Disaggregierter GPU-Markt – Größe und Marktanteil
Marktübersicht
| Studienzeitraum | 2020 - 2031 |
|---|---|
| Marktgröße (2026) | 5.34 Milliarden US-Dollar |
| Marktgröße (2031) | 22.63 Milliarden US-Dollar |
| Wachstumsrate (2026 - 2031) | 33.48% CAGR |
| Schnellstwachsender Markt | Asien-Pazifik |
| Größter Markt | Nordamerika |
| Marktkonzentration | Hoch |
Hauptakteure
*Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. |
|
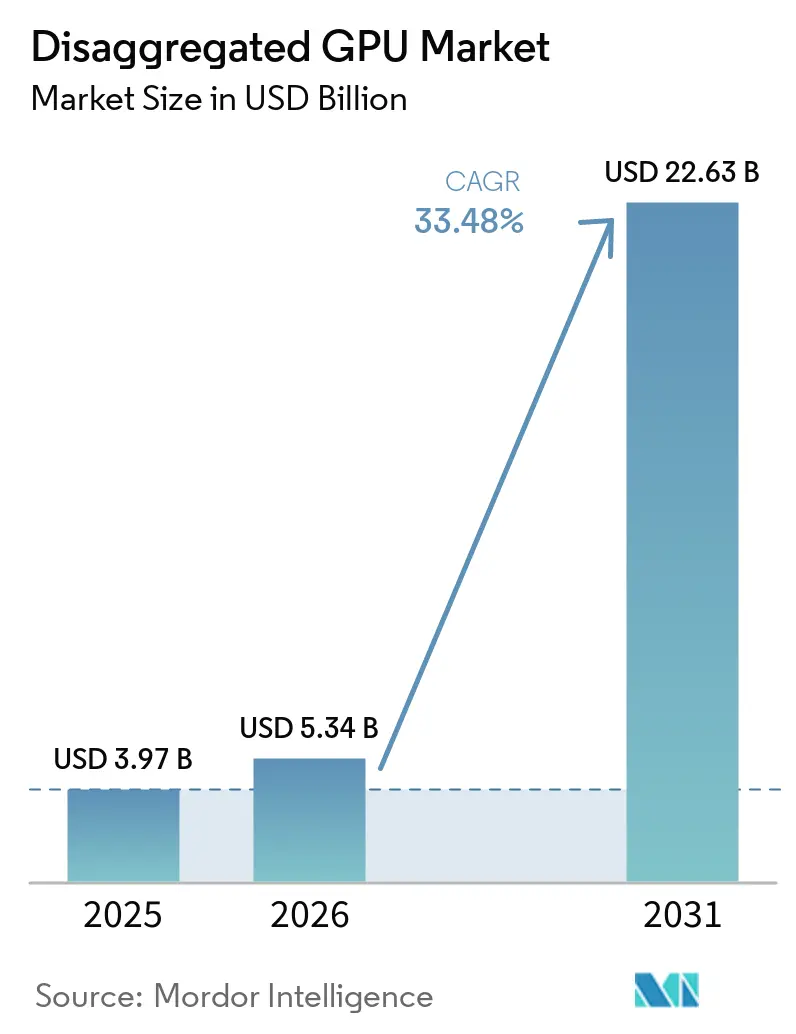
Disaggregierter GPU-Markt – Analyse von Mordor Intelligence
Die Größe des disaggregierten GPU-Marktes wird für 2025 auf 3,97 Milliarden USD, für 2026 auf 5,34 Milliarden USD prognostiziert und soll bis 2031 22,63 Milliarden USD erreichen, mit einer CAGR von 33,48 % von 2026 bis 2031. Der disaggregierte GPU-Markt expandiert, da KI-Compute-Stacks sich von Festserver-Designs hin zu fabric-verbundenen Architekturen verlagern, die es Betreibern ermöglichen, GPU-Ressourcen von Host-Servern zu trennen und sie dort zuzuweisen, wo die Nachfrage am höchsten ist. Große Kapitalprogramme von AMD und NVIDIA sowie bestätigte Bereitstellungen durch führende Cloud-Plattformen zeigen, dass der disaggregierte GPU-Markt nun mit einer umfassenden Neugestaltung von Rechenzentren verbunden ist und nicht mehr mit isolierten Hardware-Erneuerungszyklen. Das Wettbewerbsverhalten verändert sich ebenfalls, da Betreiber größeren Wert auf Auslastung, Orchestrierung und Rack-Scale-Effizienz legen als auf das bloße Hinzufügen weiterer Beschleuniger. Der disaggregierte GPU-Markt profitiert auch vom Aufstieg agentischer KI-Workloads, die einen stärkeren Druck auf den Token-Durchsatz, die KV-Cache-Bewegung und die latenzarme Koordination zwischen Prefill- und Decode-Phasen ausüben. Gleichzeitig halten Exportkontrollen, Interoperabilitätslücken und die Leistungsdichte moderner KI-Racks das Wachstum ungleichmäßig und begünstigen Betreiber mit zweckgebundener Infrastruktur und starker technischer Tiefe.
Wichtigste Erkenntnisse des Berichts
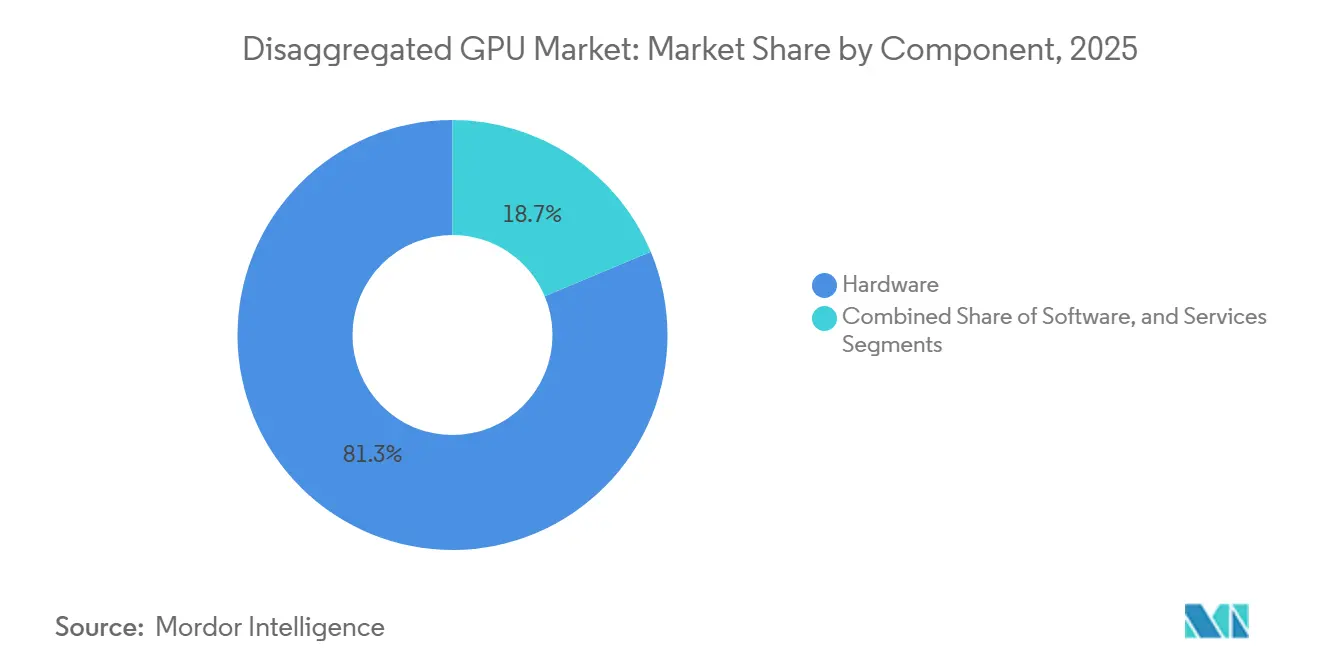
- Nach Komponente führte Hardware mit einem Umsatzanteil von 81,32 % im Jahr 2025, während Software bis 2031 voraussichtlich mit einer CAGR von 34,08 % im disaggregierten GPU-Markt wachsen wird.
- Nach Beschleunigertyp hielt NVLink/NVSwitch-basierte Disaggregation im Jahr 2025 einen Anteil von 44,21 %, während CXL-basierte Disaggregation bis 2031 voraussichtlich mit einer CAGR von 34,46 % wachsen wird.
- Nach Bereitstellungsmodus entfiel auf die Cloud-basierte Bereitstellung im Jahr 2025 ein Anteil von 61,77 % am disaggregierten Grafikprozessor (GPU)-Markt, und es wird erwartet, dass sie bis 2031 mit einer CAGR von 33,87 % wächst.
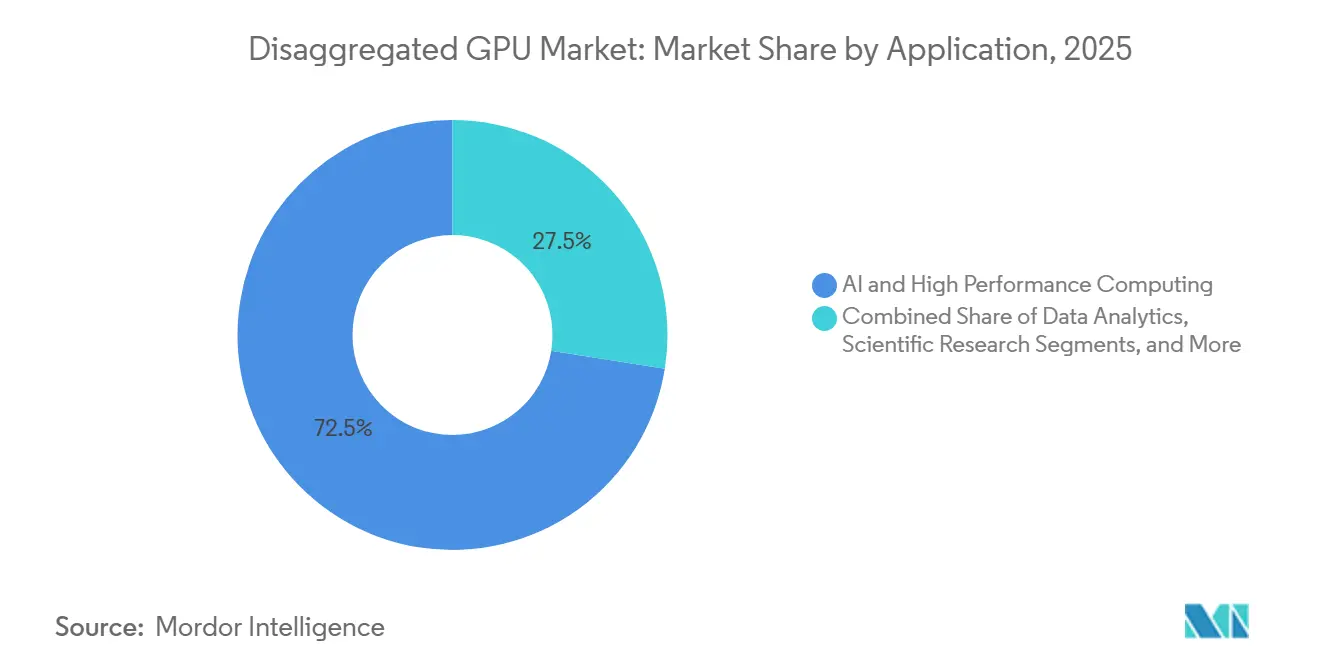
- Nach Anwendung erfasste KI und Hochleistungsrechnen im Jahr 2025 72,49 % des Marktes, während digitale Zwillinge und Simulation bis 2031 voraussichtlich mit einer CAGR von 34,42 % wachsen werden.
- Nach Endnutzer hielten Hyperscale-Cloud-Anbieter im Jahr 2025 einen Anteil von 47,63 %, während Cloud-Dienstleister bis 2031 voraussichtlich die höchste CAGR von 34,63 % verzeichnen werden.
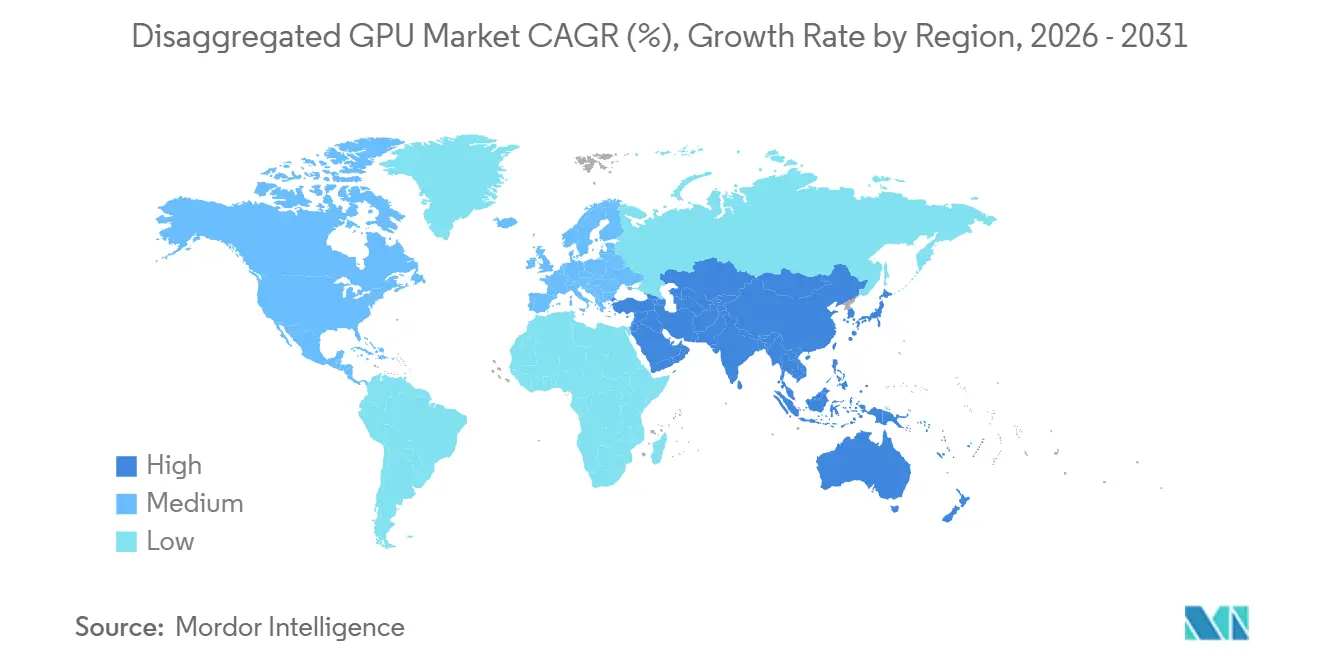
- Nach Geografie hielt Nordamerika im Jahr 2025 einen Anteil von 52,71 % am disaggregierten GPU-Markt, während der asiatisch-pazifische Raum bis 2031 voraussichtlich mit einer CAGR von 34,39 % wachsen wird.
Hinweis: Die Marktgröße und Prognosezahlen in diesem Bericht werden mithilfe des proprietären Schätzungsrahmens von Mordor Intelligence erstellt und mit den neuesten verfügbaren Daten und Erkenntnissen vom Januar 2026 aktualisiert.
Globale Trends und Erkenntnisse im disaggregierten GPU-Markt
Analyse der Treiberwirkung*
| Treiber | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Steigende Nachfrage nach GPU-Pooling in KI-Trainingsclustern | +10.2% | Global, konzentriert in nordamerikanischen und asiatisch-pazifischen Hyperscale-Hubs | Kurzfristig (≤ 2 Jahre) |
| Verlagerung hin zu getrennten Compute- und Speicherarchitekturen | +8.5% | Global, mit CXL-Einführung verankert in Nordamerika und Ostasien | Mittelfristig (2–4 Jahre) |
| Expansion von Hyperscale- und Cloud-nativer KI-Infrastruktur | +7.3% | Global, mit Nordamerika und dem asiatisch-pazifischen Raum als führende Kapitalgeber | Kurzfristig (≤ 2 Jahre) |
| Energie- und Wärmeeffizienzgewinne durch Ressourcen-Disaggregation | +4.8% | Global, beschleunigt durch EU-Energievorschriften und Energieengpässe im asiatisch-pazifischen Raum | Mittelfristig (2–4 Jahre) |
| Schnellere Flottenauslastung durch mandantenfähige GPU-Zuweisung | +3.6% | Cloud-Korridore in Nordamerika, Europa und Südostasien | Mittelfristig (2–4 Jahre) |
| Kürzere Upgrade-Zyklen in modularen Rechenzentrumsarchitekturen | +2.9% | Global, am schnellsten bei Neubauten von KI-Fabriken in Nordamerika | Langfristig (≥ 4 Jahre) |
| Quelle: Mordor Intelligence | |||
Steigende Nachfrage nach GPU-Pooling in KI-Trainingsclustern
Der disaggregierte GPU-Markt erhält direkte Unterstützung durch GPU-Pooling, da große KI-Trainingsläufe nun davon abhängen, viele physische GPUs als eine einzige gemeinsam genutzte logische Ressource zu behandeln. NVIDIAs sechste NVLink-Generation lieferte 1,8 TB/s bidirektionale Bandbreite pro GPU, und NVLink-Switch-Systeme unterstützten 72 GPUs in einem einzigen NVL72-Rack und lieferten 130 TB/s aggregierte In-Domain-Bandbreite, wodurch die Kommunikationsgrenzen reduziert wurden, die benachbarte Racks früher in isolierte Compute-Inseln trennten.[1]NVIDIA Developer Blog, "Skalierung der KI-Inferenzleistung und -Flexibilität mit NVIDIA NVLink und NVLink Fusion," NVIDIA Developer Blog, developer.nvidia.com Diese Verlagerung ist für Billionen-Parameter-Modelle bedeutsam, da der Speicher- und Bandbreitendruck sich nun über vollständige Trainingscluster erstreckt und nicht mehr auf einen einzelnen Knoten beschränkt ist, und der disaggregierte GPU-Markt reagiert mit Architekturen, die es ermöglichen, dass Leerlaufkapazität viel schneller aktiven Workloads beitritt. Agentische KI fügt eine weitere Nachfrageschicht hinzu, da Prefill-Phasen rechenintensiv sind, während Decode-Phasen speicherbandbreitenintensiv sind, und dieses Muster erfordert, dass Pools in Sekunden neu zugewiesen werden, anstatt durch langsamere manuelle Planungszyklen. AWS demonstrierte dieses Betriebsmodell in der Produktion mit llm-d und der NVIDIA Inference Xfer Library auf Blackwell-Knoten, wobei disaggregierte Inferenz den Durchsatz bei hoher Parallelität um 70 % verbesserte.
Verlagerung hin zu getrennten Compute- und Speicherarchitekturen
Der disaggregierte GPU-Markt schreitet auch voran, da Betreiber Compute von lokalem Speicher trennen und Speicherkapazität als gepoolte Infrastrukturschicht behandeln. In Tsinghua Science and Technology veröffentlichte Forschungsergebnisse beschrieben CXL-basierte Speicher-Disaggregation als einen wichtigen architektonischen Schritt für intelligente Rechenzentren, da gemeinsam genutzte Speicherpools durch Standard-Lade- und Speicheroperationen von mehreren Compute-Knoten erreicht werden können. ByteDance-Forscher erweiterten diese Richtung, indem sie einen gemeinsam genutzten 768-GB-Speicherpool demonstrierten, der aus Micron CXL Typ-3-Karten und einem TITAN-II CXL-Switch aufgebaut wurde und kollektive GPU-Kommunikation über 3 Knoten mit NVIDIA H100-GPUs ohne Änderungen am Anwendungscode ermöglichte. Dies ist bedeutsam, da Langkontext-Inferenz 1 Million Token überschreitet und die KV-Cache-Nachfrage die auf jedem Beschleuniger verfügbare HBM-Kapazität übersteigt, was das Hinzufügen von gepooltem Speicher praktischer macht als den Austausch ganzer GPU-Flotten. Der disaggregierte GPU-Markt profitiert daher von CXL nicht nur als technische Option, sondern auch als wirtschaftlicher Weg für Betreiber, die mehr Speicherkapazität benötigen, ohne eine vollständige Silizium-Erneuerung zu erzwingen.
Expansion von Hyperscale- und Cloud-nativer KI-Infrastruktur
Der disaggregierte GPU-Markt wird durch das Ausmaß der Ausgaben für Hyperscale- und Cloud-native KI-Infrastruktur nach oben getrieben, die sich von isolierten Pilotprojekten zu Rack-Scale- und Multi-Site-Rollouts ausgeweitet haben. AMD kündigte im Mai 2026 Investitionen von mehr als 10 Milliarden USD in das Taiwan-Ökosystem an, um seine Helios-Rack-Scale-Plattform über ODM-Partner, darunter Sanmina, Wiwynn, Wistron und Inventec, zu skalieren, mit Multi-Gigawatt-Bereitstellungen, die für die zweite Hälfte 2026 angestrebt werden. Google Cloud erklärte außerdem, dass sein Virgo-Netzwerk-Fabric darauf ausgelegt ist, bis zu 80.000 NVIDIA Vera Rubin NVL72-GPUs in einem einzigen Rechenzentrum und mehr als 960.000 GPUs über mehrere Standorte hinweg zu verbinden, was unterstreicht, wie der disaggregierte GPU-Markt zur Grundlage für die Skalierung von Rechenzentren wird und nicht mehr eine Nischenarchitektur darstellt. Gleichzeitig eliminieren benutzerdefinierte Silizium-Programme bei AWS, Google und Microsoft nicht den Bedarf an disaggregierten GPU-Systemen, da Multi-Vendor-Infrastruktur neben ihnen entsteht. Intel und SambaNova demonstrierten das Modell 2026 mit einem heterogenen Inferenz-Stack, bei dem Intel Xeon 6 die Orchestrierung übernahm, SambaNova RDUs die Decode-Phase und NVIDIA Blackwell-GPUs die Prefill-Phase aus einem einzigen Produktionsrechenzentrum.
Energie- und Wärmeeffizienzgewinne durch Ressourcen-Disaggregation
Der disaggregierte GPU-Markt wird auch durch Einschränkungen bei der Stromversorgung und Kühlung geprägt, die Architekturentscheidungen nun ebenso stark beeinflussen wie die reine Compute-Nachfrage. Die Diablo-Spezifikation des Open Compute Project, die von Google, Meta und Microsoft im Oktober 2025 beigesteuert wurde, definierte disaggregierte Stromversorgungs-Rack-Designs, die IT-Racks von 100 Kilowatt bis 1 Megawatt mit 400-VDC- oder 800-VDC-Versorgung unterstützen. NVIDIA fügte im Dezember 2025 mit Blackwell B200-Leistungsprofilen einen weiteren Effizienz-Hebel hinzu, der bis zu 15 % Energieeinsparungen bei nicht mehr als 3 % Leistungseinbußen liefert und einen bis zu 13 % höheren Durchsatz in Anlagen mit fester Leistung ermöglicht. Phasenbewusste disaggregierte Inferenz verbessert das Bild weiter, da Prefill-Phasen Spitzenleistung verbrauchen, während Decode-Phasen einen geringeren Leistungsbedarf haben und über separate Ressourcenpools unterschiedlich verwaltet werden können. Forschungen zur BiScale-Architektur zeigten, dass koordiniertes DVFS über disaggregierte Prefill- und Decode-Ebenen die Decode-Energie um bis zu 48 % reduzierte und dabei Latenz-Service-Ziele einhielt, was den Betriebsfall für den disaggregierten Grafikprozessor (GPU)-Markt stärkt, wo Energiegrenzen und Auslastungsziele nun gemeinsam voranschreiten.
Analyse der Hemmnisauswirkung*
| Hemmnis | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Hohe Komplexität bei der Interconnect- und Fabric-Integration | -1.8% | Global, am stärksten ausgeprägt bei Multi-Vendor-Bereitstellungen außerhalb Nordamerikas | Kurzfristig (≤ 2 Jahre) |
| Fragmentierung der Software-Orchestrierung über GPU-Stacks hinweg | -1.4% | Global, besonders einschränkend bei Unternehmens- und Schwellenmarktbereitstellungen | Mittelfristig (2–4 Jahre) |
| Kapitalintensität der Nachrüstung veralteter Rechenzentren | -1.1% | Europa und Südamerika, wo der veraltete Colocation-Bestand erheblich ist | Mittelfristig (2–4 Jahre) |
| Latenz-Kompromisse bei Remote-Speicher und disaggregiertem Zugriff | -0.8% | Global, am kritischsten für latenzempfindliche Inferenz-Workloads | Kurzfristig (≤ 2 Jahre) |
| Quelle: Mordor Intelligence | |||
Hohe Komplexität bei der Interconnect- und Fabric-Integration
Der disaggregierte GPU-Markt steht noch vor einer erheblichen Integrationsbarriere, da viele Bereitstellungen NVLink, PCIe, InfiniBand, Ethernet und CXL innerhalb eines einzigen Clusters koordinieren müssen. Auf der HotNets 2025 vorgestellte Forschungsergebnisse zeigten, dass ein effektives Pfadmanagement über intra-host heterogene Interconnects die gleichzeitige Koordination von PCIe-Switches, GPU-Fabric-Controllern, RDMA-NICs und Ethernet-Switches erfordert, und aktuelle Software-Stacks abstrahieren diese Komplexität nicht vollständig. NVIDIAs NVLink Fusion reduzierte einen Teil dieses Problems, indem es benutzerdefinierten CPUs von MediaTek, Marvell, Qualcomm und Fujitsu ermöglichte, sich nativ mit NVIDIA-GPUs zu verbinden, aber dieser Schritt erweiterte einen proprietären Pfad, anstatt ein vollständig neutrales Multi-Vendor-Fabric zu schaffen. Der Ultra Accelerator Link-Standard soll eine herstellerneutrale Alternative bieten, doch die Eingaben deuten darauf hin, dass Produktionshardware nicht vor Ende 2026 erwartet wurde und breite Bereitstellungen sich wahrscheinlich bis 2027 erstrecken werden. Der disaggregierte GPU-Markt steht in China auch vor einer regionalen Interoperabilitätsobergrenze, wo inländische Beschleuniger-Ökosysteme inkompatible Kommunikationsprotokolle verwenden, was die praktischen Pooling-Vorteile einschränkt, die Betreiber im großen Maßstab erzielen können.
Fragmentierung der Software-Orchestrierung über GPU-Stacks hinweg
Das Fehlen einer einheitlichen Orchestrierungsschicht über heterogene GPU-Umgebungen hinweg hemmt auch den disaggregierten GPU-Markt. Forschungen zur fragmentierungsbewussten Planung zeigten, dass Multi-Mandanten-Scheduler noch verschiedene Speicherisolierungs- und Partitionierungsansätze über Vendor-Stacks hinweg in Einklang bringen müssen, was den Integrationsaufwand erhöht und Bereitstellungszeitpläne verlängert. Auf der USENIX ATC 2025 vorgestellte Arbeiten zeigten, dass räumlich-zeitliche GPU-Orchestrierung auf Kernel-Ebene eine detaillierte Kontrolle über herstellerspezifische Befehlspuffer und Kontextverwaltung erfordert, ohne dass heute eine standardisierte herstellerübergreifende Logik-Fabric oder Planungssemantik vorhanden ist.[2]Shulai Zhang et al., "Effizientes leistungsbewusstes GPU-Sharing mit Kompatibilität und Isolation durch Kernel-Space-Interception," USENIX ATC 2025, usenix.org Das macht flottenweit disaggregierte Bereitstellungen für Hyperscaler mit großen Plattform-Engineering-Teams einfacher und für Unternehmenskäufer, die gemischte GPU-Bestände verwalten und eine gemeinsame Betriebsschicht benötigen, deutlich schwieriger. Der disaggregierte GPU-Markt wird daher mittelfristig wahrscheinlich weiterhin die größten Betreiber bevorzugen, da die Standardisierungsarbeit noch in einem frühen Stadium ist und proprietäre Ökosysteme wenig Anreiz haben, schnell zu konvergieren.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Komponente: Hardware führt bei frühen Ausgaben, während Software an wiederkehrendem Gewicht gewinnt
Hardware machte 2025 81,32 % des disaggregierten GPU-Marktes aus, was die hohen Vorabkosten für Interconnect-Fabrics, Switch-Trays, Speichermodule und Rack-Scale-Compute-Systeme widerspiegelt. Jedes Vera Rubin NVL72-Rack kombinierte 72 Blackwell-GPUs, 36 Vera-CPUs, NVLink-Switch-Chips, BlueField-4-DPUs und Spectrum-X-Ethernet-Netzwerke in einer einzigen fabric-basierten Kapitaleinheit, wodurch die frühen Ausgaben im disaggregierten GPU-Markt auf große Hyperscale-Beschaffungszyklen konzentriert blieben. Dieses Beschaffungsmodell ist bedeutsam, da Käufer keine isolierten Karten oder Server erwerben, sondern sich zu eng integrierten Plattformen verpflichten, die Compute-, Netzwerk- und Verwaltungsfähigkeiten innerhalb eines einzigen Bereitstellungsereignisses bündeln. Der disaggregierte GPU-Markt zeigt daher in seiner aktuellen Phase einen hardware-lastigen Umsatzmix, insbesondere da Hyperscaler neue KI-Kapazitäten in vollständigen Racks aufbauen und nicht durch schrittweise Knoten-für-Knoten-Ergänzungen. Dienste blieben die kleinste Komponentenschicht, doch Integration, verwalteter Betrieb und GPU-as-a-Service-Lieferung trugen für Systemintegratoren und spezialisierte Cloud-Betreiber noch attraktives Margenpotentzial.
Software wird voraussichtlich die schnellste CAGR von 34,08 % von 2026 bis 2031 im disaggregierten GPU-Markt verzeichnen, da Orchestrierungsschichten, Isolierungstools und Inferenz-Frameworks zunehmend den Wert bestimmen, den Betreiber aus jeder GPU ziehen. NVIDIA Dynamo trennte Prefill- und Decode-Zuweisungen, um die Auslastung auf Fabrikebene zu steigern, und dieses Design setzte einen Referenzpunkt, den Open-Source-Alternativen wie llm-d nun für Unternehmensbereitstellungen erreichen müssen. Dies verändert das Umsatzmuster der disaggregierten GPU-Branche, da Software-Upgrades auch dann fortgesetzt werden können, wenn Hardware-Erneuerungszyklen sich verlangsamen oder wenn installiertes Fabric an Ort und Stelle bleibt. Betreiber, die disaggregierte Hardware in 2024 und 2025 installiert haben, werden wahrscheinlich neue Orchestrierungsschichten hinzufügen, bevor sie physische Interconnect-Assets ersetzen, was einen Pfad für wiederkehrende Software-Einnahmen schafft, der weniger an den Zeitpunkt des Rack-Austauschs gebunden ist. Im Laufe der Zeit sollte diese Dynamik Software eine größere Rolle im disaggregierten GPU-Markt geben, auch wenn Hardware weiterhin die absoluten Ausgaben verankert.



Nach Beschleunigertyp: NVLink setzt den aktuellen Maßstab, während CXL die Architektur erweitert
NVLink/NVSwitch-basierte Disaggregation hielt 2025 einen Anteil von 44,21 % am disaggregierten GPU-Markt, was NVIDIAs starke Position in KI-Trainings-Fabrics und die installierte Präferenz für eng gekoppelte GPU-Kommunikation widerspiegelt. Die sechste NVLink-Generation lieferte 2024 1,8 TB/s pro GPU, und neuere NVLink-Switch-Systeme ermöglichten All-to-All-Kommunikation über 72 GPUs mit 130 TB/s aggregierter Bandbreite, was dem disaggregierten GPU-Markt eine Hochleistungsoption für Scale-up-Cluster bietet, die dichte lokale Kommunikation benötigen. PCIe-basierte Disaggregation behielt eine dauerhafte Rolle als Basis-Fabric in vielen Multi-GPU-Systemen und bot breite Kompatibilität ohne das gleiche Maß an proprietärer Abhängigkeit. InfiniBand- und Ethernet-basierte Ansätze blieben in Scale-out-Umgebungen relevant, und Ethernet gewann insbesondere dort an Bedeutung, wo Betreiber große KI-Cluster durch den Aufbau auf bestehenden Netzwerkinvestitionen erweitern wollten. Diese Aufteilung bedeutet, dass der disaggregierte GPU-Markt sich nicht auf ein universelles Fabric zubewegt, sondern auf ein geschichtetes Modell, bei dem Leistung, Offenheit und installierte Infrastruktur jeweils die endgültige Architektur beeinflussen.
CXL-basierte Disaggregation wird bis 2031 voraussichtlich mit einer CAGR von 34,46 % wachsen, unterstützt durch CXL 3.0-Speicher-Pooling und die CXL 4.0-Spezifikation, die die Bandbreite über physische PCIe 7.0-Schichten auf 128 GT/s verdoppelte und gebündelte Ports für einen viel höheren Gesamtdurchsatz einführte. Forschungen in Tsinghua Science and Technology zeigten, dass CXL-Speicher-Disaggregation und GPU-Compute-Disaggregation verschiedene Schichten des Stacks bedienen, was darauf hindeutet, dass zukünftige Bereitstellungen im disaggregierten GPU-Markt sie kombinieren werden, anstatt eine Wahl zwischen ihnen zu erzwingen. Samsung Electronics entwickelt seine Pangea CXL-Speicherplattform mit Marvell und Liquid AI, um GPU-Speicher zu erweitern, wo HBM-Grenzen Inferenz-Batch-Größen und die Tiefe des Arbeitskontexts einschränken können. In der Praxis ist NVLink gut für eng gekoppelte GPU-zu-GPU-Kommunikation innerhalb des Racks geeignet, während CXL die Speicherkapazität und gemeinsame Speichernutzung über Knoten und breitere Systemdomänen hinweg erweitert. Diese komplementäre Beziehung sollte dem disaggregierten GPU-Markt helfen, zu kompositionsfähigeren Architekturen zu reifen, ohne die Rolle der bereits in Produktionsclustern etablierten Hochbandbreiten-GPU-Fabrics zu verringern.
Nach Bereitstellungsmodus: Cloud-Lieferung prägt Standards, während On-Premise strategische Nachfrage hält
Cloud-basierte Bereitstellung hielt 2025 einen Anteil von 61,77 % an der disaggregierten GPU-Marktgröße, und dasselbe Segment wird bis 2031 voraussichtlich die schnellste CAGR von 33,87 % verzeichnen. AWS führte disaggregierte Inferenz auf SageMaker HyperPod und Amazon EKS durch llm-d und die NVIDIA Inference Xfer Library ein, nutzte Elastic Fabric Adapter, um KV-Cache-Daten zwischen disaggregierten Knoten zu verschieben, und lieferte auf Blackwell-basierten Instanzen bis zu 70 % mehr Token pro Sekunde als bei Standardbereitstellungen. Google Cloud setzte ein weiteres Signal, als es erklärte, dass Virgo bis zu 80.000 Vera Rubin NVL72-GPUs in einem einzigen Rechenzentrum verbinden und über 960.000 GPUs über mehrere Standorte hinweg erweitern kann, was die Rolle der Hyperscaler bei der Festlegung des Betriebsmodells für den disaggregierten Grafikprozessor (GPU)-Markt unterstreicht. Der Vorteil der Cloud-Lieferung liegt nicht nur in der Skalierung, sondern auch in der Fähigkeit, Kühl-, Fabric-Konfigurations- und Orchestrierungskomplexität hinter verwalteten Diensten zu verbergen. Deshalb neigt der disaggregierte GPU-Markt weiterhin zu Cloud-Plattformen, insbesondere für Käufer, die Zugang zu fortschrittlicher KI-Kapazität benötigen, aber keine spezialisierte Infrastruktur selbst aufbauen und betreiben möchten.
On-Premise-Bereitstellung ist im disaggregierten GPU-Markt für Unternehmen und Organisationen des öffentlichen Sektors weiterhin relevant, die sensible Workloads nicht in gemeinsam genutzte öffentliche Cloud-Umgebungen verlagern können. Die Eingaben zeigen, dass Unternehmenskäufer preissensibler sind als Hyperscaler und disaggregierte Architekturen in der Regel erst dann einführen, wenn Cloud-Betreiber sie im großen Maßstab validiert haben, was die On-Premise-Nachfrage auf einen langsameren, aber dennoch wichtigen Pfad drängt. Regierungs- und Verteidigungsorganisationen bilden eine separate On-Premise-Kohorte, da souveräne KI-Programme und nationale Sicherheitsregeln häufig luftgespaltene oder jurisdiktionsgebundene Compute-Umgebungen erfordern. Datenlokalisierungsanforderungen in der Europäischen Union und Teilen des asiatisch-pazifischen Raums unterstützen ebenfalls eine Untergrenze für dedizierte Infrastruktur, auch wenn Cloud der größere und schneller wachsende Modus bleibt. Infolgedessen wird der disaggregierte GPU-Markt wahrscheinlich eine duale Struktur beibehalten, bei der Cloud-Plattformen das Innovationstempo vorgeben, während On-Premise-Bereitstellungen wichtig bleiben, wenn Compliance, Kontrolle oder Workload-Sensitivität den gemeinsamen Zugang einschränken.
Nach Anwendung: KI und HPC treiben die aktuelle Nachfrage, während Simulation neues Volumen aufbaut
KI und Hochleistungsrechnen machten 2025 72,49 % des disaggregierten GPU-Marktes aus und sind damit der primäre Treiber aktueller Bereitstellungen. Die größten Sprachmodelle und Reasoning-Systeme erfordern Speicherkapazität und Interconnect-Leistung, die die Grenzen isolierter Knoten überschreiten, sodass sich der disaggregierte GPU-Markt um Pooling und Fabric-Koordination als grundlegende Anforderungen für Frontier-Training und -Inferenz entwickelt hat. NVIDIA erklärte, dass Vera Rubin NVL72 im Vergleich zur vorherigen Grace Blackwell-Generation einen 10-fachen Agenten-Durchsatz liefern kann, was erklärt, warum Hyperscaler diese Plattformen sowohl für Trainingscluster als auch für reasoning-intensive Inferenzumgebungen einsetzen. Wissenschaftliche Forschung bleibt ebenfalls Teil dieses Segments, da Genomik, Klimamodellierung und Teilchenphysik burst-bereite Compute-Ressourcen benötigen, die im großen Maßstab bereitgestellt werden können, ohne teure GPU-Ressourcen zwischen Jobs im Leerlauf zu lassen. Dieser Mix hält den disaggregierten GPU-Markt eng an Workloads gebunden, bei denen Auslastung, Speicher-Sharing und Interconnect-Effizienz direkt die wissenschaftliche Ausgabe oder Modellleistung beeinflussen.
Digitale Zwillinge und Simulation werden von 2026 bis 2031 voraussichtlich mit einer CAGR von 34,42 % wachsen, was die breitere Nutzung GPU-beschleunigter Physikmodelle in industriellen Betrieben, Designvalidierung und autonomem Systemtraining widerspiegelt. Der disaggregierte GPU-Markt profitiert hier, da viele Simulations-Workloads kurze Perioden sehr hoher Compute-Dichte benötigen, was gepoolte Ressourcen wirtschaftlicher macht als statische Server-Zuweisungen. NVIDIA erklärte, dass seine DSX-Plattform die Bereitstellungszeit von KI-Fabriken von Monaten auf Tage reduzieren und die Zeit bis zum ersten Umsatz beschleunigen kann, und dieses kommerzielle Modell beginnt zu beeinflussen, wie industrielle Nutzer über skalierbare Simulationsinfrastruktur nachdenken. Datenanalyse, Rendering und Visualisierung bleiben etablierte Anwendungsfälle mit stetigem Wachstum, während Rendering von Echtzeit-GPU-Beschleunigung in immersiven industriellen Schnittstellen profitiert, die geringe Frame-Latenz erfordern. Zusammen verbreitern diese Muster den disaggregierten GPU-Markt über das Frontier-KI-Training hinaus und steigern die Nachfrage von Käufern, die flexible Kapazität für operative digitale Workloads schätzen.
Nach Endnutzer: Hyperscaler halten die größte Basis, während spezialisierte Clouds schneller expandieren
Hyperscale-Cloud-Anbieter hielten 2025 einen Anteil von 47,63 % und hatten damit die größte Position im disaggregierten GPU-Markt sowie einen starken Einfluss auf Architekturstandards, Bereitstellungszeitpläne und Software-Entscheidungen. AWS, Google Cloud, Microsoft Azure und Oracle Cloud Infrastructure wurden als Bereitsteller von NVIDIA Vera Rubin NVL72-Systemen in der zweiten Hälfte 2026 identifiziert, was unterstreicht, in welchem Ausmaß der disaggregierte GPU-Markt noch von Hyperscalern für die frühe Volumeneinführung abhängt. Ihre Vorreiterrolle geht über Kaufkraft hinaus, da sie auch prägen, wie Orchestrierung, Ressourcen-Pooling und verwaltete KI-Dienste für nachgelagerte Kunden verpackt werden. Unternehmen werden zu einer größeren Einführungsgruppe, nähern sich Bereitstellungen jedoch in der Regel mit engeren Budgetkontrollen, stärkerer Sensibilität gegenüber Integrationsrisiken und einer Präferenz für dedizierte Cloud- oder On-Premise-Konfigurationen, bei denen die Datenexposition begrenzt werden kann. Regierungs- und Verteidigungskäufer bleiben ebenfalls relevant, da lange Beschaffungszyklen bei souveränen Compute-Programmen noch große Vertragswerte erzielen können.
Cloud-Dienstleister werden von 2026 bis 2031 voraussichtlich die schnellste CAGR von 34,63 % im disaggregierten GPU-Markt verzeichnen, da mittelgroße Betreiber GPU-as-a-Service-Plattformen rund um Spezialisierung und Preisflexibilität aufbauen. NVIDIA identifizierte CoreWeave, Lambda, Nebius und Nscale unter den frühen Einführern von Vera Rubin und Spectrum-X Ethernet Photonics und demonstrierte damit, wie spezialisierte Clouds Kapazitäten ausbauen, um Trainings- und Inferenznachfrage jenseits der größten Hyperscaler-Plattformen zu bedienen. Ihre Position ist vielversprechend, aber auch exponiert, da sinkende Kosten pro Token bei Hyperscalern die Mietmargen komprimieren und kleinere Anbieter zwingen können, sich durch verwaltete Dienste und Anwendungsschicht-Support zu differenzieren. Telekommunikationsanbieter treten ebenfalls als edge-fokussierte Nutzer disaggregierter GPU-Systeme auf, während Forschungs- und akademische Einrichtungen eine kleinere Umsatzrolle spielen, aber dazu beitragen, Software-Barrieren durch Open-Source-Orchestrierungsarbeit wie llm-d und verwandte Kubernetes-native Werkzeuge zu senken. Diese Kombination aus dominanten Hyperscalern, schnell agierenden spezialisierten Clouds und gezielten öffentlichen und privaten Käufern gibt dem disaggregierten GPU-Markt eine sich verbreiternde Nachfragebasis, ohne seine Abhängigkeit von einigen wenigen sehr großen Betreibern zu verringern.
Geografische Analyse
Nordamerika hielt 2025 einen Anteil von 52,71 % und damit den größten regionalen Anteil am disaggregierten GPU-Markt, was die Tiefe der Hyperscale-Ausbauten in den USA widerspiegelt. AWS, Google Cloud, Microsoft Azure und Oracle Cloud Infrastructure wurden alle als Bereitsteller von NVIDIA Vera Rubin NVL72-Systemen in der zweiten Hälfte 2026 genannt, und diese Konzentration führender Käufer verankert den disaggregierten GPU-Markt weiterhin in der Region. Nordamerika profitiert auch von einem dichten Hardware-Ökosystem, bedeutender KI-Forschungsaktivität und einer ausgereiften GPU-Cloud-Schicht, einschließlich Anbietern wie CoreWeave, Lambda und Nscale. NVIDIAs Zusammenarbeit mit Intel im September 2025 zur Entwicklung benutzerdefinierter KI-Rechenzentrum-CPUs auf Basis von NVLink und x86 vertiefte regionale Lieferketten und ermöglichte eine stärkere Integration zwischen Orchestrierungs-CPUs und GPU-Fabrics.[3]Intel Corporation, "Intel und NVIDIA entwickeln gemeinsam KI-Infrastruktur und Personal-Computing-Produkte," Intel Newsroom, newsroom.intel.com Kanada bietet Unterstützung durch die Nähe zur US-Hyperscale-Nachfrage und günstige Energiewirtschaft, während Südamerika noch in einem früheren Stadium ist und eher an Hyperscale-Verfügbarkeitszonen in Brasilien und Kolumbien als an breiten On-Premise-Bereitstellungen gebunden ist.
Europa hielt einen bedeutenden, aber kleineren Anteil am disaggregierten GPU-Markt, wobei Deutschland, das Vereinigte Königreich und Frankreich die wichtigsten Bereitstellungszentren in den Nutzereingaben waren. Die Energieeffizienzrichtlinie der Europäischen Union schreibt die Berichterstattung über die Energieeffizienz von Rechenzentren mit einer IT-Last über 500 kW vor, was effizientere, disaggregierte Designs unterstützt und von Betreibern messbare Anlagenleistung verlangt. Deutschlands Automobil- und Präzisionsfertigungsbasis unterstützt die Nachfrage nach digitalen Zwillings- und Physiksimulations-Workloads, bei denen Burst-Compute durch gepoolte Infrastruktur leichter zu rechtfertigen ist als durch feste Server-Zuweisungen. Das Vereinigte Königreich trägt durch ein aktives GPU-Cloud-Segment bei, während Frankreich und Italien souveräne KI-Compute-Programme ausweiten, die disaggregierte GPU-Kapazität einbeziehen.
Der asiatisch-pazifische Raum wird zwischen 2026 und 2031 voraussichtlich mit einer CAGR von 34,39 % wachsen und damit die schnellste Wachstumsrate im disaggregierten GPU-Markt während des Prognosezeitraums aufweisen. Die Region wird durch Chinas Hyperscale-KI-Ausgaben, Südkoreas vertikal integrierte Speicher-Lieferkette, Japans Fertigungs- und Automatisierungsbedarf sowie öffentliche KI-Infrastrukturprogramme in Indien und Singapur angetrieben. China baut inländische disaggregierte Architekturen rund um proprietäre Interconnect-Ansätze auf und schafft damit eine gespaltene regionale Struktur, in der chinesische Stacks sich von denen unterscheiden, die anderswo im disaggregierten GPU-Markt verwendet werden. Südkorea profitiert von SK Hynix's Position bei der HBM3e-Produktion, was inländischen Betreibern einen früheren Zugang zu Speicher-Subsystemen ermöglicht und eine schnellere Kapitalbereitstellung in Rechenzentren unterstützt. Indien bewegt sich ebenfalls schnell, da staatlich geförderte KI-Initiativen und Hyperscale-Cloud-Zonen expandieren, während der Nahe Osten und Afrika noch früher in der Entwicklung sind, aber durch souveräne KI-Investitionsprogramme in den Vereinigten Arabischen Emiraten und Saudi-Arabien Unterstützung erhalten.

Wettbewerbslandschaft
Der disaggregierte GPU-Markt ist in der Hardware-Interconnect-Schicht nach wie vor stark konzentriert, während Software und Dienste über Orchestrierungsanbieter, GPU-Cloud-Anbieter und Integrationsspezialisten viel stärker fragmentiert sind. NVIDIA gibt weiterhin das Tempo im disaggregierten GPU-Markt vor, da sein NVLink-Ökosystem, Rack-Scale-Plattformen und Produktionsreichweite ihm einen starken Vorteil verschaffen, wo Käufer bewährte Scale-up-Fabrics und koordinierte Hardware-Stacks benötigen. Die Einführung von NVLink Fusion im Mai 2025 war ein bemerkenswerter strategischer Schritt, da er benutzerdefinierten Silizium-Lösungen von MediaTek, Marvell, Qualcomm, Fujitsu und anderen ermöglichte, sich nativ mit NVIDIA-GPUs zu verbinden, und das adressierbare Ökosystem für semi-benutzerdefinierte KI-Infrastruktur erweiterte. Dieser Schritt reduzierte NVIDIAs Abhängigkeit von proprietärer Technologie nicht, machte aber NVIDIAs Fabric für das Systemdesign über eine breitere Gruppe von Partnern hinweg zentraler. In der Praxis gibt der disaggregierte GPU-Markt NVIDIA noch die stärkste Position, wo Hardware-Leistung und Ökosystem-Reife am meisten zählen.
AMD baut seine Position im disaggregierten Grafikprozessor (GPU)-Markt über einen anderen Weg auf, der die Helios-Rack-Scale-Plattform mit dem offenen ROCm-Software-Stack und einer breiteren Lieferantenbasis kombiniert. Die Entscheidung vom Mai 2026, mehr als 10 Milliarden USD in das Taiwan-Ökosystem zu investieren, war ein weiterer wichtiger strategischer Schritt, da er eine mehrjährige Bemühung signalisierte, die Hardware-Produktionslücke zu schließen und die Rack-Scale-Ausführung durch regionale Fertigungspartner zu stärken.[4]Advanced Micro Devices, Inc., "AMD kündigt mehr als 10 Milliarden USD an Investitionen im Taiwan-Ökosystem an, um die KI-Infrastruktur zu beschleunigen," AMD Investor Relations, ir.amd.com Intels Rolle ist asymmetrischer, da es die GPU-Fabric-Schicht nicht anführt, aber in der Orchestrierungs-CPU-Position innerhalb heterogener Systeme Wert findet. Dieser Ansatz war auf der Computex 2026 erkennbar, wo Intel Xeon 6 die Orchestrierung über einen Drei-Anbieter-disaggregierten Inferenz-Stack mit SambaNova und NVIDIA in einem einzigen kommerziellen Bereitstellungsbeispiel ermöglichte. Diese Schritte zeigen, dass der disaggregierte GPU-Markt auf Plattformebene wettbewerbsfähig ist, auch wenn das Kern-Hardware-Fabric konzentriert bleibt.
Der größte offene Bereich im disaggregierten GPU-Markt ist die Multi-Vendor-Orchestrierung, da es noch keine weit verbreitete kommerzielle Plattform gibt, die Workloads konsistent über NVLink, CXL, InfiniBand und Ethernet hinweg plant. Aufstrebende Akteure wie Exostellar, die mit Vultr zusammenarbeiten, zielen auf diese Lücke mit Workload-Ebenen-Orchestrierung über geografisch verteilte, heterogene GPU-Flotten ab, während Server-Anbieter wie Dell Technologies, Hewlett Packard Enterprise, Supermicro und Lenovo durch Systemintegration, Flüssigkeitskühlung und verwaltete Infrastrukturdienste konkurrieren. Standardisierungsaktivitäten sind ebenfalls wichtig, da jeder Weg zu offeneren disaggregierten Fabrics beeinflussen würde, wie Unternehmen und Regierungen Anbieterabhängigkeit und langfristige Beschaffung bewerten. Derzeit unterstützt der disaggregierte GPU-Markt eine geschichtete Wettbewerbsstruktur, bei der eine kleine Anzahl von Hardware-Führern die Kernarchitektur beeinflusst, während ein viel breiteres Feld darum konkurriert, Bereitstellung, Orchestrierung und Dienstleistungserbringung zu kontrollieren.
Führende Unternehmen im disaggregierten GPU-Markt
-
NVIDIA Corporation
-
Advanced Micro Devices, Inc.
-
Intel Corporation
-
Qualcomm Incorporated
-
Apple Inc.
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Jüngste Branchenentwicklungen
- Juni 2026: Amazon Web Services kündigte die allgemeine Verfügbarkeit von EC2 G7-Instanzen an, die von NVIDIA RTX PRO 4500 Blackwell Server Edition-GPUs angetrieben werden und bis zu 4,6-fache KI-Inferenzleistung der vorherigen G6-Generation liefern. Instanzen verfügen über bis zu 700 Gbps Elastic Fabric Adapter-Netzwerkbandbreite und unterstützen disaggregierte KI-Inferenz, Sprachübersetzung und groß angelegte Bildanalyse-Workloads.
- Mai 2026: NVIDIA gab bekannt, dass die Vera Rubin-Plattform in 350 Fabriken in 30 Ländern in die Vollproduktion eingetreten ist, wobei AWS, Google Cloud, Microsoft Azure und Oracle Cloud Infrastructure als bestätigte Bereitsteller für die zweite Hälfte 2026 genannt wurden. Die Plattform führte Spectrum-X Ethernet Photonics ein, die ersten co-packaged-optics Ethernet-Switches der Branche in der Produktion, die eine 5-fache Energieeffizienz gegenüber herkömmlichen Transceivern liefern und Millionen-GPU-KI-Fabrik-Bereitstellungen ermöglichen.
- Mai 2026: AMD kündigte 10 Milliarden USD an Investitionen im Taiwan-Ökosystem an, um die Helios-Rack-Scale-Plattform mit MI450X-GPUs und 6. Gen EPYC Venice-CPUs mit branchenerstmaliger 2,5D-Elevated-Fanout-Bridge-Verpackung zu skalieren. ODM-Partner Sanmina, Wiwynn, Wistron und Inventec skalieren die Produktion für Multi-Gigawatt-Bereitstellungen, die für die zweite Hälfte 2026 angestrebt werden.
- Mai 2026: Vector Core Compute, unterstützt von Vista Equity Partners und Cambium Capital, brachte auf der Computex 2026 kommerziell das erste disaggregierte Inferenzsystem auf den Markt und setzte Intel Xeon 6 für die Orchestrierung, SambaNova SN40 RDUs für die Decode-Phase und NVIDIA Blackwell-GPUs für die Prefill-Phase aus einem Rechenzentrum in Los Angeles ein. Together.ai wurde als erster kommerzieller Kunde angekündigt.


Globaler Disaggregierter GPU-Markt – Berichtsumfang
Der Disaggregierte GPU-Markt umfasst Hardware, Software und Dienste, die es ermöglichen, Grafikprozessoren (GPUs) von traditionellen Server-Architekturen zu entkoppeln und dynamisch über mehrere Compute-Ressourcen durch Hochgeschwindigkeits-Interconnects und Netzwerk-Fabrics zuzuweisen. Disaggregierte GPU-Architekturen ermöglichen es Organisationen, GPU-Ressourcen unabhängig von physischen Server-Grenzen zu poolen, zu teilen, zu virtualisieren und zu orchestrieren, was die Ressourcenauslastung, Skalierbarkeit, betriebliche Flexibilität und Infrastruktureffizienz in Rechenzentren, Cloud- und Hochleistungsrechenumgebungen verbessert.
Der Disaggregierte GPU-Marktbericht ist segmentiert nach Komponente (Hardware, Software und Dienste), Beschleunigertyp (PCIe-basierte Disaggregation, NVLink/NVSwitch-basierte Disaggregation, Ethernet-Fabric-basierte Disaggregation, InfiniBand-Fabric-basierte Disaggregation und CXL-basierte Disaggregation), Bereitstellungsmodus (On-Premise und Cloud), Anwendung (KI und Hochleistungsrechnen, Datenanalyse, Digitaler Zwilling und Simulation, Rendering und Visualisierung sowie Wissenschaftliche Forschung), Endnutzer (Hyperscale-Cloud-Anbieter, Cloud-Dienstleister, Unternehmen, Regierungs- und Verteidigungsorganisationen, Forschungs- und akademische Einrichtungen, Telekommunikationsanbieter) und Geografie (Nordamerika, Europa, Asiatisch-Pazifischer Raum, Südamerika sowie Naher Osten und Afrika). Die Marktprognosen werden in Wertangaben (USD) bereitgestellt.
| Hardware |
| Software |
| Dienste |
| PCIe-basierte Disaggregation |
| NVLink/NVSwitch-basierte Disaggregation |
| Ethernet-Fabric-basierte Disaggregation |
| InfiniBand-Fabric-basierte Disaggregation |
| CXL-basierte Disaggregation |
| On-Premise |
| Cloud-basiert |
| KI und Hochleistungsrechnen |
| Datenanalyse |
| Digitaler Zwilling und Simulation |
| Rendering und Visualisierung |
| Wissenschaftliche Forschung |
| Hyperscale-Cloud-Anbieter |
| Cloud-Dienstleister |
| Unternehmen |
| Regierungs- und Verteidigungsorganisationen |
| Forschungs- und akademische Einrichtungen |
| Telekommunikationsanbieter |
| Nordamerika | Vereinigte Staaten |
| Kanada | |
| Mexiko | |
| Europa | Deutschland |
| Vereinigtes Königreich | |
| Frankreich | |
| Italien | |
| Übriges Europa | |
| Asiatisch-Pazifischer Raum | China |
| Japan | |
| Südkorea | |
| Indien | |
| Südostasien | |
| Übriger asiatisch-pazifischer Raum | |
| Südamerika | |
| Naher Osten und Afrika |
| Nach Komponente | Hardware | |
| Software | ||
| Dienste | ||
| Nach Beschleunigertyp | PCIe-basierte Disaggregation | |
| NVLink/NVSwitch-basierte Disaggregation | ||
| Ethernet-Fabric-basierte Disaggregation | ||
| InfiniBand-Fabric-basierte Disaggregation | ||
| CXL-basierte Disaggregation | ||
| Nach Bereitstellungsmodell | On-Premise | |
| Cloud-basiert | ||
| Nach Anwendung | KI und Hochleistungsrechnen | |
| Datenanalyse | ||
| Digitaler Zwilling und Simulation | ||
| Rendering und Visualisierung | ||
| Wissenschaftliche Forschung | ||
| Nach Endnutzer | Hyperscale-Cloud-Anbieter | |
| Cloud-Dienstleister | ||
| Unternehmen | ||
| Regierungs- und Verteidigungsorganisationen | ||
| Forschungs- und akademische Einrichtungen | ||
| Telekommunikationsanbieter | ||
| Nach Geografie | Nordamerika | Vereinigte Staaten |
| Kanada | ||
| Mexiko | ||
| Europa | Deutschland | |
| Vereinigtes Königreich | ||
| Frankreich | ||
| Italien | ||
| Übriges Europa | ||
| Asiatisch-Pazifischer Raum | China | |
| Japan | ||
| Südkorea | ||
| Indien | ||
| Südostasien | ||
| Übriger asiatisch-pazifischer Raum | ||
| Südamerika | ||
| Naher Osten und Afrika | ||


Im Bericht beantwortete Schlüsselfragen
Wie groß ist der disaggregierte GPU-Markt derzeit?
Der disaggregierte GPU-Markt wurde 2025 auf 3,97 Milliarden USD bewertet, steht 2026 bei 5,34 Milliarden USD und wird bis 2031 voraussichtlich 22,63 Milliarden USD bei einer CAGR von 33,48 % erreichen.
Warum steigt die Einführung disaggregierter GPUs in der KI-Infrastruktur?
Die Einführung steigt, weil GPU-Pooling die Auslastung verbessert, agentische KI den Bedarf an Token-Durchsatz erhöht und Speicher- und Bandbreiteneinschränkungen Betreiber zu gepoolten Compute- und Speicherarchitekturen drängen.
Welche Komponente trägt heute den größten Umsatz bei?
Hardware führte 2025 mit 81,32 % des Umsatzes, da frühe Bereitstellungen große Ausgaben für Racks, Fabrics, Switches, Speichermodule und eng integrierte Compute-Systeme erforderten.
Welcher Beschleunigeransatz wächst am schnellsten?
CXL-basierte Disaggregation wird bis 2031 voraussichtlich mit einer CAGR von 34,46 % wachsen, unterstützt durch gemeinsames Speicher-Pooling und flexibleres kompositionsfähiges Systemdesign.
Welche Region expandiert am schnellsten?
Der asiatisch-pazifische Raum wird bis 2031 voraussichtlich mit einer CAGR von 34,39 % wachsen, unterstützt durch Hyperscale-KI-Ausgaben in China, HBM-Versorgungsstärke in Südkorea sowie öffentliche KI-Infrastrukturprogramme in Indien und Singapur.
Was ist das größte Hindernis für eine breitere Bereitstellung?
Die größten Einschränkungen sind die Interconnect-Komplexität, fragmentierte Orchestrierung über GPU-Stacks hinweg und die Kosten für die Anpassung von Anlagen an den Strom- und Kühlbedarf dichter KI-Racks.
Seite zuletzt aktualisiert am:




