Tamanho e Participação do Mercado de GPU Desagregada
Visão Geral do Mercado
| Período de Estudo | 2020 - 2031 |
|---|---|
| Tamanho do Mercado (2026) | 5.34 Bilhões de dólares |
| Tamanho do Mercado (2031) | 22.63 Bilhões de dólares |
| Taxa de crescimento (2026 - 2031) | 33.48% CAGR |
| Mercado de Crescimento Mais Rápido | Ásia-Pacífico |
| Maior Mercado | América do Norte |
| Concentração do Mercado | Alto |
Principais jogadores
*Isenção de responsabilidade: Principais participantes classificados em nenhuma ordem específica Imagem © Mordor Intelligence. O reuso requer atribuição conforme CC BY 4.0. |
|
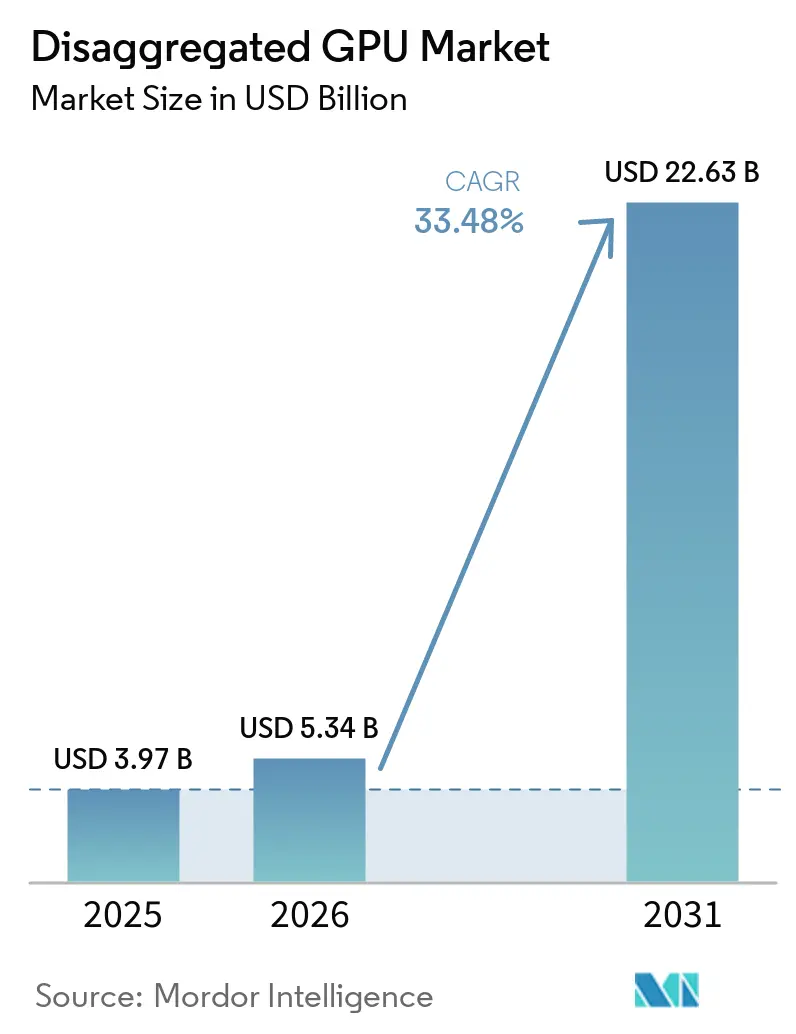
Análise do Mercado de GPU Desagregada pela Mordor Intelligence
O tamanho do mercado de GPU desagregada está projetado em 3,97 bilhões de USD em 2025, 5,34 bilhões de USD em 2026, e deve atingir 22,63 bilhões de USD até 2031, crescendo a um CAGR de 33,48% de 2026 a 2031. O mercado de GPU desagregada está em expansão à medida que as pilhas de computação de IA se afastam de designs de servidores fixos e avançam em direção a arquiteturas conectadas por malha que permitem aos operadores separar os recursos de GPU dos servidores host e alocá-los onde a demanda é maior. Grandes programas de capital da AMD e da NVIDIA, juntamente com implantações confirmadas pelas principais plataformas de nuvem, mostram que o mercado de GPU desagregada está agora vinculado à ampla reformulação de data centers, em vez de ciclos isolados de atualização de hardware. O comportamento competitivo também está mudando, pois os operadores estão dando maior ênfase à utilização, orquestração e eficiência em escala de rack do que simplesmente adicionando mais aceleradores. O mercado de GPU desagregada também se beneficia do surgimento de cargas de trabalho de IA agêntica, que exercem maior pressão sobre o rendimento de tokens, o movimento do cache KV e a coordenação de baixa latência entre os estágios de pré-preenchimento e decodificação. Ao mesmo tempo, controles de exportação, lacunas de interoperabilidade e a densidade de energia dos racks de IA modernos estão mantendo o crescimento desigual, favorecendo operadores com infraestrutura construída para esse fim e forte profundidade de engenharia.
Principais Conclusões do Relatório
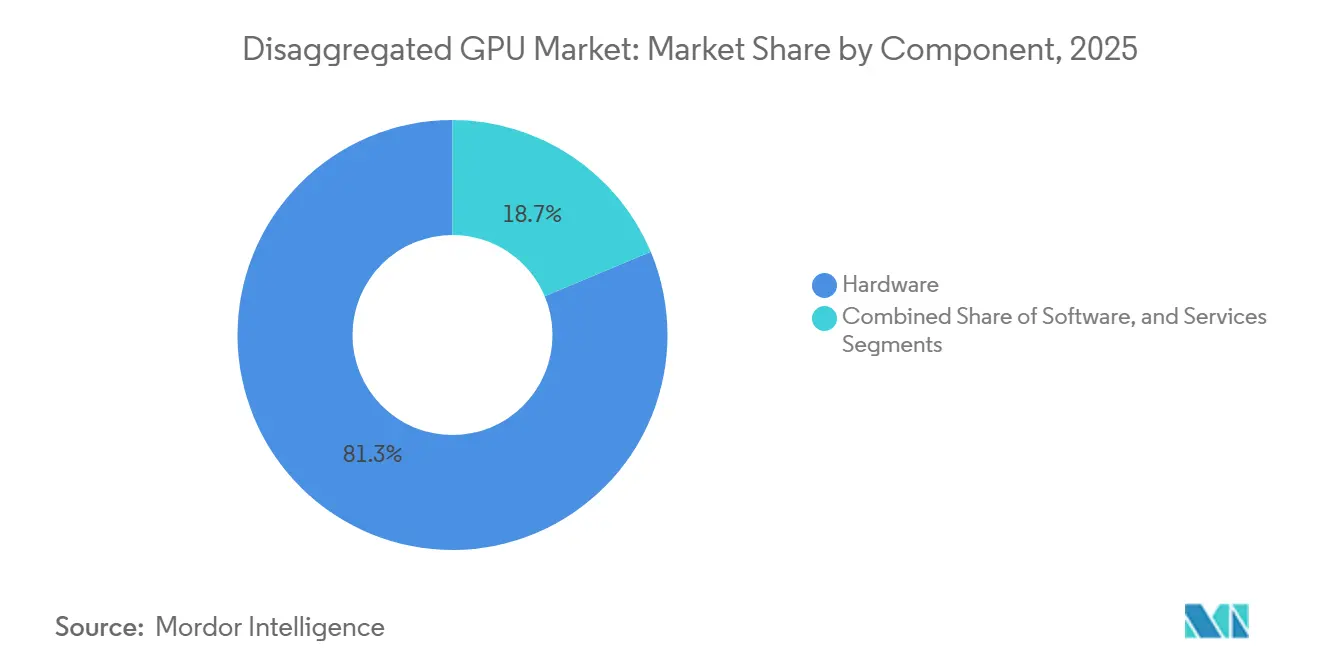
- Por componente, o hardware liderou com 81,32% de participação na receita em 2025, enquanto o software está projetado para expandir a um CAGR de 34,08% até 2031 no mercado de GPU desagregada.
- Por tipo de acelerador, a desagregação baseada em NVLink/NVSwitch detinha 44,21% de participação em 2025, enquanto a desagregação baseada em CXL está projetada para expandir a um CAGR de 34,46% até 2031.
- Por modo de implantação, a implantação baseada em nuvem representou 61,77% do mercado de unidade de processamento gráfico (GPU) desagregada em 2025 e está projetada para crescer a um CAGR de 33,87% até 2031.
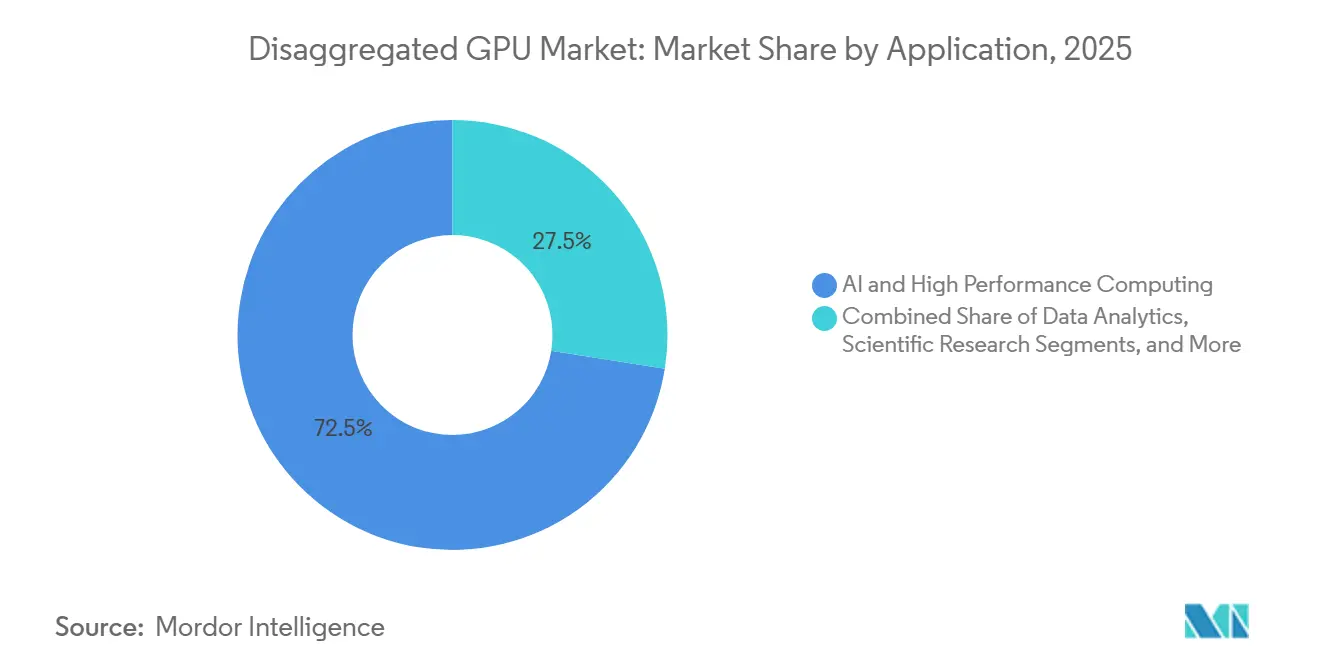
- Por aplicação, IA e computação de alto desempenho capturaram 72,49% do mercado em 2025, enquanto gêmeo digital e simulação estão projetados para expandir a um CAGR de 34,42% até 2031.
- Por usuário final, os provedores de nuvem em hiperescala detinham 47,63% de participação em 2025, enquanto os provedores de serviços em nuvem estão projetados para registrar o maior CAGR de 34,63% até 2031.
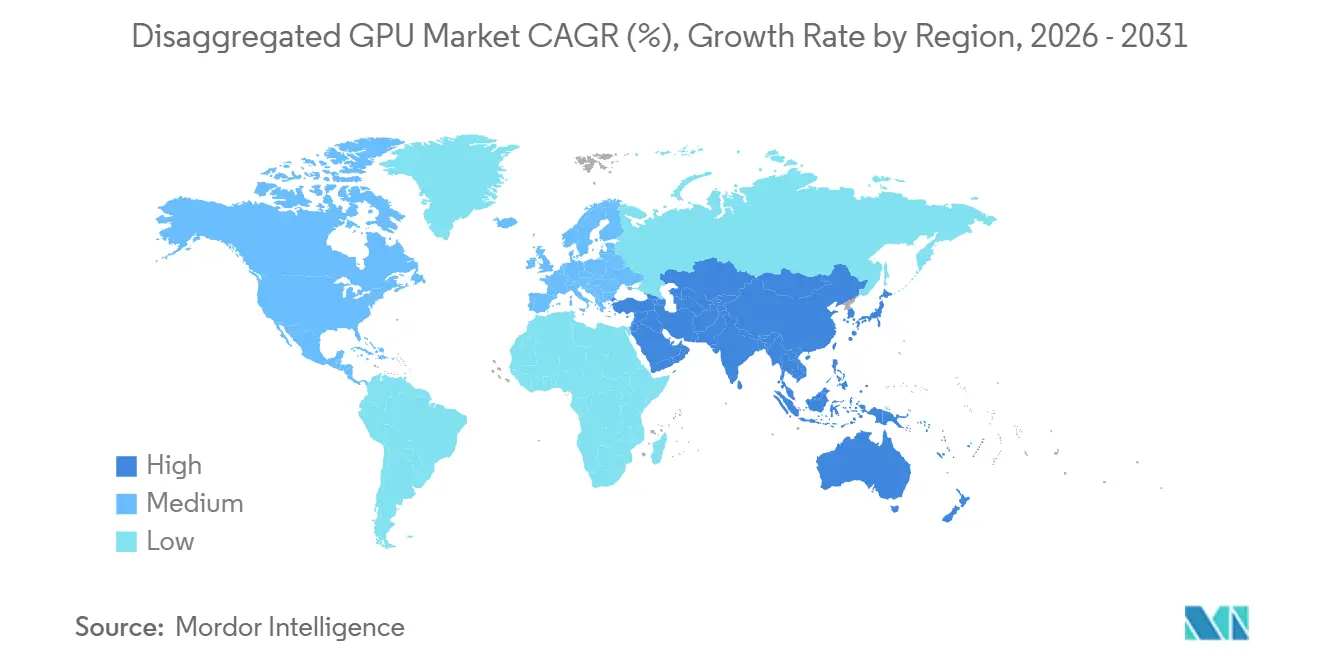
- Por geografia, a América do Norte detinha 52,71% da participação do mercado de GPU desagregada em 2025, enquanto a Ásia-Pacífico está projetada para expandir a um CAGR de 34,39% até 2031.
Nota: O tamanho do mercado e os números de previsão neste relatório são gerados usando a estrutura de estimativa proprietária da Mordor Intelligence, atualizada com os dados e percepções mais recentes disponíveis em janeiro de 2026.
Tendências e Perspectivas do Mercado Global de GPU Desagregada
Análise de Impacto dos Impulsionadores*
| Impulsionador | (~) % de Impacto na Previsão de CAGR | Relevância Geográfica | Horizonte de Impacto |
|---|---|---|---|
| Demanda Crescente por Agrupamento de GPU em Clusters de Treinamento de IA | +10.2% | Global, concentrado nos hubs de hiperescala da América do Norte e Ásia-Pacífico | Curto prazo (≤ 2 anos) |
| Mudança em Direção a Arquiteturas de Computação e Memória Separadas | +8.5% | Global, com adoção de CXL ancorada na América do Norte e no Leste Asiático | Médio prazo (2-4 anos) |
| Expansão de Infraestrutura de IA em Hiperescala e Nativa de Nuvem | +7.3% | Global, com América do Norte e Ásia-Pacífico liderando a implantação de capital | Curto prazo (≤ 2 anos) |
| Ganhos de Eficiência Energética e Térmica por Meio da Desagregação de Recursos | +4.8% | Global, acelerado pelas regulamentações de energia da UE e restrições de energia na Ásia-Pacífico | Médio prazo (2-4 anos) |
| Utilização Mais Rápida da Frota por Meio da Alocação de GPU para Múltiplos Inquilinos | +3.6% | Corredores de nuvem da América do Norte, Europa e Sudeste Asiático | Médio prazo (2-4 anos) |
| Ciclos de Atualização Mais Curtos em Arquiteturas de Data Center Modulares | +2.9% | Global, mais rápido nas construções de fábricas de IA greenfield da América do Norte | Longo prazo (≥ 4 anos) |
| Fonte: Mordor Intelligence | |||
Demanda Crescente por Agrupamento de GPU em Clusters de Treinamento de IA
O mercado de GPU desagregada está recebendo suporte direto do agrupamento de GPU, pois as grandes execuções de treinamento de IA agora dependem de tratar muitas GPUs físicas como um único recurso lógico compartilhado. O NVLink de sexta geração da NVIDIA entregou 1,8 TB/s de largura de banda bidirecional por GPU, e os sistemas NVLink Switch suportaram 72 GPUs em um único rack NVL72, entregando 130 TB/s de largura de banda agregada no domínio, reduzindo os limites de comunicação que costumavam separar racks adjacentes em ilhas de computação isoladas.[1]NVIDIA Developer Blog, "Escalando o Desempenho e a Flexibilidade de Inferência de IA com NVIDIA NVLink e NVLink Fusion," NVIDIA Developer Blog, developer.nvidia.com Essa mudança é importante para modelos de trilhões de parâmetros porque a pressão de memória e largura de banda agora se estende por clusters de treinamento completos, em vez de dentro de um único nó, e o mercado de GPU desagregada está respondendo com arquiteturas que permitem que a capacidade ociosa se junte a cargas de trabalho ativas muito mais rapidamente. A IA agêntica está adicionando outra camada de demanda, pois os estágios de pré-preenchimento são intensivos em computação enquanto os estágios de decodificação são intensivos em largura de banda de memória, e esse padrão exige que os pools sejam reatribuídos em segundos, em vez de por meio de ciclos de agendamento manual mais lentos. A AWS demonstrou esse modelo operacional em produção usando llm-d e a Biblioteca de Transferência de Inferência da NVIDIA em nós Blackwell, onde a inferência desagregada melhorou o rendimento em 70% em alta simultaneidade.
Mudança em Direção a Arquiteturas de Computação e Memória Separadas
O mercado de GPU desagregada também está avançando à medida que os operadores separam a computação da memória local e tratam a capacidade de memória como uma camada de infraestrutura agrupada. Pesquisa publicada na Tsinghua Science and Technology descreveu a desagregação de memória baseada em CXL como um grande passo arquitetônico para centros de computação inteligente, porque pools de memória compartilhada podem ser acessados por múltiplos nós de computação por meio de operações padrão de carregamento e armazenamento. Pesquisadores da ByteDance estenderam essa direção ao demonstrar um pool de memória compartilhada de 768 GB construído com cartões CXL Tipo 3 da Micron e um switch CXL TITAN-II, permitindo comunicação coletiva de GPU em 3 nós com GPUs NVIDIA H100 e sem alterações no código da aplicação. Isso é importante porque a inferência de contexto longo excede 1 milhão de tokens e a demanda de cache KV excede a HBM disponível em cada acelerador, tornando a adição de memória agrupada mais prática do que substituir frotas inteiras de GPU. O mercado de GPU desagregada, portanto, se beneficia do CXL não apenas como uma opção técnica, mas também como um caminho econômico para operadores que precisam de mais capacidade de memória sem forçar uma atualização completa de silício.
Expansão de Infraestrutura de IA em Hiperescala e Nativa de Nuvem
O mercado de GPU desagregada está sendo impulsionado pela escala dos gastos com infraestrutura de IA em hiperescala e nativa de nuvem, que se ampliou de projetos-piloto isolados para implantações em escala de rack e em múltiplos sites. A AMD anunciou mais de 10 bilhões de USD em investimentos no ecossistema de Taiwan em maio de 2026 para escalar sua plataforma Helios em escala de rack por meio de parceiros ODM, incluindo Sanmina, Wiwynn, Wistron e Inventec, com implantações de múltiplos gigawatts previstas para o segundo semestre de 2026. O Google Cloud também declarou que sua malha de rede Virgo foi projetada para conectar até 80.000 GPUs NVIDIA Vera Rubin NVL72 em um único data center e mais de 960.000 GPUs em múltiplos sites, ressaltando como o mercado de GPU desagregada está se tornando uma base para a expansão de data centers em vez de uma arquitetura de nicho. Ao mesmo tempo, os programas de silício personalizado na AWS, Google e Microsoft não estão eliminando a necessidade de sistemas de GPU desagregada, porque a infraestrutura de múltiplos fornecedores está emergindo ao lado deles. A Intel e a SambaNova demonstraram o modelo em 2026 com uma pilha de inferência heterogênea, onde o Intel Xeon 6 tratou da orquestração, os RDUs da SambaNova trataram da decodificação e as GPUs NVIDIA Blackwell trataram do pré-preenchimento a partir de um único data center de produção.
Ganhos de Eficiência Energética e Térmica por Meio da Desagregação de Recursos
O mercado de GPU desagregada também está sendo moldado por restrições de fornecimento de energia e resfriamento, que agora influenciam as decisões de arquitetura tanto quanto a demanda bruta de computação. A especificação Diablo do Open Compute Project, contribuída pelo Google, Meta e Microsoft em outubro de 2025, definiu designs de rack de energia desagregada que suportam racks de TI de 100 quilowatts a 1 megawatt usando entrega de 400 VDC ou 800 VDC. A NVIDIA adicionou outra alavanca de eficiência em dezembro de 2025 com os perfis de energia do Blackwell B200, entregando até 15% de economia de energia com não mais de 3% de impacto no desempenho, permitindo até 13% maior rendimento em instalações de energia fixa. A inferência desagregada com consciência de fase melhora ainda mais o cenário, porque os estágios de pré-preenchimento consomem energia de pico enquanto os estágios de decodificação têm necessidades de wattagem menores e podem ser gerenciados de forma diferente em pools de recursos separados. Pesquisas sobre a arquitetura BiScale mostraram que o DVFS coordenado entre os níveis de pré-preenchimento e decodificação desagregados reduziu a energia de decodificação em até 48% enquanto atendia às metas de serviço de latência, o que fortalece o caso operacional para o mercado de unidade de processamento gráfico (GPU) desagregada, onde os limites de energia e as metas de utilização agora se movem juntos.
Análise de Impacto das Restrições*
| Restrição | (~) % de Impacto na Previsão de CAGR | Relevância Geográfica | Horizonte de Impacto |
|---|---|---|---|
| Alta Complexidade de Integração de Interconexão e Malha | -1.8% | Global, mais aguda em implantações de múltiplos fornecedores fora da América do Norte | Curto prazo (≤ 2 anos) |
| Fragmentação da Orquestração de Software em Pilhas de GPU | -1.4% | Global, particularmente limitante em implantações empresariais e em mercados emergentes | Médio prazo (2-4 anos) |
| Intensidade de Capital na Modernização de Data Centers Legados | -1.1% | Europa e América do Sul, onde o estoque de colocalização legado é substancial | Médio prazo (2-4 anos) |
| Compensações de Latência em Memória Remota e Acesso Desagregado | -0.8% | Global, mais crítico para cargas de trabalho de inferência sensíveis à latência | Curto prazo (≤ 2 anos) |
| Fonte: Mordor Intelligence | |||
Alta Complexidade de Integração de Interconexão e Malha
O mercado de GPU desagregada ainda enfrenta uma barreira de integração significativa porque muitas implantações precisam coordenar NVLink, PCIe, InfiniBand, Ethernet e CXL dentro de um único cluster. Pesquisa apresentada no HotNets 2025 mostrou que o gerenciamento eficaz de caminhos em interconexões heterogêneas intra-host requer coordenação simultânea de switches PCIe, controladores de malha de GPU, NICs RDMA e switches Ethernet, e as pilhas de software atuais não abstraem completamente essa complexidade. O NVLink Fusion da NVIDIA reduziu parte desse problema ao permitir que CPUs personalizadas da MediaTek, Marvell, Qualcomm e Fujitsu se conectem nativamente com GPUs NVIDIA, mas esse movimento expandiu um caminho proprietário em vez de criar uma malha de múltiplos fornecedores totalmente neutra. O padrão Ultra Accelerator Link tem como objetivo oferecer uma alternativa neutra em relação ao fornecedor, mas as informações indicam que o hardware de produção não era esperado até o final de 2026 e as implantações amplas provavelmente se estenderiam até 2027. O mercado de GPU desagregada também enfrenta um teto de interoperabilidade regional na China, onde os ecossistemas de aceleradores domésticos usam protocolos de comunicação incompatíveis, limitando os benefícios práticos de agrupamento que os operadores podem alcançar em escala.
Fragmentação da Orquestração de Software em Pilhas de GPU
A falta de uma camada de orquestração unificada em ambientes de GPU heterogêneos também restringe o mercado de GPU desagregada. Pesquisas sobre agendamento com consciência de fragmentação mostraram que os agendadores de múltiplos inquilinos ainda precisam reconciliar diferentes abordagens de isolamento de memória e particionamento entre pilhas de fornecedores, aumentando o esforço de integração e estendendo os prazos de implantação. Trabalho apresentado no USENIX ATC 2025 mostrou que a orquestração espaço-temporal de GPU no nível do kernel depende de controle detalhado sobre buffers de comando e gerenciamento de contexto específicos do fornecedor, sem lógica de malha ou semântica de agendamento padronizada entre fornecedores disponível atualmente.[2]Shulai Zhang et al., "Compartilhamento Eficiente de GPU com Consciência de Desempenho com Compatibilidade e Isolamento por Meio de Interceptação no Espaço do Kernel," USENIX ATC 2025, usenix.org Isso torna a desagregação em toda a frota mais fácil para hiperescaladores com grandes equipes de engenharia de plataforma e muito mais difícil para compradores empresariais que gerenciam frotas de GPU mistas e precisam de uma camada operacional comum. O mercado de GPU desagregada, portanto, provavelmente continuará favorecendo os maiores operadores no médio prazo, porque o trabalho de padronização ainda está em seus estágios iniciais e os ecossistemas proprietários têm pouco incentivo para convergir rapidamente.
*Nossas previsões tratam os impactos dos impulsionadores e restrições como direcionais, e não aditivos. As previsões de impacto refletem o crescimento de base, os efeitos de composição e as interações entre variáveis.
Análise de Segmentos
Por Componente: O Hardware Lidera os Gastos Iniciais Enquanto o Software Ganha Peso Recorrente
O hardware representou 81,32% do mercado de GPU desagregada em 2025, refletindo os altos custos iniciais de malhas de interconexão, bandejas de switch, módulos de memória e sistemas de computação em escala de rack. Cada rack Vera Rubin NVL72 combinou 72 GPUs Blackwell, 36 CPUs Vera, chips de switch NVLink, DPUs BlueField-4 e rede Ethernet Spectrum-X em uma única unidade de capital baseada em malha, mantendo os gastos iniciais no mercado de GPU desagregada concentrados em grandes ciclos de aquisição em hiperescala. Esse modelo de aquisição é importante porque os compradores não estão adquirindo cartões ou servidores isolados; eles estão se comprometendo com plataformas estreitamente integradas que agrupam capacidades de computação, rede e gerenciamento em um único evento de implantação. O mercado de GPU desagregada, portanto, mostra uma combinação de receita com predominância de hardware em sua fase atual, especialmente à medida que os hiperescaladores constroem nova capacidade de IA em racks completos em vez de por meio de adições graduais nó a nó. Os serviços permaneceram como a menor camada de componentes, mas a integração, as operações gerenciadas e a entrega de GPU como serviço ainda carregavam potencial de margem atrativo para integradores de sistemas e operadores de nuvem especializados.
O software está projetado para registrar o CAGR mais rápido de 34,08% de 2026 a 2031 no mercado de GPU desagregada, à medida que as camadas de orquestração, ferramentas de isolamento e frameworks de inferência determinam cada vez mais o valor que os operadores extraem de cada GPU. O NVIDIA Dynamo separou as atribuições de pré-preenchimento e decodificação para elevar a utilização em escala de fábrica, e esse design estabeleceu um ponto de referência que alternativas de código aberto como o llm-d agora precisam igualar para implantações empresariais. Isso muda o padrão de receita do setor de GPU desagregada, porque as atualizações de software podem continuar mesmo quando os ciclos de atualização de hardware desaceleram ou quando a malha instalada permanece no lugar. Os operadores que instalaram hardware desagregado em 2024 e 2025 provavelmente adicionarão novas camadas de orquestração antes de substituir os ativos de interconexão física, criando um caminho para receita recorrente de software que está menos vinculada ao tempo de substituição de rack. Com o tempo, essa dinâmica deve dar ao software um papel maior no mercado de GPU desagregada, mesmo que o hardware continue a ancorar os gastos absolutos.



Por Tipo de Acelerador: O NVLink Define a Linha de Base Atual Enquanto o CXL Amplia a Arquitetura
A desagregação baseada em NVLink/NVSwitch detinha 44,21% da participação do mercado de GPU desagregada em 2025, refletindo a forte posição da NVIDIA nas malhas de treinamento de IA e a preferência instalada por comunicação de GPU estreitamente acoplada. O NVLink de sexta geração entregou 1,8 TB/s por GPU em 2024, e os sistemas NVLink Switch mais recentes permitiram comunicação all-to-all entre 72 GPUs com 130 TB/s de largura de banda agregada, oferecendo ao mercado de GPU desagregada uma opção de alto desempenho para clusters de expansão vertical que precisam de comunicação local densa. A desagregação baseada em PCIe manteve um papel duradouro como malha de base em muitos sistemas de múltiplas GPUs, oferecendo ampla compatibilidade sem o mesmo nível de dependência proprietária. As abordagens baseadas em InfiniBand e Ethernet continuaram a ser relevantes em configurações de expansão horizontal, e a Ethernet em particular ganhou relevância onde os operadores queriam estender grandes clusters de IA aproveitando os investimentos em rede existentes. Essa divisão significa que o mercado de GPU desagregada não está se movendo em direção a uma malha universal, mas em direção a um modelo em camadas no qual desempenho, abertura e infraestrutura instalada influenciam a arquitetura final.
A desagregação baseada em CXL está projetada para expandir a um CAGR de 34,46% até 2031, suportada pelo agrupamento de memória CXL 3.0 e pela especificação CXL 4.0, que dobrou a largura de banda para 128 GT/s por meio de camadas físicas PCIe 7.0 e introduziu portas agrupadas para um rendimento total muito maior. Pesquisas na Tsinghua Science and Technology mostraram que a desagregação de memória CXL e a desagregação de computação GPU servem a diferentes camadas da pilha, o que sugere que as implantações futuras no mercado de GPU desagregada as combinarão em vez de forçar uma escolha entre elas. A Samsung Electronics está desenvolvendo sua plataforma de memória CXL Pangea com a Marvell e a Liquid AI para expandir a memória de GPU, onde os limites de HBM podem restringir os tamanhos de lote de inferência e a profundidade do contexto de trabalho. Na prática, o NVLink é bem adequado para comunicação GPU a GPU estreitamente acoplada dentro do rack, enquanto o CXL estende a capacidade de memória e o compartilhamento de memória entre nós e domínios de sistema mais amplos. Esse relacionamento complementar deve ajudar o mercado de GPU desagregada a amadurecer em arquiteturas mais composíveis sem reduzir o papel das malhas de GPU de alta largura de banda já estabelecidas nos clusters de produção.
Por Modo de Implantação: A Entrega em Nuvem Molda os Padrões Enquanto o Local Mantém a Demanda Estratégica
A implantação baseada em nuvem detinha 61,77% da participação do tamanho do mercado de GPU desagregada em 2025, e o mesmo segmento está projetado para registrar o CAGR mais rápido de 33,87% até 2031. A AWS introduziu inferência desagregada no SageMaker HyperPod e no Amazon EKS por meio do llm-d e da Biblioteca de Transferência de Inferência da NVIDIA, usando o Elastic Fabric Adapter para mover dados de cache KV entre nós desagregados e entregando até 70% mais tokens por segundo em instâncias baseadas em Blackwell do que as implantações padrão. O Google Cloud adicionou outro sinal ao afirmar que o Virgo pode conectar até 80.000 GPUs Vera Rubin NVL72 em um único data center e estender para mais de 960.000 GPUs em múltiplos sites, reforçando o papel dos hiperescaladores na definição do modelo operacional para o mercado de unidade de processamento gráfico (GPU) desagregada. A vantagem da entrega em nuvem não é apenas a escala, mas também a capacidade de ocultar a complexidade de resfriamento, configuração de malha e orquestração por trás de serviços gerenciados. É por isso que o mercado de GPU desagregada continua a se inclinar para as plataformas de nuvem, especialmente para compradores que precisam de acesso a capacidade avançada de IA, mas não querem construir e operar infraestrutura especializada por conta própria.
A implantação local ainda é importante no mercado de GPU desagregada para empresas e organizações do setor público que não podem mover cargas de trabalho sensíveis para ambientes de nuvem pública compartilhada. As informações mostram que os compradores empresariais são mais sensíveis ao preço do que os hiperescaladores e geralmente adotam arquiteturas desagregadas depois que os operadores de nuvem as validaram em escala, o que coloca a demanda local em um caminho mais lento, mas ainda importante. Organizações governamentais e de defesa formam um grupo local separado, porque os programas de IA soberana e as regras de segurança nacional frequentemente exigem ambientes de computação isolados ou vinculados a jurisdições. Os requisitos de localização de dados na União Europeia e em partes da Ásia-Pacífico também sustentam um piso para infraestrutura dedicada, mesmo que a nuvem permaneça o modo maior e de crescimento mais rápido. Como resultado, o mercado de GPU desagregada provavelmente manterá uma estrutura dual, com plataformas de nuvem definindo o ritmo da inovação enquanto as implantações locais permanecem importantes quando conformidade, controle ou sensibilidade da carga de trabalho limitam o acesso compartilhado.
Por Aplicação: IA e HPC Impulsionam a Demanda Atual Enquanto a Simulação Constrói Novo Volume
IA e computação de alto desempenho representaram 72,49% do mercado de GPU desagregada em 2025, tornando-se o principal impulsionador das implantações atuais. Os maiores modelos de linguagem e sistemas de raciocínio requerem capacidade de memória e desempenho de interconexão que excedem os limites de nós isolados, portanto o mercado de GPU desagregada se desenvolveu em torno do agrupamento e da coordenação de malha como requisitos básicos para treinamento e inferência de fronteira. A NVIDIA afirmou que o Vera Rubin NVL72 pode entregar 10x o rendimento de agentes em comparação com a geração anterior Grace Blackwell, o que ajuda a explicar por que os hiperescaladores estão implantando essas plataformas tanto para clusters de treinamento quanto para ambientes de inferência com raciocínio intensivo. A pesquisa científica também permanece parte deste segmento, porque genômica, modelagem climática e física de partículas precisam de computação pronta para picos que pode ser provisionada em escala sem deixar recursos caros de GPU ociosos entre os trabalhos. Essa combinação mantém o mercado de GPU desagregada estreitamente vinculado a cargas de trabalho onde utilização, compartilhamento de memória e eficiência de interconexão afetam diretamente a produção científica ou o desempenho do modelo.
Gêmeo digital e simulação estão projetados para avançar a um CAGR de 34,42% de 2026 a 2031, refletindo o uso mais amplo de modelos de física acelerados por GPU em operações industriais, validação de design e treinamento de sistemas autônomos. O mercado de GPU desagregada se beneficia aqui porque muitas cargas de trabalho de simulação precisam de curtos períodos de densidade de computação muito alta, o que torna os recursos agrupados mais econômicos do que as alocações de servidor estáticas. A NVIDIA afirmou que sua plataforma DSX pode reduzir o tempo de implantação de fábricas de IA de meses para dias e acelerar o tempo para a primeira receita, e esse modelo comercial está começando a influenciar como os usuários industriais pensam sobre infraestrutura de simulação escalável. Análise de dados, renderização e visualização permanecem casos de uso estabelecidos com crescimento mais estável, enquanto a renderização se beneficia da aceleração de GPU em tempo real em interfaces industriais imersivas que exigem baixa latência de quadros. Juntos, esses padrões ampliam o mercado de GPU desagregada além do treinamento de IA de fronteira e aumentam a demanda de compradores que valorizam capacidade flexível para cargas de trabalho digitais operacionais.
Por Usuário Final: Os Hiperescaladores Detêm a Maior Base Enquanto as Nuvens Especializadas Expandem Mais Rapidamente
Os provedores de nuvem em hiperescala detinham 47,63% de participação em 2025, dando-lhes a maior posição no mercado de GPU desagregada e uma forte influência sobre os padrões de arquitetura, o tempo de implantação e as escolhas de software. AWS, Google Cloud, Microsoft Azure e Oracle Cloud Infrastructure foram identificados como implantadores do segundo semestre de 2026 dos sistemas NVIDIA Vera Rubin NVL72, o que reforça até que ponto o mercado de GPU desagregada ainda depende dos hiperescaladores para a adoção de volume inicial. Seu papel de pioneiro vai além do poder de compra, porque eles também moldam como a orquestração, o agrupamento de recursos e os serviços gerenciados de IA são empacotados para clientes downstream. As empresas estão se tornando um grupo de adotantes maior, mas geralmente abordam as implantações com controles orçamentários mais rígidos, maior sensibilidade ao risco de integração e preferência por configurações de nuvem dedicada ou local onde a exposição de dados pode ser limitada. Os compradores governamentais e de defesa também permanecem relevantes, pois longos ciclos de aquisição ainda podem gerar grandes valores de contrato quando os programas de computação soberana avançam.
Os provedores de serviços em nuvem estão projetados para registrar o CAGR mais rápido de 34,63% de 2026 a 2031 no mercado de GPU desagregada, à medida que os operadores de médio porte constroem plataformas de GPU como serviço em torno de especialização e flexibilidade de preços. A NVIDIA identificou CoreWeave, Lambda, Nebius e Nscale entre os primeiros adotantes do Vera Rubin e do Spectrum-X Ethernet Photonics, demonstrando como as nuvens especializadas estão expandindo a capacidade para atender à demanda de treinamento e inferência além das maiores plataformas de hiperescala. Sua posição é promissora, mas também exposta, porque a queda nos custos por token nos hiperescaladores pode comprimir as margens de aluguel e forçar os provedores menores a se diferenciarem por meio de serviços gerenciados e suporte na camada de aplicação. Os provedores de telecomunicações também estão emergindo como usuários focados em borda de sistemas de GPU desagregada, enquanto as instituições de pesquisa e acadêmicas desempenham um papel menor na receita, mas ajudam a reduzir as barreiras de software por meio de trabalho de orquestração de código aberto, como o llm-d e ferramentas nativas do Kubernetes relacionadas. Essa combinação de hiperescaladores dominantes, nuvens especializadas em rápido movimento e compradores públicos e privados direcionados dá ao mercado de GPU desagregada uma base de demanda em expansão sem reduzir sua dependência de alguns operadores muito grandes.
Análise Geográfica
A América do Norte detinha uma participação de 52,71% em 2025, dando-lhe a maior participação regional no mercado de GPU desagregada e refletindo a profundidade das construções de hiperescala nos EUA. AWS, Google Cloud, Microsoft Azure e Oracle Cloud Infrastructure foram todos nomeados como implantadores do segundo semestre de 2026 dos sistemas NVIDIA Vera Rubin NVL72, e essa concentração de compradores líderes continua a ancorar o mercado de GPU desagregada na região. A América do Norte também se beneficia de um ecossistema de hardware denso, grande atividade de pesquisa em IA e uma camada de nuvem de GPU madura, incluindo provedores como CoreWeave, Lambda e Nscale. A colaboração da NVIDIA em setembro de 2025 com a Intel para desenvolver CPUs personalizadas para data centers de IA baseadas em NVLink e x86 aprofundou as cadeias de suprimentos regionais e permitiu uma integração mais forte entre CPUs de orquestração e malhas de GPU.[3]Intel Corporation, "Intel e NVIDIA para Desenvolver Conjuntamente Infraestrutura de IA e Produtos de Computação Pessoal," Intel Newsroom, newsroom.intel.com O Canadá adiciona suporte por meio da proximidade com a demanda de hiperescala dos EUA e da economia de energia favorável, enquanto a América do Sul permanece em um estágio anterior e está mais vinculada às zonas de disponibilidade de hiperescala no Brasil e na Colômbia do que à implantação local ampla.
A Europa detinha uma participação significativa, mas menor, do mercado de GPU desagregada, com Alemanha, Reino Unido e França como os principais centros de implantação nas informações do usuário. A Diretiva de Eficiência Energética da União Europeia exige relatórios de efetividade do uso de energia para data centers com carga de TI acima de 500 kW, o que apoia designs mais eficientes e desagregados e exige que os operadores demonstrem desempenho mensurável das instalações. A base automotiva e de manufatura de precisão da Alemanha apoia a demanda por cargas de trabalho de gêmeo digital e simulação de física, onde a computação em picos é mais fácil de justificar por meio de infraestrutura agrupada do que por meio de alocações de servidor fixas. O Reino Unido contribui por meio de um segmento ativo de nuvem de GPU, enquanto França e Itália estão estendendo programas de computação de IA soberana que incorporam capacidade de GPU desagregada.
A Ásia-Pacífico está projetada para expandir a um CAGR de 34,39% entre 2026 e 2031, dando à região a taxa de crescimento mais rápida no mercado de GPU desagregada durante o período de previsão. A região está sendo impulsionada pelos gastos de IA em hiperescala da China, pela cadeia de suprimentos de memória verticalmente integrada da Coreia do Sul, pelas necessidades de manufatura e automação do Japão e pelos programas de infraestrutura de IA pública na Índia e em Singapura. A China está construindo arquiteturas desagregadas domésticas em torno de abordagens de interconexão proprietárias, criando uma estrutura regional dividida na qual as pilhas chinesas diferem das usadas em outros lugares no mercado de GPU desagregada. A Coreia do Sul se beneficia da posição da SK Hynix na produção de HBM3e, o que ajuda os operadores domésticos a garantir acesso mais antecipado aos subsistemas de memória e apoia uma implantação de capital de data center mais rápida. A Índia também está avançando rapidamente à medida que as iniciativas de IA apoiadas pelo governo e as zonas de nuvem em hiperescala se expandem, enquanto o Oriente Médio e a África permanecem em estágios anteriores de desenvolvimento, mas estão ganhando suporte de programas de investimento em IA soberana nos Emirados Árabes Unidos e na Arábia Saudita.

Cenário Competitivo
O mercado de GPU desagregada permanece altamente concentrado na camada de interconexão de hardware, enquanto software e serviços são muito mais fragmentados entre fornecedores de orquestração, provedores de nuvem de GPU e especialistas em integração. A NVIDIA continua a definir o ritmo no mercado de GPU desagregada porque seu ecossistema NVLink, plataformas em escala de rack e alcance de produção lhe conferem uma forte vantagem onde os compradores precisam de malhas de expansão vertical comprovadas e pilhas de hardware coordenadas. Seu lançamento do NVLink Fusion em maio de 2025 foi um movimento estratégico notável porque permitiu que o silício personalizado da MediaTek, Marvell, Qualcomm, Fujitsu e outros se conectasse nativamente com GPUs NVIDIA e ampliou o ecossistema endereçável para infraestrutura de IA semicustomizada. Esse movimento não reduziu a dependência da NVIDIA em tecnologia proprietária, mas tornou a malha da NVIDIA mais central ao design do sistema em um conjunto mais amplo de parceiros. Em termos práticos, o mercado de GPU desagregada ainda dá à NVIDIA a posição mais forte onde o desempenho de hardware e a maturidade do ecossistema são mais importantes.
A AMD está construindo sua posição no mercado de unidade de processamento gráfico (GPU) desagregada por meio de uma rota diferente que combina a plataforma Helios em escala de rack com a pilha de software aberta ROCm e uma base de fornecedores mais ampla. Sua decisão de maio de 2026 de comprometer mais de 10 bilhões de USD no ecossistema de Taiwan foi outro grande movimento estratégico, porque sinalizou um esforço de vários anos para reduzir a lacuna de produção de hardware e fortalecer a execução em escala de rack por meio de parceiros de manufatura regionais.[4]Advanced Micro Devices, Inc., "AMD Anuncia Mais de 10 Bilhões de USD em Investimentos no Ecossistema de Taiwan para Acelerar a Infraestrutura de IA," AMD Investor Relations, ir.amd.com O papel da Intel é mais assimétrico, pois ela não está liderando a camada de malha de GPU, mas está encontrando valor na posição de CPU de orquestração dentro de sistemas heterogêneos. Essa abordagem ficou evidente na Computex 2026, onde o Intel Xeon 6 habilitou a orquestração em uma pilha de inferência desagregada de três fornecedores com SambaNova e NVIDIA em um único exemplo de implantação comercial. Esses movimentos mostram que o mercado de GPU desagregada é competitivo no nível de plataforma, mesmo que a malha de hardware central permaneça concentrada.
A maior área aberta no mercado de GPU desagregada é a orquestração de múltiplos fornecedores, porque ainda não existe uma plataforma comercial amplamente adotada que agende consistentemente cargas de trabalho em NVLink, CXL, InfiniBand e Ethernet. Participantes emergentes como a Exostellar, trabalhando com a Vultr, estão mirando essa lacuna com orquestração no nível de carga de trabalho em frotas de GPU heterogêneas e geograficamente distribuídas, enquanto fornecedores de servidores como Dell Technologies, Hewlett Packard Enterprise, Supermicro e Lenovo competem por meio de integração de sistemas, resfriamento líquido e serviços de infraestrutura gerenciada. A atividade de padronização também é importante porque qualquer caminho em direção a malhas desagregadas mais abertas afetaria como empresas e governos avaliam o aprisionamento a fornecedores e as aquisições de longo prazo. Por enquanto, o mercado de GPU desagregada suporta uma estrutura competitiva em camadas onde um pequeno número de líderes de hardware influencia a arquitetura central, enquanto um campo muito mais amplo compete para controlar a implantação, a orquestração e a entrega de serviços.
Líderes do Setor de GPU Desagregada
-
NVIDIA Corporation
-
Advanced Micro Devices, Inc.
-
Intel Corporation
-
Qualcomm Incorporated
-
Apple Inc.
- *Isenção de responsabilidade: Principais participantes classificados em nenhuma ordem específica

Desenvolvimentos Recentes do Setor
- Junho de 2026: A Amazon Web Services anunciou a disponibilidade geral das instâncias EC2 G7 equipadas com GPUs NVIDIA RTX PRO 4500 Blackwell Server Edition, entregando até 4,6x o desempenho de inferência de IA da geração G6 anterior. As instâncias apresentam até 700 Gbps de largura de banda de rede do Elastic Fabric Adapter, suportando inferência de IA desagregada, tradução de idiomas e cargas de trabalho de análise de imagens em grande escala.
- Maio de 2026: A NVIDIA anunciou que a plataforma Vera Rubin entrou em produção total em 350 fábricas em 30 países, com AWS, Google Cloud, Microsoft Azure e Oracle Cloud Infrastructure como implantadores confirmados do segundo semestre de 2026. A plataforma introduziu o Spectrum-X Ethernet Photonics, os primeiros switches Ethernet com óptica co-empacotada do setor em produção, entregando 5x a eficiência energética em relação aos transceivers tradicionais e permitindo implantações de fábricas de IA com um milhão de GPUs.
- Maio de 2026: A AMD anunciou 10 bilhões de USD em investimentos no ecossistema de Taiwan para escalar a plataforma Helios em escala de rack com GPUs MI450X e CPUs EPYC Venice de 6ª geração com embalagem de ponte fanout elevada 2.5D inédita no setor. Os parceiros ODM Sanmina, Wiwynn, Wistron e Inventec estão escalando a produção para implantações de múltiplos gigawatts previstas para o segundo semestre de 2026.
- Maio de 2026: A Vector Core Compute, apoiada pela Vista Equity Partners e Cambium Capital, lançou comercialmente o primeiro sistema de inferência desagregada na Computex 2026, implantando Intel Xeon 6 para orquestração, SambaNova SN40 RDUs para decodificação e GPUs NVIDIA Blackwell para pré-preenchimento a partir de um data center em Los Angeles. A Together.ai foi anunciada como o primeiro cliente comercial.


Escopo do Relatório Global do Mercado de GPU Desagregada
O Mercado de GPU Desagregada compreende hardware, software e serviços que permitem que unidades de processamento gráfico (GPUs) sejam desacopladas das arquiteturas de servidor tradicionais e alocadas dinamicamente em múltiplos recursos de computação por meio de interconexões de alta velocidade e malhas de rede. As arquiteturas de GPU desagregada permitem que as organizações agrupem, compartilhem, virtualizem e orquestrem recursos de GPU independentemente dos limites físicos do servidor, melhorando a utilização de recursos, a escalabilidade, a flexibilidade operacional e a eficiência da infraestrutura em ambientes de data center, nuvem e computação de alto desempenho.
O Relatório do Mercado de GPU Desagregada é Segmentado por Componente (Hardware, Software e Serviços), Tipo de Acelerador (Desagregação Baseada em PCIe, Desagregação Baseada em NVLink/NVSwitch, Desagregação Baseada em Malha Ethernet, Desagregação Baseada em Malha InfiniBand e Desagregação Baseada em CXL), Modo de Implantação (Local e Nuvem), Aplicação (IA e Computação de Alto Desempenho, Análise de Dados, Gêmeo Digital e Simulação, Renderização e Visualização e Pesquisa Científica), Usuário Final (Provedores de Nuvem em Hiperescala, Provedores de Serviços em Nuvem, Empresas, Organizações Governamentais e de Defesa, Instituições de Pesquisa e Acadêmicas, Provedores de Telecomunicações) e Geografia (América do Norte, Europa, Ásia-Pacífico, América do Sul e Oriente Médio e África). As Previsões de Mercado são Fornecidas em Termos de Valor (USD).
| Hardware |
| Software |
| Serviços |
| Desagregação Baseada em PCIe |
| Desagregação Baseada em NVLink/NVSwitch |
| Desagregação Baseada em Malha Ethernet |
| Desagregação Baseada em Malha InfiniBand |
| Desagregação Baseada em CXL |
| Local |
| Baseado em Nuvem |
| IA e Computação de Alto Desempenho |
| Análise de Dados |
| Gêmeo Digital e Simulação |
| Renderização e Visualização |
| Pesquisa Científica |
| Provedores de Nuvem em Hiperescala |
| Provedores de Serviços em Nuvem |
| Empresas |
| Organizações Governamentais e de Defesa |
| Instituições de Pesquisa e Acadêmicas |
| Provedores de Telecomunicações |
| América do Norte | Estados Unidos |
| Canadá | |
| México | |
| Europa | Alemanha |
| Reino Unido | |
| França | |
| Itália | |
| Restante da Europa | |
| Ásia-Pacífico | China |
| Japão | |
| Coreia do Sul | |
| Índia | |
| Sudeste Asiático | |
| Restante da Ásia-Pacífico | |
| América do Sul | |
| Oriente Médio e África |
| Por Componente | Hardware | |
| Software | ||
| Serviços | ||
| Por Tipo de Acelerador | Desagregação Baseada em PCIe | |
| Desagregação Baseada em NVLink/NVSwitch | ||
| Desagregação Baseada em Malha Ethernet | ||
| Desagregação Baseada em Malha InfiniBand | ||
| Desagregação Baseada em CXL | ||
| Por Modelo de Implantação | Local | |
| Baseado em Nuvem | ||
| Por Aplicação | IA e Computação de Alto Desempenho | |
| Análise de Dados | ||
| Gêmeo Digital e Simulação | ||
| Renderização e Visualização | ||
| Pesquisa Científica | ||
| Por Usuário Final | Provedores de Nuvem em Hiperescala | |
| Provedores de Serviços em Nuvem | ||
| Empresas | ||
| Organizações Governamentais e de Defesa | ||
| Instituições de Pesquisa e Acadêmicas | ||
| Provedores de Telecomunicações | ||
| Por Geografia | América do Norte | Estados Unidos |
| Canadá | ||
| México | ||
| Europa | Alemanha | |
| Reino Unido | ||
| França | ||
| Itália | ||
| Restante da Europa | ||
| Ásia-Pacífico | China | |
| Japão | ||
| Coreia do Sul | ||
| Índia | ||
| Sudeste Asiático | ||
| Restante da Ásia-Pacífico | ||
| América do Sul | ||
| Oriente Médio e África | ||


Principais Perguntas Respondidas no Relatório
Qual é o tamanho atual do mercado de GPU desagregada?
O mercado de GPU desagregada foi avaliado em 3,97 bilhões de USD em 2025, está em 5,34 bilhões de USD em 2026 e tem previsão de atingir 22,63 bilhões de USD até 2031 a um CAGR de 33,48%.
Por que a adoção de GPU desagregada está crescendo na infraestrutura de IA?
A adoção está crescendo porque o agrupamento de GPU melhora a utilização, a IA agêntica aumenta as necessidades de rendimento de tokens, e as restrições de memória e largura de banda estão empurrando os operadores em direção a arquiteturas de computação e memória agrupadas.
Qual componente contribui com a maior receita atualmente?
O hardware liderou com 81,32% da receita em 2025, pois as implantações iniciais exigiram grandes gastos em racks, malhas, switches, módulos de memória e sistemas de computação estreitamente integrados.
Qual abordagem de acelerador está crescendo mais rapidamente?
A desagregação baseada em CXL está projetada para crescer a um CAGR de 34,46% até 2031, suportada pelo agrupamento de memória compartilhada e pelo design de sistema composível mais flexível.
Qual região está se expandindo mais rapidamente?
A Ásia-Pacífico está projetada para crescer a um CAGR de 34,39% até 2031, suportada pelos gastos de IA em hiperescala na China, pela força de fornecimento de HBM na Coreia do Sul e pelos programas de infraestrutura de IA pública na Índia e em Singapura.
Qual é a principal barreira que impede uma implantação mais ampla?
As maiores restrições são a complexidade de interconexão, a orquestração fragmentada entre pilhas de GPU e o custo de adaptar as instalações às necessidades de energia e resfriamento dos racks de IA densos.
Página atualizada pela última vez em:




