen. Nvidia festigte seine Position durch den Erwerb von Software-Orchestrierungsassets Anfang 2025 und positionierte sich als Komplettanbieter für KI-Plattformen nvidianews.nvidia.com. Microsoft vertiefte Partnerschaften sowohl mit OpenAI als auch mit dem aufstrebenden Labor xAI, streute das Modellrisiko und verbreiterte die Kundenattraktivität blogs.microsoft.com. Oracle schloss sich mit Microsoft und OpenAI zusammen, um Multi-Cloud-KI-Regionen anzubieten und Compliance mit elastischer GPU-Skalierung zu verbinden.
Open-Source-Herausforderer und regionale Spezialisten übertreffen ihre Gewichtsklasse, indem sie effiziente Checkpoints veröffentlichen, die kommerzielle Lizenzierungsbaselines zu niedrigeren Kosten rivalisieren. Anthropics Claude 4 verbesserte Benchmarks für mehrstufiges Schlussfolgern, während Mischpräzisions-Feinabstimmungen von Meta-abgeleiteten Modellen Community-Bestenlisten dominieren. Telekommunikationsunternehmen in Südkorea und Deutschland bauen souveräne KI-Clouds auf, mit dem Ziel, regulierte Workloads zu erfassen und Marktanteile von US-Hyperscalern zurückzugewinnen. Start-ups, die vertikale Daten, domänenspezifische Bewertungssuiten und schnelle Bereitstellungs-APIs bündeln, sichern sich Verträge in Versicherung, Logistik und Bergbau und bringen frische Dynamik in den Markt für große Sprachmodelle.
Strategische Allianzen, nicht allein Modellgewichte, entscheiden heute über Unternehmensausschreibungen. Anbieter, die Referenzarchitekturen, Kostensimulationen und Compliance-Dashboards anbieten, gewinnen Beschaffungsdynamik. Energieeffizienz, Lieferkettenresilienz und transparente Nutzungsmetriken sind in Rahmendienstleistungsverträgen stark vertreten und signalisieren ein reifendes Käuferverhalten. Da offene Gewichte proprietäre Burggräben erodieren, differenzieren sich etablierte Anbieter zunehmend durch Bereitstellungswerkzeuge, Sicherheitsintegrationen und globale Vertriebskapazitäten.
Marktführer in der Branche der großen Sprachmodelle (LLM)
Alibaba Group Holding Limited
Amazon Web Services (AWS)
Anthropic
Baidu, Inc.
Google LLC
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Jüngste Branchenentwicklungen
- Mai 2025: Anthropic lancierte Claude-4-Modelle mit verbessertem mehrstufigem Schlussfolgern.
- Mai 2025: Microsoft integrierte Technologien von Anthropic und xAI und diversifizierte seinen KI-Stack.
- Mai 2025: OpenAI stellte Codex vor, einen Agenten für Softwareentwicklungsaufgaben.
- April 2025: Google übernahm Anthropics Interoperabilitätsprotokoll für KI-Agenten.
- April 2025: Nvidia kündigte Akquisitionen an, die seine Full-Stack-KI-Kontrolle ausweiten.
- März 2025: EY Indien stellte ein feinabgestimmtes BFSI-LLM vor, das auf LLAMA 3.1-8B aufbaut.
- März 2025: Google investierte in Anthropic und stärkte damit die KI-Partnerschaft.
- März 2025: Nebius und YTL veröffentlichten Blackwell Ultra GPU-Instanzen.


Rahmen der Forschungsmethodik und Umfang des Berichts
Marktdefinitionen und wesentliche Abdeckung
Unsere Studie definiert den Markt für große Sprachmodelle (LLM) als Umsatz, der aus Softwareplattformen, Frameworks und zugehörigen Integrations- oder Feinabstimmungsdienstleistungen generiert wird, die es Transformer-basierten Modellen mit mehr als einer Milliarde Parametern ermöglichen, On-Premise, in der Cloud oder am Edge trainiert, bereitgestellt oder genutzt zu werden. Gemäß Mordor Intelligence wird der Wert an dem Punkt erfasst, an dem Software oder Dienstleistungen zahlende Nutzer erreichen, unabhängig davon, ob sie pro API-Aufruf, Abonnement oder Unternehmenslizenz abgerechnet werden.
Ausschluss aus dem Umfang: Eigenständige generative Computer-Vision-Modelle sowie der Verkauf von GPUs, ASICs oder Servern sind nicht Gegenstand dieser Studie.
Segmentierungsübersicht
- Nach Angebot
- Softwareplattformen und Frameworks
- Allgemeine LLM-Plattformen
- Domänenspezifische LLM-Lösungen
- Dienstleistungen
- Beratung und Systemintegration
- Feinabstimmung und Anpassung
- Verwaltete Inferenz und Hosting
- Softwareplattformen und Frameworks
- Nach Bereitstellung
- Cloud (öffentlich und privat)
- On-Premise / dedizierte KI-Cluster
- Edge / geräteintegriert
- Nach Modellgröße – Parameter
- Weniger als 7 Milliarden Parameter
- 7 – 70 Milliarden Parameter
- 70 – 300 Milliarden Parameter
- Mehr als 300 Milliarden Parameter
- Nach Modalität
- Text
- Code
- Bild
- Audio
- Multimodal
- Nach Anwendung
- Chatbots und virtuelle Assistenten
- Code-Generierung und -Überprüfung
- Inhalts- und Mediengenerierung
- Automatisierung des Kundendienstes
- Sprachübersetzung und Lokalisierung
- Stimmungs- und Absichtsanalyse
- Autonome Agenten und robotergestützte Prozessautomatisierung
- Nach Endnutzerbranche
- BFSI
- Gesundheitswesen und Biowissenschaften
- Einzel- und E-Commerce-Handel
- Medien und Unterhaltung
- Informationstechnologie und Telekommunikation
- Bildung
- Fertigung
- Regierung und Verteidigung
- Nach Geografie
- Nordamerika
- Vereinigte Staaten
- Kanada
- Mexiko
- Europa
- Deutschland
- Vereinigtes Königreich
- Frankreich
- Italien
- Spanien
- Übriges Europa
- Asien-Pazifik
- China
- Japan
- Südkorea
- Indien
- Südostasien
- Übriger Asien-Pazifik-Raum
- Südamerika
- Brasilien
- Übriges Südamerika
- Naher Osten und Afrika
- Naher Osten
- Vereinigte Arabische Emirate
- Saudi-Arabien
- Übriger Naher Osten
- Afrika
- Südafrika
- Übriges Afrika
- Naher Osten
- Nordamerika
Detaillierte Forschungsmethodik und Datenvalidierung
Primärforschung
Um sekundäre Erkenntnisse zu untermauern, haben wir KI-Produktleiter, Cloud-Ops-Architekten, Compliance-Beauftragte und akademische Forscher in Nordamerika, Europa und wichtigen Zentren des asiatisch-pazifischen Raums befragt. Strukturierte Fragebögen untersuchten Preismodelle, Präferenzen für Parameteranzahlen, Verhältnisse von Rechenleistung zu Inferenzkosten und erwartete Upgrade-Zyklen, was es uns ermöglichte, Datenlücken zu schließen und modellierte Annahmen zu überprüfen.
Schreibtischforschung
Mordor-Analysten sammelten grundlegende Daten aus öffentlich zugänglichen erstklassigen Quellen wie Anmeldungen beim US-Patent- und Markenamt zu neuen Transformer-Architekturen, OECD-Indikatoren zur digitalen Wirtschaft zur Verfolgung der KI-Akzeptanz, Zollcodes der Welthandelsorganisation für KI-Software-Exporte sowie Grundsatzpapieren der Arbeitsgruppe zum EU-KI-Act. Diese Erkenntnisse wurden durch Unternehmens-10-K-Berichte, Transkripte von Entwicklerkonferenzen und seriöse Branchenverbandsbriefings ergänzt (zum Beispiel die LF-AI-Projekte der Linux Foundation).
Abonnementdatenbanken, die wir pflegen – D&B Hoovers für Finanzdaten, Dow Jones Factiva für Transaktionsflüsse und Questel für Patentlandschaften – lieferten zusätzliche quantitative Signale zur Umsatzdynamik der Anbieter und zur Innovationsintensität.
Die zitierten Quellen veranschaulichen die Breite des konsultierten Materials; viele weitere Referenzen unterstützten die Datenerhebung, -validierung und -klärung.
Marktgrößenbestimmung und Prognose
Wir verwenden einen kombinierten Top-down- und Bottom-up-Ansatz. Globale Ausgaben für Unternehmenssoftware und Abrechnungsdaten für öffentliche Clouds bilden den Nachfragepool, der dann anhand von Stichproben durchschnittlicher Verkaufspreise multipliziert mit dem Bereitstellungsvolumen ausgewählter Anbieter validiert wird. Zu den Schlüsselvariablen in unserem Modell gehören (1) durchschnittlich generierte Token pro Nutzer pro Monat, (2) Anteil der Bereitstellungen auf privaten Clustern gegenüber der öffentlichen Cloud, (3) durchschnittliche Parameteranzahl in kommerziellen Veröffentlichungen, (4) Wachstum bei Feinabstimmungsdienstleistungsverträgen und (5) regionale KI-Politikanreize. Multivariate Regression kombiniert mit Szenarioanalyse projiziert jeden Treiber bis 2030; der Analystenkonsens aus der Primärforschung informiert das Basisszenario, während Sensitivitätsbänder die Volatilität erfassen. Wo Lieferantenzusammenführungen keine vollständige Offenlegung bieten, werden Teilwerte mithilfe branchenüblicher Quoten aus früheren geprüften Jahren aufgefüllt.
Datenvalidierung und Aktualisierungszyklus
Ergebnisse werden anhand unabhängiger Metriken wie KI-Server-Lieferungen und Cloud-Inferenzstunden auf Anomalien überprüft, gefolgt von einer mehrstufigen Peer-Review. Berichte werden jährlich aktualisiert, mit Zwischenrevisionen, die durch wesentliche Finanzierungsrunden, regulatorische Änderungen oder bahnbrechende Modellveröffentlichungen ausgelöst werden. Kurz vor der Lieferung liest ein Analyst die Datei erneut durch, damit Kunden die aktuellste Sichtweise erhalten.
Warum unsere Ausgangsbasis für große Sprachmodelle Zuverlässigkeit verdient
Veröffentlichte Schätzungen weichen häufig voneinander ab, weil Unternehmen unterschiedliche Basisjahre wählen, Hardware-Umsätze bündeln oder einheitliche Preisgestaltung annehmen.
Wesentliche Ursachen für Abweichungen umfassen einen engeren Umfang, der Dienstleistungen auslässt, aggressive Extrapolation des Token-Wachstums ohne Parameterobergrenzen sowie Währungsumrechnungen, die bei älteren Wechselkursen vor der jüngsten Dollarstärke eingefroren sind.
Vergleichsmaßstab
| Marktgröße | Anonymisierte Quelle | Wesentlicher Abweichungsgrund |
|---|---|---|
| 8,31 Milliarden USD (2025) | ||
| 6,4 Milliarden USD (2024) | Globales Beratungsunternehmen A | Hardware eingebunden, ältere Wechselkurse |
| 5,62 Milliarden USD (2024) | Regionales Beratungsunternehmen A | Schließt Feinabstimmungsdienstleistungen aus |
| 5,72 Milliarden USD (2024) | Fachzeitschrift B | Nimmt eine einheitliche CAGR von 40 % ohne Validierung an |
Der Vergleich zeigt, wie Umfangsentscheidungen, Preisannahmen und Aktualisierungsrhythmus die Gesamtwerte verändern. Mordors disziplinierte Variablenauswahl, jährliche Aktualisierungen und transparente Modelllogik geben Entscheidungsträgern einen zuverlässigen, ausgewogenen Ausgangspunkt für die strategische Planung.


Im Bericht beantwortete Schlüsselfragen
Wie hoch ist die aktuelle Bewertung des Marktes für große Sprachmodelle?
Die Marktgröße für große Sprachmodelle beträgt im Jahr 2026 9,98 Milliarden USD und soll bis 2031 24,92 Milliarden USD erreichen.
Welche Region wächst am schnellsten?
Der asiatisch-pazifische Raum führt das Wachstum mit einer prognostizierten CAGR von 31,40 % bis 2031 an, gestützt durch staatliche Investitionen und die Nachfrage nach mehrsprachigen Modellen.
Warum sind Edge-Bereitstellungen für das zukünftige Wachstum wichtig?
Edge-Modelle bieten geringere Latenz, stärkeren Datenschutz und reduzierte Bandbreitenkosten und führen das Bereitstellungssegment mit einer CAGR-Prognose von 27,25 % an.
Welche Branchenvertikale wird am aggressivsten investieren?
Das Gesundheitswesen soll mit einer CAGR von 25,95 % wachsen, dank klinischer Entscheidungsunterstützung, Forschungsbeschleunigung und Patienteneinbindungsanwendungen.
Wie werden Regulierungen die Akzeptanz beeinflussen?
Richtlinien wie Chinas Interimsmassnahmen und der EU-KI-Act fördern lokales Training, erhöhen Compliance-Kosten und lenken Käufer zu erklärbaren, regional gehosteten Modellen.
Ersetzen kleinere Modelle Riesenmodelle?
Unternehmen bevorzugen Modelle mit weniger als 100 Milliarden Parametern für kosteneffiziente Inferenz, doch ultragroße Modelle mit mehr als 300 Milliarden Parametern dominieren weiterhin komplexe Schlussfolgerungsaufgaben und wachsen mit einer CAGR von 29,05 %.
Seite zuletzt aktualisiert am:




