Tamaño y Participación del Mercado de GPU Desagregada
Visión General del Mercado
| Período de Estudio | 2020 - 2031 |
|---|---|
| Tamaño del Mercado (2026) | 5.34 Mil millones de dólares |
| Tamaño del Mercado (2031) | 22.63 Mil millones de dólares |
| Tasa de crecimiento (2026 - 2031) | 33.48% CAGR |
| Mercado de Crecimiento Más Rápido | Asia-Pacífico |
| Mercado Más Grande | América del Norte |
| Concentración del Mercado | Alto |
Jugadores principales
*Nota aclaratoria: los principales jugadores no se ordenaron de un modo en especial Imagen © Mordor Intelligence. El uso requiere atribución según CC BY 4.0. |
|
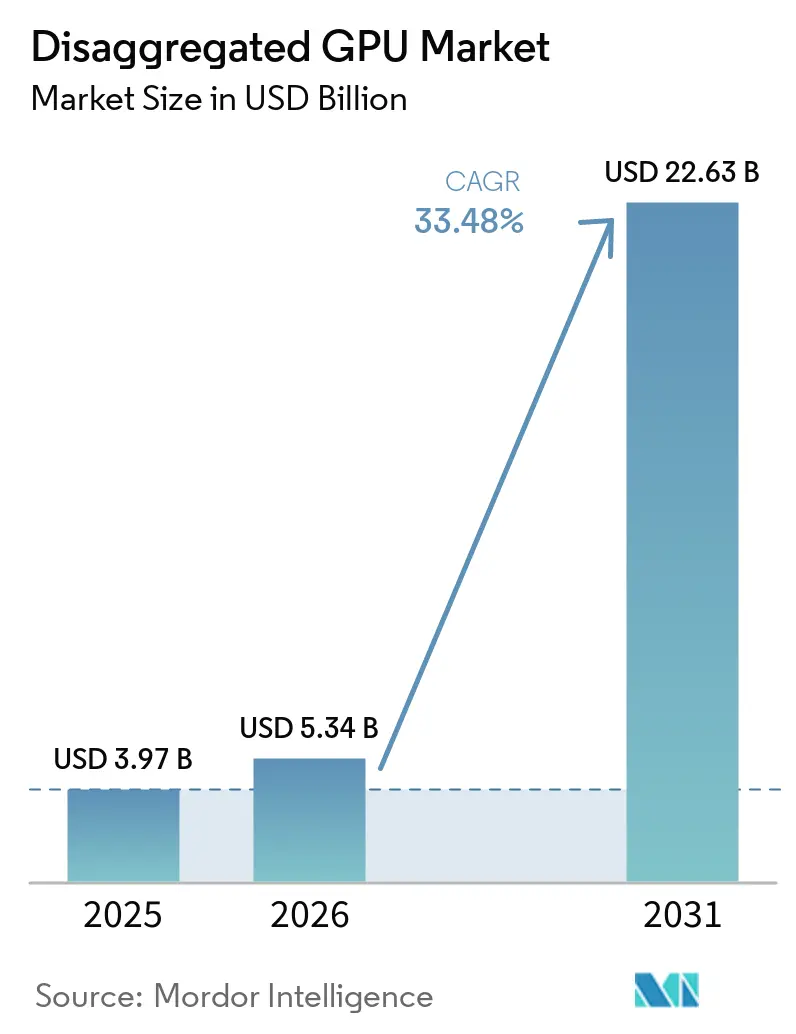
Análisis del Mercado de GPU Desagregada por Mordor Intelligence
Se proyecta que el tamaño del mercado de GPU desagregada será de 3,97 mil millones USD en 2025, 5,34 mil millones USD en 2026, y alcanzará los 22,63 mil millones USD en 2031, creciendo a una CAGR del 33,48% de 2026 a 2031. El mercado de GPU desagregada se está expandiendo a medida que las pilas de cómputo de IA se alejan de los diseños de servidores fijos y avanzan hacia arquitecturas conectadas por tejido de red que permiten a los operadores separar los recursos de GPU de los servidores anfitriones y asignarlos donde la demanda es mayor. Los grandes programas de capital de AMD y NVIDIA, junto con las implementaciones confirmadas por las principales plataformas en la nube, muestran que el mercado de GPU desagregada está ahora vinculado al rediseño amplio de centros de datos en lugar de ciclos aislados de actualización de hardware. El comportamiento competitivo también está cambiando porque los operadores están poniendo mayor énfasis en la utilización, la orquestación y la eficiencia a escala de bastidor que en simplemente agregar más aceleradores. El mercado de GPU desagregada también se beneficia del auge de las cargas de trabajo de IA agéntica, que ejercen mayor presión sobre el rendimiento de tokens, el movimiento de caché KV y la coordinación de baja latencia entre las etapas de prellenado y decodificación. Al mismo tiempo, los controles de exportación, las brechas de interoperabilidad y la densidad de potencia de los bastidores de IA modernos están manteniendo el crecimiento desigual, favoreciendo a los operadores con infraestructura diseñada específicamente y una sólida profundidad de ingeniería.
Conclusiones Clave del Informe
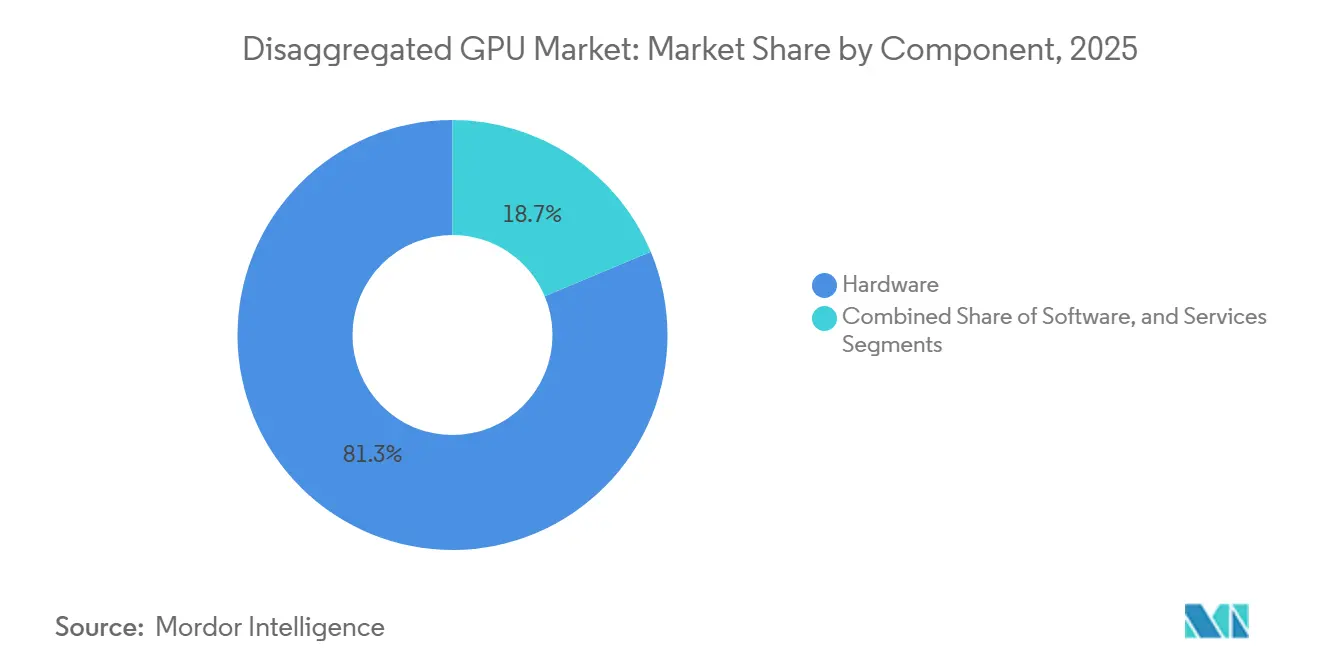
- Por componente, el hardware lideró con una participación de ingresos del 81,32% en 2025, mientras que se proyecta que el software se expandirá a una CAGR del 34,08% hasta 2031 en el mercado de GPU desagregada.
- Por tipo de acelerador, la desagregación basada en NVLink/NVSwitch mantuvo una participación del 44,21% en 2025, mientras que se proyecta que la desagregación basada en CXL se expandirá a una CAGR del 34,46% hasta 2031.
- Por modo de implementación, la implementación basada en la nube representó el 61,77% del mercado de unidades de procesamiento gráfico (GPU) desagregadas en 2025 y se proyecta que crecerá a una CAGR del 33,87% hasta 2031.
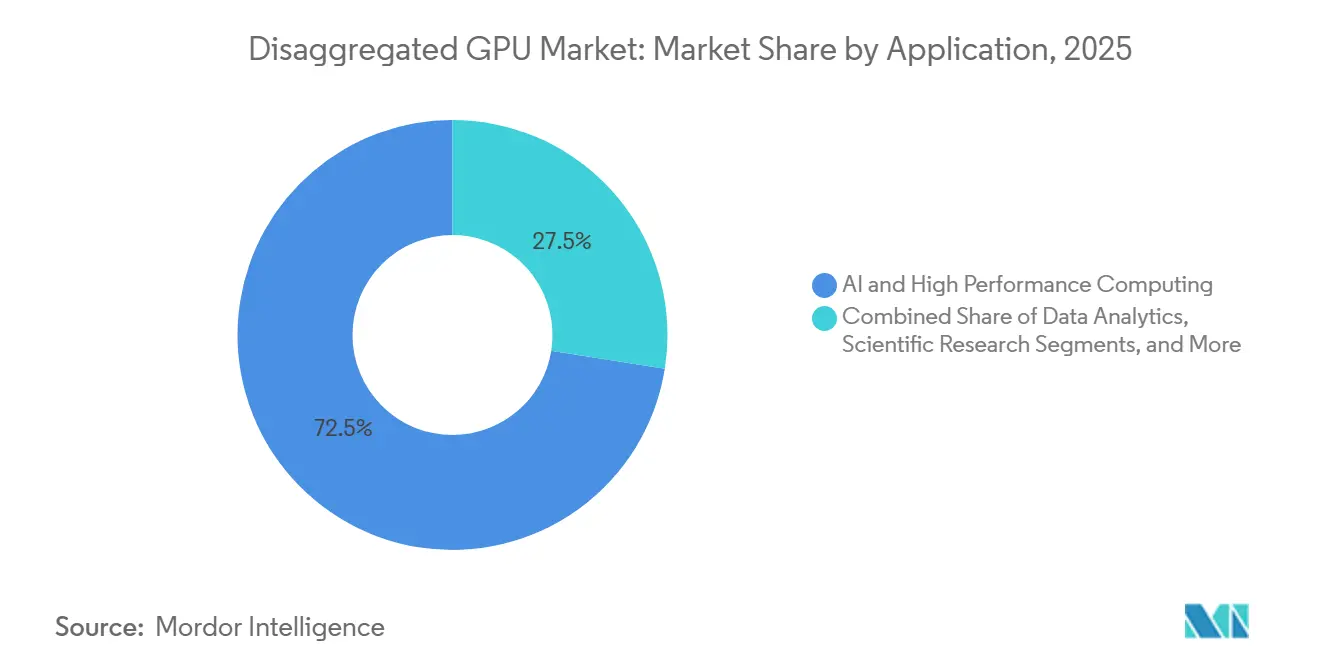
- Por aplicación, la IA y la computación de alto rendimiento capturaron el 72,49% del mercado en 2025, mientras que se proyecta que el gemelo digital y la simulación se expandirán a una CAGR del 34,42% hasta 2031.
- Por usuario final, los proveedores de nube a hiperescala mantuvieron una participación del 47,63% en 2025, mientras que se proyecta que los proveedores de servicios en la nube registren la CAGR más alta del 34,63% hasta 2031.
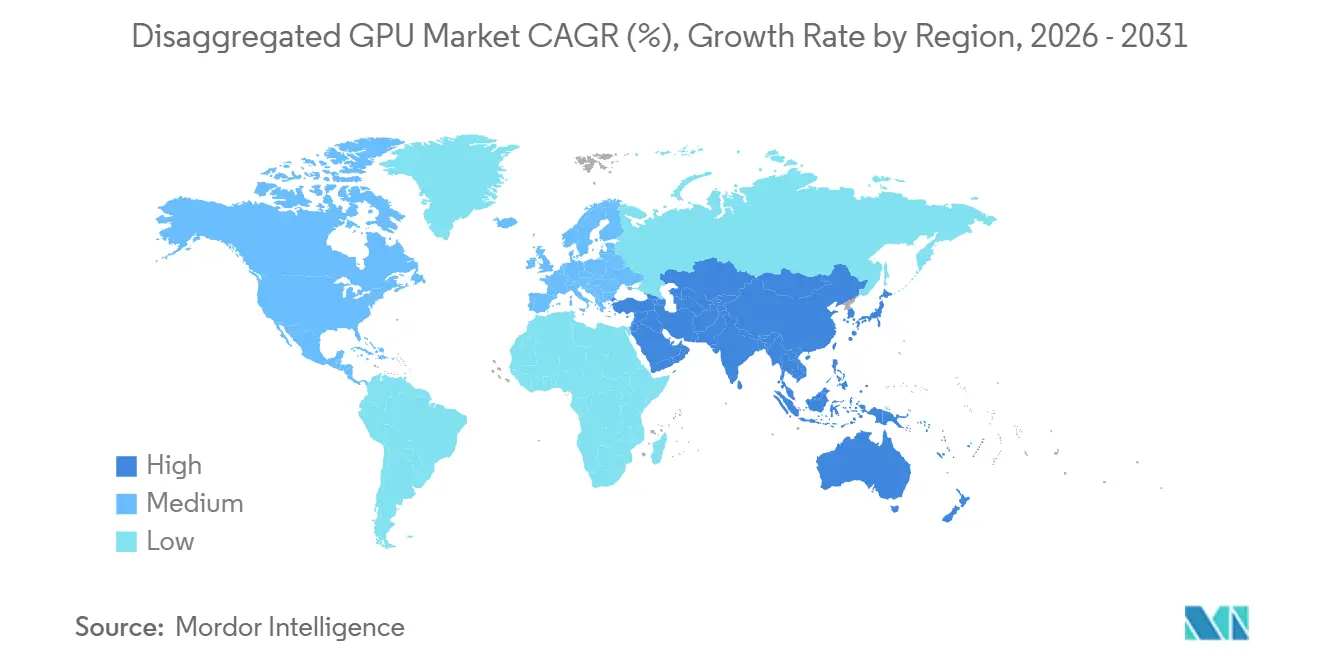
- Por geografía, América del Norte mantuvo el 52,71% de la participación del mercado de GPU desagregada en 2025, mientras que se proyecta que Asia-Pacífico se expandirá a una CAGR del 34,39% hasta 2031.
Nota: Las cifras del tamaño del mercado y los pronósticos de este informe se generan utilizando el marco de estimación patentado de Mordor Intelligence, actualizado con los datos y conocimientos más recientes disponibles a partir de enero de 2026.
Tendencias e Información del Mercado Global de GPU Desagregada
Análisis del Impacto de los Impulsores*
| Impulsor | (~) % de Impacto en el Pronóstico de CAGR | Relevancia Geográfica | Horizonte Temporal del Impacto |
|---|---|---|---|
| Creciente Demanda de Agrupación de GPU en Clústeres de Entrenamiento de IA | +10.2% | Global, concentrado en centros de hiperescala de América del Norte y Asia-Pacífico | Corto plazo (≤ 2 años) |
| Cambio Hacia Arquitecturas de Cómputo y Memoria Separados | +8.5% | Global, con la adopción de CXL anclada en América del Norte y Asia Oriental | Mediano plazo (2-4 años) |
| Expansión de la Infraestructura de IA a Hiperescala y Nativa de la Nube | +7.3% | Global, con América del Norte y Asia-Pacífico liderando el despliegue de capital | Corto plazo (≤ 2 años) |
| Ganancias de Eficiencia Energética y Térmica Mediante la Desagregación de Recursos | +4.8% | Global, acelerado por las regulaciones energéticas de la UE y las restricciones de energía en Asia-Pacífico | Mediano plazo (2-4 años) |
| Mayor Utilización de Flota Mediante la Asignación de GPU a Múltiples Inquilinos | +3.6% | Corredores de nube de América del Norte, Europa y el Sudeste Asiático | Mediano plazo (2-4 años) |
| Ciclos de Actualización Más Cortos en Arquitecturas de Centros de Datos Modulares | +2.9% | Global, más rápido en construcciones de fábricas de IA en campo verde en América del Norte | Largo plazo (≥ 4 años) |
| Fuente: Mordor Intelligence | |||
Creciente Demanda de Agrupación de GPU en Clústeres de Entrenamiento de IA
El mercado de GPU desagregada está obteniendo apoyo directo de la agrupación de GPU, ya que las grandes ejecuciones de entrenamiento de IA ahora dependen de tratar muchas GPU físicas como un único recurso lógico compartido. La sexta generación de NVLink de NVIDIA entregó 1,8 TB/s de ancho de banda bidireccional por GPU, y los sistemas NVLink Switch admitieron 72 GPU en un único bastidor NVL72, entregando 130 TB/s de ancho de banda agregado en el dominio, reduciendo los límites de comunicación que solían separar los bastidores adyacentes en islas de cómputo aisladas.[1]NVIDIA Developer Blog, "Escalando el Rendimiento y la Flexibilidad de Inferencia de IA con NVIDIA NVLink y NVLink Fusion," NVIDIA Developer Blog, developer.nvidia.com Ese cambio importa para los modelos de billones de parámetros porque la presión de memoria y ancho de banda ahora se extiende a través de clústeres de entrenamiento completos en lugar de dentro de un único nodo, y el mercado de GPU desagregada está respondiendo con arquitecturas que permiten que la capacidad inactiva se una a las cargas de trabajo activas mucho más rápidamente. La IA agéntica está añadiendo otra capa de demanda, ya que las etapas de prellenado son intensivas en cómputo mientras que las etapas de decodificación son intensivas en ancho de banda de memoria, y este patrón requiere que los grupos se reasignen en segundos en lugar de a través de ciclos de programación manual más lentos. AWS demostró este modelo operativo en producción usando llm-d y la Biblioteca de Transferencia de Inferencia de NVIDIA en nodos Blackwell, donde la inferencia desagregada mejoró el rendimiento en un 70% con alta concurrencia.
Cambio Hacia Arquitecturas de Cómputo y Memoria Separados
El mercado de GPU desagregada también avanza a medida que los operadores separan el cómputo de la memoria local y tratan la capacidad de memoria como una capa de infraestructura agrupada. Una investigación publicada en Tsinghua Science and Technology describió la desagregación de memoria basada en CXL como un paso arquitectónico importante para los centros de computación inteligente, porque los grupos de memoria compartida pueden ser accedidos por múltiples nodos de cómputo a través de operaciones estándar de carga y almacenamiento. Los investigadores de ByteDance extendieron esta dirección demostrando un grupo de memoria compartida de 768 GB construido con tarjetas CXL Tipo 3 de Micron y un conmutador CXL TITAN-II, habilitando la comunicación colectiva de GPU en 3 nodos con GPU NVIDIA H100 sin cambios en el código de la aplicación. Esto importa porque la inferencia de contexto largo supera 1 millón de tokens y la demanda de caché KV supera la HBM disponible en cada acelerador, haciendo que agregar memoria agrupada sea más práctico que reemplazar flotas completas de GPU. El mercado de GPU desagregada, por lo tanto, se beneficia de CXL no solo como una opción técnica sino también como un camino económico para los operadores que necesitan más capacidad de memoria sin forzar una actualización completa de silicio.
Expansión de la Infraestructura de IA a Hiperescala y Nativa de la Nube
El mercado de GPU desagregada está siendo impulsado al alza por la escala del gasto en infraestructura de IA a hiperescala y nativa de la nube, que se ha ampliado desde proyectos piloto aislados hasta implementaciones a escala de bastidor y multisitio. AMD anunció más de 10 mil millones USD en inversiones en el ecosistema de Taiwán en mayo de 2026 para escalar su plataforma Helios a escala de bastidor a través de socios ODM, incluidos Sanmina, Wiwynn, Wistron e Inventec, con implementaciones de múltiples gigavatios previstas para la segunda mitad de 2026. Google Cloud también declaró que su tejido de red Virgo fue diseñado para conectar hasta 80.000 GPU NVIDIA Vera Rubin NVL72 en un único centro de datos y más de 960.000 GPU en múltiples sitios, subrayando cómo el mercado de GPU desagregada se está convirtiendo en una base para la expansión de centros de datos en lugar de una arquitectura de nicho. Al mismo tiempo, los programas de silicio personalizado en AWS, Google y Microsoft no están eliminando la necesidad de sistemas de GPU desagregada, porque la infraestructura de múltiples proveedores está surgiendo junto a ellos. Intel y SambaNova demostraron el modelo en 2026 con una pila de inferencia heterogénea, donde Intel Xeon 6 manejó la orquestación, las RDU de SambaNova manejaron la decodificación y las GPU NVIDIA Blackwell manejaron el prellenado desde un único centro de datos en producción.
Ganancias de Eficiencia Energética y Térmica Mediante la Desagregación de Recursos
El mercado de GPU desagregada también está siendo moldeado por las restricciones de suministro de energía y refrigeración, que ahora influyen en las decisiones de arquitectura tanto como la demanda bruta de cómputo. La especificación Diablo del Open Compute Project, aportada por Google, Meta y Microsoft en octubre de 2025, definió diseños de bastidores de energía desagregada que admiten bastidores de TI de 100 kilovatios a 1 megavatio utilizando entrega de 400 VDC u 800 VDC. NVIDIA añadió otra palanca de eficiencia en diciembre de 2025 con los perfiles de energía Blackwell B200, entregando hasta un 15% de ahorro de energía con no más del 3% de impacto en el rendimiento, permitiendo hasta un 13% más de rendimiento en instalaciones de energía fija. La inferencia desagregada consciente de la fase mejora aún más el panorama, porque las etapas de prellenado consumen energía máxima mientras que las etapas de decodificación tienen menores necesidades de vataje y pueden gestionarse de manera diferente en grupos de recursos separados. La investigación sobre la arquitectura BiScale mostró que la gestión dinámica de voltaje y frecuencia coordinada en los niveles de prellenado y decodificación desagregados redujo la energía de decodificación hasta en un 48% mientras se cumplían los objetivos de latencia del servicio, lo que fortalece el caso operativo para el mercado de unidades de procesamiento gráfico (GPU) desagregadas, donde los límites de energía y los objetivos de utilización ahora se mueven juntos.
Análisis del Impacto de las Restricciones*
| Restricción | (~) % de Impacto en el Pronóstico de CAGR | Relevancia Geográfica | Horizonte Temporal del Impacto |
|---|---|---|---|
| Alta Complejidad de Integración de Interconexión y Tejido de Red | -1.8% | Global, más aguda en implementaciones de múltiples proveedores fuera de América del Norte | Corto plazo (≤ 2 años) |
| Fragmentación de la Orquestación de Software en Pilas de GPU | -1.4% | Global, particularmente limitante en implementaciones empresariales y de mercados emergentes | Mediano plazo (2-4 años) |
| Intensidad de Capital para la Modernización de Centros de Datos Heredados | -1.1% | Europa y América del Sur, donde el inventario de coubicación heredado es sustancial | Mediano plazo (2-4 años) |
| Compromisos de Latencia en Memoria Remota y Acceso Desagregado | -0.8% | Global, más crítico para cargas de trabajo de inferencia sensibles a la latencia | Corto plazo (≤ 2 años) |
| Fuente: Mordor Intelligence | |||
Alta Complejidad de Integración de Interconexión y Tejido de Red
El mercado de GPU desagregada todavía enfrenta una barrera de integración significativa porque muchas implementaciones deben coordinar NVLink, PCIe, InfiniBand, Ethernet y CXL dentro de un único clúster. Una investigación presentada en HotNets 2025 mostró que la gestión efectiva de rutas en interconexiones heterogéneas dentro del host requiere la coordinación simultánea de conmutadores PCIe, controladores de tejido de GPU, NIC RDMA y conmutadores Ethernet, y las pilas de software actuales no abstraen completamente esa complejidad. NVLink Fusion de NVIDIA redujo parte de ese problema al permitir que las CPU personalizadas de MediaTek, Marvell, Qualcomm y Fujitsu se conecten de forma nativa con las GPU de NVIDIA, pero ese movimiento amplió un camino propietario en lugar de crear un tejido de múltiples proveedores completamente neutral. El estándar Ultra Accelerator Link está destinado a ofrecer una alternativa neutral para los proveedores, sin embargo, la información indica que el hardware de producción no se esperaba hasta finales de 2026 y que las implementaciones amplias probablemente se extenderían hasta 2027. El mercado de GPU desagregada también enfrenta un techo de interoperabilidad regional en China, donde los ecosistemas de aceleradores domésticos utilizan protocolos de comunicación incompatibles, lo que limita los beneficios prácticos de agrupación que los operadores pueden lograr a escala.
Fragmentación de la Orquestación de Software en Pilas de GPU
La falta de una capa de orquestación unificada en entornos de GPU heterogéneos también restringe el mercado de GPU desagregada. La investigación sobre la programación consciente de la fragmentación mostró que los programadores de múltiples inquilinos aún necesitan reconciliar diferentes enfoques de aislamiento de memoria y particionamiento en las pilas de proveedores, lo que aumenta el esfuerzo de integración y extiende los plazos de implementación. El trabajo presentado en USENIX ATC 2025 mostró que la orquestación espacio-temporal de GPU a nivel de núcleo depende de un control detallado sobre los búferes de comandos específicos del proveedor y la gestión del contexto, sin ninguna lógica de tejido de programación ni semántica de programación estandarizada entre proveedores disponible hoy en día.[2]Shulai Zhang et al., "Compartición de GPU Eficiente y Consciente del Rendimiento con Compatibilidad y Aislamiento Mediante Intercepción en el Espacio del Núcleo," USENIX ATC 2025, usenix.org Eso hace que la desagregación a escala de flota sea más fácil para los hiperescaladores con grandes equipos de ingeniería de plataformas y mucho más difícil para los compradores empresariales que gestionan parques de GPU mixtos y necesitan una capa operativa común. Por lo tanto, es probable que el mercado de GPU desagregada continúe favoreciendo a los operadores más grandes en el mediano plazo, porque el trabajo de estandarización aún está en sus primeras etapas y los ecosistemas propietarios tienen pocos incentivos para converger rápidamente.
*Nuestras previsiones consideran los impactos de impulsores y restricciones como direccionales, no aditivos. Las previsiones de impacto reflejan el crecimiento base, los efectos de mezcla y las interacciones entre variables.
Análisis de Segmentos
Por Componente: El Hardware Lidera el Gasto Inicial Mientras el Software Gana Peso Recurrente
El hardware representó el 81,32% del mercado de GPU desagregada en 2025, reflejando los altos costos iniciales de los tejidos de interconexión, bandejas de conmutadores, módulos de memoria y sistemas de cómputo a escala de bastidor. Cada bastidor Vera Rubin NVL72 combinó 72 GPU Blackwell, 36 CPU Vera, chips de conmutador NVLink, DPU BlueField-4 y redes Ethernet Spectrum-X en una única unidad de capital basada en tejido, manteniendo el gasto inicial en el mercado de GPU desagregada concentrado en grandes ciclos de adquisición a hiperescala. Ese modelo de adquisición importa porque los compradores no están adquiriendo tarjetas o servidores aislados; están comprometiéndose con plataformas estrechamente integradas que agrupan capacidades de cómputo, redes y gestión dentro de un único evento de implementación. El mercado de GPU desagregada, por lo tanto, muestra una combinación de ingresos con predominio de hardware en su fase actual, especialmente a medida que los hiperescaladores construyen nueva capacidad de IA en bastidores completos en lugar de mediante adiciones graduales nodo por nodo. Los servicios siguieron siendo la capa de componentes más pequeña, aunque la integración, las operaciones gestionadas y la entrega de GPU como servicio todavía tenían un atractivo potencial de margen para los integradores de sistemas y los operadores de nube especializados.
Se proyecta que el software registre la CAGR más rápida del 34,08% de 2026 a 2031 en el mercado de GPU desagregada, a medida que las capas de orquestación, las herramientas de aislamiento y los marcos de inferencia determinan cada vez más el valor que los operadores extraen de cada GPU. NVIDIA Dynamo separó las asignaciones de prellenado y decodificación para elevar la utilización a escala de fábrica, y ese diseño estableció un punto de referencia que las alternativas de código abierto como llm-d ahora necesitan igualar para las implementaciones empresariales. Esto cambia el patrón de ingresos de la industria de GPU desagregada, porque las actualizaciones de software pueden continuar incluso cuando los ciclos de actualización de hardware se ralentizan o cuando el tejido instalado permanece en su lugar. Los operadores que instalaron hardware desagregado en 2024 y 2025 probablemente agregarán nuevas capas de orquestación antes de reemplazar los activos de interconexión física, creando un camino para ingresos recurrentes de software que están menos vinculados al momento de reemplazo de bastidores. Con el tiempo, esa dinámica debería dar al software un papel más importante en el mercado de GPU desagregada incluso si el hardware continúa anclando el gasto absoluto.



Por Tipo de Acelerador: NVLink Establece la Línea Base Actual Mientras CXL Amplía la Arquitectura
La desagregación basada en NVLink/NVSwitch mantuvo el 44,21% de la participación del mercado de GPU desagregada en 2025, reflejando la sólida posición de NVIDIA en los tejidos de entrenamiento de IA y la preferencia instalada por la comunicación de GPU estrechamente acoplada. La sexta generación de NVLink entregó 1,8 TB/s por GPU en 2024, y los sistemas NVLink Switch más nuevos habilitaron la comunicación de todos con todos en 72 GPU con 130 TB/s de ancho de banda agregado, dando al mercado de GPU desagregada una opción de alto rendimiento para clústeres de escalado vertical que necesitan comunicación local densa. La desagregación basada en PCIe mantuvo un papel duradero como tejido de referencia en muchos sistemas de múltiples GPU, ofreciendo amplia compatibilidad sin el mismo nivel de dependencia propietaria. Los enfoques basados en InfiniBand y Ethernet continuaron siendo importantes en entornos de escalado horizontal, y Ethernet en particular ganó relevancia donde los operadores querían extender grandes clústeres de IA aprovechando las inversiones en redes existentes. Esa división significa que el mercado de GPU desagregada no se está moviendo hacia un tejido universal, sino hacia un modelo en capas en el que el rendimiento, la apertura y la infraestructura instalada influyen cada uno en la arquitectura final.
Se proyecta que la desagregación basada en CXL se expanda a una CAGR del 34,46% hasta 2031, respaldada por la agrupación de memoria CXL 3.0 y la especificación CXL 4.0, que duplicó el ancho de banda a 128 GT/s mediante capas físicas PCIe 7.0 e introdujo puertos agrupados para un rendimiento total mucho mayor. La investigación en Tsinghua Science and Technology mostró que la desagregación de memoria CXL y la desagregación de cómputo de GPU sirven a diferentes capas de la pila, lo que sugiere que las implementaciones futuras en el mercado de GPU desagregada las combinarán en lugar de forzar una elección entre ellas. Samsung Electronics está desarrollando su plataforma de memoria CXL Pangea con Marvell y Liquid AI para expandir la memoria de GPU, donde los límites de HBM pueden restringir los tamaños de lote de inferencia y la profundidad del contexto de trabajo. En la práctica, NVLink es adecuado para la comunicación estrechamente acoplada de GPU a GPU dentro del bastidor, mientras que CXL extiende la capacidad de memoria y el intercambio de memoria entre nodos y dominios de sistema más amplios. Esa relación complementaria debería ayudar al mercado de GPU desagregada a madurar hacia arquitecturas más componibles sin reducir el papel de los tejidos de GPU de alto ancho de banda ya establecidos en los clústeres de producción.
Por Modo de Implementación: La Entrega en la Nube Establece Estándares Mientras la Implementación Local Mantiene Demanda Estratégica
La implementación basada en la nube mantuvo una participación del 61,77% del tamaño del mercado de GPU desagregada en 2025, y el mismo segmento proyecta publicar la CAGR más rápida del 33,87% hasta 2031. AWS introdujo la inferencia desagregada en SageMaker HyperPod y Amazon EKS a través de llm-d y la Biblioteca de Transferencia de Inferencia de NVIDIA, utilizando el Adaptador de Tejido Elástico para mover datos de caché KV entre nodos desagregados y entregando hasta un 70% más de tokens por segundo en instancias basadas en Blackwell que las implementaciones estándar. Google Cloud añadió otra señal cuando dijo que Virgo puede conectar hasta 80.000 GPU Vera Rubin NVL72 en un único centro de datos y extenderse más allá de 960.000 GPU en múltiples sitios, reforzando el papel de los hiperescaladores en el establecimiento del modelo operativo para el mercado de unidades de procesamiento gráfico (GPU) desagregadas. La ventaja de la entrega en la nube no es solo la escala, sino también la capacidad de ocultar la refrigeración, la configuración del tejido y la complejidad de la orquestación detrás de los servicios gestionados. Por eso el mercado de GPU desagregada continúa inclinándose hacia las plataformas en la nube, especialmente para los compradores que necesitan acceso a capacidad avanzada de IA pero no quieren construir y operar infraestructura especializada por su cuenta.
La implementación local todavía importa en el mercado de GPU desagregada para las empresas y organizaciones del sector público que no pueden mover cargas de trabajo sensibles a entornos de nube pública compartida. La información muestra que los compradores empresariales son más sensibles al precio que los hiperescaladores y generalmente adoptan arquitecturas desagregadas después de que los operadores de nube las han validado a escala, lo que empuja la demanda local hacia un camino más lento pero aún importante. Las organizaciones gubernamentales y de defensa forman un grupo local separado, porque los programas de IA soberana y las normas de seguridad nacional a menudo requieren entornos de cómputo con aislamiento total o vinculados a una jurisdicción. Los requisitos de localización de datos en la Unión Europea y partes de Asia-Pacífico también respaldan un piso para la infraestructura dedicada, incluso cuando la nube sigue siendo el modo más grande y de mayor crecimiento. Como resultado, es probable que el mercado de GPU desagregada mantenga una estructura dual, con plataformas en la nube marcando el ritmo de la innovación mientras las implementaciones locales siguen siendo importantes cuando el cumplimiento normativo, el control o la sensibilidad de la carga de trabajo limitan el acceso compartido.
Por Aplicación: La IA y la HPC Impulsan la Demanda Actual Mientras la Simulación Construye Nuevo Volumen
La IA y la computación de alto rendimiento representaron el 72,49% del mercado de GPU desagregada en 2025, convirtiéndola en el principal impulsor de las implementaciones actuales. Los modelos de lenguaje más grandes y los sistemas de razonamiento requieren capacidad de memoria y rendimiento de interconexión que superan los límites de los nodos aislados, por lo que el mercado de GPU desagregada se ha desarrollado en torno a la agrupación y la coordinación de tejidos como requisitos básicos para el entrenamiento e inferencia de frontera. NVIDIA declaró que Vera Rubin NVL72 puede entregar 10 veces el rendimiento de agentes en comparación con la generación anterior Grace Blackwell, lo que ayuda a explicar por qué los hiperescaladores están implementando estas plataformas tanto para clústeres de entrenamiento como para entornos de inferencia con alto razonamiento. La investigación científica también sigue siendo parte de este segmento, porque la genómica, el modelado climático y la física de partículas necesitan cómputo listo para ráfagas que pueda aprovisionarse a escala sin dejar recursos de GPU costosos inactivos entre trabajos. Esta combinación mantiene al mercado de GPU desagregada estrechamente vinculado a cargas de trabajo donde la utilización, el intercambio de memoria y la eficiencia de interconexión afectan directamente la producción científica o el rendimiento del modelo.
Se proyecta que el gemelo digital y la simulación avancen a una CAGR del 34,42% de 2026 a 2031, reflejando el uso más amplio de modelos de física acelerados por GPU en operaciones industriales, validación de diseño y entrenamiento de sistemas autónomos. El mercado de GPU desagregada se beneficia aquí porque muchas cargas de trabajo de simulación necesitan períodos cortos de muy alta densidad de cómputo, lo que hace que los recursos agrupados sean más económicos que las asignaciones de servidores estáticos. NVIDIA dijo que su plataforma DSX puede reducir el tiempo de implementación de fábricas de IA de meses a días y acelerar el tiempo hasta los primeros ingresos, y ese modelo comercial está comenzando a influir en cómo los usuarios industriales piensan sobre la infraestructura de simulación escalable. El análisis de datos, la renderización y la visualización siguen siendo casos de uso establecidos con un crecimiento más estable, mientras que la renderización se beneficia de la aceleración de GPU en tiempo real en interfaces industriales inmersivas que demandan baja latencia de fotogramas. En conjunto, estos patrones amplían el mercado de GPU desagregada más allá del entrenamiento de IA de frontera y aumentan la demanda de compradores que valoran la capacidad flexible para cargas de trabajo digitales operacionales.
Por Usuario Final: Los Hiperescaladores Mantienen la Mayor Base Mientras las Nubes Especializadas Crecen Más Rápido
Los proveedores de nube a hiperescala mantuvieron una participación del 47,63% en 2025, dándoles la mayor posición en el mercado de GPU desagregada y una fuerte influencia sobre los estándares de arquitectura, el momento de implementación y las elecciones de software. AWS, Google Cloud, Microsoft Azure y Oracle Cloud Infrastructure fueron identificados como implementadores de sistemas NVIDIA Vera Rubin NVL72 en la segunda mitad de 2026, lo que refuerza hasta qué punto el mercado de GPU desagregada todavía depende de los hiperescaladores para la adopción temprana de volumen. Su papel de pioneros va más allá del poder adquisitivo, porque también dan forma a cómo se empaquetan la orquestación, la agrupación de recursos y los servicios de IA gestionados para los clientes intermedios. Las empresas se están convirtiendo en un grupo de adoptantes más grande, aunque generalmente abordan las implementaciones con controles presupuestarios más estrictos, mayor sensibilidad al riesgo de integración y una preferencia por configuraciones de nube dedicada o locales donde la exposición de datos puede limitarse. Los compradores gubernamentales y de defensa también siguen siendo relevantes, ya que los largos ciclos de adquisición aún pueden generar grandes valores de contrato cuando los programas de cómputo soberano avanzan.
Se proyecta que los proveedores de servicios en la nube registren la CAGR más rápida del 34,63% de 2026 a 2031 en el mercado de GPU desagregada, a medida que los operadores de nivel medio construyen plataformas de GPU como servicio en torno a la especialización y la flexibilidad de precios. NVIDIA identificó a CoreWeave, Lambda, Nebius y Nscale entre los primeros adoptantes de Vera Rubin y Spectrum-X Ethernet Photonics, demostrando cómo las nubes especializadas están expandiendo la capacidad para atender la demanda de entrenamiento e inferencia más allá de las plataformas hiperescaladas más grandes. Su posición es prometedora pero también expuesta, porque la caída de los costos por token en los hiperescaladores puede comprimir los márgenes de alquiler y obligar a los proveedores más pequeños a diferenciarse a través de servicios gestionados y soporte en la capa de aplicaciones. Los proveedores de telecomunicaciones también están emergiendo como usuarios enfocados en el borde de los sistemas de GPU desagregada, mientras que las instituciones de investigación y académicas desempeñan un papel de ingresos menor pero ayudan a reducir las barreras de software a través del trabajo de orquestación de código abierto como llm-d y las herramientas nativas de Kubernetes relacionadas. Esa combinación de hiperescaladores dominantes, nubes especializadas de rápido movimiento y compradores públicos y privados específicos da al mercado de GPU desagregada una base de demanda más amplia sin reducir su dependencia de unos pocos operadores muy grandes.
Análisis Geográfico
América del Norte mantuvo una participación del 52,71% en 2025, dándole la mayor participación regional en el mercado de GPU desagregada y reflejando la profundidad de las construcciones a hiperescala en los Estados Unidos. AWS, Google Cloud, Microsoft Azure y Oracle Cloud Infrastructure fueron nombrados como implementadores de sistemas NVIDIA Vera Rubin NVL72 en la segunda mitad de 2026, y esa concentración de compradores líderes continúa anclando el mercado de GPU desagregada en la región. América del Norte también se beneficia de un denso ecosistema de hardware, una importante actividad de investigación en IA y una madura capa de nube de GPU, incluidos proveedores como CoreWeave, Lambda y Nscale. La colaboración de NVIDIA en septiembre de 2025 con Intel para desarrollar CPU personalizadas para centros de datos de IA basadas en NVLink y x86 profundizó las cadenas de suministro regionales y permitió una integración más sólida entre las CPU de orquestación y los tejidos de GPU.[3]Intel Corporation, "Intel y NVIDIA Desarrollarán Conjuntamente Infraestructura de IA y Productos de Computación Personal," Sala de Prensa de Intel, newsroom.intel.com Canadá añade apoyo a través de la proximidad a la demanda hiperescalada de los Estados Unidos y la economía favorable de la energía, mientras que América del Sur permanece en una etapa más temprana y está más vinculada a las zonas de disponibilidad de hiperescaladores en Brasil y Colombia que a la implementación local amplia.
Europa mantuvo una participación significativa pero menor del mercado de GPU desagregada, con Alemania, el Reino Unido y Francia como los principales centros de implementación según la información de los usuarios. La Directiva de Eficiencia Energética de la Unión Europea requiere informes de efectividad del uso de energía para centros de datos con una carga de TI superior a 500 kW, lo que respalda diseños más eficientes y desagregados y requiere que los operadores demuestren un rendimiento de instalaciones medible. La base automotriz y de fabricación de precisión de Alemania respalda la demanda de cargas de trabajo de gemelo digital y simulación de física, donde el cómputo en ráfagas es más fácil de justificar a través de infraestructura agrupada que a través de asignaciones de servidores fijos. El Reino Unido contribuye a través de un segmento activo de nube de GPU, mientras que Francia e Italia están extendiendo programas de cómputo de IA soberana que incorporan capacidad de GPU desagregada.
Se proyecta que Asia-Pacífico se expanda a una CAGR del 34,39% entre 2026 y 2031, dando a la región la tasa de crecimiento más rápida en el mercado de GPU desagregada durante el período de pronóstico. La región está siendo impulsada por el gasto hiperescalado de IA de China, la cadena de suministro de memoria verticalmente integrada de Corea del Sur, las necesidades de fabricación y automatización de Japón, y los programas de infraestructura de IA pública en India y Singapur. China está construyendo arquitecturas desagregadas domésticas en torno a enfoques de interconexión propietarios, creando una estructura regional dividida en la que las pilas chinas difieren de las utilizadas en otras partes del mercado de GPU desagregada. Corea del Sur se beneficia de la posición de SK Hynix en la producción de HBM3e, lo que ayuda a los operadores domésticos a asegurar un acceso más temprano a los subsistemas de memoria y respalda una implementación de capital de centros de datos más rápida. India también se está moviendo rápidamente a medida que las iniciativas de IA respaldadas por el gobierno y las zonas de nube a hiperescala se expanden, mientras que Oriente Medio y África se encuentran en una etapa más temprana de desarrollo pero están ganando apoyo de los programas de inversión en IA soberana en los Emiratos Árabes Unidos y Arabia Saudita.

Panorama Competitivo
El mercado de GPU desagregada sigue estando muy concentrado en la capa de interconexión de hardware, mientras que el software y los servicios están mucho más fragmentados entre los proveedores de orquestación, los proveedores de nube de GPU y los especialistas en integración. NVIDIA continúa marcando el ritmo en el mercado de GPU desagregada porque su ecosistema NVLink, las plataformas a escala de bastidor y el alcance de producción le otorgan una fuerte ventaja donde los compradores necesitan tejidos de escalado vertical probados y pilas de hardware coordinadas. Su lanzamiento en mayo de 2025 de NVLink Fusion fue un movimiento estratégico notable porque permitió que el silicio personalizado de MediaTek, Marvell, Qualcomm, Fujitsu y otros se conectara de forma nativa con las GPU de NVIDIA y amplió el ecosistema direccionable para la infraestructura de IA semicustomizada. Ese movimiento no redujo la dependencia de NVIDIA en la tecnología propietaria, pero hizo que el tejido de NVIDIA fuera más central para el diseño de sistemas en un conjunto más amplio de socios. En términos prácticos, el mercado de GPU desagregada todavía le da a NVIDIA la posición más sólida donde el rendimiento del hardware y la madurez del ecosistema son más importantes.
AMD está construyendo su posición en el mercado de unidades de procesamiento gráfico (GPU) desagregadas a través de una ruta diferente que combina la plataforma Helios a escala de bastidor con la pila de software abierto ROCm y una base de proveedores más amplia. Su decisión de mayo de 2026 de comprometer más de 10 mil millones USD en el ecosistema de Taiwán fue otro movimiento estratégico importante, porque señaló un esfuerzo de varios años para reducir la brecha de producción de hardware y fortalecer la ejecución a escala de bastidor a través de socios de fabricación regionales.[4]Advanced Micro Devices, Inc., "AMD Anuncia Más de 10 Mil Millones USD en Inversiones en el Ecosistema de Taiwán para Acelerar la Infraestructura de IA," Relaciones con Inversores de AMD, ir.amd.com El papel de Intel es más asimétrico, ya que no lidera la capa de tejido de GPU pero encuentra valor en la posición de CPU de orquestación dentro de los sistemas heterogéneos. Ese enfoque fue evidente en Computex 2026, donde Intel Xeon 6 habilitó la orquestación en una pila de inferencia desagregada de tres proveedores con SambaNova y NVIDIA en un único ejemplo de implementación comercial. Estos movimientos muestran que el mercado de GPU desagregada es competitivo a nivel de plataforma aunque el tejido de hardware central siga estando concentrado.
El área más abierta en el mercado de GPU desagregada es la orquestación de múltiples proveedores, porque todavía no existe una plataforma comercial ampliamente adoptada que programe de manera consistente las cargas de trabajo en NVLink, CXL, InfiniBand y Ethernet. Los actores emergentes como Exostellar, trabajando con Vultr, están apuntando a esa brecha con orquestación a nivel de carga de trabajo en flotas de GPU heterogéneas y geográficamente distribuidas, mientras que los proveedores de servidores como Dell Technologies, Hewlett Packard Enterprise, Supermicro y Lenovo compiten a través de la integración de sistemas, la refrigeración líquida y los servicios de infraestructura gestionada. La actividad de estandarización también importa porque cualquier camino hacia tejidos desagregados más abiertos afectaría cómo las empresas y los gobiernos evalúan el bloqueo de proveedores y la adquisición a largo plazo. Por ahora, el mercado de GPU desagregada respalda una estructura competitiva en capas donde un pequeño número de líderes de hardware influye en la arquitectura central, mientras que un campo mucho más amplio compite por controlar la implementación, la orquestación y la entrega de servicios.
Líderes de la Industria de GPU Desagregada
-
NVIDIA Corporation
-
Advanced Micro Devices, Inc.
-
Intel Corporation
-
Qualcomm Incorporated
-
Apple Inc.
- *Nota aclaratoria: los principales jugadores no se ordenaron de un modo en especial

Desarrollos Recientes de la Industria
- Junio de 2026: Amazon Web Services anunció la disponibilidad general de las instancias EC2 G7 impulsadas por GPU NVIDIA RTX PRO 4500 Blackwell Server Edition, entregando hasta 4,6 veces el rendimiento de inferencia de IA de la generación G6 anterior. Las instancias cuentan con hasta 700 Gbps de ancho de banda de red del Adaptador de Tejido Elástico, admitiendo cargas de trabajo de inferencia de IA desagregada, traducción de idiomas y análisis de imágenes a gran escala.
- Mayo de 2026: NVIDIA anunció que la plataforma Vera Rubin entró en plena producción en 350 fábricas en 30 países, con AWS, Google Cloud, Microsoft Azure y Oracle Cloud Infrastructure como implementadores confirmados en la segunda mitad de 2026. La plataforma introdujo Spectrum-X Ethernet Photonics, los primeros conmutadores Ethernet con óptica co-empaquetada de la industria en producción, entregando 5 veces la eficiencia energética sobre los transceptores tradicionales y habilitando implementaciones de fábricas de IA de un millón de GPU.
- Mayo de 2026: AMD anunció 10 mil millones USD en inversiones en el ecosistema de Taiwán para escalar la plataforma Helios a escala de bastidor con GPU MI450X y CPU EPYC Venice de 6.ª generación con empaquetado de puente elevado fanout 2.5D por primera vez en la industria. Los socios ODM Sanmina, Wiwynn, Wistron e Inventec están escalando la producción para implementaciones de múltiples gigavatios previstas en la segunda mitad de 2026.
- Mayo de 2026: Vector Core Compute, respaldada por Vista Equity Partners y Cambium Capital, lanzó comercialmente el primer sistema de inferencia desagregada en Computex 2026, implementando Intel Xeon 6 para la orquestación, SambaNova SN40 RDU para la decodificación y GPU NVIDIA Blackwell para el prellenado desde un centro de datos en Los Ángeles. Together.ai fue anunciado como el primer cliente comercial.


Alcance del Informe Global del Mercado de GPU Desagregada
El Mercado de GPU Desagregada comprende hardware, software y servicios que permiten que las unidades de procesamiento gráfico (GPU) se desacoplen de las arquitecturas de servidores tradicionales y se asignen dinámicamente a través de múltiples recursos de cómputo mediante interconexiones de alta velocidad y tejidos de red. Las arquitecturas de GPU desagregada permiten a las organizaciones agrupar, compartir, virtualizar y orquestar recursos de GPU independientemente de los límites físicos del servidor, mejorando la utilización de recursos, la escalabilidad, la flexibilidad operativa y la eficiencia de la infraestructura en entornos de centros de datos, nube y computación de alto rendimiento.
El Informe del Mercado de GPU Desagregada está Segmentado por Componente (Hardware, Software y Servicios), Tipo de Acelerador (Desagregación Basada en PCIe, Desagregación Basada en NVLink/NVSwitch, Desagregación Basada en Tejido Ethernet, Desagregación Basada en Tejido InfiniBand y Desagregación Basada en CXL), Modo de Implementación (Local y Nube), Aplicación (IA y Computación de Alto Rendimiento, Análisis de Datos, Gemelo Digital y Simulación, Renderización y Visualización, e Investigación Científica), Usuario Final (Proveedores de Nube a Hiperescala, Proveedores de Servicios en la Nube, Empresas, Organizaciones Gubernamentales y de Defensa, Instituciones de Investigación y Académicas, Proveedores de Telecomunicaciones) y Geografía (América del Norte, Europa, Asia-Pacífico, América del Sur y Oriente Medio y África). Los Pronósticos del Mercado se Proporcionan en Términos de Valor (USD).
| Hardware |
| Software |
| Servicios |
| Desagregación Basada en PCIe |
| Desagregación Basada en NVLink/NVSwitch |
| Desagregación Basada en Tejido Ethernet |
| Desagregación Basada en Tejido InfiniBand |
| Desagregación Basada en CXL |
| Local |
| Basado en la Nube |
| IA y Computación de Alto Rendimiento |
| Análisis de Datos |
| Gemelo Digital y Simulación |
| Renderización y Visualización |
| Investigación Científica |
| Proveedores de Nube a Hiperescala |
| Proveedores de Servicios en la Nube |
| Empresas |
| Organizaciones Gubernamentales y de Defensa |
| Instituciones de Investigación y Académicas |
| Proveedores de Telecomunicaciones |
| América del Norte | Estados Unidos |
| Canadá | |
| México | |
| Europa | Alemania |
| Reino Unido | |
| Francia | |
| Italia | |
| Resto de Europa | |
| Asia-Pacífico | China |
| Japón | |
| Corea del Sur | |
| India | |
| Sudeste Asiático | |
| Resto de Asia-Pacífico | |
| América del Sur | |
| Oriente Medio y África |
| Por Componente | Hardware | |
| Software | ||
| Servicios | ||
| Por Tipo de Acelerador | Desagregación Basada en PCIe | |
| Desagregación Basada en NVLink/NVSwitch | ||
| Desagregación Basada en Tejido Ethernet | ||
| Desagregación Basada en Tejido InfiniBand | ||
| Desagregación Basada en CXL | ||
| Por Modo de Implementación | Local | |
| Basado en la Nube | ||
| Por Aplicación | IA y Computación de Alto Rendimiento | |
| Análisis de Datos | ||
| Gemelo Digital y Simulación | ||
| Renderización y Visualización | ||
| Investigación Científica | ||
| Por Usuario Final | Proveedores de Nube a Hiperescala | |
| Proveedores de Servicios en la Nube | ||
| Empresas | ||
| Organizaciones Gubernamentales y de Defensa | ||
| Instituciones de Investigación y Académicas | ||
| Proveedores de Telecomunicaciones | ||
| Por Geografía | América del Norte | Estados Unidos |
| Canadá | ||
| México | ||
| Europa | Alemania | |
| Reino Unido | ||
| Francia | ||
| Italia | ||
| Resto de Europa | ||
| Asia-Pacífico | China | |
| Japón | ||
| Corea del Sur | ||
| India | ||
| Sudeste Asiático | ||
| Resto de Asia-Pacífico | ||
| América del Sur | ||
| Oriente Medio y África | ||


Preguntas Clave Respondidas en el Informe
¿Cuál es el tamaño actual del mercado de GPU desagregada?
El mercado de GPU desagregada fue valorado en 3,97 mil millones USD en 2025, se sitúa en 5,34 mil millones USD en 2026 y se prevé que alcance los 22,63 mil millones USD en 2031 a una CAGR del 33,48%.
¿Por qué está aumentando la adopción de GPU desagregada en la infraestructura de IA?
La adopción está aumentando porque la agrupación de GPU mejora la utilización, la IA agéntica incrementa las necesidades de rendimiento de tokens, y las restricciones de memoria y ancho de banda están empujando a los operadores hacia arquitecturas de cómputo y memoria agrupadas.
¿Qué componente contribuye más a los ingresos hoy en día?
El hardware lideró con el 81,32% de los ingresos en 2025, ya que las implementaciones tempranas requirieron un gran gasto en bastidores, tejidos, conmutadores, módulos de memoria y sistemas de cómputo estrechamente integrados.
¿Qué enfoque de acelerador está creciendo más rápido?
Se proyecta que la desagregación basada en CXL crezca a una CAGR del 34,46% hasta 2031, respaldada por la agrupación de memoria compartida y un diseño de sistema componible más flexible.
¿Qué región se está expandiendo más rápido?
Se proyecta que Asia-Pacífico crezca a una CAGR del 34,39% hasta 2031, respaldada por el gasto hiperescalado de IA en China, la fortaleza del suministro de HBM en Corea del Sur y los programas de infraestructura de IA pública en India y Singapur.
¿Cuál es la principal barrera que frena una implementación más amplia?
Las mayores restricciones son la complejidad de la interconexión, la orquestación fragmentada en las pilas de GPU y el costo de adaptar las instalaciones a las necesidades de energía y refrigeración de los bastidores de IA densos.
Última actualización de la página el:




